Некоторое время назад я начал понимать необходимость разнообразить мой опыт программирования исключительно на C#. После некоторого изучения различных вариантов, таких как Haskell, Scala, Rust и некоторых других, выбор пал на последний. Со временем я начал обращать внимание, что Rust всё больше и больше рекламируется исключительно как "системный язык", который нужен для вырвиглазно сложных компиляторов и супер-нагруженных систем, с особыми требованиями к безопасности и многопоточности, а для вариантов попроще есть Go/Python/Java/..., в то время как я с удовольствием и весьма успешно использовал его как замену моей рабочей лошадке C#.

В этой статье я хотел рассказать, почему я считаю этот тренд в целом вредным, и почему Rust является хорошим языком общего назначения, на котором можно делать любые проекты, начиная со всяких микросервисов, и заканчивая скриптованием ежедневной рутины.
Введение
Зачем, собственно, учить новый язык, тем более сложный? Мне кажется, что ближе всего к истине ответ статьи "Побеждая посредственность", а именно:
Каждый знает, что писать всю программу вручную на машинном языке — ошибочно. Но гораздо реже понимают то, что существует и более общий принцип: при наличии выбора из нескольких языков ошибочно программировать на чем-то, кроме самого мощного, если на выбор не влияют другие причины.
Чем сложнее язык, тем богаче фразы, составленные с его помощью, и тем лучше он может выразить требуемую предметную область. Т.к. концепции обычно изучаются единожды, а применяются многократно, намного выгоднее с точки зрения вложения собственного времени изучить всякие страшные слова вроде "монадические трансформеры" (а еще, желательно, их смысл), чтобы потом экономить свои ментальные силы и тратить их на что-то более приятное. И поэтому весьма грустно видеть тренд некоторых компаний делать специально "упрощенные" языки. В итоге словарь этих языков намного меньше, и выучить его не составляет особого труда, но читать потом программы "моя твоя покупать лук" весьма тяжело, не говоря про возможные неоднозначные трактовки.
Основы
Как обычно новичок знакомится с языком программирования? Он гуглит самую популярную книжку по языку, достаёт её, и начинает читать. Как правило, там содержится HelloWorld, инструкция по установке компилятора, а дальше базовая информация по языку с постепенным усложнением. В случае раста, это растбук, а первым примером является чтение числа из консоли и вывод его на экран. Как бы мы это сделали в том же C#? Ну наверное как-то так
var number = int.Parse(Console.ReadLine());
Console.WriteLine($"You guessed: {number}");А что у нас в расте?
let mut guess = String::new();
io::stdin().read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse()
.expect("Please type a number!");
println!("You guessed: {}", guess);Утроенное количество кода, все эти реверансы с созданием переменной перед использованием (привет Паскаль!), вызовом кучи вспомогательного кода, и т.п. "Что за ужас" подумает среднестатистический разработчик и в очередной раз убедится в "системности" языка.
А ведь на самом деле это можно написать существенно проще:
let mut guess = String::new();
io::stdin().read_line(&mut guess)?;
let guess: u32 = guess.trim().parse()?;
println!("You guessed: {}", guess);Всё еще остается отдельное создание переменной и чтение в неё из потока, но тут уже накладывает отпечаток идеология раста, что выделение буфера он перекладывает на пользователя. Сперва непривычно, но потом понимаешь, что с ответственностью приходит и соответствующая сила. Ну а для тех, кто не парится, всегда есть опция написать трёхстрочную функцию и забыть этот вопрос раз и навсегда.
Почему пример в книжке составлен таким образом? Скорее всего из-за того, что объяснение обработки ошибок происходит сильно позже, а игнорировать их как в случае с C# не позволяет парадигма раста, который контролирует все возможные пути, где что-то может пойти не так.
Лайфтаймы и борроучекер
Ох уж эти страшные звери. Люди бросаются непонятными заклинаниями навроде
fn search<F>(self, hash: u64, is_match: F, compare_hashes: bool)
-> RawEntryMut<'a, K, V, S>
where for<'b> F: FnMut(&'b K) -> boolНовички в панике бегут, ребята из го говорят "мы же вас предупреждали про ненужную сложность", хаскеллисты говорят "столько сложности для языка, в котором даже эффектов нет", а джависты крутят пальцем у виска "стоило ли огород городить, чтобы только от GC отказаться".
На деле же при написании прикладной программы вам скорее всего не понадобится указывать ни одного лайфтайма вообще. Причина этого в том, что в расте есть правила вывода лайфтаймов, которые почти всегда компилятор может выставить сам. Вот они:
- Each elided lifetime in input position becomes a distinct lifetime parameter.
- If there is exactly one input lifetime position (elided or not), that lifetime is assigned to all elided output lifetimes.
- If there are multiple input lifetime positions, but one of them is &self or &mut self, the lifetime of self is assigned to all elided output lifetimes.
- Otherwise, it is an error to elide an output lifetime.
Или, если в двух словах, в случае статических функций время жизни всех аргументов полагаются равными, в случае инстансных методов время жизни всех результирующих ссылок полагается равным времени жизни инстанса, на котором мы вызываем метод. И на практике это почти всегда соблюдается в случае прикладного кода. Поэтому, там вы вместо ужаса выше обычно будете писать что-то вроде
struct Point(i32, i32);
impl Point {
pub fn get_x(&self) -> &i32 {
&self.0
}
pub fn get_y(&self) -> &i32 {
&self.1
}
}И компилятор сам с радостью выведет всё, что нужно, чтобы это работало.
Лично я вижу прелесть концепции в автоматическом управлении в нескольких аспектах
- с точки зрения человека с опытом программирования на языке с GC память не является отдельным видов ресурсов. В C# есть целая история с интерфейсом
IDisposable, который используется для детерминированной очистки ресурсов, именно потому, что GC удаляет объект "когда то там", а нам может потребоваться освободить ресурс немедленно. В итоге есть целый ворох следствий: и про правильную реализацию финализаторов надо не забыть, и целое ключевое слово для этого было введено (как и try-with-resources в Java), и компилятор перелопатить, чтобы генерировал foreach с учетом этого… Унификация всех видов ресурсов, которые освободятся автоматически, и максимально быстро после последнего использования это очень приятно. Открыл себе файл, и работаешь с ним, он закроется когда нужно без всяких скоупингов. Сразу отвечу на потенциальное возражение, что DI контейнеры несколько облегчают жизнь, но не решают всех вопросов - с точки зрения человека с опытом программирования на языке с ручным управлением, в 99% случаев не надо использовать умные указатели, достаточно использовать обычные ссылки.
В итоге, код получается чистый (как в языке с GC), но в то же время все ресурсы освобождаются максимально быстро (как в языке с ручным управлением). А лайфтайм: декларативное описание ожидаемого времени жизни объекта. А декларативное описание всегда лучше, чем императивное "освободи объект здесь".
Жестокий компилятор
Некоторое следствие предыдущего пункта. Есть хорошая картинка, она в целом описывает многие языки, но нарисованна конкретно для случая раста:
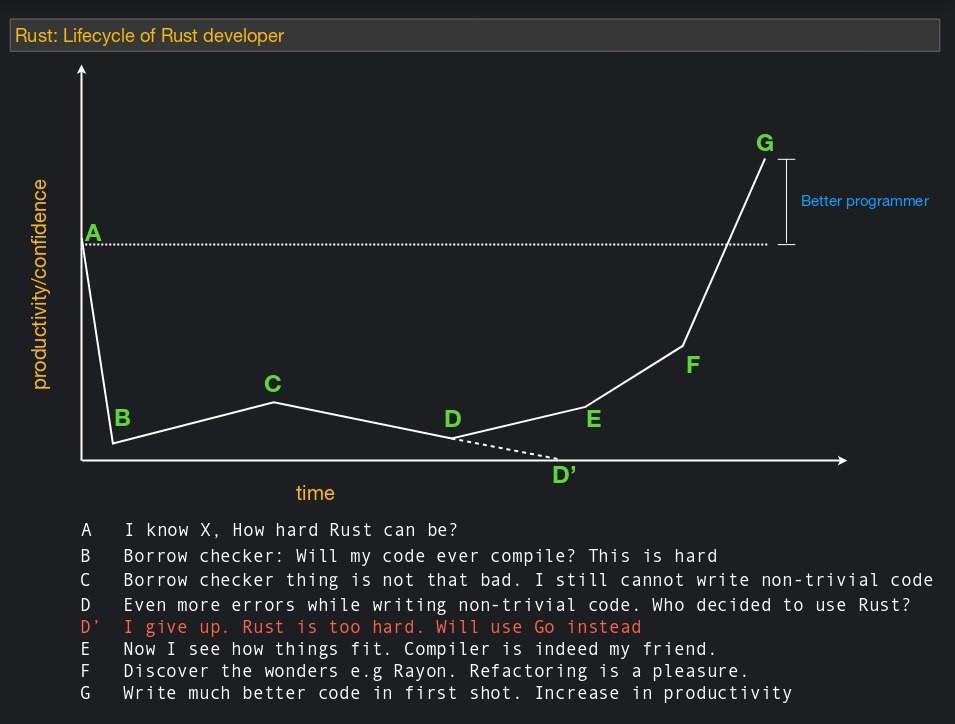
На самом деле компилятор действительно довольно придирчивый. Особенно это было верно до появления Rust 2018, когда компилятор в некоторых случаях не пропускал совершенно очевидно правильный код. Но и сейчас возникают проблемы, особенно от непонимания концепции владения. Например, когда человек пытается реализовать двусвязный список. При наивной реализации он сначала попробует сделать
pub struct Node {
value: u64,
next: Option<Box<Node>>,
prev: Option<Box<Node>>,
}Компилятор скомпилирует объявление этой структуры, но воспользоваться ей не получится, т.к. Box<Node> является владеющей ссылкой, или unique_ptr в терминах C++. А уникальная ссылка, конечно же, может быть только одна
Следующая попытка человека может выглядеть так:
pub struct Node {
value: u64,
next: Option<&Box<Node>>,
prev: Option<&Box<Node>>,
}Теперь у нас есть невладеющие ссылки (они же shared_ptr), и их может быть сколько угодно на один объект. Но тут возникает две проблемы: во-первых владелец должен где-то быть. А значит мы скорее всего получим кучу ошибок компиляции "владелец умер, когда кто-то ссылался на его данные", потому как dangling pointers раст не допускает. А во-вторых, что важнее, мы не сможем изменять эти значения, из-за правил раста "либо одна мутабельная ссылка, либо произвольное количество иммутабельных, и никак иначе".
После этого человек обычно начинает биться о клавиатуру, и писать статьи что "в расте даже связный список реализовать нормально не получится". Реализовать же его, конечно, можно, но немного сложнее чем в других языках, придется руками добавить подсчёт ссылок (примитивы Rc/Arc/Cell/RefCell), чтобы рантайме подсчитывать количество этих самых ссылок, потому что компилятор в данной ситуации бессилен.
Причины этого: эта структура данных плохо ложится на концепцию владения раста, вокруг построен весь язык и экосистема в целом. Любые структуры данных, где необходимо наличие нескольких владельцев потребуют некоторых приседаний, например реализация всевозможных лесов/деревьев/графов или тех же связных списков. Но это верно для всех языков программирования: попытки реализовать своё управление памятью в языках с GC приводит к страшным монстрам, работающих через WeakReferences с гигантскими byte[] массивам, воскрешающие объекты в деструкторах, чтобы вернуть их в пул, и прочей страшной некромантией. Попытки уйти от динамической природы JS, чтобы написать производительный код, приводит к еще более странным вещам.
Таким образом, в любом языке программирования есть своя "болевая точка", и в случае раста, это структуры данных с многими владельцами. Но, если мы смотрим с прикладной точки зрения высокоуровневых программистов, наши программы устроенны как раз таким образом. Например, в моем окружении типовое приложение выглядит как некоторый слой контроллеров, которые шарят между собой сервисы. Каждый сервис имеет ссылку на какие-то репозитории, которые возвращают какие-то объекты. Всё это отлично укладывается в концепцию ownership'а. И если учесть, что на практике основными структурами данных являются списки, массивы и хэшмапы, то оказывается, что всё не так уж и плохо.
Что же делать с этим зверем
На самом же деле компилятор изо всех сил пытается помочь. Сообщения об ошибках в расте, наверное, наиболее приятные из всех языков программирования, с которыми я работал.
Например, при попытке использовать первый вариант нашего связного списка выполучите сообщение
error[E0382]: assign to part of moved value: `head`
--> src\main.rs:23:5
|
19 | prev: Some(Box::new(head)),
| ---- value moved here
...
23 | head.next = Some(Box::new(next));
| ^^^^^^^^^ value partially assigned here after move
|
= note: move occurs because `head` has type `Node`, which does not implement the `Copy` traitОн говорит как раз о том, что мы передали владение ссылкой одному элементу, и уже не можем его использовать повторно. Также он нам рассказывает, что есть некий Copy трейт, который позволяет вместо перемещения объекта производить его копирование, из-за чего его использовать после "перемещения", потому что переместили мы копию. Если вы не знали про его существование, то ошибка компиляции снабдит вас информацией для размышления "А может стоит добавить реализацию этого трейта?".
Вообще, раст для меня первый язык, в котором есть compiler-driven development. Вы просто запускаете компиляцию, если что-то не работает, язык просто скажет вам "хмм, что-то не сходится. Я думаю, проблема в Х. Попробуй добавить вот этот код, и всё заработает". Типовой пример, допустим мы написали две функции, и забыли добавить ограничение на генерик:
fn foo<T: Copy>() {
}
fn bar<T>() {
foo::<T>();
}Компилируем, получаем ошибку:
error[E0277]: the trait bound `T: std::marker::Copy` is not satisfied
--> src\main.rs:6:5
|
6 | foo::<T>();
| ^^^^^^^^ the trait `std::marker::Copy` is not implemented for `T`
|
= help: consider adding a `where T: std::marker::Copy` bound
note: required by `foo`
--> src\main.rs:1:1
|
1 | fn foo<T: Copy>() {
| ^^^^^^^^^^^^^^^^^
error: aborting due to previous errorКопипастим where T: std::marker::Copy из сообщения об ошибке, компилируем, всё готово, поехали в прод!
Да, IDE всех современных языков умеют это делать через всякие сниппеты, но во-первых тут польза в том, что вы видите, из какого крейта/неймспейса прилетело ограничение, а во-вторых это поддержка всё же со стороны компилятора, а не IDE. Это очень помогает при кросс-платформенной разработке, когда у вас локально всё собирается, а на некоторой матрице на CI сервере где-то что-то падает из-за условной компиляции. На билд-сервере IDE нет, а так лог глянул, подставил, и всё собралось. Удобно.
Я писал некоторое время назад телеграм-бота на расте, в качестве тренировки языка. И у меня был момент, где я решил отрефакторить всё приложение. Я заменил всё, что хотел, а потом в течение получаса пытался собрать проект, и вставлял предложения от компилятора тут и там. По прошествии этого времени всё собралось и заработало с первого раза.
Ну и могу сказать, что по прошествии года с того момента как я впервые начал на расте писать, я научился писать простые сниппеты без ошибок с первого раза. Звучит смешно, особенно для людей с динамических ЯП, но для меня это был серьезный прогресс. А еще за всё время работы с растом я дебаг включал ровно два раза. И в обоих случаях я дебажил FFI с С++ кодом, который сегфолтился. Растовый код у меня либо работал правильно, либо не собирался. В случае с C# у меня уверенность сильно ниже, я все время думаю "а не придет ли тут null", "а не будет ли тут KeyNotFoundException", "правильно ли я синхронизировал доступ к этим переменным из многих потоков", и т.п. Ну а в случае с JS (когда я фуллстечил и писал фронт в том числе) после каждого изменения следовала обязательная проверка в браузере, что там изменилось.
Уверенность в том, что собралось == работает действительно имеет место. Это не значит, что в коде нет багов, это значит, что все баги связаны с логикой приложения. У вас нет неожиданных нуллов, несихнронизированного доступа, buffer overflow и так далее. А их намного легче отловить, а иногда можно вынести на уровень типов (хорошая статья на тему).
Итого
Раст — отличный язык для написания абсолютно любых приложений, а не только высоконагруженных бирж, блокчейнов и трейдинговых ботов. Всегда вместо передачи ссылки можно просто скопировать значение. Да-да, возможно, растовчане закидают меня камнями, но в в паре мест моего бота я вместо того, чтобы силиться объяснить компилятору, что переменную можно спокойно расшарить, я её клонировал, и передавал копию. Да, это не так классно, но у меня нет цели написать максимально производительное приложение, как нет такой цели у людей, пользующихся C#/Java/Go/… Я хочу быть максимально продуктивным, и получить приложение с приемлемой скоростью. Реализовать приложение на расте по всем канонам, исключив все ненужные копирования — весьма непростая задача. Но написать приложение за то же время, что и на своём любимом языке, и получить еще и бесплатный прирост производительности — очень даже реально.
Попробуйте написать приложение на расте. Если у вас не получается пройти борроучекер, проверьте ваши структуры данных и их взаимосвязи, потому что я постепенно начал понимать, что борроучекер это не просто механизм, отвечающий за возможность освобождения памяти, но и отличный детектор правильности архитектуры приложения, из разряда "хей, а почему это объект Х зависит от У, я этого не предполагал!". Если же вы всё понимаете, но объяснять борроучекеру правильный ответ слишком сложно, просто скопируйте значение. Скорее всего, вы все равно получите приложение, работающее намного быстрее (если вы пишете на Java/C#/..., как я), либо намного стабильнее (если вы пишете на С/С++), за то же самое время, которое вы бы обычно затратили.
Концепции раста очень мощные, и отлично работают на уровне прикладных приложений, которые не задумываются о производительности, но скорее только о продуктивности разработчиков, скорости внедрения новых фич и простоты поддержки. Очень грустно наблюдать, что такой отличный во всех отношениях язык всё больше получает клеймо "странного и сложного языка для низкоуровневых гиковских задач". Надеюсь, я немного пошатнул этот вредный миф, и в мире станет на сколько-то более продуктивных и счастливых разработиков больше.
