Comments 23
ох, реализация «с лазерной пушки, которая вращается на орбите планеты Земля, по воробьям»
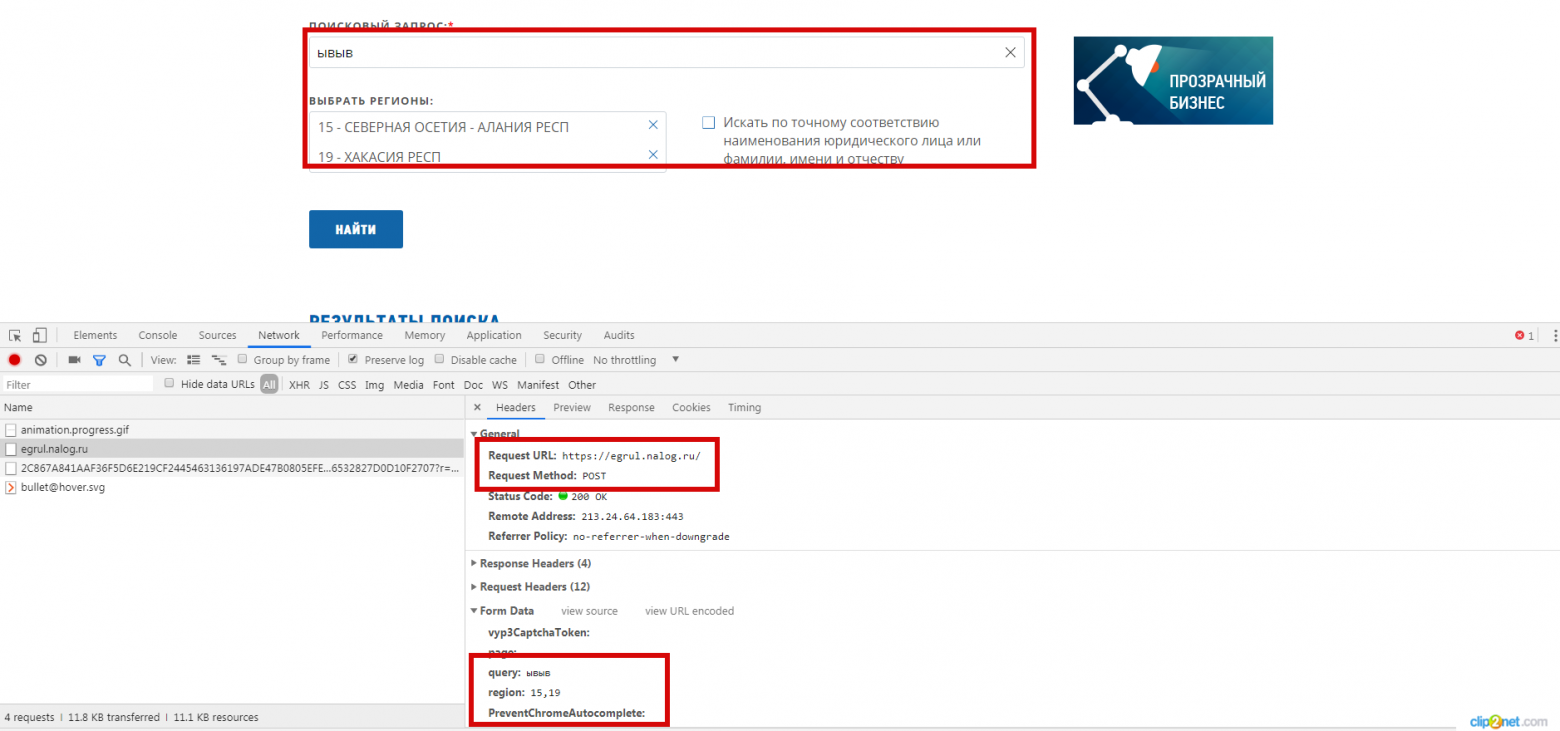
В ответе приходит хеш-строка URI, по которому есть результаты поиска в виде JSON.

В ответе приходит хеш-строка URI, по которому есть результаты поиска в виде JSON.
Заголовок спойлера
В редакторе есть тег code, для выкладок кода.
Вместо Excel, куда удобнее и проще использовать csv, который нативными модулями парсится
Вместо Excel, куда удобнее и проще использовать csv, который нативными модулями парсится
Не оставляйте, пожалуйста пробелов перед скобками (при вызове функций).
Всегда оставляйте, пожалуйста пробелы вокруг знака равно.
Pep8 вам в помощь — habr.com/ru/post/251531
если бы код был на github то нашлись бы люди, которые это поправили. А как исправить код на картинке или выложенный в частное облако?
