Всем привет! Меня зовут Саша, я CTO & Co-Founder в LoyaltyLab. Два года назад я с друзьями, как и все бедные студенты, ходил вечером за пивом в ближайший магазин у дома. Нас очень расстраивало, что ритейлер, зная, что мы придём за пивом, не предлагает скидку на чипсы или сухарики, хотя это так логично! Мы не поняли, почему такая ситуация происходит и решили сделать свою компанию. Ну и как бонус выписывать себе скидки каждую пятницу на те самые чипсы.

И дошло всё до того, что с материалом по технической стороне продукта я выступаю на NVIDIA GTC. Мы рады делиться наработками с коммьюнити, поэтому я выкладываю свой доклад в виде статьи.
Введение
Как и все в начале пути, мы стартанули с обзора того, как делаются рекомендательные системы. И самой популярной оказалась архитектура следующего типа:

Она состоит из двух частей:
- Сэмплирование кандидатов для рекомендаций простой и быстрой моделью, обычно коллаборативной.
- Ранжирование кандидатов более сложной и медленной контентной моделью c учётом всех возможных признаков в данных.
Здесь и далее буду использовать следующие термины:
- candidate/кандидат для рекомендаций — пара user-product, которая потенциально может попасть в рекомендации в продакшн.
- candidates extraction/extractor/метод извлечения кандидатов — процесс или метод извлечения “кандидатов для рекомендаций” по имеющимся данным.
На первом шаге обычно используют разные вариации коллаборативной фильтрации. Самая популярная — ALS. Удивительно, что большинство статей про рекомендательные системы раскрывают только различные улучшения коллаборативных моделей на первом этапе, но про другие методы сэмплирования особо никто не рассказывает. Для нас подход с использованием только коллаборативных моделей и различных оптимизаций с ними не сработал с качеством, которые мы ожидали, поэтому мы закопались в исследования конкретно по этой части. А в конце статьи я покажу, насколько мы смогли улучшить ALS, который был для нас baseline’ом.
Перед тем, как я перейду к описанию нашего подхода, важно отметить, что при realtime рекомендациях, когда нам важно учитывать данные, которые произошли 30 минут назад, действительно, не так много подходов, которые могут работать за нужное время. Но, в нашем случае, собирать рекомендации приходится не чаще, чем раз в день, а в большинстве случаев — раз в неделю, что даёт нам возможность использовать сложные модели и кратно повысить качество.
Возьмём за baseline то, какие метрики показывает только ALS на задаче извлечения кандидатов. Ключевые метрики, за которыми мы следим, следующие:
- Precision — доля правильно подобранных кандидатов из насэмплированных.
- Recall — доля случившихся кандидатов из тех, которые реально были в target интервале.
- F1-score — F-мера, рассчитанная на предыдущих двух пунктах.
Также будем смотреть на метрики финальной модели после обучения градиентного бустинга с дополнительными контентными признаками. Здесь тоже 3 основные метрики:
- precision@5 — средняя доля попадания товаров из топ-5 по вероятности по каждому покупателю.
- response-rate@5 — конверсия покупателей из визита в магазин в покупку хотя бы одного персонального предложения (в одном предложении 5 товаров).
- avg roc-auc per user — средний roc-auc по каждому покупателю.
Важно отметить, что все названные метрики измеряются на time-series кросс-валидации, то есть обучение происходит на первых k неделях, а в качестве test данных берётся k+1 неделя. Таким образом сезонные взлёты/падения минимально отражались на интерпретации качества моделей. Далее на всех графиках ось абсцисс будет означать номер недели в кросс-валидации, а ось ординат — значение указанной метрики. Все графики построены на транзакционных данных одного клиента, чтобы сравнение между собой было корректным.
Перед тем, как начать описывать наш подход, сначала посмотрим на baseline, который представляет из себя обученную ALS модель.
Метрики по извлечению кандидатов:
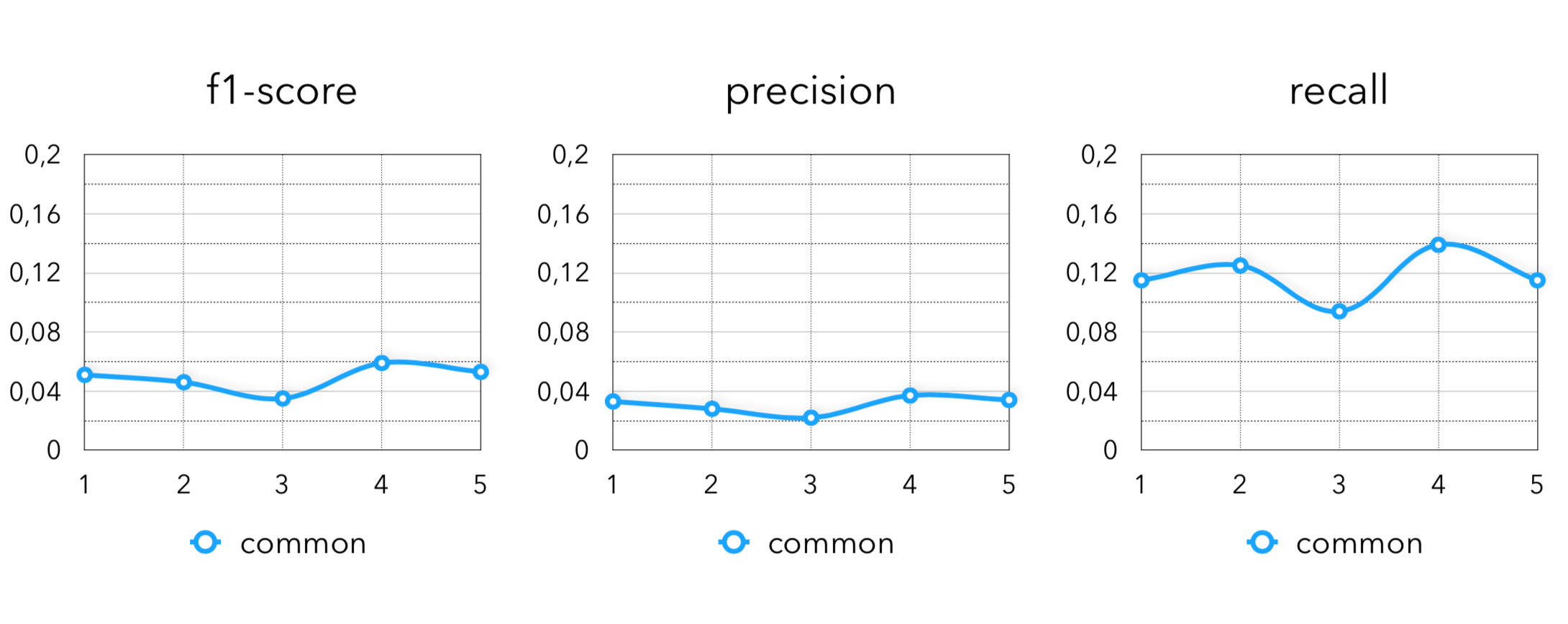
Финальные метрики:
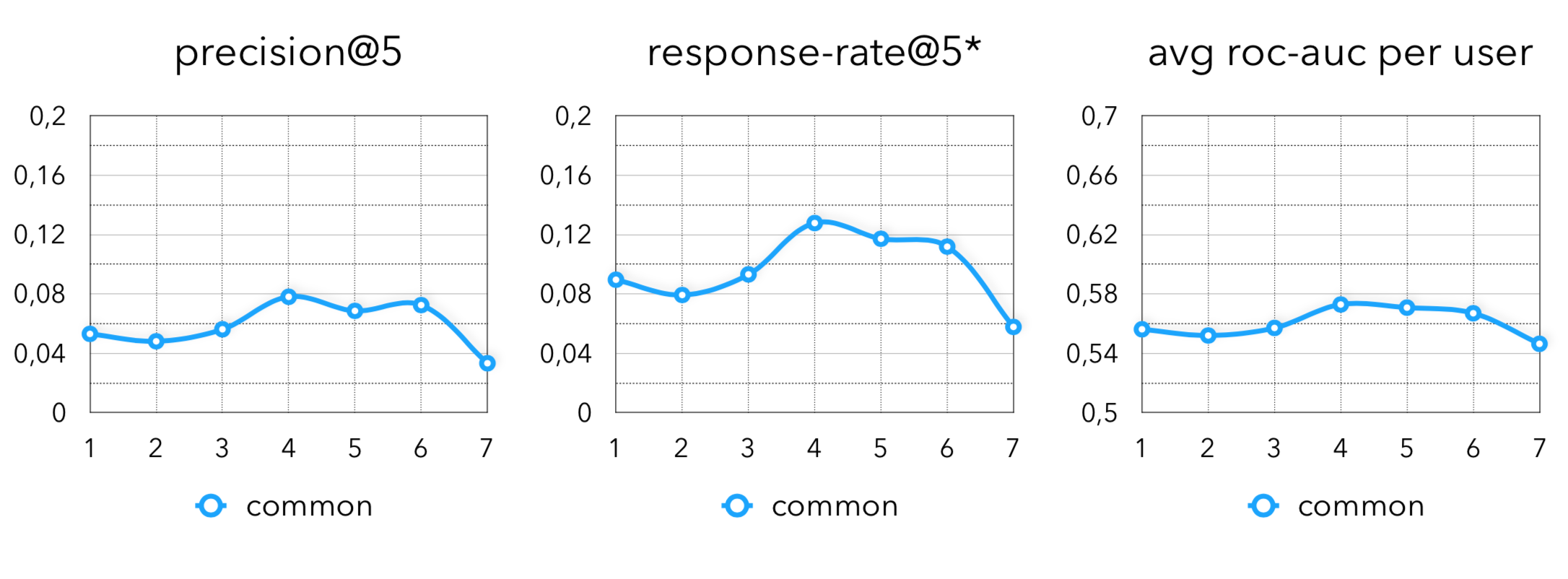
Я отношусь ко всем реализациям алгоритмов, как к некоторой бизнес гипотезе. Таким образом, очень грубо, любые коллаборативные модели можно рассматривать, как гипотезу, что “люди склонны покупать то, что покупают похожие на них люди”. Как я уже говорил, только такой семантикой мы не ограничились и вот, какие гипотезы еще круто работает на данных в оффлайн ритейле:
- Что уже покупал раньше.
