Comments 18
Боюсь спросить, какой результирующий размер «мигалки», при наличии стольких зависимостей?
ЗЫ. Боюсь, потому что очевидно что он будет огромен. Заранее говорю, что это не попытка упрекнуть в Вашей RTOS, просто интересно.
ЗЫ. Боюсь, потому что очевидно что он будет огромен. Заранее говорю, что это не попытка упрекнуть в Вашей RTOS, просто интересно.
Ну, там же оптимизатор всё неиспользуемое выкидывает, так что зависимостей бояться не стоит.
Эта книга писалась в ноябре прошлого года. Сейчас собрал проект именно этой мигалки, привязанный к ОС тех времён — получилось 18000 байт кода (я сам удивился столь круглому числу). Скорее всего, сегодня получилось бы меньше — за прошедший период был рефакторинг. Но именно этот пример именно с той версией ОС, для которой он был сделан — чуть меньше 18К занял.
И понятно, что мигалку ради мигалки лучше делать без ОС. Но демонстрировать практические опыты проще именно на мигалке.
Эта книга писалась в ноябре прошлого года. Сейчас собрал проект именно этой мигалки, привязанный к ОС тех времён — получилось 18000 байт кода (я сам удивился столь круглому числу). Скорее всего, сегодня получилось бы меньше — за прошедший период был рефакторинг. Но именно этот пример именно с той версией ОС, для которой он был сделан — чуть меньше 18К занял.
И понятно, что мигалку ради мигалки лучше делать без ОС. Но демонстрировать практические опыты проще именно на мигалке.
Ну насчёт отсутствия светодиодов вы это зря, их там аж целых 4. Второй момент, это то что работа с портами ввода — вывода, если у них правильно настроена скорость реакции то они работают с частотой шины на которой они «сидят» — AHB, а это внимание 168 МГц. То есть дело скорее в том что вы не совсем верно настроили периферию. Ну и наконец третий момент: слишком много параметров которые можно было бы по хорошему оптимизировать, поручив это грамотной системе сборки. А так хотелось бы посмотреть побольше кода и преимущества данной ОС перед другими: например стабильность планировщика, отказоустойчивость и многое другое.
Четыре светодиода на STM32F4-Discovery. А на STM32F429-DISCO (которая с экранчиком)… Хм. Сейчас проверил — да, два есть. Но только два. Я почему-то всё время только один находил. И всё равно, на них то, что показано на осциллографе — не покажешь. Тем не менее, про число — уберу.
Насчёт частоты — похоже, не правы ни Вы, ни я в тексте. Возможно, надо будет переделать. Нашёл в даташите именно на 429-й чип:
Надо будет попробовать не NOPы добавлять, а выход переключить на самый быстрый. Проверю в ближайшее время.
По остальным вопросам — данная публикация является «художественным руководством» по работе с ОС. Серьёзные и занудные вещи, что-то доказывающие надо будет рассматривать в другой публикации. Всё в одном — не смешать.
Насчёт частоты — похоже, не правы ни Вы, ни я в тексте. Возможно, надо будет переделать. Нашёл в даташите именно на 429-й чип:
3.37 General-purpose input/outputs (GPIOs)
Each of the GPIO pins can be configured by software as output (push-pull or open-drain,
with or without pull-up or pull-down), as input (floating, with or without pull-up or pull-down)
or as peripheral alternate function. Most of the GPIO pins are shared with digital or analog
alternate functions. All GPIOs are high-current-capable and have speed selection to better
manage internal noise, power consumption and electromagnetic emission.
The I/O configuration can be locked if needed by following a specific sequence in order to
avoid spurious writing to the I/Os registers.
Fast I/O handling allowing maximum I/O toggling up to 90 MHz.
Надо будет попробовать не NOPы добавлять, а выход переключить на самый быстрый. Проверю в ближайшее время.
