В предыдущей статье рассматривался подход, который мы применили к вопросу вычислительной (агрегирующей) обработки данных для визуализации на интерактивных дэшбордах. Статья затрагивала этап доставки информации от первичных источников к пользователям в разрезе аналитических кейсов, позволяющих как бы вращать информационный куб. Представленная модель преобразования данных на лету создает абстракцию, предоставляя единый формат запроса и конструктор для описания вычислений, агрегации и интеграции всех подключенных типов источников – таблиц баз данных, сервисов и файлов.
Перечисленные источники скорее относятся к структурированным, подразумевая предсказуемость формата данных и однозначность процедур их обработки и визуализации. Но для аналитика неструктурированные данные представляют не меньший интерес, который при появлении первых результатов иногда завышает ожидания от подобных систем. Аппетит приходит во время еды, и потеря осторожности может в точности повторить сказку...
– Ещё! Ещё золота!
Но его хрип уже был еле слышен и в глазах проявился ужас
(сказка «Золотая Антилопа»)

Под катом, в статье, изложены ключевые особенности и устройство многоролевого кластера и поведенческого краулера виртуальными пользователями, которые автоматизируют рутину по сбору информации со сложных интернет-ресурсов. И только затрагивается вопрос предела таких систем.
Любой гипотетический интернет-ресурс, информацию из которого нам требуется извлечь, при рассмотрении методов краулинга можно расположить на шкале с двумя крайностями – от простых статических ресурсов и API до динамических интерактивных сайтов, требующих от пользователя высокой вовлеченности. К первым можно отнести старое поколение поисковых роботов (современные, как минимум, научились обрабатывать JavaScript), ко вторым – системы с браузерными фермами и алгоритмами, имитирующими работу пользователя или привлекающие его при сборе информации.
Другими словами, технологии краулинга можно разместить на шкале сложности:

С одной стороны, под сложностью источника можно понимать цепочку действий, необходимых для получения первичной информации, с другой – технологии, которые необходимо применить для получения машиночитаемых данных, пригодных для анализа.
Даже кажущееся простым извлечение текстов из статических страниц, на практике не всегда выполняется тривиально – требуется либо разрабатывать и поддерживать правила планаризации HTML для всех типов страниц, либо автоматизировать и выдумывать эвристики и сложные решения. В какой-то мере структурирование упрощается развитием микроразметки (в частности, Schema.org, RDFa, Linked Data), но только в узких частных случаях, для загрузки карточек компаний, товаров, визиток и других продуктов поисковой оптимизации и открытых данных.
Ниже мы умышленно сузим область рассмотрения и остановимся на технологической составляющей подмножества браузерных краулеров, предназначенных для загрузки информации со сложных сайтов, в частности социальных сетей – это именно тот подходящий случай, когда другие простые способы краулинга не срабатывают.
Информационная лента
Рассмотрим подход, который сводит задачу сбора информации из социальных сетей к формированию информационной timeline ленты – обновляемой коллекции или потока объектов с атрибутами и временными метками. Перечень типов объектов и их атрибутов разный, изменяемый и расширяемый, например: посты, лайки, комментарии, репосты и другие сущности, которые добавляются в систему разработчиками и опраторами-аналитиками, а загружаются краулерами.
Так как лента представляет собой поток структурированных объектов, встает вопрос ее наполнения. Мы поддержали два типа лент:
- простая лента, которая наполняется контентом из фиксированных источников;
- тематическая лента, наполняемая контентом согласно ключевым словам, фразам и поисковым выражениям.
Пример простой ленты с фиксированными источниками (задаются списки URL профилей и страниц):

Простой тип ленты предполагает периодический обход указанных профилей и страниц в различных социальных сетях с заданной глубиной обхода и загрузкой выбранных пользователем объектов. По мере наполнения, лента становится доступной для просмотра, анализа и выгрузки данных:

Тематическая лента является расширением простой, обеспечивает полнотекстовый поиск и фильтрацию загружаемых в ленту объектов. Управление набором источников ленты и глубиной их обхода система производит автоматически, анализируя релевантность и связи источников. Такая особенность реализации обусловлена отсутствием или "странной" работой встроенного поиска по ключевым словам в социальных сетях. Даже когда такая функция доступна, то чаще всего результаты выдаются не полностью и по некоторому внутреннему алгоритму, который совершенно не сочетается с требованиями к краулеру.