- Похожее на то, что покупал раньше.
- Период давно прошедшей покупки.
- Популярное по категориям/брендам.
- Поочередные покупки разных товаров от недели к неделе (цепи Маркова).
- Похожие товары на покупателей, по характеристикам, построенным разными моделями (Word2Vec, DSSM, etc.).
Что покупал раньше
Самая очевидная эвристика, которая очень хорошо работает в продуктовом ритейле. Здесь мы берём все товары, которые обладатель карты лояльности покупал за последние K дней (обычно 1-3 недели), либо K дней за год назад. Применив только такой метод, получаем следующие метрики:
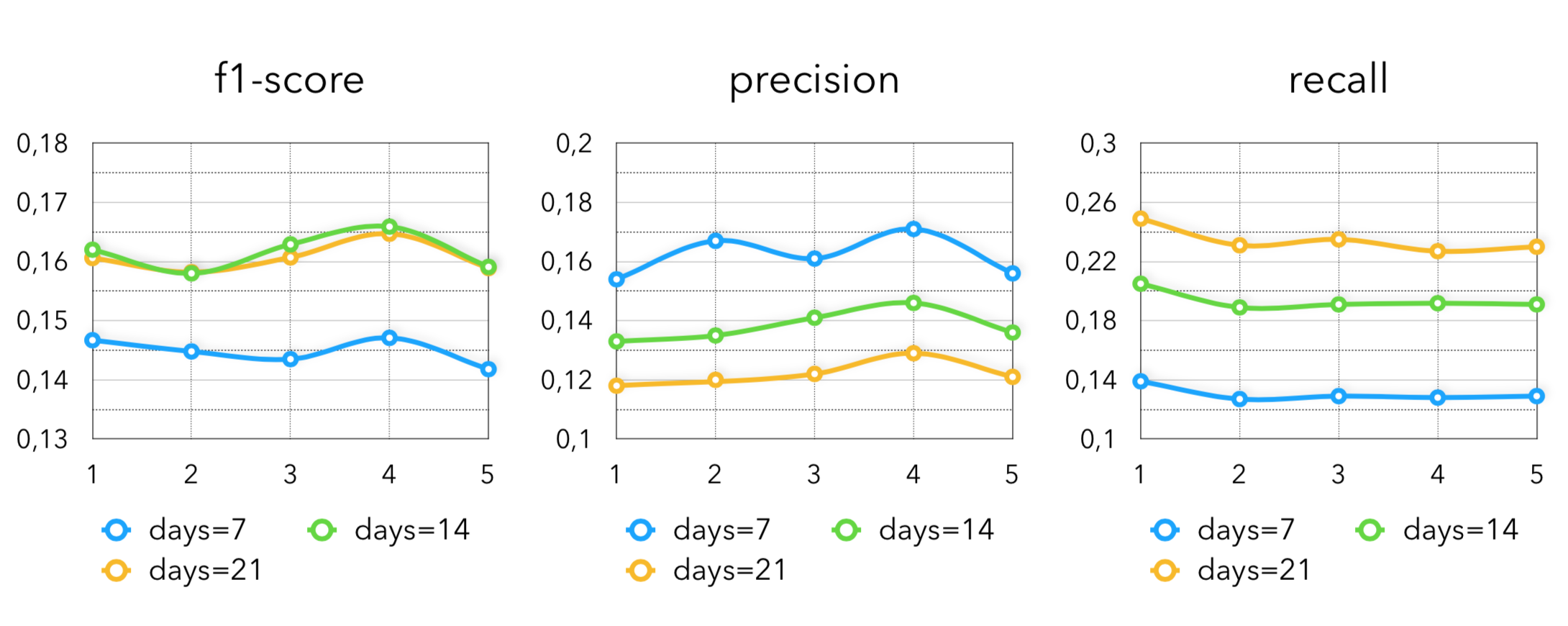
Тут вполне очевидно, что, чем больше мы берём период, тем больше у нас recall и меньше precision и наоборот. Лучше результаты в среднем по клиентам даёт “последние 2 недели”.
Похожее на то, что покупал раньше
Не удивительно, что для продуктового ритейла “что покупал раньше” работает хорошо, но извлекать кандидатов только из того, что пользователь уже покупал не очень круто, потому что так удивить покупателя каким-то новым товаром вряд ли получится. Поэтому предлагаем немного усовершенствуем эту эвристику с помощью тех же коллаборативных моделей. Из векторов, которые мы получили во время обучения ALS, можно достать похожие товары на то, что пользователь уже покупал. Такая идея очень похожа на “похожие ролики” в сервисах по просмотру видеоконтента, но так как мы не знаем, что в конкретный момент ест/покупает юзер, нам остаётся только искать похожее только к тому, что он уже покупал, тем более, что мы уже знаем, насколько это хорошо работает. Применив такой метод на транзакциях пользователей за последние 2 недели получаем следующие метрики:

Здесь k — количество похожих товаров, которые извлекаются на каждый купленный покупателем товар за последние 14 дней.
Этот подход у нас особенно хорошо сработал на клиенте, которому было критично совсем не рекомендовать то, что уже было в истории покупок пользователя.
