Comments 24
Библиотеки старые, не развиваются.
Плохо поддерживают русский язык.
Работают только с чистым, специально подготовленным, текстом
Плохо поддерживают UTF-8. Например, SriLM с флагом tolower ломает кодировку.
Из списка немного выделяется KenLM. Регулярно поддерживается и не имеет проблем с UTF-8, но она также требовательна к качеству текста.
Можно глупый вопрос в лоб.
KenLM вроде работает с русским. Даже питоний враппер есть.
Да и никто не мешает просто все эти "проблемы" решить пре-процессингом на питоне без C++. Даже будет мало кода и код легко поддерживать.
Соответственно глупый вопрос — зачем еще одна библиотека?
https://github.com/anyks/alm/#training-using-your-own-features
А токены из нескольких букв?
Или нужно делать "замену алфавита"?
Requirements Python3
Может я пропустил что-то, а интерфейса для вызова на питоне нет?
https://github.com/anyks/alm/#build-on-linux-and-freebsd
А вы планируете поддерживать пакеты в apt / pip?
Это повысит аудиторию проекта раз в 10.
1. Про KenLM, я так и написал, что она поддерживает русский язык и utf-8. Но она же наверное и самая требовательная к качеству текста, например если размер N-граммы выше 3.
2. Свои токены можно устанавливать любого размера без ограничения.
3. Интерфейса для вызова на питоне пока нет, но это в планах. Те скрипты на питоне, их интерпретацией занимается ALM, запуская внутри себя.
4. Поддержка pip будет сразу, как будет готов мост для питона.
2. Свои токены можно устанавливать любого размера без ограничения.
3. Интерфейса для вызова на питоне пока нет, но это в планах. Те скрипты на питоне, их интерпретацией занимается ALM, запуская внутри себя.
4. Поддержка pip будет сразу, как будет готов мост для питона.
Насчёт препроцессинга на питоне, здесь основная идея в токенизаторе, если он плохой, то и собственно обрабатывать нечего. Токенизатор даже в KenLM, работает исключительно по пробелам а значит с неподготовленным за ранее текстом он работать будет плохо. Именно для решения этой задачи и задумывалась библиотека.
Классно, что появляется много новых открытых проектов. Спасибо вам за открытый проект.
Но… я бы не доверил делать качественную токенизацию какой-то плохо понимаемой мной библиотеке на С, когда вместо этого можно написать простой и понятный скрипт на питоне.
Поэтому я бы вам предложил из одной библиотеки сделать две:
одну для токенизации (на питоне), вторую — для быстрого моделирования языка, на С или С++.
В качестве LM библиотеки сейчас вполне хорошо работает KenLM, особенно полезно его умение грузить 10 гб файлы с диска через mmap за долю секунды, потому что от языковой модели в первую очередь требуется скорость (как скорость работы, так и скорость загрузки!).
Я уверен, что ваша языковая модель ещё долго не будет дотягивать до такого уровня скорости, а вот хорошая токенизация из коробки — отличная штука даже сама по себе. Да и будет возможность сравнить вашу токенизацию с тем, что предлагают пользователю готовые питоновские библиотеки токенизации, скажем, razdel или nltk.
От токенизатора в первую очередь требуется управляемость, и для этого нет языка лучше питона.
Ведь, скорее всего, поиск сокращений (abbr), под которыми вы в одном месте документации почему-то понимаете слова типа «1-я», а в другом месте — «МВД», «СНИЛС» и «см.», будет неправильно работать на словах типа «рис.», «см.» (или слишком агрессивно, или никак), далее, наверняка у вас кривое правило для ссылок (https://example.com/1,2,3#сноска-1 — это ссылка до какого момента, и как учитывается остальная часть?), и тому подобное. Вообще, это всё лучше всего доверить быстрому NER, пусть он их правильно размечает. Работа на правилах здесь — полумера, ценность которой вообще непонятна: ну, половину сокращений оно найдет правильно, половину не найдёт. И как потом такой LM пользоваться?
Да и деление на предложения… скажем так, весьма нетривиальная штука. Всяко вы делаете это деление некачественно.
Если же не задумываться о токенизации, то, опять же, просто разбиваем текст по пробелам и знакам препинания, забиваем на деление на предложения, и живём счастливо… Возможно, удаляем знаки препинания, но явно не объединяем точку и запятую в один класс! У них же совсем разные роли!
Итак, чтобы не возиться с C, вы сейчас предлагаете медленное питоновское расширение для токенизации, чтобы делать её каждый раз при генерации LM — но токенизация, по сути, это отдельный этап, лучше её сделать один раз, а потом уже экспериментировать с настройками языковой модели. Да, про эту мысль разбиения на этапы мало написано (точнее, никак!) в документации к KenLM, но со временем все к этому приходят, и часть примеров по использованию KenLM именно так и говорит: сделайте отдельный скрипт для токенизации, а потом тренируйте kenlm на получившемся файле (и со стандартными настройками, ведь вы всё равно не понимаете, какой у этих настроек внутренний смысл, скажем, что такое backoff, и почему делить вероятности нужно только между не встречающимися словами, как у вас написано в тексте… и правда, почему? вероятности сочетающихся слов тоже как-то смещены, так что я вот тоже не понимаю научный смысл вашего smoothing...).
А ещё я пока что вообще не понимаю, как у вас работает питоновское расширение. Где декларируется, что есть тег "", но нету тега ""? Почему оно проверяет на наличие каждого тега независимо, это же медленнее в 10 раз, если у нас 10 тегов… И как сказать, что слова типа "" нужно полностью пропускать, вместо слов типа нужно поставить тег , а остальные слова нужно заменять на их леммы в словаре… И как это всё потом можно будет использовать из клиентского кода на питоне… там же во многих случаях нужно будет применять совпадающий с серверной версией токенизатор…
В общем, меня очень сильно смущает в вашем проекте то, что 90%, а может даже 100% всего проекта можно было бы и не делать, а взять готовые проверенные компоненты, и из них сделать всё то же самое…
Но… я бы не доверил делать качественную токенизацию какой-то плохо понимаемой мной библиотеке на С, когда вместо этого можно написать простой и понятный скрипт на питоне.
Поэтому я бы вам предложил из одной библиотеки сделать две:
одну для токенизации (на питоне), вторую — для быстрого моделирования языка, на С или С++.
