Хабр, привет!
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи.
Многие люди не знают, как работать с трендами в интернете, где их искать. Перед тем, как начинать бизнес не знают, где посмотреть будет ли этот бизнес вообще популярен и нужен ли он. Поэтому напишу полный туториал, чтобы закрыть все вопросы по этой тематике.
Работать мы будем со специальным сервисом по сбору поисковых запросов пользователей Яндекса Вордстатом, интерфейс которого довольно прост и понятен:
В начале, по традиции, поставлю цели:
- Понять весь функционал и научиться работать с Вордстатом;
- Как правильно собирать семантику с максимальной релевантностью и CTR >50%;
- Так как мы на Хабре, поработаем с API Wordstat напрямую.
Ключевая роль сервиса заключается в том, что он помогает оценить пользовательский интерес к трендам, различным тематикам и подобрать ключевые слова для контекстной рекламы.
Знакомство с сервисом
Для того, чтобы начать пользоваться Вордстатом нам необходимо авторизоваться в аккаунте Яндекса:

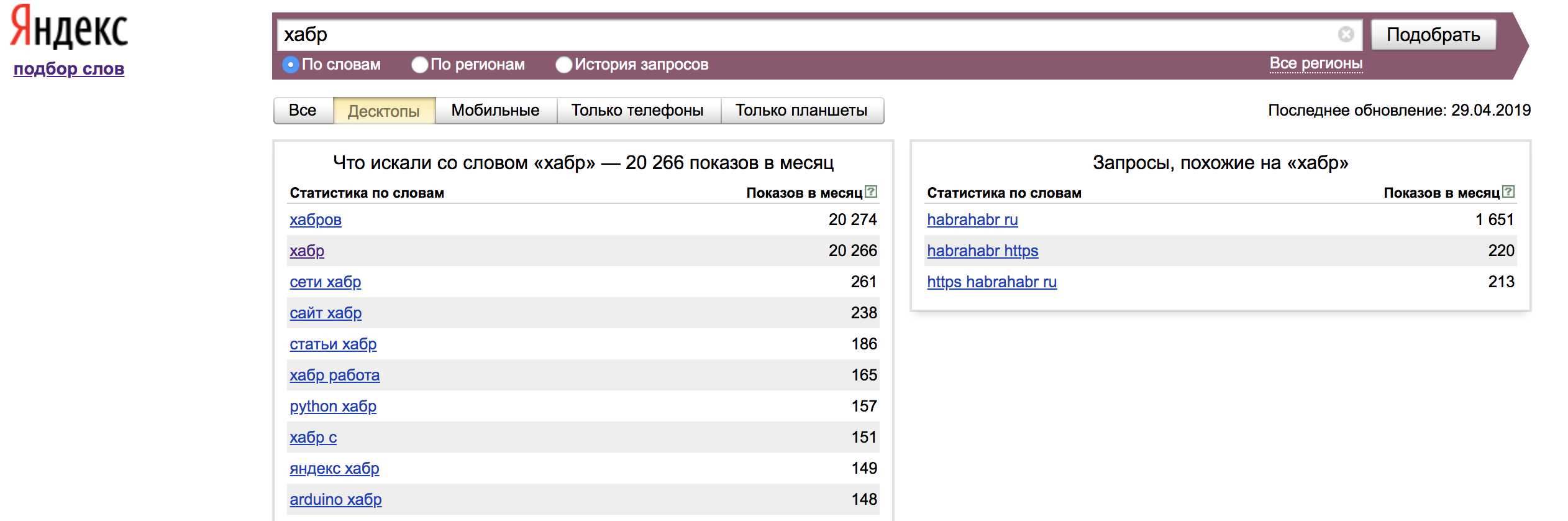
После авторизации мы можем пользоваться сервисом. Просмотр данных поисковых запросов нам доступен во вкладке «По словам»:
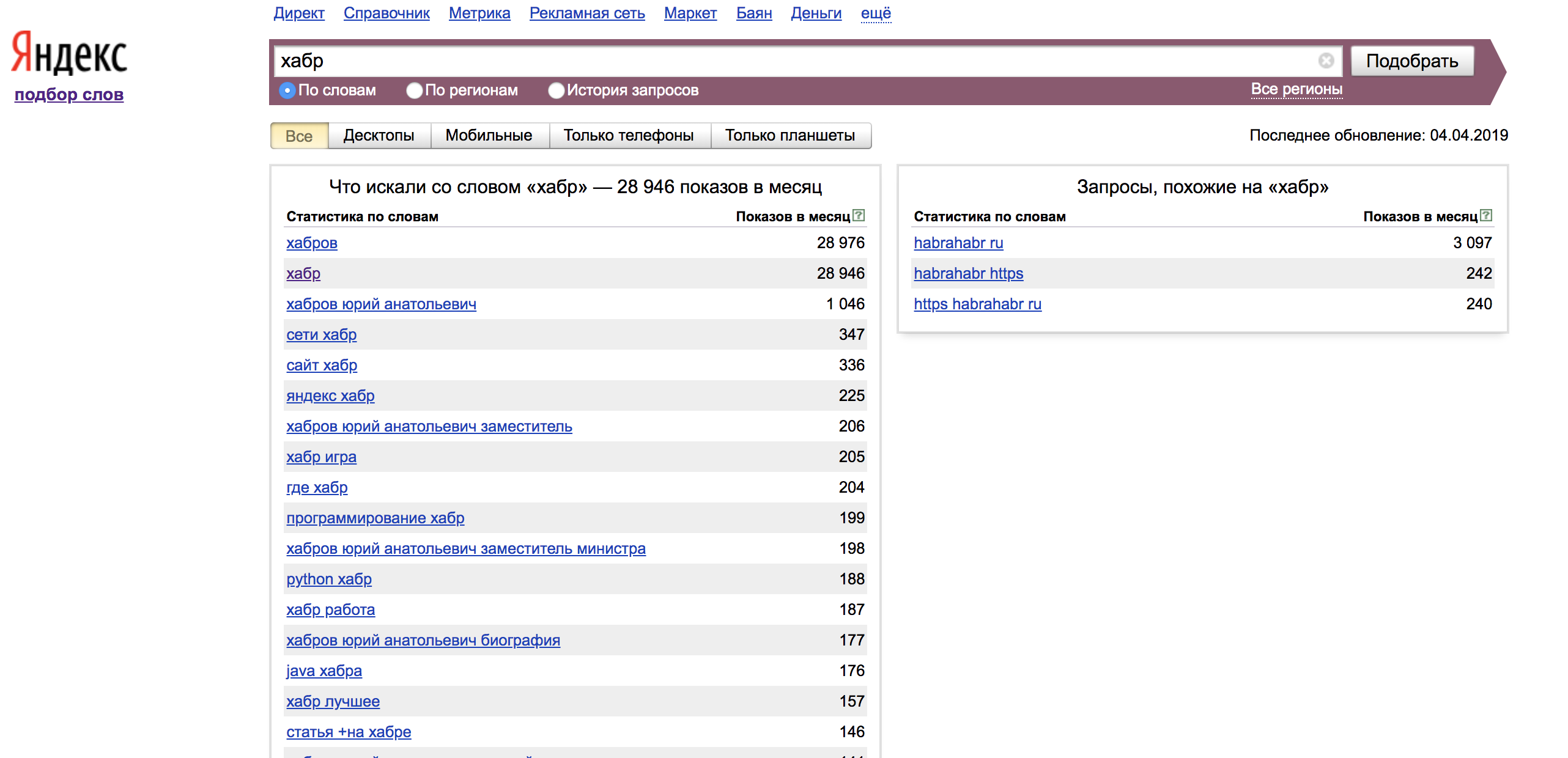
