Все мы любим и используем восхитительные возможности Availability Group на secondary репликах, такие, как проверка целостности, бэкапы и т.д.
На самом деле, невозможность сохранения этой информации в БД на реплике – это та ещё головная боль (и подумайте о таких вещах как CDC, для ещё большего дискомфорта).
Но хватит жаловаться, вот главная идея: дорогой Microsoft, позволь нам использовать наши реплики для обновления статистики… ну и делать на них намного больше всякого.
*почти всегда
Давайте перечислим известные базовые детали возможного решения на Enterprise Edition MS SQL Server:
У меня есть тестовая AG на паре виртуальных машин с SQL Server 2017 (вы можете использовать любую версию) и я создам простую таблицу, в которой хочу обновить статистику.
Вот скрипт для создания таблицы и вставки в неё миллиона строк:
Теперь давайте создадим статистику ST_SampleDataTable_C2 по столбцу c2
А потом я вставлю 1000 строк, которые будут очень важны и из-за которых мне по-настоящему нужно будет обновить статистику.
Теперь у меня есть 1000 записей, в которых, в столбце C2 указано значение 999999999. И это однозначно означает проблему нарастающих ключей (Ascending Key Problem) и мне по-настоящему нужно обновить статистику… на реплике, чтобы я не напрягал основной сервер вычислениями и не мешал ему обслуживать клиентов.
Используя старую добрую команду DBCC SHOW_STATISTICS, давайте изучим нашу статистику.
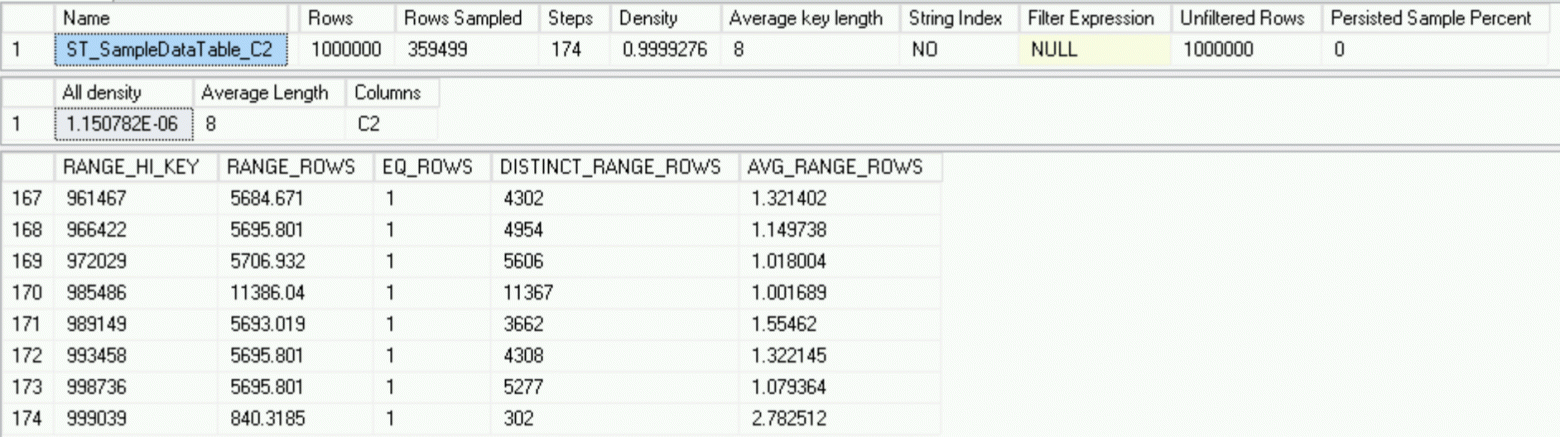
Все прекрасно в нашем королевстве и наша статистика в полном порядке, правда в ней учтён всего 1 миллион строк и нет той вредной тысячи строк, которая, в конечном счёте, должна стать частью этой статистики.
Также, мы можем посмотреть «поток статистики» (statistics stream) с помощью параметра STATS_STREAM команды DBCC SHOW_STATISTICS:

Это просто набор символов, о котором годами пишут блоги, но я всё равно не уверен, что это полностью документированная фича (хотя это никогда и не мешало людям ей пользоваться).
Давайте скопируем нашу таблицу на реплике в tempdb (хотя моя AG в синхронном режиме, тоже самое можно сделать и в асинхронном, просто данные могут прийти с небольшой задержкой).
Теперь мы готовы обновлять статистику с полным сканированием в tempdb на реплике.
