Давайте возьмём отличную японскую игру в жанре survival horror, разберёмся, как она работает, переведём её на английский и сделаем с ней ещё кое-что.
ClockTower (известная в Японии как Clocktower — The First Fear) — это игра, изначально выпущенная Human Entertainment для Super Nintendo.

Это одна из игр жанра «point and click adventure», но она также стала одним из основателей жанра survival horror. Сюжет заключается в том, что четыре сироты после закрытия приюта попали в особняк, в котором один за другим начали исчезать. Игрок управляет одной из сирот, Дженнифер, и пытается найти выход, своих друзей и выяснить, что же происходит в особняке.
Атмосфера игры сурова, события в доме происходят случайно, без какой-либо видимой причины (проще говоря, дом заколдован), иногда что-то может убить вас просто так, психопат с садовыми ножницами преследует вас по всему дому (Немезис из Resident Evil 3 был не первым таким персонажем):

В игре часто возникают опасные ситуации, требующие быстро думать, единственное спасение — выживать, убегать и прятаться, но также важно сохранение рассудка Дженнифер, иначе она может упасть и умереть от сердечного приступа (в стиле игры Illbleed).
Игра была выпущена в 1994 году на SNES, повторно выпущена с расширенным контентом на PSX в 1997 году, выпущена на консоли Wonderswan (но никого не волнует Wonderswan), и, наконец, вышла на PC (а потом перевыпущена для PC в 1999 году).
Да, для ROM под SNES группой Aeon Genesis выпущен английский перевод (кажется, это были они), но версия для SNES хуже версии для PC, у которой был гораздо лучший звук, есть вступительный FMV-ролик и т.д. Возможно, единственной версией с бОльшим количеством контента была версия на PSX, но о ней мы поговорим позже.
Для начала давайте «отучим» игру от CD!
У нас есть папка с игрой, которая выглядит так:
У нас есть папка BG, внутри которой находится что-то похожее на фоны комнат в разрезанном формате с сопровождающими файлами .MAP, который, как я предполагаю, размещает разные фрагменты на экране:

У нас есть папка DATA, содержащая файлы PTN и PYX… пока не знаю, что это такое… возможно, они связывают экраны уровней с логикой, или что-то подобное.
Также есть папка FACE, в которой содержатся bmp с лицами людей, используемыми в диалогах:
Ещё есть папка с предметами, которые может использовать Дженнифер:
В папке PATTERN содержатся файлы ABM. Думаю, они используются для спрайтовых анимаций, но могу ошибаться.
В папке SCE находятся два файла: CT.ADO и CT.ADT. Мы рассмотрим их — это логические скрипты действий, происходящие на протяжении всей игры, написанные на собственном бинарном скриптовом языке… и на них мы потратим больше всего времени.
В папке SNDDATA лежат файлы MIDI и WAV музыки и звуковых эффектов.
Папка VISUAL содержит все рендеры высокого разрешения, опции меню и т.д. в формате BMP. Также здесь хранится вступительное видео.
Наконец, у нас есть файл DATA.BIN, который… не знаю пока, что делает. Кроме того, есть исполняемый файл игры ct32.exe.
Запустив игру без CD, получаем следующее сообщение:
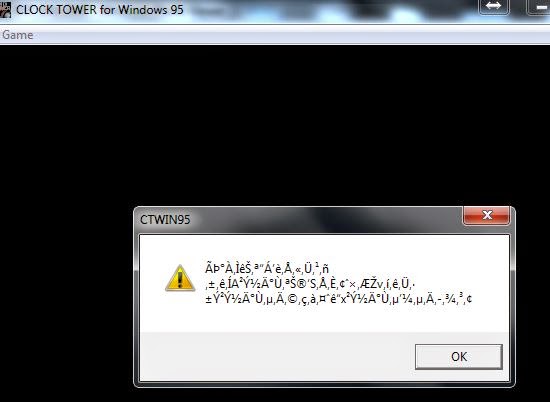
Запустим игру в отладчике, чтобы найти эту строку. Выясняется, что она просто сообщает, что игра не знает, где находятся данные игры (т.е. не вставлен CD).
Посмотрев в IDA, мы видим, что используется RegQueryValueEx, то есть считывается значение реестра. Что же игра оттуда получает?
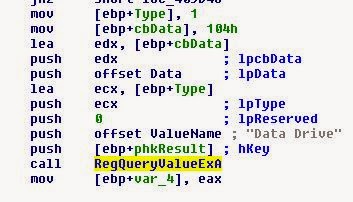
Ну… полагаю, вот и ответ.
ХОТЯ СТОП.
Давайте проверим, что её вызывает, возможно, мы сможем жёстко задать это в коде:
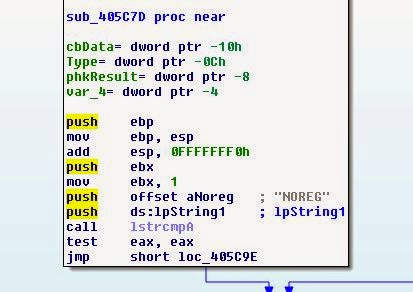
Похоже, что дополнительный труд оказался ненапрасным! Игра ищет аргумент NOREG. Если она не находит его, то проверяет значение реестра, пропускает проверку и запускает игру, предполагая, что находится в родительском каталоге. Здесь нам поможет простой патч, который заставит игру думать, что она всегда запускается с аргументом NOREG. Для этого заменим jz на 0xEB (или безусловный JMP).
Запускаем и получаем:
ДА!
Подумаем немного — можно ли ожидать, что весь текст находится в исполняемом файле? Ну, это возможно, во многих играх так и бывает. В двоичных файлах есть даже несколько статичных строк (например, найденная нами ошибка об отсутствии CD), но у меня есть ощущение, что тексты спрятаны где-то в другом месте (может, в файлах DATA?). Давайте посмотрим:
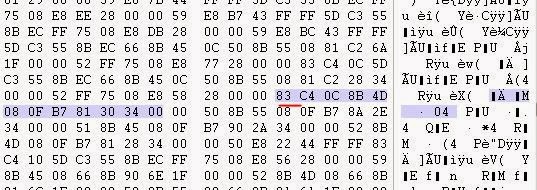
Японский текст, использующий формат SHIFT-JIS (очень популярный), обычно начинается с управляющего символа в диапазоне 0x80-0x8F… Неплохо бы начать с поиска чего-то подобного в исполняемом файле.
Затем мы скопируем эти строки в новый файл и откроем в notepad++, а потом вставим в Google Translate:

Так, это напоминает сообщения об ошибках, а не игровые диалоги. Пора искать другие файлы!
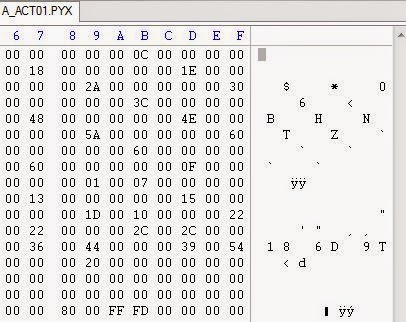
Хм, понятно — в файлах PTN и PYX нет никаких текстов. Давайте проверим папку SCE.
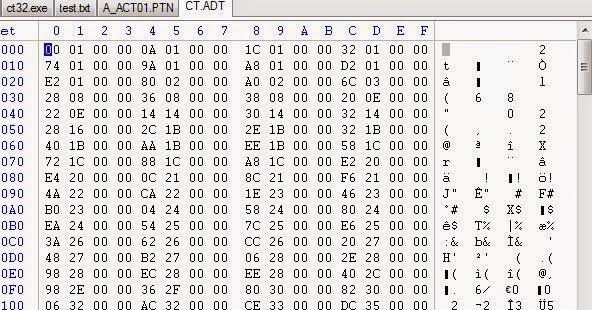
Похоже, что в файле CT.ADT находятся четырёхбайтные смещения (они до конца файла выполняют счёт вверх от 0x100, по 4 байта за раз).
Зато в файле CT.ADO…
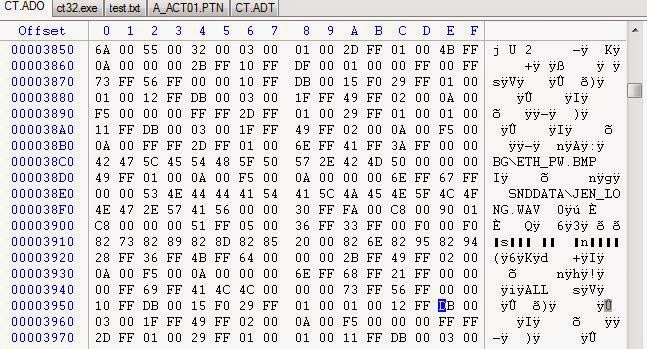
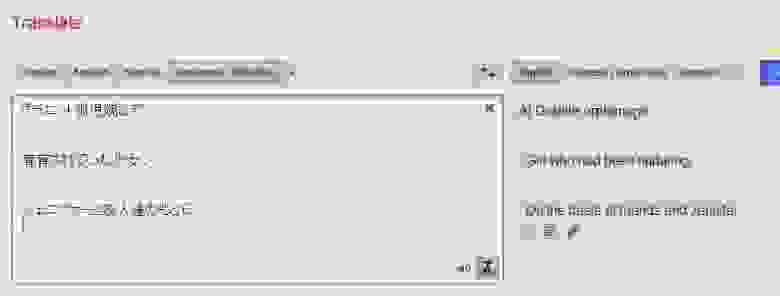
Мы что-то нашли… здесь не только строки ASCII, похожие на пути к файлам, но и текстовые строки в формате SHIFT-JIS. Данные в этом файле выглядят странно… давайте посмотрим, сможем ли мы разобраться в них лучше. Нам придётся, если мы хотим их парсить.
Мы уже немного разобрались в том, как работает ADT, так что давайте посмотрим, как выглядит ADO:
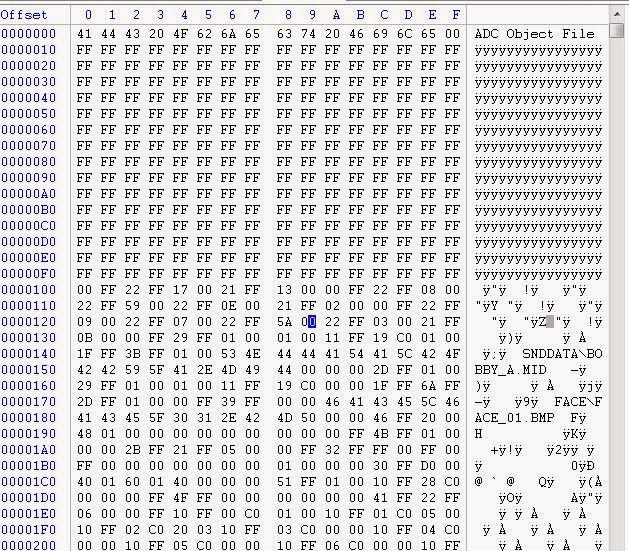
В самом верху начинается магия (ADC Object File), потому куча 0xFF для смещения на 256, потом, похоже, начинаются данные. Настало время подумать, как настоящий учёный-компьютерщик!
У нас есть все эти строки, двоичный формат без очевидного поиска, кроме, возможно файла ADT. Внутри должен быть управляющий код, перемешанный с данными, который даёт игре понять, что она видит при парсинге… у всего этого есть какая-то структура.
Изучая строки с .BMP, можно заметить, что они имеют одинаковый шаблон:
За 39FF следует нулевое двухбайтное значение (чаще всего, но иногда это 0x0100, поэтому я думаю, что это значение в WORD), затем строка ASCII, завершающаяся нулевым значением, и отступ. На самом деле при каждой загрузке BMP для FACE, перед ней стоит значение 0xFF39!
Давайте проверим исполняемый файл:
Здорово! У нас есть не только это, но и другие значения. Давайте проверим несколько строк Shift-JIS, чтобы проверить, сможем ли найти закономерность:
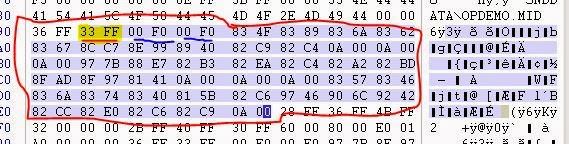
Отлично! Все строки начинаются с 0xFF33, имеют два 16-битных значения (0x0F00), за которыми идёт строка в Shift-JIS.
Примечание: можно заметить, что SHIFT-JIS НЕ завершается нулевым значением, это невозомжно. Некоторые программы могут обрабатывать и однобайтовые и многобайтовые символьные значения, но в старых программах это было серьёзной проблемой. В результате, как можно заметить, за всеми разрывами строк (0x0a) следуют 0x00. На самом деле за ВСЕМИ символами ASCII здесь идёт 0x00 (и числа или английские буквы). Таким образом рендеринг текста может поддерживать многобайтовую интерпретацию символов ASCII (0-127) и не перепутать при считывании байт данных с управляющим байтом, и наоборот.
Поэтому мы приходим к выводу, что логика игры должна парсить строку, пока каким-то образом не обнаружит конец (возможно, найдя новый опкод (обычно это 0x28FF).
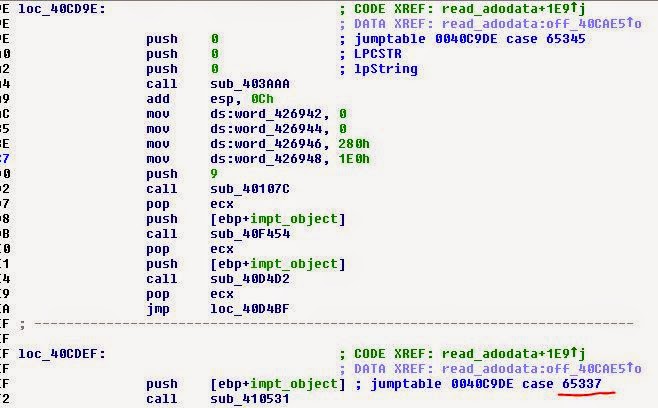
Итак, как мы знаем, файл ADO забит скриптовыми «опкодами» и следующими за ними данными. Можно теоретически предположить, что игра считывает их и на основании предшествующего опкода знает, какие данные нужно ожидать. Теперь мы можем посмотреть на конструкцию switch в исполняемом файле, которую мы нашли выше (со всеми case), чтобы выделить все опкоды, используемые в игре (для более полного понимания формата).
Мы заметим значения (0xFF20, 0xFF87) и будем искать их в файле ADO, определяя, имеют ли они то же количество байт данных перед следующим опкодом. Попробуем выяснить, являются ли они двухбайтными значениями, строками и так далее.
Кроме того, можно заметить, что в исполняемом файле есть довольно интересный текст:
На самом деле это список, и он подозрительно похож на названия опкодов. К счастью для нас, так и есть! Теперь мы знаем названия опкодов.

На этом этапе мы можем запустить игру с отладчиком и прерывать выполнение на конструкциях, чтобы наблюдать за действиями разных опкодов. Один из интересующих нас — это JMP…
На самом деле, после первого JMP (0xFF22) есть двухбайтовое значение 0x17.
Если наблюдать за ним в игре и установить в IDA в качестве наблюдаемой переменной ADO_offset, то можно увидеть, что игра переходит от этого значения к 0x1B32. Как она узнаёт, что нужно это сделать? Это не множитель… наверно:
Ага!
0x17 * 4 = 0x5C, то есть ADT — это таблица переходов для разных сцен. Вы заметите, что функция CALL (0xFF23) работает похожим образом, но через какое-то время возвращается к этому смещению… Первые несколько смещений ADT указывают на 0xFF00. Похоже, это очень важно в игре, переходы на самом деле пропускают их (они прибавляют +2 к смещению после перехода). Это что-то вроде опкода RETN? Думаю, что да.
Однако вы заметите, что файл ADT содержит в конце разные значения, намного превышающие размер файла ADO. Что они дают? Мы с этим разберёмся, но сначала немного подробнее рассмотрим процесс выполнения игры, чтобы понять, как работают эти переходы (уделив им особое внимание).
Сделав дамп памяти, можно заметить, что файл объектов ADC в памяти (CT.ADO) имеет значение 0x8000 int16, записанное в каждых 0x8000, или 32 КБ. Кроме этого ADO никак не изменён. Можно также заметить в исполняемом файле, что функция парсит значения и пропускает два байта, если видит это значение (как NOP).
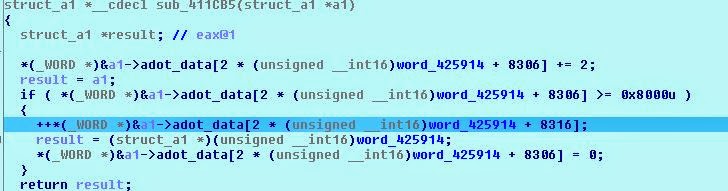
Поскольку игра разделяет данные на фрагменты по 32 КБ (скорее всего, чтобы более сегментированно обращаться к памяти; мы часто встречались с двухбайтными значениями — это важно), то для ADT должна быть какая-то трансляция адресов (потому что ADT использует для обращения к смещению 4 байта).
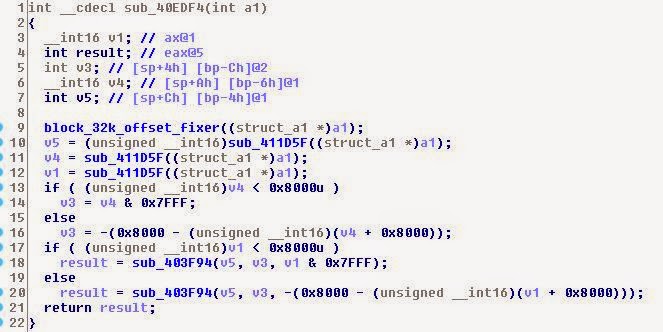
Здесь довольно много математики, которая, если вы наблюдали в отладчике, будет напоминать что-то такое:
Сначала я не нашёл функцию и дошёл до конца файла ADT, предполагая, что есть указатель на конец файла ADO (последний RETN имеет смещение 0x253F4). В списке ADT он указан как 0x453F4. Поискав разные другие адреса, я заметил, что трансляция берёт два значимых байта, делит их пополам и вставляет обратно в конец.
Неплохо, теперь мы можем генерировать файлы ADT (обратной операцией: умножением самого значимого в зависимости от того, сколько интервалов по 0x8000 мы прошли). Также у нас есть общая схема опкодов и мы знаем, где находятся строки. Прежде чем заняться дизассемблированием, давайте посмотрим на награду и приложим все усилия (сначала перевод).
Мы знаем, в каком формате хранятся строки и как считать их из файла ADO. Разумеется, вставка их обратно потребует изменения смещений ADT, потому что размеры строк могут быть гораздо больше или меньше. Для начала рассмотрим вырезание строк ADO в текстовый файл, во что-то очень легко редактируемое, что можно будет потом считать другой программой. Создадим формат, в котором мы сможем легко вставлять строки в новый файл ADO и удобно изменять смещения. Что нам для этого понадобится?
Итак, нам важно смещение, с которого начинается строка, размер исходной строки в байтах, затем сама строка, что-то вроде:
Пишем cttd.py:
Я переименовал CT.ADO в CT_J.ADO, чтобы потом сгенерировать новый файл.
Эта программа считывает файл ADO, находит 0xFF33, пропускает 6 байтов (чтобы обойти опкод и два двухбайтных значения), а затем записывает в новый файл начальное смещение строки, длину строки и саму строку в формат с разделителями табуляцией, завершающийся новой строкой.
Вы заметите, что я заменяю все значения 0x0a (новая строка) на [NEWLINE]. Я делаю так потому, что хочу, чтобы вся строка обрабатывалась в одной строке и я мог определять новые строки там, где хочу, не изменяя формат текстового файла.
Ради интереса давайте сделаем что-нибудь глупое: мы спарсим этот текст с помощью translator. Это модуль Python, загружающий данные в Google Translate, автоматически распознающий язык, переводящий и возвращающий текст на нужном языке:
cttt.py:
Теперь давайте попробуем пару строк с инъектором — последняя программа в этом пакете парсит текстовый файл, добавляет отбивку нулями ко всем символам ASCII в строках, считывает строки в словарь, чтобы мы знали, какие смещения задействуются. Кроме того, он воссоздаёт ADO с нуля (он считывает ADT, загружает все «сцены» в массив с их смещениями, копирует все данные между строками и после них), а затем повторно генерирует ADT на основании размеров «сцен» ADO:
ctti.py:
Проверим, как он работает:

Отлично!
Английский язык будет довольно ужасным, к счастью, я нашёл на фан-форуме Clocktower файл rtf с переводом и смог вручную отредактировать строки на основании грубых переводов.
Всё переведено и готово к работе! Давайте запустим:
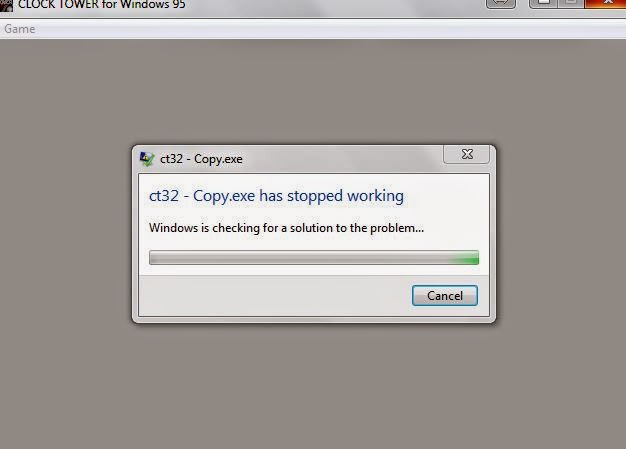
Чёрт возьми!
Что-то не так, давайте забросим файл в IDA и посмотрим, что происходит:

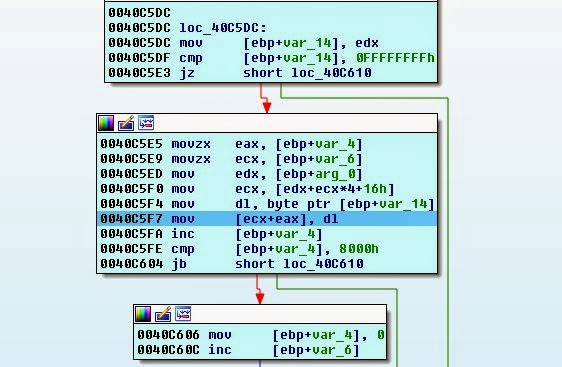
Похоже, что мы считываем файл ADO в память, но он пытается использовать указатель и не может, потому что в этом месте ничего нет.
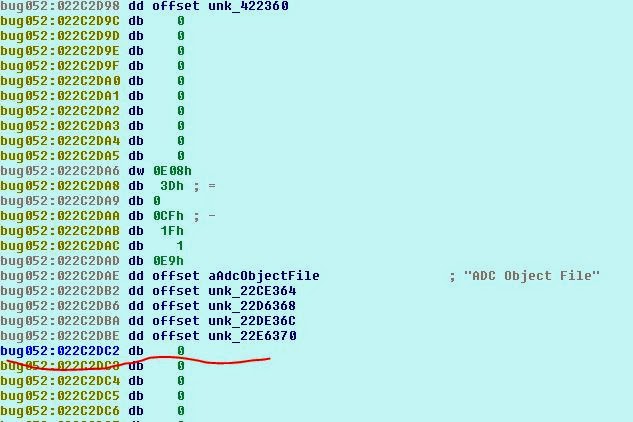
Понаблюдаем за struct a1 и за выполняемыми ею malloc, наверно, проблема в этом. Покопавшись подольше, мы выясним, что эти указатели создаются здесь:
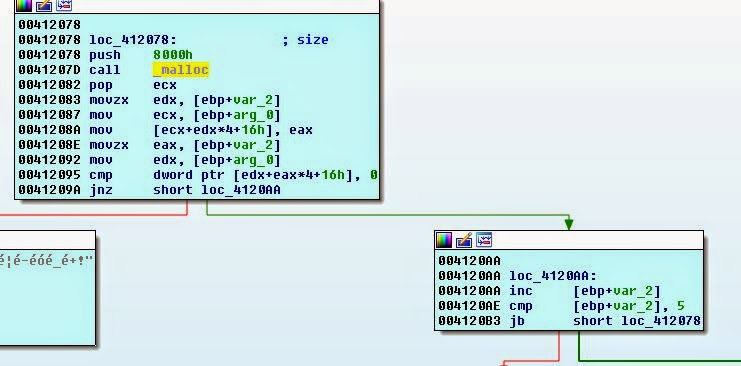
То есть игра (на основании опкода cmp5) создаёт указатели только для фрагментов ADO 5 * 0x8000, но считывает данные ADO до EOF (это определённо ошибка). В результате мы можем загрузить файл ADO размером не более 0x28000. Остановит ли это нас? Конечно нет! Давайте подробнее изучим структуру SCE в памяти…
Мы можем изменить все случаи загрузки указателей ADO с 5 на 6, чтобы добавить ещё один указать, но что будет после этого последнего указателя? Конечно же, начнутся смещения ADT
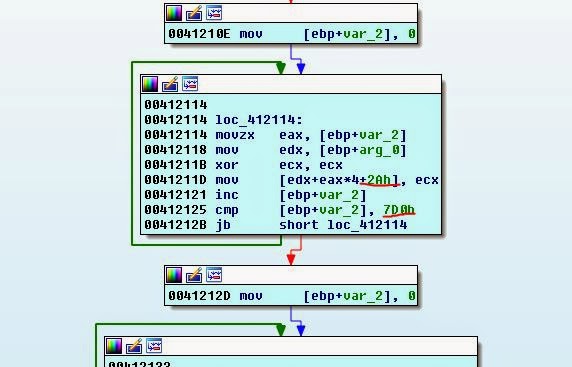
Мы видим, что смещение ADT 0x00 находится по адресу struct_head + 0x2A и переходит на 0x7D0… серьёзно? Указетели на 0x7D0??? Постойте, это похоже на 0x8000.
В результате у нас есть только 0x4800 байт для файла ADT. Можно сказать, что снизив начальный индекс ADT до, скажем, 0x2E, мы получим в четыре раза больше байт для записи ещё одного указателя ADO и у нас ещё останется куча свободного места в конце!
Находим ссылки struct на 0x2A и меняем их тоже на 0x2E:

Да! Люблю объектно-ориентированный реверс-инжиниринг.
Отлично, теперь игра полностью переведена. Что дальше?
Нам надо внести двоичные изменения в CT32.exe с помощью шестнадцатеричного редактора:
Следующим логичным шагом будет дизассемблирование всех других опкодов для создания текстового файла, который будет считываться в игре/редакторе.
Что-то вроде такого:
Потом, разумеется, нам нужно будет засунуть всё это обратно в пару ADO/ADT.
В версии игры для PSX тоже используются ADO/ADT. Похоже, мы сможем преобразовать ресурсы и добавить эксклюзивный контент с PSX в версию для PC.
Введение
ClockTower (известная в Японии как Clocktower — The First Fear) — это игра, изначально выпущенная Human Entertainment для Super Nintendo.

Это одна из игр жанра «point and click adventure», но она также стала одним из основателей жанра survival horror. Сюжет заключается в том, что четыре сироты после закрытия приюта попали в особняк, в котором один за другим начали исчезать. Игрок управляет одной из сирот, Дженнифер, и пытается найти выход, своих друзей и выяснить, что же происходит в особняке.
Атмосфера игры сурова, события в доме происходят случайно, без какой-либо видимой причины (проще говоря, дом заколдован), иногда что-то может убить вас просто так, психопат с садовыми ножницами преследует вас по всему дому (Немезис из Resident Evil 3 был не первым таким персонажем):
В игре часто возникают опасные ситуации, требующие быстро думать, единственное спасение — выживать, убегать и прятаться, но также важно сохранение рассудка Дженнифер, иначе она может упасть и умереть от сердечного приступа (в стиле игры Illbleed).
Игра была выпущена в 1994 году на SNES, повторно выпущена с расширенным контентом на PSX в 1997 году, выпущена на консоли Wonderswan (но никого не волнует Wonderswan), и, наконец, вышла на PC (а потом перевыпущена для PC в 1999 году).
Да, для ROM под SNES группой Aeon Genesis выпущен английский перевод (кажется, это были они), но версия для SNES хуже версии для PC, у которой был гораздо лучший звук, есть вступительный FMV-ролик и т.д. Возможно, единственной версией с бОльшим количеством контента была версия на PSX, но о ней мы поговорим позже.
Для начала давайте «отучим» игру от CD!
Часть 1 — Исследование
У нас есть папка с игрой, которая выглядит так:
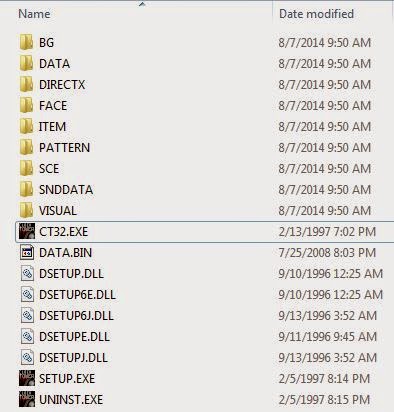
У нас есть папка BG, внутри которой находится что-то похожее на фоны комнат в разрезанном формате с сопровождающими файлами .MAP, который, как я предполагаю, размещает разные фрагменты на экране:

У нас есть папка DATA, содержащая файлы PTN и PYX… пока не знаю, что это такое… возможно, они связывают экраны уровней с логикой, или что-то подобное.
Также есть папка FACE, в которой содержатся bmp с лицами людей, используемыми в диалогах:

Ещё есть папка с предметами, которые может использовать Дженнифер:

В папке PATTERN содержатся файлы ABM. Думаю, они используются для спрайтовых анимаций, но могу ошибаться.
В папке SCE находятся два файла: CT.ADO и CT.ADT. Мы рассмотрим их — это логические скрипты действий, происходящие на протяжении всей игры, написанные на собственном бинарном скриптовом языке… и на них мы потратим больше всего времени.
В папке SNDDATA лежат файлы MIDI и WAV музыки и звуковых эффектов.
Папка VISUAL содержит все рендеры высокого разрешения, опции меню и т.д. в формате BMP. Также здесь хранится вступительное видео.

