Попалась задача под названием «Квартет Энскомба (Анскомба)» (англ.версия).
На рисунке 1 представлено табличное распределение 4 случайных функций (взято из Википедии).
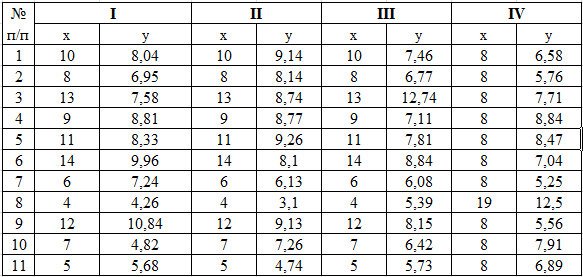
Рис. 1. Табличное распределение четырех случайных функций
На рисунке 2 представлены параметры распределения этих случайных функций

Рис. 2. Параметры распределений четырех случайных функций
И их графики на рисунке 3.
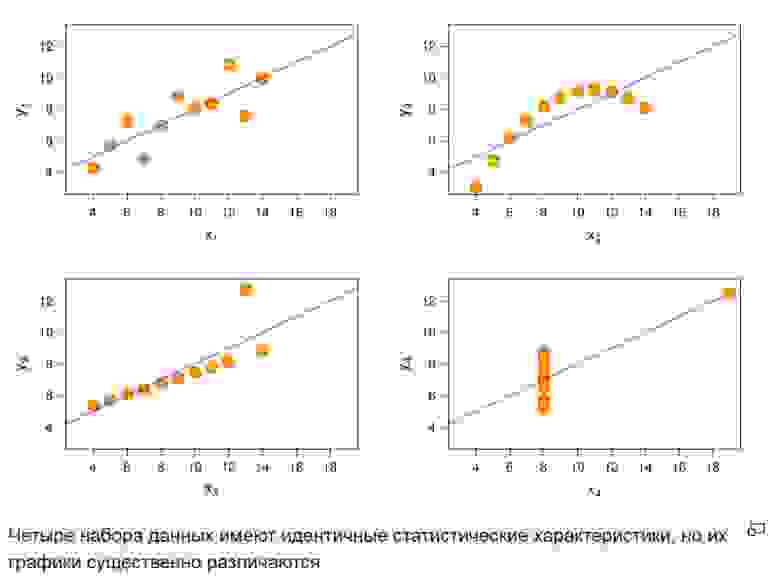
Рис. 3. Графики четырех случайных функций
Проблема различения этих функций решается достаточно просто, путем сопоставления моментов высших порядков и их нормированных показателей: коэффициента асимметрии и коэффициента эксцесса. Данные показатели представлены на рисунке 4.

Рис. 4. Показатели моментов третьего и четвертого порядка и коэффициентов асимметрии и эксцесса четырех случайных функций
Как видно из таблицы рисунка 4, комбинация этих показателей для всех функций различна.
Первый вывод, который, напрашивался естественным образом, что информация о взаимном расположении точек сохраняется в параметрах распределения на более высоком уровне, чем дисперсия случайного распределения.
Множество аналитиков пытаются выделить частные уравнения регрессии в больших данных и пока, на сегодняшний день, это методом подбора уравнения с наименьшей остаточной дисперсией. Тут особо добавить не получилось. Но обратил внимание на то, что это все информация, а у информации есть показатель энтропии. И она, энтропия, имеет свои границы от 0, когда информация полностью определена до белого шума. И белый шум, в канале передачи, имеет равномерное распределение.
Когда требуется проанализировать данные, то изначально предполагается, что в них есть связанные данные, которые необходимо формализовать в виде взаимосвязи. А это предполагает, что данные не являются белым шумом. То есть первый этап это подбор уравнения регрессии и определение остаточной дисперсии. Если регрессия подобрана правильно, то остаточная дисперсия будет подчиняться закону нормального распределения. Посмотрим и, на рисунках 5-7, представлены формулы энтропий для равномерно распределенной и нормально распределенной случайной величины.

