Comments 83
В последнем моём проекте попробовал GreenDAO и меня ждало разочарование. Переписал всё вручную в итоге. Возможно, есть и более удачные фреймворки
А что не устроило? Потому что как раз думал мигрировать с ormlite на greendao на одном legacy-проекте.
Самое основное — это скорость. В Ormlite вовсю используется рефлексия, что на андроиде довольно дорого. Ну и не развивается уже давно. Это расстраивает.
По поводу кодогенерации: если у вас есть какой-нибудь объект, который вы хотите записать в базу, то после добавления аннотаций GreenDAO модифицирует класс добавляя ненужные геттеры/сеттеры. Об иммутабельности класса можно забыть.
Далее, поле id должно быть обязательно объявлено @Nullable для того, чтобы GreenDAO смог обновить его после вставки в базу, т.е. о примитивных типах можно забыть.
Я уже мигрировал. И что могу сказать — да, greendao не идеален. Модификации прямо моих классов, конечно, раздражают, как и непримитивный Long для ID. Но он дал приложению прирост производительности основных запросов в 2(sic!) раза. Так что с парой ограничений и косяков можно смириться. А насчёт иммутабельности… Тема, конечно, забавная, но для модели с 40 полями если на каждую модификацию новый объект делать, GC обидится. Иммутабельность для тех, кто пишет очередную читалку новостей и пьет смузи :) Ну, или предпочитает красоту и "правильность" кода пользовательскому опыту.
Испльзовать ORM-фреймворк — отличная методология создания свой БД.
Сначала пишешь при коннекте «DBI:itsmysql:database=test;host=localhost» — устраняешь все ошибки, затем другие и другие ошибки.
Между «я не знаю» и «этого нет» на самом деле очень большая разница. Этой теме уже лет 20, как минимум, и книг написано полно. Вы где-то не там ищете видимо.
Я знаю примерно один существенный фактор, который реально влияет именно на проектирование, когда мы говорим про Андроид — что у вас обычно очень мало ресурсов. И в общем-то довольно узкий выбор самих СУБД.
Сам подход создания таким образом БД очень не удобный. Причем ладно я, Я зарабатываю на хлеб программированием на PL/SQL и я знаю инструменты для работы с БД и как они работают. Я могу найти способы как использовать уже имеющиеся знания для помощи при написания приложения (правильный или не правильный у меня подход это другой разговор). Собственно говоря, этой теме как раз и посвященна моя статья.
А вот новичку в программировании вынос мозга при проектировании своего приложения (при внедрения sql кода в java код), которое использует БД, гарантирован (это мое имхо).
То есть эта статья, не что иное как выработка подхода проектирования БД и внедрения его в приложение, которое будет работать на устройстве.
И не просто прочитать, а попрактиковаться, а иначе будет как у меня в одном проекте, когда новые «работники», придя в проект, начали заявлять «а у вас тут база данных ненормализованная».
Тему «куда деть SQL при разработке на Java» тоже можно долго обсуждать, она тоже необъятная, и от нее можно будет прийти как к ORM, так и к инструментам типа JOOQ, QueryDSL и прочим, но тоже не сразу, и предварительно понимая некоторые другие базовые вещи — например, как сопровождать приложение, и какого рода изменения в SQL-запросах в нем возможны. И это все равно тема далеко не для одной книги.
Да согласен, но есть одно но. Книги по программированию под Android в отличие от книг БД по сути проводят читателя по всей технологической цепочке создания ПО: от простого Hello world и до публикации в маркете. Моя статья не о том как правильно программировать, ниже мне вполне справедливо накидали замечаний по коду, моя статья скорей о том с помощью каких инструментов и как следствие подходов к написанию самого кода можно себе немного облегчить жизнь.
Просто тема внедрения SQL в java (а на самом деле и не в java вовсе — в большинстве других языков есть все теже самые проблемы, решаемые примерно также, плюс-минус особенности языка) — она не имеет одного наилучшего решения.
Что до вашего конкретного примера — то я бы посмотрел наверное на liquibase. Не буквально, и не прямо в том виде, в каком его обычно используют в проектах (не на Андроид), а скорее на заложенные в нем идеи, в том числе — возможность написания java-миграций. Тем более он open source, можно и в код заглянуть.
Может, что-то прояснится или наоборот, уже знакомо.
 "
" 2) Что касается миграции с версии 3 на версию 6 — это хороший вопрос… пока не готов на него ответить. Спасибо что подняли его, буду думать :)
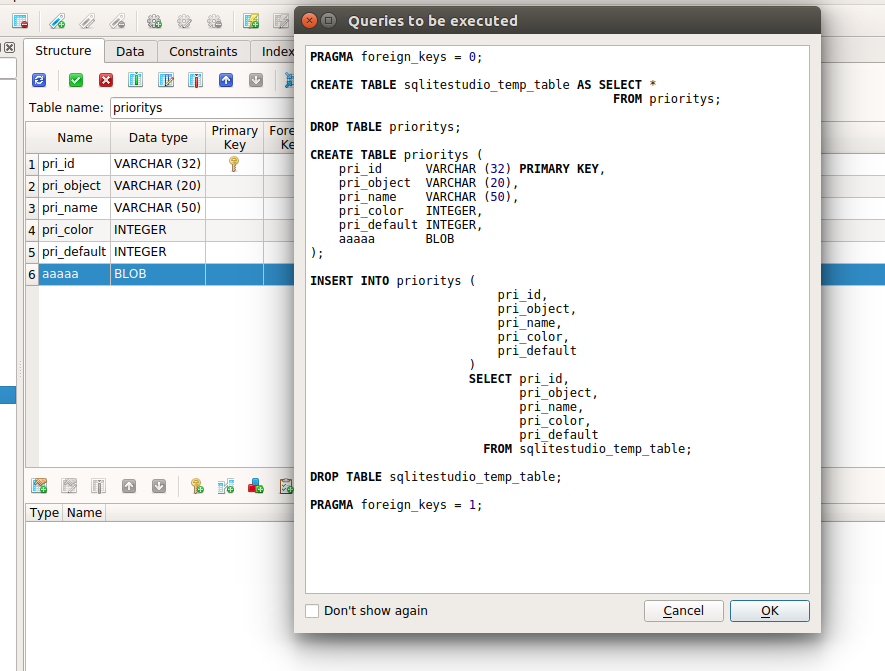
ALTER TABLE xxx add column aaaaa BLOB;
Представь, что размер таблицы 5гб а места на диске всего свободно 3…
а если есть индексы/триггера — студия их восстанавливает?
по-моему скрипты миграции нужно писать руками и обрабатывать все исключительные ситуации
иначе есть риск, что ваше приложение у конечного пользователя сломается.
для этого в sqlite придумана PRAGMA user_version
по нему можно ветвится в коде миграции и делать нужные модификации базы в онлайне.
ну и во вторых если вам надо добавить колонку в конец таблицы то да, Ваш вариант правильней. Если же Вам надо добавить колонку внутри других колонок то такой вариант уже не прокатит.
менять позиции колонок — бомба замедленного действия.
могут сломаться клиенты где «зашито» что-то вроде select * from…
из полезного я помню только один случай реорганизации:
в oracle если колонки не заполнены(null) и находятся в конце, то они не занимают место в блоке.
т.е. разместив редко заполняемые поля в конец — можно сэкономить на диске.
менять позиции колонок — бомба замедленного действия.работать с индексами а не с именами — бомба замедленного действия.