Наконец, у нас есть файл DATA.BIN, который… не знаю пока, что делает. Кроме того, есть исполняемый файл игры ct32.exe.
Запустив игру без CD, получаем следующее сообщение:
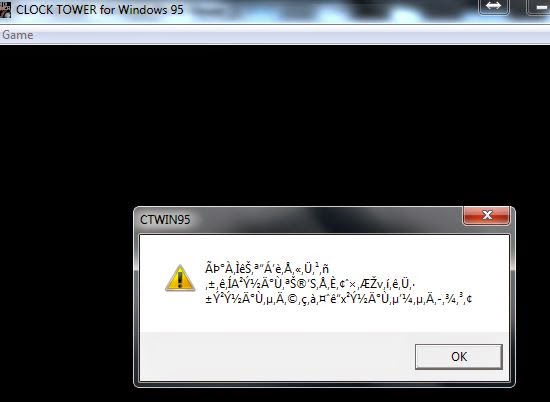
Запустим игру в отладчике, чтобы найти эту строку. Выясняется, что она просто сообщает, что игра не знает, где находятся данные игры (т.е. не вставлен CD).
Часть 2 — Создаём NoCD
Посмотрев в IDA, мы видим, что используется RegQueryValueEx, то есть считывается значение реестра. Что же игра оттуда получает?
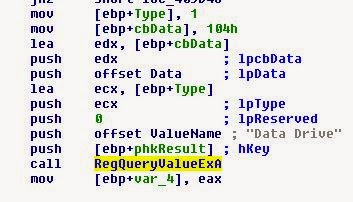
Ну… полагаю, вот и ответ.
ХОТЯ СТОП.
Давайте проверим, что её вызывает, возможно, мы сможем жёстко задать это в коде:
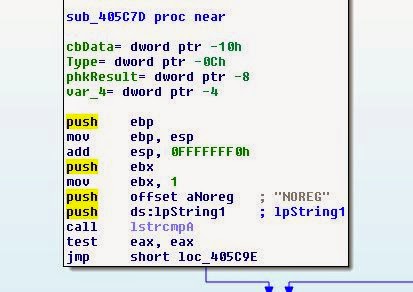
Похоже, что дополнительный труд оказался ненапрасным! Игра ищет аргумент NOREG. Если она не находит его, то проверяет значение реестра, пропускает проверку и запускает игру, предполагая, что находится в родительском каталоге. Здесь нам поможет простой патч, который заставит игру думать, что она всегда запускается с аргументом NOREG. Для этого заменим jz на 0xEB (или безусловный JMP).
Запускаем и получаем:
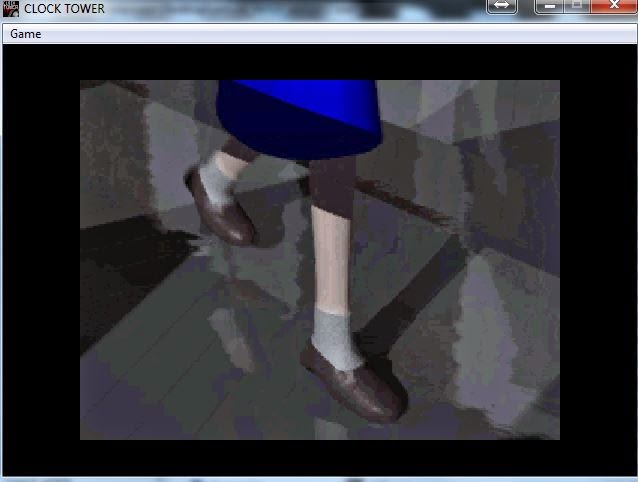
ДА!
Часть 3 — Ищем внутриигровой текст
Подумаем немного — можно ли ожидать, что весь текст находится в исполняемом файле? Ну, это возможно, во многих играх так и бывает. В двоичных файлах есть даже несколько статичных строк (например, найденная нами ошибка об отсутствии CD), но у меня есть ощущение, что тексты спрятаны где-то в другом месте (может, в файлах DATA?). Давайте посмотрим:
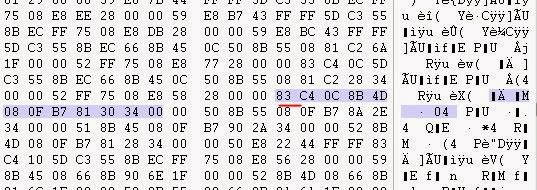
Японский текст, использующий формат SHIFT-JIS (очень популярный), обычно начинается с управляющего символа в диапазоне 0x80-0x8F… Неплохо бы начать с поиска чего-то подобного в исполняемом файле.
Затем мы скопируем эти строки в новый файл и откроем в notepad++, а потом вставим в Google Translate:
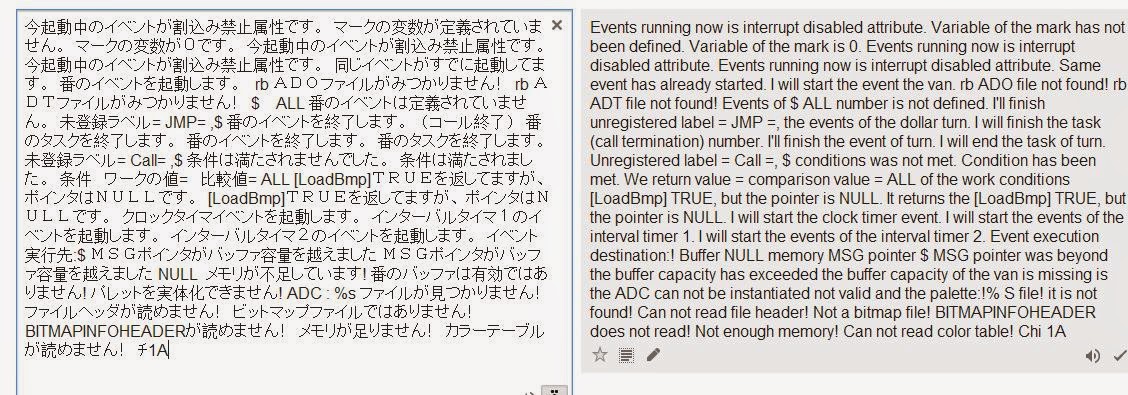
Так, это напоминает сообщения об ошибках, а не игровые диалоги. Пора искать другие файлы!
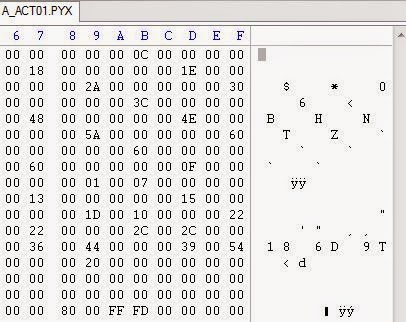
Хм, понятно — в файлах PTN и PYX нет никаких текстов. Давайте проверим папку SCE.
Похоже, что в файле CT.ADT находятся четырёхбайтные смещения (они до конца файла выполняют счёт вверх от 0x100, по 4 байта за раз).
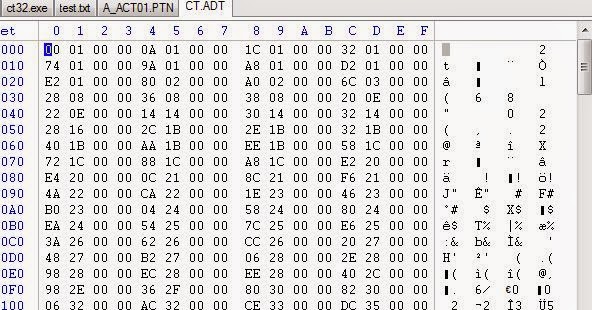
Зато в файле CT.ADO…


Мы что-то нашли… здесь не только строки ASCII, похожие на пути к файлам, но и текстовые строки в формате SHIFT-JIS. Данные в этом файле выглядят странно… давайте посмотрим, сможем ли мы разобраться в них лучше. Нам придётся, если мы хотим их парсить.
Часть 4 — Углубляемся в ADO/ADT
Мы уже немного разобрались в том, как работает ADT, так что давайте посмотрим, как выглядит ADO:
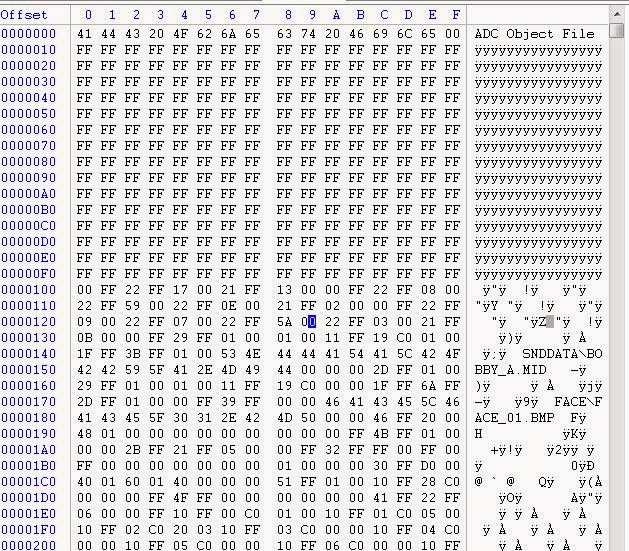
В самом верху начинается магия (ADC Object File), потому куча 0xFF для смещения на 256, потом, похоже, начинаются данные. Настало время подумать, как настоящий учёный-компьютерщик!
У нас есть все эти строки, двоичный формат без очевидного поиска, кроме, возможно файла ADT. Внутри должен быть управляющий код, перемешанный с данными, который даёт игре понять, что она видит при парсинге… у всего этого есть какая-то структура.
Изучая строки с .BMP, можно заметить, что они имеют одинаковый шаблон:
За 39FF следует нулевое двухбайтное значение (чаще всего, но иногда это 0x0100, поэтому я думаю, что это значение в WORD), затем строка ASCII, завершающаяся нулевым значением, и отступ. На самом деле при каждой загрузке BMP для FACE, перед ней стоит значение 0xFF39!
Давайте проверим исполняемый файл:
Здорово! У нас есть не только это, но и другие значения. Давайте проверим несколько строк Shift-JIS, чтобы проверить, сможем ли найти закономерность:

Отлично! Все строки начинаются с 0xFF33, имеют два 16-битных значения (0x0F00), за которыми идёт строка в Shift-JIS.
Примечание: можно заметить, что SHIFT-JIS НЕ завершается нулевым значением, это невозомжно. Некоторые программы могут обрабатывать и однобайтовые и многобайтовые символьные значения, но в старых программах это было серьёзной проблемой. В результате, как можно заметить, за всеми разрывами строк (0x0a) следуют 0x00. На самом деле за ВСЕМИ символами ASCII здесь идёт 0x00 (и числа или английские буквы). Таким образом рендеринг текста может поддерживать многобайтовую интерпретацию символов ASCII (0-127) и не перепутать при считывании байт данных с управляющим байтом, и наоборот.
Поэтому мы приходим к выводу, что логика игры должна парсить строку, пока каким-то образом не обнаружит конец (возможно, найдя новый опкод (обычно это 0x28FF).
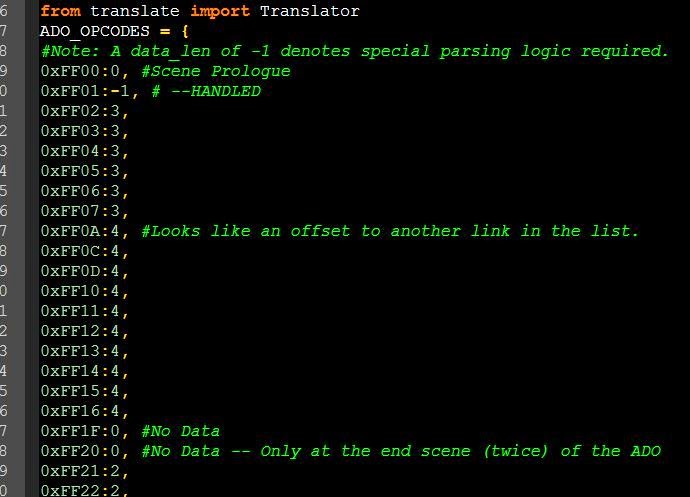
Итак, как мы знаем, файл ADO забит скриптовыми «опкодами» и следующими за ними данными. Можно теоретически предположить, что игра считывает их и на основании предшествующего опкода знает, какие данные нужно ожидать. Теперь мы можем посмотреть на конструкцию switch в исполняемом файле, которую мы нашли выше (со всеми case), чтобы выделить все опкоды, используемые в игре (для более полного понимания формата).
Мы заметим значения (0xFF20, 0xFF87) и будем искать их в файле ADO, определяя, имеют ли они то же количество байт данных перед следующим опкодом. Попробуем выяснить, являются ли они двухбайтными значениями, строками и так далее.
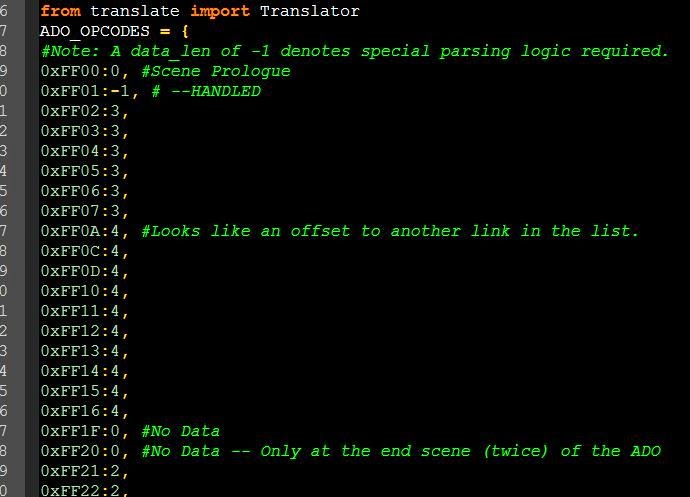
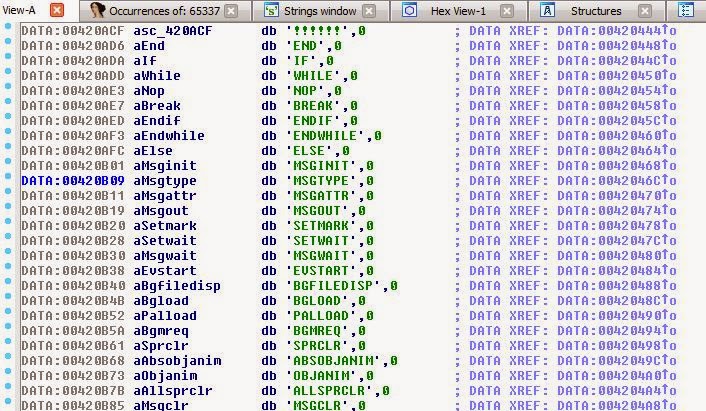
Кроме того, можно заметить, что в исполняемом файле есть довольно интересный текст:
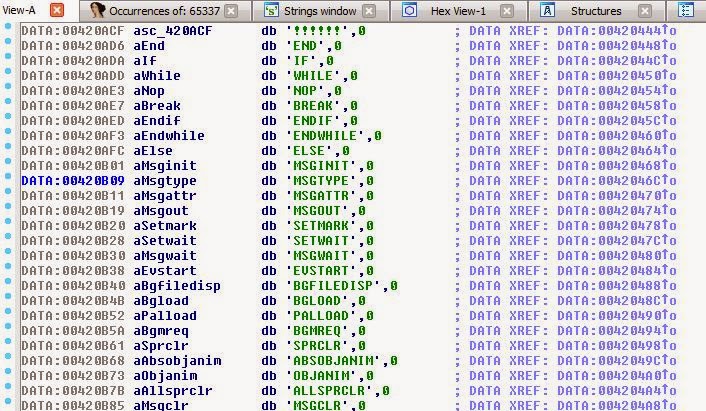
На самом деле это список, и он подозрительно похож на названия опкодов. К счастью для нас, так и есть! Теперь мы знаем названия опкодов.
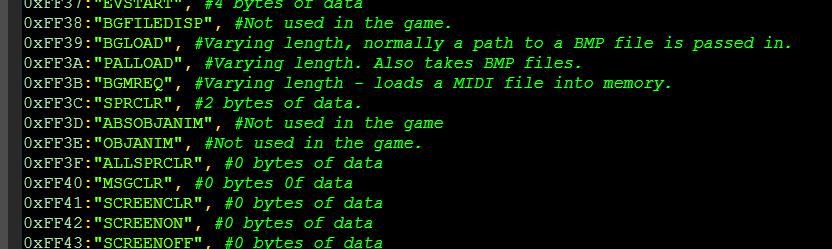
На этом этапе мы можем запустить игру с отладчиком и прерывать выполнение на конструкциях, чтобы наблюдать за действиями разных опкодов. Один из интересующих нас — это JMP…
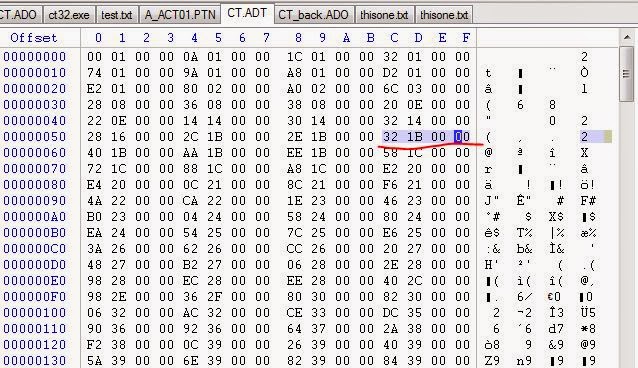
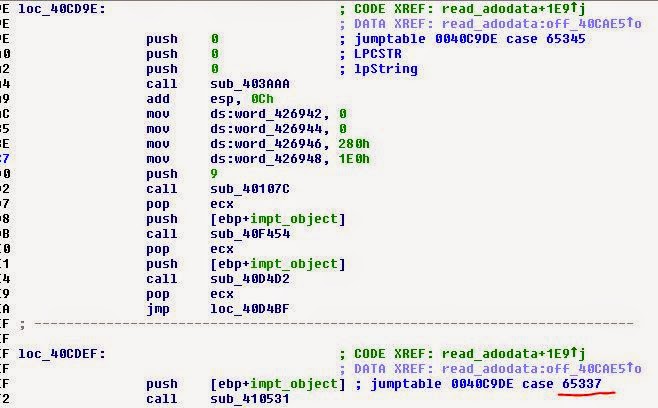
На самом деле, после первого JMP (0xFF22) есть двухбайтовое значение 0x17.
Если наблюдать за ним в игре и установить в IDA в качестве наблюдаемой переменной ADO_offset, то можно увидеть, что игра переходит от этого значения к 0x1B32. Как она узнаёт, что нужно это сделать? Это не множитель… наверно:

Ага!
0x17 * 4 = 0x5C, то есть ADT — это таблица переходов для разных сцен. Вы заметите, что функция CALL (0xFF23) работает похожим образом, но через какое-то время возвращается к этому смещению… Первые несколько смещений ADT указывают на 0xFF00. Похоже, это очень важно в игре, переходы на самом деле пропускают их (они прибавляют +2 к смещению после перехода). Это что-то вроде опкода RETN? Думаю, что да.
Однако вы заметите, что файл ADT содержит в конце разные значения, намного превышающие размер файла ADO. Что они дают? Мы с этим разберёмся, но сначала немного подробнее рассмотрим процесс выполнения игры, чтобы понять, как работают эти переходы (уделив им особое внимание).
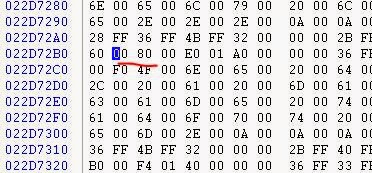
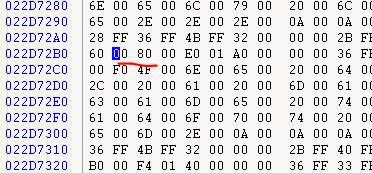
Сделав дамп памяти, можно заметить, что файл объектов ADC в памяти (CT.ADO) имеет значение 0x8000 int16, записанное в каждых 0x8000, или 32 КБ. Кроме этого ADO никак не изменён. Можно также заметить в исполняемом файле, что функция парсит значения и пропускает два байта, если видит это значение (как NOP).
Поскольку игра разделяет данные на фрагменты по 32 КБ (скорее всего, чтобы более сегментированно обращаться к памяти; мы часто встречались с двухбайтными значениями — это важно), то для ADT должна быть какая-то трансляция адресов (потому что ADT использует для обращения к смещению 4 байта).

