Открытие, связанное с логикой
Логика служит основой множества вещей. Но каковы основы самой логики?
В символьной логике вводятся символы вроде p и q, обозначающие утверждения (или «пропозиции») типа «это интересное эссе». Ещё есть определённые правила логики, к примеру, для любого p и любого q выражение NOT (p AND q) аналогично (NOT p) OR (NOT q).
Но откуда берутся эти «правила логики»? Логика – система формальная. Как и евклидову геометрию, её можно построить на аксиомах. Но что такое аксиомы? Можно начать с таких утверждений, как p AND q = q AND p, или NOT NOT p = p. Но сколько аксиом требуется? Насколько они могут быть простыми?
Этот вопрос довольно давно был мучительным. Но в 20:31 в воскресенье, 29 января 2000 года, на экране моего компьютера появилась единственная аксиома. Я уже показал, что проще ничего быть не может, но вскоре установил, что этой единственной небольшой аксиомы было достаточно, чтобы создать всю логику:
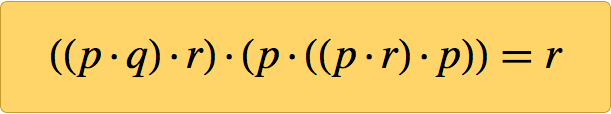
Откуда мне было знать, что она верна? Потому что я заставил компьютер доказать её. И вот доказательство, распечатанное мною в книге "Новый тип науки" (уже доступной в репозитории Wolfram Data):

Используя последнюю версию Wolfram Language любой способен сгенерировать это доказательство не более, чем за минуту. И каждый его шаг легко проверить. Но почему результат будет верным? Как его объяснить?
Подобные вопросы всё чаще задают по поводу всяческих вычислительных систем и приложений, связанных с машинным обучением и ИИ. Да, мы видим, что происходит. Но можем ли мы это понять?
Я думаю, что этот вопрос глубок по своей сути – и критически важен для будущего науки и технологии, и для будущего всего интеллектуального развития.
Но перед тем, как мы будем говорить об этом, давайте обсудим аксиому, обнаруженную мною.
История
Логика как формальная дисциплина происходит от Аристотеля, жившего в 4-м веке до нашей эры. В рамках работы своей жизни по каталогизации вещей (животных, причин, и т.п.) Аристотель составлял каталог допустимых форм аргументов и создавал символические шаблоны для них, которые, по сути, обеспечили главное содержание логики на две тысячи лет вперёд.
Однако к XV веку изобрели алгебру, а с ней появилось более ясное представление вещей. Но только в 1847 году Джордж Буль, наконец, сформулировал логику так же, как алгебру, с логическими операциями типа AND и OR, работающими по правилам, похожим на правила алгебры.
Через несколько лет люди уже записывали аксиоматические системы для логики. Типичным примером было:
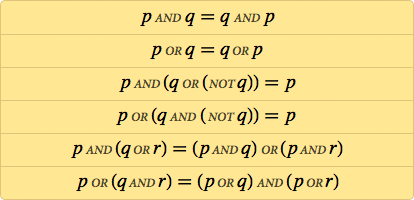
Но нужны ли на самом деле для логики AND, OR и NOT? После первого десятилетия XX века несколько людей обнаружили, что достаточно будет единственной операции, которую мы теперь называем NAND, и, к примеру, p OR q можно вычислить, как (p NAND p) NAND (q NAND q). «Функциональная полнота» NAND могла навеки остаться диковиной, если бы не разработка полупроводниковой технологии – она реализует все миллиарды логических операций в современном микропроцессоре при помощи комбинации транзисторов, выполняющих лишь функцию NAND или связанную с ней NOR.
Ну хорошо, так как же выглядят аксиомы логики в терминах NAND? Вот первый известный их вариант, записанный Генри Шеффером в 1913 году (здесь точка обозначает NAND):
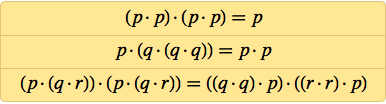
В 1910-м Principia Mathematica, трёхтомный труд по логике и философии математики Альфреда Норта Уайтхеда и Бертрана Рассела, популяризовал идею о том, что, возможно, всю математику можно вывести из логики. Учитывая это, довольно интересно было изучить вопрос того, насколько простыми могут быть аксиомы логики. Наиболее значимые работы в этой области проводили во Львове и Варшаве (тогда эти города были в составе Польши), в частности, Ян Лукасевич (в качестве побочного эффекта своей работы в 1920-м изобрёл «польскую» запись, не требующую скобок). В 1944 году в возрасте 66 лет Лукасевич бежал от наступающей советской армии и в 1947-м оказался в Ирландии.
Тем временем ирландец Кэрью Мередит, учившийся в Винчестере и Кембридже, и ставший преподавателем математики в Кембридже, из-за своего пацифизма был вынужден вернуться в Ирландию в 1939-м. В 1947-м Мередит попал на лекцию Лукасевича в Дублине, что вдохновило его заняться поисками простых аксиом, чем он и занимался, по большей части, всю оставшуюся жизнь.
Уже к 1949 Мередит обнаружил двухаксиомную систему:
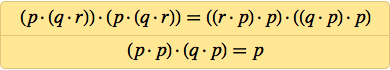
Почти 20 лет работы спустя, в 1967 ему удалось упростить это до:
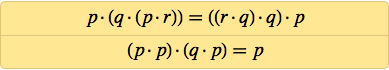
А можно ли упростить это и далее? Мередит годами возился с этим, выясняя, где ещё можно убрать лишние NAND. Но после 1967-го дальше он уже не продвинулся (и умер в 1976), хотя в 1969-м он нашёл трёхаксиомную систему:
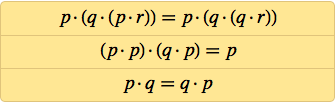
Когда я начал изучать аксиомные системы логики, я ничего не знал о работе Мередита. Я увлёкся этой темой в рамках попыток понять, какое поведение может вырастать из простых правил. В 1980-х я сделал неожиданное открытие, что даже клеточные автоматы с простейшими из возможных правил – таких, как моё любимое правило 30 – могут приводить к невероятно сложному поведению.
Проведя 1990-е в попытках понять общность этого явления, я в итоге захотел посмотреть, как его можно применить к математике. В математике мы, по сути, начинаем работать с аксиом (допустим, в арифметике, в геометрии, в логике), а потом на их основе пытаемся доказать целый набор сложных теорем.
Однако насколько простыми могут быть аксиомы? Именно это я хотел установить в 1999-м. В качестве первого примера я решил изучить логику (или, что то же самое, булеву алгебру). Опровергая все мои ожидания, мой опыт с клеточными автоматами, машинами Тьюринга и другими системами – включая даже дифференциальные уравнения в частных производных – говорит о том, что можно просто начать перечислять наиболее простые случаи из возможных, и в какой-то момент увидеть кое-что интересное.
Но можно ли таким способом «открыть логику»? Был лишь один способ сказать это. И в конце 1999 я устроил всё так, чтобы начать изучать пространство всех возможных систем аксиом, начиная с самых простых.
В каком-то смысле, любая система аксиом задаёт набор ограничений, допустим, на p · q. Она не говорит, что такое p · q, она только даёт свойства, которым должно удовлетворять p · q (к примеру, она может заявить, что q · p = p · q). Тогда вопрос в том, можно ли из этих свойств вывести все теоремы логики, выполняющиеся, когда p · q является Nand[p, q]: ни больше, ни меньше.
Кое-что можно проверить напрямую. Можно взять систему аксиом и посмотреть, какие формы p · q удовлетворяют аксиомам, если p и q будут, допустим, означать true и false. Если система аксиом состоит в том, что q · p = p · q, тогда да, p · q могут быть Nand[p, q] – но не обязательно. Оно может также быть And[p, q] или Equal[p, q], или ещё многими другими вариантами, не удовлетворяющими тех же самых уровней, как функция NAND в логике. Но к тому времени, когда мы доходим до системы аксиом {((p · p) · q) · (q · p) = q}, мы доходим до состояния, в котором Nand[p, q] (и эквивалент Nor[p, q]) остаются единственными работающими моделями p · q – по крайней мере, если предположить, что у q и p бывает только два возможных значения.
Является ли тогда это системой аксиом для логики? Нет. Потому что оно подразумевает, к примеру, существование варианта, когда у p и q есть три значения, а в логике такого нет. Однако тот факт, что эта система аксиом из одной аксиомы близко подходит к тому, что нам нужно, говорит о том, что стоит поискать единую аксиому, из которой воспроизводится логика. Именно это я и сделал в январе 2000 (в наше время эта задача облегчилась, благодаря достаточно новой и очень удобной функции Wolfram Language, Groupings).
Было довольно легко проверить, что аксиомы, в которых было 3 или меньше NAND (или «оператора точка») не работали. К 5 утра в воскресенье, 29 января (ага, тогда я был совой), я обнаружил, что не сработают и аксиомы, содержащие 4 NAND. Когда я прекратил работу, примерно к 6 утра, у меня на руках было 14 кандидатов с пятью NAND. Но продолжив работу вечером в воскресенье и проведя дополнительные испытания, пришлось отбросить их все.
Незачем и говорить, что следующим шагом стала проверка аксиом с 6 NAND. Их оказалось 288 684. Но мой код работал эффективно, и прошло не так много времени перед тем, как на экране появилось следующее (да, из Mathematica Version 4):

Сначала я не понял, что у меня получилось. Я только знал, что у меня есть 25 неэквивалентных аксиом с 6 NAND, которым удалось продвинуться дальше, чем аксиомам с 5 NAND. Но были ли среди них аксиомы, порождающие логику? У меня был эмпирический метод, способный отбрасывать ненужные аксиомы. Но единственным способом точно узнать правильность конкретной аксиомы было доказать, что она успешно способна воспроизвести, допустим, аксиомы Шеффера для логики.
Потребовалось немного поиграться с программами, но по прошествии нескольких дней я обнаружил, что большая часть из полученных 25 аксиом не работает. В итоге выжили две:
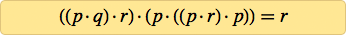

И к моей великой радости, я сумел при помощи компьютера доказать, что обе являются аксиомами для логики. Использованная техника гарантировала отсутствие более простых аксиом для логики. Поэтому я знал, что пришёл к цели: после века (а может, и пары тысячелетий) поисков мы, наконец, можем заявить, что нашли простейшую аксиому для логики.
Вскоре после этого я обнаружил системы из двух аксиом с 6 NAND в целом, которыке, как я доказал, способны воспроизводить логику:
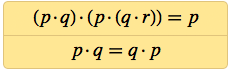
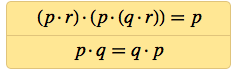
А если принять коммутативность p · q = q · p, как само собой разумеющееся, тогда логику можно получить из аксиомы, содержащей всего 4 NAND.
Почему это важно
Ладно, допустим, очень прикольно иметь возможность сказать, что кто-то «завершил дело, начатое Аристотелем» (или хотя бы Булем) и обнаружил простейшую из возможных систему аксиом для логики. Это просто диковинка, или у данного факта есть важные последствия?
До платформы, разработанной мною в книге A New Kind of Science, думаю, было бы сложно считать этот факт чем-то большим, чем просто диковинка. Но теперь должно быть видно, что он связан со всяческими базовыми вопросами, вроде того, нужно ли считать математику открытием или изобретением.
Та математика, которой занимаются люди, основана на горстке определённых систем аксиом – каждая из которых определяет особую область математики (логика, теория групп, геометрия, теория множеств). Но говоря абстрактно, есть бесконечное множество систем аксиом – каждая из которых определяет область математики, которую можно изучать, даже если люди ещё этим не занимались.
До книги A New Kind of Science я, видимо, подразумевал, что всё, существующее «где-то там» в вычислительной вселенной, должно быть «менее интересным» чем то, что люди создали и изучили. Но мои открытия, касающиеся простых программ, указывают что в системах, которые просто «где-то там» существуют, скрыты не менее богатые возможности, чем в системах, тщательно отобранных людьми.
Так что насчёт системы аксиом для математики? Чтобы сравнить существующее «где-то там» с тем, что изучали люди, нужно знать, лгут ли системы аксиом для существующих областей математики, изученных нами. И, основываясь на традиционных системах, созданных людьми, можно заключить, что они должны быть где-то очень, очень далеко – и вообще их можно найти, только если уже знать, где вы находитесь.
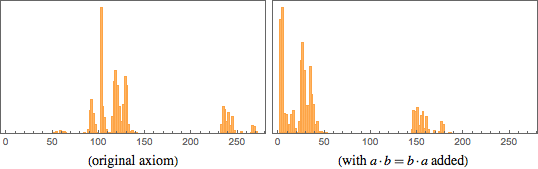
Но моё открытие системы аксиом ответило на вопрос «Как далеко находится логика?» Для таких вещей, как клеточный автомат, довольно просто пронумеровать (как сделал я в 1980-х) все возможные клеточные автоматы. Чуть сложнее сделать это с системами аксиом – но не сильно. В одном из подходов мою аксиому можно обозначить, как 411;3;7;118 – или, на языке Wolfram Language:
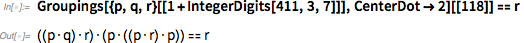
И, по крайней мере, в пространстве возможных функциональных форм (не учитывая разметку переменных) существует визуальное представление местонахождения этой аксиомы:

Учитывая фундаментальное значение логики для такого большого количества формальных систем, которые изучают люди, можно было подумать, что в любом разумном представлении логика соответствует одной из наипростейших из возможных систем аксиом. Но, по крайней мере в презентации, использующей NAND, это не так. Для неё всё ещё существует очень простая система аксиом, но это, вероятно, окажется стотысячная система аксиом из всех возможных, которые встретятся, если просто начать нумеровать системы аксиом, начиная с самой простой.
Учитывая это, очевидным следующим вопросом будет: что насчёт всех остальных систем аксиом? Как они ведут себя? Именно этот вопрос и исследует книга A New Kind of Science. И в ней я утверждаю, что такие вещи, как системы, наблюдаемые в природе, чаще всего лучше описываются этими самыми «другими правилами», которые мы можем найти, нумеруя возможности.
Что до систем аксиом, то я сделал картину, представляющую происходящее в «областях математики», соответствующих различным системам аксиом. Ряд показывает последствия определённой системы аксиом, а квадратики обозначают истинность определённой теоремы в данной системе аксиом (да, в какой-то момент вступает в силу теорема Гёделя, после чего становится невероятно сложно доказывать или опровергать заданную теорему в заданной системе аксиом; на практике, с моими методами это происходит чуть правее того, что изображено на картинке).

Есть ли что-то фундаментально особенное в областях математики, «исследованных людьми»? Судя по этой и другим картинкам, ничего очевидного в голову не приходит. Я подозреваю, что особенность у этих областей лишь одна – исторический факт того, что изучали именно их. (Можно делать заявления типа того, что «они описывают реальный мир» или «связаны с тем, как работает мозг», но результаты, описанные в книге, утверждают обратное).
Ну хорошо, а каково значение моей системы аксиом для логики? Её размер даёт почувствовать итоговое информационное наполнение логики как аксиоматической системы. И заставляет считать – по крайней мере, пока – что нам нужно считать логику больше «конструкцией, изобретённой человеком», чем «открытием», случившимся по «естественным причинам».
Если бы история шла по-другому, и мы бы постоянно искали (как это делается в книге) множество возможных простейших систем аксиом, то мы, возможно, «открыли» бы систему аксиом для логики, как ту систему, чьи свойства нам кажутся интересными. Но поскольку мы изучили такое небольшое количество из всех возможных систем аксиом, думаю, разумно будет считать логику «изобретением» – специально созданной конструкцией.
В каком-то смысле в Средние века логика так и выглядела — когда возможные силлогизмы (допустимые виды аргументов) представлялись в виде латинской мнемоники вроде bArbArA и cElErAnt. Поэтому сейчас интересно находить мнемоническое представление того, что мы знаем сейчас, как простейшую систему аксиом для логики.
Начиная с ((p · q) · r) · (p · ((p · r) · p)) = r, можно представить каждую p · q в виде префикса или польской записи (обратной к «обратной польской записи» калькулятора HP) в виде Dpq – поэтому всю аксиому можно записать, как =DDDpqrDpDDprpr. Есть ещё английская мнемоника на эту тему — FIGure OuT Queue, где роли p, q, r играют u, r, e. Или можно смотреть на первые буквы слов в следующем предложении (где B – оператор, а в роли p, q, r выступают a, p, c): «Bit by bit, a program computed Boolean algebra’s best binary axiom covering all cases» [понемногу вычисленная при помощи программы лучшая бинарная аксиома булевой алгебры описывает все случаи].
Механика доказательства
Ладно, так как же доказать корректность моей системы аксиом? Первое, что приходит в голову – показать, что из неё можно вывести известную систему аксиом для логики – например, систему аксиом Шеффера:
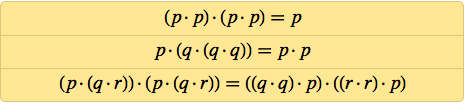
Здесь присутствуют три аксиомы, и нам надо вывести каждую. Вот, что можно сделать для вывода первой, при помощи последней версии Wolfram Language:
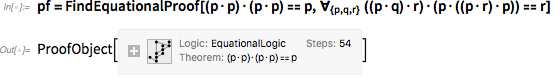
Примечательно, что сейчас стало возможным сделать это. В «объекте доказательства» записано, что для доказательства было использовано 54 шага. Исходя из этого объекта мы можем сгенерить «notebook », описывающий каждый из шагов:
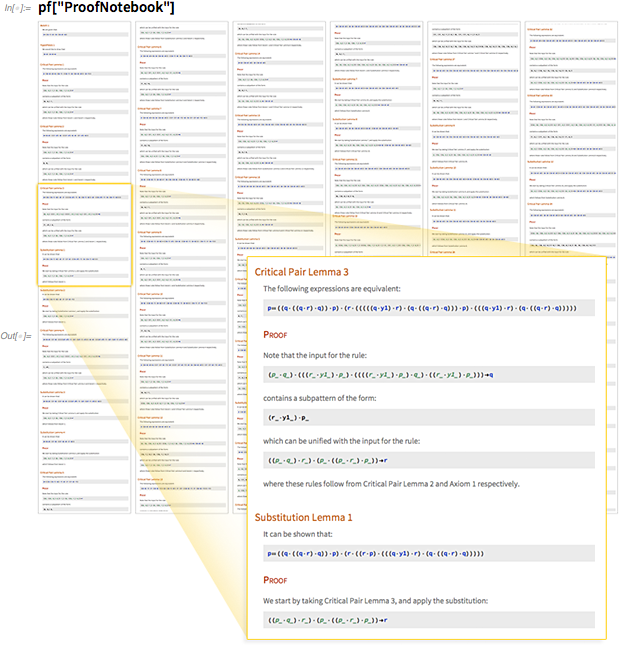
В общем здесь доказывается вся последовательность промежуточных лемм, что позволяет в итоге вывести конечный результат. Между леммами существует целая сеть взаимных зависимостей:
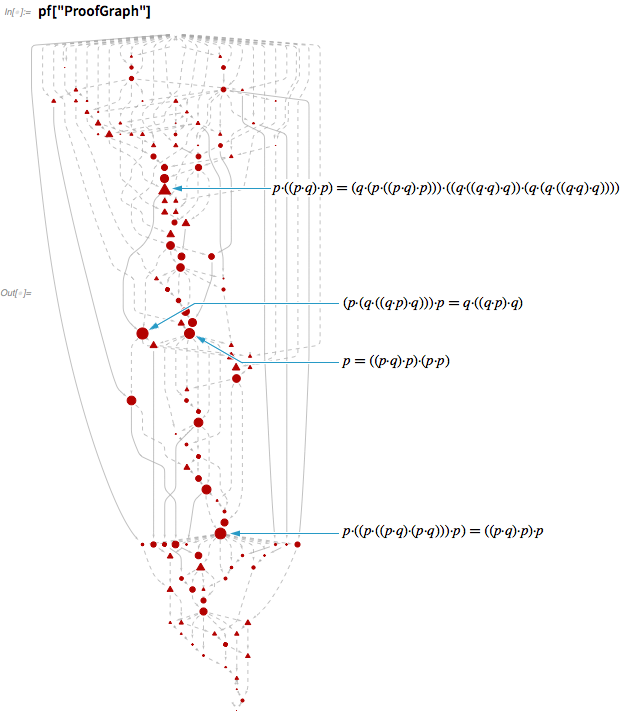
А вот сети, участвующие в выводе всех трёх аксиом в системе аксиом Шеффера – для последней используются невероятные 504 шага:

Да, очевидно, что эти сети довольно запутаны. Но перед тем, как обсудить, что означает эта сложность, поговорим о том, что происходит на каждом шаге этих доказательств.
Главная идея проста. Представим, что у нас есть аксиома, которая просто записывается, как p · q = q · p (математически это означает, что оператор коммутативен). Точнее, аксиома говорит, что для любых выражений p и q, p · q эквивалентно q · p.
Хорошо, допустим мы хотим вывести из этой аксиомы, что (a · b) · (c · d) = (d · c) · (b · a). Это можно сделать, используя аксиому для превращения d · c в c · d, b · a в a · b, и, наконец, (c · d) · (a · b) в (a · b) · (c · d).
FindEquationalProof делает по сути то же самое, хотя она выполняет эти шаги не совсем в том же порядке, и изменяет как левую часть уравнения, так и правую.
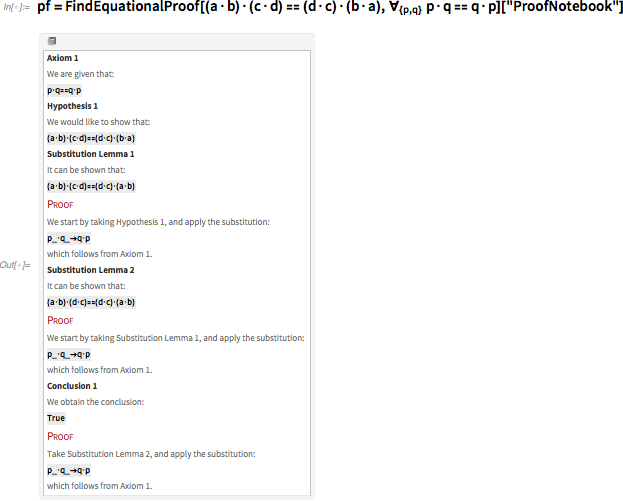
Получив такое доказательство, можно просто отследить каждый шаг и проверить, что они выдают заявленный результат. Но как найти доказательство? Существует множество возможных последовательностей подстановок и преобразований. Как найти последовательность, успешно доводящую до конечного результата?
Можно было бы решить: почему бы не попробовать все возможные последовательности, и если среди них есть рабочая, то она должна в итоге найтись? Проблема в том, что можно быстро прийти к астрономическому количеству последовательностей. Основная часть искусства автоматического доказательства теорем состоит из поиска способов уменьшения количества последовательностей для проверки.
Это быстро скатывается в технические подробности, но основную идею легко обсудить, если знать азы алгебры. Допустим, мы пытаемся доказать алгебраический результат вроде
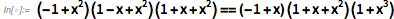
Существует гарантированный способ сделать это: просто применив правила алгебры для раскрытия каждой из сторон, можно сразу увидеть их сходство:
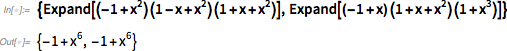
Почему это работает? Потому, что существует способ работы с такими выражениями, систематически уменьшающий их до тех пор, пока они не примут стандартную форму. А можно ли проделать такую же операцию в произвольных системах аксиом?
Не прямо сразу. В алгебре это работает, поскольку у неё есть особое свойство, гарантирующее, что всегда можно «продвигаться» по пути упрощения выражений. Но в 1970-х разные учёные несколько раз независимо друг от друга открыли (под названиями вроде алгоритм Кнута-Бендикса или базис Грёбнера), что даже если у системы аксиом нет необходимого внутреннего свойства, потенциально можно обнаружить «дополнения» этой системы, у которых оно есть.
Именно это происходит в типичных доказательствах, которые выдаёт FindEquationalProof (основанная на системе Валдмейстера, «master of trees»). Существуют т.н. «леммы критических пар», которые напрямую не продвигают доказательство, но делают возможным появление путей, способных на это. Усложняется всё из-за того, что, хотя окончательное выражение, которые мы хотим получить, довольно короткое, на пути к нему, возможно, приходится проходить через куда как более длинные промежуточные выражения. Поэтому, к примеру, у доказательства первой аксиомы Шеффера есть такие промежуточные шаги:
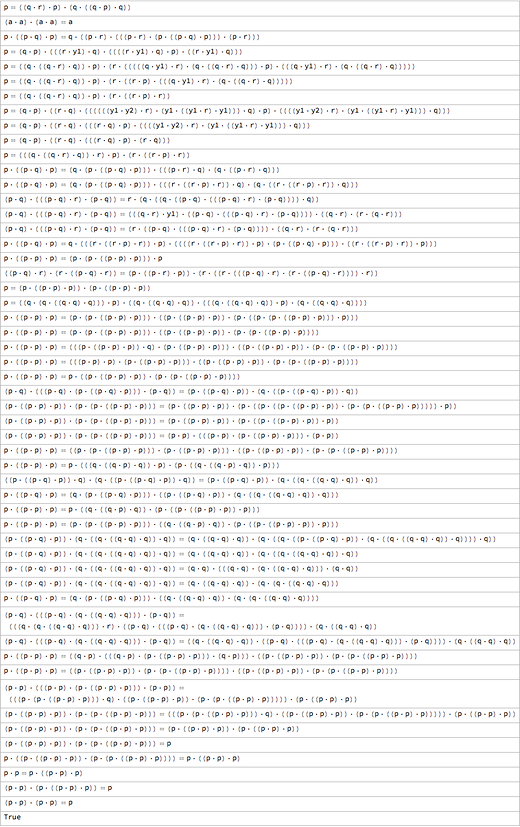
В данном случае крупнейший из шагов оказывается в 4 раза больше оригинальной аксиомы:
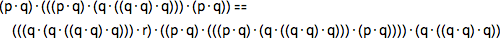
Такие выражения можно представлять в виде дерева. Вот его дерево, в сравнении с деревом первоначальной аксиомы:
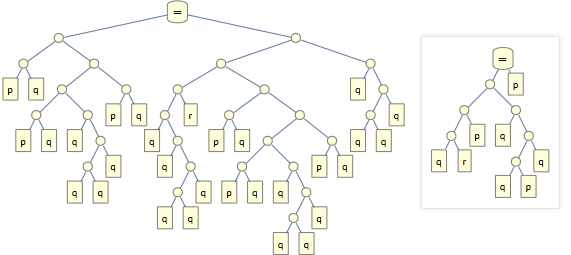
И вот как размеры промежуточных шагов развиваются в ходе доказательств каждой из аксиомы Шеффера:

Почему это так сложно?
Так ли удивительно, что эти доказательства настолько сложны? На самом деле, не особенно. Ведь нам хорошо известно, что математика бывает сложной. В принципе, могло быть и так, что все истины в математике было бы легко доказать. Но один из побочных эффектов теоремы Гёделя 1931 года состоит в том, что даже у тех вещей, у которых есть доказательства, путь к ним может быть сколь угодно длинным.
Это симптом гораздо более общего явления, которое я называю вычислительной несводимостью. Рассмотрим систему, управляемую простым правилом клеточного автомата (конечно, в любом моём эссе где-то обязательно будут клеточные автоматы). Запустим эту систему.
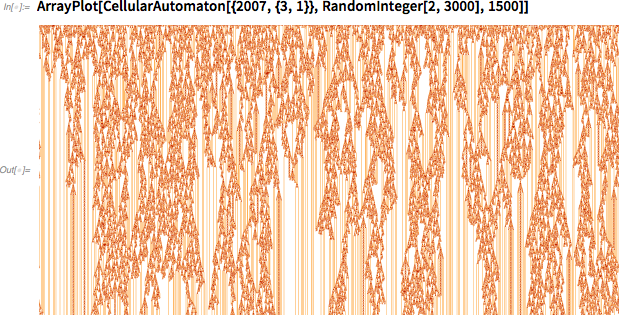
Можно было бы решить, что если в основе системы лежит простое правило, то должен быть быстрый способ понять, что делает система. Но это не так. Согласно моему принципу вычислительной эквивалентности, работа системы часто соответствует вычислениям, сложность которых совпадает с любыми вычислениями, которые мы могли бы провести, чтобы понять поведение системы. Это значит, что реальное поведение системы, по сути, соответствует такому количеству вычислительной работы, которое в принципе нельзя уменьшить.
Касательно картинки выше: допустим, мы хотим узнать, умрёт ли в итоге закономерность. Мы могли бы продолжать её выполнять, и если нам повезёт, она в итоге выродится во что-то, судьба чего будет очевидной. Однако в общем не существует верхней границы на то, сколько времени нам придётся потратить, по сути, на доказательство.
Когда что-то такое происходит с логическими доказательствами, оно происходит немного по-другому. Вместо того, чтобы запустить нечто, работающее по определённым правилам, мы спрашиваем, существует ли способ прийти к определённому результату, пройдя через несколько шагов, каждый из которых подчиняется определённому правилу. И эта задача, как практическая вычислительная задача, оказывается гораздо сложнее. Но суть сложности – это то же явление вычислительной несводимости, и это явление говорит о том, что не существует общего способа кратко обойти процесс изучения того, что сделает система.
Излишне говорить, что в мире существует множество вещей – особенно в технологии и научном моделировании, а также в областях, где присутствуют различные формы правил – традиционно разработанных так, чтобы избежать вычислительной несводимости, и работать так, чтобы результат их работы был сразу же виден, без необходимости проводить неуменьшаемое количество вычислений.
Но одно из следствий моего принципа вычислительной эквивалентности состоит в том, что эти случаи единичны и неестественные – он утверждает, что вычислительная несводимость существует во всех системах вычислительной вселенной.
А что же насчёт математики? Может, правила математики специально выбраны так, чтобы продемонстрировать вычислительную сводимость. И в некоторых случаях это так и есть (и в каком-то смысле это бывает и в логике). Но по большей части кажется, что системы аксиом математики не являются нетипичными для пространства всех возможных систем аксиом – где неизбежно буйствует вычислительная несводимость.
Зачем нужны доказательства?
В каком-то смысле, доказательство нужно, чтобы знать истинность чего-либо. Конечно, особенно в наше время, доказательство отошло на второй план, уступив место чистым вычислениям. На практике гораздо чаще встречается желание сгенерировать что-либо вычислениями, чем желание «отойти назад» и сконструировать доказательство истинности чего-либо.
В чистой математике, тем не менее, часто приходится сталкиваться с понятиями, включающими в себя, хотя бы номинально, бесконечное количество случаев («истинно для всех простых чисел», и т.п.), для которых вычисления «в лоб» не подойдут. А когда встаёт вопрос о подтверждении («может ли эта программа завершиться с ошибкой?» или «можно ли потратить эту криптовалюту дважды?») чаще разумнее попытаться до казать это, чем просчитать все возможные случаи.
Но в реальной математической практике, доказательство – это нечто большее, чем установление истины. Когда Евклид писал свои "Начала", он просто указывал результаты, а доказательства «оставлял читателю». Но, так или иначе, особенно за последнее столетие, доказательство превратилось в нечто, что не просто происходит за кулисами, а является основным носителем, через которые необходимо транслировать понятия.
Мне кажется, что в результате какой-то причуды истории доказательства сегодня предлагаются как предмет, который должны понять люди, а программы считаются просто чем-то, что должен исполнять компьютер. Почему так случилось? Ну, по крайней мере, в прошлом, доказательства можно было представлять в текстовом виде – поэтому, если их кто и использовал, то только люди. А программы практически всегда записывались в виде компьютерного языка. И очень долго эти языки создавались такими, чтобы их можно было более-менее напрямую транслировать в низкоуровневые операции компьютера – то есть, компьютер их понимал сразу, а люди – не обязательно.
Но одной из основных целей моей деятельности за последние несколько десятилетий было изменить такое положение вещей, и разработать в Wolfram Language настоящий «язык вычислительного общения», в котором вычислительные идеи можно передавать так, что их смогут понять и компьютеры, и люди.
У такого языка есть много последствий. Одно из них – изменение роли доказательства. Допустим, мы смотрим на какой-то математический результат. В прошлом единственным правдоподобным способом довести его до понимания было выдать доказательство, читаемое людьми. Но теперь возможно и другое: можно выдать программу для Wolfram Language, подсчитывающую результат. И это во многих смыслах гораздо более богатый способ донести истинность результата. Каждая часть программы представляет собой нечто точное и недвусмысленное – каждый желающий может её запустить. Нет такой проблемы, как попытки понять какую-то часть текста, требующие заполнять некие пробелы. Всё указано в тексте совершенно чётко.
Что насчёт доказательств? Есть ли недвусмысленные и точные способы писать доказательства? Потенциально да, хотя это не особенно легко. И хотя основа Wolfram Language существует уже 30 лет, только сегодня появился разумный способ представлять с его помощью такие структурно прямолинейные доказательства, как одна из моих аксиом выше.
Можно представить себе создание доказательств в Wolfram Language так же, как люди создают программы – и мы работаем над тем, чтобы предоставить высокоуровневые версии такой функциональности, «помогающей с доказательствами». Однако доказательство моей системы аксиом никто не создавал – его нашёл компьютер. И это уже больше похоже на выходные данные программы, чем на саму программу. Однако, как и программу, доказательство в некотором смысле тоже можно «запустить» для проверки результата.
Создавая понятность
Большую часть времени люди, использующие Wolfram Language, или Wolfram|Alpha, хотят что-то подсчитать. Им нужно получить результат, а не понять, почему они получили именно такие результаты. Но в Wolfram|Alpha, особенно в таких областях, как математика и химия, популярной среди студентов функцией является построение «пошаговых» решений.
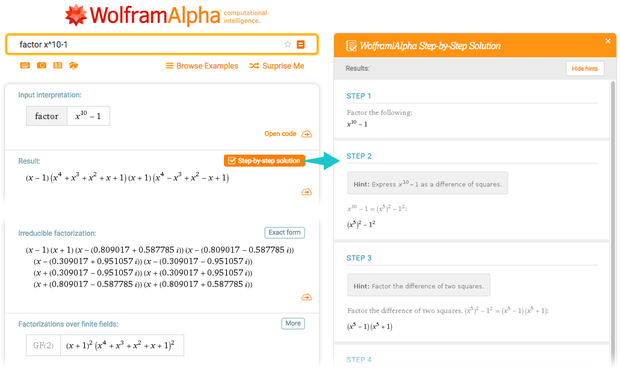
Когда систему Wolfram|Alpha вычисляет, например, интеграл, она использует всякие мощные алгоритмические техники, оптимизированные для получения ответов. Но когда её просят показать этапы расчётов, она делает нечто другое: ей нужно объяснить по шагам, почему получен именно такой результат.
Пользы в том, чтобы объяснить, как результат был получен на самом деле, не было бы; это очень неподходящий для человека процесс. Ей нужно понять, какие операции, выученные людьми, можно использовать для получения результата. Часто она придумывает какой-нибудь полезный трюк. Да, у неё есть систематический способ для этого, который всегда работает. Но в нём слишком много «механических» этапов. А «трюк» (подстановка, частичное интегрирование, и т.п.) не сработает в общем случае, но в данном конкретном он выдаст более быстрый путь к ответу.
А что же насчёт получения понятных версий других вещей? Например, работы программ в общем случае. Или доказательства моей системы аксиом.
Начнём с программ. Допустим, мы написали программу и хотим объяснить, как она работает. Один из традиционных подходов – включить в код комментарии. Если мы пишем на традиционном языке низкого уровня, это может быть лучшим выходом. Но вся суть Wolfram Language как языка вычислительного общения состоит в том, что сам язык должен позволять транслировать идеи, без необходимости включения дополнительных кусков текста.
Нужно затрачивать усилия на то, чтобы программа на Wolfram Language была хорошим описанием процесса, как и на то, чтобы простой текст на английском языке был хорошим описанием процесса. Однако можно получить такой кусок кода на Wolfram Language, который очень чётко объясняет, как всё работает, сам по себе.
Конечно, часто бывает так, что реальное выполнение кода приводит к таким вещам, которые не следуют очевидно из программы. Я вскоре упомяну о таких экстремальных случаях, как клеточные автоматы. Но пока что давайте представим, что мы создали программу, по которой можно представить, что она в целом делает.
В таком случае я обнаружил, что вычислительные эссе, представленные в виде Wolfram Notebooks, являются прекрасным инструментом для пояснения происходящего. Важно, что Wolfram Language, это позволяет запускать даже самые мелкие части программ по отдельности (с соответствующими символическими выражениями в роли входных и выходных данных). После этого можно представить себе последовательность шагов программы как последовательность элементов диалога, формирующего основу вычислительной записной книжки.
На практике часто необходимо создавать визуализации входных и выходных данных. Да, всё можно выразить в виде однозначного символического представления. Но людям гораздо проще понимать визуальное представление вещей, чем какую-нибудь одномерную языкоподобную строчку.
Конечно, создание хороших визуализаций сродни искусству. Но в Wolfram Language мы проделали большую работу по автоматизации этого искусства – часто при помощи довольно сложного машинного обучения и других алгоритмов, выполняющих такие вещи, как раскладка сетей или графических элементов.
Что насчёт того, чтобы начать с простого отслеживания работы программы? Это тяжело сделать. Я десятилетиями экспериментировал с этим, и никогда не был полностью удовлетворён результатами. Да, можно увеличить масштаб и увидеть множество деталей происходящего. Но я так и не обнаружил достаточно хороших техник, позволяющих понять всю картину целиком, и автоматически выдающих какие-то особенно полезные вещи.
На каком-то уровне эта задача похожа на реверс-инжиниринг. Вам демонстрируют машинный код, схему чипа, что угодно. А вам надо сделать шаг назад и воссоздать высокоуровневое описание, от которого отталкивался человек, которое каким-то образом «скомпилировалось» в то, что вы видите.
В традиционном подходе к инженерному делу, когда люди создают продукт по шагам, всегда имея возможность предвидеть последствия того, что они создают, этот подход в принципе может сработать. Но если вместо этого просто бродить по вычислительной вселенной в поисках оптимальной программы (так, как я искал возможные системы аксиом, чтобы найти систему для логики), то нет гарантии, что за этой программой окажется какая-то «человеческая история» или объяснение.
Сходная проблема встречается в естественных науках. Вы видите, как в биологической системе развивается сложный набор всяких процессов. Можно ли подвергнуть их «реверс-инжинирингу» с целью найти «объяснение»? Иногда можно сказать, что к этому приведёт эволюция с естественным отбором. Или что это часто встречается в вычислительной вселенной, поэтому вероятность его возникновения высока. Но нет гарантий, что естественный мир обязательно устроен так, чтобы люди могли его объяснить.
Естественно, при моделировании вещей мы неизбежно рассматриваем только интересующие нас аспекты, и идеализируем всё остальное. И особенно в таких областях, как медицина, часто приходиться работать с приближённой моделью с неглубоким деревом решений, которое легко объяснить.
Природа объяснимости
Что означает фраза «нечто можно объяснить»? По сути это значит, что люди могут это понять.
Что же требуется от людей для того, чтобы что-то понять? Нам нужно каким-то образом это осознать. Возьмём типичный клеточный автомат со сложным поведением. У компьютера нет никаких проблем с тем, чтобы пройти каждый шаг в его эволюции. С огромными усилиями и трудозатратами человек мог бы воспроизвести работу компьютера.
Но нельзя сказать, что в этом случае человек «понял» бы, что делает клеточный автомат. Для этого человек должен был бы с лёгкостью рассуждать о поведении клеточного автомата на высоком уровне. Или, иначе говоря, человек должен был бы суметь «рассказать историю» о поведении автомата, которую могли бы понять другие люди.
Есть ли универсальный способ для этого? Нет, из-за вычислительной несводимости. Однако может случиться так, что определённые особенности, важные для людей, можно объяснить на высоком уровне с определёнными ограничениями.
Как это работает? Для этого нужно создать некий язык высокого уровня, который может описывать интересующие нас особенности. Изучая типичный рисунок работы клеточного автомата, можно попытаться говорить не в терминах цветов огромного количества отдельных клеток, а в терминах структур более высоко уровня, которые можно обнаружить. Главное, что можно составить по крайней мере частичный каталог таких структур: хотя в них будет много деталей, не укладывающихся в классификацию, определённые структуры встречаются часто.
И если мы хотим начать «объяснять» поведение клеточного автомата, мы начнём с наименования структур, а потом расскажем о том, что происходит с точки зрения этих структур.
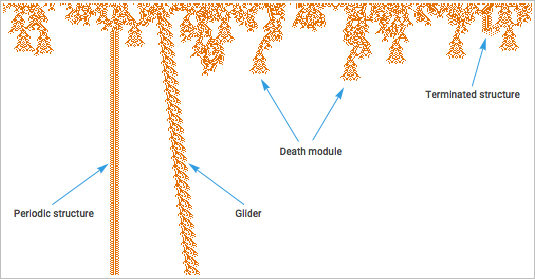
У случая с клеточным автоматом есть одна упрощающая особенность: поскольку он работает на основе простых детерминистских правил, у него есть одинаково повторяющиеся структуры. В природе, к примеру, мы обычно не сталкиваемся с подобным идентичным повторением. Там просто один, допустим, тигр, очень похож на другого, поэтому мы называем их обоих «тигр», хотя расположение их атомов не идентично.
Каков во всём этом общий смысл? Он состоит в использовании идеи символической репрезентации. Мы говорим, что можем назначить некий символ – часто это слово – которое можно использовать для символического описания целого класса вещей, без того, чтобы всякий раз детально перечислять все составляющие этих вещей.
Это похоже на сжатие информации: мы используем символические конструкции, чтобы отыскать более краткий способ описания интересующих нас вещей.
Допустим, мы сгенерировали гигантскую структуру, например, математическую:

Первый шаг – создать некое внутреннее представление высокого уровня. К примеру, мы можем обнаружить повторно употребляемые структуры. И мы можем назначить им имена. А потом показать «скелет» всей структуры с их помощью:

Да, эта, похожая на «словарное сжатие» схема, полезна для выхода на первый уровень объяснимости.
Но давайте вернёмся к доказательству моей системы аксиом. Леммы, созданные в этом доказательстве, специально выбраны как элементы, используемые повторно. Однако исключив их, мы всё ещё остаёмся с доказательством, которое люди не могут понять прямо сразу.
Какой ещё можно сделать шаг? Нам нужно придумать какое-то описание ещё более высокого уровня. Что это может быть?
Концепция концепций
Если вы пытаетесь что-либо кому-либо объяснить, то сделать это будет гораздо легче, если найти нечто другое, но похожее, что человек уже смог понять. Представьте, как вы будете объяснять концепцию современного дрона человеку из Каменного века. Это будет сложно сделать. Но объяснить это человеку, жившему 50 лет назад, и уже видевшему вертолёты и модели самолётов, будет гораздо легче.
И в итоге суть в том, что когда мы что-то объясняем, мы делаем это на языке, известном как нам, так и тому, кому мы это объясняем. И чем богаче язык, тем меньше новых элементов нам приходится вводить, чтобы передать то, что мы пытаемся объяснить.
Есть закономерность, повторяющаяся на протяжении всей истории разума. Определённый набор вещей замечают множество раз. Постепенно начинают понимать, что эти вещи каким-то образом абстрактно похожи, и всех их можно описать в терминах новой концепции, которую описывают каким-то новым словом или фразой.
Допустим, мы заметили такие вещи, как вода, кровь и масло. В какой-то момент мы понимаем, что существует обобщённая концепция «жидкости», и всех их можно описать как жидкость. И когда у нас появляется такая концепция, в её терминах можно начинать рассуждать, находя больше концепций – допустим, вязкость – основанных на ней.
