Comments 112
Судя по скорости исправления багов что-то такое использует Microsoft
Картинка прикольная, взгляд заступорился на красной шестерёнке секунда на 5 :)
Не хочу разжигать очередной спор, но фраза
«У нас зачастую забраковывается ночная сборка системы из-за упавших юнит-тестов, а потом оказывается, что сама система работает как надо, просто кто-то забыл обновить юнит-тест, добавив новый функционал в основной код.»
говорит о не вполне правильном использовании TDD. Такая ситуация в применении TDD в принципе не может получаться, поскольку связь обратная. Не «тесты следуют за кодом», а «код пишется для выполнения тестов», то есть — сначала обновляются тесты — потом дописывается/рефакторится код.
Хотя, возможно, речь не о TDD как о конкретной практике, а именно о частичном применении юнит-тестирования «время от времени». Опять же по опыту — в этом случае тесты будут только лишними, так как занимают время, но при этом не отображают полностью состояния готовности продукта.
«У нас зачастую забраковывается ночная сборка системы из-за упавших юнит-тестов, а потом оказывается, что сама система работает как надо, просто кто-то забыл обновить юнит-тест, добавив новый функционал в основной код.»
говорит о не вполне правильном использовании TDD. Такая ситуация в применении TDD в принципе не может получаться, поскольку связь обратная. Не «тесты следуют за кодом», а «код пишется для выполнения тестов», то есть — сначала обновляются тесты — потом дописывается/рефакторится код.
Хотя, возможно, речь не о TDD как о конкретной практике, а именно о частичном применении юнит-тестирования «время от времени». Опять же по опыту — в этом случае тесты будут только лишними, так как занимают время, но при этом не отображают полностью состояния готовности продукта.
Надо над этим подумать. Судя по описанию в википедии, TDD является одной из основных практик экстремального программирования. Мы XP почти нигде не применяем, поэтому, наверное, и про TDD я не слышал. Идея интересная. Надо только поисследовать, как ее применение влияет на скорость разработки.
Даже тут на Хабре уже были споры о целесообразности TDD. Но лично я, субъективно, но по реальному опыту использования XP и TDD как одной из ключевых дисциплин, уверен в ее абсолютной необходимости в современных процессах разработки софта.
Кроме этого, как я уже упоминал в одном из тех, полных споров, топиков — это ведет к другой шикарной (!) дисциплине — CI (Continuous Integration) или «постоянная интеграция», что, кстати, ведет к решению обозначенной вами проблеме интеграционного тестирования. Практический CI невозможен без TDD.
Кроме этого, как я уже упоминал в одном из тех, полных споров, топиков — это ведет к другой шикарной (!) дисциплине — CI (Continuous Integration) или «постоянная интеграция», что, кстати, ведет к решению обозначенной вами проблеме интеграционного тестирования. Практический CI невозможен без TDD.
Да, еще при TDD, процесс, названный у вас «детальный дизайн» не ограничен рамками отдельного процесса и проводится в рамках разработки. Это позволяет гибко менять дизайн по мере движения проекта и поступления запросов на изменение (change requests).
Test Driven Development или дословно «Разработка Управляемая Тестами» и подход изложенный в статье, прямо противоположны.
Просто использование unit test'ов не делает вас TDD разработчиком :)
Камень преткновения в том _когда_ писать тесты. До кода или после. Ночные поломаные сборки, действительно из-за того что после. Тестирование почти только кода выполняющего математические расчеты, тоже результат позднего написания тестов. Ведь когда архитектура уже придумана, код уже написан, так не хочется что-то менять, чтобы была возможность написать простой unit тест.
Но даже минимум unit-тестов может быть полезным, тем более если есть более высокоуровневое тестирование, которое хоть и плохо локализует место ошибки, но все равно позволяет на раннем этапе обнаружить проблему.
Просто использование unit test'ов не делает вас TDD разработчиком :)
Камень преткновения в том _когда_ писать тесты. До кода или после. Ночные поломаные сборки, действительно из-за того что после. Тестирование почти только кода выполняющего математические расчеты, тоже результат позднего написания тестов. Ведь когда архитектура уже придумана, код уже написан, так не хочется что-то менять, чтобы была возможность написать простой unit тест.
Но даже минимум unit-тестов может быть полезным, тем более если есть более высокоуровневое тестирование, которое хоть и плохо локализует место ошибки, но все равно позволяет на раннем этапе обнаружить проблему.
Ну я бы не стал сравнивать TDD и высокоуровневое тестирование, ибо первое — это разработка, а второе — тестирование.
Однако юнит-тесты, как таковые, могут использоваться и за пределами TDD как такового (один из примеров — топик).
А на практике, «минимум юнит-тестов» часто бывает опасен. Здесь довольно тонкая грань между покрытой (test covered) и непокрытой частью кода и часто она не определена точно (а точнее — почти никогда не определена). Это может вселять излишнюю уверенность в работоспособности кода, в то время как он таковым может не являться. А вот тогда поиск ошибок становится особо сложным, так как надо еще и дополнительно выяснять, где же код работает, а где нет.
Однако юнит-тесты, как таковые, могут использоваться и за пределами TDD как такового (один из примеров — топик).
А на практике, «минимум юнит-тестов» часто бывает опасен. Здесь довольно тонкая грань между покрытой (test covered) и непокрытой частью кода и часто она не определена точно (а точнее — почти никогда не определена). Это может вселять излишнюю уверенность в работоспособности кода, в то время как он таковым может не являться. А вот тогда поиск ошибок становится особо сложным, так как надо еще и дополнительно выяснять, где же код работает, а где нет.
>>Ну я бы не стал сравнивать TDD и высокоуровневое тестирование
Я не сравниваю TDD и высокоуровневые тесты, я сравниваю подходы к тому _когда_ надо писать тесты. Unit тесты после кода это _не_ TDD. А если тесты пишуться после, то ИМХО вопрос только в удобстве написания и в уровне локализации ошибки.
В архитектуре не всегда заранее заложена возможность создания простых unit-тестов, без закапывания в кучу mock'ов, заглушек, и хаков с кодом. Но как правило, возможности по гибкой интеграции придусмотрены. Поэтому иногда проше положится на интеграцинное тесты, которые могут работать с файловой системой, с бд, и быть не очень быстрыми, чем писать кучу ужасных unit тестов.