(прим. переводчика – Нико забыл создать статистику, и использует некорректный синтаксис операции UPDATE STATISTICS, вместо UPDATE должно быть CREATE, т.е. статистика не обновляется, а создаётся)
Возвращаемся к DBCC SHOW_STATISTICS и посмотрим на неё:
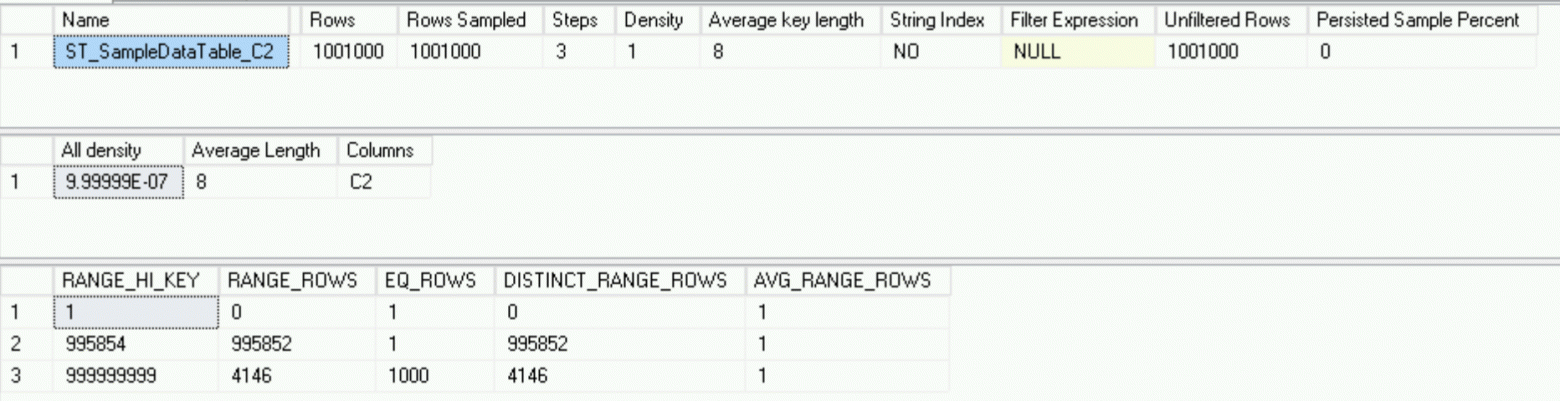
Она выглядит совершенно иначе, по сравнению с тем, что было на основном сервере – всего лишь 3 строки против 178, но описывает данные превосходно – у нас есть миллион уникальных строк и 1000 строк с одинаковым значением столбца C2 – гистограмма настолько хороша, насколько это возможно.
Посмотрим на поток статистики:

Не нужно быть гением, чтобы заметить, что поток выглядит совершенно по-другому – мы видим символы 5689A0C6 в обновлённом потоке, тогда как в оригинальном, между всеми этими нулями мы видели EDF10EB4.
Давайте теперь сконцентрируемся на экспорте этих данных в текстовый файл куда-то за пределы SQL Server и сделаем это с помощью чудесной команды BCP, которая требует, чтобы CMDSHELL был разрешён (внимание: вероятно вы не хотите этого на своём продакшен-сервере):
А вот насколько большим будет файл stats.txt в нашей шаре:

Всего-то пара килобайт! Легко передавать, легко управлять.
На основном сервере нам нужно будет создать временную таблицу, которая будет хранить поток статистики, прежде чем мы сможем обновить из него статистику в нашей основной таблице SampleDataTable (на практике же, мы можем расширить эту таблицу для множества БД, таблиц, статистик).
Давайте импортируем данные из нашего текстового файла в нашу новую временную таблицу и посмотрим что же мы импортировали:

Мы можем увидеть те же самые данные, что мы рассчитали на реплике, но эти данные уже на нашем основном сервере и всё, что нам остаётся сделать – это обновить из них нашу статистику в таблице. Эта операция может быть выполнена с помощью операции UPDATE STATISTICS с использованием параметра WITH STATS_STREAM = …
Этот скрипт выше читает импортированное значение (да, я знаю – я делал этот пример для одной таблицы и не заморачивался со множественными статистиками, таблицами, базами и т.д.), формирует инструкцию UPDATE STATISTICS, выводит её на экран и, в финале, выполняет её же.
Вот, что я получаю на выходе:
Выполнение DBCC SHOW_STATISTICS на основном сервере даёт мне тот самый результат, на который я и надеялся – тот же самый, что мы наблюдали на реплике. Круг замкнулся.
По-настоящему офигенная часть этой истории – это то, что размер объекта со статистикой, очень небольшой и мы можем передавать его на основной сервер очень легко/моментально.
Если у вас есть несколько AG между одними и теми же репликами, где одна реплика основная в одной AG, а другая основная во второй, то вы можете вставить BLOB-данные в поток данных между репликами и добавить крошечную БД с передаваемыми данными.
