Первый сервис в Nomad я запустил в сентябре 2016 года. На данный момент пользуюсь как программист и занимаюсь поддержкой как администратор двух Nomad кластеров — один "домашний" для своих личных проектов (6 микро-виртуалок в Hetzner Cloud и ArubaCloud в 5 разных датацентрах Европы) и второй рабочий (порядка 40 приватных виртуальных и физических серверов в двух датацентрах).
За прошедшее время накопился довольно большой опыт работы с Nomad окружением, в статье опишу встреченные проблемы Nomad и как с ними можно справиться.

Ямальский кочевник делает Continous Delivery инстанса вашего ПО © National Geographic Россия
1. Количество серверных нод на один датацентр
Решение: на один датацентр достаточно одной серверной ноды.
В документации явно не указано, какое число серверных нод требуется в одном датацентре. Указано только, что на регион нужно 3-5 нод, что логично для консенсуса raft протокола.
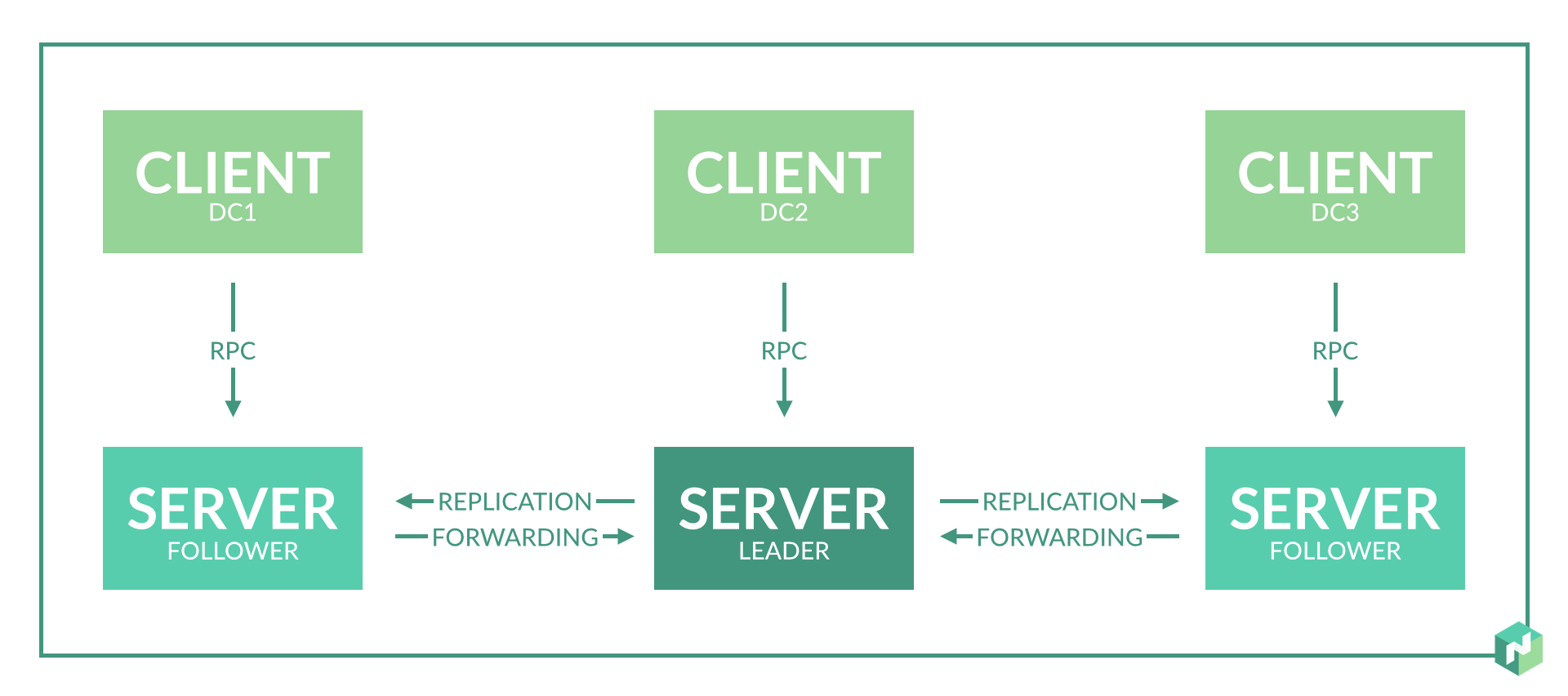
В начале я запланировал 2-3 серверных ноды в каждом датацентре для обеспечения резервирования.
По факту использования оказалось:
- Этого просто не требуется, так как при отказе ноды в датацентре, роль серверной ноды для агентов в данном датацентре будут выполнять другие серверные ноды данного региона.
