Comments 20
Важная тема для экспериментаторов. Кое что непонятною
Так вот в чем здесь суть/особенность аппроксимации-то?
Я так понимаю, что нужно задаться некоторой функцией, скажем полиномом, из МНК получить коэффициенты, дальше вычесть из исходных данных наш полином — и готово,
или задать несколько аппроксимирующих полиномов на разных участках — причем желательно позаботиться о гладкости на границах.
Это всё очевидно и на поверхности, у вас видимо есть какой-то изюм, но я его не могу навскидку уловить, а очень хочется.
Для выделения тренда производится аппроксимация исходного процесса x[i], состоящего из N+1 отсчетов, с помощью малого количества k составляющих тренд функций uj[i]:
Так вот в чем здесь суть/особенность аппроксимации-то?
Я так понимаю, что нужно задаться некоторой функцией, скажем полиномом, из МНК получить коэффициенты, дальше вычесть из исходных данных наш полином — и готово,
или задать несколько аппроксимирующих полиномов на разных участках — причем желательно позаботиться о гладкости на границах.
Это всё очевидно и на поверхности, у вас видимо есть какой-то изюм, но я его не могу навскидку уловить, а очень хочется.
Насколько я понял, идея автора в том, что он не рассматривает высокочастотные составляющие как шум — а значит, что и при нахождении тренда условие минимизации среднеквадратичного отклонения вовсе необязательно. В матричной форме полиномиальной регрессии он просто обнулил вектор ошибок.
Как же оно необязательно, когда он на шаге (4) применяет МНК?
Метод наименьших квадратов — не единственный способ решения переопределённой системы уравнений, и из формулы (4) оно вовсе не следует — можно минимизировать и сумму высших (чётных) степеней — 4, 6 и т.д. Как я понял, у автора решение находится за счёт просто обнуления суммы отклонений от тренда. Но я не математик, могу ошибаться.
Вы не могли бы пояснить, чем для экспериментальных данных предложенный метод лучше того же простейшего ФНЧ «скользящего среднего» с нужным ядром? В чем «цимус» то?
Метод лучше тем, что даёт уравнение тренда. Это очень полезно, например, для компенсации температурных трендов датчиков. Однако то, что у автора получилось, — это обычный метод наименьших квадратов (см. мой комментарий ниже).
Прикиньте, какого порядка (размера) понадобится такой нерекурсивный фильтр, чтобы «выловить» линейный или «квадратный» тренд (ширину главного «горба» этого ядра Дирихле, чтобы частота отсечения соответствовала периоду, скажем, в две длины реализации сигнала). Тренды обычно очень «медленные» по сравнению с длиной реализации. Фильтруя длинным фильтром, придется потерять значительную часть реализации в начале и в конце (или «достраивать нулями», что привнесет свои ощутимые искажения), и при этом, скорее всего, все равно в «тренд» будут включены (и вместе с ним впоследствии исключены) ценные низко- и даже среднечастотные составляющие.
Странный текст. Так и остаётся непонятным, в чём заслуга автора. Либо я всё неверно понял, либо этот метод обсуждается в стандартных учебных курсах.
- Возможности представления тренда базисными функциями соответствуют обычному МНК. В МНК вовсе не требуется выбирать полиномы 1, 2, 3 степени; функции могут быть любыми. У Лапласа, который изобрёл МНК, это был, например, квадрат синуса. Желательно лишь, чтобы коэффициенты b входили в x(t) линейно. Здесь это требование не поколеблено. Если степень полинома и ограничивают, то только из-за очень высокой чувствительности более высоких степеней к ошибкам и плохой предсказательной способности. Это ограничение здесь тоже в силе.
- Автор желает избавить нас от необходимости «умножать процесс на определенные последовательности». Однако именно это умножение он и делает неявно в уравнении (4). Смысл в самой неявности? Но никто и не требует делать это явно (свидетельствует ссылка выше).
Почему «это умножение он делает неявно»? Явно. Явно находите UTx. Коэффициенты UTU, которые далее понадобятся, легко и очевидно (о чем и речь) находятся средствами матричной алгебры. А не так, как, например, в указанном очень авторитетном источнике (и не только) — приравниванием нулю частных производных. Явным приравниванием.
Моё замечание означало, что вначале вы будто бы желаете исключить «умножение процесса на определённые последовательности». А затем сами делаете то же самое умножение, только не говорите об этом. Оно у вас скрыто в уравнении (4).
