Привет, Хабражители. Сегодняшний пост будет о том, как не затеряться в дебрях многообразия вариантов использования TensorFlow для машинного обучения и достигнуть своей цели. Статья рассчитана на то, что читатель знает основы принципов работы машинного обучения, но пока еще не пробовал это делать своими руками. В итоге мы получим работающее демо на Андроиде, которое кое-что распознает с довольно высокой точностью. Но обо всем по порядку.

Посмотрев последние материалы — было решено заюзать Tensorflow, который сейчас набирает высокие обороты, да и статей на английском и русском становится вроде бы достаточно, чтобы не закопаться в этом всём и суметь разобраться что к чему.
Потратив недели две, изучая статьи и многочисленные экзамплы на оф. сайте, я поняла, что ничего не поняла. СЛИШКОМ много информации и вариантов того, как можно использовать Tensorflow. Голова уже пухла от того, как много они предлагают разных решений и что с ними делать, применительно к моей задаче.

Тогда я решила попробовать все, начиная от самых простых и практически готовых вариантов (в которых от меня требовалось прописать зависимость в gradle и добавить пару строчек кода) до более сложных (в которых пришлось бы самим создавать и обучать модели графов и научиться использовать их в мобильном приложении).
В конце концов пришлось юзать сложный вариант, о котором будет подробнее чуть ниже. А пока я составила для вас список вариантов попроще, которые не менее эффективные, просто каждый подходит для своей цели.
1. ML KIT

Самое простое в использовании решение — парой строчкой кода вы сможете воспользоваться:
- Text recognition (текст, латинские символы)
- Face detection (лица, эмоции)
- Barcode scanning (баркод, qr-код)
- Image labeling (ограниченное количество типов объектов на изображении)
- Landmark recognition (достопримечательности)
Немного сложнее с помощью данного решения можно также использовать свою собственную TensorFlow Lite model, но конвертация в данный формат вызвала сложности, поэтому данный пункт не был испробован.
Как пишут создатели этого детища — можно решить большУю часть задач, с использованием данных разработок. Но если это не относится к вашей задачи — Вам придется использовать кастомные модели.
2. Custom Vision

Очень удобное средство создания и тренировки своих кастомных моделей с помощью изображений.
Из Плюсов — есть бесплатная версия, которая позволяет держать один проект.
Из Минусов — бесплатная версия ограничивает количество "входящих" изображений в 3000 шт. Чтобы попробовать и сделать средненькую по точности сеть — вполне хватит. Для более точных задач — нужно больше.
Все, что требуется от пользователя — добавить изображения с пометкой (например — image1 — это "racoon", image2 — "sun"), обучить и заэкспортить граф для дальнейшего использования.
Заботливый Microsoft даже предлагает свой семпл, с помощью которого можно опробовать свой полученный граф.
Для тех, кто уже "в теме" — граф генерируется уже в состоянии Frozen, т.е. с ним дополнительно делать\конвертировать ничего не надо.
Это решение хорошо в случае, когда у вас большая выборка и (внимание) МНОГО разных классов при обучении. Т.к. в противном случае будет много ложных определений на практике. Например, вы обучили на енотиков и солнышках, а если на входе будет человек — то он может с равной вероятность быть определенным такой системой как то, или другое. Хотя по факту — НИ то, НИ другое.
3. Создание модели вручную

Когда нужно самим более тонко настроить модель для распознавания изображения — в дело приходят более сложные манипуляции со входной выборкой изображений.
Например, мы не хотим иметь ограничений по объему входной выборки (как в пред. пункте), или хотим более точно обучить модель, сами настроив количество epoch и других параметров обучения.
В данном подходе есть несколько примеров от Tensorflow, которые описывают порядок действий и конечный результат.
Вот несколько таких примеров:
- Классный кодлаб Tensorflow for Poets.
В нем приводится пример того, как создать классификатор видов цветов на основе открытой базы изображений ImageNet — подготовить изображения, а затем обучить модель. Также немного упоминается то, как можно работать с довольно интересным тулом — TensorBoard. Из его самых простых функций — он наглядно демонстрирует структуру вашей готовой модели, а также процесс обучения по многим параметрам.
Кодлаб Tensorflow for Poets 2 — продолжение работы с классификатором цветов. Показывает как при наличии файлов графа и его меток (которые были получены в предыдущем кодлабе) можно запустить приложение на андроид. Один из пунктов кодлаба — конвертация из "обычного" формата графа ".pb" в формат Tensorflow lite (который предусматривает проведение неких оптимизаций файла для уменьшения итогового размера файла графа, ибо мобильные устройства к этому требовательны).
Распознавание рукописных символов MNIST.
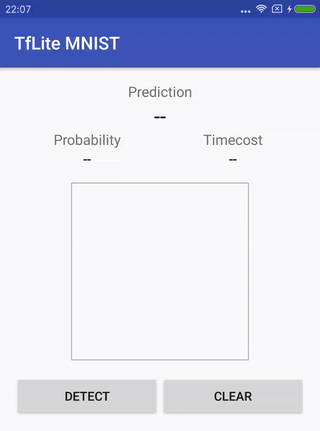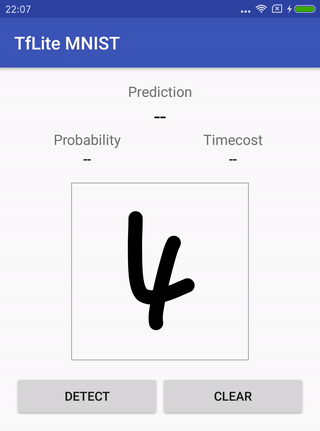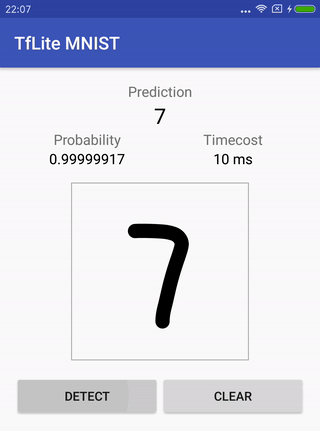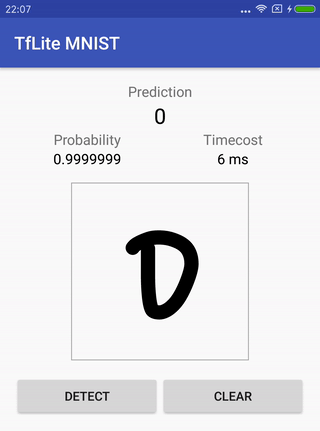
В репе размещена исходная модель (которая уже подготовлена под данную задачу), инструкции по тому, как ее тренировать, сконвертировать, и как в конце запустить проект под Андроид, чтобы проверить как это все работает
На основе данных примеров можно разобраться с тем, как устроена работа с кастомными моделями в Tensorflow и попробовать либо сделать свою, либо взять одну из уже пред-обученных моделей, которые собирают на гитхабе:
Модели от Tensorflow
Кстати говоря о "пред-обученных" моделях. Интересные нюансы при использовании таковых:
- Их структура уже подготовлена к выполнению конкретной задачи
- Они уже обучены на больших объемах выборок