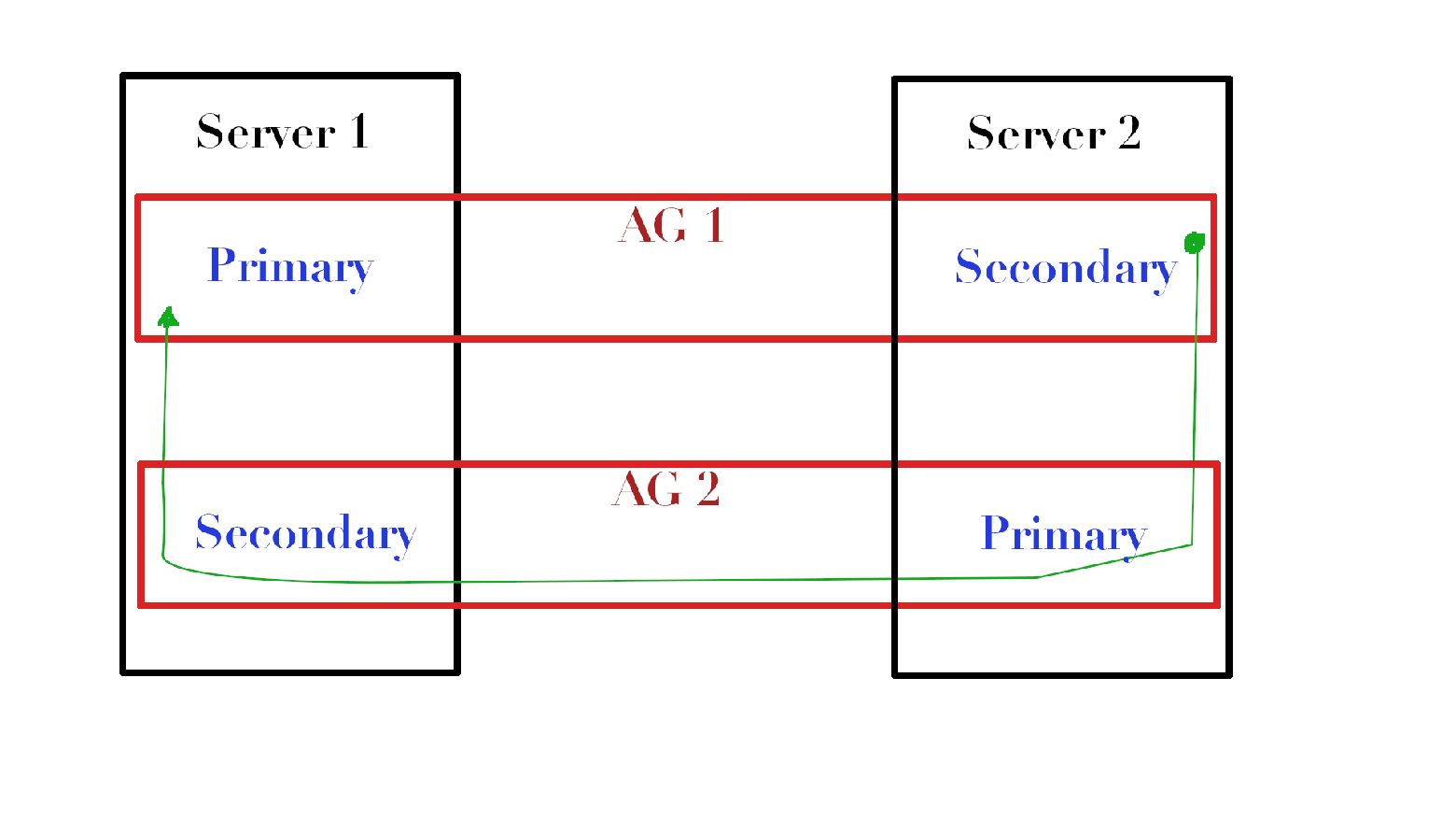
Посмотрите на картинку. Если у нас есть две AG (AG1 & AG2), которые расположены на разных серверах и у нас есть определённая таблица на Server1 в AG1, для которой мы хотим обновить статистику, то на Server2 мы можем скопировать эту таблицу (давайте назовём её dbo.MyTable) в tempdb, обновить, и, используя AG2, отправить объект с потоком статистики обратно на Server1, где просто импортировать статистику из этого потока в нужную нам статистику.
Да, знаю, звучит запутанно, но просто думайте об этом как о канале обратной связи, по которому доставляются результаты, вместо того, чтобы помещать их на файловые шары.
У вас может быть несколько возражений, например:
Это канал с обратной связью от реплики к основному серверу – после того как мы залоггировали транзакцию в синхронной AG, основной сервер будет ждать подтверждения от реплики – и я думаю, что этот канал может быть использован для реализации этого улучшения. Посмотрите на картинку, которая была взята в посте Simon Su.

Которая представляет весь механизм действующего канала обратной связи. Реплика, используя шаг 12 и последующие подтверждает основному серверу, что информация была сохранена. Тот же самый канал может использоваться для отправки объекта потока статистики после пересчёта на реплике. Конечно, мы должны будем не использовать tempdb для этой цели, а создавать in-memory объект внутри БД, который не должен постоянно храниться (посмотрите на свои In-Memory OLTP Schema-Only таблицы, или подумайте о NOLOGGING-таблицах в Oracle), а должен удаляться в конце операции – это было бы по-настоящему круто.