В качестве LM библиотеки сейчас вполне хорошо работает KenLM, особенно полезно его умение грузить 10 гб файлы с диска через mmap за долю секунды, потому что от языковой модели в первую очередь требуется скорость (как скорость работы, так и скорость загрузки!).
Я уверен, что ваша языковая модель ещё долго не будет дотягивать до такого уровня скорости, а вот хорошая токенизация из коробки — отличная штука даже сама по себе. Да и будет возможность сравнить вашу токенизацию с тем, что предлагают пользователю готовые питоновские библиотеки токенизации, скажем, razdel или nltk.
От токенизатора в первую очередь требуется управляемость, и для этого нет языка лучше питона.
Ведь, скорее всего, поиск сокращений (abbr), под которыми вы в одном месте документации почему-то понимаете слова типа «1-я», а в другом месте — «МВД», «СНИЛС» и «см.», будет неправильно работать на словах типа «рис.», «см.» (или слишком агрессивно, или никак), далее, наверняка у вас кривое правило для ссылок (https://example.com/1,2,3#сноска-1 — это ссылка до какого момента, и как учитывается остальная часть?), и тому подобное. Вообще, это всё лучше всего доверить быстрому NER, пусть он их правильно размечает. Работа на правилах здесь — полумера, ценность которой вообще непонятна: ну, половину сокращений оно найдет правильно, половину не найдёт. И как потом такой LM пользоваться?
Да и деление на предложения… скажем так, весьма нетривиальная штука. Всяко вы делаете это деление некачественно.
Если же не задумываться о токенизации, то, опять же, просто разбиваем текст по пробелам и знакам препинания, забиваем на деление на предложения, и живём счастливо… Возможно, удаляем знаки препинания, но явно не объединяем точку и запятую в один класс! У них же совсем разные роли!
Итак, чтобы не возиться с C, вы сейчас предлагаете медленное питоновское расширение для токенизации, чтобы делать её каждый раз при генерации LM — но токенизация, по сути, это отдельный этап, лучше её сделать один раз, а потом уже экспериментировать с настройками языковой модели. Да, про эту мысль разбиения на этапы мало написано (точнее, никак!) в документации к KenLM, но со временем все к этому приходят, и часть примеров по использованию KenLM именно так и говорит: сделайте отдельный скрипт для токенизации, а потом тренируйте kenlm на получившемся файле (и со стандартными настройками, ведь вы всё равно не понимаете, какой у этих настроек внутренний смысл, скажем, что такое backoff, и почему делить вероятности нужно только между не встречающимися словами, как у вас написано в тексте… и правда, почему? вероятности сочетающихся слов тоже как-то смещены, так что я вот тоже не понимаю научный смысл вашего smoothing...).
А ещё я пока что вообще не понимаю, как у вас работает питоновское расширение. Где декларируется, что есть тег "", но нету тега ""? Почему оно проверяет на наличие каждого тега независимо, это же медленнее в 10 раз, если у нас 10 тегов… И как сказать, что слова типа "" нужно полностью пропускать, вместо слов типа нужно поставить тег , а остальные слова нужно заменять на их леммы в словаре… И как это всё потом можно будет использовать из клиентского кода на питоне… там же во многих случаях нужно будет применять совпадающий с серверной версией токенизатор…
В общем, меня очень сильно смущает в вашем проекте то, что 90%, а может даже 100% всего проекта можно было бы и не делать, а взять готовые проверенные компоненты, и из них сделать всё то же самое…
Имхо, токенизация для одного домена — собирается за выходные из говна и палок зная домен.
И аналогично допинывается по скорости.
А для всех доменов — писать общую либу токенизации это благие намерения.
Спасибо за критику, буду благодарен за тестирование. Согласитесь, что догадки хорошо а конкретные результаты намного лучше.
buriy, по вашим замечаниям я проверил токенизатор.
Тест:
Результат:
Результат:
P.S. ALM тоже загружает данные с диска через mmap.
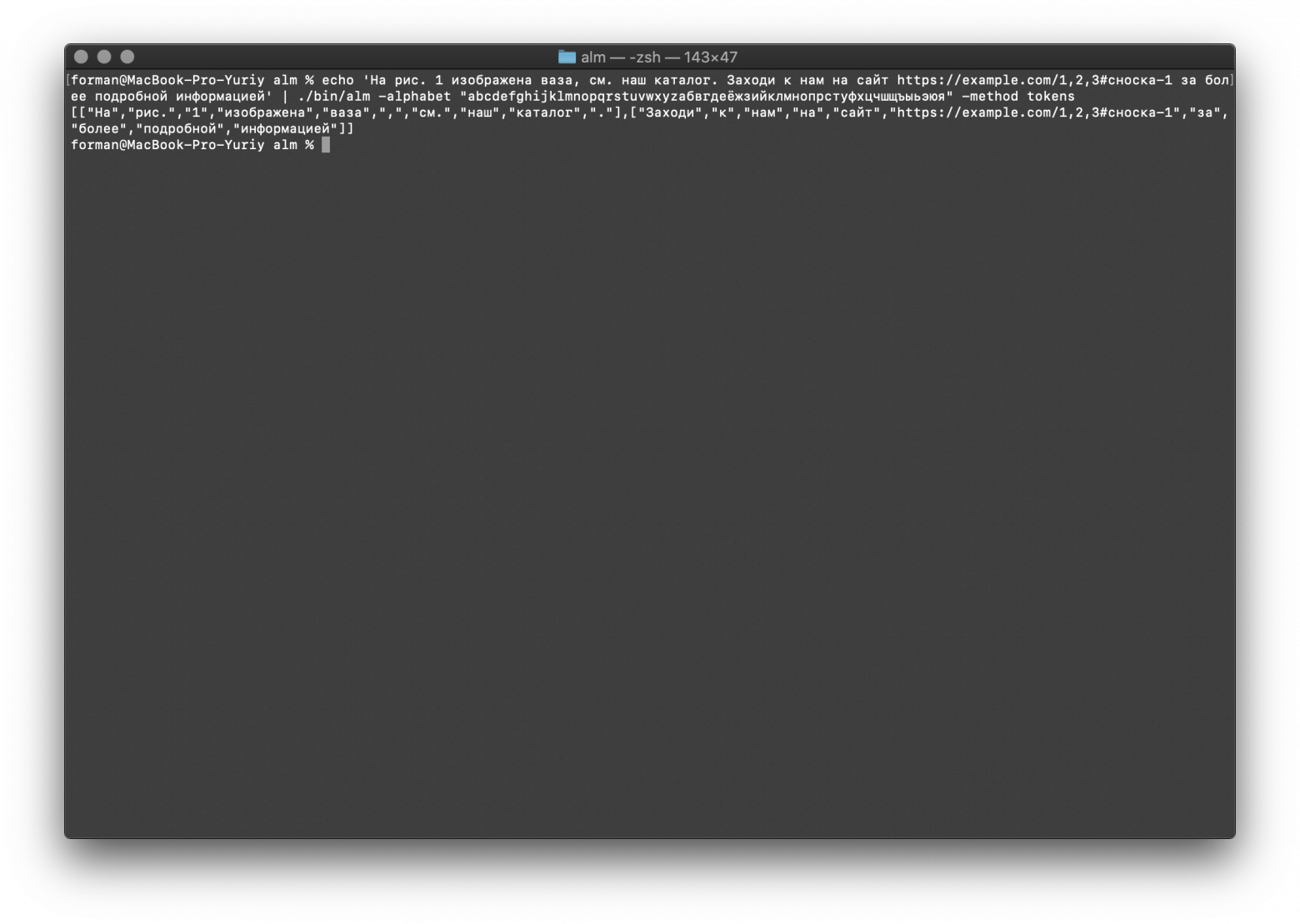
$ echo 'На рис. 1 изображена ваза, см. наш каталог. Заходи к нам на сайт https://example.com/1,2,3#сноска-1 за более подробной информацией' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens

Тест:
На рис. 1 изображена ваза, см. наш каталог. Заходи к нам на сайт https://example.com/1,2,3#сноска-1 за более подробной информацией
Результат:
[
[
"На",
"рис.",
"1",
"изображена",
"ваза",
",",
"см.",
"наш",
"каталог",
"."