Но если ошибка происходит в интеграционном тесте, или пришла от QA, то в особо тяжелых случаях иного варианта, как засесть за дебагер нет.
Ошибка, найденная unit-тестом, практически всегда локализуется просто глядя на код.
Я не сравниваю TDD и высокоуровневые тесты, я сравниваю подходы к тому _когда_ надо писать тесты. Unit тесты после кода это _не_ TDD. А если тесты пишуться после, то ИМХО вопрос только в удобстве написания и в уровне локализации ошибки.
В архитектуре не всегда заранее заложена возможность создания простых unit-тестов, без закапывания в кучу mock'ов, заглушек, и хаков с кодом. Но как правило, возможности по гибкой интеграции придусмотрены. Поэтому иногда проше положится на интеграцинное тесты, которые могут работать с файловой системой, с бд, и быть не очень быстрыми, чем писать кучу ужасных unit тестов.
Но если ошибка происходит в интеграционном тесте, или пришла от QA, то в особо тяжелых случаях иного варианта, как засесть за дебагер нет.
Ошибка, найденная unit-тестом, практически всегда локализуется просто глядя на код.
Судя по всему, вы тоже использовали или используете TDD на практике.
Мы говорим об одном и том же, однако с разных аспектов — двух разных подходов к юнит-тестированию. Мы всегда придерживались тестирования поведения (и использованию mocks), а вы, судя по всему склоняетесь к тестированию состояния.
Разумеется, это в любом случае не отменяет главных правил TDD — «Test-First Design» и «Red-Green-Refactor».
Хотелось бы заодно разделить интеграционные тесты и тестирование логики приложения, модели и так далее. Мы также используем интеграционные тесты. В чем то, на первый взгляд может показаться, что они повторяют юнит-тесты, использующие mock-объекты. Однако, это не так. Интеграционные тесты тестируют строго «контекст связи с внешними механизмами» и обычно этот набор несколько меньше, чем набор тестов, описывающих непосредственно логику.
Согласен, в ряде случаев тестирование состояний может быть проще, однако оба подхода применимы и каждый выбирает для себя сам. Подробно о разнице между ними писал Мартин Фаулер у себя в одной из статей.
А на 100% дебаггер не исключается ни при каком подходе. Однако, TDD позволил в разы сократить время, проводимое в нем, иногда все-таки сводя такую необходимость вообще на нет.
Мы говорим об одном и том же, однако с разных аспектов — двух разных подходов к юнит-тестированию. Мы всегда придерживались тестирования поведения (и использованию mocks), а вы, судя по всему склоняетесь к тестированию состояния.
Разумеется, это в любом случае не отменяет главных правил TDD — «Test-First Design» и «Red-Green-Refactor».
Хотелось бы заодно разделить интеграционные тесты и тестирование логики приложения, модели и так далее. Мы также используем интеграционные тесты. В чем то, на первый взгляд может показаться, что они повторяют юнит-тесты, использующие mock-объекты. Однако, это не так. Интеграционные тесты тестируют строго «контекст связи с внешними механизмами» и обычно этот набор несколько меньше, чем набор тестов, описывающих непосредственно логику.
Согласен, в ряде случаев тестирование состояний может быть проще, однако оба подхода применимы и каждый выбирает для себя сам. Подробно о разнице между ними писал Мартин Фаулер у себя в одной из статей.
А на 100% дебаггер не исключается ни при каком подходе. Однако, TDD позволил в разы сократить время, проводимое в нем, иногда все-таки сводя такую необходимость вообще на нет.
Обычный подход, по-моему, для больших и распределенных команд.
Может подскажете, есть ли отличия в Team Software Process от Rational Unified Process в плане этапов и процедур разработки?
Может подскажете, есть ли отличия в Team Software Process от Rational Unified Process в плане этапов и процедур разработки?
Да, в целом хорошо, что люди стремятся к усовершенствованию методов работы в больших командах и над большими проектами. Топик — перечисление массы дельных моментов, которые многим надо бы взять на вооружение (если еще не взяли).
Правда, отдельно хотелось бы узнать у автора, как у них осуществляется внутрипроектное управление изменениями (change request'ами) и рисками на уровне реализации (по идее и всего проекта, но здесь, как я вижу, рассматриваются только процессы, имеющие отношение к разработке и ее управлению).
Правда, отдельно хотелось бы узнать у автора, как у них осуществляется внутрипроектное управление изменениями (change request'ами) и рисками на уровне реализации (по идее и всего проекта, но здесь, как я вижу, рассматриваются только процессы, имеющие отношение к разработке и ее управлению).
На мой взгляд, основным, при написании софта является мотивация. Особенно, если речь идет о создании чего-то нового и опережающего конкурентов.
По исследованиями, люди более мотивированы, когда они близки к результату, т.е. до него буквально подать рукой. В этом плане TDD является отличным мотиватором — исправить один не работающий тест — это же так просто.
Исправил — молодец. 20 раз за день молодец — да я просто умница!
То, что вы описали — для меня сразу нарисовало картину: ходят зомби с потухшими глазами. Пьют чай, читают новости в интернете, пол часа в день от безысходности пишут несколько строк и опять впадают в депрессию.
Я бы не хотел у вас работать. Ни на каких условиях.
По исследованиями, люди более мотивированы, когда они близки к результату, т.е. до него буквально подать рукой. В этом плане TDD является отличным мотиватором — исправить один не работающий тест — это же так просто.
Исправил — молодец. 20 раз за день молодец — да я просто умница!
То, что вы описали — для меня сразу нарисовало картину: ходят зомби с потухшими глазами. Пьют чай, читают новости в интернете, пол часа в день от безысходности пишут несколько строк и опять впадают в депрессию.
Я бы не хотел у вас работать. Ни на каких условиях.
Полностью поддерживаю насчет TDD. Многие почему-то этого не хотят понять, но даже та уверенность, которую дают тесты, исключает общую панику в команде, связанную со все нарастающей некотролируемостью кода проекта. Ибо контроль как раз и сохраняется.
Того, что Вы описали, у нас, к счастью, нет :)
Все подготовительные этапы типа архитектуры и дизайна делаются в основном архитекторами. Да, это скучновато, но Вы тоже не предложили альтернативы. Неужели в Вашей компании вся работа — это лишь кодирование и юнит-тесты?