За управление лентой в системе отвечает специальный механизм, обладающий определённой эвристикой – он анализирует данные и историю, добавляет релевантные источники (ленты профилей и сообществ), на которых либо упоминаются заданные выражения, либо они как-то связаны с таковыми, и удаляет нерелевантные.
Пример тематической ленты:

В дальнейшем ленты используются как источник в аналитических преобразованиях с последующей визуализацией результатов, например, в виде графа:

В одних случаях производится потоковая обработка поступающих объектов с сохранением в специализированные целевые коллекции или выгрузкой через REST API с целью использования собранного контента в сторонних системах (пример). В других выполняется блочная обработка по таймеру. Сценарий обработки оператор описывает скриптом или конструирует процесс с управляющими сигналами и функциональными блоками, например:

Пул задач
Активные ленты задают первичный пул задач, каждая из которых формирует связанные задачи. Например, одна задача обхода профиля может породить множество связанных подзадач – обход друзей, подписчиков или загрузка новых постов и детальной информации, и т.п. Также существует этап предварительной обработки новых объектов тематической ленты, который также формирует задачи, связанные с новыми релевантными источниками.
В итоге мы получаем огромное число разнотипных задач, связанных между собой, имеющих приоритеты, время и условия выполнения – всем этим зоопарком нужно правильно управлять, чтобы не возникали ситуации, при которых одни задачи перетягивали бы на себя все ресурсы кластера во вред задачам от других лент.
Для разрешения возникающих противоречий в системе реализованы разделяемые виртуальные ресурсы и механизм динамической расстановки приоритетов, которые учитывают типы задач, текущее время и имеют вероятность запуска в форме "купола". В общих словах – приоритет к определенному моменту становится максимальным, но вскоре угасает, задача "прокисает", но при определенных обстоятельствах может снова вырасти.
Формула такого купола учитывает несколько факторов, в частности: приоритет родительских задач, релевантность связанного источника и время последней попытки (при повторном обходе для отслеживания изменений или при возникновении ошибки).
Виртуальные пользователи
Под виртуальным пользователем в широком смысле можно понимать максимальную имитацию действий человека, в практическом – набор свойств, которыми должен обладать краулер:
- исполнять код страницы с использованием тех же средств, что и пользователь – ОС, браузер, UserAgent, плагины, наборы шрифтов и прочее;
- взаимодействовать со страницей, имитируя работу человека с клавиатурой и мышью – перемещать курсор по странице, совершать случайные движения, паузы, нажимать на клавиши при печати текста и прочее (не стоит забывать и о мобильных устройствах);
- взаимодействовать с центром принятия решений, учитывающим контекст и контент страницы:
- учитывать дубликаты, релевантность объектов на странице, глубину обхода, временные рамки и прочее;
- реагировать на нестандартные ситуации – в случае появления капчи или ошибки формировать запрос и ожидать решения либо с использованием стороннего сервиса, либо с привлечением оператора системы;
- иметь правдоподобную легенду – сохранять историю посещений и куки (профиль браузера), использовать определенные IP адреса, учитывать периоды наибольшей активности (например, утро-вечер или обед-ночь).
В идеализированном представлении один виртуальный пользователь может иметь несколько аккаунтов, использовать несколько браузеров в разные периоды времени и быть связанным с другими виртуальными пользователями, а также обладать поведением и привычками интернет-серфинга, свойственными человеку.
Например, представим такую ситуацию – виртуальный пользовать использует один браузер и IP как бы на работе (тот же IP может использоваться "коллегами"), другой браузер и IP как бы дома (их же используют "соседи"), а еще время от времени на мобильнике. При таком взгляде на проблему противодействие автоматизированному сбору со стороны интернет сервисов представляется задачей нетривиальной и, возможно, нецелесообразной.
На практике, всё гораздо проще – борьба с краулерами имеет волновой характер и включает небольшой набор приемов: ручное модерирование, анализ поведения пользователя (частота и однотипность действий) и показ капчи. Кларулер, обладающий хотя бы в какой-то мере свойствами из перечня выше, вполне реализует концепцию виртуальных пользователей и при должном внимании оператора долгое время может выполнять свою функцию, оставаясь "неуловимым Джо".
А как же этическая и юридическая сторона использования виртуальных пользователей?
Чтобы не заиграться понятиями публичных и персональных данных, – у каждой из сторон есть свои весомые аргументы, – коснемся только принципиальных моментов.
