
Deep Learning applications have changed a lot of things. Some which give hope for a brighter future, and some which raise suspicions. However, for developers, the growth of deep learning applications has made them more perplexed about choosing the best among so many deep learning frameworks out there.
TensorFlow is one of the deep learning frameworks that comes in mind. It is arguably the most popular deep learning framework out there. Nothing justifies the statement better than the fact that Tensorflow is used by the likes of Uber, Nvidia, Gmail among other big corporations for developing state-of-the-art deep learning applications.
But right now, I am on a quest to find whether it indeed is the best deep learning framework. Or perhaps find what makes it the best out of all other frameworks it competes against.
Here’s is All About TensorFlow 2.0
Most developers and data scientists prefer using Python with TensorFlow. TensorFlow runs across not just Windows, Linux and Mac, but also iOS & Android operating systems.
TF uses a static computation graph for operations. This means that developers first define the graph, run all calculations, make changes to the architecture if necessary and then re-train the model. In general, a lot of concepts of machine learning and deep learning can be solved using multi-dimensional matrices. This is what Tensorflow 2.0 does that help describe linear relationships between geometrical objects. Tensor is a primitive unit where we can apply matrix operations easily and effectively.
import tensorflow as TF
const1 = TF.constant([[05,04,03], [05,04,03]]);
const2 = TF.constant([[01,02,00], [01,02,00]]);
result = TF.subtract(const1, const2);
print(result)The output of the above code will look like this:
TF.Tensor([[04 02 03] [04 02 03]])As you can see I have given here two constants and I have subtracted one value from the other and got a Tensor object by subtracting two values. Also, with Tensorflow 2.0 there is no need to create sessions before running the code.
One thing to know before working with TensorFlow 2.0 is that you will have to code a lot and also you don’t just need to perform arithmetic operations with TensorFlow. It is more about doing deep learning research, building AI predictors, classifiers, generative models, neural networks, and so on. Sure, TF helps with the latter, but important tasks such as defining the architecture of the neural network, defining a volume for output and input data, all need to be done with careful human thought.
The fastest way to train these AI models is the tensor processing unit (TPUs) introduced by Google back in 2016. TPU handles the issue of neural network training in several ways.
Quantization — It is a powerful tool that uses an 8-bit integer to calculate a neural network prediction. For example, when you apply quantization to an image recognition model like Inception v3, you will get it compressed about one-fourth from the original size of 91MB to 23MB.
Parallel Processing — Parallel processing on the Matrix multiplier unit is a well-known way to improve the performance of large matrix operations through Vector processing. Machines with vector processing support can process up to hundreds and thousands of elements of operations in a single clock cycle.
CISC — TPU works on a CISC design that focuses on implementing high-level instructions that run high-level tasks such as multiplying and adding many times etc. TPU use the following resources for performing complex tasks:
- Matrix Multiplier Unit (MXU): 65,536 8-bit multiply-and-add units for matrix operations.
- Unified Buffer (UB): 24MB of SRAM that works as registers.
- Activation Unit (AU): Hardwired activation functions.
Systolic array — Systolic array is based on the new architecture of the MXU that is also called the heart of the TPU. The MXU read the value once but use it for many different operations without storing it back to a register. It reuses input many times for producing the output. This array is called systolic because the data flows through the chip in waves in the same way that our heart pumps blood. It improves operational flexibility in coding and offers a much higher operation density rate.
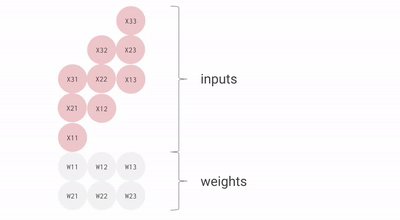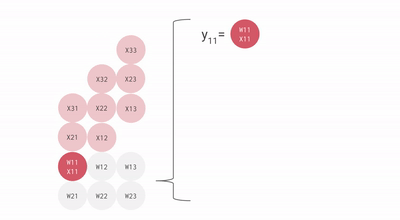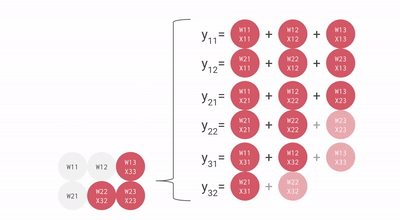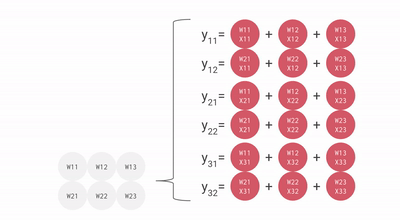
As you can see that all these major points of TPU help to analyze and handle the data effectively. Apart from that, it provides TensorFlow datasets that developers can use for training some of custom-designed AI solutions and for further research work.
Also as per the latest update, Cerebras Systems (a new artificial intelligence company) unveils the largest semiconductor chip based on the TPU model. In this chip, you can find the largest processor ever built that is designed to process, train, and handle the AI applications. The giant chip is equal to the size of an iPad and holds 1.2 Trillion transistors.
One of the greatest advantages of TensorFlow over other deep learning frameworks is in terms of scalability. Unlike other frameworks such as PyTorch, TensorFlow is built for large-scale inference and distributed training. However, it can also be used to experiment with new machine learning models and optimization. This flexibility also allows developers to deploy deep learning models on more than a single CPU/GPU with TensorFlow.
Cross-Platform Compatibility
TensorFlow 2.0 is compatible across all major OS platforms such as Windows, Linux, macOS, iOS and Android. Additionally, Keras can also be used with TensorFlow as an interface.
Hardware Scalability
TensorFlow 2.0 is deployable on a wide range of hardware machines, from cellular devices to large-scale computers with complex setups. It can be deployed on a gamut of hardware machines such as cellular devices and computers with complex setups. It can incorporate different APIs to built at scale deep learning architectures such as CNN or RNN.
Visualization
The TensorFlow framework is based on graph computation and provides a handy visualization tool for training purposes. This visualization tool, called TensorBoard allows developers to visualize the construction of a neural network, which in turn facilitates easy visualization and problem-solving.
Debugging
Tensorflow lets users execute the subparts of a graph for the introduction and retrieval of discrete data on edge, thus providing a neat debugging method.
Dynamic Graph Capability for Easy Deployment
TensorFlow uses a feature called “Eager execution” which facilitates dynamic graph capability for easy deployment. It allows saving the graph as a protocol buffer which could then be deployed to something different from python-relation infrastructures, say, Java.
Why TensorFlow Will Keep Growing?
TensorFlow has the fastest rate of growth amongst all other deep learning frameworks in existence today. It has the highest GitHub activity among all other repositories in the deep learning section, and the highest number of starts as well.
In the annual Stack Overflow developer survey 2019, TensorFlow was voted as the most popular deep learning framework, the second-most popular framework, Torch/PyTorch was far, far away.
These statistics are enough to prove the dominance of TensorFlow. But for how long will it sustain this growth? would it end up exceeding its current popularity? With the introduction and great reception of TensorFlow 2.0, the latter seems possible.
