Comments 25
В зависимости от постановки, задачи машинного обучения делят на задачи классификации, регрессии и логистической регрессии.
…
Логистическая регрессия сочетает свойства перечисленных выше двух постановок задач. В ней задаются совершившиеся события на объектах, а требуется предсказать их вероятности на новых объектах.
Фантастика. И откуда же вы это взяли?
И более того:
Или дают классы и просят предсказать классы, ..., или дают классы и просят предсказать вероятности
И то, и другое является определением задачи классификации.
Зачем городить велосипеды и придумывать своё собственное разделение задач ML на типы, когда есть общепринятое? Категориальная целевая переменная — классификация, непрерывная — регрессия.
По второй же — описан один конкретный (из многих) алгоритм, решающий задачу логистической регрессии. Точно так же эту задачу можно решать с помощью нейросетей, алгоритмов на основе ансамблей решающих деревьев и т п.
Ну казалось бы постановки задач «дали классы, хотят классы» и «дали классы, хотят вероятности» различаются, не правда ли?
Различаются, и тем не менее обе они относятся к задачам классификации (более того, первая из них сводима ко второй с отсечением по порогу).
А вот ваш пример ("задача предсказания вероятности перехода пользователя по рекомендательной ссылке или рекламному объявлению") — это просто регрессия.
Различаются, и тем не менее обе они относятся к задачам классификации (более того, первая из них сводима ко второй с отсечением по порогу).
Мне кажется вполне разумным разделить их на два разных класса в классификации «по формулировке». Все-таки и суть и форма ощутимо различаются.
А вот ваш пример («задача предсказания вероятности перехода пользователя по рекомендательной ссылке или рекламному объявлению») — это просто регрессия.
Ой, да ладно. Нам дают свершившиеся события (наличие или отсутствие перехода по рекламной ссылке, 0 или 1) и просят предсказать вероятность этого события (действительное число от 0 до 1) и это регрессия (задача, в которой по набору значений некоторой действительнозначной функции надо аппроксимировать эту функцию). Ну-ну.
Кстати, вот например в википедии — и в русскоязычной, и в англоязычной логистическая регрессия находится в секции, относящейся к регрессии. Еще один аргумент для выделения задач с такой постановкой в отдельный класс для снятия неопределенности.
Нам дают свершившиеся события (наличие или отсутствие перехода по рекламной ссылке, 0 или 1) и просят предсказать вероятность этого события (действительное число от 0 до 1)
Это каноничная логистическая регрессия. Прямо по определению — en.wikipedia.org/wiki/Logistic_regression
задача, в которой по набору значений некоторой действительнозначной функции надо аппроксимировать эту функцию
А это не регрессия, это аппроксимация.
Это каноничная логистическая регрессия. Прямо по определению — en.wikipedia.org/wiki/Logistic_regression
Так и я в основном тексте говорю, что это «логистическая регрессия». А мой комментатор утверждает, что это не «логистическая регрессия» а «просто регрессия», а «логистическая регрессия» как постановка задачи — это «классификация». И кто прав?
А это не регрессия, это аппроксимация.
Ну не совсем. Допустим мы предсказываем, скажем, цену на товары и уже выбрали функцию, отображающую входящие данные в фичевектор. Тогда (несколько упрощая) у нас есть некая неизвестная функция из R^n в R и набор точек (соответствующий размеченной выборке) на которых известные ее значение. После этого построение модели, сопоставляющей любой точке в R^n значение в R — это и есть построение новой функции специального вида, приближающей исходную, т. е. аппроксимация.
А мой комментатор утверждает, что это не «логистическая регрессия» а «просто регрессия», а «логистическая регрессия» как постановка задачи — это «классификация».
Наверное, вас вводит в заблуждение многозначный термин «регрессия». Давайте, я попробую разложить по полочкам:
1) Когда мы говорим «регрессия» про методологию, мы имеем в виду регрессионный анализ и его приложения.
2) Когда мы говорим про типы задач в ML, мы говорим «регрессия» про обучение с учителем на непрерывный таргет, а «классификация» — на категориальный.
3) Логистическая регрессия — это конкретный алгоритм, где мы строим регрессию (в первом значении), поверх которой используем логит, чтобы предсказывать целевую переменную в диапазоне от 0 до 1, таким образом получая бинарную классификацию.