Период давно прошедшей покупки
Как мы уже выяснили, из-за высокой периодичности покупки товаров первый подход хорошо работает на нашей специфике. Но как быть с товарами, типа стиральный порошок/шампунь/тд. То есть с такими продуктами, которые вряд ли нужны каждые неделю-две и которые предыдущие методы не могут извлечь. Отсюда вытекает следующая идея — предлагается вычислять период покупки каждого товара в среднем по покупателям, которые приобретали товар больше k раз. А дальше извлекать то, что скорее всего у покупателя уже закончилось. Подсчитанные периоды по товарам можно проверить глазами на адекватность:
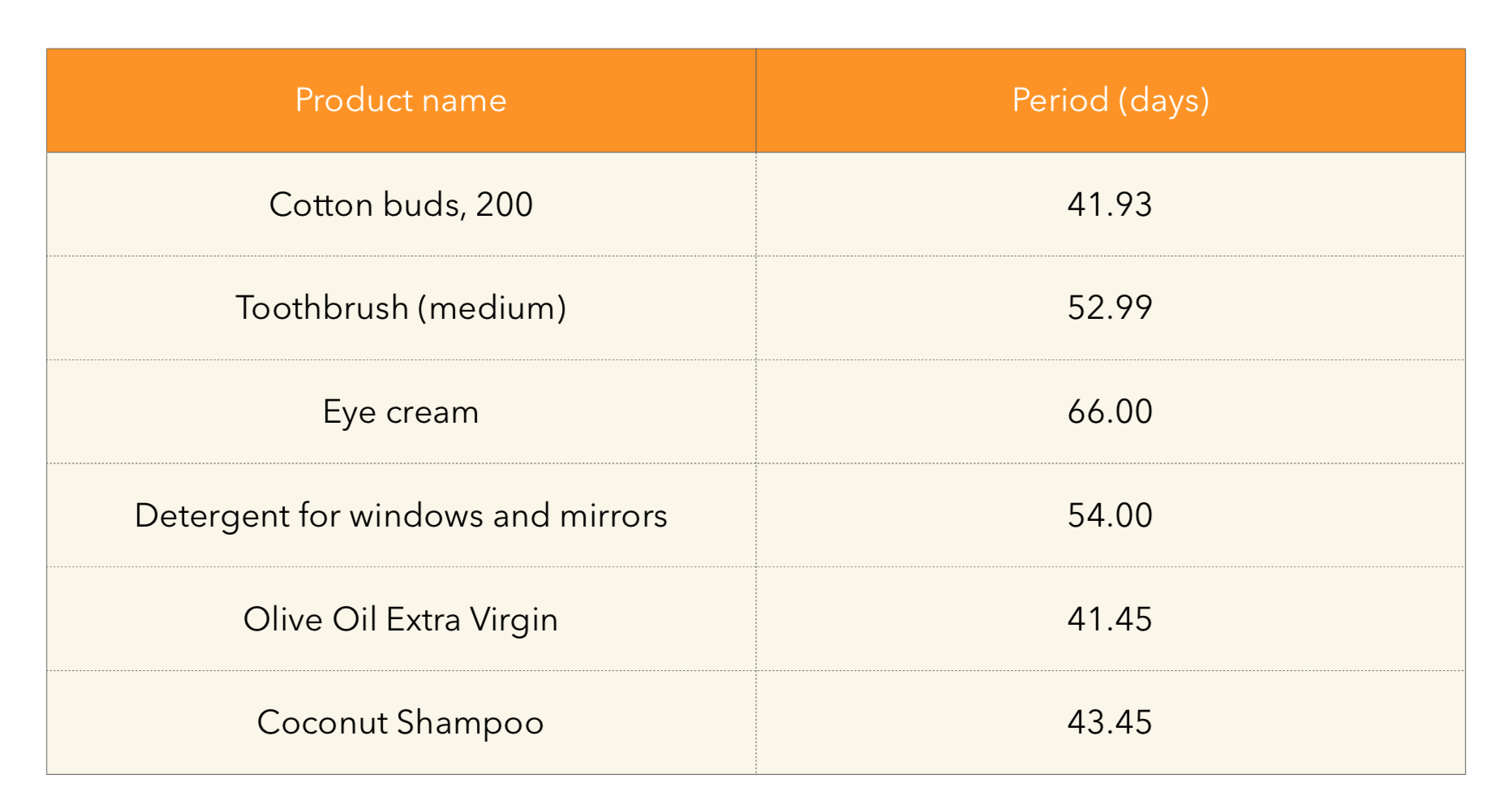
А дальше будем смотреть, попадает ли конец периода продукта в интервал времени, когда рекомендации будут в продакшн и сэмплировать то, что попадает. Проиллюстрировать подход можно так:
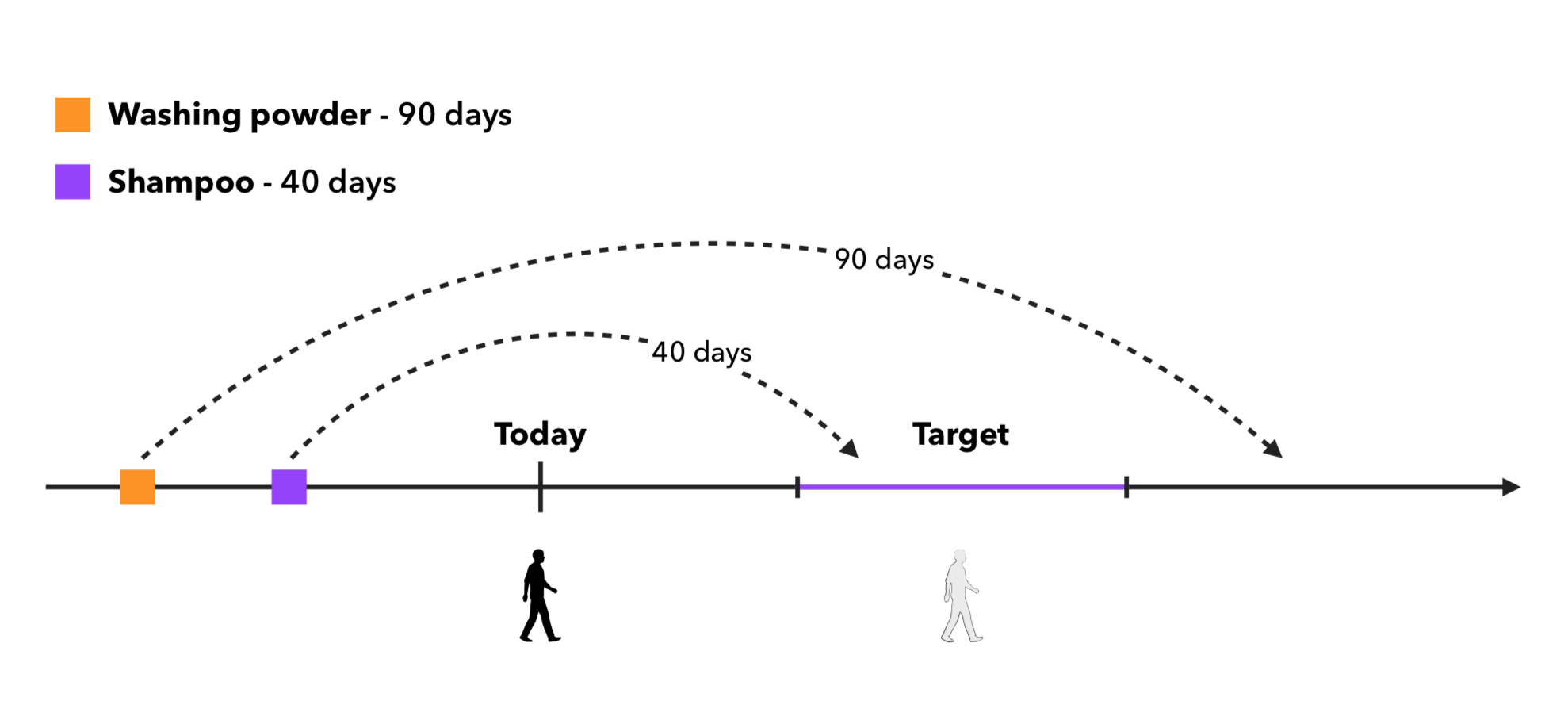
Тут у нас есть 2 основных кейса, которые можно рассмотреть:
- Нужно ли сэмплировать товары покупателям, которые покупали товар меньше, чем K раз.
- Нужно ли сэмплировать товар, если конец его периода попадает до начала таргет интервала.
На следующем графике видно, какие результаты достигает такой метод с разными гиперпараметрами:

ft — Брать только покупателей, которые покупали продукт не менее K (здесь K=5) раз
tm — Брать только кандидатов, которые попадают в таргет интервал
Не удивительно, что в состоянии (0, 0) самый большой recall и самый маленький precision, так как при таком условии извлекается больше всего кандидатов. Однако лучших результатов достигает ситуация, когда мы не сэмплируем товары для покупателей, которые покупали конкретный товар менее k раз и извлекаем в том числе товары, конец периода которых попадает до таргет интервала.
