В моем предыдущем проекте перед нами встала задача провести обратное геокодирование для множества пар географических координат. Обратное геокодирование — это процедура, которая паре широта-долгота ставит в соответствие адрес или название объекта на карте, к которому принадлежит или близка заданная координатами точка. То есть, берем координаты, скажем такие: @55.7602485,37.6170409, и получаем результат либо «Россия, Центральный федеральный округ, Москва, Театральная площадь, дом такой-то», либо например «Большой театр».
Если на входе адрес или название, а на выходе координаты, то эта операция — прямое геокодирование, об этом мы, надеюсь, поговорим позже.
В качестве исходных данных у нас на входе было примерно 100 или 200 тысяч точек, которые лежали в кластере Hadoop в виде таблицы Hive. Это чтобы был понятен масштаб задачи.
В качестве инструмента обработки в конце концов был выбран Spark, хотя в процессе мы попробовали как MapReduce, так и Apache Crunch. Но это отдельная история, возможно заслуживающая своего поста.
Для начала мы попробовали подойти к проблеме так сказать «в-лоб». В качестве инструмента имелся сервер ArcGIS, который предоставляет REST-сервис обратного геокодирования. Пользоваться им достаточно просто, для этого выполняем http GET запрос со следующим URL:
Из множества параметров достаточно задать location=x,y (главное не перепутайте, кто из них широта, а кто — долгота ;). И вот мы уже имеем JSON с результатами: страна, регион, город, улица, номер дома. Пример из документации:
Можно дополнительно указать, какие виды ответов мы хотим — почтовые адреса, или скажем POI (point of interest, это чтобы получить ответы вида «Большой театр»), или нужны ли нам пересечения улиц, например. Также можно указать радиус, внутри которого от указанной точки будет произведен поиск именованного объекта.
Для быстрой проверки качества ответа можно прикинуть расстояние между исходной точкой в параметрах запроса, и точкой полученной — location в ответе сервиса.
Казалось бы, сейчас все будет хорошо. Но не тут-то было. Наш экземпляр ArcGIS был достаточно медленный, серверу было выделено кажется 4 ядра, и примерно 8 гигабайт оперативной памяти. В итоге задача на кластере могла прочитать наши 200 тыс точек очень быстро, но упиралась в REST и производительность ArcGIS. И геокодирование всех точек занимало часы. При этом на Hadoop мы выделяли всего каких-то 8 ядер, и немного памяти, но так как загрузка сервера ArcGIS была близка к 100% в течение многих часов, лишние ресурсы в кластере нам ничего не давали.
Пакетные операции обратного геокодирования ArcGIS делать не умеет, так что запрос выполняется один раз на каждую точку. И кстати, если сервис не отвечает, то мы отваливаемся по таймауту или с ошибкой, и что с этим делать — проблема с неочевидным ответом. Может быть попробовать еще раз, а может быть завершить весь процесс, и потом повторить его для необработанных точек.
Для начала мы выяснили, что многие точки в нашем наборе имеют повторяющиеся координаты. Причина тут простая — очевидно, точность GPS недостаточно хороша, чтобы координаты расположенных двух метрах друг от друга точек отличались на выходе, или же в исходную базу просто вводились координаты, полученные не с GPS, а из другой базы. В общем, неважно, почему это так, главное что это вполне типичная ситуация, так что кеш результатов, полученных от сервиса, позволит выполнить геокодирование каждой пары координат только однократно. А памяти для кеша мы вполне можем себе позволить.
Собственно, первая модификация алгоритма была сделана тривиальная — все полученные от REST результаты складывались в кеш, и для всех точек сначала производился поиск по координатам в нем. Мы даже не стали заводить общий кеш для всех процессов спарка — на каждом узле кластера он был свой.
Таким несложным образом мы смогли получить ускорение примерно до 10 раз, что примерно на глаз соответствует числу повторов координат в исходном наборе. Это уже было приемлемо, но все равно очень медленно.
Хорошо, сказал нам в это время наш заказчик, если мы не можем вычислить адреса быстрее, можем ли мы быстро определить хотя бы город? И мы взялись за…
Что у нас есть, чтобы определить город? У нас была геометрия регионов России, административно-территориальное деление, примерно с точностью до районов города.