Это не должно зависеть от того синхронная реплика или нет – большую часть времени статистики обновляются не каждые пару секунд и это приводит нас ко второй части идеи – сделать вызов обновления статистики на основном сервере с параметром, таким как
где с помощью параметра SECONDARY указывается где должна быть выполнена операция.
И точно так же, как и с бэкапами, мы должны иметь возможность указать предпочтительную реплику для выполнения UPDATE STATISTICS (или любой другой операции, в будущем) в настройках.
Я уверен, что такая возможность сподвигнет множество пользователей Enterprise Edition переехать на новую версию SQL Server, которая позволит распределить тяжёлые операции между репликами.
Что касается текущей ситуации – я точно вижу как можно автоматизировать это решение с помощью Powershell.
Microsoft, твоя очередь! ;)
Проголосовать за предложенную фичу можно здесь.
Примечание переводчика: любые предложения и замечания по переводу и стилистике, как обычно, приветствуются.
primary replica в переводе я обычно называл «основным сервером», а secondary replica — просто репликой. Возможно, это не совсем корректно, но мне меньше режет ухо, чем «первичная» и «вторичная» реплики на msdn.
На самом деле, невозможность сохранения этой информации в БД на реплике – это та ещё головная боль (и подумайте о таких вещах как CDC, для ещё большего дискомфорта).
Но хватит жаловаться, вот главная идея: дорогой Microsoft, позволь нам использовать наши реплики для обновления статистики… ну и делать на них намного больше всякого.
Всегда* есть путь, или типа того
*почти всегда
Давайте перечислим известные базовые детали возможного решения на Enterprise Edition MS SQL Server:
- мы можем сделать реплики доступными на чтение и читать данные с них (не то, чтобы вам всегда нужно было так делать, но если вы действительно знаете что делаете…);
- мы можем копировать наши объекты в Tempdb (да, ваши много-терабайтные таблицы, вероятно не очень подходят для такой операции), или в другую БД, доступную для записи;
- мы можем записывать результаты в общую папку, доступную обеим репликам (пусть это будет текстовый файл в файловой шаре);
- мы можем экспортировать статистику в виде BLOB-объекта из SQL Server;
- мы можем импортировать выгруженный BLOB-объект в статистику.
Давайте сделаем это
У меня есть тестовая AG на паре виртуальных машин с SQL Server 2017 (вы можете использовать любую версию) и я создам простую таблицу, в которой хочу обновить статистику.
Вот скрипт для создания таблицы и вставки в неё миллиона строк:
DROP TABLE IF EXISTS dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
C2 BIGINT NOT NULL,
CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1)
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT t.RN, t.RN
FROM
(
SELECT TOP (1000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);Теперь давайте создадим статистику ST_SampleDataTable_C2 по столбцу c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);А потом я вставлю 1000 строк, которые будут очень важны и из-за которых мне по-настоящему нужно будет обновить статистику.
set nocount on;
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT 10000000 + t.RN, 999999999
FROM
(
SELECT TOP (1000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);Теперь у меня есть 1000 записей, в которых, в столбце C2 указано значение 999999999. И это однозначно означает проблему нарастающих ключей (Ascending Key Problem) и мне по-настоящему нужно обновить статистику… на реплике, чтобы я не напрягал основной сервер вычислениями и не мешал ему обслуживать клиентов.
Используя старую добрую команду DBCC SHOW_STATISTICS, давайте изучим нашу статистику.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')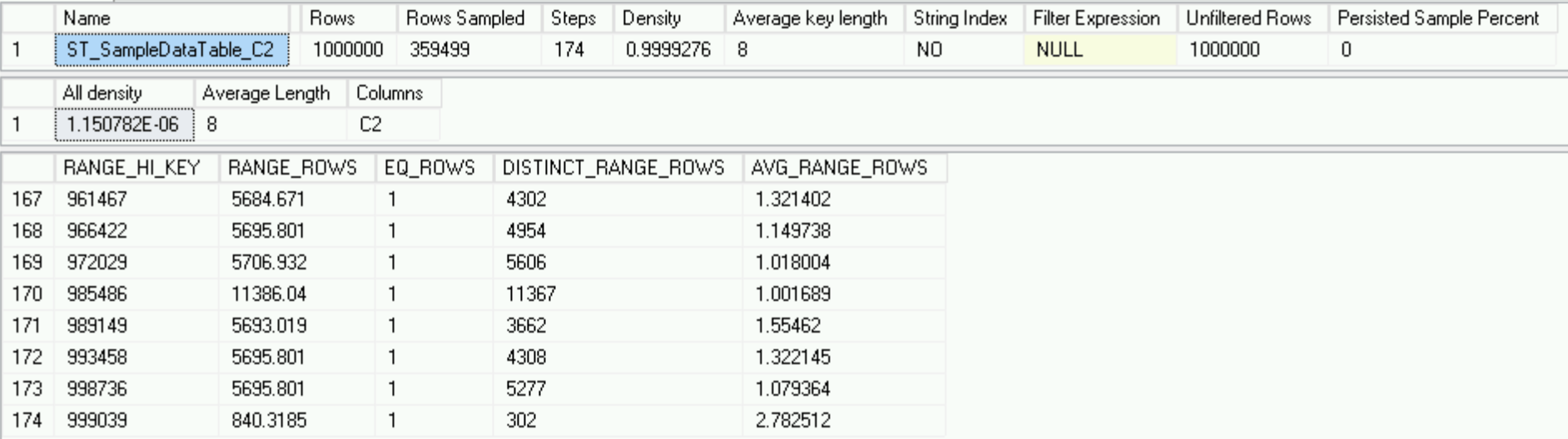
Все прекрасно в нашем королевстве и наша статистика в полном порядке, правда в ней учтён всего 1 миллион строк и нет той вредной тысячи строк, которая, в конечном счёте, должна стать частью этой статистики.