По остальным вопросам — данная публикация является «художественным руководством» по работе с ОС. Серьёзные и занудные вещи, что-то доказывающие надо будет рассматривать в другой публикации. Всё в одном — не смешать.
Это да, то насколько быстро способны меняться сигналы на вводе-выводе, а так периферия работает на частоте системной шины. Тут согласен не увидите.
Проверил. На максимальном токе выходов заработало на частоте 28 МГц. С плохой скважностью. Начинаю думать, как бы это в текст вставить, чтобы не сильно его покрушить. NOP скважность хорошую обеспечивал. С одной стороны — он, с другой — переход. То на то и выходило. Сейчас буду думать, как и ляп в тексте убрать, и не сильно его менять.
Если что — с проверки настройки PLL я начал. Там всё по максимуму настроено (ну, по такому максимуму, на котором USB работает, разумеется, а так — можно и шустрее, я в курсе)
28 МГц — это именно частота выходного сигнала, то есть, порт шевелится быстрее, разумеется.
Если что — с проверки настройки PLL я начал. Там всё по максимуму настроено (ну, по такому максимуму, на котором USB работает, разумеется, а так — можно и шустрее, я в курсе)
28 МГц — это именно частота выходного сигнала, то есть, порт шевелится быстрее, разумеется.
Просто тут такой вопрос что оно реально на выходе даёт 90 МГц — так как для работы ULPI (Physic Layer USB 2.0 HS) нужно 60 МГц на вводе — выводе. Там конечно могут другие факторы накладываться, но факт остаётся фактом.
Скажу прямо. Раздел про флэш перечитал много раз, не всё понял. Понял только, что на трёх вольтах и частотах ядра от 150 до 180 МГц, Latency должно быть равно пяти. У меня оно равно пяти.
Все аппаратные блоки работают внутри себя (это касается и упомянутого Вами блока для работы с ULPI). Ядро — если Вы научите меня считать точные цифры — я буду рад. Точно знаю, что все настройки выставлены верно, а точную цифру рассчитать пока не смог, на какой частоте всё это обязано работать.
Сейчас я вижу, что когда крутятся 4 команды — частота сигнала на выходе равна 21 МГц, когда три команды — 28 МГц. Это я вижу по приборам. И я никогда не доверял прямому управлению через GPIO в критичных к скорости вещах, предпочитая аппаратные блоки.
Все аппаратные блоки работают внутри себя (это касается и упомянутого Вами блока для работы с ULPI). Ядро — если Вы научите меня считать точные цифры — я буду рад. Точно знаю, что все настройки выставлены верно, а точную цифру рассчитать пока не смог, на какой частоте всё это обязано работать.
Сейчас я вижу, что когда крутятся 4 команды — частота сигнала на выходе равна 21 МГц, когда три команды — 28 МГц. Это я вижу по приборам. И я никогда не доверял прямому управлению через GPIO в критичных к скорости вещах, предпочитая аппаратные блоки.
Хм, очень интересно, у меня просто нет в наличие именно этого процессора, А вообще проверить частоту которая на выходе из ФАПЧ достаточно несложно — берём эту частоту, запускаем для таймера делитель равный нулю (что даёт частоту кратную той что приходит на таймер) (учитывая делители для шин AHB и APBx(где х это та шина на которой висит таймер). Далее заполняем для таймера регистр перезагрузки в значение 1000, а для регистра совпадения — 500, выставляем режим — шим, и получается таймер будет аппаратно переключать с частотой не более 180 кГц. Это и будет частота на которую вы настроили ФАПЧ (PLL).
