На Хабре появились интересные статьи (например), о том как стереть информацию на Flash SSD накопителе, так, что бы информация действительно была стерта. Производители заявляют, что обычное стирание не гарантирует невозможность восстановления информации, и рекомендует использовать специальные функции стирания, которые сотрут не только таблицы размещения блоков данных, но и собственно сами блоки данных в памяти, содержащие стираемую информацию. А можно ли восстановить полноценно стертую информацию во Flash памяти? Не просто найти неиспользуемые области, в которых сохранились «ошметки» более не нужной (якобы стертой) информации, а именно восстановить исходное значение битов памяти после физического процесса стирания этих бит? Наш интерес к этой теме вызван не попыткой найти что-то тайное, а наоборот, дать рекомендации как стереть, чтобы никто не нашел (или правильней сказать затруднить). Сейчас в ряде приборов заложены алгоритмы 10 и более кратных процедур стирания, что во-первых, долго, а во-вторых, расходует ресурс Flash памяти и быстро выводит ее из строя. Но для того, что бы рекомендации были не абстрактные «сотрите дважды» или «сотрите, запишите и еще раз сотрите», а имели некое количественное выражение, нужно сначала научиться восстанавливать информацию. Интересно? Тогда поехали…

Биты информации во Flash памяти хранятся в виде заряда на «плавающем» затворе либо в области подзатворного диэлектрика МОП-транзистора. Если уровень заряда больше некоторого уровня, то ячейка запрограммирована, если ниже — то считается чистой. Пока мы остановимся на SLC Flash памяти, когда одна ячейка кодирует один бит. Есть более сложные типы, когда уровнем заряда в одной ячейки кодируется несколько бит. Например, MLC — два бита на ячейку, условно отсутствие заряда = «11», 1/3 заряда = «01», 2/3 заряда = «10» и полный заряд соответствует коду«00». Для QLC на одной ячейке хранится уже четыре бита. Поверх всего этого наложены еще всевозможные блочные корректирующие коды, которые дают уже достаточно высокий уровень надежности, даже при физических отказах нескольких ячеек. Но как уже отмечено ранее, мы пока остановимся на ячейках памяти, кодирующих один бит. И в частности подопытным кроликом будет отечественная микросхема 1636РР4, объемом 16Мбит. И чтобы облегчить восприятие, воспользуемся аналогией — представим ячейку Flash памяти как стакан воды. И если стакан пустой — то это «1». Если полный — то «0». Во время операции программирования заряд заносится на «плавающий затвор» — наполняем стакан водой, при стирании заряд удаляется — выливаем из стакана воду. После каждой операции стирания большая часть этого заряда уходит, но малая часть остается — стакан остается мокрым. И если наш стакан мокрый — значит ранее в нем была вода — ячейка была запрограммирована — на этом эффекте и строится основной принцип восстановления стертой информации.
Сергей Скоробогатов из Кембриджского университета (много интересного можно у него почитать) провел эксперимент на ячейках с плавающим затвором. Он выполнял операцию стирания для ячеек, в которые были предварительно записаны «0» и «1». Тенденция разницы пороговых напряжений показана на следующем рисунке.

Несмотря на то, что операция стирания выполняется 100 раз, отличие порогового напряжения запрограммированных и затем стертых ячеек от ни разу не программированных, очевидно существует. Т.е. если из пустого, но мокрого, стакана еще раз вылить воду, то он все равно остается мокрым. Таким образом, дублирование операции стирания не является безопасным и эффективным способом защиты от восстановления стираемой информации.
Предположим, что у нас полностью чистая, ранее не использованная микросхема памяти, тогда ее ячейки памяти выглядят вот так
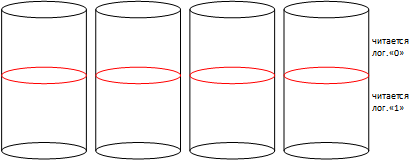
Все ячейки читаются как «1», т.е. чистые.
Теперь мы ее запрограммируем.
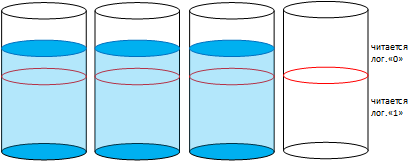
Часть ячеек запрограммированы (заполнены водой), и читаются как «0». Часть ячеек осталась чистыми.
Выполним стандартную процедуру стирания.

