В последнее время Jupyter Notebook стал очень популярен среди специалистов Data Science, став де-факто стандартом для быстрого прототипирования и анализа данных. В Netflix, стараемся раздвинуть границы его возможностей еще дальше, переосмысливая то, чем может быть Notebook, кем может быть использован, и что они могут могут с ним делать. Мы вкладываем много сил, чтобы воплотить наше видение в реальность.
В данной статье мы хотим рассказать почему считаем что Jupyter Notebooks настолько привлекательным и что вдохновляет нас на этом пути. Кроме того, опишем компоненты нашей инфраструктуры и сделаем обзор новых способов использования Jupyter Notebook в Netflix.

Примечание от переводчика: осторожно, много текста и мало картинок
Если у вас не так много времени предлагаем сразу переходит в раздел Use Cases.
Зачем всё это?
Данные – это мощь Netflix. Они пропитывают наши мысли, влияют на наши решения, и бросают вызов нашим гипотезам. Они заряжают эксперименты и появление нового в невиданных масштабах. Данные позволяют раскрыть неожиданные смыслы и ощутить невероятный персонализированный опыт 130 миллионам наших пользователей по всему миру.
Претворение всего этого в реальность — немалое достижение, требующее внушительной инженерной и инфраструктурной поддержки. Каждый день более 1 триллиона событий принимаются в поток (streaming ingestion pipeline) которые обрабатывается и записывается в облачное хранилище размером 100ПБ. И каждый день наши пользователи выполняют больше 150,000 задач на этих данных, охватывающих всё от отчетов до машинного обучения и рекомендательных алгоритмов.
Для поддержки подобных сценариев использования в таких масштабах мы построили одну из лучших в отрасли, гибкую, мощную и в меру необходимости сложную платформу для работы с данными (Netflix Data Platform). Также мы разработали дополнительные инструменты и сервисы, такие как Genie (сервис выполнения задач) и Metacat (метахранилище). Данные инструменты позволяют сократить сложность, тем самым, делая возможным поддержку более широкого круга пользователей по всей компании.

Разнообразие пользователей впечатляет, но за это приходится платить: Netflix Data Platform и его экосистема инструментов и сервисов должна масштабироваться для поддержки дополнительных сценариев использования, языков, схем доступа и многое другое. Для лучшего понимания проблемы рассмотрим три распространенные позиции: инженер аналитик, Data engineer и Data scientist.

Различие в предпочтении языков и инструментов для разных позиций
Как правило, каждая позиция предпочитает использовать свой набор инструментов и языков. Например Data engineer может создать новый ансамбль данных содержащий триллионы потоков событий используя Scala в IntelliJ. Аналитик может использовать их в новом отчете качества глобальной потоковой передачи используя SQL и Tableau. Этот отчет может попасть к Data scientist, который построит новую модель потокового сжатия используя R и RStudio. На первый взгляд данные процессы кажутся разрозненными пусть и взаимодополняющими, но если заглянуть глубже, каждый из этих процессов имеет несколько пересекающихся задач:
data exploration — возникает на раннем этапе проекта; может включать обзор выборочных данных, запросов для статистического анализа и визуализации данных
data preparation — повторяющаяся задача, может включать очистку, стандартизацию, преобразование, денормализацию и агрегацию данных; обычно наиболее времязатратная часть проекта
data validation — регулярно возникающая задача; может включать обзор выборочных данных, статистический анализ, aggregate analysis и визуализация данных; обычно возникает как часть data exploration, data preparation, development, pre-deployment, и post-deployment
productionalization — происходит на поздней стадии проекта; может включать в себя развертывание кода, дополнение выборок, обучение моделей, валидацию данных и планирование выполнения рабочих процессов (scheduling workflows)
Чтобы расширить возможности наших пользователей, мы хотим сделать данные задачи настолько легко выполнимыми насколько это возможно.
Чтобы расширить возможности нашей платформы, мы хотим минимизировать количество инструментов, которые необходимо поддерживать. Но как? Ни один инструмент в одиночку не может покрыть все перечисленные задачи. Более того нередко одна задача требует использования нескольких инструментов. Однако, если абстрагироваться возникает общий паттерн для всех инструментов и языков: исполнять код, исследовать данные, представить результат.