Когда имеет смысл объединять вещи в концепцию? Сложный вопрос, на который нельзя ответить, не предусмотрев всё, что можно с этой концепцией сделать. На практике, в процессе эволюции языка и идей человека, наблюдается некий процесс последовательной аппроксимации.
В современной системе машинного обучения происходит куда как более быстрое суммирование информации. Представьте, что мы взяли всяческие объекты окружающего мира, и скормили их функции FeatureSpacePlot, чтобы посмотреть, что получится. Если мы получим определённые кластеры в пространстве особенностей, то можно заключить, что каждый из них можно определить, как соответствующий некоей «концепции», которую можно, к примеру, пометить словом.
Честно говоря, то, что происходит с FeatureSpacePlot – как и в процессе интеллектуального развития человека – в каком-то смысле пошаговый процесс. Чтобы распределить объекты по пространству особенностей, FeatureSpacePlot использует особенности, которые она научилась извлекать на основе предыдущих попыток разделения на категории.
Хорошо, если мы примем мир, какой он есть, какие наилучшие категории – или концепции – можно использовать для описания вещей? Этот вопрос постоянно развивается. И вообще, все прорывы – будь то наука, технология или что-то ещё – часто точно связываются с осознанием возможности полезным образом идентифицировать новую категорию или концепцию.
Но в процессе эволюции нашей цивилизации присутствует некая спираль. Во-первых, определяется некая определённая концепция – допустим, идея программы. После этого люди начинают её использовать и размышлять в её терминах. Довольно скоро на базе этой концепции оказывается построенным множество разных понятий. А затем определяется ещё один уровень абстракции, создаются новые концепции, стоящие на основе предыдущей.
История характерна для технологического набора знаний современной цивилизации, и её интеллектуального набора знаний. И туда и туда входят башни концепций и идущие один за другим уровни абстракции.
Проблема обучения
Чтобы люди могли общаться, используя некую концепцию, им нужно про неё узнать. И, да, некоторые концепции (типа постоянства объектов) люди осознают автоматически, просто наблюдая за природой. Но, допустим, если посмотреть на список распространённых слов современного английского, станет ясно, что большая часть используемых нашей современной цивилизацией концепций не относятся к тем, которые люди осознают самостоятельно, наблюдая за природой.
Вместо этого – что очень напоминает современное машинное обучение – им необходимо особое познание мира «под присмотром», организованное с тем, чтобы подчеркнуть важность определённых концепций. А в более абстрактных областях (типа математики) им, вероятно, требуется столкнуться с концепциями в их непосредственном абстрактном виде.
Хорошо, а нужно ли нам будет всё время узнавать всё больше и больше с ростом количества накопленных интеллектуальных знаний цивилизации? Может возникнуть беспокойство о том, что в какой-то момент наш мозг просто не сможет поспевать за развитием, и нам придётся добавить какую-то дополнительную помощь. Но мне кажется, что это, к счастью, один из тех случаев, когда проблему можно решить «на уровне софта».
Проблема в следующем: в любой момент истории существует определённый набор концепций, важный для жизни в мире в этот период. И, да, с развитием цивилизации раскрываются новые понятия и вводятся новые концепции. Однако есть и иной процесс: новые концепции вводят новые уровни абстракции, обычно включающие в себя большое количество более ранних концепций.
Мы часто можем наблюдать это в технологии. Было время, когда для работы на компьютере нужно было знать множество подробностей низкого уровня. Но со временем эти подробности абстрагировались, поэтому теперь вам нужна лишь общая концепция. Вы нажимаете на иконку и процесс запускается – вам не надо понимать тонкости работы операционных систем, обработчиков прерываний, планировщиков, и все остальные детали.
И, конечно, Wolfram Language даёт прекрасный пример такой работы. Он прилагает много усилий к тому, чтобы автоматизировать множество низкоуровневых деталей (к примеру, какой из алгоритмов следует использовать) и позволяет пользователям думать высокоуровневыми концепциями.
Да, всё ещё требуются люди, понимающие детали, лежащие в основе абстракций (хотя не уверен, сколько камнетёсов требуется современному обществу). Но по большей части, образование может концентрироваться на высоком уровне знаний.
Часто предполагается, что для достижения концепций высокого уровня в процессе обучения человеку сначала надо как-то суммировать историю того, как к этим концепциям пришли исторически. Но обычно – а, может, и всегда – это вроде бы не так. Можно привести экстремальный пример: представьте, что для обучения работе с компьютером сначала надо пройти всю историю математической логики. Однако же на самом деле известно, что люди сразу же обращаются к современным концепциям вычислений, без необходимости изучать какую-то историю.
Но как же в итоге выглядит понятность сети концепций? Существуют ли концепции, которые можно понять, только разобравшись в других концепциях? Учитывая обучение людей на основе взаимодействия с окружением (или тренировку нейросети), вероятно, может существовать некий их порядок.
Но мне кажется, что некий принцип, аналогичный универсальности вычислений, говорит о том, что имея на руках «чистый мозг», можно начинать откуда угодно. Так что, если некие пришельцы узнали бы о теории категорий и почти ни о чём другом, они бы, без сомнения, построили сеть концепций, где эта теория находится в корне, а то, что известно нам, как основы арифметики, у них изучали бы где-то в аналоге нашего института.
Конечно, такие пришельцы могли бы строить свой набор технологий и своё окружение очень отличным от нас образом – точно так же, как наша история могла бы стать совершенно другой, если бы компьютеры удалось успешно разработать в XIX веке, а не в середине XX-го.
Прогресс математики
Я часто размышлял над тем, до какой степени историческая траектория математики подвержена роли случая, а в какой степени она была неизбежной. Как я уже упоминал, на уровне формальных систем существует множество возможных систем аксиом, на которых можно конструировать нечто, формально напоминающее математику.
Но реальная история математики началась не с произвольной системы аксиом. Она во времена вавилонян началась с попыток использовать арифметику для коммерции, и для геометрии с целью освоения земель. И с этих практических корней начали добавляться последующие уровни абстракции, которые в итоге привели к современной математике – к примеру, числа постепенно обобщались от положительных целых к рациональным, потом к корням, потом ко всем целым, к десятичным дробям, к комплексным числам, к алгебраическим числам, к кватернионам, и так далее.
Существует ли неизбежность такого пути развития абстракций? Подозреваю, что до некоторой степени, да. Возможно, так же обстоит дело и с другими типами формирования концепций. Достигнув некоего уровня, вы получаете возможность изучать различные вещи, а со временем группы этих вещей становятся примерами более общих и абстрактных конструкций – которые в свою очередь определяют новый уровень, отталкиваясь от которого, можно изучать что-то новое.
Есть ли способы вырваться из этого цикла? Одна из возможностей может быть связана с математическими экспериментами. Можно систематически доказывать вещи, связанные с определёнными математическими системами. Но можно и эмпирически просто замечать математические факты – как Рамануджан заметил однажды, что
 очень близко к целому числу. Вопрос: являются ли такие вещи «случайными математическими фактами» или они как-то встраиваются в «ткань математики»?
очень близко к целому числу. Вопрос: являются ли такие вещи «случайными математическими фактами» или они как-то встраиваются в «ткань математики»?Такой же вопрос можно задать касательно вопросов математики. Является ли вопрос существования нечётных совершенных чисел (ответ на который не найден со времён Пифагора) ключевым для математики, или это в каком-то смысле случайный вопрос, не связанный с тканью математики?
Точно так же, как можно пронумеровать системы аксиом, можно представить нумерацию возможных вопросов в математике. Но с этим сразу возникает проблема. Теорема Гёделя утверждает, что в таких системах аксиом, как та, что относится к арифметике, существуют «формально неразрешимые» теоремы, которые нельзя доказать или опровергнуть в рамках этой системы аксиом.
Однако конкретные примеры, созданные Гёделем, казались очень далёкими от того, что реально может возникнуть при занятиях математикой. И долгое время считалось, что каким-то образом феномен неразрешимости был чем-то, что в принципе есть, но к «реальной математике» отношения иметь не будет.
Однако согласно моему принципу вычислительной эквивалентности и моему опыту в вычислительной вселенной, я почти уверен, что это не так – и что на самом деле неразрешимость очень близка даже в типичной математики. Я не удивлюсь, если ощутимая часть нерешённых на сегодня задач математики (гипотеза Римана, P = NP, и т.д.) окажутся неразрешимыми.
Но если вокруг полно неразрешимости, как же получается, что так много всего в математике успешно разрешается? Думаю, это оттого, что успешно решённые задачи специально выбирались так, чтобы избежать неразрешимости, просто из-за того, как строится развитие математики. Потому что, если мы, по сути, формируем последовательные уровни абстракции, основанные на понятиях, которые мы доказали, то мы пролагаем путь, способный двигаться вперёд, не заворачивая в неразрешимость.
Конечно, экспериментальная математика или «случайные вопросы» могут сразу же привести нас в область, полную неразрешимости. Но, по крайней мере пока, основная дисциплина математики развивалась не так.
