Привет, Хабр! Представляю вашему вниманию перевод статьи "Understanding How Graal Works — a Java JIT Compiler Written in Java".
Введение
Одной из причин по которой я стал исследователем языков программирования является то, что, в большом сообществе людей связанных с компьютерными технологиями, почти все используют языки программирования, и многие интересуются тем как они работают. Когда я впервые столкнулся с программированием, будучи ребенком, и познакомился с языком программирования, первым, о чем я хотел узнать, было то как это работает, и самым первым, что мне хотелось сделать, было создание собственного языка.
В этом выступлении я покажу некоторые механизмы работы используемого всеми вами языка — Java. Особенностью является то, что я буду использовать проект под названием Graal, который реализует концепцию Java на Java.
Graal является только одной из составляющих в работе Java — это just-in-time компилятор. Это та часть JVM, которая преобразует байткод Java в машинный код в ходе работы программы, и является одним из факторов обеспечивающих высокую производительность платформы. Также это, как мне кажется, то, что большинство людей считают одной из наиболее сложных и туманных частей JVM, которая находится вне рамок их понимания. Изменить это мнение является целью данного выступления.
Если вы знаете, что такое JVM; в целом понимаете, что означают термины байткод и машинный код; и способны читать код написанный на Java, то, я надеюсь, этого будет достаточно, чтобы понять излагаемый материал.
Я начну с обсуждения того почему мы можем хотеть новый JIT-компилятор для JVM написанный на Java, а после покажу, что в этом нет чего-то сверх особенного, как вы могли бы думать, разбив задачу на сборку компилятора, использование, и демонстрацию того, что его код является таким же как и в любом другом приложении.
Я совсем немного затрону теорию, и потом покажу как она применяется в ходе всего процесса компиляции от байткода до машинного кода. Еще я покажу некоторые детали, и в конце мы поговорим о пользе данной возможности помимо реализации Java на Java ради её самой.
Я буду использовать скриншоты кода в Eclipse, вместо их запуска в ходе презентации, чтобы избежать неминуемых проблем live-кодинга.
Что такое JIT-компилятор?
Я уверен, что многие из вас знают что такое JIT-компилятор, но все-таки коснусь основ чтобы никто не сидел тут боясь задать этот главный вопрос.
Когда вы запускаете команду javac или compile-on-save в IDE, ваша программа на Java компилируется из Java-кода в байткод JVM, который является бинарным представлением программы. Он более компактен и прост, чем исходный Java-код. Однако, обычный процессор вашего ноутбука или сервера не может просто так выполнить байткод JVM.
Для работы вашей программы JVM интерпретирует этот байткод. Интерпретаторы, обычно, значительно медленнее, чем машинный код запускаемый на процессоре. По этой причине JVM, во время работы программы, может запустить еще один компилятор, который преобразует ваш байткод в машинный код, выполнить который процессор уже в состоянии.
Этот компилятор, обычно, намного более изощрённый, чем javac, выполняет сложные оптимизации чтобы в результате выдать высококачественный машинный код.
Зачем писать JIT-компилятор на Java?
На сегодняшний день реализация JVM под названием OpenJDK включает два основных JIT-компилятора. Клиентский компилятор, известный как C1, спроектирован для более быстрой работы, но, при этом, выдает менее оптимизированный код. Серверный компилятор, известный как opto или C2, требует несколько больше времени на работу, но выдает более оптимизированный код.
Идея заключалась в том, что клиентский компилятор лучше подходил для настольных приложений, где нежелательны длительные паузы JIT-компилятора, а серверный — для долгоиграющих серверных приложений в которых позволительно потратить больше времени на компиляцию.
На сегодня они могут быть совмещены, чтобы код сперва компилировался C1, и после, если он продолжает интенсивно выполняться и имеет смысл затратить дополнительное время, — C2. Это называется ступенчатой компиляцией (tiered compilation).
Давайте остановимся на C2 — серверном компиляторе, который выполняет больше оптимизаций.
Мы можем склонировать OpenJDK с зеркала на GitHub, или просто открыть дерево проекта на сайте.
$ git clone https://github.com/dmlloyd/openjdk.gitКод C2 находится в openjdk/hotspot/src/share/vm/opto.
Прежде всего стоит отметить, что C2 написан на C++. Конечно, в этом нет чего-то плохого, но есть определенные недостатки. С++ — небезопасный язык. Это означает, что ошибки в C++ могут привести к краху VM. Возможно, что причиной тому возраст кода, но код C2 на C++ стало очень трудно поддерживать и развивать.
Одна из ключевых фигур, стоящих за компилятором C2, Cliff Click сказал, что никогда бы больше не стал писать VM опять на C++, и мы слышали как JVM-команда Twitter высказывала мнение о том, что C2 пришел в застойное состояние и требует замены по причине трудности дальнейшей разработки.


https://www.youtube.com/watch?v=Hqw57GJSrac
Итак, возвращаясь к вопросу, что такого есть в Java, что может помочь решить эти проблемы? Тоже самое, что дает написание программы на Java вместо C++. Это, вероятно, безопасность (исключения вместо крахов, отсутствие реальной утечки памяти или висячих указателей), хорошие вспомогательные средства (отладчики, профилировщики, и инструменты вроде VisualVM), хорошая поддержка IDE и т.д.
Вы могли бы подумать: Как можно написать что-то вроде JIT-компилятора на Java?, и что это возможно только на низкоуровневом языке системного программирования, таком как C++. В этом выступлении я надеюсь убедить вас, что это совсем не так! По существу, JIT-компилятор должен просто принять байткод JVM и выдать машинный код — вы даете ему byte[] на входе, и назад также хотите получить byte[]. Требуется выполнить много сложной работы, чтобы это осуществить, но она никак не затрагивает системный уровень, и поэтому не требует системного языка, такого как C или C++.
Настройка Graal
Первое, что нам понадобится, — это Java 9. Используемый Graal интерфейс под названием JVMCI был добавлен в Java в рамках JEP 243 Java-Level JVM Compiler Interface и первой версией, его включающей, является Java 9. Я использую 9+181. В случае каких-то особенных требований имеются порты (backports) для Java 8.
$ export JAVA_HOME=`pwd`/jdk9
$ export PATH=$JAVA_HOME/bin:$PATH
$ java -version
java version "9"
Java(TM) SE Runtime Environment (build 9+181)
Java HotSpot(TM) 64-Bit Server VM (build 9+181, mixed mode)Следующее, что нам понадобится, это система сборки под названием mx. Она немного похожа на Maven или Gradle, но, скорее всего, вы бы не выбрали её для своего приложения. Она реализует определенный функционал для поддержки некоторых сложных вариантов использования, но мы будем использовать её только для простых сборок.
Склонировать mx можно с GitHub. Я использую коммит #7353064. Теперь просто добавьте исполняемый файл в путь.
$ git clone https://github.com/graalvm/mx.git
$ cd mx; git checkout 7353064
$ export PATH=`pwd`/mx:$PATHТеперь нам надо склонировать сам Graal. Я использую дистрибутив под названием GraalVM версии 0.28.2.
$ git clone https://github.com/graalvm/graal.git --branch vm-enterprise-0.28.2Этот репозиторий содержит и другие проекты, которые нам сейчас не интересны, поэтому мы просто перейдем в подпроект compiler, который и является JIT-компилятором Graal, и соберем его используя mx.
$ cd graal/compiler
$ mx buildДля работы с кодом Graal я буду использовать Eclipse IDE. Я использую Eclipse 4.7.1. mx может сгенерировать для нас файлы Eclipse-проекта.
$ mx eclipseinitЧтобы открыть каталог graal как рабочую область (workspace) нужно выполнить File, Import…, General, Existing projects и опять выбрать каталог graal. Если вы запустили Eclipse не на Java 9, то, возможно, также, потребуется прикрепить и исходники JDK.
Хорошо. Теперь, когда все готово, давайте посмотрим как это работает. Мы будем использовать этот очень простой код.
class Demo {
public static void main(String[] args) {
while (true) {
workload(14, 2);
}
}
private static int workload(int a, int b) {
return a + b;
}
}Сначала мы скомпилируем этот код javac, а после запустим JVM. Сперва я покажу работу стандартного JIT-компилятора C2. Для этого укажем несколько флагов: -XX:+PrintCompilation, который нужен чтобы JVM писала лог при компиляции метода, и -XX:CompileOnly=Demo::workload, чтобы компилировался только данный метод. Если мы этого не сделаем, то будет выведено слишком много информации, и JVM будет умнее, чем нам надо, и оптимизирует код который мы хотим увидеть.
$ javac Demo.java
$ java \
-XX:+PrintCompilation \
-XX:CompileOnly=Demo::workload \
Demo
...
113 1 3 Demo::workload (4 bytes)
...Я не буду подробно это пояснять, а скажу лишь, что это вывод лога, который показывает, что метод workload был скомпилирован.
Теперь, в качестве JIT-компилятора нашей Java 9 JVM, мы используем только что скомпилированный Graal. Для этого необходимо добавить еще несколько флагов.
--module-path=... и --upgrade-module-path=... добавляют Graal в module path. Напомню, что module path появился в Java 9 как часть системы модулей Jigsaw, и для наших целей мы можем рассматривать его по аналогии с classpath.
Нам нужен флаг -XX:+UnlockExperimentalVMOptions из-за того, что JVMCI (интерфейс, используемый Graal) в данной версии является экспериментальной возможностью.
Флаг -XX:+EnableJVMCI нужен чтобы сказать, что мы хотим использовать JVMCI, а -XX:+UseJVMCICompiler — для включения и установки нового JIT-компилятора.
Чтобы не усложнять пример, и, вместо использования C1 совместно с JVMCI, иметь только JVMCI-компилятор, укажем флаг -XX:-TieredCompilation, который отключит ступенчатую компиляцию.
Как и ранее укажем флаги -XX:+PrintCompilation и -XX:CompileOnly=Demo::workload.
Как и в предыдущем примере мы видим, что был скомпилирован один метод. Но, в этот раз, для компиляции мы использовали только что собранный Graal. Пока просто поверьте мне на слово.
$ java \
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar \
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar \
-XX:+UnlockExperimentalVMOptions \
-XX:+EnableJVMCI \
-XX:+UseJVMCICompiler \
-XX:-TieredCompilation \
-XX:+PrintCompilation \
-XX:CompileOnly=Demo::workload \
Demo
...
583 25 Demo::workload (4 bytes)
...Интерфейс компилятора JVM
Вам не кажется, что мы сделали что-то достаточно необычное? У нас есть установленная JVM, и мы заменили JIT-компилятор на только что скомпилированный новый не меняя что-либо в самой JVM. Эту возможность обеспечивает новый интерфейс JVM под названием JVMCI, — JVM compiler interface, — то, что как я говорил выше, было JEP 243 и вошло в Java 9.
Идея аналогична некоторым другим существующим технологиям JVM.
Возможно вы когда-нибудь уже сталкивались с дополнительной обработкой исходного кода в javac с использованием API Java для обработки аннотаций (Java annotation processing API). Этот механизм дает возможность выявления аннотаций и модели исходного кода, в которой они используются, и создания новых файлов на их основе.
Также, вы, возможно, использовали дополнительную обработку байткода в JVM с помощью Java-агентов (Java agents). Этот механизм позволяет модифицировать байткод Java перехватывая его при загрузке.
Идея JVMCI схожа. Он позволяет подключить собственный Java JIT-компилятор, написанный на Java.
Сейчас я хочу сказать пару слов о том как буду показывать код в ходе этой презентации. Сначала, для понимания идеи, я буду показывать несколько упрощенные идентификаторы и логику в виде текста на слайдах, а после буду переключаться на скриншоты Eclipse и показывать реальный код, который может быть немного сложнее, но главная идея останется той же. Основная часть этого выступления имеет целью показать, что с реальным кодом проекта действительно можно работать, и поэтому я не хочу его скрывать, хотя он и может быть несколько сложным.
С этого момента я приступаю к развеиванию мнения, которое могло у вас быть, что JIT-компилятор — это очень сложно.
Что JIT-компилятор принимает на вход? Он принимает байткод метода, который надо скомпилировать. А байткод, как подсказывает название, это просто массив байт.
Что JIT-компилятор выдает в качестве результата? Он выдает машинный код метода. Машинный код это тоже просто массив байт.
В итоге, интерфейс, который надо реализовать при написании нового JIT-компилятора, для его встраивания в JVM, будет выглядеть примерно так.
interface JVMCICompiler {
byte[] compileMethod(byte[] bytecode);
}Поэтому, если вы не представляли как Java может делать что-то настолько низкоуровневое как JIT-компиляция в машинный код, то теперь видно, что это не такая уж и низкоуровневая работа. Правда? Это просто функция из byte[] в byte[].
В действительности все несколько сложнее. Только байткода недостаточно — нам, также, нужна еще некоторая информация, такая как количество локальных переменных, необходимый размер стека, и информация собранная профилировщиком интерпретатора, чтобы понимать как код выполняется по факту. Поэтому представим вход в виде CompilationRequest, который скажет нам о требующем компиляции JavaMethod, и предоставит всю необходимую информацию.
interface JVMCICompiler {
void compileMethod(CompilationRequest request);
}
interface CompilationRequest {
JavaMethod getMethod();
}
interface JavaMethod {
byte[] getCode();
int getMaxLocals();
int getMaxStackSize();
ProfilingInfo getProfilingInfo();
...
}Также, интерфейс не требует возврата скомпилированного кода. Вместо этого, для установки (install) машинного кода в JVM, используется еще одно API.
HotSpot.installCode(targetCode);Теперь, чтобы написать новый JIT-компилятор для JVM, надо просто реализовать этот интерфейс. Мы получаем информацию о требующем компиляции методе, и должны скомпилировать его в машинный код и вызвать installCode.
class GraalCompiler implements JVMCICompiler {
void compileMethod(CompilationRequest request) {
HotSpot.installCode(...);
}
}Давайте переключимся в Eclipse IDE с Graal и посмотрим на некоторые реальные интерфейсы и классы. Как говорилось ранее, они будут несколько сложнее, но не намного.
