 Напомним на всякий случай, если кто-то забыл, что GitHub – это одна из крупнейших платформ для разработки программного обеспечения и дом для многих популярных проектов с открытым исходным кодом. На страничке «Explore» GitHub вы можете найти информацию о проектах, которые набирают популярность, проектах, понравившихся людям, на которых вы подписаны, а также популярные проекты, объединенные по направлениям или языкам программирования.
Напомним на всякий случай, если кто-то забыл, что GitHub – это одна из крупнейших платформ для разработки программного обеспечения и дом для многих популярных проектов с открытым исходным кодом. На страничке «Explore» GitHub вы можете найти информацию о проектах, которые набирают популярность, проектах, понравившихся людям, на которых вы подписаны, а также популярные проекты, объединенные по направлениям или языкам программирования.
Чего вы не найдете, так это персональных рекомендаций проектов, основанных на вашей активности. Это несколько удивляет, поскольку пользователи ставят огромное количество звезд различным проектам ежедневно, и это информация может быть с легкостью использована для построения рекомендаций.
В этой статье мы делимся нашим опытом построения системы рекомендаций для GitHub от идеи до реализации.
Идея
Каждый пользователь GitHub может поставить звезду приглянувшемуся ему проекту. Имея информацию о том, каким репозиториям каждый пользователь поставил звезды, мы можем найти похожих пользователей и рекомендовать им обратить внимание на проекты, которые они, возможно, еще не видели, но которые уже понравились пользователям со схожими вкусами. Схема работает и в обратную сторону: мы можем найти проекты, похожие на те, что уже понравились пользователю, и рекомендовать их ему.
Другими словами, идея может быть сформулирована так: получить данные о пользователях и звездах, которые они поставили, применить методы коллаборативной фильтрации к этим данным и обернуть все в веб-приложение, с помощью рекомендации станут доступны для конечных пользователей.
Собираем данные
GHTorrent – замечательный проект, который собирает данные, полученные с помощью публичных GitHub API, и предоставляет к ним доступ в виду ежемесячных дампов MySQL. Эти дампы можно найти в разделе «Downloads» сайта GHTorrent.
Внутри каждого дампа можно найти SQL-файл с описанием схемы базы данных, а также несколько CSV-файлов с данными из таблиц. Как мы уже говорили в предыдущем разделе, наш подход основан на коллаборативной фильтрации. Этот подход подразумевает, что нам необходима информация о пользователях и их предпочтениях или, перефразируя это в терминах GitHub, о пользователях и звездах, которые они поставили различным проектам.
К счастью, упомянутые дампы содержат всю необходимую информацию в следующих файлах:
watchers.csvсодержит список репозиториев и пользователей, которые поставили им звездыusers.csvсодержит пары user id и имя пользователя на GitHubprojects.csvделает то же самое для проектов.
Давайте посмотрим на данные более внимательно. Ниже приведено начало файла watchers.csv (названия колонок добавлены для удобства):

Можно видеть, что проект с id=1 понравился пользователям с id=1, 2, 4, 6, 7, … Колонка с временной меткой нам не понадобится.
Неплохое начало, но прежде чем переходить к построению модели, было бы неплохо посмотреть на на данные более пристально и, возможно, почистить их.
Исследование данных
Интересный вопрос, который сразу же приходит в голову, звучит так: «Сколько звезд в среднем поставил каждый пользователь?» Гистограмма, показывающая количество пользователей, поставивших различное количество звезд, приведена ниже:
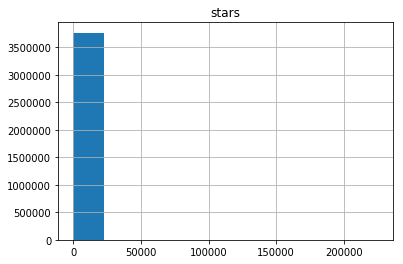
Хмм… Выглядит не очень информативно. Похоже, что абсолютное большинство пользователей поставили очень малое количество звезд, но некоторые пользователи поставили их более 200 тысяч (ого!). Визуализация данных ниже подтверждает наши предположения:

Все сходится: один из пользователей поставил более 200 тысяч звезд. Также мы видим большое количество выбросов – пользователей с более чем 25 тысячами звезд. Перед тем как продолжить, давайте посмотрим, кто этот пользователь с 200 тысячами звезд. Встречайте нашего героя – пользователь с ником 4148. В момент написания этой статьи страница возвращает 404-ю ошибку. Серебряный призер по количеству поставленных звезд – пользователь с «говорящим» именем StarTheWorld с 46 тысячами звезд (страница также возвращает 404-ю ошибку).
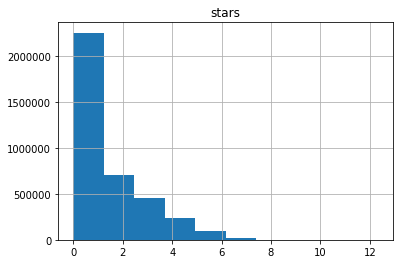
Теперь видно, что переменная подчинена экспоненциальному распределению (нахождение его параметров может оказаться интересной задачей). Важное наблюдение заключается в том, что примерно половина пользователей оценила менее пяти проектов. Это наблюдение окажется полезным, когда мы приступим к моделированию.
Давайте обратимся к репозиториям и взглянем на распределение количества звезд:

Как и в случае с пользователями, мы имеем один очень заметный выброс – проект freeCodeCamp с более чем 200 тысячами звезд!
Гистограмма случайной величины количества звезд у репозитория после логарифмического преобразования приведена внизу и показывает, что мы снова имеем дело с экспоненциальным распределением, но с более резким спуском. Как можно видеть, только малая часть репозиториев имеет более десяти звезд.

Предварительная обработка данных
Чтобы понять, какие манипуляции с данными нам необходимо проделать, мы должны более пристально ознакомиться с методом коллаборативной фильтрации, который мы собираемся использовать.
Большинство алгоритмов коллаборативной фильтрации основаны на факторизации матриц и факторизуют матрицы предпочтений пользователей. В ходе факторизации находятся скрытые характеристики продуктов и реакция пользователя на них. Зная параметры продукта, который пользователь еще не оценил, мы можем предсказать его реакцию, основываясь на его предпочтениях.
В нашем случае мы имеем матрицу размером m x n, где каждая строка представляет пользователя, а каждый столбец – репозиторий. r_ij равно единице, если i-ый пользователь поставил звезду j-му репозиторию.