Популярное по категории
Ещё одна довольно очевидная идея — сэмплировать популярные товары по разным категориям, либо брендам. Здесь мы для каждого покупателя вычисляем топ-k “любимых” категорий/брендов и извлекаем “популярное” из этой категории/бренда. В нашем случае определим “любимые” и “популярные” по количеству покупок товара. Дополнительным преимуществом этого подхода является применимость в кейсе холодного старта. То есть для покупателей, которые совершили либо очень мало покупок, либо давно не были в магазине, либо вообще только оформили карту лояльности. Для них проще и лучше всего накидывать товары из популярного у покупателей с имеющейся историей. Метрики получаются следующие:
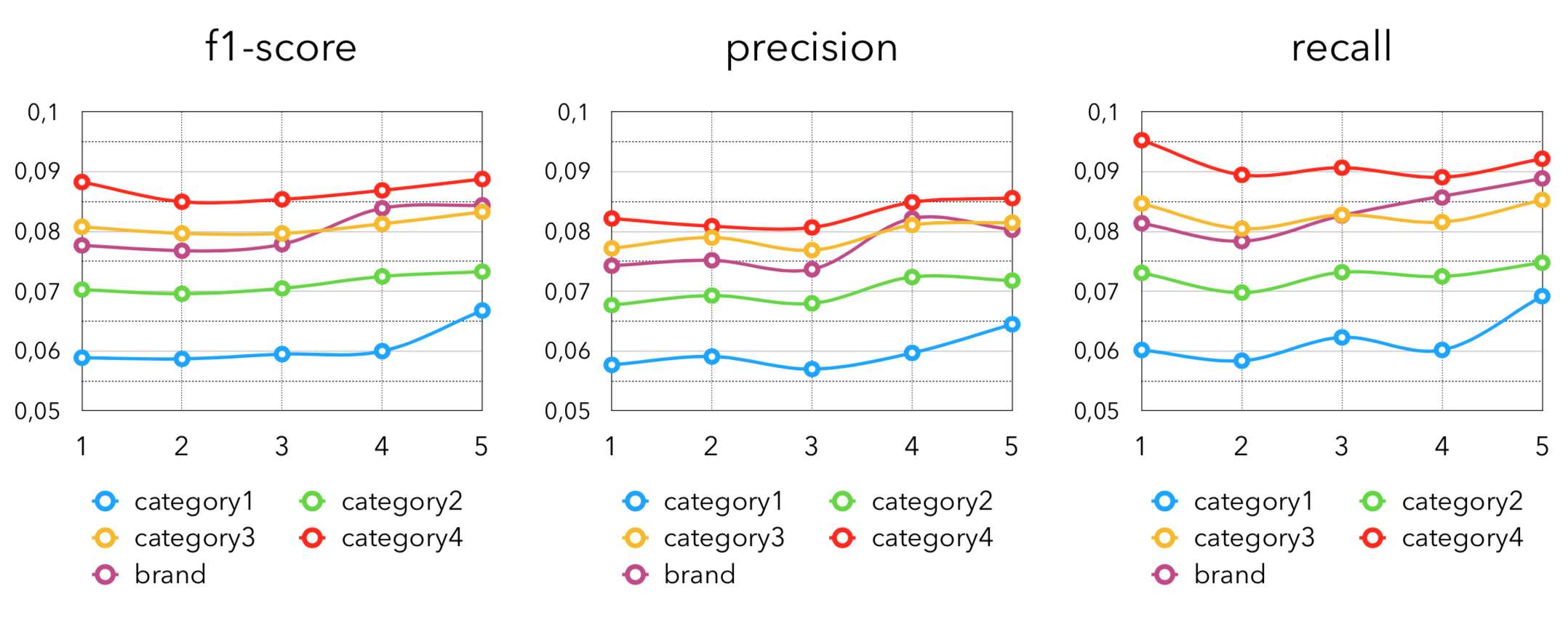
Здесь цифра после слова “category” означает уровень вложенности категории.
В целом, также не удивительно, что лучших результатов достигают более узкие категории, так как извлекают более точные “любимые” товары для покупателей.
Поочередные покупки разных товаров от недели к неделе
Интересный подход, который я не видел в статьях про рекомендательные системы — довольно простой и одновременно рабочий статистический метод цепей Маркова. Здесь мы берём 2 разные недели, далее по каждому покупателю строим пары продуктов [купил в неделю i]-[купил в неделю j], где j > i, а отсюда считаем для каждого товара вероятность перехода в другой товар на следующей неделе. То есть для каждой пары товаров producti-productj считаем их количество в найденных парах и делим на количество пар, где producti был на первой неделе. Для извлечения кандидатов берём последний чек покупателя и достаем топ-k наиболее вероятных следующих товаров из матрицы переходов, которую мы получили. Процесс построения матрицы переходов выглядит так:
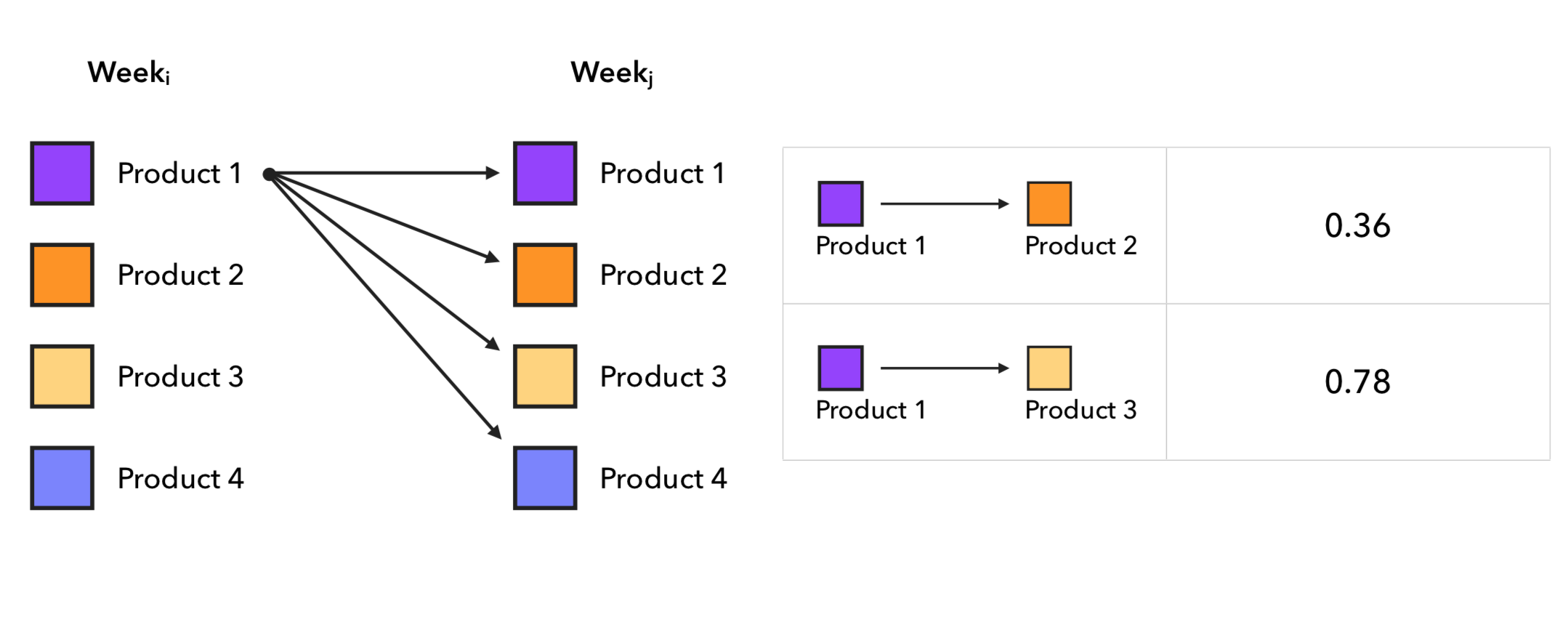
Из реальных примеров в матрице вероятностей переходов видим следующие интересные явления:
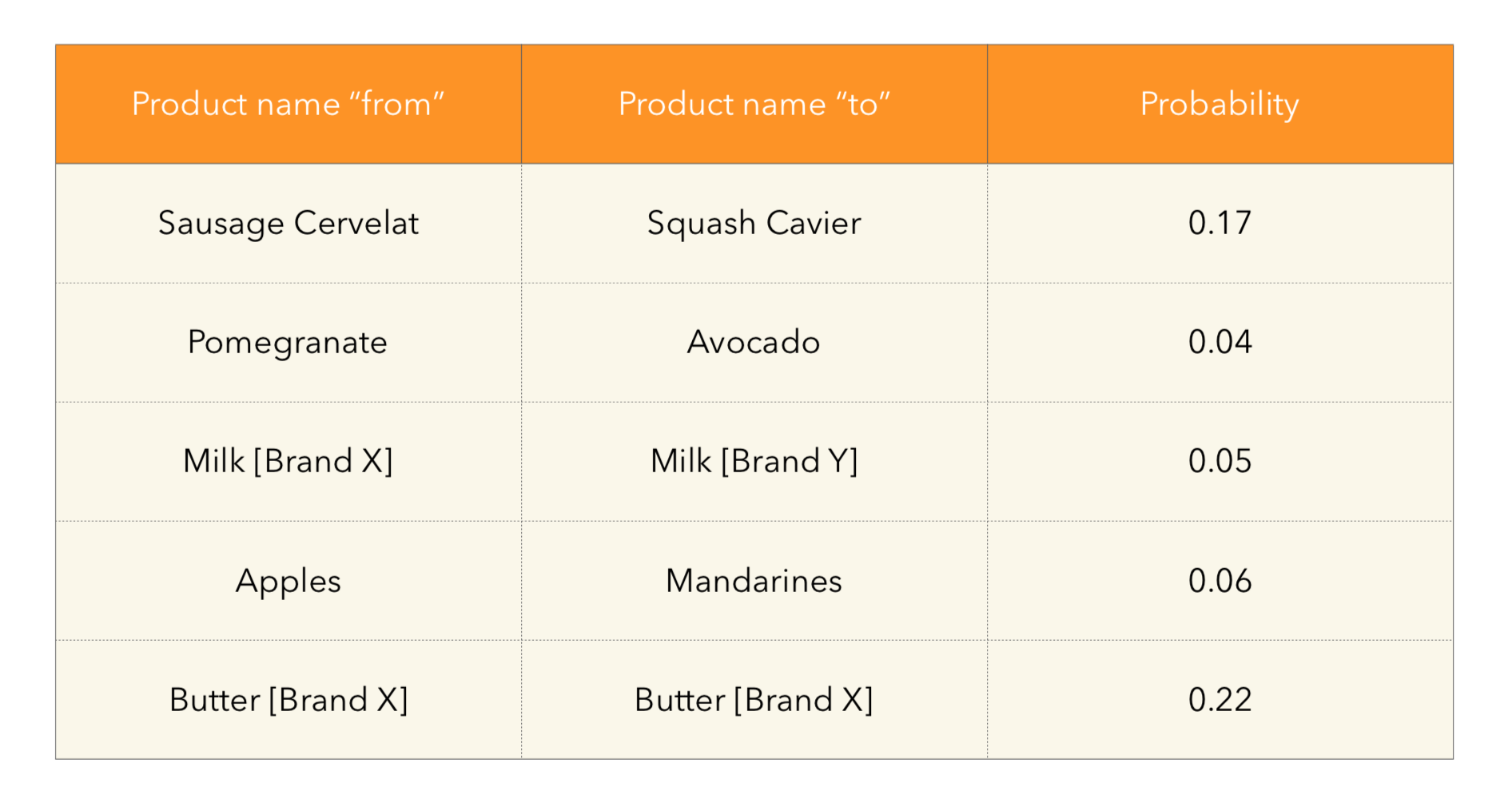