Взять эти данные можно например вот тут. Что там лежит? Это база данных административных границ РФ, для уровней от 2 (страна) до 9 (городские округа). Формат либо geojson, либо CSV (при этом сама геометрия в формате wkt). Всего в базе примерно 20 тыс записей.
Новое упрощенное решение задачи выглядело так:
В итоге на выходе получаем что-то вроде: Россия, Центральный федеральный округ, Москва, такой-то административный округ, район такой-то, то есть, список территорий, в которые входит наша точка.
Чтобы загрузить CSV попроще, мы применим kite. Этот инструмент умеет очень хорошо строить схему для Hive на основе заголовков колонок в CSV. Фактически, импорт сводится к трем командам (одна из которых повторяется для каждого файла уровня):
Что мы тут сделали? Первая команда построила нам Avro-схему для csv, для чего мы указали некоторые параметры схемы (класс, в данном случае), и разделитель полей для CSV. Далее стоит посмотреть на полученную схему глазами, и возможно внести некоторые исправления, потому что Kite при анализе данных смотрит не на все строки нашего файла, а лишь на некоторую выборку, поэтому может делать иногда неверные предположения о типе данных (увидел три числа — решил что колонка числовая, а дальше пошли строки).
Ну а дальше на основе схемы мы создаем dataset (это общий термин Kite, обобщающий таблицы в Hive, таблицы в HBase, и кое-то еще). В данном случае default это база данных (для Hive тоже что и схема), а levelswkt — название нашей таблицы.
Ну и последние команды загружают CSV файлы в наш датасет. После успешного завершения загрузки вы уже можете выполнить запрос:
где-нибудь в Hue.
Для работы с геометрией в Java мы выбрали Java Geometry API от компании Esri (разработчик ArcGIS). В принципе, можно было взять и другие фреймворки, некоторый выбор Open Source имеется, например широко известный пакет JTS Topology Suite, или Geotools.
С первой задачей нам позволяет справиться еще один фреймворк от той же компании Esri, именуемый Spatial Framework for Hadoop, и основанный на первом. По сути, из него нам нужен так называемый SerDe, модуль сериализации-десериализации для Hive, который позволяет представить пачку geojson файлов как таблицу в Hive, колонки которой берутся из атрибутов geojson. А сама геометрия становится еще одной колонкой (с бинарными данными). В итоге у нас есть таблица, одна из колонок которой — геометрия некоего региона, а остальные — его атрибуты (название, уровень в АТД, и пр.). Эта таблица доступна Spark приложению.
Если же мы загружаем в базу данные в формате CSV, то мы имеем колонку, где геометрии лежат в текстовом виде, в формате WKT. В этом случае Spark может создать объект геометрии при выполнении, применяя Geometry API.
Мы выбрали именно CSV формат (и WKT), по одной простой причине — как все знают, Россия занимает на карте область с координатами Чукотки за 180 меридианом. У формата geojson есть ограничение — все полигоны внутри него должны быть ограничены 180 градусами, а те что пересекают 180 меридиан, нужно порезать на две части по нему. В итоге, при импорте геометрии в Geometry API мы получаем объект, для которого Geometry API неправильно определяет Bounding Box (объемлющий прямоугольник) для границы России. Получается ответ -180,180 по долготе. Что конечно же не правда — в реальности Россия занимает примерно от 20 до -170 градусов. Это проблема Geometry API, на сегодня она возможно уже исправлена, но тогда нам пришлось ее обходить.
У WKT такой проблемы нет. Вы спросите, зачем нам Bounding Box? Потом расскажу ;)
Остается решить так называемую задачу PIP, point in poligon. Это снова умеет Java Geometry API, для нас это просто, одна геометрия типа Point, вторая полигон (Multipoligon) для региона, и один метод contains.
В итоге, второе решение, и тоже в лоб, выглядело так: Spark приложение загружает АТД, включая геометрии. Из них строится нечто типа Map название->геометрия (на самом деле чуть сложнее, так как АТД вложены друг в друга, и нам нужно искать только в тех нижних уровнях, которые входят в уже найденный верхний. В итоге тут некое дерево геометрий, которое по исходным данным еще нужно построить). А дальше мы строим Spark Dataset с нашими точками, и к каждой точке применяем свою UDF, которая проверяет вхождение точки во все геометрии (по дереву).