4) Почти любой алгоритм классификации может работать как в вероятностном режиме (так называемый «soft classification»), так и в режиме выдачи меток классов («hard classification»). Очевидно, что первый режим всегда включает в себя второй, как вам уже указывал выше другой комментатор. Второй не всегда включает в себя первый, но такие классификаторы сейчас редко используются (например, SVM), и чтобы добиться от них вероятности, приходится немного модифицировать алгоритм.
Вы же не будете называть «логистической регрессией», например, нейронную сеть с сигмоидой на выходном слое, правда? Ведь если вы так будете делать, вас никто не поймет.
Вы же не будете называть «логистической регрессией», например, нейронную сеть с сигмоидой на выходном слое, правда? Ведь если вы так будете делать, вас никто не поймет.
Казалось бы буду. Только не с сигмоидой, а с софтмаксом. Ссылки тут, там и сям подтверждают, что общепринято логистической регрессией называть скорее постановку задачи, а не конкретный алгоритм, ее реализующий.
4) Да, разумеется, но постановка задачи другая, метрики другие. Мне кажется — вполне достаточно для того, чтобы выделить в отдельную логическую единицу в классификации задач машинного обучения по формулировкам.
Так и я в основном тексте говорю, что это «логистическая регрессия». А мой комментатор утверждает, что это не «логистическая регрессия» а «просто регрессия», а «логистическая регрессия» как постановка задачи — это «классификация». И кто прав?
Ну я бы не смешивал понятия «логистическая регрессия» и «классификатор». Несмотря на то, логистическую регрессию МОЖНО использовать для построения классификатора, это все же совсем разные вещи.
После этого построение модели, сопоставляющей любой точке в R^n значение в R — это и есть построение новой функции специального вида, приближающей исходную, т. е. аппроксимация.
Ну вот, если быть точным, то регрессия — это полученная модель, а аппроксимация — один из методов ее построения (но не единственный).
Ну я бы не смешивал понятия «логистическая регрессия» и «классификатор». Несмотря на то, логистическую регрессию МОЖНО использовать для построения классификатора, это все же совсем разные вещи.
Я бы тоже не смешивал. И не смешиваю, а коллеги не соглашаются.
Ну вот, если быть точным, то регрессия — это полученная модель, а аппроксимация — один из методов ее построения (но не единственный).
Вот тут бы я хотел чуть точнее договориться по поводу терминологии. Итоговая модель в случае задачи регрессии в узком смысле (когда у нас уже есть зафиксированное отображение из пространства объектов в R^n) — это просто функция из R^n в R, вообще говоря, — произвольной природы. Метод построения такой функции — это алгоритм машинного обучения, берущий на вход размеченную выборку и дающий ее на выходе. Аппроксимация в данном контексте — это просто математический жаргон, не имеющий строгого определния и означающий приближение одних объектов другими.
Я бы тоже не смешивал. И не смешиваю, а коллеги не соглашаются.
Коллеги, вероятно, не сталкивались с регрессионным анализом вне контекста машинного обучения.
Метод построения такой функции — это алгоритм машинного обучения, берущий на вход размеченную выборку и дающий ее на выходе.
Вот физики сейчас удивились, что их любимые МНК и градиентный спуск — это оказывается методы машинного обучения, а не методы оптимизации.
Аппроксимация в данном контексте — это просто математический жаргон, не имеющий строгого определния и означающий приближение одних объектов другими.
А меня вот учили, что аппроксимация — это научный метод для построения мат. моделей. И целый раздел мат. анализа. Про полиномы Лагранжа и Ньютона и вот это все.
Вот физики сейчас удивились, что их любимые МНК и градиентный спуск — это оказывается методы машинного обучения, а не методы оптимизации.
В чем отличие от «методов машинного обучения» на уровне математического определения? И там и там надо определенным способом определить функцию специального вида на некотором множестве (почти всегда — в R^n), по набору пар соответствующих точек в областях определения и значений, оптимизирующую некоторый функционал качества. Я могу спуститься на уровень совсем-совсем строгих и математичных определений, так или иначе сейчас для меня все выглядит так, что МНК — это (простой) метод машинного обучения из той эпохи, когда еще не было термина «машинное обучение» и современных алгоритмов, составляющих его сущность.
А меня вот учили, что аппроксимация — это научный метод для построения мат. моделей. И целый раздел мат. анализа. Про полиномы Лагранжа и Ньютона и вот это все.