Также, мы можем посмотреть «поток статистики» (statistics stream) с помощью параметра STATS_STREAM команды DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
Это просто набор символов, о котором годами пишут блоги, но я всё равно не уверен, что это полностью документированная фича (хотя это никогда и не мешало людям ей пользоваться).
На реплике
Давайте скопируем нашу таблицу на реплике в tempdb (хотя моя AG в синхронном режиме, тоже самое можно сделать и в асинхронном, просто данные могут прийти с небольшой задержкой).
use TempDB;
DROP TABLE IF EXISTS dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
C2 BIGINT NOT NULL,
CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1)
);
INSERT INTO dbo.SampleDataTable
SELECT C1, C2
FROM AvGroupDb.dbo.SampleDataTable;Теперь мы готовы обновлять статистику с полным сканированием в tempdb на реплике.
use TempDB;
UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;(прим. переводчика – Нико забыл создать статистику, и использует некорректный синтаксис операции UPDATE STATISTICS, вместо UPDATE должно быть CREATE, т.е. статистика не обновляется, а создаётся)
Возвращаемся к DBCC SHOW_STATISTICS и посмотрим на неё:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')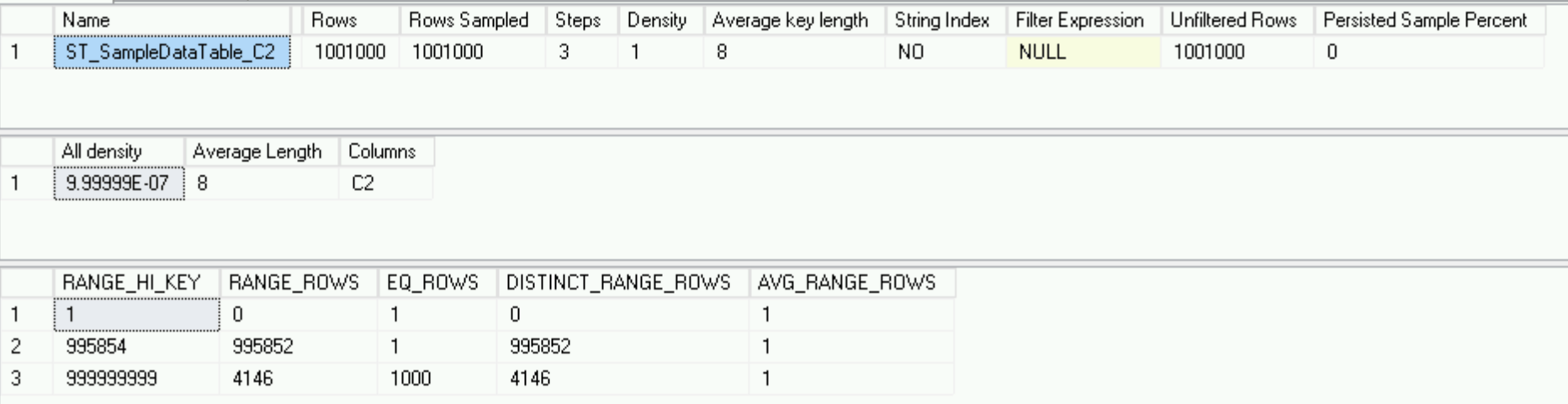
Она выглядит совершенно иначе, по сравнению с тем, что было на основном сервере – всего лишь 3 строки против 178, но описывает данные превосходно – у нас есть миллион уникальных строк и 1000 строк с одинаковым значением столбца C2 – гистограмма настолько хороша, насколько это возможно.
Посмотрим на поток статистики:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
Не нужно быть гением, чтобы заметить, что поток выглядит совершенно по-другому – мы видим символы 5689A0C6 в обновлённом потоке, тогда как в оригинальном, между всеми этими нулями мы видели EDF10EB4.