Я тоже очень хочу попробовать XP/TDD, просто пока не удалось — слишком много работы по maintenance продакшен-систем :(
Но есть команды, которые занимаются новым девелопментом в чистом виде. Конечно, за такую работу все соревнуемся :)
Все подготовительные этапы типа архитектуры и дизайна делаются в основном архитекторами. Да, это скучновато, но Вы тоже не предложили альтернативы. Неужели в Вашей компании вся работа — это лишь кодирование и юнит-тесты?
Я тоже очень хочу попробовать XP/TDD, просто пока не удалось — слишком много работы по maintenance продакшен-систем :(
Но есть команды, которые занимаются новым девелопментом в чистом виде. Конечно, за такую работу все соревнуемся :)
Если есть реальный интерес — советую нанять профессиональных «коучеров» или консультантов по внедрению Agile-методик (только действительно профессиональных и знающих свое дело).
Есть набор методик, позволяющих перевести и текущие «legacy»- проекты и код в соответствие с практиками разработки и поддержки, определяемыми XP.
Есть набор методик, позволяющих перевести и текущие «legacy»- проекты и код в соответствие с практиками разработки и поддержки, определяемыми XP.
Сам agile говорит что он для небольших групп, до 10 или что-то около. Тут, как я понял, совсем другой масштаб!
Можно и больше, вот только процесс планирования спринта получается весьма продолжительным по времени. Так что наибольшую эффективность можно достигнуть при команде 5-8 человек.
Да, команды разработки желательно не более 10 человек, иначе становятся трудноуправляемыми.
Однако, это вовсе не означает, что нельзя организовать большую компанию с тысячей разработчиков в таком режиме. Главное грамотно устроить способы организации команд, ротацию сотрудников между проектами и делить работу на реалистичные отдельные кусочки.
Насколько мне известно, даже Microsoft сейчас при разработки новых технологий использует именно такой подход.
Однако, это вовсе не означает, что нельзя организовать большую компанию с тысячей разработчиков в таком режиме. Главное грамотно устроить способы организации команд, ротацию сотрудников между проектами и делить работу на реалистичные отдельные кусочки.
Насколько мне известно, даже Microsoft сейчас при разработки новых технологий использует именно такой подход.
понятно, что можно разбить 100 человек на 10 групп и там применять agile, но надо ж как-то этими группами управлять, вот тут agile уже не поможет.
Что значит не поможет? Вполне можно управлять и 10-ю группами. Разумеется, 10 team-lead'ов, но это аюсолютно нормально. Ибо управлять в одиночку сотней — тоже не вариант. Любая большая толпа народу сложно управляема.
А по поводу agile — к примеру, Scrum и MSF достаточно ясно и понятно определяют, как именно управлять несколькими командами. Можно управлять хоть подразделениями из тысяч.
А по поводу agile — к примеру, Scrum и MSF достаточно ясно и понятно определяют, как именно управлять несколькими командами. Можно управлять хоть подразделениями из тысяч.
а где в Scrum написано про тысячи и большие команды?
Там про тысячи не написано, а написано просто про концепции управления, когда команд несколько на один проект, а также когда несколько распределенных географически команд.
Все это хорошо рассматривается в книжке Henrik'а Kniberg'а «Scrum and XP from the Trenches».
Все это хорошо рассматривается в книжке Henrik'а Kniberg'а «Scrum and XP from the Trenches».
и мы, и мы этим занимаемся (интернет-трейдинг) :)
вы случайно не квик делаете?
вы случайно не квик делаете?
Нет :) www.cqg.com
Собственно, ваш процесс разработки можно сказать «традиционный». Вы уделяете много времени инспектированию кода, это разумно. Я полагаю, любая софтверная компания в том или ином виде использует традиционный подход.
Непонятно другое — почему так много плохих программ, если всем понятно как делать правильно?.. Вопрос риторический :)
Непонятно другое — почему так много плохих программ, если всем понятно как делать правильно?.. Вопрос риторический :)
Как красиво Вы сказали :))
почему так много плохих программ, если всем понятно как делать правильно?..
в цитатник однозначно!
«Непонятно другое — почему так много плохих программ, если всем понятно как делать правильно?»
Вполне понятно. Человеческий фактор.
Можно разработать четко детерминированную систему для управления каким-либо процессом, где будут определены все действия и процедуры. И это будет работать. Но как только в процессе появляются люди — они сразу становятся самым слабым звеном системы и являются основным источником рисков.
Вполне понятно. Человеческий фактор.
Можно разработать четко детерминированную систему для управления каким-либо процессом, где будут определены все действия и процедуры. И это будет работать. Но как только в процессе появляются люди — они сразу становятся самым слабым звеном системы и являются основным источником рисков.
Спасибо, очень интересно!
Я как раз в этом семестре изучал в университете Software Enginering. И через пару дней будет экзамен.
Я как раз в этом семестре изучал в университете Software Enginering. И через пару дней будет экзамен.
UFO just landed and posted this here
Интересно было прочесть о том, что, собственно, в полной мере используем. Причем с теми же вытекающими проблемами :)
Единственное, чем можно дополнить, это то, что в процессе подготовки и оценке задач мы следуем механизму, описанному в книжке «Scrum And Xp From The Trenches», при котором как раз учитывается, что реально на кодирование уходит только 50% времени.
Единственное, чем можно дополнить, это то, что в процессе подготовки и оценке задач мы следуем механизму, описанному в книжке «Scrum And Xp From The Trenches», при котором как раз учитывается, что реально на кодирование уходит только 50% времени.
Спорный и холивароопасный комментарий, но все же.
Чем оправдано использование C++? Ведь уже то, что регламентируется число запусков компилятора говорит о том, что дело это небыстрое (что в порядке вещей для C++), и, как следствие, страдает производительность (ИМХО). Мне, например, проще после каждого логического куска запустить компиляцию и продолжить себе работу (C#).
Второе — по поводу VCS. Промежуточные чекины разрешены у вас?
И третье — юнит тесты (как следствие первого пункта). Вообще говоря, их принято запускать на машине разработчика (чтобы он, помимо всего прочего, не закоммитил совсем уж нерабочий код). Почему у вас так, как оно есть?