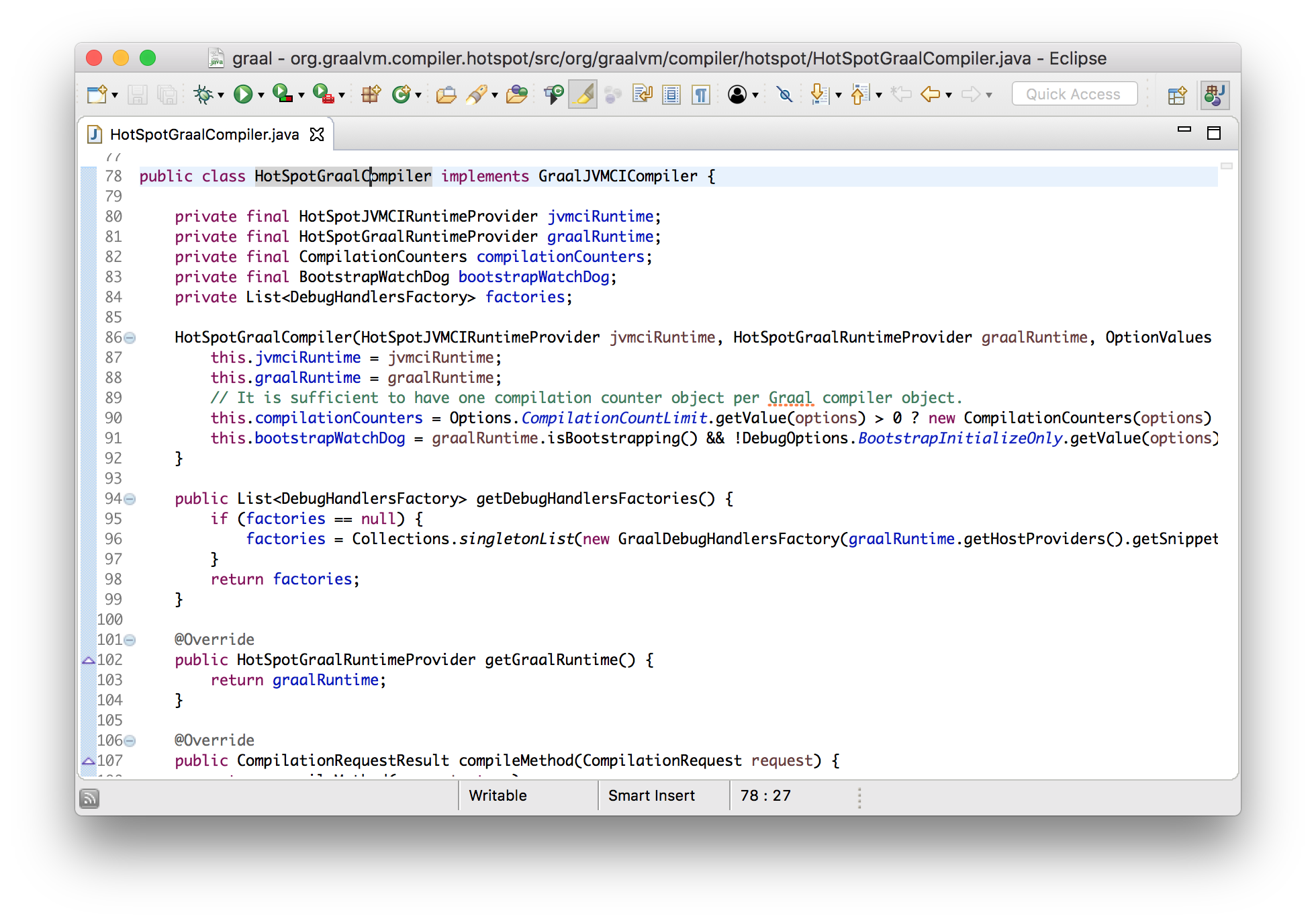
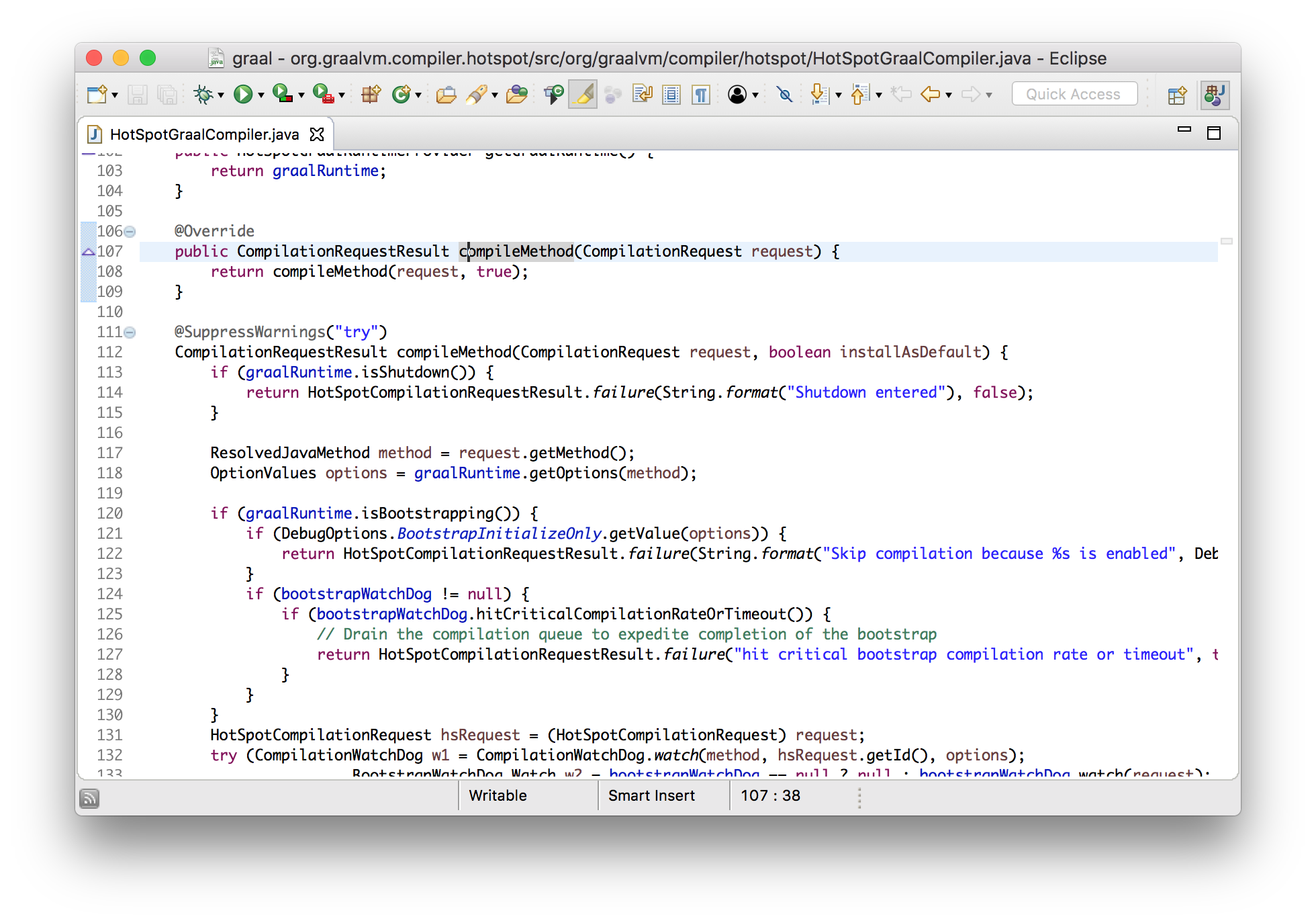
Сейчас я хочу показать, что мы можем вносить в Graal изменения, и сразу использовать их в Java 9. Я добавлю новое сообщения лога, которое будет выводиться при компиляции метода с использованием Graal. Добавим его в реализованный метод интерфейса, который вызывается JVMCI.
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationRequestResult compileMethod(CompilationRequest request) {
System.err.println("Going to compile " + request.getMethod().getName());
...
}
}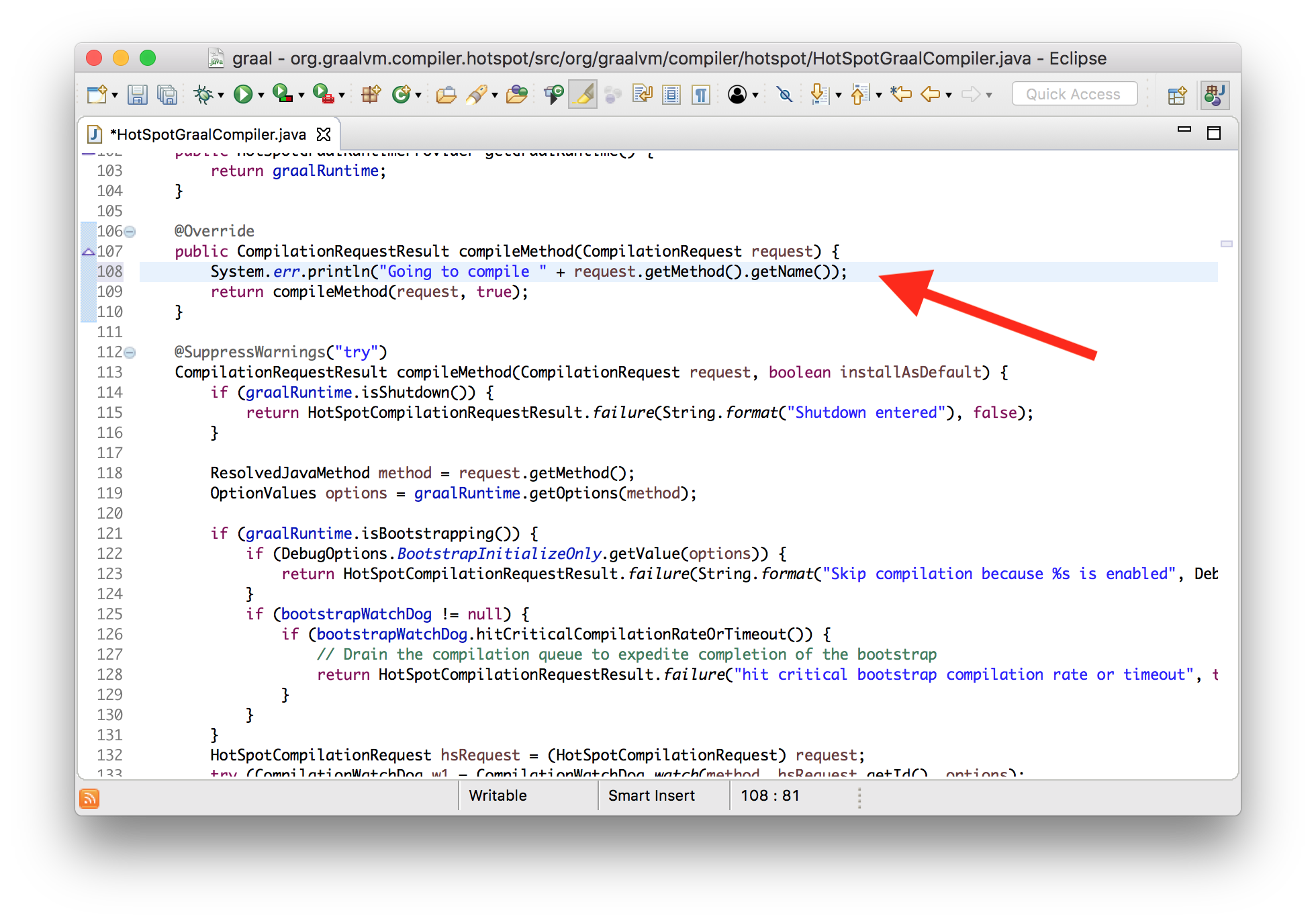
Пока отключим существующее в HotSpot логирование компиляции. Теперь мы можем видеть наше сообщение из измененной версии компилятора.
$ java \
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar \
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar \
-XX:+UnlockExperimentalVMOptions \
-XX:+EnableJVMCI \
-XX:+UseJVMCICompiler \
-XX:-TieredCompilation \
-XX:CompileOnly=Demo::workload \
Demo
Going to compile workloadЕсли вы попробуете повторить это сами, то заметите, что не требуется даже запуска нашей системы сборки — mx build. Достаточно, обычного для Eclipse, compile on save. И уж точно нам не надо пересобирать саму JVM. Мы просто встраиваем модифицированный компилятор в существующую JVM.
Граф Graal
Ну что же, мы знаем, что Graal преобразует один byte[] в другой byte[]. Теперь давайте поговорим о теории и структурах данных, которые он использует, т.к. они немного необычны даже для компилятора.
По сути, компилятор занимается обработкой вашей программы. Для этого программу необходимо представить в виде какой-то структуры данных. Одним из вариантов является байткод и подобные ему списки инструкций, но они не очень выразительны.
Вместо этого, для представления вашей программы, Graal использует граф. Если взять простой оператор сложения, который суммирует две локальных переменных, то граф будет включать по одному узлу для загрузки каждой переменной, один узел для суммы, и два ребра, которые показывают, что результат загрузки локальных переменных поступает на вход оператора сложения.
Иногда это называют графом зависимостей программы (program dependency graph).
Имея выражение вида x + y мы получим узлы для локальных переменных x и y, и узел их суммы.
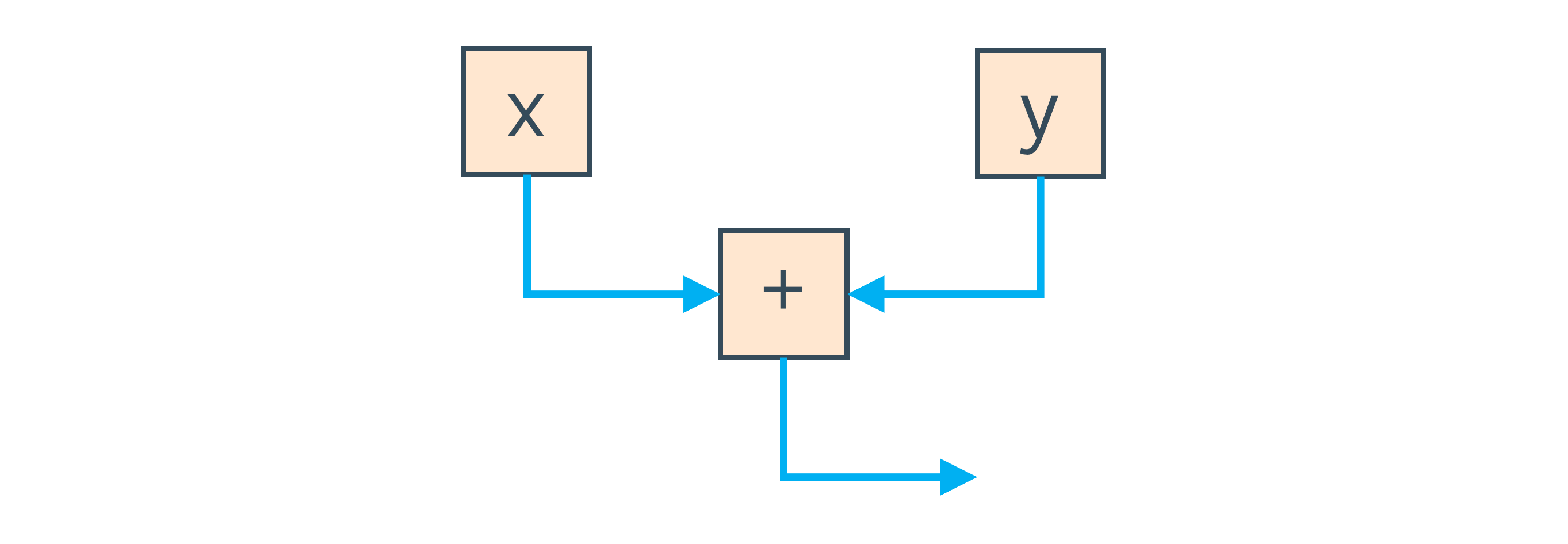
Синие ребра на этом графе показывают направление потока данных от чтения локальных переменных к суммированию.
