Comments 47
Где можно получить такие знания или это все только опытным путем?
Знания об устройстве RAID массивов формируются на основе анализа распределения данных RAID контроллерами. Какой-либо ценной литературы, где подробно изложено устройство массивов и нюансы метаданных RAID контроллеров мне не встречалось. Только исследовательский путь в познании нюансов работы конкретных RAID контроллеров.
В новостях писали, что крупнейшие компании по восстановлению данных (вроде Seagate и Ontrack) получали документацию по контроллерам SSD от производителей, наверняка и по RAID-контроллерам у них есть все спецификации под NDA.
А не могли бы Вы указать адрес подобной новости?
В случае классических RAID информация о контроллере дает не так уже и много. В лучшем случае вы найдете метаданные на дисках и по ним узнаете конфигурацию. Однако есть еще очень много других проблем:
— умирающие HDD
— неактуальные участники (относительно «живые» диски, которые были давно исключены из массива)
— всякие попытки «самолечения» из-за которых образуется каша в данных
— умирающие HDD
— неактуальные участники (относительно «живые» диски, которые были давно исключены из массива)
— всякие попытки «самолечения» из-за которых образуется каша в данных
Спасибо за статью! Жаль, что не упомянули. Было бы очень интересно узнать чем пользуются для восстановления данных с RAID (ПО и программно-аппаратные комплексы).
Материал в заметка подан так, чтобы не привязываться к конкретным ПАК. Описана сама методика.
Насчет комплексов, то сегодня на мой взгляд на рынке стран СНГ два ценных продукта:
1. Raid Explorer от Soft-Center (но без понимания устройства файловых систем может показаться совсем бесполезным)
2. DataExtractor RAID Edition от НПП АСЕ (Привязывается либо к PC3000Express, либо к PC3000SAS)
В каждом из инструментов есть намеки на автоматизацию, но сработают они, как правило лишь в случае массивов без серьезных проблем. Для качественного выполнения работ все равно будут требоваться знания основ и понимание устройства того или иного RAID массива.
Насчет комплексов, то сегодня на мой взгляд на рынке стран СНГ два ценных продукта:
1. Raid Explorer от Soft-Center (но без понимания устройства файловых систем может показаться совсем бесполезным)
2. DataExtractor RAID Edition от НПП АСЕ (Привязывается либо к PC3000Express, либо к PC3000SAS)
В каждом из инструментов есть намеки на автоматизацию, но сработают они, как правило лишь в случае массивов без серьезных проблем. Для качественного выполнения работ все равно будут требоваться знания основ и понимание устройства того или иного RAID массива.
На скриншотах WinHex — удобен для анализа сложных повреждений. Позволял собирать относительно сложные массивы до появления других продуктов с зачатками автоматизации. Иллюстрации к кейсам по RAID я, например, тоже люблю делать в Excel.
Пример иллюстрации из кейса "Восстановление RAID6 после выпадения 5 дисков подряд":
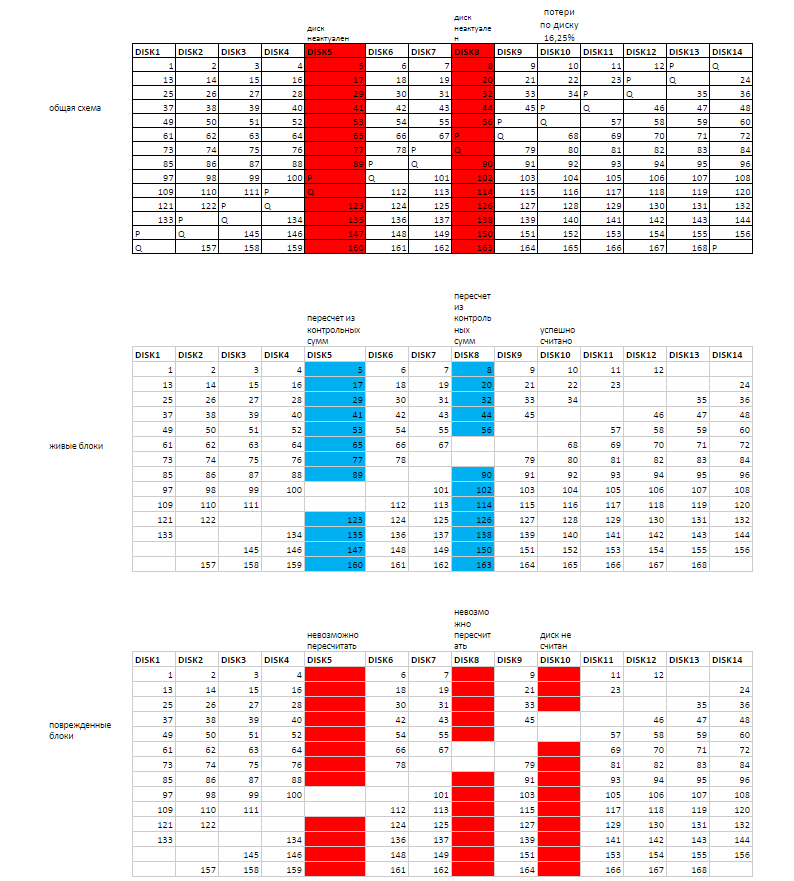
Пример иллюстрации из кейса "Восстановление RAID6 после выпадения 5 дисков подряд":

На скриншотах WinHex — удобен для анализа сложных повреждений.