Тут можно заметить интересные зависимости, которые выявляются в потребительском поведении: например, любители цитрусов или бренд молока, с которого с большой вероятности переходят на другой. Также не удивительно, что товары с большой частотой повторных покупок, как масло, тоже здесь оказываются.
Метрики в методе с цепями Маркова получаются следующие:

k — количество товаров, которые извлекаются на каждый купленный товар из последней транзакции покупателя.
Как мы видим, лучший результат показывает конфигурация с k=4. Всплеск на 4 неделе можно объяснить сезонным поведением в праздничные дни.
Похожие товары на покупателей, по характеристикам, построенным разными моделями
Вот мы и подошли к самой сложной и интересной части — поиску ближайших соседей по векторам покупателей и продуктов, построенных по различным моделям. В своей работе мы таких моделей используем 3:
- ALS
- Word2Vec (Item2Vec для таких задач)
- DSSM
С ALS мы уже разобрались, почитать про то, как он обучается можно здесь. В случае с Word2Vec, мы используем всем известную реализацию модели из gensim. По аналогии с текстами, определяем предложение, как чек покупки. Таким образом, при построении вектора продукта, модель учится предсказывать по товару в чеке его “контекст” (остальные товары в чеке). В ecommerce данных лучше вместо чека использовать сессию покупателя, про это круто написали ребята из Ozon. А DSSM разобрать интереснее. Изначально его написали ребята из Microsoft, как модельку для поиска, тут можно почитать исходный research paper. Архитектура модели выглядит так:
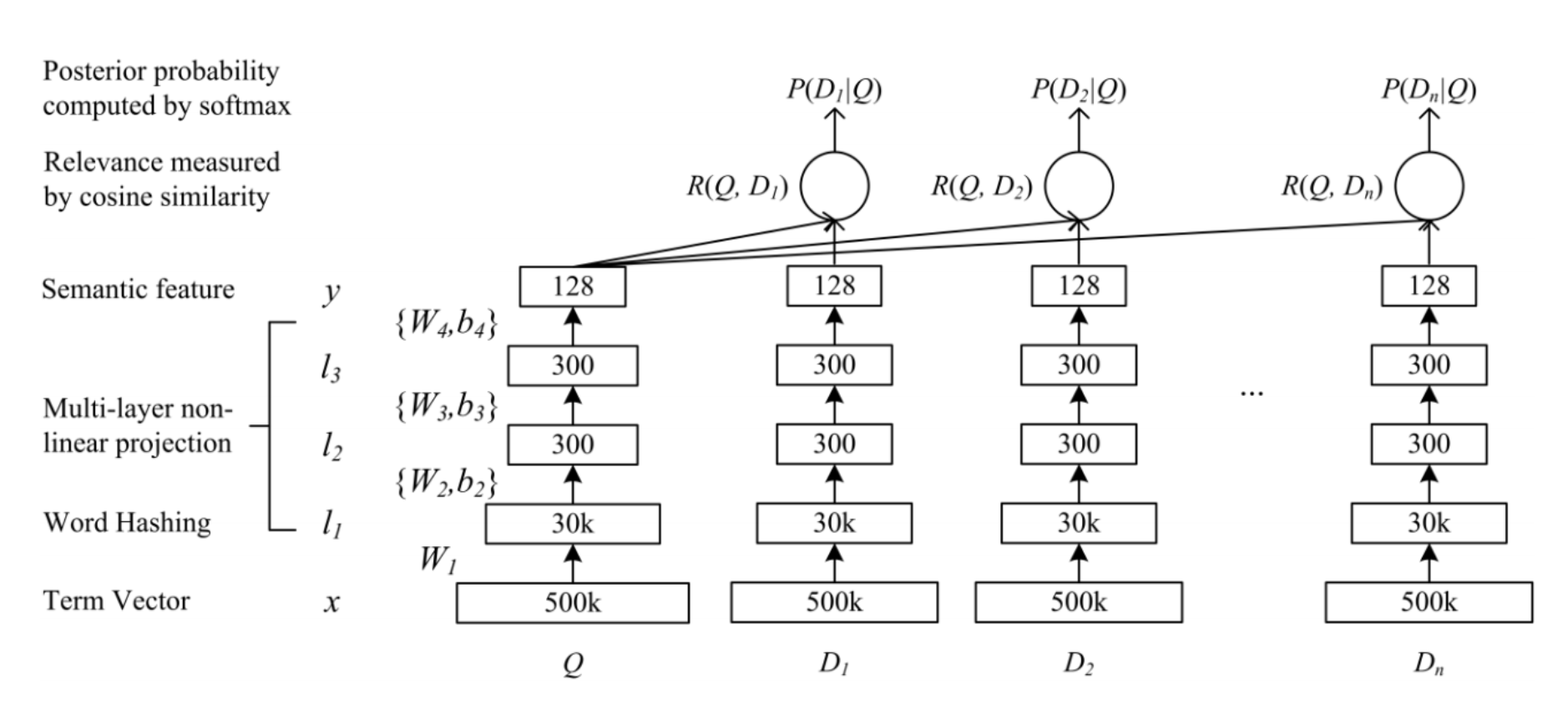
Здесь Q — query, поисковый запрос пользователя, D[i] — document, интернет-страница. На вход модели поступают признаки запроса и страниц, соответственно. После каждого входного слоя идёт некоторое количество полносвязных слоев (multilayer perceptron). Далее модель учится минимизировать косинус между векторами, получившимися в последних слоях модели.
