Comments 116
Спасибо за очень интересный материал. Жаль, что нельзя поставить +1 больше одного раза.
Стараемся, спасибо)
Если получите значёк «Старожил» или «Звезда», то вес вашего голоса будет +2, если «Легенда», то +3. Все в ваших руках! )
Если получите значёк «Старожил» или «Звезда», то вес вашего голоса будет +2, если «Легенда», то +3. Все в ваших руках! )
А ведь точно. Над кармой совсем немного нужно поработать ;-)
Держи трехочковый, бро! :)
+2
+3) Не зря ачивку получал.
Иван, большой спасиб! Ваш старый пост про то, чем мазать зубы заметно поменял мои практики. Жалею только, что не узнал все это на десяток лет раньше )
Всегда пожалуйста) жаль редко находится время писать.
Чтобы не искать, если кого заинтересует: Что намазать на зубы, чтобы они не выпали.
Осталось только докинуть в этот спискок QPU и точно ожидать приход Скайнета. Кстати, в рамках задач нейросетей QPU будет иметь какие-то серьёзные преимущества? Помимо собственных преимуществ QPU, само собой — я про неожиданный буст спрашиваю.
Если речь про квантовые компьютеры (а не про QPU от Broadcom), то это дело не завтрашнего, а сильно послезавтрашнего дня. Уже просто потому, что там решает количество элементом, а с их наращиванием у квантовых большие проблемы. А вот нарастить (по числу на чипе) аналоговые транзисторы — совершенно реально. Вот проблемы хранения аналогового сигнала порешают и там очень интересные перспективы.
Про терминатора было интересно. Ждем подробную статью с разбором фильмов :) Анализ технологий, что можно сделать уже сейчас, что может быть в будущем, а что невозможно в принципе. Получился бы хороший научпоп для привлечению молодежи к нейросетям. Например: «Какие модели обучения использует Skynet?», «Почему взбунтовался HAL9000 из Космической Одиссеи 2001?», «Снятся ли андроидам электроовцы» и т.д.
Естественно, применять FPGA имеет смысл уже на этапе применения нейросети (для обучения в большинстве случаев маловато памяти).
Подразумевается использование исключительно внутренней памяти? Так то снаружи можно пристроить что-нить достаточное бодрое, вроде HBM2 на Alveo U280.
Да, по крайней мере в этом направлении сейчас очень активно должны двигаться производители. Вот тут arxiv.org/pdf/1901.00121.pdf — довольно годный обзор реализаций нейросетей на FPGA со скоростями + обзор применения разных технологий. Вопрос скорее всего в скорости работы самого FPGA.
Всё же немного странно, что вы достаточно категорично отсекаете от FPGA сферу обучения. На мой взгляд широкая внешняя память делает обучение вполне возможным.
За ссылку на обзор спасибо, выглядит интересно.
За ссылку на обзор спасибо, выглядит интересно.
FPGA для обучения менее подходят, скорее. Что что-то крайне интересное могут вдруг выпустить отсекать нельзя. ) В основном DNN+FPGA — ускорение инференс. Для этого отдельные архитектуры выпускают.
Исключительно интересный и хорошо изложеный материал! Несмотря на объем, читается на одном дыхании! Спасибо за труды!
У TPU от гугла есть один большой недостаток — он их не продает. Поэтому он наверно и отсутствует на диаграмме вычисленний на доллар… А отдавать данные гуглу не все готовы. К тому же никто точно не знает что именно может, а что не может TPU (гугл даже производителя чипов скрывает). Нельзя исключить что на какой-нибудь особой архитектуре выплывут какие-то косяки. Да и вообще все эти красивые картинки с эффективностью и скоростью вычислений гугловских TPU нельзя проверить, тк никому в руки их не дают! Решения от NVIDIA гораздо более открытые…
По недостаткам — проверить производительность-то (правда за неплохие деньги cloud.google.com/tpu/docs/pricing) — вполне можно и другие компании уже вполне их используют. Так что скорость вычислений проверить можно. Энергоэффективность — да, нужно гуглу верить. Ну и у них появились так называемые Edge TPU aiyprojects.withgoogle.com/edge-tpu — которые вполне продаются. И там вполне линейка намечается, правда с прицелом на малые девайсы coral.withgoogle.com/products — у Edge TPU с открытостью все более чем.
Почему в случае нейросетей речь идёт о FP16 и даже int8? Неужели нейросетям вполне себе позволительно насколько неточно работать с данными?
P.S. А ещё такие нейросети бывают:
https://habr.com/ru/post/418847/
Ага, позволено и даже приветствуется, особенно на inference ( arxiv.org/abs/1510.00149 ) и особенно для встраиваемых систем.
(вам уже правильно ответили — посмотрите квантование весов и сжатие сетей)
А ещё такие нейросети бывают:Точнее — не сети, а акселераторы. Да, забавно. Оптический акселератор, инференс которого напечатан на 3D принтере и вычисления со скоростью света за один такт — это, конечно, клевая идея ). Вопрос, как скоро это может до реальной жизни дойти.
habr.com/ru/post/418847
Супер статья, грамотно написана и по делу. Спасибо большое! А из плюсов FPGA я бы еще добавил возможность реализации арифметики произвольной точности, что очень активно используется как в выполнении (после квантования может остаться исключительно целочисленная арифметика низкой точности (до 8 бит и иногда даже меньше), что позволяет синтезировать больше арифметических модулей на FPGA), так и в обучении (пока на стадии исследований, например, arxiv.org/abs/1803.03383).
Спасибо!
У меня кратко есть ссылка на IBM Research, которая к 4-битной точности и ниже эффективно сводит, да это прям праздник для FPGA & ASIC, конечно. Для них, как и для аналоговых вычислений это крайне перспективно.
У меня кратко есть ссылка на IBM Research, которая к 4-битной точности и ниже эффективно сводит, да это прям праздник для FPGA & ASIC, конечно. Для них, как и для аналоговых вычислений это крайне перспективно.
на FPGA не только арифметика произвольной точности доступна а ещё чертовски важна возможность сохранять и обрабатывать данные произвольной битности. Например в надоевшем всем MobileNetV2 W и B коэффициентов слишком много и их заквантовать можно без особой потери точности только до 16 бит, или же придётся переучивать. Но если внутрь глянуть и собрать статистику по каналам и слоям то можно увидеть что все 16 бит используются только на входе на первых 1000 W коэффициентов, остальные pointwise имеют 8- 11 бит, реально же важны из них только 2-3 старших бита и знак, и статистика использования каналов такая что много каналов где вообще нули, или малые значения, либо каналы где почти все значения 8-11 бит, т.е. можно экспаненту прибить гвоздями в компайлтайме и не хранить т.е. по факту можно сохранить в ROM памяти не 16 битные а 4 битные значения и даже можно вместить на дешёвых FPGA всю нейросеть без особой потери точности (менее 1%), а так же обрабатывать на скоростях до десятков тыщь FPS c latency такой что получаем ответ нейросети сразу как заканчивается приём кадра.
При вычислении в ряде мест особенно я вообще умудрялся заталкивать в строчный буфер одну только экспоненту и знак! т.к. dephwise чувствительна скорее к нему.
В ряде мест я использовал сжатие звука u-law с редуцированной битностью и сохранением нуля (ЭТО КАПЕЦ ВАЖНО! звуковые кодеки не сохраняют нуль а в сетке нулевых коэф много и они обязаны быть нулями).
Ах да, при вычислениях часто очень хорошо помогает дизеринг в ряде мест, особенно до Релу6, на фпга его реализовать очень просто, а ошибки квантования он сводит на ура.
А так же свои видеопроцессоры особым образом уменьшающие шум дабы предотвротить смычку субпространств в соседнюю область и не дать ложно срабатывать сетке из за шума (всем известные баги сети когда спец шумом можно взломать сеть)
(извиняюсь за возможную путаницу в терминалогии, обычно я их использую только на японском)
При вычислении в ряде мест особенно я вообще умудрялся заталкивать в строчный буфер одну только экспоненту и знак! т.к. dephwise чувствительна скорее к нему.
В ряде мест я использовал сжатие звука u-law с редуцированной битностью и сохранением нуля (ЭТО КАПЕЦ ВАЖНО! звуковые кодеки не сохраняют нуль а в сетке нулевых коэф много и они обязаны быть нулями).
Ах да, при вычислениях часто очень хорошо помогает дизеринг в ряде мест, особенно до Релу6, на фпга его реализовать очень просто, а ошибки квантования он сводит на ура.
А так же свои видеопроцессоры особым образом уменьшающие шум дабы предотвротить смычку субпространств в соседнюю область и не дать ложно срабатывать сетке из за шума (всем известные баги сети когда спец шумом можно взломать сеть)
(извиняюсь за возможную путаницу в терминалогии, обычно я их использую только на японском)
обрабатывать на скоростях до десятков тыщь FPS c latency такой что получаем ответ нейросети сразу как заканчивается приём кадра.Прям бальзамом поливаете мою израненную душу! )
Вопрос, насколько это реально.
Если реально — то мы скоро увидим и такие реализации, и фреймворки, заточенные под такое неравномерное квантование и переложение на FPGA (и ASIC). Так? Ибо сейчас все сильно не так волшебно.
часто очень хорошо помогает дизеринг в ряде местдизеринг коэффициентов? В смысле не просто округлять, а добавлять шумы? Хотите сказать, что везде при сжатии для FPGA просто округляют?
У вас все очень хорошо с терминологией! ) Где работаете в Японии?
Вопрос, насколько это реально.
в реальности не так шоколадно, разумеется есть ограничения:
я сделал и совершенствую сейчас сразу связку видеопроца и сетки в виде
sensor->raw->rgb->NN->
нейросеть это одна из разновидностей видеопроцессинга. внутри неё есть фильтры не только 1х1 а 3х3 и выше. Чтоб они корректно работали нужен паддинг. Паддинг же заставляет не сразу обрабатывать данные а накопив в начале две строки, т.е. задержка в одну строку по Х будет на один этап обработки.
Для сигментации когда изображение сжимается а потом разжимается обратно задержка выходит в среднем N*2… N*3 строк горизонтальных строк самых узких этапов обработки, причем N — количество таких этапов.
наглядно

Если сетка сворачивает в 1х1x1024 например как MobileNetV2 — то это худший случай — в этом случае latency получается равна времени вычисления одного кадра из за архитектуры самой сетки, более подробный расчёт «3/8 + 7/15 + 3/29+3/57+2/113=1.01544563652», т.е. 2 этапа по 112х112 плюс паддинг, три этапа по 57х57 плюс паддинг и тд
Весь этот разговор в том случае, если полная конвейеризация вычислений: все этапы вычисляются параллельно внутри FPGA без промежуточных буферов во внешней памяти, W и B так же лежат внутри FPGA в её ROM.
заточенные под такое неравномерное квантование и переложение на FPGA (и ASIC)
А про квантование: моя идея в том что если на ряде этапах вычисления W коэффициенты для канала №0 изменяются только от +50 до -50 то имеет смысл сжать битность до 7, а если от -123 до +124 например то до 8 (включая знак). Всё равно внутри FPGA все каналы рассчитываются параллельно за такт, и эти блоки памяти по 7, 8 и тд объединяются в один большой параллельный кусок ROM памяти с битностью порядком несколько десятков тысячь бит. Ну и далее если младшие биты из них не сильно влияют ни на результат ни на точность, то и они откидываются по месту.
Единственная проблема в автоматическом вычислении оптимальной битности и алгоритма сжатия (откидывать, мью закон, насыщать), симуляция RTL уровня дизайна на один кадр всей сетки занимает порядка нескольких десятков секунд, весь валидационный датасет один раз прогнать уже немало времени требует, а перебор параметров становиться вообще долгим. всё руки не доходят сделать транслятор в GCC на AVX256 с точностью вычислений bitperfect (если сравнивать с верилогом FPGA по шагам) и подбирать битность уже с скоростью в десятки и сотни FPS на том же обычном ПК (надо же просто хитро изменять константные сэты W и B, а их использовать может что угодно главное подсчитать быстро).
Кстати заметил интересную особенность что если сетка немного переобучена то внутри W коэффициентов fc есть резкие пики, т.е. все изменяются для примера от -100 до +100 но парочка +10000 то если их насытить до 255 например и усечь битность до 9 то качество такой сетки наоборот немного вырастает (доли процента).
дизеринг коэффициентов?нет дизеринг промежуточных результатов вычислений, когда вычисляешь в FixedPoint результат dot product а — в битах как два Fractional part, и на одну дробную часть бит надо сдвинуть — вот тут имеет смысл иногда добавлять дизеринг, а иногда он вреден, а иногда бесполезен например после fc этапа в софтмакс всё равно запрессуется по экспоненте и к мелочам придираться бесполезно.
