В общем случае с помощью shell команды можно получить любую метрику, без написания кода и интеграций. А значит в консоли должен быть простой и удобный инструмент для визуализации.
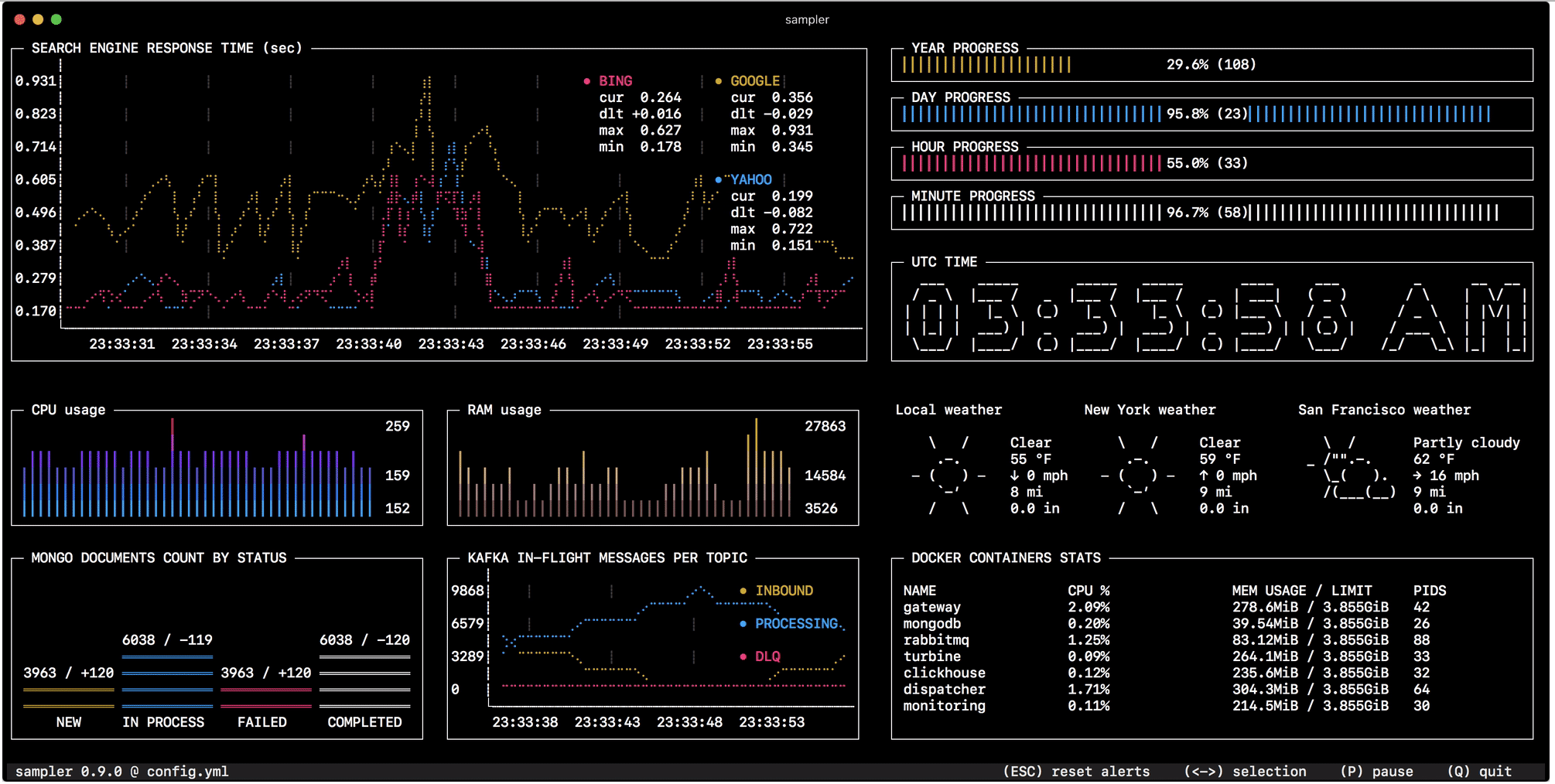
Наблюдение за изменением состояния в базе данных, мониторинг размера очередей, телеметрия с удаленных серверов, запуск деплой скриптов и получение нотификации по завершению — конфигурируется за минуту простым YAML файлом.
