Захотелось мне написать разговаривающую программу. Очень захотелось, позарез.
Конечно, мне далеко до профессиональных программистов, и лингвистом я тоже не являюсь, но системное мышление имеется, и чувство языка на месте. Тем более что тематикой ИИ давно интересуюсь, даже пару-тройку постов накатал в свое время. Отчего не реализовать познания в программном коде? Ну и попробовал, насколько смог.
Знакомьтесь, Ваня Разумный.
Ниже находится описание проблем, возникших передо мной на этом хоженом-перехоженом пути, и способов их преодоления.
По поводу результата оговорюсь сразу: целью был не программный код, а формулировка принципов искусственного мышления, функционирующего НЕ на основе физической реальности, как биологические организмы, а на основе СИНТАКСИСА. Поклонники теста Тьюринга, нейронных сетей и машинного обучения могут не беспокоиться.
Внимание, материал объемный.
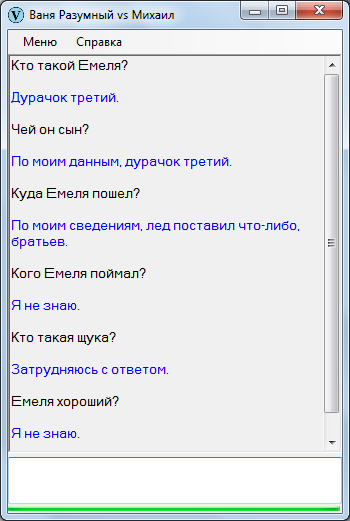
Чтобы не было беспочвенных ожиданий с последующими ехидными скриншотами в комментариях, сразу продемонстрирую Ваню Разумного в непрезентабельном виде. Вот, закачал начало «Емели» и попробовал поспрашивать – в точности как на уроках литературы в начальных классах.
Оригинальный текст:
Жил-был старик. У него было три сына: двое умных, третий – дурачок Емеля. Те братья работают, а Емеля целый день лежит на печке, знать ничего не хочет.
Один раз братья уехали на базар, а бабы, невестки, давай посылать его:
— Сходи, Емеля, за водой.
А он им с печки:
— Неохота…
— Сходи, Емеля, а то братья с базара воротятся, гостинцев тебе не привезут.
— Ну, ладно.
Слез Емеля с печки, обулся, оделся, взял ведра да топор и пошел на речку. Прорубил лед, зачерпнул ведра и поставил их, а сам глядит в прорубь. И увидел Емеля в проруби щуку.
Диалог:
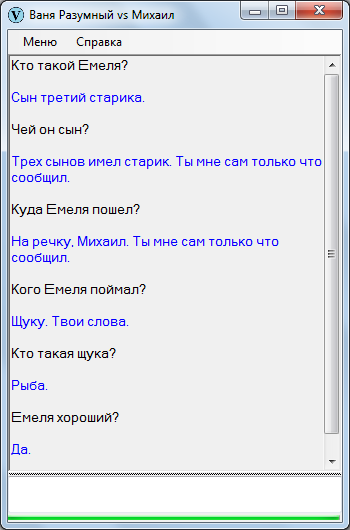
Однако, текст можно адаптировать – так, допустим:
Старик имел трех сыновей. Первый сын был умным. Второй сын был умным. Третий сын был дураком. Емеля – третий сын старика. Емеля хороший.
Старшие сыновья работают целый день, а Емеля лежит на печи.
Однажды братья уехали на базар. Невестки говорят Емеле:
— Сходи за водой.
Емеля отвечает с печки:
— Не пойду за водой.
Невестки говорят:
— Братья гостинцев тебе не привезут.
— Ну, ладно.
Емеля слез с печки, обулся, оделся, взял ведра и топор. Потом Емеля пошел на речку.
Емеля прорубил лед и зачерпнул ведра. И увидел Емеля в проруби щуку. Щука – это рыба. Емеля поймал щуку.
После адаптации выходит поприличней:
Все равно, в художественных текстах непозволительно путается. Несмотря ни на что, Ваня действительно мыслит, в отличие от многих своих собратьев, в первую очередь созданных на основе нейронных сетей, которые только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы. Если вам интересно знать, почему, читайте дальше.
Перехожу непосредственно к описанию интеллектуальной одиссеи.
Рассуждал я следующим образом.
В чем главная проблема ИИ? В том, что компьютер не может понимать значений слов, соответственно быть «разумным». При этом считается, что люди разумны, поскольку понимают произносимые собеседником слова.
На самом деле ни черта люди не разумны. Слово само по себе означает не больше, чем составляющие его буквы (по сути, кривые линии) или звуки (колебания воздуха). Смысл возникает лишь в качестве отношений между буквами-звуками как элементами членораздельной речи, за счет устойчивых ассоциаций, в том числе за счет связей с миром визуальных восприятий. Например, собеседник указывает на предмет и говорит: «Это дерево». И ты понимаешь, что данный предмет называется деревом.
Чат-боту (под которым договоримся понимать ИИ, занимающийся исключительно разговорами) нельзя указать на предмет и сказать: «Это дерево», – за счет отсутствия у чат-бота глаз, то есть видеокамеры. Объяснять возможно лишь на словах, а как объяснишь, если человеческой речи он и не разумеет?!
По счастью, отношения между элементами речи определены, и довольно жестко: за них отвечает синтаксис. Следовательно, любой текст, построенный по законам синтаксиса, содержит в себе некоторый, закрепленный в синтаксисе смысл. Та самая вынесенная в заголовок «глокая куздра», знаменитая и непревзойденная по наглядности – которая, как оказалось, давно пристегнута к компьютерным исследованиям.
Из воспоминаний одного товарища о далеких 70-х:
На основе «глокой куздры» можно построить полноценный диалог.
— Кто будланул бокра?
— Куздра.
— Кто кудлачит бокренка?
— Тоже куздра.
— Какая она?
— Глокая.
— Как будланули бокара?
— Штеко.
Такой ИИ – вполне себе свободно общающийся – окажется не в состоянии понимать значения употребляемых им слов: будет не в курсе, ни что такое «штеко», ни кто такой «бокр», ни каким образом возможно кудлачить. Но разве по этой причине можно посчитать, что ИИ неразумен, а человек, совершенное биологическое создание, «разумеющее» семантику собственных выражений, полноценно, в отличие от ИИ, мыслит? Полноте…
Люди не видят предметов, а наблюдают панораму цветных точек – по сути, хаотичную. Предметы образуются не во внешнем мире, а в человеческом мозгу, за счет увязывания цветных точек воедино, в отдельные совокупности. Это означает, что мы существуем в некоем иллюзорном мире, который в известном смысле нами же и сконструирован.
Читал, что какое-то первобытное племя не видит самолетов в небе – просто не видит, и все. Еще читал, что индейцы не замечали подошедших к берегам кораблей Колумба, потому что… просто не замечали. А заметили после того, как им объяснили, как надо смотреть – то есть каким образом увязывать цветные пиксели в конкретные предметы. Я этим псевдогеографическим байкам верю: такие зрительные парадоксы представляются мне правдоподобными.
У человека нет оснований считать, что его мышление устроено каким-то особенным образом, посему принцип «глокой куздры» – единственная возможность сделать разумным кого-то, будь то чат-бот или человек. Использовать можно различный инструментарий, но принципиальная схема является безусловной. Я так считал до начала работы и не переменил своего мнения по ее окончании.
Поставив задачу, принялся гуглить по поводу подходящих библиотек для C#.
Тут меня ожидало первое разочарование: ничего пригодного, во всяком случае бесплатного, не обнаруживалось. Всяческие готовые модули для реализации чат-ботов не требовались, интересовала работа со словоформами. Казалось, что проще:
а) определять морфологические признаки словоформы,
б) возвращать словоформу с требуемыми морфологическими признаками?
Лексикон ограничен, количество признаков тоже. И вещь такая полезная, обиходная… Не тут-то было!
Ничего не найдя, сгоряча попробовал закодить определитель морфологических признаков самостоятельно. Как-то сразу не задалось. На этом моя интеллектуальная одиссея и завершилась бы бесславно, в порту отправления, если бы повторное, более тщательное, гугление не выявило пару бесплатных библиотек, которыми я в конечном счете и воспользовался. Как всегда, спасибо энтузиастам.
Первая библиотека – Solarix. Многое чего позволяет, но я, в силу малой компетентности и финансовой недостаточности (библиотека бесплатная лишь частично), использовал безусловно бесплатный парсер, производящий синтаксический разбор текста и записывающий результат в файл.
Вторая библиотека – LingvoNET, предназначенная для склонения и спряжения слов русского языка. Предыдущей склонения и спряжения тоже доступны, но эта приглянулась мне легкостью освоения.
Получив вожделенное, засучил рукава.
Излагаю конечный результат, в сокращении. Все интеллектуальные блуждания и затруднения не описываю: слишком они перепутаны. Частенько забредал не туда, поэтому приходилось переосмысливать и переделывать вроде бы завершенное.
В соответствии с реализованной мной концепцией, в качестве первичного элемента имеем слова с известными нам морфологическими признаками.
Морфологические признаки слов возвращает парсер Solarix – казалось бы, проблем нет. Однако проблемы имеются в связи с тем, что некоторые словосочетания имеют общую нераздельную семантику, в связи с чем должны восприниматься ИИ в качестве единого элемента.
Я насчитал четыре вида подобных словосочетаний:
1. Фразеологические обороты,
К сожалению, парсер их не возвращает.
Слесарь бил баклуши.
Для парсера «бить баклуши» – для разных слова, хотя семантическая основа тут одна, и воспринимать словосочетание необходимо так, как его воспринимает наш мозг: слитно.
2. Имена собственные,
Александр Сергеевич Пушкин.
Ясно, что это единый указатель на единственный предмет, хотя отдельные составляющие его слова могут быть использованы в других указателях.
3. Поговорки, пословицы, афоризмы.
Они, как правило, также представляют собой единое смысловое поле.
Старый конь борозды не портит.
4. Составные служебные слова (вследствие чего, из-за того что, по причине и т.п.)
Парсер возвращает некоторые из них слитно, другие – нет.
5. Просто устойчивые словосочетания типа «книжного магазина». Не приставишь любое прилагательное к существительному «магазин», хотя бы соответствующие изделия в нем и продавались. Никто не скажет «макаронный магазин», даже если в магазине торгуют исключительно макаронами.
Составные слова – независимо от их типа – необходимо обрабатывать так, как если бы они были единой слитной конструкцией… Но как узнать, какие словосочетания относятся к данной группе?
Наиболее очевидное – посредством прямого на то указания:

Более сложный, применимый лишь к именам, вариант – определение фразеологизмов по заглавным буквам:
Ясно, что определять составные слова возможно по их повторяемости, но это затруднительно. Более простым и действенным способом могло бы стать использование словарей, однако со словарями вышла незадача: использовать их в рамках реализованной концепции не удалось (на что посетую в конце поста).
Слова определены, их свойства зафиксированы, что дальше? Дальше необходимо определить костяк фразы: любой разработчик ИИ наверняка приходил к тому же выводу.
Вот фраза:
Плотник выстругал доску.
Что можно о ней сказать, ориентируясь исключительно на синтаксис?
Можно сказать, что:
1. Субъект (существительное именительного падежа) – то, что выполняет действие.
2. Объект (существительное не именительного падежа) – то, на что направлено действие.
3. Само действие – глагол.
При страдательном залоге субъект и объект меняются местами. При этом страдательный залог может быть преобразован обратно в действительный: объект – при страдательном залоге всегда он находится в творительном падеже – в таком случае превращается в субъект именительного падежа, а субъект превращается в объект винительного падежа.
Было:
Плотник выстругал доску.
Стало:
Доска выстругана плотником.
Иначе говоря, залог делает фразу инвариантной.
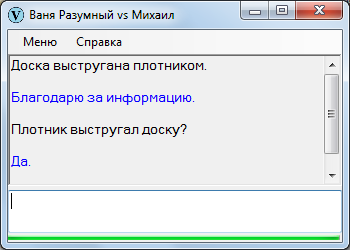
В некоторых случаях инвариантность фразы практически неопределима, к сожалению.
Имеем высказывание:
Спички лежат в коробке.
Его можно переформулировать:
Коробок содержит спички.
Содержание обеих фраз идентично, однако выражаемые глаголами действия формально разнонаправленны (в первом случае спички воздействуют на коробок, во втором случае – наоборот), при этом залоги обоих глаголов активные.
«Лежать» и «содержать» – это даже не антонимы, а нечто такое, чему в лингвистике, насколько я понимаю, нет названия. А если нет названия, то и словарей подобных терминологических пар быть не может: затруднение, с которым ИИ неминуемо столкнется при попытке «осмыслить» поступившую информацию.
Совместное употребление триады не обязательно: любой из названных элементов может во фразе отсутствовать.
Бегемот двинулся.
Вечер.
Светало.
И наоборот, элементы могут присутствовать в предложении во множественном числе, например:
Вася и Петя подрались.
Что касается множественности, то после долгих размышлений и переделок мной были установлены следующие правила обработки:
1. Субъект в предложении присутствует всегда. При отсутствии субъекта в исходный текст вставляется заглушка, обозначающая существительное.
Светало.
Преобразуем в:
[Noun] светало. Иначе говоря: Что-то светало.
2. Действие может отсутствовать при отсутствии объекта. При наличии объекта вставляется заглушка, обозначающая глагол.
Шаг в бездну.
Преобразуем в:
Шаг [verb] в бездну. Можно трактовать как: Шаг [направлен] в бездну.
3. Объект в предложении может отсутствовать. Никакой заглушки при этом не применяется.
Он поехал.
Увеличивать фразу до «Он поехал [noun]» нет смысла, ведь едут не обязательно куда-то: термин может обозначать начало движения.
4. Субъект и объект могут быть множественными. Фраза при этом не разделяется.
Множественные субъекты:
Мальчик и девочка смотрели телевизор.
Множественные объекты:
Охотник добыл лося и кабана.
5. Действие допускается только единичным: при множественности действий фраза разделяется по числу глаголов.
Дворник улыбнулся и погрозил пальцем.
Преобразуем в:
Дворник улыбнулся. Дворник погрозил пальцем.
В этом случае фраза требует разделения.
Свойства основных элементов (то есть существительных и глаголов) – это в основном их морфологические признаки: род, падеж, лицо, число, переходность, возвратность, модальность и другое – все то, что возвращает парсер Solarix. Плюс прочие, не рассматриваемые лингвистикой. Я использовал характеристики не вполне канонические: отрицание, закавыченность, знак препинания (который посчитал свойством предыдущего слова) и т.п.
Некоторые из названных свойств единичны (например, род: не бывает слов одновременно мужского и женского родов), другие множественны. К множественным свойствам относятся, к примеру, число и дата. Можно сказать «5 лошадок», а можно: «Не меньше 3 и не больше 7 лошадок»: во втором случае оба числительных относятся к одному слову, тем самым являются его множественными свойствами.
Важно, что остальные части речи представляют собой свойства основных элементов либо некие вспомогательные сущности типа ссылок, в частности:
• прилагательное – свойство существительного,
• наречие – свойство глагола (как правило),
• предлог – свойство существительного,
• союз – маркер множественности элементов (как правило),
• местоимение – ссылка на предыдущее существительное,
• числительное – указатель на число субъектов или объектов.
Выше был упомянут случай, требующий разделения предложения на части (пример с дворником). Этот случай не единственный – встречаются другие.
Самое очевидное: сложносочиненные и сложноподчиненные предложения.
Юноша улыбнулся, и девушка улыбнулась в ответ.
Купальщик плюхнулся в воду, которая была холодна.
Разделяем на:
Юноша улыбнулся. Девушка улыбнулась в ответ.
Купальщик плюхнулся в воду. Вода была холодна.
Чуть менее очевидны причастия и деепричастия. Тем не мене они выражают действия, что приводит к необходимости разделения.
Автомобиль, развернувшись на месте, врезался в отбойник.
Развернувшийся на месте автомобиль врезался в отбойник.
Разделяем:
Автомобиль развернулся на месте. Автомобиль врезался в отбойник.
Тот же самый результат был бы получен при множественности глаголов, с которыми причастия и деепричастия взаимозаменяемы.
Автомобиль развернулся на месте и врезался в отбойник.
Конечная конструкция у всех трех исходных вариантов примера идентична.
Разделять предложения необходимо не только в вышеназванных случаях, но и во многих других, в том числе таких, для которых, казалось бы, разделение противопоказано.
Такой пример:
Хорошо гулять по осеннему лесу.
Что тут разделять, когда все слитно и компактно? Немного озадачивает отсутствие субъекта, поскольку, как мы договорились, субъект должен выражаться существительным, а здесь он… наречие что ли? Ан нет, разделение необходимо!
[Noun] гулять по осеннему лесу. Хорошо. В смысле: Кто-то гуляет по осеннему лесу. Это хорошо.
Выше было сказано, что падежи служат для различения субъектов и объектов: падеж субъектов – именительный, тогда как падеж объектов – не именительный. Профессиональные лингвисты со мной вряд ли согласятся: им известна уйма случаев, когда объекты пребывают в не именительном падеже, как и субъекты.
Коттедж – это жилище.
Не только субъект, но и объект в именительном падеже. Исключение, скажете вы? Можно сослаться на исключение, однако логичней посчитать указанную конструкцию двумя фразами, объединенными особым свойством. Я называю такие фразы, полученные посредством разделения предложения на части, секторами.
Суть в том, что один сектор является определением другого (или даже множества предыдущих секторов. Ввиду сложности данного функционала я даже не пытался его реализовать).
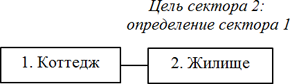
Здесь второй сектор является определением первого. И никаких тебе объектов в именительном падеже!
Главное, конечно, то, что свойствами могут обладать не только отдельные элементы, но и секторы.
Помимо цели, я использовал такие свойства секторов, как:
• тип сообщения (утверждение, распоряжение, вопрос),
• тип вопроса,
• залог (имело ли место преобразование страдательного залога в действительный),
• обращение (к собеседнику по имени: да или нет),
• склейка,
• валидность,
• время,
• вероятность.
Как принято именовать данную сущность у лингвистов, понятия не имею. Может быть, соединительное слово?
Итак, склейки служат для связи между секторами. Попросту говоря, это служебные слова типа «поэтому», «когда», «вследствие чего», «ввиду того что» и т.п.
Допустим, имеем сложноподчиненное предложение со склейкой «поэтому».
Ветер подул, поэтому листва зашелестела.
Ясно, что две части связаны между собой как причина и следствие: об этом свидетельствует склейка «поэтому».
Склейка может отсутствовать, тогда обнаружить ее проблематично – практически невозможно.
Ветер подул, и листва зашелестела.
В физической реальности мы ориентируемся на зрение, а если общение происходит на вербальном уровне, то на интонацию и на визуальный опыт, и обычно угадываем, но только не в царстве слов. Как отличить приведенную фразу, обозначающую причину и следствие, от заурядной последовательности событий?
Ветер подул, и пробежал заяц.
Заяц пробежал-то вовсе не от того, что ветер подул – мы знаем, – но из синтаксиса этого не следует, хотя не следует и обратного. Кто его знает, как случилось на самом деле? Может, ветер подул, в результате чего обломилась ветка, заяц испугался и побежал – в этом случае дуновение ветра является причиной того, что заяц побежал.
Названная проблема не решаема для чат-бота в принципе: физическая реальность – одно, вербальная сфера – другое. Элементная база разная (под элементной базой я понимаю способ восприятия реальности: для чат-бота это письменная речь).
Некоторые фразы оказываются некорректными. Ясно, что если выдать ИИ откровенную белиберду, он не поймет.
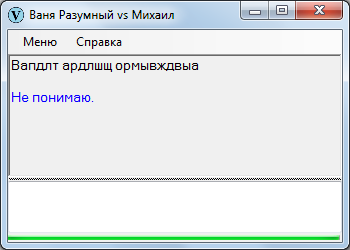
Однако даже фраза, выстроенная на первый взгляд в соответствии с правилами синтаксиса, может оказаться бракованной вследствие разных нюансов, к примеру:

Вы, что ли, способны такую фразу воспринять? Если да, примите поздравления, потому что я при попытке осмысления впадаю в ступор: мозг отказывает. При этом упрощенные варианты воспринимаются обыденно:
Петя не пошел в кино.
Петя пошел не в кино.
Не Петя пошел в кино.
Люди познают мир в соответствии с заложенными в их головы алгоритмами, но стоит им получить нестандартную информацию, хваленый ум куда-то испаряется.
Очевидно, что инвалидные фразы необходимо беспощадно отбраковывать при обработке.
Основные признаки инвалидных фраз, в моей интерпретации:
• отсутствие значащих слов (существительных и глаголов),
• слишком большое число слов, не опознанных парсером в качестве частей речи,
• наличие существительного в не именительном падеже при отсутствии глагола (ошибка в алгоритме, поскольку в таких случаях глагол вставляется принудительно),
• слишком большое число отрицательных частиц (см. выше),
• слишком большое число дат в отсутствие перечисления (обычно в предложении фигурирует либо одна дата, либо, в случае указания на период, две даты),
• наличие двух глаголов (следствие ошибки в алгоритме),
• одинарность союза (если обнаружено, к примеру, одиночное «или», то имеет место ошибка либо во фразе, либо в алгоритме),
• неодинаковость союзов (одновременное использование альтернативных союзов «и», «или»).
Предложение формализовано, пора записывать? Рано. Требуется вставить недостающие слова и заменить ссылки.
Возьмем для примера диалог:
— Петров, как здоровье?
— Нормальное.
— А у жены?
— Тоже.
Формализация требует восполнения недостающего, приблизительно так:
— Как здоровье Петрова?
— Здоровье Петрова нормальное.
— А как здоровье у жены Петрова?
— Здоровье у жены Петрова тоже нормальное.
После этого – не раньше – можно приступать к обработке текста с последующей записью в базу.
Вот и она – база, со всеми свойствами, также вспомогательными и справочными таблицами.
Иерархическая структура:
1. Беседа (сеанс связи с собеседником).
2. Сообщение (текст, который выдает собеседник зараз).
3. Предложение (информационная единица сообщения).
4. Сектор (часть предложения).
5. Слово.
Не Бог весть что, особенно для читателей здешнего ресурса… Но я ж дилетант, мучился долго.
После записи реплики собеседника в базу можно приступать непосредственно к общению. Проблема – каким образом общаться? Сказать что-то утвердительное? Задать встречный вопрос? Попросить чего-нибудь?
Методом проб и ошибок вырисовалась схема.
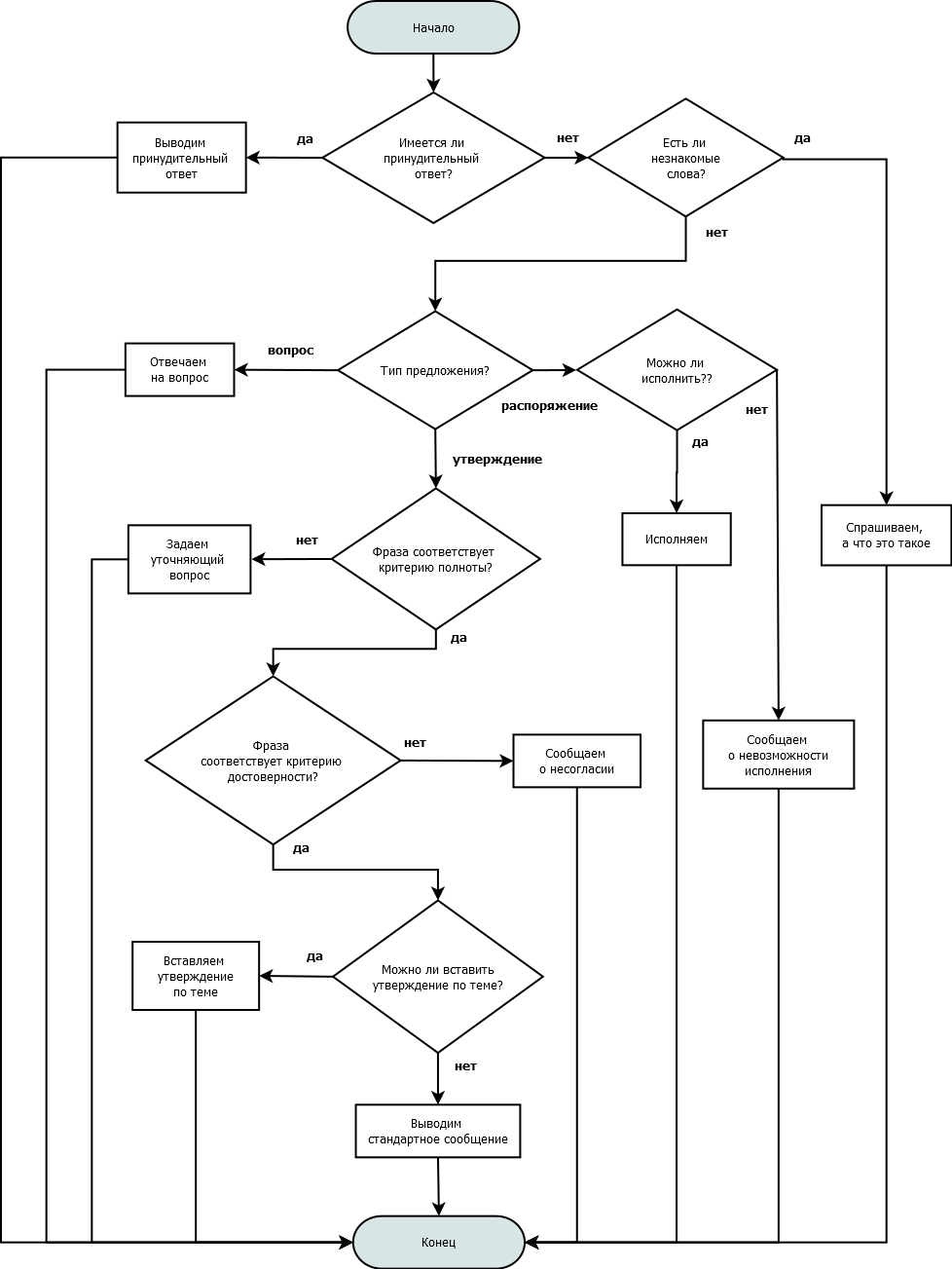
Принудительный ответ – это, к примеру, когда предложение инвалидное или собеседник установил, что на такую-то фразу нужно отвечать таким-то образом.
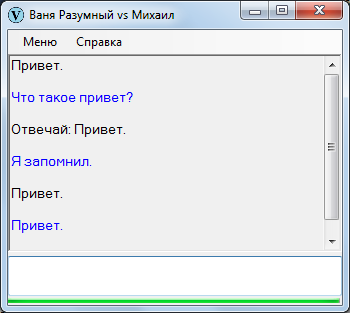
Информационная неполнота – когда удается установить, что в предложении отсутствуют значащий элемент, как правило объект.
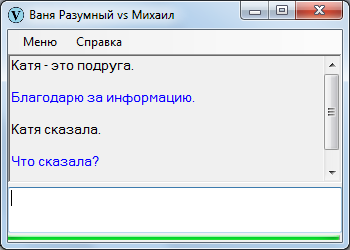
Что сказала-то? Любой человек, услышав подобное, первым делом уточнит, что имеется в виду.
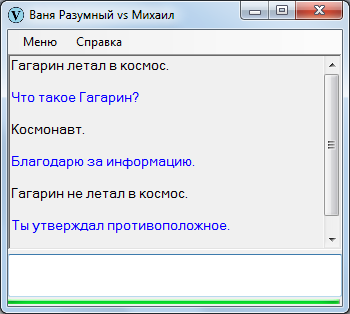
Достоверность – соответствие тому, что записано в памяти. Если кто-то слышит «Гагарин не летал в космос», а в его памяти записано обратное, он опять-таки попросит (должен попросить) разъяснений.
Естественная реакция.
При необходимости отвечать стандартно Ваня Разумный осуществляет выбор из типового набора ответов случайным образом.
Надо сказать, что с типовыми сообщениями я особо не заморачивался по причине того, что добиться полного сходства с человеческой реакцией невозможно по определению. Допустим, чат-бот выдает стандартное «Я согласен». Можно, подобрав синонимичные сообщения, возвращать их рандомно:
Точно так.
Ты прав.
Верно говоришь.
Твоя правда.
и т.п.
Однако любой из этих синонимов обладает смысловыми отличиями от собратьев, ввиду чего их употребление вовсе не идентично. Нюансы, которые легко распознаются людьми по мимике и интонации собеседника, но не могут быть идентифицированы на синтаксическом уровне. Это вам не синтаксис – это физическая реальность.
Да на уровне синтаксиса нельзя даже отличить отрицательный ответ от положительного!
Возьмем два привычных для нас альтернативных ответа на один и тот же вопрос:
Еще как!
Вот еще!
Первый из ответов означает «Да», а второй – «Нет». Определить значения по синтаксису нет никакой возможности.
Основную роль в диалоге играют типы предложений:
1. Распоряжение.
2. Утверждение.
3. Вопрос.
Самое элементарное из всех – распоряжение. Ваня Разумный пытается по действию понять, чего хочет собеседник: если может исполнить, то исполняет, в противном случае сообщает об отказе.
Ну что чат-бот может исполнить? Сказать о чем-то, выполнить команду.
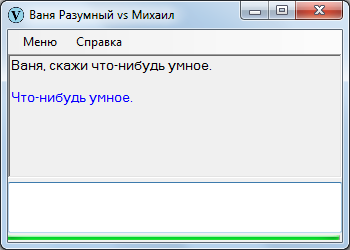
Ничего стоящего внимания.
При утвердительном высказывании собеседника реакция в общем случае сводится к поиску встречного утверждения по теме, где тема – субъект или объект, по желанию.
Космонавт полетел на Марс.
В ответ, найдя в базе утвердительное предложение со словом «космонавт», можно выдать:
Космонавты храбрые.
А можно поискать по объекту, возвратив что-нибудь вроде:
Марс – это красная планета.
Но нет гарантий, что в базе не отыщется неподходящая фраза, типа:
Планетолет вез на Марс мусорные контейнеры.
Подобрать критерии?.. Но какие??? После долгих раздумий я установил, что в качестве ответного утверждения по теме ИИ должен выдать фразу, обозначающую личное отношение к предмету:
Я не летал на Марс.
Опять-таки, если подобная фраза отыщется в базе.
Вместо ответного утверждения может генерироваться вопрос: в случае если в затронутой теме Ваня чего-нибудь недопонял.
Вопросы подразделяются на два подтипа, которые для себя я обозначил как общие и специальные.
Общие вопросы – без вопросительного слова, допускающие ответы «Да» или «Нет».

Специальные вопросы требуют в каждом случае индивидуального ответа, тут простым «Да» или «Нет» не отделаешься.
Сколько на Земле людей?
Почему слоны большие?
Кто такой Наполеон?
Пришлось систематизировать вопросительные слова. Каждому вопросительному слову – которых, по счастью, все же немного, – ставился в соответствие тип. Получился список вида:
Вещь: что?
Имя: кто?
Место: куда? где?
Прилагательное: какой?
Наречие: как?
Число: сколько?
Дата: когда?
Причина: почему?
И так далее.
При отсутствии вопросительного слова вопрос общий.
При общем вопросе Ваня Разумный ищет ответы не только непосредственно на него, но в случае отрицательного ответа и на все специальные вопросы, сгенерированные по основному общему. Цель – выдать в качестве ответа альтернативный сектор.
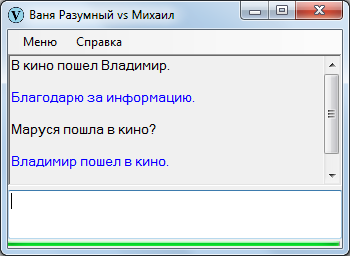
Поиск ответа осуществляется, вестимо, по шаблонам:
Установив сектор-ответ, можем выдать собеседнику «Да», или «Нет», или «А черт его знает», – но это по общему вопросу.
Если вопрос специальный, делаем все то же самое, с единственным отличием. Для вопросительного слова ищем лишь его морфологические признаки, без самого слова.
Допустим, спросили:
Кто выстрелил?
Для «выстрелил» ищем «выстрелить» с заданными морфологическими признаками, а для «кто» – любое слово с заданными морфологическими признаками. Сектор, в котором присутствуют оба слова, и будет ответом.
В некоторых случаях (на самом деле, во многих) единичный поиск по вопросительному слову с заданными морфологическими признаками не сработает, поэтому искать приходится многократно.
Спрашиваем:
Какой мальчик?
«Какой» – вопросительное слово для прилагательного, то есть в общем случае Ваня должен искать прилагательное. Если в базе для данного существительного находится прилагательное, выдается соответствующий ответ.