],[
"Заходи",
"к",
"нам",
"на",
"сайт",
"https://example.com/1,2,3#сноска-1",
"за",
"более",
"подробной",
"информацией"
]
]
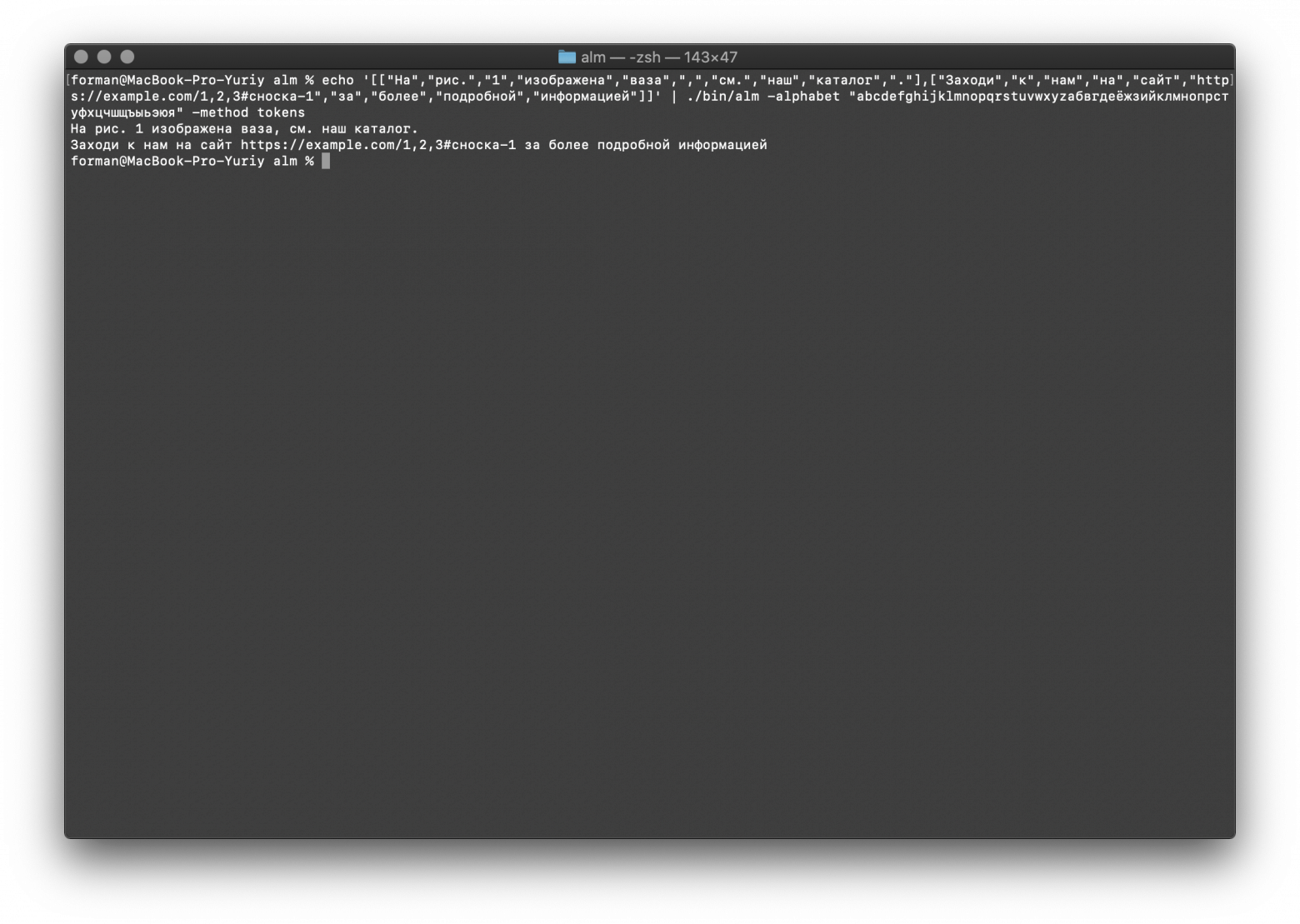
$ echo '[["На","рис.","1","изображена","ваза",",","см.","наш","каталог","."],["Заходи","к","нам","на","сайт","https://example.com/1,2,3#сноска-1","за","более","подробной","информацией"]]' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens

[["На","рис.","1","изображена","ваза",",","см.","наш","каталог","."],["Заходи","к","нам","на","сайт","https://example.com/1,2,3#сноска-1","за","более","подробной","информацией"]]
Результат:
На рис. 1 изображена ваза, см. наш каталог.
