
Разработчики сходят с ума от самых странных вещей. Мы все предпочитаем считать себя супер-рациональными существами, но когда дело доходит до выбора той или иной технологии, мы впадаем в некое подобие безумия, перескакивая от комментария на HackerNews к посту в каком-нибудь блоге, и вот уже будто в забытье, мы беспомощно плывем по направлению к самому яркому источнику света и покорно преклоняемся перед ним, абсолютно позабыв о том, что именно мы изначально искали.
Это совсем не так, как рациональные люди принимают решения. Но ровно так разработчики решают использовать, к примеру, MapReduce.
Как отметил Джо Хеллерштайн в своей лекции по базам данных для студентов-баклавров (на 54-й минуте):
Дело в том, что существует примерно 5 компаний в мире, которые выполняют настолько масштабные задачи. Что касается всех остальных… они тратят невероятные ресурсы, чтобы обеспечить отказоустойчивость системы, которая им на самом деле не нужна. У людей была своеобразная «гугломания» в 2000х: «мы будем делать всё точно так же, как делает Google, потому что мы ведь тоже управляем самым большим сервисом по обработке данных в мире…» [иронично покачивает головой и ждет смеха из зала]

Сколько этажей в здании вашего дата-центра? Google решили остановиться на четырех, по крайней мере, в этом конкретном дата-центре, расположенном в округе Мейс, Оклахома.
Да, ваша система более отказоустойчива, чем вам необходимо, но подумайте, чего это может стоить. Дело не только в необходимости обрабатывать большие объемы данных. Вероятно, вы размениваете полноценную систему — с транзакциями, индексами и оптимизацией запросов — на нечто относительно слабое. Это значительный шаг назад. Сколько пользователей Hadoop идут на это осознанно? Сколько из них принимают действительно взвешенное решение?
MapReduce/Hadoop — это весьма простой пример. Даже последователи «карго-культа» уже поняли, что самолеты не решат всех их проблем. Тем не менее, использование MapReduce позволяет сделать важное обобщение: если вы используете технологию, созданную для крупной корпорации, но при этом решаете небольшие задачи, возможно вы действуете необдуманно. Даже не так, наиболее вероятно, что вы руководствуетесь мистическими представлениями о том, что имитируя гигантов вроде Google и Amazon, вы достигните тех же вершин.

Да, эта статья — очередной противник «карго-культа». Но подождите, у меня для вас полезный чек-лист, который вы можете использовать, чтобы принимать более взвешенные решения.
Классный фреймворк: UNPHAT
В следующий раз, когда вы будете гуглить какую-нибудь новенькую крутую технику (ре)формирования вашей системы, я призываю вас остановиться и просто воспользоваться фреймворком UNPHAT:
- Даже не пытайтесь обдумывать возможные решения до того, как понять (Understand) проблему. Ваша основная цель — это «решить» проблему в терминах проблемы, а не в терминах решений.
- Перечислить (eNumerate) несколько возможных решений. Не нужно сразу же показывать пальцем на ваш любимый вариант.
- Рассмотрите отдельное решение, а потом прочитайте документацию (Paper), если таковая имеется.
- Определите исторический контекст (Historical context), в котором данное решение было создано.
- Сопоставьте достоинства (Advantages) с недостатками. Проанализируйте, чем авторам решения пришлось пожертвовать, чтобы достичь своей цели.
- Думайте(Think)! Трезво и спокойно обдумайте, насколько хорошо данное решение подходит для удовлетворения вашей потребности. Что именно должно измениться, чтобы вы передумали? Например, насколько меньший объем данных должен быть, чтобы вы предпочли не использовать Hadoop?
Вы не Amazon
Применять UNPHAT весьма просто. Вспомним мой недавний разговор с компанией, которая спешно решила использовать Cassandra для процесса интенсивного считывания данных, загружаемых по ночам.
Так как я уже был знаком с документацией по Dynamo и знал, что Cassandra является производной системой, я понимал, что в этих базах данных основной фокус направлен на возможность производить запись (в Amazon была потребность сделать так, чтобы действие «добавить в корзину» никогда не подводило). Я также оценил, что разработчики пожертвовали целостностью данных — да и, по сути, каждой фичей, присущей традиционным РСУБД. Но ведь у компании, с которой я общался, возможность производить запись не была в приоритете. Честно говоря, проектом подразумевалось создание одной большой записи в день.

