Модель fastText — одно из самых эффективных векторных представлений слов для русского языка. Однако её прикладная польза страдает из-за внушительных (несколько гигабайт) размеров модели. В этой статье мы показываем, как можно уменьшить модель fastText с 2.7 гигабайт до 28 мегабайт, не слишком потеряв в её качестве (3-4%). Спойлер: квантизация и отбор признаков работают хорошо, а матричные разложения — не очень. Также мы публикуем пакет на Python для этого сжатия и примеры компактной модели для русских слов.

Зачем и о чём это
Я не первый, кто пытается сжать fastText: сами разработчики fastText давно предусмотрели этот режим для своих классификаторов, сжимая их на порядки с помощью квантизации и отбора признаков. В прошлом году Андрей Васнецов описал один из способов сжатия для unsupervised модели — переупаковку матрицы хэшей n-грамм. Чуть позже Александр Кукушкин опубликовал navec — библиотеку с очень компактными квантизированными glove-эмбеддингами для русских слов. Здесь я собираю все эти идеи воедино.
Немного контекста: зачем вообще всё это нужно? Эмбеддинг, или векторное представление слова — это, натурально, числовой вектор фиксированного размера (скажем, 300-мерный), описывающий какие-то признаки этого слова. Обычно эти эмбеддинги выучиваются нейросетью, которая пытается угадать пропущенное слово по его контексту (соседнему тексту). Ожидается, что слова, похожие по смыслу, встречаются в похожих контекстах, а значит, и эмбеддинги у них будут похожи. Использование предобученных эмбеддингов, хотя бы приблизительно обладающих таким свойством, позволяет обучать хорошие модели для понимания текста (например, определения тематики или распознавания сущностей) даже на небольшом количестве размеченных примеров. На практике это применимо, например, для создания "умных" чатботов.
Самые современные эмбеддинги слов — контекстные, такие как ELMO или BERT. Но эти модели заметно медленнее и сложнее в обслуживании, чем fastText. А самое интересное свойство fastText'а — что он учитывает (простым усреднением, но тем не менее) символьные n-граммы (подстроки фиксированной длины) при построении эмбеддинга слова. То есть слова, содержащие похожие подстроки, могут получить похожие векторные представления, что весьма актуально для русского языка, богатого на словообразование. Но это же свойство делает модели fastText весьма объемными, ведь различных символьных n-грамм существует очень много.
Подробнее про устройство модели fastText можно почитать в оригинальной статье от Facebook AI Research. Её применение можно приблизительно описать следующим псевдокодом:
def embed(word, model):
if word in model.vocab:
# после предподсчёта мы бы сразу отдали результат
# return model.vectors[word]
result = model.vectors_vocab[word]
else:
result = zeros()
n = 1
for ngram in get_ngrams(word, model.min_n, model.max_n):
result += model.vectors_ngrams[hash(ngram)]
n += 1
return result / nТо есть: эмбеддинг каждого слова — это среднее из его "личного" эмбеддинга (если таковой имеется), и всех эмбеддингов его n-грамм. Такой подход позволяет модели догадаться, что, скажем, ранее не виденное слово минуточка — это что-то среднее из минут, уточк, точка, и некоторых других менее понятных n-грамм. Что, конечно, не очень умно, но гораздо лучше, чем не обрабатывать неизвестное слово вообще никак.
Для обучения и применения моделей fastText стандартом являются две библиотеки: собственно fastText (доступна в Python и из командной строки), и Gensim (чисто Python). В моей статье я привожу питонячий код, совместимый с Gensim.
По факту, после обучения в Gensim происходит предподсчёт эмбеддингов всех слов, входящих в словарь модели. То есть на основе model.vectors_vocab и model.vectors_ngrams вышеописанным кодом формируется матрица словных эмбеддингов model.vectors, в которой учтены и "личные" эмбеддинги слов, и эмбеддинги n-грамм. Теперь model.vectors_vocab больше напрямую не используется, а model.vectors_ngrams используется только для незнакомых слов.
Методы сжатия моделей
FastText (как и все другие нейросетевые модели) состоит из больших числовых матриц. Конкретно в этой модели их две: эмбеддинги отдельно взятых слов, и эмбеддинги буквенных n-грамм, из которых строятся эмбеддинги незнакомых слов. Возможных буквенных n-грамм комбинаторно много, и чтобы не учитывать их всех явно, fastText использует hashing trick: номер строки в матрице эмбеддингов, соответствующий n-грамме, вычисляется как хэш этой n-граммы. Чем длиннее матрица эмбеддингов, тем меньше в таком подходе будет коллизий (а значит, выше точность эмбеддингов), но тем больше будет в ней неиспользуемых строк. Например, в модели ruscorpora_none_fasttextskipgram_300_2_2019 с RusVectores 2 миллиона строк в матрице эмбеддингов, но только 330 тысяч из них реально используются.
