Comments 69
Впечатляет статистика невысоких отказов дисков больших объемов — научились делать однако.
Еще интересен факт малого количества дисков WD — боятся испарения гелия?
Еще интересен факт малого количества дисков WD — боятся испарения гелия?
По статистике видно же что ВДшки дохнут намного чаще и от них отказываются.
Как раз по статистике ничего не видно: 45 штук вестернов, против десятков тысяч каких-нибудь сегейтов — хреновая база для сбора статистики.
45 штук вестернов ОСТАЛОСЬ, смотрите статистику за предыдущие годы, там были партии по несколько тысяч.
Помнится, почитывал их бложик и там как раз были рассуждения о закупке дисков различных производителей. Так вот, там все диктуется не прикидками «надежный-ненадежный», а ценой и возможностью купить крупную партию. Кроме того, ненадежные диски — это обычно отдельные неудачные партии, а не все вообще диски одного производителя.
Конкретно про WD смутно вспоминается, что в среднем их цена была выше, чем у конкурентов аналогичного объема, а возможности купить крупную партию почему-то не было.
Можно было купить дешевые WD-шки во внешних корпусах, а потом сидеть и выламывать их, но они от этого отказались: во-первых, теряется гарантия, а во-вторых, инженеры должны заниматься более интересными делами, чем раскурочивание тысяч внешних дисков.
А надежность у них обеспечивается избыточностью и активным мониторингом дисковых массивов, так что плюс-минус пара процентов сдохших дисков для бизнеса некритична.
Конкретно про WD смутно вспоминается, что в среднем их цена была выше, чем у конкурентов аналогичного объема, а возможности купить крупную партию почему-то не было.
Можно было купить дешевые WD-шки во внешних корпусах, а потом сидеть и выламывать их, но они от этого отказались: во-первых, теряется гарантия, а во-вторых, инженеры должны заниматься более интересными делами, чем раскурочивание тысяч внешних дисков.
А надежность у них обеспечивается избыточностью и активным мониторингом дисковых массивов, так что плюс-минус пара процентов сдохших дисков для бизнеса некритична.
Их и куплено было мало, статистика слабая.
Что странно. Похоже что инженеры-вредители делавшие раньше убогие диски для сигейта которые дохли пачками все ушли в WD и теперь гадят уже там. При этом надёжность дисков HGST вопросов не вызывает — видимо туда криворукие из сигейта ещё не добрались). В целом же для домашнего использования похоже как рулила тошиба так и рулит.
Дешевые тошибы дохнут ничуть не реже накопителей прочих производителей.
UFO just landed and posted this here
Я понимаю что мой личный опыт не очень релевантен, но почему-то у меня практически все умершие диски это именно HGST и Hitachi (в основном 2.5). А еще они от рождения шумные как правило. При этом умер всего один Segate (но правда из старых, до 2009 года) и один WD. Toshiba еще не умирали (но первую Тошибу я купил года три назад).
Вот из домашнего, где-то до 2012 всегда пользовался Seagate. Потом как-то увидел у HGST диски с гарантией 5 лет, и из 3-х штук купленных примерно в одно время, все ещё работают.
UFO just landed and posted this here
WD'шки все живые (из тех что у меня остались и не были проданы, например 200гб кажется 2004(5) года). Очень плохая личная статистика Seagate — посыпался 2тб и 500гб винты, в связи с чем больше никогда Seagate брать не буду. Еще увалился 500гб Hitachi.
Ну моя личная статистика, за 15 лет в течении 3-5 лет умерли ВСЕ seagate (серия 11-12 даже не вспоминаю, они просто как мухи дохли). По WD были и хорошие диски 2 из них досихпор работают и если умирали в первые 2 года то как правило с китайскими БП, но в целом можно считать отработали 5-6 лет и умерли все. Хитачи из около 30 штук умерло 3 шт причем все умерли в течении гарантии, остальные снимал тупо потому что ставил более новые. По тошиба если в ноуте умирали в течении 3-5 лет ВСЕ, если в NAS или кампудахторе то живут либо досих пор либо снял в рабочем состоянии и продал (тошибу начал брать недавно буквально последние 2-3 года назад)
P.s.: Кстати по сегату в одном серваке вообще чудо было, 15к на 600 гигов sas Seagete умирали по 1 раз в год, причем когда гарантия на сервак в целом кончилась те что поменяли (4 года назад к примеру) начали умирать по второму кругу, а вот те где вместо сегата присылали тошибу живут и не чихают. Замечу в одном серваке!!!