Написание новой версии занимает примерно день работы, благо в комплекте Spatial Framework for Hadoop были неплохие примеры прямо для решения PIP задачи (правда, несколько другими средствами).
Запускаем, и… о ужас, быстрее-то не стало. Снова часы. Пора подумать над оптимизацией.
Причина тормозов достаточно очевидная — скажем, геометрия России, т.е. внешние границы, это мегабайты geojson, здоровенный полигон, и не один. Если вспомнить, как решается задачка PIP, то одним из широко известных методов является построение луча из точки скажем куда-то вверх, до бесконечности, и определение, в скольких точках он пересекает полигон. Если число точек четное, точка вне полигона, если нечетное — внутри.
Вот скажем описание из вики.

Понятно, что для огромного полигона решение задачи пересечения усложняется во столько раз, сколько у нас в полигоне отрезков прямой. Поэтому желательно как-то отбросить те полигоны, в которые точка заведомо входить не может. И в качестве дополнительного лайфхака — возможно отбросить проверку на вхождение в границы России (если мы знаем, что все координаты в нее заведомо входят).
Для этого нам подойдет дерево квадрантов. Благо реализация есть все в том же Geometry API (и много где еще).

Решение на основе дерева выглядит примерно так:
Далее, при обработке точек:
На это все уходит еще часа четыре разработки. Запускаем еще раз, и видим, что задачка завершилась уж как-то очень быстро. Проверяем — все нормально, решение получено. И все — за пару минут. QuadTree дает нам ускорение на несколько порядков.
Итак, что мы в итоге получили? Мы получили механизм обратного геокодирования, который эффективно параллелится на Hadoop кластере, и который решает нашу исходную задачу с 200 тыс точек примерно за минуты. Т.е. мы спокойно можем применить это решение к миллионам точек.
Какие ограничения у данного решения? Первое, очевидное — оно основано на доступных нам данных АТД, которые а) могут быть не актуальны б) ограничены только Россией.
И второе — мы не умеем решать задачу обратного геокодирования для объектов, отличных от замкнутых полигонов. А это значит — для улиц в том числе.
Что с этим можно сделать?
Чтобы иметь актуальные геометрии АТД, самое простое — взять их из OpenStreetMap. Над ними конечно придется немного поработать, но это вполне решаемая задача. Если будет интерес, о задаче загрузки данных OpenStreetMap в кластер Hadoop я расскажу как-нибудь в другой раз.
Что можно сделать для улиц и домов? В принципе, улицы есть в том же OSM. Но это уже не замкнутые структуры, а линии. Чтобы определить, что точка «близка» к некоторой улице, придется построить для улицы полигон из равноудаленных от нее точек, и проверить попадание в него. В итоге эдакая сосиска получается… выглядит это примерно так:
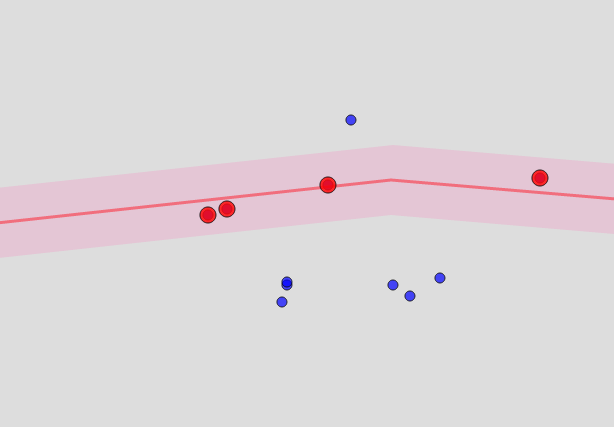
Насколько точка близка? Это является параметром, и примерно соответствует тому радиусу, внутри которого ищет объекты ArcGIS, и о котором я упоминал в самом начале.
Таким образом мы находим улицы, расстояние от точки до которых меньше некоторого предела (скажем, 100 метров). И чем этот предел меньше — тем быстрее работает алгоритм, но тем больше шансов, что вы не найдете ни одного совпадения.