Опять же, сошлюсь на википедию. Вот здесь утверждается, что «Аппроксима́ция (от лат. proxima — ближайшая) или приближе́ние — научный метод, состоящий в замене одних объектов другими, в каком-то смысле близкими к исходным, но более простыми.» — объектами (в разумном смысле этого слова) произвольной природы, в частности помимо анализа в статье упоминается теория чисел, а люди, разбирающиеся в математике на более энциклопедичном уровне, чем я, наверняка приведут еще массу примеров не менее далеких от упомянутых полиномов специального вида, чем диофантовы уравнения. Таким образом обсуждаемый термин — это именно профессиональный жаргон, не имеющий строгого смысла даже в пределах одной научной дисциплины.
то МНК — это (простой) метод машинного обучения
Вот тут товарищ нечаянно вывел МНК из Баейса.
habrahabr.ru/post/276355
Мне кажется вполне разумным разделить их на два разных класса в классификации «по формулировке». Все-таки и суть и форма ощутимо различаются.
Простите, но какая разница, что вам кажется, если все data scientist-ы пользуются другой классификацией задач машинного обучения?
Вот выделите вы эти задачи в отдельный класс, а дальше получится смешное.
Вот возьму я задачу классификации (где на выходе надо давать метки), и решу ее с помощью логистической регрессии с отсечением по порогу (каноническое решение, если что).
Или вот возьму я задачу предсказания вероятностей отнесения к классу и решу ее… с помощью дерева — но называть ее все еще надо, по-вашему, логистической регрессией.
Стало ли меньше путаницы? Нет.
Нам дают свершившиеся события (наличие или отсутствие перехода по рекламной ссылке, 0 или 1) и просят предсказать вероятность этого события (действительное число от 0 до 1) и это регрессия (задача, в которой по набору значений некоторой действительнозначной функции надо аппроксимировать эту функцию).
Ну так вы не забывайте, что любое свершившееся событие можно выразить действительным числом, обозначающим его вероятность.
1. Задача классификации состоит в построении классификатора.
2. Классификатор может быть пострен на базе логистической регрессии.
3. Логистическая регрессия — это статистическая модель, которая может быть построена разными методами — регрессионным анализом, машинным обучением, etc.
Я вот в твоих определениях не понимаю, почему внезапно ты задачу решаешь моделью, а не методом.
Различаются, и тем не менее обе они относятся к задачам классификации (более того, первая из них сводима ко второй с отсечением по порогу).
Мне кажется вполне разумным разделить их на два разных класса в классификации «по формулировке». Все-таки и суть и форма ощутимо различаются.
А вот ваш пример («задача предсказания вероятности перехода пользователя по рекомендательной ссылке или рекламному объявлению») — это просто регрессия.
Ой, да ладно. Нам дают свершившиеся события (наличие или отсутствие перехода по рекламной ссылке, 0 или 1) и просят предсказать вероятность этого события (действительное число от 0 до 1) и это регрессия (задача, в которой по набору значений некоторой действительнозначной функции надо аппроксимировать эту функцию). Ну-ну.
1) Противоположность детерминированному — стохастичное (случайное, вероятностное). Нечеткость явно не подразумевает не детерминированность. Насколько я понимаю, случайность в машинном обучении не в том, что при предсказании на обученной модели участвует ГПСЧ, а в том, что на выходе зачастую байесовская вероятность (на нечетких множествах, например, функция принадлежности не обязательно рассматривается как вероятностная).
2) ЕМНИП, feature selection — часть feature engineering, как и construcion, extraction, learning. Суть feature selection в том, чтобы попытаться отбросить признаки, которые имеют либо «ложную корреляцию», либо пренебрежительно малое влияние на целевую переменную. Bag of words, например, относится к feature construction.
И, уже ради общего интереса, можно ссылку на классификацию задач машинного обучения? Мне немного не понятны имеющиеся классификаторы. Куда отнести, например, object detection, image segmentation, machine translation и т.п. (где задача не полностью сводится к классификации)? И как туда входят такие штуки, как transfer learning, active learning и т.п.?
И, уже ради общего интереса, можно ссылку на классификацию задач машинного обучения? Мне немного не понятны имеющиеся классификаторы. Куда отнести, например, object detection, image segmentation, machine translation и т.п. (где задача не полностью сводится к классификации)? И как туда входят такие штуки, как transfer learning, active learning и т.п.?
Object detection — это классификация (какой объект найден?) плюс регрессия (координаты Х и Y объекта, например).
Image segmentation — это классификация (каждому пикселю присваивается метка класса).
С Machine translation всё сложнее. Я бы выделил тут отдельный класс задач «sequence-to-sequence learning».