- Получается даже хуже, если не решена проблема №8. При перевыборах мастера могут случаться рассогласования и Nomad будет перезапускать какую-то часть сервисов.
2. Ресурсы сервера для серверной ноды
Решение: для серверной ноды достаточно небольшой виртуальной машины. На этом же сервере допускается запускать другие служебные нересурсоёмкие сервисы.
Потребление памяти демоном Nomad зависит от количества запущенных задач. Потребление CPU — от количества задач и от количества серверов/агентов в регионе (не линейно).
В нашем случае: для 300 запущенных задач потребление памяти — около 500 МБ для текущей мастер-ноды.
В рабочем кластере виртуальная машина для серверной ноды: 4 CPU, 6 GB RAM.
Дополнительно запущены: Consul, Etcd, Vault.
3. Консенсус при нехватке датацентров
Решение: делаем три виртуальных датацентра и три серверных ноды на два физических датацентра.
Работа Nomad в рамках региона основана на протоколе raft. Для корректной работы нужно не менее 3 серверных нод, расположенных в разных датацентрах. Это даст возможность корректной работы при полной потере сетевой связности с одним из датацентров.
Но у нас только два датацентра. Идём на компромисс: выбираем датацентр, которому мы доверяем больше, и делаем в нём дополнительную серверную ноду. Делаем это путём введения дополнительного виртуального датацентра, которой физически будет находится в том же датацентре (см. подпункт 2 проблемы 1).
Альтернативное решение: разбиваем датацентры на отдельные регионы.
В итоге датацентры функционируют независимо и консенсус нужен только внутри одного датацентра. Внутри датацентра в таком случае лучше сделать 3 серверных ноды путём реализации трёх виртуальных датацентров в одном физическом.
Этот вариант менее удобен для распределения задач, но даёт 100% гарантии независимости работы сервисов в случае сетевых проблем между датацентрами.
4. "Сервер" и "агент" на одном сервере
Решение: допустимо, если у вас ограничено число серверов.
В документации Nomad написано, что так делать нежелательно. Но если у вас нет возможности выделить под серверные ноды отдельные виртуальные машины — можно разместить серверную и агентскую ноду на одном сервере.
Под одновременным запуском подразумевается запуск демона Nomad одновременно в режиме клиента и в режиме сервера.
Чем это грозит? При большой нагрузке на CPU данного сервера серверная нода Nomad будет работать нестабильно, возможны потери консенсуса и хартбитов, перезагрузки сервисов.
Чтобы этого избежать — увеличиваем лимиты из описания проблемы №8.
5. Реализация пространств имён (namespaces)
Решение: возможно, через организацию виртуального датацентра.
Иногда требуется запустить часть сервисов на отдельных серверах.
Решение первое, простое, но более требовательное к ресурсам. Разделяем все сервисы на группы по назначению: frontend, backend,… Добавляем meta атрибуты серверам, прописываем атрибуты для запуска всем сервисам.
Решение второе, простое. Добавляем новые сервера, прописываем им meta атрибуты, прописываем эти атрибуты запуска нужным сервисам, всем остальным сервисам прописываем запрет запуска на серверах с этим атрибутом.
Решение третье, сложное. Создаём виртуальный датацентр: запускаем Consul для нового датацентра, запускаем серверную ноду Nomad для данного датацентра, не забывая о количестве серверных нод для данного региона. Теперь можно запускать отдельные сервисы в данном выделенном виртуальном датацентре.
6. Интеграция с Vault
Решение: избегать циклических зависимостей Nomad<->Vault.
Запускаемый Vault не должен иметь никаких зависимостей от Nomad. Прописываемый в Nomad адрес Vault желательно должен указывать напрямую на Vault, без прослоек балансеров (но допустимо). Резервирование Vault в таком случае можно делать через DNS — Consul DNS или внешний.
Если в конфигурационных файлах Nomad прописаны данные Vault, то Nomad при запуске пытается получить доступ к Vault. Если доступ неуспешен, то Nomad отказывается запускаться.
Ошибку с циклической зависимостью я сделал давно, этим однажды кратковременно почти полностью разрушив кластер Nomad. Vault был запущен корректно, независимо от Nomad, но Nomad смотрел на адрес Vault через балансеры, которые были запущены в самом Nomad. Переконфигурация и перезагрузка серверных нод Nomad вызвала перезагрузку сервисов балансера, что привело к отказу запуска самих серверных нод.
7. Запуск важных statefull сервисов
Решение: допустимо, но я так не делаю.
Можно ли запускать PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB через Nomad?
Представьте, что у вас есть набор важных сервисов, на работу которых завязана большая часть остальных сервисов. Например, БД в PostgreSQL/ClickHouse. Или общее кратковременное хранилище в Redis Cluster/MongoDB. Или шина данных в Redis Cluster/RabbitMQ.