Клёвая статья! Пять копеек про FPGA, на конец 2019 года несколько производителей ПЛИС анонсировали новые семейства, ориентированные как раз под машинное обучение. Обратите внимание на новшества в архитектуре — появляются блоки спец.вычислителей для нейросетей вместо/в дополнение к dsp-блокам у Xilinx и у Achronix, а также на количество интерфейсов к DDR.
Отличные ссылки, спасибо! Вы FPGA занимаетесь?
Да
А что у Альтеры творится в целом (за мишурой маркетинга) отслеживаете? Или вы на Xilinx?
На Xilinx. За Альтерой мало наблюдал. И свежего не в курсе совсем, из более давнего, знаю, что Интел совместил логику ПЛИС Альтеры, Arm и свой Xeon на одном кристалле, и вроде как обещал возможность программировать ПЛИС через какие-то программные API, практически из кода, но не знаю, как это вышло на деле.
Понял, хотел пообщаться с теми, кто с ними работал, какие впечатления.)
Вашу наводку на Everest FPGA чуть позднее посмотрю повнимательней, еще раз спасибо!
Вашу наводку на Everest FPGA чуть позднее посмотрю повнимательней, еще раз спасибо!
Что-то похожее пытаются сделать и в рамках проекта TVM в частности ( tvm.ai/about), где стек восстановлен от фронденда (того же самого Keras) и до самого низа. Как я понял, основная новизна этого конкретно проекта — поддержка «высоко»-гетерогенного железа (bare metal, процессоры с кастомным ISA, FPGA и тд.) с уклоном во встраиваемые системы и edge computing. Есть ряд исследовательских групп сформировавшихся вокруг TVM пытающихся прикрутить HLS к TVM как бэкэнд для FPGA. Хороший HLS может сделать парадигму программирование FPGA «ближе» к мировозрению софтварного программиста, и (в идеале) сделать универсальное прототипирование сеток под FPGA так же из коробки, как и под GPU/TPU сейчас.
P.S. Еще FPGA позволяют реализовывать концепцию transparent hardware (и рядом — open-source hardware), что может помочь решить вопросы безопасности и конфиденциальности, что особенно важно если вы оффлоадите свою уникальную модель (да еще и с «деликатными» данными) в облачко на обучение. Но это пока скорее ресерч-ресерч. В общем, FPGA в новом свете современных нагрузок и требований — это реально круто и это направление надо копать ;)
P.S. Еще FPGA позволяют реализовывать концепцию transparent hardware (и рядом — open-source hardware), что может помочь решить вопросы безопасности и конфиденциальности, что особенно важно если вы оффлоадите свою уникальную модель (да еще и с «деликатными» данными) в облачко на обучение. Но это пока скорее ресерч-ресерч. В общем, FPGA в новом свете современных нагрузок и требований — это реально круто и это направление надо копать ;)
FPGA «обречены» в хорошем смысле этого слова на сближение с хорошими фрейморками и эта тема явно будет бурно развиваться.
Не смотрели sampl.cs.washington.edu/tvmconf? Что там наиболее интересно?
Не смотрели sampl.cs.washington.edu/tvmconf? Что там наиболее интересно?
В общем, FPGA в новом свете современных нагрузок и требований — это реально круто и это направление надо копать ;)С одним «но» — если специализированные TPU/GPU не побьют их по соотношению «цена/качество», им это проще, поскольку они (пока?))) более массовые.
>Хороший HLS может сделать парадигму программирование FPGA «ближе» к мировозрению софтварного программиста, и (в идеале) сделать универсальное прототипирование сеток под FPGA так же из коробки, как и под GPU/TPU сейчас.
Не знаю как сейчас, но года 2 назад в рамках курса по FPGA хороший HLS(vivado, quartus) к сожалению пытался как правило синтезировать не очень хорошие схемы, которые нужно либо допиливать руками(порты, конвееризация и др.) даже для достаточно простых задач вроде матричной обработки, расчёта схемы крест и пр. А про OpenCL и говорить не хочется, потому что он диктует парадигму не «слишком» оптимальную для FPGA.
Не знаю как сейчас, но года 2 назад в рамках курса по FPGA хороший HLS(vivado, quartus) к сожалению пытался как правило синтезировать не очень хорошие схемы, которые нужно либо допиливать руками(порты, конвееризация и др.) даже для достаточно простых задач вроде матричной обработки, расчёта схемы крест и пр. А про OpenCL и говорить не хочется, потому что он диктует парадигму не «слишком» оптимальную для FPGA.
подтверждаю, я тоже с этим столкнулся, если конкретно, то что смело на верилоге можно реализовать на 200MHz, то на HLS кое как влазит в 100MHz а часто до 50-60 не дотягивает. В итоге я все уравнения RTL уровня и общую структуру реализую на MinGW gcc, получается особо извращённый си код который строго соответствует порядку вычисления в FPGA, он вызывается в одном единственном так сказать «тактовом» цикле, сразу отлаживаю по частям и в целом, и получаю наборы входных и выходных данных включая внутренние состояния и функции для тестбенчей: юнит тестов и интеграционных. А потом всё это отлаженное реализую на верилоге и использую компиляторы которые позволяют на плюсах и си запускать ранее сделанные тест бенчи.
Получается недо-HLS вот такой вот: си код вручную переписывается в верилог но с тестбенчами на си
Получается недо-HLS вот такой вот: си код вручную переписывается в верилог но с тестбенчами на си
Тоже подтверждаю: HLS это всё ещё для «быстро сделать», а не для «оптимально сделать».
Хотя и это «быстро сделать» нужно уметь получить.
P.S. От планов Xilinx-а оставить только OpenCL в своём HLS-е становится немного грустно.
Хотя и это «быстро сделать» нужно уметь получить.
P.S. От планов Xilinx-а оставить только OpenCL в своём HLS-е становится немного грустно.
Фай они почти похоронили уже.
После покупки Интелом там весело. Стратиксы наконец запустили (сорвав все сроки), и теперь поход они идут из «купи ПЛИС» на «купи Ускоритель», т.к. карты реально дешевле, чем одиночные чипы в разумных пределах(т.е. до 1 тысячи выходит частенько дешевле). Плюс с техподдержкой стало всё плохо.
Думаете, сильно просядут?
Надеюсь что нет, благо Xilinx подтянулся оч. хорошо в плане трансиверов и всякого сетевого, и парочка NVidia+Mellanox=Love тоже серьёзно будет нажимать. Меня заботит сильнее то, что квартус в последнее время стал ещё более дико забагованным, а вменяемая техподдержка, которой можно было закинуть SR и получить ответ в нормальные сроки, закончилась.
Обратите внимание на новшества в архитектуре — появляются блоки спец.вычислителей для нейросетей вместо/в дополнение к dsp-блокам у Xilinx и у Achronix, а также на количество интерфейсов к DDR.У вас один из наиболее содержательных комментариев к статье. У меня пару дней заняло вкурить ваши ссылки (и что открывалось по ним). Крайне интересно!
Вам надо статью написать (короткую, емкую и интересную))), а то хабр не дает поднимать вашу карму.
Что думаете про критику FPGA? )
habr.com/ru/post/455353/#comment_20271224
Благодарю!
Что касается критики, имхо, она во многом справедлива, FPGA действительно гораздо слабее ASIC-ов. Однако у FPGA есть и очень сильные преимущества: они программируемы и достаточно дёшевы для небольших партий, в то время как на изготовление ASIC требуются месяца и миллионы долларов, запрограммить FPGA может буквально студент на тест-ките за пару сотен долларов. Т.е. порог вхождения в железо гораздо-гораздо ниже для простых смертных. Мне кажется это очень существенным для маленьких стран и для маленьких фирм, ASIC-и, имхо, весьма тяжеловесны в этом плане. Кроме того, время выхода на рынок для изделий на FPGA гораздо быстрее, чем у ASIC.
Далее, в сравнении с CPU, FPGA имеют более высокую производительность для многих задач с параллелизмом уровня данных, но если нужна сложная управляющая логика, то это уже не к ПЛИС в основном.
Имхо, в сравнении с GPU для того же ИИ первоначально казалось, что у FPGA практически не было шансов, но они во многом вырулили: в частности, во-первых энергоэффективностью, здесь они делают GPU легко во многом за счет того, что используют ровно столько сколько надо ресурсов, без оверхедов на питание неиспользуемых, во-вторых даже производительностью (но здесь это часто больше хаки, чем очевидный выигрыш, в частности, уменьшение разрядности операндов, в FPGA это проще простого, а в GPU такие вещи появляются только сейчас, насколько могу судить). В целом, FPGA выглядит очень круто для быстроизменяющихся нестабильных задач, таких как ИИ, если задачи стабилизируются, то можно выкатывать ASIC-и.
По этому пути пошли в датацентрах Microsoft (проект Catapult v.2), сделав там у каждого сервера навесной FPGA-акселератор. Они заявляют, что сейчас это самое крупное вложение в FPGA. И планируют часть стабильной логики (инфраструктуру) впоследствии изготовить в кремнии.
Ещё одной интересной темой в контексте FPGA и ИИ мне кажется всякие программные решения вроде Ristretto и Deephi, которые подрезают нужным образом нейронные сети, а Deephi ещё и генерят под это логику FPGA. Но в целом, я не спец по ИИ, так что может многого ещё не вижу из того, что происходит.
Серьезная проблема FPGA состоит в сложности программирования для нежелезячных программистов и её пытаются решить самые различные стартапы.
Что касается критики, имхо, она во многом справедлива, FPGA действительно гораздо слабее ASIC-ов. Однако у FPGA есть и очень сильные преимущества: они программируемы и достаточно дёшевы для небольших партий, в то время как на изготовление ASIC требуются месяца и миллионы долларов, запрограммить FPGA может буквально студент на тест-ките за пару сотен долларов. Т.е. порог вхождения в железо гораздо-гораздо ниже для простых смертных. Мне кажется это очень существенным для маленьких стран и для маленьких фирм, ASIC-и, имхо, весьма тяжеловесны в этом плане. Кроме того, время выхода на рынок для изделий на FPGA гораздо быстрее, чем у ASIC.
Далее, в сравнении с CPU, FPGA имеют более высокую производительность для многих задач с параллелизмом уровня данных, но если нужна сложная управляющая логика, то это уже не к ПЛИС в основном.
Имхо, в сравнении с GPU для того же ИИ первоначально казалось, что у FPGA практически не было шансов, но они во многом вырулили: в частности, во-первых энергоэффективностью, здесь они делают GPU легко во многом за счет того, что используют ровно столько сколько надо ресурсов, без оверхедов на питание неиспользуемых, во-вторых даже производительностью (но здесь это часто больше хаки, чем очевидный выигрыш, в частности, уменьшение разрядности операндов, в FPGA это проще простого, а в GPU такие вещи появляются только сейчас, насколько могу судить). В целом, FPGA выглядит очень круто для быстроизменяющихся нестабильных задач, таких как ИИ, если задачи стабилизируются, то можно выкатывать ASIC-и.
По этому пути пошли в датацентрах Microsoft (проект Catapult v.2), сделав там у каждого сервера навесной FPGA-акселератор. Они заявляют, что сейчас это самое крупное вложение в FPGA. И планируют часть стабильной логики (инфраструктуру) впоследствии изготовить в кремнии.
Ещё одной интересной темой в контексте FPGA и ИИ мне кажется всякие программные решения вроде Ristretto и Deephi, которые подрезают нужным образом нейронные сети, а Deephi ещё и генерят под это логику FPGA. Но в целом, я не спец по ИИ, так что может многого ещё не вижу из того, что происходит.
Серьезная проблема FPGA состоит в сложности программирования для нежелезячных программистов и её пытаются решить самые различные стартапы.
Вы страшный человек, я предыдущие ваши ссылки 2 дня парсил))) Спасибо!
Да, MS красиво FPGA в облаках разрекламировали.
В целом — да, такие же впечатления.
В этом плане, кто успешнее всего прокинет эффективный интерфейс от TensorFlow, PyTorch, Caffe до железки, тот и будет в дамках. А для исследователя это будет просто галочка в гиперпараметрах или некие ограничения на архитектуру сети.
И понятно, что это огромная работа и огромные усилия. TVM собрал Amazon, Intel, Facebook, Xilinx, Microsoft, NTT, Qualcomm (пока на тусовку). Но если компании поддержат — будет гибкий механизм, который поддержит и FPGA, и ASIC, и любого, кто эффективное железо сделает. Т.е. снизится порог входа для железячных стартапов, что критично. Выглядит, похоже перспективнее Ristretto (пока не поддержана) и Deephi (частное решение, кстати, тоже планирующее поддержку TensorFlow, PyTorch, Caffe).
TVM зарелизили поддержку PyTorch на позапрошлой неделе, кстати. Поддержку TF им Алибаба помогал делать. Еще стороны железок список расширить — и будет сильно.
Да, MS красиво FPGA в облаках разрекламировали.
В целом — да, такие же впечатления.
Серьезная проблема FPGA состоит в сложности программирования для нежелезячных программистовЧестно говоря, современным data scientists глубоко безразлично, что там ускоряет его сетку и где она вообще тренируется и выполняется.