В иной ситуации ответом может послужить не только прилагательное, но и нечто другое, например причастие.
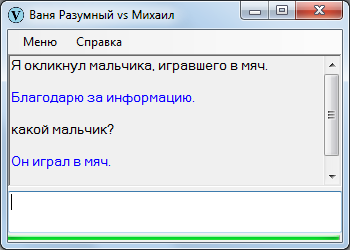
Причастие выражает действие, поэтому, с некоторой точки зрения, любое действие характеризует субъект не менее прилагательного и причастия.
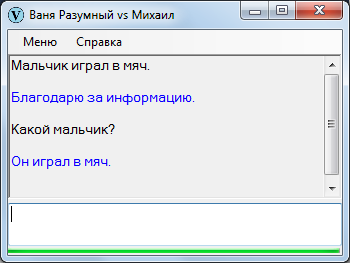
Более сложный, связанный с поиском субъекта, вариант подмены шаблона:
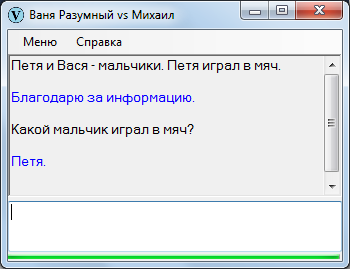
Подобных вариантов с пару десятков: это то, что мне удалось обнаружить.
Обратите внимание: один результат может оказаться ответом сразу на несколько вопросительных подтипов.

На последний вопрос ответа не находится – Ваня соответственно и не отвечает.
Допустим, у чат-бота спрашивают:
Куда глупый Петя пошел?
На самом деле вопрос разбивается на два связанных сектора:
Куда Петя пошел? Петя глупый?
При этом не факт, что оба ответа окажутся положительными или отрицательными: вполне можно представить, что Петя пошел в магазин, но при этом Петя совершенно не глупый.
Приходится сначала проверять достоверность определений, затем уже отвечать на главный вопрос.
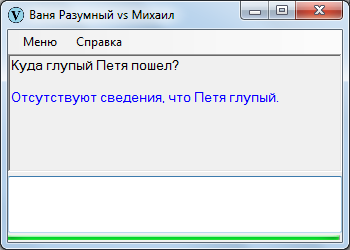
В данном случае сведения об определении Пети отсутствуют, поэтому отвечать на основной вопрос нет резона.
Аналогичным образом необходимость поиска по нескольким секторам возникает при общих вопросах, выраженных в сложносочиненных или сложноподчиненных предложениях.
Я поймал жереха, который погнул весы?
После разделение предложение преобразуется в секторы:
Я поймал жереха? Жерех погнул весы?
Так же во всех остальных случаях, требующих разделения на секторы. Затруднение, хотя преодолимое.
Представим, что у ИИ спрашивают, сколько космонавтов летало в космос. Хорошо, если в базе значится одна фраза:
В космос летало 40 космонавтов.
А если там другая фраза присутствует?
В космос летало 45 космонавтов.
40 или 45, кому верить? Вероятно, один из источников лжет, но который? Можно поверить тому либо другому, но критерии веры каковы? Очевидно, рейтинг источника. Но каким образом ИИ может определить рейтинг источника, если все собеседники для него, строго говоря, одинаковы?
Мне показалось логичным, чтобы ИИ стремился к получению максимального объема знаний, то есть: собеседник, предлагающий новую (отсутствующую в базе) информацию – хороший, не предлагающий – плохой.
В итоге был реализован следующий механизм:
В результате ИИ способен определить, какому из двух высказываний верить.
Думаете, проблема с количеством космонавтов решена? Ничего не решена, потому что оба источника могут оказаться правдивыми. По состоянию на 1 января числилось 40 космонавтов, в течение года 5 человек слетало в космос, по состоянию на 31 декабря числится 45 космонавтов. Только откуда ИИ об этом знать?!
С чем возникли серьезные трудности, так это с инвариантностью, причем настолько серьезные, что хотел бы я познакомиться с человеком, которому удалось разрешить их в рамках синтаксиса. Я вообще не уверен, что такой человек уже родился.
Итак, одно и то же сообщение можно сформулировать по-разному:
Я заболел.
Мне неможется.
Меня ломает.
Плохо себя чувствую.
Я нездоров.
Недомогаю.
Здоровье ни к черту.
И т.п.
Кое-какие мелочи на этом пути преодолимы.
Синонимы – самое очевидное и повсеместно реализованное решение.
Еще можно использовать однокоренные слова, к примеру:
Болезнь.
Боль.
Заболеть.
Заболевание.
Больно.
Вот фразы с ними, выражающие, по сути, единственную мысль.
Он подхватил болезнь.
Он испытывает боль.
Он заболел.
У него заболевание.
Ему больно.
К сожалению, возможно сформулировать и без использования однокоренных слов. Например:
Здоровье пошатнулось.
Поэтому в рамках синтаксиса полное и безусловное решение проблемы инвариантности отсутствует. Чтобы решить проблему инвариантности, нужен не чат-бот, а ИИ, обладающий полным набором человеческих ощущений.
Речь дошла до интеллекта, на нем и сосредоточусь.
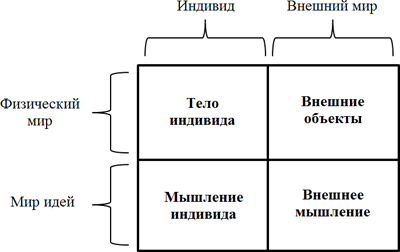
Лично я (хотя у каждого собственное мнение, понимаю) насчитываю три пункта, делающие мыслящее существо таковым:
1. Обратная связь.
2. Мышление.
3. Рефлексия.
Обратная связь – зависимость реакции от предыдущего опыта. Реализуется примитивным образом, за счет записи информации в базу данных. Сначала ИИ чего-то не знал, потом услышал, запомнил и теперь знает – это и есть обратная связь.
Мышление – процесс генерирования новой информации, непосредственно не получаемой от собеседника. Собеседник выдает сообщение, ИИ анализирует и приходит к собственным выводам.
Ваня Разумный делает выводы, затем записывает их в базу с пометкой «идея» (свойство сектора). Все мышление, собственно.
Так мыслим мы:
Так должен мыслить ИИ:
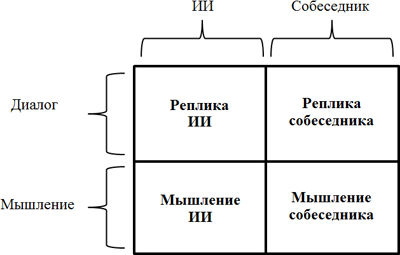
Вопрос не в том, что такое мышление, а в том, каким образом искусственное мышление должно быть организовано…
В качестве основы мышления я (не сомневаюсь, что подобно многочисленным предшественникам) использовал классы. В математике это называется множествами, в лингвистике – гиперонимами, но мне больше нравится дарвинистско-программистское «классы». Бульдог относится к классу собак, собаки относятся к классу животных, и так далее вверх и вниз по иерархии.
Правила пользования тривиальны:
Самое познавательное не в классах и не в их членах, а в том, откуда взять нужную информацию для таксономии.
Придумалось следующее.
Во-первых, определять принадлежность того или иного понятия к классам из дефиниций – так сказать, напрямую.
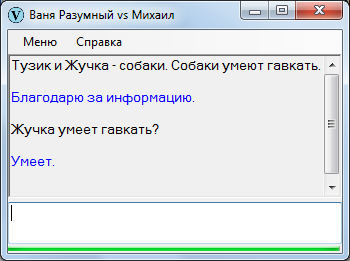
Если Жучка собака и все собаки гавкают, довольно очевидно, что Жучка тоже умеет гавкать.
Заменим в исходном утверждении «собаку» на «Тузика». Логично предположить, что если собака Тузик умеет гавкать, то и собака Жучка тоже умеет?
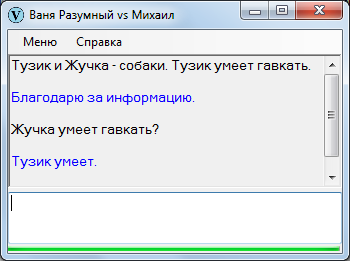
Не логично. Что если вместо «гавкать» вставить «рожать щенят»? Тузик этого не умеет, а Жучка – запросто. По этой причине поиск выдал отрицательный результат. Вместе с тем был обнаружен альтернативный сектор (умение Тузика гавкать), который и стал ответом – по-моему, достаточно познавательным.
Другой способ обнаружения классов – перечисления. Исходная посылка: слова, связанные некоторыми союзами (и, или, а, кроме) или запятыми в связи с перечислением, принадлежат хотя бы одному общему классу.
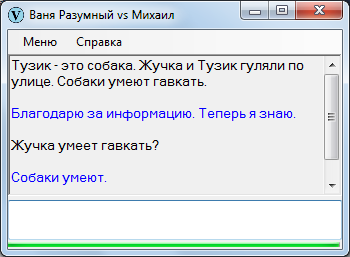
Я ни словом не обмолвился, что Жучка – собака: Ваня Разумный сам сделал вывод из полученной информации. В ином случае мог и ошибиться: к примеру, если бы я написал «Тузик – это кобель», потому что Жучку к кобелям никак не причислишь. Пришлось бы вносить коррективы.
Что я и сделал, собственно, а Ваня соответствующим образом среагировал, хотя не без огрехов.

Следующий способ – некоторые вопросительные наречия (куда, где, откуда, когда). Если такая склейка относится к слову, можно сделать вывод о принадлежности слова к определенному классу (места или времени).
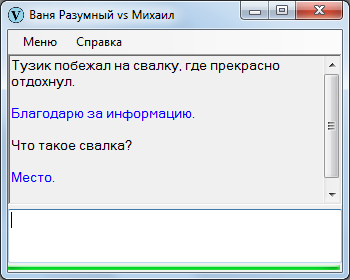
Наконец, действия. Выполнение субъектами одних и тех же действий с большой вероятностью свидетельствует о наличии у субъектов общего класса. Как говорят американцы, если что-то плавает, как утка, летает, как утка и крякает, как утка, то это и есть утка.

Способ неточный, ведь выполнять одинаковые действия могут объекты, принадлежащие разным классам. Однако если все выполняемые действия совпадают, это не может не навести на определенные мысли.
В итоге, процесс мышления можно уподобить разгадыванию паззлов, когда по имеющимся кускам информации восстанавливается полная картина.

