На этой неделе я начал работать над своим движком для игры Vagabond и приступил к реализации шаблона entity-component-system.
В этой статье я хочу рассказать о своей реализации, которая свободно доступна на GitHub. Но вместо простого комментирования кода я хочу объяснить, как проектировалась его структура. Поэтому я начну с первой написанной мной реализации, проанализирую её сильные и слабые стороны, а затем покажу, как улучшил её. В конце я перечислю список аспектов, которые также можно улучшить.
Введение
Мотивация
Я не буду рассказывать о преимуществах ECS перед объектно-ориентированным подходом, потому что с этим хорошо справились многие люди до меня. Одним из первых про ECS рассказал на GDC 2002 Скотт Билас. Среди других знаменитых введений в тему можно назвать Evolve Your Hierarchy Майка Уэста и главу Components из потрясающей книги Game Programming Patterns Роберта Нистрома.
Вкратце скажу, что задача ECS — создание ориентированного на обработку данных подхода к игровым сущностям и удобное разделение данных и логики. Сущности (Entities) составляются из компонентов, содержащих данные. А системы, содержащие логику, обрабатывают эти компоненты.
Если вдаваться в детали, то вместо наследования в ECS используется композиция. Более того, этот подход, ориентированный на обработку данных, оптимальнее использует кэш, а значит, достигает отличной производительности.
Примеры
Прежде чем углубляться в код, я бы хотел показать вам, что мы собираемся проектировать.
Задание компонентов выполнятся очень просто:
struct Position : public Component<Position>
{
float x;
float y;
};
struct Velocity : public Component<Velocity>
{
float x;
float y;
};Как видите, мы будем использовать шаблон CRTP.
Затем, по техническим причинам, которые я объясню позже, нам нужно зафиксировать количество компонентов и количество систем:
constexpr auto ComponentCount = 32;
constexpr auto SystemCount = 8;Далее можно задать систему, которая будет брать все сущности, имеющие оба компонента, и обновлять их позиции:
class PhysicsSystem : public System<ComponentCount, SystemCount>
{
public:
PhysicsSystem(EntityManager<ComponentCount, SystemCount>& entityManager) : mEntityManager(entityManager)
{
setRequirements<Position, Velocity>();
}
void update(float dt)
{
for (const auto& entity : getManagedEntities())
{
auto [position, velocity] = mEntityManager.getComponents<Position, Velocity>(entity);
position.x += velocity.x * dt;
position.y += velocity.y * dt;
}
}
private:
EntityManager<ComponentCount, SystemCount>& mEntityManager;
};Для объявления интересующих её компонентов система просто использует метод
setRequirements. Затем в методе update она может вызывать getManagedEntities для итеративного обхода всех сущностей, удовлетворяющих требованиям.Наконец, давайте создадим менеджер сущностей, зарегистрируем компоненты, создадим систему и несколько сущностей, а затем будем обновлять их позиции при помощи системы:
auto manager = EntityManager<ComponentCount, SystemCount>();
manager.registerComponent<Position>();
manager.registerComponent<Velocity>();
auto system = manager.createSystem<PhysicsSystem>(manager);
for (auto i = 0; i < 10; ++i)
{
auto entity = manager.createEntity();
manager.addComponent<Position>(entity);
manager.addComponent<Velocity>(entity);
}
auto dt = 1.0f / 60.0f;
while (true)
system->update(dt);Бенчмарки
Не буду притворяться, что создал самую лучшую библиотеку ECS. Мне просто хотелось написать её самостоятельно. Кроме того, я работал над ней всего лишь неделю.
Однако это не причина, чтобы создавать нечто совершенно неэффективное. Поэтому давайте установим бенчмарки:
- Первый будет создавать сущности;
- Второй будет использовать систему для итеративного обхода сущностей;
- Последний будет создавать и уничтожать сущности;
Параметрами всех этих бенчмарков являются количество сущностей, количество компонентов у каждой сущности, максимальное количество компонентов и максимальное количество систем. Таким образом, мы сможем увидеть, насколько хорошо масштабируется наша реализация. В частности, я покажу результаты для трёх разных профилей:
- Профиль A: 32 компонента и 16 систем;
- Профиль AA: 128 компонентов и 32 системы;
- Профиль AAA: 512 компонента и 64 системы.
Несмотря на то, что эти бенчмарки дадут нам представление о качестве реализации, они довольно просты. Например, в этих бенчмарках мы используем только однородные сущности, а их компоненты малы.