Все ячейки читаются чистыми «1». Остаточного заряда не хватает, чтобы превысить порог. Но лишний заряд в ранее записанных ячейках остается — стаканы мокрые.
Теперь если начать понемногу доливать во все стаканы воды, то ранее мокрые стаканы быстрее превысят порог, чем те, которые всегда были сухими.
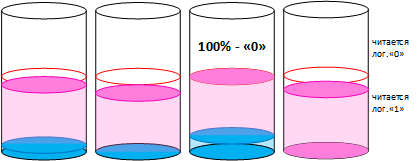
И так далее понемногу доливаем

Пока все ранее записанные ячейки не перейдут снова в запрограммированное состояние.
Вроде бы все просто, система взломана, все сейчас начнут восстанавливать прошивки защищенных микроконтроллеров, «фиксить» использованные метрошные карты, и о боже, начнут реверс инженеринг банковских. Рынок Flash памяти рухнет и поглотит за собой всю микроэлектронику… но нет. Все гораздо сложнее. Есть три аспекта, которые значительно затрудняют процесс.
Обычно у микросхем Flash памяти стандартный процесс записи одного бита занимает до нескольких микросекунд. В частности у микросхемы 1636РР4 время программирования одного байта составляет не более 200 мкс. С одной стороны это достаточно длительный процесс, который легко можно «укоротить», например прервать. Но с другой стороны процесс записи очень сложный. Во-первых, для программирования ячейки Flash необходимо высокое напряжение 7...15В. В современных микросхемах для удобства пользователей блок накачки высокого напряжения встроен в микросхему и высокое напряжение не требуется подавать извне. Блок автоматически включается при начале операции записи, накачивает достаточный уровень из основного напряжения питания, а уже затем запускаются процессы подачи высокого напряжения в затворы для внесения заряда. После завершения процесса записи, выключается блок накачки, а накаченное высокое напряжение «сливается» для возможности безопасного переключения на следующую ячейку памяти. За все эти процессы отвечает внутренний цифровой автомат, который не предполагает какое-либо вмешательство и изменение его поведения. Даже команда «сброса» игнорируется в процессах записи или стирания. Остается только завершить процесс по выключению питания. Но на самом деле, разработчикам микросхемы, знающим как она работает, доступны различные методы, например, используемые при тестировании, в которых они имеют больше возможностей для управления. Но данная информация закрыта, и ее публикация в открытых источниках не допустима. В любом случае, мы смогли безопасно управлять квантами дозаписи (долива), и определили минимальный при котором возникал эффект восстановления данных.
На следующей картинке представлено, через сколько дозаписей минимального кванта ячейка превышает порог.

Как видно, в конечном итоге все ячейки превышают порог «запрограммированности», но часть ячеек делает это быстро, а часть позже. И хотя на рисунке представлены некие уровни остаточных данных и дозаписанных данных — это не более чем абстракция, так как для каждой ячейки мы можем сказать только, то, что после стирания и начала записи минимальными квантами она запрограммировалась на N шаге.
Пора перейти к обработке больших объемов данных. Для этого была разработана программа, позволяющая проводить маннипуляции над большим объемом ячеек Flash памяти.

Программа позволяет графически отобразить получаемые результаты, так как человеческий глаз замечает, то, что сложно описать чистой математикой. Кроме того, программа выполняет ряд операций по статистической обработке. Например, после каждого цикла дозаписи выполняется несколько циклов чтения и значение ячейки определятся как среднеарифиметическое. И да, процесс восстановления очень долгий, и без автоматизации провести такое исследование крайне затруднительно. Но к сожалению обнадеживающие результаты при манипулировании с несколькими ячейками перестал работать при оперировании на больших массивах. Итак, второй аспект.
Как видно из рисунка, в ходе исследований мы использовали паттерн «Шахматный код» для заполнения памяти и последующего восстановления информации. На следующем рисунке представлено как выглядит память после программирования и после стандартной процедуры стирания.
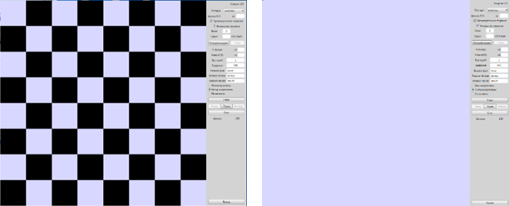
Поиграв настройками, нам удавалось восстановить более-менее воспринимаемую глазом картину в отдельной области, но при переходе к другой области, картина полностью разрушалась. Особенно это было заметно на границе секторов. Таким образом возникло понимание, что все ячейки разные. В микроэлектроннике этот эффект называют «miss-match» или повторяемостью элементов, т.е. рядом расположенные одинаковые элементы очень похожи, и имеют очень близкие параметры, а стоит их разнести на достаточное расстояние, даже полностью одинаково нарисованные элементы начинают отличаться по своим параметрам. Так и в нашем случае, с одной стороны все ячейки должны быть одинаковыми, но поведение их сильно разнится. Последующий анализ показал, что даже соседние ячейки могут быть разными. Т.е. если вернуться к нашей аналогии со стаканами, то все ячейки выглядят примерно так.

