Comments 14
По вектору смежности — это случаи а2 и б.
Если ребра целочислены (случай а2), то это просто каждое третье число. Например, по графу 1->2:2, 2->3:-1, 3->1:6 4->4:5 это будет просто std::vector = {1,2,2, 2,3,1, 3,1,6, 4,4,5}
Для того же графа по ассоциативному массиву смежности будет std::map <std::pair < int, int>, int> (ну или же multimap), где ключи — пара номеров вершин, а значение — длина ребра.
Если ребра — нецелочислены (случай б), то вектор смежности графа будет храниться в паре векторов std::pair < std::vector, std::vector>, где в первом векторе — сами ребра (каждое ребро задается парой соответствующих вершин), а во втором — их длины.
Т.обр., для графа 1->2:0.2, 2->3:-0.1, 3->1:0.6 4->4:0.5 у нас будет std::pair < std::vector, std::vector> (первый вектор: {1,2,2,3,3,1,4,4}, а второй: {0.2, -0.1, 0,6, 0.5})
Для ассоциативного массива смежности — аналогично случаю с целочисленными, только у нас будет std::map <std::pair < int, int>, double> (ну или, опять же, multimap)
Ну а про другие структуры данных — подробнее с примерами можно посмотреть, например, по ссылкам к заметке (4; 5). так, в частности, для матрицы смежности вес ребра из вершины i в вершину j может быть задан как раз элементом матрицы a(i, j). И т.д.
Я как-то использовал списки смежности но очень по хитрому. Задача хранить узлы и ребра с мета информацией. Идея такая:
- узлы и ребра имеют одинаковый размер. Это позволяет выделять элементы сегментами по фиксированому поличеству как массивы. Что позволяет получать доступ к любому элементу за О(1).
- в моем случае ребра могут соединять не только узлы. Начальным/конечным элементом для ребра может быть не только узел, но и другое ребро.
- соответственно каждый элемент имеет ссылку на первое ребро в списке смежности входящих и отдельно ссылку на первый элемент в списке выходящих ребер. По сути ссылка это адрес 32 бита, в котором старшие 16 бит указывают на номер сегмента, а младшие 16 бит на индекс элемента в сегменте. Опять доступ за О(1).
- чтобы не хранить списки смежности отдельно они запрятаны в ребра, которые хранятся в сегментах. Каждое ребро имеет ссылку (32 бит) на следующий и предыдущий элемент в списке смежности входящих и выходящих ребер для исходного и конечного элементов (может картинка внесет ясность):
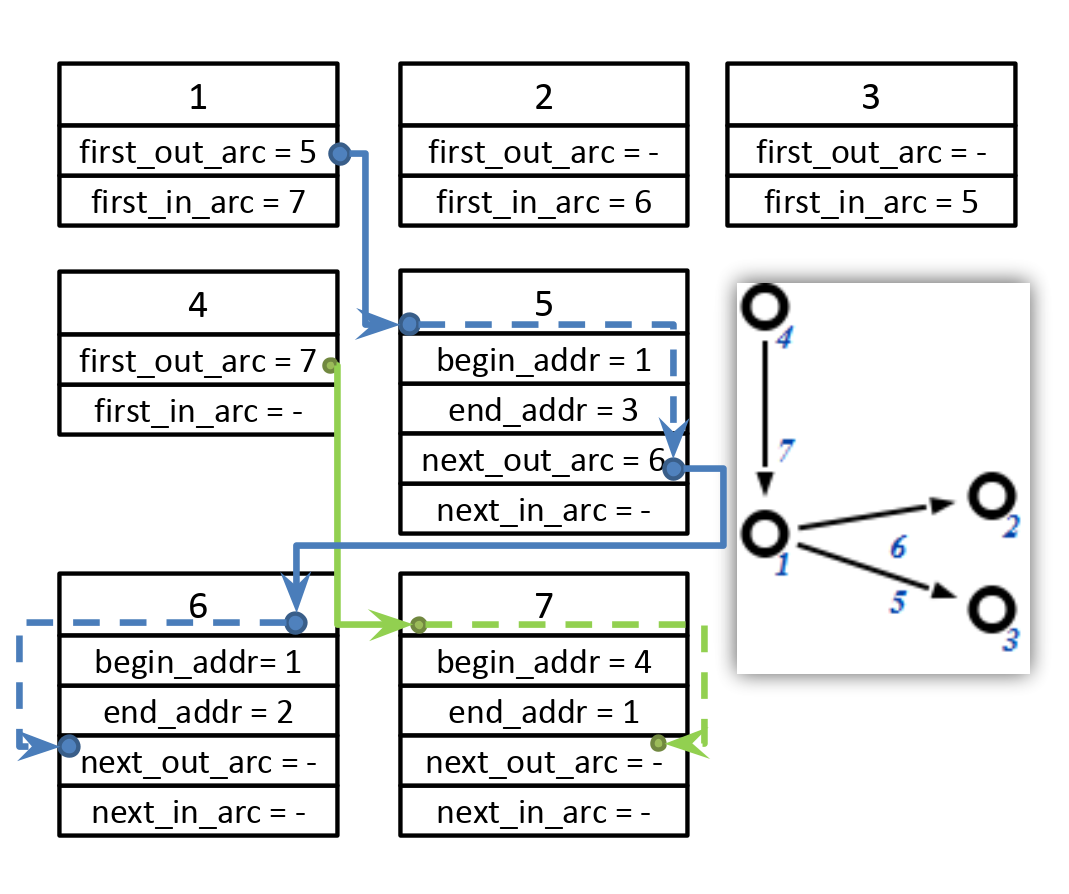

И так получается что вставка ребер очень быстрая, как вставка в обычный двунаправленный список. Удаление также. И все быстро работает за счет доступа к любому элементу за О(1), если не учитывать блокировки и т. д… Это отдельная история.
Вот ссылка на структуры данных в коде:
https://github.com/deniskoronchik/sc-machine/blob/dev/sc-memory/sc-core/sc-store/sc_element.h
Вот код создания новой дуги (ребра):
https://github.com/deniskoronchik/sc-machine/blob/dev/sc-memory/sc-core/sc-store/sc_storage.c#L645-L766
А про «в моем случае ребра могут соединять не только узлы» подробнее не расскажете?
Да, конечно. У нас используется семантическая сеть, которая построена на основе теории множеств. Базовым кирпичем такой теории является отношение которое связывает множество с его элементов. Это базовая дуга. Поэтому например есть множество отношенией, элементами которого являются подмножества разных отношений, например отношение "быть изображением чего либо". Оно задается узлом в графе (сем. сети). Этот узел обозначает множество всех экземпляром такого отношения. Экземпляром такого отношения является другая дуга, которая обозначает конкретное отношение такого типа. Вот пример:
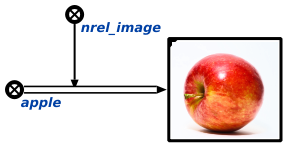
Немного дополнительных подробностей есть тут: https://habr.com/ru/post/328238/
В реализации все просто, все можно соединить со всем с помощью дуг/ребер
При использовании ассоциативных массивов смежности для хранения графов с множественными петлями и ребрами можно использовать не только multimap, но и map, если применить подход «расширенных ассоциативных массивов смежности» (раздел 4).
Итак, если есть граф 1->2:2, 1->2:-1, то можно задать его так:
std::map <std::pair < int, int>, std::vector >: ключ std::pair < int, int> (1, 2) — значение std::vector — {2, -1}.
Как выяснилось, удобно.
Структуры данных для хранения графов: обзор существующих и две «почти новых»