Рис. 5. Формула дифференциальной энтропии для нормально распределенной величины (Афанасьев В.В. Теория вероятностей в вопросах и задачах. Министерство образования и науки Российской Федерации Ярославский государственный педагогический университет имени К. Д. Ушинского)

Рис. 6. Формула дифференциальной энтропии для нормально распределенной величины (Пугачев В.С. Теория случайных функций и ее применение к задачам автоматического управления. Изд. 2-ое, перераб. и допол. — М.: Физматлит, 1960. — 883 с.)

Рис. 7. Формула дифференциальной энтропии для равномерно распределенной величины (Пугачев В.С. Теория случайных функций и ее применение к задачам автоматического управления. Изд. 2-ое, перераб. и допол. — М.: Физматлит, 1960. — 883 с.)
Далее покажем на примере. Но предварительно возьмем условия что каждая из четырех функций это координата гиперплоскости, то есть одновременно проверим работу модели в многомерном пространстве. Проведем свертку гиперкуба до плоскости. Механизм представим на рисунке 8.
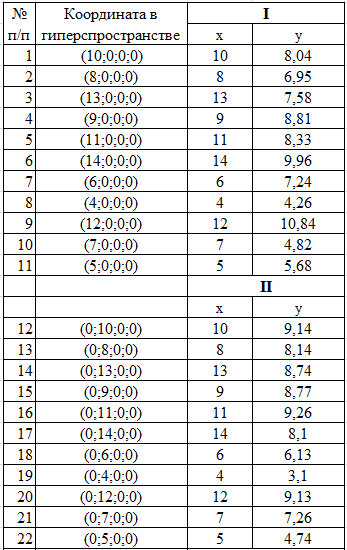
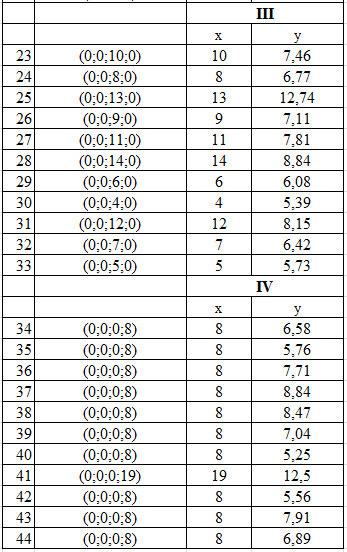
Рис. 8. Исходные данные с механизмом свертки
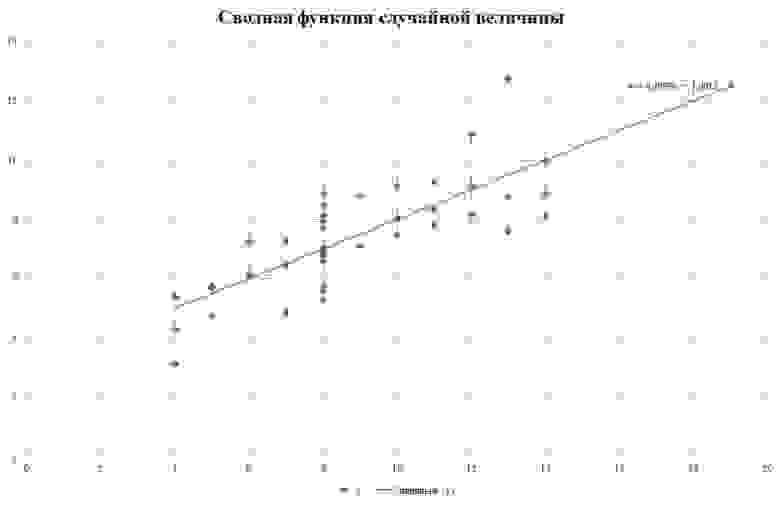
Рис. 9. Сводная группировка на рисунке.
