Comments 9
Спасибо за статью — очень интересно, можно бы и поразвернутей!
Уточню кое-что:
То что абсолютное изменение частоты в разных диапазонах воспринимается по разному — это давно известно и в общем очевидно, а вот что субъективное ощущение высоты звука зависит не только от частоты звука (что бы на не говорили в музыкальной школе), а еще и от громкости и тембра — вот это некоторая новость — вот для измерения этой субъективной величины и придумали этот «мел».
Субъективная громкость кстати тоже зависит от частоты, а не только от амплитуды.
Уточню кое-что:
Эксперименты ученых показали, что человеческое ухо более чувствительно к изменениям звука на низких частотах, чем на высоких. То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
В связи с этим была введена новая единица измерения высоты звука — мел.
То что абсолютное изменение частоты в разных диапазонах воспринимается по разному — это давно известно и в общем очевидно, а вот что субъективное ощущение высоты звука зависит не только от частоты звука (что бы на не говорили в музыкальной школе), а еще и от громкости и тембра — вот это некоторая новость — вот для измерения этой субъективной величины и придумали этот «мел».
Субъективная громкость кстати тоже зависит от частоты, а не только от амплитуды.
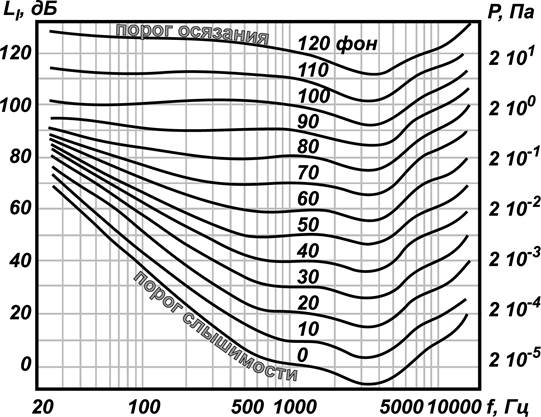
Ну дык графики восприятия звука для обеспечения тон-коррекции в звуковой аппаратуре существуют практически с истоков:
И в той же музыкальной школе кроме, может, камертона никто чистый синус без гармоник не слушает. А изменение уровня гармоник и приводит к изменению субъективного восприятия высоты тона.
И в той же музыкальной школе кроме, может, камертона никто чистый синус без гармоник не слушает. А изменение уровня гармоник и приводит к изменению субъективного восприятия высоты тона.
Неее, всё гораздо интересней, по-хорошему для решения задач распознавания звуков а-ля человек, нужно плясать не от субъективного восприятия, а от самого устройства сенсора, которое весьма занятно.
Скажем так, сигналов без гармоник мы не слышим в принципе, ибо смысл механических элементов внутреннего уха не только в согласовании импеданса и регулировки чувствительности, они ещё и гармоники производят. В итоге частотное разрешение получается сильно выше чем количество рецепторов позволяет.
То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
Неудачный пример. Во втором случае, просто процент, на который изменилась частота, существенно ниже. 20% и 0.2% это две огромные разницы и особенности уха в данном случае совершенно не при чём.
И что? В чём научная новизна? Ребята изобрели вэйвлеты :-) и причём тут обратное распространение ошибки.
Или эта публикация ради публикации, или учёные в очередной раз гнусно надругались над журналистом.
Странно, что не оптимизировали подход до конца. Можно ведь генерировать мел-окно, пихать в вектор и подавать нейросети. Затем, после обучения, удалить самые бесполезные параметры. В результате, на нейросеть будет меньше нагрузка и она сама будет меньше, а значит быстрее.
Взять, например MelNet, там очень здорово придумали с повышением размерности, но из-за невозможности применить сжатие гармоник, по скорости она не превосходит tacotron2
Взять, например MelNet, там очень здорово придумали с повышением размерности, но из-за невозможности применить сжатие гармоник, по скорости она не превосходит tacotron2
Sign up to leave a comment.
Как нейронная сеть SincNet выделяет значимые частоты в звуке через Back Propagation