// Настроим ножку PA2 на выход ШИМа
GPIOA->MODER = (2<<(2*2));
GPIOA->AFR[0] = (1<<(2*4));
// На скорую руку настроим таймер
RCC->APB1ENR |= RCC_APB1ENR_TIM2EN;
TIM2->PSC = 0;
TIM2->ARR = 1000;
TIM2->CCR3 = 500;
TIM2->CCMR2 |= TIM_CCMR2_OC3M_2 | TIM_CCMR2_OC3M_1;
TIM2->CCER |= TIM_CCER_CC3E;
TIM2->CR2 = 0;
TIM2->CR1 = TIM_CR1_CEN;
Получаем 84 КГц
При том, что
RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1;
RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV4;
RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2;
Согласно описанию STM32F4, если делитель APB не равен одному, то частота на таймеры удваивается. Получем (168/4)*2 = 84. Дальше делитель таймера 1000, итого 84 КГц. Тут всё верно.
Так что проблема работы с GPIO не в настройке PLL. Где-то ещё возникает деление на два. Потому что 21*4 = 28 * 3 = 84. Всё работает на 84 МГц. Можно было бы сказать, что перед нами такт на выборку и такт на запись, но все книжки говорят про Гарвардскую архитектуру…
В общем, в тексте моего руководства, вроде, особых ляпов больше нет, я там убрал неверное утверждение. Но задачку Вы задали интересную. Если разберусь, то напишу.
А ларчик просто открывался. Ну, или почти просто…
Запись в GPIO у STM32F4 требует двух тактов. Тогда понятно, что в описании команды STR срабатывает оговорка:
8.2 GPIO main features
…
• Fast toggle capable of changing every two clock cycles
Запись в GPIO у STM32F4 требует двух тактов. Тогда понятно, что в описании команды STR срабатывает оговорка:
STR Rx,[Ry,#imm] is always one cycle. This is because the address generation is performed in the initial cycle, and the data store is performed at the same time as the next instruction is executing. If the store is to the write buffer, and the write buffer is full or not enabled, the next instruction is delayed until the store can complete. If the store is not to the write buffer, for example to the Code segment, and that transaction stalls, the impact on timing is only felt if another load or store operation is executed before completion.Почему «почти просто » — команда NOP не должна исполняться два такта. Но спишем это на какие-то особенности, вытекающие из выше сказанного, с учётом гарвардской архитектуры. Тем более, что реально скважность не строго 50%, как выяснилось при снижении частоты шины (я много экспериментировал сейчас). Тем не менее — кажущиеся глобальные странности разрешены. И они не относятся ни к проблемам ОС, ни к проблемам повествования. Просто я нашёл ссылки на официальные документы, говорящие, что это — совершенно нормальное поведение программы. Теперь можно спать спокойно.
Вообще, эти ARMы всех запутать хотят. Перечитал процитированное ранее. Не очень убедительно. Но ниже они пишут
И в другой таблице — чётко пишут, что 2 цикла и всё тут.
Все описания касаются именно Cortex M4. То есть, обсуждаемой архитектуры.
•Other instructions cannot be pipelined after STR with register offset. STR can only be pipelined when it follows an LDR, but nothing can be pipelined after the store. Even a stalled STR normally only takes two cycles, because of the write buffer.
И в другой таблице — чётко пишут, что 2 цикла и всё тут.
Все описания касаются именно Cortex M4. То есть, обсуждаемой архитектуры.
Нет, не могу уснуть. Провел ещё одно исследование, которое несколько подмывает официальные документы, но зато никак не противоречит моему основному трактату. Итак. Чтобы сделать красивые фронты на моём осциллографе, делим частоту на 16. 168000000/16=10500000, один такт примерно 95.2 нс.
Переписываем программу вот так
Получаем вот такие импульсы

Один, один, один такт на состояние! Чушь какая-то!