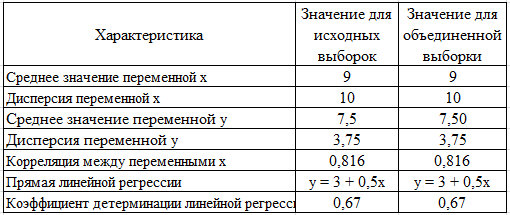
Рис. 10. Параметры распределений четырех случайных функций и сводной группировки.
Рассмотрим механизм выбора величины интервала разбиения. Первоначальные условия представлены на рисунке 11.
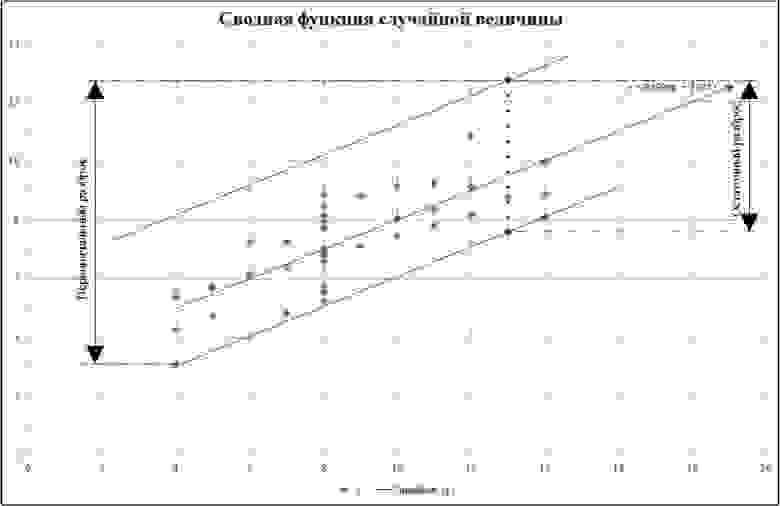
Рис. 11. Первоначальные условия разбиения на интервалы.
Условие 1. Он должен быть с ненулевой вероятностью на области вариации, так как в противном случае, энтропия равна бесконечности. Как для первоначальной выборки, так и для остаточной.
Условие 2. Так как нельзя игнорировать возможность выброса, в новых данных, и т.п., то для крайних интервалов, необходимо установить вероятность по нормальному, либо другому общепринятому теоретическому закону распределения вероятностей, по принципу вероятности хвостов.
Условие 3. Шаг интервала должен обеспечивать минимально необходимое количество интервалов на разбросе остаточной выборки.
Условие 4. Количество интервалов должно быть нечетное.
Условие 5. Количество интервалов должно обеспечивать надежное согласование с теоретическим законом распределения, выбранного для исследования.
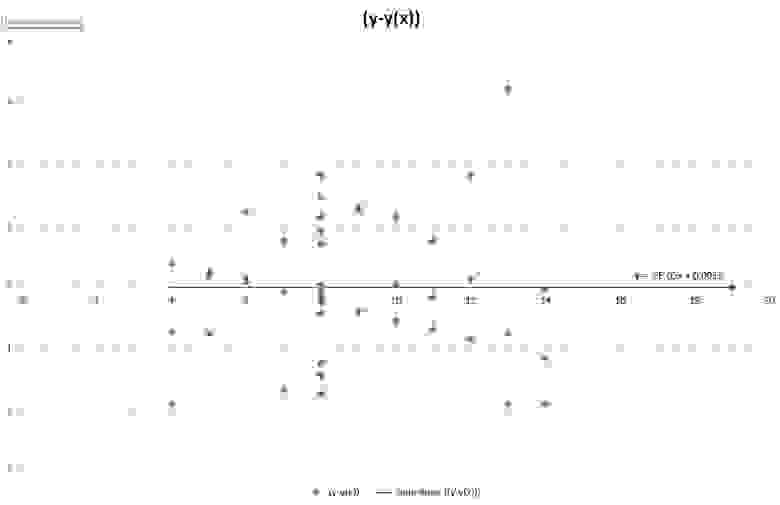
Рис. 12. Остаточный ряд распределения
Определим механизм выбора интервалов на рисунке 13.