Также, мы можем использовать ребра для отражения порядка выполнения программы. Если, вместо чтения локальных переменных, мы вызываем методы, то нам нужно запомнить порядок вызова, и мы не можем переставлять их местами (не зная о коде внутри). Для этого есть дополнительные ребра которые и задают этот порядок. Они показаны красным цветом.
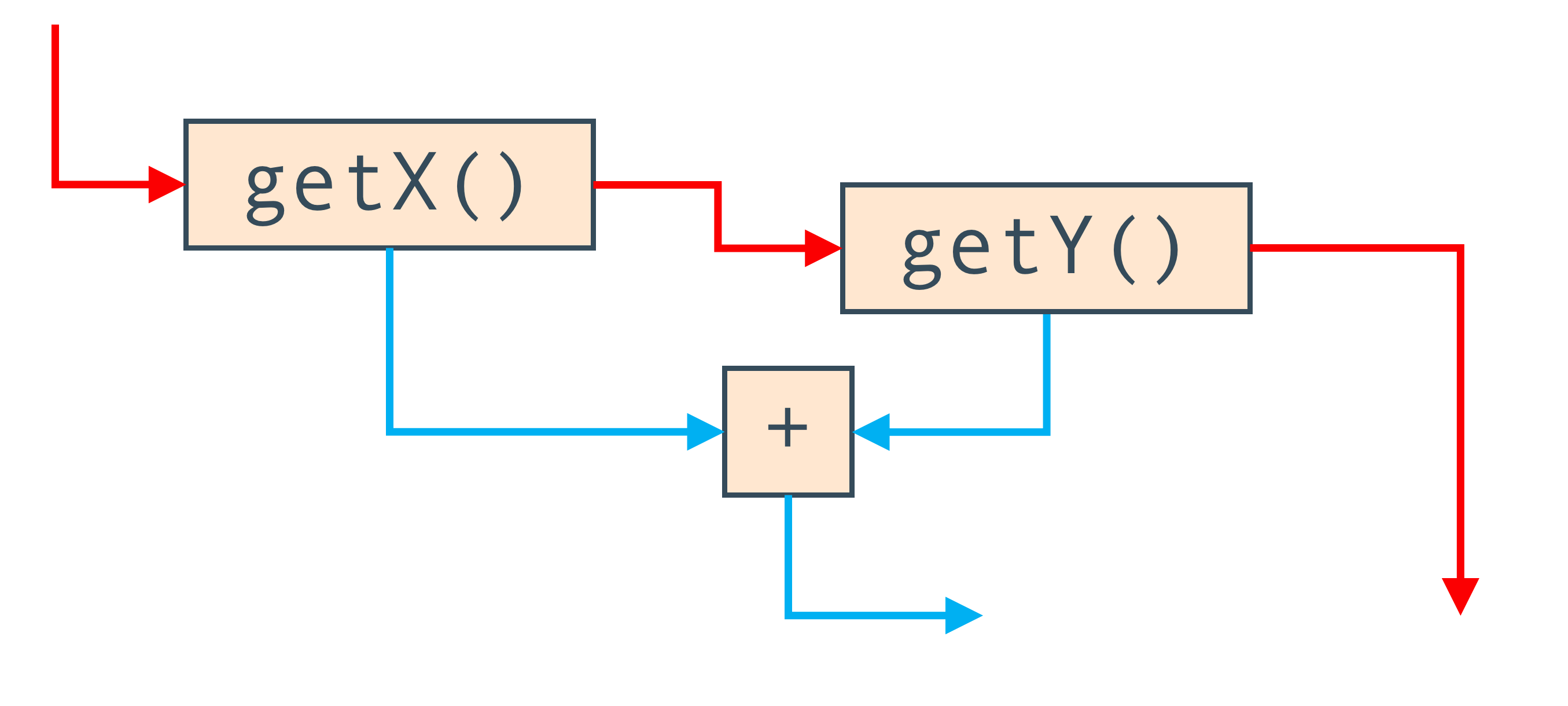
Итак, граф Graal, на самом деле, это два графа совмещенных в одном. Узлы одинаковые, но одни ребра показывают направление потока данных, а другие — порядок передачи управления между ними.
Чтобы увидеть граф Graal можно воспользоваться инструментом под названием IdealGraphVisualiser или IGV. Запуск выполняется с помощью команды mx igv.
После этого запустите JVM с флагом -Dgraal.Dump.
Простой поток данных можно увидеть написав несложное выражение.
int average(int a, int b) {
return (a + b) / 2;
}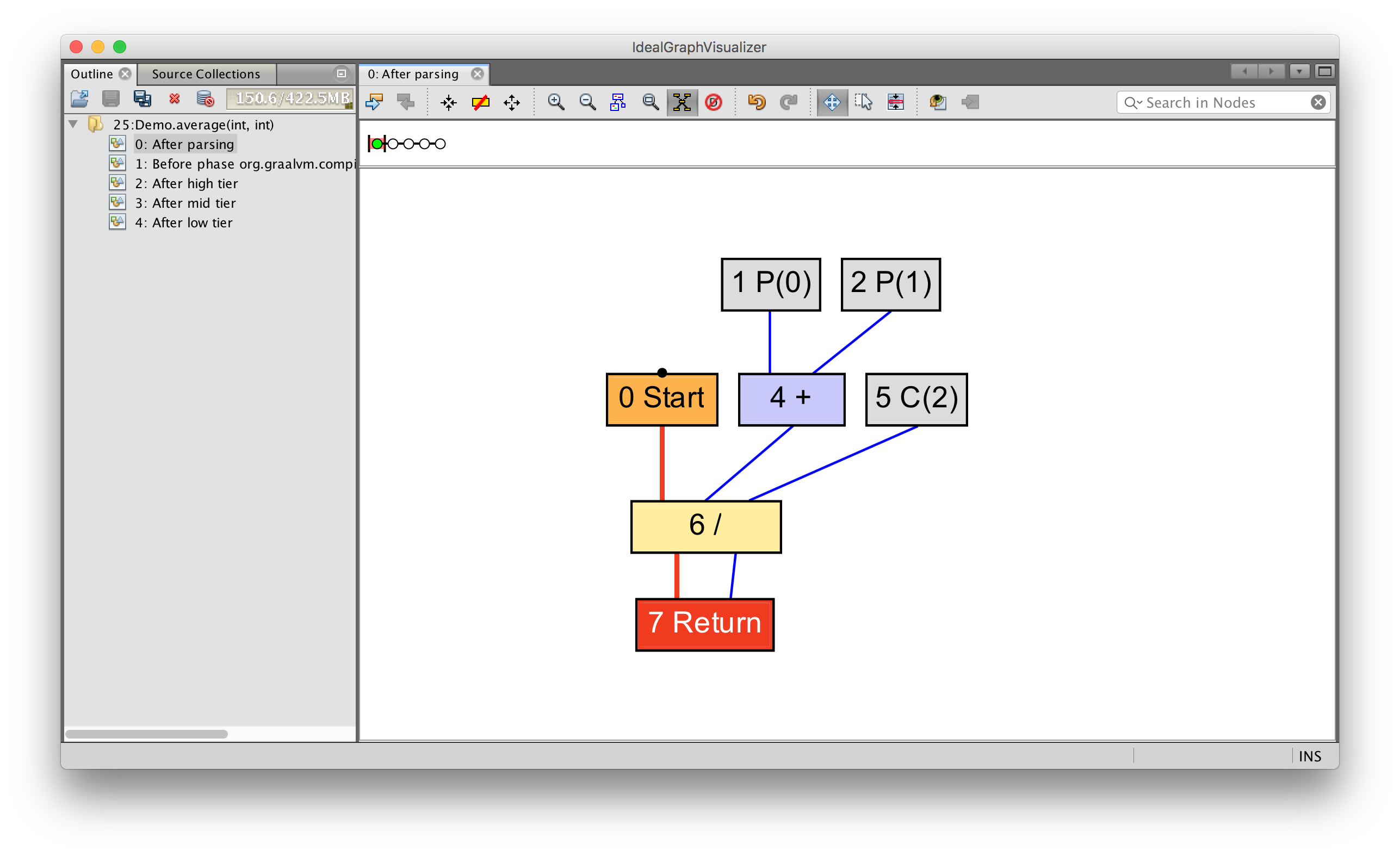
Можно видеть как параметры 0 (P(0) и 1 (P(1)) поступают на вход операции сложения, которая, вместе с константой 2 (C(2)) поступает на вход операции деления. После данное значение возвращается.
Для того чтобы посмотреть на более сложный поток данных и управления введем цикл.
int average(int[] values) {
int sum = 0;
for (int n = 0; n < values.length; n++) {
sum += values[n];
}
return sum / values.length;
}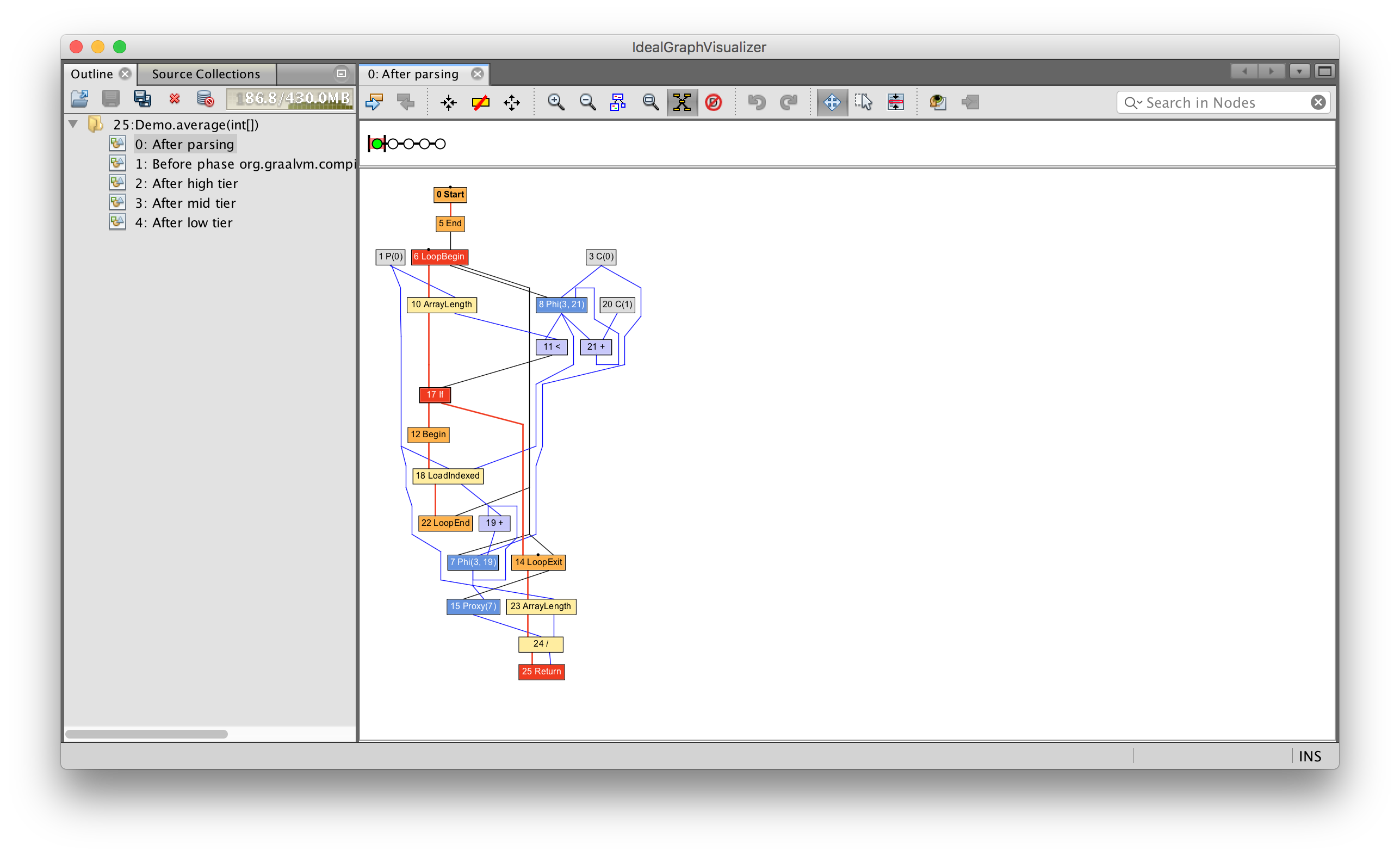
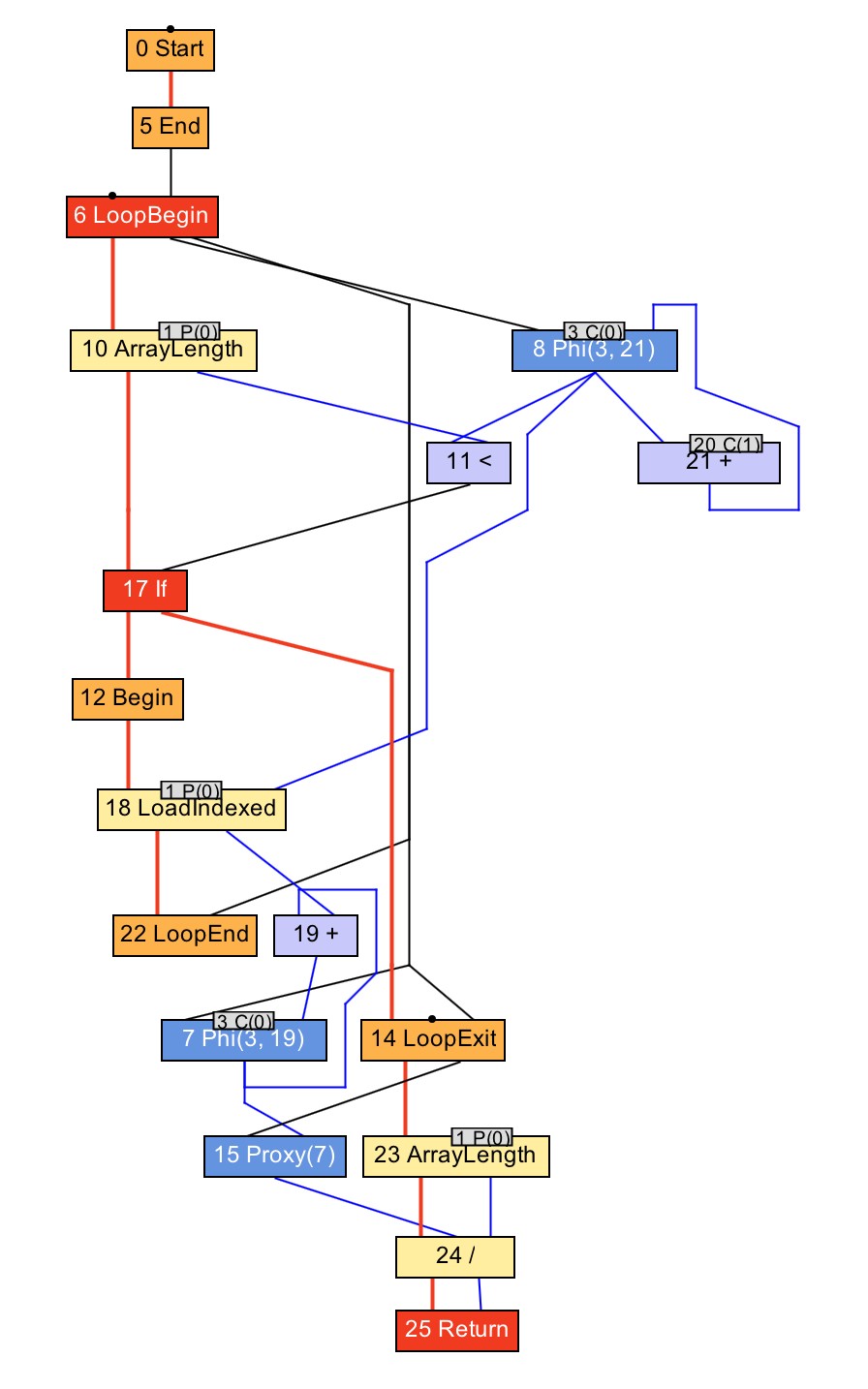
В этом случае у нас есть узлы начала и окончания цикла, чтения элементов массива, и чтения длины массива. Как и ранее, синие линии показывают направление потока данных, а красные — поток управления.