Код доступен на гитхабе. Инструкции по установке — для Linux, macOS и (экспериментально) Windows.
Зачем мне это, когда есть полноценные системы мониторинга?
Сразу оговорюсь, что это ни в коей мере не альтернатива полномасштабным дашбордам и мониторингу. Сравнивать Sampler c Prometheus+Grafana — то же что сравнивать tail и less с Elastic Stack или Splunk.
Но если поднимать и настраивать продакшн мониторинг для вашей задачи — как из пушки по воробьям, то возможно Sampler будет ответом на вопрос. Он задумывался как инструмент для прототипирования, демонстраций, или просто наблюдения за метриками на локали и удаленном сервере.
Значит его надо ставить на все сервера?
Нет, Sampler можно запускать локально, но метрики забирать со многих удаленных машин. Каждый компонент на дашборде имеет init секцию, где можно произвести вход по ssh (или сделать любое другое действие для входа в interactive shell — установить соединение с БД, подключиться по JMX, авторизоваться в API, итп)
Виды компонентов и примеры конфигурации
В примерах конфигурации приведены команды для macOS. Многие будут работать без изменений под Linux, но некоторые нужно адаптировать.
Runchart

runcharts:
- title: Search engine response time
rate-ms: 500 # sampling rate, default = 1000
scale: 2 # number of digits after sample decimal point, default = 1
legend:
enabled: true # enables item labels, default = true
details: false # enables item statistics: cur/min/max/dlt, default = true
items:
- label: GOOGLE
sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com
- label: YAHOO
sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com
- label: BING
sample: curl -o /dev/null -s -w '%{time_total}' https://www.bing.comSparkline

sparklines:
- title: CPU usage
rate-ms: 200
scale: 0
sample: ps -A -o %cpu | awk '{s+=$1} END {print s}'
- title: Free memory pages