Так получилось что проект с открытым кодом был разработан специально для этого: Project Jupyter.
Jupyter Notebooks

Jupyter notebook в nteract отображает Vega и Altair
Проект Jupyter был запущен в 2014 с целью создания единообразного множества инструментов с открытым кодом для научных исследований, воспроизводимых workflow и анализа данных. Эти инструменты были высоко оценены в индустрии и сегодня Jupyter стал неотъемлемой частью инструментария любого Data scientist. Чтобы понять масштабы его влияния, отметим, что Jupyter был удостоен 2017 ACM Software Systems Award — престижной награды которую он разделяет вместе с Java, Unix, и the_Web.
Чтобы понять почему Jupyter Notebook настолько привлекателен для нас, рассмотрим его основные функциональные возможности:
- протокол обмена сообщениями для анализа и выполнения кода вне зависимости от языка
- формат файла с возможностью редактирования, для описания, отображения и выполнения кода, вывода и заметок markdown
- веб интерфейс для интерактивного написания, запуска кода, а также визуализации результатов
Jupyter protocol предоставляет стандартизированное API обмена сообщениями с ядрами, которые выступают как вычислительные модули и обеспечивает составную(composable) архитектуру, тем самым разделяя место, где хранится код (UI) и где он исполняется (ядро). Таким образом разделив интерфейс и ядро, Notebook могут работать на нескольких языках при этом сохраняя гибкость настройки среды выполнения. Если для языка существует ядро, которое умеет обмениваться сообщениями используя протокол Jupyter, Notebook может исполнять код посредством отправки и получения сообщений этому ядру.
В дополнение ко всему, всё это поддерживается за счет формата файла который позволяет хранить как сам код так и результаты его выполнения в одном месте. Это означает что можно просмотреть результаты выполнения позже без необходимости перезапуска самого кода. Также ноутбуки могут хранить развернутое описание контекста, и что именно происходит внутри него. Это делает его идеальным форматом для передачи бизнес контекста, фиксирования предположений, комментирования кода, описания выводов и многое другое.
Use Cases
Среди множества сценариев, самые популярные варианты использования следующие: доступ к данным (data access), шаблоны (notebook templates), и планировщик выполнения (scheduling notebooks).
Data Access
Jupyter Notebook изначально появились в Netflix для поддержки data science workflows. По мере роста их использования среди специалистов Data science мы увидели потенциал для расширения возможностей нашего инструментария. Мы поняли что можем использовать универсальность и архитектуру Jupyter Notebook и расширить его возможности для общего доступа к данным. В третьем квартале 2017 мы всерьез начали работу над тем, чтобы сделать Notebook из инструмента для узкого круга специалистов в первоклассного представителя Netflix Data Platform.
С точки зрения наших пользователей, Notebook предлагают удобный интерфейс интерактивного выполнения команд, исследования вывода, и визуализации данных — всё в одной облачной среде разработки. Также мы поддерживаем Python библиотеку, которая объединяет в себе доступ к API платформы. Это означает что пользователи имеют программный доступ практически ко всей платформе Netflix через Notebook. Благодаря этой комбинации гибкости, мощи и легкости использования, в компании произошел резкий рост его использования всеми типами пользователей платформы.
Сегодня notebook самый популярный инструмент для работы с данными в Netflix.
Notebook Templates (Шаблоны)
По мере расширения поддержки Jupyter Notebook внутри платформы, мы начали вводить новые возможности его использования для удовлетворения новых сценариев использования. Отсюда появились параметризованные ноутбуки. Параметризованные ноутбуки представляют именно то, о чем говорит их название: notebook который позволяет задавать параметры в коде и принимать входные данные во время выполнения. Это дает хороший механизм для пользователей определить notebook как шаблоны для многократного использования.