Реализация
Сущность
В моей реализации сущность — это всего лишь id:
using Entity = uint32_t;Более того, в Entity.h мы также определим псевдоним
Index, который нам пригодится позже:using Index = uint32_t;
static constexpr auto InvalidIndex = std::numeric_limits<Index>::max();Я решил вместо 64-битного типа или
std::size_t использовать uint32_t, чтобы сэкономить пространство и повысить оптимизацию кэша. Потеряем мы не так много: маловероятно, что у кого-то будут миллиарды сущностей.Компонент
Теперь давайте определим базовый класс для компонентов:
template<typename T, auto Type>
class Component
{
public:
static constexpr auto type = static_cast<std::size_t>(Type);
};Класс шаблона очень прост, он всего лишь хранит id типа, который мы позже будем использовать для индексации структур данных по типу компонентов.
Первый параметр шаблона — это тип компонента. Второй — это значение, преобразуемое в
std::size_t, которое будет служить id типа компонента.Например, мы можем определить компонент
Position следующим образом:struct Positon : Component<Position, 0>
{
float x;
float y;
};Однако удобнее может быть использовать перечисление:
enum class ComponentType
{
Position
};
struct Positon : Component<Position, ComponentType::Position>
{
float x;
float y;
};Во вводном примере есть только один параметр шаблона: нам не нужно указывать id типа вручную. Позже мы увидим, как улучшить структуру и генерировать идентификаторы типов автоматически.
EntityContainer
Класс
EntityContainer будет отвечать за управление сущностями и хранение для каждой из них std::bitset. Этот набор битов будет обозначать компоненты, которыми владеет сущность.Так как мы будем использовать сущности для индексации контейнеров и в частности
std::vector, нам нужно, чтобы id были как можно меньше и занимали меньше памяти. Поэтому мы будем заново использовать id уничтоженных сущностей. Для этого свободные id будут сохраняться в контейнере под названием mFreeEntities.Вот объявление
EntityContainer:template<std::size_t ComponentCount, std::size_t SystemCount>
class EntityContainer
{
public:
void reserve(std::size_t size);
std::vector<std::bitset<ComponentCount>>& getEntityToBitset();
const std::bitset<ComponentCount>& getBitset(Entity entity) const;
Entity create();
void remove(Entity entity);
private:
std::vector<std::bitset<ComponentCount>> mEntityToBitset;
std::vector<Entity> mFreeEntities;
};Давайте посмотрим, как реализованы методы.
getEntityToBitset и getBitset — это обычные небольшие геттеры:std::vector<std::bitset<ComponentCount>>& getEntityToBitset()
{
return mEntityToBitset;
}
const std::bitset<ComponentCount>& getBitset(Entity entity) const
{
return mEntityToBitset[entity];
}Метод
create более интересен:Entity create()
{
auto entity = Entity();
if (mFreeEntities.empty())
{
entity = static_cast<Entity>(mEntityToBitset.size());
mEntityToBitset.emplace_back();
}
else
{
entity = mFreeEntities.back();
mFreeEntities.pop_back();
mEntityToBitset[entity].reset();
}
return entity;
}Если есть свободная сущность, он использует её повторно. В противном случае метод создаёт новую сущность.
Метод
remove просто добавляет сущность для удаления в mFreeEntities:void remove(Entity entity)
{
mFreeEntities.push_back(entity);
}Последний метод — это
reserve. Его задача — резервирование памяти под различные контейнеры. Как мы возможно знаете, выделение памяти — это затратная операция, поэтому если мы приблизительно знаем количество будущих сущностей в игре, то резервирование памяти позволит ускорить работу:void reserve(std::size_t size)
{
mFreeEntities.resize(size);
std::iota(std::begin(mFreeEntities), std::end(mFreeEntities), 0);
mEntityToBitset.resize(size);
}Кроме простого резервирования памяти он также заполняет
mFreeEntities.ComponentContainer
Класс
ComponentContainer будет отвечать за хранение всех компонентов заданного типа.В моей архитектуре все компоненты заданного типа хранятся вместе. То есть существует один большой массив для каждого типа компонентов, называемый
mComponents.Кроме того, чтобы иметь возможность добавления, получения или удаления компонента из сущности за постоянное время, нам нужен способ перехода от сущности к компоненту и от компонента к сущности. Для этого нам понадобятся ещё две структуры данных под названием
mComponentToEntity и mEntityToComponent.Вот объявление
ComponentContainer:template<typename T, std::size_t ComponentCount, std::size_t SystemCount>
class ComponentContainer : public BaseComponentContainer
{
public:
ComponentContainer(std::vector<std::bitset<ComponentCount>>& entityToBitset);
virtual void reserve(std::size_t size) override;
T& get(Entity entity);
const T& get(Entity entity) const;
template<typename... Args>
void add(Entity entity, Args&&... args);
void remove(Entity entity);
virtual bool tryRemove(Entity entity) override;
Entity getOwner(const T& component) const;
private:
std::vector<T> mComponents;
std::vector<Entity> mComponentToEntity;
std::unordered_map<Entity, Index> mEntityToComponent;
std::vector<std::bitset<ComponentCount>>& mEntityToBitset;
};Можно заметить, что он наследуется от
BaseComponentContainer, который задаётся так:class BaseComponentContainer
{
public:
virtual ~BaseComponentContainer() = default;
virtual void reserve(std::size_t size) = 0;
virtual bool tryRemove(Entity entity) = 0;
};Единственное предназначение этого базового класса заключается в том, чтобы иметь возможность хранить все экземпляры
ComponentContainer в контейнере.Давайте теперь посмотрим на определение методов.
