Написать эту статью меня сподвигло большое количество материалов о статическом анализе, всё чаще попадающихся на глаза. Во-первых, это блог PVS-studio, который активно продвигает себя на Хабре при помощи обзоров ошибок, найденных их инструментом в проектах с открытым кодом. Недавно PVS-studio реализовали поддержку Java, и, конечно, разработчики IntelliJ IDEA, чей встроенный анализатор является на сегодня, наверное, самым продвинутым для Java, не могли остаться в стороне.
При чтении таких обзоров возникает ощущение, что речь идёт про волшебный эликсир: нажми на кнопку, и вот он — список дефектов перед глазами. Кажется, что по мере совершенствования анализаторов, багов автоматически будет находиться всё больше и больше, а продукты, просканированные этими роботами, будут становиться всё лучше и лучше, без каких-либо усилий с нашей стороны.
Но волшебных эликсиров не бывает. Я хотел бы поговорить о том, о чём обычно не говорят в постах вида «вот какие штуки может найти наш робот»: чего не могут анализаторы, в чём их реальная роль и место в процессе поставки софта, и как внедрять их правильно.

Храповик (источник: википедия).
Что такое, с практической точки зрения, анализ исходного кода? Мы подаём на вход некоторые исходники, и на выходе за короткое время (гораздо более короткое, чем прогон тестов) получаем некоторые сведения о нашей системе. Принципиальное и математически непреодолимое ограничение состоит в том, что получить мы таким образом можем лишь довольно узкий класс сведений.
Самый знаменитый пример задачи, не решаемой при помощи статического анализа — проблема останова: это теорема, которая доказывает, что невозможно разработать общий алгоритм, который бы по исходному коду программы определял, зациклится она или завершится за конечное время. Расширением данной теоремы является теорема Райса, утверждающая, для любого нетривиального свойства вычислимых функций определение того, вычисляет ли произвольная программа функцию с таким свойством, является алгоритмически неразрешимой задачей. Например, невозможно написать анализатор, по любому исходному коду определяющий, является ли анализируемая программа имплементацией алгоритма, вычисляющего, скажем, возведение в квадрат целого числа.
Таким образом, функциональность статических анализаторов имеет непреодолимые ограничения. Статический анализатор никогда не сможет во всех случаях определить такие вещи, как, например, возникновение «null pointer exception» в языках, допускающих значение null, или во всех случаях определить возникновение «attribute not found» в языках с динамической типизацией. Всё, что может самый совершенный статический анализатор — это выделять частные случаи, число которых среди всех возможных проблем с вашим исходным кодом является, без преувеличения, каплей в море.
Из вышесказанного следует вывод: статический анализ — это не средство уменьшения количества дефектов в программе. Рискну утверждать: будучи впервые применён к вашему проекту, он найдёт в коде «занятные» места, но, скорее всего, не найдёт никаких дефектов, влияющих на качество работы вашей программы.
Примеры дефектов, автоматически найденных анализаторами, впечатляют, но не следует забывать, что эти примеры найдены при помощи сканирования большого набора больших кодовых баз. По такому же принципу взломщики, имеющие возможность перебрать несколько простых паролей на большом количестве аккаунтов, в конце концов находят те аккаунты, на которых стоит простой пароль.
Значит ли это, что статический анализ не надо применять? Конечно, нет! И ровно по той же причине, по которой стоит проверять каждый новый пароль на попадание в стоп-лист «простых» паролей.
На самом деле, практически решаемые анализом задачи гораздо шире. Ведь в целом статический анализ — это любая проверка исходников, осуществляемая до их запуска. Вот некоторые вещи, которые можно делать:
Как видим, поиск багов в этом списке занимает наименее важную роль, а всё остальное доступно путём использования бесплатных open source инструментов.
Какие из этих типов статического анализа следует применять в вашем проекте? Конечно, все, чем больше — тем лучше! Главное, внедрить это правильно, о чём и пойдёт речь дальше.
Классической метафорой непрерывной интеграции является трубопровод (pipeline), по которому протекают изменения — от изменения исходного кода до поставки в production. Стандартная последовательность этапов этого конвейера выглядит так:
Изменения, забракованные на N-ом этапе конвейера, не передаются на этап N+1.
Почему именно так, а не иначе? В той части конвейера, которая касается тестирования, тестировщики узнают широко известную пирамиду тестирования.

Тестовая пирамида. Источник: статья Мартина Фаулера.
В нижней части этой пирамиды расположены тесты, которые легче писать, которые быстрее выполняются и не имеют тенденции к ложному срабатыванию. Потому их должно быть больше, они должны покрывать больше кода и выполняться первыми. В верхней части пирамиды всё обстоит наоборот, поэтому количество интеграционных и UI тестов должно быть уменьшено до необходимого минимума. Человек в этой цепочке — самый дорогой, медленный и ненадёжный ресурс, поэтому он находится в самом конце и выполняет работу только в том случае, если предыдущие этапы не обнаружили никаких дефектов. Однако по тем же самым принципам строится конвейер и в частях, не связанных непосредственно с тестированием!
Я бы хотел предложить аналогию в виде многокаскадной системы фильтрации воды. На вход подаётся грязная вода (изменения с дефектами), на выходе мы должны получить чистую воду, все нежелательные загрязнения в которой отсеяны.

Многоступенчатый фильтр. Источник: Wikimedia Commons
Как известно, очищающие фильтры проектируются так, что каждый следующий каскад может отсеивать всё более мелкую фракцию загрязнений. При этом каскады более грубой очистки имеют бОльшую пропускную способность и меньшую стоимость. В нашей аналогии это означает, что входные quality gates имеют бОльшее быстродействие, требуют меньше усилий для запуска и сами по себе более неприхотливы в работе — и именно в такой последовательности они и выстроены. Роль статического анализа, который, как мы теперь понимаем, способен отсеять лишь самые грубые дефекты — это роль решётки-«грязевика» в самом начале каскада фильтров.
Статический анализ сам по себе не улучшает качество конечного продукта, как «грязевик» не делает воду питьевой. И тем не менее, в общей связке с другими элементами конвейера его важность очевидна. Хотя в многокаскадном фильтре выходные каскады потенциально способны уловить всё то же, что и входные — ясно, к каким последствиям приведёт попытка обойтись одними лишь каскадами тонкой очистки, без входных каскадов.
Цель «грязевика» — разгрузить последующие каскады от улавливания совсем уж грубых дефектов. Например, как минимум, человек, производящий code review, не должен отвлекаться на неправильно отформатированный код и нарушение установленных норм кодирования (вроде лишних скобок или слишком глубоко вложенных ветвлений). Баги вроде NPE должны улавливаться модульными тестами, но если ещё до теста анализатор нам указывает на то, что баг должен неминуемо произойти — это значительно ускорит его исправление.
Полагаю, теперь ясно, почему статический анализ не улучшает качество продукта, если применяется эпизодически, и должен применяться постоянно для отсеивания изменений с грубыми дефектами. Вопрос, улучшит ли применение статического анализатора качество вашего продукта, примерно эквивалентен вопросу «улучшатся ли питьевые качества воды, взятой из грязного водоёма, если её пропустить через дуршлаг?»
Важный практический вопрос: как внедрить статический анализ в процесс непрерывной интеграции в качестве «quality gate»? В случае с автоматическими тестами всё очевидно: есть набор тестов, падение любого из них — достаточное основание считать, что сборка не прошла quality gate. Попытка таким же образом установить gate по результатам статического анализа проваливается: на legacy-коде предупреждений анализа слишком много, полностью игнорировать их не хочется, но и останавливать поставку продукта только потому, что в нём есть предупреждения анализатора, невозможно.
Будучи применён впервые, на любом проекте анализатор выдаёт огромное количество предупреждений, подавляющее большинство которых не имеют отношения к правильному функционированию продукта. Исправлять сразу все эти замечания невозможно, а многие — и не нужно. В конце концов, мы же знаем, что наш продукт в целом работает, и до внедрения статического анализа!
В итоге, многие ограничиваются эпизодическим использованием статического анализа, либо используют его лишь в режиме информирования, когда при сборке просто выдаётся отчёт анализатора. Это эквивалентно отсутствию всякого анализа, потому что если у нас уже имеется множество предупреждений, то возникновение ещё одного (сколь угодно серьёзного) при изменении кода остаётся незамеченным.
Известны следующие способы введения quality gates:
Работает это таким образом:
Так понемногу, но неуклонно (как при работе храповика), число предупреждений будет стремиться к нулю. Конечно, систему можно обмануть, внеся новое предупреждение, но исправив чужое. Это нормально, т. к. на длинной дистанции даёт результат: предупреждения исправляются, как правило, не по одиночке, а сразу группой определённого типа, и все легко-устраняемые предупреждения довольно быстро оказываются устранены.
На этом графике показано общее количество Checkstyle-предупреждений за полгода работы такого «храповика» на одном из наших OpenSource проектов. Количество предупреждений уменьшилось на порядок, причём произошло это естественным образом, параллельно с разработкой продукта!

Я применяю модифицированную версию этого метода, отдельно подсчитывая предупреждения в разбивке по модулям проекта и инструментам анализа, формируемый при этом YAML-файл с метаданными о сборке выглядит примерно следующим образом:
В любой продвинутой CI-системе «храповик» можно реализовать для любых инструментов статического анализа, не полагаясь на плагины и сторонние инструменты. Каждый из анализаторов выдаёт свой отчёт в простом текстовом или XML формате, легко поддающемся анализу. Остаётся прописать только необходимую логику в CI-скрипте. Подсмотреть, как это реализовано в наших open source проектах на базе Jenkins и Artifactory, можно здесь или здесь. Оба примера зависят от библиотеки ratchetlib: метод
Интересный вариант реализации «храповика» возможен для анализа правописания комментариев, текстовых литералов и документации с помощью aspell. Как известно, при проверке правописания не все неизвестные стандартному словарю слова являются неправильными, они могут быть добавлены в пользовательский словарь. Если сделать пользовательский словарь частью исходного кода проекта, то quality gate по правописанию может быть сформулирован таким образом: выполнение aspell со стандартным и пользовательским словарём не должно находить никаких ошибок правописания.
В заключение нужно отметить следующее: каким бы образом вы бы ни внедряли анализ в ваш конвейер поставки, версия анализатора должна быть фиксирована. Если допустить самопроизвольное обновление анализатора, то при сборке очередного pull request могут «всплыть» новые дефекты, которые не связаны с изменением кода, а связаны с тем, что новый анализатор просто способен находить больше дефектов — и это поломает вам процесс приёмки pull request-ов. Апгрейд анализатора должен быть осознанным действием. Впрочем, жёсткая фиксация версии каждой компоненты сборки — это в целом необходимое требование и тема для отдельного разговора.
При чтении таких обзоров возникает ощущение, что речь идёт про волшебный эликсир: нажми на кнопку, и вот он — список дефектов перед глазами. Кажется, что по мере совершенствования анализаторов, багов автоматически будет находиться всё больше и больше, а продукты, просканированные этими роботами, будут становиться всё лучше и лучше, без каких-либо усилий с нашей стороны.
Но волшебных эликсиров не бывает. Я хотел бы поговорить о том, о чём обычно не говорят в постах вида «вот какие штуки может найти наш робот»: чего не могут анализаторы, в чём их реальная роль и место в процессе поставки софта, и как внедрять их правильно.
Храповик (источник: википедия).
Чего никогда не смогут статические анализаторы
Что такое, с практической точки зрения, анализ исходного кода? Мы подаём на вход некоторые исходники, и на выходе за короткое время (гораздо более короткое, чем прогон тестов) получаем некоторые сведения о нашей системе. Принципиальное и математически непреодолимое ограничение состоит в том, что получить мы таким образом можем лишь довольно узкий класс сведений.
Самый знаменитый пример задачи, не решаемой при помощи статического анализа — проблема останова: это теорема, которая доказывает, что невозможно разработать общий алгоритм, который бы по исходному коду программы определял, зациклится она или завершится за конечное время. Расширением данной теоремы является теорема Райса, утверждающая, для любого нетривиального свойства вычислимых функций определение того, вычисляет ли произвольная программа функцию с таким свойством, является алгоритмически неразрешимой задачей. Например, невозможно написать анализатор, по любому исходному коду определяющий, является ли анализируемая программа имплементацией алгоритма, вычисляющего, скажем, возведение в квадрат целого числа.
Таким образом, функциональность статических анализаторов имеет непреодолимые ограничения. Статический анализатор никогда не сможет во всех случаях определить такие вещи, как, например, возникновение «null pointer exception» в языках, допускающих значение null, или во всех случаях определить возникновение «attribute not found» в языках с динамической типизацией. Всё, что может самый совершенный статический анализатор — это выделять частные случаи, число которых среди всех возможных проблем с вашим исходным кодом является, без преувеличения, каплей в море.
Статический анализ — это не поиск багов
Из вышесказанного следует вывод: статический анализ — это не средство уменьшения количества дефектов в программе. Рискну утверждать: будучи впервые применён к вашему проекту, он найдёт в коде «занятные» места, но, скорее всего, не найдёт никаких дефектов, влияющих на качество работы вашей программы.
Примеры дефектов, автоматически найденных анализаторами, впечатляют, но не следует забывать, что эти примеры найдены при помощи сканирования большого набора больших кодовых баз. По такому же принципу взломщики, имеющие возможность перебрать несколько простых паролей на большом количестве аккаунтов, в конце концов находят те аккаунты, на которых стоит простой пароль.
Значит ли это, что статический анализ не надо применять? Конечно, нет! И ровно по той же причине, по которой стоит проверять каждый новый пароль на попадание в стоп-лист «простых» паролей.
Статический анализ — это больше, чем поиск багов
На самом деле, практически решаемые анализом задачи гораздо шире. Ведь в целом статический анализ — это любая проверка исходников, осуществляемая до их запуска. Вот некоторые вещи, которые можно делать:
- Проверка стиля кодирования в широком смысле этого слова. Сюда входит как проверка форматирования, так и поиск использования пустых/лишних скобок, установка, пороговых значений на метрики вроде количества строк / цикломатической сложности метода и т. д. — всего, что потенциально затрудняет читаемость и поддерживаемость кода. В Java таким инструментом является Checkstyle, в Python — flake8. Программы такого класса обычно называются «линтеры».
- Анализу может подвергаться не только исполняемый код. Файлы ресурсов, такие как JSON, YAML, XML, .properties могут (и должны!) быть автоматически проверяемы на валидность. Ведь лучше узнать о том, что из-за каких-нибудь непарных кавычек нарушена структура JSON на раннем этапе автоматической проверки Pull Request, чем при исполнении тестов или в Run time? Соответствующие инструменты имеются: например, YAMLlint, JSONLint.
- Компиляция (или парсинг для динамических языков программирования) — это тоже вид статического анализа. Как правило, компиляторы способны выдавать предупреждения, сигнализирующие о проблемах с качеством исходного кода, и их не следует игнорировать.
- Иногда компиляция — это не только компиляция исполняемого кода. Например, если у вас документация в формате AsciiDoctor, то в момент превращения её в HTML/PDF обработчик AsciiDoctor (Maven plugin) может выдавать предупреждения, например, о нарушенных внутренних ссылках. И это — весомый повод не принять Pull Request с изменениями документации.
- Проверка правописания — тоже вид статического анализа. Утилита aspell способна проверять правописание не только в документации, но и в исходных кодах программ (комментариях и литералах) на разных языках программирования, включая C/C++, Java и Python. Ошибка правописания в пользовательском интерфейсе или документации — это тоже дефект!
- Конфигурационные тесты (о том, что это такое — см. этот и этот доклады), хотя и выполняются в среде выполнения модульных тестов типа pytest, на самом деле также являются разновидностью статического анализа, т. к. не выполняют исходные коды в процессе своего выполнения.
Как видим, поиск багов в этом списке занимает наименее важную роль, а всё остальное доступно путём использования бесплатных open source инструментов.
