Особо представлять базу ФИАС нет необходимости:

Скачать ее можно перейдя по ссылке, данная база является открытой и содержит все адреса объектов по России (адресный реестр). Интерес к этой базе вызван тем, что файлы, которые в ней содержатся достаточно объемны. Так, например, самый маленький составляет 2,9 Гб. Предлагается остановиться на нем и посмотреть, справится ли с ним pandas, если работать на машине, располагая только 8 Гб оперативной памяти. А если не справится, какие есть опции, для того, чтобы скормить pandas данный файл.
Положа руку на сердце, не разу не сталкивался с данной базой и это дополнительное препятствие, т.к. абсолютно не ясен формат данных, представленных в ней.
Скачав архив fias_xml.rar с базой, достанем из него файл — AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. Файл имеем формат xml.
Для более удобной работы в pandas рекомендуется конвертировать xml в csv или json.
Однако все попытки конвертации сторонними программами и самим python приводят к ошибке «MemoryError» либо зависанию.
Хм. Что, если разрезать файл и частями конвертировать? Хорошая идея, но все «резчики» также пытаются считать файл в память целиком и виснут, не режет его и сам python, идущий по пути «резчиков». 8 Гб явно маловато? Что ж, посмотрим.
Придется воспользоваться сторонней программой vedit.
Данная программа позволяет считать файл xml размером 2,9 Гб и поработать с ним.
Также она позволяет его разделить. Но тут есть небольшая хитрость.
Как видно при считывании файла, в нем, помимо прочего, есть открывающий тег AddressObjects:
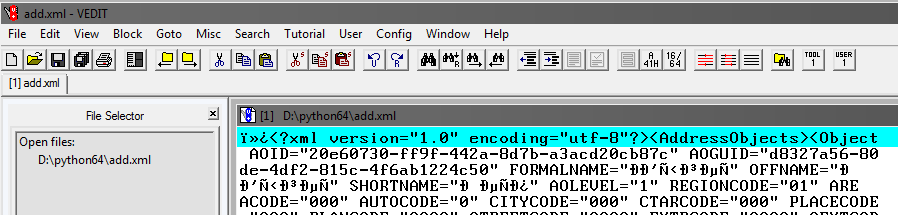
Значит, создавая части данного большого файла, надо не забывать его(тег) закрывать.
То есть начало каждого xml файла будет таким:
а окончание:
Теперь отрежем первую часть файла (для остальных частей шаги те же).
В программе vedit:

Далее выбираем Goto и Line#. В открывшемся окне пишем номер строки, например 1000000:

Далее надо подкорректировать выделенный блок, чтобы он захватил до конца объект в базе до закрывающего тега:
Ничего страшного, если будет небольшой нахлест на последующий объект.
Далее в программе vedit сохраняем выделенный фрагмент — File, Save as.
Таким же способом создаем остальные части файла, помечая начало блока выделения и окончание с шагом 1млн строк.
В итоге должно получиться 4-е xml файла размером примерно по 610 Мб.
Теперь надо во вновь созданных файлах xml добавить теги, чтобы они читались как xml.
Откроем поочередно файлы в vedit и добавим в начале каждого файла:
и в конце:
Таким образом, теперь у нас 4 xml части разделенного первоначального файла.
Теперь переведем xml в csv, написав программу на python.
Код программы
С помощью программы надо конвертировать все 4-е файла в csv.
Размер файлов уменьшится, каждый будет по 236 Мб (сравните с 610 Мб в xml).
В принципе, теперь с ними уже можно работать, через excel или notepad++.
Однако файлов пока 4-е вместо одного, и мы не добрались до цели — обработка файла в pandas.
В Windows это может оказаться непростым занятием, поэтому воспользуемся консольной утилитой на python, которая называется csvkit. Устанавливается как модуль python:
*На самом деле это целый набор утилит, но оттуда потребуется одна.
Зайдя в папку с файлами для склейки в консоли, выполним склейку в один файл. Так как все файлы без заголовков, то назначим при склейке стандартные названия столбцов: a,b,c и т.д.:
На выходе получаем готовый csv файл.
Если сразу загрузить в pandas файл
и проверить сколько он займет памяти, результат может неприятно удивить:

3 Гб! И это при том, что при считывании данных первый столбец «пошел» в качестве индекс-столбца*, а так объем был бы еще больше.
*По умолчанию pandas задает свой индекс-столбец.
Проведем оптимизацию, используя методы из предыдущего поста и статьи:
— object в category;
— int64 в uint8;
— float64 в float32.
Для этого при считывании файла добавим dtypes и считывание столбцов в коде будет выглядеть так:
Теперь, открыв файл pandas использование памяти будет разумным:
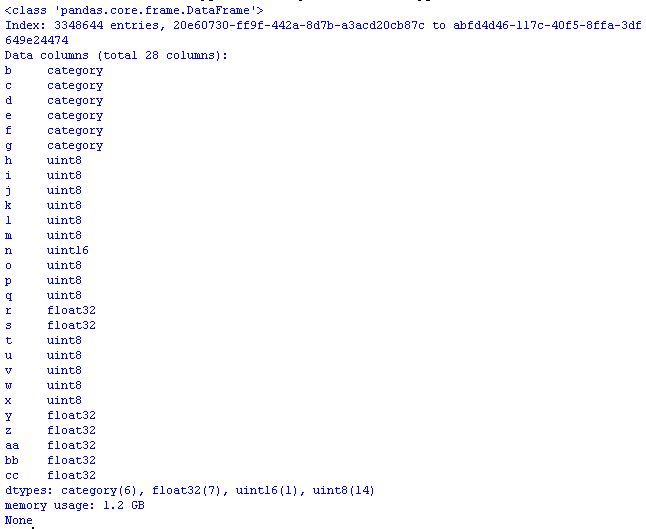
Осталось добавить в csv файл, при желании, строку-фактические названия столбцов, чтобы данные обрели смысл:
*Этой строкой можно заменить названия столбцов, но тогда придется поменять код.
Сохраним первые строки файла из pandas
и посмотрим, что получилось в excel:

Код программы для оптимизированного открытия csv файла с базой:
В завершение посмотрим размер датасета:
3,3 млн строк, 28 столбцов.
Итог: при первоначальном объеме файла csv 890 Мб, «оптимизированный» для целей работы с pandas он занимает в памяти 1,2 Гб.
Таким образом, при грубом расчете можно предположить что файл размером 7,69 Гб можно будет открыть в pandas, предварительно его «оптимизировав».

Скачать ее можно перейдя по ссылке, данная база является открытой и содержит все адреса объектов по России (адресный реестр). Интерес к этой базе вызван тем, что файлы, которые в ней содержатся достаточно объемны. Так, например, самый маленький составляет 2,9 Гб. Предлагается остановиться на нем и посмотреть, справится ли с ним pandas, если работать на машине, располагая только 8 Гб оперативной памяти. А если не справится, какие есть опции, для того, чтобы скормить pandas данный файл.
Положа руку на сердце, не разу не сталкивался с данной базой и это дополнительное препятствие, т.к. абсолютно не ясен формат данных, представленных в ней.
Скачав архив fias_xml.rar с базой, достанем из него файл — AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. Файл имеем формат xml.
Для более удобной работы в pandas рекомендуется конвертировать xml в csv или json.
Однако все попытки конвертации сторонними программами и самим python приводят к ошибке «MemoryError» либо зависанию.
Хм. Что, если разрезать файл и частями конвертировать? Хорошая идея, но все «резчики» также пытаются считать файл в память целиком и виснут, не режет его и сам python, идущий по пути «резчиков». 8 Гб явно маловато? Что ж, посмотрим.
Программа Vedit
Придется воспользоваться сторонней программой vedit.
Данная программа позволяет считать файл xml размером 2,9 Гб и поработать с ним.
Также она позволяет его разделить. Но тут есть небольшая хитрость.
Как видно при считывании файла, в нем, помимо прочего, есть открывающий тег AddressObjects:

Значит, создавая части данного большого файла, надо не забывать его(тег) закрывать.
То есть начало каждого xml файла будет таким:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
а окончание:
</AddressObjects>
Теперь отрежем первую часть файла (для остальных частей шаги те же).
В программе vedit:
Далее выбираем Goto и Line#. В открывшемся окне пишем номер строки, например 1000000:

Далее надо подкорректировать выделенный блок, чтобы он захватил до конца объект в базе до закрывающего тега:
Ничего страшного, если будет небольшой нахлест на последующий объект.
Далее в программе vedit сохраняем выделенный фрагмент — File, Save as.
Таким же способом создаем остальные части файла, помечая начало блока выделения и окончание с шагом 1млн строк.
В итоге должно получиться 4-е xml файла размером примерно по 610 Мб.
Доработаем xml-части
Теперь надо во вновь созданных файлах xml добавить теги, чтобы они читались как xml.
Откроем поочередно файлы в vedit и добавим в начале каждого файла:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
и в конце:
</AddressObjects>
Таким образом, теперь у нас 4 xml части разделенного первоначального файла.
Xml-to-csv
Теперь переведем xml в csv, написав программу на python.
Код программы
здесь
.# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import codecs,os
import xml.etree.ElementTree as ET
import csv
from datetime import datetime
parser = ET.XMLParser(encoding="utf-8")
tree = ET.parse("add-30-40.xml",parser=parser)
root = tree.getroot()
Resident_data = open('fias-30-40.csv', 'w',encoding='UTF8')
csvwriter = csv.writer(Resident_data)
start = datetime.now()
for member in root.findall('Object'):
object = []
object.append(member.attrib['AOID'])
object.append(member.attrib['AOGUID'])
try:
object.append(member.attrib['PARENTGUID'])
except:
object.append(None)
try:
object.append(member.attrib['PREVID'])
except:
object.append(None)
#try:
# object.append(member.attrib['NEXTID'])
#except:
# object.append(None)
object.append(member.attrib['FORMALNAME'])
object.append(member.attrib['OFFNAME'])
object.append(member.attrib['SHORTNAME'])
object.append(member.attrib['AOLEVEL'])
object.append(member.attrib['REGIONCODE'])
object.append(member.attrib['AREACODE'])
object.append(member.attrib['AUTOCODE'])
object.append(member.attrib['CITYCODE'])
object.append(member.attrib['CTARCODE'])
object.append(member.attrib['PLACECODE'])
object.append(member.attrib['STREETCODE'])
object.append(member.attrib['EXTRCODE'])
object.append(member.attrib['SEXTCODE'])
try:
object.append(member.attrib['PLAINCODE'])
except:
object.append(None)
try:
object.append(member.attrib['CODE'])
except:
object.append(None)
object.append(member.attrib['CURRSTATUS'])
object.append(member.attrib['ACTSTATUS'])
object.append(member.attrib['LIVESTATUS'])
object.append(member.attrib['CENTSTATUS'])
object.append(member.attrib['OPERSTATUS'])
try:
object.append(member.attrib['IFNSFL'])
except:
object.append(None)
try:
object.append(member.attrib['IFNSUL'])
except:
object.append(None)
try:
object.append(member.attrib['OKATO'])
except:
object.append(None)
try:
object.append(member.attrib['OKTMO'])
except:
object.append(None)
try:
object.append(member.attrib['POSTALCODE'])
except:
object.append(None)
#print(len(object))
csvwriter.writerow(object)
Resident_data.close()
print(datetime.now()- start)
#0:00:21.122437С помощью программы надо конвертировать все 4-е файла в csv.
Размер файлов уменьшится, каждый будет по 236 Мб (сравните с 610 Мб в xml).
В принципе, теперь с ними уже можно работать, через excel или notepad++.
Однако файлов пока 4-е вместо одного, и мы не добрались до цели — обработка файла в pandas.
Склеим файлы в один
В Windows это может оказаться непростым занятием, поэтому воспользуемся консольной утилитой на python, которая называется csvkit. Устанавливается как модуль python:
pip install csvkit*На самом деле это целый набор утилит, но оттуда потребуется одна.
Зайдя в папку с файлами для склейки в консоли, выполним склейку в один файл. Так как все файлы без заголовков, то назначим при склейке стандартные названия столбцов: a,b,c и т.д.:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csvНа выходе получаем готовый csv файл.
Поработаем в pandas над оптимизацией использования памяти
Если сразу загрузить в pandas файл
import pandas as pd
import numpy as np
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a')
print (gl.info(memory_usage='deep')) # использование памяти
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # предположим, что если это не датафрейм, то серия
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # преобразуем байты в мегабайты
return "{:03.2f} МВ" .format(usage_mb)
и проверить сколько он займет памяти, результат может неприятно удивить:

3 Гб! И это при том, что при считывании данных первый столбец «пошел» в качестве индекс-столбца*, а так объем был бы еще больше.
*По умолчанию pandas задает свой индекс-столбец.
Проведем оптимизацию, используя методы из предыдущего поста и статьи:
— object в category;
— int64 в uint8;
— float64 в float32.
Для этого при считывании файла добавим dtypes и считывание столбцов в коде будет выглядеть так:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={
'b':'category', 'c':'category','d':'category','e':'category',
'f':'category','g':'category',
'h':'uint8','i':'uint8','j':'uint8',
'k':'uint8','l':'uint8','m':'uint8','n':'uint16',
'o':'uint8','p':'uint8','q':'uint8','t':'uint8',
'u':'uint8','v':'uint8','w':'uint8','x':'uint8',
'r':'float32','s':'float32',
'y':'float32','z':'float32','aa':'float32','bb':'float32',
'cc':'float32'
})
Теперь, открыв файл pandas использование памяти будет разумным:

Осталось добавить в csv файл, при желании, строку-фактические названия столбцов, чтобы данные обрели смысл:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE*Этой строкой можно заменить названия столбцов, но тогда придется поменять код.
Сохраним первые строки файла из pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
и посмотрим, что получилось в excel:

Код программы для оптимизированного открытия csv файла с базой:
код
import os
import time
import pandas as pd
import numpy as np
#используем оптимизацию памяти при считывании датафрейма: для object-category,для float64-float32,для int64-int
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={
'b':'category', 'c':'category','d':'category','e':'category',
'f':'category','g':'category',
'h':'uint8','i':'uint8','j':'uint8',
'k':'uint8','l':'uint8','m':'uint8','n':'uint16',
'o':'uint8','p':'uint8','q':'uint8','t':'uint8',
'u':'uint8','v':'uint8','w':'uint8','x':'uint8',
'r':'float32','s':'float32',
'y':'float32','z':'float32','aa':'float32','bb':'float32',
'cc':'float32'
})
pd.set_option('display.notebook_repr_html', False)
pd.set_option('display.max_columns', 8)
pd.set_option('display.max_rows', 10)
pd.set_option('display.width', 80)
#print (gl.head())
print (gl.info(memory_usage='deep')) # использование памяти
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # предположим, что если это не датафрейм, то серия
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # преобразуем байты в мегабайты
return "{:03.2f} МВ" .format(usage_mb)В завершение посмотрим размер датасета:
gl.shape(3348644, 28)3,3 млн строк, 28 столбцов.
Итог: при первоначальном объеме файла csv 890 Мб, «оптимизированный» для целей работы с pandas он занимает в памяти 1,2 Гб.
Таким образом, при грубом расчете можно предположить что файл размером 7,69 Гб можно будет открыть в pandas, предварительно его «оптимизировав».
