Введение
Разворачивая очередную систему, столкнулись с необходимостью обрабатывать большое количество разнообразных логов. В качестве инструмента выбрали ELK. В данной статье пойдёт речь о нашем опыте настройки этого стека.
Не ставим цели описать все его возможности, но хотим сконцентрироваться именно на решении практических задач. Вызвано это тем, что при наличии достаточно большого количества документации и уже готовых образов, подводных камней достаточно много, по крайней мере у нас они обнаружились.
Мы разворачивали стек через docker-compose. Более того, у нас был хорошо написанный docker-compose.yml, который позволил нам практически без проблем поднять стек. И нам казалось, что победа уже близка, сейчас немного докрутим под свои нужды и всё.
К сожалению, попытка донастроить систему на получение и обработку логов от нашего приложения, с ходу не увенчалась успехом. Поэтому, мы решили, что стоит изучить каждый компонент отдельно, а потом уже вернуться к их связям.
Итак, начали с logstash.
Окружение, развёртывание, запуск Logstash в контейнере
Для развёртывания используем docker-compose, описанные здесь эксперименты проводились на MacOS и Ubuntu 18.0.4.
Образ logstash, который был прописан у нас в исходном docker-compose.yml, это docker.elastic.co/logstash/logstash:6.3.2
Его мы будем использовать для экспериментов.
Для запуска logstash мы написали отдельный docker-compose.yml. Можно конечно было из командной строки образ запускать, но мы ведь конкретную задачу решали, где у нас всё из docker-compose запускается.
Кратко про конфигурационные файлы
Как следует из описания, logstash можно запускать как для одного канала, в этом случае, ему нужно передать файл *.conf или для нескольких каналов, в этом случае ему надо передать файл pipelines.yml, который, в свою очередь, будет ссылаться на файлы .conf для каждого канала.
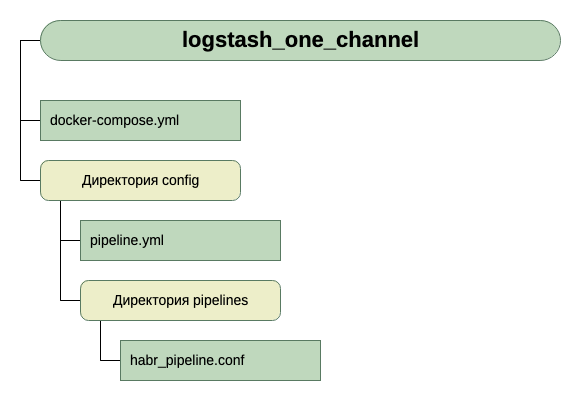
Мы пошли по второму пути. Он нам показался более универсальным и масштабируемым. Поэтому, мы создали pipelines.yml, и сделали директорию pipelines, в которую будем класть файлы .conf для каждого канала.
Внутри контейнера есть ещё один конфигурационный файл — logstash.yml. Мы его не трогаем, используем как есть.
Итак, структура наших каталогов:
Для получения входных данных пока считаем, что это tcp по порту 5046, а для вывода будем использовать stdout.
Вот такая простая конфигурация для первого запуска. Поскольку ведь начальная задача — запустить.
Итак, у нас есть вот такой docker-compose.yml
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
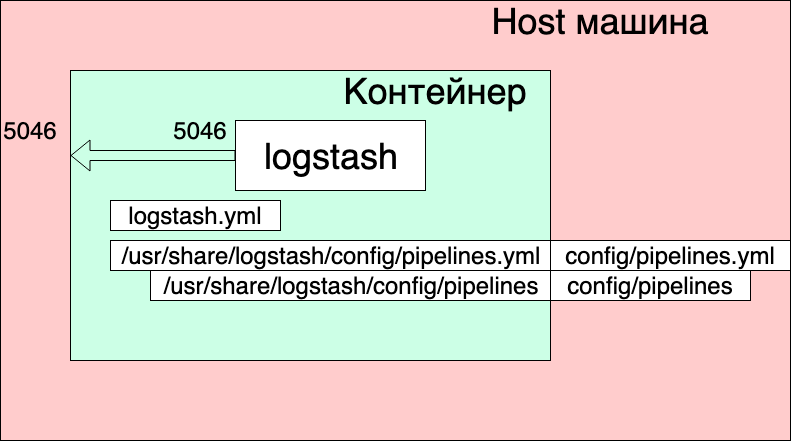
Что мы здесь видим?