Заходи к нам на сайт https://example.com/1,2,3#сноска-1 за более подробной информацией
P.S. ALM тоже загружает данные с диска через mmap.
К любым правилам легко подбирается контрпример.
Если у вас правило разбиения предложений на ". [Большая буква]" идёт первым, то оно будет глючить на таких примерах:
Люди любят г. Волгоград, имеющий историю, уходящую в века.
Если вы его сдвинете позже выделения слов, то токенизация для «Люди любят рис. Нью-дели имеет историю, уходящую в века» сломается.
А правило на ссылки будет глючить на часто встречающихся прилепленных буквах и скобочках к ссылке:
Наш сайт выпивка.рф объявляет набор гостей. Ваш адрес: выпивка.рф/1,2 человека уже зашли, будь третьим! (Напоминаю: выпивка.рф/1)
А уж сколько у вас будет проблем с прямой и косвенной речью… И мы ещё не касались токенизации слов с дефисом (и в целом проблемы разделения дефисов и тире).
Ну и руками тестировать токенизацию бесперспективно, посмотрите хотя бы на github.com/natasha/razdel и их метрики.
P.S. и было бы более продуктивно, если бы вы убрали скриншоты, и оставили только вход и выход программы в текстовом виде. Тяжело листать 3 страницы, в которых лишь 3 уникальных строки, а всё остальное — их повторы. Скажем, так:
Вход:
Если у вас правило разбиения предложений на ". [Большая буква]" идёт первым, то оно будет глючить на таких примерах:
Люди любят г. Волгоград, имеющий историю, уходящую в века.
Если вы его сдвинете позже выделения слов, то токенизация для «Люди любят рис. Нью-дели имеет историю, уходящую в века» сломается.
А правило на ссылки будет глючить на часто встречающихся прилепленных буквах и скобочках к ссылке:
Наш сайт выпивка.рф объявляет набор гостей. Ваш адрес: выпивка.рф/1,2 человека уже зашли, будь третьим! (Напоминаю: выпивка.рф/1)
А уж сколько у вас будет проблем с прямой и косвенной речью… И мы ещё не касались токенизации слов с дефисом (и в целом проблемы разделения дефисов и тире).
Ну и руками тестировать токенизацию бесперспективно, посмотрите хотя бы на github.com/natasha/razdel и их метрики.
P.S. и было бы более продуктивно, если бы вы убрали скриншоты, и оставили только вход и выход программы в текстовом виде. Тяжело листать 3 страницы, в которых лишь 3 уникальных строки, а всё остальное — их повторы. Скажем, так:
Вход:
На рис. 1 изображена ваза, см. наш каталог. Заходи к нам на сайт https://example.com/1,2,3#сноска-1 за более подробной информацией[["На","рис.","1","изображена","ваза",",","см.","наш","каталог","."],["Заходи","к","нам","на","сайт","https://example.com/1,2,3#сноска-1","за","более","подробной","информацией"]]Я понимаю о чем вы говорите и от части даже согласен, но выходит, что мы играем в угадайку тыкая пальцем в небо. Вы предполагаете, что будет ошибка и преподносите это как истину, при этом ничего не проверяя. Да, какие-то недочеты будут, угадать все, везде и вся невозможно. Если вернуться к контексту то KenLM не умеет даже этого. А ALM не ограничивает разработчика в использовании стороннего препроцессинга.
Проверил предложенные вами варианты, самому стало интересно и вот результат.
Первый вариант
Тест:
Результат:
Тест:
Результат:
Второй вариант
Тест:
Результат:
Тест:
Результат:
Третий вариант
Тест:
Результат:
Тест:
Результат:
Как видим, все тесты отработали правильно.
Первый вариант
echo 'Люди любят г. Волгоград, имеющий историю, уходящую в века.' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
Люди любят г. Волгоград, имеющий историю, уходящую в века.
Результат:
[
[
"Люди",
"любят",
"г.",
"Волгоград",
",",
"имеющий",
"историю",
",",
"уходящую",
"в",
"века",
"."
]
]
echo '[["Люди","любят","г.","Волгоград",",","имеющий","историю",",","уходящую","в","века","."]]' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
[["Люди","любят","г.","Волгоград",",","имеющий","историю",",","уходящую","в","века","."]]
Результат:
Люди любят г. Волгоград, имеющий историю, уходящую в века.
Второй вариант
echo 'Люди любят рис. Нью дели имеет историю, уходящую в века' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
Люди любят рис. Нью дели имеет историю, уходящую в века
Результат:
[
[
"Люди",
"любят",
"рис",
"."
],[
"Нью",
"дели",
"имеет",
"историю",
",",
"уходящую",
"в",
"века"
]
]
echo '[["Люди","любят","рис","."],["Нью","дели","имеет","историю",",","уходящую","в","века"]]' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
[["Люди","любят","рис","."],["Нью","дели","имеет","историю",",","уходящую","в","века"]]
Результат:
Люди любят рис.
Нью дели имеет историю, уходящую в века
Третий вариант
echo 'Наш сайт выпивка.рф объявляет набор гостей. Ваш адрес: выпивка.рф/1,2 человека уже зашли, будь третьим! (Напоминаю: выпивка.рф/1)' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
Наш сайт выпивка.рф объявляет набор гостей. Ваш адрес: выпивка.рф/1,2 человека уже зашли, будь третьим! (Напоминаю: выпивка.рф/1)
Результат:
[
[
"Наш",
"сайт",
"выпивка.рф",
"объявляет",
"набор",
"гостей",
"."
],[
"Ваш",
"адрес",
":",
"выпивка.рф/1,2",
"человека",
"уже",
"зашли",
",",
"будь",
"третьим",
"!"
],[
"(",
"Напоминаю",
":",
"выпивка.рф/1",
")"
]
]
echo '[["Наш","сайт","выпивка.рф","объявляет","набор","гостей","."],["Ваш","адрес",":","выпивка.рф/1,2","человека","уже","зашли",",","будь","третьим","!"],["(","Напоминаю",":","выпивка.рф/1",")"]]' | ./bin/alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
[["Наш","сайт","выпивка.рф","объявляет","набор","гостей","."],["Ваш","адрес",":","выпивка.рф/1,2","человека","уже","зашли",",","будь","третьим","!"],["(","Напоминаю",":","выпивка.рф/1",")"]]
Результат:
Наш сайт выпивка.рф объявляет набор гостей.
Ваш адрес: выпивка.рф/1,2 человека уже зашли, будь третьим!