Наши пользователи нашли немало способов использования подобных шаблонов. Перечислим несколько чаще всего используемых:
- Data Scientist: проводить эксперименты с различными коэффициентами и обобщать результаты
- Data Engineer: выполнять коллекцию аудитов качества данных как часть процесса развертывания
- Data Analyst: обмениваться подготовленными запросами и визуализациями для того чтобы заинтересованные стороны могли исследовать данные глубже, чем позволяет Tableau
- Software Engineer: рассылать результаты выполнения скрипта по устранению неполадок при возникновении сбоев
Scheduling Notebooks (Планировщик)
Один из оригинальных способов использования Notebook — это создание объединяющего слоя для scheduling workflows.
Так как каждый ноутбук может выполнятся на произвольном ядре, мы можем поддерживать любую среду выполнения определенную пользователем. И так как notebook описывают линейный поток выполнения, разделенный на ячейки, мы можем соотнести сбой к конкретной ячейке. Это позволяет пользователям в более повествовательной форме описать выполнение и визуализации, что можно точно зафиксировать при запуске в более поздний момент времени.
Подобная парадигма позволяет использовать ноутбук для интерактивной работы и плавно перейти к многократному выполнению и использованию планировщика. Что оказалось весьма удобно для пользователей. Многие пользователи создают целые workflow в notebook только для того чтобы потом дублировать их в отдельные файлы и запускать в нужные моменты времени. Обращаясь с notebook как c последовательным описанием процесса, мы с легкостью планируем их выполнение так же как любой другой workflow.
Мы можем планировать выполнение и других типов работ через notebooks. Когда Spark или Presto job выполняется из планировщика(scheduler), исходный код вставляется в заново созданный notebook и выполняется. Этот notebook становится хранилищем истории, содержащим исходный код, параметры, конфигурации, логи выполнения, сообщения об ошибках и т.д. При устранении неисправностей это обеспечивает быструю отправную точку для расследования, поскольку вся соответствующая информация находится внутри и notebook может быть запущен для интерактивной отладки.
Notebook Infrastructure (Инфраструктура)
Поддержка сценариев описанных выше в масштабах Netflix требует обширной вспомогательной инфраструктуры. Кратко представим несколько проектов о которых пойдет речь в следующих разделах:
nteract новое поколение React-based UI для Jupyter notebooks. Предоставляет простой, интуитивный интерфейс и предлагает несколько улучшений для классического Jupyter UI такие, как inline cell toolbars, ячейки с возможностью drag&drop и встроенный проводник.
Papermill библиотека для параметризации, исполнения и анализа Jupyter notebooks. С помощью которого можно размножить несколько notebooks с различными параметрами и выполнять их одновременно. Papermill также позволяет собрать и обобщить метрики для целой коллекции notebook.
Commuter легковесный, вертикально масштабируемый сервис для просмотра и обмена notebook. Он предоставляет Jupyter-совместимую версию API для содержимого и упрощает чтение notebook хранящихся локально на Amazon S3. Также предлагает проводник для поиска и обмена файлами.
Titus платформа для управления контейнерами, который предоставляет масштабируемый и надежный запуск контейнеров и cloud-native интеграцию с Amazon AWS. Titus был разработан в Netflix и используется в боевых условиях для поддержки потоковых, рекомендательных и контентных систем Netflix.
Более подробно описание архитектуры можно найти в статье Scheduling Notebooks at Netflix. Для целей этого поста, мы ограничимся тремя фундаментальными компонентами системы: хранение, выполнение и интерфейс.

Инфраструктура Notebook в Netflix
Storage (Хранение)
Netflix Data Platform использует облачные хранилища Amazon S3 и EFS, которые воспринимаются notebooks как виртуальные файловые системы. Это означает, что каждый пользователь имеет домашнюю директорию на EFS, содержащую личное рабочее пространство для notebooks. В данном пространстве мы храним любой notebook созданный или загруженный пользователем. Также это место, где происходит чтение и запись при интерактивном запуске ноутбука пользователем. Мы используем комбинацию [workspace + filename] для пространства имен, т.е. /efs/users/kylek/notebooks/MySparkJob.ipynb для просмотра, обмена и в планировщике выполнения. Подобное соглашение предотвращает коллизии и облегчает идентификацию как пользователя, так и местоположения notebook в EFS.