Все эти сервисы в каком-то виде реализуют отказоустойчивую схему: Stolon/Patroni для PostgreSQL, своя реализация raft в Redis Cluster, своя реализация кластера в RabbitMQ, MongoDB, ClickHouse.
Да, все эти сервисы вполне можно запустить через Nomad с привязкой к конкретным серверам, но зачем?
Плюс — удобство запуска, единый формат сценариев, как и у остальных сервисов. Не нужно мучаться со сценариями ansible/чем-то ещё.
Минус — дополнительная точка отказа, которая не даёт никаких преимуществ. Лично я полностью ронял кластер Nomad два раза по разным причинам: один раз "домашний", один раз рабочий. Это было на первых этапах внедрения Nomad и из-за неаккуратности.
Так же, Nomad начинает себя плохо вести и перезапускать сервисы из-за проблемы №8. Но даже если та проблема у вас решена, опасность остаётся.
8. Стабилизация работы и рестартов сервисов в нестабильной сети
Решение: использование опций тюнинга хартбитов.
По умолчанию Nomad сконфигурирован так, что любая кратковременная проблема сети или нагрузка на CPU, вызывает потерю консенсуса и перевыборы мастера или пометку агентской ноды недоступной. И это приводит к самопроизвольным перезагрузкам сервисов и перенос их на другие ноды.
Статистика "домашнего" кластера до исправления проблемы: максимальное время жизни контейнера до рестарта — около 10 дней. Тут всё ещё отягощается запуском агента и сервера на одном сервере и размещением в 5 разных датацентрах Европы, что предполагает большую нагрузку на CPU и менее стабильную сеть.
Статистика рабочего кластера до исправления проблемы: максимальное время жизни контейнера до рестарта — больше 2 месяцев. Тут всё относительно хорошо из-за отдельных серверов для серверных нод Nomad и отличной сети между датацентрами.
Значения по умолчанию
heartbeat_grace = "10s"
min_heartbeat_ttl = "10s"
max_heartbeats_per_second = 50.0Судя по коду: в такой конфигурации хартбиты делаются каждые 10 секунд. При потере двух хартбитов начинаются перевыборы мастера или перенос сервисов с агентской ноды. Спорные настройки, на мой взгляд. Отредактируем их в зависимости от применения.
Если у вас все сервисы запущены в нескольких экземплярах и разнесены по датацентрам, то скорее всего, для вас не имеет значения долгий период определения недоступности сервера (примерно 5 минут, в примере ниже) — делаем реже интервал хартбитов и больший период определения недоступности. Это пример настройки моего "домашнего" кластера:
heartbeat_grace = "300s"
min_heartbeat_ttl = "30s"
max_heartbeats_per_second = 10.0Если же у вас хорошая сетевая связность, отдельные сервера для серверных нод и важен период определения недоступности сервера (есть какой-то сервис, запущенный в одном экземпляре и важно его быстро перенести), то увеличиваем период определения недоступности (heartbeat_grace). Опционально можно сделать чаще хартбиты (уменьшив min_heartbeat_ttl) — от этого незначительно вырастет нагрузка на CPU. Пример конфигурации рабочего кластера:
heartbeat_grace = "60s"
min_heartbeat_ttl = "10s"
max_heartbeats_per_second = 50.0Данные настройки полностью устраняют проблему.
9. Запуск периодических задач
Решение: периодические сервисы Nomad использовать можно, но "cron" удобнее для поддержки.
В Nomad есть возможность периодического запуска сервиса.
Единственный плюс — простота такой конфигурации.
Первый минус — если сервис будет запускаться часто, то он будет захламлять список задач. Например, при запуске каждые 5 минут — в список будет добавляться 12 лишних задач каждый час, до срабатывания GC Nomad, который удалит старые задачи.
Второй минус — непонятно, как нормально настраивать мониторинг такого сервиса. Как понять, что сервис запускается, отрабатывает и выполняет свою работу до конца?
В итоге, для себя я пришёл к "cron" реализации периодических задач:
- Это может быть обычный cron в постоянно запущенном контейнере. Cron периодически запускает некий скрипт. На такой контейнер легко добавляется script-healthcheck, который проверяет какой-либо флажок, который создаёт запускаемый скрипт.
- Это может быть постоянно запущенный контейнер, с постоянно запущенным сервисом. Внутри сервиса уже реализован периодический запуск. На такой сервис легко добавляется или аналогичный script-healthcheck, или http-healthcheck, который проверяет статус сразу по своим "внутренностям".
На данный момент я большую часть времени пишу на Go, соответственно, предпочитаю второй вариант с http healthcheck'ами — на Go и периодический запуск, и http healthcheck'и добавляются несколькими строчками кода.
10. Обеспечение резервирования сервисов
Решение: простого решения нет. Есть два варианта посложнее.