По идее, если надо мигрировать через несколько версий, поочередно будут происходить миграции 3->4->5->6
Да, это очевидно. Я для своих проектов использую подобное. Но с недавних пор начал задумываться над подобным стилем, что привел автор: хелпер + скрипты в ассетах. Вот и стало интересно как он это делает. В моем подходе я использую массив миграций, соответственно если если первая версия базы имеет номер 1, но ее можно привести к индексу массива: версия — 1, соответственно для миграции с n на m надо взять срез n...m-1. В подходе автора не совсем очевидно как это взять. А так было бы полезно адаптировать под свои нужды.
ArrayList<HashMap<String, ContentValues>> data = new ArrayList<>();
Вообще принято писать как-то так:
List<Map<String, ContentValues>> data = new ArrayList<>();
А начать можно с того, что ваш кусок кода можно просто и логично разбить минимум на два метода — один из которых будет работать с одним файлом.
Читал по диагонали… но имхо, для любителей SQL есть square/sqldelight, который при всех его недостатках предоставляет больше удобства чем велосипед в статье.
>Моя же статья больше предназначена для начинающих, как им облегчить жизнь…
Я пока увидел только как усложнить жизнь начинающему разработчику по сравнению с обычным опен хелпером при сомнительных преимуществах. По моему опыту с начинающими программистами, любой ОРМ без скл им облегчает жизнь гораздо больше ибо нынче начинающий разработчик под андроид вообще не знает скл)) ну а для ценителей есть упомянутая мной либа, которая на этом скл и базируется.
Oracle SQL Developer Modeler
может Oracle SQL Developer Data Modeler?
Есть стандартный способ работы с бд, который все знают, а с вашим придется разбираться.
Ну, и, как заметили, если очень хочется, лучше использовать orm.
Также можно использовать такое ПО как Dia для визуализации связей БД.
Для себя сделал вывод.
На этапе проектирования структуры базы данных действительно очень полезно использовать графические инструменты, какие угодно. Даже тот же MS ACess неплохо может справиться.
Но создавать объекты в БД лучше ручками, написав запросы.
Все это авто создание объектов — после него дольше править.
Если БД простая то достаточно SQLiteOpenHelper'а, можно спроектировать всё в голове и написать класс — слой доступа к ней что бы уж где-то дальше не встречались sql-запросы.
А если табличек становиться уже много и так просто не разобраться то можно спроектировать, протестировать, наполнить данными базу где-нибудь во внешнем инструменте. Я отыскал для себя SQLite Expert Professional, в ней можно как и мышкой / мастером создавать таблички / запросы так и поработать с ними потом чистыми sql-запросами. Но эта софтина платная.

А затем что бы не переносить скрипты создания и заполнения БД можно положить наш готовый файл БД db2.sqlite в assets/databases и подцепить его SQLiteAssetHelper'ом
public class DatabaseOpenHelper extends SQLiteAssetHelper{
private static final String DATABASE_NAME = "DB2.sqlite";
private static final int DATABASE_VERSION = 1;
public DatabaseOpenHelper(Context context) {
super(context, DATABASE_NAME, null, DATABASE_VERSION);
}
}
Если же структура и содержимое БД меняются только при обновлении версии приложения, то вообще никаких проблем нет.
Про изменение не понял. У Вас обновилась программа. Необходимо изменить структуру таблиц но при этом не потерять там данные.
Если нет, то и с обновлением нет проблем — БД лежит в assets-ах и обновляется вместе приложением. Миграцию поддерживать нет необходимости.
Почему в книгах и в статьях, посвященных программированию под Android, не описываются инструменты для проектирования архитектуры базы данных и какие-нибудь паттерны для работы с базами данных на этапе их создания я честно говоря не знаю
Чаще всего потому, что вычислительная мощность мобильных девайсов сильно уступает мощности компьютеров, потому, смысла в проектировании сложной БД особо не возникает, посколько это может оказать негативный эффект на перформанс.
… хотя нужно уточнить длину строк и скрин
Пока ехал домой с работы, осознал какой не тривиальный должен быть интерфейс программы в которой в БД лежит 20 таблиц, даже без отношений many_to_many…
Как я создаю базу данных для своих приложений