Путь к workspace позволяет абстрагироваться от сложности облачного хранения для пользователя. Например, только названия файлов notebook отображается в директории, т.е. MySparkJob.ipynb. Тот же файл доступен через терминал: ~/notebooks/MySparkJob.ipynb.

Notebook хранение vs. доступ
Когда пользователь ставит задачу запуска notebook, планировщик копирует notebook пользователя из EFS в общую директорию на S3. Notebook в S3 становится первоисточником (the source of truth) для планировщика, или исходным notebook. Каждый раз когда планировщик (диспетчер) запускает notebook, он создает новый notebook из исходного. Этот новый notebook то, что на самом деле запускается и становится неизменной записью конкретного выполнения, содержащей исполняемый код, вывод, и логи каждой ячейки. Мы называем его output(выходной) notebook.
Сотворчество это фундаментальная особенность работы в Netflix. Поэтому было не удивительно, когда пользователи начали обмениваться ссылками URL на notebook. С ростом такой практики, мы столкнулись с проблемой случайной перезаписи вызванной одновременным доступом нескольких пользователей к одному и тому же notebook. Наши пользователи хотели чтобы был способ поделится своим активным notebook в режиме read-only. Это привело к созданию Commuter. Под капотом Commuter отображает API Jupyter для вывода /files и /api/contents в список директорий, для просмотра содержимого файлов, и доступа к метаданным файлов. Это означает, что пользователи могут просматривать notebook без последствий для боевых задач или live-running notebooks.
Compute (Выполнение)
Управление вычислительными ресурсами одно из самых сложных частей работы с данными. Особенно это актуально в Netflix, где мы используем высоко масштабируемую контейнерную архитектуру в AWS. Все задания на Data Platform выполняются в контейнерах, включая запросы, конвейеры и notebook. Естественно, мы хотели абстрагироваться как можно больше от этой сложности.
Контейнер предоставляется, когда пользователь запускает сервер notebook. Мы предоставляем рациональные значения по умолчанию для ресурсов контейнера, которые работают для ~ 87,3% шаблонов выполнения. Когда этого недостаточно, пользователи могут запрашивать больше ресурсов, используя простой интерфейс.

Users can select as much or as little compute + memory as they need
Мы также предоставляем унифицированную среду исполнения с готовым образом контейнера. Образ имеет общие библиотеки и предварительно установленное множество ядер по умолчанию. Не все в образе статично — наши ядра используют самые последние версии Spark и последние конфигурации кластеров для нашей платформы. Это уменьшает помехи и время настройки для новых ноутбуков и в целом удерживает нас в единой среде исполнения.
Под капотом мы управляем оркестрацией и окружениями с помощью Titus, нашей службы управления контейнерами Docker. Мы дополнительно создаем обертку над этой службой, управляя конкретной конфигурацией сервера пользователя и образами. Образ также включает в себя группы безопасности пользователя и роли, а также общие переменные среды для идентификации во включенных библиотеках. Это означает, что наши пользователи могут тратить меньше времени на инфраструктуру и больше времени на данные.
Interface
Ранее мы описали наше видение, что notebooks должны стать наиболее эффективным и оптимальным инструментом для работы с данными. Но это представляет собой интересный вызов: как может один интерфейс поддерживать всех пользователей? Мы не знаем точного ответа, но у нас есть некоторые идеи.
Мы знаем что необходима простота. Это означает интуитивный UI с минималистичным стилем, и это также требует продуманного UX, который позволяет легко делать сложные вещи. Данная философия хорошо соответствует с целями nteract, написанный на React фронтенд для Jupyter notebook. Он подчеркивает простоту и сочетаемость(composability), как основополагающие принципы дизайна, благодаря чему делают его идеальной частью нашей задумки.
Самая частая жалоба от наших пользователей – это отсутствие нативной визуализации для совокупности всех языков, особенно для не Python языков. Data Explorer в nteract — хороший пример как можно сделать сложные вещи легко, предоставив независимый от языка способ оперативно исследовать данные.