rate-ms: 200
scale: 0
sample: memory_pressure | grep 'Pages free' | awk '{print $3}'Barchart

barcharts:
- title: Local network activity
rate-ms: 500 # sampling rate, default = 1000
scale: 0 # number of digits after sample decimal point, default = 1
items:
- label: UDP bytes in
sample: nettop -J bytes_in -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: UDP bytes out
sample: nettop -J bytes_out -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: TCP bytes in
sample: nettop -J bytes_in -l 1 -m tcp | awk '{sum += $4} END {print sum}'
- label: TCP bytes out
sample: nettop -J bytes_out -l 1 -m tcp | awk '{sum += $4} END {print sum}'Gauge

gauges:
- title: Minute progress
rate-ms: 500 # sampling rate, default = 1000
scale: 2 # number of digits after sample decimal point, default = 1
percent-only: false # toggle display of the current value, default = false
color: 178 # 8-bit color number, default one is chosen from a pre-defined palette
cur:
sample: date +%S # sample script for current value
max:
sample: echo 60 # sample script for max value
min:
sample: echo 0 # sample script for min value
- title: Year progress
cur:
sample: date +%j
max:
sample: echo 365
min:
sample: echo 0Textbox

textboxes:
- title: Local weather
rate-ms: 10000 # sampling rate, default = 1000
sample: curl wttr.in?0ATQF
border: false # border around the item, default = true
color: 178 # 8-bit color number, default is white
- title: Docker containers stats
rate-ms: 500
sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"Asciibox

asciiboxes:
- title: UTC time
rate-ms: 500 # sampling rate, default = 1000
font: 3d # font type, default = 2d
border: false # border around the item, default = true
color: 43 # 8-bit color number, default is white
sample: env TZ=UTC date +%rДополнительная функциональность
Триггеры
