Comments 1044
Колян, 40 лет.
Ну не у всех. Я еще живчик, без всяких там. А ребята типо автора вызывают только жалость. Пить нужно меньше, спортом заниматься, и в 80 мозги будут в порядке.
Луркмоар
Луркнуар :)
… и осознание — только скорость восприятия держит вас в реальности
это только ваш личный выбор — да, я «википедия», пусть меня читают… или еще нет ;)))
Нытье 40 летнего программиста — 2017-40=1977 года рождения
+ 18 лет = 1995 год начала работы по профессии — по сути первая массовая волна как раз тех, кто занимался этим «с рождения».
2017-1995 ~= 20 лет, аккурат тот срок когда можно начинать ныть о «старых добрых временах» (при дельте в 10-15 лет как-то это еще не так звучит).
Чем дальше — тем больше будет таких статей и тем больше будет упоминаемый возраст.
В 2037 вангуем статью «Куда деваются программисты после 60».
При чем занудство сие постигло не только программистов, достаточно посмотреть аналогичные посты в контактике типа «лайкни если ты помнишь» и дальше какая-нибудь жевачка, которую почти никто не жевал, но вкладыши от которой были местной валютой:)
А вообще программист как таковой это типичная профессия со стеклянным потолком. Проблема стеклянного потолка умноженная на устаревание технологий не только в том что рано или поздно некуда больше расти, а еще в и в том, что опыт больше 5 лет по сути не имеет значения в большинстве случаев, поэтому эффект «не успел разогнаться тебя уже догнали» очень силен. А смена профы на менеджера или управленца это именно смена профы.
Смена профессии на менеджера тоже не серебрянная пуля — в связи с более низкой ликвидностью среднего сферического менеджера относительно разработчика такой же геометрии.
Гы. И кудаж мне теперь деваться? Я начал программировать в 1975, а деньги зарабатывать в 1978. В это время все студенты у нас к диплому изучали пару языков, если было на то желание, Алгол-60 давали на первом курсе, а Фортран приходилось учить самостоятельно, так как появилась потребность. И это не программисты, а инженеры-механики, между прочим.
Это я насчет «массы», если что.
А с остальным совершенно согласен — причем опыт больше 5 лет не просто не имеет значения — его еще и практически невозможно подтвердить, и если угодно, монетизировать — потому что управленцы, в большинстве своем, не в состоянии оценить этот самый уровень.
А по поводу «массы» все же. Массовой профессией программист стал когда на рынок массово пришли персональные компьютеры, это все же никак не 1975, даже на западе это ближе к 1985 году, а в ссср/россии ближе к 1995. До этих лет профессия программисты была не массовой, скорее областью для энтузиастов любителей и узких специалистов
Это все равно как сейчас назвать массовой профессию физика-ядерщика, то что их много — неоспоримо, но массовой профессией это станет не раньше выхода 120 айфона на ядерных батарейках, который будет жить аж 3 дня без дозарядки и на каждом углу будет киоск с починкой оных.
на самом деле вопрос кодирования и возраста имеет еще измерение — уровень достижений и желание самого процесса
вы можете хотеть кодировать — но социальный статус уже требует другого и не оставляет времени
вы можете не хотеть кодировать… (социальный статус тогда по фиг в общем то)
вы можете хотеть (и быть в состоянии) и социальный статус позволяет! (бинго! ну или может быть ;)… просто я в этой группе )))
в частности з/п как раз одно из измерений социального статуса ))
кратко, примеры с/с — наемный сотрудник, предприниматель, пенсионер, наследник о;;%?;«го состояния (то есть все на халяву),
… а «за деньги» или «по любви» это уже второстепенные детали ;)))))
ps — предупреждая инсинуации — кодирую я не «вместо»! одно другому не мешает" ;)))))))))))))
Если социальный статус не оставляет времени на то, что хочется, то зачем он тогда нужен?
А какое это имеет отношение к социальному статусу?
Очень странная аналогия. Социальный статус — ярлык, который на тебя навешивают некоторые окружающие и соответственно ему относятся к тебе. Причём тут ПДД, которые требуют от тебя что-то?
ps… чет я не понял вложенность и отступ?
в каких то пределах можно пренебрегать условностями, одними с малым риском, другими с большим…
и можно даже бравировать этим…
ПДД, УК, ГК — это не условности, это чётко оформленные правила поведения в обществе.
А социальный статус — это уже негласные правила.
уголовные понятия — гласные или не гласные правила? они приняты в обществе?
… однако реальны ситуации смертельной опасности при их нарушении
и кстати уж точно социальный статус не является «не гласным» правилом
конституции под текущего правителя переписываются сплошь и рядом
не редко вообще меняют социальное устройство, в том числе как вооруженным путем, так и без применения силы (ну или иногда лишь угрожая таковой…
социум штука на много более иллюзорная, чем может показаться на первый взгляд
Что значит "пренебрегать социальным статусом"? Вот допустим мой социальный статус "люмпен", как я могу им пренебрегать или не пренебрегать?
так что тут аналогия вполне себе…
автомобиль может сбить, но и ФНС может однажды «наехать» более чем бумажно… и снова аналогия вполне себе возможна
хотя цена нарушения может быть различной, суть от этого не меняется
пока ты «один в поле
однако когда захочется влиться в команду, скорее всего придется следовать набору правил (ты прикинь — любые правила всего лишь «соглашения») иначе возможно команде придется сказать тебе «давайдосвидания»
я даже вспомнил анекдот:
День рождения Наташи Ростовой. Наташа пригласила на праздник поручика Ржевского и всех гусаров полка.
Поручик следит за моральным обликом гусар – чтобы чего не ляпнули.
За столом Наташа пытается завести светскую беседу:
— Вы знаете, я купила 17 свечек для праздничного торта, а на него влезло только 16. Ума не приложу, куда всунуть еще одну?..
Из-за стола встает поручик Ржевский и кричит:
— ГУСАРЫ МОЛЧАТЬ!
социальный статус — это ярлык, который вам навесят социологи при очередном исследовании/обзоре/переписи… а опера — при описи или в протоколе… и так далее
а еще это то что вы сами напишите в разного рода анкетах, когда идете на поклон к государству…
Термин "самоирония" вам не знаком?
Боюсь, что социологи затруднятся однозначно определить мой социальный статус, если выдать им всю информацию. А что пишу для государства зависит от цели обращения к государству, где-то лучше наемный работник, где-то иностранный предприниматель, где-то рантье, где-то безработный (увольнялся пару раз, чтобы государство потроллить — забавно смотрится безработный бомж с недвижимостью по всей стране и доходом на порядок большим средней зарплаты :), правда налоговая юмора не оценила, пришлось предоставлять первичные документы )
Так можно же показывать им эти семь шагов вперед. Если это делать с целью действительно показать, с конструктивными намерениями, без желания покрасоваться, они примут это и скажут спасибо.
Плохим разработчикам что-либо рассказывать попросту бесполезно, а хорошие склонны мерить всё по себе.
Один пример: в одном из компонентов у нас был реализован «белый список» системных вызовов, которые этот компонент имел право совершать. Ну и комментарий типа «если нужно что-то то ещё — пишите, мы список расширим!»).
Как вы думаете сколько подобных запросов мы получили за пять лет? Предположение «нуль» всё же неверно — один запрос был. От нашей же команды. Зато какие «чудеса героизма» были обнаружены в компонентах, созданных партнёрами, которые были совершены для того, чтобы не писать письмо!
И вот тут — можно говорить что угодно, но «хотьба по граблям» всё-таки продолжится. Просто потому что даже умным людям, но без опыта, сложно представить насколько по-разному могут быть устроены компьютерные компании. И никакие «конструктивные намерения» вам не помогут, так как вы предлагаете тратить ресурсы на решение проблем, которых, с точки зрения «молодежи» нет и быть не может!
Вы сделали ограничения?

А вам лучше такие вещи вынести в конфигурациионный файл.
мне 36, в IT я с 18 лет. на собственном опыте отлично знаю, к чему может привести плохо продуманное решение. но попробуй докажи.
Вы не задумывались, что проблема может быть в способах, которыми вы высказываете своё мнение?
По опыту, «опять ты со своим брюзжанием, видишь одно только говно» — обычно ответ на условное «всё говно, архитектура говно, код плохой, всё будет только хуже» и в таком духе далее. И никакой другой реакции ожидать не приходится — посыл изначально деструктивен и вызвает желание ему сопротивляться.
Другое дело:
Колоеги, я провёл анализ результатов нашей работы по задаче А и хочу обсудить замеченные мною проблемы, а также предложить несколько решений для улучшения нашего продукта, кажущихся мне оптимальными.