Здесь довольно много математики, которая, если вы наблюдали в отладчике, будет напоминать что-то такое:
Сначала я не нашёл функцию и дошёл до конца файла ADT, предполагая, что есть указатель на конец файла ADO (последний RETN имеет смещение 0x253F4). В списке ADT он указан как 0x453F4. Поискав разные другие адреса, я заметил, что трансляция берёт два значимых байта, делит их пополам и вставляет обратно в конец.
Неплохо, теперь мы можем генерировать файлы ADT (обратной операцией: умножением самого значимого в зависимости от того, сколько интервалов по 0x8000 мы прошли). Также у нас есть общая схема опкодов и мы знаем, где находятся строки. Прежде чем заняться дизассемблированием, давайте посмотрим на награду и приложим все усилия (сначала перевод).
Часть 4: настала очередь CTTDTI
Мы знаем, в каком формате хранятся строки и как считать их из файла ADO. Разумеется, вставка их обратно потребует изменения смещений ADT, потому что размеры строк могут быть гораздо больше или меньше. Для начала рассмотрим вырезание строк ADO в текстовый файл, во что-то очень легко редактируемое, что можно будет потом считать другой программой. Создадим формат, в котором мы сможем легко вставлять строки в новый файл ADO и удобно изменять смещения. Что нам для этого понадобится?
Итак, нам важно смещение, с которого начинается строка, размер исходной строки в байтах, затем сама строка, что-то вроде:
0xE92 25 blahblahblahПишем cttd.py:
'''
CTD - Clocktower Text Dumper by rFx
'''
import os,sys,struct,binascii
f = open("CT_J.ADO","rb")
data = f.read()
f.close()
g = open("ct_txt.txt","wb")
for i in range(0,len(data)-1):
if(data[i] == '\x33' and data[i+1] == '\xff'):
#Нам нужно пропускать 6 из-за опкодов и значений, изменения которых нам не важны.
i+=6
str_offset = i
str_end = data[i:].index('\xff') -1
newstr = data[i:i+str_end]
strlen = len(newstr)
newstr = newstr.replace("\x0a\x00","[NEWLINE]")
#Игра ставит нули после каждого символа ASCII, нам нужно удалить их.
newstr = newstr.replace("\x00","")
g.write("%#x\t%d\t" % (str_offset,strlen))
g.write(newstr)
g.write("\n")
g.close()Я переименовал CT.ADO в CT_J.ADO, чтобы потом сгенерировать новый файл.
Эта программа считывает файл ADO, находит 0xFF33, пропускает 6 байтов (чтобы обойти опкод и два двухбайтных значения), а затем записывает в новый файл начальное смещение строки, длину строки и саму строку в формат с разделителями табуляцией, завершающийся новой строкой.
Вы заметите, что я заменяю все значения 0x0a (новая строка) на [NEWLINE]. Я делаю так потому, что хочу, чтобы вся строка обрабатывалась в одной строке и я мог определять новые строки там, где хочу, не изменяя формат текстового файла.
Ради интереса давайте сделаем что-нибудь глупое: мы спарсим этот текст с помощью translator. Это модуль Python, загружающий данные в Google Translate, автоматически распознающий язык, переводящий и возвращающий текст на нужном языке:
cttt.py:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
Clocktower Auto Translator by rFx
'''
import os,sys,binascii,struct
from translate import Translator
translator = Translator(to_lang="en") #Set to English by Default
f = open("ct_txt.txt","rb")
g = open("ct_txt_proc2.txt","wb")
proc_str = []
for line in f.readlines():
proc_str.append(line.rstrip())
for x in range(0,len(proc_str)):
line = proc_str[x]
o,l,instr = line.split("\t")
ts = translator.translate(instr.decode("SHIFT-JIS").encode("UTF-8"))
ts = ts.encode("SHIFT-JIS","replace")
proc_str[x] = "%s\t%s\t%s" % (o,l,ts)
g.write(proc_str[x]+"\n")
#for pc in proc_str:
# g.write(pc)
g.close()Теперь давайте попробуем пару строк с инъектором — последняя программа в этом пакете парсит текстовый файл, добавляет отбивку нулями ко всем символам ASCII в строках, считывает строки в словарь, чтобы мы знали, какие смещения задействуются. Кроме того, он воссоздаёт ADO с нуля (он считывает ADT, загружает все «сцены» в массив с их смещениями, копирует все данные между строками и после них), а затем повторно генерирует ADT на основании размеров «сцен» ADO:
ctti.py:
'''
Clocktower Text Injector by rFx
'''
import os,sys,struct,binascii
def is_ascii(s):
return all(ord(c) < 128 for c in s)
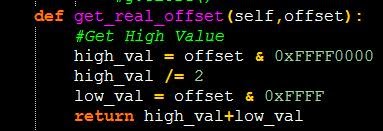
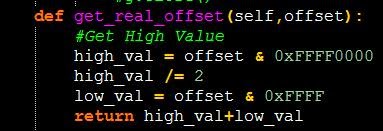
def get_real_offset(offset):
#Получаем верхнее значение
high_val = offset & 0xFFFF0000
high_val /= 2
low_val = offset & 0xFFFF
return high_val+low_val
def get_fake_offset(offset):
#Получаем верхнее значение
mult = int(offset / 0x8000)
shft_val = 0x8000 * mult
low_val = offset & 0xFFFF
return offset + shft_val
f = open("CT_J.ADO","rb")
data = f.read()
f.close()
offset_vals = []
adt_list = []
newdata = ""
f = open("ct_txt_proc.txt","rb")
lines = f.readlines()
o,l,s = lines[0].split("\t")
first_offset = int(o,16)
o,l,s = lines[0].split("\t")
last_offset_strend = int(o,16) + int(l)
newdata = data[:first_offset]
for i in range(0,len(lines)):
line = lines[i]
offset, osl, instr = line.split("\t")
offset = int(offset,16)
instr = instr.rstrip('\n')
instr = instr.replace("[NEWLINE]","\x0a")
#Исправляем символы ASCII.
instr = instr.decode("SHIFT-JIS")
newstr = ""
for char in instr:
if(is_ascii(char)):
newstr+=char+'\x00'
else:
newstr+=char
instr = newstr
instr = instr.encode("SHIFT-JIS")
newstrlen = len(instr)
osl = int(osl)
strldiff = newstrlen - osl
#Заменяем данные
if(i < len(lines)-1):
nextline = lines[i+1]
nextoffset,nsl,nstr = nextline.split("\t")
offset_vals.append({"offset":offset,"val":strldiff})
nextoffset = int(nextoffset,16)
newdata += instr+data[offset+osl:nextoffset]
else:
offset_vals.append({"offset":offset,"val":strldiff})
newdata += instr + data[offset+osl:]
#Конец последней строки до EOF
f.close()
#Записываем новый файл ADO.
g = open("CT.ADO","wb")
g.write(newdata)
g.close()
#Исправляем файл ADT.
f = open("CT_J.ADT","rb")
datat = f.read()
f.close()
g = open("CT.ADT","wb")
for i in range(0,len(datat),4):
cur_offset = get_real_offset(struct.unpack("<I",datat[i:i+4])[0])
final_adj = 0
for offset in offset_vals:
if(cur_offset > offset["offset"]):
final_adj += offset["val"]
g.write(struct.pack("<I",get_fake_offset(cur_offset + final_adj)))
g.close()Проверим, как он работает:

Отлично!
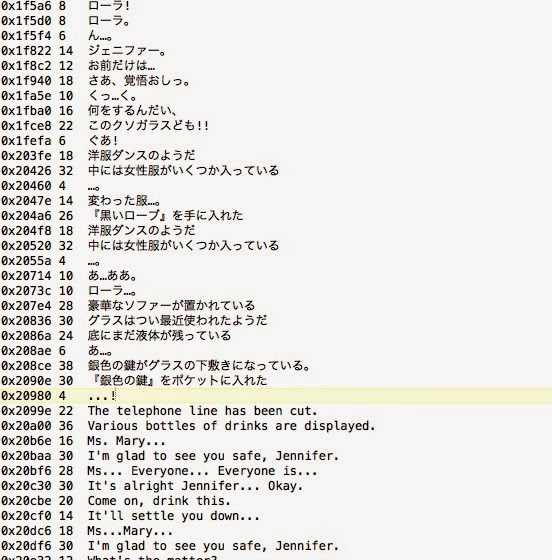
Английский язык будет довольно ужасным, к счастью, я нашёл на фан-форуме Clocktower файл rtf с переводом и смог вручную отредактировать строки на основании грубых переводов.