Рис. 13. Алгоритм выбора интервалов
Основной проблемой, на мой взгляд, было принятие решения о необходимости вводить или не вводить хвостовые интервалы. Если для остаточной дисперсии это выглядело достаточно естественно, то для основного ряда, достаточно натянуто.
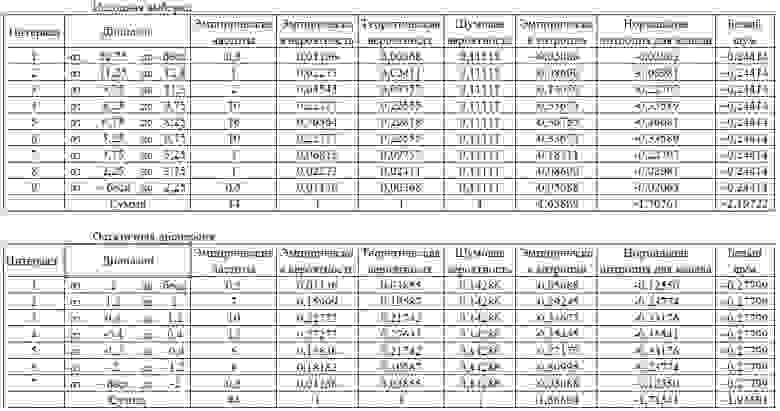
Рис. 14. Результаты обработки значений данных при определении информационной энтропии
Сравнивая результирующие показатели таблицы на рисунке 14, видно, что они отреагировали на изменение структуры данных. А это значит, что инструмент имеет чувствительность, и позволяет решать задачи аналогичные задаче «квартета Энскомба».
Без сомнения эти задачи можно решать и с помощью моментов высших порядков. Но по своей сути, информационная энтропия зависит от дисперсии случайной величины, то есть, это сторонняя характеристика дисперсии. А значит, может нам указать интервалы, где использования дисперсионного анализа может привести к конкретному результату.
Числовая характеристика энтропии дает возможность проведение корреляционного анализа с независимыми переменными. Как один из примеров проявления возможной связи, следующий: Допустим на интервале от а до b увеличилась, в существенной степени, шумность ряда данных, сопоставляя значения независимых переменных, обнаружили, что переменная хn вошла в диапазон более 5 ед., после того как она, переменная, снизилась ниже +5, шум снизился. Далее можно сделать дополнительную проверку и, если эта гипотеза подтвердиться, то в дальнейших исследованиях запретить переменной xn повышаться выше +5. Так как в этом случае данные становятся бесполезными.
Предполагаю, что есть и другие варианты использования данного инструмента.
В этом аспекте просматривается естественный механизм «скользящего среднего», предполагаю, что объем выборки полученный по формуле объема выборки из статистического анализа, даст разумный объем области скольжения. По текущему анализу был сделан вывод, что объем выборки следует определять из минимальной доли, которая приходится на с наименьшей вероятностью. В нашем примере, для остаточной дисперсии, минимальная доля эмпирического интервала 0,15909. Это необходимо делать, так как если какой-то интервал, в объеме скольжения окажется пустым, то в этом случае показатель шума окажется запредельным или сработает правило что логарифм 0 равен минус бесконечности. А при правильно выбранном объеме выборки, запредельные значения этого показателя засвидетельствуют об кардинальном изменении структуры информации.
На рисунке 1 представлено табличное распределение 4 случайных функций (взято из Википедии).

Рис. 1. Табличное распределение четырех случайных функций
На рисунке 2 представлены параметры распределения этих случайных функций