Чем оправдано использование C++? Ведь уже то, что регламентируется число запусков компилятора говорит о том, что дело это небыстрое (что в порядке вещей для C++), и, как следствие, страдает производительность (ИМХО). Мне, например, проще после каждого логического куска запустить компиляцию и продолжить себе работу (C#).
Второе — по поводу VCS. Промежуточные чекины разрешены у вас?
И третье — юнит тесты (как следствие первого пункта). Вообще говоря, их принято запускать на машине разработчика (чтобы он, помимо всего прочего, не закоммитил совсем уж нерабочий код). Почему у вас так, как оно есть?
1). C++ используется для realtime сервисов. C# здесь совсем не конкурент, к сожалению… Производительность разработчика — это важно, но важнее производительность системы. Борьба идет почти за микросекунды. На железе, кстати, не экономим совсем, поэтому аргумент поставить сервер побыстрее не принимается :)
2). Промежуточные чекины в HEAD разрешены в определенные этапы проекта и всегда разрешены в бранч.
3). Юнит-тесты мы запускаем на машине разработчика, но после сборки все юнит-тесты прогоняются автоматически — не всегда можно полагаться на сознательность программистов, а проконтролировать это сложно :)
2). Промежуточные чекины в HEAD разрешены в определенные этапы проекта и всегда разрешены в бранч.
3). Юнит-тесты мы запускаем на машине разработчика, но после сборки все юнит-тесты прогоняются автоматически — не всегда можно полагаться на сознательность программистов, а проконтролировать это сложно :)
1). Я к тому спросил, что в настоящий момент как-то для себя переосмысляю программистскую деятельность и, как следствие, сталкиваюсь с кучей вопросов. Одним из оных является «Так ли хорошо C++ подходит для решения тех задач, которые на нем решают?». Ответ (мой, внутренний) — исключительно не подходит. Доводов много, и не в тему они здесь будут. Интересно вот что: для высокопроизводительных сервисов вы рассматривали какие-либо другие языки? Erlang, например?
По поводу 2 и 3 — спасибо, все понятно. Так и думал.
По поводу 2 и 3 — спасибо, все понятно. Так и думал.
Странная последовательность — сначала архитектурный анализ, а только потом требования к системе. Так все и обстоит — сначала думаем, из каких кусков должна состоять система, а потом — что она собственно делает?
Это сильно зависит от проекта. Если это новая система, то, скорее всего, требования будут разработаны вперед. Если изменения функционала, то неплохо сначала подумать, а можем ли мы это вообще в текущей архитектуре. И, конечно, требования могут дополняться после архитектурного анализа. И даже (это уже ересь! :) в процессе кодирования.
Отличная статья! с некоторыми поправками и упрощениями я примерно так и планирую организовывать у себя рабочий процесс, правда команда небольшая.
Мне с коллегой сейчас как раз поручили разработать жизненный цикл и артефакты, которые создаются на каждом этапе. У нас проекты поменьше, по 10-15 мифических человекомесяцев.
Я немного не понял, на базе чего создаётся архитектурный анализ — на требованиях высокого уровня, которые описаны руководством в документе (пачке документов), которые тут опущены?
И ещё — интересно, которые из этих артефактов подписаны клиентом? Думаю, требования — а дальше? Ведь требования, скорее всего примерно такого формата «Система должна позволять вводить и сохранять данные сделки». Доказать, что это требование выполнено — можно, но клиент-то имел ввиду другое. Например, со своей практики знаю, что многие очень интересуются тем, как это всё будет выглядеть на практике — какие экраны, кнопочки? Потом много придирок — тут должна была таблица, а не поля, а тут заголовок не тот, а тут… Как с этим?
Я немного не понял, на базе чего создаётся архитектурный анализ — на требованиях высокого уровня, которые описаны руководством в документе (пачке документов), которые тут опущены?
И ещё — интересно, которые из этих артефактов подписаны клиентом? Думаю, требования — а дальше? Ведь требования, скорее всего примерно такого формата «Система должна позволять вводить и сохранять данные сделки». Доказать, что это требование выполнено — можно, но клиент-то имел ввиду другое. Например, со своей практики знаю, что многие очень интересуются тем, как это всё будет выглядеть на практике — какие экраны, кнопочки? Потом много придирок — тут должна была таблица, а не поля, а тут заголовок не тот, а тут… Как с этим?
Общие требования обычно описаны в документе «Видения проекта» (результат фазы Envisioning), более детально описанные возможности (фичи) заносятся в ТЗ и/или product backlog (по терминологии Scrum, не знаю как лучше перевести).
То, что касается UI — очень многое решается с помощью прототипов.
А что насчет «Доказать, что это требование выполнено — можно, но клиент-то имел ввиду другое» — есть множество методов и приемов «доказать» что-то, но в общем смысле, это задача управления ожиданиями (Expectations Management) проекта. Ведь даже безупречно выполненный технически и дизайнерски проект может не удовлетворить клиента, потому что не соответствует ожиданиям. Поэтому на этом тоже стоит заострить внимание и кроме обсуждения технических и чисто проектных аспектов, также потихоньку «готовить клиента» к реальному результату (который часто может отличаться от изначально радужной картины, нарисовавшейся у него в голове до проекта).
То, что касается UI — очень многое решается с помощью прототипов.
А что насчет «Доказать, что это требование выполнено — можно, но клиент-то имел ввиду другое» — есть множество методов и приемов «доказать» что-то, но в общем смысле, это задача управления ожиданиями (Expectations Management) проекта. Ведь даже безупречно выполненный технически и дизайнерски проект может не удовлетворить клиента, потому что не соответствует ожиданиям. Поэтому на этом тоже стоит заострить внимание и кроме обсуждения технических и чисто проектных аспектов, также потихоньку «готовить клиента» к реальному результату (который часто может отличаться от изначально радужной картины, нарисовавшейся у него в голове до проекта).
Да, близкая мне технология. Спасибо за статью. Есть вопрос к автору, возможно, не по теме: как Вы осуществляете ресурсное планирование. Интересует инструменты и методы.
Я немного далек от этого, просто это работа ПМ-ов. Инструментов особых, по-моему, не используется, каждую неделю каждый ПМ уточняет, какая команда и в каком объеме ему принадлежит. Исходя из этого проводится планирование. Мы перепробовали разные измерения — человеко-месяцы, functional points (собственное изобретение), персональные оценки разработчиков. Тут нет полной ясности, и мы достаточно часто ошибаемся, но не очень сильно. Работаем над этим
Отличный текст! Очень компактно и в то же время полно изложенные мысли.
