Comments 14
Я просто хочу делать игры.
Альтернатива только для совсем не сложных систем
Вы считаете задачу обучить машину играть в игры для Атари имея на входе только скриншоты "совсем несложной системой"? На этой задаче предложенный алгоритм работает наравне с reinforced learning, в каких-то играх побеждает, в других немного отстает.
Атари игры разные, как и прочие энвайронменты участвующие в тестах >> но и так видно (и понятно) что эволючионный «hill-climbing» может на простых вещах только соперничать с некоторыми алг-ми RL (в примере vanilla A3C feb 2016)
Ну вот Вам понятно, а этим господам непонятно: Andrej Karpathy, Tim Salimans, Jonathan Ho, Peter Chen, Ilya Sutskever, John Schulman, Greg Brockman & Szymon Sidor.
А они прям «боги» какие-то?) Они тоже иногда «фигню» делают и пишут, также как и совершают ошибки — это нормально >> при этом они сами пишут что может иногда рассм-ся как альтернатива и также подразумевают про более простые задачи
Для вложения накоплений Вы обратитесь за консультацией к домохозяйке? Она ведь управляет бюджетом собственной семьи, а банкиры не «боги» какие-то?
Я нет. И хоть они не боги, но к их мнению считаю разумным прислушаться.
Я нет. И хоть они не боги, но к их мнению считаю разумным прислушаться.
Спасибо за комплимент) Просто у многих достаточно поверхностное восприятие, тем более если апеллировать каким-то абстрактным «мнением» — это все немного раздутый пузырь. Вы посмотрите на код кот-ый они пишут, тот же Schulman, Karpathy, Zaremba — уровени их восприятия вам тоже может что-то уже показать, поэтому да — они несомненно крутые товарищи аля банкиры-vs-домохозяйки. Но вторые как раз это те, кто не понимает всей глубины и таких несомненно почти весь крутящийся шар.
Спасибо за комплимент
Подозреваю, что Вы перенесли мое сравнение на себя. Не стоит, мне просто нужно было привести сравнение, которое раскроет мысль о том, что Ваша реплика о богах, хоть и справедлива, но не рациональна, т.к. статистически их мнение кое-чего значит. Да, и в смысле этого разделения на банкиры-домохозяйки, я с Вами в одной категории :).
Чтобы дискуссия не была поверхностной, предлагаю простой эксперимент. Запустим скрипт оптимизации, приведенный в статье, для разный уровней сложностей.
Уровень сложности задачи определяется только размерностью вектора параметров w. Вот табличка достигнутой погрешности решения и затраченного числа итераций для разного уровня сложности:
По-моему совсем неплохой результат для задачи, которая в принципе никак не ограничена дифференцируемостью функции, числом шагов эмуляции эпизода и т.п. Никаких оптимизаций в коде не проводилось, очевидно что нужно постепенно снижать скорость обучения и т.п.
График обучения при сложности 30:
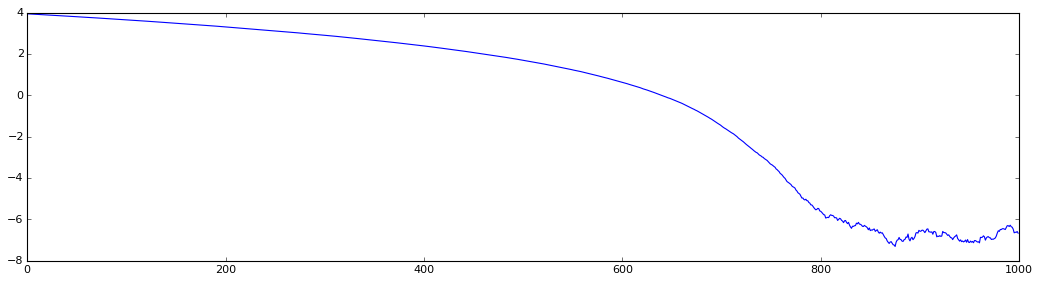
График обучения при сложности 300:
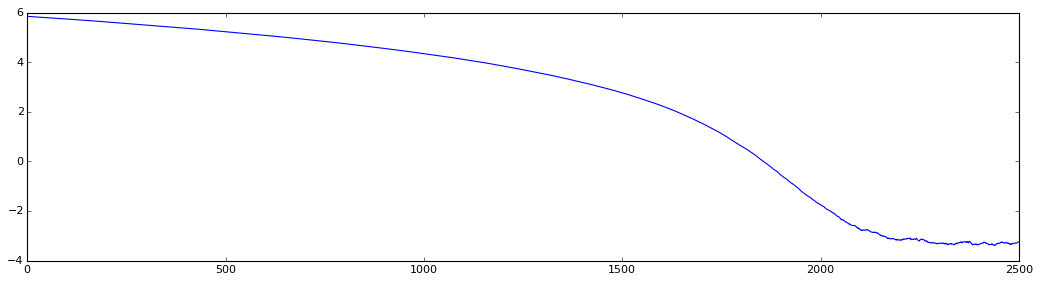
График обучения при сложности 3000:
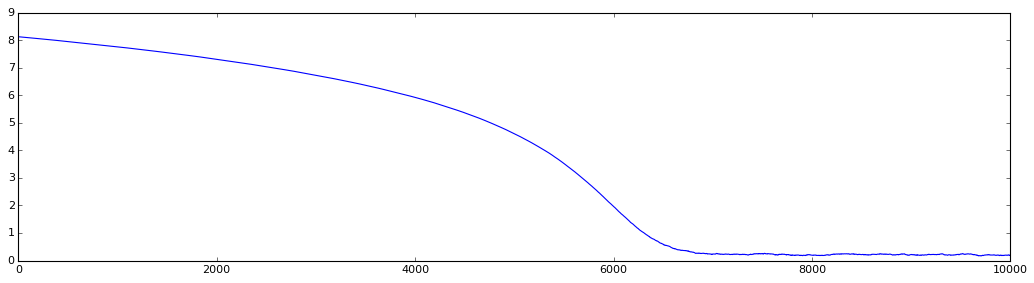
График обучения при сложности 30000:
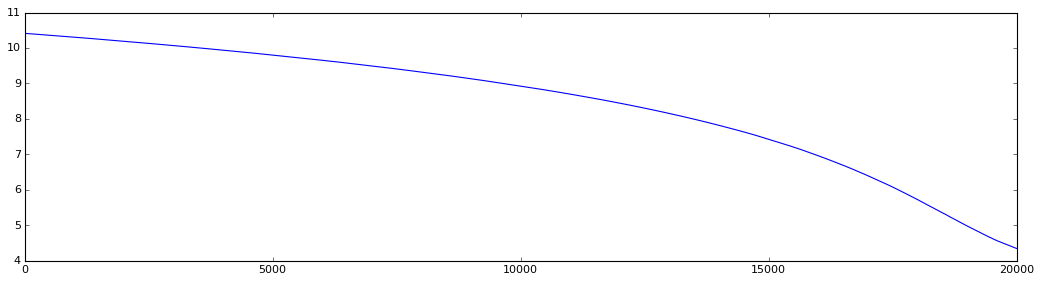
Модифицированный код
import numpy as np
from matplotlib import pyplot as plt
def f(w): return -np.sum((w - solution)**2)
npop = 50 # population size
sigma = 0.1 # noise standard deviation
alpha = 0.001 # learning rate
N = 1000 # iterations number
SIZE = 10 # task size (times 3)
w = np.random.randn(SIZE *3) # initial guess
solution = np.array([0.5, 0.1, -0.3] * SIZE).flatten()
graph = np.zeros(N)
for i in range(N):
N = np.random.randn(npop, SIZE * 3)
R = np.zeros(npop)
for j in range(npop):
w_try = w + sigma*N[j]
R[j] = f(w_try)
A = (R - np.mean(R)) / np.std(R)
w = w + alpha/(npop*sigma) * np.dot(N.T, A)
graph[i]= f(w)
plt.figure()
plt.plot(np.log(-graph))
plt.show()
Уровень сложности задачи определяется только размерностью вектора параметров w. Вот табличка достигнутой погрешности решения и затраченного числа итераций для разного уровня сложности:
Размерность w Число итераций Погрешность (f(w))
3 250 10E-12
30 1000 10E-7
300 2500 10E-3
3000 7000 10E0
30000 >20000 Не доучилась за полчаса, см. график
По-моему совсем неплохой результат для задачи, которая в принципе никак не ограничена дифференцируемостью функции, числом шагов эмуляции эпизода и т.п. Никаких оптимизаций в коде не проводилось, очевидно что нужно постепенно снижать скорость обучения и т.п.
График обучения при сложности 30:

График обучения при сложности 300:

График обучения при сложности 3000:

График обучения при сложности 30000:

Уровень сложности задачи определяется только размерностью вектора параметров w— это неплохое заблуждение, даже для тех же игр Атари. Даже статья написана так, что кажется что это действительно так)
Вот попалась страничка с анонсом релиза (!) пяти статей на эту тему от Убера: eng.uber.com/deep-neuroevolution
Sign up to leave a comment.
Эволюционные стратегии как масштабируемая альтернатива обучению с подкреплением