Поэтому если Ваша выборка недостаточно наполнена, вы можете взять пред-обученную модель, которая близка по области к вашей задаче. Воспользовавшись такой моделью, добавив свои правила обучения — вы получите более качественный результат, нежели чем пытались бы обучать модель с нуля.
4. Object Detection API + cоздание модели вручную
Однако все предыдущие пункты не давали нужного результата. С самого начала было трудно понять, что же нужно делать и с помощью какого подхода. Потом была найдена классная статья по Object Detection API, в которой рассказывается как можно на одном изображении найти несколько категорий, а также несколько экземпляров одной категории. В процессе работы по этому сэмплу оказались более удобными исходные статьи и видео уроки по распознаванию кастомных объектов (ссылки будут в конце).
Но работа так и не смогла бы быть завершенной без статьи о распознавании Пикачу — потому что там был указан очень важный нюанс, который почему-то не в одном гайде или примере нигде не упоминается. А без него вся проделанная работа была бы впустую.
Итак, теперь наконец о том, что же все-таки пришлось сделать и что получилось на выходе.
- Во-первых — муки установки Tensorflow. У кого не получится его установить, или воспользоваться стандартными скриптам создания, обучения модели — просто наберитесь терпения и гуглите. Почти каждую проблему уже написали в issues на гитхибе или на stackoverflow.
По инструкции для распознавания объектов нам нужно до обучения модели подготовить входную выборку. В указанных статьях подробно написано как это сделать с помощью удобного инструмента — labelImg. Единственная трудность здесь — это проделать очень долгую и скрупулезную работу по выделению границ нужных нам объектов. В данном случае печатей-штампов на изображениях документов.
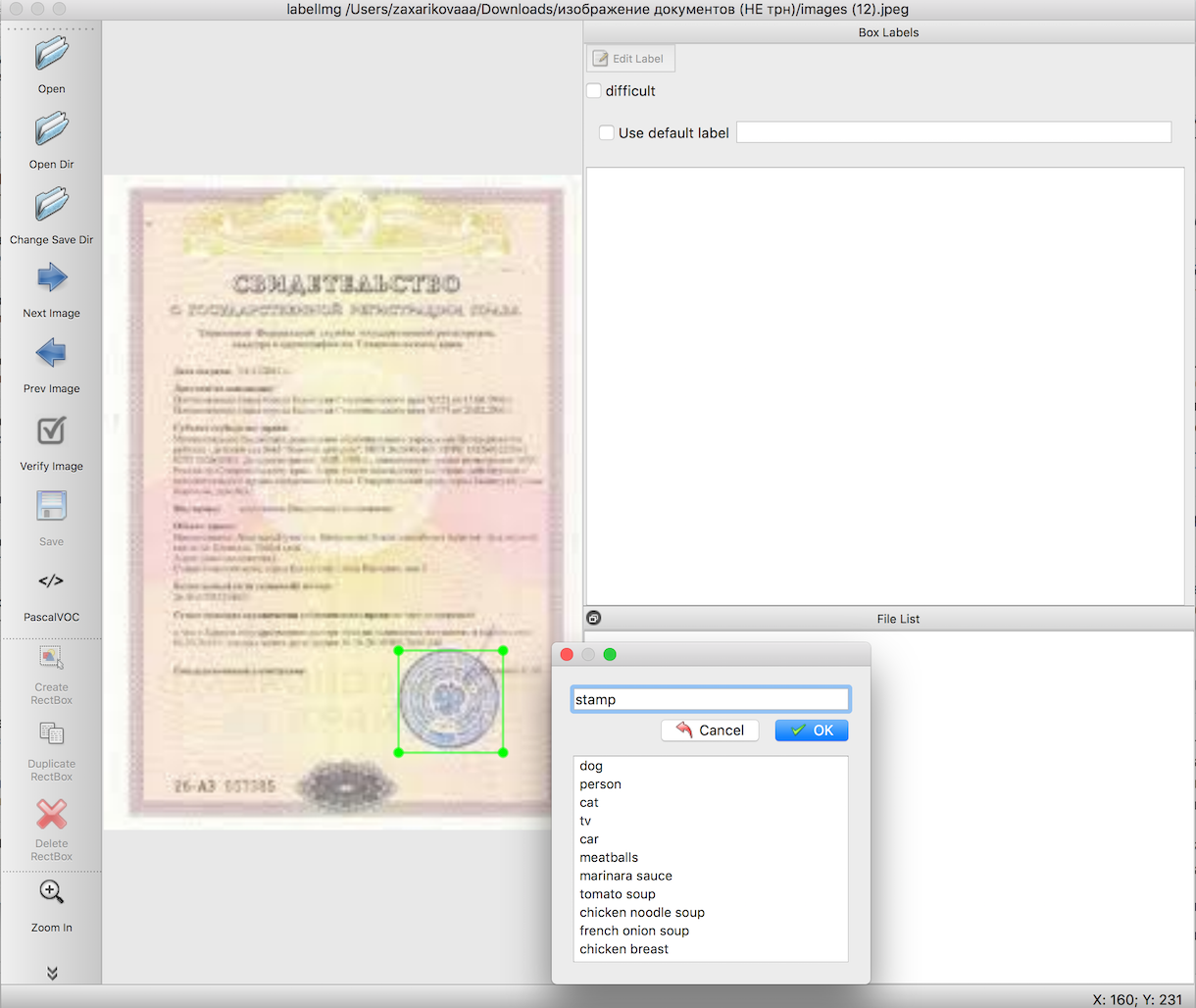
Следующим шагом с помощью уже готовых скриптов экспортируем данные из п.2 сначала в csv файлы, затем в TFRecords — формат входных данных Tensorflow. Здесь никаких трудностей возникать не должно.
Выбор пред-обученной модели, на основе которой мы будем до-обучивать граф, а также само обучение. Вот здесь может возникнуть самое огромное количество неведомых ошибок, причина которых — неустановленные (или криво поставленные) пакеты, необходимые для работы. Но у вас все получится, не отчаивайтесь, результат того стоит.

