Comments 13
Объем кода — принято считать, что чем меньше написано строк кода, тем он производительнее и лучше. Мое мнение кардинально отличается, поскольку, написав одну строчку кода можно создать такую утечку памяти или вечный цикл, что браузер просто умрет.
Ну и представьте себе, что будет, если вы напишете 10 таких строчек кода.
Скорость сборки — ни для кого не секрет, что сейчас практически ни один из проектов не обходится без сборщиков вроде Webpack или Gulp, поэтому данная характеристика отображает правильность настройки сборщика проекта.
Как же классно использовать сборщик, который не требует настройки. И уж тем более угадывания его "правильных" параметров в тьюринг-полном конфиге.
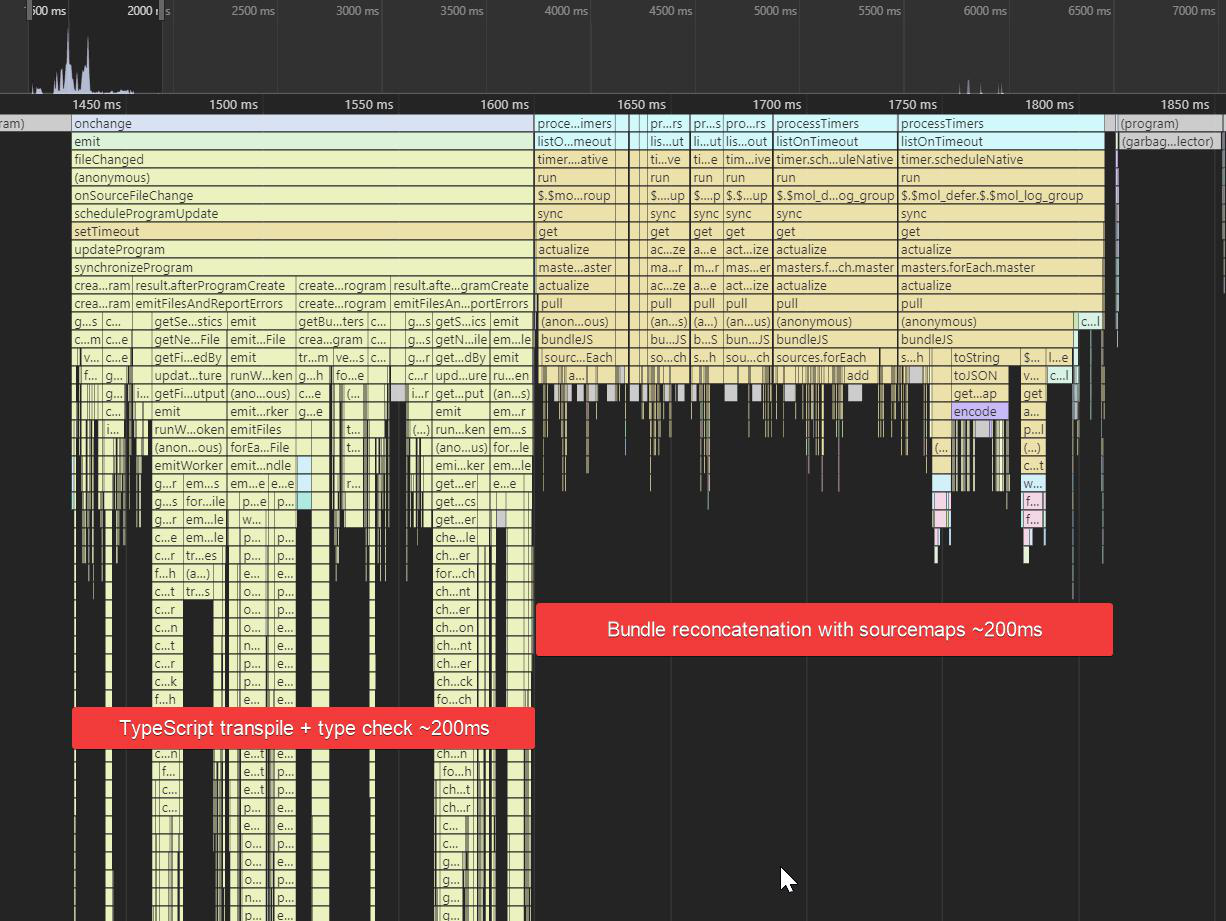
Вот, например, я взял реализацию простенького приложения realworld на react+redux+typescript, который основан на create-react-app, который использует webpack@4. И вижу такую картину при изменении исходника: где-то за пол секунды ребилдится бандл, но типы при этом не чекаются, в результате чего приложение стартует, благополучно падает и только через 2 секунды по вебсокетам прилетает результат тайпчека:

В сумме весь процесс от изменения до сообщения об ошибке занимает 4 секунды. Как это всё настроить так, чтобы тайпчекалось оно всё сразу за те же пол секунды и время до вывода ошибки было не более секунды, как тут:
Ну и напоследок самое вкусное. Тут, к сожалению, не у всех хватает опыта понять нюанс. Я против использования рекурсивных функций. Да, они сокращают объем написанного кода, но, не обходится без подвоха: часто такие рекурсивные функции не имеют условий выхода, про них просто-напросто забывают.