все же на этапе анализа я отдаю предпочтение ручному режиму в Raid Explorer от Soft-Center. Очень быстро можно заглядывать в одни и те же места по разным дискам и удобные горячие клавиши для пролистывания окна редактора с нужным шагом. Winhex в этой заметке использовался для наглядности, чтоб не вызывать вопросов у читателей по поводу hex редактора.
Я ранее себе на сайт материал по сбору RAID 6 выкладывал много лет назад, но в виде обычного примера, без рассмотрения практического случая.И уже не показывал сырец из Excel как здесь.
Я так давно начал пользоваться винхексом, что все остальные утилиты для анализа не рассматриваю даже. Каждый любит тот инструмент, к которому привык и все они чем-то хороши.
А вот для финальной сборки чего-то действительного сложного в последнее время предпочитаю data extractor raid edition. Их скилл разработки явно выше и мой самописный дестрайпер (написан в середине 2000-х, когда не было софта для сборки не только для hp delay, но даже для forward dynamic) давно пылится без дела.
На сколько я знаю, еще полтора года назад (осень 2015-го) raid explorer не умел пересчитывать второй missing диск в raid6. А о поддержке разных полиномов для второй контрольной суммы RAID6, думаю, речи нет и сейчас.
Или есть?
Очень круто сделаны иллюстрации! Так логично сделать их таблицами! Респект!
А вот для финальной сборки чего-то действительного сложного в последнее время предпочитаю data extractor raid edition. Их скилл разработки явно выше и мой самописный дестрайпер (написан в середине 2000-х, когда не было софта для сборки не только для hp delay, но даже для forward dynamic) давно пылится без дела.
На сколько я знаю, еще полтора года назад (осень 2015-го) raid explorer не умел пересчитывать второй missing диск в raid6. А о поддержке разных полиномов для второй контрольной суммы RAID6, думаю, речи нет и сейчас.
Или есть?
Я ранее себе на сайт материал по сбору RAID 6 выкладывал много лет назад, но в виде обычного примера, без рассмотрения практического случая.И уже не показывал сырец из Excel как здесь.
Очень круто сделаны иллюстрации! Так логично сделать их таблицами! Респект!
На сколько я знаю, еще полтора года назад (осень 2015-го) raid explorer не умел пересчитывать второй missing диск в raid6. А о поддержке разных полиномов для второй контрольной суммы RAID6, думаю, речи нет и сейчас.
Или есть?
К сожалению Raid Explorer для RAID 6 только и умеет пересчитывать XOR и по сию пору нет поддержки VMFS. Для финальных сборов не самых простых массивов тоже использую PC3000SAS&DE Raid Edition.
Спасибо. Было очень интересно.
Читаешь вот это всё и думаешь: это какой же багаж знаний по теме у автора!
А что в домашних условиях? Недавно пришлось спасать семейный архив с диска, который не хотел нормально работать. Несколько секторов не прочиталось, и хотя все файлы успешно перенеслись с образа на новый жиск, непонятно, как определить их целостность. Как в таких случаях "дешево и сердито" защититься от сбоя накопителя?