В задачах рекомендаций используется точно такая же архитектура, только вместо запроса идёт пользователь, а вместо страниц — товары. И в нашем случае такая архитектура трансформируется в следующее:

Теперь для проверки результатов осталось покрыть последний момент — если в случае ALS и DSSM векторы пользователей у нас явно определены, то в случае с Word2Vec у нас есть только векторы товаров. Здесь для построения вектора пользователя мы определили 3 основных подхода:
- Просто сложить векторы, тогда для косинусного расстояния получится, что мы просто усреднили товары в покупательской истории.
- Суммирование векторов с некоторым взвешиванием по времени.
- Взвешивание товаров с TF-IDF коэффициентом.
В случае линейного взвешивания вектора покупателя мы исходим из гипотезы о том, что товар, который пользователь купил вчера больше влияет на его поведение, чем товар, который он купил полгода назад. Так мы считаем предыдущую неделю покупателя с коэффициентом 1, а то, что было дальше с коэффициентами ½, ⅓, и тд.:
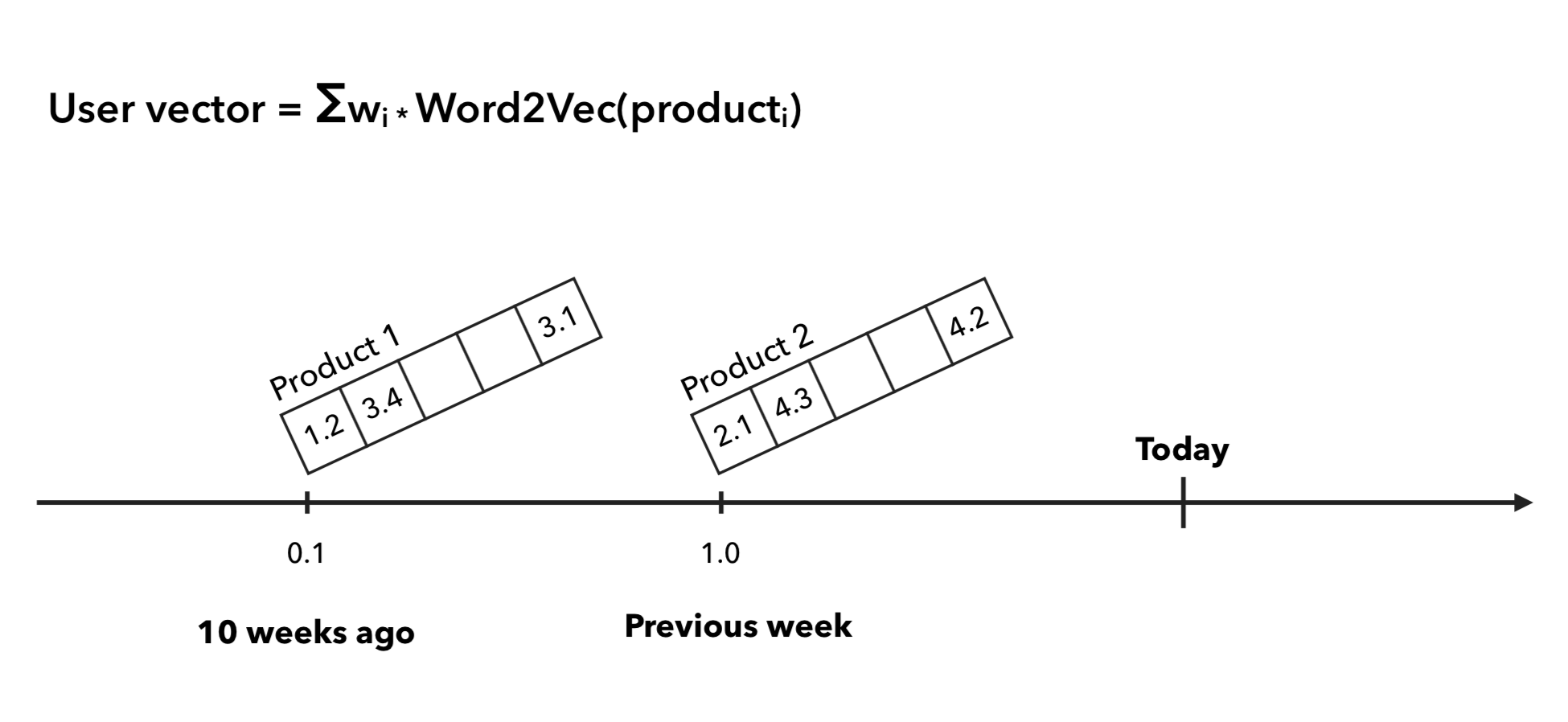
Для TF-IDF коэффициентов мы делаем ровно то же самое, что и в TF-IDF для текстов, только считаем покупателя за документ, а чек за предложение, соответственно, слово — товар. Так вектор пользователя будет больше сдвигаться в сторону редких товаров, а частые и привычные для покупателя товары его изменять особо не будут. Проиллюстрировать подход можно так:

Теперь посмотрим на метрики. Так выглядят результаты ALS:

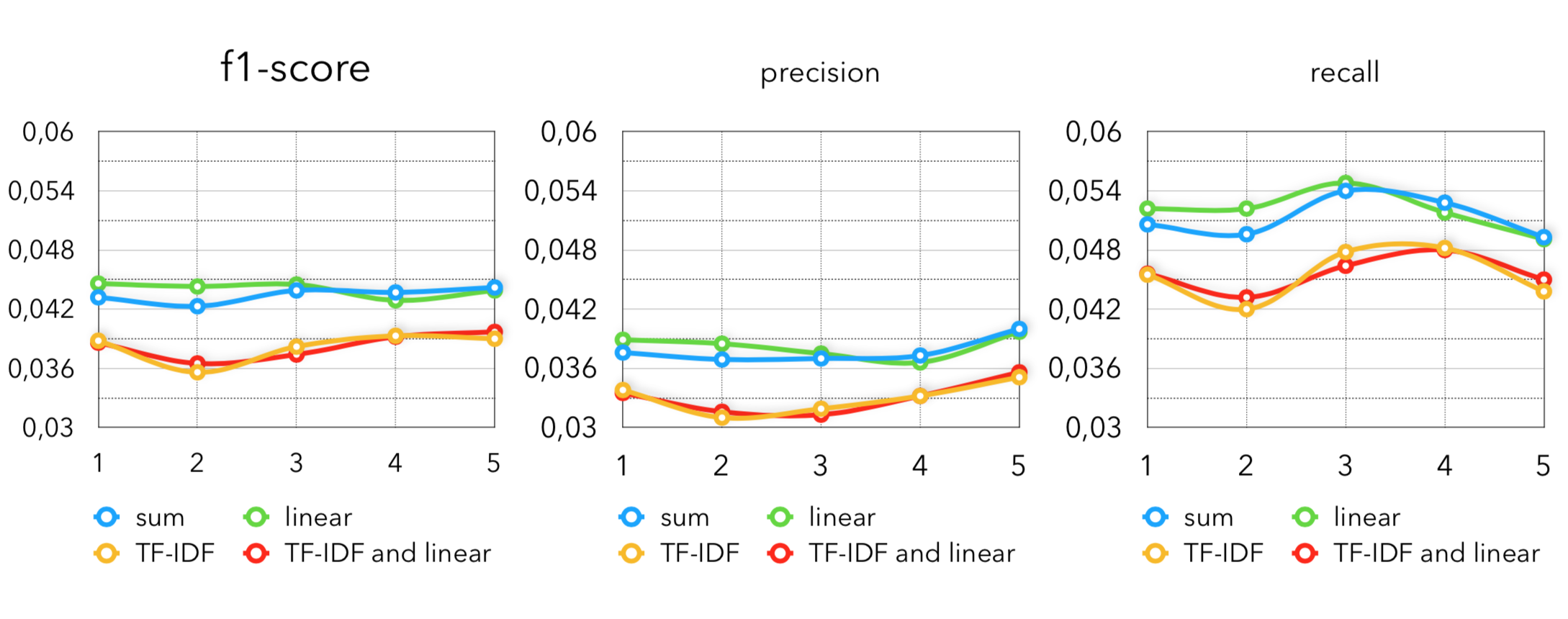
Метрики по Item2Vec с разными вариациями построения вектора покупателя:
В данном случае используется ровно та же модель, что и в нашем baseline. Разница лишь в том, какое k мы будем использовать. Для того, чтобы использовать только коллаборативные модели, приходится брать порядка 50-70 ближайших товаров на каждого покупателя.
И метрики по DSSM:

Как объединить все методы?