В этом плане, кто успешнее всего прокинет эффективный интерфейс от TensorFlow, PyTorch, Caffe до железки, тот и будет в дамках. А для исследователя это будет просто галочка в гиперпараметрах или некие ограничения на архитектуру сети.
И понятно, что это огромная работа и огромные усилия. TVM собрал Amazon, Intel, Facebook, Xilinx, Microsoft, NTT, Qualcomm (пока на тусовку). Но если компании поддержат — будет гибкий механизм, который поддержит и FPGA, и ASIC, и любого, кто эффективное железо сделает. Т.е. снизится порог входа для железячных стартапов, что критично. Выглядит, похоже перспективнее Ristretto (пока не поддержана) и Deephi (частное решение, кстати, тоже планирующее поддержку TensorFlow, PyTorch, Caffe).
TVM зарелизили поддержку PyTorch на позапрошлой неделе, кстати. Поддержку TF им Алибаба помогал делать. Еще стороны железок список расширить — и будет сильно.
UFO just landed and posted this here
Надо же, как нынче популярен брутфорс.
Не то слово. Недавно был перевод «Горький урок отрасли ИИ» — ровно о том, что люди годами разрабатывали специализированные методы, а потом пришли общие методы и всех порвали. И ситуация будет усугубляться (AutoML, все дела).
А почему нет ни слова о достижениях AMD / ATI? Разве сами достижения на этом поприще у них тоже отсутствуют?
1/ Оптические процессоры. В конце 90-ых — начале 2000-х израильская компания Lenslet ltd (можно найти на archive.org) представила оптический dsp-процессор EnLight256, которых совершал типа 8 триллионов операций умножения/сложения в секунду и, вроде бы, — здесь я не уверен, но легко гуглится — был в сравнении с серверным процессором Ксеон 2 в 13,000 раз быстрее. Процессор был заточен под обработку видео и датамайнинг и заявлялось, что есть заказы от израильской военщины. Но к 2006 году компания прекратила своё существование, причины гуглежу не полежат, а патенты, связанные с этим оптическим матричным процессором, кстати, прекрасно гуглятся.
2/ Альтернативная арифметика, вроде цепных логарифмов (continued logarithms). Их особенность в том, что элементарные операции совершаются параллельно, что и дает ускорение, также позволяют произвольную точность. В статьях двух с половиной активистов по этой теме указывается, что примирение арифметики на цепных логарифмах в 100 MHz fpga показывало ускорение в 6 раз (то есть как эквивалентное выполнению задачи на 600-а мегагерцевом процессоре), если экстраполировать на 2ггц процессор, то это был бы эквивалент 12ггц.
2/ Альтернативная арифметика, вроде цепных логарифмов (continued logarithms). Их особенность в том, что элементарные операции совершаются параллельно, что и дает ускорение, также позволяют произвольную точность. В статьях двух с половиной активистов по этой теме указывается, что примирение арифметики на цепных логарифмах в 100 MHz fpga показывало ускорение в 6 раз (то есть как эквивалентное выполнению задачи на 600-а мегагерцевом процессоре), если экстраполировать на 2ггц процессор, то это был бы эквивалент 12ггц.
1. Заявления стартапов в принципе желательно делить на 2 (а умирающих стартапов минимум на 10), но тема оптических вычислений, вы правы, очень перспективна. Область не моя, но как я понимаю, проблема там та же, что и при аналоговых вычислениях нейросетей — память. Т.е. как сохранить данные в процессе. Что резко ограничивает круг применения технологии. И здесь, конечно, было бы интересно, что за последние 10 лет произошло.
2. Continued logarithms — тема интересная. Кстати — интересно, как оно переводится, поскольку гугл на «цепные логарифмы» выдал 3 страницы в интернете, включая эту ))). Как я понимаю, дело в задачах, где бы эта арифметика была актуальна. В математике много красивых преобразований и иногда некоторые из них «выстреливают». Увы, большинство продолжает пылиться и ждать своего часа (что тоже неплохо, наверное).
2. Continued logarithms — тема интересная. Кстати — интересно, как оно переводится, поскольку гугл на «цепные логарифмы» выдал 3 страницы в интернете, включая эту ))). Как я понимаю, дело в задачах, где бы эта арифметика была актуальна. В математике много красивых преобразований и иногда некоторые из них «выстреливают». Увы, большинство продолжает пылиться и ждать своего часа (что тоже неплохо, наверное).
Ну компании Ленслет лично я поверил и окончательно меня убедила как раз статья, в которой сравнивали оптический процессор с серверным ксеоном. Авторы статьи были американской профессурой и, на первый взгляд, с Ленслетом не связаны.
Мне кажется, вариантов два: «цепные логарифмы» и «непрерывные логарифмы» — и то, и другое плохой вариант, вероятно, как и английское название, потому что это в первую очередь дробь, а потом уж логарифм.
Мне кажется, вариантов два: «цепные логарифмы» и «непрерывные логарифмы» — и то, и другое плохой вариант, вероятно, как и английское название, потому что это в первую очередь дробь, а потом уж логарифм.
Видимо настало время для ДЦ на луне, дабы избежать глобального потепления.
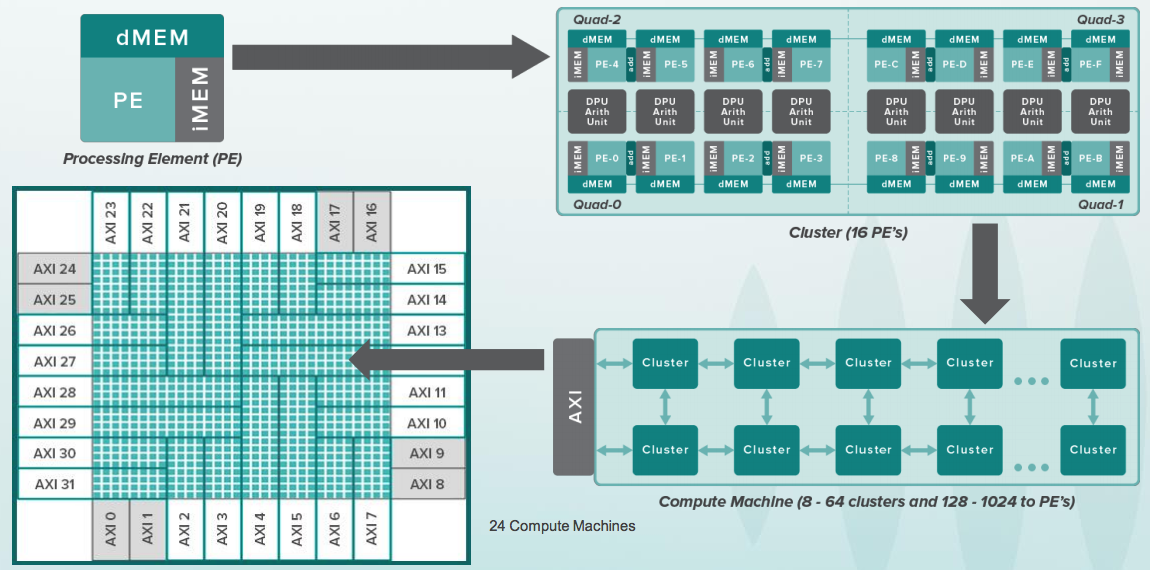
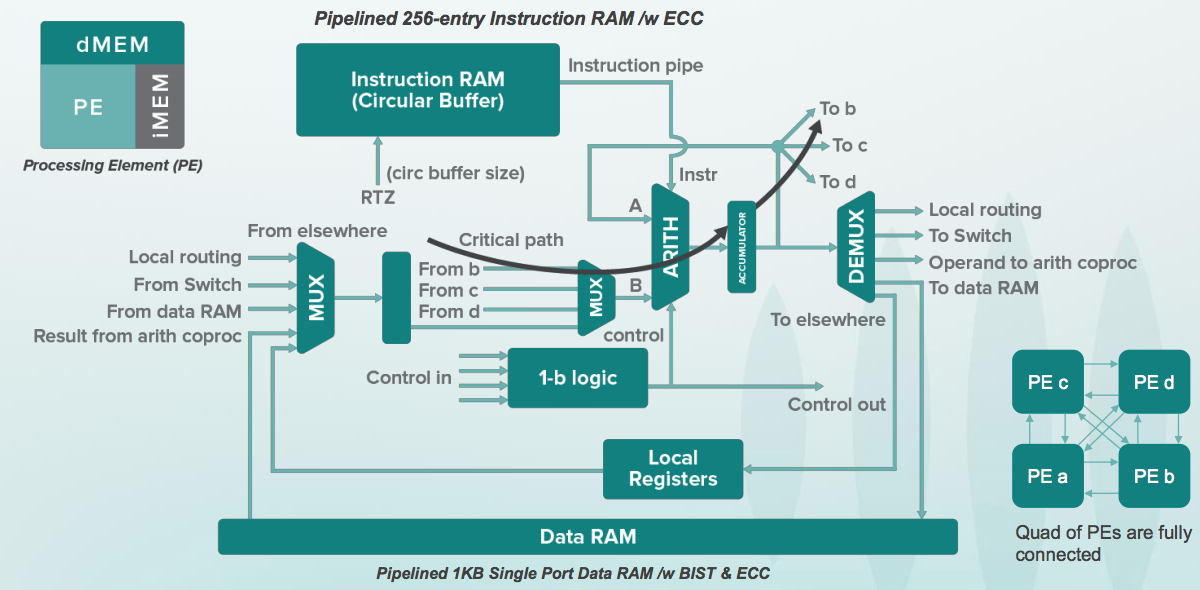
В посте недостаточно раскрыта тема ускорения нейросетей с помощью процессоров потоков данных (dataflow processor) на основании архитектуры крупнозернистого реконфигурируемого массива CGRA (Coarse Grained Reconfigurable Array). Такой процессор от Wave Computing состоит он из переменного массива процессорообразных элементов (от нескольких до десятков тысяч), которые соединены между собой сетью из переключателей на одном большом кристалле с парой миллиардов транзисторов.
Dataflow-процессор вытягивает из памяти целый «тензор» (матрицу данных) через сеть переключателей, рассылающих эти данные между кластерами для обработки. В каждом кластере находится специальная небольшая программа, которая получает данные нейросети извне и делает с ними различные операции. Причем не только умножение со сложением, как это происходит в матричных умножителях, но и более сложные операции.
Dataflow-процессор по вычислительной мощности и гибкости находится между классическим процессором и матричным умножителем и при этом конкурирует с графическим процессором. То есть хотя графические процессоры тоже находятся между классическим процессорами и матричными умножителями, но графические процессоры изначально были сделаны для оптимизации графики. Они не настолько хорошо подходят для типов вычислений, которые делаются для нейросетей.
См. www.silicon-russia.com/2019/04/15/triton-skolkovo-robotics-ai


Dataflow-процессор вытягивает из памяти целый «тензор» (матрицу данных) через сеть переключателей, рассылающих эти данные между кластерами для обработки. В каждом кластере находится специальная небольшая программа, которая получает данные нейросети извне и делает с ними различные операции. Причем не только умножение со сложением, как это происходит в матричных умножителях, но и более сложные операции.
Dataflow-процессор по вычислительной мощности и гибкости находится между классическим процессором и матричным умножителем и при этом конкурирует с графическим процессором. То есть хотя графические процессоры тоже находятся между классическим процессорами и матричными умножителями, но графические процессоры изначально были сделаны для оптимизации графики. Они не настолько хорошо подходят для типов вычислений, которые делаются для нейросетей.
См. www.silicon-russia.com/2019/04/15/triton-skolkovo-robotics-ai
Текст получился и так слишком длинным. 37К — это многовато. Бета-тестирование показало, что многие молодые люди, даже которым интересна тема и несмотря на массу приемов облегчения восприятия, с трудом дочитывают… Поэтому многие моменты просто выбрасывались и сокращались под конец.
Dataflow Processing Unit (DPU) от WAVE Computing в тексте, если заметите, есть (причем слайд взят из той же презентации, из которой слайды приводите вы). Основная причина, по которой оно не раскрыто — большой вопрос, насколько этот подход будет быстрее, чем GPU.
Что в теме работают уже десятки стартапов — понятно. Что в интернете море материалов, как они ОБЕЩАЮТ всех порвать — тоже понятно. С реальными достижениями — все уже на порядок хуже.
А ощутимые цифры обычно приводятся явно на избранных кейсах, т.е. очень похоже, что приходилось точиться, чтобы получить результат. И это при том, что прогресс на GPU идет весьма впечатляющий, как по железу, так и по оптимизации библиотек (что тоже дает заметный прирост скорости).