Хранить резервную копию и считать md5/sha-1 хэши файлов. Периодически проверять. Для дома — лучше не используйте уровни raid, кроме простого зеркала. Помните, что raid не заменяет резервную копию. Можно использовать какой-либо контроллер с raid и поддержкой ecc памяти, который сам делает периодическую проверку данных.
Какие бы вы меры защиты не придумывали, как бы бережно не относились к накопителю, но потерять данные можно в одно мгновение. Нет более дешевого и сердитого метода защитить себя от потери данных, чем заниматься резервным копированием. И чем больше копий дорогих Вам данных на разных и не зависимых друг от друга накопителях, тем ниже вероятность потери.
По вопросу проверки целостности: в процессе копирования желательно было использовать ПО, которое умеет заполнять непрочитанные сектора в копии произвольным паттерном (по желанию оператора). Далее стояла бы задача воспользоваться поиском и найти файлы содержащие внутри себя паттерн.
P.S. пытаясь копировать HDD с дефектами в домашних условиях помните, что Вы сильно рискуете усугубить проблему вплоть до невозможности восстановления данных. Современные накопители весьма склонны к запиливанию, в связи с чем методика линейного чтения неуместна.
По вопросу проверки целостности: в процессе копирования желательно было использовать ПО, которое умеет заполнять непрочитанные сектора в копии произвольным паттерном (по желанию оператора). Далее стояла бы задача воспользоваться поиском и найти файлы содержащие внутри себя паттерн.
P.S. пытаясь копировать HDD с дефектами в домашних условиях помните, что Вы сильно рискуете усугубить проблему вплоть до невозможности восстановления данных. Современные накопители весьма склонны к запиливанию, в связи с чем методика линейного чтения неуместна.
UFO just landed and posted this here
К сожалению во многих организациях администрированием заняты либо ленивые и безответственные, либо не обладающие должной квалификацией кадры. В итоге организации несут убытки в результате действий или бездействия своих же работников.
UFO just landed and posted this here
UFO just landed and posted this here
UFO just landed and posted this here
Если рассматривать только такое событие, как выход диска из строя, то выше вероятность потерять данные на одиночном диске, чем например на двух дисках организованных средствами ОС в RAID 1 (зеркало). Но как показывает практика рассматривать нужно куда большее число потенциально возможных событий.
UFO just landed and posted this here
Как, у тебя ошибки црц из за кабеля? Срочно развалить рейд!
описан случай с SAS накопителями, в сервере в корзине. Дефекты поверхности не из-за кабеля. RAID остановлен, так как не хватило избыточности данных для продолжения работы. Аварийное отключение дисков или отвал кабеля не приводит к массовому образования дефектов.
Однажды утром биос фирмы говнобайд сказал мне 'какой такой рейд, не знаю ничего'. С зеркал удалось что-то собрать, а вот чередующиеся разделы утерялись
так с зеркал без проблем можно было получить 100% результат. По поводу чередующихся разделов тоже нет больших сложностей. Но создавая чередующийся раздел без избыточности сами должны понимать, что это в угоду скорости, а не надежности.
UFO just landed and posted this here
UFO just landed and posted this here
Скорость интернета многим не позволит комфортно работать с облачными хранилищами. Также всплывает вопрос стоимости хранилищ большого объема и вопрос конфиденциальности. Не каждый человек хочет, чтобы его информация подвергалась анализу.
Вспомнить относительно недавний случай с dropbox. Подобные случаи очень наглядно демонстрируют, что не все гладко с исполнением договорных обязательств со стороны облачных сервисов.
Вспомнить относительно недавний случай с dropbox. Подобные случаи очень наглядно демонстрируют, что не все гладко с исполнением договорных обязательств со стороны облачных сервисов.
SSD всё ещё слишком дорогие. Облачные хранилища — тоже не бесплатны. Плюс интернет нужен неслабый. Так что не надо быть столь категоричным. Зеркало на встроенном в мать чипсете из больших дешёвых HDD — вполне себе нормальное решение для дома, которое спасёт данные при умирании одного из дисков.
всегда для восстановления пользовался R-studio.
Но и из проблем были единичные диски с незначительными повреждениями.
В подобном случае как в статье, R studio могла бы помочь?
Но и из проблем были единичные диски с незначительными повреждениями.
В подобном случае как в статье, R studio могла бы помочь?