Рис. 2. Параметры распределений четырех случайных функций
И их графики на рисунке 3.
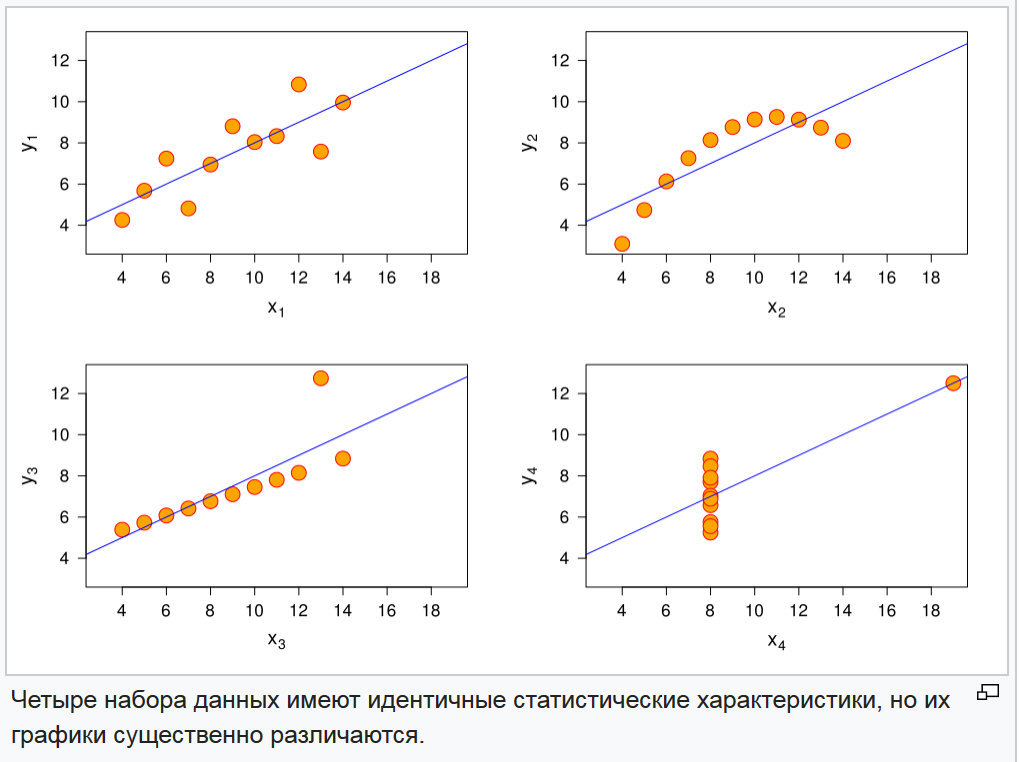
Рис. 3. Графики четырех случайных функций
Проблема различения этих функций решается достаточно просто, путем сопоставления моментов высших порядков и их нормированных показателей: коэффициента асимметрии и коэффициента эксцесса. Данные показатели представлены на рисунке 4.

Рис. 4. Показатели моментов третьего и четвертого порядка и коэффициентов асимметрии и эксцесса четырех случайных функций
Как видно из таблицы рисунка 4, комбинация этих показателей для всех функций различна.
Первый вывод, который, напрашивался естественным образом, что информация о взаимном расположении точек сохраняется в параметрах распределения на более высоком уровне, чем дисперсия случайного распределения.
Множество аналитиков пытаются выделить частные уравнения регрессии в больших данных и пока, на сегодняшний день, это методом подбора уравнения с наименьшей остаточной дисперсией. Тут особо добавить не получилось. Но обратил внимание на то, что это все информация, а у информации есть показатель энтропии. И она, энтропия, имеет свои границы от 0, когда информация полностью определена до белого шума. И белый шум, в канале передачи, имеет равномерное распределение.
Когда требуется проанализировать данные, то изначально предполагается, что в них есть связанные данные, которые необходимо формализовать в виде взаимосвязи. А это предполагает, что данные не являются белым шумом. То есть первый этап это подбор уравнения регрессии и определение остаточной дисперсии. Если регрессия подобрана правильно, то остаточная дисперсия будет подчиняться закону нормального распределения. Посмотрим и, на рисунках 5-7, представлены формулы энтропий для равномерно распределенной и нормально распределенной случайной величины.

Рис. 5. Формула дифференциальной энтропии для нормально распределенной величины (Афанасьев В.В. Теория вероятностей в вопросах и задачах. Министерство образования и науки Российской Федерации Ярославский государственный педагогический университет имени К. Д. Ушинского)

Рис. 6. Формула дифференциальной энтропии для нормально распределенной величины (Пугачев В.С. Теория случайных функций и ее применение к задачам автоматического управления. Изд. 2-ое, перераб. и допол. — М.: Физматлит, 1960. — 883 с.)