Собственно, на этом параметре — длине матрицы эмбеддингов n-грамм — основан рецепт сжатия fastText от Андрея Васнецова. Он уменьшает число строк в ней с 2 миллионов до 500 тысяч, размещая в каждой строке новой матрицы средневзвешенное из строк старой матрицы. В качестве весов используется число пар "слово + n-грамма из него", попадавших в соответствующие строки в старой и новой матрице; сами слова берутся из фиксированного словаря той же модели. Это позволяет сжать модель в несколько раз, не сильно изменив эмбеддинги слов, и без необходимости обучать модель заново. Насколько именно "не сильно", Васнецов предлагает оценивать по среднему косинусному сходству между эмбеддингами старой и новой модели. У него получается сжать англоязычную модель с 16 до 2 гигабайт, сохранив 94% сходство моделей, сжав вышеописанным образом эмбеддинги n-грамм, и отбросив эмбеддинги наименее частотных слов (частота слов в обучающей выборки зашита внутри модели gensim).
Коллеги из Фейсбука, исходно придумавшие fastText, сами предложили ещё один простой способ сократить число строк в матрице — обнулить "не очень полезные" эмбеддинги, и написали об этом (и о квантизации, о которой речь пойдёт ниже) блогпост и статью. "Полезность" эмбеддинга слова или n-граммы для задачи классификации можно грубо оценить по векторной норме этого эмбеддинга. А для задачи получения представлений слов (она, в отличие от классификации, self-supervized) полезность можно оценить по частотности.
Кроме длины матрицы эмбеддингов, можно пытаться сократить её ширину. Стандартная размерность эмбеддинга fasttext — 300. Выполнив сингулярное разложение (SVD), можно представить матрицу n*300 как произведение двух матриц n*k и k*300. Чем меньше k — тем более экономным и менее точным будет такое представление. Этот способ достаточно универсален (им можно сжимать любые матрицы, а значит, любые нейронки), но не то чтобы очень эффективен, если размерность уже не очень высокая (а 300 для нейросетей — это мало).
Ещё одно направление для экономии — уменьшать "глубину" матрицы, то есть её точность. Обычно веса нейронок представляются 32-разрядными числами с плавающей точкой. Заменив их на 16-разрядные, можно сократить размер модели вдвое, почти не поплатившись точностью. Ещё более коротких float'ов Python не поддерживает, но можно обнаглеть, и перейти сразу на целочисленное представление. С помощью 8 бит можно описать 256 различных значений. Значит, можно разделить все числа из исходной матрицы эмбеддингов на 256 кластеров, и хранить в большой матрице только номера кластеров, а отдельно хранить их центры. Такой подход называется квантизацией (или квантованием) векторов, и широко применяется в народном хозяйстве.
Итак, мы заменили 300 32-разрядных дробных чисел на 300 8-разрядных целых. Как сжать матрицу ещё больше? Правильно, сопоставить каждому целому числу не одно дробное, а несколько — целый небольшой вектор! Например, можно разрезать 300-мерный вектор на 100 3-мерных векторов, и каждый 3-мерный вектор заменить одним целым числом. Таблица с ключами, соответственно, будет сопоставлять эти целые числа 3-мерным векторам, полученным в результате кластеризации всех таких 3-мерных кусочков. Это называется product quantization, и это тоже очень популярно. В частности, на такой квантизации основана библиотека navec Александра Кукушкина, с помощью которой он сжал матрицы glove-эмбеддингов до невероятно компактных размеров, 25 и 50 мб. Если бы существовал простой способ обобщить его эмбеддинги для незнакомых слов, то и сжимать fasttext особо не было бы нужды. А так я всё-таки попробовал.
Моя методология
Все вышеописанные подходы я попытался так или иначе воспроизвести. Я стартовал с модели ruscorpora_none_fasttextskipgram_300_2_2019 c 300-мерными эмбеддингами, 165K словами в словаре и 2000K эмбеддингами n-грамм (n от 3 до 5), обученную на леммах. В памяти такая занимает "всего лишь" 2.7 гигабайт. Я загружал модель в формате gensim, и везде дальше будет иметься в виду именно он (версия gensim==3.8.1). Кроме того, во всех экспериментах я по умолчанию буду уменьшать матрицу словаря и матрицу n-грамм в одно и то же число раз (просто чтобы измерять зависимость от одного параметра, а не от двух).