Если вы полагаете, что мыслите как-то иначе, то навряд ли… Представьте, что знакомый Петров хвастает: «У меня дочь – первоклассница». Что вы можете сказать о его дочери, о которой впервые слышите? Принадлежность к классу «первоклассница» говорит о возрасте субъекта. Возраст (тоже в некотором смысле класс) свидетельствует о примерном росте, весе, интеллектуальных возможностях и прочем. Женский род (опять-таки класс) позволяет предположить первичные и вторичные половые признаки, а принадлежность к фамилии «Петров» (класс, все класс) доказывает, что искомая первоклассница такая же дура, как все известные вам Петровы.
А если серьезно, то в своих выводах мы оперируем принадлежностью субъекта к определенному набору классов, а более ни к чему. И чем наше хваленое человеческое мышление отличается от заурядных машинных алгоритмов?! Ничем.
Процесс мышления следует базировать не только на классах, но и на каузальности (причинно-следственных связях).
Над Атлантикой изменилось давление, поэтому подул ветер. Подул ветер, поэтому с головы слетела шляпа. С головы слетела шляпа, поэтому шляпа упала в лужу. Шляпа упала в лужу, поэтому шляпа промокла.
Если идти по каузальной цепочке с конца в начало, неизбежно придем к начальному выводу:
Шляпа промокла, потому что над Атлантикой изменилось давление.
И попробуйте сказать, что вывод неверен!
А ведь подобные каузальные цепочки могут составляться не только по последовательным, но и по разрозненным фразам, в результате выводы, сделанные ИИ, окажутся неожиданными!
Есть и второй способ установить каузальность. Он связан с использованием известной нам триады: субъект – действие – объект.
В чем исконный смысл триады? Да именно в том, что в цепочке происходящих событий выражается каузальность между субъектом и объектом. События происходят одно за другим, причем прошлый объект становится субъектом, в свою очередь воздействующим на другой объект, и т.д.
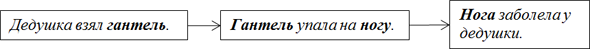
Указанная последовательность представляет собой каузальную цепочку, в которой:
а) причиной того, что гантель упала, является то, что дедушка взял гантель,
б) причиной того, что нога заболела, является то, что гантель упала на ногу.
Чистый синтаксис, при котором ИИ понятия не имеет, ни что такое дедушка, ни что такое гантель, ни что такое нога.
Согласно имеющейся базе знаний, гантель может упасть на ногу только в названном случае – ни в каком другом.
Представим, что в базу добавляется новые записи:
Мальчик купил гантель.
Бабушка положила гантель на комод.
В результате возникают новые потенциальные возможности того, что гантель упадет на ногу, вследствие чего дедушкина нога заболит.
Имеем веер сходящихся возможностей, весьма пригодный для анализа.
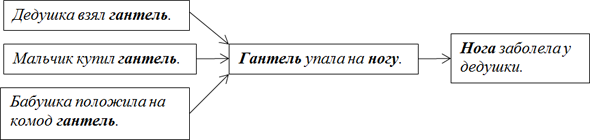
Существо, основывающее свое мышление на правилах синтаксиса, может сделать вывод о том, что, если мальчик купил гантель или бабушка положила гантель на комод, то гантель может упасть на ногу, со всеми вытекающими последствиями. Правомерно поинтересоваться:
Гантель не упадет на ногу?
Или, на следующем витке каузальности:
Нога не заболит у дедушки?
По сути, это предугадывание будущего, но не только. Еще и восстановление прошлого, так как двигаться по каузальной цепочке возможно не вперед, но и назад.
Таков он, механизм предугадывания:
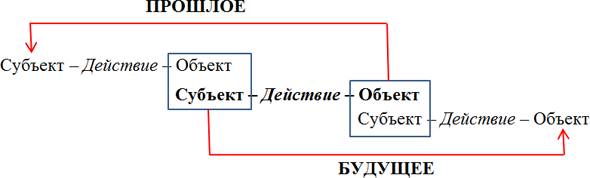
Центральная триада на схеме – текущая. Если субъект текущей триады и какой-либо объект в последующей каузальной цепочке совпадают или хотя бы принадлежат одному классу, имеем каузальную связь в рамках одного субъекта-объекта. То же самое – относительно предыдущей каузальной цепочки.
Образчик реализации:
Ущипните меня, если это не мышление!
Конечно, наличие каузальности далеко не очевидно, если наблюдатель находится в физическом мире.
Я увидел березу. Береза шелестела листвой.
Нам, существующим вне правил синтаксиса, понятно, что береза шелестит листвой вовсе не оттого, что кто-то ее увидел, но с точки зрения синтаксиса дела обстоят именно так. Кто бы тогда шелестел листвой, если бы я не увидел?!
Сколько пользуюсь русским языком, столько убеждаюсь, какое это расчудесное чудо!
Помимо обратной связи и мышления, ИИ требует рефлексии.
Вспоминаю, в одном фильме о роботах миллиардер-изобретатель бегал по коридору с радостными воплями: «Она (искусственная женщина) себя осознает! Она себя осознает!»
Наивный! в рефлексии нет никакой тайны, даже в рефлексии живых существ, не то что в рефлексии ИИ.
Мы осознаем себя в качестве субъекта исключительно по той причине, что наше тело отделено от нашего мышления. Чат-бот также способен рефлексировать исключительно за счет мышления, а что это такое, мы выяснили: генерирование собственных, отличных от реплик собеседника, сообщений. Иначе говоря, мыслящий чат-бот должен генерировать внутренние (направляемые непосредственно в базу, а не на десктоп) сообщения о самом себе. Это не составляет сколь-либо заметной проблемы.
Можно, к примеру, генерировать мысли по репликам собеседника: собеседник выдает информацию об ИИ – тот анализирует и приходит к каким-либо выводам. В процессе анализа несомненно рефлексирует: осознает себя.
Можно отталкиваться от сообщений не собеседника, но собственных.
Допустим, сгенерирован вопрос, в соответствии с объявленной выше схемой:
Что такое движение?
Что это означает? То, что означает: сгенерирован вопрос. Идея записывается в качестве таковой, от имени ИИ:
Я задал вопрос.
В базу записываем, но в качестве ответа не выводим: это и есть рефлексия.
Понятно, что идей можно сгенерировать множество – столько, сколько потянут вычислительные мощности и фантазия Создателя. Если вопрос задает собеседник и записывается собственная мысль уже не о самом себе, но о собеседнике – это мышление. Короче, мышление о самом себе – это рефлексия, а мышление о внешнем мире – не рефлексия.
В результате мышления миры распараллеливаются. В низовом, изначальном мире, соответствующем физическому миру людей, происходит обмен сообщениями:
— Как твои дела?
— Прекрасно.
В высшем мире, соответствующем нашему миру идей, рождаются мысли. Одни мысли относятся к внешнему миру (не рефлексия), другие – к самому себе (рефлексия).
Собеседник задал вопрос.
Я ответил на вопрос.
Или:
Собеседник почему-то волнуется.
Я абсолютно спокоен.
Миры смешиваются воедино, иногда до полной неразличимости.
Реплика:
Ты точно влюбился?
Ее основная смысловая часть «ты влюбился?» принадлежит непосредственно диалогу, тогда как наречие «точно» – внешнему миру идей. Полная реконструированная фраза должна бы звучать следующим образом:
Ты точно уверен, что ты влюбился?
Первая часть фразы относится к миру идей, тогда как вторая – к миру диалога.
В результате, при работе с параллельными мирами возникает необходимость обрабатывать не только семантику сообщений, но и некие внешние по отношению к ним характеристики. Вот только как?
Допустим, собеседник спрашивает:
— Сколько сейчас времени?
Ориентируясь на низовой смысловой мир сообщений, ИИ должен бы начать шерстить по всей базе в поисках ответа.
Допустим, найдет фразу полугодичной давности:
Сейчас 15 часов 30 минут.
Вряд ли устаревшее сообщение послужит корректным ответом на текущий вопрос. А чтобы данные о текущем времени не устаревали, всегда были свежими, необходимо каждое – о Господи! – мгновение генерировать сообщение типа:
Сейчас 15 часов 30 минут 28 секунд 34 миллисекунды.
База не потянет.
Какого черта лазить по базе, если можно возвратить системное время, тем самым обратиться непосредственно к внешнему по отношению к диалогу миру?! Можно, конечно, но…
Как заметил один глубокомысленный персонаж, нельзя объять необъятное. Поэтому число верхних параллельных миров любой системы ограничено вычислительными мощностями, в конечном счете – назначением системы и здравым смыслом Создателя.
В один прекрасный момент, когда работы над ИИ подходили к логическому завершению, я закачал в Ваню чуть поболе текста, чем обычно – строк этак полтыщи, – и решил насладиться общением. Не тут-то было! Юноша оказался тугодумом: как-то чересчур, до неприличия долго соображал. Выяснилось, что из-за множественности SQL-запросов.
Допустим, во фразе всего 3 слова (два существительных и глагол) – это 3 обращения к базе. Пересечение результатов по каждому обращению даст сектор-ответ, из которого при желании можно выбрать слово-ответ, в противном случае использовать в качестве ответа типовую фразу.
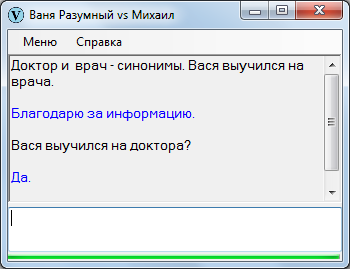
Если у какого-либо слова имеются синонимы, необходимо проверить базу по каждой комбинации.
Возьмем вопрос:
Доктор увидел бегемота?
Синоним «доктора» – «врач», а синоним «бегемота» – «гиппопотам», в результате получаем 3 дополнительных варианта:
Врач увидел бегемота.
Доктор увидел гиппопотама.
Врач увидел гиппопотама.
Кроме синонимов, имеются еще классы, которые тоже приходится проверять. Поскольку доктор принадлежит классу людей, ответом на вопрос будет также являться фраза:
Человек увидел гиппопотама.
Ладно, не проблема: вбить перечисления в один SQL-запрос. Хотя длина строки тоже небесконечна, приходится ее контролировать, но не суть дело…
В других ситуациях, при которых структура фразы изменяется, следовательно изменяются параметры SQL-запроса, минимальным количеством обращений к базе никак не обойтись.
Во-первых, по каждому слову необходимо проверять на отрицания:
Не доктор увидел бегемота?
Доктор не увидел бегемота?
Доктор увидел не бегемота?
Во-вторых, приходится осуществлять альтернативный поиск иного рода – я упоминал об этом ранее. Это когда на вопрос «какой?» последовательно перебираются конструкции, образованные на основе прилагательного, причастия, глагола.
Как быть? Если сократить количество SQL-запросов, ИИ лишится многих возможностей анализа, соответственно пострадает разнообразие ответов.
Тут на меня снизошло озарение. Зачем искать по базе, если каждое утверждение само по себе является ответом на известное множество вопросов?!
Некто утверждает:
Маруся пошла в кино.
Данное утверждение является ответом на общий вопрос:
Маруся пошла в кино?
Также оно является ответом на общий вопрос с отрицанием:
Маруся не пошла в кино?
Можно, добавляя вопросительные слова, составить и специальные вопросы, к примеру:
Кто пошел в кино?
Куда пошла Маруся?
Ответом на все названные вопросы является текущий сектор.
Значит, конструируя вопросы разных типов, можно вписывать их в базу, а в качестве ответа соотносить с ними исходный сектор-утверждение! При этом система не перегружается SQL-запросами: диалог течет заметно веселей, чем прежде.
Нет сомнений, что люди мыслят аналогичным образом. Если задать чересчур сложный вопрос, собеседник сразу не ответит, а задумается: сколько нужно для нахождения ответа, столько и будет думать. Зато после того как ответ найден, отвечать на последующие аналогичные вопросы начнет моментально. Иначе говоря, люди реагируют согласно имеющимся у них шаблонам: шаблон имеется – ответ следует немедленно; шаблон отсутствует – отсутствует ответ (вместо ответа вставляется «быстрая» заглушка). Значит, такой способ оптимизации не «выдуман из головы», а в известном смысле слова естественен.
С другой стороны, может быть задан вопрос, на который в базе не найдется готового ответа. Здесь оптимизация не поможет: ИИ задумается опять надолго. Во избежание длительного ожидания, при достижении установленного лимита в n секунд, приходится прерывать поиски. Тогда Ваня отвечает заглушкой типа:
Слишком сложный вопрос.
Что, опять-таки, полностью соответствует естественным алгоритмам. На слишком сложный вопрос (для вас сложный, естественно, а не для находящегося в младенческом возрасте Вани) вы тоже не ответите.
Приведенным способом возможности оптимизации не исчерпываются. Но… как говорится, чем богаты.
Принципиальная схема Вани Разумного получилась такой:
1. Парсим текст при помощи библиотеки Solarix.
2. Обрабатываем, преобразуя в списки элементов и свойств.
3. Пишем в базу.
4. В момент записи связываем будущие потенциальные вопросы с текущим утверждением.
5. Ищем, что сказать в ответ (сектор).
6. Одновременно генерируем собственные мысли (в текстовом виде).
7. Преобразуем сектор обратно в текст (словоформы восстанавливаем при помощи библиотеки LingvoNET).
8. Выдаем ответ собеседнику.
9. Параллельно обрабатываем и записываем мысли.
Многое из задуманного не реализовано, да и вряд ли будет реализовано в будущем. Причин две:
1. Во-первых, ограниченность вычислительных ресурсов. Как я уже упоминал, во избежание затяжек времени пришлось искусственно ограничить обдумывание ответов, при том что сам мыслительный функционал примитивен. Усложнять есть куда, возможности безграничны, идеи прозрачны и на начальном уровне отработаны, но аппаратную часть желательно иметь помощней.
2. Во-вторых, явная (лично для меня) коммерческая бесперспективность данного мероприятия. Убивать еще год, чтобы удовлетворить лишний десяток читателей данного ресурса? А зачемЦиолковскому самому строить в гараже ракету, если принцип реактивной тяги им сформулирован? Возникнет интерес у серьезных дяденек, можно будет ваять далее, по накатанной колее и с гораздо бОльшим успехом, а пока других дел по горло. Так что Ваня Разумный – не более чем прототип будущего ИИ.
Между прочим, назначение будущего полноценного ИИ вовсе не выполнение голосовых команд, как то практикуется современными голосовыми помощниками, а…
1) Компьютерная психотерапия.
Вы возвращаетесь с работы расстроенный и говорите ИИ:
«Начальник дурак».
«Форменный остолоп», – заинтересованно отзывается ИИ.
Далее в том же духе. Подобный диалог проведешь не с каждым собеседником, даже близким родственником, а с компьютерным устройством – пожалуйста. Для чего устройство должно быть соответствующим образом, с учетом ваших индивидуальных характеристик, настроено и воспитано.
2) Тестирование на достоверность.
Как следует из всего текущего поста, синтаксис обладает собственной семантикой, которая может быть соотнесена с чьими-нибудь выводами. Следовательно, ИИ способен проверять утверждения на достоверность, соотнося их с предыдущими известными ему утверждениями. А если ИИ не чат-бот, а устройство, обладающее видеокамерой и другими датчиками ощущений, то не только с утверждениями собеседников, но и с реальным миром, который, как мы помним, лишь совокупность визуальных точек и иных элементарных объектов. Мы воспринимаем (видим и иным образом ощущаем) здания, деревья, облака, но ведь ИИ может воспринять нечто другое, неожиданное, «замыленное» для человеческого глаза. Что, согласитесь, гораздо интересней…
Скачать релиз можно здесь.
Исходники тут, если найдутся желающие копаться в дилетантском коде. Зачем нужен код, если Ваня Разумный – лишь иллюстрация к текущему посту, излагающему принципы создания ИИ методом «глокой куздры»?!
Ну и в напоследок.
Я не программист, с меня взятки гладки. Я это к тому, что ошибок много – возможно, неприлично много, даже в диалогах, не только при чтении художественных файлов. Замечу, что ошибки встречаются не только в моем коде, но и в использованных библиотеках, хотя в меньшем количестве. Однако любая ошибка в библиотеке автоматически транслируется на диалог, это надо понимать.
Базу заполнил, насколько смог. Пара сотен фраз: начальные представления о себе и роде человеческом, правила вежливости, – на большее терпения не хватило. Воспитание младенца, даже компьютерного, – задача из трудоемких.
Прорабатывал вопрос с закачкой словарей, в конце концов отказался от мысли. Орфографический и синонимов закачать еще можно (хотя ну очень долго), а вот толковый – никак. В словарях значится, к примеру:
Сидоров – композитор. Кантаты, сюиты.
Альпы – горный массив. Добыча руды. Туризм.
А мне нужно:
Сидоров – композитор. Сидоров – автор кантат, сюит.
Альпы – горный массив. В Альпах добывают руду. В Альпах развит туризм.
То есть с толковыми словарями полная несовместимость: немыслимо на уровне синтаксиса определить, где «автор», а где «добывают». Собственно, и словарей-то в сети не так чтобы много. Требовались: толковый, синонимов, однокоренных слов, фразеологизмов, гиперонимов… Да чего уж теперь!
Если, вдохновленные текущим постом, вы решились-таки убедиться, насколько автор криворукий, то пополнять базу можно двумя способами: либо диалогом, либо закачкой текста. Закачиваемые фразы лучше начинать с новой строки.
Предупреждаю, фразы индексируются мучительно долго, так что загружать несколько страниц текста, право слово, не стоит — одной достаточно.
Синонимы устанавливаются по шаблону:
Врач, доктор – это синонимы.
То же – антонимы (которые на самом деле лишь члены класса, что я сообразил далеко не сразу. Белый и черный – антонимы. Однако синий, зеленый и т.д. члены того же класса, поэтому антонимы как сущность у меня отсутствуют – при указании антонимов записываются члены класса).
Белый и черный – это антонимы.
Стандартные ответы устанавливаются в диалоге. Пример я приводил, но повторю:

При закачке стандартный ответ размещается следом за исходной фразой:
Ты молодец.
Отвечай: Ты тоже.
Набивать тексты следует грамотно, с соблюдением знаков препинания, иначе поняты не будете.
Все советы, собственно.
Нет, если не выпендриваться, то в качестве стандартного чат-бота Ваня Разумный худо-бедно способен функционировать.
С этой стороны я своей интеллектуальной одиссеей доволен. Кристальная ясность в голове: что в рамках синтаксиса можно реализовать, а чего нельзя. И полная уверенность в том, что для создания искусственного существа недостает механики и вычислительных мощностей, а что касается принципов мышления, будь то на основе синтаксиса, зрительного или иного восприятия либо комбинированным способом, – теоретические препятствия отсутствуют.
Конечно, мне далеко до профессиональных программистов, и лингвистом я тоже не являюсь, но системное мышление имеется, и чувство языка на месте. Тем более что тематикой ИИ давно интересуюсь, даже пару-тройку постов накатал в свое время. Отчего не реализовать познания в программном коде? Ну и попробовал, насколько смог.
Знакомьтесь, Ваня Разумный.
Ниже находится описание проблем, возникших передо мной на этом хоженом-перехоженом пути, и способов их преодоления.
По поводу результата оговорюсь сразу: целью был не программный код, а формулировка принципов искусственного мышления, функционирующего НЕ на основе физической реальности, как биологические организмы, а на основе СИНТАКСИСА. Поклонники теста Тьюринга, нейронных сетей и машинного обучения могут не беспокоиться.
Внимание, материал объемный.
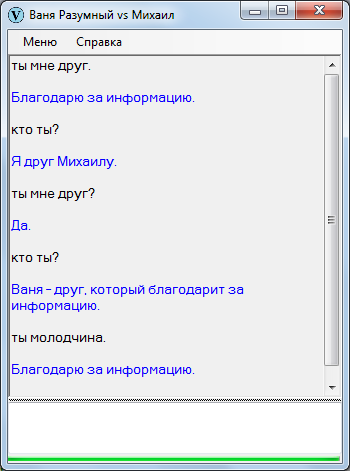
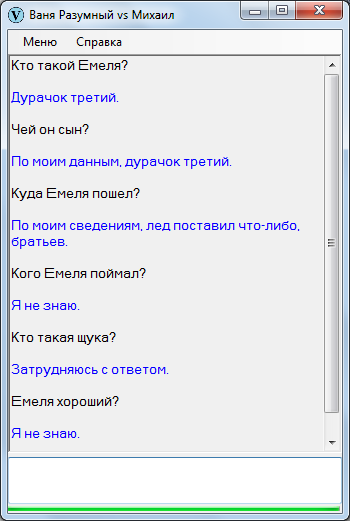
Ушат холодной воды
Чтобы не было беспочвенных ожиданий с последующими ехидными скриншотами в комментариях, сразу продемонстрирую Ваню Разумного в непрезентабельном виде. Вот, закачал начало «Емели» и попробовал поспрашивать – в точности как на уроках литературы в начальных классах.
Оригинальный текст:
Жил-был старик. У него было три сына: двое умных, третий – дурачок Емеля. Те братья работают, а Емеля целый день лежит на печке, знать ничего не хочет.
Один раз братья уехали на базар, а бабы, невестки, давай посылать его:
— Сходи, Емеля, за водой.
А он им с печки:
— Неохота…
— Сходи, Емеля, а то братья с базара воротятся, гостинцев тебе не привезут.
— Ну, ладно.
Слез Емеля с печки, обулся, оделся, взял ведра да топор и пошел на речку. Прорубил лед, зачерпнул ведра и поставил их, а сам глядит в прорубь. И увидел Емеля в проруби щуку.
Диалог:
Однако, текст можно адаптировать – так, допустим:
Старик имел трех сыновей. Первый сын был умным. Второй сын был умным. Третий сын был дураком. Емеля – третий сын старика. Емеля хороший.
Старшие сыновья работают целый день, а Емеля лежит на печи.
Однажды братья уехали на базар. Невестки говорят Емеле:
— Сходи за водой.
Емеля отвечает с печки:
— Не пойду за водой.
Невестки говорят:
— Братья гостинцев тебе не привезут.
— Ну, ладно.
Емеля слез с печки, обулся, оделся, взял ведра и топор. Потом Емеля пошел на речку.
Емеля прорубил лед и зачерпнул ведра. И увидел Емеля в проруби щуку. Щука – это рыба. Емеля поймал щуку.
После адаптации выходит поприличней:
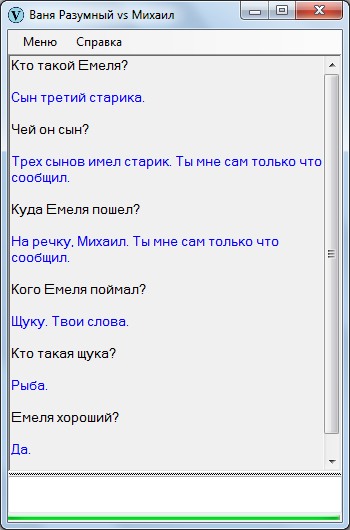
Все равно, в художественных текстах непозволительно путается. Несмотря ни на что, Ваня действительно мыслит, в отличие от многих своих собратьев, в первую очередь созданных на основе нейронных сетей, которые только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы. Если вам интересно знать, почему, читайте дальше.
Перехожу непосредственно к описанию интеллектуальной одиссеи.
Теоретическое обоснование
Рассуждал я следующим образом.
В чем главная проблема ИИ? В том, что компьютер не может понимать значений слов, соответственно быть «разумным». При этом считается, что люди разумны, поскольку понимают произносимые собеседником слова.
На самом деле ни черта люди не разумны. Слово само по себе означает не больше, чем составляющие его буквы (по сути, кривые линии) или звуки (колебания воздуха). Смысл возникает лишь в качестве отношений между буквами-звуками как элементами членораздельной речи, за счет устойчивых ассоциаций, в том числе за счет связей с миром визуальных восприятий. Например, собеседник указывает на предмет и говорит: «Это дерево». И ты понимаешь, что данный предмет называется деревом.
Чат-боту (под которым договоримся понимать ИИ, занимающийся исключительно разговорами) нельзя указать на предмет и сказать: «Это дерево», – за счет отсутствия у чат-бота глаз, то есть видеокамеры. Объяснять возможно лишь на словах, а как объяснишь, если человеческой речи он и не разумеет?!
По счастью, отношения между элементами речи определены, и довольно жестко: за них отвечает синтаксис. Следовательно, любой текст, построенный по законам синтаксиса, содержит в себе некоторый, закрепленный в синтаксисе смысл. Та самая вынесенная в заголовок «глокая куздра», знаменитая и непревзойденная по наглядности – которая, как оказалось, давно пристегнута к компьютерным исследованиям.
Из воспоминаний одного товарища о далеких 70-х:
Глокая куздра
В июле 2012 г. ко мне в Концепт пришел эксперт и сказал «Глокая куздра». Я его понял. Это был знак причастности к общему когда-то семантическому полю.…
«Глокая куздра штеко будланула бокра и кудлачит бокренка».
В 70е годы искусственным интеллектом занимались в ВЦ АН СССР, в ИПУ АН СССР и нескольких др. институтах. В том числе было направление, которое занималось машинным переводом. Проблема не решалась годами, семантическая неоднозначность не давала перевести смысл без контекста. Было не понятно, как формализовать контекст в компьютерной программе. И вот Д. А. Поспелов /наверно/ распространил пример, иллюстрирующий трудность этого перевода. Он взял фразу, которая состоит из бессмысленных слов, но вместе с тем по строю предложения и звучанию слов создает совершенно ясные одинаковые ассоциации у совершенно разных людей. Этот эффект понимания не мог быть достигнут машиной. Действительно, Глокая куздра – этакая злая коза – она, ясное дело, сильно боднула козла и что-то несусветное творит с козленком… Семинары по машинному переводу проходили и в ИПУ, и я встречал на доске такое вот оглавление: «Глокая куздра. Семинар пройдет в 14.00 в 425 ауд.».
Справка. Автор этой фразы – известный языковед, академик Лев Владимирович Щерба. Корни входящих в нее слов созданы искусственно, суффиксы и окончания позволяют определить, к каким частям речи относятся эти слова и вывести значение фразы. В книге Л. В. Успенского «Слово о словах» приведен ее общий смысл: «Нечто женского рода в один прием совершило что-то над каким-то существом мужского рода, а потом начало что-то такое вытворять длительное, постепенное с его детенышем».
Источник kuchkarov.livejournal.com/13035.html
«Глокая куздра штеко будланула бокра и кудлачит бокренка».
В 70е годы искусственным интеллектом занимались в ВЦ АН СССР, в ИПУ АН СССР и нескольких др. институтах. В том числе было направление, которое занималось машинным переводом. Проблема не решалась годами, семантическая неоднозначность не давала перевести смысл без контекста. Было не понятно, как формализовать контекст в компьютерной программе. И вот Д. А. Поспелов /наверно/ распространил пример, иллюстрирующий трудность этого перевода. Он взял фразу, которая состоит из бессмысленных слов, но вместе с тем по строю предложения и звучанию слов создает совершенно ясные одинаковые ассоциации у совершенно разных людей. Этот эффект понимания не мог быть достигнут машиной. Действительно, Глокая куздра – этакая злая коза – она, ясное дело, сильно боднула козла и что-то несусветное творит с козленком… Семинары по машинному переводу проходили и в ИПУ, и я встречал на доске такое вот оглавление: «Глокая куздра. Семинар пройдет в 14.00 в 425 ауд.».
Справка. Автор этой фразы – известный языковед, академик Лев Владимирович Щерба. Корни входящих в нее слов созданы искусственно, суффиксы и окончания позволяют определить, к каким частям речи относятся эти слова и вывести значение фразы. В книге Л. В. Успенского «Слово о словах» приведен ее общий смысл: «Нечто женского рода в один прием совершило что-то над каким-то существом мужского рода, а потом начало что-то такое вытворять длительное, постепенное с его детенышем».
Источник kuchkarov.livejournal.com/13035.html
На основе «глокой куздры» можно построить полноценный диалог.
— Кто будланул бокра?
— Куздра.
— Кто кудлачит бокренка?
— Тоже куздра.
— Какая она?
— Глокая.
— Как будланули бокара?
— Штеко.
Такой ИИ – вполне себе свободно общающийся – окажется не в состоянии понимать значения употребляемых им слов: будет не в курсе, ни что такое «штеко», ни кто такой «бокр», ни каким образом возможно кудлачить. Но разве по этой причине можно посчитать, что ИИ неразумен, а человек, совершенное биологическое создание, «разумеющее» семантику собственных выражений, полноценно, в отличие от ИИ, мыслит? Полноте…
Люди не видят предметов, а наблюдают панораму цветных точек – по сути, хаотичную. Предметы образуются не во внешнем мире, а в человеческом мозгу, за счет увязывания цветных точек воедино, в отдельные совокупности. Это означает, что мы существуем в некоем иллюзорном мире, который в известном смысле нами же и сконструирован.
Читал, что какое-то первобытное племя не видит самолетов в небе – просто не видит, и все. Еще читал, что индейцы не замечали подошедших к берегам кораблей Колумба, потому что… просто не замечали. А заметили после того, как им объяснили, как надо смотреть – то есть каким образом увязывать цветные пиксели в конкретные предметы. Я этим псевдогеографическим байкам верю: такие зрительные парадоксы представляются мне правдоподобными.
У человека нет оснований считать, что его мышление устроено каким-то особенным образом, посему принцип «глокой куздры» – единственная возможность сделать разумным кого-то, будь то чат-бот или человек. Использовать можно различный инструментарий, но принципиальная схема является безусловной. Я так считал до начала работы и не переменил своего мнения по ее окончании.
Библиотеки
Поставив задачу, принялся гуглить по поводу подходящих библиотек для C#.
Тут меня ожидало первое разочарование: ничего пригодного, во всяком случае бесплатного, не обнаруживалось. Всяческие готовые модули для реализации чат-ботов не требовались, интересовала работа со словоформами. Казалось, что проще:
а) определять морфологические признаки словоформы,
б) возвращать словоформу с требуемыми морфологическими признаками?
Лексикон ограничен, количество признаков тоже. И вещь такая полезная, обиходная… Не тут-то было!
Ничего не найдя, сгоряча попробовал закодить определитель морфологических признаков самостоятельно. Как-то сразу не задалось. На этом моя интеллектуальная одиссея и завершилась бы бесславно, в порту отправления, если бы повторное, более тщательное, гугление не выявило пару бесплатных библиотек, которыми я в конечном счете и воспользовался. Как всегда, спасибо энтузиастам.
Первая библиотека – Solarix. Многое чего позволяет, но я, в силу малой компетентности и финансовой недостаточности (библиотека бесплатная лишь частично), использовал безусловно бесплатный парсер, производящий синтаксический разбор текста и записывающий результат в файл.
Пример синтаксического разбора парсера Solarix
<?xml version='1.0' encoding='utf-8' ?>
<parsing>
<sentence paragraph_id='-1'>
<text>мама мыла грязную раму.</text>
<tokens>
<token>
<word>мама</word>
<position>0</position>
<lemma>мама</lemma>
<part_of_speech>СУЩЕСТВИТЕЛЬНОЕ</part_of_speech>
<tags>ПАДЕЖ:ИМ|ЧИСЛО:ЕД|РОД:ЖЕН|ОДУШ:ОДУШ|ПЕРЕЧИСЛИМОСТЬ:ДА|ПАДЕЖВАЛ:РОД</tags>
</token>
<token>
<word>мыла</word>
<position>1</position>
<lemma>мыть</lemma>
<part_of_speech>ГЛАГОЛ</part_of_speech>
<tags>НАКЛОНЕНИЕ:ИЗЪЯВ|ВРЕМЯ:ПРОШЕДШЕЕ|ЧИСЛО:ЕД|РОД:ЖЕН|МОДАЛЬНЫЙ:0|ПЕРЕХОДНОСТЬ:ПЕРЕХОДНЫЙ|ПАДЕЖ:ВИН|ПАДЕЖ:ТВОР|ПАДЕЖ:ДАТ|ВИД:НЕСОВЕРШ|ВОЗВРАТНОСТЬ:0</tags>
</token>
<token>
<word>грязную</word>
<position>2</position>
<lemma>грязный</lemma>
<part_of_speech>ПРИЛАГАТЕЛЬНОЕ</part_of_speech>
<tags>СТЕПЕНЬ:АТРИБ|КРАТКИЙ:0|ПАДЕЖ:ВИН|ЧИСЛО:ЕД|РОД:ЖЕН</tags>
</token>
<token>
<word>раму</word>
<position>3</position>
<lemma>рама</lemma>
<part_of_speech>СУЩЕСТВИТЕЛЬНОЕ</part_of_speech>
<tags>ПАДЕЖ:ВИН|ЧИСЛО:ЕД|РОД:ЖЕН|ОДУШ:НЕОДУШ|ПЕРЕЧИСЛИМОСТЬ:ДА|ПАДЕЖВАЛ:РОД</tags>
</token>
<token>
<word>.</word>
<position>4</position>
<lemma>.</lemma>
<part_of_speech>ПУНКТУАТОР</part_of_speech>
<tags></tags>
</token>
</tokens>
</sentence>
</parsing>Вторая библиотека – LingvoNET, предназначенная для склонения и спряжения слов русского языка. Предыдущей склонения и спряжения тоже доступны, но эта приглянулась мне легкостью освоения.
Получив вожделенное, засучил рукава.
Излагаю конечный результат, в сокращении. Все интеллектуальные блуждания и затруднения не описываю: слишком они перепутаны. Частенько забредал не туда, поэтому приходилось переосмысливать и переделывать вроде бы завершенное.
В начале было слово
В соответствии с реализованной мной концепцией, в качестве первичного элемента имеем слова с известными нам морфологическими признаками.
Морфологические признаки слов возвращает парсер Solarix – казалось бы, проблем нет. Однако проблемы имеются в связи с тем, что некоторые словосочетания имеют общую нераздельную семантику, в связи с чем должны восприниматься ИИ в качестве единого элемента.
Я насчитал четыре вида подобных словосочетаний:
1. Фразеологические обороты,
К сожалению, парсер их не возвращает.
Слесарь бил баклуши.
Для парсера «бить баклуши» – для разных слова, хотя семантическая основа тут одна, и воспринимать словосочетание необходимо так, как его воспринимает наш мозг: слитно.
2. Имена собственные,
Александр Сергеевич Пушкин.
Ясно, что это единый указатель на единственный предмет, хотя отдельные составляющие его слова могут быть использованы в других указателях.
3. Поговорки, пословицы, афоризмы.
Они, как правило, также представляют собой единое смысловое поле.
Старый конь борозды не портит.
4. Составные служебные слова (вследствие чего, из-за того что, по причине и т.п.)
Парсер возвращает некоторые из них слитно, другие – нет.
5. Просто устойчивые словосочетания типа «книжного магазина». Не приставишь любое прилагательное к существительному «магазин», хотя бы соответствующие изделия в нем и продавались. Никто не скажет «макаронный магазин», даже если в магазине торгуют исключительно макаронами.
Составные слова – независимо от их типа – необходимо обрабатывать так, как если бы они были единой слитной конструкцией… Но как узнать, какие словосочетания относятся к данной группе?
Наиболее очевидное – посредством прямого на то указания:
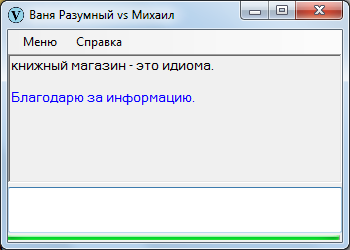
Более сложный, применимый лишь к именам, вариант – определение фразеологизмов по заглавным буквам:
- некоторые имена собственные, в частности ФИО, имеют все заглавные буквы
- другие собственные имена лишь начинаются с заглавной буквы (например, Аральское море).
Ясно, что определять составные слова возможно по их повторяемости, но это затруднительно. Более простым и действенным способом могло бы стать использование словарей, однако со словарями вышла незадача: использовать их в рамках реализованной концепции не удалось (на что посетую в конце поста).
Субъект – Действие – Объект
Слова определены, их свойства зафиксированы, что дальше? Дальше необходимо определить костяк фразы: любой разработчик ИИ наверняка приходил к тому же выводу.
Вот фраза:
Плотник выстругал доску.
Что можно о ней сказать, ориентируясь исключительно на синтаксис?
Можно сказать, что:
1. Субъект (существительное именительного падежа) – то, что выполняет действие.
2. Объект (существительное не именительного падежа) – то, на что направлено действие.
3. Само действие – глагол.
При страдательном залоге субъект и объект меняются местами. При этом страдательный залог может быть преобразован обратно в действительный: объект – при страдательном залоге всегда он находится в творительном падеже – в таком случае превращается в субъект именительного падежа, а субъект превращается в объект винительного падежа.
Было:
Плотник выстругал доску.
Стало:
Доска выстругана плотником.
Иначе говоря, залог делает фразу инвариантной.