Рис. 7. Формула дифференциальной энтропии для равномерно распределенной величины (Пугачев В.С. Теория случайных функций и ее применение к задачам автоматического управления. Изд. 2-ое, перераб. и допол. — М.: Физматлит, 1960. — 883 с.)
Далее покажем на примере. Но предварительно возьмем условия что каждая из четырех функций это координата гиперплоскости, то есть одновременно проверим работу модели в многомерном пространстве. Проведем свертку гиперкуба до плоскости. Механизм представим на рисунке 8.


Рис. 8. Исходные данные с механизмом свертки

Рис. 9. Сводная группировка на рисунке.

Рис. 10. Параметры распределений четырех случайных функций и сводной группировки.
Рассмотрим механизм выбора величины интервала разбиения. Первоначальные условия представлены на рисунке 11.

Рис. 11. Первоначальные условия разбиения на интервалы.
Условие 1. Он должен быть с ненулевой вероятностью на области вариации, так как в противном случае, энтропия равна бесконечности. Как для первоначальной выборки, так и для остаточной.
Условие 2. Так как нельзя игнорировать возможность выброса, в новых данных, и т.п., то для крайних интервалов, необходимо установить вероятность по нормальному, либо другому общепринятому теоретическому закону распределения вероятностей, по принципу вероятности хвостов.
Условие 3. Шаг интервала должен обеспечивать минимально необходимое количество интервалов на разбросе остаточной выборки.
Условие 4. Количество интервалов должно быть нечетное.
Условие 5. Количество интервалов должно обеспечивать надежное согласование с теоретическим законом распределения, выбранного для исследования.

Рис. 12. Остаточный ряд распределения
Определим механизм выбора интервалов на рисунке 13.

Рис. 13. Алгоритм выбора интервалов
Основной проблемой, на мой взгляд, было принятие решения о необходимости вводить или не вводить хвостовые интервалы. Если для остаточной дисперсии это выглядело достаточно естественно, то для основного ряда, достаточно натянуто.

Рис. 14. Результаты обработки значений данных при определении информационной энтропии
Выводы. Где этот инструмент можно применить
Сравнивая результирующие показатели таблицы на рисунке 14, видно, что они отреагировали на изменение структуры данных. А это значит, что инструмент имеет чувствительность, и позволяет решать задачи аналогичные задаче «квартета Энскомба».
Без сомнения эти задачи можно решать и с помощью моментов высших порядков. Но по своей сути, информационная энтропия зависит от дисперсии случайной величины, то есть, это сторонняя характеристика дисперсии. А значит, может нам указать интервалы, где использования дисперсионного анализа может привести к конкретному результату.
Числовая характеристика энтропии дает возможность проведение корреляционного анализа с независимыми переменными. Как один из примеров проявления возможной связи, следующий: Допустим на интервале от а до b увеличилась, в существенной степени, шумность ряда данных, сопоставляя значения независимых переменных, обнаружили, что переменная хn вошла в диапазон более 5 ед., после того как она, переменная, снизилась ниже +5, шум снизился. Далее можно сделать дополнительную проверку и, если эта гипотеза подтвердиться, то в дальнейших исследованиях запретить переменной xn повышаться выше +5. Так как в этом случае данные становятся бесполезными.
Предполагаю, что есть и другие варианты использования данного инструмента.
Как использовать
В этом аспекте просматривается естественный механизм «скользящего среднего», предполагаю, что объем выборки полученный по формуле объема выборки из статистического анализа, даст разумный объем области скольжения. По текущему анализу был сделан вывод, что объем выборки следует определять из минимальной доли, которая приходится на с наименьшей вероятностью. В нашем примере, для остаточной дисперсии, минимальная доля эмпирического интервала 0,15909. Это необходимо делать, так как если какой-то интервал, в объеме скольжения окажется пустым, то в этом случае показатель шума окажется запредельным или сработает правило что логарифм 0 равен минус бесконечности. А при правильно выбранном объеме выборки, запредельные значения этого показателя засвидетельствуют об кардинальном изменении структуры информации.