В левой колонке мы видим статистику по словам, которые были вместе с вашим поисковым запросом и показы в месяц по ним. Для того, чтобы мы нашли наше слово в точном соответствии мы должны использовать операторы. В правой колонке показываются похожие по смыслу запросы на заданную нами фразу.
Наглядный пример использования ключевых слов с операторами:
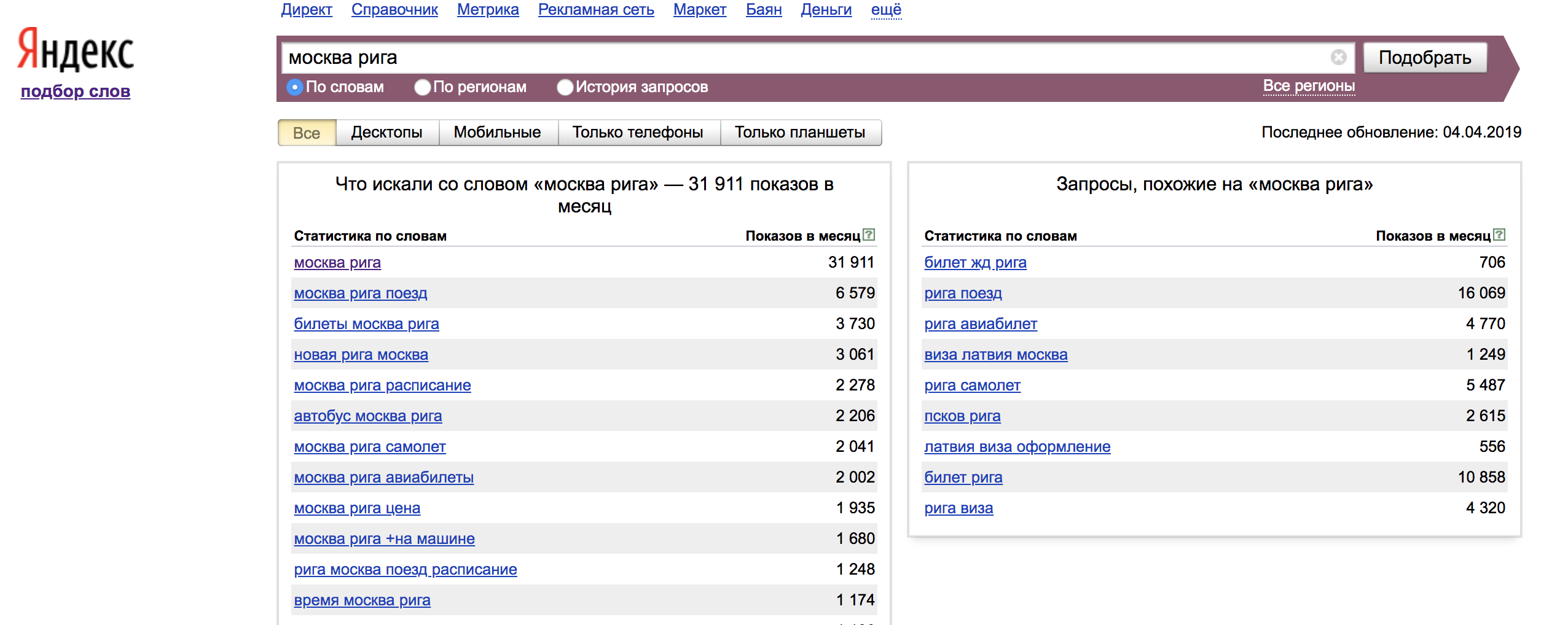
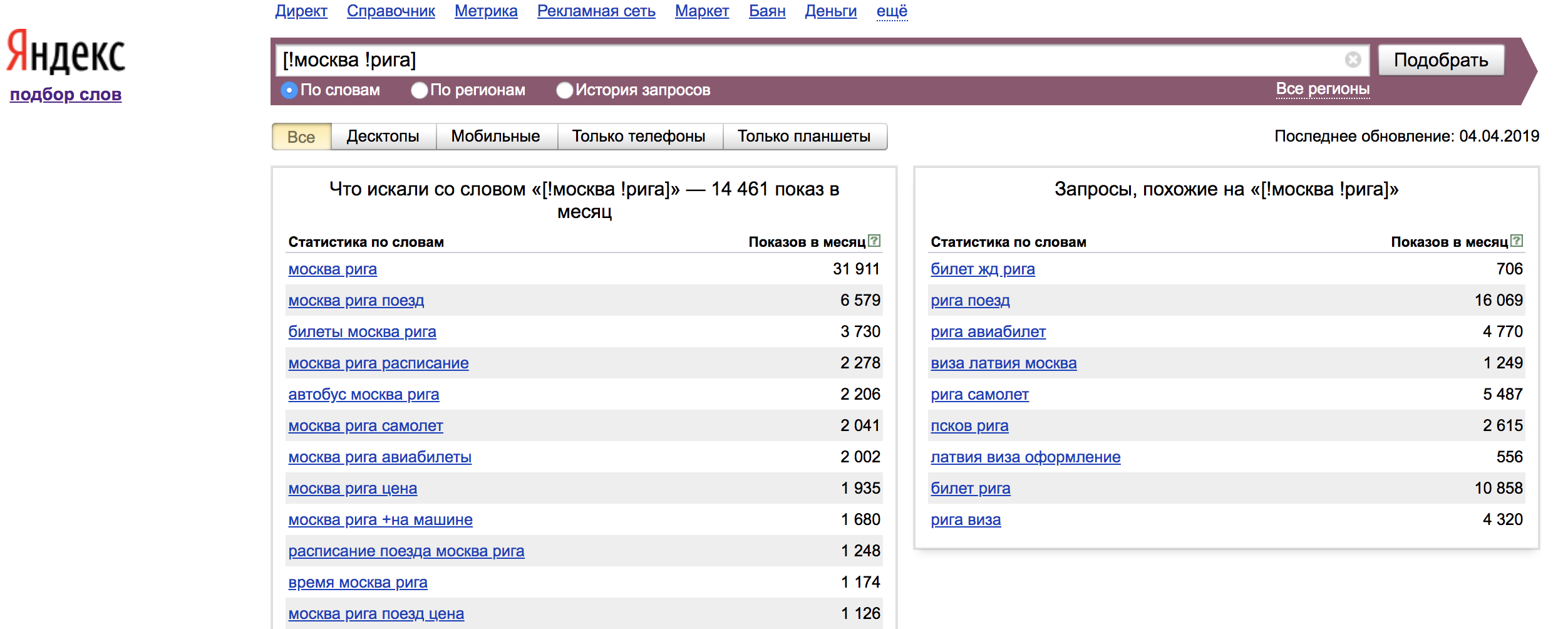
Оператор "!" — фиксирует форму слова (число, падеж, время);

Оператор "[]" — Фиксирует порядок слов. При этом учитываются все словоформы и стоп-слова.
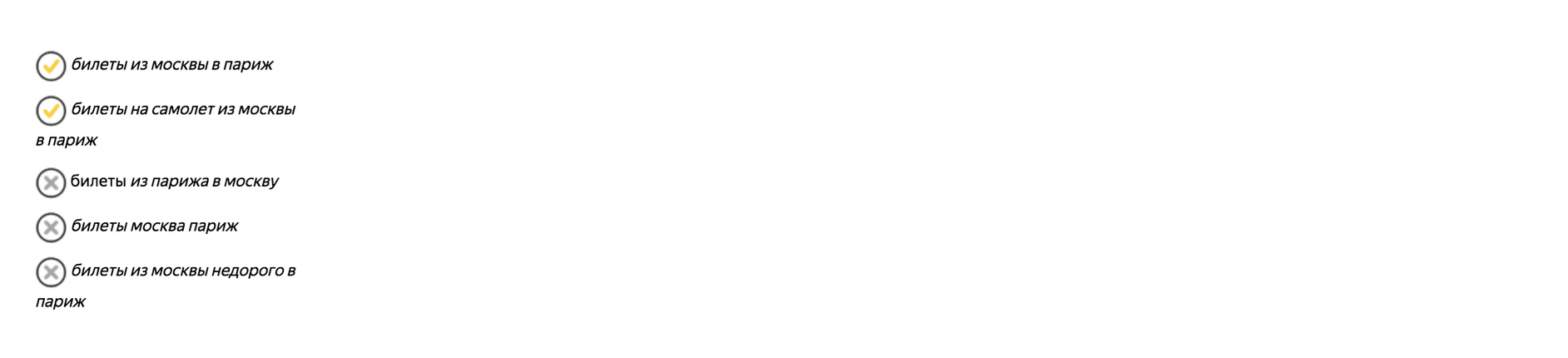
Подробнее об операторах читаем здесь.