P.s.: Кстати по сегату в одном серваке вообще чудо было, 15к на 600 гигов sas Seagete умирали по 1 раз в год, причем когда гарантия на сервак в целом кончилась те что поменяли (4 года назад к примеру) начали умирать по второму кругу, а вот те где вместо сегата присылали тошибу живут и не чихают. Замечу в одном серваке!!!
«В целом же для домашнего использования похоже как рулила тошиба так и рулит.»
Для дома вообще рулит любой диск + бэкап важного на работе/облаке.
Я меняю диски после 3 лет эксплуатации, за 20 лет ни одного не померло. Не удивительно, ибо в 3% брака тяжело попасть. И разницы вообще нет, 0.2% брак у лучших или 3% у худших.
Я, кстати, WDшки всегда беру, которые якобы мусор.
Для дома вообще рулит любой диск + бэкап важного на работе/облаке.
Я меняю диски после 3 лет эксплуатации, за 20 лет ни одного не померло. Не удивительно, ибо в 3% брака тяжело попасть. И разницы вообще нет, 0.2% брак у лучших или 3% у худших.
Я, кстати, WDшки всегда беру, которые якобы мусор.
в 3% брака тяжело попастьНо дисков же много эксплуатируется. Вероятность, что из 20 дисков с 3% брака откажет хотя бы один, равна 45%.
А откуда цифра в «3% брака»? У Seagate есть модели с 50% доживаемостью до конца 3 года, по статистике Backblaze.
Я тоже WD беру, в основном потому что у них есть сервисный центр в Москве, правда ни разу им не пользовался, т.к. дохли только диски сильно устаревшие по объему. Выбираю всегда самые дешевые (у которых наименьшее соотношение цена/объем), сейчас это ~4 ТБ, но откровенного брака ни разу не было, все переживали гарантийный срок (всего штук 20-30 купил, точно не помню).
Ну, ST10000NM0086 тоже гелиевый, а ставят, значит, не гелия боятся.
Скорее всего отдел закупок ограничен какими-нибудь устоявшимися контрактами. Или же просто из WD скидку не смогли выбить. К примеру для хорошей скидки им нужно в год закупать по 10к дисков, а в год нужно 22к, вот и выбрали пару вендоров, которые предоставили лучшие условия.
В оригинальной статье пишут, что HGST принадлежит WD. А именно с WD не договорились по хорошей цене.
Да, при этом бренд HGST будет ликвидирован. Но вот насчет производства я так и не понял, поменяется ли в самих изделиях что-то кроме наименования.
Элементарно. Вагон винтов HGST сложнее купить, чем вагон винтов WD.
500 000 дней, 50 000 дней — это огого!
Не понимаю, почему они не фокусируются в своих отчётах на time-dependent survival rate, как на графике. Какой толк от Annualized Failure Rate, если они сами говорят, что этот показатель меняется во времени и для одной и той же модели будет разным в зависимости от возраста экземпляров. Наверняка распределение возрастов для разных моделей разной, тогда что о чем нам говорит AFR?