Тем не менее, видны вот такие чёткие пачки

у которых провал равен пяти тактам. Один такт на состояние и четыре — на ветвление. В целом, не противоречит документу, где сказано 1+P, P зависит от Pipeline, и может быть до трёх. То есть, 1+3 = 4. Оставляем один переброс на итерацию, провал как был, так и есть пять тактов
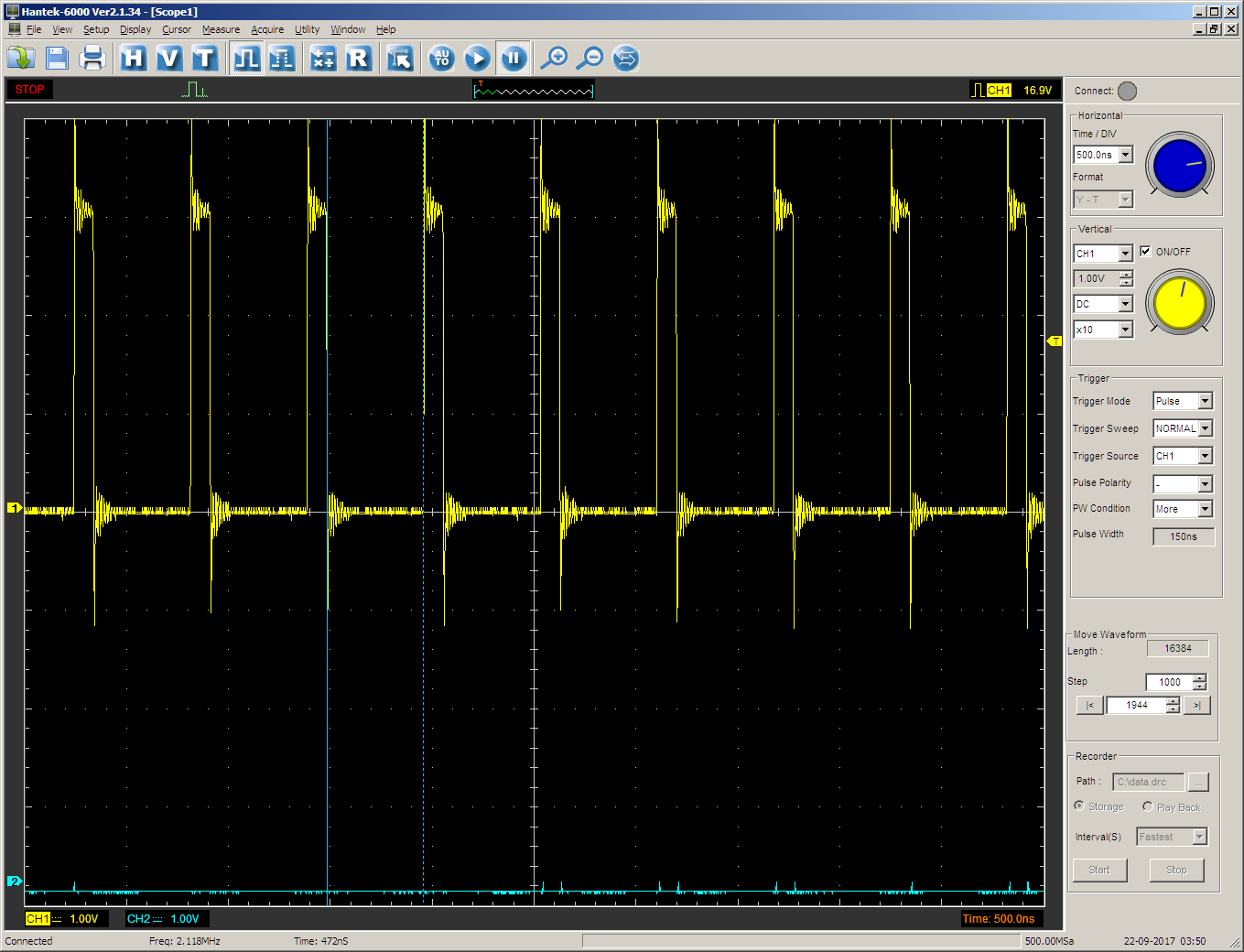
Получаем одно подтверждение (ветвление 4 такта) и одно противоречие (GPIO работает за один такт). Возвращаем частоту на 168 МГц

1 такт равен 5.95 нс. У нас явно два такта! Два, два, два! А поменяна только частота. Вернее, делитель частоты. И ничего больше. В нуле находится 5 тактов. Я измерял на более крутом стационарном осциллографе.
Получается, что запись идёт 2 такта, но если буфер занят (две записи подряд) — ждём, если свободен (после записи идёт ветвление) — продолжаем работать. Но всё это — только на предельной частоте.
В общем, спишем это всё на то, что система как-то определяет, что работает на высокой частоте и добавляет лишний такт при записи в порт. Иного объяснения я не вижу. Возможно, это касается только отдельных чипов, так как я уже ловил несоответствие моего F429 более новым. Там DWT по умолчанию по-разному настроен, знаменитая ошибка с приёмом младшего бита в SPI по-разному проявляется/не проявляется. Может и тут что-то такое.
Но как видим, это — практическое поведение чипа, а не грубый ляп в моём повествовании. Надеюсь.
Переписываем программу вот так
while (true)
{
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
}
Получаем вот такие импульсы

Один, один, один такт на состояние! Чушь какая-то!
Тем не менее, видны вот такие чёткие пачки

у которых провал равен пяти тактам. Один такт на состояние и четыре — на ветвление. В целом, не противоречит документу, где сказано 1+P, P зависит от Pipeline, и может быть до трёх. То есть, 1+3 = 4. Оставляем один переброс на итерацию, провал как был, так и есть пять тактов

Получаем одно подтверждение (ветвление 4 такта) и одно противоречие (GPIO работает за один такт). Возвращаем частоту на 168 МГц

1 такт равен 5.95 нс. У нас явно два такта! Два, два, два! А поменяна только частота. Вернее, делитель частоты. И ничего больше. В нуле находится 5 тактов. Я измерял на более крутом стационарном осциллографе.
Получается, что запись идёт 2 такта, но если буфер занят (две записи подряд) — ждём, если свободен (после записи идёт ветвление) — продолжаем работать. Но всё это — только на предельной частоте.
В общем, спишем это всё на то, что система как-то определяет, что работает на высокой частоте и добавляет лишний такт при записи в порт. Иного объяснения я не вижу. Возможно, это касается только отдельных чипов, так как я уже ловил несоответствие моего F429 более новым. Там DWT по умолчанию по-разному настроен, знаменитая ошибка с приёмом младшего бита в SPI по-разному проявляется/не проявляется. Может и тут что-то такое.
Но как видим, это — практическое поведение чипа, а не грубый ляп в моём повествовании. Надеюсь.
Тут запись идёт в ODR, но сути не меняет, как бы человек получил 84 МГц на выходе из пинов ввода — вывода:
vjordan.info/log/fpga/stm32f4-bare-metal-start-up-and-real-bit-banging-speed.html
vjordan.info/log/fpga/stm32f4-bare-metal-start-up-and-real-bit-banging-speed.html
Не вижу никаких противоречий. Он писал много раз на итерацию, как и я в ночном эксперименте. В основном же примере, я пишу 1 раз на итерацию, и 4 такта каждый раз тратится на переход. Ну, потому что у меня немного другая задача, мне надо показать, как работает ОС, а не как добиться максимальной частоты. Хотя, факты катастрофической просадки «ниоткуда» я и отмечаю.
Чтобы закрыть тему окончательно и бесповоротно (судя по оценкам, она нравится не всем), я сделал следующее: Как и ночью, увеличил делитель частоты на 16, чтобы попасть в область точных измерений моего осциллографа. Убедился, что тратится 8 тактов на итерацию.
Дальше, модифицировал код следующим образом:
Получил следующую осциллограмму в чёткой области работы осциллографа:
Напомню, 1 такт равен примерно 95.2 нс. Здесь чётко видно, что сначала имеем взлёт на 1 такт (запись единицы), затем — падение на 1 такт (запись нуля). Затем — взлёт на 3 такта (запись единицы + NOP), затем — падение на 5 тактов (запись нуля + ветвление).