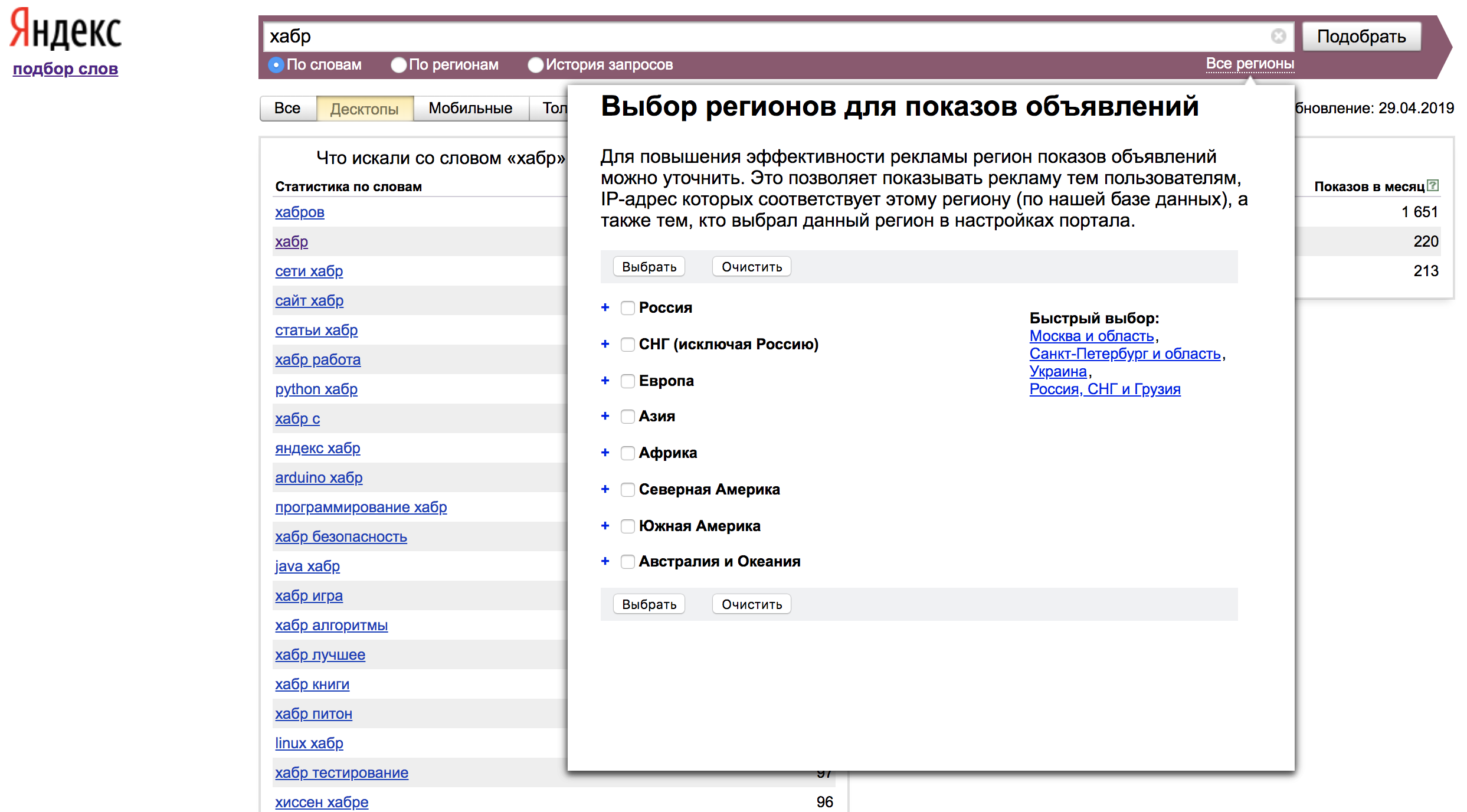
По умолчанию Вордстат показывает запросы по всем типам устройств. Настройки можно изменять: десктоп/мобайл/только телефоны/только планшеты. В нашем случае отфильтруем только десктопы.