Всегда оставляйте, пожалуйста пробелы вокруг знака равно.
Pep8 вам в помощь — habr.com/ru/post/251531
если бы код был на github то нашлись бы люди, которые это поправили. А как исправить код на картинке или выложенный в частное облако?
Воот матёрые програмисты подтянулись. PEP8 и прочее. Ребят, просто порадуйтесь за человека. Хочу сказать что иногда не обязательно быть прям хардкор-программистом чтобы просто радоваться плюсам автоматизации.
У меня случилась недавно такая история на работе — мы собираем досье на медизделие и в нём соответствующая нормативная документация на сырьё. На всё на это порядка 10 однотипных докуметов. Я за полчаса написал скрипт и сгенерировал более 2500 файлов съэкономив тем самым кучу времени и нервных клеток, себе и коллегам.
Я не программист (я химик), но иногда мне нравиться поступать разумно (пусть даже и с пушкой по пернатым).
Автору удачи!!!
У меня случилась недавно такая история на работе — мы собираем досье на медизделие и в нём соответствующая нормативная документация на сырьё. На всё на это порядка 10 однотипных докуметов. Я за полчаса написал скрипт и сгенерировал более 2500 файлов съэкономив тем самым кучу времени и нервных клеток, себе и коллегам.
Я не программист (я химик), но иногда мне нравиться поступать разумно (пусть даже и с пушкой по пернатым).
Автору удачи!!!
Хорошо бы втянуть excel в pandas через df = pandas.read_xls(“ЕГРЮЛ.xlsx”) и там уже при помощи len(df.index) определить длину столбца, а не вписывать руками 30 в начало скрипта.
Впрочем, если скрипт для разового применения — сойдёт и так. А если для регулярного — лучше от «ручника» уйти.
Впрочем, если скрипт для разового применения — сойдёт и так. А если для регулярного — лучше от «ручника» уйти.
А почему код картинкой? В Хабр можно легко вставить код с подсветкой.
спасибо за комменты. первый пост, он такой ) тем более, что я юрист, а не программер. порой проще написать «лазерную пушку по воробьям» самому, чем идти в ИТ и объяснять, что это и зачем надо.
Лучше идите к начальству холдинга и выбивайте денег на какую нибудь платную систему, где будет вся свежая информация и из налоговой и из судов и еще откуда нибудь. Думаю, юрист не пропускающий важные события более ценен чем юрист умеющий программировать.
Вот именно, и «еще откуда-нибудь». Все существующие системы Спарк, Правобот и т.п. предоставляют какую-то информацию. Эта информация не особо-то и нужна, иногда не релевантна, а иногда вообще вводит в заблуждение. Кроме того, разрабатывать мелкие сервисы такие программные монстры не будут. Здесь и рождается ниша для IT-юристов.
import requests, json, os, datetime, traceback; from time import sleep
inn = 6724005460 #инн из воздуха
s = requests.Session()
r = s.get("https://egrul.nalog.ru/index.html",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
}
)
req = requests.Request(
'POST',
'https://egrul.nalog.ru/',
data=b'vyp3CaptchaToken=&page=&query='+bytes(inn)+'®ion=&PreventChromeAutocomplete=', # хабр почему то заменяет rеg в слове rеgion (буква е заменена на русскую) на знак ®, магия
headers = {
"Host": "egrul.nalog.ru",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://egrul.nalog.ru/index.html",
"Content-Type": "application/x-www-form-urlencoded",
"X-Requested-With": "XMLHttpRequest"
}
)
r = s.prepare_request(req)
r = s.send(r)
#print(r.text)
t = json.loads(r.text)['t']
sleep(0.5)
r = s.get("https://egrul.nalog.ru/search-result/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
#print(r.text)
jsn = json.loads(r.text)
try:
while True:
if jsn['status'] != 'wait': break
sleep(0.2)
except Exception:
pass
try:
item = (jsn["rows"])[0]
if str(item['tot']) != '0':
if len(item['n']) < 50: name = str(item['n'])
else: name = str(item['i'])
name = name.replace('"',"'").replace('\\','⧵').replace('/','⁄').replace('|','¦').replace(':',';').replace('*','✱').replace('?','').replace('<','«').replace('>','»')
try:
os.mkdir(name)
except Exception:
pass
name = name + ' '+str(datetime.datetime.strftime(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=3))),'%x %X %Z')).replace('/','.').replace(':','-')
os.mkdir(name)
f = open(name+'\\'+name+'.txt','w+',encoding='utf-8')
f.write('по состоянию на ' + str(datetime.datetime.strftime(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=3))),'%x %X %Z')).replace('/','.')+'\n'+str(item))
f.close()
t = item['t']
r = s.get("https://egrul.nalog.ru/vyp-request/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
sleep(0.5)
while True:
r = s.get("https://egrul.nalog.ru/vyp-status/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
st = json.loads(r.text)['status']
if st == 'ready': break
sleep(0.5)
r = s.get("https://egrul.nalog.ru/vyp-download/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
#print(r.text)
f = open(name+'\\'+name+' выписка.pdf','wb+')
f.write(r.content)
f.close()
except Exception as e:
print(e)
traceback.print_exc()
passКапча, обработка jsona с ответом и всякое такое в сделку не входит, но дописывается просто
отлично! большой труд.