Классно, скажете вы, но что делать с таким большим набором инструментов для извлечения кандидатов? Как подобрать оптимальную конфигурацию под свои данные? Здесь у нас возникает несколько задач:
- Надо как-то ограничить пространство поиска гиперпараметров в каждом методе. Оно, конечно, дискретное везде, но количество возможных точек очень большое.
- Как по небольшой ограниченной выборке из конкретных методов с конкретными гиперпараметрами подобрать лучшую конфигурацию под свою метрику?
Однозначно верного ответа на первый вопрос мы пока не нашли, поэтому исходим из следующего: под каждый метод написан ограничитель пространства поиска гиперпараметров в зависимости от некоторых статистик по данным, которые мы имеем. Таким образом, зная средний период между покупками у людей, мы можем предполагать, с каким периодом использовать метод “что уже покупали” и “период давно прошедшей покупки”.
А после того, как мы перебрали некоторое адекватное количество вариаций разных методов, заметим следующее: каждая реализация извлекает некоторое количество кандидатов и имеет некоторое значение ключевой для нас метрики (recall). Мы хотим в сумме получить определенное количество кандидатов, зависящее от наших допустимых вычислительных мощностей, с максимально возможной метрикой. Тут задача красиво схлопывается в задачу о рюкзаке.
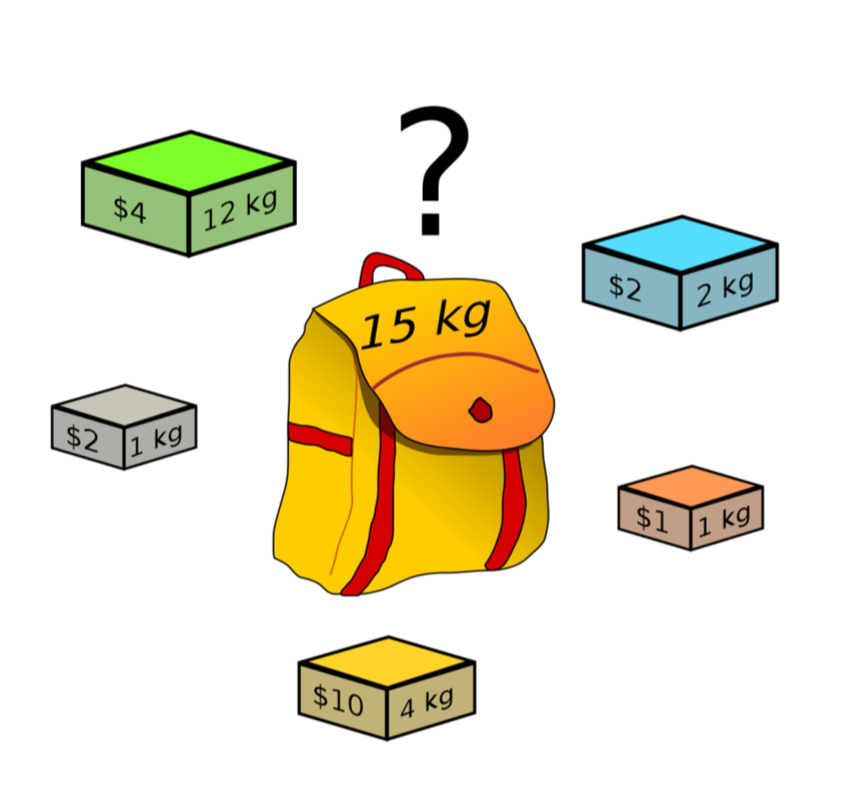
Здесь количество кандидатов — вес слитка, а recall метода — его ценность. Однако есть ещё 2 момента, которые стоит закладывать при реализации алгоритма:
- У методов может быть пересечение в кандидатах, которые они достают.
- В некоторых случаях взять один метод два раза с разными параметрами будет корректно и кандидаты на выходе из первого не будут являться подмножеством второго.
Например, если взять реализацию метода «то, что уже покупал» с разными интервалами для извлечения, то их множества кандидатов будут вложены друг в друга. В то же время, разные параметры в “периодических покупках” на выходе не дают полное пересечение. Поэтому мы делим методы сэмплирования с разными параметрами на блоки так, что из каждого блока мы хотим взять не более одного подхода извлечения с конкретными гиперпараметрами. Для этого нужно немного исхитриться в реализации задачи о рюкзаке, но асимптотика и результат от этого не поменяются.
Такая умная комбинация позволяет получить нам следующие метрики в сравнении с просто коллаборативными моделями:

На финальных метриках видим следующую картину:
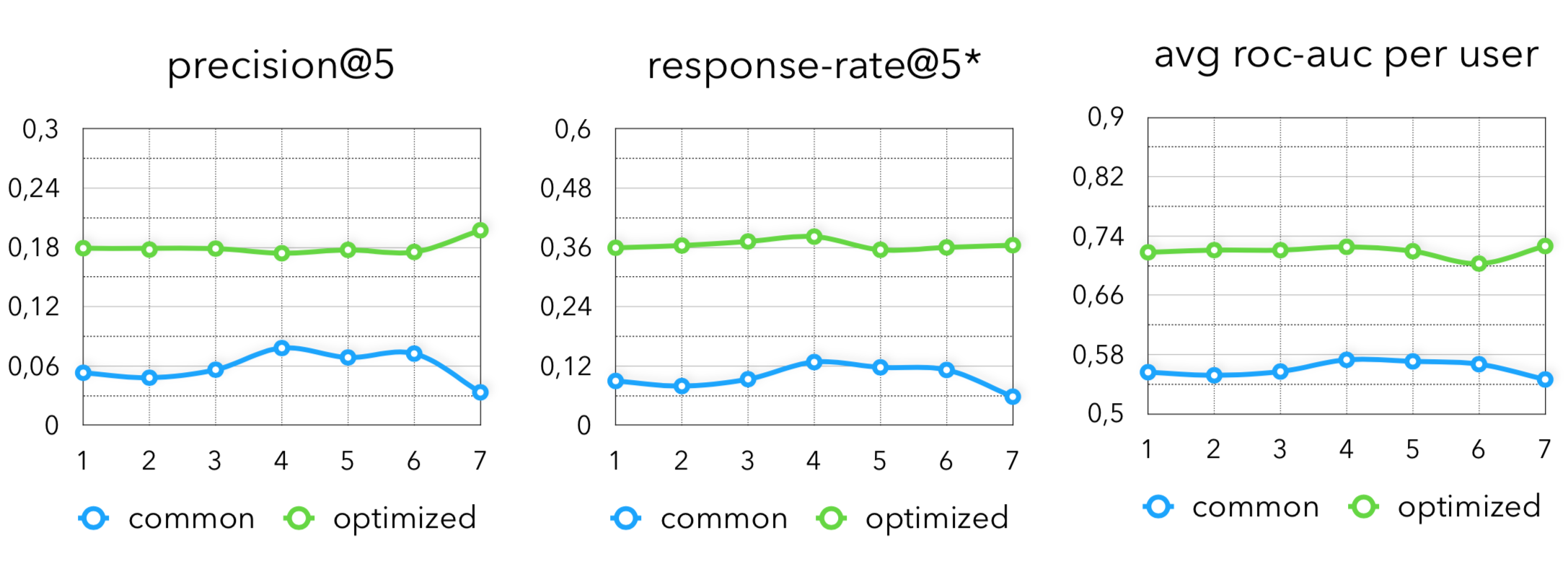
Однако здесь можно заметить, что остался один непокрытый момент для рекомендаций, полезных бизнесу. Сейчас мы просто научились круто предсказывать то, что пользователь купит, например, на следующей неделе. Но просто давать скидку на то, что он и так купит не очень прикольно. Зато круто максимизировать матожидание, например, следующих метрик:
- Маржу/товарооборот по персональным рекомендациям.
- Средний чек покупателей.
- Частоту визитов.
Так мы умножаем полученные вероятности на разные коэффициенты и переранжируем их так, чтобы в топ попадали товары, влияющие на метрики выше. Здесь нет готового решения, какой подход лучше использовать. Даже мы экспериментируем с такими коэффициентами проводим прямо в продакшн. Но вот интересные приемы, которые чаще всего дают у нас лучшие результаты:
- Домножать на цену/маржу товара.
- Домножать на средний чек, в котором встречается товар. Так наверх вылезут товары, с которыми берут обычно ещё что-то.
- Домножать на среднюю частоту визитов покупателей данного товара, исходя из гипотезы, что этот товар провоцирует почаще за ним возвращаться.