Можно посмотреть на Data Explorer в действии на этом примере на MyBinder. (загрузка может занять несколько минут)

Visualizing the World Happiness Report dataset with nteract’s Data Explorer
Также мы внедряем встроенную поддержку параметризации, которая упрощает планирование запуска notebook, и создаем шаблоны для многократного использования.
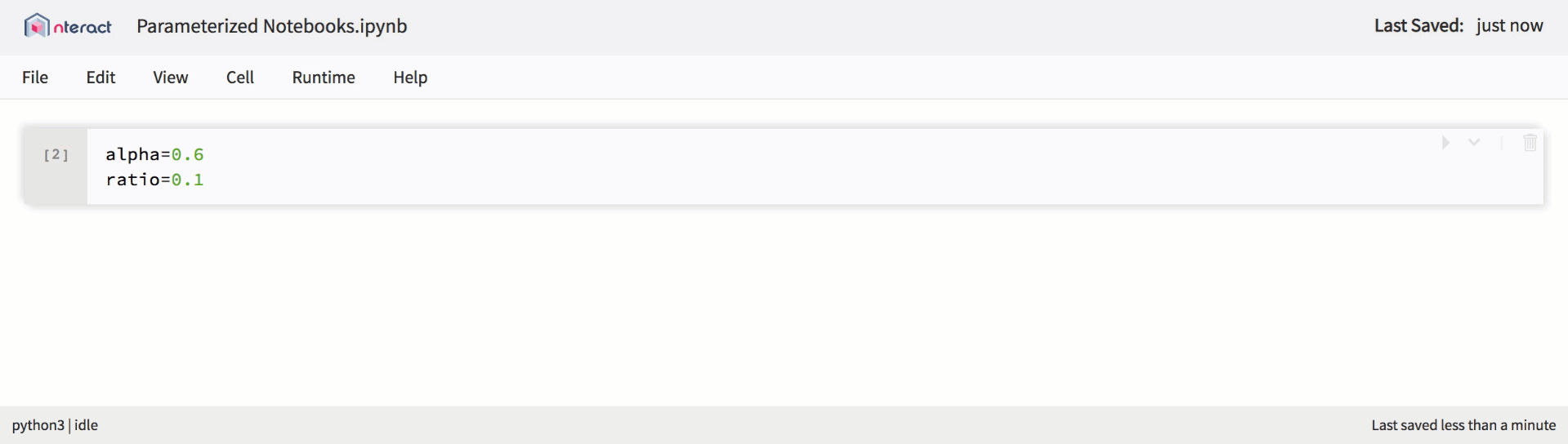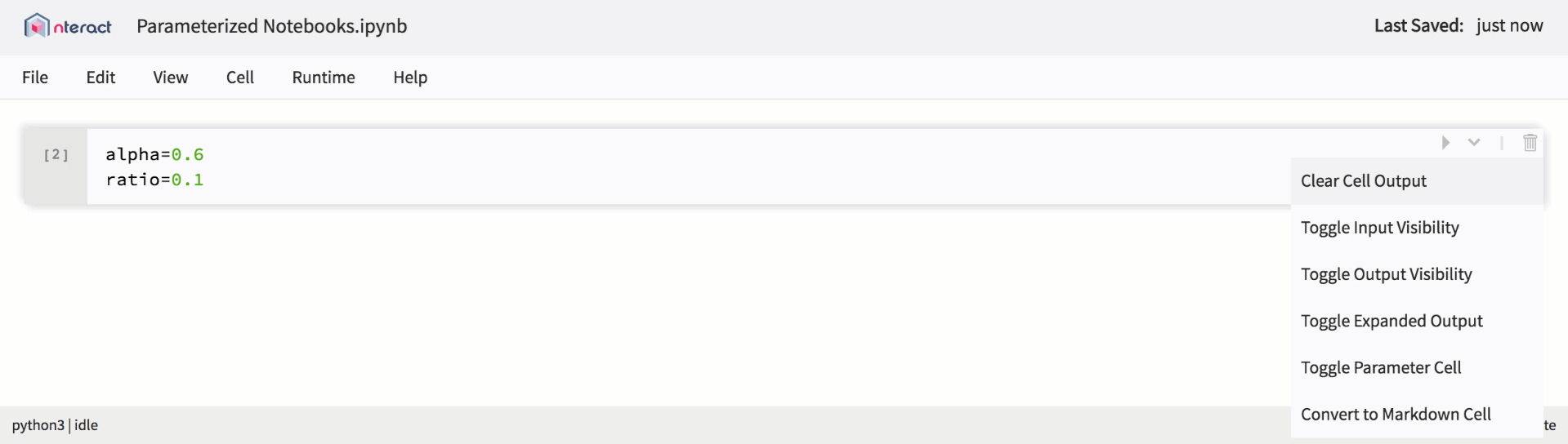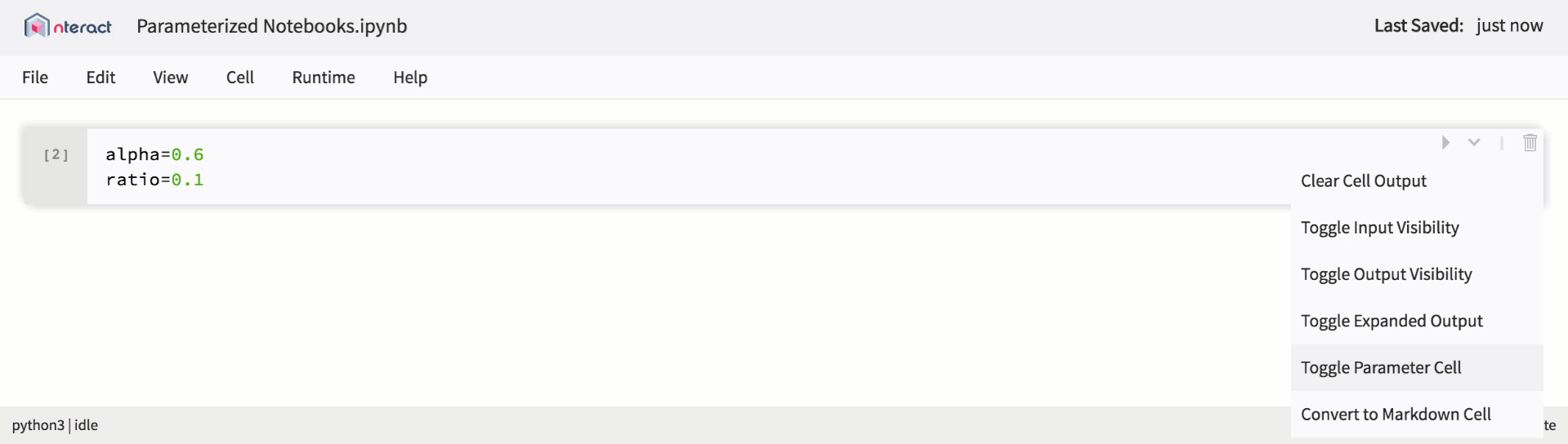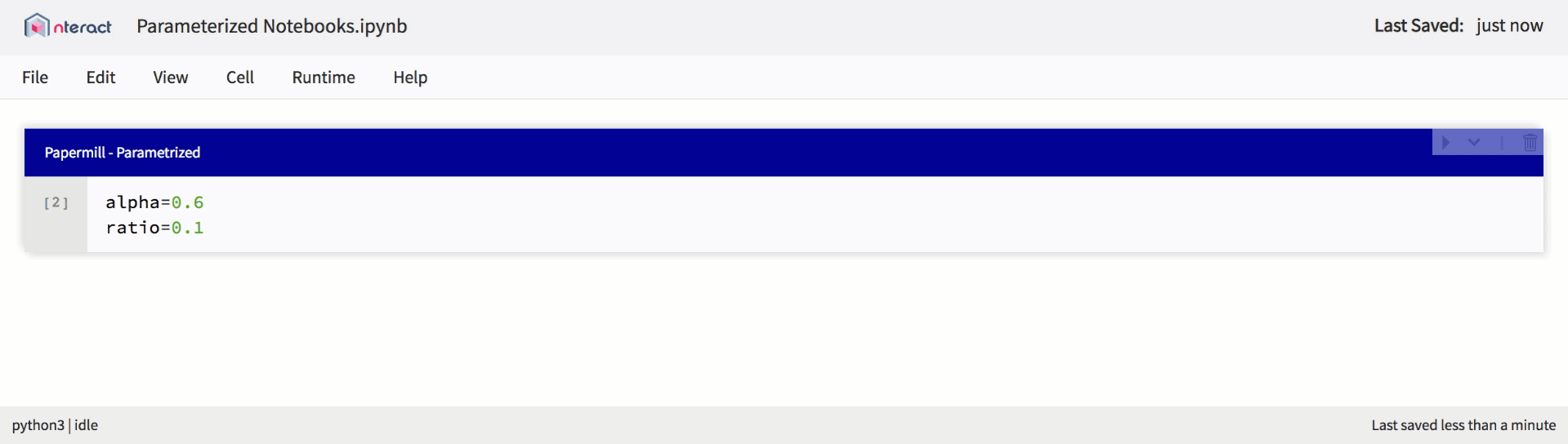
Native support for parameterized notebooks in nteract
Несмотря на то что Jupyter notebook уже принесли немалую пользу, мы только в начале пути. Мы знаем что необходимы большие инвестиции и в фронтенд, и в бэкенд для улучшения опыта работы с notebook. Наша работа за следующие 12 месяцев будет сосредоточена на улучшении надежности, прозрачности и совместной работы. Контекст имеет первостепенное значение для пользователей, поэтому мы улучшаем видимость статуса кластеров, состояния ядер, истории задач и так далее. Также мы работаем над системой автоматического контроля версий, встроенным планировщиком в приложении, улучшенной поддержкой визуализации Spark DataFrames, и стабильностью ядер Scala. Более подробно об этой работе мы расскажем в следующей статье.