Схема обеспечения резерва, предусмотренная разработчиками Nomad, состоит в поддержке количества запущенных сервисов. Говоришь номаду "запусти мне 5 инстансов сервиса" и он их где-то там запускает. Контроля над распределением нет. Инстансы могут запуститься на одном сервере.
Если сервер упал — инстансы переносятся на другие сервера. Пока инстансы переносятся — сервис не работает. Это плохой вариант обеспечения резерва.
Делаем правильно:
- Распределяем инстансы по серверам через distinct_hosts.
- Распределяем инстансы по датацентрам. К сожалению, только через создание копии сценария вида сервис1, сервис2 с одинаковым содержимым, разными именами и указанием запуска в разных датацентрах.
В Nomad 0.9 появится функционал, который устранит эту проблему: возможно будет распределять сервисы в процентном соотношении между серверами и датацентрами.
11. Web UI Nomad
Решение: встроенный UI — ужасен, hashi-ui — прекрасен.
Консольный клиент выполняет большую часть требуемого функционала, но иногда хочется посмотреть графики, понажимать кнопочки...
В Nomad встроен UI. Он не очень удобен (даже хуже консольного).
Единственная, известная мне альтернатива — hashi-ui.
По факту, сейчас консольный клиент лично мне нужен только для "nomad run". И даже это в планах перенести в CI.
12. Поддержка oversubscription по памяти
Решение: нет.
В текущих версия Nomad обязательно указывать строгий лимит памяти для сервиса. При превышении лимита — сервис будет убит OOM Killer.
Oversubscription — это когда лимиты сервису могут быть указаны "от и до". Некоторым сервисам при запуске требуется больше памяти, чем при обычной работе. Некоторые сервисы могут кратковременно потреблять больше памяти, чем обычно.
Выбор строго ограничения или мягкого — тема для дискуссий, но, например, Kubernetes даёт программисту сделать выбор. К сожалению, в текущих версиях Nomad такой возможности нет. Допускаю, что появится в будущих версиях.
13. Очистка сервера от сервисов Nomad
Решение:
sudo systemctl stop nomad
mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ
sudo rm -rf /var/lib/nomad
sudo docker ps | grep -v '(служебный-сервис1|служебный-сервис2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ
sudo systemctl start nomadИногда "что-то идёт не так". На сервере убивает агентскую ноду и она отказывается запускаться. Или агентская нода перестаёт отвечать на запросы. Или агентская нода "теряет" сервисы на данном сервере.
Такое иногда случалось со старыми версиями Nomad, сейчас такое или не происходит, или очень редко.
Что в таком случае сделать проще всего, учитывая, что drain сервера не даст нужного результата? Очищаем сервер вручную:
- Останавливаем агента nomad.
- Делаем umount на создаваемые им mount.
- Удаляем все данные агента.
- Удаляем все контейнеры, фильтруя служебные контейнеры (если есть).
- Запускаем агента.
14. Как лучше разворачивать Nomad?
Решение: конечно, через Consul.
Consul в данном случае — отнюдь не лишняя прослойка, а органично вписывающийся в инфраструктуру сервис, который даёт больше плюсов, чем минусов: DNS, KV хранилище, поиск сервисов, мониторинг доступности сервиса, возможность безопасного обмена информацией.
Кроме того, он разворачивается так же просто, как и сам Nomad.
15. Что лучше — Nomad или Kubernetes?
Решение: зависит от...
Раньше у меня иногда появлялась мысль начать миграцию в Kubernetes — так сильно меня раздражал периодическая самопроизвольная перезагрузка сервисов (см. проблему №8). Но после полного решения проблемы могу сказать: Nomad меня устраивает на данный момент.
С другой стороны: в Kubernetes так же существует полу-самопроизвольная перезагрузка сервисов — когда планировщик Kubernetes перераспределяет инстансы в зависимости от нагрузки. Это не очень здорово, но там это настраивается скорее всего.
Плюсы Nomad: очень легко разворачивается инфраструктура, простые сценарии, хорошая документация, встроенная поддержка Consul/Vault, что в свою очередь даёт: простое решение проблемы хранения паролей, встроенный DNS, простые в настройке хелсчеки.
Плюсы Kubernetes: сейчас это "стандарт де факто". Хорошая документация, множество готовых решений, с хорошим описанием и стандартизацией запуска.
К сожалению, у меня нет такого же большого экспертного опыта в Kubernetes, чтобы однозначно ответить на вопрос — что использовать для нового кластера. Зависит от планируемых потребностей.
Если у вас планируется множество неймспейсов (проблема №5) или ваши специфические сервисы потребляют много памяти на старте, далее освобождая её (проблема №12) — однозначно Kubernetes, т.к. эти две проблемы в Nomad решены не до конца или неудобно.