Теперь вы можете видеть почему эту структуру данных иногда называют морем узлов (sea of nodes) или солянкой узлов (soup of nodes).
Хочу сказать, что C2 использует очень схожую структуру данных, и, в действительности, именно C2 популяризировал идею компилятора моря узлов, так что это не нововведение Graal.
Я не буду показывать процесс построения этого графа до следующей части выступления, но когда Graal получает программу в таком формате, оптимизация и компиляция выполняется при помощи модификации данной структуры данных. И это одна из причин почему написание JIT-компилятора на Java имеет смысл. Java — объектно-ориентированный язык, а граф — это набор объектов, соединенных ребрами в виде ссылок.
От байткода к машинному коду
Давайте посмотрим как эти идеи выглядят на практике, и проследим некоторые этапы процесса компиляции.
Получение байткода
Компиляция начинается с байткода. Вернемся к нашему небольшому примеру с суммированием.
int workload(int a, int b) {
return a + b;
}Выведем принимаемый на входе байткод непосредственно перед началом компиляции.
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationRequestResult compileMethod(CompilationRequest request) {
System.err.println(request.getMethod().getName() + " bytecode: "
+ Arrays.toString(request.getMethod().getCode()));
...
}
}workload bytecode: [26, 27, 96, -84]Как видно, входными данными для компилятора является байткод.
Парсер байткода и построитель графа
Построитель, воспринимая этот массив байт как байткод JVM, преобразует его в граф Graal. Это является, своего рода, абстрактной интерпретацией — построитель интерпретирует байткод Java, но, вместо передачи значений, манипулирует свободными концами ребер и постепенно соединяет их друг с другом.
Давайте воспользуемся преимуществом того, что Graal написан на Java, и посмотрим как это работает используя инструменты навигации Eclipse. Мы знаем, что в нашем примере есть узел сложения, поэтому давайте найдем где он создается.
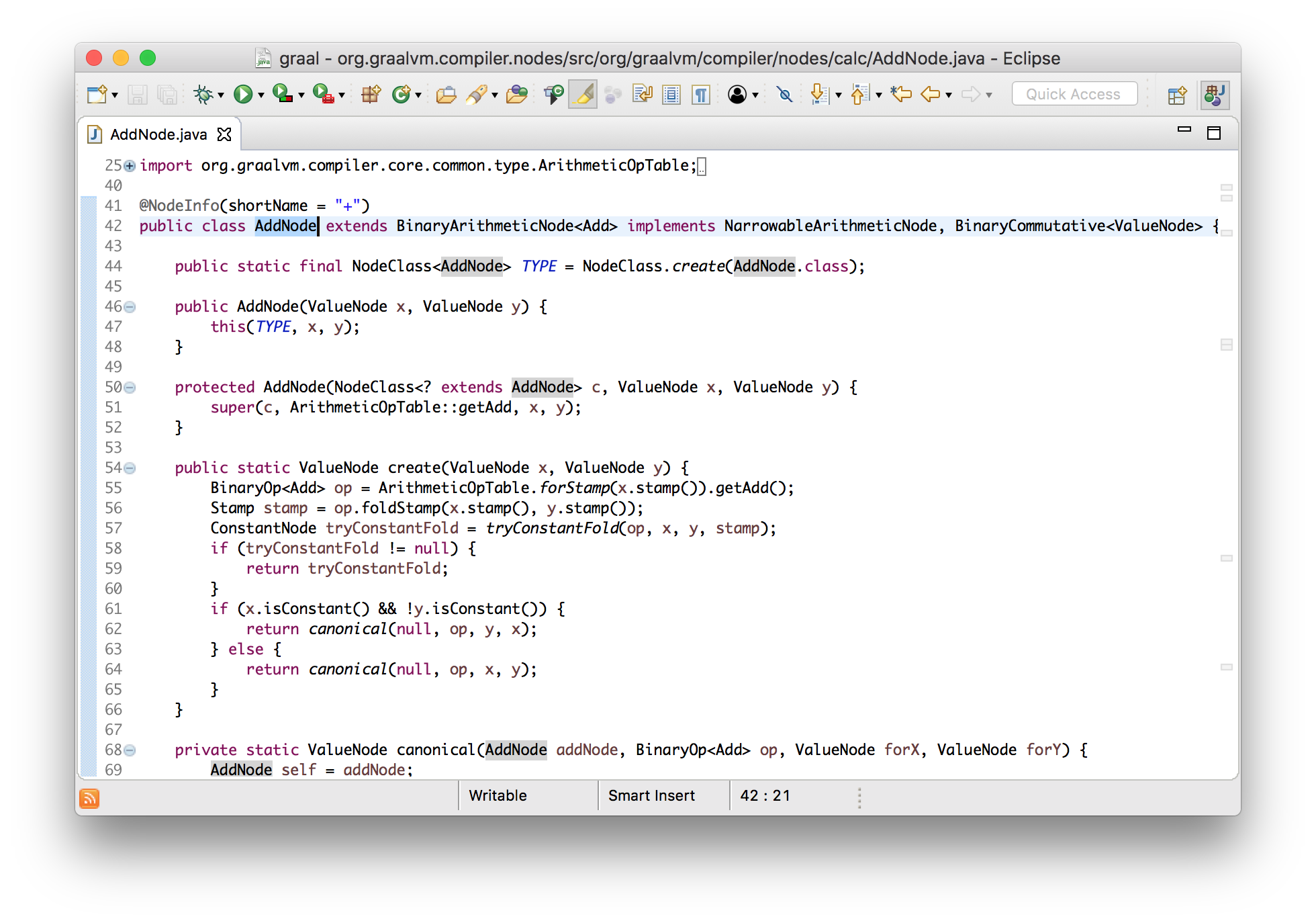
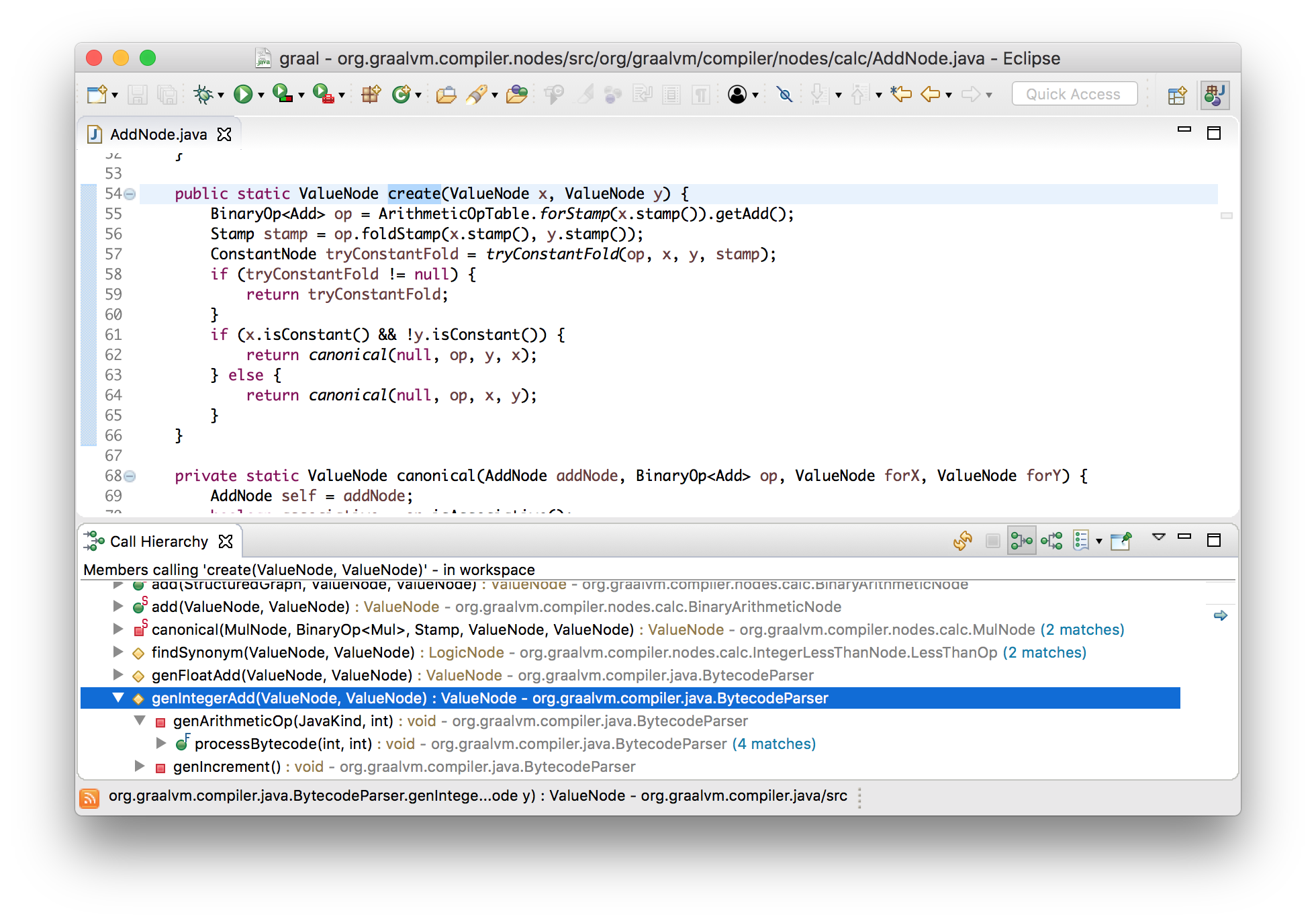
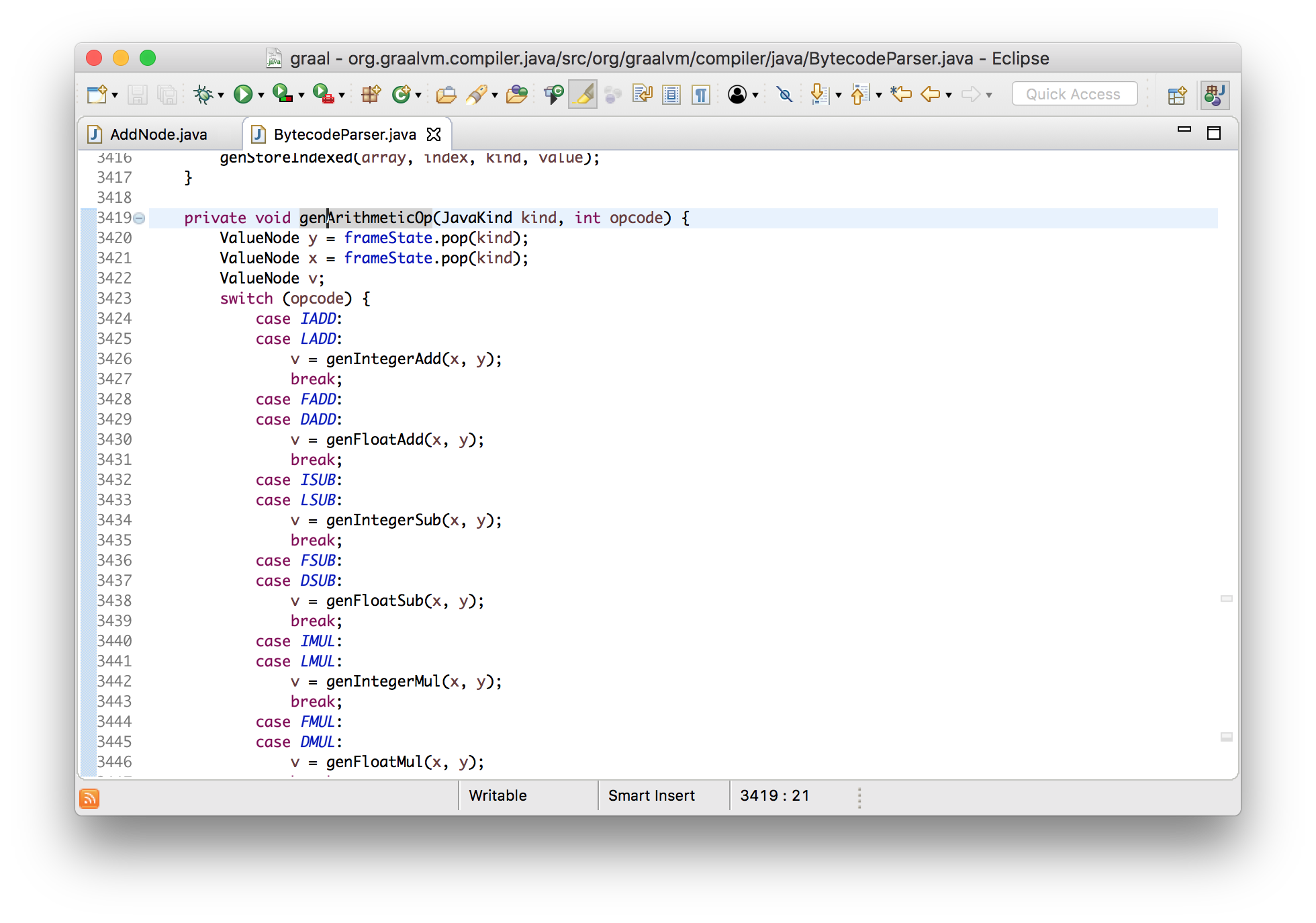
Видно, что их создает парсер байткода, и это привело нас к коду обработки IADD (96, которое мы видели в распечатанном входном массиве).
private void genArithmeticOp(JavaKind kind, int opcode) {
ValueNode y = frameState.pop(kind);
ValueNode x = frameState.pop(kind);
ValueNode v;
switch (opcode) {
...
case LADD:
v = genIntegerAdd(x, y);
break;
...