Вот нашел более полезный анализ:
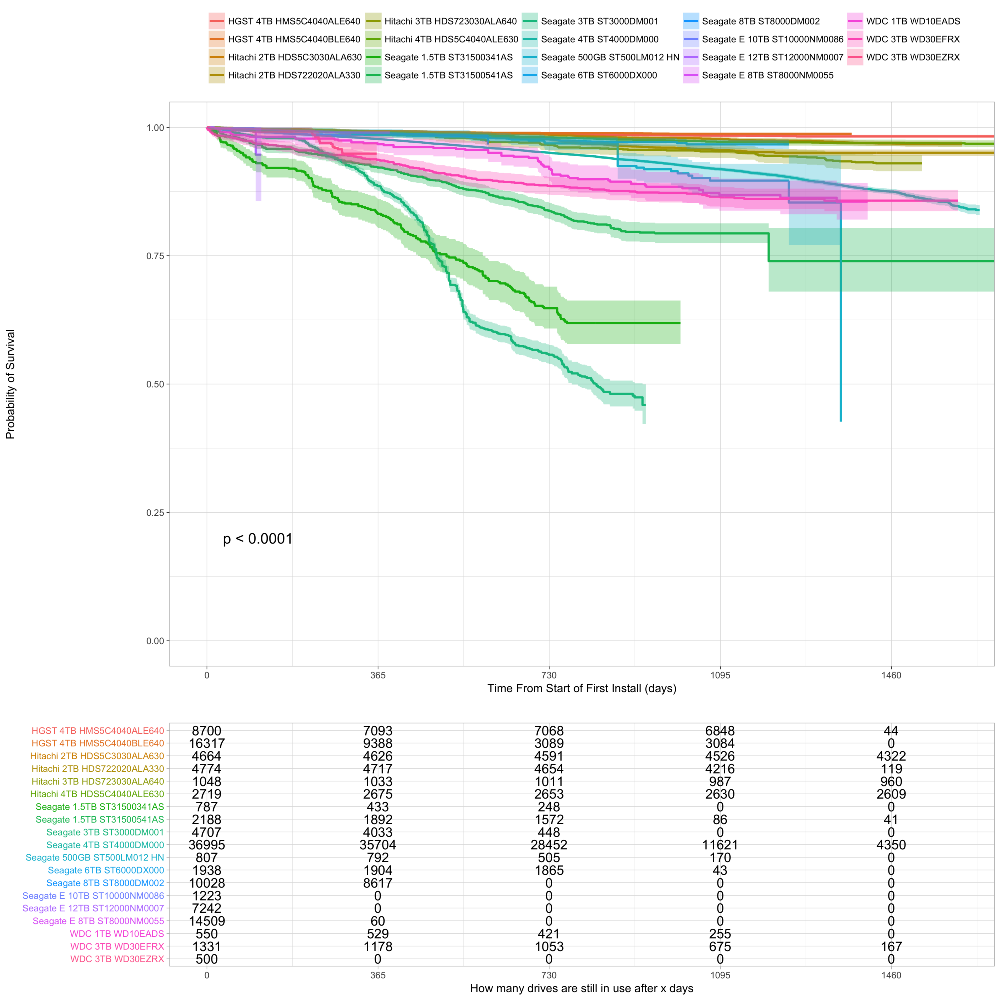
Вот нашел более полезный анализ:

Да. И вопрос, как они меняют HDD — по мере отказов, или по истечению определенного срока службы?
Если считать как в в приведенном мной анализе, — это неважно, а так как в посте, то да, ерунда получается.
ЕМНИП, по мере выхода новых винтов большего объема они закупают эти винты и заменяют ими старые, мелкие. Потому как количество данных постоянно растет, а держать кучу старых мелких дисков — это лишние расходы на электричество и обслуживание. Собственно, этот процесс постепенно привел к тому, что диски в их отчетах уже не совсем потребительские. Далеко не каждый потребитель готов купить себе дисочек на 12 терабайт.
Могу подтвердить надежность Хитачей: много лет юзаю дома в режиме 24х7 3Тб модели HUA5C3030ALA640 и HUA723030ALA640 (5900 и 7200rpm), штук 15 в сумме — ни один не помер, даже Reallocated секторов нет. Уже лет 8 им, как мне кажется. Power-on Hours у многих более 6 лет.
Аниме? Семейные фото? Фильмы с Пауло Виладжо?
Все вышеперечисленное и многое другое :)
Ну, на самом деле, там не все винты у меня — я родителям NAS делал в т.ч.
Хотя, я тут немного не в топике — эти винты скорее серверного класса, поэтому удивляться надежности не стоит наверное.
Ну, на самом деле, там не все винты у меня — я родителям NAS делал в т.ч.
Хотя, я тут немного не в топике — эти винты скорее серверного класса, поэтому удивляться надежности не стоит наверное.
Во времена 11 серии Seagate у меня их было 2 обычных и один серверный. И «серверность» последнего совершенно никак не повлияла на его долголетие. Так что я думаю, enterprise может быть про гарантию, про прошивку, про оптимзации скорости или энергопотребления, но никак не про надежность. Ну и вообще, бывает еще «энтерпрайзнее», «брендовее» и дороже, например, у какого нибудь HP или Dell, но там просто такой же диск, салазки и наклейка.