Amazon продает очень много всего. Если бы функция «добавить в корзину» вдруг перестала работать, они потеряли бы ОЧЕНЬ МНОГО денег. А у вас проблема того же порядка?
Эта компания решила использовать Cassandra, потому что выполнение PostgreSQL запроса, о котором идет речь, занимало несколько минут, и они решили, что это технические ограничения со стороны их железа. После прояснения пары моментов мы поняли, что таблица состояла примерно из 50 миллионов строк по 80 байт. Её чтение с SSD заняло бы около 5 секунд, если бы требовалось пройтись по ней полностью. Это медленно, но это всё равно на два порядка быстрее, чем скорость выполнения запроса составляла на тот момент.
На данном этапе у меня было много вопросов (U = understand, понять проблему!) и я начал взвешивать около 5 различных стратегий, которые могли бы решить первоначальную проблему (N = eNumerate, перечислить несколько возможных решений!), но в любом случае к тому моменту уже было совершенно ясно, что использование Cassandra было в корне неверным решением. Всё, что им было необходимо – это немного терпения для настройки, вероятно, новый дизайн для базы данных и, возможно (хотя вряд ли), выбор другой технологии… Но совершенно точно не хранилище данных в формате «ключ-значение» с возможностью интенсивной записи, которое создали в Amazon для их корзины!
Вы не LinkedIn
Я был весьма удивлен, обнаружив, что один студенческий стартап решил строить свою архитектуру вокруг Kafka. Это было удивительно. Насколько я мог судить, их бизнес проводил всего несколько десятков очень крупных операций в день. Возможно, несколько сотен в самые успешные дни. При такой пропускной способности основным хранилищем данных могли бы служить рукописные записи в обыкновенной книге.
Для сравнения вспомним, что Kafka создавался для обработки всех аналитических событий в LinkedIn. Это просто колоссальное количество данных. Даже пару лет назад это было порядка 1 триллиона событий ежедневно, с пиковой нагрузкой в 10 миллионов сообщений в секунду. Я, конечно, понимаю, что Kafka можно использовать для работы с более низкими нагрузками, но чтобы на 10 порядков меньше?

Солнце, будучи весьма массивным объектом, и то всего лишь на 6 порядков тяжелее Земли.
Может быть, разработчики даже приняли обдуманное решение, основываясь на ожидаемых потребностях и хорошем понимании назначения Kafka. Но я думаю, что они скорее подпитывались (как правило оправданным) энтузиазмом сообщества относительно Kafka и практически не задумывались, действительно ли это тот инструмент, который им был необходим. Вы только представьте… 10 порядков!
Я уже говорил? Вы не Amazon
Ещё более популярным, чем распределенное хранилище данных от Amazon, является архитектурный подход к разработке, который обеспечил им возможности масштабирования: сервисно-ориентированная архитектура. Как отметил Вернер Фогельс в этом интервью 2006 года, которое он давал Джиму Грею, в 2001 году в Amazon осознали, что они испытывают трудности с масштабированием интерфейса (фрон-энд части) и, что сервисно-ориентированная архитектура могла им помочь. Эта идея заражала одного разработчика за другим пока стартапы, состоящие из всего лишь пары разработчиков и практически не имеющие клиентов, не принялись дробить свой софт на наносервисы.
К тому времени, когда Amazon решили перейти на SOA (Service-oriented architecture), у них было около 7800 сотрудников, а их объемы продаж превышали $3 млрд.