На текущий момент у нас есть проблемы с архитектурой в %название_модуля%, заключающиеся в том, что %краткое_описание_проблем%. В дальнейшем, если мы продолжим развивать это решение, при разработке задачи Б, имеющейся в плане, нам придётся пойти на внедрение компромиссного решения %костыль%, что, впоследствии, в свою очередь, также увеличит трудозатраты на реализацию задачи В, в силу %список_причин%. Также возможно и %другое_решение% задачи Б, не имеющее этих недостатков, зато имеющее %другие_недостатки%. Кроме того, задача Г может оказаться и вовсе нерешаемой, так как %причины%.
Таким образом, мы можем оказаться в ситуации, когда дальнейшая разработка на основе текущего решения станет настолько трудозатратна, что выгоднее будет реализовать модуль заново. В пррцессе наверняка всплывут дополнительные проблемы, которые заранее предсказать невозможно, а так как продукт будет уже в зрелом состоянии, придётся тестировать гораздо больший объём взаимосвязанного функционала. Кроме того, на локализацию и устранение неизбежных ошибок также уйдёт труднопрогнозируемое количество времени, что повлечёт негатив от пользователей / риск срыва сроков по контракту / юридические последствия.
Исходя из вышесказнного, я предлагаю начать решать проблему сейчас, пока мы можем это сделать с меньшими трудозатратами. Хочу предложить %ряд_решений%, которые хороши тем, что %обоснование_решений%, а также дадут нам %дополнительные_возможности% и помогут избежать %ряда_проблем%. Для их реализации потребуется %время%, %человекочасы% и %иные_ресурсы%.
Возможно, я учёл не всё, а в некоторых оценках проблем ошибаюсь. Предложенные мною решения вряд ли идеальны, но, думаю, вполне подойдут в качестве стартовой точки для выработки дальнейшей стратегии. Хотелось бы услышать ваши мнения по поводу вышесказанного.
Конечно же, эта пламенная речь должна сопровождаться хотя бы парой слайдов, то есть, представлена в форме презентации. Важно внятно аргументировать свою позицию и пригласить к обсуждению. А главное — быть готовым тому, что ваша точка зрения может оказаться неверна.
Пробовали так?
А вот эти пламенные речи и презентации когда делать, в рабочее время, вместо основных задач? Или в свободное время, за свой счёт?
Это ваш выбор.
Если можете самостоятельно выделить время в рамках рабочего, без ущерба для остальных задач — замечательно (это вообще важный навык).
Не можете или опасаетесь наказания за самодеятельность — обратитесь к руководителю и согласуйте с ним.
Боитесь просить руководителя или получили отказ, но сердце болит за проект — сделайте в личное время и заставьте выслушать.
Но сначала — сформулируйте, для себя в первую очередь, какой цели вы хотите достичь с точки зрения бизнеса. К примеру, «Сейчас мы тратим по два-три дня дорогого разработчика на добавление нового отчёта, так как надо писать SQL-запросы и готовить шаблоны на PHP. Эти задачи у нас регулярны. Если мы потратим две недели на новый модуль отчётов — в дальнейшем будем делать новые отчёты за считанные часы силами дешёвого верстальщика, потому что будет знакомый верстальщику XSLT и простенький генератор запросов. Это реальная экономия денег и времени, плюс мы сможем быстрее реагировать на пожелания пользователей, а разработчики займутся реальными задачами», вместо «Наши отчёты шляпа, легаси и говнокод, давайте сделаем нормально». Редкий вменяемый руководитель наотрез откажет, видя заинтересованность работника в результате. А если и откажет — можно не смириться сразу, а выяснить причины решения, возможно, вы видите не всю картину. В конце концов, если в руководстве реально невменько — что вы делаете на такой работе?
Я повторю вопрос и вам — что вас держит на такой работе?
Если у вас есть аргументы, а у начальства нет — смысл такой работы? Быть инструментом автоматизации желаний? Чувствовать себя ничтожным? Просиживать штаны, выполняя тикет буква-в-букву?
Или просто не нравятся аргументы руководства? Или даже не пытались узнать?
Реально, я персонажей с такими настроениями повидал достаточно за пятнадцать лет в разработке. Всё плохо, руководство тупое, никто не слушает, накажут за инициативу… А чаще всего это означает завышенное самомнение, недостаток знаний и коммуникативных навыков, нерешительность и отсутствие инициативы. И, в конечном счёте — отрыв от реальности.
Можно быть гением программиррвария, но в жизни программирование должно приносить прибыль. Самая прекрасная архитектура бесполезна, если решает не те задачи, что требуются бизнесу. Для многих разработчиков профессия выросла из хобби, и удовольствие для них, по привычке, на первом месте. Но нанимают нас вовсе не для того, чтобы мы пускали радостные пузыри, полируя код, а чтобы мы эффективно решали задачи бизнеса в рамках имеющихся ограничений. И, на самом деле, это — реальный интересный вызов, а не игры в 30 строк на JavaScript.
И, замечу, эффективные социальные взаимодействия — тоже часть работы. Без понимания этих простых вроде вещей вы рискуете однажды обнаружить себя сорокалетним миддлом, изливающим душу на хабре.
Если десятичасовые объяснения не возымели эффекта, нужно выяснять, почему. Как минимум, разузнать (и понять) аргументацию отказа. Убедиться, что вы преследуете совместимые цели. В конце концов, вы либо поймёте, как правильно преподнести своё предложение, либо найдёте альтернативный вариант, всех устраивающий. Либо, в худшем случае — узнаете, что ваши старания напрасны, смысла в трате сил на попытки применить свои профессиональные качества нет, здесь уже не исправить ничего, Господь, жги.
С работы, на которой вы не востребованы, уходить вполне нормально, иначе есть риск демотивации и профессиональной стагнации, а то и личностной деградации. Это вас тоже должно волновать, а не судьба компании, которой вы не нужны. Стокгольмский синдром, ей богу.
Вася и Петя одновременно начали писать один и тот же продукт. Помните?
Умение управлять техническим долгом — приходит ещё позже, чем понимание, к чему приводит неудачная архитектура.
Но Вася выпустил уже через месяц первую версию программы, пусть и не идеальную, пусть с багами, но рабочую, и ...
… получил разгромный фидбек, низкие оценки, негативные отзывы, в результате продал очень мало версий, потерял репутацию и по пьяни разбился на старых жигулях.
А Петя — через пару месяцев выпустил отличный продукт, который принес ему заслуженые деньги и славу.
Обе истории выдуманные, конец будет такой, как автор захочет, а оправдывать сообственный быдлокод сказками — низко.
cache1.c: содержит виртуальную файловую систему (sic!) и процедуры системы кэширования.
a.c: реализация на C воссозданного обратной разработкой кода, который был высокооптимизированным x86-ассемблером. Код работает, но читать его — огромная мука!
Так что увы, в реальности как в сказке.
Но верно и то, что линейка Win95 загнулась, потому что просто не смогла развиваться. Так что быдлокод — хорош в короткой перспективе, но плох для длительной поддержки.
А быдлокод вообще-то называется технический долг. Просто использовать этот долг надо умеючи.
Да, оно может дать некоторые выгоды в очень короткой перспективе (две недели, максимум месяц, но уже через 3 месяца внесения правок в продукт траты из-за технического долга значительно увеличиваются в сравнении с выиграшем.
Запускать технический долг выгодно только в одном случае — вы закончите продукт как его видите и никогда не будете поддерживать. Потому этот подход используют для прототипов, которые идут на выброс.
void Error (char *error, ...)
{
va_list argptr;
#ifndef __NeXT__
if ( *(byte *)0x449 == 0x13)
TextMode ();
#endif
va_start (argptr,error);
vprintf (error,argptr);
va_end (argptr);
printf ("\n");
exit (1);
}
Ну если if ( *(byte *)0x449 == 0x13) для вас хороший код — то вы на 100% правы. Потому что до такого мы даже в прототипах не скатываемся.
Потому и живут у нас неоптимальные технические решения лет 5-10. И вполне переносят модификации. Та же Windows при всей её быдлокодовости проживала 25 лет.
Так что с вашей оценкой кода — у нас быдлокода вообще нет… :-) А с нашей оценкой — ну скорее всего весь ваш код плох.
но уже через 3 месяца внесения правок в продукт
Мда… Что это за анализ предметной области, если код нужно править в ближайшие полгода? Что-то мне вспоминается мой бывший коллега, который в своей книжке писал:
С другой стороны, любая неясность в постановке задачи вынуждает разработчиков сосредотачиваться не на её решении, а на архитектуре, позволяющей «без особых затруднений» менять логику приложения и переходить с расчёта зарплаты колхоза на прогноз удоев фермы.