(Напоминаю: выпивка.рф/1)
Как видим, все тесты отработали правильно.
Пожалуйста, уберите лишний вывод, ну мешает же! Оставьте только две строчки: вход и выход. Детокенизация не нужна, картинки тоже.
Во-первых, одни и те же правила не смогут отличить «г.» от «рис.», разве что вы как-то отдельно обрабатываете эти слова или же у вас не система на правилах, а что-то иное.
Давайте добавим сразу все варианты, с запятой после слова, и без неё:
«Так. Я люблю г. Волгоград, я люблю рис. Волгоград, расположенный на реке, красив.
Я люблю гор. Волгоград, я люблю лес. Волгоград, расположенный на реке, красив.»
И да, в вашем коде без дебаггера хрен разберёшься, как я и думал:
github.com/anyks/alm/blob/master/src/tokenizer.cpp#L988
Даже несмотря на комментарии. Чего стоит только эвристика на слова длиной 4 символа.
И, кажется, «я.» будет считать аббревиатурой.
Да и классы символов захардкожены.
В общем, поддерживать кроме вас такой код никто не сможет, а уж тем более, добавить в токенайзер поддержку другого языка…
А так — правила для русского языка вроде бы вы неплохие сделали, можно будет попробовать их использовать.
Во-вторых, тут ошибка:
>[[«Наш»,«сайт»,«выпивка.рф»,«объявляет»,«набор»,«гостей»,"."],[«Ваш»,«адрес»,":",«выпивка.рф/1,2»,«человека»,«уже»,«зашли»,",",«будь»,«третьим»,"!"],["(",«Напоминаю»,":",«выпивка.рф/1»,")"]]
А должно быть «выпивка.рф/1»,«2», «человека».
К тексту из социальных сетей ваш токенайзер ещё рано подпускать, там с расположением пробелов проблемы, да и с большими буквами тоже. Туда — только нейросети.
Во-первых, одни и те же правила не смогут отличить «г.» от «рис.», разве что вы как-то отдельно обрабатываете эти слова или же у вас не система на правилах, а что-то иное.
Давайте добавим сразу все варианты, с запятой после слова, и без неё:
«Так. Я люблю г. Волгоград, я люблю рис. Волгоград, расположенный на реке, красив.
Я люблю гор. Волгоград, я люблю лес. Волгоград, расположенный на реке, красив.»
И да, в вашем коде без дебаггера хрен разберёшься, как я и думал:
github.com/anyks/alm/blob/master/src/tokenizer.cpp#L988
Даже несмотря на комментарии. Чего стоит только эвристика на слова длиной 4 символа.
И, кажется, «я.» будет считать аббревиатурой.
Да и классы символов захардкожены.
В общем, поддерживать кроме вас такой код никто не сможет, а уж тем более, добавить в токенайзер поддержку другого языка…
А так — правила для русского языка вроде бы вы неплохие сделали, можно будет попробовать их использовать.
Во-вторых, тут ошибка:
>[[«Наш»,«сайт»,«выпивка.рф»,«объявляет»,«набор»,«гостей»,"."],[«Ваш»,«адрес»,":",«выпивка.рф/1,2»,«человека»,«уже»,«зашли»,",",«будь»,«третьим»,"!"],["(",«Напоминаю»,":",«выпивка.рф/1»,")"]]
А должно быть «выпивка.рф/1»,«2», «человека».
К тексту из социальных сетей ваш токенайзер ещё рано подпускать, там с расположением пробелов проблемы, да и с большими буквами тоже. Туда — только нейросети.
Хочу заметить, что очевидно перед данным решением стояла не только задача токенизации, а более объемная задача статистической языковой модели. Жаль это осталось без рассмотрения.
Большое спасибо за фидбек по кодовой базе — я обязательно учту некоторые моменты.
Но, к сожалению, не только семантика делает понимание исходников сложным, но и требования по уровню экспертизы читающего. Данное решение по умолчанию не простое ввиду необходимой специфики для решения задач. Специалистов с хорошей экспертизой в инженерии по данной теме, а не использовании подобных решений, очень мало.
Классы символов не захардкожены. В статье описано какие символы к каким токенам относятся.
Есть механизм переопределения и отключения токенов.
выпивка.рф/1,2 — отработал правильно, такой формат URI разрешен спецификацией.
В данном варианте не каждый человек поймёт, а мысли пока приложения читать не умеют.
>> А так — правила для русского языка вроде бы вы неплохие сделали, можно будет попробовать их использовать.
Все европейские языки, с азиатскими конечно будут проблемы. Поддержка токенизатором языка, ограничивается только алфавитом ну и передаваемым списком аббревиатур.
>> К тексту из социальных сетей ваш токенайзер ещё рано подпускать, там с расположением пробелов проблемы, да и с большими буквами тоже. Туда — только нейросети.
Чтобы обучить нейросеть, нужна разметка и эмбеддинг.
И повторюсь, статья не о токенизаторе а о языковой модели, токенизатор это небольшой функционал библиотеки.
Если для работы вы используете KenLM, то в ALM все те же самые подходы также будут работать.
Токенизатор не ограничивает функционал и никто вам, не мешает чистить текст перед обучением своими скриптами.
P.S. Я не думаю, что код в SriLM или KenLM проще или что есть много желающих его дописать.
Большое спасибо за фидбек по кодовой базе — я обязательно учту некоторые моменты.
Но, к сожалению, не только семантика делает понимание исходников сложным, но и требования по уровню экспертизы читающего. Данное решение по умолчанию не простое ввиду необходимой специфики для решения задач. Специалистов с хорошей экспертизой в инженерии по данной теме, а не использовании подобных решений, очень мало.
Классы символов не захардкожены. В статье описано какие символы к каким токенам относятся.
Есть механизм переопределения и отключения токенов.
выпивка.рф/1,2 — отработал правильно, такой формат URI разрешен спецификацией.
В данном варианте не каждый человек поймёт, а мысли пока приложения читать не умеют.
>> А так — правила для русского языка вроде бы вы неплохие сделали, можно будет попробовать их использовать.
Все европейские языки, с азиатскими конечно будут проблемы. Поддержка токенизатором языка, ограничивается только алфавитом ну и передаваемым списком аббревиатур.
>> К тексту из социальных сетей ваш токенайзер ещё рано подпускать, там с расположением пробелов проблемы, да и с большими буквами тоже. Туда — только нейросети.