Автоматизированная публикация контента, спам рассылка, регистрация аккаунтов и прочая "активная" деятельность виртуальных пользователей легко может рассматриваться как противозаконная или затрагивающая интересы третьих лиц. В связи с этим, в системе реализован подход, при котором виртуальные пользователи являются только любопытными наблюдателями, представляющими пользователя (своего оператора) и выполняющие рутину по сбору информации вместо него.
Управление разделяемыми виртуальными ресурсами
Как было описано выше, виртуальный пользователь представляет собой собирательную сущность, которая в процессе работы испольует несколько системных и виртуальных ресурсов. Некоторые ресурсы используются единолично, а другие являются общими и используются несколькими виртуальными пользователями, например:
- адрес выходного узла (внешний IP) – связан с одним или несколькими виртуальными пользователями;
- профиль браузера – связан с единственным виртуальным пользователем;
- вычислительный ресурс – связан с сервером, задает ограничения сервера в целом и для каждого типа задач;
- виртуальный экран – задает ограничения сервера, но используется виртуальным пользователем.
Каждый виртуальный ресурс имеет тип и группу экземпляров, называемых слотами. На каждом узле кластера определена конфигурация виртуальных ресурсов и слотов, которые добавляютя в пул виртуальных ресурсов и доступны всем узлам кластера. При этом для одного типа виртуального ресурса может быть добавлено как фиксированное так и переменное число слотов.
Каждый слот может иметь атрибуты, которые будут использованы как условия при связывании и выделении ресурсов. Например, каждого виртуального пользователя мы можем привязать к определенным типам задач, серверам, IP адресам, аккаунтам, периодам наибольшей активности краулинга и другим произвольным атрибутам.
В общем случае, жизненный цикл ресурса состоит из определенных этапов:
- При запуске узла кластера в общем пуле виртуальных ресурсов регистрируются дополнительные открытые слоты, а также связи между ресурсами;
- При запуске задачи диспетчером из пула виртуальных ресурсов подбирается и блокируется подходящий свободный слот. В свою очередь, блокирование родительского ресурса приводит к блокированию связанных ресурсов, а в случае отсутствия свободных слотов формируется отказ;
- По завершению задачи слот основного ресурса и связанные с ним слоты освобождаются.
Помимо заданных в конфигурации узла, также существуют пользовательские виртуальные ресурсы – сущности, с которыми работает оператор системы. В частности, оператор использует интерфейс реестра виртуальных пользователей, который поддерживает сразу несколько полезных функций:
- управление реквизитами и дополнительными атрибутами, указывающими на специфику использования, в частности, виртуальных пользователей можно поделить на группы и использовать в разных целях;
- отслеживание статуса и статистики работы виртуальных пользователей;
- подключение к виртуальному экрану – отслеживание работы в реальном времени, выполнение действий в браузере вместо виртуального пользователя (виджет удаленного рабочего стола).
Пример реестра пользовательских виртуальных ресурсов:

Классный кейс, который не прижился
В дополнение к информационным лентам в качестве "киллер-фитчи" нами был разработан прототип поискового графа для выполнения сложного поиска и проведения интернет-расследований. Основная идея заключается в построении визуального графа, в котором узлами являются шаблоны объектов (персоны, организации, группы, публикации, лайки и т.п.), а связями шаблоны связей между найденными объектами.
Пример простого поискового графа из персон и связей между ними:

Данный подход предполагает, что поиск начинается с минимума известной информации. После первичного поиска пользователь исследует результаты и постепенно добавляет в поисковый граф дополнительные условия, сужая выборку и увеличивая глубину обхода и точность результата. В конечном итоге граф принимает вид, при котором каждый из узлов представляет собой отдельную информационную ленту с результатами. Такую ленту также можно использовать как источник для дальнейшего анализа и визуализации на дэшбордах и виджетах.

В качестве примера можно рассмотреть несколько простых кейсов:
- найти всех друзей персоны с заданным именем;
- найти все посты друзей персоны с заданным именем и другими атрибутами;
- найти всех подписчиков страниц, на которых упоминаютя заданные ключевые фразы, или собрать окружение вокруг определенных постов или авторов;
- или найти пересечения – авторов комментариев ко всем постам, которые написаны авторами, однажды опубликовавшими посты на определенные темы.