Оговорюсь про ещё одну поправку: после загрузки исходной модели, я применил к ней метод adjust_vectors, приводящий в соответствие друг другу векторы для слов и для n-грамм. Теоретически, он не должен менять в модели вообще ничего. Но модель ruscorpora_none_fasttextskipgram_300_2_2019 была обучена до обновления пакета gensim, векторы в ней хранятся как-то иначе, и adjust_vectors меняет их значения. Почему это важно: с новыми значениями качество intrinsic evalution (про него будет ниже) ухудшается. То есть в ходе всех своих экспериментов я пытаюсь сжимать не самую лучшую модель. А чтобы избежать просадки в качестве, методы сжатия модели, меняющие словарь, нужно применять к моделям, обученным на достаточно новой версии пакета gensim. Но конкретно для моей задачи это не очень важно: мне нужно измерить, насколько падает качество модели при её сжатии, а не насколько качественна модель сама по себе.
Для подсчёта размера модели в памяти я всюду использовал функцию, комбинирующую sys.getsizeof (для оценки всех объектов, кроме numpy-массивов), numpy.ndarray.nbytes (для них, родимых), и gc.get_referents для получения ссылок на "дочерние" объекты. Размер модели, сохранённой на диск (стандартным методом save из gensim, который, в свою очередь, использует pickle) может отличаться от её размера в оперативной памяти, но в целом, кажется, неплохо с ним коррелирует.
Качество сжатия, как и Андрей Васнецов, я решил оценивать по средней косинусной близости векторов сжатой и оригинальной модели. Эту близость я усредняю по корпусу из 80К лемм, наиболее часто встречающихся (хотя бы 10 раз) в социальном сегменте корпуса Тайга. Леммы извлекал с помощью pymorphy2, выкидывал все однобуквенные слова и слова, не содержащие кириллицы; заменял ё на е. Оказалось, что 54К этих лемм входят в словарь исходной модели fastText, а 26К — отсутствуют. Сырые и лемматизированные словари выложены в репозиторий.
Не очевидно, как качество сжатия влияет на полезность эмбеддингов для прикладных задач. Поэтому кроме сходства старых и новых векторов я провёл так называемое intrinsic evaluation: проверку, насколько косинусное сходство векторов для пары слов соответствует человеческой оценке сходства этих слов. Это ещё не совсем то, чего хочется на самом деле измерить: на самом деле нас интересует, насколько хорошо эмбеддинги позволяют решить задачи классификации, NER, и т.п. Но такое сложно измерить быстро и качественно, т.к. нужно обучать дополнительные модели. Поэтому обойдёмся только сходствами векторов.
Для intrinsic оценки я использовал четыре размеченных датасета: hj, ae и rt взяты с воркшопа RUSSE, а simlex965 (далее sl) — с RusVectores (статья с описанием). hj и sl содержат дробные оценки сходства пар слов, и на них я оцениваю корреляцию Спирмана этих оценок и косинусного расстояния векторов. ae и rt содержат бинарные оценки сходства пар слов, и для них я оцениваю 2*ROC_AUC-1, где ROC AUC вычисляется также для косинусного расстояния относительно бинарных меток. Я использую эту метрику, а не предлагаемую авторами ae и rt precision, чтобы не заниматься отдельно подбором порога для классификации. Все четыре датасета также выложены в репозиторий.
Эксперименты
Первый и самый дешёвый шаг: отпиливаем от модели матрицу vectors_vocab (она нужна только для обучения модели, а не для применения), и сокращаем разрядность матриц vectors и vectors_ngrams с 32 до 16 бит. Эмбеддинги не изменились практически никак, а модель похудела с 2.7 до 1.28 ГБ. Что ж, хорошее начало. Любопытства ради оставляю в такой модели только n-граммы (1.14 ГБ) или только слова (136 МБ).
Следующая попытка: сокращение размерности матриц с помощью модели TruncatedSVD из scikit-learn. Сокращается она не очень охотно: при уменьшении матриц всего лишь вдвое теряется уже 8% точности. А мне хотелось бы с такой потерей качества сокращать модель в десятки раз.
