1. Исходные данные
Очистка данных – это одна из проблем стоящих перед задачами анализа данных. В этом материале отразил наработки, решения, которые возникли в результате решения практической задачи по анализу БД при формировании кадастровой стоимости. Исходники здесь «ОТЧЕТ № 01/ОКС-2019 об итогах государственной кадастровой оценки всех видов объектов недвижимости (за исключением земельных участков) на территории Ханты-Мансийского автономного округа — Югры».
Рассматривался файл «Сравнительный модель итог.ods» в «Приложение Б. Результаты определения КС 5. Сведения о способе определения кадастровой стоимости 5.1 Сравнительный подход».
Таблица 1. Статпоказатели датасета в файле «Сравнительный модель итог.ods»
Общее количество полей, шт. — 44
Общее количество записей, шт. — 365 490
Общее количество символов, шт. — 101 714 693
Среднее количество символов в записи, шт. — 278,297
Стандартное отклонение символов в записи, шт. — 15,510
Минимальное количество символов в записи, шт. — 198
Максимальное количество символов в записи, шт. — 363
2. Вводная часть. Базовые нормы
Занимаясь анализом указанной БД сформировалась задача по конкретизации требований к степени очистки, так как, это понятно всем, указанная БД формирует правовые и экономические последствия для пользователей. В процессе работы оказалось, что особо никаких требований к степени очистки больших данных не сформировано. Анализируя правовые нормы в этом вопросе пришел к выводу, что все они сформированы от возможностей. То есть появилась определенная задача, под задачу комплектуются источники информации, далее формируется датасет и, на основе создаваемого датасета, инструменты для решения задачи. Полученные решения являются реперными точками в выборе из альтернатив. Представил это на рисунке 1.

Так как, в вопросах определения каких-либо норм, предпочтительно опираться на проверенные технологии, то выбрал за основу критериев анализа, требования изложенные в «MHRA GxP Data Integrity Definitions and Guidance for Industry», потому что посчитал этот документ наиболее целостным для этого вопроса. В частности в этом документе раздел написано «It should be noted that data integrity requirements apply equally to manual (paper) and electronic data.» (пер. «… требования к целостности данных распространяются в равной степени на ручные (бумажные) и электронные данные»). Такая формулировка достаточно конкретно связывается с понятием «письменное доказательство», в нормах ст.71 ГПК, ст. 70 КАС, ст.75 АПК, «письменном виде» ст. 84 ГПК.
На рисунке 2 представил схему формирования подходов к видам информации в юриспруденции.

Рис. 2. Источник здесь.
На рисунке 3 представлен механизм рисунка 1, для задач вышеуказанного «Guidance». Несложно, проводя сопоставление, увидеть, что используемые подходы, при выполнении требований к целостности информации, в современных нормах к информационным системам, существенно ограничены, в сравнении с правовым понятием информации.