Когда мы анонсировали разработку такой фитчи, наши заказчики и партнеры горячо поддерживали такую идею, она представлялась именно тем, чего сильно не хватает в существующих похожих решениях. Но по завершению рабочего прототипа, на практике оказалось, что клиенты не готовы изменять свои внутренние процессы, а интернет-расследования скорее рассматривались как то, что может пригодиться, если вдруг потребуется. При этом с технологической стороны – функционал серьезный и требовал дальнейшей доработки и поддержки. В результате из-за отсутствия спроса и практической заинтересованности наших партнеров, данную фитчу пришлось временно заморозить до лучших времен.
Перевоплощение
С учетом текущего вектора развития наших решений данная фитча по-прежнему кажется актуальной, но с технической стороны уже видится по-другому. Скорее как расширение функционала Cubisio, а именно редактора модели предметных областей и редактора процессов обработки данных, которые пока реализованны в виде прототипа, но предусматривают подобный подход в обобщенном виде.
Пример онтологической модели предметной области "Социальные сети" (по клику откроется изображение редактора):
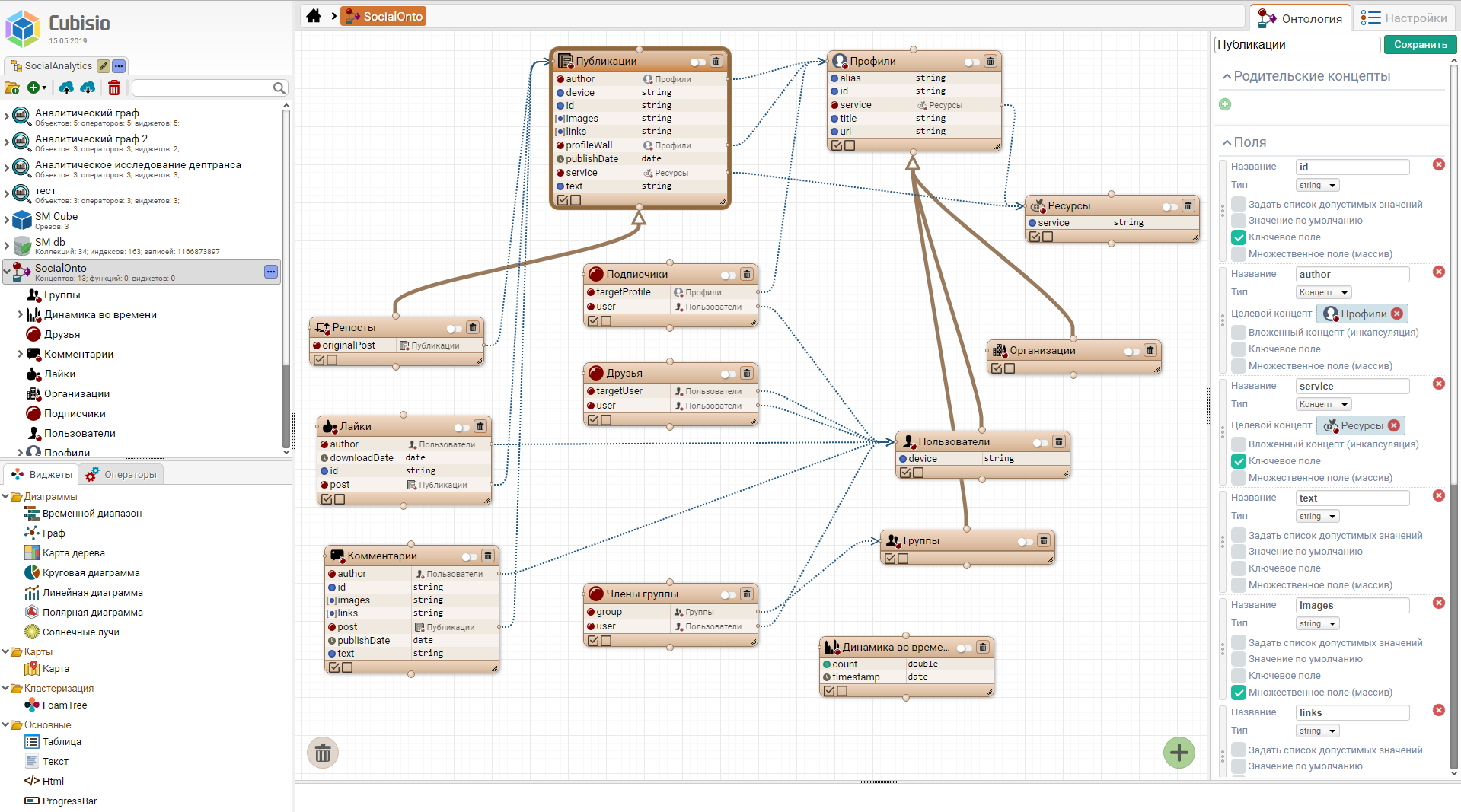
Пример поисково-аналитического графа, основанного на вышеприведенной онтологии (по клику откроется изображение редактора):
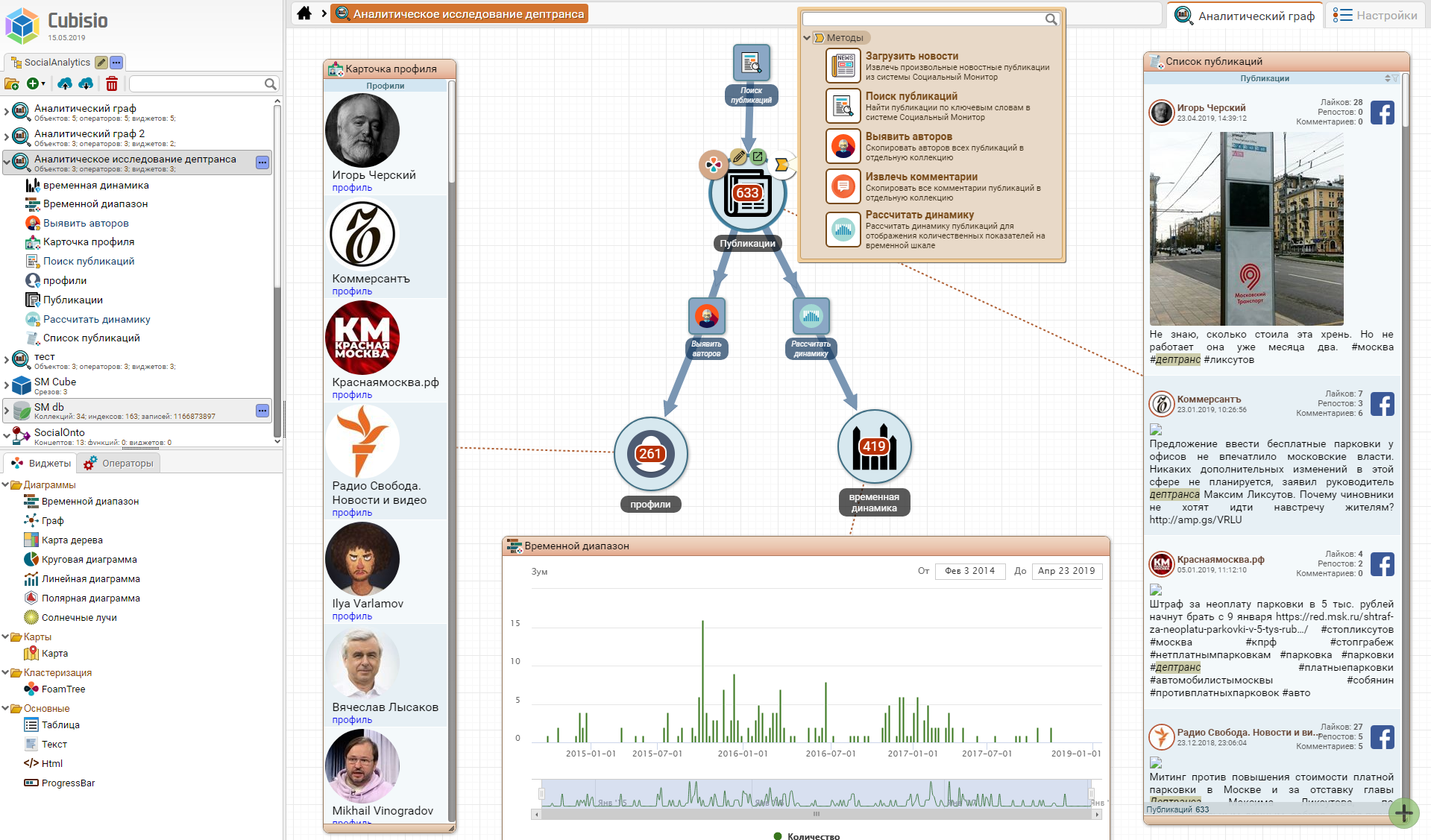
Технологический стек кластера
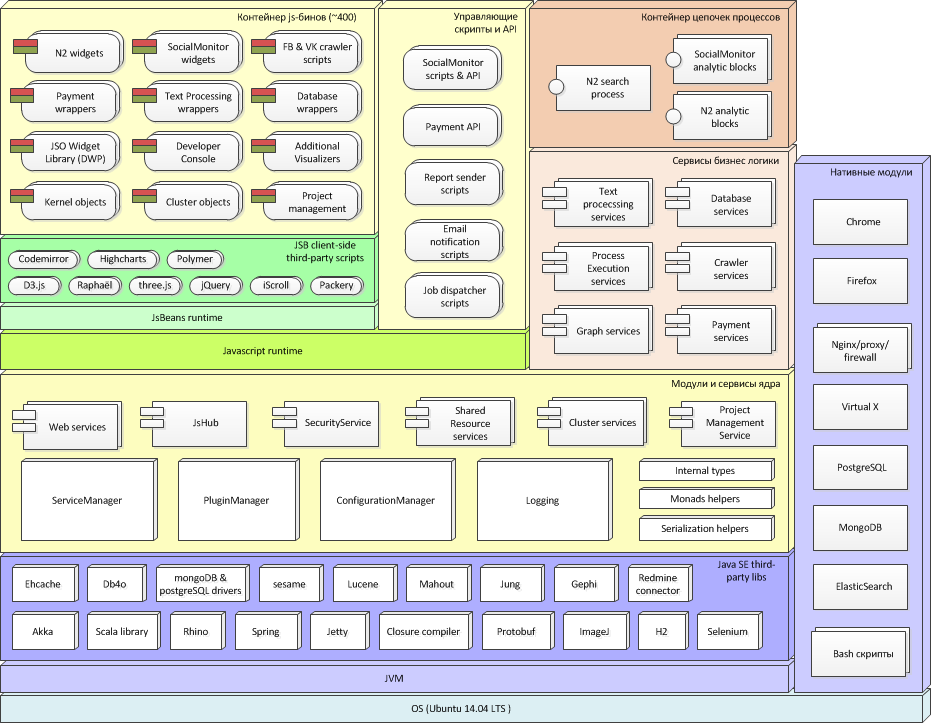
Описанная система была разработана совместно с платформой (мы ее называем dWires) несколько лет назад, функционирует и используется до сих пор. Главные удачные решения естественным образом перекочевали в наши новые разработки. В