Очевидная проблема состоит в том, что вычислить эти так называемые buffers заранее невозможно — их размер является параметром сервиса. Их нужно строить на лету, после того, как мы определили искомый район города, и отобрали из базы OSM улицы, которые проходят через этот район. Улицы, впрочем, можно отобрать и заранее.
Дома, которые находятся в найденном районе, тоже никуда не движутся, поэтому и их список можно построить заранее — но попадание в них все равно придется считать налету.
То есть, нужно предварительно построить индекс вида «район города»-> список домов со ссылками на геометрии, и аналогичный для списка улиц.
И как только мы определили район, достаем список домов и улиц, строим по улицам границы, и уже только для них решаем задачу PIP (вероятно, с применением тех же оптимизаций, как и для границ регионов). Дерево квадрантов для домов в этом случае очевидно можно тоже построить заранее, и куда-то сохранить.
Основная наша цель — максимально сократить объем вычислений, при этом максимально рассчитав и сохранив заранее все, что можно рассчитать и сохранить. В этом случае процесс будет состоять из медленного этапа построения индексов, и второго этапа расчета, который уже будет проходить быстро, близко к онлайн-варианту.
Если на входе адрес или название, а на выходе координаты, то эта операция — прямое геокодирование, об этом мы, надеюсь, поговорим позже.
В качестве исходных данных у нас на входе было примерно 100 или 200 тысяч точек, которые лежали в кластере Hadoop в виде таблицы Hive. Это чтобы был понятен масштаб задачи.
В качестве инструмента обработки в конце концов был выбран Spark, хотя в процессе мы попробовали как MapReduce, так и Apache Crunch. Но это отдельная история, возможно заслуживающая своего поста.
Прямолинейное решение доступными средствами
Для начала мы попробовали подойти к проблеме так сказать «в-лоб». В качестве инструмента имелся сервер ArcGIS, который предоставляет REST-сервис обратного геокодирования. Пользоваться им достаточно просто, для этого выполняем http GET запрос со следующим URL:
http://базовый-url/GeocodeServer/reverseGeocode?<параметры>
Из множества параметров достаточно задать location=x,y (главное не перепутайте, кто из них широта, а кто — долгота ;). И вот мы уже имеем JSON с результатами: страна, регион, город, улица, номер дома. Пример из документации:
{
"address": {
"Match_addr": "Beeman's Redlands Pharmacy",
"LongLabel": "Beeman's Redlands Pharmacy, 255 Terracina Blvd, Redlands, CA, 92373, USA",
"ShortLabel": "Beeman's Redlands Pharmacy",
"Addr_type": "POI",
"Type": "Pharmacy",
"PlaceName": "Beeman's Redlands Pharmacy",
"AddNum": "255",
"Address": "255 Terracina Blvd",
"Block": "",
"Sector": "",
"Neighborhood": "South Redlands",
"District": "",
"City": "Redlands",
"MetroArea": "Inland Empire",
"Subregion": "San Bernardino County",
"Region": "California",
"Territory": "",
"Postal": "92373",
"PostalExt": "",
"CountryCode": "USA"
},
"location": {
"x": -117.20558993392585,
"y": 34.037880040538894,
"spatialReference": {
"wkid": 4326,
"latestWkid": 4326
}
}
}
Можно дополнительно указать, какие виды ответов мы хотим — почтовые адреса, или скажем POI (point of interest, это чтобы получить ответы вида «Большой театр»), или нужны ли нам пересечения улиц, например. Также можно указать радиус, внутри которого от указанной точки будет произведен поиск именованного объекта.
Для быстрой проверки качества ответа можно прикинуть расстояние между исходной точкой в параметрах запроса, и точкой полученной — location в ответе сервиса.
Казалось бы, сейчас все будет хорошо. Но не тут-то было. Наш экземпляр ArcGIS был достаточно медленный, серверу было выделено кажется 4 ядра, и примерно 8 гигабайт оперативной памяти. В итоге задача на кластере могла прочитать наши 200 тыс точек очень быстро, но упиралась в REST и производительность ArcGIS. И геокодирование всех точек занимало часы. При этом на Hadoop мы выделяли всего каких-то 8 ядер, и немного памяти, но так как загрузка сервера ArcGIS была близка к 100% в течение многих часов, лишние ресурсы в кластере нам ничего не давали.
