Comments 12
Константин, отличное применение! Добавлю 5 копеек:
- Можно взглянуть на
doFuture. С ним этап сбора данных можно распараллелить не по ядрам, а по доп. процессам, а их можно запустить больше и получить результат еще быстрее, поскольку процессы будут просто ждать ответа от контролллеров. - В параллельных расчетах неплохо вести единый лог файл, чтобы понимать, что происходит.
DoFuture почитаю. Спасибо. Единый лог файл, да. Согласен, что не помешал бы. Попробую добавить.
Еще пара трюков по ggplot:
facet_wrapпо сути более подходит, поскольку набор данных одномерный по разбивке.- В фасетах лучше поставить
scales = "free_y", тогда графики будут более читаемые, поскольку каждый тип ошибки получит свою нормировку. - Для того, чтобы у каждого графика сделать ось X можно использовать трюк с принудительным выставлением лимитов на X наподобие:
scale_x_datetime(labels = date_format("%H:%M", tz = "Europe/Moscow"), breaks = date_breaks("1 hour"), limits = base::range(df$time, na.rm = TRUE)) +
При этом надо в facet указать
scales = "free"
Спасибо за советы. Завтра попробую — покажу, что получилось на примере имеющихся данных.
Применил рекомендации.
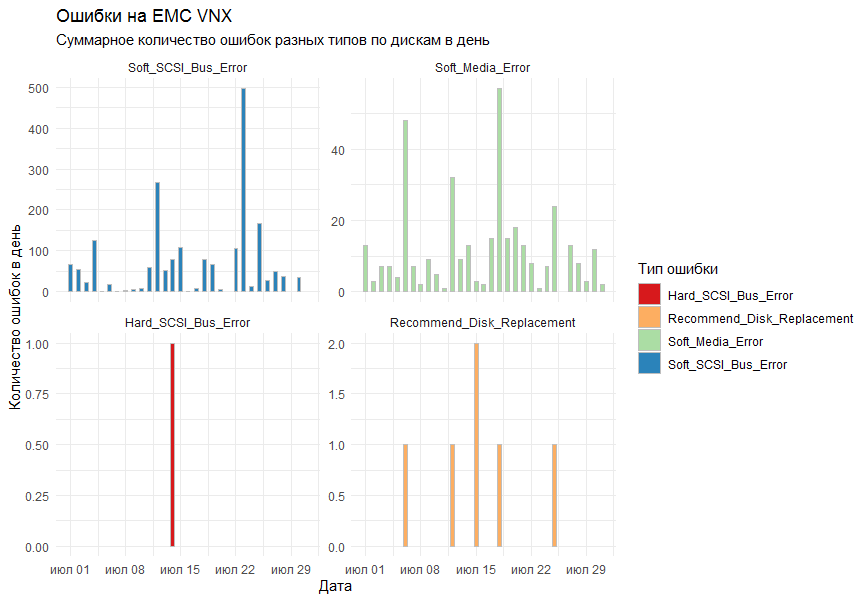
- facet_wrap для нашей задачи, действительно больше подходит. По факту оказалось, что сетка 2 на 2 из графиков смотрится лучше, чем колонка из 4.
- Динамическая ось y (scales = "free_y") также крайне положительно сказалась. Единичные ошибки на других графиках стали заметными.
- А вот ось Х подписывать не стал. Попробовал, но, в итоге, показалось избыточно именно для этой задачи.
Так что большое спасибо за рекомендации.
Итоговый результат.
Есть у нас ЦОД. Там не очень свежие СХД.
Мониторинг по SNMP этими СХД не поддерживается
Скажите, пожалуйста, а что это за «не очень свежие» СХД (извините если в тексте не прочел)?
И, кстати, почему именно R? В моей реальности он обычно в около ML'ных задачах используется.
Но статья — крутая.
Спасибо на добром слове.
Это EMC VNX 5300.
Ну и, на самом деле, если бы был мониторинг по SNMP — это бы не помогло, потому что интересующие нас сообщения не являются аварийными. Может, по ним snmp trap и не получилось бы генерить. А если бы получилось забирать весь лог через snmp poll, то всё равно всё свелось бы к тому, что результат надо чем-то парсить и т.д. По факту в тот же код можно пару строчек поменять и будет опрос через snmp :)
Именно R, по простой причине, что я его более-менее знаю и уже использовал в подобных задачах. Думаю, что на Python можно сделать всё плюс-минус то же самое. Вопрос того кому что удобнее.
А что по ML делали на R? Поделитесь.
А что по ML делали на R? Поделитесь.
Эээ, ну если учесть, что в моей терминологии ML — Machine Learning, то на R в этой сфере пишут все, что только можно. Сложнее «змейки», однако функциональнее по отзывам знающих. Например, у нас в BI-отделе ML Архитектор не знает и не хочет знать Python, и все модели пишет на R в R-studio. Задачи стандартные для телекома — отток, допродажи, CVM.
Я просто редко сталкивался с использованием R в неML задачах.
А в R вы выполняете только naviseccli getlog… конечно, такой вариант будет выполняться значительно быстрее.
Спасибо за внимательность :)
Согласен, что в этом плане сравнение скорости выполнение не очень честное.
Оно скорее, как рекламный слоган со звёздочкой.
Дело в том, что в изначальном коде с помощью getdisk ещё собираются серийные номера дисков, а на момент переписывания кода на R стало понятно, что эти данные не нужны.
Помечу в тексте данную оговорку, чтобы было честно.
Пишите в процессе. Буду рад помочь, если что.
Только учтите пожалуйста, что в коде учитывается вариант, что по какой-то СХД не будет ошибок, но не учитывается вариант, когда вообще нигде не будет ошибок (у нас такого не бывает, так что я поленился). Если у вас такое может быть, то это надо учесть. :)
Отчёты по состоянию СХД с помощью R. Параллельные вычисления, графики, xlsx, email и всё вот это