Некоторые очень долго невозможно залить до порога, даже если заведомо известно, что они были ранее записанны, некоторые наоборот, известно что она точно чистая, но после первого кванта становится записанной. Для каждой ячейки мы можем примерно оценить ее поведение. Но для этого необходимо ее многократно стереть и записать квантами — создать модель. При этом модель каждой ячейки в разных образцах микросхемы будет разной. Т.е. модель создается для каждого образца, который мы исследовали. Очевидно, что постоянные записи и стирания, необходимые для создания модели окончательно сотрут остатки атакуемой (восстанавливаемой) информации. Поэтому подход следующий:
1. Делается «слепок» образца атакуемой микросхемы, где для каждой ячейки записывается номер кванта, при котором превышен порог запрограммированности.

2. Для данного образца микросхемы формируется модель ее ячеек «фон».

3. Результатом является разница между «слепком» и «фоном».


В результате чего получается достаточно качественно восстановить информацию. По результатам статистической обработки, четко различимы «горбы» восстановленных «0» и «1».

Именно наличие таких «горбов» является критерием наличия факта восстановления информации, т.е. есть группа бит с малым числом шагов и с большим числом шагов. Отношение величины площади горбов — отражает соотношение «0» и «1» в исходной информации. И теперь можно переходить к основной части нашей задачи. Как стереть исходную информацию, чтобы ее восстановление было затруднено.
Напомню, что целью работы было не восстановить информацию, а найти метод стирания, который наибольшим образом затруднит восстановление. Для начала посмотрим, как работает многократное повторение стандартной функции стирания.
Как видно, обычное стирание памяти стандартной функцией оставляет возможность восстановления исходной информации. Раз просто стирание не помогает, остается только одно — что-то записать перед стиранием, а потом стирать. Что же можно записать? Были проанализированы следующие варианты:
— запись псевдослучайной последовательности.
— запись во все ячейки «0», включая ранее запрограммированные (еще раз напомню, что стертая или чистая ячейка = «1»).
— запись инверсных данных, т.е. дозаписать «0» в чистые ячейки.
В результате были получены вот такие результаты.
50% — как было отмечено в затравочном вопросе, является минимумом восстановления информации.
Таким образом, для безопасного стирания информации в Flash памяти лучше всего подходит метод «запись инверсных данных и стирание», когда перед стиранием все ранее незапрограммированные ячейки дозаписываются, после чего выполняется общее стирание. Это не исключает выполнение дополнительно других методов в зависимости от паранойи заказчика. Но общая рекомендация — перед любым стиранием нужно дозапрограммировать все незапрограммированные ячейки.
В итоге у нас получился вот такой заключительный график
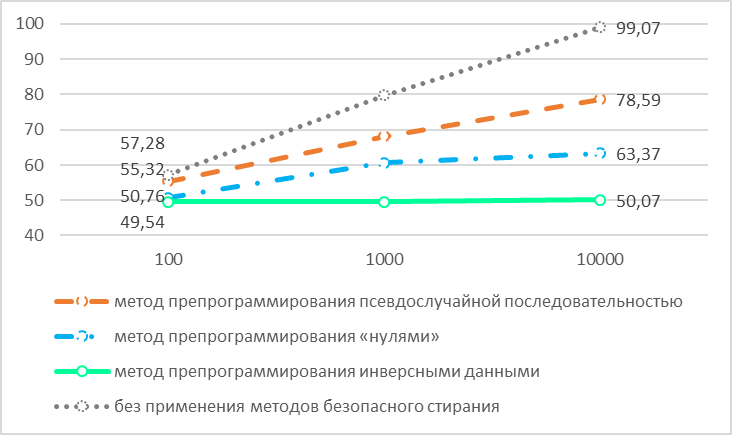
И если, дорогой читатель, ты еще не устал от этого длинного повествования, то в этом графике тебя должно что-то смутить.
Смутить вас должны цифры 100, 1000 и 10 000 по оси Х!
Что же они означают? Так вот, все выше описанное действительно, только в том случае, если исходная информация во Flash память была записана 10 000 (десять тысяч) раз. Т.е. «Шахматный код» перед попыткой восстановления записывался и стирался 10 000 раз, только после этого наш метод восстановления позволял восстановить информацию. Это и есть третий аспект. То, как снижается уровень восстановления при 1000 и 100 записях, показывает как раз этот график. При однократной записи восстановить какую-либо информацию нам не удалось. Так что рынок Flash памяти и микроэлектроники может чувствовать себя спокойно.
P.S. Данная статья является результатом большого коллектива, и я выражаю огромную благодарность всем участникам.
P.P.S. А что будет если 10 000 записей в одну микросхему заменить на 10 000 разных микросхем с одной и той же информацией? Например, закрытая битами «Read Protect» прошивка в микроконтроллерах? Но об этом в следующий раз…