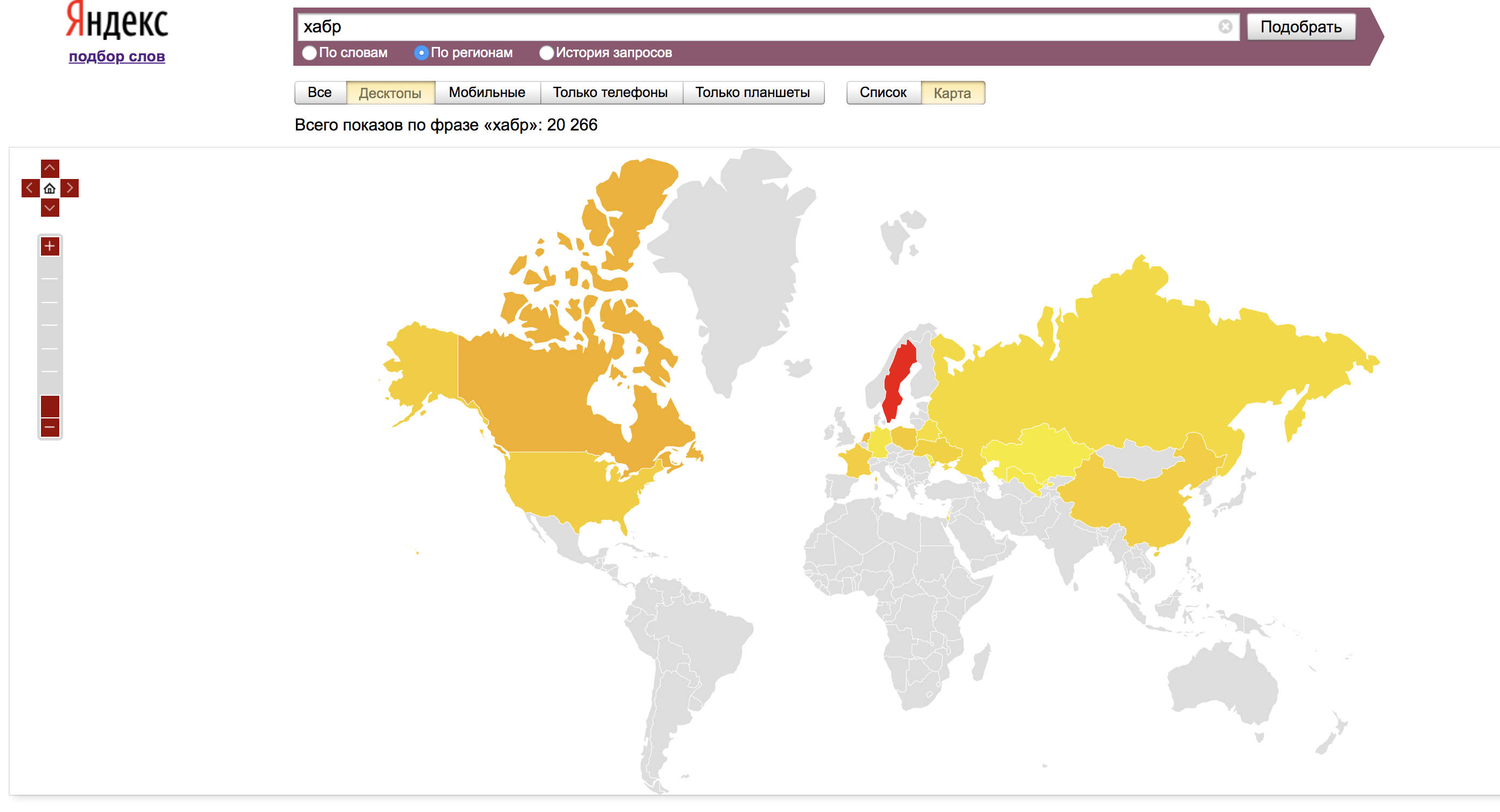
По умолчанию статистика показывается для всех регионов. Выбрать отображение статистики по интересующему нас региону можно во вкладке «Все регионы»:
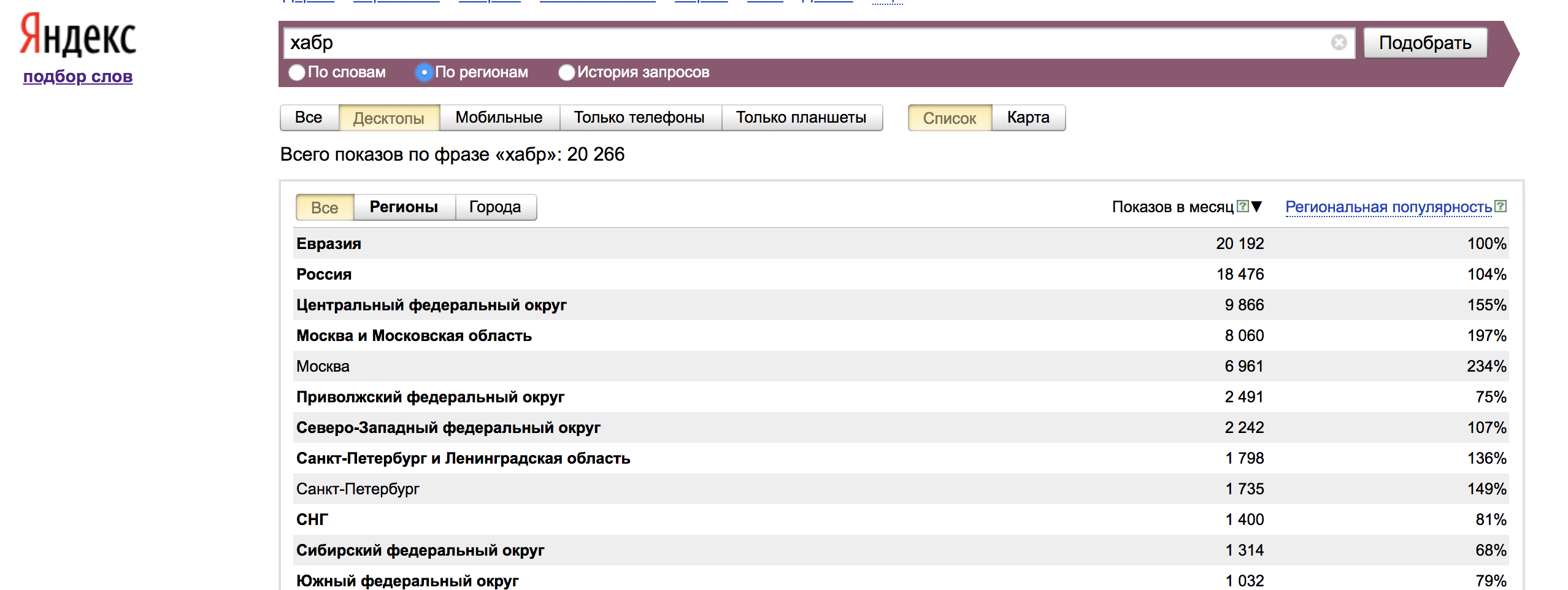
Во вкладке «По регионам» отображаются данные со всех регионов, а также региональная популярность — доля, которую занимает регион в показах по слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.