}
frameState.push(kind, append(v));
}Выше я сказал, что это абстрактная интерпретация, т.к. все это очень похоже на интерпретатор байткода. Если бы это был реальный интерпретатор JVM, тогда он бы снял два значения со стека, выполнил сложение, и положил результат обратно. В данном случае мы снимаем со стека два узла, которые, при запуске программы, будут представлять собой вычисления, добавляем, представляющий собой результат суммирования, новый узел для сложения, и размещаем его в стеке.
Таким образом строится граф Graal.
Получение машинного кода
Для преобразования графа Graal в машинный код нужно сгенерировать байты для всех его узлов. Это делается отдельно для каждого узла с помощью вызова его метода generate.
void generate(Generator gen) {
gen.emitAdd(a, b);
}Повторюсь, тут мы работаем на очень высоком уровне абстракции. У нас есть класс, с помощью которого мы выдаем инструкции машинного кода не вдаваясь в детали того как это работает.
Детали emitAdd несколько сложны и абстрактны по той причине, что арифметические операторы требуют кодирования для множества различных комбинаций операндов, но, при этом, могут совместно использовать большую часть их кода. Поэтому я еще немного упрощу программу.
int workload(int a) {
return a + 1;
}В данном случае будет использована инструкция инкремента, и я покажу как это выглядит в ассемблере.
void incl(Register dst) {
int encode = prefixAndEncode(dst.encoding);
emitByte(0xFF);
emitByte(0xC0 | encode);
}
void emitByte(int b) {
data.put((byte) (b & 0xFF));
}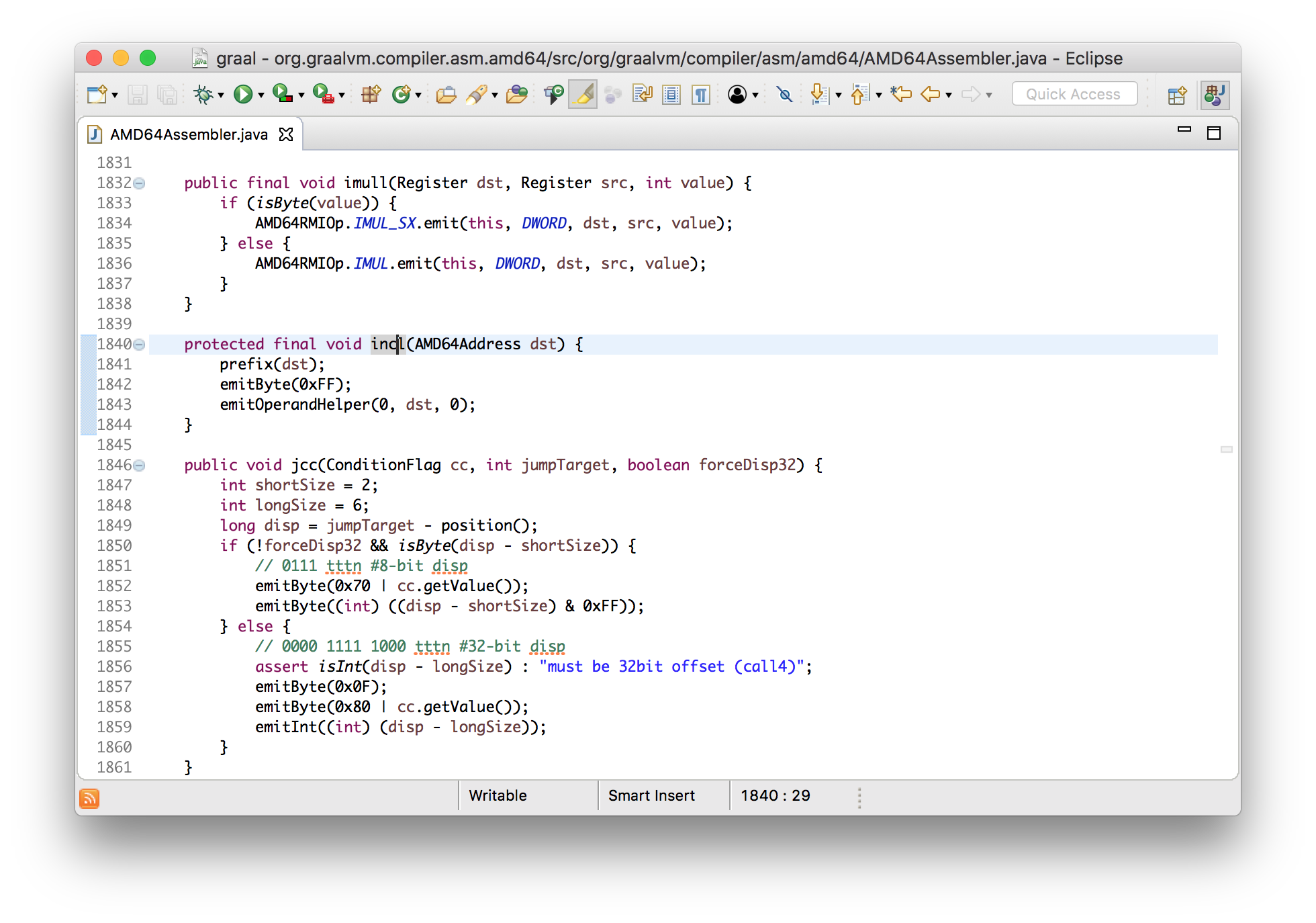
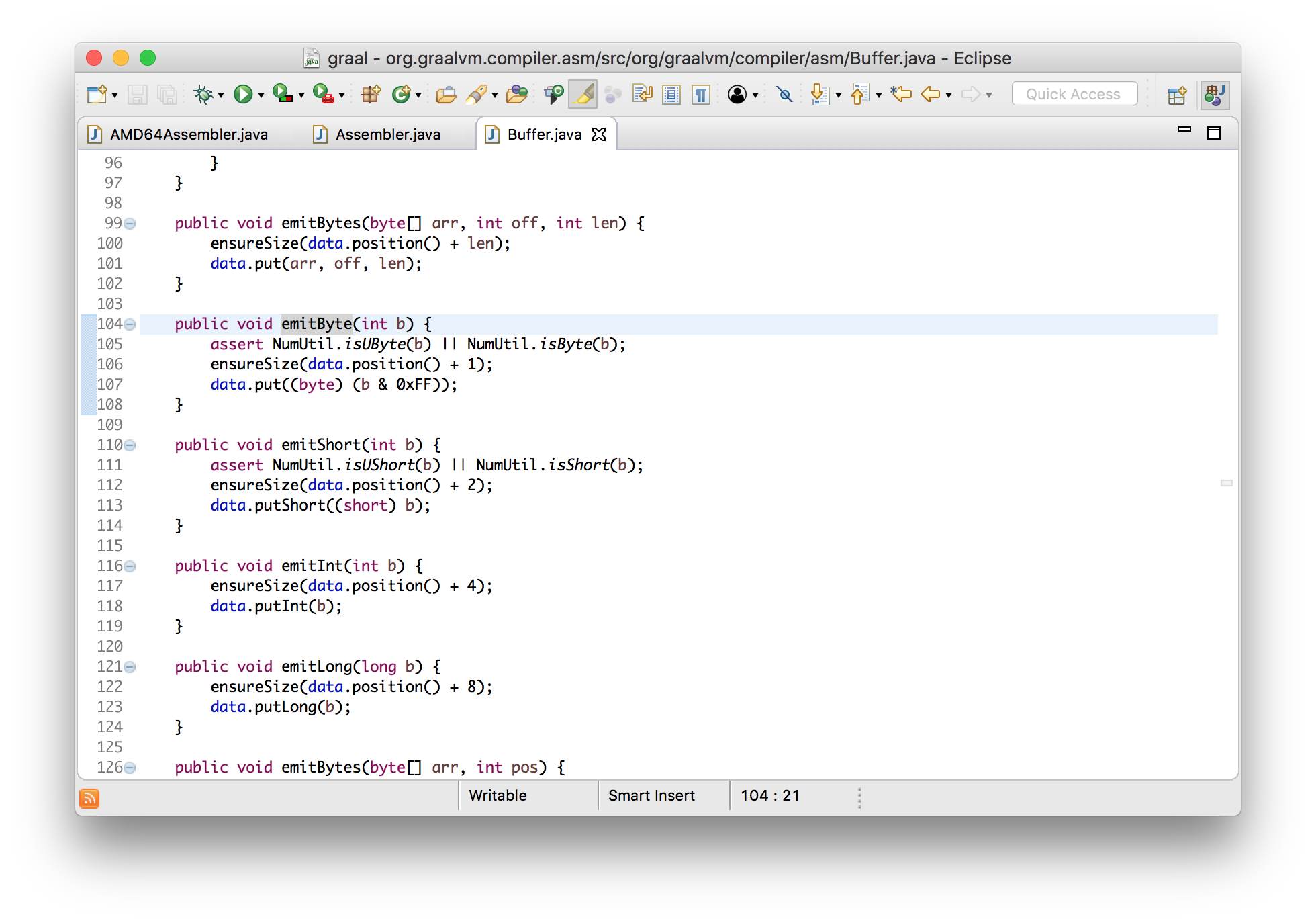
Можно видеть, что результатом являются байты, которые добавляются в стандартный ByteBuffer — просто создание массива байт.
Выходной машинный код
Давайте посмотрим на выходной машинный код также как ранее мы делали с входным байткодом — добавим распечатку байт в месте его установки.
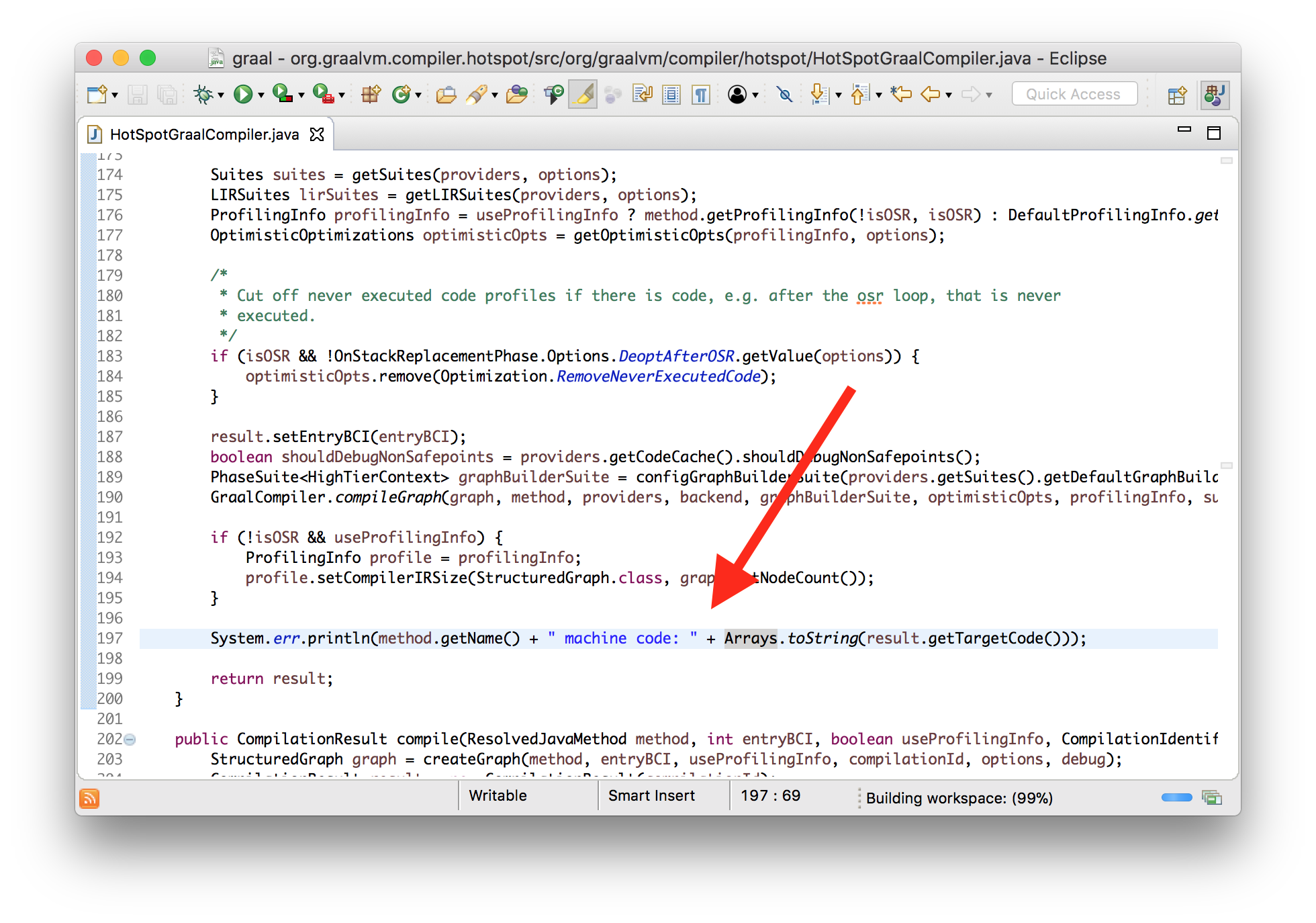
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationResult compileHelper(...) {
...
System.err.println(method.getName() + " machine code: "
+ Arrays.toString(result.getTargetCode()));
...
}
}
Также я воспользуюсь инструментом который дизассемблирует машинный код при его установке. Это стандартное средство HotSpot. Я покажу как его собрать. Оно находится в репозитории OpenJDK, но, по-умолчанию, не включено в поставку JVM, поэтому нам надо собрать его самим.
$ cd openjdk/hotspot/src/share/tools/hsdis
$ curl -O http://ftp.heanet.ie/mirrors/gnu/binutils/binutils-2.24.tar.gz
$ tar -xzf binutils-2.24.tar.gz
$ make BINUTILS=binutils-2.24 ARCH=amd64 CFLAGS=-Wno-error
$ cp build/macosx-amd64/hsdis-amd64.dylib ../../../../../..Еще я добавлю два новых флага: -XX:+UnlockDiagnosticVMOptions и -XX:+PrintAssembly.
$ java \
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar \
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar \
-XX:+UnlockExperimentalVMOptions \
-XX:+EnableJVMCI \
-XX:+UseJVMCICompiler \
-XX:-TieredCompilation \
-XX:+PrintCompilation \
-XX:+UnlockDiagnosticVMOptions \
-XX:+PrintAssembly \
-XX:CompileOnly=Demo::workload \
DemoТеперь мы можем запустить наш пример и увидеть вывод инструкций для нашего сложения.
workload machine code: [15, 31, 68, 0, 0, 3, -14, -117, -58, -123, 5, ...]
...
0x000000010f71cda0: nopl 0x0(%rax,%rax,1)
0x000000010f71cda5: add %edx,%esi ;\*iadd {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@2 (line 10)
0x000000010f71cda7: mov %esi,%eax ;\*ireturn {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@3 (line 10)
0x000000010f71cda9: test %eax,-0xcba8da9(%rip) # 0x0000000102b74006
; {poll_return}
0x000000010f71cdaf: vzeroupper
0x000000010f71cdb2: retqХорошо. Давайте проверим, что мы действительно контролируем все это и превратим суммирование в вычитание. Я изменю метод generate узла суммирования так, чтобы вместо инструкции сложения он выдавал инструкцию для вычитания.
class AddNode {
void generate(...) {
... gen.emitSub(op1, op2, false) ... // changed from emitAdd
}
}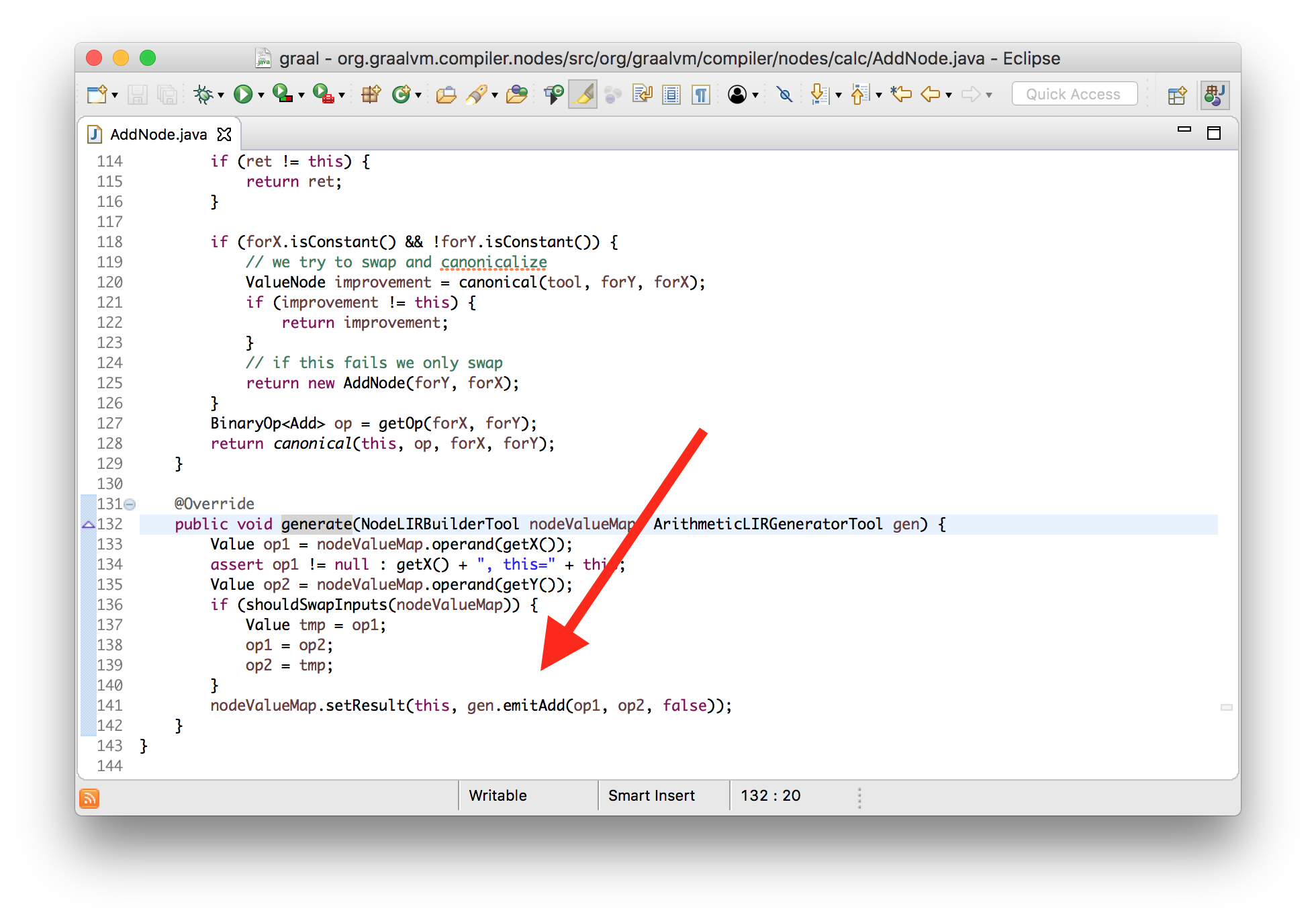
Если мы запустим это, то увидим, что оба байта машинного кода изменились, и на печать выводятся новые инструкции.
workload mechine code: [15, 31, 68, 0, 0, 43, -14, -117, -58, -123, 5, ...]
0x0000000107f451a0: nopl 0x0(%rax,%rax,1)
0x0000000107f451a5: sub %edx,%esi ;\*iadd {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@2 (line 10)
0x0000000107f451a7: mov %esi,%eax ;\*ireturn {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@3 (line 10)
0x0000000107f451a9: test %eax,-0x1db81a9(%rip) # 0x000000010618d006
; {poll_return}
0x0000000107f451af: vzeroupper
0x0000000107f451b2: retqИтак, что мы узнали? Graal просто принимает массив байт байткода; мы можем увидеть как из него создается граф узлов; мы можем увидеть как узлы выдают инструкции; и как они кодируются. Мы видели, что можем внести изменения в сам Graal.
[26, 27, 96, -84] → [15, 31, 68, 0, 0, 43, -14, -117, -58, -123, 5, ...]Оптимизация
И так, мы посмотрели как строится граф, и как узлы графа преобразуются в машинный код. Теперь давайте поговорим о том как Graal оптимизирует граф, делая его более эффективным.
Фаза оптимизации — это просто метод у которого есть возможность выполнить модификацию графа. Фазы создаются с помощью реализации интерфейса.
interface Phase {
void run(Graph graph);
}Каноникализация (canonicalisation)
Каноникализация означает переупорядочивание узлов в единообразное представление. У этой техники есть и другие задачи, но для целей данного выступления я скажу, что в действительности это означает свёртывание констант (constant folding) и урощение узлов.
Узлы сами ответственны за свое упрощение — для этого у них есть метод canonical.
interface Node {
Node canonical();
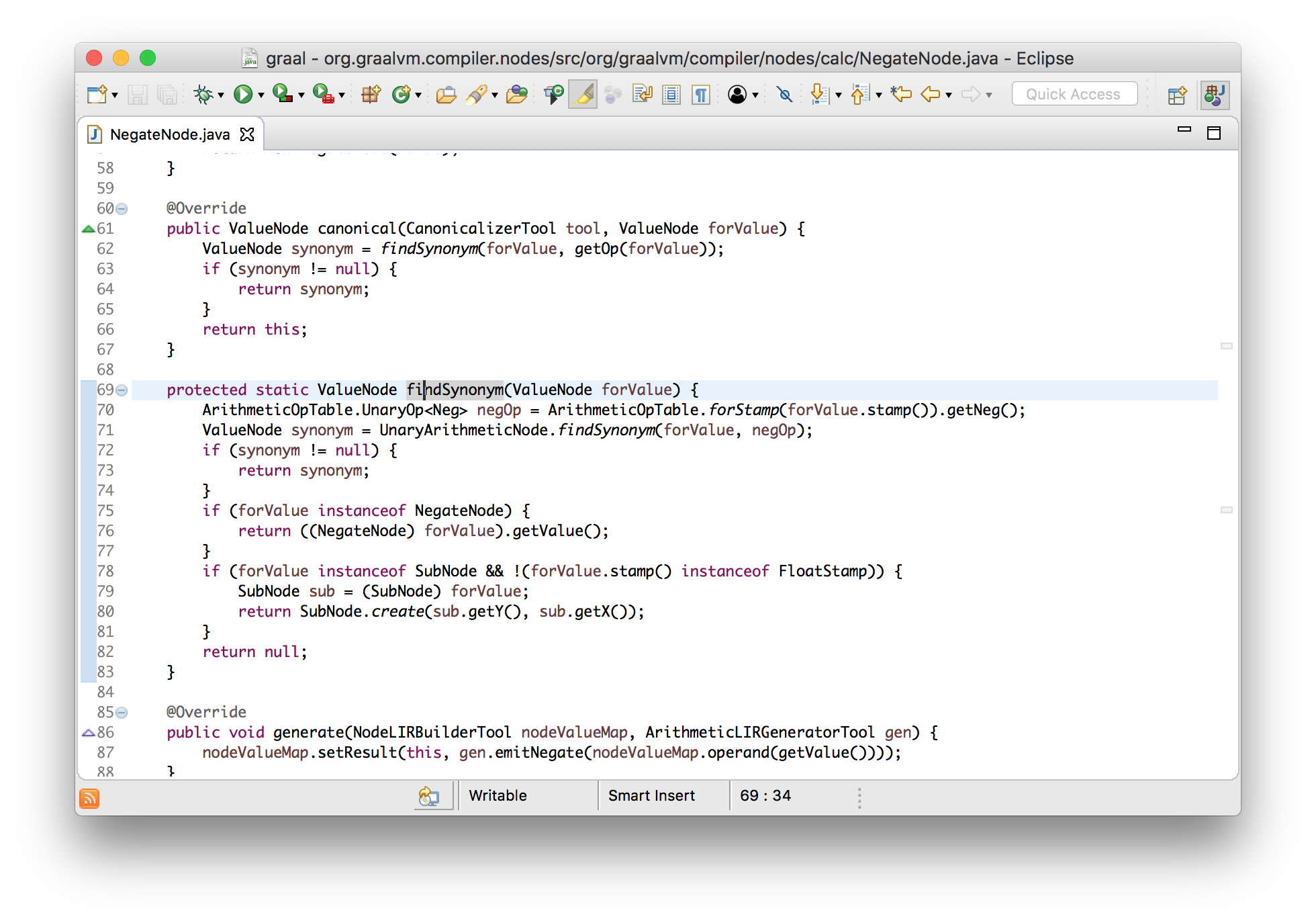
}Давайте, для примера, рассмотрим узел операции отрицания, который представляет собой унарный оператор вычитания. Узел операции отрицания удалит себя и своего потомка в случае если он применяется к другой операции отрицания — останется только само значение. Эта оптимизация упростит -(-x) до x.
class NegateNode implements Node {
Node canonical() {
if (value instanceof NegateNode) {
return ((NegateNode) value).getValue();
} else {
return this;
}
}
}
Это действительно хороший пример того насколько Graal прост для понимания. Практически, данная логика проста настолько насколько это возможно.
Если у вас есть хорошая идея как упростить операцию в Java, вы можете реализовать её в методе canonical.
Global value numbering
Global value numbering (GVN) — это техника удаления многократно повторяющегося избыточного кода. В примере ниже a + b может быть вычислено единожды, а результат — переиспользован.
int workload(int a, int b) {
return (a + b) * (a + b);
}Graal может сравнивать узлы на равенство. Это просто — они равны если у них одинаковые входные значения. В фазе GVN выполняется поиск одинаковых узлов и их замена единственной копией. Эффективность этой операции достигается за счет использования hash map в виде, своего рода, кэша узлов.
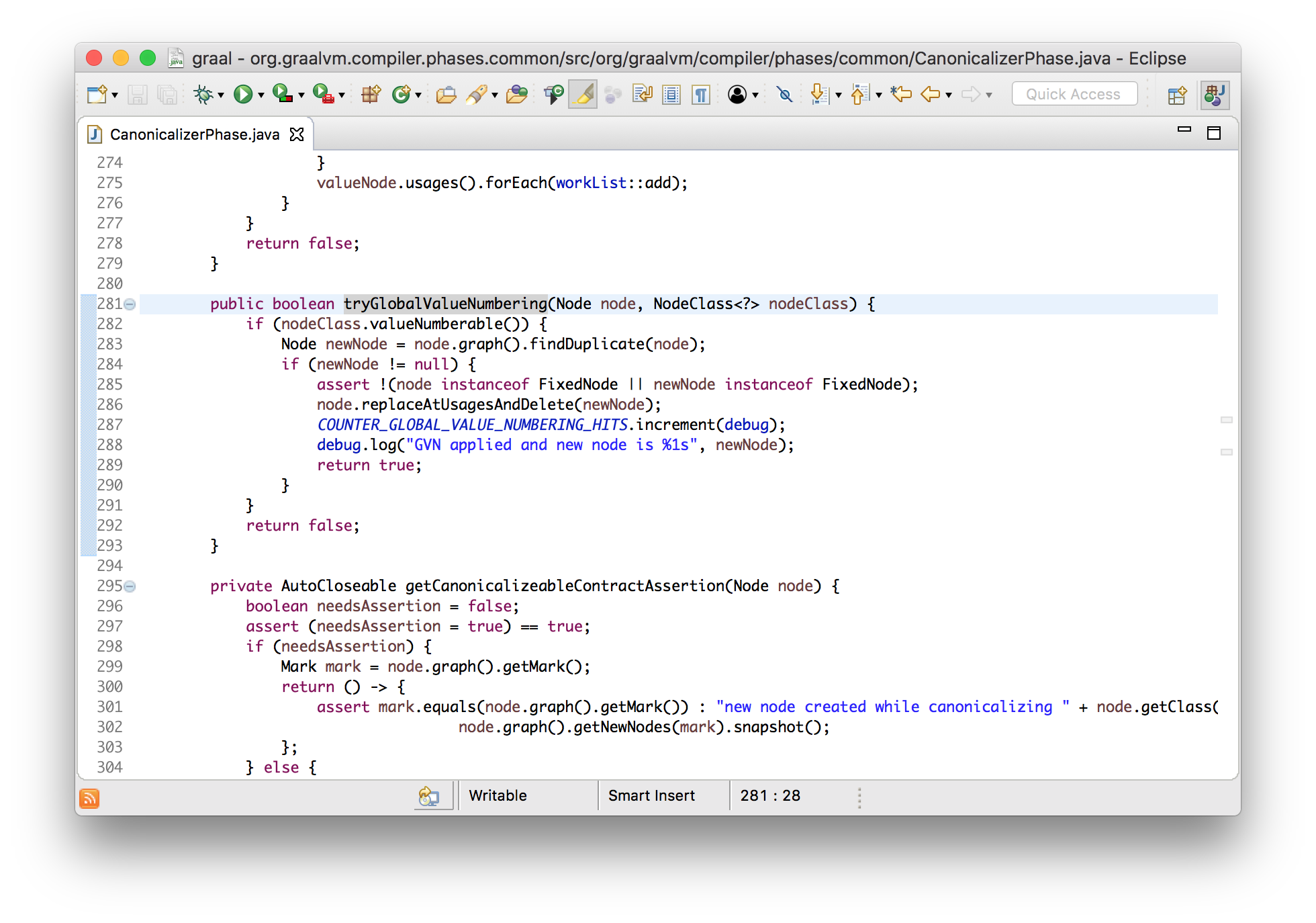
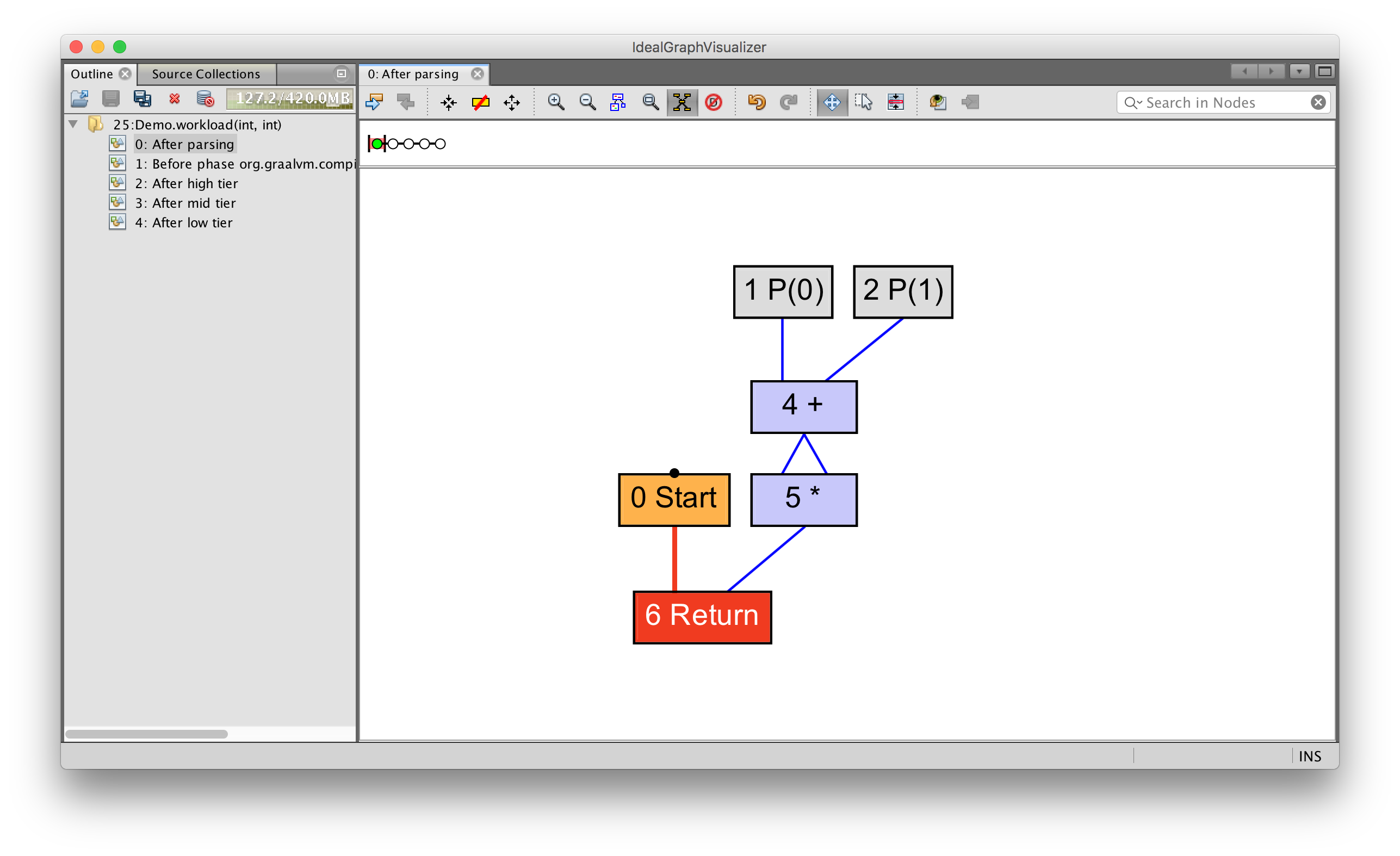
Заметьте проверку на то, что узел нефиксированный — это означает, что он не обладает побочным эффектом, который может проявиться в какой-то момент времени. Если бы, вместо этого, вызывался метод, то терм стал бы фиксированным и неизбыточным, а их слияние в один — невозможным.
int workload() {
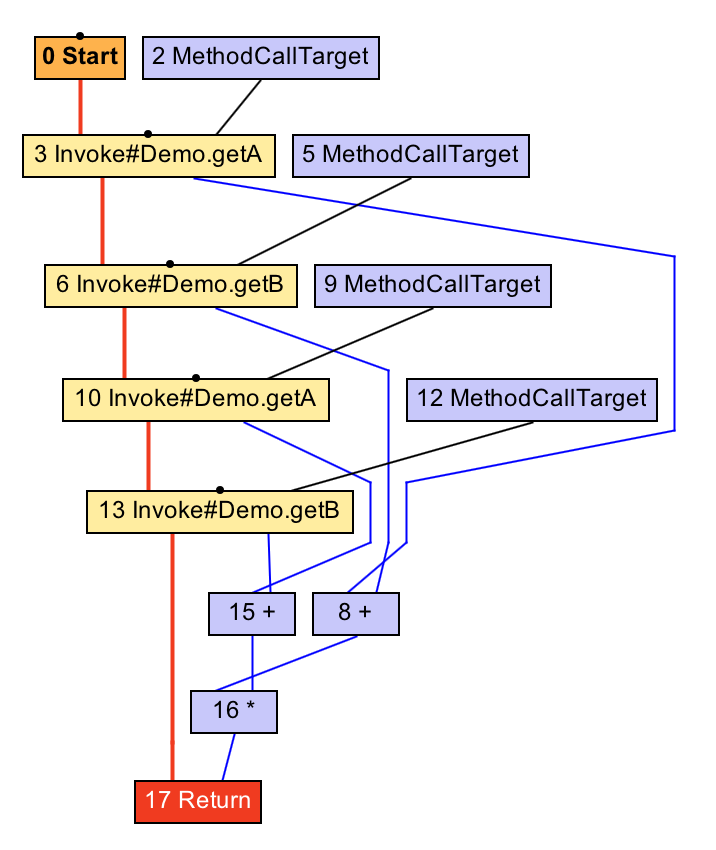
return (getA() + getB()) * (getA() + getB());
}
Укрупнение блокировок (lock coarsening)
Давайте рассмотрим более сложный пример. Иногда программисты пишут код который два раза подряд синхронизируется на одном и том же мониторе. Возможно, что они так не писали, но это стало результатом других оптимизаций, таких как встраивание (inlining).
void workload() {
synchronized (monitor) {
counter++;
}
synchronized (monitor) {
counter++;
}
}Если развернуть конструкции, то мы увидим, что, фактически, происходит.
void workload() {
monitor.enter();
counter++;
monitor.exit();
monitor.enter();
counter++;
monitor.exit();
}Мы можем оптимизировать этот код захватывая монитор только один раз вместо его освобождения и повторного захвата на следующем же шаге. Это и есть укрупнение блокировок.
void workload() {
monitor.enter();
counter++;
counter++;
monitor.exit();
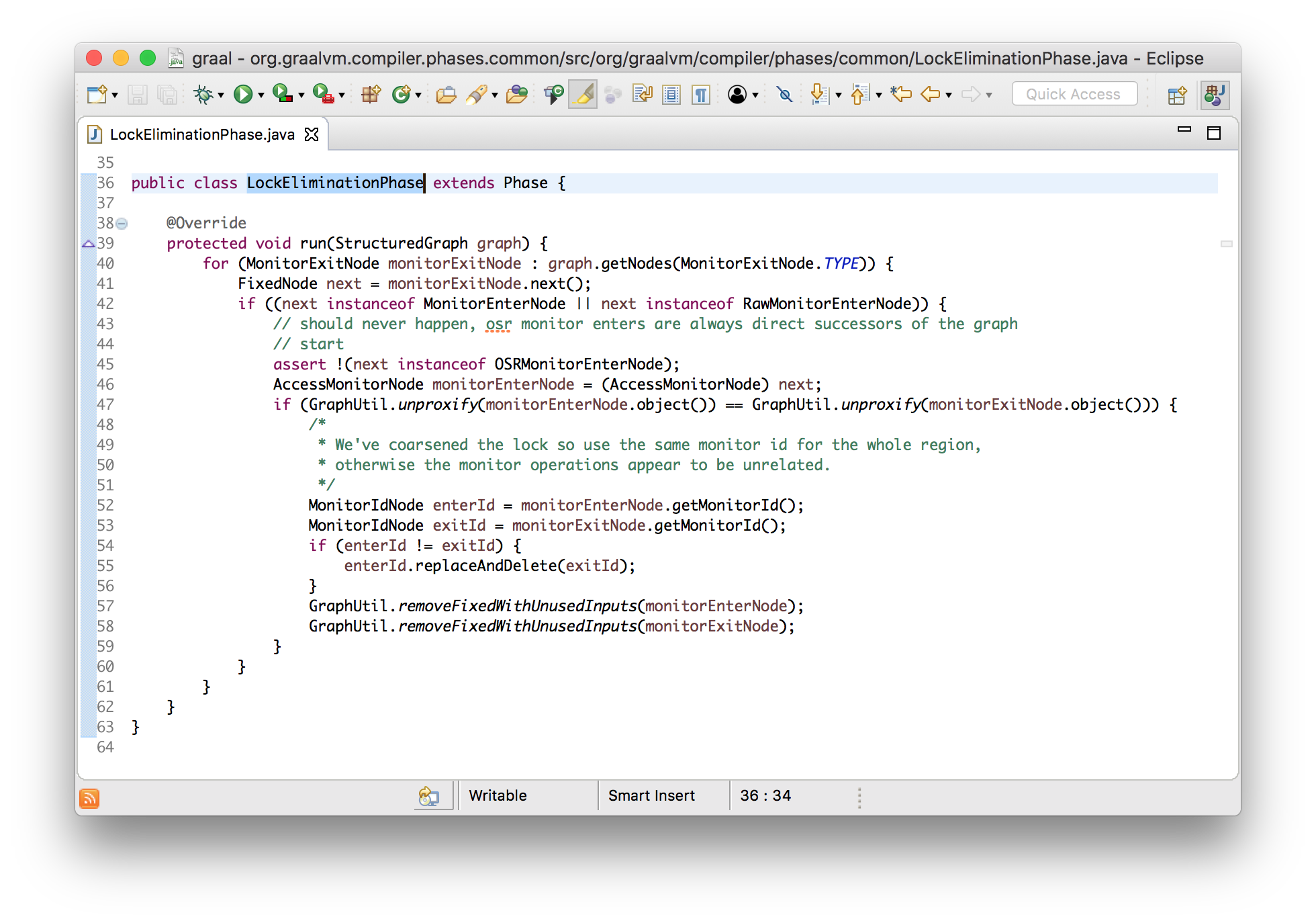
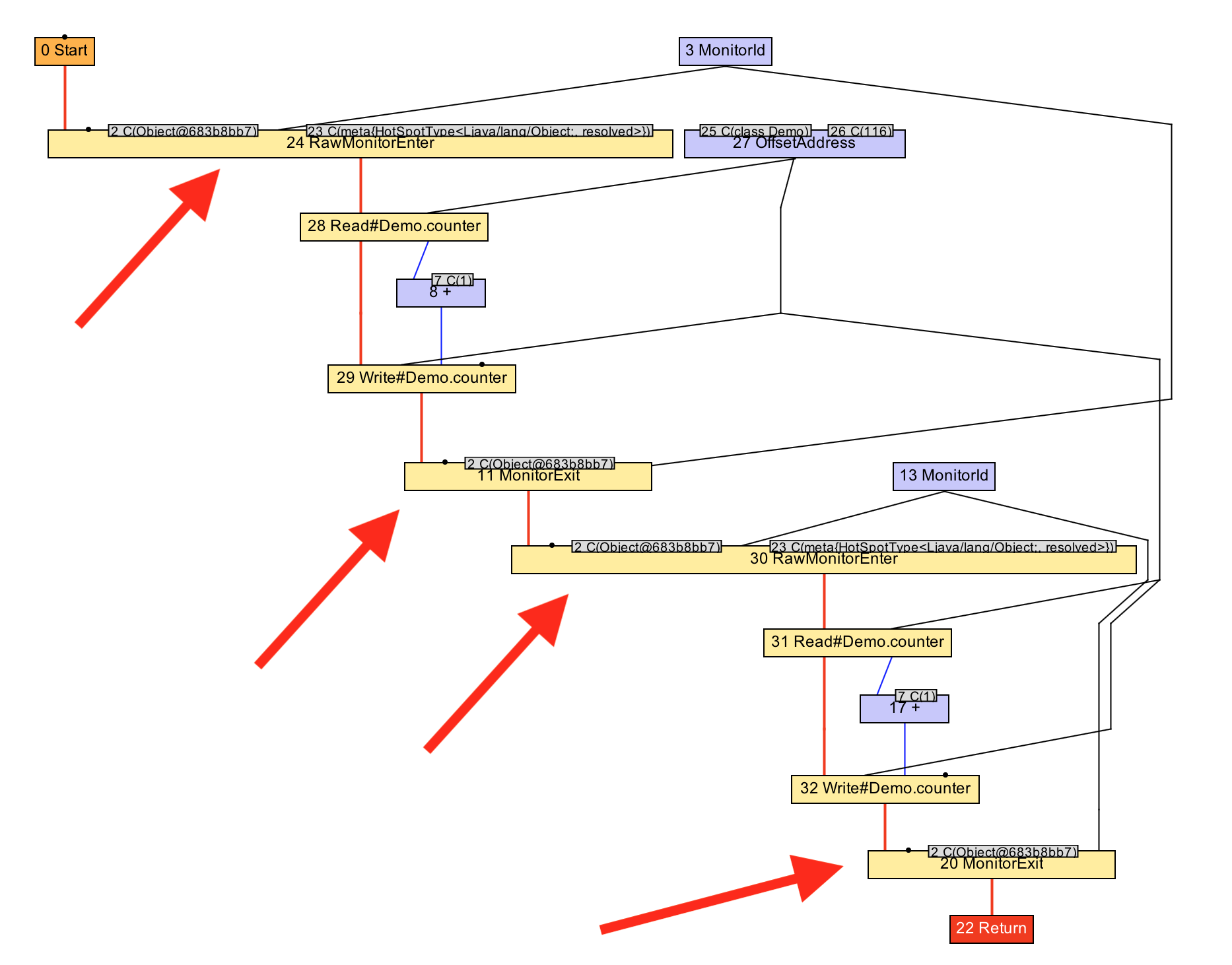
}В Graal это реализовано в фазе под названием LockEliminationPhase. В методе run производится поиск всех узлов освобождения монитора, и выполняется проверка непосредственного следования за ними узлов захвата. После этого, в случае использования одного и того же монитора, выполняется их удаление и остаются только объемлющие узлы захвата и освобождения.