У нас схема немного другая. Требования уже включают в себя фрагменты высокоуровневой архитектуры, но лишь самые общие. Есть даже детальный шаблон SRS, по которому пишется документ.
Перед коммитом обязательная стадия — ревью кода. То есть код может попасть в репозиторий только после того, как будет одобрен всеми участниками ревью.
Ну, и ещё по мелочам.
Хотелось бы узнать, как у вас работает QA. А именно: насколько процесс автоматизирован, по какому графику работает QA (есть ли ночные смены, например), ну, и сколько тестеров приходится на одного девелопера.
У нас схема немного другая. Требования уже включают в себя фрагменты высокоуровневой архитектуры, но лишь самые общие. Есть даже детальный шаблон SRS, по которому пишется документ.
Перед коммитом обязательная стадия — ревью кода. То есть код может попасть в репозиторий только после того, как будет одобрен всеми участниками ревью.
Ну, и ещё по мелочам.
Хотелось бы узнать, как у вас работает QA. А именно: насколько процесс автоматизирован, по какому графику работает QA (есть ли ночные смены, например), ну, и сколько тестеров приходится на одного девелопера.
То есть код может попасть в репозиторий только после того, как будет одобрен всеми участниками ревью.Вот это, я считаю, глупость несусветная. Вы либо недоговариваете (к примеру, коммитить можно только в специальную ветку, откуда изменения сливаются в транк), либо занимаетесь каким-то изощренным надругательством над подчиненными. Вы патчами обмениваетесь, что ли?
Ревью делается через Code Collaborator. Процесс оптмимизирован и много времени не отнимает. Естественно, что SVN, CC, bugzilla интегрироанны между собой.
Про структуру репозитория особо распространяться не буду, скажу лишь, что она самая обычная, примерно как в KDE4.
Про структуру репозитория особо распространяться не буду, скажу лишь, что она самая обычная, примерно как в KDE4.
Кстати, устанавливать правила типа «код может попасть в репозиторий только после того, как будет одобрен всеми участниками ревью» и других — дело каждой отдельной организации. В любом случае, рецензирование — это должна быть стандартизированная процедура (если уж проводится) и быть как-то систематизирована и зависеть от определенных условий.
Так что требование товарища Cancel к рецензированию более, чем адекватно.
Так что требование товарища Cancel к рецензированию более, чем адекватно.
Касаемо правила «код может попасть в репозиторий только после того...» — такое может породить только больная голова. Мотивация такого решения от меня ускользает.
Жесткие диски «внезапно смертны», так что проблем и головной боли от скоропостижного отказа накопителя на машине разработчика (single point of failure) будет очень и очень много. А всего-то надо было разрешить коммититься в любое удобное _разработчику_ время (в свою ветку, скажем). Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.
Жесткие диски «внезапно смертны», так что проблем и головной боли от скоропостижного отказа накопителя на машине разработчика (single point of failure) будет очень и очень много. А всего-то надо было разрешить коммититься в любое удобное _разработчику_ время (в свою ветку, скажем). Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.
Могу сказать про нас — у нас не особо много проблем с вылетом жестких дисков. За 5 лет работы было, по-моему, пару раз. А чекинить непроверенный код — вот это действительно головная боль, т.к. этот код может кто-то тут же взять из хранилища и дополнить своим. И если Вы потом найдете несколько ошибок в своем наспех зачекиненом коде, то, скорее всего, придется делать merge и просить взять свежую версию всех, кто успел уже что-то поменять.
Если у вас с этим не бывает проблем, значит у вас очень высокая культура персональной рецензии кода.
Да, в девелоперский бранч у нас, при крайней необходимости, позволено делать чекин до формальной инспекции, но инспекцию код обязан пройти, и это проверяется.
Если у вас с этим не бывает проблем, значит у вас очень высокая культура персональной рецензии кода.
Да, в девелоперский бранч у нас, при крайней необходимости, позволено делать чекин до формальной инспекции, но инспекцию код обязан пройти, и это проверяется.
> Касаемо правила «код может попасть в репозиторий только после того...» — такое может породить только больная голова. Мотивация такого решения от меня ускользает.
Мотивация очень простая. Контроль за качеством кода, соблюдением принятого подхода и так далее. Штука необычайно полезная, хотя и отнимает какое-то время, но зато позволяет оценивать чужой код и писать более стройный и согласованный код.
> Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.
Такой подход работает только для идеальных сферических программистов в вакууме. Реальность прозаичнее и грубее. Естественно, не весь код проходит через ревью. У каждого девелопера есть своя ветка и так далее. Но весь код в главные ветки обязан быть проревьюенным.
Мотивация очень простая. Контроль за качеством кода, соблюдением принятого подхода и так далее. Штука необычайно полезная, хотя и отнимает какое-то время, но зато позволяет оценивать чужой код и писать более стройный и согласованный код.
> Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.
Такой подход работает только для идеальных сферических программистов в вакууме. Реальность прозаичнее и грубее. Естественно, не весь код проходит через ревью. У каждого девелопера есть своя ветка и так далее. Но весь код в главные ветки обязан быть проревьюенным.
Вы, кстати, упомянули одну важную деталь: у вас у каждого девелопера есть ветка в репозитории. У нас этого нет, и мы от этого страдаем, потому что нам очень затруднили чекин кода, не прошедшего инспекцию — каждый чекин привязан к инспекции, и если систему обманешь, то потом придется объясняться с ПМ-ом.
А вот я полностью и бесповоротно согласен с тем, что:
«Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.»
Странно спорить с этим.
Насчет отдельных девелоперских веток — главное чтобы этими «ветками» не были просто рабочие копии на девелопмент-машинах :) Да и куча веток ни к чему. Можете завести отдельную специальную ветку рецензирования.
«Репозиторий системы контроля версий — это не «дом высокой культуры быта» и не образцово-показательное хранилище исходников. Это, прежде всего, рабочий инструмент, так что и отношение к нему должно быть соответствующее.»
Странно спорить с этим.
Насчет отдельных девелоперских веток — главное чтобы этими «ветками» не были просто рабочие копии на девелопмент-машинах :) Да и куча веток ни к чему. Можете завести отдельную специальную ветку рецензирования.