По вашей ссылке, кстати, тоже есть констатация, что решения NVIDIA & Google хороши (и что вы афиллированы с WAVE Computing), но нет ни одной цифры сравнения. А без результатов большинство стартапов в области будут закрыты оставив после себя только рекламные обещания. У меня были основания не раскрывать эту тему. Есть ли у вас основания, что ее обязательно нужно раскрыть? )
Что у Dataflow-процессоров с реальной производительностью на тренировке и инференс DNN в сравнении с топовыми GPU? Что со стоимостью?
Заранее крайне благодарен за аргументированный ответ! )
Dataflow Processing Unit (DPU) от WAVE Computing в тексте, если заметите, есть (причем слайд взят из той же презентации, из которой слайды приводите вы). Основная причина, по которой оно не раскрыто — большой вопрос, насколько этот подход будет быстрее, чем GPU.
Что в теме работают уже десятки стартапов — понятно. Что в интернете море материалов, как они ОБЕЩАЮТ всех порвать — тоже понятно. С реальными достижениями — все уже на порядок хуже.
А ощутимые цифры обычно приводятся явно на избранных кейсах, т.е. очень похоже, что приходилось точиться, чтобы получить результат. И это при том, что прогресс на GPU идет весьма впечатляющий, как по железу, так и по оптимизации библиотек (что тоже дает заметный прирост скорости).
По вашей ссылке, кстати, тоже есть констатация, что решения NVIDIA & Google хороши (и что вы афиллированы с WAVE Computing), но нет ни одной цифры сравнения. А без результатов большинство стартапов в области будут закрыты оставив после себя только рекламные обещания. У меня были основания не раскрывать эту тему. Есть ли у вас основания, что ее обязательно нужно раскрыть? )
Что у Dataflow-процессоров с реальной производительностью на тренировке и инференс DNN в сравнении с топовыми GPU? Что со стоимостью?
Заранее крайне благодарен за аргументированный ответ! )
Я сделан в Советском Союзе без клипового мышления, текст читал полностью и с интересом. Тема мне близкая и интересная, но я больше по железу — собрал вот машину с GPGPU уже вторую версию.
Выпущенная версия Dataflow процессора не предназначена для трейнинга, так как в частности использует только целочисленные типы данных. Будущая версия содержит дополнения для локального трейнинга, но в трейнинге GPU лидируют.
Я неоднократно предлагал менеджменту публиковать бенчмарки и открыть toolchain, на что они указывали, что NVidia сами химичат с бенчмарками. Я надеюсь, что это измениться в течение года.
*** У меня были основания не раскрывать эту тему. Есть ли у вас основания, что ее обязательно нужно раскрыть? ) ***
Если вы вашу статью писал я, я бы поместил картинки с микроархитектурными блоками и конвейером, чтобы читатель наглядно увидел, как fetch, decode, alu и прочие элементы выполнения отличаются у CPU и GPU. В этом случае картинка с dataflow processor была бы интересной опцией, просто чтобы показать пространство решений.
Вы это вероятно не сделали потому что, по вашим словам, вы непосредственно не работали с железом.
Пример картинки из интернета с микроархитектурными блоками для GPU. Она не очень наглядна, я поищу и найду другую картинку с сравнением конвейера CPU и GPU — она у меня была:

Далее, из вашего текста про FPGA возникает ощущение, что вы не совсем четко представляете размеры накладок (на порядок), которые возникают у FPGA по сравнению с фиксированными микросхемами на standard cells (ASIC CPU, GPU итд) по необходимому количеству логических элементов (логический элемент реализованный в FPGA cells требует в несколько раз больше места на кристалле чем в standard cells на ASIC ), и по частоте (если вы попробуете прямолинейно положить на FPGA стандартный встроенный CPU который на ASIC работает с частотой 2 GHz, вы можете обнаружить, что на FPGA он работает 20 MHz) итд.
Конечно, FPGA компенсирует последнее с помощью массивного параллелизма, но вот с computational density (количеством вычисление на квадратный миллиметр микросхемы) у него большая проблема, по сравнению например с систолическими массивами, реализованными в ASIC, как скажем Google TPU.
В этом ракурсе введение в статью CGRA было бы уместным как опция в пространстве решений, которая по массированному параллелизму похожа на FPGA, но из-за операций (грубо говоря) не с индивидуальными битами, а с группами бит, снижает огромные накладки FPGA.
См. картинку из интернета www.researchgate.net/figure/Parallel-between-the-evolution-of-fine-grained-architectures-cells-from-simple-gates-to_fig1_224128061
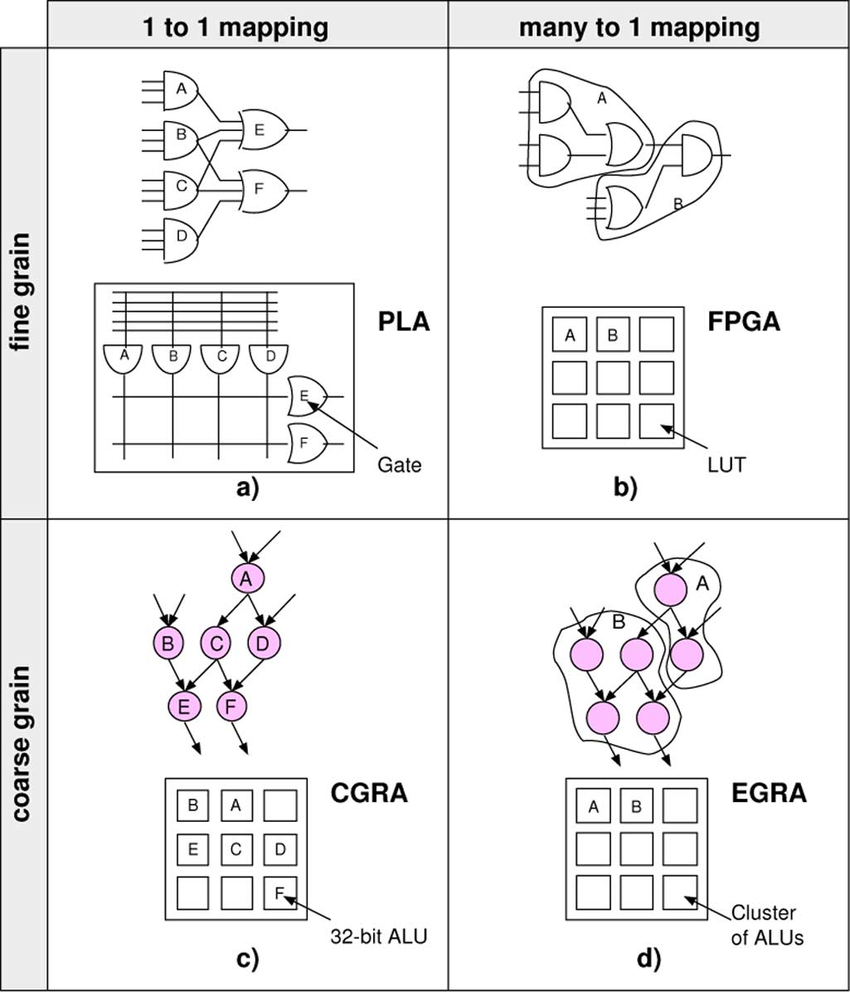
Но я понимаю вашу позицию — описывать не пространство хардверных решений, а то что есть на рынке с точки зрения софтверного пользователя этих решений.
Я неоднократно предлагал менеджменту публиковать бенчмарки и открыть toolchain, на что они указывали, что NVidia сами химичат с бенчмарками. Я надеюсь, что это измениться в течение года.
*** У меня были основания не раскрывать эту тему. Есть ли у вас основания, что ее обязательно нужно раскрыть? ) ***
Если вы вашу статью писал я, я бы поместил картинки с микроархитектурными блоками и конвейером, чтобы читатель наглядно увидел, как fetch, decode, alu и прочие элементы выполнения отличаются у CPU и GPU. В этом случае картинка с dataflow processor была бы интересной опцией, просто чтобы показать пространство решений.
Вы это вероятно не сделали потому что, по вашим словам, вы непосредственно не работали с железом.
Пример картинки из интернета с микроархитектурными блоками для GPU. Она не очень наглядна, я поищу и найду другую картинку с сравнением конвейера CPU и GPU — она у меня была:
Далее, из вашего текста про FPGA возникает ощущение, что вы не совсем четко представляете размеры накладок (на порядок), которые возникают у FPGA по сравнению с фиксированными микросхемами на standard cells (ASIC CPU, GPU итд) по необходимому количеству логических элементов (логический элемент реализованный в FPGA cells требует в несколько раз больше места на кристалле чем в standard cells на ASIC ), и по частоте (если вы попробуете прямолинейно положить на FPGA стандартный встроенный CPU который на ASIC работает с частотой 2 GHz, вы можете обнаружить, что на FPGA он работает 20 MHz) итд.
Конечно, FPGA компенсирует последнее с помощью массивного параллелизма, но вот с computational density (количеством вычисление на квадратный миллиметр микросхемы) у него большая проблема, по сравнению например с систолическими массивами, реализованными в ASIC, как скажем Google TPU.
В этом ракурсе введение в статью CGRA было бы уместным как опция в пространстве решений, которая по массированному параллелизму похожа на FPGA, но из-за операций (грубо говоря) не с индивидуальными битами, а с группами бит, снижает огромные накладки FPGA.
См. картинку из интернета www.researchgate.net/figure/Parallel-between-the-evolution-of-fine-grained-architectures-cells-from-simple-gates-to_fig1_224128061
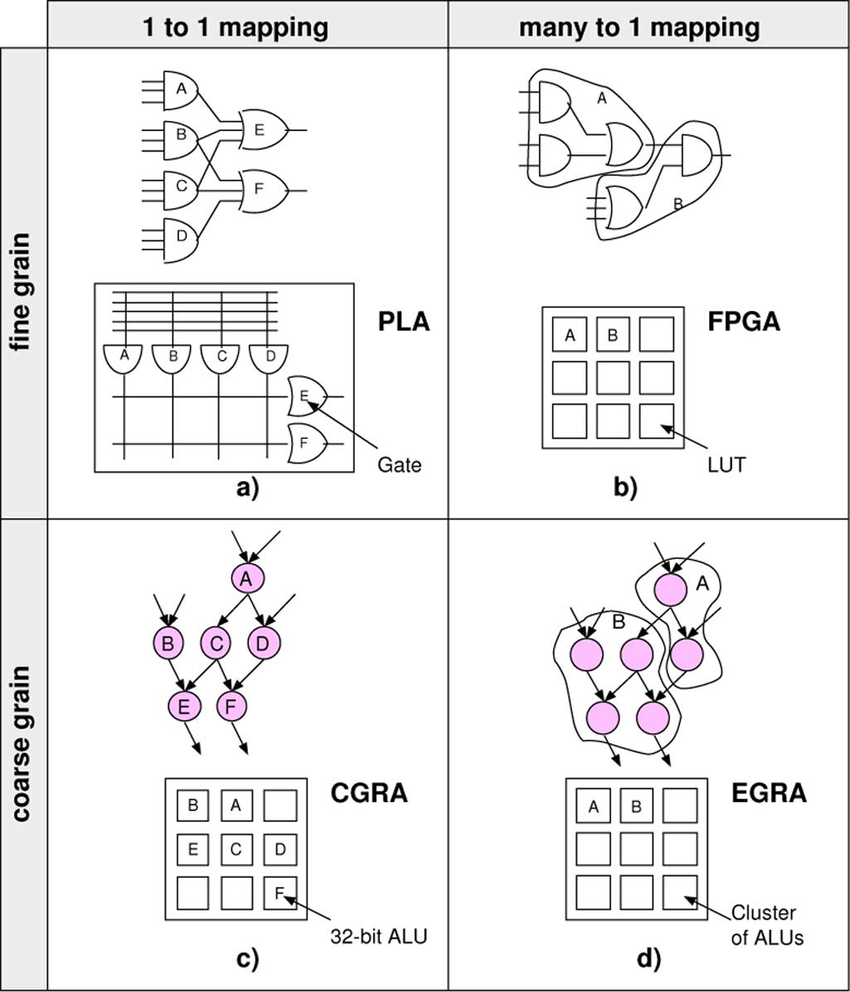
Но я понимаю вашу позицию — описывать не пространство хардверных решений, а то что есть на рынке с точки зрения софтверного пользователя этих решений.
Выпущенная версия Dataflow процессора не предназначена для трейнинга, так как в частности использует только целочисленные типы данных.Ок, спасибо!
Я неоднократно предлагал менеджменту публиковать бенчмарки и открыть toolchain, на что они указывали, что NVidia сами химичат с бенчмарками. Я надеюсь, что это измениться в течение года.В этой области десятки стартапов. Причем публикации лучших результатов вполне есть. И когда бенчмарки не публикуются, моя нейронная сеть (и, думаю, не только) сразу классифицирует вас, как компанию, которая делает интересные, но неконкурентоспособные вещи (с некоторой вероятностью после софтмакса, конечно))). Поскольку таких, пожалуй, большиниство.
Это резко снижает интерес в том числе к вашей технологии.