Сначала рассмотрим конструктор: он получает ссылку на контейнер, содержащий наборы битов сущностей. Этот класс будет использовать её для проверки наличия у сущности компонента и для обновления набора битов сущности при добавлении или удалении компонента:
ComponentContainer(std::vector<std::bitset<ComponentCount>>& entityToBitset) :
mEntityToBitset(entityToBitset)
{
}Метод
get прост, мы всего лишь используем mEntityToComponent для нахождения индекса компонента сущности entity в mComponents:T& get(Entity entity)
{
return mComponents[mEntityToComponent[entity]];
}Метод
add использует свои аргументы для вставки нового компонента в конец mComponents, а затем он подготавливает ссылки для перехода от сущности к компоненту и от компонента к сущности. В конце он присваивает биту набора битов entity, который соответствует компоненту, значение true:template<typename... Args>
void add(Entity entity, Args&&... args)
{
auto index = static_cast<Index>(mComponents.size());
mComponents.emplace_back(std::forward<Args>(args)...);
mComponentToEntity.emplace_back(entity);
mEntityToComponent[entity] = index;
mEntityToBitset[entity][T::type] = true;
}Метод
remove присваивает соответствующему компоненту биту значение false, а затем перемещает последний компонент mComponents по индексу того, который мы хотим удалить. Он обновляет ссылки на компонент, который мы только что переместили, и удаляет один из компонентов, который мы хотим уничтожить:void remove(Entity entity)
{
mEntityToBitset[entity][T::type] = false;
auto index = mEntityToComponent[entity];
// Update mComponents
mComponents[index] = std::move(mComponents.back());
mComponents.pop_back();
// Update mEntityToComponent
mEntityToComponent[mComponentToEntity.back()] = index;
mEntityToComponent.erase(entity);
// Update mComponentToEntity
mComponentToEntity[index] = mComponentToEntity.back();
mComponentToEntity.pop_back();
}Перемещение за постоянное время мы можем выполнять благодаря перемещению последнего компонента по индексу, который мы хотим уничтожить. И в самом деле, тогда нам просто достаточно будет удалить последний компонент, что можно выполнить в
std::vector за постоянное время.Метод
tryRemove проверяет, есть ли у сущности компонент, прежде чем пытаться удалить его:virtual bool tryRemove(Entity entity) override
{
if (mEntityToBitset[entity][T::type])
{
remove(entity);
return true;
}
return false;
}Метод
getOwner возвращает сущность, которая владеет компонентом, для этого он пользуется арифметикой указателей и mComponentToEntity:Entity getOwner(const T& component) const
{
auto begin = mComponents.data();
auto index = static_cast<std::size_t>(&component - begin);
return mComponentToEntity[index];
}Последний метод — это
reserve, он имеет такое предназначение, что и аналогичный метод в EntityContainer:virtual void reserve(std::size_t size) override
{
mComponents.reserve(size);
mComponentToEntity.reserve(size);
mEntityToComponent.reserve(size);
}Система
Теперь давайте рассмотрим класс
System.Каждая система имеет набор битов
mRequirements, описывающий необходимые ей компоненты. Кроме того, она хранит набор сущностей mManagedEntities, удовлетворяющих этим требованиям. Повторюсь, чтобы иметь возможность реализовать все операции за постоянное время, нам нужен способ перехода от сущности к её индексу в mManagedEntities. Для этого мы воспользуемся std::unordered_map под названием mEntityToManagedEntity.Вот как выглядит объявление
System:template<std::size_t ComponentCount, std::size_t SystemCount>
class System
{
public:
virtual ~System() = default;
protected:
template<typename ...Ts>
void setRequirements();