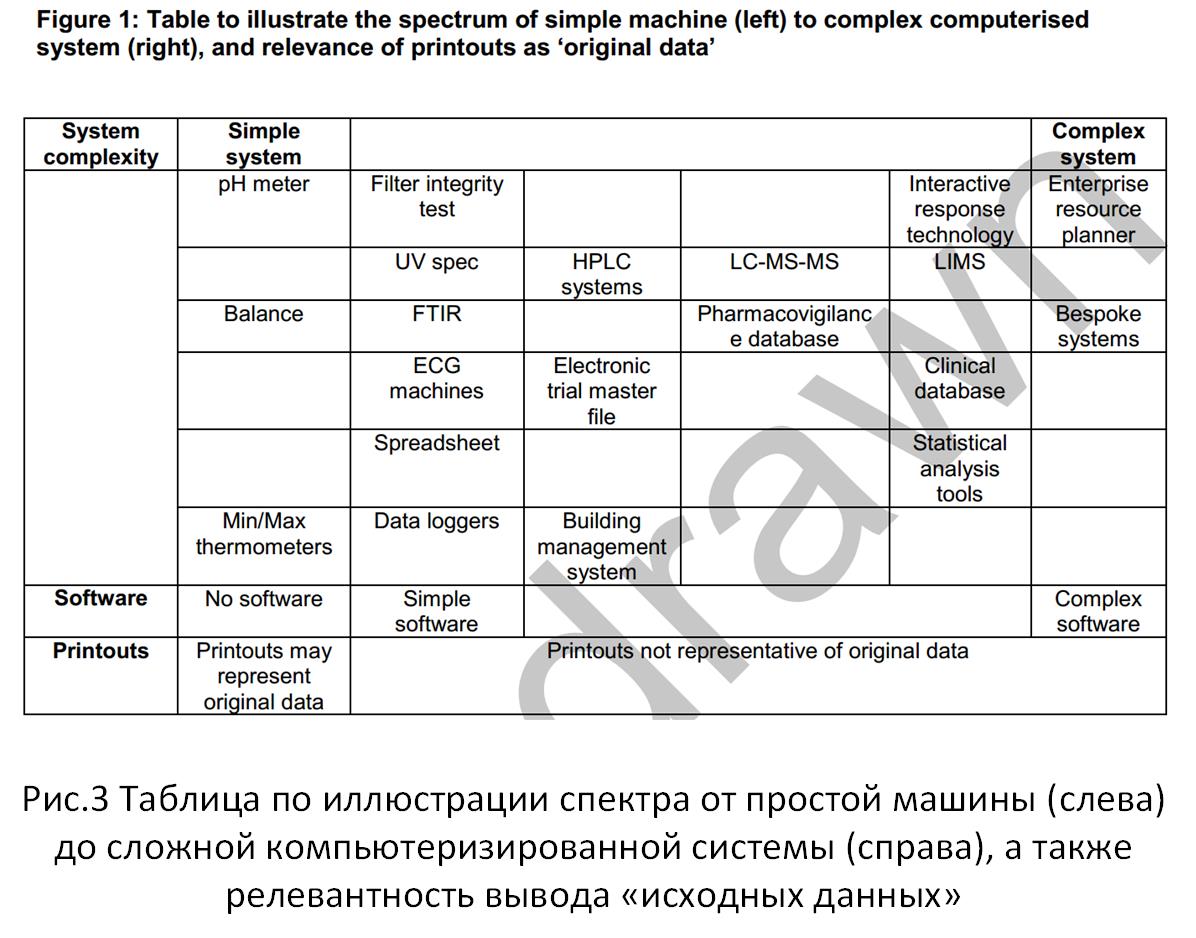
Рис.3
В указанном документе (Guidance) привязка к технической части, возможностей по обработке и хранению данных, хорошо подтверждается цитатой из главы 18.2. Relational database: «This file structure is inherently more secure, as the data is held in a large file format which preserves the relationship between data and metadata».
По сути, в таком подходе – от существующих технических возможностей, нет ничего не нормального и, сам по себе, это естественный процесс, так как расширение понятий происходит от наиболее изученной деятельности – проектирование баз данных. Но, с другой стороны, появляются правовые нормы, в которых не предусмотрено скидки на технические возможности имеющихся систем, например: GDPR — General Data Protection Regulation.

Рис. 4. Воронка технических возможностей (Источник).
В указанных аспектах становится понятным, что первоначальный датасет (рис. 1) должен будет, в первую очередь, сохраняться, а во вторую очередь быть базой для извлечения из него дополнительной информации. Ну как пример: повсеместно распространены камеры фиксации ПДД, системы информационной обработки отсеивают нарушителей, но остальная информация также может быть предложена другим потребителям, допустим как маркетинговый мониторинг структуры потока покупателей к торговому центру. А это источник дополнительной добавленной стоимости при использовании Бигдата. Вполне можно допустить, что собираемые сейчас датасеты, где-то в будущем, будут иметь ценность по механизму аналогичному ценности раритетных изданий 1700 годов в настоящее время. Ведь, по сути, временные датасеты уникальны и маловероятно, что повторяться в будущем.