Для удобства эти же данные отображаются на карте:
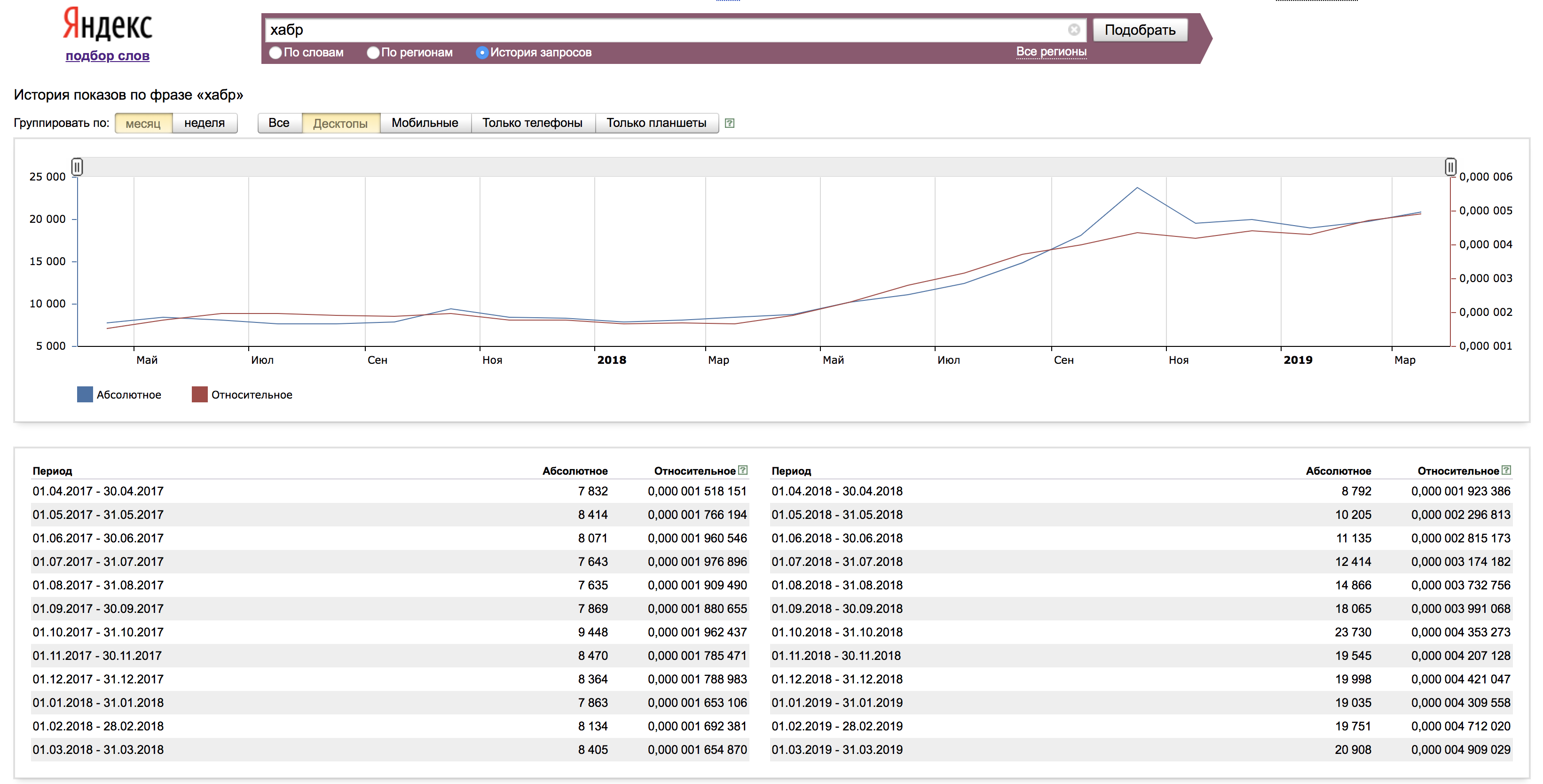
Во вкладке «История запросов» мы видим данные по запросу, обычно за 1,5 года. Здесь наглядно можем оценить тренды и влияние их на определенные запросы.