Матрица R может быть легко построена с помощью файла watchers.csv. Однако давайте вспомним, что большинство пользователей поставили очень мало звезд! Какую информацию о предпочтениях пользователя мы можем выяснить, имея так мало информации? По факту, никакую. Очень сложно делать предположения о чьих-то вкусах, зная только об одном предмете, который вам нравится.
В то же время «однозвездочные» пользователи могут существенно повлиять на предсказательную силу модели, внося неоправданный шум. Поэтому было решено исключить пользователей, о которых мы имеем мало информации. Эксперименты показали, что исключение пользователей с менее чем тридцатью звездами дает хорошие результаты. Для исключенных пользователей рекомендации строятся на основании популярности проектов, что дает неплохой результат.
Оценка эффективности модели
Давайте теперь обсудим важный вопрос оценки эффективности модели. Мы использовали следующие метрики:
- точность и полнота (precision and recall)
- среднеквадратическая ошибка (root mean squared error, RMSE)
и пришли к выводу, что метрика «точность-полнота» не слишком помогает в нашем случае.
Но прежде, чем мы начнем, имеет смысл упомянуть о еще одном простом и эффективном методе оценки эффективности – построении рекомендаций для самих себя и субъективной оценки, насколько они хороши. Конечно, это не тот метод, о котором вы захотите упоминать в вашей докторской диссертации, но он помогает избежать ошибок на ранних стадиях. Например, построение рекомендаций для самих себя с использованием полного набора данных показало, что получаемые рекомендации не совсем релевантны. Релевантность значительно возросла после удаления пользователей с малым количеством звезд.
Вновь обратимся к метрике «точность-полнота». Говоря по-простому, точность модели, предсказывающей один из двух возможных исходов, – это отношение числа истинно-положительных предсказаний к общему числу предсказаний. Это определение можно записать в виде формулы:
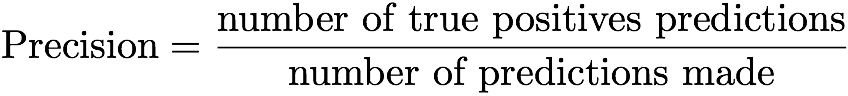
Таким образом, точность – это количество попаданий в цель к общему количеству попыток.
Полнота – это отношение числа истинно-положительных предсказаний к количеству положительных примеров во всех данных:
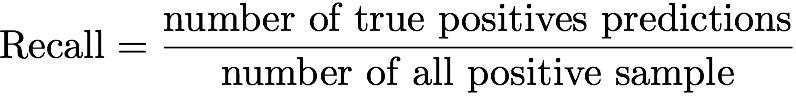
В терминах нашей задачи точность может быть определена как отношение репозиториев в рекомендациях, которым пользователь поставил звезды. К сожалению, эта метрика дает нам не очень много, так как наша цель – предсказать не то, что пользователь уже оценил, а что он с большой долей вероятности оценит. Может случиться так, что некоторые проекты имеют набор параметров, делающих их хорошими кандидатами на роль следующих понравившихся пользователю проектов, и единственная причина, почему пользователь не оценил их, – это то, что он их еще не видел.
Можно модифицировать эту метрику с тем, чтобы сделать ее полезной: если бы мы могли измерить, сколько из рекомендованных проектов пользователь в последующем оценил, и разделить ее на число выданных рекомендаций, то мы бы получили более корректное значение точности. Однако в данный момент мы не собираем никакой обратной связи, так что точность – это не та метрика, которой бы мы хотели пользоваться.
Полнота, применительно к нашей задаче, – это отношение количества репозиториев в рекомендациях, которым пользователь поставил звезды, к количеству всех репозиториев, оцененных пользователем. Как и в случае с точностью, эта метрика не слишком полезна, потому что количество репозиториев в рекомендациях фиксировано и достаточно мало (100 в данный момент), и значение для точности близко к нулю для пользователей, оценивших большое количество проектов.
Принимая во внимание мысли, изложенные выше, было решено использовать среднеквадратическое отклонение в качестве основной метрики для оценки эффективности модели. В терминах нашей задачи метрика может быть записана так:
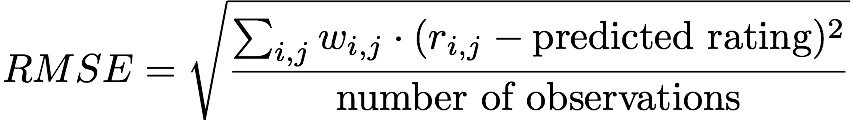
Иначе говоря, мы измеряем среднеквадратическую ошибку между пользовательским рейтингом проекта (0 и 1) и предсказанным рейтингом, который будет близок к 1 для репозиториев, которые, по мнению модели, пользователь оценит. Заметим, что w равно 0 для всех r_ij = 0.
Собираем все вместе – моделирование
Как уже было сказано, наша система рекомендаций основана на факторизации матриц, а точнее на алгоритме alternating least squares (ALS). Стоит заметить, что согласно нашим экспериментам, любой алгоритм факторизации матриц также будет работать (SVD, NNMF).
Реализации ALS доступны во многих программных пакетах для машинного обучения (смотрите, например, реализацию для Apache Spark). Алгоритм пытается разложить оригинальную матрицу размера m x n на произведение двух матриц размера m x k и n x k:

Параметр k определяет количество «скрытых» параметров проекта, которые мы пытаемся найти. Значение k влияет на эффективность модели. Значение k следует подбирать с помощью кросс-валидации. График, приведенный ниже, показывает зависимость величины RMSE от значения k на тестовом наборе данных. Значение k=12 выглядит как оптимальный выбор, поэтому было использовано для финальной модели.