В некоторых случаях инвариантность фразы практически неопределима, к сожалению.
Имеем высказывание:
Спички лежат в коробке.
Его можно переформулировать:
Коробок содержит спички.
Содержание обеих фраз идентично, однако выражаемые глаголами действия формально разнонаправленны (в первом случае спички воздействуют на коробок, во втором случае – наоборот), при этом залоги обоих глаголов активные.
«Лежать» и «содержать» – это даже не антонимы, а нечто такое, чему в лингвистике, насколько я понимаю, нет названия. А если нет названия, то и словарей подобных терминологических пар быть не может: затруднение, с которым ИИ неминуемо столкнется при попытке «осмыслить» поступившую информацию.
Совместное употребление триады не обязательно: любой из названных элементов может во фразе отсутствовать.
Бегемот двинулся.
Вечер.
Светало.
И наоборот, элементы могут присутствовать в предложении во множественном числе, например:
Вася и Петя подрались.
Что касается множественности, то после долгих размышлений и переделок мной были установлены следующие правила обработки:
1. Субъект в предложении присутствует всегда. При отсутствии субъекта в исходный текст вставляется заглушка, обозначающая существительное.
Светало.
Преобразуем в:
[Noun] светало. Иначе говоря: Что-то светало.
2. Действие может отсутствовать при отсутствии объекта. При наличии объекта вставляется заглушка, обозначающая глагол.
Шаг в бездну.
Преобразуем в:
Шаг [verb] в бездну. Можно трактовать как: Шаг [направлен] в бездну.
3. Объект в предложении может отсутствовать. Никакой заглушки при этом не применяется.
Он поехал.
Увеличивать фразу до «Он поехал [noun]» нет смысла, ведь едут не обязательно куда-то: термин может обозначать начало движения.
4. Субъект и объект могут быть множественными. Фраза при этом не разделяется.
Множественные субъекты:
Мальчик и девочка смотрели телевизор.
Множественные объекты:
Охотник добыл лося и кабана.
5. Действие допускается только единичным: при множественности действий фраза разделяется по числу глаголов.
Дворник улыбнулся и погрозил пальцем.
Преобразуем в:
Дворник улыбнулся. Дворник погрозил пальцем.
В этом случае фраза требует разделения.
Свойства элементов
Свойства основных элементов (то есть существительных и глаголов) – это в основном их морфологические признаки: род, падеж, лицо, число, переходность, возвратность, модальность и другое – все то, что возвращает парсер Solarix. Плюс прочие, не рассматриваемые лингвистикой. Я использовал характеристики не вполне канонические: отрицание, закавыченность, знак препинания (который посчитал свойством предыдущего слова) и т.п.
Некоторые из названных свойств единичны (например, род: не бывает слов одновременно мужского и женского родов), другие множественны. К множественным свойствам относятся, к примеру, число и дата. Можно сказать «5 лошадок», а можно: «Не меньше 3 и не больше 7 лошадок»: во втором случае оба числительных относятся к одному слову, тем самым являются его множественными свойствами.
Важно, что остальные части речи представляют собой свойства основных элементов либо некие вспомогательные сущности типа ссылок, в частности:
• прилагательное – свойство существительного,
• наречие – свойство глагола (как правило),
• предлог – свойство существительного,
• союз – маркер множественности элементов (как правило),
• местоимение – ссылка на предыдущее существительное,
• числительное – указатель на число субъектов или объектов.
Разделение предложений на секторы
Выше был упомянут случай, требующий разделения предложения на части (пример с дворником). Этот случай не единственный – встречаются другие.
Самое очевидное: сложносочиненные и сложноподчиненные предложения.
Юноша улыбнулся, и девушка улыбнулась в ответ.
Купальщик плюхнулся в воду, которая была холодна.
Разделяем на:
Юноша улыбнулся. Девушка улыбнулась в ответ.
Купальщик плюхнулся в воду. Вода была холодна.
Чуть менее очевидны причастия и деепричастия. Тем не мене они выражают действия, что приводит к необходимости разделения.
Автомобиль, развернувшись на месте, врезался в отбойник.
Развернувшийся на месте автомобиль врезался в отбойник.
Разделяем:
Автомобиль развернулся на месте. Автомобиль врезался в отбойник.
Тот же самый результат был бы получен при множественности глаголов, с которыми причастия и деепричастия взаимозаменяемы.
Автомобиль развернулся на месте и врезался в отбойник.
Конечная конструкция у всех трех исходных вариантов примера идентична.
Разделять предложения необходимо не только в вышеназванных случаях, но и во многих других, в том числе таких, для которых, казалось бы, разделение противопоказано.
Такой пример:
Хорошо гулять по осеннему лесу.
Что тут разделять, когда все слитно и компактно? Немного озадачивает отсутствие субъекта, поскольку, как мы договорились, субъект должен выражаться существительным, а здесь он… наречие что ли? Ан нет, разделение необходимо!
[Noun] гулять по осеннему лесу. Хорошо. В смысле: Кто-то гуляет по осеннему лесу. Это хорошо.
Выше было сказано, что падежи служат для различения субъектов и объектов: падеж субъектов – именительный, тогда как падеж объектов – не именительный. Профессиональные лингвисты со мной вряд ли согласятся: им известна уйма случаев, когда объекты пребывают в не именительном падеже, как и субъекты.
Коттедж – это жилище.
Не только субъект, но и объект в именительном падеже. Исключение, скажете вы? Можно сослаться на исключение, однако логичней посчитать указанную конструкцию двумя фразами, объединенными особым свойством. Я называю такие фразы, полученные посредством разделения предложения на части, секторами.
Суть в том, что один сектор является определением другого (или даже множества предыдущих секторов. Ввиду сложности данного функционала я даже не пытался его реализовать).
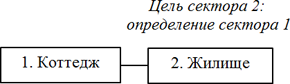
Здесь второй сектор является определением первого. И никаких тебе объектов в именительном падеже!
Главное, конечно, то, что свойствами могут обладать не только отдельные элементы, но и секторы.
Помимо цели, я использовал такие свойства секторов, как:
• тип сообщения (утверждение, распоряжение, вопрос),
• тип вопроса,
• залог (имело ли место преобразование страдательного залога в действительный),
• обращение (к собеседнику по имени: да или нет),
• склейка,
• валидность,
• время,
• вероятность.
Склейка
Как принято именовать данную сущность у лингвистов, понятия не имею. Может быть, соединительное слово?
Итак, склейки служат для связи между секторами. Попросту говоря, это служебные слова типа «поэтому», «когда», «вследствие чего», «ввиду того что» и т.п.
Допустим, имеем сложноподчиненное предложение со склейкой «поэтому».
Ветер подул, поэтому листва зашелестела.
Ясно, что две части связаны между собой как причина и следствие: об этом свидетельствует склейка «поэтому».
Склейка может отсутствовать, тогда обнаружить ее проблематично – практически невозможно.
Ветер подул, и листва зашелестела.
В физической реальности мы ориентируемся на зрение, а если общение происходит на вербальном уровне, то на интонацию и на визуальный опыт, и обычно угадываем, но только не в царстве слов. Как отличить приведенную фразу, обозначающую причину и следствие, от заурядной последовательности событий?
Ветер подул, и пробежал заяц.
Заяц пробежал-то вовсе не от того, что ветер подул – мы знаем, – но из синтаксиса этого не следует, хотя не следует и обратного. Кто его знает, как случилось на самом деле? Может, ветер подул, в результате чего обломилась ветка, заяц испугался и побежал – в этом случае дуновение ветра является причиной того, что заяц побежал.
Названная проблема не решаема для чат-бота в принципе: физическая реальность – одно, вербальная сфера – другое. Элементная база разная (под элементной базой я понимаю способ восприятия реальности: для чат-бота это письменная речь).
Валидность
Некоторые фразы оказываются некорректными. Ясно, что если выдать ИИ откровенную белиберду, он не поймет.
Однако даже фраза, выстроенная на первый взгляд в соответствии с правилами синтаксиса, может оказаться бракованной вследствие разных нюансов, к примеру:
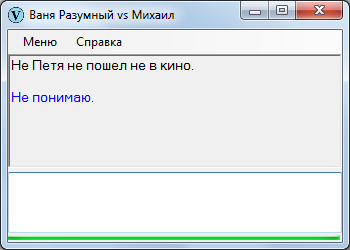
Вы, что ли, способны такую фразу воспринять? Если да, примите поздравления, потому что я при попытке осмысления впадаю в ступор: мозг отказывает. При этом упрощенные варианты воспринимаются обыденно:
Петя не пошел в кино.
Петя пошел не в кино.
Не Петя пошел в кино.
Люди познают мир в соответствии с заложенными в их головы алгоритмами, но стоит им получить нестандартную информацию, хваленый ум куда-то испаряется.
Очевидно, что инвалидные фразы необходимо беспощадно отбраковывать при обработке.
Основные признаки инвалидных фраз, в моей интерпретации:
• отсутствие значащих слов (существительных и глаголов),
• слишком большое число слов, не опознанных парсером в качестве частей речи,
• наличие существительного в не именительном падеже при отсутствии глагола (ошибка в алгоритме, поскольку в таких случаях глагол вставляется принудительно),
• слишком большое число отрицательных частиц (см. выше),
• слишком большое число дат в отсутствие перечисления (обычно в предложении фигурирует либо одна дата, либо, в случае указания на период, две даты),
• наличие двух глаголов (следствие ошибки в алгоритме),
• одинарность союза (если обнаружено, к примеру, одиночное «или», то имеет место ошибка либо во фразе, либо в алгоритме),
• неодинаковость союзов (одновременное использование альтернативных союзов «и», «или»).
Вставка недостающих слов. Замена ссылок
Предложение формализовано, пора записывать? Рано. Требуется вставить недостающие слова и заменить ссылки.
Возьмем для примера диалог:
— Петров, как здоровье?
— Нормальное.
— А у жены?
— Тоже.
Формализация требует восполнения недостающего, приблизительно так:
— Как здоровье Петрова?
— Здоровье Петрова нормальное.
— А как здоровье у жены Петрова?
— Здоровье у жены Петрова тоже нормальное.
После этого – не раньше – можно приступать к обработке текста с последующей записью в базу.
Вот и она – база, со всеми свойствами, также вспомогательными и справочными таблицами.
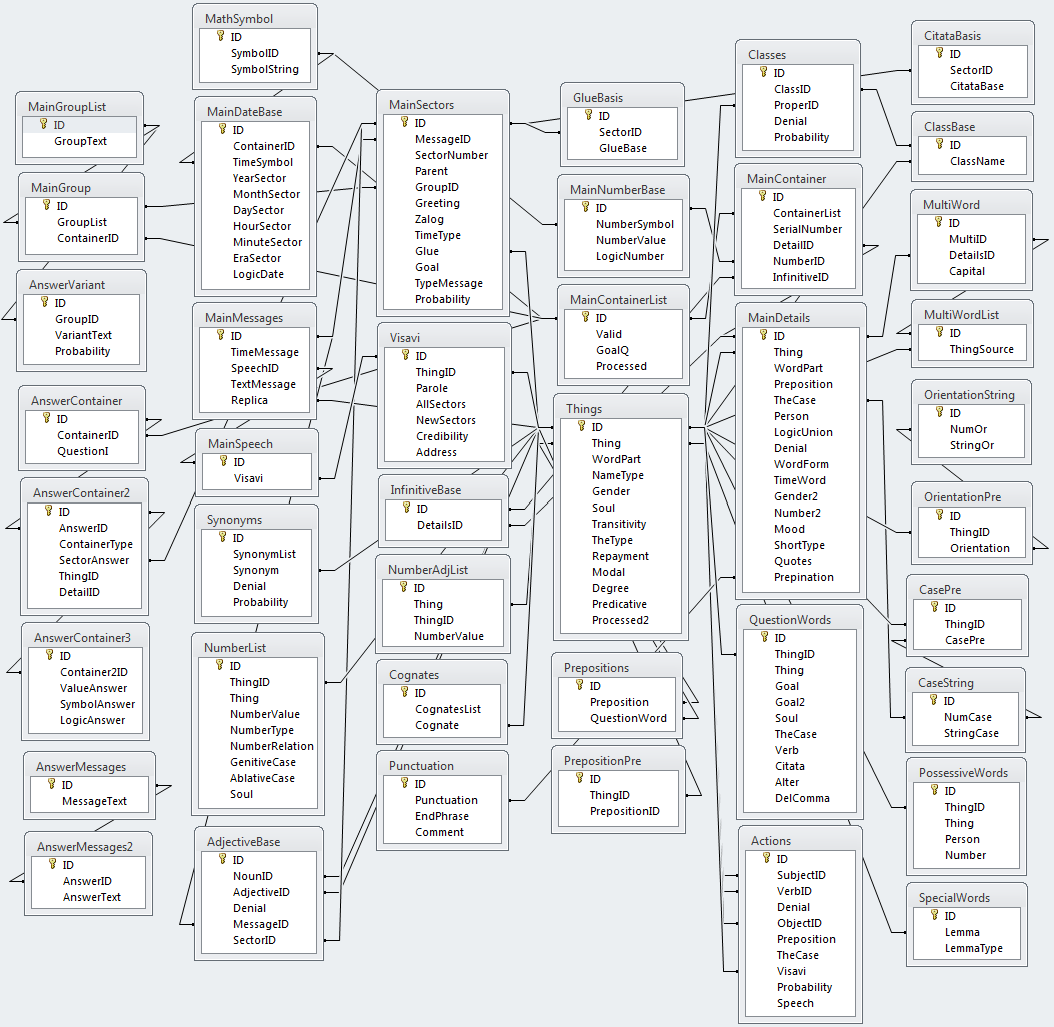
Иерархическая структура:
1. Беседа (сеанс связи с собеседником).
2. Сообщение (текст, который выдает собеседник зараз).
3. Предложение (информационная единица сообщения).
4. Сектор (часть предложения).
5. Слово.
Не Бог весть что, особенно для читателей здешнего ресурса… Но я ж дилетант, мучился долго.
Общение
После записи реплики собеседника в базу можно приступать непосредственно к общению. Проблема – каким образом общаться? Сказать что-то утвердительное? Задать встречный вопрос? Попросить чего-нибудь?
Методом проб и ошибок вырисовалась схема.
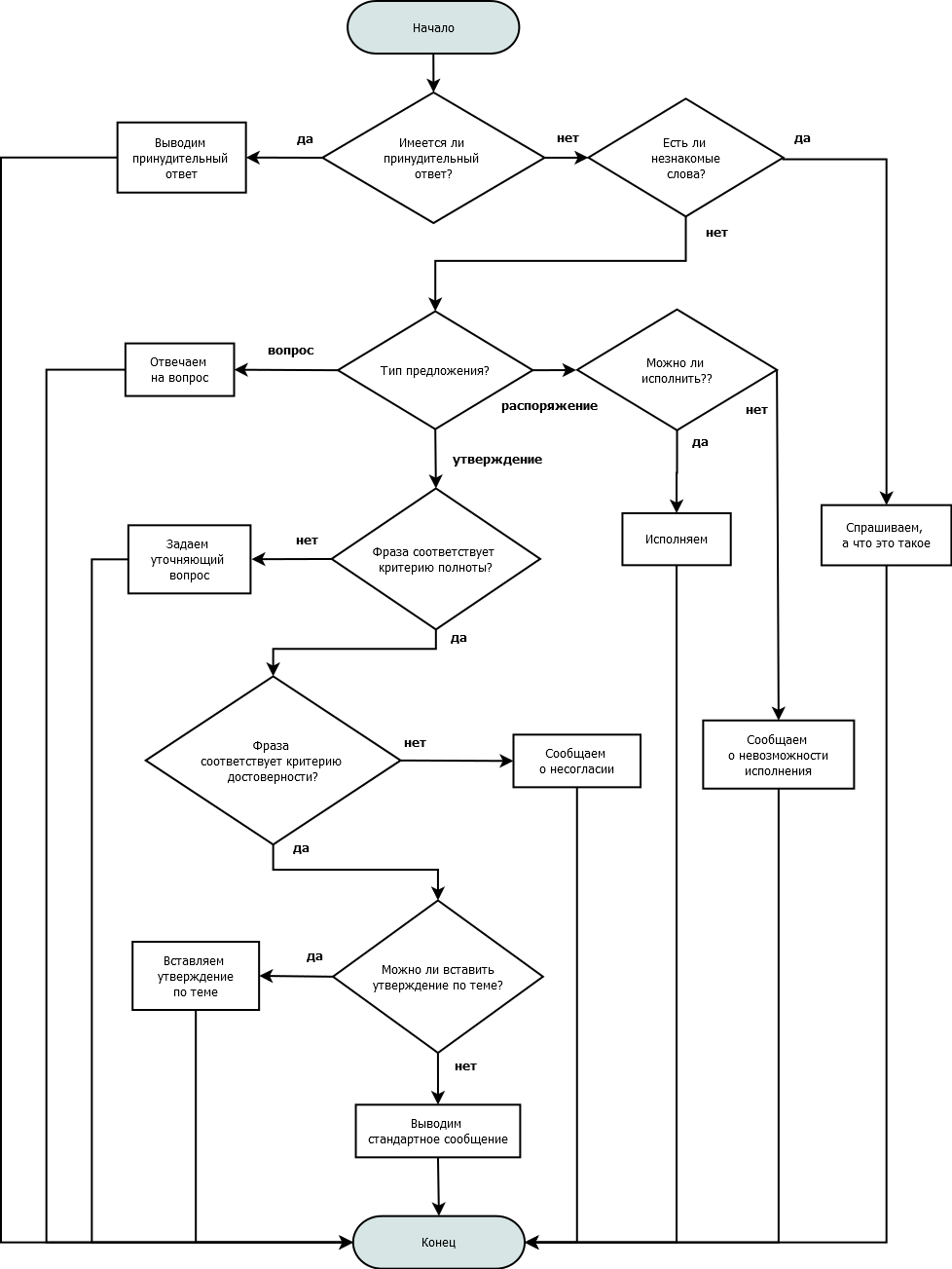
Принудительный ответ – это, к примеру, когда предложение инвалидное или собеседник установил, что на такую-то фразу нужно отвечать таким-то образом.