Пакетные операции обратного геокодирования ArcGIS делать не умеет, так что запрос выполняется один раз на каждую точку. И кстати, если сервис не отвечает, то мы отваливаемся по таймауту или с ошибкой, и что с этим делать — проблема с неочевидным ответом. Может быть попробовать еще раз, а может быть завершить весь процесс, и потом повторить его для необработанных точек.
Второе приближение, внедряем кеш
Для начала мы выяснили, что многие точки в нашем наборе имеют повторяющиеся координаты. Причина тут простая — очевидно, точность GPS недостаточно хороша, чтобы координаты расположенных двух метрах друг от друга точек отличались на выходе, или же в исходную базу просто вводились координаты, полученные не с GPS, а из другой базы. В общем, неважно, почему это так, главное что это вполне типичная ситуация, так что кеш результатов, полученных от сервиса, позволит выполнить геокодирование каждой пары координат только однократно. А памяти для кеша мы вполне можем себе позволить.
Собственно, первая модификация алгоритма была сделана тривиальная — все полученные от REST результаты складывались в кеш, и для всех точек сначала производился поиск по координатам в нем. Мы даже не стали заводить общий кеш для всех процессов спарка — на каждом узле кластера он был свой.
Таким несложным образом мы смогли получить ускорение примерно до 10 раз, что примерно на глаз соответствует числу повторов координат в исходном наборе. Это уже было приемлемо, но все равно очень медленно.
Хорошо, сказал нам в это время наш заказчик, если мы не можем вычислить адреса быстрее, можем ли мы быстро определить хотя бы город? И мы взялись за…
Упрощенное решение, внедряем Geomerty API
Что у нас есть, чтобы определить город? У нас была геометрия регионов России, административно-территориальное деление, примерно с точностью до районов города.
Взять эти данные можно например вот тут. Что там лежит? Это база данных административных границ РФ, для уровней от 2 (страна) до 9 (городские округа). Формат либо geojson, либо CSV (при этом сама геометрия в формате wkt). Всего в базе примерно 20 тыс записей.
Новое упрощенное решение задачи выглядело так:
- Загружаем данные АТД в Hive.
- Для каждой точки с координатами ищем в таблице территориального деления полигоны, куда эта точка входит.
- Найденные полигоны сортируем по уровню.
В итоге на выходе получаем что-то вроде: Россия, Центральный федеральный округ, Москва, такой-то административный округ, район такой-то, то есть, список территорий, в которые входит наша точка.
Загрузка АТД
Чтобы загрузить CSV попроще, мы применим kite. Этот инструмент умеет очень хорошо строить схему для Hive на основе заголовков колонок в CSV. Фактически, импорт сводится к трем командам (одна из которых повторяется для каждого файла уровня):
kite-tools csv-schema admin_level_2.csv --class al --delimiter \; >adminLevel.avrs
kite-tools create dataset:hive:/default/levelswkt -s adminLevel.avrs
kite-tools csv-import admin_level_2.csv dataset:hive:/default/levelswkt --delimiter \;
...
kite-tools csv-import admin_level_10.csv dataset:hive:/default/levelswkt --delimiter \;
Что мы тут сделали? Первая команда построила нам Avro-схему для csv, для чего мы указали некоторые параметры схемы (класс, в данном случае), и разделитель полей для CSV. Далее стоит посмотреть на полученную схему глазами, и возможно внести некоторые исправления, потому что Kite при анализе данных смотрит не на все строки нашего файла, а лишь на некоторую выборку, поэтому может делать иногда неверные предположения о типе данных (увидел три числа — решил что колонка числовая, а дальше пошли строки).
Ну а дальше на основе схемы мы создаем dataset (это общий термин Kite, обобщающий таблицы в Hive, таблицы в HBase, и кое-то еще). В данном случае default это база данных (для Hive тоже что и схема), а levelswkt — название нашей таблицы.
Ну и последние команды загружают CSV файлы в наш датасет. После успешного завершения загрузки вы уже можете выполнить запрос:
select * from levelswkt;где-нибудь в Hue.