вставлю свои 5 копеек:
— сравните теперь длину кода;
— requests, которые здесь использованы, к сожалению отваливаются из-за капч в дальнейшем;
— только один ИНН?
вставлю свои 5 копеек:
— сравните теперь длину кода;
— requests, которые здесь использованы, к сожалению отваливаются из-за капч в дальнейшем;
— только один ИНН?
сравните теперь длину кода;
Де-факто большинство кода распсывание HTTP заглоловков
requests, которые здесь использованы, к сожалению отваливаются из-за капч в дальнейшем;
С чего это вдруг? Попробую сегодня обработать и отпишусь
только один ИНН?
Не-а любой запрос для поиска ФНС т.е. ОГРН, ИНН или название
по поводу ИНН — только одну компанию можно проверить?
Да, но ничто не мешает сделать цикл и небольшую задержку во избежание капч
Так в тексте программы уже этот цикл есть )
Небольшая задержка, к сожалению, не всегда спасает. Ранее писал под старый сервис, там задержку надо было ставить до 15 мин.
Небольшая задержка, к сожалению, не всегда спасает. Ранее писал под старый сервис, там задержку надо было ставить до 15 мин.
Добавил обработку капч, с задержкой в 5 секунд они достаточно редко появляются + бонусом парсинг jsona от фнс
Заголовок спойлера
import requests, json, os, datetime, traceback, bs4, webbrowser; from time import sleep;
querys = ['7707510023', 'ООО Яндекс', '1057749528100']
s = requests.Session()
n = 0
for item in querys:
query = querys[n]
r = s.get("https://egrul.nalog.ru/index.html",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
}
)
req = requests.Request(
'POST',
'https://egrul.nalog.ru/',
data=b'vyp3CaptchaToken=&page=&query='+query.encode()+b'®ion=&PreventChromeAutocomplete=',
headers = {
"Host": "egrul.nalog.ru",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://egrul.nalog.ru/index.html",
"Content-Type": "application/x-www-form-urlencoded",
"X-Requested-With": "XMLHttpRequest"
}
)
r = s.prepare_request(req)
r = s.send(r)
#print('31',r.text)
item = json.loads(r.text)
try:
if item["ERRORS"] != '' and (item["ERRORS"])["captchaSearch"] != '':
while True:
r = s.get('https://egrul.nalog.ru/captcha-dialog.html',
headers = {
"Host": "egrul.nalog.ru",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html",
"Pragma": "no-cache",
"Cache-Control": "no-cache"
})
b = bs4.BeautifulSoup(r.content.decode(),features="lxml").find('div',class_='field-data').find('img').get('src')
#print('\r\n\r\nb =',b,'\r\n\r\n')
webbrowser.open('https://egrul.nalog.ru' + b)
ct = b.split('?a=')[1].split('&')[0]
captcha = input('Введите капчу: ')
#print('ct=',ct)
r = requests.Request(
'POST',
'https://egrul.nalog.ru/captcha-proc.json',
data=b'captcha='+captcha.encode()+b'&captchaToken='+ct.encode(),
headers = {
"Host": "egrul.nalog.ru",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
r = s.prepare_request(req)
r = s.send(r)
#print('captcha r', r.text)
item = json.loads(r.text)
try:
tr = False
if item["ERRORS"] != '':
tr = True
except Exception as e:
print(e)
pass
if tr == False: break
except Exception as e:
#print(e)
pass
t = json.loads(r.text)['t']
sleep(0.5)
r = s.get("https://egrul.nalog.ru/search-result/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
#print('95', r.text)
jsn = json.loads(r.text)
try:
while True:
if jsn['status'] != 'wait': break
sleep(0.2)
except Exception:
pass
try:
item = (jsn["rows"])[0]
itemParse = ''
itemParse += item['n'] + '\n'
itemParse += item['g'] + '\n'
itemParse += 'Адрес: ' + item['a']+'\n'
itemParse += 'ИНН: ' + item['i']+'\n'
itemParse += 'ОГРН: ' + item['o']+'\n'
itemParse += 'КПП: ' + item['p']+'\n'
itemParse += 'Дата регистрации: ' + item['r']+'\n'
try:
itemParse += 'ДАТА ПРЕКРАЩЕНИЯ ДЕЯТЕЛЬНОСТИ: ' + item['e']+'\n'
except Exception:
pass
if str(item['tot']) != '0':
if len(item['n']) < 50: name = str(item['n'])
else: name = str(item['i'])
name = name.replace('"',"'").replace('\\','⧵').replace('/','⁄').replace('|','¦').replace(':',';').replace('*','✱').replace('?','').replace('<','«').replace('>','»')
try:
os.mkdir(name)