Информационная неполнота – когда удается установить, что в предложении отсутствуют значащий элемент, как правило объект.
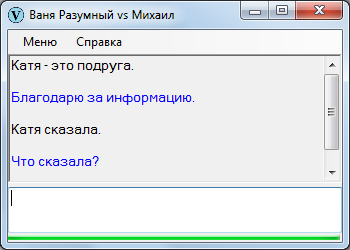
Что сказала-то? Любой человек, услышав подобное, первым делом уточнит, что имеется в виду.
Достоверность – соответствие тому, что записано в памяти. Если кто-то слышит «Гагарин не летал в космос», а в его памяти записано обратное, он опять-таки попросит (должен попросить) разъяснений.
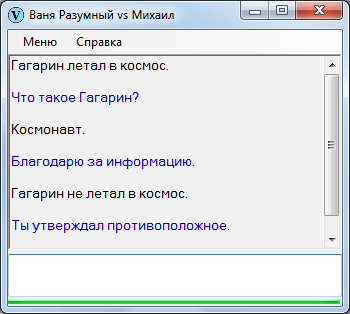
Естественная реакция.
При необходимости отвечать стандартно Ваня Разумный осуществляет выбор из типового набора ответов случайным образом.
Надо сказать, что с типовыми сообщениями я особо не заморачивался по причине того, что добиться полного сходства с человеческой реакцией невозможно по определению. Допустим, чат-бот выдает стандартное «Я согласен». Можно, подобрав синонимичные сообщения, возвращать их рандомно:
Точно так.
Ты прав.
Верно говоришь.
Твоя правда.
и т.п.
Однако любой из этих синонимов обладает смысловыми отличиями от собратьев, ввиду чего их употребление вовсе не идентично. Нюансы, которые легко распознаются людьми по мимике и интонации собеседника, но не могут быть идентифицированы на синтаксическом уровне. Это вам не синтаксис – это физическая реальность.
Да на уровне синтаксиса нельзя даже отличить отрицательный ответ от положительного!
Возьмем два привычных для нас альтернативных ответа на один и тот же вопрос:
Еще как!
Вот еще!
Первый из ответов означает «Да», а второй – «Нет». Определить значения по синтаксису нет никакой возможности.
Типы предложений
Основную роль в диалоге играют типы предложений:
1. Распоряжение.
2. Утверждение.
3. Вопрос.
Самое элементарное из всех – распоряжение. Ваня Разумный пытается по действию понять, чего хочет собеседник: если может исполнить, то исполняет, в противном случае сообщает об отказе.
Ну что чат-бот может исполнить? Сказать о чем-то, выполнить команду.
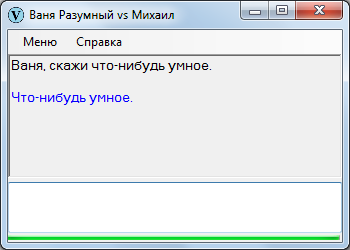
Ничего стоящего внимания.
При утвердительном высказывании собеседника реакция в общем случае сводится к поиску встречного утверждения по теме, где тема – субъект или объект, по желанию.
Космонавт полетел на Марс.
В ответ, найдя в базе утвердительное предложение со словом «космонавт», можно выдать:
Космонавты храбрые.
А можно поискать по объекту, возвратив что-нибудь вроде:
Марс – это красная планета.
Но нет гарантий, что в базе не отыщется неподходящая фраза, типа:
Планетолет вез на Марс мусорные контейнеры.
Подобрать критерии?.. Но какие??? После долгих раздумий я установил, что в качестве ответного утверждения по теме ИИ должен выдать фразу, обозначающую личное отношение к предмету:
Я не летал на Марс.
Опять-таки, если подобная фраза отыщется в базе.
Вместо ответного утверждения может генерироваться вопрос: в случае если в затронутой теме Ваня чего-нибудь недопонял.
Вопросы
Вопросы подразделяются на два подтипа, которые для себя я обозначил как общие и специальные.
Общие вопросы – без вопросительного слова, допускающие ответы «Да» или «Нет».
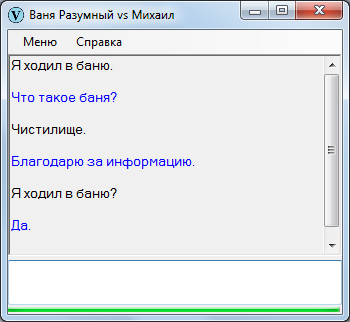
Специальные вопросы требуют в каждом случае индивидуального ответа, тут простым «Да» или «Нет» не отделаешься.
Сколько на Земле людей?
Почему слоны большие?
Кто такой Наполеон?
Пришлось систематизировать вопросительные слова. Каждому вопросительному слову – которых, по счастью, все же немного, – ставился в соответствие тип. Получился список вида:
Вещь: что?
Имя: кто?
Место: куда? где?
Прилагательное: какой?
Наречие: как?
Число: сколько?
Дата: когда?
Причина: почему?
И так далее.
При отсутствии вопросительного слова вопрос общий.
При общем вопросе Ваня Разумный ищет ответы не только непосредственно на него, но в случае отрицательного ответа и на все специальные вопросы, сгенерированные по основному общему. Цель – выдать в качестве ответа альтернативный сектор.
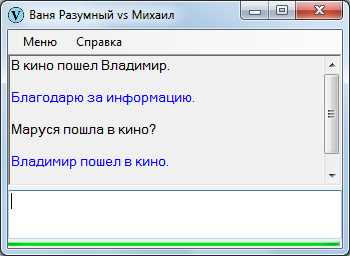
Ответы
Поиск ответа осуществляется, вестимо, по шаблонам:
- Берем слово, со всеми морфологическими признаками, и ищем секторы, в которых указанная словоформа присутствует. Так по всем словам вопросительной фразы.
- Затем находим пересечение результатов, полученных по каждому слову. Сектор, являющийся пересечением, является ответом. Если секторов несколько, выбираем какой больше понравится.
Установив сектор-ответ, можем выдать собеседнику «Да», или «Нет», или «А черт его знает», – но это по общему вопросу.
Если вопрос специальный, делаем все то же самое, с единственным отличием. Для вопросительного слова ищем лишь его морфологические признаки, без самого слова.
Допустим, спросили:
Кто выстрелил?
Для «выстрелил» ищем «выстрелить» с заданными морфологическими признаками, а для «кто» – любое слово с заданными морфологическими признаками. Сектор, в котором присутствуют оба слова, и будет ответом.
В некоторых случаях (на самом деле, во многих) единичный поиск по вопросительному слову с заданными морфологическими признаками не сработает, поэтому искать приходится многократно.
Спрашиваем:
Какой мальчик?
«Какой» – вопросительное слово для прилагательного, то есть в общем случае Ваня должен искать прилагательное. Если в базе для данного существительного находится прилагательное, выдается соответствующий ответ.

В иной ситуации ответом может послужить не только прилагательное, но и нечто другое, например причастие.

Причастие выражает действие, поэтому, с некоторой точки зрения, любое действие характеризует субъект не менее прилагательного и причастия.
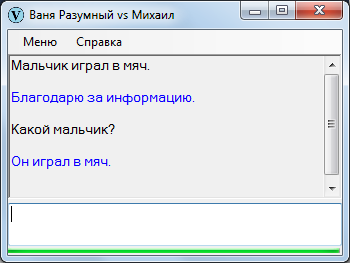
Более сложный, связанный с поиском субъекта, вариант подмены шаблона:
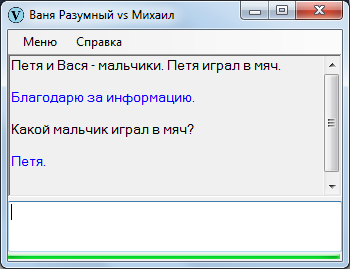
Подобных вариантов с пару десятков: это то, что мне удалось обнаружить.
Обратите внимание: один результат может оказаться ответом сразу на несколько вопросительных подтипов.
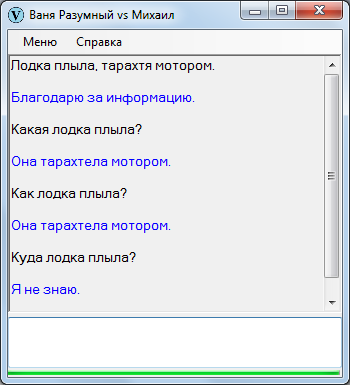
На последний вопрос ответа не находится – Ваня соответственно и не отвечает.
Последовательный поиск по связанным секторам
Допустим, у чат-бота спрашивают:
Куда глупый Петя пошел?
На самом деле вопрос разбивается на два связанных сектора:
Куда Петя пошел? Петя глупый?
При этом не факт, что оба ответа окажутся положительными или отрицательными: вполне можно представить, что Петя пошел в магазин, но при этом Петя совершенно не глупый.
Приходится сначала проверять достоверность определений, затем уже отвечать на главный вопрос.

В данном случае сведения об определении Пети отсутствуют, поэтому отвечать на основной вопрос нет резона.
Аналогичным образом необходимость поиска по нескольким секторам возникает при общих вопросах, выраженных в сложносочиненных или сложноподчиненных предложениях.
Я поймал жереха, который погнул весы?
После разделение предложение преобразуется в секторы:
Я поймал жереха? Жерех погнул весы?
Так же во всех остальных случаях, требующих разделения на секторы. Затруднение, хотя преодолимое.
Противоречивость информации
Представим, что у ИИ спрашивают, сколько космонавтов летало в космос. Хорошо, если в базе значится одна фраза:
В космос летало 40 космонавтов.
А если там другая фраза присутствует?
В космос летало 45 космонавтов.
40 или 45, кому верить? Вероятно, один из источников лжет, но который? Можно поверить тому либо другому, но критерии веры каковы? Очевидно, рейтинг источника. Но каким образом ИИ может определить рейтинг источника, если все собеседники для него, строго говоря, одинаковы?
Мне показалось логичным, чтобы ИИ стремился к получению максимального объема знаний, то есть: собеседник, предлагающий новую (отсутствующую в базе) информацию – хороший, не предлагающий – плохой.
В итоге был реализован следующий механизм:
- Рейтинг собеседника рассчитывается на основании отношения выданных новых секторов к общему их числу – соответственно, изменяется с каждой фразой.
- Сектору присваивается текущий рейтинг собеседника.
- Если секторы разных собеседников антагонистичны, доверие вызывает тот, который обладает наибольшим рейтингом.
- Если антагонистичны секторы одного собеседника, последний по времени сектор считается истинным (то есть себя можно в любой момент поправить, но поправить утверждение другого визави возможно, если обладаешь бОльшим рейтингом)).
В результате ИИ способен определить, какому из двух высказываний верить.
Думаете, проблема с количеством космонавтов решена? Ничего не решена, потому что оба источника могут оказаться правдивыми. По состоянию на 1 января числилось 40 космонавтов, в течение года 5 человек слетало в космос, по состоянию на 31 декабря числится 45 космонавтов. Только откуда ИИ об этом знать?!
Инвариантность
С чем возникли серьезные трудности, так это с инвариантностью, причем настолько серьезные, что хотел бы я познакомиться с человеком, которому удалось разрешить их в рамках синтаксиса. Я вообще не уверен, что такой человек уже родился.
Итак, одно и то же сообщение можно сформулировать по-разному:
Я заболел.
Мне неможется.
Меня ломает.
Плохо себя чувствую.
Я нездоров.
Недомогаю.
Здоровье ни к черту.
И т.п.
Кое-какие мелочи на этом пути преодолимы.
Синонимы – самое очевидное и повсеместно реализованное решение.
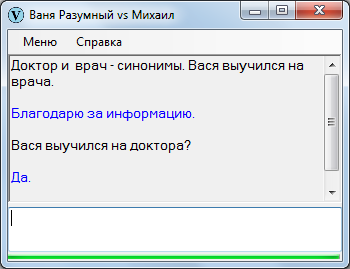
Еще можно использовать однокоренные слова, к примеру:
Болезнь.
Боль.
Заболеть.
Заболевание.
Больно.
Вот фразы с ними, выражающие, по сути, единственную мысль.
Он подхватил болезнь.
Он испытывает боль.
Он заболел.
У него заболевание.
Ему больно.
К сожалению, возможно сформулировать и без использования однокоренных слов. Например:
Здоровье пошатнулось.
Поэтому в рамках синтаксиса полное и безусловное решение проблемы инвариантности отсутствует. Чтобы решить проблему инвариантности, нужен не чат-бот, а ИИ, обладающий полным набором человеческих ощущений.
Что такое интеллект
Речь дошла до интеллекта, на нем и сосредоточусь.
Лично я (хотя у каждого собственное мнение, понимаю) насчитываю три пункта, делающие мыслящее существо таковым:
1. Обратная связь.
2. Мышление.
3. Рефлексия.
Обратная связь – зависимость реакции от предыдущего опыта. Реализуется примитивным образом, за счет записи информации в базу данных. Сначала ИИ чего-то не знал, потом услышал, запомнил и теперь знает – это и есть обратная связь.
Мышление – процесс генерирования новой информации, непосредственно не получаемой от собеседника. Собеседник выдает сообщение, ИИ анализирует и приходит к собственным выводам.
Ваня Разумный делает выводы, затем записывает их в базу с пометкой «идея» (свойство сектора). Все мышление, собственно.
Так мыслим мы:

Так должен мыслить ИИ:

Вопрос не в том, что такое мышление, а в том, каким образом искусственное мышление должно быть организовано…
Мышление при помощи классов
В качестве основы мышления я (не сомневаюсь, что подобно многочисленным предшественникам) использовал классы. В математике это называется множествами, в лингвистике – гиперонимами, но мне больше нравится дарвинистско-программистское «классы». Бульдог относится к классу собак, собаки относятся к классу животных, и так далее вверх и вниз по иерархии.
Правила пользования тривиальны:
- Понятия могут относиться одновременно к нескольким классам. Например, Сидоров одновременно относится к классу мужчин и к классу курильщиков.
- Классы не могут зацикливаться в своей иерархии. Понятие, расположенное на какой-либо иерархической ветке, не может повториться ниже или выше по своей иерархии. Если Сидоров относится к классу курильщиков, то курильщик не относится к классу Сидоровых.
Самое познавательное не в классах и не в их членах, а в том, откуда взять нужную информацию для таксономии.
Придумалось следующее.
Во-первых, определять принадлежность того или иного понятия к классам из дефиниций – так сказать, напрямую.

Если Жучка собака и все собаки гавкают, довольно очевидно, что Жучка тоже умеет гавкать.
Заменим в исходном утверждении «собаку» на «Тузика». Логично предположить, что если собака Тузик умеет гавкать, то и собака Жучка тоже умеет?

Не логично. Что если вместо «гавкать» вставить «рожать щенят»? Тузик этого не умеет, а Жучка – запросто. По этой причине поиск выдал отрицательный результат. Вместе с тем был обнаружен альтернативный сектор (умение Тузика гавкать), который и стал ответом – по-моему, достаточно познавательным.
Другой способ обнаружения классов – перечисления. Исходная посылка: слова, связанные некоторыми союзами (и, или, а, кроме) или запятыми в связи с перечислением, принадлежат хотя бы одному общему классу.

Я ни словом не обмолвился, что Жучка – собака: Ваня Разумный сам сделал вывод из полученной информации. В ином случае мог и ошибиться: к примеру, если бы я написал «Тузик – это кобель», потому что Жучку к кобелям никак не причислишь. Пришлось бы вносить коррективы.
Что я и сделал, собственно, а Ваня соответствующим образом среагировал, хотя не без огрехов.

Следующий способ – некоторые вопросительные наречия (куда, где, откуда, когда). Если такая склейка относится к слову, можно сделать вывод о принадлежности слова к определенному классу (места или времени).

Наконец, действия. Выполнение субъектами одних и тех же действий с большой вероятностью свидетельствует о наличии у субъектов общего класса. Как говорят американцы, если что-то плавает, как утка, летает, как утка и крякает, как утка, то это и есть утка.

Способ неточный, ведь выполнять одинаковые действия могут объекты, принадлежащие разным классам. Однако если все выполняемые действия совпадают, это не может не навести на определенные мысли.
В итоге, процесс мышления можно уподобить разгадыванию паззлов, когда по имеющимся кускам информации восстанавливается полная картина.

Если вы полагаете, что мыслите как-то иначе, то навряд ли… Представьте, что знакомый Петров хвастает: «У меня дочь – первоклассница». Что вы можете сказать о его дочери, о которой впервые слышите? Принадлежность к классу «первоклассница» говорит о возрасте субъекта. Возраст (тоже в некотором смысле класс) свидетельствует о примерном росте, весе, интеллектуальных возможностях и прочем. Женский род (опять-таки класс) позволяет предположить первичные и вторичные половые признаки, а принадлежность к фамилии «Петров» (класс, все класс) доказывает, что искомая первоклассница такая же дура, как все известные вам Петровы.
А если серьезно, то в своих выводах мы оперируем принадлежностью субъекта к определенному набору классов, а более ни к чему. И чем наше хваленое человеческое мышление отличается от заурядных машинных алгоритмов?! Ничем.
Мышление при помощи каузальности
Процесс мышления следует базировать не только на классах, но и на каузальности (причинно-следственных связях).
Над Атлантикой изменилось давление, поэтому подул ветер. Подул ветер, поэтому с головы слетела шляпа. С головы слетела шляпа, поэтому шляпа упала в лужу. Шляпа упала в лужу, поэтому шляпа промокла.
Если идти по каузальной цепочке с конца в начало, неизбежно придем к начальному выводу:
Шляпа промокла, потому что над Атлантикой изменилось давление.
И попробуйте сказать, что вывод неверен!
А ведь подобные каузальные цепочки могут составляться не только по последовательным, но и по разрозненным фразам, в результате выводы, сделанные ИИ, окажутся неожиданными!
Есть и второй способ установить каузальность. Он связан с использованием известной нам триады: субъект – действие – объект.
В чем исконный смысл триады? Да именно в том, что в цепочке происходящих событий выражается каузальность между субъектом и объектом. События происходят одно за другим, причем прошлый объект становится субъектом, в свою очередь воздействующим на другой объект, и т.д.