Концертный зал Bill Graham Auditorium в Сан-Франциско вмещает 7000 человек. У Amazon было около 7800 сотрудников, когда они перешли на SOA.
Это не значит, что вы должны откладывать переход на SOA пока ваша компания не достигнет отметки в 7800 сотрудников… просто всегда думайте своей головой. Действительно ли это лучшее решение в рамках вашей задачи? Какая именно задача перед вами стоит и есть ли иные пути её решения?
Если же вы мне скажете, что работа вашей организации, состоящей из 50 разработчиков, попросту встанет без SOA, то я поинтересуюсь, почему так много крупных компаний просто замечательно функционируют используя единое, но хорошо организованное приложение.
Даже Google — не Google
Примеры использования систем обработки высоконагруженных потоков данных (Hadoop или Spark) могут действительно вызывать недоумение. Очень часто традиционные СУБД лучше подходят для имеющейся нагрузки, а иногда объемы данных настолько малы, что для них хватило бы даже имеющейся памяти. Вы знали, что можно купить 1Тб оперативной памяти где-то за $10 000? Даже если бы у вас был миллиард пользователей, вы бы всё равно смогли обеспечить каждого из них 1 Кб оперативки.
Возможно, этого не будет достаточно для вашей нагрузки, ведь нужно будет производить чтение и запись на диск. Но неужели вам действительно потребуется несколько тысяч дисков для чтения и записи? Вот сколько у вас данных по факту? GFS и MapReduce были созданы для решения вычислительных задач в масштабах всего интернета… например, для пересчета поискового индекса во всем Интернете.
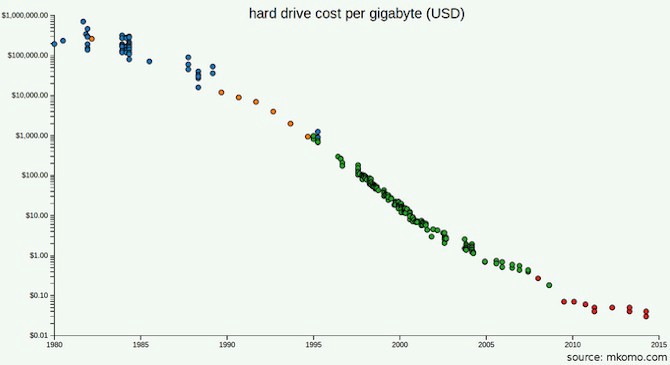
Цены на жесткие диски сейчас гораздо ниже, чем в 2003 году, когда была опубликована документация GFS.
Может быть, вы читали документацию GFS и MapReduce и обратили внимание, что одной из проблем для Google являлись не объемы данных, а пропускная способность (скорость их обработки): они использовали распределенное хранилище, потому что слишком много времени уходило на передачу байтов с дисков. Но какова же будет пропускная способность устройств, которую вы будете использовать в этом году? Учитывая, что вам даже близко не нужно будет столько же устройств, сколько было нужно Google, может быть лучше просто купить более современные диски? Во что вам обойдется использование SSD?
Может быть, вы хотите заранее учесть возможность масштабирования. А вы уже провели все необходимые расчеты? Будете ли вы накапливать данные быстрее, чем цены на SSD будут идти вниз? Во сколько раз должен будет вырасти ваш бизнес, чтобы все имеющиеся данные больше не умещались на одном устройстве? По состоянию на 2016 год, Stack Exchange обрабатывал 200 миллионов запросов в день при поддержке лишь 4 SQL серверов: основного для Stack Overflow, ещё одного для всего остального, и двух копий.
Опять же, вы можете прибегнуть к UNPHAT и всё равно решить использовать Hadoop или Spark. И решение даже возможно будет верным. Главное, это чтобы вы действительно использовали подходящую технологию для решения вашей задачи. Кстати, в Google это хорошо известно: когда они решили, что MapReduce не подходит для индексации, они прекратили его использовать.
Перво-наперво, понять проблему
Пусть мой посыл и не является чем-то новым, но, возможно, именно в таком виде он отзовется в вас или может быть, вам попросту будет легко запомнить UNPHAT и применять его в жизни. Если же нет, вы можете посмотреть речь Рича Хики на Hammock Driven Development, или книгу Поля «How to Solve it», или курс Хэмминга «The Art of Doing Science and Engineering». Потому что главное, о чем мы все просим — это думать!
И действительно понимать задачу, которую вы пытаетесь решить. Говоря вдохновляющими словами Поля:
«Глупо отвечать на вопрос, который вы не понимаете. Грустно стремиться к цели, которую вы не желаете достичь.»
Перевод на русский
Перевод: Александр Трегубов
Редактура: Алексей Иванов (@ponchiknews)
Сообщество: @ponchiknews
Иллюстрация: LucidChart Content Team