Что ж, раз матричное разложение работает так себе, надо пробовать квантизацию. Я скопипастил квантизованное представление матриц из библиотеки navec, чуть упростив его (мне не нужны предподсчтёты для вычисления сходства векторов). Квантизация работает заметно приятнее: без сокращения размерности (чисто за счёт замены float на int) размер модели падает вдвое при 99.6% сходстве векторов. Если сократить размерность ещё втрое, сходство остаётся порядка 96%. Однако при дальнейшем сокращении размерности качество начинает падать драматически. Интуитивно это объяснимо: при уменьшении размерность сжатой матрицы, растет размерность кластеризуемых векторов, растёт (экспоненциально!) их многообразие, и они всё хуже приближаются 256 точками. Если сжать размерность в 12 раз (разбив эмбеддинг на 25 векторов), такая моделька будет занимать чуть меньше 94 МБ, но её сходство с оригиналом будет только 75%. Негоже.
Следующий эксперимент — избавление от редких слов и увеличение плотности хэшей в матрице n-грамм, т.е. метод Васнецова. Для меня было неожиданностью, что этот метод дал заметно более пологую кривую зависимости качества от размера модели. Так, при сжатии модели до 128 МБ (x10, по сравнению с базовым 16-разрядным вариантом) векторы остались похожи на 95%, а при сжатии до 25 МБ — на 82%. Ещё не идеал, но уже близко.
Почему переупаковка n-грамм так хорошо работает? Потому что большая часть строк в их матрице не используется или используется очень редко. Можно попробовать использовать это явно, вернувшись к старой идее отбора признаков. То есть: вместо изменения хэш-функции можно просто запомнить, какие строки матрицы n-грамм используются наиболее часто (в наибольшем количестве разных слов из словаря модели), и все остальные строки просто выкинуть. Если выкинуть только неиспользуемые строки (векторы от этого не изменятся почти ни насколько) и сохранить в словарике соответствие между старыми и новыми номерами строк, размер модели "бесплатно" сократится до 450 МБ (почти втрое). 45-мегабайтная версия даёт 93.6% сходства.
Чтобы жить стало совсем хорошо, можно сделать ещё один маленький шаг: объединить, как это сделали разработчики fastText-классификатора, "отбор признаков" и квантизацию. Одна из первых гибридных моделек (20К слов, 100К n-грамм, 100-мерная квантизация), при размере в 28 мегабайт (в 100 раз!), дала 96.15% сходство с оригиналом. Что можно считать успехом. Вдохновившись им, я перебрал 36 комбинаций размеров сокращенных словарей и степени квантизации.
Рисунок ниже отражает эти эксперименты. По горизонтальной оси — размер модели, по вертикальной — среднее косинусное сходство старых и новых словных эмбеддингов. Чем ближе мы к левому верхнему углу, тем лучше: маленькая модель воспроизводит полную достаточно точно. На всех трёх рисунках одни и те же модели, но раскрашены они в зависимости от размерности квантизованного вектора, либо от размера матрицы слов, либо от размера матрицы n-грамм.

Оказалось, что ни для одного из параметров нет "наилучшего" значения: любой из размеров словарей или степени квантизации является оптимальным при каком-то значении других параметров.
Подобным же образом можно отобразить все мои эксперименты (из 36 смешанных моделей здесь и далее я отобразил только 15 Парето-оптимальных, чтобы не засорять график). Видим, что фильтрация словаря эффективнее остальных методов, а применение квантизации делает её ещё эффективнее.
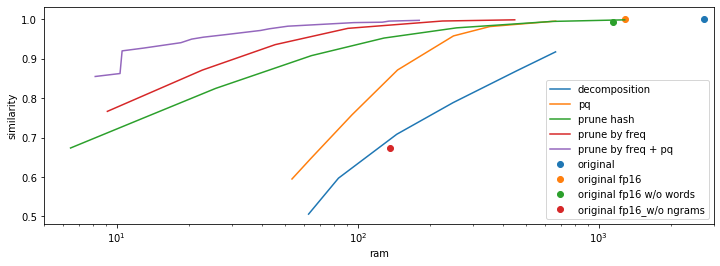
Больше метрик богу метрик!
В ходе экспериментов я сопоставлял размер модели в RAM и сходство её векторов с векторами оригинала на 80К леммах из корпуса Тайга. А что с остальными метриками?
Для начала, посмотрим на сходство эмбеддингов по отдельности для слов, входящих и не входящих в словарь исходной модели. Качественно зависимость примерно одинаковая. В целом, это неудивительно, ведь в большинстве экспериментов я сжимал эмбеддинги слов и эмбеддинги n-грамм в одно и то же число раз. При этом видно, что при квантизации незнакомые слова (т.е. n-граммы) страдают особенно сильно, по сравнению со знакомыми словами. Видимо, это связано с тем, что кластеризация, на которой основана квантизация, никак не учитывает то, что одни n-граммы встречаются чаще других — а значит, более важные.