3. Вводная часть. Критерии оценок
В процессе обработки была выработана следующая классификация ошибок.
1. Класс ошибки (за основу взят ГОСТ Р 8.736-2011): а) систематические ошибки; б) случайные ошибки; в) грубая ошибка.
2. По множественности: а) моноискажение; б) мультиискажение.
3. По критичности последствий: а) критическая; б) не критическая.
4. По источнику возникновения:
А) Техническая – ошибки возникающие в процессе работы оборудования. Достаточно актуальная ошибка для IoT-систем, систем со значительной степенью влияния качества связи, оборудования (железа).
Б) Операторские – ошибки в широком диапазоне от опечатки оператора при вводе до ошибок в техзадании на проектирование БД.
В) Пользовательские – тут ошибки пользователя во всем диапазоне от «забыл переключить раскладку» до того что метры принял за футы.
5. Выделил в отдельный класс:
а) «задачу разделителя», то есть пробела и «:» (в нашем случае) когда его продублировали;
б) слитно написанных слов;
в) отсутствия пробела после служебных символов
г) симметрично-множественные символы: (), «», «…».
В совокупностью, с систематизацией ошибок БД представленных на рисунке 5, складывается достаточно эффективная система координат для поиска ошибок и выработки алгоритма очистки данных, для этого примера.
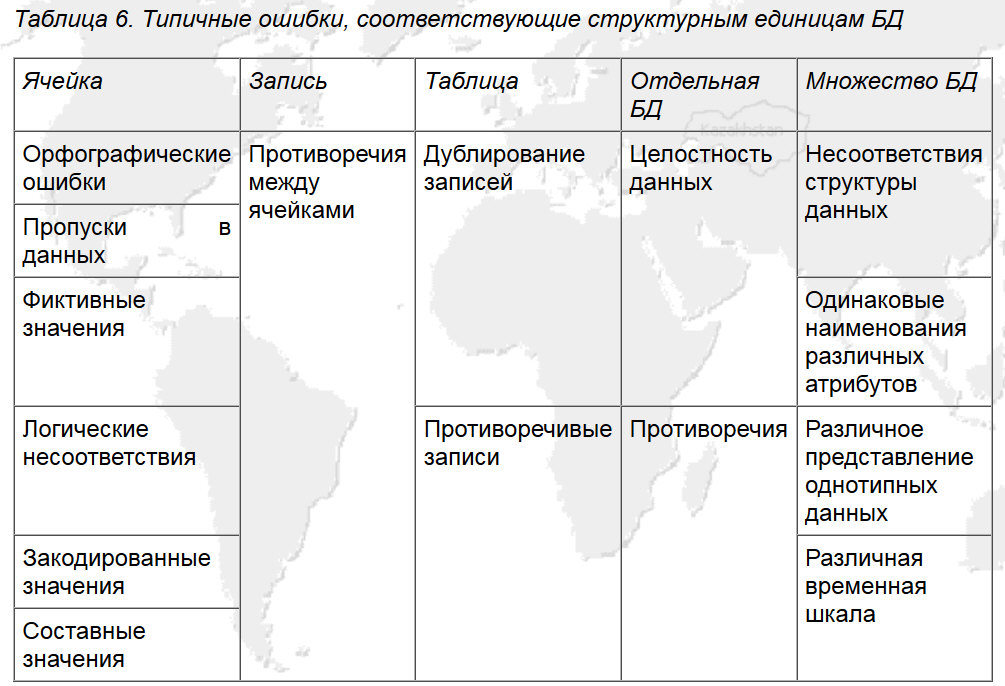
Рис. 5. Типичные ошибки, соответствующие структурным единицам БД (Источник: Орешков В.И., Паклин Н.Б. «Ключевые понятия консолидации данных»).