Итого, в примере из моего основного текста имеем взлёт (1) NOP (ничего не знаю, чётко видно, что 2), падение (1), ветвление (4). 1 + 2 + 1 + 4 = 8. 168/8 = 21. Всё сходится.
Если писать много раз за итерацию — да, будет почти 84. До первого ветвления, которое у автора по ссылке не попало на экран (тем более, что он пишет, что осциллограф ловит сигнал, уже поделённый в ПЛИС, как именно он там делится — не говорит).
Чтобы закрыть тему окончательно и бесповоротно (судя по оценкам, она нравится не всем), я сделал следующее: Как и ночью, увеличил делитель частоты на 16, чтобы попасть в область точных измерений моего осциллографа. Убедился, что тратится 8 тактов на итерацию.
Дальше, модифицировал код следующим образом:
while (true)
{
GPIOE->BSRR = (1<<nBit);
GPIOE->BSRR = (1<<(nBit+16));
GPIOE->BSRR = (1<<nBit);
asm{nop}
GPIOE->BSRR = (1<<(nBit+16));
}
Получил следующую осциллограмму в чёткой области работы осциллографа:

Напомню, 1 такт равен примерно 95.2 нс. Здесь чётко видно, что сначала имеем взлёт на 1 такт (запись единицы), затем — падение на 1 такт (запись нуля). Затем — взлёт на 3 такта (запись единицы + NOP), затем — падение на 5 тактов (запись нуля + ветвление).
Итого, в примере из моего основного текста имеем взлёт (1) NOP (ничего не знаю, чётко видно, что 2), падение (1), ветвление (4). 1 + 2 + 1 + 4 = 8. 168/8 = 21. Всё сходится.
Если писать много раз за итерацию — да, будет почти 84. До первого ветвления, которое у автора по ссылке не попало на экран (тем более, что он пишет, что осциллограф ловит сигнал, уже поделённый в ПЛИС, как именно он там делится — не говорит).
Поправка: Перечитал. Автор говорит, как делит частоту. Но зато ещё он говорит, что осциллограф работает почти на пределе частотного диапазона. А я после этой ночи чего-то перестал доверять показаниям китайских осциллографов на высоких пределах. Я вёл проверку сразу двумя. У обоих полоса 250 МГц, дискретизация — у одного 1ГГц, у второго — целых 2 ГГц (разумеется, прямая, а не стробоскоп). Но похоже, там АЦП в таком режиме работает, что лучше конкретные импульсы было не измерять…
В общем, на уменьшенных частотах всё у меня сошлось (8 тактов с NOP, 6 тактов без NOP дают 21 и 28 МГц соответственно), а у автора по ссылке всё может оказаться не строго 84 МГц, так как RIGOL — тоже китайская марка. И он работает без курсоров, на предельных частотах этого осциллографа… Но чем больше записей в порты на итерацию, тем ближе будет частота именно к 84 МГц. Однако, к обсуждаемому тексту, это уже не имеет никакого отношения.
В общем, на уменьшенных частотах всё у меня сошлось (8 тактов с NOP, 6 тактов без NOP дают 21 и 28 МГц соответственно), а у автора по ссылке всё может оказаться не строго 84 МГц, так как RIGOL — тоже китайская марка. И он работает без курсоров, на предельных частотах этого осциллографа… Но чем больше записей в порты на итерацию, тем ближе будет частота именно к 84 МГц. Однако, к обсуждаемому тексту, это уже не имеет никакого отношения.
А можно как-то это пощупать руками? Если да, то где можно скачать и сколько это стоит?
Бесплатно (тестовая версия). В планах, ходят слухи, сделать ядро бесплатным и для коммерческого использования. Скачать можно на официальном сайте.
Sign up to leave a comment.
Обзор одной российской RTOS, часть 5. Первое приложение