Не люблю аналогии, но тут прямо-таки не обойтись без них.
Рабочий инструмент нужно содержать в порядке. Иначе он ржавеет и начинает плохо выполнять свои прямые обязанности. Так и репозиторий очень легко загадить, причём загадить так, что проблема всплывёт лишь через полгода, например.
Использование соответствующих инструментов рецензировани кода очень помогает в жизни, это я говорю как обычный девелопер, напрямую работавший с такой системой. Это достаточно просто, надёжно, быстро и полезно.
Рабочий инструмент нужно содержать в порядке. Иначе он ржавеет и начинает плохо выполнять свои прямые обязанности. Так и репозиторий очень легко загадить, причём загадить так, что проблема всплывёт лишь через полгода, например.
Использование соответствующих инструментов рецензировани кода очень помогает в жизни, это я говорю как обычный девелопер, напрямую работавший с такой системой. Это достаточно просто, надёжно, быстро и полезно.
Ааа, извиняюсь, упустил :) В репозиторий (системы контроля версий), конечно же попасть может, точнее обязан, возможно даже в специальный «review branch».
Разумеется, это зависит от того, кто как технологию выстроит, но есть такая штука, как «жесткие диски внезапно смертны», поэтому лучше страховаться (здесь речь не только о жестких дисках — это как пример, речь о любом риске, связанном с хранением наработок только в виде рабочей копии на отдельной машине без commit'а в репозиторий).
Разумеется, это зависит от того, кто как технологию выстроит, но есть такая штука, как «жесткие диски внезапно смертны», поэтому лучше страховаться (здесь речь не только о жестких дисках — это как пример, речь о любом риске, связанном с хранением наработок только в виде рабочей копии на отдельной машине без commit'а в репозиторий).
Для меня наш QA достаточно туманен — у них какие-то грандиозные многотомные тест-планы, какие-то свои методики :)
В ночных сменах нет необходимости, т.к. офис в Москве и Денвере покрывают почти все 24 часа. Если что-то срочное — работаем 24x7, но так бывает редко.
Насчет количества, я бы сказал наоборот — у нас тестеров совсем не много, человек 15-20, кажется, а девелоперов 300. Т.е. получается 0.05 тестера на одного разработчика :)
В ночных сменах нет необходимости, т.к. офис в Москве и Денвере покрывают почти все 24 часа. Если что-то срочное — работаем 24x7, но так бывает редко.
Насчет количества, я бы сказал наоборот — у нас тестеров совсем не много, человек 15-20, кажется, а девелоперов 300. Т.е. получается 0.05 тестера на одного разработчика :)
Офигеть, не думал, что так бывает; обычно QA отдел как минимум такого же размера, как девелоперский.
Мы вообще обсуждаем вопрос о его упразднении и переводе тестирования на плечи девелоперов :) Но это пока вилами по воде. Скорее всего, все останется как было.
— а какой у вас процесс для мелких исправлений?
— обычно в больших системах, которые живут не первый год, нет человека, который бы хорошо знал все закоулки кода. И выясняется, что весь тот красивый nicely decoupled архитектурный дизайн, которых архитекторы сархитекторили не учитывает, какую-нибудь цацку, которая была сделана три года назад (и совершенно через ж… у), но её очень любит Самый Главный Трейдер.
И весь процесс предварительног дизайна идёт коту под хвост. Как вы с этим боретесь?
— обычно в больших системах, которые живут не первый год, нет человека, который бы хорошо знал все закоулки кода. И выясняется, что весь тот красивый nicely decoupled архитектурный дизайн, которых архитекторы сархитекторили не учитывает, какую-нибудь цацку, которая была сделана три года назад (и совершенно через ж… у), но её очень любит Самый Главный Трейдер.
И весь процесс предварительног дизайна идёт коту под хвост. Как вы с этим боретесь?
Для мелких исправлений тот же процесс, я об этом упомянул в статье. Поэтому maintenance никто не любит — кодирования там 1%, а остальное — бюрократия с хотфиксом.
Насчет знания систем — я думаю, что эта проблема не решается. Текучесть кадров в большей или меньшей мере есть везде, даже там, где очень хорошо. Поэтому приходится заранее готовить замену для тех, от кого слишком много зависит. Заменяемость сотрудников выгодна для больших компаний, эффективность от этого страдает, но в масштабах компании не сильно. Если уж приходится что-то срочно править в старом неизвестном коде, то приходится разбираться, ничего не поделаешь.
Насчет знания систем — я думаю, что эта проблема не решается. Текучесть кадров в большей или меньшей мере есть везде, даже там, где очень хорошо. Поэтому приходится заранее готовить замену для тех, от кого слишком много зависит. Заменяемость сотрудников выгодна для больших компаний, эффективность от этого страдает, но в масштабах компании не сильно. Если уж приходится что-то срочно править в старом неизвестном коде, то приходится разбираться, ничего не поделаешь.
Про контору я выше в комментариях отвечал.
Над проектом работает от 3-5 до 50-70 человек, все зависит от масштаба и срочности.
Поддерживают потенциально все, кто писал код, для этого составляется experience matrix — кто какой компонент знает.
Архитекторы у нас в отдельной команде — их человек 5, каждый отвечает за свою систему.
Над проектом работает от 3-5 до 50-70 человек, все зависит от масштаба и срочности.
Поддерживают потенциально все, кто писал код, для этого составляется experience matrix — кто какой компонент знает.
Архитекторы у нас в отдельной команде — их человек 5, каждый отвечает за свою систему.
UFO just landed and posted this here
Не советую SourceSafe в приличном обществе советовать. Не поймут-с.
UFO just landed and posted this here
Хотелось бы узнать ваши претензии к VSSОоо, их есть у меня.
Сразу оговорюсь: работал только с VSS от 2003 студии (6.0d, кажется).
Начнем с того, что она файл-серверная. Автоматом: никакой удаленной работы, никаких атомарных транзакций, блокировки файлов хранилища (VSS любит делать это, намертво и совершенно непредсказуемо) и прочие прелести SMB.
Мало того, рекомендации лучших собаководов имеют сказать, что размер репозитория лучше держать в пределах 5 Гб, что надо еженедельно его анализировать (что занимает немало времени, а в процессе доступ к VSS принудительно закрывается), что Sharing and Branching надо использовать предварительно перекрестившись, что чем больше пользователей — тем медленнее, что, черт побери, часы надо синхронизировать.