Accuracy (Точность), Domain Integrity (Целостность), Data Type (Тип данных), Consistency (Консистенция), Redundancy (Избыточность), Completeness (Полнота), Duplication (Дублирование), Conformance to Business Rules (Соблюдение бизнес-правил), Structural Definiteness (Структурная Определенность), Data Anomaly (Аномалия Данных), Clarity (Ясность), Timely (Своевременность), Adherence to Data Integrity Rules (Соблюдение правил целостности данных). (Стр. 334. Data warehousing fundamentals for IT professionals / Paulraj Ponniah.—2nd ed.)
Представил английские формулировки и в скобках русский машинный перевод.
Accuracy. The value stored in the system for a data element is the right value for that occurrence of the data element. If you have a customer name and an address stored in a record, then the address is the correct address for the customer with that name. If you find the quantity ordered as 1000 units in the record for order number 12345678, then that quantity is the accurate quantity for that order.
[Точность. Значение, сохраненное в системе для элемента данных, является правильным значением для этого вхождения элемента данных. Если у вас есть имя клиента и адрес, сохраненные в записи, то адрес является правильным адресом для клиента с этим именем. Если вы найдете количество, заказанное как 1000 единиц в записи для заказа номер 12345678, то это количество является точным количеством для этого заказа.]
Domain Integrity. The data value of an attribute falls in the range of allowable, defined values. The common example is the allowable values being “male” and “female” for the gender data element.
[Целостность Домена. Значение данных атрибута попадает в диапазон допустимых, определенных значений. Общий пример-допустимые значения «мужской” и „женский“ для элемента гендерных данных.]
Data Type. Value for a data attribute is actually stored as the data type defined for that attribute. When the data type of the store name field is defined as “text,” all instances of that field contain the store name shown in textual format and not numeric codes.
[Тип данных. Значение атрибута данных фактически сохраняется как тип данных, определенный для этого атрибута. Если тип данных поля имя магазина определен как „текст“, все экземпляры этого поля содержат имя магазина, отображаемое в текстовом формате, а не в числовых кодах.]
Consistency. The form and content of a data field is the same across multiple source systems. If the product code for product ABC in one system is 1234, then the code for this product is 1234 in every source system.
[Консистенция. Форма и содержание поля данных одинаковы в разных системах-источниках. Если код продукта для продукта ABC в одной системе равен 1234, то код для этого продукта равен 1234 в каждой исходной системе.]
Redundancy. The same data must not be stored in more than one place in a system. If, for reasons of efficiency, a data element is intentionally stored in more than one place in a system, then the redundancy must be clearly identified and verified.
[Избыточность. Одни и те же данные не должны храниться более чем в одном месте системы. Если по соображениям эффективности элемент данных намеренно хранится в нескольких местах системы, то избыточность должна быть четко определена и проверена.]
Completeness. There are no missing values for a given attribute in the system. For example, in a customer file, there must be a valid value for the “state” field for every customer. In the file for order details, every detail record for an order must be completely filled.
[Полнота. В системе нет пропущенных значений для данного атрибута. Например, в файле клиента должно быть допустимое значение поля „состояние“ для каждого клиента. В файле сведений о заказе каждая запись сведений о заказе должна быть полностью заполнена.]
Duplication. Duplication of records in a system is completely resolved. If the product file is known to have duplicate records, then all the duplicate records for each product are identified and a cross-reference created.
[Дублирование. Дублирование записей в системе полностью устранено. Если известно, что файл продукта содержит повторяющиеся записи, то все повторяющиеся записи для каждого продукта идентифицируются и создается перекрестная ссылка.]
Conformance to Business Rules. The values of each data item adhere to prescribed business rules. In an auction system, the hammer or sale price cannot be less than the reserve price. In a bank loan system, the loan balance must always be positive or zero.
[Соблюдение бизнес-правил. Значения каждого элемента данных соответствуют установленным бизнес-правилам. В аукционной системе цена молотка или продажи не может быть меньше резервной цены. В банковской кредитной системе баланс кредита всегда должен быть положительным или нулевым.]