Если вы вашу статью писал я, я бы поместил картинки с«Если бы вы преследовали мои цели...» ))) Если бы я писал ваши статьи, я бы уделил больше внимания не теории, а практическим результатам, бенчмаркам и тому, какое влияние это оказывает на производительность на видео. ;)
Но вы преследуете свои цели, это нормально.
FPGA cells требует в несколько раз больше места на кристалле чем в standard cells на ASIC, и по частоте (если вы попробуете прямолинейно положить на FPGA стандартный встроенный CPU который на ASIC работает с частотой 2 GHz, вы можете обнаружить, что на FPGA он работает 20 MHz) итд.Это само собой. Но обратите внимание на процент комментариев к этому тексту про FPGA! Я сам, честно говоря, не ожидал. Люди массово делают решения, т.е. по соотношению цена/качество FPGA более чем конкурентоспособны сегодня. А учитывая новые поколения, в которых DSP ядра дополняют матричными вычислителями специально для нейросетей — это как раз перевод нейросетевой части с FPGA cells на условные ASIC cells и это выглядит крайне интересно, учитывая текущие успехи FPGA.
Я с большим уважением отношусь к теории, без нее развитие невозможно, но не всегда красивые теоретические идеи побеждают на практике более простые подходы, скажем так.
Но я понимаю вашу позицию — описывать не пространство хардверных решений, а то что есть на рынке с точки зрения софтверного пользователя этих решений.Есть (часто красивая!) теория. Есть практика. В моей родной области масса замечательных очень красивых идей, которые на практике бесполезны. Тому масса причин. Проигрывают по соотношению цена/качество (причем проигрыш может быть не в силу свойств алгоритма, а просто потому, что конкурирующее решение поддержано крайне популярными библиотеками с хорошей лицензией). Покрыты патентами (и хотя «алгоритмы не патентуются» — это большая печальная тема). Более сложны в отладке и т.д… И они реально мало кого интересуют.
Для специалиста хорошо в них разбираться — дело чести. Именно это делает его специалистом и при изменении условий (истечении патентов, появлении возможностей...) оперативно использовать, делая лучший продукт. Но кладбище красивых подходов велико, растет и будет расти…
Искренне желаю вашей компании получить продукт, который не только красиво дополняет пространство решений, но и реально показывает отличные результаты по производительности (а может это уже сделано!), успешно сделать массовый продукт, сделав чип конкурентоспособным по цене, выдержать все патентные войны и (скорее всего) поглощение и стать основной для массовой линейки продуктов! )))
И спасибо за отличные популярные статьи на хабре! )
мне думается что FPGA это вынужденная мера:
они удачно совмещают относительную дешевизну, скорость вычислений и скорость прототипирования и внесения изменений по сравнению с ASIC.
Для примера:
FPGA
нужно организовать ускорение вычисления (но не обучения), надо несколько рабочих мест (один комплект лицензии квартуса, моделсима, лицензий на IP ядра и сторонних корок стоил 30-50к баксов лет 5 назад когда я их покупал).
надо купить карточек, хотябы середнички типа Аррию10 по количеству рабочих мест плюс одну (если сожгут и не ждать), это уже по 5кбаксов*(N+1)
ну и зарплаты, офис, бугалтерия и прочие расходы — грубо говоря по 10к баксов в месяц на разработчика, работать они явно будут не пару месяцев а пару лет, это уже 120к*N
за это время можно сделать десяток версий (один год делать первую удачную, а потом каждый месяц — полтора вносить правки)
Итого за год: (120+50+5)*N, для 5 человек это 880т баксов
немало но найти желающих оплатить попробовать без гарантий можно
ASIC:
Тут я не специалист но мне кажется что софт будет стоить гораздо дороже (оптимистично предположу что в 2 раза)
заказ чипа стоить будет уже в диапазоне миллиона долларов за одну итерацию
одна итерация от верилога до железа заёмёт в разы больше (3-4 месяца)
в ASIC не закинешь узкоспециализированную сеть с «прибытыми гвоздями» разрядностями и архитектурой нет смысла делать — значит структура станет сложнее: должна быть в меру универсальной, это в разы сложнее
нужны переговорщики, крупный финансовый капитал и имя (в первую очередь завод залезет в кошелёк и если ты мелочь тебя вообще проигнорируют), менеджеры, прочие инженеры тоже нужны — под чип нужна плата и желательно корпус с охлаждением, это очень нетривиального уровня схематехники и технологи.
вот заметье: что в том же майнинге платы специально сделаны примитивными — всё постарались затолкать внутрь чипа, включая импульсные регуляторы напряжений, токовые драйверы для интерфейсов и тд и тп.
А это опять таки нужны не простые верилог разработчики а с знанием аналога плюс знания физики полупроводников и технологий (я такое поверхностно изучал в MiT — это ОЧЕНЬ СЛОЖНО, это просто космос и передовой край сплава науки и техники, суровый такой без смузи и единорогов и проповедников от маркетинга стартапов, чистая инженерия и наука)
итог по асику подсчитать сложно, но это явно десятки миллионов долларов, штат раз в 10 больше по людям и сроки первого выхода глючного но как то работающего уже 3-5 лет, с очень большим риском неудачи (и социальные — заставить работать команду, удержать и вывести к финишу, и технические — не факт что запланированная архитектура выстрелит, и бизнес — не факт что все подрядчики не подведут) и шансов сделать несколько разных попыток с разной архитектурой мало, точнее всего одна попытка: переделывать с нуля никто не даст.
это дело мега корпораций с! уже! имеющимися наработками и людьми. например NEC и SONY (c ними и олимпусам по бионику работал, примерно краем уха знаю реальные сроки в 10-15 лет на одну самую первую итерацию с нуля, это уже не тайна)
Кратко: FPGA это способ ускорить и удешевить разработку в десятки и сотни раз относительно ASIC.
PS. это только мои догадки и фантазии. хотелось бы призвать сюда специалистов например amartology для аудита моих расчётов и догадок (мне самому интересно насколько порядков я промахнулся)
они удачно совмещают относительную дешевизну, скорость вычислений и скорость прототипирования и внесения изменений по сравнению с ASIC.
Для примера:
FPGA
нужно организовать ускорение вычисления (но не обучения), надо несколько рабочих мест (один комплект лицензии квартуса, моделсима, лицензий на IP ядра и сторонних корок стоил 30-50к баксов лет 5 назад когда я их покупал).
надо купить карточек, хотябы середнички типа Аррию10 по количеству рабочих мест плюс одну (если сожгут и не ждать), это уже по 5кбаксов*(N+1)
ну и зарплаты, офис, бугалтерия и прочие расходы — грубо говоря по 10к баксов в месяц на разработчика, работать они явно будут не пару месяцев а пару лет, это уже 120к*N
за это время можно сделать десяток версий (один год делать первую удачную, а потом каждый месяц — полтора вносить правки)
Итого за год: (120+50+5)*N, для 5 человек это 880т баксов
немало но найти желающих оплатить попробовать без гарантий можно
ASIC:
Тут я не специалист но мне кажется что софт будет стоить гораздо дороже (оптимистично предположу что в 2 раза)
заказ чипа стоить будет уже в диапазоне миллиона долларов за одну итерацию
одна итерация от верилога до железа заёмёт в разы больше (3-4 месяца)
в ASIC не закинешь узкоспециализированную сеть с «прибытыми гвоздями» разрядностями и архитектурой нет смысла делать — значит структура станет сложнее: должна быть в меру универсальной, это в разы сложнее
нужны переговорщики, крупный финансовый капитал и имя (в первую очередь завод залезет в кошелёк и если ты мелочь тебя вообще проигнорируют), менеджеры, прочие инженеры тоже нужны — под чип нужна плата и желательно корпус с охлаждением, это очень нетривиального уровня схематехники и технологи.
вот заметье: что в том же майнинге платы специально сделаны примитивными — всё постарались затолкать внутрь чипа, включая импульсные регуляторы напряжений, токовые драйверы для интерфейсов и тд и тп.
А это опять таки нужны не простые верилог разработчики а с знанием аналога плюс знания физики полупроводников и технологий (я такое поверхностно изучал в MiT — это ОЧЕНЬ СЛОЖНО, это просто космос и передовой край сплава науки и техники, суровый такой без смузи и единорогов и проповедников от маркетинга стартапов, чистая инженерия и наука)
итог по асику подсчитать сложно, но это явно десятки миллионов долларов, штат раз в 10 больше по людям и сроки первого выхода глючного но как то работающего уже 3-5 лет, с очень большим риском неудачи (и социальные — заставить работать команду, удержать и вывести к финишу, и технические — не факт что запланированная архитектура выстрелит, и бизнес — не факт что все подрядчики не подведут) и шансов сделать несколько разных попыток с разной архитектурой мало, точнее всего одна попытка: переделывать с нуля никто не даст.
это дело мега корпораций с! уже! имеющимися наработками и людьми. например NEC и SONY (c ними и олимпусам по бионику работал, примерно краем уха знаю реальные сроки в 10-15 лет на одну самую первую итерацию с нуля, это уже не тайна)
Кратко: FPGA это способ ускорить и удешевить разработку в десятки и сотни раз относительно ASIC.
PS. это только мои догадки и фантазии. хотелось бы призвать сюда специалистов например amartology для аудита моих расчётов и догадок (мне самому интересно насколько порядков я промахнулся)
Добавлено: С текущим бурным развитием нейросетей имеет ли смысл разрабатывать даже универсальный нейро-процессор в ASIC? Может выгоднее стратегия накопить на FPGA библиотеку архитектурных решений и постепенно из конкретной её реализации делать всё более и более обобщённые блоки, а потом когда всё уляжется и изменения перестанут быть такими кардинальными очень быстро выпустить ASIC по сути портировав уже готовый дизайн с минимальными затратами и рисками.
Другими словами: может лучше сделать на FPGA десяток обрабатывающих универсальных блоков на 200-300MHz и софт к нему, а когда всё уляжется быстро за год выпустить чип на тысячи универсальных блоков на гигагерцы с около нулевой себестоимостью на R&D.
Другими словами: может лучше сделать на FPGA десяток обрабатывающих универсальных блоков на 200-300MHz и софт к нему, а когда всё уляжется быстро за год выпустить чип на тысячи универсальных блоков на гигагерцы с около нулевой себестоимостью на R&D.
С текущим бурным развитием нейросетей имеет ли смысл разрабатывать даже универсальный нейро-процессор в ASIC? Может выгоднее стратегия накопить на FPGA библиотеку архитектурных решенийС точки зрения общего здравого смысла — вы однозначно правы! )
Но это рынок. Десятки стартапов рванули ставить на разные клетки, как пишет Юрий «пространства решений», в этой технологической рулетке. А большие компании внимательно отслеживают ситуации, чтобы тоже сделать свою ставку и купить возможного лидера. Естественно тоже раньше, чем все станет понятно (потому, что когда все станет понятно, он уже будет куплен конкурентом))).
Отсюда чудовищно неэффективные инвестиции миллиардов долларов в железные стартапы, большая часть которых будет списана. Но общее время ожидания «финального ASIC» это сокращает ). И это нормально.
Никого же не удивляет, когда четыре V100 запрягают греть воздух ради 20% прироста производительности по сравнению с одной(!). ))) То же самое, вид сбоку. )))
FPGA это вынужденная мера: они удачно совмещают относительную дешевизну, скорость вычислений и скорость прототипирования и внесения изменений по сравнению с ASIC.Спасибо за отличный расклад по FPGA/ASIC! Пусть оценки примерные, но компромиссные решения в инженерии в итоге побеждают и накрывают рынок ОЧЕНЬ часто.
Кратко: FPGA это способ ускорить и удешивить в десятки раз и сотни ASIC.
Если amartology выскажется, будет здорово, конечно!
Если кратко, то два пункта:
1) Производительность и энергопотребление FPGA отстает на 5 поколений от ASIC на тех же проектных нормах. Или, говоря по другому, алгоритм, зашитый в 32 нм FPGA, можно с той же производительностью реализовать на 180 нм ASIC.
2) С точки зрения экономики ASIC радикально больше NRE и время разработки, у FPGA — стоимость одного экземпляра девайса. То есть FPGA экономически выгоднее на малых сериях и тогда, когда время критично. ASIC становится выгоднее, как только NRE размазывается на достаточно большое количество девайсов.
Если чуть длиннее, то конкретно в нейросетевых приложениях в ASIC все упирается в то, сможете вы сделать нейрон красиво и удобно, или нет, а в FPGA он всегда будет некрасивый и неудобный.
Плюс ASIC нельзя переконфигурировать на лету. Точнее, на самом деле встраиваемые блоки FPGA для кастомизации уже существуют, и наиболее выгодным с точки зрения производительности и срока активной службы девайса будет жестко сделать все, что можно, а остатки запихнуть в конфигурируемые блоки.