Чтобы обучить нейросеть, нужна разметка и эмбеддинг.
И повторюсь, статья не о токенизаторе а о языковой модели, токенизатор это небольшой функционал библиотеки.
Если для работы вы используете KenLM, то в ALM все те же самые подходы также будут работать.
Токенизатор не ограничивает функционал и никто вам, не мешает чистить текст перед обучением своими скриптами.
P.S. Я не думаю, что код в SriLM или KenLM проще или что есть много желающих его дописать.
>Хочу заметить, что очевидно перед данным решением стояла не только задача токенизации, а более объемная задача статистической языковой модели. Жаль это осталось без рассмотрения.
Надеюсь, теперь вы понимаете, как ваша разработка видится со стороны.
При продуктивизации пользователи всегда фокусируются на одной части продукта.
У вас же — два, а в перспективе даже три разных продукта, с разным позиционированием и разными пользователями.
ALM как LM — международный продукт для N-gram LM для замены KenLM,
русский токенайзер — российский продукт с более широким применением, чем LM — ведь хорошая токенизация нужна любому парсингу и пониманию текста.
А потом ещё будут и статистические модели, снова будет отдельный продукт: какие-то готовые модели, наверное, будете делать и распространять.
Если же вы будете совмещать эти вещи вместе, то кто-то будет на него смотреть как на «токенизатор с хардкодом для русского языка без API на питоне и зачем-то сбоку прикрученной LM», кто-то — как на «неплохую LM с зачем-то сбоку прикрученным токенизатором», и так далее.
Один продукт должен хорошо решать одну задачу, а не две, но средненько.
Продукты могут друг с другом взаимодействовать, но зачем им при этом быть одним неделимым продуктом? К тому же, в вашем случае, даже взаимодействия между ними никакого нет, просто один продукт использует результаты другого.
Надеюсь, теперь вы понимаете, как ваша разработка видится со стороны.
При продуктивизации пользователи всегда фокусируются на одной части продукта.
У вас же — два, а в перспективе даже три разных продукта, с разным позиционированием и разными пользователями.
ALM как LM — международный продукт для N-gram LM для замены KenLM,
русский токенайзер — российский продукт с более широким применением, чем LM — ведь хорошая токенизация нужна любому парсингу и пониманию текста.
А потом ещё будут и статистические модели, снова будет отдельный продукт: какие-то готовые модели, наверное, будете делать и распространять.
Если же вы будете совмещать эти вещи вместе, то кто-то будет на него смотреть как на «токенизатор с хардкодом для русского языка без API на питоне и зачем-то сбоку прикрученной LM», кто-то — как на «неплохую LM с зачем-то сбоку прикрученным токенизатором», и так далее.
Один продукт должен хорошо решать одну задачу, а не две, но средненько.
Продукты могут друг с другом взаимодействовать, но зачем им при этом быть одним неделимым продуктом? К тому же, в вашем случае, даже взаимодействия между ними никакого нет, просто один продукт использует результаты другого.
В python библиотека будет доступна уже в эти выходные. Можно использовать токенизатор отдельно от языковой модели. Я все же не согласен с тем, что токенизатор не нужен языковой модели, в моём понимании языковая модель сильно зависит от токенизатора. Во всяком случае я предусмотрел возможности его отключения и в ситуациях когда он не нужен, можно работать также как допустим с KenLM или SriLM.
На русский язык упор был сделан потому, что в нашем мире принято его в лучшем случае учитывать как данность нежели полноценно его поддерживать. Но хочу заметить, жестко ничего не вшито в библиотеку, что относится к русскому языку и мешает другим языкам. В равной степени поддерживаются все европейские языки.
На русский язык упор был сделан потому, что в нашем мире принято его в лучшем случае учитывать как данность нежели полноценно его поддерживать. Но хочу заметить, жестко ничего не вшито в библиотеку, что относится к русскому языку и мешает другим языкам. В равной степени поддерживаются все европейские языки.
А вот скажите, какой алфавит должен быть у английского? Какой у французского? Какой у русского? Одинаковый? Как вы будете обрабатывать документ со смесью языков? А датасет? У вас «don't» и «c'est» будут неправильно токенизироваться, и, кстати, вы не сможете наверное нормализовать don't до do not. И умляуты обработать… Прямая речь оформляется по-разному, значит, у вас будут проблемы с границами предложений. Дефисы…
В «l'astronomie» обычно должно выделяться «l'» как токен, например. А попробуйте теперь токенизировать «On nous dit qu'aujourd'hui c'est le cas, encore faudra-t-il l'évaluer» вашей библиотекой.
Прям эффект Даннинга — Крюгера в чистом виде. Мало знаете про токенизацию в разных языках, но думаете, что всё знаете.
В «l'astronomie» обычно должно выделяться «l'» как токен, например. А попробуйте теперь токенизировать «On nous dit qu'aujourd'hui c'est le cas, encore faudra-t-il l'évaluer» вашей библиотекой.
Прям эффект Даннинга — Крюгера в чистом виде. Мало знаете про токенизацию в разных языках, но думаете, что всё знаете.
Послушайте себя, это не конструктивный диалог. Может мы перестанем играть в угадайку? Пришлите конкретный результат, собственно тестирование я просил уже много раз. Вы же не знаете как он работает но зато много предположений. Если будут ошибки, я буду исправлять. Я ни разу не преподносил токенизатор как панацею от всех болезней и сразу сказал, что возможны баги.
Насчёт нормализации текстов don't -> do not — это не задача токенизатора, это совершенно уже другой продукт.
Прям эффект Даннинга — скорее относится к вам, уже не раз это замечаю.
Я не говорил, что всё знаю, я сделал продукт, если есть предложения по его доработке, я также готов выслушать.
Насчёт нормализации текстов don't -> do not — это не задача токенизатора, это совершенно уже другой продукт.
Прям эффект Даннинга — скорее относится к вам, уже не раз это замечаю.
Я не говорил, что всё знаю, я сделал продукт, если есть предложения по его доработке, я также готов выслушать.
Как я его сейчас протестирую сам? Это надо его ставить долго сейчас, запускать. Подождём pip install хотя бы. Далее, какой смысл тестировать руками на нескольких предложениях? Надо делать датасет для тестирования.
«Если будут ошибки, я буду исправлять.» — очень медленный процесс, и я считаю его несколько бестолковым в ИИ-задачах, уж извините.