Работа с геометрией
Для работы с геометрией в Java мы выбрали Java Geometry API от компании Esri (разработчик ArcGIS). В принципе, можно было взять и другие фреймворки, некоторый выбор Open Source имеется, например широко известный пакет JTS Topology Suite, или Geotools.
С первой задачей нам позволяет справиться еще один фреймворк от той же компании Esri, именуемый Spatial Framework for Hadoop, и основанный на первом. По сути, из него нам нужен так называемый SerDe, модуль сериализации-десериализации для Hive, который позволяет представить пачку geojson файлов как таблицу в Hive, колонки которой берутся из атрибутов geojson. А сама геометрия становится еще одной колонкой (с бинарными данными). В итоге у нас есть таблица, одна из колонок которой — геометрия некоего региона, а остальные — его атрибуты (название, уровень в АТД, и пр.). Эта таблица доступна Spark приложению.
Если же мы загружаем в базу данные в формате CSV, то мы имеем колонку, где геометрии лежат в текстовом виде, в формате WKT. В этом случае Spark может создать объект геометрии при выполнении, применяя Geometry API.
Мы выбрали именно CSV формат (и WKT), по одной простой причине — как все знают, Россия занимает на карте область с координатами Чукотки за 180 меридианом. У формата geojson есть ограничение — все полигоны внутри него должны быть ограничены 180 градусами, а те что пересекают 180 меридиан, нужно порезать на две части по нему. В итоге, при импорте геометрии в Geometry API мы получаем объект, для которого Geometry API неправильно определяет Bounding Box (объемлющий прямоугольник) для границы России. Получается ответ -180,180 по долготе. Что конечно же не правда — в реальности Россия занимает примерно от 20 до -170 градусов. Это проблема Geometry API, на сегодня она возможно уже исправлена, но тогда нам пришлось ее обходить.
У WKT такой проблемы нет. Вы спросите, зачем нам Bounding Box? Потом расскажу ;)
Остается решить так называемую задачу PIP, point in poligon. Это снова умеет Java Geometry API, для нас это просто, одна геометрия типа Point, вторая полигон (Multipoligon) для региона, и один метод contains.
В итоге, второе решение, и тоже в лоб, выглядело так: Spark приложение загружает АТД, включая геометрии. Из них строится нечто типа Map название->геометрия (на самом деле чуть сложнее, так как АТД вложены друг в друга, и нам нужно искать только в тех нижних уровнях, которые входят в уже найденный верхний. В итоге тут некое дерево геометрий, которое по исходным данным еще нужно построить). А дальше мы строим Spark Dataset с нашими точками, и к каждой точке применяем свою UDF, которая проверяет вхождение точки во все геометрии (по дереву).
Написание новой версии занимает примерно день работы, благо в комплекте Spatial Framework for Hadoop были неплохие примеры прямо для решения PIP задачи (правда, несколько другими средствами).
Запускаем, и… о ужас, быстрее-то не стало. Снова часы. Пора подумать над оптимизацией.
Оптимизированное решение, QuadTree
Причина тормозов достаточно очевидная — скажем, геометрия России, т.е. внешние границы, это мегабайты geojson, здоровенный полигон, и не один. Если вспомнить, как решается задачка PIP, то одним из широко известных методов является построение луча из точки скажем куда-то вверх, до бесконечности, и определение, в скольких точках он пересекает полигон. Если число точек четное, точка вне полигона, если нечетное — внутри.
Вот скажем описание из вики.

Понятно, что для огромного полигона решение задачи пересечения усложняется во столько раз, сколько у нас в полигоне отрезков прямой. Поэтому желательно как-то отбросить те полигоны, в которые точка заведомо входить не может. И в качестве дополнительного лайфхака — возможно отбросить проверку на вхождение в границы России (если мы знаем, что все координаты в нее заведомо входят).
Для этого нам подойдет дерево квадрантов. Благо реализация есть все в том же Geometry API (и много где еще).