Давайте теперь сконцентрируемся на экспорте этих данных в текстовый файл куда-то за пределы SQL Server и сделаем это с помощью чудесной команды BCP, которая требует, чтобы CMDSHELL был разрешён (внимание: вероятно вы не хотите этого на своём продакшен-сервере):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';А вот насколько большим будет файл stats.txt в нашей шаре:

Всего-то пара килобайт! Легко передавать, легко управлять.
Назад на основной сервер
На основном сервере нам нужно будет создать временную таблицу, которая будет хранить поток статистики, прежде чем мы сможем обновить из него статистику в нашей основной таблице SampleDataTable (на практике же, мы можем расширить эту таблицу для множества БД, таблиц, статистик).
CREATE TABLE dbo.TempStats(
Stats_Stream VARBINARY(MAX),
Rows BIGINT,
DataPages BIGINT );Давайте импортируем данные из нашего текстового файла в нашу новую временную таблицу и посмотрим что же мы импортировали:
BULK INSERT dbo.TempStats
FROM '\\SharedServer\Tempdb\stats.txt'
SELECT *
FROM dbo.TempStats;
Мы можем увидеть те же самые данные, что мы рассчитали на реплике, но эти данные уже на нашем основном сервере и всё, что нам остаётся сделать – это обновить из них нашу статистику в таблице. Эта операция может быть выполнена с помощью операции UPDATE STATISTICS с использованием параметра WITH STATS_STREAM = …
DECLARE @script NVARCHAR(MAX)
SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1)
FROM dbo.TempStats
PRINT @script;
EXECUTE sp_executesql @script;Этот скрипт выше читает импортированное значение (да, я знаю – я делал этот пример для одной таблицы и не заморачивался со множественными статистиками, таблицами, базами и т.д.), формирует инструкцию UPDATE STATISTICS, выводит её на экран и, в финале, выполняет её же.
Вот, что я получаю на выходе:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = 0x010000000100000000000000000000005689A0C6000000007D020000000000003D020000000000007F0300007F0000000800130000000000000000000000000007000000C5BB2F0172AA000028460F000000000028460F00000000000000803FB4378635000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003000000030000000100000018000000000000418062744900000000000000410000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000190400000000000000000000000000006900000000000000B900000000000000C100000000000000C900000000000000180000000000000033000000000000004E00000000000000100018000000803F000000000000803F0100000000000000040000100018000000803FC02073490000803F0E320F00000000000400001000180000007A44009081450000803FFFC99A3B000000000400000100000079DC280172AA00000000000080842E4140420F0000000000AE000000000000A0924EB33E9BD9BB9DFC19B4404449E6ABFE2F84400000000000408F400000000000000000DFE68293BDC8803F28460F00000000000000000000000000Выполнение DBCC SHOW_STATISTICS на основном сервере даёт мне тот самый результат, на который я и надеялся – тот же самый, что мы наблюдали на реплике. Круг замкнулся.