Comments 6
Обосновать не могу (возможно, меня поправят специалисты в комментариях), но похоже, что система вставила коммутаторы за нас!
Ну так у Avalon-MM блока шина адреса же работает как шина только для внутренних регистров устройства, то есть сам Avalon-MM не знает своего адреса на шине, а значит же кто то должен этим рулить, вот система и ставит. спец блоки для этого.(хотя я в этом далеко не специалист)
В следующей статье мы заменим ОЗУ на контроллер SDRAM, а таймер — на реальную «голову» и сделаем первый логический анализатор. Будет ли он работать —пока не знаю. Надеюсь, проблемы не появятся.
Вот это интересно, давно хотелось, что то подобное для DE0-Nano-SoC сваять, чувствую скоро понадобится анализатор на шину 32 байта плюс, управляющие биты.
Ну так у Avalon-MM блока шина адреса же работает как шина только для внутренних регистров устройства, то есть сам Avalon-MM не знает своего адреса на шине, а значит же кто то должен этим рулить
Чип Селект же в AVALON-MM устройство приходит. Ну, точнее, персональные RE/WE. На классических шинах этого вполне было бы достаточно. Здесь же, судя по полученным результатам, даже данные коммутируются. И это — здорово (пока ресурсов хватает, разумеется).
Простите, но можно полную структурную схему работы с DMA? У меня пока сформировалось такое представление, но оно не стыкуется с исходником из статьи.
Схема
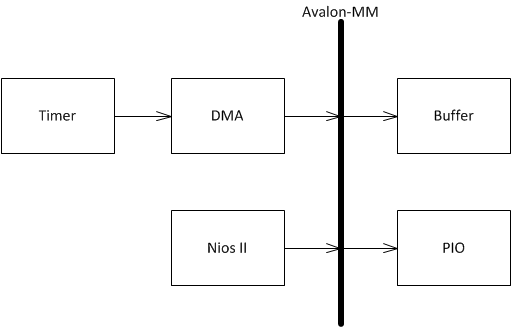
У DMA есть Slave для Avalon-MM, которые я так понимаю используются для настройки DMA?
Да, именно для доступа к управляющим регистрам DMA. Именно к этим регистрам я обращался, чтобы спровоцировать разрывы в работе канала Данные_DMA->шина->буфер. Я надеялся, что иногда шина будет занята прокачкой регистр_DMA->Nios II (поэтому стрелку и в направлении к Nios II надо добавить). Но разрывов в потоке данных не было! Тогда я стал занимать шину тактами записи в PIO. Но и это не испортило картины!!!
Буфер доступен на запись и чтение. DMA туда пишет, затем — Nios II своим JTAG блоком мне спокойно всё перекидывает в отладочное окно. Я разношу эти вещи по времени чисто организационным путём.
То есть, добавляем двунаправленную стрелку доступа к регистрам DMA, делаем двунаправленными стрелки для Buffer и Nios II. Получаем на Вашей схеме то, что задумано.
Когда DMA гонит данные в Buffer, в это время другие устройства на шине могут общаться друг с другом, не мешая процессу. Выяснено опытным путём. Если начать обращения от других устройств к Buffer — там уже начинаются конфликты за шину. У нас такое другое устройство, разумеется, одно — Nios II.
Буфер доступен на запись и чтение. DMA туда пишет, затем — Nios II своим JTAG блоком мне спокойно всё перекидывает в отладочное окно. Я разношу эти вещи по времени чисто организационным путём.
То есть, добавляем двунаправленную стрелку доступа к регистрам DMA, делаем двунаправленными стрелки для Buffer и Nios II. Получаем на Вашей схеме то, что задумано.
Когда DMA гонит данные в Buffer, в это время другие устройства на шине могут общаться друг с другом, не мешая процессу. Выяснено опытным путём. Если начать обращения от других устройств к Buffer — там уже начинаются конфликты за шину. У нас такое другое устройство, разумеется, одно — Nios II.
Да, действительно, интерконнекты разделяют каналы для каждого master. То есть, если два master на шине не конкурируют за доступ к одному slave то работать они будут независимо (без взаимных блокировок). Это сделано сознательно и такая реализация интерконнекта не сильно увеличивает потребление ресурсов, а плюсы очевидны.
Для конкурирующих master применяется round-robin (даже можно покрутить приоритеты). Есть ещё сигнал lock, позволяющий захватить шину в эксклюзивное пользование на неопределённое время (но лучше не надо).
Для конкурирующих master применяется round-robin (даже можно покрутить приоритеты). Есть ещё сигнал lock, позволяющий захватить шину в эксклюзивное пользование на неопределённое время (но лучше не надо).
Sign up to leave a comment.
Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM