Comments 26
Мне показалось или весь файл дёргается с S3 до пагинации? Это в лучше случае неэффективно (по времени и data transfer), в худшем при разрастании файла и нагрузка бюджет будет расти очень быстро, а в какой-то момент лямбда начнёт падать из-за недостатка памяти. Ну и завернуть бы всё хотя бы в CloudFormation, чтобы действительно за 5 минут разворачивать.
Основная идея статьи — это дать представление как можно создавать облачный API используя сервисы Amazon AWS API Gateway, без привязки к какой-либо конкретной реализации это API. Если Вы обратили внимание, то в статье упомянуто, что информация для текущих целей не столь важна.
Ps. Вы правы, пагинация выдаваемой информации из базы данных, наверное, смотрелась бы более эффектно, но цель статьи, еще раз повторюсь, показать простоту процесса создания автомасштабируемого API.
Буду благодарен, если Вы поделитесь более эффективным способом считывания информации из текстового файла :)
Ps. Вы правы, пагинация выдаваемой информации из базы данных, наверное, смотрелась бы более эффектно, но цель статьи, еще раз повторюсь, показать простоту процесса создания автомасштабируемого API.
Буду благодарен, если Вы поделитесь более эффективным способом считывания информации из текстового файла :)
Check S3 select: aws.amazon.com/blogs/aws/s3-glacier-select
Бессерверный REST API
Сильно напрягает термин «бессерверный». Если вы реализуете не всю серверную логику, это не значит, что сервера нет.
Инструменты, которые используются в статье, Amazon в официальной документации позиционирует как «бессерверные», и каждый раз указывает на это как на преимущество: AWS Lambda — бессерверный сервис вычислений, AWS API Gateway — бессерверные автомасштабируемые API.
Рекомендую для краткого ознакомиться здесь:
Так же у AWS достаточно подробная документация с примерами.
Рекомендую для краткого ознакомиться здесь:
Так же у AWS достаточно подробная документация с примерами.
У меня не к вам претензия, а к маркетологам. Они создают новые термины, чтобы поменять мышление конечного пользователя в нужную им сторону. На самом деле сервера как были так и есть, просто они в облаке (еще один прекрасный термин) Amazon и ты этот сервер не контролируешь не замечаешь.
Зачем потребителю сервиса вообще об этом знать, если он к этому отношения не имеет от слова «совсем»? Вы, когда газом дома пользуетесь, много знаете о магистральных газовых делах?
Постойте, что не так? Лямбда-подход существенно отличается от классического и тут не о чем спорить. Тот факт, что сервер так или иначе какой-то всё же есть от вас тоже никто не скрывает. Ну наивно же. Вполне разумное желание дать концепции и подходу в целом какое-то «имя». Чем плохо называть его бессерверным я не понимаю.
Это как сказать, что облачные решения harwareless. Понятно, что железо там где-то в кишочках амазона есть, но оно не стоит в вашем датацентре, не нуждается в ТО, в смазке, в охлаждении, в замене кулеров, в обновлении… В этом же смысле это бессерверное решение. Вы не оперируете понятием сервер в некотором аспекте, в котором раньше оперировали.
Тот же stateless не избаляет же вас от любых состояний во всех смыслах. Вы придеритесь ещё, что прога либо работает, либо нет, и это уже состояние.
Не обижайте маркетологов за это. Они где угодно нагрешили, но не тут. Просто вы придираетесь. Понимайте бессерверное, как новый уровень абстракции.
Это как сказать, что облачные решения harwareless. Понятно, что железо там где-то в кишочках амазона есть, но оно не стоит в вашем датацентре, не нуждается в ТО, в смазке, в охлаждении, в замене кулеров, в обновлении… В этом же смысле это бессерверное решение. Вы не оперируете понятием сервер в некотором аспекте, в котором раньше оперировали.
Тот же stateless не избаляет же вас от любых состояний во всех смыслах. Вы придеритесь ещё, что прога либо работает, либо нет, и это уже состояние.
Не обижайте маркетологов за это. Они где угодно нагрешили, но не тут. Просто вы придираетесь. Понимайте бессерверное, как новый уровень абстракции.
Serverless — устоявшийся термин и все в индустрии его понимают
Сильно напрягает и слово «бессерверный». Вроде бы всегда было «безсерверный».
Думаю, есть смысл немного освежить в памяти вот какое правило определения букв в приставках:
Приставки Без-/Бес-
Примеры широкого использования формулировки «бессерверный»:
Википедия
Amazon
Приставки Без-/Бес-
Примеры широкого использования формулировки «бессерверный»:
Википедия
Amazon
Не знаю… меня бы «безсерверный» напрягло бы. Если дофига читать в детстве, то можно, к примеру, получать двойки в школе по русскому за лень учить правила, но пятёрки на диктантах за «инстинктивную» грамотность из-за гигабайтов прочитанного текста. Читаешь Азимова и Хайнлайна, а нейроночка-то в голове тренируется сама собой.
Эдакий лайфхак, если позволите.
Эдакий лайфхак, если позволите.
Спасибо за статью.
Небольшая ремарка: насколько я помню, лямбда всё же имеет ограничение по кол. запросов, что не маловажно при её концепции… А то было у меня..., думаю, нафига мне сервер, возьму лямбду, и пусть она кипитится милион раз в день. А фигушки, там есть свой порог…
Небольшая ремарка: насколько я помню, лямбда всё же имеет ограничение по кол. запросов, что не маловажно при её концепции… А то было у меня..., думаю, нафига мне сервер, возьму лямбду, и пусть она кипитится милион раз в день. А фигушки, там есть свой порог…
Вы использовали Лямбду совместно с API Gateway? Дело в том, что у вызова API Gateway могут быть заданы ограничения по количеству запусков в день/неделю/месяц: 
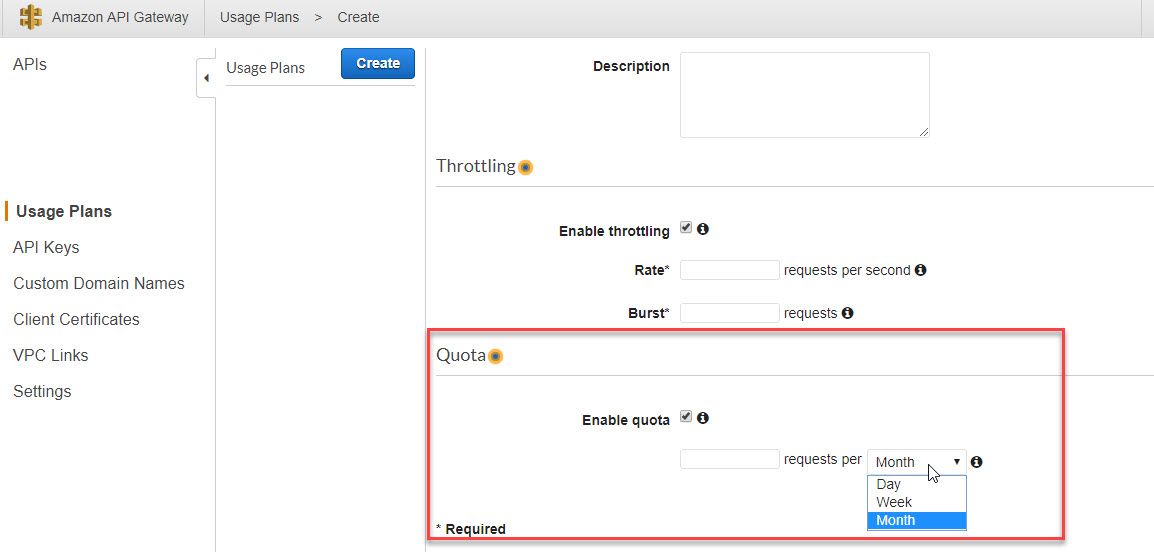
нет, я лишь хотел сказать, что Лямбда не решает проблему, когда речь идёт о бешенном количестве запросов. Кажется лимит в 1000 запросов за секунду — крыжка. Когда я услышал о лямбде, думал, ну всё, сношу 10 XL Instance и бегу на лямбду…
Все правильно, у Лямбды (как у любого другого сервиса Amazon) есть некоторые ограничения (AWS Lambda Limits) по умолчанию — 1000 параллельных запусков. Для увеличения лимита — необходимо обратиться в поддержку с просьбой об увеличении лимита сервиса в конкретном регионе.

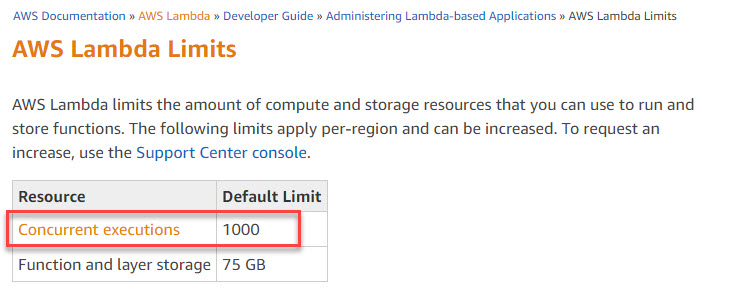
Это искусственный лимит, который можно увеличить по запросу в службу поддержки. Такие лимиты есть для всех сервисов AWS и почти все их можно увеличить при необходимости. Созданы они были, как я понимаю, для защиты от фрода или попыток целенаправленно съесть все ресурсы AWS.
docs.aws.amazon.com/lambda/latest/dg/limits.html
docs.aws.amazon.com/lambda/latest/dg/limits.html
Поддерживаемые языки: Node.js, Java, C#, Go, Python
Что-то устарела у них документация.
11.09.2018 — Today we are excited to release support for PowerShell Core 6.0
Через Lambda Layers можно практически любой язык теперь подключить, например, PHP:
aws.amazon.com/blogs/apn/aws-lambda-custom-runtime-for-php-a-practical-example
aws.amazon.com/blogs/apn/aws-lambda-custom-runtime-for-php-a-practical-example
Для создания простых API в Lambda на Питоне пользуюсь Chalice, очень упрощает жизнь и избавляет от рутины. Напоминает обычное приложение на Фласке. :)
Или можно SAM посмотреть — еще более суровая штука.
Chalice, кстати, умеет и просто лямбды делать без API (это у них нефига не очевидно из документации)
Chalice, кстати, умеет и просто лямбды делать без API (это у них нефига не очевидно из документации)
Sign up to leave a comment.
Бессерверный REST API «на коленке за 5 минут»