Comments 18
Не упомянули ещё что auto_explain можно включать на отдельного пользователя:
Штука хорошая, особенно если надо ловить некий подземный стук когда план внезапно плывёт. Или интересный фокус был с приложением, которое неверно заявляло типы данных для prepared statement (передавался numeric вместо int), из-за чего планировщиком не использовался индекс, но сам запрос выполнялся корректно. Выполнялся медленно, и не ловилось через explain, т.к. не было видно передаваемый тип.
Если интересуют просто тяжёлые запросы — лучше включить pg_stat_statements и раз в сутки (или своим мониторингом) строить отчёт по времени выполнения. Мы например кругом настраиваем вот такой отчёт с топ-40 запросами по общему времени выполнения за сутки.
Окметр — хорошая штука, и даже если не используете его, то весьма советую посмотреть какие метрики выводятся на графиках postgresql и сделать в своём мониторинге такие же. Ну а вообще у них огромная куча метрик собирается. (циферки по конкретным запросам к слову именно pg_stat_statements и собирает)
ALTER ROLE some_user SET session_preload_libraries TO 'auto_explain';
ALTER ROLE some_user SET "auto_explain.log_min_duration" TO '100ms';Штука хорошая, особенно если надо ловить некий подземный стук когда план внезапно плывёт. Или интересный фокус был с приложением, которое неверно заявляло типы данных для prepared statement (передавался numeric вместо int), из-за чего планировщиком не использовался индекс, но сам запрос выполнялся корректно. Выполнялся медленно, и не ловилось через explain, т.к. не было видно передаваемый тип.
Если интересуют просто тяжёлые запросы — лучше включить pg_stat_statements и раз в сутки (или своим мониторингом) строить отчёт по времени выполнения. Мы например кругом настраиваем вот такой отчёт с топ-40 запросами по общему времени выполнения за сутки.
Окметр — хорошая штука, и даже если не используете его, то весьма советую посмотреть какие метрики выводятся на графиках postgresql и сделать в своём мониторинге такие же. Ну а вообще у них огромная куча метрик собирается. (циферки по конкретным запросам к слову именно pg_stat_statements и собирает)
UFO just landed and posted this here
Вы описали работу pg_stat_statements за двумя оговорками: автоматически результата explain в нём пока нет (потому что неясно какой именно план писать в результат, патчи есть для записи лучшего/худшего планов, но в pg11 они не вошли), зато нормализация запросов давно есть и отлично работает с plain text запросами даже без prepared statements.
Попутно заметки:
если логи пишутся на отдельный раздел, то его переполнение не приведёт к остановке базы. Просто за это время не будет логов. Logging collector не считает недостаток места поводом останавливать работу.
Разгрести лог аварии — упомянутый pgbadger и другие утилитки такого плана.
Попутно заметки:
если логи пишутся на отдельный раздел, то его переполнение не приведёт к остановке базы. Просто за это время не будет логов. Logging collector не считает недостаток места поводом останавливать работу.
Разгрести лог аварии — упомянутый pgbadger и другие утилитки такого плана.
диск 100%
Я запоздало сообразил, что вы скорее имели в виду дисковую утилизацию в потолок.
Вообще понять только по логам что пошло не так — весьма непросто бывает. Графики мониторинга нужны, простой график top-N запросов по общему времени выполнения — уже значительно упрощает жизнь. Цифры есть в pg_stat_statements и даже отдельно время для дисковых операций. И единственная сложность — счётчики инкрементные, значит мониторинг должен показывать разницу между метриками во времени, а не сиюминутные stateless значения, как большинство системных метрик.
UFO just landed and posted this here
при этом их запрос убивается количеством FilteredАга, и ещё гигантские выборки могут отлично страдать от Recheck Cond
Я так понял речеги это когда выборка слишком велика, чтобы карта версий строк влезла в ОЗУ (параметр work_mem). Тогда строится битовая карта страниц, хотя бы с одной найденной TID. Занимает меньше ОЗУ, но перепроверяет все строки страниц
min/max filtered. И эта чиселка в общем случае будет алертом для админа/разработчика
А сможете описать (лучше сразу на английском), зачем вам именно счётчики фильтров, вернее чем для таких алертов не годятся min/max/mean/stddev счётчики времени выполнения?
Если QueryDesc->totaltime->nfiltered1 и nfiltered2 — то о чём я думаю, то их совсем не сложно вытащить в pg_stat_statements. С хорошей аргументацией целесообразности патч и принять могут.
[типовой в общем-то] случай когда все запросы оптимизированы и один-два запросов пошли вдруг к базе без индексов
Нет, не соглашусь что это типовой случай. Общаюсь как DBA с несколькими десятками команд разработчиков, проблемы вызывают в основном новые запросы, которые выкатывают разработчики с релизом или сами релизы миграций. Внезапно поплывший план — большая редкость.
Ну а в целом любой проект имеет конечное число уникальных запросов к БД, количество которых сводится всего к нескольким десяткам, ну максимум к сотням
Сильно не соглашусь. У четверти из моих пары сотен подопечных серверов больше тысячи уникальных запросов в сутки. Меньше сотни — у другой четверти, включая отчёты с резервных реплик без нагрузки.
А выборка даже по первичному ключу может замечательно тупить на частообновляемых таблицах если мешать работать автовакууму. В explain(analyze,buffers) тогда видны чудесные тысячи просмотренных страниц в поиске единственной нужной строки.
UFO just landed and posted this here
Почему это не будет?
После lossy индексов (например gist или brin) всегда будут recheck.
После bitmap index scan — тоже.
После lossy индексов (например gist или brin) всегда будут recheck.
После bitmap index scan — тоже.
Да, именно так
Может кому будет интересно
GIN:
GiST — в виду того, что хранятся в индексе не значения, а логические суммы лексем документов (сигнатуры доков) — могут быть коллизии, потому тоже речек, даже если был простой Index Scan
Да и вообще рекомендую прочесть все статьи из серии ) там ещё brin, sp-gist, hash, rum, bloom
Может кому будет интересно
GIN:
Особенность метода доступа gin состоит в том, что результат всегда возвращается в виде битовой карты: выдавать TID-ы по одному этот метод не умеет. Именно поэтому все планы запросов, которые встречаются в этой части, используют сканирование по битовой карте (bitmap scan)
GiST — в виду того, что хранятся в индексе не значения, а логические суммы лексем документов (сигнатуры доков) — могут быть коллизии, потому тоже речек, даже если был простой Index Scan
Да и вообще рекомендую прочесть все статьи из серии ) там ещё brin, sp-gist, hash, rum, bloom
UFO just landed and posted this here
Погодите, он же работает только с битовой картой
Речек обязательно есть
Вот пример с пустой таблицей и вашим условием habrastorage.org/webt/zo/-m/mw/zo-mmw7k4vcbtwk7sgztbrlbe20.png
Вот с непустой таблицей — hsto.org/webt/gz/ec/gx/gzecgxj2obtrsgghgzq-htesh3o.png
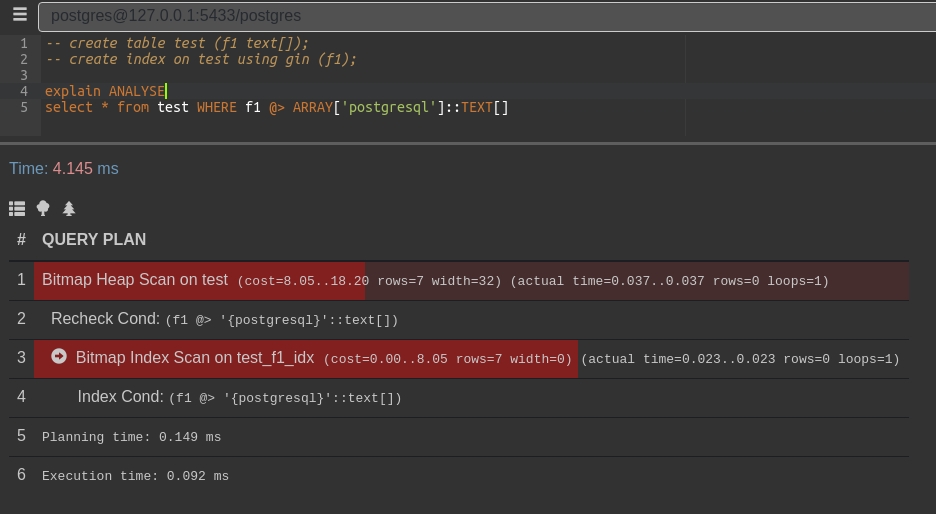
Прошу заметить, что Bitmap Index Scan вернул одну строку, но после был её речек
Речек обязательно есть
Вот пример с пустой таблицей и вашим условием habrastorage.org/webt/zo/-m/mw/zo-mmw7k4vcbtwk7sgztbrlbe20.png
{kind=link}
Вот с непустой таблицей — hsto.org/webt/gz/ec/gx/gzecgxj2obtrsgghgzq-htesh3o.png
{kind=link}
Прошу заметить, что Bitmap Index Scan вернул одну строку, но после был её речек
Скрипт, можете проверить
create table test (f1 text[]);
create index on test using gin (f1);
insert into test VALUES(ARRAY['postgresql']);
insert into test VALUES(ARRAY['postgresql2', 'mysql']);
insert into test VALUES(ARRAY['postgresql2', 'mysql', 'mssql']);
explain ANALYSE
select * from test WHERE f1 @> ARRAY['postgresql']::TEXT[];
Sign up to leave a comment.
Postgres auto_explain: автолог плана запроса