Статистику можно смотреть как в абсолютных значениях, так и в относительных. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
На этом изучение инструменты можно закончить и приступить к следующей нашей цели — правильный сбор семантического ядра.
Правильный сбор семантического ядра
В интернете уйма сервисов и способов для сбора семантического ядра, а также искусственного его создания. Мы не будем создавать велосипед и танцевать с бубном, а соберем семантику легко, просто и бесплатно.
Для того, чтобы нам собрать нашу семантику, первым делом мы скачиваем с официального сайта Яндекса Директ Коммандер последней версии.
После загрузки запускаем программу, логинимся и создаем (без разницы с каким названием) кампанию:
Добавляем группу объявлений (по прежнему нет смысле заморачиваться с его названием):
Переходим во вкладку «Подбор фраз», и вуаля! Это тот же самый Вордстат, только в программе Директ Коммандер. Логика работы с ним такая же, только в отличии от веб версии Вордстата здесь мы можем сразу указать минус слова:
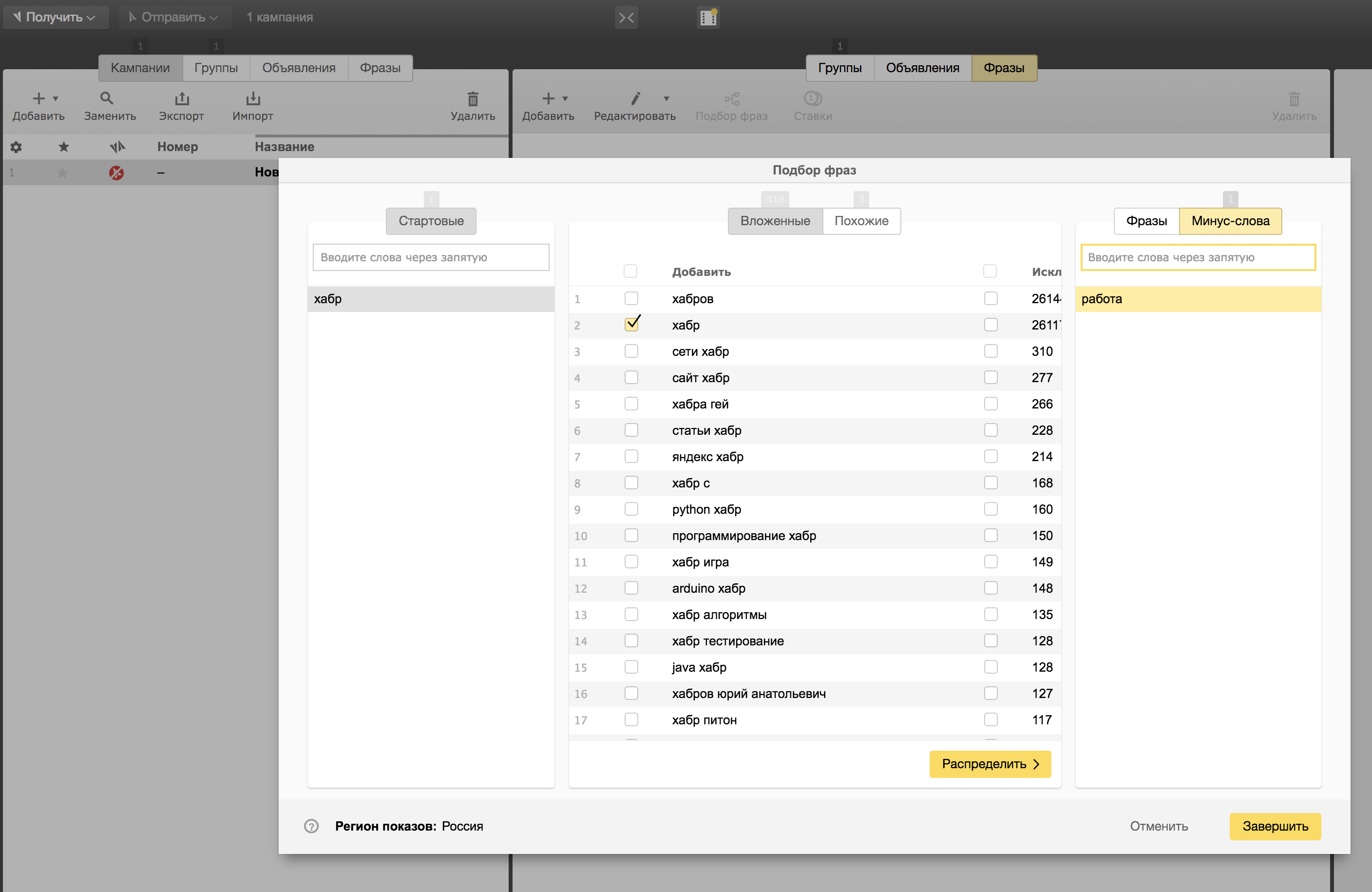
После того как мы тщательно отфильтруем весь список поисковых запросов от лишних запросов, можно приступать к экспорту нашей кампании в csv файл. Все, что остается нам сделать, это удалить лишние столбцы. Наше семантическое ядро находится в столбце «Фраза (с минус-словами)»:
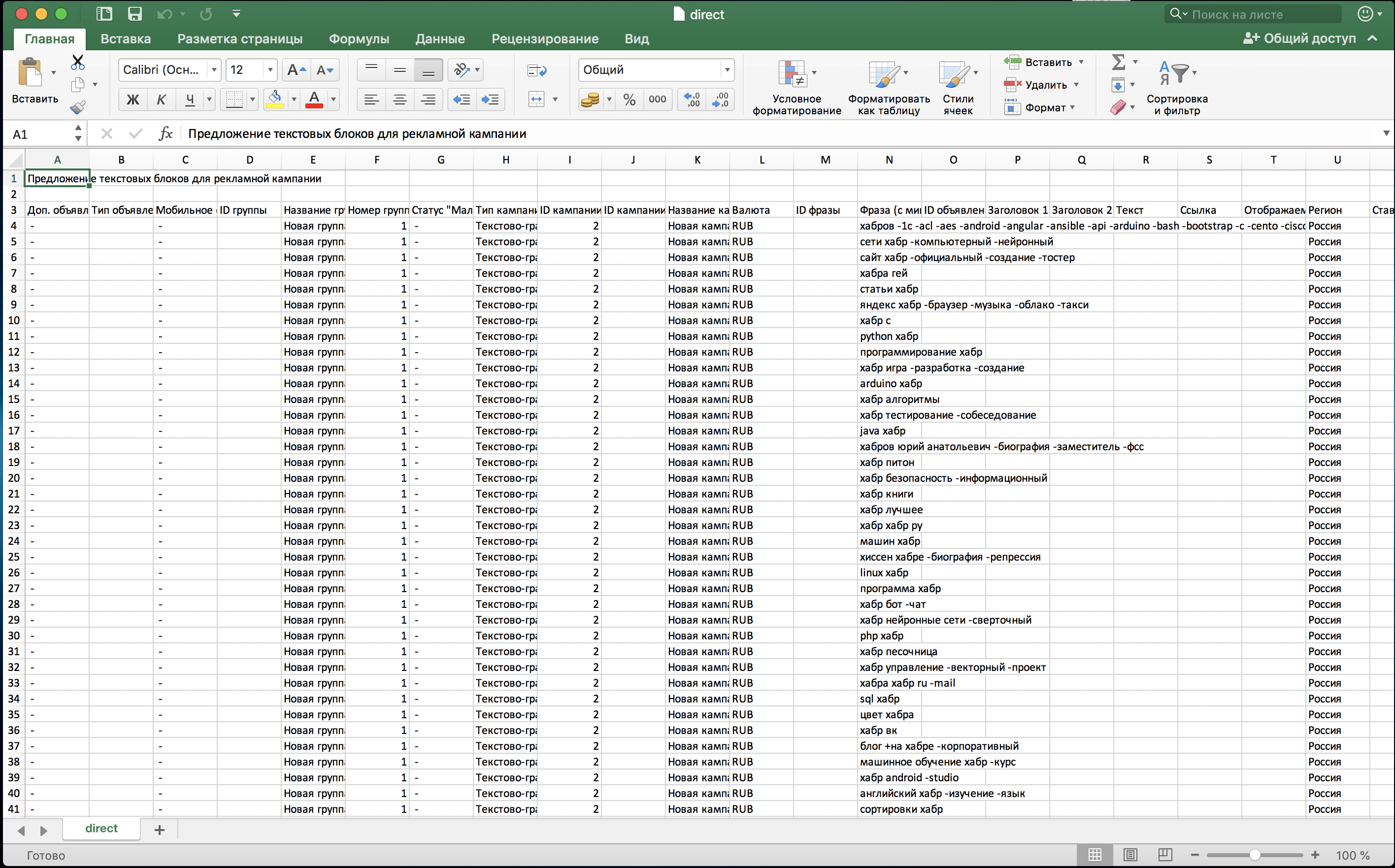
Плюсы сбора семантики таким способом:
- Охват запросов с частотностью до 1 в месяц;