1) Производительность и энергопотребление FPGA отстает на 5 поколений от ASIC на тех же проектных нормах. Или, говоря по другому, алгоритм, зашитый в 32 нм FPGA, можно с той же производительностью реализовать на 180 нм ASIC.
2) С точки зрения экономики ASIC радикально больше NRE и время разработки, у FPGA — стоимость одного экземпляра девайса. То есть FPGA экономически выгоднее на малых сериях и тогда, когда время критично. ASIC становится выгоднее, как только NRE размазывается на достаточно большое количество девайсов.
Если чуть длиннее, то конкретно в нейросетевых приложениях в ASIC все упирается в то, сможете вы сделать нейрон красиво и удобно, или нет, а в FPGA он всегда будет некрасивый и неудобный.
Плюс ASIC нельзя переконфигурировать на лету. Точнее, на самом деле встраиваемые блоки FPGA для кастомизации уже существуют, и наиболее выгодным с точки зрения производительности и срока активной службы девайса будет жестко сделать все, что можно, а остатки запихнуть в конфигурируемые блоки.
Другими словами: может лучше сделать на FPGA десяток обрабатывающих универсальных блоков на 200-300MHz и софт к нему, а когда всё уляжется быстро за год выпустить чип на тысячи универсальных блоков на гигагерцы с около нулевой себестоимостью на R&D.Портирование готового отлаженного FPGA дизайна в ASIC все равно будет долгим и дорогим (хотя и намного дешевле, чем разработка с нуля). Intel недавно прикупил себе компанию eASIC, которая ровно этим и занимается.
спасибо за развёрнутый ответ.
А для этого достаточно будет скиллов того кто разрабатывал для FPGA на верилоге? Или обязательно надо получить пару лет опыт в крупной организации которая этим занимается? Подготовка верилог-исходника насколько глубокая нужна? (за исключением того что завод например может понимать стандарт 2001 года а ты на более поздних написал — об этом знаю уже по проблеммам японцев)
Есть ли архитекутры FPGA: Когда вместо скажем 1000 дсп блоков на 300мгц ставится 1000 дсп блоков на 3Ггц и перед ними конвеерный мультиплесор входа и демультиплексор выхода с задержкой ессно в такт каждый. это даст задержку но прозрачно удесятерит кол-во дсп ресурсов. Извиняюсь, об этом я краем уха слышал о работах в таких направлениях в начале 2000ых когда только начинал кодить под мк и верилог, с тех пор нислуху нидуху.
И интересно почему по моей практике на всех что я использовал FPGA и MCU внешняя память в разы медленее чем на ПК или ARM ядрах? Я в конце 2000ых полностью реализовал с нуля SDRAM контроллер и удивился что такая грубая реализация работала в 2-3 раза быстрее встроенного в MCU (а был дедлайн и вот нижить не быть закрыть фатальные баги аппаратного надо было и мне в час ночи в воскресенье было плевать на оптимальность и красоту и какую либо оптимизацию — тупо быдлокодил что сейчас стыдно такое кому либюо показать — вот такое вот качество реализации было), в последствии и на FPGA я такую же беду встречал, что одна и та же память одного и того же профиля скоростей и поколения работает заметно медленнее, в разы. Например DDR3-800Mhz 32бита выдавала всего 1.5Гигабайт в секунду точно та же микросхема что и в плашке памяти в пк в которой в 32битном режиме на тех же таймингах стабильно около 3.1гигабайт в том же порядке и алгоритме доступа. Да я всю времянку проверил вплодь до точек коннекта к аппартному блоку — всё идеально было.
Совсем недавно тоже на STM32H7 32битная SDRAM выдавала всего 200мбсек вместо обычных 400 на последовательном чтении.
Это ограничение скорости как то лимитируется самой технологией ASIC/FPGA? (завалы фронтов портов ввода вывода и автоматом ключается мультицикл или ещё как физикой?)
Портирование готового отлаженного FPGA дизайна в ASIC все равно будет долгим и дорогим
А для этого достаточно будет скиллов того кто разрабатывал для FPGA на верилоге? Или обязательно надо получить пару лет опыт в крупной организации которая этим занимается? Подготовка верилог-исходника насколько глубокая нужна? (за исключением того что завод например может понимать стандарт 2001 года а ты на более поздних написал — об этом знаю уже по проблеммам японцев)
Есть ли архитекутры FPGA: Когда вместо скажем 1000 дсп блоков на 300мгц ставится 1000 дсп блоков на 3Ггц и перед ними конвеерный мультиплесор входа и демультиплексор выхода с задержкой ессно в такт каждый. это даст задержку но прозрачно удесятерит кол-во дсп ресурсов. Извиняюсь, об этом я краем уха слышал о работах в таких направлениях в начале 2000ых когда только начинал кодить под мк и верилог, с тех пор нислуху нидуху.
И интересно почему по моей практике на всех что я использовал FPGA и MCU внешняя память в разы медленее чем на ПК или ARM ядрах? Я в конце 2000ых полностью реализовал с нуля SDRAM контроллер и удивился что такая грубая реализация работала в 2-3 раза быстрее встроенного в MCU (а был дедлайн и вот нижить не быть закрыть фатальные баги аппаратного надо было и мне в час ночи в воскресенье было плевать на оптимальность и красоту и какую либо оптимизацию — тупо быдлокодил что сейчас стыдно такое кому либюо показать — вот такое вот качество реализации было), в последствии и на FPGA я такую же беду встречал, что одна и та же память одного и того же профиля скоростей и поколения работает заметно медленнее, в разы. Например DDR3-800Mhz 32бита выдавала всего 1.5Гигабайт в секунду точно та же микросхема что и в плашке памяти в пк в которой в 32битном режиме на тех же таймингах стабильно около 3.1гигабайт в том же порядке и алгоритме доступа. Да я всю времянку проверил вплодь до точек коннекта к аппартному блоку — всё идеально было.
Совсем недавно тоже на STM32H7 32битная SDRAM выдавала всего 200мбсек вместо обычных 400 на последовательном чтении.
Это ограничение скорости как то лимитируется самой технологией ASIC/FPGA? (завалы фронтов портов ввода вывода и автоматом ключается мультицикл или ещё как физикой?)
А для этого достаточно будет скиллов того кто разрабатывал для FPGA на верилоге?Нет, надо же физический дизайн (топологию кристалла) делать — все то, что в случае с FPGA за вас делает производитель FPGA.
Или обязательно надо получить пару лет опыт в крупной организации которая этим занимается?Пару лет — это еще оптимистично. Проще нанять специально отдельного человека (или отдел).
Есть ли архитекутры FPGA: Когда вместо скажем 1000 дсп блоков на 300мгц ставится 1000 дсп блоков на 3ГгцНе знаю, я в очень сильно другой области работаю.
И интересно почему по моей практике на всех что я использовал FPGA и MCU внешняя память в разы медленее чем на ПК или ARM ядрах?Тут тоже нечего прокомментировать, кроме того, что это мог быть просто неудачный личный опыт, и того, что современные MCU чаще всего и есть ARM)
ASIC — это не технология, а принцип. Процессор Intel из ПК — тоже ASIC по большому-то счету.
И интересно почему по моей практике на всех что я использовал FPGA и MCU внешняя память в разы медленее чем на ПК или ARM ядрах?
Память — это не только частоты, память — это ещё и протокол обмена. Сделать контроллер тормозным — легче лёгкого. Что, видимо, и происходит. Ведь все эти коры, даже официальные от Xilinx-а и Альтеры пишут такие же
А если даже реализация аппаратная, всё может заткнуться на какой-нить внутренней шине чипа со своим особым, самым правильным и мега-универсальным, протоколом.
В давние времена я тоже прикручивал руками SDRAM к FPGA и это, при всей моей молодости и криворукости, работало вполне сносно по производительности. В то время как MIG вообще не смог сгенерить кору для памяти требуемой ширины в тот корпус FPGA.
а ещё возможно из за того что контроллер памяти нередко отдельный кристалл внутри одного корпуса. Я замечал: что на Xilinx, что на Altera, как только пересекаешь между кристаллами барьер, особенно если на той же глобальной тактовой, так сразу скорость в разы падает. Даже если D-ff впихнёшь физически вплотную к этому внутреннему пину и зафиксируешь и не будешь ничего вычислять вообще — только Д и клоковый вход и его сурс тоже такой же D триггер (судя по отчёту таймквеста) на мин расстоянии, ганантированно без глобального роутинга, то сразу с 500-400Mhz скорость падает до 150-200Mhz (принудительно запихать триггер в пин тоже не помогает и не везде есть).
Я писал о возможных проблемах со скоростью обмена при условии, что дизайн работает на приемлемой тактовой частоте.
А когда проседает частота, то нужно сначала решать вопрос проседания, а уже потом про остальное думать. :)
А когда проседает частота, то нужно сначала решать вопрос проседания, а уже потом про остальное думать. :)
Ну так нагрузочная ёмкость больше на пару порядков, если надо два кристалла между собой соединить. И индуктивность. Могут просто схемы ввода-вывода быть неподходящими, или с неподходящими настройками.
Спасибо за подробные комментарии!
Конечно, FPGA компенсирует последнее с помощью массивного параллелизма, но вот с computational density (количеством вычисление на квадратный миллиметр микросхемы) у него большая проблема,А если посмотреть на развитие?
"The Speedster7t FPGA family is optimized for high-bandwidth workloads and eliminates the performance bottlenecks associated with traditional FPGAs. Built on TSMC’s 7nm FinFET process, Speedster7t FPGAs feature a revolutionary new 2D network-on-chip (NoC), an array of new machine learning processors (MLPs) optimized for high-bandwidth and artificial intelligence/machine learning (AI/ML) workloads, high-bandwidth GDDR6 interfaces, 400G Ethernet and PCI Express Gen5 ports — all interconnected to deliver ASIC-level performance while retaining the full programmability of FPGAs."

Итого — видим массив до 2560 MLP с поддержкой вычислений от 24 до 4-битных(!), 300Мб на борту, высокоскоростные интерфейсы внутри и наружу, и все это счастье на 7нм. В общем — решение проблем «традиционно ассоциирующихся с FPGA».
Или вот Xilinx Everest FPGA. Тоже до 300Мб памяти на борту. Тоже до 300Tb/s — пропускная памяти внутри и до 1.2Tb/s — наружу к DDR4, тоже оптимизация целочисленой арифметики, тоже 7нм.
Вот — потенциальные данные на обучение для новой серии Xilinx Everest FPGA (понятно, что обещать — не мешки ворочать, и тем не менее заявка очень сильная, учитывая, что GPU2&3 — это предельно современные V100 и Т4):
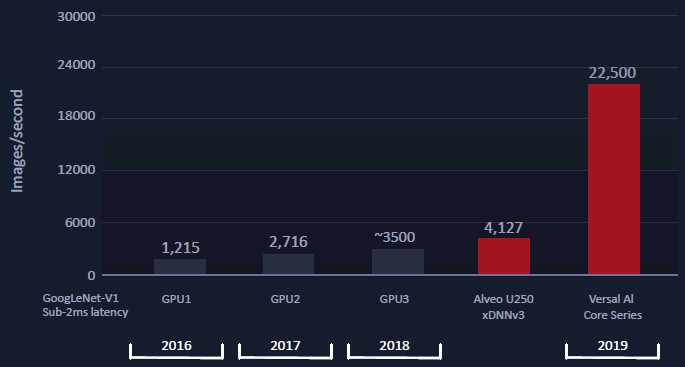
Причем на текущих доступных они выглядят вполне конкурентоспособными (что меня традиционно радует указываются картинки в секунду — еще когда разрешение будут указывать и для разных разрешений производительность приводить — совсем хорошо будет):
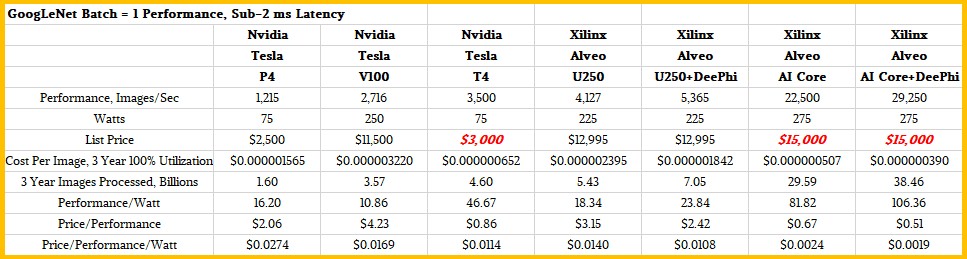
Что скажете в свете вашей критики FPGA?