В подобном случае как в статье, R studio могла бы помочь?
в автоматическом режиме нет. Если проводить все анализы в hex редакторе, как описано в заметке, то можно собрать два отдельных RAID 5, потом из двух собранных RAID5 собрать RAID 0. Но потребуется несколько пересборов, чтобы исключить диск с неактуальными данными. И насколько мне помнится в R-Studio не декларировалась поддержка VMFS. Потребуются дополнительные средства для разбора VMFS.
Также потребовались бы средства для вычитывания проблемных дисков в файлы образы. Исходя из их состояния вряд ли бы R-Studio продемонстрировала бы максимально возможный результат вычитывания проблемных зон.
Данный RAID 50 представляет из себя комбинированный массив, который рассматриваем как два массива RAID 5, объединенных в массив RAID 0.
По описанию звучит как попытка самоубиства
По описанию звучит как попытка самоубиства
Описание на самом деле не более страшное, чем в случае обычного RAID 5. Отмечены достоинства в сравнении с обычным RAID 5 для подобного количества дисков. Страшным данный массив может показаться в случае отказа, так как автоматического решения посредством программ автоматического восстановления не будет. Но если системный администратор знает устройство массива или делает своевременно резервные копии, то бояться совершенно нечего.
RAID50 — это легитимный уровень RAID как и другие составные уровни RAID(wiki Nested RAID levels). Попытка самоубийства (с элементами экономии и садомазо) это:
Ссылка на полное описание кейса.
- собрать из 8 разношерстных дисков 4 штуки RAID1 средствами контроллера Adaptec
- на каждом RAID1 создать VMFS datastore
- на них создать 1 виртуальную машину и к ней 4 flat vmdk диска
- в машину установить Windows Server, в котором из подключенных 4 дисков сделать один LDM том, на котором и хранить данные
Ссылка на полное описание кейса.
Человек не знал про экстенты в VMFS и/или древняя версия ESXi, не умеющая диски больше 2 ТБ?
Это уже не попытка вовсе, а самое настоящее преднамеренное сомоубиство.
Рэйд 0 тоже Легитимный и корерктный уровень рейда, только это сосвсем не означает что запихнуть в него 12 дисков и не бекапиться — норма.
Рэйд 0 тоже Легитимный и корерктный уровень рейда, только это сосвсем не означает что запихнуть в него 12 дисков и не бекапиться — норма.
Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков.Интересно, что должно было произойти с массивом, чтобы у него перестали читаться четыре диска из десяти в одной и той-же области?
Интересно что за диски и откуда одинаковые повреждения? Физические повреждения на диске между LBA 424 000 000 и LBA 425 000 000 или нет?
Всегда много проблем с восстановлением рэйдов, а статья хороша.
Определив положение fdc.sf (file descriptor system file), проведем анализ его содержимого. Во многих случаях анализ этой структуры позволит найти место, где присутствуют ошибочные записи.
Непонятно. Если диск выпал из массива незадолго перед крушением, то как определить какой именно, если метаданные в конце диска стёрты клиентом?
В обоих случаях в этом файле будет служетная информация, несильно отличающаяся.
Есть какой-то более общий алгоритм для определения выпавшего диска, чтобы потом исключить его из сборки?
Непонятно. Если диск выпал из массива незадолго перед крушением, то как определить какой именно, если метаданные в конце диска стёрты клиентом?
анализ метаданных файловых систем позволяет установить набор актуальных дисков в 99% случаев. Если расхождение между отвалами дисков совсем малозначимое, то необходимо анализировать содержимое последних файлов.
С помощью профессиональных инструментов, таких как Raid Explorer или PC3000Dataextractor RAID edition можно собирать разные варианты массива виртуально (поочередно исключая разные диски и каждый раз вести комплекс анализов). В случае серьезных расхождений данных не особо сложно определить неактуальный диск даже в обычном HEX редакторе.
Разумеется для этого необходимо знать устройство файловых систем и устройство различных типов файлов.
В случае VMFS при малой разнице по времени исключения дисков из массива можно и не определить тот, который нужно исключить при анализе метаданных VMFS. В таком случае необходимо анализировать файловые системы и данные в виртуальных машинах.
Sign up to leave a comment.
Восстановление данных из поврежденного массива RAID 50