Наклейка HP еще повышает шанс не нарваться на какую-нить неудачную партию винтов с повышенным шансом брака.
Да и вопрос гарантии при больших объемах, когда в ДЦ едешь с коробкой винтов под замену дохлым — становится навязчивым в финансовом плане.
Мы как-то закупили у непроверенного поставщика большую партию винтов и по результатам сборки схд в отбраковку ушло 7% — решили вернуть их по гарантии. Поставщик в результате кинул нас через одно место найдя на винтах какие-то невидимые невооруженным глазом следы физического воздействия. С брендовыми винтами с наклейкой HP думаю такой бы проблемы не было.
Хотя это конечно никак не может оправдать итоговую стоимость этой наклейки, в ынтерпрайзе она совсем уж какая-то неприличная становится
Да и вопрос гарантии при больших объемах, когда в ДЦ едешь с коробкой винтов под замену дохлым — становится навязчивым в финансовом плане.
Мы как-то закупили у непроверенного поставщика большую партию винтов и по результатам сборки схд в отбраковку ушло 7% — решили вернуть их по гарантии. Поставщик в результате кинул нас через одно место найдя на винтах какие-то невидимые невооруженным глазом следы физического воздействия. С брендовыми винтами с наклейкой HP думаю такой бы проблемы не было.
Хотя это конечно никак не может оправдать итоговую стоимость этой наклейки, в ынтерпрайзе она совсем уж какая-то неприличная становится
Много лет держу дома сервер. Всего 6 хардов разного объема и производителя. С Сеагейтами раньше всегда была проблема, дохли регулярно. Сейчас уже 5 лет тьфу тьфу работают как надо все харды что есть. А там и сеагейт и вд и даже хитачи. У всех наработано уже больше 50к часов, а на некоторых и все 80, однако отказов нет, хоть и работают 24\7.
Ну, износ механики чаще всего как раз происходит при парковке головок и старте-остановке (кроме подшипников шпинделя), поэтому возможно режим 24х7 как раз более щадящий для многих дисков…
Помнится, были какие-то (ноутбучные?) диски WD, которые парковались как бешеные при любом простое — у многих у меня было по 200-300к Load-In/Out в смарте. Лечилось утилиткой wdidle.
Помнится, были какие-то (ноутбучные?) диски WD, которые парковались как бешеные при любом простое — у многих у меня было по 200-300к Load-In/Out в смарте. Лечилось утилиткой wdidle.
Это были WD Green, 3,5" 5к, которые парковали головки уже через 8 секунд.
Нынешние WD Blue точно так же норовят упарковаться в ноль за пару дней. Помню, поставил в NAS свежую вэдешку WD30EZRZ, через пару дней посмотрел ее смарт — и офигел. Пришлось срочно искать, чем ей подкрутить время таймаута до парковки (подсказка: idle3ctl).
UFO just landed and posted this here
Так несколько лет назад WD «упразднил» линейку Green, объединив её с Blue, а то у первой слишком много нелицеприятных отзывов было. И если раньше сразу понятно было: вот Blue — десктопный диск со средними характеристиками, а вот Green — тормознутое глючное убожество, то после этого стало нужно лезть и в характеристики и смотреть, кто есть ху. Короче, WD30EZRZ — это грин и есть.
Может и они тоже, но мои были синие и 2.5" форм-фактором :)
Судя по комменту выше про слияние синих и зеленых — ожидаемо.
Судя по комменту выше про слияние синих и зеленых — ожидаемо.
Каким образом 9 отказов на 1205 дисков превратились в 3.03%?
Да и для обычного пользователя эта статистика ни о чем не говорит. Эти диски стоят в серверах и у них другие условия эксплуатации.
Да и для обычного пользователя эта статистика ни о чем не говорит. Эти диски стоят в серверах и у них другие условия эксплуатации.
ну так уж прям «ниочем». Отличия могут быть, но в отсутствии других данных, статистика Backblaze — это очень хорошее приближение для домашнего NAS, к примеру.
Эти 9 отказов произошли за 108536 дней совокупной работы 1205 дисков (т.е. за три месяца, 90 дней работы каждого диска в среднем). Т.е. за 3 месяца вылетело 9 дисков, «36 годовых», и 36/1205 это вполне три процента.
Не очень понял, как они в последней таблице для ST4000DM000 получили 2,77% отказов.