Какие из этих типов статического анализа следует применять в вашем проекте? Конечно, все, чем больше — тем лучше! Главное, внедрить это правильно, о чём и пойдёт речь дальше.
Конвейер поставки как многоступенчатый фильтр и статический анализ как его первый каскад
Классической метафорой непрерывной интеграции является трубопровод (pipeline), по которому протекают изменения — от изменения исходного кода до поставки в production. Стандартная последовательность этапов этого конвейера выглядит так:
- статический анализ
- компиляция
- модульные тесты
- интеграционные тесты
- UI тесты
- ручная проверка
Изменения, забракованные на N-ом этапе конвейера, не передаются на этап N+1.
Почему именно так, а не иначе? В той части конвейера, которая касается тестирования, тестировщики узнают широко известную пирамиду тестирования.

Тестовая пирамида. Источник: статья Мартина Фаулера.
В нижней части этой пирамиды расположены тесты, которые легче писать, которые быстрее выполняются и не имеют тенденции к ложному срабатыванию. Потому их должно быть больше, они должны покрывать больше кода и выполняться первыми. В верхней части пирамиды всё обстоит наоборот, поэтому количество интеграционных и UI тестов должно быть уменьшено до необходимого минимума. Человек в этой цепочке — самый дорогой, медленный и ненадёжный ресурс, поэтому он находится в самом конце и выполняет работу только в том случае, если предыдущие этапы не обнаружили никаких дефектов. Однако по тем же самым принципам строится конвейер и в частях, не связанных непосредственно с тестированием!
Я бы хотел предложить аналогию в виде многокаскадной системы фильтрации воды. На вход подаётся грязная вода (изменения с дефектами), на выходе мы должны получить чистую воду, все нежелательные загрязнения в которой отсеяны.

Многоступенчатый фильтр. Источник: Wikimedia Commons
Как известно, очищающие фильтры проектируются так, что каждый следующий каскад может отсеивать всё более мелкую фракцию загрязнений. При этом каскады более грубой очистки имеют бОльшую пропускную способность и меньшую стоимость. В нашей аналогии это означает, что входные quality gates имеют бОльшее быстродействие, требуют меньше усилий для запуска и сами по себе более неприхотливы в работе — и именно в такой последовательности они и выстроены. Роль статического анализа, который, как мы теперь понимаем, способен отсеять лишь самые грубые дефекты — это роль решётки-«грязевика» в самом начале каскада фильтров.
Статический анализ сам по себе не улучшает качество конечного продукта, как «грязевик» не делает воду питьевой. И тем не менее, в общей связке с другими элементами конвейера его важность очевидна. Хотя в многокаскадном фильтре выходные каскады потенциально способны уловить всё то же, что и входные — ясно, к каким последствиям приведёт попытка обойтись одними лишь каскадами тонкой очистки, без входных каскадов.
Цель «грязевика» — разгрузить последующие каскады от улавливания совсем уж грубых дефектов. Например, как минимум, человек, производящий code review, не должен отвлекаться на неправильно отформатированный код и нарушение установленных норм кодирования (вроде лишних скобок или слишком глубоко вложенных ветвлений). Баги вроде NPE должны улавливаться модульными тестами, но если ещё до теста анализатор нам указывает на то, что баг должен неминуемо произойти — это значительно ускорит его исправление.
Полагаю, теперь ясно, почему статический анализ не улучшает качество продукта, если применяется эпизодически, и должен применяться постоянно для отсеивания изменений с грубыми дефектами. Вопрос, улучшит ли применение статического анализатора качество вашего продукта, примерно эквивалентен вопросу «улучшатся ли питьевые качества воды, взятой из грязного водоёма, если её пропустить через дуршлаг?»
Внедрение в legacy-проект
Важный практический вопрос: как внедрить статический анализ в процесс непрерывной интеграции в качестве «quality gate»? В случае с автоматическими тестами всё очевидно: есть набор тестов, падение любого из них — достаточное основание считать, что сборка не прошла quality gate. Попытка таким же образом установить gate по результатам статического анализа проваливается: на legacy-коде предупреждений анализа слишком много, полностью игнорировать их не хочется, но и останавливать поставку продукта только потому, что в нём есть предупреждения анализатора, невозможно.