const std::vector<Entity>& getManagedEntities() const;
virtual void onManagedEntityAdded([[maybe_unused]] Entity entity);
virtual void onManagedEntityRemoved([[maybe_unused]] Entity entity);
private:
friend EntityManager<ComponentCount, SystemCount>;
std::bitset<ComponentCount> mRequirements;
std::size_t mType;
std::vector<Entity> mManagedEntities;
std::unordered_map<Entity, Index> mEntityToManagedEntity;
void setUp(std::size_t type);
void onEntityUpdated(Entity entity, const std::bitset<ComponentCount>& components);
void onEntityRemoved(Entity entity);
void addEntity(Entity entity);
void removeEntity(Entity entity);
};Для задания значений битов
setRequirements использует выражение свёртки:template<typename ...Ts>
void setRequirements()
{
(mRequirements.set(Ts::type), ...);
}getManagedEntities — это геттер, который будет использоваться порождёнными классами для доступа к обрабатываемым сущностям:const std::vector<Entity>& getManagedEntities() const
{
return mManagedEntities;
}Он возвращает константную ссылку, чтобы порождённые классы не пытались изменять
mManagedEntities.onManagedEntityAdded и onManagedEntityRemoved пусты. В дальнейшем они будут переопределены. Эти методы будут вызываться при добавлении сущности в mManagedEntities или её удалении.Следующие методы будут приватными и доступными только из
EntityManager, который объявляется как дружественный класс.setUp будет вызываться менеджером сущностей для назначения id системе. Затем он может использовать его для индексации массивов:void setUp(std::size_t type)
{
mType = type;
}onEntityUpdated вызывается при изменении сущности, т.е. при добавлении или удалении компонента. Система проверяет, удовлетворены ли требования и была ли уже обработана сущность. Если она удовлетворяет требованиям и пока не была обработана, то система её добавляет. Однако если сущность не удовлетворяет требованиям и уже была обработана, то система её удаляет. Во всех остальных случаях система ничего не делает:void onEntityUpdated(Entity entity, const std::bitset<ComponentCount>& components)
{
auto satisfied = (mRequirements & components) == mRequirements;
auto managed = mEntityToManagedEntity.find(entity) != std::end(mEntityToManagedEntity);
if (satisfied && !managed)
addEntity(entity);
else if (!satisfied && managed)
removeEntity(entity);
}onEntityRemoved вызывается менеджером сущностей при удалении сущности. Если сущность была обработана системой, он удаляет её:void onEntityRemoved(Entity entity)
{
if (mEntityToManagedEntity.find(entity) != std::end(mEntityToManagedEntity))
removeEntity(entity);
}addEntity и removeEntity — это просто вспомогательные методы.addEntity задаёт ссылку для перехода от добавленной сущности по её индексу в mManagedEntities, добавляет сущность и вызывает onManagedEntityAdded:void addEntity(Entity entity)
{
mEntityToManagedEntity[entity] = static_cast<Index>(mManagedEntities.size());
mManagedEntities.emplace_back(entity);
onManagedEntityAdded(entity);
}removeEntity сначала вызывает onManagedEntityRemoved. Затем он перемещает последнюю обработанную сущность по индексу той, которая удаляется. Он обновляет ссылку на перемещённую сущность. В конце он удаляет сущность, которую нужно было удалить, из mManagedEntities и mEntityToManagedEntity:void removeEntity(Entity entity)
{
onManagedEntityRemoved(entity);
auto index = mEntityToManagedEntity[entity];
mEntityToManagedEntity[mManagedEntities.back()] = index;
mEntityToManagedEntity.erase(entity);
mManagedEntities[index] = mManagedEntities.back();
mManagedEntities.pop_back();
}EntityManager
Вся важная логика находится в других классах. Менеджер сущностей просто связывает всё вместе.