- Networks и volumes были взяты из исходного docker-compose.yml (тот где целиком стек запускается) и думаю, что сильно здесь на общую картинку не влияют.
- Мы создаём один сервис (services) logstash, из образа docker.elastic.co/logstash/logstash:6.3.2 и присваиваем ему имя logstash_one_channel.
- Мы пробрасываем внутрь контейнера порт 5046, на такой же внутренний порт.
- Мы отображаем наш файл настройки каналов ./config/pipelines.yml на файл /usr/share/logstash/config/pipelines.yml внутри контейнера, откуда его подхватит logstash и делаем его read-only, просто на всякий случай.
- Мы отображаем директорию ./config/pipelines, где у нас лежат файлы с настройками каналов, в директорию /usr/share/logstash/config/pipelines и тоже делаем её read-only.
Файл pipelines.yml
- pipeline.id: HABR
pipeline.workers: 1
pipeline.batch.size: 1
path.config: "./config/pipelines/habr_pipeline.conf"
Здесь описан один канал с идентификатором HABR и путь к его конфигурационному файлу.
И наконец файл «./config/pipelines/habr_pipeline.conf"
input {
tcp {
port => "5046"
}
}
filter {
mutate {
add_field => [ "habra_field", "Hello Habr" ]
}
}
output {
stdout {
}
}
Не будем пока вдаваться в его описание, пробуем запустить:
docker-compose up
Что мы видим?
Контейнер запустился. Можем проверить его работу:
echo '13123123123123123123123213123213' | nc localhost 5046
И видим в консоли контейнера ответ:
Но при этом, видим также:
logstash_one_channel | [2019-04-29T11:28:59,790][ERROR][logstash.licensechecker.licensereader] Unable to retrieve license information from license server {:message=>«Elasticsearch Unreachable: [http://elasticsearch:9200/][Manticore::ResolutionFailure] elasticsearch», …
logstash_one_channel | [2019-04-29T11:28:59,894][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>".monitoring-logstash", :thread=>"#<Thread:0x119abb86 run>»}
logstash_one_channel | [2019-04-29T11:28:59,988][INFO ][logstash.agent ] Pipelines running {:count=>2, :running_pipelines=>[:HABR, :".monitoring-logstash"], :non_running_pipelines=>[]}
logstash_one_channel | [2019-04-29T11:29:00,015][ERROR][logstash.inputs.metrics ] X-Pack is installed on Logstash but not on Elasticsearch. Please install X-Pack on Elasticsearch to use the monitoring feature. Other features may be available.
logstash_one_channel | [2019-04-29T11:29:00,526][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
logstash_one_channel | [2019-04-29T11:29:04,478][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://elasticsearch:9200/, :path=>"/"}
logstash_one_channel | [2019-04-29T11:29:04,487][WARN ][logstash.outputs.elasticsearch] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/][Manticore::ResolutionFailure] elasticsearch»}
logstash_one_channel | [2019-04-29T11:29:04,704][INFO ][logstash.licensechecker.licensereader] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://elasticsearch:9200/, :path=>"/"}
logstash_one_channel | [2019-04-29T11:29:04,710][WARN ][logstash.licensechecker.licensereader] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/][Manticore::ResolutionFailure] elasticsearch»}
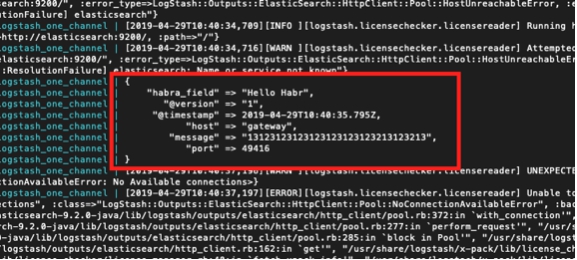
И наш лог всё время ползёт вверх.
Здесь я выделил зелёным цветом сообщение о том, что pipeline успешно запустилась, красным — сообщение об ошибке и жёлтым — сообщение о попытке связаться с elasticsearch:9200.