Будучи применён впервые, на любом проекте анализатор выдаёт огромное количество предупреждений, подавляющее большинство которых не имеют отношения к правильному функционированию продукта. Исправлять сразу все эти замечания невозможно, а многие — и не нужно. В конце концов, мы же знаем, что наш продукт в целом работает, и до внедрения статического анализа!
В итоге, многие ограничиваются эпизодическим использованием статического анализа, либо используют его лишь в режиме информирования, когда при сборке просто выдаётся отчёт анализатора. Это эквивалентно отсутствию всякого анализа, потому что если у нас уже имеется множество предупреждений, то возникновение ещё одного (сколь угодно серьёзного) при изменении кода остаётся незамеченным.
Известны следующие способы введения quality gates:
- Установка лимита общего количества предупреждений или количества предупреждений, делённого на количество строк кода. Работает это плохо, т. к. такой gate свободно пропускает изменения с новыми дефектами, пока их лимит не превышен.
- Фиксация, в определённый момент, всех старых предупреждений в коде как игнорируемых, и отказ в сборке при возникновении новых предупреждений. Такую функциональность предоставляет PVS-studio и некоторые онлайн-ресурсы, например, Codacy. Мне не довелось работать в PVS-studio, что касается моего опыта с Codacy, то основная их проблема заключается в том, что определение что есть «старая», а что «новая» ошибка — довольно сложный и не всегда правильно работающий алгоритм, особенно если файлы сильно изменяются или переименовываются. На моей памяти Codacy мог пропускать в пулл-реквесте новые предупреждения, и в то же время не пропускать pull request из-за предупреждений, не относящихся к изменениям в коде данного PR.
- На мой взгляд, наиболее эффективным решением является описанный в книге Continuous Delivery «метод храповика» («ratcheting»). Основная идея заключается в том, что свойством каждого релиза является количество предупреждений статического анализа, и допускаются лишь такие изменения, которые общее количество предупреждений не увеличивают.
Храповик
Работает это таким образом:
- На первоначальном этапе реализуется запись в метаданных о релизе количества предупреждений в коде, найденных анализаторами. Таким образом, при сборке основной ветки в ваш менеджер репозиториев записывается не просто «релиз 7.0.2», но «релиз 7.0.2, содержащий 100500 Checkstyle-предупреждений». Если вы используете продвинутый менеджер репозиториев (такой как Artifactory), сохранить такие метаданные о вашем релизе легко.
- Теперь каждый pull request при сборке сравнивает количество получающихся предупреждений с тем, какое количество имеется в текущем релизе. Если PR приводит к увеличению этого числа, то код не проходит quality gate по статическому анализу. Если количество предупреждений уменьшается или не изменяется — то проходит.
- При следующем релизе пересчитанное количество предупреждений будет вновь записано в метаданные релиза.
Так понемногу, но неуклонно (как при работе храповика), число предупреждений будет стремиться к нулю. Конечно, систему можно обмануть, внеся новое предупреждение, но исправив чужое. Это нормально, т. к. на длинной дистанции даёт результат: предупреждения исправляются, как правило, не по одиночке, а сразу группой определённого типа, и все легко-устраняемые предупреждения довольно быстро оказываются устранены.