Structural Definiteness. Wherever a data item can naturally be structured into individual components, the item must contain this well-defined structure. For example, an individual’s name naturally divides into first name, middle initial, and last name. Values for names of individuals must be stored as first name, middle initial, and last name. This characteristic of data quality simplifies enforcement of standards and reduces missing values.
[Структурная Определенность. Там, где элемент данных может быть естественным образом структурирован на отдельные компоненты, элемент должен содержать эту четко определенную структуру. Например, имя человека естественным образом делится на имя, средний инициал и фамилию. Значения для имен физических лиц должны храниться в виде имени, среднего инициала и фамилии. Эта характеристика качества данных упрощает применение стандартов и уменьшает недостающие значения.]
Data Anomaly. A field must be used only for the purpose for which it is defined. If the field Address-3 is defined for any possible third line of address for long addresses, then this field must be used only for recording the third line of address. It must not be used for entering a phone or fax number for the customer.
[Аномалия Данных. Поле должно использоваться только для той цели, для которой оно определено. Если поле Address-3 определено для любой возможной третьей строки адреса для длинных адресов, то это поле должно использоваться только для записи третьей строки адреса. Он не должен использоваться для ввода номера телефона или факса для клиента.]
Clarity. A data element may possess all the other characteristics of quality data but if the users do not understand its meaning clearly, then the data element is of no value to the users. Proper naming conventions help to make the data elements well understood by the users.
[Ясность. Элемент данных может обладать всеми другими характеристиками качественных данных, но если пользователи не понимают его значения ясно, то элемент данных не представляет ценности для пользователей. Правильные соглашения об именовании помогают сделать элементы данных хорошо понятными пользователям.]
Timely. The users determine the timeliness of the data. lf the users expect customer dimension data not to be older than one day, the changes to customer data in the source systems must be applied to the data warehouse daily.
[Своевременно. Пользователи определяют своевременность данных. если пользователи ожидают, что данные измерения клиента не будут старше одного дня, изменения данных клиента в исходных системах должны применяться к хранилищу данных ежедневно.]
Usefulness. Every data element in the data warehouse must satisfy some requirements of the collection of users. A data element may be accurate and of high quality, but if it is of no value to the users, then it is totally unnecessary for that data element to be in the data warehouse.
[Полезность. Каждый элемент данных в хранилище данных должен удовлетворять некоторым требованиям коллекции пользователей. Элемент данных может быть точным и иметь высокое качество, но если он не представляет ценности для пользователей, то совершенно необязательно, чтобы этот элемент данных находился в хранилище данных.]
Adherence to Data Integrity Rules. The data stored in the relational databases of the source systems must adhere to entity integrity and referential integrity rules. Any table that permits null as the primary key does not have entity integrity. Referential integrity forces the establishment of the parent–child relationships correctly. In a customer-to-order relationship, referential integrity ensures the existence of a customer for every order in the database.
[Соблюдение правил целостности данных. Данные, хранящиеся в реляционных базах данных исходных систем, должны соответствовать правилам целостности сущностей и ссылочной целостности. Любая таблица, допускающая null в качестве первичного ключа, не обладает целостностью сущности. Ссылочная целостность заставляет правильно устанавливать отношения между родителями и детьми. В отношениях клиент-заказ ссылочная целостность обеспечивает существование клиента для каждого заказа в базе данных.]
4. Качество очистки данных
Качество очистки данных достаточно проблематичный вопрос в бигдата. Ответить на вопрос какая степень очистки данных необходима при выполнении поставленной задачи, является основным для каждого датаанлитика. В большинстве текущих задач каждый аналитик устанавливает это сам и вряд ли кто-то со стороны способен оценить этот аспект в его решении. Но для поставленной задачи в этом случае этот вопрос был крайне важен, так как достоверность правовых данных должна стремиться к единице.