Давайте взглянем на его объявление:
template<std::size_t ComponentCount, std::size_t SystemCount>
class EntityManager
{
public:
template<typename T>
void registerComponent();
template<typename T, typename ...Args>
T* createSystem(Args&& ...args);
void reserve(std::size_t size);
Entity createEntity();
void removeEntity(Entity entity);
template<typename T>
bool hasComponent(Entity entity) const;
template<typename ...Ts>
bool hasComponents(Entity entity) const;
template<typename T>
T& getComponent(Entity entity);
template<typename T>
const T& getComponent(Entity entity) const;
template<typename ...Ts>
std::tuple<Ts&...> getComponents(Entity entity);
template<typename ...Ts>
std::tuple<const Ts&...> getComponents(Entity entity) const;
template<typename T, typename... Args>
void addComponent(Entity entity, Args&&... args);
template<typename T>
void removeComponent(Entity entity);
template<typename T>
Entity getOwner(const T& component) const;
private:
std::array<std::unique_ptr<BaseComponentContainer>, ComponentCount> mComponentContainers;
EntityContainer<ComponentCount, SystemCount> mEntities;
std::vector<std::unique_ptr<System<ComponentCount, SystemCount>>> mSystems;
template<typename T>
void checkComponentType() const;
template<typename ...Ts>
void checkComponentTypes() const;
template<typename T>
auto getComponentContainer();
template<typename T>
auto getComponentContainer() const;
};Класс
EntityManager имеет три переменных членов класса: mComponentContainers, хранящую указатели std::unique_ptr на BaseComponentContainer, mEntities, которая просто является экземпляром EntityContainer и mSystems, которая хранит указатели unique_ptr на System.Класс имеет множество методов, но на самом деле все они очень просты.
Давайте сначала взглянем на
getComponentContainer, который возвращает указатель на контейнер компонентов, обрабатывающий компоненты типа T:template<typename T>
auto getComponentContainer()
{
return static_cast<ComponentContainer<T, ComponentCount, SystemCount>*>(mComponentContainers[T::type].get());
}Ещё одна вспомогательная функция — это
checkComponentType, которая просто проверяет, что id типа компонента ниже максимального числа компонентов:template<typename T>
void checkComponentType() const
{
static_assert(T::type < ComponentCount);
}checkComponentTypes использует выражение свёртки для выполнения проверки нескольких типов:template<typename ...Ts>
void checkComponentTypes() const
{
(checkComponentType<Ts>(), ...);
}registerComponent создаёт новый контейнер компонентов указанного типа:template<typename T>
void registerComponent()
{
checkComponentType<T>();
mComponentContainers[T::type] = std::make_unique<ComponentContainer<T, ComponentCount, SystemCount>>(
mEntities.getEntityToBitset());
}createSystem создаёт новую систему указанного типа и задаёт её тип:template<typename T, typename ...Args>
T* createSystem(Args&& ...args)
{
auto type = mSystems.size();
auto& system = mSystems.emplace_back(std::make_unique<T>(std::forward<Args>(args)...));
system->setUp(type);
return static_cast<T*>(system.get());
}Метод
reserve вызывает методы reserve контейнеров ComponentContainer и EntityContainer:void reserve(std::size_t size)
{
for (auto i = std::size_t(0); i < ComponentCount; ++i)
{
if (mComponentContainers[i])
mComponentContainers[i]->reserve(size);
}
mEntities.reserve(size);
}Метод
createEntity возвращает результат метода create менеджера EntityManager:Entity createEntity()
{
return mEntities.create();
}hasComponent использует набор битов сущности для быстрой проверки того, что у этой сущности есть компонент указанного типа:template<typename T>
bool hasComponent(Entity entity) const
{
checkComponentType<T>();
return mEntities.getBitset(entity)[T::type];
}hasComponents использует выражение свёртки для создания набора битов, обозначающего требуемые компоненты, а затем использует его с набором битов сущности для проверки того, есть ли у сущности все требуемые компоненты:template<typename ...Ts>
bool hasComponents(Entity entity) const
{
checkComponentTypes<Ts...>();
auto requirements = std::bitset<ComponentCount>();
(requirements.set(Ts::type), ...);
return (requirements & mEntities.getBitset(entity)) == requirements;
}getComponent переправляет запрос нужному контейнеру компонентов:template<typename T>
T& getComponent(Entity entity)
{
checkComponentType<T>();
return getComponentContainer<T>()->get(entity);
}getComponents возвращает кортеж ссылок на запрошенные компоненты. Для этого он использует std::tie и выражение свёртки:template<typename ...Ts>
std::tuple<Ts&...> getComponents(Entity entity)
{
checkComponentTypes<Ts...>();
return std::tie(getComponentContainer<Ts>()->get(entity)...);
}addComponent и removeComponent переправляют запрос к нужному контейнеру компонентов, а затем вызывают метод системы onEntityUpdated:template<typename T, typename... Args>
void addComponent(Entity entity, Args&&... args)
{
checkComponentType<T>();
getComponentContainer<T>()->add(entity, std::forward<Args>(args)...);
// Send message to systems
const auto& bitset = mEntities.getBitset(entity);
for (auto& system : mSystems)
system->onEntityUpdated(entity, bitset);
}
template<typename T>
void removeComponent(Entity entity)
{
checkComponentType<T>();
getComponentContainer<T>()->remove(entity);
// Send message to systems
const auto& bitset = mEntities.getBitset(entity);
for (auto& system : mSystems)
system->onEntityUpdated(entity, bitset);
}Наконец,
getOwner переправляет запрос нужному компоненту контейнеров:template<typename T>
Entity getOwner(const T& component) const
{
checkComponentType<T>();
return getComponentContainer<T>()->getOwner(component);
}Такой была моя первая реализация. Она состоит всего из 357 строк кода. Весь код можно найти в этой ветке.