Решение на основе дерева выглядит примерно так:
- Загружаем геометрии АТД
- Для каждой геометрии определяем объемлющий прямоугольник
- Помещаем ее в QuadTree, получаем в ответ индекс
- индекс запоминаем
Далее, при обработке точек:
- Спрашиваем у QuadTree, в какие из известных ей геометрий может входить точка
- Получаем индексы геометрий
- Только для них проверяем вхождение решением задачи PIP
На это все уходит еще часа четыре разработки. Запускаем еще раз, и видим, что задачка завершилась уж как-то очень быстро. Проверяем — все нормально, решение получено. И все — за пару минут. QuadTree дает нам ускорение на несколько порядков.
Итоги
Итак, что мы в итоге получили? Мы получили механизм обратного геокодирования, который эффективно параллелится на Hadoop кластере, и который решает нашу исходную задачу с 200 тыс точек примерно за минуты. Т.е. мы спокойно можем применить это решение к миллионам точек.
Какие ограничения у данного решения? Первое, очевидное — оно основано на доступных нам данных АТД, которые а) могут быть не актуальны б) ограничены только Россией.
И второе — мы не умеем решать задачу обратного геокодирования для объектов, отличных от замкнутых полигонов. А это значит — для улиц в том числе.
Развитие
Что с этим можно сделать?
Чтобы иметь актуальные геометрии АТД, самое простое — взять их из OpenStreetMap. Над ними конечно придется немного поработать, но это вполне решаемая задача. Если будет интерес, о задаче загрузки данных OpenStreetMap в кластер Hadoop я расскажу как-нибудь в другой раз.
Что можно сделать для улиц и домов? В принципе, улицы есть в том же OSM. Но это уже не замкнутые структуры, а линии. Чтобы определить, что точка «близка» к некоторой улице, придется построить для улицы полигон из равноудаленных от нее точек, и проверить попадание в него. В итоге эдакая сосиска получается… выглядит это примерно так:
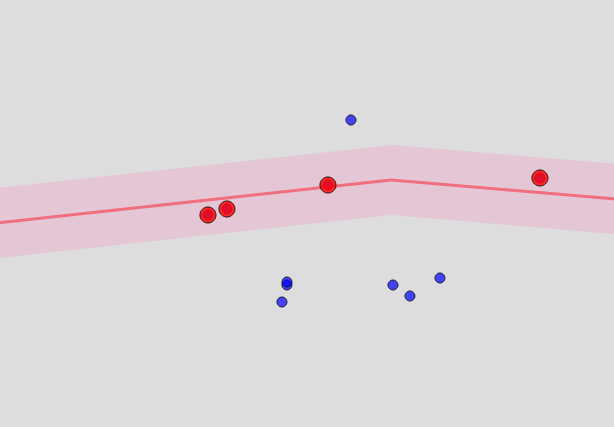
Насколько точка близка? Это является параметром, и примерно соответствует тому радиусу, внутри которого ищет объекты ArcGIS, и о котором я упоминал в самом начале.
Таким образом мы находим улицы, расстояние от точки до которых меньше некоторого предела (скажем, 100 метров). И чем этот предел меньше — тем быстрее работает алгоритм, но тем больше шансов, что вы не найдете ни одного совпадения.
Очевидная проблема состоит в том, что вычислить эти так называемые buffers заранее невозможно — их размер является параметром сервиса. Их нужно строить на лету, после того, как мы определили искомый район города, и отобрали из базы OSM улицы, которые проходят через этот район. Улицы, впрочем, можно отобрать и заранее.
Дома, которые находятся в найденном районе, тоже никуда не движутся, поэтому и их список можно построить заранее — но попадание в них все равно придется считать налету.
То есть, нужно предварительно построить индекс вида «район города»-> список домов со ссылками на геометрии, и аналогичный для списка улиц.
И как только мы определили район, достаем список домов и улиц, строим по улицам границы, и уже только для них решаем задачу PIP (вероятно, с применением тех же оптимизаций, как и для границ регионов). Дерево квадрантов для домов в этом случае очевидно можно тоже построить заранее, и куда-то сохранить.
Основная наша цель — максимально сократить объем вычислений, при этом максимально рассчитав и сохранив заранее все, что можно рассчитать и сохранить. В этом случае процесс будет состоять из медленного этапа построения индексов, и второго этапа расчета, который уже будет проходить быстро, близко к онлайн-варианту.