Если у рекурсии не будет условий выхода то она будет выполняться бесконечно. И статический анализатор мог бы проверить что условий выхода нет и подсветить ошибку в редакторе.
Вообще у меня есть мнение что для высокоуровневого языка программирования надо запрещать как раз таки циклы и оставить рекурсию как единственное средство для итераций. Суть такого решения в том что не нужно для языка программирования иметь несколько способов сделать одно то же — раз мы одну и ту же задачу можем решить и с помощью рекурсии и с помощью циклов то очевидно что одно их этих средств является избыточным. И появляется вопрос что убрать — циклы или рекурсию. Очевидно что рекурсия это более высокий уровень абстракции (рекурсия сводится к циклам через стек) — а значит более мощный и удобный инструмент. А что касается производительности то это уже задача компилятора (или статического анализатора с транспиляцией) преобразовать tail-call рекурсию в цикл без стека или провести кучу других оптимизаций. Что же касается циклов то мало того что в том же js для них есть разные избыточные синтаксические конструкции (while, do-while, for) да еще и с кучей нюансов и вопросов на который не каждый js-миддл ответит правильно (https://www.youtube.com/watch?v=Nzokr6Boeaw)
Как компилятору соптимизировать такой код?
function fib(n) {
return n <= 1 ? n : fib(n - 1) + fib(n - 2);
}Не знаю насколько сейчас продвинулись компиляторы в анализе но если человек будет оптимизировать код вручную то с рекурсией он получит аналогичную производительность (если конечно поддерживается базовая оптимизация хвостовой рекурсии)
Например n-ное значение последовательности фибоначчи
function fib(n) {
return n <= 1 ? n : fib(n - 1) + fib(n - 2);
}человек заоптимизирует через цикл так
function fib (n){
if(n <= 1) return n;
let fib = [0, 1];
for (let i = 2; i <= n; i++) {
fib[i] = fib[i - 2] + fib[i - 1];
}
return fib[fib.length - 1];
}но с рекурсией можно записать так
function fib (n){
if(n <= 1) return n;
let fib = [0, 1];
let i = 1;
let recur = () => {
i++;
fib[i] = fib[i - 2] + fib[i - 1];
if(i < n) recur();
};
recur();
return fib[fib.length - 1];
}И любой компилятор который умеет в хвостовую рекурсию будет выполнять этот код так же быстро как и с циклом.
Что касается удобства — да, получается на пару строчек больше но сейчас и так мало где можно встретить ручные циклы (обычно всякие .map(), .filter и т.д) так что экономия пары строчек для кода который будет занимать меньше 1 процента от всего проекта не имеет смысла. Зато мы избавились от кучи лишних синтаксический конструкций в языке (for, while, break, continue и labels) и упростили не только язык но и работу статическому анализатору (так как ему теперь нужно будет заняться анализом только рекурсии а не учитывать еще кучу кейсов и контрукций обычных циклов)
Не забывайте, что в Воркер нужно передавать только сериализованные данные или строки. Запихнуть туда json-объект для обработки не выйдет, перед этим его нужно превратить в строку, а на другом конце распарсить, что уже будет в разы сложнее для браузера по сравнению с оригинальным алгоритмом.
Оптимизация или как не выстрелить себе в ногу