Результат неизменно стабильный…
Случайно это не ваш случай? Если ваш — то мне вас жаль.
Я сказал про три месяца правок. Они могут начаться и значительно позже.
А в геймдеве и вообще активные правки с самого начала — единственный путь для нешаблонной игры. И да, геймдев — мой случай.
Кстати, вы про аджайл и итеративную разработку слышали? Или только на водопаде с заранее прописанной документацией работаете?
Про аджайл и так далее — почитайте "дефрагментацию мозга". Серега там хорошо и по аджайлу прошелся.
5. Одни из наших конкурентов широко используют agile-методы и TDD[121], но что-то оно им не очень помогает писать безошибочный код. Мы сравнивали количество найденных проблем в течение месяца-двух после major release, у нас показатели лучше в разы, если не на порядок. Частый выпуск версий просто не позволяет им довести код до ума и провоцирует исправление старых и серьёзных проблем методом написания «залепени». (Прим. автора: исправление ошибок, добавляющее новые проблемы.)
А у нас что-то среднее. Не аджайл, но и не жесткий водопад. И да, мы обычно на 3-5 лет понимаем, что может потребоваться, а что — нет. Неожиданности бывают, но редко.
А претензии к красивому коду у меня как у Жванецкого — "включаешь – не работает.". То есть шик, блеск, красота… но работает только для сферической лошади в вакууме. А на реальных данных — валится, как бык по скользи. Потому что программер думал об архитектуре, декомпозиции, делегировании, концепции… о чем угодно, но не о том, что модуль должен работать. Работать на реальных данных. С выбросами, лакунами и прочим
И любой работающий быдлокод — в 100 раз лучше неработающей красоты.
Особенно, если автор этой «красоты» заявляет, что адаптировать к реальным данным нельзя, ибо «архитектура не позволяет» и «концепция сломается». :-)
Ну судя по статьям Мосигры — далеко не единственный
При чем тут Мосигра? У них коробки делают, а не софт. Там делал-делал пока не закончил, а потом выпустил, что сделал. И имеешь очень мало влияния на проданные продукты.
И да, мы обычно на 3-5 лет понимаем, что может потребоваться, а что — нет
Так это ж просто ляпота, никаких сложностей.
Одни из наших конкурентов широко используют agile-методы и TDD[121], но что-то оно им не очень помогает писать безошибочный код
Очень странное понимание целей agile. Он и не создавался для того, чтобы код был качественнее, а для того, чтобы на изменения можно было реагировать быстро. Билд на продакшн, где сотни тысяч пользователей и огромное количество правок по их фидбеку каждые две-три недели, в том числе довольно серьезных. Куда уж там вашим 3-5 годам. Конечно у людей, которые работают по 3-летнему циклу будет багов в среднем меньше, чем у тех, которые работают по 2-недельному. Потому что 3-летний значительно проще.
Потому что программер думал об архитектуре, декомпозиции, делегировании, концепции… о чем угодно, но не о том, что модуль должен работать. Работать на реальных данных. С выбросами, лакунами и прочим дерьмом отклонением от идеала.
У вас странные понимания качественного кода. Не удивительно, что вы так агритесь на него. Качественный код — это не когда «много интерфейсов», а когда регулярные правки не вносят множество регрессий, когда новые фичи органично и легко вписываются в архитектуру, когда поддерживаются любые данные, или легко дореализовываются, когда сложность добавления фичей не растет с каждой новой фичей геометически.
Я понимаю, с таким циклом как у вас и на редаксе можно поговнокодить. За 5 лет оно все утрясется, костыли покроются пылью, которая потом отвердеет, а если пользователям что-то не нравится, то проект уже сдан и пусть приспосабливаются.
При живой разработке быдлокод приводит к очень быстрому росту сложности приложения и уже через несколько месяцев пропадает выгода от его использования, а дальше только хуже.
Мне помнится, в блоге Мосигры (а может и не в нем) были рассказы про разработку компьютерных игр. Не все игры писались «методом тыка», иногда люди хорошо представляли, что именно они хотят сделать.
У нас нету трехлетнего цикла. Есть основные продукты и есть заказы на конкретную модфикацию основного софта. Но, поскольку компания маленькая, аналитики и программисты — одно и то же. При разработке понимается, ну грубо говоря, что танк с вертикальным взлетом возможен, розовый танк с оборками и стразиками — невероятен, а вот деревянная броня — возможна, хотя и маловероятна.
Соответственно может и придется писать, как горит синим пламенем деревянная броня, но точно не нужно будет писать, как развиваются на ветру розовые оборки с кружевами или как на кочках вылетают стразики.
Если угадали — код дописывается легко. Если не угадали — ну или отказываться от заказа — или переписывать код, Но каждый раз, когда мы не угадали — это наша ошибка, как аналитиков.
Вы немного путаете качество кода со способностью кода к модификации.
Качественный код может быть написан методом контрактного программирования и всеми фибрами своей души сопротивляться изменению контракта. С другой стороны, откровенно индийский код — может отказаться легким в модификации.
В целом легкость модификации больше зависит от качества архитектуры приложения, чем от качества кода. При хорошей архитектуре быдлокод не модифицируется, а переписывается. И это иногда сильно быстрее, чем модифицировать качественный код.
P.S. Если не трудно, расскажите что такое редакс. А то «мужики-то и не знают». :-)

Вот есть восьмислойная плата, качественная-перекачественная. Чипы на BGA, рассыпуха 01005 (0,4 × 0,2 мм), дины линий выверены, импедансы рассчитаны и смоделированы, все фронты — ровненькие, хоть на 5 гигагрерц работой. Но вот только срок обновления у неё — 6 месяцев. И ремонтабельность нулевая.
А есть макетка. Быдло-быдло. Чипы — на DIP, рассыпуха — 1210 (3,2 × 2,5 мм), монтаж — проводом МГФТ, фронты завалены, об импедансе и длине линий и разговора нет, дай бог, чтобы на 150 мегагерц завелась. Но срок обновления у такой платы — 3 часа. И ремонт — хоть дома, хоть в офисе.
И что в железе, что в коде — у нас так. Чем выше качество — тем сложнее менять. Чем былокодистей — тем менять проще.
Ну у нас не макетки, но ближе к этому концу. За 3 недели можно новую плату сделать и софт на неё переделать. И даже за две, если печатную плату не заводским методом делать, а ЛУТом.
И любой работающий быдлокод — в 100 раз лучше неработающей красоты.
А вы действительно не путаете проблемность целевой области и заточку кода под неё (что может включать в себя массу адских хаков на частные случаи исключительно из-за ТЗ) и некачественность самого кода?
Если первое, то это не принято называть быдлокодом (разве что быдлозадачей).
Если второе, то покэпствую
1) красивый неработающий код, скорее всего, легче довести до рабочего состояния;
2) после этого он лучше сопровождаем, в отличие от быдлокода.
Пример с Doom и куском для NeXT, кстати, тут очень хорош дидактически :) С одной стороны, там очевидные странности в виде магических констант, которые по обычным нормативам надо описать в виде #define. Но я бы тут вместо этого поставил комментарий с описанием смысла конкретного числа.
С другой стороны, стиль, рекомендуемый во многих местах, потребовал бы сделать тут безусловно вызванное макро, которое было бы определено в непустое действие только для NeXT. А вот это уже хуже потерей локальности — надо идти неизвестно куда только для того, чтобы узнать, что для 99.999% случаев макро просто пустое.
- Быдлокод — это простой, некрасивый код, написанный в лоб. Часто большие размеры процедур, связь через глобальные переменные и так далее.
- Хакерский код — эффективный, но очень сложный в понимании код с множеством трюков.
- «красивый» код — эффективный код, написанный по всем правилам (классы, методы на все случаи жизни).
И вот вам пример, чем быдлокод лучше. Известная "Задача о восьми ферзях": Простой вариант с 8 циклами — легко обеспечивает переход к доскам непрямоугольной формы. А вот быстрый алгоритм Дейкстры…
1) красивый неработающий код, скорее всего, легче довести до рабочего состояния;
2) после этого он лучше сопровождаем, в отличие от быдлокода.
Увы и ах. Если в «красивом, эффективном коде» неверно понято ТЗ — заставить его работать можно лишь путем хакережа. И сопровождаемость после этого падает в ноль.
Неужели непонятно, что красота и эффективность идет за счет специализации кода (по условиям ТЗ)? Что вся декомпозиция — хороша лишь, пока программист верно понимает ТЗ и спектр его изменений? А если программер построил "мост вдоль реки", то его разворот обойдется дороже, чем написать его заново.
Неужели непонятно, что красота и эффективность идет за счет специализации кода (по условиям ТЗ)?
EPARSE, простите. Красота и эффективность — следствие специализации кода, или они страдают (ухудшаются) из-за специализации кода?
Что вся декомпозиция — хороша лишь, пока программист верно понимает ТЗ и спектр его изменений?
Нет, непонятно. На практике можно считать, например, что через год изменятся 10% требований, а за десятилетний цикл развития — чуть менее, чем все. (Реальные цифры с одной из моих прошлых работ.) Но каким образом из этого следует рекомендация писать всё так, что не заботиться о его сопровождении? Ведь даже если 20% изменилось, остальные 80% те же, а сопровождать надо каждый день.
А если программер построил "мост вдоль реки", то его разворот обойдется дороже, чем написать его заново.
Если построен мост вдоль реки по предыдущему ТЗ, то, значит, так и надо было. Но если продолжать использовать эту аналогию, то очень вероятно, что те же решения (быки-опоры, пролёты, методы их сцепления, покрытие для дороги) годятся для моста что вдоль, что поперёк, что через реку, что через каменный провал. И мне такая интерпретация кажется более реальной.
И вот вам пример, чем быдлокод лучше. Известная "Задача о восьми ферзях": Простой вариант с 8 циклами — легко обеспечивает переход к доскам непрямоугольной формы. А вот быстрый алгоритм Дейкстры…
Ну я её вообще писал через бэктрекинг с переходами. Но если и брать какой-то вывод из этого примера, то такой, что предсказать изменение задач в большинстве случаев невозможно. Пусть в какой-то момент доска превращается в кубическую гранецентрированную кристаллическую решётку — и оба метода перестают быть применимыми, от слова "совсем". У меня были аналоги такой ситуации, и это не примхи маркетинга, а осмысленные бизнес-требования.
Давайте разделим:
Быдлокод — это простой, некрасивый код, написанный в лоб.
Вот из написания "в лоб" никак не следуют огромные процедуры и связь через глобальные переменные, и наоборот.
На практике можно считать, например, что через год изменятся 10% требований, а за десятилетний цикл развития — чуть менее, чем все.
МДА. Ну или у вас аналитики действуют методом
А у нас программирование не настоящее. И не только потому, что иногда и осциллограф используется при отладке. Наши проекты всегда связаны с реальным миром. Мы знаем, что атомный ледокол не полетит над Москвой (даже низенько-низенько), что газонокосилка не будет печь блины, а стан для оцинковки стали не станет вязать веники.
С другой стороны газонокосилка вполне может начать отстреливаться очередями, стан для оцинковки — делать алюминирование, а атомный ледокол — перейти экватор. Это маловероятно — но возможно.
Точно так же я понимаю, что на компе может не быть часов, а в байте неожиданно может оказать 32 бита,
Так что если я решил, что какого-то изменения не будет, а оно произошло — это моя ошибка. Дописываний бывает много и очень разных, а вот непредсказанные изменения — это редкость. Ну, разумеется, если понимаешь предметную область.
Дописывания отличаются от переписываний тем, что при нормальной структуре почти не меняют существующий код. А при плохой структуре — вызывают рефакторинг кода. В обоих случаях — речь об усталости кода идет редко.
Красота и эффективность — следствие специализации кода, или они страдают (ухудшаются) из-за специализации кода?
Ни то ни то. Делая код эффективным — мы теряем в его универсальности. Делая код красивым — опять теряем в универсальности.
Чтобы было понятней — вспомните дискуссию про goto сороколетней давности. Код с goto -очень гибкий. Но и некрасивый.
очень вероятно, что те же решения (быки-опоры, пролёты, методы их сцепления, покрытие для дороги) годятся для моста что вдоль, что поперёк
Документация — сойдет за основу. Ну с учетом того, что быки встанут на другие места, то есть глубина будет не та и все прочностные расчеты придется пересчитывать. Особенно — на резонансные частоты.
A вот сами быки и пролеты — выкидываются. Ибо после демонтажа быка половина остается под руслом. Там же сваи, они глубоко забиваются.
Так что в сухом остатке — всего лишь опыт и образец документации.
Вот из написания «в лоб» никак не следуют огромные процедуры и связь через глобальные переменные, и наоборот.
Соглашусь, лоб у всех разный, естественный код — тоже.
В моей юности процедуры на 5 страниц считались отличным (и понятным кодом). Именно в этом стиле и писали в журналах и книгах по программированию. Ну и блок глобальных данных — был вообще единственным способом эффективной связи по данным.
Так что если я решил, что какого-то изменения не будет, а оно произошло — это моя ошибка. Дописываний бывает много и очень разных, а вот непредсказанные изменения — это редкость. Ну, разумеется, если понимаешь предметную область.
Никакое понимание предметной области не спасёт от странных инновационных требований заказчика. Или, как вариант: "когда мы это обсуждали 5 лет назад, то было совсем другое правовое поле, никому в голову не могло прийти, что законодатель ограничит размер пени сверху". Не думаю, что следует считать своей ошибкой то, что никому в голову прийти не могло.
Кроме того, изменения вообще редки. Ограничение размера пени — это дополнение, а не изменение ТЗ. Ну разумеется, если ваша архитектура позволяет формировать проверки и корректировки финансовых операций как дополнения.
В качестве примера, придумайте изменения ТЗ для программы, работающей в стиральной машине.
Новый режим стирки — дополнение. Изменение параметров режима стирки — тоже дополнение, пишем новый режим, а старый просто не вызывается.
Замена датчика — опять дополнение. Пишем чтение с нового датчика и не вызываем код для старого датчика.
ДА, исходники разбухают. Но одним кодом + таблица конфигурации мы поддерживаем всю линейку стиральных машин от царя гороха до наших дней.
В качестве примера, придумайте изменения ТЗ для программы, работающей в стиральной машине.
Вы раз за разом приводите в пример вотерфол-подобные методологии. Да, такой подход есть и он накладывает повышенную ответственность на аналитика и снимает эту ответственность с программиста. Я же вам привел пример — почти весь современный ГеймДев, трехнедельные итерации, есть поверхностное понимание, что будет в задачах в ближайшие два месяца и максимум — хорошее понимание на ближайший спринт. И сам домен к этому располагает — в любой нешаблонной игре любая фича может зайти или не зайти.
Посмотрите на историю развития World of Tanks, к примеру. Или Hearthstone. Или RimWorld. Или Minecraft.
Я прекрасно понимаю, что вотерфол значительно снисходительнее к плохому коду — представляешь конечную цель, знаешь, что у тебя не будет ничего сверхординарного и продюсер не скажет «можно атомный ледокол полетит над Москвой (ну хотя бы низенько-низенько можно?)». Если пришло что-то неординарное или ошибся немного — костыль подставил, благо такое крайне редко бывает.
Да, на таких проектах в среднесрочной перспективе говнокод может вполне себе работать. Именно потому я в самом начале ветки написал следующее:
Запускать технический долг выгодно только в одном случае — вы закончите продукт как его видите и никогда не будете поддерживать
И ваш пример со стиральной машинкой — отличный. Вы сделали, как сделали, небольшая группа потестила, всё, что криво — записали в руководство «дважды кнопку не нажимать» и отдали пользователям — пускай себе трахаются. А вот если стиральную машинку отдаете пользователям, а потом понимаете, что барабан должен быть на 60% больше и вам это нужно сделать не в новой машинке, а за три недели. А потом понимаете, что механические кнопки слева не подходят и надо поставить рычажки справа и у вас на это три недели. А потом понимаете, что рычажки справа не подходят, а сверху надо поставить тач-скрин. А после этого понимаете, что слив в том месте у 20% вызывает разлив воды потому что они его неправильно подключают и вы переделываете слив. И так три года.
Если вы в таком режиме будете быдлокодить — поймете, о чем я говорю.
Вы раз за разом приводите в пример вотерфол-подобные методологии.
Отнюдь. Вполне можно и по скраму.
У вас есть 200 сейчас продающихся моделей стиральных машин, 100 — уже не продающихся, но поддерживаемых и 50 в новой разработке. Реально это выливается в поддержку 7 вариантов процессорной платы, 30 вариантов пультов и по 3-5 вариантов каждого датчика и исполнительного устройства + не на всех моделях есть все датчики и все агрегаты.
И вот всю эту армаду в 350 моделей вы и делаете по скраму. По модели (или группе моделей на спринт).
Единственное упрощение — вы не поддерживаете старый код ядра. Нашлась ошибка в старой модели — вы берете самое последнее ядро, берете коды датчиков и исполнительных механизмов для старой модели и допиливаете их для нового ядра (если они ещё не допилены).
А вот если стиральную машинку отдаете пользователям, а потом понимаете, что барабан должен быть на 60% больше и вам это нужно сделать не в новой машинке, а за три недели.
Это не за три недели, в нормальном коде это делается за день, если не за час. Изменили константу в конфигурации, потестили и отдали в production.
Если вы в таком режиме будете быдлокодить — поймете, о чем я говорю.
я в таком режиме уже почти 10 лет работаю. 6 операционок (Linux, Windows, FreeRTOS, FreeBSD, MS-DOS, QNX, МСВС считаем за linux), 6 компиляторов (gcc, clang, lcc, borland C++, С Builder, MS VC++) 3 разных архитектуры (x86, ARM, SPARC) и куча конкретных продуктов. Ну не 350, но к двум десяткам. И всё это — на единой кодовой базе и с приличным техническим долгом.
Ниша у нас такая — полузаказные продукты делать. И поддержка пожизненная. То есть лет на 10-20.
Да, такой подход есть и он накладывает повышенную ответственность на аналитика и снимает эту ответственность с программиста.
Последние лет 15-20 лет я занимаюсь и тем и тем. То есть для меня это перекладывание ответственности с одного плеча на другое.
есть поверхностное понимание, что будет в задачах в ближайшие два месяца
Это называется разработка методом тыка. Или вы настолько мелкая сошка, что аналитики не считают нужным ставить вас в известность.
А основное отличие в другом. Мы делаем для реального мира. Наши приборы и решения реально нужны. За них платят потому, что без них — обходится дороже.
А вы — делаете для выдуманного, цифрового мира. Если не будет игрушек — никто денег не потеряет. Никто не придет к вам и не скажет — сделайте мне систему, это мне сэкономит полмиллиона долларов в месяц. Сделали. Сэкономили в итого больше сотни миллионов в год на отдельных режимах.
Вы можете позволить себе сидеть без заказов и действовать методом тыка. Мы — не можем. Методом тыка мы можем только по миру пойти.
Мы знаем, что мы можем сделать за 2 месяца, за год, за 3 года… И постоянно ищем себе заказы. И постоянно выбираем, в какие ниши идти, а в какие нет.
Мы не можем сказать «а давайте попробуем вот такой вариант, вдруг он кому-то нужен». Прежде чем что-то делать, мы должны понимать, кому мы продадим, по какой цене, каким тиражом.
А что касается гавнокода, то я уже описывал вам, чем гавнокод лучше. И что именно из-за гавнокода мы имеем короткий цикл модификации. Увы, вы на это ничего не ответили.
Это не за три недели, в нормальном коде это делается за день, если не за час. Изменили константу в конфигурации, потестили и отдали в production.
Эй, не выходите за пределы сообственной аналогии! У вас новый барабан не вмещается в старый корпус, даже если не учитывать, что управляющие конструкции вы сделали быдлокодом и они впритык упираются в барабан существующего размера.
У вас есть 200 сейчас продающихся моделей стиральных машин...
Вы теоретизуруете. А я говорю о реальных проектах.
А что касается гавнокода, то я уже описывал вам, чем гавнокод лучше. И что именно из-за гавнокода мы имеем короткий цикл модификации. Увы, вы на это ничего не ответили.
Я в разработке железа не разбираюсь и мне это не очень интересно. А силу отсутствия знаний специфики — сказать мне нечего. Может в железе это и правильный подход, а может опытный человек и сказал бы, что вы — неправы. Тем не менее, это не код. Мы ведь про софт, написание программ говорим, а не про создание железа.
А вы — делаете для выдуманного, цифрового мира
Да, я знаю, что вы обижены на game-developer'ов и web-developer'ов, но эти факты не делают вас лучше. Вот я какое-то время писал медицинский софт, то не говорю ведь вам теперь: «вот, вы просто за бездушные деньги работаете, а я жизни людей спасал». Странно звучит, правда. А вы так постоянно говорите.
Это называется разработка методом тыка. Или вы настолько мелкая сошка, что аналитики не считают нужным ставить вас в известность.
Молодцы. Возьмите с полки пряник. Это специфика вашей отрасли. Огромное количество фирм сейчас живет по другим принципам.
Это называется разработка методом тыка.
Я стараюсь не судить о том, в чем не разбираюсь. А зачем вы поступаете иначе?
Или вы настолько мелкая сошка, что аналитики не считают нужным ставить вас в известность.
Оскорбления. Прекрасный ход. Сразу видно силу и аргументированность вашей позиции.
Да, я знаю, что вы обижены на game-developer'ов и web-developer'ов
Отнюдь. Это отсылка к делению на хабр и гиктаймс. «Программирование» на HTML+CSS было признано настоящим, а всякое автовождение и прочий embeded — ненастоящим.
Логика тут есть. Настоящее — это то, что делается цифрового мира. А то, что делается для реального мира — ненастоящее. Цифровой мир — намного гибче и допускает работу методом тыка. И масштабы гигантские. 10 тысяч пользователей цифрового мира — это ерунда, 10 тысяч пользователей реального устройства — это очень много.
Я в разработке железа не разбираюсь и мне это не очень интересно.
Хорошо, вот вам аналогия из вашей работы. Насколько проще бы бы вам работать, если бы вместо реалистичного 3D использовалась анимация спрайтами или ASCII-Art? Чувствуете? Там, где вы месяцы будете отрисовывать красивую 3D-картинку, ASCII-art меняется за день. Вот так быдлотехнологии и ведут к быстрому циклу изменений.
Оскорбления. Прекрасный ход. Сразу видно силу и аргументированность вашей позиции.
Отнюдь. Когда я был молодым меня тоже не интересовала глобальная стратегия фирмы. Она не была тайной, просто при её выработке мое мнение не спрашивали. Интересовать стала лишь тогда, когда я стал отвечать за архитектуру всего проекта.
Собственно вы помладше моей старшей дочки, так что вряд ли являетесь ведущим программистом тех же танков. Но вполне допущу, что вы кое-что умышленно скрываете, чтобы юзеры просьбами не доставали. Сотня миллионов игроков WoT — достаточный повод, чтобы скрываться.
Вы теоретизуруете. А я говорю о реальных проектах.
Реально — к паре десятков.
Эй, не выходите за пределы сообственной аналогии! У вас новый барабан не вмещается в старый корпус, даже если не учитывать, что управляющие конструкции вы сделали быдлокодом и они впритык упираются в барабан существующего размера.
Аналогия — код для 350 разных стиральных машин. А то, о чем вы говорите — это даже не электроника, а механика.
Подозреваю, что в механике все так же. Если вы делаете литую раму заводского изготовления, то на её переделку потребуются месяцы — сначала гипсовая модель, потом пресс-форма, а уж потом — новые отливки. А если вы используете быдлорешение, то вырезаете основу из металлического листа обычными ножницами по металлу, а сгибаете — кувалдой. И тут за пару часов можно поменять все размеры.
Это специфика вашей отрасли. Огромное количество фирм сейчас живет по другим принципам.
Скорее должности, чем отрасли.
А итоговые тезисы такие:
- Применяя технологии вчерашнего и позавчерашнего дня (быдлокод) в современной обработке — мы уменьшаем цикл разработки (и легкость переделок) за счет скорости, эффективности, красоты кода и прочего. И наоборот — чем качественней код, тем сложнее он изменяется, оставаясь качественным.
- ООП — очень гибкая вещь, но только если угадали со структурой. В случае ошибки в выборе структуры — изменения становятся настолько тяжелыми, что проще все переписать заново.
- Технический долг — абсолютно нормальная штука, если им грамотно управлять. Но это уровень менеджеров, аналитиков и темлидов, а не рядовых программистов.
Хорошо, вот вам аналогия из вашей работы. Насколько проще бы бы вам работать, если бы вместо реалистичного 3D использовалась анимация спрайтами или ASCII-Art? Чувствуете? Там, где вы месяцы будете отрисовывать красивую 3D-картинку, ASCII-art меняется за день. Вот так быдлотехнологии и ведут к быстрому циклу изменений.
Какая-то аналогия левая. Это ведь просто разные жанры или стили. При чем тут быдлотехнологии? Или если делаешь 2д-игру вместо 3д-игры, то уже быдлятник? Если хорошо написан код, то легче работать и с 3д и с 2д.