except Exception:
pass
name = name + ' '+str(datetime.datetime.strftime(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=3))),'%x %X %Z')).replace('/','.').replace(':','-')
os.mkdir(name)
f = open(name+'\\'+name+'.txt','w+',encoding='utf-8')
f.write('по состоянию на ' + str(datetime.datetime.strftime(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=3))),'%x %X %Z')).replace('/','.')+'\n'+str(itemParse))
f.close()
t = item['t']
r = s.get("https://egrul.nalog.ru/vyp-request/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
sleep(0.5)
while True:
r = s.get("https://egrul.nalog.ru/vyp-status/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
st = json.loads(r.text)['status']
if st == 'ready': break
sleep(0.5)
r = s.get("https://egrul.nalog.ru/vyp-download/"+str(t),
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Accept-Language": "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3",
"Referer": "https://egrul.nalog.ru/index.html"
}
)
#print(r.text)
f = open(name+'\\'+name+' выписка.pdf','wb+')
f.write(r.content)
f.close()
n += 1
sleep(5)
except Exception as e:
#print(e)
traceback.print_exc()
passи ещё, в 129 строке в replace('?') должен вот этот символ стоять unicode-table.com/ru/2753 но хабр его заменяет
upd. закрвл try для ИП шников
itemParse += item['n'] + '\n'
try:
itemParse += item['g'] + '\n'
except Exception:
pass
try:
itemParse += 'Адрес: ' + item['a']+'\n'
except Exception:
pass
itemParse += 'ИНН: ' + item['i']+'\n'
itemParse += 'ОГРН: ' + item['o']+'\n'
try:
itemParse += 'КПП: ' + item['p']+'\n'
except Exception:
pass
itemParse += 'Дата регистрации: ' + item['r']+'\n'А почему проект сделан на питоне а не на VBA EXCEL? Данные же изначально в excel хранятся.
Потому что использовался python. Вы можете изложить свое решение
Мое решение для mac и windows отличается, если надо для всех систем — в макросе файла Excel можно установить проверку наличия библиотек или использовать VBA-tools/VBA-Web
Для Excel Windows можно использовать объект «MSXML2.XMLHTTP», причем не надо заниматься парсингом страницы, отправляйте POST на egrul.nalog.ru с query=inn, получите Json. Я ни разу не получил требование по вводу капчи, потому не понял, в чем прикол 30 секунд.
В Excel Mac Os есть Workbook.Querytable, увы она не работает так хорошо, хотя и выполняет вашу задачу. Я все равно рекомендую использовать либо vba-tools, либо выполнение запросов через обертку командной строки на StackOwerflow можно найти скрипт executeInShell, кстати там же решение с переключением mac-windows
Я дошел только до этого момента, но подозреваю, что получение файла через второй запрос выполняется аналогично.
Объем — 6 строк для получения ссылки на один файл, + цикл + объявление переменных.
Никаких питонов и зависимостей, кроме Excel, который ТОЖЕ участвует в вашем процессе.
Использование Python и Selenium в данном примере оправдывается только незнанием автора возможностей VBA excel.
Для Excel Windows можно использовать объект «MSXML2.XMLHTTP», причем не надо заниматься парсингом страницы, отправляйте POST на egrul.nalog.ru с query=inn, получите Json. Я ни разу не получил требование по вводу капчи, потому не понял, в чем прикол 30 секунд.
В Excel Mac Os есть Workbook.Querytable, увы она не работает так хорошо, хотя и выполняет вашу задачу. Я все равно рекомендую использовать либо vba-tools, либо выполнение запросов через обертку командной строки на StackOwerflow можно найти скрипт executeInShell, кстати там же решение с переключением mac-windows
Я дошел только до этого момента, но подозреваю, что получение файла через второй запрос выполняется аналогично.
Объем — 6 строк для получения ссылки на один файл, + цикл + объявление переменных.
Никаких питонов и зависимостей, кроме Excel, который ТОЖЕ участвует в вашем процессе.
Использование Python и Selenium в данном примере оправдывается только незнанием автора возможностей VBA excel.
Sign up to leave a comment.
Получить выписки из ЕГРЮЛ на сайте ФНС, используя python