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');По-настоящему офигенная часть этой истории – это то, что размер объекта со статистикой, очень небольшой и мы можем передавать его на основной сервер очень легко/моментально.
Не настолько базовый сценарий.
Если у вас есть несколько AG между одними и теми же репликами, где одна реплика основная в одной AG, а другая основная во второй, то вы можете вставить BLOB-данные в поток данных между репликами и добавить крошечную БД с передаваемыми данными.
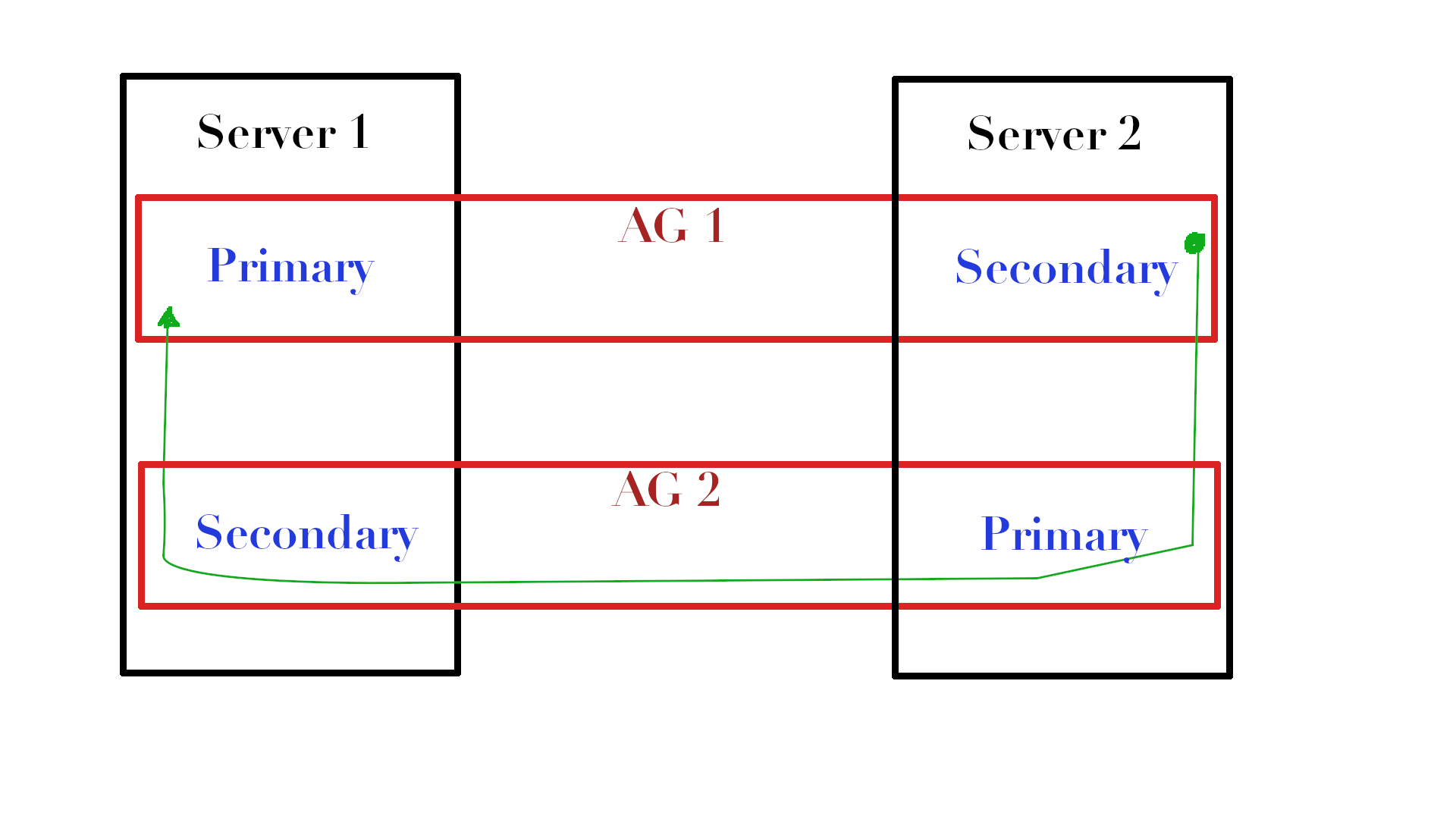
Посмотрите на картинку. Если у нас есть две AG (AG1 & AG2), которые расположены на разных серверах и у нас есть определённая таблица на Server1 в AG1, для которой мы хотим обновить статистику, то на Server2 мы можем скопировать эту таблицу (давайте назовём её dbo.MyTable) в tempdb, обновить, и, используя AG2, отправить объект с потоком статистики обратно на Server1, где просто импортировать статистику из этого потока в нужную нам статистику.
Да, знаю, звучит запутанно, но просто думайте об этом как о канале обратной связи, по которому доставляются результаты, вместо того, чтобы помещать их на файловые шары.
Место для сомнений
У вас может быть несколько возражений, например:
- зачем мне делать это на реплике, если я спокойно могу сделать это на основном сервере? (ну, вообще, идея в том, чтобы разгрузить основной сервер)
- но разве мы, потенциально, не нагружаем реплику (да, но если она простаивает – то именно поэтому мы и хотим использовать её мощности)
- а мы не можем как-то подействовать на основной сервер? (нет, мы просто читаем данные с реплики и отправляем назад пару килобайт, что в наш век гигабайт и терабайт звучит как «штоа?») (прим. переводчика — вообще, как раз в случае читаемой реплики AG, можем)
- что если в середине процесса основной сервер начнёт обновлять статистику самостоятельно? (в этом случае, он может или прервать второй процесс, или перезапуститься с обновлёнными данными).
Канал обратной связи AG
Это канал с обратной связью от реплики к основному серверу – после того как мы залоггировали транзакцию в синхронной AG, основной сервер будет ждать подтверждения от реплики – и я думаю, что этот канал может быть использован для реализации этого улучшения. Посмотрите на картинку, которая была взята в посте Simon Su.