Давайте подведем итог и посмотрим на получившуюся последовательность действий:
- Загружаем данные из файла
watchers.csvи удаляем всех пользователей, оценивших менее 30-ти проектов. - Делим данные на тренировочный и тестовый наборы.
- Выбираем параметр
k, используя RMSE и тестовые данные. - Обучаем модель на объединенном наборе данных, используя ALS с количеством факторов =
k.
Имея устраивающую нас модель, мы можем приступить к обсуждению вопроса о том, как сделать ее доступной для конечных пользователей. Другими словами, как построить веб-приложение вокруг нее.
Backend
Вот список того, что должен уметь наш бэкенд:
- авторизация через GitHub для получения имен пользователей
- REST API для отправки запросов вроде «дай мне 100 рекомендаций для пользователя с ником X»
- Сбор информации о подписках пользователей на обновления
Поскольку мы хотели сделать все быстро и просто, выбор пал на следующие технологии: Django, Django REST framework, React.
Для того чтобы корректно обрабатывать запросы, необходимо хранить некоторые данные, полученные с GHTorrent. Основная причина в том, что GHTorrent использует свои собственные идентификаторы пользователей, не совпадающие с идентификаторами на GitHub. Таким образом, мы должны хранить у себя пары user id <-> user GitHub name. То же самое касается репозиториев.
Поскольку количество пользователей и репозиториев достаточно велико (20 и 64 миллиона соответственно) и мы не хотели тратить большое количество денег на инфраструктуру, было решено попробовать «новый» тип хранилища с компрессией в MongoDB.
Итак, мы имеем две коллекции в MongoDB: users и projects.
Документы из коллекции users выглядят следующим образом:
{
"_id": 325598,
"login": "yurtaev"
}
и проиндексированы по полю login для ускорения обработки запросов.
Пример документа из коллекции projects приведен ниже:
{
"_id": 32415,
"name": "FreeCodeCamp/FreeCodeCamp",
"description": "The https://freeCodeCamp.org open source codebase and curriculum. Learn to code and help nonprofits."
}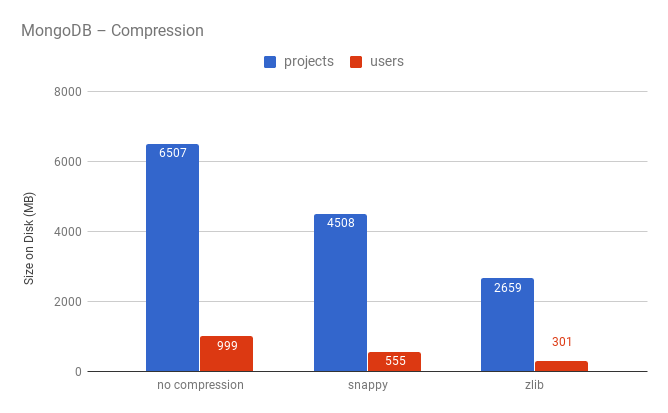
Как можно видеть, компрессия с использованием zlib дает нам двукратный выигрыш в плане использования дискового пространства. Одним из опасений, связанных с использованием сжатия, была скорость обработки запросов, но эксперименты показали, что время меняется в пределах статистической погрешности. Больше информации о влиянии сжатия на производительность можно найти тут.
Резюмируя, можно сказать, что компрессия в MongoDB дает существенный выигрыш с точки зрения использования дискового пространства. Другим преимуществом является простота масштабирования – это будет очень кстати, когда объем данных о репозиториях и пользователях перестанет помещаться на один сервер.
Модель в действии
Существует два подхода к использованию модели:
- Предварительная генерация рекомендаций для каждого пользователя и сохранение их в базе данных.
- Генерация рекомендаций по запросу.
Преимуществом первого подхода является то, что модель не будет «бутылочным горлышком» (в данный момент модель может обрабатывать от 30 до 300 запросов на рекомендации в секунду). Главный недостаток – объем данных, который необходимо хранить. Есть 20 миллионов пользователей. Если мы будем хранить 100 рекомендаций для каждого пользователя, то это выльется в 2 миллиарда записей! Кстати, большинство из этих 20 миллионов пользователей никогда не воспользуются сервисом, а это значит, что большая часть данных будет храниться просто так. И последнее, но не менее важное: построение рекомендаций занимает время.
Преимущества и недостатки второго подхода – зеркальное отображение преимуществ и недостатков подхода первого. Но что нам нравится в построении рекомендаций по запросу – это гибкость. Второй подход позволяет возвращать любое количество рекомендаций, которое нам необходимо, а также позволяет легко заменить модель.
Взвесив все «за» и «против», мы выбрали второй вариант. Модель была упакована в Docker контейнер, и возвращает рекомендации с помощью RPC вызова.
Frontend
Ничего сверхинтересного: React, Create React App и Semantic UI. Единственная хитрость – React Snapshot был использован для предварительной генерации статической версии главной страницы сайта для лучшей индексации поисковиками.
Полезные ссылки
Если вы пользователь GitHub, то вы можете получить свои рекомендации на сайте GHRecommender. Обратите внимание, если вы оценили менее 30 репозиториев, то вы получите в качестве рекомендаций самые популярные проекты.
Исходники GHRecommender доступны здесь.
✎ Соавтор текста и проекта avli