Подозреваю, что в механике все так же. Если вы делаете литую раму заводского изготовления, то на её переделку потребуются месяцы — сначала гипсовая модель, потом пресс-форма, а уж потом — новые отливки. А если вы используете быдлорешение, то вырезаете основу из металлического листа обычными ножницами по металлу, а сгибаете — кувалдой. И тут за пару часов можно поменять все размеры.
Эй, не забывайте — мы каждые три недели отдаем серию пользователю, тысячи машинок вручную не вырежешь.
Отнюдь. Когда я был молодым меня тоже не интересовала глобальная стратегия фирмы. Она не была тайной, просто при её выработке мое мнение не спрашивали. Интересовать стала лишь тогда, когда я стал отвечать за архитектуру всего проекта.
И снова, ничего о мне не зная — делаете выводы и вешаете ярлыки. И плевать, что у меня 10 лет опыта в индустрии.
То, что вы, судя по вашим словам, в молодости были не очень — не означает, что все остальные прошли тот же путь.
А еще то, что раз за разом скатываетесь в атаку на мою личность вместо аргументированного спора тоже указывает на слабость ваших аргументов.
И как вывод — скорее всего, где-то в душе вы понимаете, что быдлокод вам мешает, но, может, вы просто не знаете, как написать хороший код, чтобы он при этом легко поддерживался и изменялся. А такая агрессия — это просто защитная реакция.
И как вывод — скорее всего, где-то в душе вы понимаете, что быдлокод вам мешает, но, может, вы просто не знаете, как написать хороший код, чтобы он при этом легко поддерживался и изменялся
Кстати да, напомнили вы мне своим комментарием о вопросе, который меня сильно мучает: как писать в рамках TDD (про BDD молчу — там я сам принцип не понимаю)… Сам принцип я понимаю, но вот как перейти к нему?..
как писать в рамках TDD
Я переходил волевым решением. Не знаю, насколько оптимально, но, в целом, доволен реультатом. Проще всего в новых проектах это делать (даже в рамках того же продукта).
Потихоньку. Пришел багрепорт — воспроизвели его тестом (падающим), а не руками. Добились, чтобы тест прошёл любым костылём — баг исправлен. Если костылём, то отрефакторили и убедились, что тест всё ещё проходит. Так же и с фичереквестами.
Если имеющийся код очень сложно тестировать, то выделять новый код (багфиксы, фичеимплементации) в легкотестируемый, пускай и в труднотестируемой обвязке.
Было бы точно так же — уже давно больше половины разработчиков перешла бы на TDD… А я вот до сих пор вижу кучу проектов с покрытием юнит-тестами ниже 30%!
PS Да и на своём примере я чётко вижу, что это не так просто…
Угу. я о том, что 1 намного важнее, чем 3. Ну в смысле для надежных систем.
3, как правило, закрывает только конкретный баг. 1 дает возможность работать при целом классе багов.
Вы удивитесь, но большинство веб-сервисов перманентно забагованы, но при этом основной функционал умудряются выполнять...
Для багфиксов это суперудобно: сначала фейлящийся тест, а потом багфикс, который его вылечивает (как вам тут уже написал VolCh). Очень удобно и логично. И покрытие не страдает.
Для фич пишем h-ники, потом заглушки тестов (покрытие 90%) по максимуму, потом функционал, потом тесты до конца, потом их отлаживаем.
Это чистой воды TDD. В софте нет какой-то нужной функциональности, пишем тест проверяющий, что она работает, тест падает, изменяем исходники чтобы тест не падал, то есть чтобы эта функциональность работала.
Это просто элемент TDD, потому что TDD придуман не для этого.
Смысл TDD — это методология написания программ, а не исправления ошибок.
Что исправление ошибок, что доделки, что переделки с точки зрения TDD одно — нет нужной функциональности в системе, пишем (в случае переделки переписываем) тест, проверяющий её наличие, убеждаемся, что он падает и изменяем код так, чтобы перестал падать.
TDD, как и любое (ну, почти) тестирование не страхует от ошибок, это заблуждение. Тесты лишь фиксируют поведение системы для конкретных частных случаев входных данных и ничего не говорят о поведении даже при минимально отличающемся наборе. Из того, что проходит тест assert(4, add(2,2) нельзя делать логический вывод без анализа кода хотя бы функции add, что пройдёт тест assert(3, add(1,2)). Интуитивно, предполагая разумность и внимательность разработчика должен пройти, но это не логически выведенное утверждение, а лишь предположение, рабочая гипотеза, которая может быть опровергнута даже при промышленной эксплуатации.
Кстати, мой коллега в одной из ЭВМ обнаружил, что 2.0 равно 16.0, то есть сравнивались лишь мантисы, без ординат. Завод-изготовитель потом долго извинялся. :-) Машина была с серийным номером три.
TDD не является альтернативой какой-то технологии, она дополняет имеющиеся.
Почему ложную? Я вот уверен, что метод, который я написал последним, оттестирован для двух кейсов и если в будущем метод будет меняться, то сразу будет заметно, если поведение метода для одного из них или для обоих изменится. Но при этом я понимаю и то, что оттестирован код исключительно для двух кейсов, один из которых граничный случай, а второй — общий. Я не строю никаких предположений о том, как он поведёт себя в каких-то других граничных случаях. Придёт баг-репорт, что поведение не соответствует ожидаемому в каком-то случае — будет третий кейс. Не исключено, что его нормальное исправление будет осуществляться вообще не в нашей кодовой базе, а в трансляторе языка или его стандартной библиотеке.
TDD нарушает одну из основных заповедей тестирования — никогда не тестировать свой собственный код. Грубо говоря, при неверном прочтении ТЗ ошибка попадает и в тесты и в код, поэтому тестирование бесполезно.
Как говорит мой коллега, если программеры работают по TDD, то работает только то, что попало в тесты. Шаг влево, шаг вправо — не работает. При этом коллеги обычно не правится по 5 лет с момента написания, ибо багов просто нет.
Вы удивитесь, но большинство веб-сервисов перманентно забагованы, но при этом основной функционал умудряются выполнять...
А что удивляться? Тому, что кто-то до сих пор умеет писать программы, которые не падают после первой ошибки? Это нормально! У самолетов кроме постоянной забагованности, как ещё и цикл правки багов по 2-3 года.
Мы у себя в одном проекте решили, что баги есть, были и будут, в итоге работает 15 лет 365 на 24.
А потом и тесты, и код пуллреквестят специально обученные люди. Да и до написания и тестов, и кода обычно советуются с людьми, разбирающимися в бизнесе. Вероятность "неправильно понять" стремится к 0.
Основное назначение тестов в виде используемом в TDD — не обнаружение несоответствий поведения программы ТЗ, а фиксация понимания ТЗ и регулярная проверка соответствия поведения этому пониманию. Тесты в TDD — часть процесса кодирования, а не тестирования, чистый development, а не Q&A.
В остальных случаях — где-то он полезен, а где-то просто мода или религия.
Если вы думаете, что подсчитанная вручную пара матриц понятнее ТЗ — вы сильно ошибаетесь. :-)
TDD — отличный инструмент, если вы рассчитываете довести код до состояния, когда почти любая правка багов вызывает новые баги. :-)
Если уж вы довели код до такой ситуации, то будете сильно рады, что работали по TDD.
Первое: тут уже упоминалось, но повторю: формально TDD никак не требует собственно писать по ТЗ, оно требует только удовлетворения теста. Поэтому, если мы напишем умножение в виде
multiply(0, 0) -> 0;
multiply(2, 0) -> 0;
multiply(2, 2) -> 4.
и никто не проверит, что работа вообще не делается, будет полное формальное соответствие, которое никому не нужно.
Для объяснения этого вообще нужно вернуться к тому, зачем же тест нужен. Тут лучшая формулировка, что я слышал, дана коллегой landerhigh с RSDN: «Тесты — не для поиска багов, а для написания верифицируемого в контролируемых условиях кода.» Под верификацией имеется в виду любая верификация, начиная с банального просмотра глазами. Код должен обеспечивать своим содержимым выполнение ТЗ так, чтобы это могли проверить средства верификации (сам автор, коллеги-ревьюеры, автоматические средства...), а тест — чтобы ловить то, что верификация не ловит: человек не заметил опечатку или крайний случай; вместо символа ';' шутник подставил ';' (U+037E); не выловлен какой-то крайний случай; и тому подобное.
Далее, в классическом TDD объявляется, что
1) пишутся тесты до кода («test first»);
2) тесты должны быть проверены на то, что они не проходят (тупо — запустили, увидели отказ и только после этого имеем право двигаться дальше);
3) пишется код для их удовлетворения.