частности, описанная платформа представляет собой первое поколение конструктора информационно аналитических систем, от которого отпочковалась платформа jsBeans и наши другие разработки.
Если коротко, то в основе системы лежит Akka кластер, интерпретатор Rhino и встроенный веб-сервер Jetty. Некоторые полезные особенности архитектуры можно увидеть на схеме выше. Но стоит отметить, что особого внимания, на наш взгляд, тут заслуживает только концепция JavaScript-бинов и реализующий ее коммуникационный движок, которые легли в основу jsBeans.
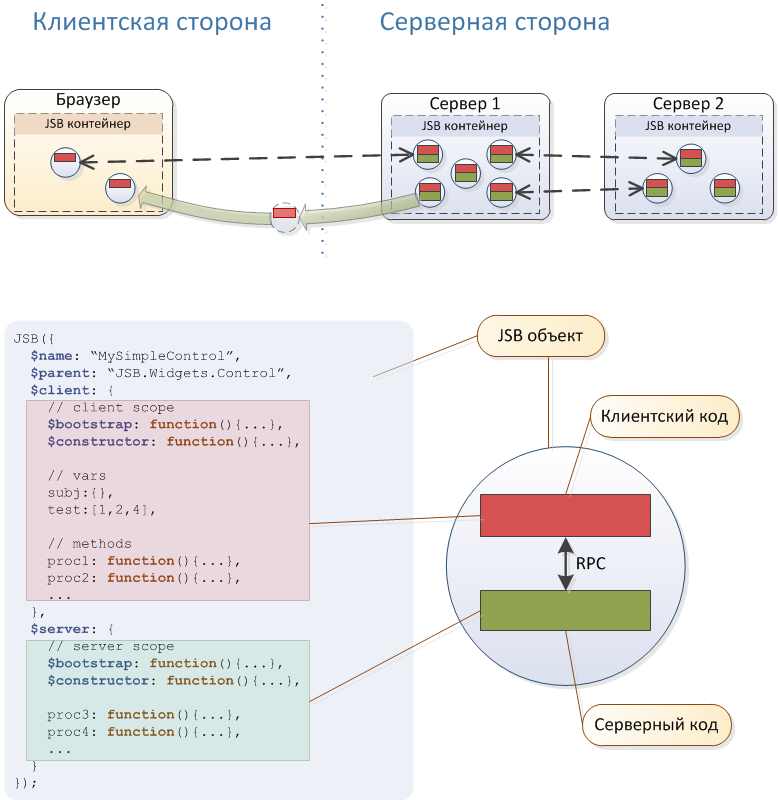
В остальном, с архитектурной точки зрения в данной системе ничего уникального внедрено не было и не планировалось – все решения заведомо основывались на интеграции знакомых разработчикам и предсказуемых в эксплуатации сторонних компонентов.