Триггеры позволяют запустить некоторое дополнительное действие, если замеряемое значение удовлетворяет заданному условию. Как условие, так и реакция — это так же shell команды, в которые подаются переменные $label, $cur и $prev. В первую очередь триггеры задумывались для алертинга (встроены звуковые и визуальные нотификации), но c опцией вашего собственного скрипта для реакции на срабатывание триггера его действие можно кастомизировать как угодно (например отправить нотификацию на телефон с Pushover)
Пример ниже иллюстрирует конфигурацию триггеров. Если latency ответа поисковой системы превысит 0.3 sec — Sampler моргнет стандартным terminal bell, проиграет NASA quindar tone, покажет визуальную нотификацию на графике и запустит скрипт, который в данном случае голосом произносит измеренное значение latency:
runcharts:
- title: SEARCH ENGINE RESPONSE TIME (sec)
rate-ms: 200
items:
- label: GOOGLE
sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com
- label: YAHOO
sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com
triggers:
- title: Latency threshold exceeded
condition: echo "$prev < 0.3 && $cur > 0.3" |bc -l # ожидает "1" как TRUE
actions:
terminal-bell: true # default = false
sound: true # NASA quindar tone, default = false
visual: true # default = false
script: 'say alert: ${label} latency exceeded ${cur} second'Interactive shell
Если до начала семплирования необходимо произвести вход в interactive shell (для единовременного подключения к БД, входа по SSH, подключения к JMX, итп) — можно указать init script, который исполнится один раз при старте. Пример подключения и опроса mongoDB:
textboxes:
- title: MongoDB polling
rate-ms: 500
init: mongo --quiet --host=localhost test # выполнится один раз
sample: Date.now(); # сработает в рамках mongo shell