Происходит это из за того, что в logstash.conf, включенном в состав образа, стоит проверка на доступность elasticsearch. Ведь logstash предполагает, что работает в составе Elk стека, а мы его отделили.
Работать можно, но не удобно.
Решением является отключить эту проверку через переменную окружения XPACK_MONITORING_ENABLED.
Внесём изменение в docker-compose.yml и снова запускаем:
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Вот теперь, всё нормально. Контейнер готов к экспериментам.
Можем снова набрать в соседней консоли:
echo '13123123123123123123123213123213' | nc localhost 5046
И увидеть:
logstash_one_channel | {
logstash_one_channel | "message" => "13123123123123123123123213123213",
logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "host" => "gateway",
logstash_one_channel | "port" => 49418
logstash_one_channel | }
Работа в рамках одного канала
Итак, мы запустились. Теперь собственно можно уделить время настройке непосредственно logstash. Не будем пока трогать файл pipelines.yml, посмотрим, что можно получить, работая с одним каналом.
Надо сказать, что общий принцип работы с файлом конфигурации канала хорошо описан в официальном руководстве, вот здесь
Если хочется почитать по-русски, то мы пользовались вот этой статьёй(но синтаксис запросов там старый, надо это учитывать).
Пойдем последовательно от секции Input. Работу по tcp мы уже видели. Что ещё здесь может быть интересного?
Тестовые сообщения, используя heartbeat
Есть такая интересная возможность генерировать автоматические тестовые сообщения.
Для этого в input секцию нужно включить плагин heartbean.
input {
heartbeat {
message => "HeartBeat!"
}
}
Включаем, начинаем раз в минуту получать
logstash_one_channel | {
logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z,
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "HeartBeat!",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "host" => "a0667e5c57ec"
logstash_one_channel | }
Хотим получать почаще, надо добавить параметр interval.
Вот так будем получать раз в 10 секунд сообщение.
input {
heartbeat {
message => "HeartBeat!"
interval => 10
}
}
Получение данных из файла
Ещё решили посмотреть режим file. Если нормально с файлом работает, то возможно, и агента никакого не потребуется, ну хотя бы для локального использования.
По описанию, режим работы должен быть аналогичный tail -f, т.е. читает новые строки или, как опция, читает весь файл.
Итак, что мы хотим получить:
- Мы хотим получать строки, которые дописываются в один лог файл.
- Мы хотим получать данные, которые записываются в несколько лог файлов, при этом, иметь возможность разделить что откуда получено.
- Мы хотим проверить, что при перезапуске logstash он не получит эти данные повторно.
- Мы хотим проверить, что если logstash отключить, а данные в файлы продолжают писаться, то, когда мы его запустим, то мы эти данные получим.
Для проведения эксперимента добавим ещё одну строчку в docker-compose.yml, открыв директорию, в которую мы кладём файлы.
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
- ./logs:/usr/share/logstash/input
И изменим секцию input в habr_pipeline.conf
input {
file {
path => "/usr/share/logstash/input/*.log"
}
}
Запускаемся:
docker-compose up
Для создания и записывания лог файлов будем пользоваться командой:
echo '1' >> logs/number1.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log"
logstash_one_channel | }
Ага, работает!
При этом, мы видим, что у нас автоматически добавилось поле path. Значит в дальнейшем, мы сможем по нему фильтровать записи.
Попробуем ещё:
echo '2' >> logs/number1.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "2",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log"
logstash_one_channel | }
А теперь в другой файл:
echo '1' >> logs/number2.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log"
logstash_one_channel | }
Отлично! Файл подхватился, path указался верно, всё хорошо.
Остановим logstash и запусти заново. Подождём. Тишина. Т.е. Повторно мы эти записи не получаем.
А теперь самый смелый эксперимент.
Кладём logstash и выполняем:
echo '3' >> logs/number2.log
echo '4' >> logs/number1.log
Снова запускаем logstash и видим:
logstash_one_channel | {
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "3",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log",
logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z
logstash_one_channel | }
logstash_one_channel | {
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "4",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log",
logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z
logstash_one_channel | }
Ура! Всё подхватилось.