Ну и понеслась.
— Интерфейс, оставшийся со времен, наверное, Windows 3.1
— Совершенно никакая поддержка бранчинга и обратного слияния. Вы видели этот GUI?
— Оставляет удаленные файлы на диске
— Практически невозможно обновлять однажды добавленные сторонние исходники
— Невероятно медленный просмотр истории
— Отвратительная поддержка нескольких «рабочих копий»
— Феерические баги с целостностью данных (не поддерживаются переименования; шаринг файлов, вредный сам по себе, работает через специальное отверстие; SSARC генерирует архивы, из которых потом ничего не восстановить)
Ах да, поспорить-то забыл.
> Он быстр.
Он нифига не быстр даже для среднего размера проектов. Все файлы передаются целиком, в то время как все прогрессивное человечество давно пользуется диффами
> Визуальные средства
Лучше бы их не было.
> Дисциплинирует разработчика…
Крики «отпусти проект!» через всю комнату знакомы? Это вы называете дисциплина? Отключение же такой блокировки повлечет использование встроенной мерджилки, которую лучше не видеть.
> Три щелчка мышью…
… и полтора часа ожидания.
> Он быстр.
Он нифига не быстр даже для среднего размера проектов. Все файлы передаются целиком, в то время как все прогрессивное человечество давно пользуется диффами
> Визуальные средства
Лучше бы их не было.
> Дисциплинирует разработчика…
Крики «отпусти проект!» через всю комнату знакомы? Это вы называете дисциплина? Отключение же такой блокировки повлечет использование встроенной мерджилки, которую лучше не видеть.
> Три щелчка мышью…
… и полтора часа ожидания.
Браво! :) Я сам с мерджилкой в SorceSafe не работал, но, судя по Вашим комметариям — это тихий ужас. В CVS с мерджем особых проблем у меня не было.
А Вы смотрели на VS Team Edition? Там что-то более продвинутое теперь используется, насколько я слышал.
А Вы смотрели на VS Team Edition? Там что-то более продвинутое теперь используется, насколько я слышал.
В TFVC мержилка выглядит примерно так:
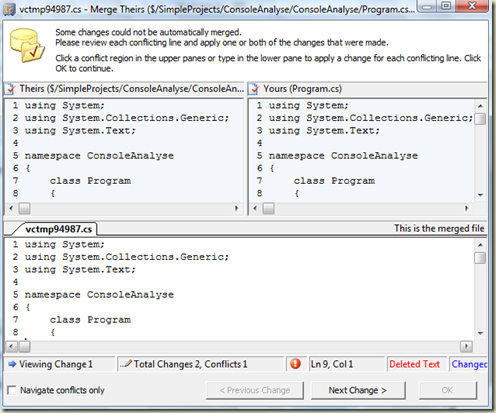
Насчет продвинутого… Более неповоротливое, я бы сказал — система контроля версий построена на Windows SharePoint Services. В качестве хранилища используется SQL Server (что зело хорошо).

Насчет продвинутого… Более неповоротливое, я бы сказал — система контроля версий построена на Windows SharePoint Services. В качестве хранилища используется SQL Server (что зело хорошо).
Спасибо! Араксис в качестве диффа все равно удобнее, по-моему.
А насчет SQL-Server — правда ли то, что там каждое сохранение файла попадает в базу?
А насчет SQL-Server — правда ли то, что там каждое сохранение файла попадает в базу?
Вот по поводу как подружить одно с другим.
А насчет вопроса — не знаю, честно говоря. Надеюсь, что таки диффы хранятся там.
А насчет вопроса — не знаю, честно говоря. Надеюсь, что таки диффы хранятся там.
UFO just landed and posted this here
Оке, меняемся :) Вы, кстати, о какой версии говорите?
2. Если переименовать транзакции в более модные в VSTS Change-set'ы, то все встает на свои места: одна транзакция — единый кусок работы.
4. На предыдущем месте 3Гб мы достигли вполне себе быстро — ничего криминального не предпринимали.
5. Рекомендации ж не просто так писаны. Да и этот анализатор и починятор ничего толком не починяет.
6. Расшарьте файл из проекта А в проект Б, поработайте, а потом удалите файл из проекта А. Файл в Б потеряет всю историю.
7. Вы избегали, похоже, потому что VSS. Ошибаюсь?
8. То есть, если положить рядом манифест, то вот это:
12. А как добавить файл в проект/проект в солюшен не делая чекат проекта и солюшена соответственно? И _очень_ спорная позиция по поводу организации разработки, коротких итераций и пр.
13. Поправить что-нибудь критичное в старой версии (банально: на сервере сайт версии 1.1, в настоящий момент сайт в разобранном состоянии; в 1.1 надо поправить критическую ошибку и обновить сайт).
превратится в красивые Aero-окошки?
10. Ну а теперь сравните с svn:externals и простой перезаписью папки в рабочей копии с последующим коммитом. Ненужные файлы останутся, да. Но это, ИМХО, мелочи.
2. Если переименовать транзакции в более модные в VSTS Change-set'ы, то все встает на свои места: одна транзакция — единый кусок работы.
4. На предыдущем месте 3Гб мы достигли вполне себе быстро — ничего криминального не предпринимали.
5. Рекомендации ж не просто так писаны. Да и этот анализатор и починятор ничего толком не починяет.
6. Расшарьте файл из проекта А в проект Б, поработайте, а потом удалите файл из проекта А. Файл в Б потеряет всю историю.
7. Вы избегали, похоже, потому что VSS. Ошибаюсь?
8. То есть, если положить рядом манифест, то вот это:

12. А как добавить файл в проект/проект в солюшен не делая чекат проекта и солюшена соответственно? И _очень_ спорная позиция по поводу организации разработки, коротких итераций и пр.
13. Поправить что-нибудь критичное в старой версии (банально: на сервере сайт версии 1.1, в настоящий момент сайт в разобранном состоянии; в 1.1 надо поправить критическую ошибку и обновить сайт).
превратится в красивые Aero-окошки?
10. Ну а теперь сравните с svn:externals и простой перезаписью папки в рабочей копии с последующим коммитом. Ненужные файлы останутся, да. Но это, ИМХО, мелочи.