рекламным материалам в том числе и к FPGA у меня есть бооольшой такой вагон и маленькая тележка скепсиса:
почти всегда заявляется что LUT и регистры работают под 500MHz, DSP и память 300-400Mhz а как что реальное реализуешь, просто чёкнуться можно оптимизируя это до 150-200Mhz. — оказывается что эти цифры если всё рядышком топологически стоит и не гуляет по глобальному роутингу, в реальном дизайне такие условия в принципе невозможно. А если где в целом с архитектурой неудачно попал то и все 100мгц просто счастье и сказка, и то с нарушением констрайнов (формально выражаясь — нестабильный оверклокинг)
почти всегда заявляется что LUT и регистры работают под 500MHz, DSP и память 300-400Mhz а как что реальное реализуешь, просто чёкнуться можно оптимизируя это до 150-200Mhz. — оказывается что эти цифры если всё рядышком топологически стоит и не гуляет по глобальному роутингу, в реальном дизайне такие условия в принципе невозможно. А если где в целом с архитектурой неудачно попал то и все 100мгц просто счастье и сказка, и то с нарушением констрайнов (формально выражаясь — нестабильный оверклокинг)
Это тоже понятно. Если посмотреть исходный текст «Teasing Out The Bang For The Buck Of Inference Engines», из которого я картинки взял, там большинство сравнений более скромные. Но в любом случае бьются типа топовые GPU и бьются конкретно. Выглядит обнадеживающе.
Слушайте, вы меня неправильно понимаете. Я совсем не критик FPGA. Более того, я с FPGA каждый день работаю. У нас в компании FPGA используются как для отладки процессорных ядер, так и матричных умножителей, а также dataflow процессора.
Я также один из авторов лабника по FPGA, который скоро выходит под эгидой ВШЭ МИЭМ, с участием преподавателей ИТМО и ВМК МГУ (Михаила Шуплецова, у которого я проводил семинары по FPGA еще в 2015 году). А также профориентационного курса для школьников по RTL2GDSII flow для ASIC-ов — см. habr.com/ru/post/443234
Так вот. Я просто хочу обратить внимание на один простой и очевидный факт. Если вы посмотрите на устройство FPGA cell, то вы увидите, что чтобы на FPGA реализовать некую простую логическую операцию, например И, нужно использовать в нагрузку целый логический блок с кучей дополнительных мультиплексоров, D-триггеров, избыточной сети соединений итд. (Понятно, что можно несколько логических операций паковать в один блок, но тем не менее дополнительные мультиплексоры остаются, как для определения функции cell, так и для routing/трассировки). А вот чтобы сделать это же на ASIC standard cells, нужно в несколько раз меньше транзисторов и дорожек. Разница, грубо говоря, как между компилируемым языком программирования типа Си и интерпретируемым языком программирования типа Питона. Сколько интерпретатор Питона не оптимизировать, в Си он не превратится. Другая лига.
Наглядно: Вот библиотека примитивов standard cells для ASIC. Как видно, чтобы сделать NAND gate, нужно 4 транзистора:
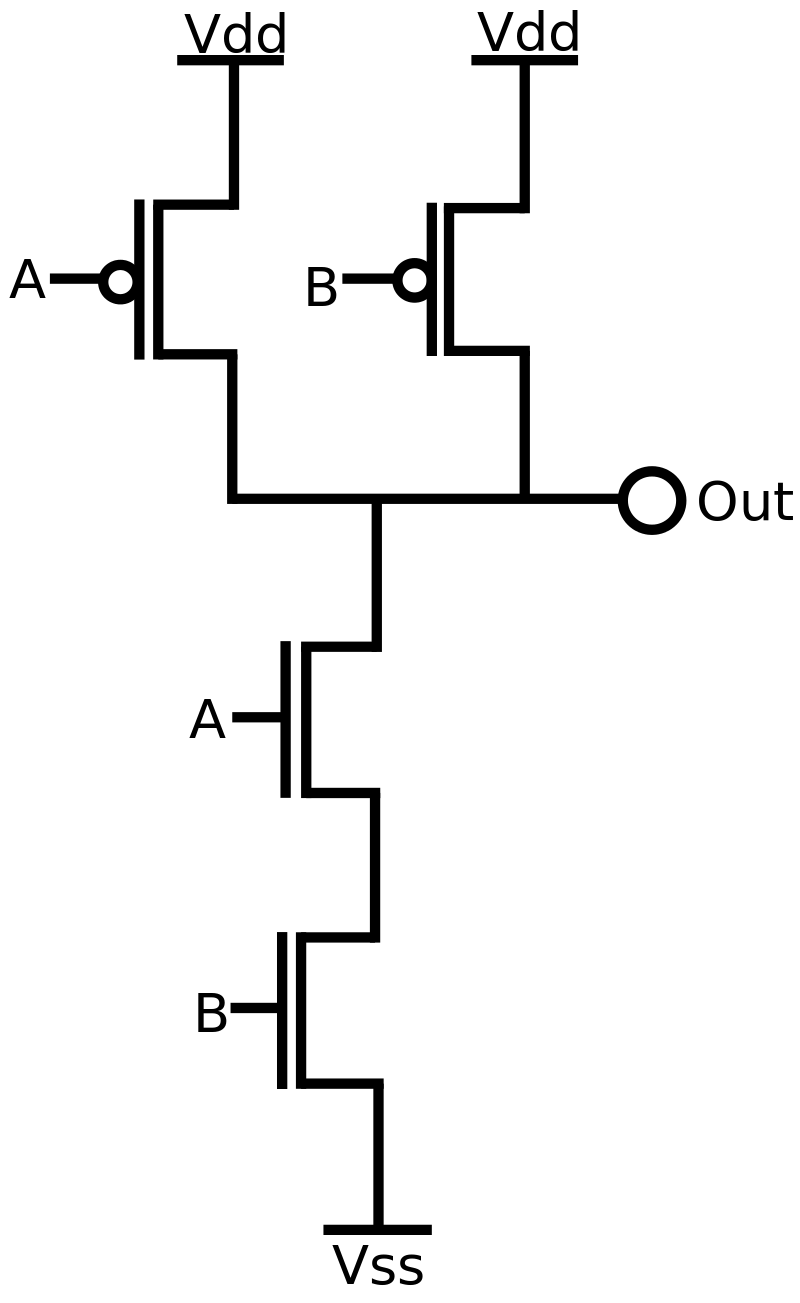
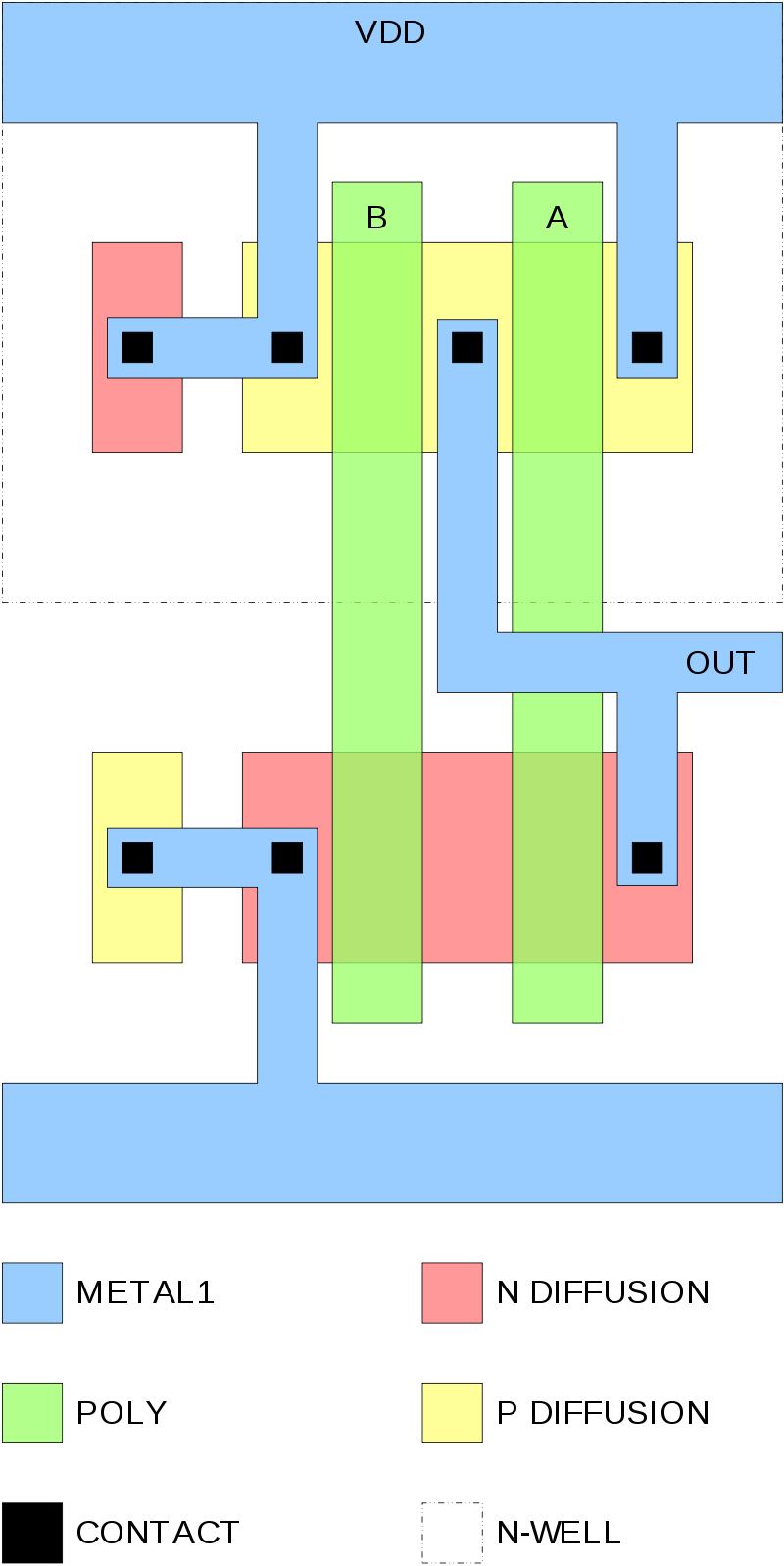
А вот слева структура одной cell в FPGA на уровне логических элементов и LUT-ов, без routing-а вокруг. В каждом квадратике много транзисторов:

Погуглите сколько транзисторов в одной FPGA cell и это исчерпает нашу дискуссию, так как речь идет о разнице на порядки. Это фундаментальная проблема с FPGA, которая никуда никогда не денется. Один и тот же дизайн, реализованный на ASIC и FPGA, всегда будет намного больше в FPGA, поглощать больше ватт в FPGA, работать с более низкой частотой в FPGA.
FPGA хороши для 1) прототипирования ASIC-ов; 2) специальных приложений которые из-за малого тиража не имеет смысла заказывать на фабрике (обработка сигналов или скажем сетевых пакетов) 3) образования.
Я также один из авторов лабника по FPGA, который скоро выходит под эгидой ВШЭ МИЭМ, с участием преподавателей ИТМО и ВМК МГУ (Михаила Шуплецова, у которого я проводил семинары по FPGA еще в 2015 году). А также профориентационного курса для школьников по RTL2GDSII flow для ASIC-ов — см. habr.com/ru/post/443234
Так вот. Я просто хочу обратить внимание на один простой и очевидный факт. Если вы посмотрите на устройство FPGA cell, то вы увидите, что чтобы на FPGA реализовать некую простую логическую операцию, например И, нужно использовать в нагрузку целый логический блок с кучей дополнительных мультиплексоров, D-триггеров, избыточной сети соединений итд. (Понятно, что можно несколько логических операций паковать в один блок, но тем не менее дополнительные мультиплексоры остаются, как для определения функции cell, так и для routing/трассировки). А вот чтобы сделать это же на ASIC standard cells, нужно в несколько раз меньше транзисторов и дорожек. Разница, грубо говоря, как между компилируемым языком программирования типа Си и интерпретируемым языком программирования типа Питона. Сколько интерпретатор Питона не оптимизировать, в Си он не превратится. Другая лига.