Рассматривая технологии тестирования программного обеспечения по определению надежности в работе. Этих моделей на сегодняшний день более 200. Многие из моделей используют модель обслуживания заявок:
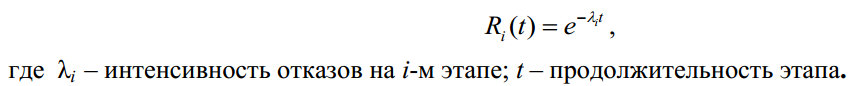
Рис. 6
Размышляя следующим образом: «Если найденная ошибка это событие аналогичное событию отказа в данной модели, то как найти аналог параметра t?» И составил следующую модель: Представим, что время которое необходимо тестировщику для проверки одной записи равно 1 минута (для рассматриваемой БД), тогда чтобы отыскать все ошибки ему потребуется 365 494 минут, что приблизительно составляет 3 года и 3 месяца рабочего времени. Как мы понимаем это очень не малый объем работы и затраты за проверку базы данных будут неподъемны для составителя этой БД. В данном размышлении появляется экономическое понятие затраты и после анализа пришел к выводу, что это достаточно эффективный инструмент. Опираясь на закон экономики: «Объем производства (в ед.), при котором достигается максимальная прибыль фирмы, находится в той точке где предельные затраты на выпуск новой единицы продукции сравниваются с ценой, которую эта фирма может получить за новую единицу». Опираясь на постулат, что нахождение каждой следующей ошибки, требует все больше и больше проверки записей, то это и есть фактор затрат. То есть принятый в моделях тестирования постулат принимает физически смысл, в следующей закономерности: если для нахождение i-той ошибки потребовалось проверить n записей, то для нахождения следующей (i+1) ошибки уже потребуется проверить m записей и при этом n<m. Этот постулат, в моделях тестирования, формулируются, в основном тем требованием, что найденные ошибки нужно фиксировать, но не исправлять, чтобы ПО тестировалось в своем естественном состоянии, то есть поток отказов был однороден. Соответственно, для нашего случая, проверка записей может проявить два варианта однородности:
- Когда количество проверенных записей до нахождения новой ошибки стабилизируется;
- Когда количество проверенных записей до нахождения следующей ошибки будет увеличиваться.
Для определения критического значения обратился к понятию экономической целесообразности, которое в данном случае, при использовании понятия общественных затрат можно сформулировать следующим образом: «Затраты по исправлению ошибки должен нести тот экономический агент, который сможет это сделать с наименьшими издержками». Одного агента мы имеем – это тестировщик, который тратит на проверку одной записи 1 минуту. В денежном эквиваленте, при заработке 6000 руб./день, это составит 12,2 руб. (приблизительно на сегодняшний день). Осталось определить вторую сторону равновесия в экономическом законе. Рассуждал так. Существующая ошибка потребует от того, кого она касается потратить усилия по ее исправлению, то есть владельца недвижимости. Допустим для этого нужно 1 день действий (отнести заявление, получить исправленный документ). Тогда с общественной точки зрения его затраты будут равны средней з/п за день. Средняя начисленная з/п в ХМАО по «Итоги социально-экономического развития Ханты-Мансийского автономного округа – Югры за январь-сентябрь 2019 года» 73285 руб. или 3053,542 руб./день. Соответственно получаем критическое значение равное:
3053,542: 12,2 = 250,4 ед.записей.
Это означает, с общественной точки зрения, если тестировщик проверил 251 запись и нашел одну ошибку это равноценно тому, что пользователь исправил эту ошибку самостоятельно. Соответственно если тестировщик потратил на нахождение следующей ошибки время равное проверке 252 записей, то в этом случае затраты на исправление лучше переложить на пользователя.