Но, надо предупредить о следующем. Если контейнер с logstash удаляется (docker stop logstash_one_channel && docker rm logstash_one_channel), то ничего не подхватится. Внутри контейнера была сохранена позиция файла, до которой он был считан. Если запускать «с нуля», то он будет принимать только новые строки.
Считывание уже существующих файлов
Допустим мы первый раз запускаем logstash, но у нас уже есть логи и мы хотели бы их обработать.
Если мы запустим logstash с той секцией input, которую использовали выше, то мы ничего не получим. Только новые строки будут обрабатываться logstash.
Для того, чтобы подтянулись строки из существующих файлов, следует добавить в input секцию дополнительную строчку:
input {
file {
start_position => "beginning"
path => "/usr/share/logstash/input/*.log"
}
}
Причём, есть нюанс, это действует только на новые файлы, которые logstash ещё не видел. Для тех же файлов, что уже попадали в поле зрения logstash, он уже запомнил их размер и теперь будет брать только новые записи в них.
Остановимся на этом на изучении секции input. Там ещё множество вариантов, но нам, для дальнейших экспериментов пока хватит.
Маршрутизация и преобразование данных
Попробуем решить следующую задачу, допустим у нас идут сообщения из одного канала, часть из них информационные, а часть сообщение об ошибках. Отличаются тегом. Одни INFO, другие ERROR.
Нам нужно на выходе их разделить. Т.е. Информационные сообщения пишем в один канал, а сообщения об ошибках в другой.
Для этого, от секции input переходим к filter и output.
С помощью секции filter мы разберём входящее сообщение, получив из него hash(пары ключ-значение), с которым уже можно работать, т.е. разбирать по условиям. А в секции output, отберём сообщения и отправим каждое в свой канал.
Разбор сообщения с помощью grok
Для того, чтобы разбирать текстовые строки и получать из них набор полей, в секции filter есть специальный плагин — grok.
Не ставя себе целью дать здесь его детальное описание (за этим отсылаю к официальной документации), приведу свой простой пример.
Для этого, надо определиться с форматом входных строк. У меня они такие:
1 INFO message1
2 ERROR message2
Т.е. Идентификатор на первом месте, затем INFO/ERROR, затем какое-то слово без пробелов.
Не сложно, но для понимания принципа работы хватит.
Итак, в секции filter, в плагине grok мы должны определить паттерн для разбора наших строк.
Выглядеть он будет так:
filter {
grok {
match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] }
}
}
По сути, это регулярное выражение. Используются уже готовые паттерны, такие как INT, LOGLEVEL, WORD. Их описание, а также другие паттерны, можно посмотреть вот здесь
Теперь, проходя через этот фильтр, наша строка превратится в hash из трёх полей: message_id, message_type, message_text.
Именно они будут выводиться в секции output.
Маршрутизация сообщений в секции output с помощью команды if
В секции output, как мы помним, мы собирались разделить сообщения на два потока. Одни — которые iNFO, будем выводить на консоль, а с ошибками, будем выводить в файл.
Как нам разделить эти сообщения? Условие задачи уже подсказывает решение — у нас ведь есть уже выделенное поле message_type, которое может принимать только два значения INFO и ERROR. Именно по нему и сделаем выбор с помощью оператора if.
if [message_type] == "ERROR" {
# Здесь выводим в файл
} else
{
# Здесь выводим в stdout
}
Описание работы с полями и операторами, можно посмотреть вот в этой секции официального мануала.
Теперь, про собственно сам вывод.
Вывод в консоль, здесь всё понятно — stdout {}
А вот вывод в файл — вспоминаем, что мы это всё запускаем из контейнера и чтобы файл, в который мы пишем результат, был доступен снаружи, нам необходимо открыть эту директорию в docker-compose.yml.
Итого:
Секция output нашего файла выглядит вот так:
output {
if [message_type] == "ERROR" {
file {
path => "/usr/share/logstash/output/test.log"
codec => line { format => "custom format: %{message}"}
}
} else
{stdout {
}
}
}
В docker-compose.yml добавляем ещё один том, для вывода:
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
- ./logs:/usr/share/logstash/input
- ./output:/usr/share/logstash/output
Запускаем, пробуем, видим разделение на два потока.