А что с этими «случайными фактами математики»? Да то же, что и с другими областями интеллектуальных исследований. «Случайные факты» не включаются в путь интеллектуального развития, пока какая-нибудь структура – обычно это некие абстрактные концепции – не будет построена вокруг них.
Хорошим примером служат мои любимые открытия происхождения сложности в таких системах, как правило 30 клеточного автомата. Да, похожие явления уже наблюдались даже и тысячи лет назад (допустим, случайность в последовательности простых чисел). Но без более широкой концептуальной платформы на них мало кто обращал внимание.
Ещё один пример – вложенные последовательности (фракталы). Есть отдельные примеры того, как они встречались в мозаике XIII века, но никто не обращал на них внимания, пока в 1980-х вокруг фракталов не возникла целая платформа.
Одна и та же история повторяется снова и снова: пока абстрактные концепции не определяться, сложно рассуждать о новых понятиях, даже когда сталкиваешься с явлением, демонстрирующим их.
Подозреваю, что так и в математике: есть определённое неизбежное наслоение одних абстрактных концепций поверх других, определяющее траекторию математики. Уникален ли этот путь? Несомненно, нет. В огромном пространстве возможных математических фактов существуют определённые направления, которые выбираются для дальнейших построений. Но можно было выбрать и другие.
Значит ли это, что темы в математике неизбежно задаются историческими случайностями? Не так сильно, как можно было бы подумать. Ведь – по мере того, как математику открывали снова и снова, начиная с таких вещей, как алгебра и геометрия – существует примечательная тенденция, по которой различные направления и различные подходы приводят к эквивалентным или соответствующим друг другу результатам.
Возможно, в какой-то степени это является следствием принципа вычислительной эквивалентности, и явления вычислительной универсальности: хотя базовые правила (или «язык»), использующиеся в разных областях математики, разнятся, в итоге появляется способ перевода между ними – и на следующем уровне абстракции выбранный путь уже не будет настолько критически важным.
Логическое доказательство и автоматизация абстракции
Вернёмся к логическим доказательствам. Как они связаны с типичной математикой? Пока что никак. Да, у доказательства есть номинально та же форма, что и у стандартного математического доказательства. Но оно не «дружелюбно к людям-математикам». Это только механические детали. Оно не связано с абстрактными концепциями высокого уровня, которые будут понятными человеку-математику.
Нам бы очень помогло, если бы мы обнаружили, что нетривиальные леммы доказательства уже появлялись в математической литературе (не думаю, чтобы это было так, но наши возможности поиска по теоремам пока не дошли до такого уровня, чтобы мы могли быть уверены). Но если они появляются, это, вероятно, даст нам способ связать эти леммы с другими вещами в математике, и определить их круг абстрактных концепций.
Но как без этого сделать объяснимым доказательство?
Возможно, существует какой-то другой способ провести доказательство, фундаментально сильнее связанный с существующей математикой. Но даже с таким доказательством, которое у нас есть сейчас, можно представить себе «подстройку» новых концепций, которые бы определили более высокий уровень абстракции и поместили это доказательство в более общий контекст.
Не уверен, как это сделать. Я рассматривал возможность назначить премию (что-то вроде моей премии 2007 года за машину Тьюринга) за «преобразование доказательства в объяснимый вид». Однако совершенно непонятно, как можно оценить «объяснимость». Можно было бы попросить записать часовое видео, в котором было бы дано успешное объяснение доказательства, подходящее для типичного математика – но это было бы весьма субъективно.
Но точно так же, как можно автоматизировать поиск красивых раскладок сетей, возможно, мы можем автоматизировать и процесс превращения доказательства в объяснимое. Текущее доказательство, по сути, без объяснения предлагает рассмотреть несколько сотен лемм. Но допустим, мы могли бы определить небольшое число «интересных» лемм. Возможно, мы могли как-то добавить их в наш канон известной математики, а потом сумели бы использовать их для понимания доказательства.
Здесь прослеживается аналогия с разработкой языков. Создавая Wolfram Language, я пытаюсь идентифицировать «куски вычислительной работы», которые часто нужны людям. Мы создаём из них встроенные в язык функции, с определёнными именами, которые люди могут использовать, чтобы на них ссылаться.
Похожий процесс идёт – хотя вовсе не так организованно – в эволюции естественных языков. «Куски смысла», оказывающиеся полезными, в итоге получают свои слова в языке. Иногда они начинаются с фраз, состоящих из нескольких существующих слов. Но наиболее влиятельные обычно оказываются настолько далеко от существующих слов, что они появляются в виде новых слов, дать определение которым потенциально довольно сложно.
При разработке Wolfram Language, функции которого называются при помощи английских слов, я полагаюсь на общее понимание человеком английского языка (и иногда на понимание слов, используемое в распространённых компьютерных приложениях).
Нужно было бы сделать нечто подобное при определении того, какие леммы добавлять к математическому канону. Нужно было бы не только убедиться, что каждая лемма каким-то образом будет «интересной по сути», а также по возможности выбирать леммы, которые «легко вывести» из существующих математических концепций и результатов.
Но что делает лемму «интересной по сути»? Надо сказать, что до того, как я поработал над своей книгой, я обвинял в выборе лемм (или терем) в любой области математики, которую описывают и именуют в учебниках, большой произвол и исторические случайности.
Но, детально разобрав теоремы из базовой логики, я удивился, найдя нечто совсем другое. Допустим, что мы выстроили все правильные теоремы логики по порядку их размера
(к примеру, p = p будет первой, p AND p = p – чуть позже, и т.д.). В этом списке довольно много избыточности. Большая часть теорем оказывается тривиальным расширением теорем, которые уже появлялись в списке.
Но иногда появляется теорема, выдающая новую информацию, которую нельзя доказать на основе теорем, уже появлявшихся в списке. Примечательный факт: таких теорем 14, и они, по сути, точно соответствуют теоремам, которым обычно дают названия в учебниках по логике (здесь AND – это ∧, OR это ∨, а NOT это ¬.)

Иначе говоря, в данном случае именованными, или «интересными» теоремами оказываются именно те, что делают заявления о новой информации минимального размера. Да, по такому определению через какое-то время новой информации уже не останется, поскольку мы получим все аксиомы, необходимые для того, чтобы доказать всё, что можно – хотя можно пойти и дальше, начав ограничивать сложность допустимых доказательств.
Что насчёт теорем NAND, например, тех, что встречаются в доказательстве? Опять-таки, можно выстроить все истинные теоремы по порядку, и найти, какие из них нельзя доказать на основе предыдущих теорем из списка:

У NAND нет такой исторической традиции, как у AND, OR и NOT. И, судя по всему, не существует человеческого языка, в котором бы NAND обозначалось одним словом. Но в списке теорем NAND первую из отмеченных легко опознать как коммутативность NAND. После этого нужно лишь немного переводов, чтобы дать им имена: a = (a · a) · (a · a) похожа на двойное отрицание, a = (a · a) · (a · b) похожа на закон поглощения, (a · a) · b = (a · b) · b похожа на «ослабление», и так далее.
Хорошо, если мы собираемся выучить несколько «ключевых теорем» логики NAND, какие это должны быть теоремы? Возможно, это должны быть «популярные леммы» в доказательствах.
Конечно, у любой теоремы может существовать много возможных доказательств. Но, допустим, мы будем использовать только доказательства, которые выдаёт FindEquationalProof. Тогда оказывается, что в доказательстве первой тысячи теорем NAND самой популярной леммой будет a · a = a · ((a · a) · a), за которой следуют леммы типа (a · ((a · a) · a)) · (a · (a · ((a · a) · a))) = a.
Что это за леммы? Они полезны для методов, используемых FindEquationalProof. Но для людей они, кажется, не очень подходят.
А что насчёт лемм, которые оказываются короткими? a · b = b · a определённо не самая популярная, но самая короткая. (a · a) · (a · a) = a популярнее, но длиннее. А ещё есть такие леммы, как (a · a) · (b · a) = a.
Насколько эти леммы будут полезны? Вот один из способов проверить это. Посмотрим на первую тысячу теорем NAND и оценим, насколько добавление лемм укорачивает доказательства этих теорем (по крайней мере тех, что нашла FindEquationalProof):
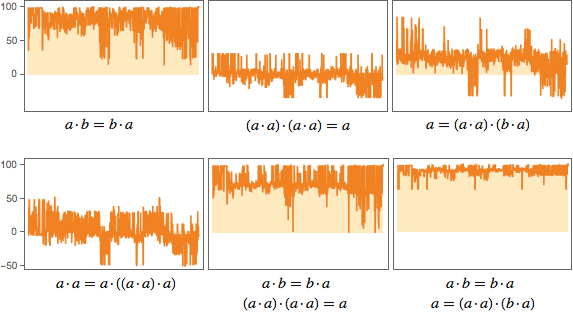
a · b = b · a очень успешна, и часто урезает доказательство почти на 100 шагов. (a · a) · (a · a) = a гораздо менее успешна; она иногда даже «сбивает с толку» FindEquationalProof, заставляя сделать больше шагов, чем нужно (отрицательные величины на графиках). (a · a) · (b · a) = a неплохо справляется с сокращением, но не так хорошо, как a · b = b · a. Хотя, если скомбинировать её с a · b = b · a, в результате сокращения случаются чаще.
Анализ можно продолжать, допустим, включив сравнение того, насколько конкретная лемма укорачивает длины доказательств по отношению к изначальной их длине. Но проблема в том, что если добавить несколько «полезных лемм» вроде a · b = b · a и (a · a) · (b · a) = a, остаётся ещё много длинных доказательств – то есть, много того, что необходимо «понять».
Что мы можем понять?
Существуют разные способы моделирования вещей. Несколько сотен лет в точных науках доминировала идея нахождения математических уравнений, которые можно было решить, чтобы показать, как система будет себя вести. Но со времени появления моей книги случился активный сдвиг к созданию программ, которые можно запустить, чтобы посмотреть, как будут себя вести системы.
Иногда такие программы пишутся под конкретную задачу; иногда их долго ищут. И в наше время по крайней мере один класс таких программ выводится при помощи машинного обучения, методом обратного движения от известных примеров поведения системы.
И насколько же легко «понять, что происходит» при помощи этих различных видов моделирования? Нахождение «точного решения» математических уравнений служит большим плюсом – тогда поведение системы можно описать точной математической формулой. Но даже когда этого нет, часто можно записать некоторые математические утверждения, достаточно абстрактные для того, чтоб их можно было связать с другими системами и поведениями.
Как я уже писал выше, с программой – такой, как клеточный автомат – всё может быть по-другому. Довольно часто бывает так, что мы сразу сталкиваемся с вычислительной несводимостью, которая ограничивает нашу возможность пройти коротким путём и «объяснить», что происходит.
А что насчёт машинного обучения и нейросетей? В каком-то смысле тренировка нейросети похожа на краткое суммирование индуктивного поиска, идущего в естественных науках. Мы пытаемся, начав с примеров, вывести модель поведения системы. Но можно ли будет потом понять модель?
И снова встречаются проблемы с вычислительной несводимостью. Но давайте обсудим случай, в котором можно представить, как бы выглядела ситуация, в которой мы можем понять, что происходит.
Вместо использования нейросети для моделирования поведения системы, давайте рассмотрим создание нейросети, классифицирующей некоторый аспект мира: допустим, берущей изображения и распределяющей их по содержимому («лодка», «жираф», и т.п.). Когда мы тренируем нейросеть, она учится выдавать правильные выходные данные. Но потенциально можно представить себе этот процесс, как внутреннее построение последовательности различий (что-то вроде игры в "двадцать вопросов"), которое в итоге определяет правильный вывод.
Но что это за различия? Иногда мы можем их узнать. Например, «много ли синего цвета на картинке?» Но большую часть времени это некоторые свойства мира, которые люди не замечают. Возможно, существует альтернативная история естественных наук, в которой некоторые из них проявили бы себя. Но они не являются частью текущего канона восприятия или анализа.
Если бы мы захотели их добавить, то, возможно, пришли бы к тому, чтобы придумывать для них названия. Но эта ситуация похожа на ситуацию с логическими доказательствами. Автоматическая система создала некие вещи, которые она использует, как путевые вехи для генерации результата. Но мы не узнаём эти вехи, они для нас ничего не значат.
Опять-таки, если бы мы обнаружили, что какие-то определённые различия часто встречаются у нейросетей, мы могли бы решить, что они достойны того, чтобы мы изучили их для себя, и добавили бы их в стандартный канон способов описания мира.
Можно ли ожидать, что небольшое количество таких различий позволят нам создать нечто значимое? Это похоже на вопрос, поможет ли небольшое количество теорем понять нам такую вещь, как логическое доказательство.
Я думаю, что ответ не ясен. Если изучить, к примеру, большой набор научных работ по математике, можно задать вопросы о частоте использования различных теорем. Оказывается, что частота теорем почти идеально соответствует закону Ципфа (и на первых местах окажутся центральная предельная теорема, теорема о неявной функции и теорема Тонелли — Фубини). То же самое, вероятно, происходит с различиями, которые «стоит знать», или новыми теоремами, которые «стоит знать».
Знание нескольких теорем даст нам возможность продвинуться достаточно далеко, но всегда будет бесконечный экспоненциальный хвост, и до конца добраться не получится.
Будущее познания
Изучая математику, науку или технологии, можно увидеть сходные базовые пути качественного развития, состоящие в построении набора всё увеличивающихся абстракций. Было бы неплохо количественно оценить этот процесс. Возможно, можно подсчитать, как определённые термины или описания, часто встречавшиеся в одно время, включаются в более высокие уровни абстракции, на которых в свою очередь появляются новые термины или описания, связанные с ними.
Возможно, получится создать идеализированную модель этого процесса при помощи формальной модели вычислений типа машин Тьюринга. Представим, что на самом низком уровне есть базовая машина Тьюринга без абстракций. Теперь представим, что мы выбираем программы для этой машины Тьюринга согласно некоторому определённому случайному процессу. Потом мы запускаем эти программы и анализируем их, чтобы посмотреть, какая модель «более высокого» уровня вычислений может успешно воспроизвести совместное поведение этих программ без необходимости исполнять каждый шаг в каждой из них.
Можно было бы решить, что вычислительная несводимость приведёт к тому, что создание этой модели вычислений более высокого уровня неизбежно будет более сложным. Но ключевой момент в том, что мы лишь пытаемся воспроизвести совместное поведение программ, а не их отдельное поведение.
Но что же произойдёт, если этот процесс будет повторяться снова и снова, воспроизводя идеализированную интеллектуальную историю человека и создавая растущую всё выше башню абстракций?
Предположительно, тут можно провести аналогию с критическими явлениями в физике и методом ренормализационной группы. Если так, можно представить, что мы сможем определить траекторию в пространстве платформ для представления концепций. Что будет делать эта траектория?
Возможно, у неё будет фиксированное значение, когда в любой момент истории существует примерно одинаковое количество стоящих изучения концепций – новые концепции медленно открываются, а старые поглощаются.
Что это может означать для математики? Например, что любые «случайные математические факты», открытые эмпирически, в итоге будут рассмотрены при достижении определённого уровня абстракции. Нет очевидного понимания того, как этот процесс будет работать. Ведь на любом уровне абстракции всегда есть новые эмпирические факты, к которым надо «перепрыгнуть». Может произойти и так, что «поднятие уровня абстракции» будет двигаться медленнее, чем нужно для совершения этих «прыжков».
Будущее понимания
Что же всё это означает для будущего понимания?
В прошлом, когда люди изучали природу, у них было небольшое количество причин для её понимания. Иногда они персонифицировали определённые её аспекты в виде духов или божеств. Но они принимали её такой, какая она есть, не думая о возможности понять все детали причин процессов.
С появлением современной науки – и особенно когда всё большая часть наших жизней проходит в искусственных окружениях, где доминируют технологии, разработанные нами – эти ожидания поменялись. И когда мы изучаем вычисления, проводимые ИИ, нам не нравится, что мы можем их не понять.
Однако всегда будет существовать соревнование между тем, что делают системы нашего мира, и тем, что из их поведения наш мозг способен вычислить. Если мы решим взаимодействовать только с системами, которые по вычислительной мощности гораздо проще мозга, тогда мы можем ожидать, что мы систематически сможем понимать то, что они делают.
Но если мы хотим использовать все вычислительные возможности, доступные во вселенной, то неизбежно системы, с которыми мы взаимодействуем, достигнут вычислительной мощности нашего мозга. А это значит, что, согласно принципу вычислительной несводимости, мы никогда не сможем систематически «обгонять» или «понимать» работу этих систем.
Но как мы тогда сможем их использовать? Ну, так же, как люди всегда использовали системы природы. Мы, конечно, не знаем всех подробностей их работы или возможностей. Но на некоем уровне абстракции нам известно достаточно для того, чтобы понять, как достичь наших целей с их помощью.
Что насчёт таких областей, как математика? В математике мы привыкли к тому, что мы строим набор наших знаний так, чтобы мы могли понимать каждый шаг. Но экспериментальная математика – как и такие возможности, как автоматическое доказательство теорем – делают очевидным существование таких областей, в которых нам будет недоступен такой метод.
Будем ли мы называть их «математикой»? Думаю, что должны. Но эта традиция отличается от той, к которой мы привыкли за последнее тысячелетие. Мы всё ещё можем создавать там абстракции, и конструировать новые уровни понимания.
Но где-то в её основе будут существовать всякие разные варианты вычислительной несводимости, которую мы никогда не сможем перенести в область человеческого понимания. Примерно это и происходит в доказательстве моей небольшой аксиомы логики. Это ранний пример того, что, как я думаю, будет одним из основных аспектов математики – и многого чего ещё – в будущем.