Наглядно: Вот библиотека примитивов standard cells для ASIC. Как видно, чтобы сделать NAND gate, нужно 4 транзистора:
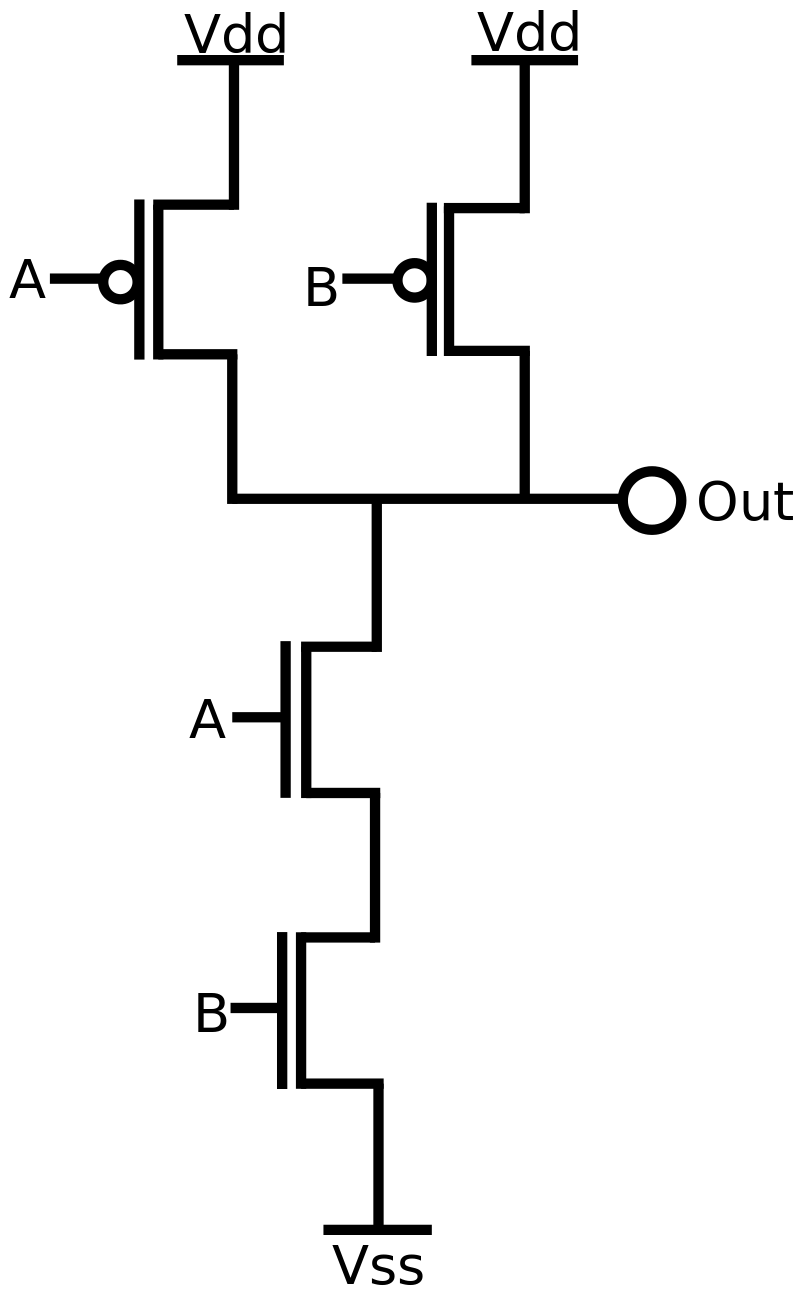

А вот слева структура одной cell в FPGA на уровне логических элементов и LUT-ов, без routing-а вокруг. В каждом квадратике много транзисторов:

Погуглите сколько транзисторов в одной FPGA cell и это исчерпает нашу дискуссию, так как речь идет о разнице на порядки. Это фундаментальная проблема с FPGA, которая никуда никогда не денется. Один и тот же дизайн, реализованный на ASIC и FPGA, всегда будет намного больше в FPGA, поглощать больше ватт в FPGA, работать с более низкой частотой в FPGA.
FPGA хороши для 1) прототипирования ASIC-ов; 2) специальных приложений которые из-за малого тиража не имеет смысла заказывать на фабрике (обработка сигналов или скажем сетевых пакетов) 3) образования.
ВМК МГУ Михаила ШуплецоваДа, знаю Михаила, конечно.
Так вот. Я просто хочу обратить внимание на один простой и очевидный факт.Откуда следует, что я его не понимаю? )
Разница, грубо говоря, как между компилируемым языком программирования типа Си и интерпретируемым языком программирования типа Питона. Сколько интерпретатор Питона не оптимизировать, в Си он не превратится.У вас отличный пример!
Смотрите — Питон заведомо менее эффективен, чем С++. И тем не менее, сегодня он прочно захватил «рынок» исследований. Причина — большое количество библиотек и фрейворков, в результате которых у вас наверху может быть Питон-ноутбук, а внизу — GPU, FPGA или любая другая эффективная железка. В результате при всей имеющейся «неэффективности» Питона — сегодня это никого не волнует. Никому в голову не придет тратить время на реализацию обучения сети на «эффективном» С++, даже несмотря на то, что результат в итоге может оказаться несколько лучше (с точки зрения компилятора).
По большому счету добавление MLP в FPGA — это как добавление библиотек в Питон будет повышать производительность, оставляя гибкость. А ведь там не только MLP.
FPGA хороши для 1) прототипирования ASIC-ов; 2) специальных приложений которые из-за малого тиража не имеет смысла заказывать на фабрике (обработка сигналов или скажем сетевых пакетов) 3) образования.FPGA уже сегодня почему-то часто используют для inference. Но вы пропускаете огромную тему training, на которую нацелились те же FPGA Speedster7t и Everest (младшие модели которых, к слову, явно заточены на inference).
Понятно, что конкуренция велика и GPU без боя не сдадутся, и TPU (и иже с ними) совершенствуются быстро. Но шанс у FPGA, очевидно, есть.
Почему Microsoft выбрали FPGA для Catapult? Непонимание очевидного факта их неэффективности? )
А если текущие заявления производителей FPGA (по планируемой производительности) подтвердятся и они займут ощутимую долю в облаках? Вы исключаете такой сценарий?
Прошу прощения за сознательную ироничность и провокационность вопросов )
Смотрите — Питон заведомо менее эффективен, чем С++. И тем не менее, сегодня он прочно захватил «рынок» исследований. Причина — большое количество библиотек и фрейворков, в результате которых у вас наверху может быть Питон-ноутбук, а внизу — GPU, FPGA или любая другая эффективная железка.
Не совсем, Питон захватил свою нишу в высоконагруженных приложениях во многом благодаря его нахождения поверх самой реализации примитивов этих приложений на нативных языках. А в случае FPGA, никакого «нативного» бэкенда с ASIC'ми нет и это надо неизбежно принять: FPGA фундаментально медленнее/менее эффективны, чем ASIC'и.
FPGA хороши для 1) прототипирования ASIC-ов; 2) специальных приложений которые из-за малого тиража не имеет смысла заказывать на фабрике (обработка сигналов или скажем сетевых пакетов) 3) образования.
Но как мне, человеку с малым опытом (опыт исследований в области меньше года пока) видится, из-за возможности быстрой реализации и «software defined hardware», FPGA находят очень много применений в традиционных Computer Science областях:
- In-network processing (было озвучено)
- Глубокое обучение, пока inference (было озвучено)
- Системы хранения дынных. Тут большой выигрыш получается из-за возможности разместить сетевой стек и логику базы данных на одном чипе — очень важно для уменьшения latency. В частности, люди используют FPGA для реализации систем хранения данных Ключ-Значение (Key-value store) и графовых баз данных. Посмотрите на один из форков Microsoft Catapult: www.microsoft.com/en-us/research/project/honeycomb
- «Традиционные» алгоритмы баз данных тоже неплохо ускоряются на FPGA
- RDMA системы (программируемые NIC уже достаточно давно основаны и на FPGA, в том числе
- И вагончик более специализированных применений: биоинформатика, финансовая аналитика (HFT, например), сжатие данных и тд...
И все это сейчас без проблем можно найти на оффлоаде в одном облаке и в примерно одно время. Конечно, если сделать ASIC под каждый пример использования и напичкать ими датацентры, то все будет гораздо круче, чем с FPGA, но это просто не реалистично. А FPGA можно быстро реконфигурировать под текущую нагрузку на центр. Этот аргумент мне в последнее время довелось очень часто слышать.
Салют, комрэйд. Я проектировал один из таких, но заточеный только под расчеты ИНС. Чрезмерно большие вычислительные мощности ставить пока бессмысленно из-за ограничений объема накристальной памяти и скорости обмена данными с DDR. Для сетей с «тяжелыми» слоями увеличение количества АЛУ в два раза при неизменной пропускной способности канала связи с DDR требует четырехкратного увеличения размеров памяти. Сейчас быстро развиваются новые архитектуры сетей, требующие с потоками данных такой же гибкости обращения, какой обладают CPU по отношению к обычным числам (RAM модель памяти, условный оператор и условное ветвление программ). Скорее всего в ближайшее время вы увидите сильно изменившиеся архитектуры сетей, оптимальный расчет которых возможен на сильно нестандартных, в плане вычислительной модели, процессорах. Будущее редко бывает таким, как его представляют себе писатели-фантасты.
вот именно из за проблем с памятью мне больше нравится новый stratix-10-mx с его HBM2.
Хотелось бы узнать подробности на практике если кто либо что на нём реализовывал. Теоретически обычно при портировании нейросетки 90+% времени идёт именно на оптимизацию памяти — побольше во внутреннюю память уместить и поменьше внешнюю вызывать. А тут сразу на борту гигабайты сверхбыстрой памяти по спец протоколу да ещё с много тысяч килобитной шириной шины.
Хотелось бы узнать подробности на практике если кто либо что на нём реализовывал. Теоретически обычно при портировании нейросетки 90+% времени идёт именно на оптимизацию памяти — побольше во внутреннюю память уместить и поменьше внешнюю вызывать. А тут сразу на борту гигабайты сверхбыстрой памяти по спец протоколу да ещё с много тысяч килобитной шириной шины.
Интересная и полезная статья. Моя ставка на Тесла К20Х и р106-100 как дешевую версию 1060 6 гб себя оправдывает.
преобразование цветовых пространств — типичное перемножение матриц — было в каждом цветном телевизоре до середины 90-хГде это было, простите? Не в одном из трёх стандартов ЦТВ не припоминаю…
Речь про аналоговое преобразование цветовых пространств (см., например, en.wikipedia.org/wiki/YUV), которое было на лампах в телевизорах с 60-х, потом на транзисторах, и только потом в цифре.
Ничего особо нового, «вычисления» те ещё en.wikipedia.org/wiki/NTSC, на резисторах. В простом микшерском пульте таких вычислений больше десятка. Подъемные машины на шахтах используют вообще двойное интегрирование!
Про гугл и хуавей конечно интересно, но хотелось бы ещё узнать как идет процесс у нас в Сколково, там финансирование, наверное, не меньше :)
Я бы поставил денег на то, что финансирование этой теме мы в Сколково порядков на пять меньше, чем в Хуавее, но не уверен, что кто-то может подтвердить точные цифры)
Но энивэй, в Сколково денег на инновации ничтожно мало.
Но энивэй, в Сколково денег на инновации ничтожно мало.
В Сколково сети применяют, а в комментариях были (на удивление) практически исключительно железячники.
Вообще из моих разговоров — те, кто применяет сетки (особенно глубоко теоретически) редко даже задумываются над тем, что там внизу в железе. Появится железка, где быстрее будет по разумной цене — будут смотреть. Не появятся — направлений программного ускорения много.
Ну и денег в Сколково меньше, чем у Гугла, конечно )
Вообще из моих разговоров — те, кто применяет сетки (особенно глубоко теоретически) редко даже задумываются над тем, что там внизу в железе. Появится железка, где быстрее будет по разумной цене — будут смотреть. Не появятся — направлений программного ускорения много.
Ну и денег в Сколково меньше, чем у Гугла, конечно )
Ну железки для ускорения делаются. Правда отечественного там как правило только схема и разводка платы, иногда ещё изготовление самой платы и монтаж встречаются.
Большое спасибо за материал, сейчас работаю на диссером по распознаванию объектов медицинских данных, очень пригодились материалы по размерам памяти для глубоких нейросетей, а также очень круто описаны узкие места проблемы — достаточно фундаментально проработаны современные косяки производительности и представлена наглядная динамика. Верю, что мтарый добрый метод индукции и оптимизация кода с точки зрения алгоритмического программирования снова возродится как культура в 80х.
только характер оптимизации сильно изменится скорее всего (уменьшение разрядности при минимальном падении точности)
У меня есть карты, стики, Edge TPU Board и пр. от www.sophon.ai и гугла, было бы интересно их сравнить тоже, мог бы дать на тест или организовать удалённый доступ.
Большое спасибо за статью. Позвольте один noob question: в чем же все-таки принципиальное отличие решений ASIC и Analog?
В том, что ASIC - это хорошо проработанный и активно используемый подход, а аналоговые схемы - это новый пока недостаточно проработанный (но очень перспективный) подход.
Analog ASIC — тоже ASIC)
Принципиальное различие между цифровым и аналоговым подходом состоит в том, как перемножать матрицы — в цифровом виде или в аналоговом. С цифрой все понятно, а в аналоге строятся какие-то схемы, способные физически перемножать и суммировать напряжения и токи. Предполагается, что такой подход может быть намного более энергоэффективноэым, чем громоздкие цифровые решения.
Принципиальное различие между цифровым и аналоговым подходом состоит в том, как перемножать матрицы — в цифровом виде или в аналоговом. С цифрой все понятно, а в аналоге строятся какие-то схемы, способные физически перемножать и суммировать напряжения и токи. Предполагается, что такой подход может быть намного более энергоэффективноэым, чем громоздкие цифровые решения.
Sign up to leave a comment.
Аппаратное ускорение глубоких нейросетей: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP и другие буквы