Введение.
Затравочный вопрос
Попробуйте сформулировать критерий оценки объема восстановленной информации? Если мы восстановили все, то это 100%, если ничего, то 0%. При этом нужно понимать, что если ни один «0» и ни одна «1» не совпадает с исходной информацией, то это означает, что мы восстановили 100% информации, но только проинвертировали ее. Мы так и не пришли к какому либо устраивающих всех критерию, и при 50% совпадения с исходной информацией — мы считали минимумом возможного восстановления. Возможно коллективный Хабр-разум даст другие идеи?
Биты информации во Flash памяти хранятся в виде заряда на «плавающем» затворе либо в области подзатворного диэлектрика МОП-транзистора. Если уровень заряда больше некоторого уровня, то ячейка запрограммирована, если ниже — то считается чистой. Пока мы остановимся на SLC Flash памяти, когда одна ячейка кодирует один бит. Есть более сложные типы, когда уровнем заряда в одной ячейки кодируется несколько бит. Например, MLC — два бита на ячейку, условно отсутствие заряда = «11», 1/3 заряда = «01», 2/3 заряда = «10» и полный заряд соответствует коду«00». Для QLC на одной ячейке хранится уже четыре бита. Поверх всего этого наложены еще всевозможные блочные корректирующие коды, которые дают уже достаточно высокий уровень надежности, даже при физических отказах нескольких ячеек. Но как уже отмечено ранее, мы пока остановимся на ячейках памяти, кодирующих один бит. И в частности подопытным кроликом будет отечественная микросхема 1636РР4, объемом 16Мбит. И чтобы облегчить восприятие, воспользуемся аналогией — представим ячейку Flash памяти как стакан воды. И если стакан пустой — то это «1». Если полный — то «0». Во время операции программирования заряд заносится на «плавающий затвор» — наполняем стакан водой, при стирании заряд удаляется — выливаем из стакана воду. После каждой операции стирания большая часть этого заряда уходит, но малая часть остается — стакан остается мокрым. И если наш стакан мокрый — значит ранее в нем была вода — ячейка была запрограммирована — на этом эффекте и строится основной принцип восстановления стертой информации.
Сергей Скоробогатов из Кембриджского университета (много интересного можно у него почитать) провел эксперимент на ячейках с плавающим затвором. Он выполнял операцию стирания для ячеек, в которые были предварительно записаны «0» и «1». Тенденция разницы пороговых напряжений показана на следующем рисунке.

Несмотря на то, что операция стирания выполняется 100 раз, отличие порогового напряжения запрограммированных и затем стертых ячеек от ни разу не программированных, очевидно существует. Т.е. если из пустого, но мокрого, стакана еще раз вылить воду, то он все равно остается мокрым. Таким образом, дублирование операции стирания не является безопасным и эффективным способом защиты от восстановления стираемой информации.
Предположим, что у нас полностью чистая, ранее не использованная микросхема памяти, тогда ее ячейки памяти выглядят вот так

Все ячейки читаются как «1», т.е. чистые.
Теперь мы ее запрограммируем.

Часть ячеек запрограммированы (заполнены водой), и читаются как «0». Часть ячеек осталась чистыми.
Выполним стандартную процедуру стирания.