transform: echo result = $sample # выполнится в рамках локальной сессии для преобразования значенияКроме того, есть поддержка PTY режима и multistep-init скриптов.
Переменные
Если в конфигурации присутствуют часто используемые части, которые не хочется повторять — их можно вынести в переменные и использовать в любом месте YML файла.
На практике
Как бекенд-программисту, мне часто приходится отлаживать, прототипировать и измерять. Отсюда и регулярная необходимость визуализации и мониторинга на скорую руку. Писать каждый раз что-то кастомное — неоправданно долго, но если процесс кастомизации был бы быстрым и (более-менее) удобным, такая визуализация вполне могла бы экономить время и решать задачи. Ничего подобного мне найти не удалось, поэтому было решено писать такой инструмент самому, и сделать его как можно более универсально конфигурабельным.
В самый первый раз по назначению я начал его использовать для отладки механизма группировки и аккумуляции данных, который быстро меняет статусы "событий" в памяти. Чтение состояния системы из логов или опрос отдельных счетчиков по каждому из статусов никак не помогает быстро сориентироваться и понять что к чему, а один взгляд на Sampler вполне решает эту задачу —
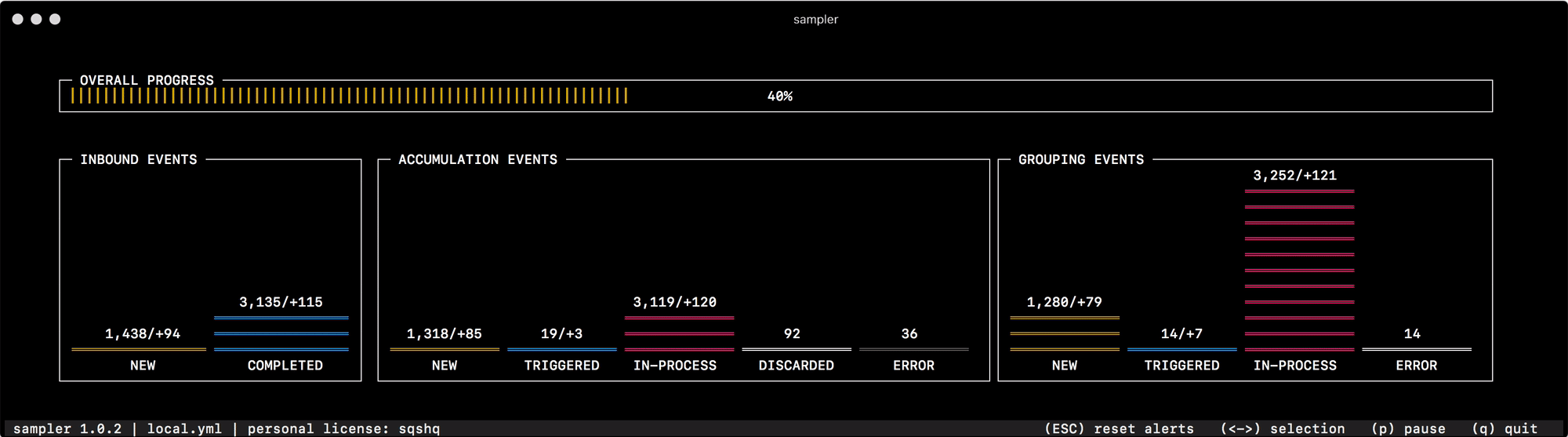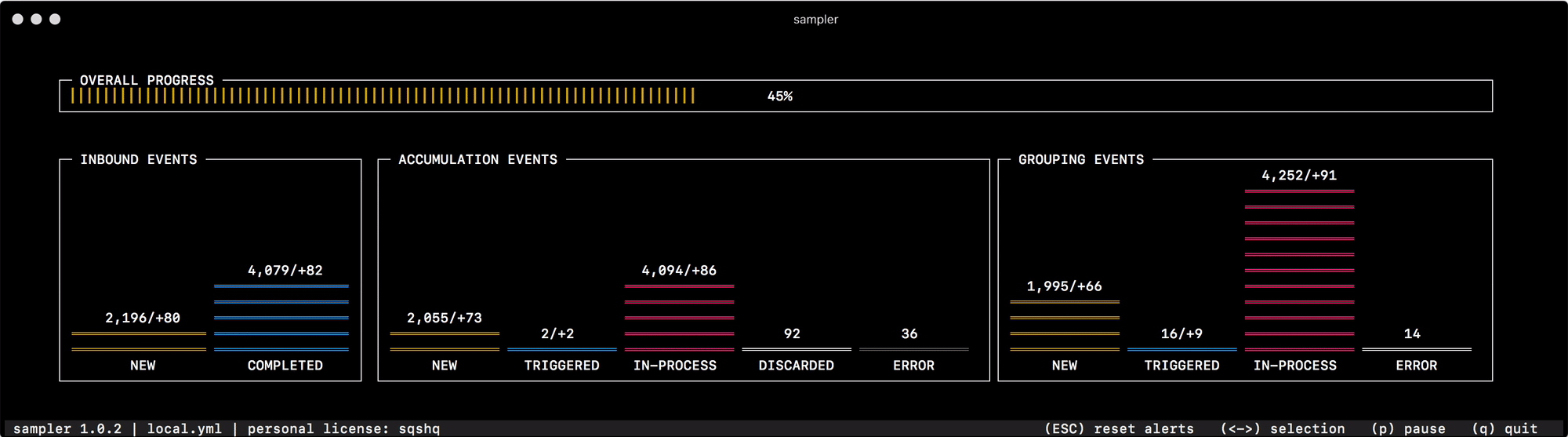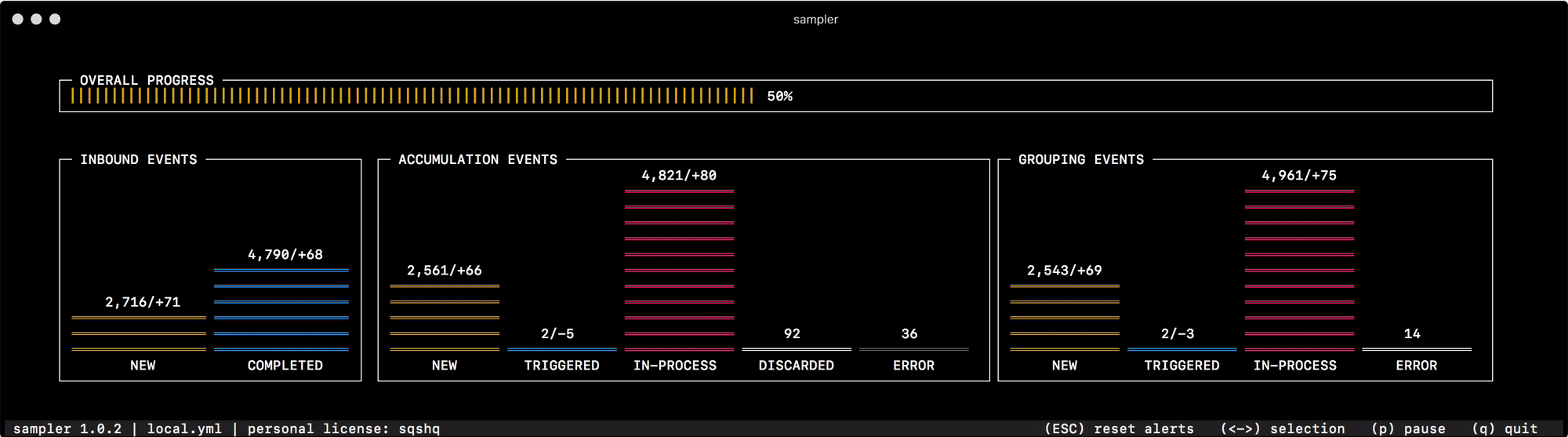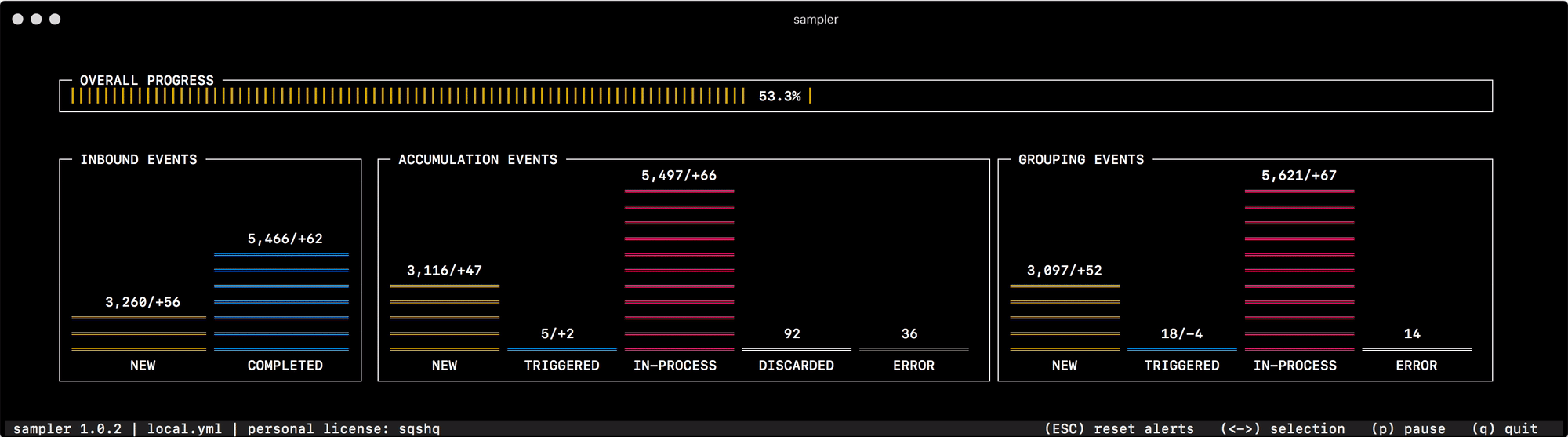
Для всего что использую сам, я приготовил сборник "рецептов" — моковых конфигураций, которые можно скопировать и сразу начать кастомизировать под свои задачи
- Соединения с базами данных: MySQL, PostgreSQL, MongoDB, Neo4J
- Kafka
- Docker
- SSH
- JMX
Этот список будет дополняться (и ваш вклад очень приветствуются), а тем временем в issues люди начали делиться своими конфигурациями для дашбордов Kubernetes, Github, и прочим.
Это все, хабр. Буду рад, если кому-то окажется полезным.