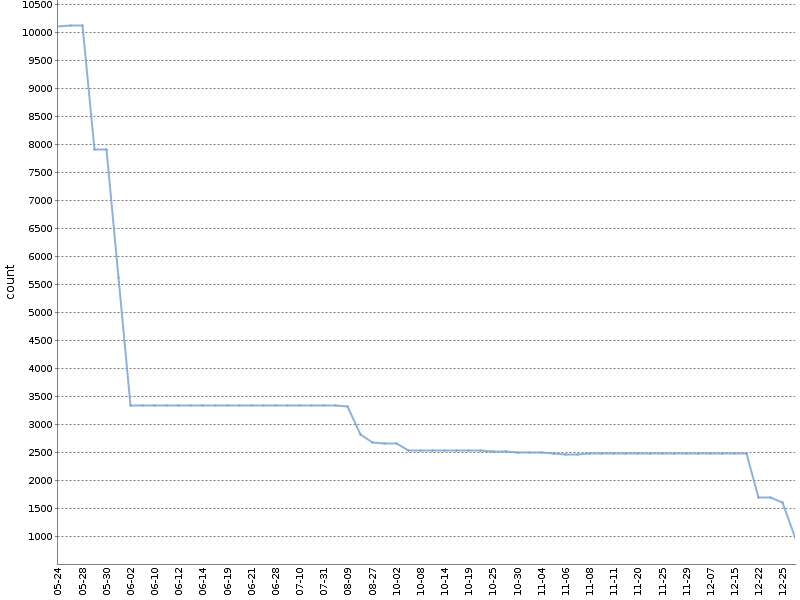
На этом графике показано общее количество Checkstyle-предупреждений за полгода работы такого «храповика» на одном из наших OpenSource проектов. Количество предупреждений уменьшилось на порядок, причём произошло это естественным образом, параллельно с разработкой продукта!
Я применяю модифицированную версию этого метода, отдельно подсчитывая предупреждения в разбивке по модулям проекта и инструментам анализа, формируемый при этом YAML-файл с метаданными о сборке выглядит примерно следующим образом:
celesta-sql:
checkstyle: 434
spotbugs: 45
celesta-core:
checkstyle: 206
spotbugs: 13
celesta-maven-plugin:
checkstyle: 19
spotbugs: 0
celesta-unit:
checkstyle: 0
spotbugs: 0
В любой продвинутой CI-системе «храповик» можно реализовать для любых инструментов статического анализа, не полагаясь на плагины и сторонние инструменты. Каждый из анализаторов выдаёт свой отчёт в простом текстовом или XML формате, легко поддающемся анализу. Остаётся прописать только необходимую логику в CI-скрипте. Подсмотреть, как это реализовано в наших open source проектах на базе Jenkins и Artifactory, можно здесь или здесь. Оба примера зависят от библиотеки ratchetlib: метод
countWarnings() обычным образом подсчитывает xml-тэги в файлах, формируемых Checkstyle и Spotbugs, а compareWarningMaps() реализует тот самый храповик, выбрасывая ошибку в случае, когда количество предупреждений в какой-либо из категорий повышается.Интересный вариант реализации «храповика» возможен для анализа правописания комментариев, текстовых литералов и документации с помощью aspell. Как известно, при проверке правописания не все неизвестные стандартному словарю слова являются неправильными, они могут быть добавлены в пользовательский словарь. Если сделать пользовательский словарь частью исходного кода проекта, то quality gate по правописанию может быть сформулирован таким образом: выполнение aspell со стандартным и пользовательским словарём не должно находить никаких ошибок правописания.
О важности фиксации версии анализатора
В заключение нужно отметить следующее: каким бы образом вы бы ни внедряли анализ в ваш конвейер поставки, версия анализатора должна быть фиксирована. Если допустить самопроизвольное обновление анализатора, то при сборке очередного pull request могут «всплыть» новые дефекты, которые не связаны с изменением кода, а связаны с тем, что новый анализатор просто способен находить больше дефектов — и это поломает вам процесс приёмки pull request-ов. Апгрейд анализатора должен быть осознанным действием. Впрочем, жёсткая фиксация версии каждой компоненты сборки — это в целом необходимое требование и тема для отдельного разговора.
Выводы
- Статический анализ не найдёт вам баги и не улучшит качество вашего продукта в результате однократного применения. Положительный эффект для качества даёт лишь его постоянное применение в процессе поставки.
- Поиск багов вообще не является главной задачей анализа, подавляющее большинство полезных функций доступно в opensource инструментах.
- Внедряйте quality gates по результатам статического анализа на самом первом этапе конвейера поставки, используя «храповик» для legacy-кода.
Ссылки
- Continuous Delivery
- А. Кудрявцев: Анализ программ: как понять, что ты хороший программист доклад о разных методах анализа кода (не только статическом!)

{kind=link}
{kind=link}