Профилирование и бенчмарки
Бенчмарки
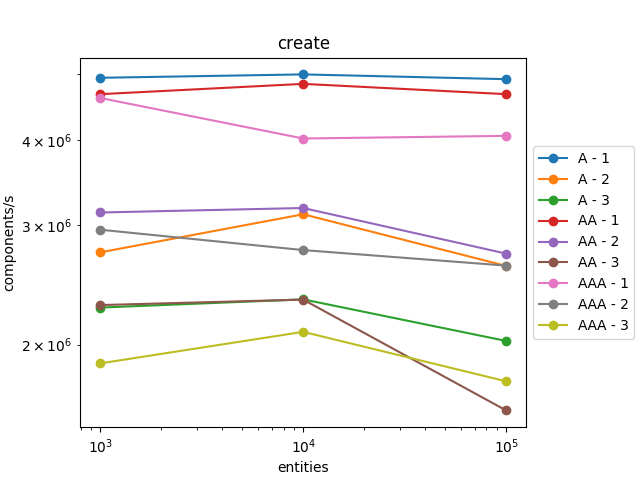
Теперь настало время провести бенчмарки моей первой реализации ECS!
Вот результаты:


Шаблон достаточно хорошо масштабируется! Количество обработанных за секунду приблизительно одинаково при увеличении количества сущностей и смене профилей (A, AA и AAA).
Кроме того, он хорошо масштабируется с увеличением количества компонентов в сущностях. Когда мы выполняем итерации по сущностям с тремя компонентами, они происходят в три раза медленее, чем итерации по сущностям с одним компонентом. Это ожидаемо, потому что нам нужно получить три компонента.
Промахи кэша
Для проверки количества промахов кэша я запустил взятый отсюда пример с cachegrind.
Вот результат для 10 000 сущностей:
==1652== D refs: 277,577,353 (254,775,159 rd + 22,802,194 wr)
==1652== D1 misses: 20,814,368 ( 20,759,914 rd + 54,454 wr)
==1652== LLd misses: 43,483 ( 7,847 rd + 35,636 wr)
==1652== D1 miss rate: 7.5% ( 8.1% + 0.2% )
==1652== LLd miss rate: 0.0% ( 0.0% + 0.2% )Вот результат для 100 000 сущностей:
==1738== D refs: 2,762,879,670 (2,539,368,564 rd + 223,511,106 wr)
==1738== D1 misses: 207,415,181 ( 206,902,072 rd + 513,109 wr)
==1738== LLd misses: 207,274,328 ( 206,789,289 rd + 485,039 wr)
==1738== D1 miss rate: 7.5% ( 8.1% + 0.2% )
==1738== LLd miss rate: 7.5% ( 8.1% + 0.2% )Результаты довольно неплохи. Только немного странно, почему так много промахов LLd при 100 000 сущностей.
Профилирование
Чтобы понять, какие части текущей реализации занимают больше времени, я профилировал пример при помощи gprof.