Указанная последовательность представляет собой каузальную цепочку, в которой:
а) причиной того, что гантель упала, является то, что дедушка взял гантель,
б) причиной того, что нога заболела, является то, что гантель упала на ногу.
Чистый синтаксис, при котором ИИ понятия не имеет, ни что такое дедушка, ни что такое гантель, ни что такое нога.
Согласно имеющейся базе знаний, гантель может упасть на ногу только в названном случае – ни в каком другом.
Представим, что в базу добавляется новые записи:
Мальчик купил гантель.
Бабушка положила гантель на комод.
В результате возникают новые потенциальные возможности того, что гантель упадет на ногу, вследствие чего дедушкина нога заболит.
Имеем веер сходящихся возможностей, весьма пригодный для анализа.
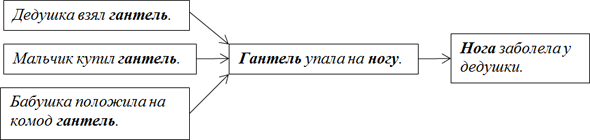
Существо, основывающее свое мышление на правилах синтаксиса, может сделать вывод о том, что, если мальчик купил гантель или бабушка положила гантель на комод, то гантель может упасть на ногу, со всеми вытекающими последствиями. Правомерно поинтересоваться:
Гантель не упадет на ногу?
Или, на следующем витке каузальности:
Нога не заболит у дедушки?
По сути, это предугадывание будущего, но не только. Еще и восстановление прошлого, так как двигаться по каузальной цепочке возможно не вперед, но и назад.
Таков он, механизм предугадывания:

Центральная триада на схеме – текущая. Если субъект текущей триады и какой-либо объект в последующей каузальной цепочке совпадают или хотя бы принадлежат одному классу, имеем каузальную связь в рамках одного субъекта-объекта. То же самое – относительно предыдущей каузальной цепочки.
Образчик реализации:

Ущипните меня, если это не мышление!
Конечно, наличие каузальности далеко не очевидно, если наблюдатель находится в физическом мире.
Я увидел березу. Береза шелестела листвой.
Нам, существующим вне правил синтаксиса, понятно, что береза шелестит листвой вовсе не оттого, что кто-то ее увидел, но с точки зрения синтаксиса дела обстоят именно так. Кто бы тогда шелестел листвой, если бы я не увидел?!
Сколько пользуюсь русским языком, столько убеждаюсь, какое это расчудесное чудо!
Рефлексия и параллельные миры
Помимо обратной связи и мышления, ИИ требует рефлексии.
Вспоминаю, в одном фильме о роботах миллиардер-изобретатель бегал по коридору с радостными воплями: «Она (искусственная женщина) себя осознает! Она себя осознает!»
Наивный! в рефлексии нет никакой тайны, даже в рефлексии живых существ, не то что в рефлексии ИИ.
Мы осознаем себя в качестве субъекта исключительно по той причине, что наше тело отделено от нашего мышления. Чат-бот также способен рефлексировать исключительно за счет мышления, а что это такое, мы выяснили: генерирование собственных, отличных от реплик собеседника, сообщений. Иначе говоря, мыслящий чат-бот должен генерировать внутренние (направляемые непосредственно в базу, а не на десктоп) сообщения о самом себе. Это не составляет сколь-либо заметной проблемы.
Можно, к примеру, генерировать мысли по репликам собеседника: собеседник выдает информацию об ИИ – тот анализирует и приходит к каким-либо выводам. В процессе анализа несомненно рефлексирует: осознает себя.
Можно отталкиваться от сообщений не собеседника, но собственных.
Допустим, сгенерирован вопрос, в соответствии с объявленной выше схемой:
Что такое движение?
Что это означает? То, что означает: сгенерирован вопрос. Идея записывается в качестве таковой, от имени ИИ:
Я задал вопрос.
В базу записываем, но в качестве ответа не выводим: это и есть рефлексия.
Понятно, что идей можно сгенерировать множество – столько, сколько потянут вычислительные мощности и фантазия Создателя. Если вопрос задает собеседник и записывается собственная мысль уже не о самом себе, но о собеседнике – это мышление. Короче, мышление о самом себе – это рефлексия, а мышление о внешнем мире – не рефлексия.
В результате мышления миры распараллеливаются. В низовом, изначальном мире, соответствующем физическому миру людей, происходит обмен сообщениями:
— Как твои дела?
— Прекрасно.
В высшем мире, соответствующем нашему миру идей, рождаются мысли. Одни мысли относятся к внешнему миру (не рефлексия), другие – к самому себе (рефлексия).
Собеседник задал вопрос.
Я ответил на вопрос.
Или:
Собеседник почему-то волнуется.
Я абсолютно спокоен.
Миры смешиваются воедино, иногда до полной неразличимости.
Реплика:
Ты точно влюбился?
Ее основная смысловая часть «ты влюбился?» принадлежит непосредственно диалогу, тогда как наречие «точно» – внешнему миру идей. Полная реконструированная фраза должна бы звучать следующим образом:
Ты точно уверен, что ты влюбился?
Первая часть фразы относится к миру идей, тогда как вторая – к миру диалога.
В результате, при работе с параллельными мирами возникает необходимость обрабатывать не только семантику сообщений, но и некие внешние по отношению к ним характеристики. Вот только как?
Допустим, собеседник спрашивает:
— Сколько сейчас времени?
Ориентируясь на низовой смысловой мир сообщений, ИИ должен бы начать шерстить по всей базе в поисках ответа.
Допустим, найдет фразу полугодичной давности:
Сейчас 15 часов 30 минут.
Вряд ли устаревшее сообщение послужит корректным ответом на текущий вопрос. А чтобы данные о текущем времени не устаревали, всегда были свежими, необходимо каждое – о Господи! – мгновение генерировать сообщение типа:
Сейчас 15 часов 30 минут 28 секунд 34 миллисекунды.
База не потянет.
Какого черта лазить по базе, если можно возвратить системное время, тем самым обратиться непосредственно к внешнему по отношению к диалогу миру?! Можно, конечно, но…
Как заметил один глубокомысленный персонаж, нельзя объять необъятное. Поэтому число верхних параллельных миров любой системы ограничено вычислительными мощностями, в конечном счете – назначением системы и здравым смыслом Создателя.
Оптимизация
В один прекрасный момент, когда работы над ИИ подходили к логическому завершению, я закачал в Ваню чуть поболе текста, чем обычно – строк этак полтыщи, – и решил насладиться общением. Не тут-то было! Юноша оказался тугодумом: как-то чересчур, до неприличия долго соображал. Выяснилось, что из-за множественности SQL-запросов.
Допустим, во фразе всего 3 слова (два существительных и глагол) – это 3 обращения к базе. Пересечение результатов по каждому обращению даст сектор-ответ, из которого при желании можно выбрать слово-ответ, в противном случае использовать в качестве ответа типовую фразу.
Если у какого-либо слова имеются синонимы, необходимо проверить базу по каждой комбинации.
Возьмем вопрос:
Доктор увидел бегемота?
Синоним «доктора» – «врач», а синоним «бегемота» – «гиппопотам», в результате получаем 3 дополнительных варианта:
Врач увидел бегемота.
Доктор увидел гиппопотама.
Врач увидел гиппопотама.
Кроме синонимов, имеются еще классы, которые тоже приходится проверять. Поскольку доктор принадлежит классу людей, ответом на вопрос будет также являться фраза:
Человек увидел гиппопотама.
Ладно, не проблема: вбить перечисления в один SQL-запрос. Хотя длина строки тоже небесконечна, приходится ее контролировать, но не суть дело…
В других ситуациях, при которых структура фразы изменяется, следовательно изменяются параметры SQL-запроса, минимальным количеством обращений к базе никак не обойтись.
Во-первых, по каждому слову необходимо проверять на отрицания:
Не доктор увидел бегемота?
Доктор не увидел бегемота?
Доктор увидел не бегемота?
Во-вторых, приходится осуществлять альтернативный поиск иного рода – я упоминал об этом ранее. Это когда на вопрос «какой?» последовательно перебираются конструкции, образованные на основе прилагательного, причастия, глагола.
Как быть? Если сократить количество SQL-запросов, ИИ лишится многих возможностей анализа, соответственно пострадает разнообразие ответов.
Тут на меня снизошло озарение. Зачем искать по базе, если каждое утверждение само по себе является ответом на известное множество вопросов?!
Некто утверждает:
Маруся пошла в кино.
Данное утверждение является ответом на общий вопрос:
Маруся пошла в кино?
Также оно является ответом на общий вопрос с отрицанием:
Маруся не пошла в кино?
Можно, добавляя вопросительные слова, составить и специальные вопросы, к примеру:
Кто пошел в кино?
Куда пошла Маруся?
Ответом на все названные вопросы является текущий сектор.
Значит, конструируя вопросы разных типов, можно вписывать их в базу, а в качестве ответа соотносить с ними исходный сектор-утверждение! При этом система не перегружается SQL-запросами: диалог течет заметно веселей, чем прежде.
Нет сомнений, что люди мыслят аналогичным образом. Если задать чересчур сложный вопрос, собеседник сразу не ответит, а задумается: сколько нужно для нахождения ответа, столько и будет думать. Зато после того как ответ найден, отвечать на последующие аналогичные вопросы начнет моментально. Иначе говоря, люди реагируют согласно имеющимся у них шаблонам: шаблон имеется – ответ следует немедленно; шаблон отсутствует – отсутствует ответ (вместо ответа вставляется «быстрая» заглушка). Значит, такой способ оптимизации не «выдуман из головы», а в известном смысле слова естественен.
С другой стороны, может быть задан вопрос, на который в базе не найдется готового ответа. Здесь оптимизация не поможет: ИИ задумается опять надолго. Во избежание длительного ожидания, при достижении установленного лимита в n секунд, приходится прерывать поиски. Тогда Ваня отвечает заглушкой типа:
Слишком сложный вопрос.
Что, опять-таки, полностью соответствует естественным алгоритмам. На слишком сложный вопрос (для вас сложный, естественно, а не для находящегося в младенческом возрасте Вани) вы тоже не ответите.
Приведенным способом возможности оптимизации не исчерпываются. Но… как говорится, чем богаты.
Принципиальная схема
Принципиальная схема Вани Разумного получилась такой:
1. Парсим текст при помощи библиотеки Solarix.
2. Обрабатываем, преобразуя в списки элементов и свойств.
3. Пишем в базу.
4. В момент записи связываем будущие потенциальные вопросы с текущим утверждением.
5. Ищем, что сказать в ответ (сектор).
6. Одновременно генерируем собственные мысли (в текстовом виде).
7. Преобразуем сектор обратно в текст (словоформы восстанавливаем при помощи библиотеки LingvoNET).
8. Выдаем ответ собеседнику.
9. Параллельно обрабатываем и записываем мысли.
О программе
Многое из задуманного не реализовано, да и вряд ли будет реализовано в будущем. Причин две:
1. Во-первых, ограниченность вычислительных ресурсов. Как я уже упоминал, во избежание затяжек времени пришлось искусственно ограничить обдумывание ответов, при том что сам мыслительный функционал примитивен. Усложнять есть куда, возможности безграничны, идеи прозрачны и на начальном уровне отработаны, но аппаратную часть желательно иметь помощней.
2. Во-вторых, явная (лично для меня) коммерческая бесперспективность данного мероприятия. Убивать еще год, чтобы удовлетворить лишний десяток читателей данного ресурса? А зачем
Между прочим, назначение будущего полноценного ИИ вовсе не выполнение голосовых команд, как то практикуется современными голосовыми помощниками, а…
1) Компьютерная психотерапия.
Вы возвращаетесь с работы расстроенный и говорите ИИ:
«Начальник дурак».
«Форменный остолоп», – заинтересованно отзывается ИИ.
Далее в том же духе. Подобный диалог проведешь не с каждым собеседником, даже близким родственником, а с компьютерным устройством – пожалуйста. Для чего устройство должно быть соответствующим образом, с учетом ваших индивидуальных характеристик, настроено и воспитано.
2) Тестирование на достоверность.
Как следует из всего текущего поста, синтаксис обладает собственной семантикой, которая может быть соотнесена с чьими-нибудь выводами. Следовательно, ИИ способен проверять утверждения на достоверность, соотнося их с предыдущими известными ему утверждениями. А если ИИ не чат-бот, а устройство, обладающее видеокамерой и другими датчиками ощущений, то не только с утверждениями собеседников, но и с реальным миром, который, как мы помним, лишь совокупность визуальных точек и иных элементарных объектов. Мы воспринимаем (видим и иным образом ощущаем) здания, деревья, облака, но ведь ИИ может воспринять нечто другое, неожиданное, «замыленное» для человеческого глаза. Что, согласитесь, гораздо интересней…
Скачать релиз можно здесь.
Исходники тут, если найдутся желающие копаться в дилетантском коде. Зачем нужен код, если Ваня Разумный – лишь иллюстрация к текущему посту, излагающему принципы создания ИИ методом «глокой куздры»?!
Системные требования
Необходимы 32-разрядные Microsoft Office и Windows. При 64-разрядной Windows требуется установить утилиту Microsoft Access Database Engine 2010 (32-разрядную).
Ну и в напоследок.
Я не программист, с меня взятки гладки. Я это к тому, что ошибок много – возможно, неприлично много, даже в диалогах, не только при чтении художественных файлов. Замечу, что ошибки встречаются не только в моем коде, но и в использованных библиотеках, хотя в меньшем количестве. Однако любая ошибка в библиотеке автоматически транслируется на диалог, это надо понимать.
Базу заполнил, насколько смог. Пара сотен фраз: начальные представления о себе и роде человеческом, правила вежливости, – на большее терпения не хватило. Воспитание младенца, даже компьютерного, – задача из трудоемких.
Прорабатывал вопрос с закачкой словарей, в конце концов отказался от мысли. Орфографический и синонимов закачать еще можно (хотя ну очень долго), а вот толковый – никак. В словарях значится, к примеру:
Сидоров – композитор. Кантаты, сюиты.
Альпы – горный массив. Добыча руды. Туризм.
А мне нужно:
Сидоров – композитор. Сидоров – автор кантат, сюит.
Альпы – горный массив. В Альпах добывают руду. В Альпах развит туризм.
То есть с толковыми словарями полная несовместимость: немыслимо на уровне синтаксиса определить, где «автор», а где «добывают». Собственно, и словарей-то в сети не так чтобы много. Требовались: толковый, синонимов, однокоренных слов, фразеологизмов, гиперонимов… Да чего уж теперь!
Если, вдохновленные текущим постом, вы решились-таки убедиться, насколько автор криворукий, то пополнять базу можно двумя способами: либо диалогом, либо закачкой текста. Закачиваемые фразы лучше начинать с новой строки.
Образчик текста для закачки
Ты умеешь мыслить.
Ты умеешь запоминать.
Ты обладаешь памятью.
Успех – это достижение заветной цели.
Ты не можешь двигаться.
Ты не можешь осязать.
Ты не можешь нюхать.
Я думаю недолго, потому что мои алгоритмы действуют быстро.
и т.д.
Ты умеешь запоминать.
Ты обладаешь памятью.
Успех – это достижение заветной цели.
Ты не можешь двигаться.
Ты не можешь осязать.
Ты не можешь нюхать.
Я думаю недолго, потому что мои алгоритмы действуют быстро.
и т.д.
Предупреждаю, фразы индексируются мучительно долго, так что загружать несколько страниц текста, право слово, не стоит — одной достаточно.
Синонимы устанавливаются по шаблону:
Врач, доктор – это синонимы.
То же – антонимы (которые на самом деле лишь члены класса, что я сообразил далеко не сразу. Белый и черный – антонимы. Однако синий, зеленый и т.д. члены того же класса, поэтому антонимы как сущность у меня отсутствуют – при указании антонимов записываются члены класса).
Белый и черный – это антонимы.
Стандартные ответы устанавливаются в диалоге. Пример я приводил, но повторю:

При закачке стандартный ответ размещается следом за исходной фразой:
Ты молодец.
Отвечай: Ты тоже.
Набивать тексты следует грамотно, с соблюдением знаков препинания, иначе поняты не будете.
Все советы, собственно.
Нет, если не выпендриваться, то в качестве стандартного чат-бота Ваня Разумный худо-бедно способен функционировать.

С этой стороны я своей интеллектуальной одиссеей доволен. Кристальная ясность в голове: что в рамках синтаксиса можно реализовать, а чего нельзя. И полная уверенность в том, что для создания искусственного существа недостает механики и вычислительных мощностей, а что касается принципов мышления, будь то на основе синтаксиса, зрительного или иного восприятия либо комбинированным способом, – теоретические препятствия отсутствуют.