void run(StructuredGraph graph) {
for (monitorExitNode monitorExitNode : graph.getNodes(MonitorExitNode.class)) {
FixedNode next = monitorExitNode.next();
if (next instanceof monitorEnterNode) {
AccessmonitorNode monitorEnterNode = (AccessmonitorNode) next;
if (monitorEnterNode.object() ## monitorExitNode.object()) {
monitorExitNode.remove();
monitorEnterNode.remove();
}
}
}
}
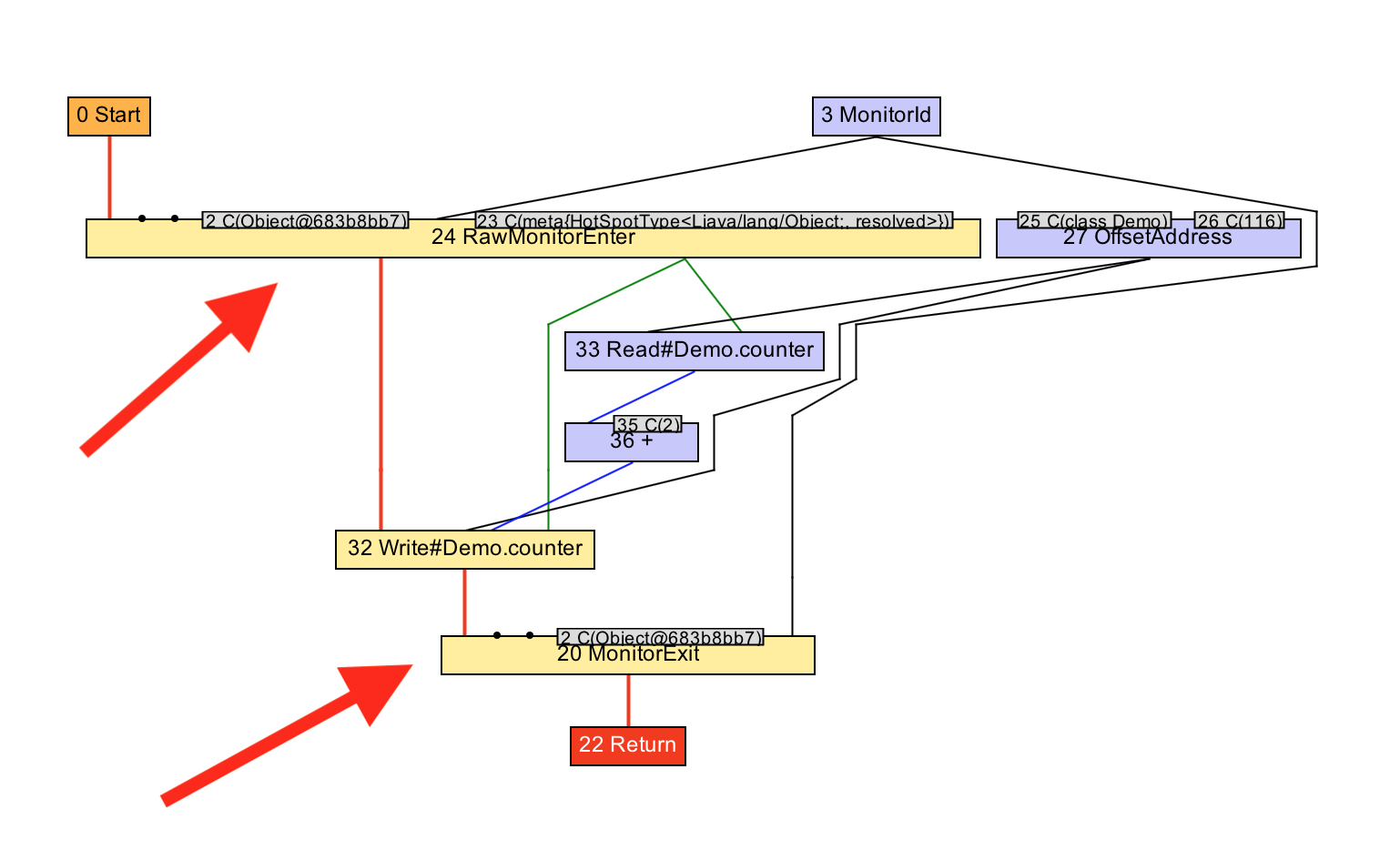
Основной причиной для этой оптимизация является уменьшение кода избыточных захватов и освобождений, но, также, это позволяет выполнять и другие оптимизации, такие как комбинация двух инкрементов в одно сложение с 2.
void workload() {
monitor.enter();
counter += 2;
monitor.exit();
}Давайте посмотрим в IGV как это работает. Мы видим, после выполнения оптимизации, как граф направляется от двух пар захвата\освобождения монитора к одной, и как, после, два инкремента преобразуются в одно сложение с 2.
Не затронутые практические аспекты
Рассматривая работу Graal на высоком уровне, конечно же, я упустил множество важных практических деталей, которые обеспечивают его хорошую работу и создание эффективного машинного кода. Фактически, я, также, пропустил некоторые базовые вещи необходимые для его работы в принципе.
Я не рассказал о некоторых частях Graal по той причине, что они, концептуально, не так просты для демонстрации как приведенный выше код, но я покажу где, при желании, вы сможете их найти.
Назначение регистров
В модели графа Graal у нас есть узлы по которым, с помощью ребер, перемещаются значения. Но что собой представляют эти ребра в реальности? Если машинным инструкциям нужны входные данные или возможность вернуть результат, то что они для этого используют?
Ребра, в итоге, отображаются на регистры процессора. Регистры подобны локальным переменным для процессора. Они являются высшей частью иерархии системной памяти, находясь над различными уровнями кешей процессора, которые, в свою очередь, находятся над оперативной памятью. Машинные инструкции могут писать и читать из регистров, и значения, таким образом, могут передаваться от одной инструкции к другой с помощью их записи первой и, после, чтения второй.
Задача выбора регистров для каждого ребра называется назначением регистров (register allocation). Graal использует, схожий с другими JIT-компиляторами, алгоритм назначения регистров — алгоритм линейной развёртки (linear scan algorithm).
Диспетчеризация
Еще одна базовая проблема, о которой я не упомянул, заключается в том, что у нас есть граф узлов без какого-либо точного порядка их выполнения, а процессору требуется линейная последовательность инструкций в определенном порядке.
Например, инструкция сложения принимает на вход два значения, которые нужно просуммировать, и, если нет необходимости вычисления одного значения раньше другого (т.е. они не имеют побочного эффекта), то граф тоже не говорит нам об этом. Но, при выдаче машинного кода, необходимо определить порядок входных значений.
Эта проблема называется диспетчеризацией графа (graph scheduling). Диспетчер требуется для определения порядка обработки узлов. Он определяет последовательность вызова кода учитывая требование, что все значения должны быть вычислены на момент их использования. Можно создать диспетчер который будет просто работать, но есть возможность улучшить производительность кода, например, не вычисляя значение до момента его фактического использования.
Можно сделать еще хитрее применив знание об имеющихся ресурсах процессора и давать ему работу таким образом, чтобы они использовались наиболее эффективно.
В каких случаях использовать Graal?
В начале выступления в вводном слайде я говорил, что, на данный момент, Graal — это исследовательский проект, а не находящийся на поддержке продукт Oracle. Каким может быть практическое применение исследований, осуществляемых в рамках Graal?
Компилятор нижнего уровня (final-tier compiler)
C помощью JVMCI Graal может использоваться как компилятор нижнего уровня в HotSpot — то, что я и демонстрировал выше. По мере появления новых (и отсутствующих в HotSpot) оптимизаций в Graal он может стать компилятором, используемым для повышения производительности.
Twitter говорили про то как они используют Graal для этой цели, а имея релиз Java 9 и желание экспериментировать вы уже сегодня можете начать практиковаться в этом. Для того чтобы начать нужны только флаги: -XX:+UseJVMCICompiler и др.
Огромная польза от JVMCI заключается в том, что он дает возможность подгружать Graal отдельно от JVM. Вы можете развертывать (deploy) какую-то версию JVM, и отдельно подключать новые версии Graal. Как и в случае с Java-агентами, при использовании Graal, обновление компилятора не требует пересборки самой JVM.
Проект OpenJDK по названием Metropolis имеет своей целью реализацию большей части JVM на языке Java. Graal представляет собой один из шагов в этом направлении.
http://cr.openjdk.java.net/\~jrose/metropolis/Metropolis-Proposal.html
Пользовательские оптимизации
Graal можно расширять дополнительными оптимизациями. Так же как Graal подключается к JVM, есть возможность подключения к Graal новых фаз компиляции. Если у вас есть желание применить определенную оптимизацию к вашему приложению, в Graal вы можете написать для этого новую фазу. Или, если у вас есть какой-то особенный набор кодов машинных инструкций, который вы хотите использовать, вы можете просто написать новый метод вместо использования низкоуровневого кода и его последующего вызова с помощью JNI.
Charles Nutter уже предложил проделать это для JRuby и продемонстрировал рост производительности от добавления новой фазы Graal смягчающей идентификацию объектов для упакованных чисел Ruby. Думаю, что скоро он выступит с этим на какой-нибудь конференции.
AOT (ahead-of-time) компиляция
Graal — это просто библиотека Java. JVMCI предоставляет интерфейс, используемый Graal, для осуществления низкоуровневых действий, таких как установка машинного кода, но большая часть Graal достаточно изолирована от всего этого. Это означает, что вы можете использовать Graal и для других приложений, а не только как JIT-компилятор.
На самом деле между JIT- и AOT-компилятором не такая уж и большая разница, и Graal можно использовать в обоих случаях. В действительности существует два проекта реализующих AOT с помощью Graal.
Java 9 включает инструмент предварительной компиляции классов в машинный код для сокращения времени требуемого для JIT-компиляции, особенно на фазе запуска приложения. Для работы этого кода все еще нужна JVM, только вместо запуска компилятора по требованию используется предварительно скомпилированный код.
AOT Java 9 использует несколько устаревшую версию Graal, которая включена только в сборки для Linux. Именно по этой причине я не стал использовать её для демо и, вместо этого, продемонстрировал сборку более свежей версии и необходимые для использования аргументы командной строки.
Второй проект более амбициозен. SubstrateVM — это AOT-компилятор, который компилирует Java-приложение в независимый от JVM машинный код. Фактически, на выходе вы имеете статически-связанный (statically linked) исполняемый модуль. В этом случае JVM не требуется, а исполняемый файл может иметь размер всего несколько мегабайт. Для выполнения такой компиляции SubstrateVM использует Graal. В некоторых конфигурациях для компиляции кода во время выполнения (just-in-time) SubstrateVM, также, может скомпилировать Graal в себя. Таким образом Graal AOT-компилирует себя самого.
$ javac Hello.java
$ graalvm-0.28.2/bin/native-image Hello
classlist: 966.44 ms
(cap): 804.46 ms
setup: 1,514.31 ms
(typeflow): 2,580.70 ms
(objects): 719.04 ms
(features): 16.27 ms
analysis: 3,422.58 ms
universe: 262.09 ms
(parse): 528.44 ms
(inline): 1,259.94 ms
(compile): 6,716.20 ms
compile: 8,817.97 ms
image: 1,070.29 ms
debuginfo: 672.64 ms
write: 1,797.45 ms
[total]: 17,907.56 ms
$ ls -lh hello
-rwxr-xr-x 1 chrisseaton staff 6.6M 4 Oct 18:35 hello
$ file ./hello
./hellojava: Mach-O 64-bit executable x86_64
$ time ./hello
Hello!
real 0m0.010s
user 0m0.003s
sys 0m0.003sTruffle
Еще один проект использующий Graal в качестве библиотеки имеет название Truffle. Truffle — это фреймворк для создания интерпретаторов языков программирования поверх JVM.
Большинство языков, работающих на JVM, выдают байткод, который потом JIT-компилируется как обычно (но, как я говорил выше, по той причине, что JIT-компилятор JVM представляет собой черный ящик, довольно трудно контролировать что произойдет с этим байткодом). Truffle использует другой подход — вы пишете простой интерпретатор для вашего языка, следуя определенным правилам, и Truffle, автоматически, комбинирует программу и интерпретатор для получения оптимизированного машинного кода используя технику известную как частичное вычисление (partial evaluation).
Частичное вычисление имеет в своей основе интересную теоретическую часть, но с практической точки зрения мы можем говорить об этом как о включении кода (inlining) и сворачивании констант (constant folding) программы вместе с используемыми ею данными. Graal имеет функционал включения кода и сворачивания констант, поэтому Truffle может использовать его в качестве частичного вычислителя.
Именно так я и познакомился с Graal — через Truffle. Я работаю над реализацией языка программирования Ruby, которая называется TruffleRuby и использует фреймворк Truffle и, также, Graal. TruffleRuby — это самая быстрая реализация Ruby, обычно в 10 раз быстрее других, которая, при этом, реализует практически все возможности языка и стандартную библиотеку.
https://github.com/graalvm/truffleruby
Выводы
Главная идея, которую я хотел донести этим выступлением, заключается в том, что с JIT-компилятором Java можно работать также как и с любым другим кодом. JIT-компиляция включает множество сложностей, в основном наследуя их от лежащей в основе архитектуры и, также, из-за желания выдачи как можно более оптимизированного кода за возможно кратчайшее время. Но, все равно, это верхнеуровневая задача. Интерфейс к JIT-компилятору представляет собой не больше, чем конвертер byte[] байткода JVM в byte[] машинного кода.
Эта задача, которая хорошо подходит для реализации на Java. Сама компиляция не является задачей требующей низкоуровневого и небезопасного языка программирования, такого как C++.
Java-код Graal не является какой-то магией. Не буду притворяться, что он всегда прост, но заинтересованный новичок будет в состоянии прочесть и понять большую его часть.
Очень советую вам самим поэкспериментировать с этим пользуясь данными подсказками. Если вы начнете с изучения приведенных выше классов, то не потеряетесь в коде впервые открыв Eclipse и увидев длинный список пакетов. От этих стартовых точек вы можете двигаться к реализациям методов (definitions), местам их вызова и т.д. постепенно исследуя кодовую базу.
Если у вас уже есть опыт контроля и настройки JIT с использованием инструментов для существующих JIT-компиляторов JVM, таких как JITWatch, то вы заметите, что чтение кода поможет лучше понять почему Graal компилирует ваш код именно так, а не иначе. И, если вы поймете, что что-то работает не так как вы того ожидаете, то сможете внести в Graal изменения и просто перезапустить JVM. Для этого вам даже не потребуется покидать вашу IDE, как я показал на примере с hello-world.
Мы работаем над такими потрясающими исследовательскими проектами как SubstrateVM и Truffle, которые используют Graal, и действительно меняют картину того, что будет возможно в Java в будущем. Все это возможно благодаря тому, что весь Graal написан на обычной Java. Если бы, для написания нашего компилятора, мы использовали что-то вроде LLVM, как предлагают некоторые компании, то, во многих случаях, переиспользование кода было бы затруднено.
И, наконец, на данный момент есть возможность использовать Graal не внося изменений в саму JVM. Т.к. JVMCI является частью Java 9, Graal может быть подключен также как и, уже существующие, процессоры аннотаций или Java-агенты.
Graal — это большой проект над которым работает много людей. Как уже говорилось выше, я не работаю непосредственно над Graal. Я просто им пользуюсь, и вы тоже можете это делать!
More information about TruffleRuby
Top 10 Things To Do With GraalVM
Ruby Objects as C Structs and Vice Versa
Understanding How Graal Works — a Java JIT Compiler Written in Java
Flip-Flops — the 1-in-10-million operator
Very High Performance C Extensions For JRuby+Truffle
Optimising Small Data Structures in JRuby+Truffle
Pushing Pixels with JRuby+Truffle
Tracing With Zero Overhead in JRuby+Truffle
How Method Dispatch Works in JRuby+Truffle