UFO just landed and posted this here
7. То есть даже какие-то ну совсем новые фичи/мощный рефакторинг — все в основной ветви происходило?
12. Жуть. Вот это «добавить файлы в репозиторий» — это как? В «блокноте» быстренько набросать класс, ничего не скомпилировав залить его в хранилище, потом сделать чекаут проекту, добавить файлы и закоммитить потенциально неработающий код? Поясню: в «блокноте» писать придется потому, что студия без чекаута файла проекта не даст туда ничего добавить, так что придется изворачиваться и делать какой-нибудь File — New — C# File, там писать (без интеллисенса, без ничего) и потом проделывать все описанные манипуляции. Или я где-то чего-то недопонимаю?
13. Промблемо в том, что VSS считает себя самой умной и за каким-то лешим хранит на сервере путь, куда каждый отдельно взятый пользователь выгрузил себе исходники. Сделав «чекаут» в два места, прицепиться обратно к первому так просто (AFAIR) не выйдет.
12. Жуть. Вот это «добавить файлы в репозиторий» — это как? В «блокноте» быстренько набросать класс, ничего не скомпилировав залить его в хранилище, потом сделать чекаут проекту, добавить файлы и закоммитить потенциально неработающий код? Поясню: в «блокноте» писать придется потому, что студия без чекаута файла проекта не даст туда ничего добавить, так что придется изворачиваться и делать какой-нибудь File — New — C# File, там писать (без интеллисенса, без ничего) и потом проделывать все описанные манипуляции. Или я где-то чего-то недопонимаю?
13. Промблемо в том, что VSS считает себя самой умной и за каким-то лешим хранит на сервере путь, куда каждый отдельно взятый пользователь выгрузил себе исходники. Сделав «чекаут» в два места, прицепиться обратно к первому так просто (AFAIR) не выйдет.
Хочу пояснить насчет бранчинга — когда в системе пара миллионов строк кода, и в ней одновременно идет несколько проектов, затрагивающих все модули (бизнес есть бизнес!) то без бранчей, я думаю, просто невозможно выкрутиться. Для релиза очередной версии с определенным функционалом код бранчуется и затем в бранч чекинятся только эти изменения. В другой бранч — другие. После выхода версии в продакшен, эта версия продолжает поддерживаться, и если находим дефект, то фиксим его в нашем релизном бранче, и никакой головной боли с тем, что какая-то сырая функциональность из транка попала в наш релиз. Вот это уже действительно будет головная боль!
А насчет слияния веток — это не так сложно на самом деле. Когда я работал с Source Safe — тоже боялся слияния, как огня. Сейчас у нас бывают случаи, когда параллельная разработка в двух бранчах идет год, а потом мы это мерджим. Исключение, конечно, но ничего ужасного…
А насчет слияния веток — это не так сложно на самом деле. Когда я работал с Source Safe — тоже боялся слияния, как огня. Сейчас у нас бывают случаи, когда параллельная разработка в двух бранчах идет год, а потом мы это мерджим. Исключение, конечно, но ничего ужасного…
Это не совсем банальный момент.
Если система живёт в нескольких проектах репозитория, то у меня один check-in может состоять из нескольких индивидуальных.
Хочется, чтобы на одно логическое действие посылалось одно письмо.
Если система живёт в нескольких проектах репозитория, то у меня один check-in может состоять из нескольких индивидуальных.
Хочется, чтобы на одно логическое действие посылалось одно письмо.
А ведь есть ещё Git, который гораздо быстрее и функциональнее SVN.
Огромное спасибо Вам от индивидуальных разработчиков!
Много полезного для себя вынес.
Много полезного для себя вынес.
Вообще жутковато :). А нельзя никак применить Unix-way — разбить на много маленьких утилит с грамотно продуманной взаимосвязью между собой и каждую из этих утилит уже писать по простом?
Отличная статья!
Как не вспомнить любимую песню:
«Every build you break
Or refactoring you make
Every mock you fake
You little snake
I'll be watching you
Every Stand Up meeting
I believe you're cheating
Every Unit test
Pains my chest
I'll be stopping you»
(http://weblogs.asp.net/rosherove/archive/2007/11/21/song-every-build-you-break.aspx)
:-)
Как не вспомнить любимую песню:
«Every build you break
Or refactoring you make
Every mock you fake
You little snake
I'll be watching you
Every Stand Up meeting
I believe you're cheating
Every Unit test
Pains my chest
I'll be stopping you»
(http://weblogs.asp.net/rosherove/archive/2007/11/21/song-every-build-you-break.aspx)
:-)
Если вас интересует критика, советую поинтересоваться различием между Waterfall process vs Iterative and incremental development.
Респект. Именно так я представляю себе идеальную работу — все четко.
А излишняя «бюрократия» все же лучше, чем полный хаос с кучей емейлов, факсов, записок и прочего.
А излишняя «бюрократия» все же лучше, чем полный хаос с кучей емейлов, факсов, записок и прочего.
Ну ладно, все красиво, четко… А как вы на самом деле работаете? =)
Наконец-то правильный вопрос! :) Вспомнился случай: как то раз я выложил в корпоративной сети электронные книги по программированию, скачанные неизвестно где, т.е. почти наверняка у пиратов. Мне намекнули, что этого делать не следует. Тогда я их решил не удалять, а переименовать папку в нечто незаметное типа «q», чтобы те, кому надо, могли скачать и при этом не создавать прецедента. Но, естественно, сообщил, что книги удалил. Американские коллеги печально сказали «жаль», а наши задали правильный вопрос — «ну и какое новое имя папки?» :))))
На самом деле все печально — мы именно так и работаем, как написано… :) Причем следование процессам контролируется специальными надзирателями — процесс-коучами, и раз в 2-3 недели с ними проводится очная ставка, где нас ругают. То, что можно опустить из фаз разработки, опускаем. Об этом я упоминал. Но в основном следуем всему, как ни странно :)
На самом деле все печально — мы именно так и работаем, как написано… :) Причем следование процессам контролируется специальными надзирателями — процесс-коучами, и раз в 2-3 недели с ними проводится очная ставка, где нас ругают. То, что можно опустить из фаз разработки, опускаем. Об этом я упоминал. Но в основном следуем всему, как ни странно :)
Sign up to leave a comment.
Издержки больших проектов или взгляд на программирование в команде изнутри