Здесь представлен упрощенный подход, так как с общественной точки зрения необходимо учитывать всю дополнительную стоимость генерируемую каждым специалистом, то есть затраты с учетом налогов и соцплатежей, но модель понятна. Следствием из этой взаимосвязи становится требование к специалистам следующее: специалист из IT отрасли должен иметь з/п большую чем в среднем по стране. Если его з/п меньше, чем в среднее значение з/п потенциальных пользователей БД, то он сам должен проверить всю БД в рукопашную.
При использовании описанного критерия формируется первое требование к качеству БД:
I(тр). Доля критических ошибок не должна превышать величины 1/250,4 = 0,39938%. Чуть меньше чем аффинажная очистка золота в промышленности. И в натуральном измерении не более 1459 записей с ошибками.
Экономическое отступление.
По сути, допуская такое количество ошибок в записях, общество соглашается на экономические потери в объеме:
1459*3053,542 = 4 455 118 руб.
Данная сумма определяется тем фактом, что у общества отсутствуют инструменты позволяющие снизить эти издержки. Отсюда следует, если у кого-то появится технология, которая позволяет снизить количество записей с ошибками до, например, 259, то это позволяет обществу экономить:
1200*3053,542 = 3 664 250 руб.
Но при этом он может попросить за свой талант и труд, ну допустим — 1 млн. руб.
То есть общественные издержки сокращаются на:
3 664 250 – 1 000 000 = 2 664 250 руб.
По сути, этот эффект является добавленной стоимостью, от использования технологий Бигдата.
Но тут следует учитывать, что это общественный эффект, а владельцем БД являются муниципальные органы власти, их доход от использования имущества, зафиксированного в данной БД, при ставке 0,3% составляет: 2,778 млрд. руб./год. А эти издержки (4 455 118 руб.) его сильно не волнуют, так как переложены на владельцев имущества. И, в этом аспекте, разработчик, более аффинажных технологий в Бигдата, должен будет проявить умение убедить владельца этой БД, а на такие вещи нужен немалый талант.
В данном примере алгоритм оценки ошибок был выбран на основе модель Шумана [2] проверки ПО при тестировании на безотказность. По причине ее распространённости в сети и возможности получить необходимые статистические показатели. Методология взята из Монахов Ю.М. «Функциональная устойчивость информационных систем», смотрите под спойлером на рис. 7-9.
Рис. 7 – 9 Методология модели Шумана





Во второй части данного материала представлен пример очистки данных, в котором получены результаты использования модели Шумана.
Представлю полученные результаты:
Предполагаемое количество ошибок N = 3167 шN.
Параметр С, лямбда и функция надежности:
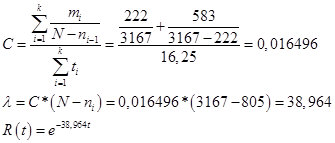
Рис.17
По сути, лямбда — это фактический показатель с какой интенсивностью на каждом этапе обнаруживаются ошибки. Если посмотреть, во второй части, то оценка этого показателя составляла 42,4 ошибки в час, что, достаточно, сравнимо с показателем Шумана. Выше, было определено, что интенсивность нахождения ошибок разработчиком должна быть не ниже чем 1 ошибка на 250,4 записей, при проверке 1 записи в минуту. Отсюда критическое значение лямбда для модели Шумана:
60/250,4 = 0,239617.
То есть необходимость проведения процедур нахождения ошибок нужно проводить до тех пор, пока лямбда, с имеющихся 38,964, не снизится до 0,239617.
Либо пока показатель N (потенциальное количество ошибок) минус n (исправленное количество ошибок) не снизится меньше принятого нами порога – 1459 шт.
Литература
- Монахов, Ю. М. Функциональная устойчивость информационных систем. В 3 ч. Ч. 1. Надежность программного обеспечения: учеб. пособие / Ю. М. Монахов; Владим. гос. ун-т. – Владимир: Издво Владим. гос. ун-та, 2011. – 60 с. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, «Probabilistic models for software reliability prediction».
- Data warehousing fundamentals for IT professionals / Paulraj Ponniah.—2nd ed.
Часть вторая. Теоретическая