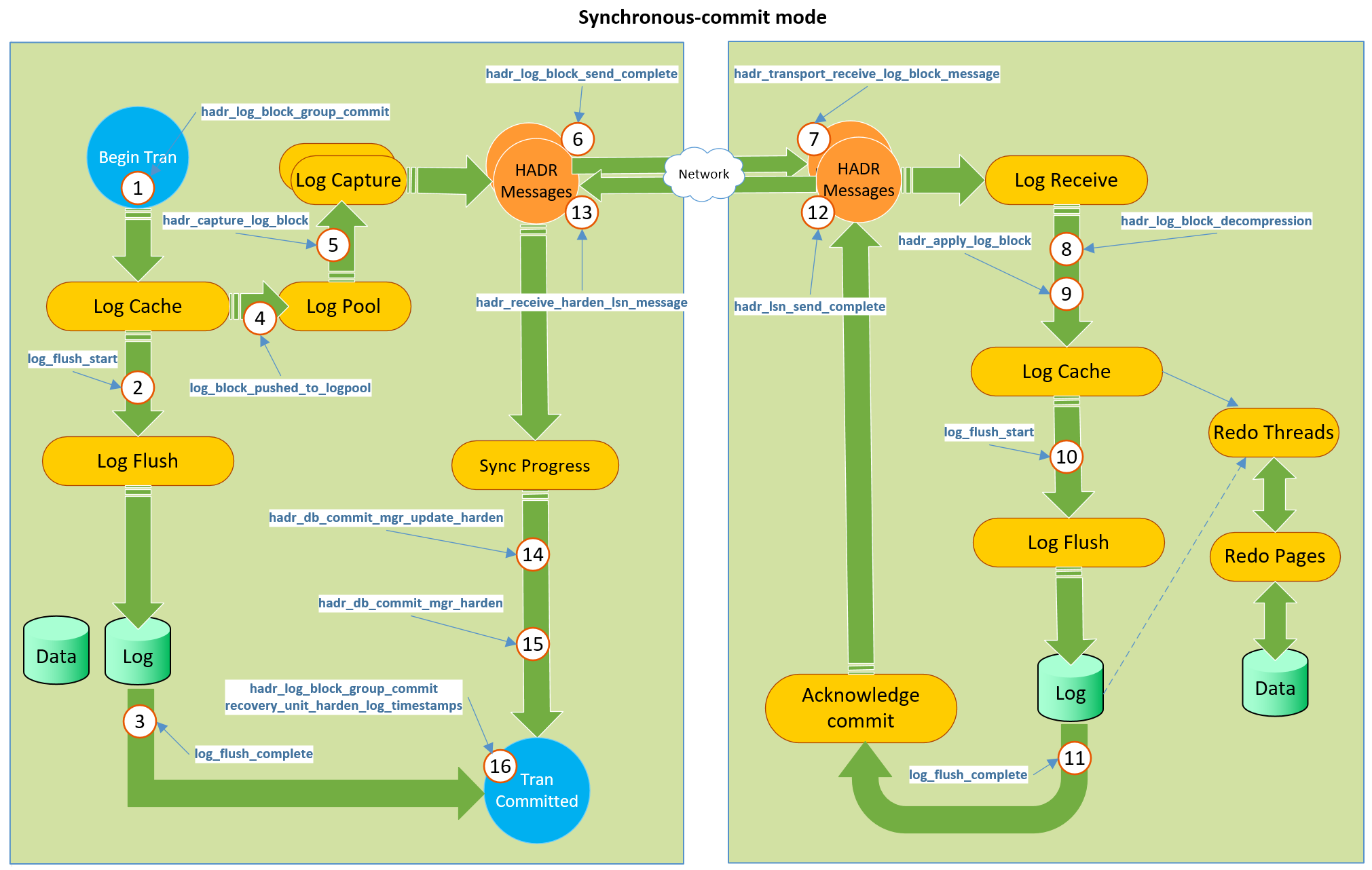
Которая представляет весь механизм действующего канала обратной связи. Реплика, используя шаг 12 и последующие подтверждает основному серверу, что информация была сохранена. Тот же самый канал может использоваться для отправки объекта потока статистики после пересчёта на реплике. Конечно, мы должны будем не использовать tempdb для этой цели, а создавать in-memory объект внутри БД, который не должен постоянно храниться (посмотрите на свои In-Memory OLTP Schema-Only таблицы, или подумайте о NOLOGGING-таблицах в Oracle), а должен удаляться в конце операции – это было бы по-настоящему круто.
Общие мысли
Это не должно зависеть от того синхронная реплика или нет – большую часть времени статистики обновляются не каждые пару секунд и это приводит нас ко второй части идеи – сделать вызов обновления статистики на основном сервере с параметром, таким как
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARYгде с помощью параметра SECONDARY указывается где должна быть выполнена операция.
И точно так же, как и с бэкапами, мы должны иметь возможность указать предпочтительную реплику для выполнения UPDATE STATISTICS (или любой другой операции, в будущем) в настройках.
Я уверен, что такая возможность сподвигнет множество пользователей Enterprise Edition переехать на новую версию SQL Server, которая позволит распределить тяжёлые операции между репликами.
Что касается текущей ситуации – я точно вижу как можно автоматизировать это решение с помощью Powershell.
Microsoft, твоя очередь! ;)
Проголосовать за предложенную фичу можно здесь.
Примечание переводчика: любые предложения и замечания по переводу и стилистике, как обычно, приветствуются.
primary replica в переводе я обычно называл «основным сервером», а secondary replica — просто репликой. Возможно, это не совсем корректно, но мне меньше режет ухо, чем «первичная» и «вторичная» реплики на msdn.