Ядро
Основная часть ядра написана на Java. На акторах реализована плагинная и сервисная шина, а также ключевые сервисы, главные из которых – веб-сервер и движок JavaScript. На JavaScript реализован весь интерфейс системы (клиентский и серверный код), а также ключевые проектные скрипты, описывающие бизнес логику, пользовательские и краулерные сценарии. Вокруг ядра реализовано всё необходимое окружение – шина сообщений, отладчик, консоль администрирования, шина доступа к данным, работа с текстом, библиотека веб-компонент и многое другое.
Кластер
Управление Akka кластером и контроль входа-выхода узлов запрограммированы в специальном сервисе. Из-за некоторых особенностей режимов работы кластера стандартные Akka Cluster сценарии не соответствовали ожиданиям, и наши виртуальные пользователи подвисали в самый неподходящий момент. В результате доработки связь узлов кластера и виртуальных ресурсов стала неразрывной, появилась возможность "на горячую" (при работающих краулерах и пользователях) вводить в работу новые узлы и производить обслуживание.
Краулеры
Ферма виртуальных пользователей реализована на основе Selenium WebDriver с некоторыми важными доработками, например: управление сохраняемыми профилями браузеров и сетевым доступом, а также дополнительная абстракция, реализующая API виртуальных пользователей и важные фитчи. Запуск WebDriver и браузера в некоторой мере переписан также с целью обеспечить неразрывную работу с виртуальными ресурсами (профиль браузера, внешний IP и виртуальный экран).
Каждый виртуальный экран представляет несколько модулей (в разное время использовались разные сторонние компоненты):
- сам экран, например, Xvfb;
- локальный VNC сервер, например, x11vnc;
- VNC Web Viewer для удаленного управления оператором, например, связка noVNC сервера и его веб-компонента.
Хранилища
В качестве основной СУБД для системных персистентных индексов и данных выбрана MongoDB, которая на каждом узле присутствует в двух ролях – локальное и глобальное хранилище. В качестве полнотекстового индекса использован Elasticsearch, работающий в связке с MongoDB. Также в некоторых сервисах используются другие базы данных и хранилища (H2, EhCache, Db4o).
Администрирование
Автоматическое развертывание узлов на "голую ОС", управление зоопарком компонент, обновления и администрирование выполняется набором bash скриптов, работающих через единый интерфейс (команды администратора). Такой подход оказался самым простым и понятным. Для каждой конфигурации развертывания используется универсальный дистрибутив и уникальный набор конфигурационных файлов, участие администратора минимально.
В заключение
При беглом взгляде описанный выше подход использования виртуальных пользователей для автоматизации загрузки информации со сложных интернет ресурсов кажется универсальным и предоставляет почти безграничные возможности массовой загрузки любой информации, доступной обычному пользователю.
Но на практике не всё так радужно. Показанная выше диаграмма сложности краулеров работает в отношении еще одного проявления – существует нижняя грань и технологический потолок по скорости и объемам загружаемой информации. Такой подход не предусматривает загрузку миллионов объектов в сутки без развертывания дорогого кластера из десятков серверов, а в случае с простыми задачами получается "стрельба из пушки по воробьям".
Всё это накладывает некоторые ограничения и позволяет комплексно решать задачу сбора информации из интернет источников только в сочетании с другими подходами, в целом обеспечивая золотую середину.
Мальчик поблагодарил Золотую антилопу за свое спасение и они вместе отправились в джунгли, где никто не просил золота и каждый верил в доброту
(сказка «Золотая Антилопа»)