Каждое из первого и второго не допускает возможности его применения для уже существующего кода, что неизбежно в случае, когда происходит изменение спецификации к уже написанному, или при заимствовании готовой чужой разработки с адаптацией под себя. А это неизбежная ситуация как во многих случаях начальной разработки, так и тем более при поддержке.
Чтобы допустить в принципе ситуацию, когда код меняется, надо допустить, если использовать правило «test first», что новые тесты соответствуют TDD, но старые — нет, часть тестов может работать и до новой разработки, и после. А это значит, что они уже нарушают этот принцип — их нельзя проверить на корректность той проверкой, что «тест до написания упал => он, вроде, правильный».
Поэтому, или вы доверяете корректности уже существующих тестов согласно их коду, но тогда правило «сначала тест должен упасть» вообще теряет смысл, или вы вводите другие методы контроля корректности тестов (в моём случае это инверсии тестов, когда проверяется нарушение выходных данных при заведомых отклонениях входных данных). А в этом случае уже пофиг, были написаны тесты до или после: это вопрос административного контроля качества покрытия тестами, но не собственно их выполнения.
Также с этим напрямую связано, что TDD никак не решает вопрос качества самого тестового окружения. Например, что будет, если в результате сбоя в одном файле assertEqual() станет проверять не равенство результата ожидаемому, а просто наличия результата?
Пригодный к длительному сопровождению (а не к одиночному «хренак, отдали заказчику и забыли») тестовый комплект должен быть таким, чтобы корректность самого тестирования можно было проверить автоматизированно в любой момент без ручного вмешательства. Например, мы вводили инверсии тестов — аналог «мутационного тестирования» именно для кода тестов, в явно продуманных местах. Общая идея: пусть тест ожидает, что если на входе A, на выходе B. Модифицируем код посылки на вход так, чтобы посылалось C, но так, что верхний уровень контроля теста ничего про это не знает. Тест должен упасть (а вокруг него строится другой, который проверяет факт падения вложенного теста). Ошибка инверсного теста у нас срабатывала очень редко, но каждый такой случай означал серьёзные скрытые проблемы в коде.
И с такими средствами исходный принцип TDD про «сначала тест должен упасть» теряет свой методический смысл: что прямой тест работает, а инверсный падает — проверяется в любой момент независимо от того, был ли написан тест раньше кода, или нет.
Далее, полное следование TDD в принципе не допускает грамотную алгоритмизацию. Речь о правилах типа «причиной каждого ветвления или цикла должен быть упавший тест». Для примера представим себе задачу сортировки массива. Представим себе написание метода сортировки по принципу TDD тем, кто не знает этих алгоритмов.
Вы вначале решите, что должен пройти тест для (1,2) и (2,1). OK, сравнили два элемента, прошли. Теперь добавляем третий… четвёртый… двадцатый… во что превратилась функция? В лучшем случае вы получите сортировку вставками (если кодер очень умён), а скорее всего это будет «пузырёк». При совсем тупом кодере это вообще не будет читаемо даже после ста грамм. И Вы никак не получите ни метод Хоара, ни тем более метод Бэтчера. Потому что для них надо сначала реализовать алгоритм, хотя бы в уме, со всеми циклами, ветвлениями и тому подобным, а уже затем тестировать.
Можно сказать тут, конечно, что алгоритм в уме и алгоритм в коде — разные. Но когда вы заранее знаете, какое именно ветвление вы напишете и почему — вы уже действуете не под тест, а под алгоритм. Идея предварительного разделения на два подмассива, как у Хоара, а тем более математически подобранная сортировка подпоследовательностей, как у Бэтчера — тестом не решится.
В вычислительной математике таких случаев ещё больше. Тестирование решения СЛАУ через построение треугольной матрицы — очень хреново ложится на TDD, а тонкие эффекты на долях эпсилона в принципе не могут быть заранее просчитаны.
Следующее — проблема уже состоявшихся требований. Пусть есть изменение ТЗ — добавилось новое требование. Но что будет, если оно уже реализуется кодом? Например, требование — чтобы сортировка была устойчивой — но она уже такая в реализации. Такая ситуация в принципе не покрыта TDD. Решение я уже описал выше — отказ от заложения на важность теста его изначальной неработой.
В каком же случае TDD может идеально работать, и даже быть полезным, в его каноническом виде? Это
1) написание только нового кода, или расширение на безусловно новые требования;
2) полное отсутствие необходимости R&D, весь проект ясен с самого начала (сюда входит и вариант изменения ТЗ на ходу — просто таких начал становится несколько);
3) большое количество низкоквалифицированных сотрудников и аналогичного управления ими, которое способно сэкономить на тестах, но для которого угроза административного наказания за нарушение инструкций важнее проблемы собственно качества выходного кода.
То есть это идеальная технология для классической оффшорной галеры. Антиполюс — то, где TDD способно только навредить — разработка собственного наукоёмкого продукта. (Как раз случай коллеги Jef239, поэтому я не удивляюсь его отношению. И мой случай для всех прошлых и нынешних работ.)
Резюмирую: я никак не против отдельных функциональных тестов всех уровней (от юнит- и до интеграционных верхнего уровня). Они должны быть. Более того, они должны быть и для нормального заказчика (который обязан не верить, пока не покажут работающее), и для собственного контроля. И разработчик должен сам писать тесты на все подозрительные и крайние случаи, и контроль должен это поощрять и требовать. Но требование 100% покрытия и «test first» — это то, что превращает разумный подход в религию.
И ещё один PS — речь не про тесты для прямой проверки ТЗ (я их отношу к BDD, а не TDD).
Чуть сумбурно получилось, но, надеюсь, понятно.
Каждое из первого и второго не допускает возможности его применения для уже существующего кода
TDD про написание нового кода или изменение существующего. Если принято решение перевести развитие существующего проекта на TDD, то есть два глобальных варианта:
- забиваем на существующую кодовую базу, тесты пишем только под задачи на развитие (новая или изменяющаяся функциональность), рефакторя существующий код без автоматизированного юнит-тестирования регрессий
- перед переходом на TDD покрываем существующую кодовую базу тестами с применением практик из Q&A и прочих "tests last"
Допустимы, конечно, комбинации, компромиссы между этими вариантами, но суть в том, что покрытие тестами существующего кода — процесс ортогональный TDD.
Представим себе написание метода сортировки по принципу TDD тем, кто не знает этих алгоритмов.
Вы при описании TDD забыли ещё один этап при разработке — рефакторинг. Замена пузырька или вставок на Бэтчера — это как раз и он есть: видимое поведение не изменяется, а код оптимизируется по какой-то метрике. Обычно по читаемости, улучшению поддерживаемости, но это не догма.
Это никак не относится к тому, что я говорил — о проблемах работы с существующим кодом, уже покрытом тестами, согласно TDD.
> Вы при описании TDD забыли ещё один этап при разработке — рефакторинг. Замена пузырька или вставок на Бэтчера — это как раз и он есть: видимое поведение не изменяется, а код оптимизируется по какой-то метрике.
Это не к тому, что я описывал. Во-первых, Вы почему-то предположили, что какая-то сортировка уже была. Ну ладно, примем. Тогда, при буквальном следовании TDD данный вид рефакторинга просто невозможен — его не допустит догма.
TDD — отличный инструмент для создания легкотестируемой архитектуры с покрытием тестами близким к 100%.
Если вы меняете архитектуру ради TDD, то вы проигрываете в другом. Как минимум приходится выбирать кристалл с большей памятью данных и кода.
Не спорю, что в 20% проектов TDD дает выигрыш. Речь не о них. А о том, что для остальных 80% — это религия или маркетинговый код.
По вашим же словам:
Так что однозначная выгода от TDD — лишь в ситуации, когда тест дошел до состояния, когда почти любая правка вызывает вторичные ошибки. Вот тогда массив накопленных регрессионных тестов будет сильно полезен.
Все остальное — зависит от проекта. Я, например, больше люблю «assert driven development», то есть агрессивное расставление ассертов с сохранением их в production. В сочетании со структурными исключениями и перезапуском подсистем по возникновению исключений получаем неубиваемое приложение.
Главное — это то, что технологию надо выбирать исходя их технических свойств, а не по шуму хайпа вокруг неё.
Я не знаком с исследованиями насколько TDD увеличивает потребности в памяти в продакшене. Вы знакомы?