Экспорт полученного после обучения файла в формат 'pb'. Просто выбирайте последний файл 'ckpt' и экспортируйте его.
Запуск примера работы на Андроиде.
Качаем официальный сэмпл по распознавания объектов с гитхаба Tensorflow — TF Detect. Вставляем туда свою модель и файл с labels. Но. Ничего не будет работать.

Вот тут как раз возник самый большой затык во всей работе, как ни странно — ну не хотели сэмплы Tensorflow никак работать. Все падало. Только могучий Пикачу со своей статьей сумел помочь привести все в работу.
В файлt labels.txt обязательно первой строчкой должна быть надпись "???", т.к. по умолчанию в Object Detection API номера id объектов начинаются не с 0 как обычно, а с 1. В связи с тем, что нулевой класс является зарезервированным — и нужно указывать волшебные вопросики. Т.е. ваш файл с метками будет примерно таким:
???
stampА дальше — запускаем сэмпл и видим распознавание объектов и уровень confidience, с которым оно было получено.
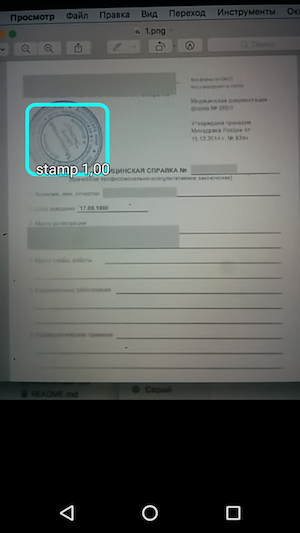
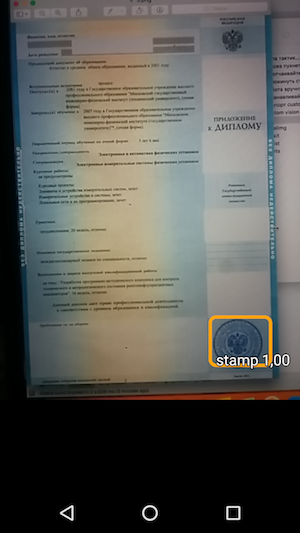
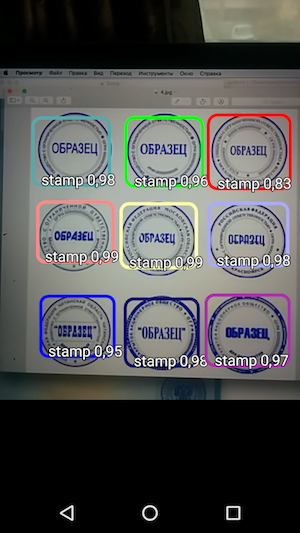
Таким образом, в итоге получилось простое приложение, которое при наведении камеры распознает границы штампа на документе и указывает их вместе с точностью распознавания.
А если исключить то время, что было затрачено на поиски нужного подхода и попыток его запустить — то в целом работа получилась довольна быстрая и на самом деле не сложная. Просто надо знать нюансы, прежде чем приступать к работе.
Уже в качестве дополнительной секции (тут можно уже закрывать статью, если Вы устали от информации), хотелось бы написать пару лайфхаков, которые помогали в работе со всем этим.
довольно часто скрипты tensorflow не работали потому, что они запускались не из тех директорий. Причем на разных ПК было по-разному: кому-то требовалось для работы запускаться из директории "
tensroflowmodels/models/research", а кому-то — на уровень глубже — из "tensroflowmodels/models/research/object-detection"
помните о том, что для каждого открытого терминала нужно заново выполнять экспорт пути с помощью команды
export PYTHONPATH=/ваш локальный путь/tensroflowmodels/models/research/slim:$PYTHONPATH
если вы используете не свой граф и хотите узнать информацию о нем (например "
input_node_name", который требуется в дальнейшем при работе), выполните из корневой папки две команды:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ваш локальный путь/frozen_inference_graph.pb"
где "
/ваш локальный путь/frozen_inference_graph.pb" — это путь к графу, о котором вы хотите узнать информацию
Для просмотра информации о графе можно воспользоваться Tensorboard
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
где нужно указать путь к графу (
model_dir) и путь к файлам, которые были получены в процессе обучения (log_dir). Потом просто открыть localhost в бразуере и смотреть то, что вас интересует.
И самая последняя часть — по работе с python скриптами в инструкции по Object Detection API — для Вас подготовлена маленькая шпаргалка ниже с командами и подсказками.
Экспорт из labelimg в csv (из object_detection директории)
python xml_to_csv.pyДалее все этапы, которые перечислены ниже, надо выполнять из одной и той же папки Tensorflow ("tensroflowmodels/models/research/object-detection" или на уровень выше — в зависимости от того, как у вас пойдет дело) — т.е все изображения входной выборки, TFRecords и прочие файлы до начала работ нужно скопировать внутрь этой директории.
Экспорт из csv в tfrecord
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record*Не забывайте менять в самом файле (generate_tfrecord.py) строчки ‘train’ и ‘test’ в путях, а также
название распознаваемых классов в функции class_text_to_int (которые должны быть продублированы в pbtxt файле, который вы создадите перед обучением графа).
Обучение
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config ** Перед обучением не забудьте проверить файл "training/object-detection.pbtxt" — там должны быть указаны все распознаваемые классы и файл "training/ssd_mobilenet_v1_coco.config" — там нужно поменять параметр «num_classes» на число ваших классов.
Экспорт модели в pb
python export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=training/pipeline.config \
--trained_checkpoint_prefix=training/model.ckpt-110 \
--output_directory=outputСпасибо за проявленный интерес к данной теме!
Ссылки