Слишком много примеров парсеров на правилах, которые люди дописывают годами, а потом «внезапно» их существенно обходят нейросети. Да и свой такой же опыт есть, и с правилами, и с нейросетями. Токенайзер типа вашего я делал, представьте себе. Многоязычный. Давно, лет 6 назад, наверное.
И вообще, возьмите датасет из razdel, да протестируйте. Всё открыто, там сотни тысяч предложений.
«Если будут ошибки, я буду исправлять.» — очень медленный процесс, и я считаю его несколько бестолковым в ИИ-задачах, уж извините.
Слишком много примеров парсеров на правилах, которые люди дописывают годами, а потом «внезапно» их существенно обходят нейросети. Да и свой такой же опыт есть, и с правилами, и с нейросетями. Токенайзер типа вашего я делал, представьте себе. Многоязычный. Давно, лет 6 назад, наверное.
И вообще, возьмите датасет из razdel, да протестируйте. Всё открыто, там сотни тысяч предложений.
Версия для Python скоро будет, я сообщу. Конечно надо тестировать на датасете а не руками. В razdel разве есть датасет для французского языка?
>В razdel разве есть датасет для французского языка?
Так вам для французского правильный ответ нужен? Как-то так будет норм, преимущественно апостроф влево докладывается, кажется, иногда всё же вправо бывает что ли… не помню уже: On|nous|dit|qu'|aujourd'|hui|c'|est|le|cas|,|encore|faudra|-|t|-|il|l'| évaluer. Но иногда лучше восстанавливать изначальные слова: qu' -> que, для тех же ASR LM.
А в английском где-то налево, где-то направо, в принципе часто можно склеивать.
А как разделять -t -il — по-разному можно, в идеале я бы дефис слева доложил к этим словам, а не отдельно сложил, и уж точно не превращал в [punct]. Вообще, для ASR пунктуацию удаляют, для OCR обычно оставляют, для spell checking оставляют. Нужно смотреть. И так же нужно смотреть особенности каждого европейского языка.
Конечно, это максимум единицы процентов качества, но в некоторых более популярных случаях будет очень обидно, если LM будет косячить из-за токенайзера, а починить это потом крайне трудно, поэтому я считаю, что уж если делать кастомный токенайзер, то делать хороший, а иначе можно взять любой готовый.
Датасеты для кучи языков можно взять в датасетах universaldependencies.org для морфо-синтаксического парсинга. Правда, там не будет слитного написания знаков препинания (но можно вручную рандомно зааугментировать датасет), но вот дефисы там будут, и предложения можно будет посклеивать и посмотреть, правильно ли ваша либа их потом разрезает.
Так вам для французского правильный ответ нужен? Как-то так будет норм, преимущественно апостроф влево докладывается, кажется, иногда всё же вправо бывает что ли… не помню уже: On|nous|dit|qu'|aujourd'|hui|c'|est|le|cas|,|encore|faudra|-|t|-|il|l'| évaluer. Но иногда лучше восстанавливать изначальные слова: qu' -> que, для тех же ASR LM.
А в английском где-то налево, где-то направо, в принципе часто можно склеивать.
А как разделять -t -il — по-разному можно, в идеале я бы дефис слева доложил к этим словам, а не отдельно сложил, и уж точно не превращал в [punct]. Вообще, для ASR пунктуацию удаляют, для OCR обычно оставляют, для spell checking оставляют. Нужно смотреть. И так же нужно смотреть особенности каждого европейского языка.
Конечно, это максимум единицы процентов качества, но в некоторых более популярных случаях будет очень обидно, если LM будет косячить из-за токенайзера, а починить это потом крайне трудно, поэтому я считаю, что уж если делать кастомный токенайзер, то делать хороший, а иначе можно взять любой готовый.
Датасеты для кучи языков можно взять в датасетах universaldependencies.org для морфо-синтаксического парсинга. Правда, там не будет слитного написания знаков препинания (но можно вручную рандомно зааугментировать датасет), но вот дефисы там будут, и предложения можно будет посклеивать и посмотреть, правильно ли ваша либа их потом разрезает.
Юрий — Вас подтолкнули на очень неоднозначный пример, но поскольку он решился именно с таким результатом, мне стала интересна логика принятия решения.
Если чуть подробнее, то в строке: "На рис. 1 изображена ваза, см. наш каталог." кроется двойная неоднозначность при токенизации и разборе:
В этой связи у меня два вопроса:
— какова у Вас универсальная логика принятия решения при токенизации в данном случае?
— каков механизм разрешения неоднозначности, ну хотя бы для того, чтобы ответить однозначно на вопрос, что фраза «имеет верный контекст с точки зрения собранной языковой модели.»?
Заранее благодарен за ответ.
Если чуть подробнее, то в строке: "На рис. 1 изображена ваза, см. наш каталог." кроется двойная неоднозначность при токенизации и разборе:
- токенизация: давайте попробуем другую фразу, скажем в «Смотри на этот рис. 4 месяц 1912 года стал трагедией для Титаника.». Здесь «рис» — это конец предложения, даже будучи сокращением слова рисунок.
- анализ текста: при попытке лемматизации Вашего предложения или переделанного мной, на «рис.» мы получим минимум два значения — сокращение от рисунок и «рис» — как растение. При этом, контекст многих предложений не даст однозначного ответа, какое из двух слов имелось ввиду.
В этой связи у меня два вопроса:
— какова у Вас универсальная логика принятия решения при токенизации в данном случае?
— каков механизм разрешения неоднозначности, ну хотя бы для того, чтобы ответить однозначно на вопрос, что фраза «имеет верный контекст с точки зрения собранной языковой модели.»?
Заранее благодарен за ответ.
avl33, ведь это — просто токенизатор, неоднозначности в таком виде он снимать не умеет.
Предложенный вами вариант будет интерпретирован как аббревиатура.
Токенизатор это только часть функционала библиотеки, основной функционал это — языковая модель.
Неоднозначности такого рода можно снимать только после обучения языковой модели, когда контекст будет собран. На этапе сборки, контекст ещё неизвестен.
После сборки языковой модели, по уже известному контексту — можно снимать неоднозначности. Такой функционал на половину реализован, сам токенизатор предстоит еще доработать, для работы с обученной языковой моделью.
По поводу: «имеет верный контекст с точки зрения собранной языковой модели.»
Если собирать языковую модель обычным токенизатором который работает по пробелам, любые знаки препинания будут ломать N-граммы.