Проведя эксперименты с коэффициентами мы получили следующие метрики в продакшн:
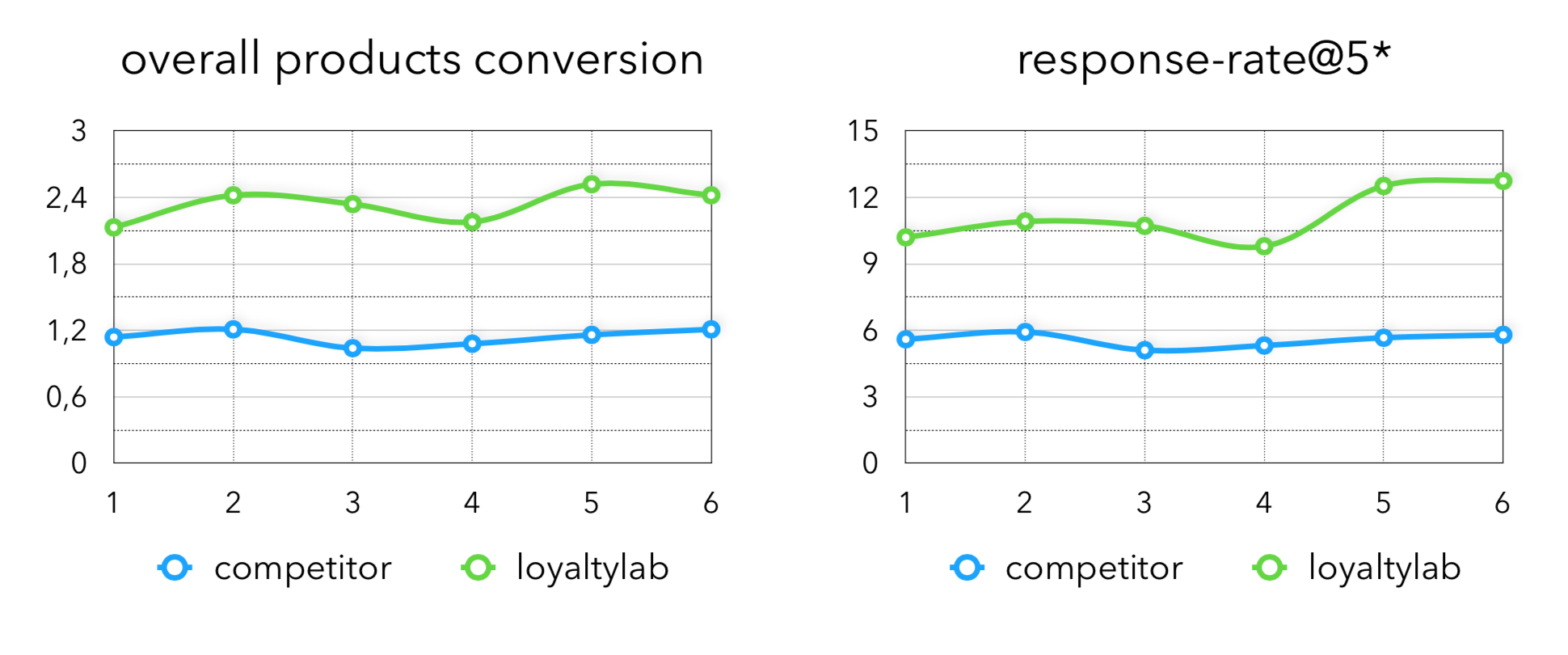
Здесь overall products conversion — доля купленных товаров из всех товаров в рекомендациях, которые мы сгенерировали.
Внимательный читатель заметит существенную разницу между оффлайн и онлайн метриками. Такое поведение объясняется тем, что далеко не все динамические фильтры по товарам, которые можно рекомендовать, возможно учитывать при обучении модели. Для нас нормальная история, когда половина извлеченных кандидатов может быть отфильтрована, такая специфика характерна в нашей отрасли.
По выручке получается следующая история, видно, что после запуска рекомендаций, выручка у тестовой группы сильно растёт, сейчас средний прирост выручки с нашими рекомендациями — 3-4%:
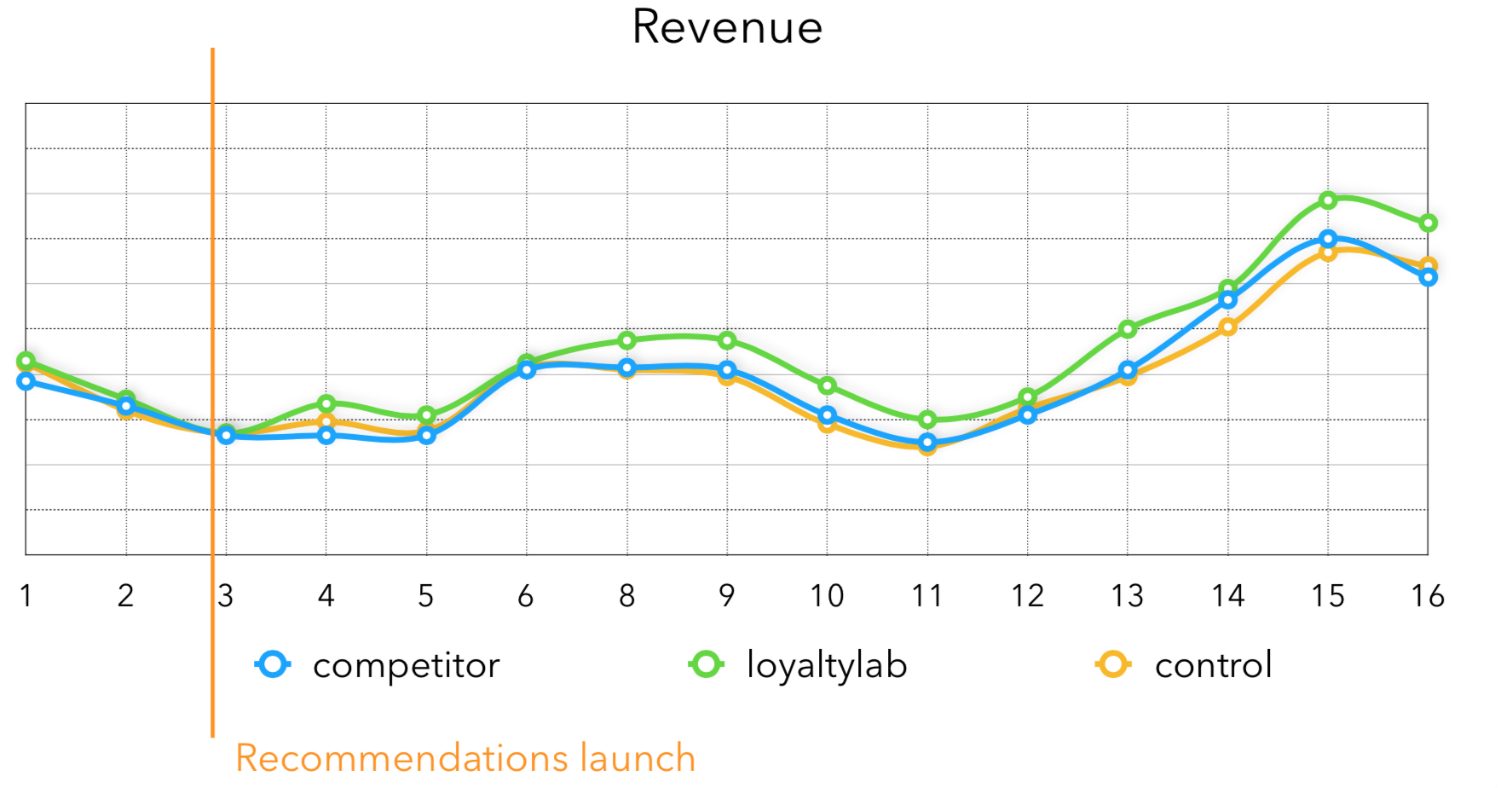
В заключение хочу сказать, что, если вам нужны не realtime рекомендации, то очень большой прирост в качестве находится в экспериментах с извлечением кандидатов для рекомендаций. Большое количество времени для их генерации дает возможность комбинировать много хороших методов, что в сумме даст крутые результаты для бизнеса.
Буду рад пообщаться в комментариях со всеми, кто сочтет материал интересным. Вопросы задать можно мне лично в telegram. Также я делюсь своими мыслями про AI/стартапы в своём telegram канале — welcome :)