Все ячейки читаются чистыми «1». Остаточного заряда не хватает, чтобы превысить порог. Но лишний заряд в ранее записанных ячейках остается — стаканы мокрые.
Теперь если начать понемногу доливать во все стаканы воды, то ранее мокрые стаканы быстрее превысят порог, чем те, которые всегда были сухими.

И так далее понемногу доливаем

Пока все ранее записанные ячейки не перейдут снова в запрограммированное состояние.
Вроде бы все просто, система взломана, все сейчас начнут восстанавливать прошивки защищенных микроконтроллеров, «фиксить» использованные метрошные карты, и о боже, начнут реверс инженеринг банковских. Рынок Flash памяти рухнет и поглотит за собой всю микроэлектронику… но нет. Все гораздо сложнее. Есть три аспекта, которые значительно затрудняют процесс.
1. Как «чуть-чуть» запрограммировать ячейку памяти ?
Обычно у микросхем Flash памяти стандартный процесс записи одного бита занимает до нескольких микросекунд. В частности у микросхемы 1636РР4 время программирования одного байта составляет не более 200 мкс. С одной стороны это достаточно длительный процесс, который легко можно «укоротить», например прервать. Но с другой стороны процесс записи очень сложный. Во-первых, для программирования ячейки Flash необходимо высокое напряжение 7...15В. В современных микросхемах для удобства пользователей блок накачки высокого напряжения встроен в микросхему и высокое напряжение не требуется подавать извне. Блок автоматически включается при начале операции записи, накачивает достаточный уровень из основного напряжения питания, а уже затем запускаются процессы подачи высокого напряжения в затворы для внесения заряда. После завершения процесса записи, выключается блок накачки, а накаченное высокое напряжение «сливается» для возможности безопасного переключения на следующую ячейку памяти. За все эти процессы отвечает внутренний цифровой автомат, который не предполагает какое-либо вмешательство и изменение его поведения. Даже команда «сброса» игнорируется в процессах записи или стирания. Остается только завершить процесс по выключению питания. Но на самом деле, разработчикам микросхемы, знающим как она работает, доступны различные методы, например, используемые при тестировании, в которых они имеют больше возможностей для управления. Но данная информация закрыта, и ее публикация в открытых источниках не допустима. В любом случае, мы смогли безопасно управлять квантами дозаписи (долива), и определили минимальный при котором возникал эффект восстановления данных.
На следующей картинке представлено, через сколько дозаписей минимального кванта ячейка превышает порог.

Как видно, в конечном итоге все ячейки превышают порог «запрограммированности», но часть ячеек делает это быстро, а часть позже. И хотя на рисунке представлены некие уровни остаточных данных и дозаписанных данных — это не более чем абстракция, так как для каждой ячейки мы можем сказать только, то, что после стирания и начала записи минимальными квантами она запрограммировалась на N шаге.
Пора перейти к обработке больших объемов данных. Для этого была разработана программа, позволяющая проводить маннипуляции над большим объемом ячеек Flash памяти.

Программа позволяет графически отобразить получаемые результаты, так как человеческий глаз замечает, то, что сложно описать чистой математикой. Кроме того, программа выполняет ряд операций по статистической обработке. Например, после каждого цикла дозаписи выполняется несколько циклов чтения и значение ячейки определятся как среднеарифиметическое. И да, процесс восстановления очень долгий, и без автоматизации провести такое исследование крайне затруднительно. Но к сожалению обнадеживающие результаты при манипулировании с несколькими ячейками перестал работать при оперировании на больших массивах. Итак, второй аспект.
2. Все стаканы разные.
Как видно из рисунка, в ходе исследований мы использовали паттерн «Шахматный код» для заполнения памяти и последующего восстановления информации. На следующем рисунке представлено как выглядит память после программирования и после стандартной процедуры стирания.

Поиграв настройками, нам удавалось восстановить более-менее воспринимаемую глазом картину в отдельной области, но при переходе к другой области, картина полностью разрушалась. Особенно это было заметно на границе секторов. Таким образом возникло понимание, что все ячейки разные. В микроэлектроннике этот эффект называют «miss-match» или повторяемостью элементов, т.е. рядом расположенные одинаковые элементы очень похожи, и имеют очень близкие параметры, а стоит их разнести на достаточное расстояние, даже полностью одинаково нарисованные элементы начинают отличаться по своим параметрам. Так и в нашем случае, с одной стороны все ячейки должны быть одинаковыми, но поведение их сильно разнится. Последующий анализ показал, что даже соседние ячейки могут быть разными. Т.е. если вернуться к нашей аналогии со стаканами, то все ячейки выглядят примерно так.