Текст:
Собранные N-граммы длины 3:
Из этого мы имеем сломанные N-граммы от которых пользы ноль
Конечно, большинство людей скажут, мол за ранее удаляем все знаки препинания и задача решена. Но нет, в этом случае мы получаем также сломанные N-граммы выбитые из контекста. Другие скажут, берём n-граммы между знаками препинаний, но тогда мы сильно теряем в контексте получая мало информации. Куда правильнее знаки препинания учитывать также отдельными N-граммами, да неоднозначности будут, да они всегда будут и не важно какое приложение работает с текстом, будь нейросетевые решения или решения основанные на алгоритмах и шаблонах.
Токенизатор ALM соберет эти N-граммы таким образом:
Таким образом мы не теряем контекст и учитываем его более правильно. Для большинства вариантов текстов, этого достаточно. Бывает, что знаки препинания очень важны и их следует разделять, учитывать как отдельные N-граммы, чтобы точка была — точкой а запятая — запятой. Для этого — предусмотрен механизм с помощью скриптов python, переопределять N-граммы по своему. Собственно это и есть подконтрольный токенизатор. В данном случае, каждая новая N-грамма будет передана в скрипт и разработчик по своему мнению может её обработать.
Предложенный вами вариант будет интерпретирован как аббревиатура.
Токенизатор это только часть функционала библиотеки, основной функционал это — языковая модель.
Неоднозначности такого рода можно снимать только после обучения языковой модели, когда контекст будет собран. На этапе сборки, контекст ещё неизвестен.
После сборки языковой модели, по уже известному контексту — можно снимать неоднозначности. Такой функционал на половину реализован, сам токенизатор предстоит еще доработать, для работы с обученной языковой моделью.
По поводу: «имеет верный контекст с точки зрения собранной языковой модели.»
Если собирать языковую модель обычным токенизатором который работает по пробелам, любые знаки препинания будут ломать N-граммы.
Текст:
Если поставить simple.c в конец, то получается, что использование символа ...
Собранные N-граммы длины 3:
Если поставить simple.c
поставить simple.c в
simple.c в конец,
в конец, то
конец, то получается,
то получается, что
получается, что использование
что использование символа
Из этого мы имеем сломанные N-граммы от которых пользы ноль
simple.c в конец,
в конец, то
конец, то получается,
то получается, что
получается, что использование
Конечно, большинство людей скажут, мол за ранее удаляем все знаки препинания и задача решена. Но нет, в этом случае мы получаем также сломанные N-граммы выбитые из контекста. Другие скажут, берём n-граммы между знаками препинаний, но тогда мы сильно теряем в контексте получая мало информации. Куда правильнее знаки препинания учитывать также отдельными N-граммами, да неоднозначности будут, да они всегда будут и не важно какое приложение работает с текстом, будь нейросетевые решения или решения основанные на алгоритмах и шаблонах.
Токенизатор ALM соберет эти N-граммы таким образом:
Если поставить simple.c
поставить simple.c в
simple.c в конец
в конец <punct>
конец <punct> то
<punct> то получается
то получается <punct>
получается <punct> что
<punct> что использование
что использование символа
Таким образом мы не теряем контекст и учитываем его более правильно. Для большинства вариантов текстов, этого достаточно. Бывает, что знаки препинания очень важны и их следует разделять, учитывать как отдельные N-граммы, чтобы точка была — точкой а запятая — запятой. Для этого — предусмотрен механизм с помощью скриптов python, переопределять N-граммы по своему. Собственно это и есть подконтрольный токенизатор. В данном случае, каждая новая N-грамма будет передана в скрипт и разработчик по своему мнению может её обработать.
ведь это — просто токенизатор, неоднозначности в таком виде он снимать не умеет.
Предложенный вами вариант будет интерпретирован как аббревиатура.
Токенизатор это только часть функционала библиотеки, основной функционал это — языковая модель.
Мой вопрос как раз и касался того, что токенизатор дал однозначный ответ в неоднозначной ситуации ещё до того, как модель была проанализирована. Вот эта неоднозначность: "На рис. 1 изображена ваза".
Токенизатор принял однозначное решение, что это — одно предложение.
Именно это меня заинтересовало в первую очередь, отсюда и возник вопрос, каков универсальный алгоритм принятия решения токенизатором в подобной ситуации. Для большей наглядности я дал чуть другой пример: "Смотри на этот рис. 4 месяц 1912 года стал трагедией для Титаника".
Принятие решения токенизатором о том, что это одно предложение — уже будет неверным.
В этом был мой вопрос.
После Вашего пояснения (я полностью с ним согласен и у себя в токенизаторе применяю почти такой же подход) о том, что при обработке и анализе важно учитывать, а не обнулять знаки препинания, ситуация с такой работой токенизатора будет «вводить в заблуждение» дальнейший алгоритм анализа текста.
Ну, я во всяком случае, получаю на своих тестах, именно такой результат. И мои тесты показывают, что словарь сокращений — путь назад от автоматизации.
Поскольку моё видение и тесты не есть истина в последней инстанции, мне и стала интересна Ваша логика для токенизатора. Кстати, по статистике — пояснительные сокращения после цифр в тексте появляются в десятки процентов раз больше, чем до.
Я с вами согласен, по этому в ALM предусмотрены механизмы свободы действий, все, что не нужно в конкретной работе — отключается. В одной ситуации нужно учитывать знаки препинания как они есть, в другой удобнее когда это единый тег. Токенизатор также хорошо работает по обычным пробелам, текст можно обрабатывать отдельно.
На самом деле в ALM два токенизатора, вернее есть надстройка над основной токенизатор которая используется отдельно. Токенизатор доступный как инструмент помимо языковой модели, выдает только токены которые он отловил, именно его работу я показывал. Надстройка в языковой модели уже выполняет распределение этих токенов по классам.
В выходные будет доступна версия библиотеки для python где все методы ALM (за исключением методов обучения), будут доступны для свободного использования.
На самом деле в ALM два токенизатора, вернее есть надстройка над основной токенизатор которая используется отдельно. Токенизатор доступный как инструмент помимо языковой модели, выдает только токены которые он отловил, именно его работу я показывал. Надстройка в языковой модели уже выполняет распределение этих токенов по классам.
В выходные будет доступна версия библиотеки для python где все методы ALM (за исключением методов обучения), будут доступны для свободного использования.
Sign up to leave a comment.
Альтернативное понимание контекста с помощью статистической языковой модели