Вот результат:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
57.45 1.16 1.16 200300000 0.00 0.00 std::__detail::_Map_base<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true>, true>::operator[](unsigned int const&)
19.31 1.55 0.39 main
16.34 1.88 0.33 200500000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::_M_find_before_node(unsigned long, unsigned int const&, unsigned long) const
3.96 1.96 0.08 300000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::_M_insert_unique_node(unsigned long, unsigned long, std::__detail::_Hash_node<std::pair<unsigned int const, unsigned int>, false>*)
2.48 2.01 0.05 300000 0.00 0.00 unsigned int& std::vector<unsigned int, std::allocator<unsigned int> >::emplace_back<unsigned int&>(unsigned int&)
0.50 2.02 0.01 3 3.33 3.33 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::~_Hashtable()
0.00 2.02 0.00 200000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::find(unsigned int const&)Результаты могут быть немного искажены, потому что я компилировал с флагом
-O1, чтобы gprof выводил нечто осмысленное. Похоже, что при повышении уровня оптимизации компилятор начинает агрессивно всё встраивать и gprof почти ничего не сообщает.По данным gprof, очевидным узким местом в этой реализации являются
std::unordered_map. Если мы хотим оптимизировать её, то стоит попробовать от них избавиться.Сравнение с std::map
Мне стала любопытна разница в производительности между
std::unordered_map и std::map, поэтому я заменил в коде все std::unordered_map на std::map. Эта реализация выложена здесьВот результаты бенчмарков:



Мы можем увидеть, что на этот раз реализация плохо масштабируется при увеличении количества сущностей. И даже при 1000 сущностей она в два раза медленнее в итерациях, чем версия с
std::unordered_map.Заключение
Мы создали простую, но уже практичную библиотеку шаблона entity-component-system. В дальнейшем мы будем использовать в качестве фундамента для улучшений и оптимизаций.
В следующей части мы покажем, как повысить производительность, заменив
std::unordered_map на std::vector. Кроме того, мы покажем, как автоматически назначать компонентам id типа.Замена std::unordered_map на std::vector
Как мы увидели,
std::unordered_map были узким местом нашей реализации. Поэтому вместо std::unordered_map мы используем в mEntityToComponent для ComponentContainer и в mEntityToManagedEntity для System векторы std::vector.Изменения
Изменения будут очень простыми, посмотреть на них можно здесь.
Единственная тонкость заключается в том, чтобы
vector в mEntityToComponent и mEntityToManagedEntity были достаточно длинными для индексации любой сущностью. Чтобы сделать это простым способом, я решил хранить эти vector в EntityContainer, в котором мы знаем максимальный id сущности. Тогда я передаю векторы vector контейнерам компонентов по ссылке или указателю в менеджере сущностей.Изменённый код можно найти в этой ветке.
Результаты
Давайте проверим, насколько лучше работает эта версия, чем предыдущая:



Как видите, создание и удаление при большом количестве компонентов и систем стали немного
медленнее.
Однако итерация стала намного быстрее, почти в десять раз! И масштабируется она очень хорошо. Это ускорение с сильно перевешивает замедление создания и удаления. И это логично: итерации сущности будут происходить множество раз, а создаётся и удаляется она только один раз.
Теперь давайте посмотрим, снизило ли это количество промахов кэша.
Вот выходные данные cachegrind при 10 000 сущностях:
==1374== D refs: 94,563,949 (72,082,880 rd + 22,481,069 wr)
==1374== D1 misses: 4,813,780 ( 4,417,702 rd + 396,078 wr)
==1374== LLd misses: 378,905 ( 9,626 rd + 369,279 wr)
==1374== D1 miss rate: 5.1% ( 6.1% + 1.8% )
==1374== LLd miss rate: 0.4% ( 0.0% + 1.6% )А вот вывод для 100 000 сущностей:
==1307== D refs: 938,405,796 (715,424,940 rd + 222,980,856 wr)
==1307== D1 misses: 51,034,738 ( 44,045,090 rd + 6,989,648 wr)
==1307== LLd misses: 5,866,508 ( 1,997,948 rd + 3,868,560 wr)
==1307== D1 miss rate: 5.4% ( 6.2% + 3.1% )
==1307== LLd miss rate: 0.6% ( 0.3% + 1.7% )Мы видим, что эта версия создаёт примерно в три раза меньше ссылок и в четыре раза меньше промахов кэша.
Автоматические типы
Последним улучшением, о котором я расскажу, станет автоматическая генерация идентификаторов типов компонентов.
Изменения
На все изменения для реализации автоматической генерации id типов можно посмотреть здесь.
Для, чтобы иметь возможность назначать один уникальный id каждому типу компонентов, нужно воспользоваться CRTP и функцией со статическим счётчиком:
template<typename T>
class Component
{
public:
static const std::size_t type;
};
std::size_t generateComponentType()
{
static auto counter = std::size_t(0);
return counter++;
}
template<typename T>
const std::size_t Component<T>::type = generateComponentType();Можно заметить, что id типа теперь генерируется во время выполнения, а ранее он был известен во время компиляции.
Код после внесённых изменений можно посмотреть в этой ветке.
Результаты
Для проверки производительности этой версии я провёл бенчмарки:



Для создания и удаления результаты остались примерно теми же. Однако можно заметить, что итерация стала чуть медленнее, примерно на 10%.