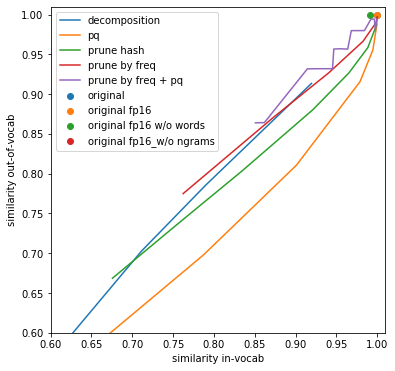
Размер модели на диске, что ожидаемо, почти идентичен её размеру в памяти. Тут никаких сюрпризов.

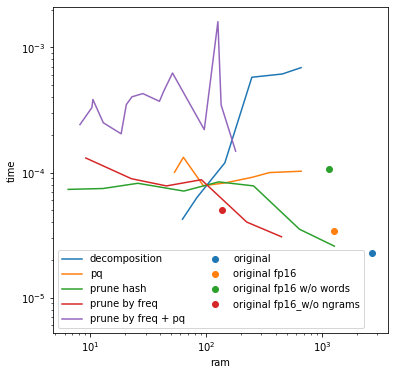
Скорость модели будем оценивать средним временем на получение эмбеддинга слова, по тем же 80К леммам из Тайги. Здесь тоже ничего удивительного: квантизация и разложение матриц сильно замедляют работу модели. Методы, связанные с удалением строк в матрице, тормозят не так сильно, но только пока словарь остаётся достаточно большим — а потом всё чаще приходится составлять эмбеддинг из n-грамм, а не из готовых слов, и замедление таки происходит. Замедление от квантизации и от уменьшения словаря суммируется.
Наконец, intrinsic evaluation. На всех четырёх датасетах зависимость качества от размера и типа модели выглядит качественно примерно одинаково и точно так же, как сходство старых векторов с новыми. Единственное очевидное различие — сравнительное изменение качества при выкидывании из модели только слов либо только n-грамм. В зависимости от того, какую долю датасета составляют OOV слова, эти изменения сказываются на качестве модели по-разному.
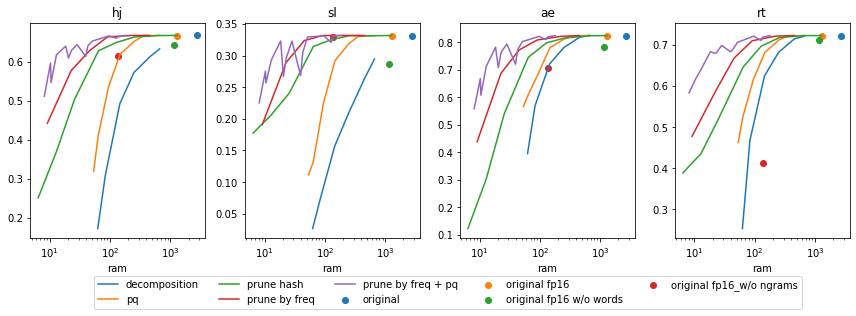
Впрочем, точность воспроизведения векторов и intrinsic evaluation не равносильны друг другу. При том же значении среднего сходства, квантизация и сокращение размерности дают более высокое качество на парах слов, чем уменьшение словаря. Видимо, эти методы сильно искажают слова, но при этом искажают семантически близкие слова похожим образом, и поэтому intrinsic evaluation не так сильно страдает в результате сжатия.

Числа, по которым построены все вышеприведённые графики, выложены в репозитории проекта.
Итоги
Fasttext — полезная и удобная модель, но внушительные размеры не позволяют запускать её на тесных бесплатных хостингах, на которых можно было бы разместить чат-бота, включать её в мобильные продукты, или извлекать из неё пользу множеством других способов. Предложенные коллегами и собранные мною методы — квантизация и отбор признаков — позволяют сократить размеры модели в 100 раз, увеличивая её доступность для разработчиков. При этом векторы сжатой модели имеют 96% сходство с оригиналом, и лишь на 3% хуже работают на задачах оценки семантической близости.
Код для сжатия моделей их последующего применения доступен в репозитории и на PyPI. Также для скачивания доступны 13, 28, 51 и 180-мегабайтные модели — сжатые версии модели ruscorpora_none_fasttextskipgram_300_2_2019 с сайта RusVectores.
В ближайшем будущем я перейду от сжатия словных эмбеддингов к созданию компактной модели фразных эмбеддингов для русского языка. Если хотите поучаствовать, либо предложить или покритиковать что-нибудь, пишите мне на Хабр или в ODS.
Апдейт от 10.06.2021: успешно обучил компактный русский BERT.