Всё переведено и готово к работе! Давайте запустим:

Чёрт возьми!
Что-то не так, давайте забросим файл в IDA и посмотрим, что происходит:

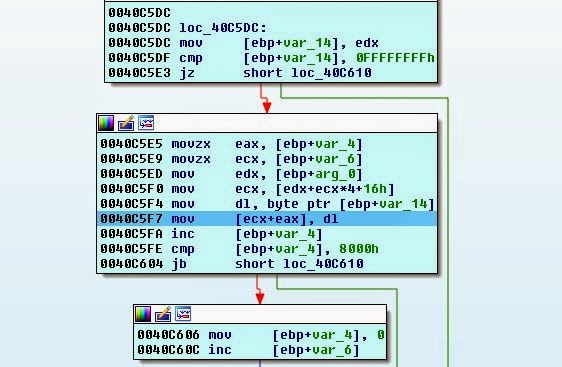
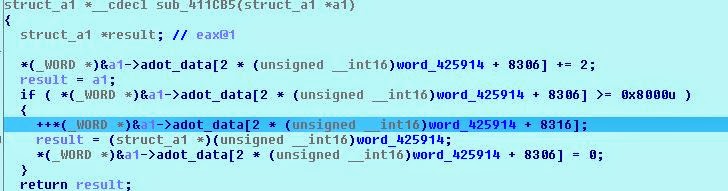
Похоже, что мы считываем файл ADO в память, но он пытается использовать указатель и не может, потому что в этом месте ничего нет.
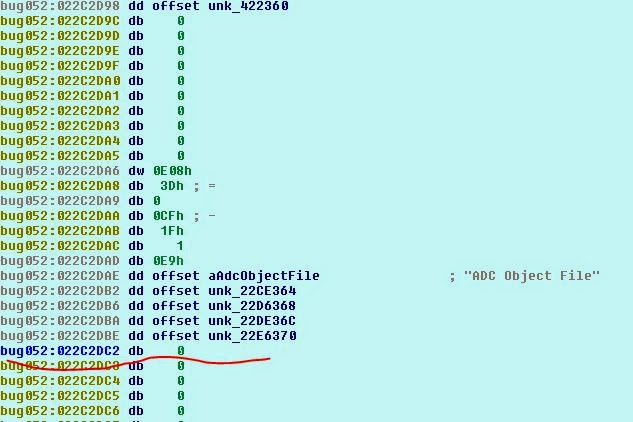
Понаблюдаем за struct a1 и за выполняемыми ею malloc, наверно, проблема в этом. Покопавшись подольше, мы выясним, что эти указатели создаются здесь:

То есть игра (на основании опкода cmp5) создаёт указатели только для фрагментов ADO 5 * 0x8000, но считывает данные ADO до EOF (это определённо ошибка). В результате мы можем загрузить файл ADO размером не более 0x28000. Остановит ли это нас? Конечно нет! Давайте подробнее изучим структуру SCE в памяти…
Мы можем изменить все случаи загрузки указателей ADO с 5 на 6, чтобы добавить ещё один указать, но что будет после этого последнего указателя? Конечно же, начнутся смещения ADT

Мы видим, что смещение ADT 0x00 находится по адресу struct_head + 0x2A и переходит на 0x7D0… серьёзно? Указетели на 0x7D0??? Постойте, это похоже на 0x8000.
В результате у нас есть только 0x4800 байт для файла ADT. Можно сказать, что снизив начальный индекс ADT до, скажем, 0x2E, мы получим в четыре раза больше байт для записи ещё одного указателя ADO и у нас ещё останется куча свободного места в конце!
Находим ссылки struct на 0x2A и меняем их тоже на 0x2E:

Да! Люблю объектно-ориентированный реверс-инжиниринг.
Отлично, теперь игра полностью переведена. Что дальше?
Нам надо внести двоичные изменения в CT32.exe с помощью шестнадцатеричного редактора:
529B: 74 EB
BC7B: 2A 2E
BC8D: D0 CC
BD35: 2A 2E
BD62: 2A 2E
D4DA: 2A 2E
D4FC: 2A 2E
DA58: 2A 2E
DA79: 2A 2E
103DA: 2A 2E
10407: 2A 2E
104F8: 2A 2E
105BB: 2A 2E
105E8: 2A 2E
10703: 2A 2E
10730: 2A 2E
115FA: 2A 2E
116B2: 05 06
116E8: 05 06
11720: 2A 2E
11729: D0 CC
1195D: 05 06
1C50F: 20 00Работа на будущее — часть 5 — SCEDASM — дизассемблер SCE
Следующим логичным шагом будет дизассемблирование всех других опкодов для создания текстового файла, который будет считываться в игре/редакторе.
Что-то вроде такого:
'''
Clocktower ADC Object File Disassembler by rFx
'''
import os,sys,binascii,struct
ADO_FILENAME = "CT_J.ADO"
ADT_FILENAME = "CT_J.ADT"
ADO_OP = {
0xFF00:"RETN", #Scene Prologue - 0 bytes of data. - Also an END value... the game looks to denote endings.
0xFF01:"UNK_01", # varying length data
0xFF02:"UNK_02", # 3 bytes of data
0xFF03:"UNK_03", # 3 bytes of data
0xFF04:"UNK_04", # 3 bytes of data
0xFF05:"UNK_05", # 3 bytes of data
0xFF06:"UNK_06", # 3 bytes of data
0xFF07:"UNK_07", # 3 bytes of data
0xFF0A:"UNK_0A", # 4 bytes of data. Looks like an offset to another link in the list?
0xFF0C:"UNK_0C", # 4 bytes of data
0xFF0D:"UNK_0D", # 4 bytes of data
0xFF10:"UNK_10", # 4 bytes of data
0xFF11:"UNK_11", # 4 bytes of data
0xFF12:"UNK_12", # 4 bytes of data
0xFF13:"UNK_13", # 4 bytes of data
0xFF14:"UNK_14", # 4 bytes of data
0xFF15:"UNK_15", # 4 bytes of data
0xFF16:"UNK_16", # 4 bytes of data
0xFF1F:"UNK_1F", # 0 bytes of data
0xFF20:"ALL", # 0 bytes of data. Only at the end of the ADO (twice)
#All opcodes above this are like... prologue opcodes (basically in some other list)
0xFF21:"ALLEND", # 2 bytes of data
0xFF22:"JMP", # 2 bytes of data - I think it uses the value for the int offset in adt as destination +adds 2
0xFF23:"CALL", # 6 bytes of data
0xFF24:"EVDEF", # Not used in the game
0xFF25:"!!!!!!", #Not used in the game
0xFF26:"!!!!!!", #Not used in the game
0xFF27:"!!!!!!", #Not used in the game
0xFF28:"!!!!!!", #0 bytes of data.
0xFF29:"END_IF", # 4 bytes of data
0xFF2A:"WHILE", # 4 bytes of data
0xFF2B:"NOP", # 0 bytes of data
0xFF2C:"BREAK", # Not used in the game
0xFF2D:"ENDIF", # 2 bytes of data
0xFF2E:"ENDWHILE", # 2 bytes of data
0xFF2F:"ELSE", # 2 bytes of data
0xFF30:"MSGINIT", # 10 bytes of data
0xFF31:"MSGTYPE", # Not used in the game
0xFF32:"MSGATTR", # 16 bytes of data
0xFF33:"MSGOUT", # Varying length, our in-game text uses this. :)
0xFF34:"SETMARK", #Varying length
0xFF35:"SETWAIT", #Not used in the game
0xFF36:"MSGWAIT", #0 bytes of data
0xFF37:"EVSTART", #4 bytes of data
0xFF38:"BGFILEDISP", #Not used in the game.
0xFF39:"BGLOAD", #Varying length, normally a path to a BMP file is passed in.
0xFF3A:"PALLOAD", #Varying length. Also takes BMP files.
0xFF3B:"BGMREQ", #Varying length - loads a MIDI file into memory.
0xFF3C:"SPRCLR", #2 bytes of data.
0xFF3D:"ABSOBJANIM", #Not used in the game
0xFF3E:"OBJANIM", #Not used in the game.
0xFF3F:"ALLSPRCLR", #0 bytes of data
0xFF40:"MSGCLR", #0 bytes 0f data
0xFF41:"SCREENCLR", #0 bytes of data
0xFF42:"SCREENON", #0 bytes of data
0xFF43:"SCREENOFF", #0 bytes of data
0xFF44:"SCREENIN", # Not used in the game.
0xFF45:"SCREENOUT", # Not used in the game.
0xFF46:"BGDISP", # Always 12 bytes of data.
0xFF47:"BGANIM", #14 bytes of data.
0xFF48:"BGSCROLL",#10 bytes of data.
0xFF49:"PALSET", #10 bytes of data.
0xFF4A:"BGWAIT", #0 bytes of data.
0xFF4B:"WAIT", #4 bytes of data.
0xFF4C:"BWAIT", #Not used in the game.
0xFF4D:"BOXFILL", #14 bytes of data.
0xFF4E:"BGCLR", # Not used in the game.
0xFF4F:"SETBKCOL", #6 bytes of data.
0xFF50:"MSGCOL", #Not used in the game.
0xFF51:"MSGSPD", #2 bytes of data.
0xFF52:"MAPINIT", #12 bytes of data.
0xFF53:"MAPLOAD", #Two Paths... Sometimes NULL NULL - Loads the background blit bmp and the map file to load it.
0xFF54:"MAPDISP", #Not used in the game.
0xFF55:"SPRENT", #16 bytes of data.
0xFF56:"SETPROC", #2 bytes of data.
0xFF57:"SCEINIT", #0 bytes of data.
0xFF58:"USERCTL", #2 bytes of data.
0xFF59:"MAPATTR", #2 bytes of data.
0xFF5A:"MAPPOS", #6 bytes of data.
0xFF5B:"SPRPOS", #8 bytes of data.
0xFF5C:"SPRANIM", #8 bytes of data.
0xFF5D:"SPRDIR", #10 bytes of data.
0xFF5E:"GAMEINIT", #0 bytes of data.
0xFF5F:"CONTINIT", #0 bytes of data.
0xFF60:"SCEEND", #0 bytes of data.
0xFF61:"MAPSCROLL", #6 bytes of data.
0xFF62:"SPRLMT", #6 bytes of data.
0xFF63:"SPRWALKX", #10 bytes of data.
0xFF64:"ALLSPRDISP", #Not used in the game.
0xFF65:"MAPWRT", #Not used in the game.
0xFF66:"SPRWAIT", #2 bytes of data.
0xFF67:"SEREQ", #Varying length - loads a .WAV file.
0xFF68:"SNDSTOP", #0 bytes of data.
0xFF69:"SESTOP", #Varying length - specifies a .WAV to stop or ALL for all sounds.
0xFF6A:"BGMSTOP", #0 bytes of data.
0xFF6B:"DOORNOSET", #0 bytes of data.
0xFF6C:"RAND", #6 bytes of data.
0xFF6D:"BTWAIT", #2 bytes of data
0xFF6E:"FAWAIT", #0 bytes of data
0xFF6F:"SCLBLOCK", #Varying length - no idea.
0xFF70:"EVSTOP", #Not used in the game.
0xFF71:"SEREQPV", #Varying length - .WAV path input, I think this is to play and repeat.
0xFF72:"SEREQSPR", #Varying length - .WAV path input, I think this is like SEREQPV except different somehow.
0xFF73:"SCERESET", #0 bytes of data.
0xFF74:"BGSPRENT", #12 bytes of data.
0xFF75:"BGSPRPOS", #Not used in the game.
0xFF76:"BGSPRSET", #Not used in the game.
0xFF77:"SLANTSET", #8 bytes of data.
0xFF78:"SLANTCLR", #0 bytes of data.
0xFF79:"DUMMY", #Not used in the game.
0xFF7A:"SPCFUNC", #Varying length - usage uncertain.
0xFF7B:"SEPAN", #Varying length - guessing to set the L/R of Stereo SE.
0xFF7C:"SEVOL", #Varying length - guessing toe set the volume level of SE
0xFF7D:"BGDISPTRN", #14 bytes of data.
0xFF7E:"DEBUG", #Not used in the game.
0xFF7F:"TRACE", #Not used in the game.
0xFF80:"TMWAIT", #4 bytes of data.
0xFF81:"BGSPRANIM", #18 bytes of data.
0xFF82:"ABSSPRENT", #Not used in the game.
0xFF83:"NEXTCOM", #2 bytes of data.
0xFF84:"WORKCLR", #0 bytes of data.
0xFF85:"BGBUFCLR", #4 bytes of data.
0xFF86:"ABSBGSPRENT", #12 bytes of data.
0xFF87:"AVIPLAY", #This one is used only once - to load the intro AVI file.
0xFF88:"AVISTOP", #0 bytes of data.
0xFF89:"SPRMARK", #Only used in PSX Version.
0xFF8A:"BGMATTR",#Only used in PSX Version.
#BIG GAP IN OPCODES... maybe not even in existence.
0xFFA0:"UNK_A0", #12 bytes of data.
0xFFB0:"UNK_B0", #12 bytes of data.
0xFFDF:"UNK_DF", #2 bytes of data.
0xFFE0:"UNK_E0", #0 bytes of data.
0xFFEA:"UNK_EA", #0 bytes of data.
0xFFEF:"UNK_EF" #12 bytes of data.
}
if(__name__=="__main__"):
print("#Disassembling ADO/ADT...")
#Read ADO/ADT Data to memory.
f = open(ADO_FILENAME,"rb")
ado_data = f.read()
f.close()
f = open(ADT_FILENAME,"rb")
adt_data = f.read()
f.close()
scene_count = -1
#Skip ADO Header
i = 256
while i < (len(ado_data) -1):
cur_val = struct.unpack("<H",ado_data[i:i+2])[0]
if(cur_val in ADO_OP.keys()):
#0xFF00
if(cur_val == 0xFF00):
scene_count +=1
print("#----SCENE %d (Offset %#x)" % (scene_count,i))
print(ADO_OP[cur_val])
i+=2
elif(cur_val == 0xFF1F or cur_val == 0xFF20 or cur_val == 0xFF84 or cur_val == 0xFFEA or cur_val == 0xFFE0
or cur_val == 0xFF88 or cur_val == 0xFF78 or cur_val == 0xFF73 or cur_val == 0xFF6E or cur_val == 0xFF6B
or cur_val == 0xFF6A or cur_val == 0xFF68 or cur_val == 0xFF60 or cur_val == 0xFF5F or cur_val == 0xFF5E
or cur_val == 0xFF57 or cur_val == 0xFF4A or cur_val == 0xFF43 or cur_val == 0xFF42 or cur_val == 0xFF41
or cur_val == 0xFF40 or cur_val == 0xFF36 or cur_val == 0xFF3F or cur_val == 0xFF36 or cur_val == 0xFF2B or cur_val == 0xFF28):
print(ADO_OP[cur_val])
i+=2
#0xFF22
elif(cur_val == 0xFF22 or cur_val == 0xFF51 or cur_val == 0xFF21 or
cur_val == 0xFF2D or cur_val == 0xFF2E or cur_val == 0xFF2F or cur_val == 0xFF3C
or cur_val == 0xFF56 or cur_val == 0xFF58 or cur_val == 0xFF59 or cur_val == 0xFF66
or cur_val == 0xFF6D or cur_val == 0xFF83 or cur_val == 0xFFDF):
i+=2
jmpdata = struct.unpack("<H",ado_data[i:i+2])[0]
print("%s %d" % (ADO_OP[cur_val],jmpdata))
i+=2
#0xFF23
elif(cur_val == 0xFF23):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_3 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
print("%s %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3))
elif cur_val == 0xFF29 or cur_val == 0xFF2A or cur_val == 0xFF37:
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
print("%s %d %d" % (ADO_OP[cur_val],val_1,val_2))
elif cur_val in range(0xFF02,0xFF08):
i+=2
pri_val = struct.unpack("b",ado_data[i])[0]
i+=1
sec_val = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
print("%s %d %d" % (ADO_OP[cur_val],pri_val,sec_val))
elif cur_val in range(0xFF0A,0xFF17):
i+=2
pri_val = struct.unpack("<I",ado_data[i:i+4])[0]
i+=4
print("%s %#x" % (ADO_OP[cur_val],pri_val))
elif (cur_val == 0xFF30):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_3 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_4 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_5 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
print("%s %#x %#x %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5))
elif (cur_val == 0xFF33):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
endstr_offset = ado_data[i:].index("\xff")
endstr_offset -=1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
#Decode to UTF-8
instr = instr.replace("\x0a\x00","[NEWLINE]")
instr = instr.replace("\x00","[NULL]")
instr = instr.decode("SHIFT-JIS")
instr = instr.encode("UTF-8")
print("%s %#x %#x ``%s``" % (ADO_OP[cur_val],val_1,val_2,instr))
elif (cur_val == 0xFF32):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_3 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_4 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_5 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_6 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_7 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_8 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
print("%s %#x %#x %#x %#x %#x %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,val_6,val_7,val_8))
elif(cur_val == 0xFF34):
i+=2
endval_offset = ado_data[i:].index("\xff") - 1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
print("%s %s" % (ADO_OP[cur_val],binascii.hexlify(instr)))
i+=2
elif(cur_val in range(0xFF39,0xFF3C) or cur_val == 0xFF67):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
endstr_offset = ado_data[i:].index("\xff") - 1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
if(instr.find("\x00\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_2 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0]
val_3 = struct.unpack("b",instr[instr.index("\x00")+2:])[0]
print("%s %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,finstr,val_2,val_3))
elif(instr.find("\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_2 = struct.unpack("b",instr[instr.index("\x00")+1:])[0]
print("%s %#x %s %#x" % (ADO_OP[cur_val],val_1,finstr,val_2))
elif(cur_val == 0xFF69):
i+=2
endstr_offset = ado_data[i:].index("\xff") - 1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
if(instr.find("\x00\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_2 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0]
val_3 = struct.unpack("b",instr[instr.index("\x00")+2:])[0]
print("%s %s %#x %#x" % (ADO_OP[cur_val],finstr,val_2,val_3))
elif(instr.find("\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_2 = struct.unpack("b",instr[instr.index("\x00")+1:])[0]
print("%s %s %#x" % (ADO_OP[cur_val],finstr,val_2))
elif(cur_val == 0xFF71 or cur_val == 0xFF72):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_3 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
endstr_offset = ado_data[i:].index("\xff") - 1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
if(instr.find("\x00\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_4 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0]
val_5 = struct.unpack("b",instr[instr.index("\x00")+2:])[0]
print("%s %#x %#x %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,finstr,val_4,val_5))
elif(instr.find("\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_4 = struct.unpack("b",instr[instr.index("\x00")+1:])[0]
print("%s %#x %#x %#x %s %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,finstr,val_4))
elif(cur_val == 0xFF87):
i+=2
val_1 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_2 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_3 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_4 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
val_5 = struct.unpack("<H",ado_data[i:i+2])[0]
i+=2
endstr_offset = ado_data[i:].index("\xff") - 1
instr = ado_data[i:i+endstr_offset]
i+= len(instr)
if(instr.find("\x00\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_6 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0]
val_7 = struct.unpack("b",instr[instr.index("\x00")+2:])[0]
print("%s %#x %#x %#x %#x %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,finstr,val_6,val_7))
elif(instr.find("\x00\x00") != -1):
finstr = instr[:instr.index("\x00")]
val_6 = struct.unpack("b",instr[instr.index("\x00")+1:])[0]
print("%s %#x %#x %#x %#x %#x %s %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,finstr,val_6))
#NOT DONE YET
else:
i+=1
else:
i+=1Потом, разумеется, нам нужно будет засунуть всё это обратно в пару ADO/ADT.
Работа на будущее — часть 6 — версия для PSX
В версии игры для PSX тоже используются ADO/ADT. Похоже, мы сможем преобразовать ресурсы и добавить эксклюзивный контент с PSX в версию для PC.