Open Source Projects
Netflix является сторонником открытого исходного кода. Мы ценим энтузиазм, открытые стандарты, и обмен идеями возникающими в результате сотрудничества. Многие из приложений которые мы разработали для Netflix Data Platform уже являются открытыми в Netflix OSS. Мы также не намерены создавать одноразовые решения и не поддаваться менталитету “Not Invented Here”. При любой возможности мы пользуемся и вносим свой вклад в существующие проекты с открытым кодом такие Spark, Jupyter и pandas.
Инфраструктура, которую мы описали, существенно опирается на экосистему Jupyter Project, но в некоторых моментах мы решили сделать иначе. Например, мы выбрали nteract в качестве notebook UI в Netflix. Подобное решение было принято по многим причинам, включая соответствие технологическому стеку компании и философию дизайна. По мере того, как мы продолжим расширять границы возможностей Jupyter Notebook, вероятно, будем создавать новые инструменты, библиотеки и сервисы. Эти проекты также будут с открытым исходным кодом как часть экосистемы nteract.
Мы осознаем что не всё, что подходит для Netflix, будет актуально для остальных. Поэтому, создавая эти проекты, старались делать их модульным, чтобы можно было выбрать и использовать только те компоненты, которые необходимы для вас. Например, Papermill, который не требует использования всей экосистемы.
What’s Next (Что дальше)
Как команда разработчиков платформы, наша обязанность – дать возможность пользователям(Netflixers) делать удивительные вещи с данными. Notebook уже оказывает существенное влияние на Netflix. Учитывая огромные вложения которые мы делаем в эту среду, мы рады видеть как это влияние растет. Здесь могла быть ссылка на вакансии нэтфликс, которую удалили до прилета НЛО.
Фух! Спасибо что смогли осилить этот огромный пост. Мы затронули только верхушку того, что мы делаем с notebook. Этот пост является первой из серии статей про использование notebook в Netflix, которые мы будет публиковать в течении нескольких следующих недель. На данный момент уже опубликованы две статьи:
Часть I: Notebook Innovation (этот пост)
Часть II: Scheduling Notebooks
От переводчика:
Слова Scheduling и workflows тяжело переводится на русский язык, если вы знаете лаконичный вариант перевода — дайте знать в комментариях.