Transfer learning — это не вид задач ML, а способ обучения нейросети.
Active learning — это semi-supervised learning, про который в статье также не упомянули.
В целом, у автора поста весьма специфичные взгляды на типизацию ML-задач, так что я бы пользовался этой диаграммой.
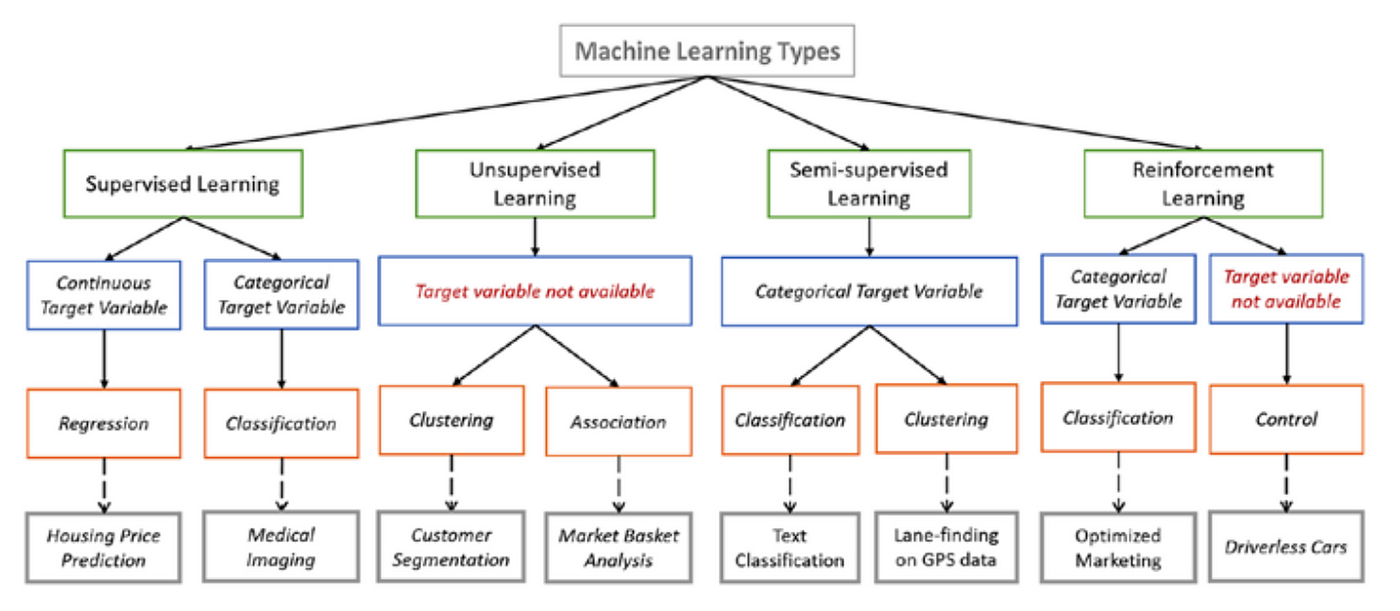{kind=link}
1) Это вопрос выбора термина. Мне хочется как-то более или менее четко разделить (классические) алгоритмы, в которых мы фактически гарантируем верный результат на каждом входящем объекте (упоминавшиеся сортировка и реализация словаря, а также реализации других классических структур данных (таких как массивы, очереди, деки) и алгоритмов) и алгоритмы эвристического и машиннообучабельного характера, в которых мы не гарантируем такого результата (упоминавшееся распознавание цифр, предсказание цен на товары, погоды, переходы по ссылкам — в общем на практике любые абстракции более высокого уровня).
2) Я употребляю термин «feature selection» в смысле «feature engineering» — в целом процесс выбора «хорошей» функции, задающей отображение из пространства объектов (instances) в пространство примеров (фичевекторов, samples). На практике существует большая неопределенность в терминах — и в этом конкретном тоже. Говорят «тут надо немного поселектить фичи» — именно в смысле подбора новых значений, при добавлении которых метрика качества на валидационной выборке растет.
Ссылку на более или менее общепринятые классификации поищу, но по факту сейчас с этим трудно. Грубо говоря перечисленные понятия (object detection, image segmentation, machine translation) относятся скорее к тематике, а не к форме постановки задачи. И уже в свою очередь сводятся к хорошо исследованным заготовкам прикладным исследователем.
Анализ данных — основы и терминология