Некоторые очень долго невозможно залить до порога, даже если заведомо известно, что они были ранее записанны, некоторые наоборот, известно что она точно чистая, но после первого кванта становится записанной. Для каждой ячейки мы можем примерно оценить ее поведение. Но для этого необходимо ее многократно стереть и записать квантами — создать модель. При этом модель каждой ячейки в разных образцах микросхемы будет разной. Т.е. модель создается для каждого образца, который мы исследовали. Очевидно, что постоянные записи и стирания, необходимые для создания модели окончательно сотрут остатки атакуемой (восстанавливаемой) информации. Поэтому подход следующий:
1. Делается «слепок» образца атакуемой микросхемы, где для каждой ячейки записывается номер кванта, при котором превышен порог запрограммированности.

2. Для данного образца микросхемы формируется модель ее ячеек «фон».

3. Результатом является разница между «слепком» и «фоном».


В результате чего получается достаточно качественно восстановить информацию. По результатам статистической обработки, четко различимы «горбы» восстановленных «0» и «1».

Именно наличие таких «горбов» является критерием наличия факта восстановления информации, т.е. есть группа бит с малым числом шагов и с большим числом шагов. Отношение величины площади горбов — отражает соотношение «0» и «1» в исходной информации. И теперь можно переходить к основной части нашей задачи. Как стереть исходную информацию, чтобы ее восстановление было затруднено.
Стирание
Напомню, что целью работы было не восстановить информацию, а найти метод стирания, который наибольшим образом затруднит восстановление. Для начала посмотрим, как работает многократное повторение стандартной функции стирания.
| 1 стирание 99% совпадения |
100 стираний 98,6% совпадения |
1000 стираний 98,2% совпадения |
10 000 стираний 98,1% совпадения |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
Как видно, обычное стирание памяти стандартной функцией оставляет возможность восстановления исходной информации. Раз просто стирание не помогает, остается только одно — что-то записать перед стиранием, а потом стирать. Что же можно записать? Были проанализированы следующие варианты:
— запись псевдослучайной последовательности.
— запись во все ячейки «0», включая ранее запрограммированные (еще раз напомню, что стертая или чистая ячейка = «1»).
— запись инверсных данных, т.е. дозаписать «0» в чистые ячейки.
В результате были получены вот такие результаты.
| Стандартное стирание | Запись псевдослучайной последовательности и стирание |
Запись всех «0» и стирание | Запись инверсных данных и стирание |
|---|---|---|---|
| Восстановление 99,1% | Восстановление 78,6% | Восстановление 63,6% | Восстановление 50,1% |
 |
 |
 |
 |
50% — как было отмечено в затравочном вопросе, является минимумом восстановления информации.
Таким образом, для безопасного стирания информации в Flash памяти лучше всего подходит метод «запись инверсных данных и стирание», когда перед стиранием все ранее незапрограммированные ячейки дозаписываются, после чего выполняется общее стирание. Это не исключает выполнение дополнительно других методов в зависимости от паранойи заказчика. Но общая рекомендация — перед любым стиранием нужно дозапрограммировать все незапрограммированные ячейки.
В итоге у нас получился вот такой заключительный график

И если, дорогой читатель, ты еще не устал от этого длинного повествования, то в этом графике тебя должно что-то смутить.
Смутить вас должны цифры 100, 1000 и 10 000 по оси Х!
Что же они означают? Так вот, все выше описанное действительно, только в том случае, если исходная информация во Flash память была записана 10 000 (десять тысяч) раз. Т.е. «Шахматный код» перед попыткой восстановления записывался и стирался 10 000 раз, только после этого наш метод восстановления позволял восстановить информацию. Это и есть третий аспект. То, как снижается уровень восстановления при 1000 и 100 записях, показывает как раз этот график. При однократной записи восстановить какую-либо информацию нам не удалось. Так что рынок Flash памяти и микроэлектроники может чувствовать себя спокойно.
P.S. Данная статья является результатом большого коллектива, и я выражаю огромную благодарность всем участникам.
P.P.S. А что будет если 10 000 записей в одну микросхему заменить на 10 000 разных микросхем с одной и той же информацией? Например, закрытая битами «Read Protect» прошивка в микроконтроллерах? Но об этом в следующий раз…