Не, ну понятно что это фэйлз * 100 / каунт, и поделили на три с пловиной года ещё… но блин… три процента afr, или девять процентов за три года — для ЭТОЙ модели цифра вообще нереальная.
Что-то тут не так с этой математикой.
Не, ну понятно что это фэйлз * 100 / каунт, и поделили на три с пловиной года ещё… но блин… три процента afr, или девять процентов за три года — для ЭТОЙ модели цифра вообще нереальная.
Что-то тут не так с этой математикой.
Число дисков как таковое здесь не играет вообще никак, так как они рабочие диски спустя сколько-то лет тоже меняют. А методика расчета простая, fails/total drive years, или fails*365/total drive days.
А, ну да. Там же время везде в рассчётах участвует изначально, а не так, как я посчитал. Посему достаточно вывести диски из эксплуатации вовремя, до начала массовых отказов — и получишь прекрасный AFR.
Вот как раз выше DaylightIsBurning выложил картинку про survival rate. Там если глянуть в табличку «still in use» то по этой модели через три года от 35 тысяч остаётся 11, а ещё через год — 4. Вот эти цифры уже как-то пореальней выглядят.
Видимо, обнаружив всплеск afr их просто стали вовремя выводить из эксплуатации, «по симптомам и подозрениям», т.е. до того момента, когда фиксируется именно отказ накопителя. Вот оттого и получили такую щадящую статистику.
Вот как раз выше DaylightIsBurning выложил картинку про survival rate. Там если глянуть в табличку «still in use» то по этой модели через три года от 35 тысяч остаётся 11, а ещё через год — 4. Вот эти цифры уже как-то пореальней выглядят.
Видимо, обнаружив всплеск afr их просто стали вовремя выводить из эксплуатации, «по симптомам и подозрениям», т.е. до того момента, когда фиксируется именно отказ накопителя. Вот оттого и получили такую щадящую статистику.
Статистика вещь хорошая, но применяться должна в тех-же размерностях что и собиралась.
Например для покупателя одного диска — шанс его поломки в первый год эксплуатации будет равен 50%. Может сломаться, а может и нет.
А вот если купить и эксплуатировать сразу тысячу дисков — тогда статистика с большой долей вероятности совпадёт.
Например для покупателя одного диска — шанс его поломки в первый год эксплуатации будет равен 50%. Может сломаться, а может и нет.
А вот если купить и эксплуатировать сразу тысячу дисков — тогда статистика с большой долей вероятности совпадёт.
Простите, а вы какой гуманитарный ВУЗ заканчивали?
для покупателя одного диска — шанс его поломки в первый год эксплуатации будет равен 50%. Может сломаться, а может и нетНапишите, пожалуйста, на Хабр пост-мини-лекцию по теории вероятностей.
А то заинтриговали тем, что будет с этим диском на второй год работы: он станет надёжнее (0.5 * 0.5 = 0.25 = 25%) или гарантированно умрёт (0.5 + 0.5 = 1 = 100%)?
А на третий? Ещё окрепнет (0.5 * 0.5 * 0.5 = 0.125 = 12.5%) или умерев, с вероятностью 50% прихватит с собой соседа (0.5 + 0.5 + 0.5 = 1.5 = 150%)?
Особенно интересно было бы оценить, что ждёт этот жёсткий диск в XXII веке — он станет самым надёжным устройством во вселенной (p = 7,8886090522101180541172856528279e-31 = 7,8886e-29%) или выйдя из строя, гарантированно аннигилирует Солнечную систему (p = 5000%)?
Напишите, пожалуйста, на Хабр пост-мини-лекцию по теории вероятностей.
Уже написал, чуть выше в первом моём сообщении. Это всё что нужно знать про теорию вероятностей и про статистику в чистом виде.
Вероятность поломки жёстких дисков будет совпадать в ситуации когда их количество, место и способ эксплуатации будет совпадать с условиями сбора первоначальной статистики. По этому не стоит рассматривать отчёты от Backblaze — как рекламный листок для покупки одного!, самого надёжного диска для своего компьютера.
По этому не стоит рассматривать отчёты от Backblaze — как рекламный листок для покупки одного!, самого надёжного диска для своего компьютера.
Конечно не стоит, скорее стоит рассматривать как рекламный листок для покупки ~14 тысяч дисков для своего дата-центра.