Однако всё это второстепенно. Главное — хочется понять, чем же ваш метод отличается от приведённого мною по ссылке, найденной за пять минут в Гугле. Неупоминание метода в отдельно взятой книге — ей-богу, не аргумент. Любая книга ограничена в объёме.
Однако всё это второстепенно. Главное — хочется понять, чем же ваш метод отличается от приведённого мною по ссылке, найденной за пять минут в Гугле. Неупоминание метода в отдельно взятой книге — ей-богу, не аргумент. Любая книга ограничена в объёме.
Он не «отличается», он «применен к...» :))), чего не наблюдалось не только в «отдельно взятой книге», но и среди «некоторых» практикующих исследователей — им это могло бы быть интересно. А вот тех, кто его применял на практике (а наверняка есть такие), интересно было бы услышать — а их вот чего-то и нет пока что. А ведь «подводные камни» могут быть и кроме упомянутого — опыт наработан с таким методом очень небольшой — поэтому и интересно услышать. А пока вот только теоретики.
Странно: сначала вы анонсируете «новый» метод, а затем признаёте, что он ничем не отличается от старого и лишь «применён к...». Кстати, к чему применён? О применении у вас практически ничего нет.
Ну, если вам интересно, то я этим тоже занимался. На реальных, а не синтезированных данных — в частности, аппроксимацией импульсной характеристики. И кстати, удаление тренда при спектральном анализе не помогает, а скорее наоборот. И даже самостоятельно выводил формулы для аппроксимации синусом и косинусом, чтобы спектральную интерполяцию можно было делать, типа такого:
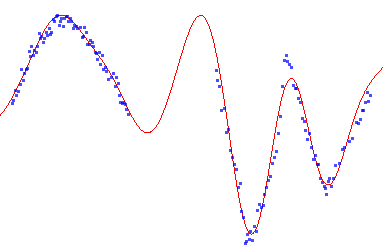
Здесь гарантированно нет частот выше заданной.

Здесь гарантированно нет частот выше заданной.
Я тоже что-то не вкуриваю в чём заслуга автора. Регрессионный анализ методом наименьших квадратов — штука хорошо и давно известная, и базисные функции допускает любые достаточно гладкие. И даже совсем несложная, первокурсники успешно справляются.
Хм, слишком сложно. Не всякий МК с таким справится, а если справится, то все ресурсы изведет.
На мой взгляд, лучше обычный HPF, подобные тем, что стоят в звуковых картах и отсекают дрейф входного смещения и частот 5Гц и ниже (экспоненциальное скользящее средее, по сути, имитация RC цепочки).
На мой взгляд, лучше обычный HPF, подобные тем, что стоят в звуковых картах и отсекают дрейф входного смещения и частот 5Гц и ниже (экспоненциальное скользящее средее, по сути, имитация RC цепочки).
Вы говорите о фильтре с бесконечной импульсной характеристикой. Здесь он не подойдёт, потому что приведёт к фазовому сдвигу и как следствие — изменению формы экспериментальных данных. Есть принципиальная разница между трендом и низкочастотной составляющей. Если и применять низкочастотную фильтрацию, то только фазолинейным КИХ-фильтром.
МНК для произвольных линейно независимых функций, конечно, давно открыт. Он описан, например, William H. Press «Numerical Recipes in C++» 2nd edition, глава 15.4 — «General Linear Least Squares».
Но на самом деле ничто не мешает приближать данные функциями, которые зависят от своих параметров и нелинейно. Есть нелинейные методы приближения по наименьшим квадратам, в их числе — метод Гаусса-Ньютона, реализованный для Матлаб-функции «nlinfit»; также представляет интерес метод Levenberg-Marquardt (гл. 15.5 той же книги).
Результаты имеют множество применений, помимо удаления тренда!
Но на самом деле ничто не мешает приближать данные функциями, которые зависят от своих параметров и нелинейно. Есть нелинейные методы приближения по наименьшим квадратам, в их числе — метод Гаусса-Ньютона, реализованный для Матлаб-функции «nlinfit»; также представляет интерес метод Levenberg-Marquardt (гл. 15.5 той же книги).
Результаты имеют множество применений, помимо удаления тренда!
Sign up to leave a comment.
Об удалении тренда из экспериментальных данных