- Не наращиваем искусственную семантику, в которой наверняка будут запросы, которых в реальной истории поиска на самом деле нет;
- Увеличиваем CTR объявлений максимально (конечно не только благодаря семантике, но и правильному разбиению объявлений по кластерам запросов и их текстам. Однако все это на основе нашей семантики);
- Клики становятся для нас дешевле;
- Это абсолютно бесплатно.
Работа с API Wordstat
Прежде чем начать, ознакомимся с базовой информацией из справки Яндекс Директа.
Справка по API Wordstat
Описание параметров
Обязательные GET параметры
request — Данные запроса
GET параметры
lr — код региона, если 0 — то все регионы
imp — если 1 — то важный запрос
Ответ содержит
status — Код статуса (0 — нет ошибок)
err_msg — Текст ошибок
data — Количество показов в месяц
Для указания региона используются коды из Яндекса. Скачать список регионов можно по ссылке
<?php
$array = array();
$array["user"] = '#логин_юзера';
$array["password"] = '123456';
$array["lr"] = "1";
$array["imp"]=1;
$array["request"] = "Хабр";
$content = file_get_contents("#url_user_auth".http_build_query($array));
$json = json_decode($content);
if( !is_object($json) ){
echo 'Не удалось разобрать данные';
exit();
}
if($json->status!=0){
echo $json->err_msg;
exit;
}
echo $json->data . " показов в месяц. ";
?>
Результат:
{«status»:0,«err_msg»:«OK»,«data»:«11284»,«date_update»:«29.04.2019»}
На этом все цели, которые мы поставили перед собой, в конце статьи были достигнуты.
Всем знаний!