А если серьезно, то статистика на то и статистика, тем более техническая и она полезна для специалистов, чтобы получать хоть какую-нибудь оценку качества оборудования на реальной системе.
Забавно наблюдать реакцию читателей хаба, у которых только-что отобрали надежду.
Но лучше так, чем вопли о потерянных данных с единственного винчестера.
Но лучше так, чем вопли о потерянных данных с единственного винчестера.
Интересно, как они решают вопрос с падающей производительностью. При замене 3ТБ дисков на 12ТБ количество шпинделей сокращается в 4 раза. IOPS и полоса для SATA дисков не особо растут с годами
Они писали об этом где-то в своем блоге (https://www.backblaze.com/blog/) Насколько я помню, они этот вопрос никак не решают, потому что в их конкретном случае такой проблемы нет. Продают они, в основном, место для бэкапов, поэтому обмен данными у них относительно неактивный.
При замене 3ТБ дисков на 12ТБ количество шпинделей сокращается в 4 раза.
У них storage pods вроде как на 45 дисков. Заменяются все диски сразу (ибо RAID). В результате объем хранимых данных растет, а количество шпинделей в поде — то же самое.
Я думаю имеется в виду не общее кол-во шпинделей, а кол-во шпинделей на условный ТБ места. И этот показатель как раз падает при примерно сравнимой скорости работы дисков в 4Тб и 12Тб…
Шпинделей то то же количество, но в результате на ту же корзину может записаться в 4 раза больше данных и юзать ее будет в 4 раза больше клиентов подняв интенсивность записи в те же самые 4 раза.
Но в случае бэкапов вопрос иопса конечно стоит не так остро
Но в случае бэкапов вопрос иопса конечно стоит не так остро
Есть несколько моментов, которые могут поднять уровень IO нагрузки на диски:
1) механизм индексации файлов и изменений — пофаловый backup новых версий документов или на уровне измененных блоков
2) использование дедупликации для еще большей эффективности по capacity
Кроме всего прочего, есть еще такой момент, как восстановление. И если домашнему пользователю важно в первую очередь, что восстановиться в принципе возможно, до бизнес-клиент еще хочет и разумный срок получить, а не несколько дней / недель.
И не забываем про B2 Cloud Object Storage. Насколько я помню, там тот же аппаратный backend, что и под backup…
1) механизм индексации файлов и изменений — пофаловый backup новых версий документов или на уровне измененных блоков
2) использование дедупликации для еще большей эффективности по capacity
Кроме всего прочего, есть еще такой момент, как восстановление. И если домашнему пользователю важно в первую очередь, что восстановиться в принципе возможно, до бизнес-клиент еще хочет и разумный срок получить, а не несколько дней / недель.
И не забываем про B2 Cloud Object Storage. Насколько я помню, там тот же аппаратный backend, что и под backup…
Работаю с кластерами Hadoop, заметил забавную вещь: максимум отказов у нового, только из коробки, железа и у железа ближе к истечению гарантийного срока.
Между этими временными отрезками происходит минимум отказов.
Между этими временными отрезками происходит минимум отказов.
Ну, это давно известная закономерность…
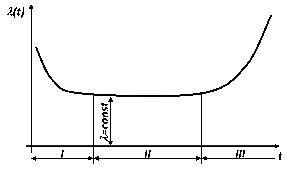
Типичная зависимость интенсивности отказов от времени: I — период приработки и отказов некачественных изделий; II — период нормальной эксплуатации; III — период старения (отказы вызваны износом деталей или старением материалов)
Вот собственно для дна этой ванны и имеет значение AFR. Но для этого надо грамотно учитывать все данные — выкидывать из статистики детскую смертность и вследствие износа.
Но подождите, период старения как и нормальной работы может задаваться маркетологами. Это в плановой экономике может и работает.
А зачем? Потребность в замене дисков и так обеспечена постоянно растущими объемами хранимых данных. Ну и специально портить показатели надежности у товара, у которого с ними и так не все гладко и для которого долгий срок службы — важное конкурентное преимущество, как-то странно. С таким маркетингом, кмк, можно очень быстро заработать дурную славу и вообще слиться с рынка, особенно в b2b, где считают окупаемость.
Sign up to leave a comment.
Backblaze опубликовала статистику надёжности HDD за 2018 год