Это замедление можно объяснить тем, что раньше компилятор знал идентификаторы типов во время компиляции, а значит мог лучше оптимизировать код.
Ручное назначение id типов немного неудобно и может приводить к ошибкам. Таким образом, пусть мы даже немного снизили производительность, это всё равно является улучшением юзабилити нашей библиотеки ECS.
Идеи для дальнейших усовершенствований
Перед завершением статьи я хотел бы поделиться с вами идеями других улучшений. Пока я их не реализовал, но возможно, сделаю это в будущем.
Динамическое количество компонентов и систем
Неудобно заранее указывать максимальное количество компонентов и систем в виде параметров шаблона. Думаю, возможно будет заменить
std::array в EntityManager на std::vector без сильного снижения производительности.Однако
std::bitset требует знать во время компиляции количество битов. Пока я думаю устранить эту проблему заменой std::vector<bitset<ComponentCount>> в EntityContainer на std::vector<char> и выделением достаточного количества байтов для представления наборов битов всех сущностей. Затем мы реализуем облегчённый класс BitsetView, который получает на входе пару указателей на начало и конец набора битов, а затем выполнять все нужные операции с std::bitset в этом диапазоне памяти.Ещё одна идея: больше не использовать наборы битов и просто проверять в
mEntityToComponent, есть ли у сущности компонент.Упрощённая итерация по компонентам
В настоящий момент, если система хочет итеративно обойти компоненты обрабатываемых ею сущностей, нам нужно делать это так:
for (const auto& entity : getManagedEntities())
{
auto [position, velocity] = mEntityManager.getComponents<Position, Velocity>(entity);
...
}Было бы красивее и проще, если бы могли сделать нечто подобное:
for (auto& [position, velocity] : mEntityManager.getComponents<Position, Velocity>(mManagedEntities))
{
...
}Реализовать это будет проще простого с помощью
std::view::transform в C++20 из библиотеки ranges.
К сожалению, её пока нет. Я мог бы использовать библиотеку range Эрика Ниблера, но не хочу добавлять зависимости.
Решение могло бы заключаться в реализации класса
EntityRangeView, который бы получал в качестве параметров шаблона типы компонентов, которые нужно получить, а в качестве параметра конструктора ссылку на std::vector сущностей. Тогда нам бы нужно было только реализовать begin, end и тип итератора, чтобы добиться желаемого поведения. Это не особо сложно, но немного трудоёмко в написании.Оптимизация управления событиями
В текущей реализации при добавлении или удалении компонента из сущности мы вызываем
onEntityUpdated всех систем. Это немного неэффективно, потому что многие системы не интересует тип компонента, который только что был изменён.Чтобы минимизировать урон, мы можем хранить указатели на системы, заинтересованные в указанном типе компонентов, в структуре данных, например
std::array<std::vector<System<ComponentCount, SystemCount>>, ComponentCount>. Тогда при добавлении или удалении компонента мы просто вызывали бы метод onEntityUpdated систем, заинтересованных в этом компоненте.Подмножества сущностей, управляемые менеджером сущностей вместо систем
Моя последняя идея привела бы к более обширным изменениям в структуре библиотеки.
Вместо систем, управляющих своими множествами сущностей, этим бы занимался менеджер сущностей. Преимущество такой схемы заключается в том, что если две системы заинтересованы в одном множестве компонентов, мы не дублируем подмножество сущностей, удовлетворяющих этим требованиям.
Системы просто могли бы заявлять о своих требованиях менеджеру сущностей. Тогда менеджер сущностей хранил бы все разные подмножества сущностей. Наконец, системы бы запрашивали сущности при помощи подобного синтаксиса:
for (const auto& entity : mEntityManager.getEntitiesWith<Position, Velocity>())
{
...
}Заключение
Пока это завершение статьи о моей реализации entity-component-system. Если я внесу другие улучшения, то, возможно, напишу в будущем новые статьи.
Описанная в статье реализация достаточно проста: она состоит из менее чем 500 строк кода, а также обладает хорошей производительностью. Все операции реализованы за (амортизированное) постоянное время. Более того, на практике она оптимально использует кэш и очень быстро получает и итерирует сущности.
Надеюсь, эта статья была для вас интересной или даже полезной.
Дополнительное чтение
Вот пара полезных ресурсов для более глубокого изучения шаблона entity-component-system:
- Мишель Кайни, автор entt, пишет очень интересную серию статьей об entity-component-system под названием ECS back and forth.
- Entity Systems Wiki содержатся очень полезная информация и ссылки.