Ну, я выбираю TDD по субъективной оценке технических и не очень свойств:
- не влияет на рантайм (кроме архитектурных решений)
- при разумном применении уменьшает связанность кода (те самые архитектурные решения)
- несёт документирующую нагрузку
- обеспечивает покрытие тестами меньшей ценой чем тесты после кода
- обеспечивает страховку (неполную, конечно) от нежелательных изменений
А выполнять тесты на одном кристалле, а боевую программу на втором — это профанация.
Ну что там верно именно для вашего кода — я не знаю, потому и не спорю. Но…
обеспечивает покрытие тестами меньшей ценой чем тесты после кода
Тесты (что железа, что софта) бывают двух видов. Одни — чтобы доказать, что ошибок нет. Другие — чтобы найти ошибки. TDD дает лишь тесты первого рода.
Пример (чуть утрированный) из моей бытности руководителем группы тестирования на похожем на ваш проекте. Один человек регулярно делает ошибку типа ±1. Ну то есть вообще считает, что «не меньше» — это «больше» (на самом деле — больше либо равно). Программер вполне нормальный, багов не больше, чем у других, просто часты ошибки вот такого типа.
Что у него будет в TDD? Да ровно то же, что и в коде. В тестах он тоже решит, что «не меньше — это больше». И так у каждого, хороший тестер — это психолог, он ещё до тестирования понимает, куда стоит «потыкать палочкой»
Время написания теста — для тестеров не важно, тестеры все рано не читают код. Разумеется, оно важно для программера — если уж программер тестирует свой собственный код, то тесты надо писать до кода.
Но, если, вы хотите качества продукта, то есть несколько «золотых» правил":
- Никогда не тестировать свой собственный код.
- Оценка работы тестеров идет по найденным багам, оценка работы программеров — по тому, чтобы багов было меньше и самой малой значимости.
И вот из разности интересов программера и тестера и получается качество продукта.
При этом я не отрицаю полезности TDD в отдельных нишах. И сам использовал его больше 25 лет назад (лет за 10 до того, как TDD получил своё имя), при написании электронных таблиц для УКНЦ. Там основную сложность представлял компилятор формул, а придуманный мной язык формул — хорошо ложился на схему TDD.
Но массовое использование TDD, где надо и где не надо — это карго-культ.
TDD дает лишь тесты первого рода.
Именно. И то весьма ограниченно, она не доказывает отсутствия ошибок вообще, только показывает, что программер получает ожидаемые им результаты. Именно им, а не кем-то другим. И если для программера 4 больше 4, то тесты и покажут, что код себя так ведёт.
Никогда не тестировать свой собственный код.
Собственно отличие подхода tests first от других именно в том, что программер не тестирует свой собственній код по сути. Тест написан, а кода ещё нет, есть только декларация намерений написать код, который в таких-то случаях будет вести себя так-то, практически окончательная постановка задачи самому себе в формализованном и, главное, автоматически верифицируемом by design виде. Естественно, что если такая постановка изначально неверная, не соответствует ТЗ или иным ожиданиям заказчика, то реализация тоже будет неверной с точки зрения заказчика, как и в случае если он сам налажал и не смог поставить задачу корректно, не смог описать свои ожидания.
Зачем уж так маньячить и слепо следовать "концепции TDD"? Берите оттуда то, что вам нужно. Интерфейсы конечно пишите до тестов, если так лучше.
Интерфейсы не программируются в моем понимании, а описываются. программируется их реализация. Тестами мы описываем желаемое поведение модуля (включая интерфейсы), а потом его имплементируем уже имея интерфейсы как часть постановки задачи.
Если мы пишем быдлокод методом экстремального программирования, то интерфейсы (классы, методы) будут примитивными, берем первый попавшийся вариант, фигак-фигак и
А вот если мы неделю думаем над архитектурой модуля и его API, а потом за день кодируем то, что придумали, то юнит-тесты никак не получается писать вначале — они пишутся до кодирования, но когда 80% работы уже сделано.В уме — но сделано
В TDD по сути тесты и есть зримый результат вашего "неделю думаем над архитектурой модуля и его API". Придумали — зафиксировали в тесте.
А API и структуры данных — описываются до теста, они нужны, чтобы тест хоть как-то компилился.
А кто говорил о фиксации алгоритма? Фиксируются именно API, структуры данных для него и какие-то контрольные точки. Какой конкретно алгоритм используется в вычислении факториала дело десятое, это уже не функциональные требования или решения к разрабатываемому модулю. Главное, проверить, что это именно факториал, а не н-ое число Фибоначчи, например. Тесты в TDD про функциональные требования, независящие от способа реализации.
Ну вот вам пример. Одно дело — функция четырех аргументов (курс и путевой угол по GNSS, курсы по гироскопу и магнитометру). Другое дело — класс с четырьмя property для аргументов и функцией извлечения результата. Чувствуете отличия в тесте? Ну как минимум надо проверить, что будет, если входные данные ещё не заданы.
А третья реализация — с фильтром Калмана внутри. Тут уже и предыстроия влияет…
Если мы для магнитометра не учитываем наличие магнитных полей от ближних объектов — то проверки проще, если учитываем — сложнее. Как минимум калибровка магнитометра добавится.
А ТЗ простое «сделать комплексирование курса от GNSS, гироскопа и магнитометра». :-) Просто это НИР — люди об этом реальные научные статьи пишут.
Даже с факториалов не так просто. Если мы будем кэшировать 10 вычисленных значений факториала и отталкиваться от подходящего закэшированного, то добавится много новых тестов. Как минимум — расчет с нуля, расчет с предыдущего значения и расчет делением с последующего значения. И вcё это надо будет учесть.
А вот что в нём хорошо — поиск маргинальных случаев. Но можно и не дождаться.
3 раза пересоздали подряд объект — перезапускаем нить (подсистему). 3 перезапуска подсистемы — уходим на резервный сервер, а этот перезапускаем.
Просто надо без фанатизма — контролировать лишь те инварианты, которые просто контролировать.
Напишите последовательность тестов, которые выявят эту ситуацию. И сравните с тем, сколько тестов нужно для тестирования реализации факториала без кэширования.
Вообще, состояние гонки (и все на него похожее) плохо поддается тестированию. Лучше уж сразу писать корректно или использовать верификацию.
Вообще, состояние гонки (и все на него похожее) плохо поддается тестированию. Лучше уж сразу писать корректно или использовать верификацию.
состояние гонки и прочая асинхронщина/многопоточность, а также работа хитрых кешей, к интеграционному тестированию, а не юнит. TDD вроде эти уровнем абстракций не рулит...
И чего это нам тут включать модуль в состав большой программы и заниматься интеграционным тестированием? :-)
Не, тут юнит-тесты, только хитрые. И assertы внутри функции расставить на соблюдение инвариантов.
Но лучше — сразу писать корректно. А ошибки искать — вычиткой кода.
Не путайте настоящую гонку с псевдогонкой, возникающей при работе кэша в одной нити. Выглядит как гонка, но намного более воспроизводимо,
Да ну? Написали модуль об одной функции — вычисления фактриала. Мы эут функцию как тестируем? Юнит-тестом, верно?
Это верно.
А потом поменяли потроха этой функции, чтобы использовать кэш. Интерфейс функции остался прежним.
А вот это неверно. Интерфейс функции изменился, в него добавился модуль кеша. То, что тестируемо — оно лежит после вычитки из кеша (т.е. фактическое вычисление). А кеш должен тестироваться отдельно. А функция подсчёта факториала + кеш == интеграционное тестирование двух модулей.
И чего это нам тут включать модуль в состав большой программы и заниматься интеграционным тестированием? :-)
Вы видимо не совсем корректно понимаете термин интеграционное тестирование… или юнит-тестирование.
Не, тут юнит-тесты, только хитрые. И assertы внутри функции расставить на соблюдение инвариантов.
тут именно интеграционные тесты — тесты взаимосвязи двух модулей — вычислительного и кеширующего.
Но лучше — сразу писать корректно. А ошибки искать — вычиткой кода.
вообще не спасёт
Не путайте настоящую гонку с псевдогонкой, возникающей при работе кэша в одной нити. Выглядит как гонка, но намного более воспроизводимо,
А это зависит исключительно от реализации модуля кеша и окружения, на котором он исполняется. Если писать на Java — вполне может быть, что это будет именно гонка состояний. А вот на каком-нибудь кристалле с единственным вычислительным потоком это будет именно псевдогонкой… Вы слишком подгоняете ситуацию под привычный вам кейс.
А вот это неверно. Интерфейс функции изменился, в него добавился модуль кеша.
И нафига для кэша отдельный модуль? С одной стороны кэш — это просто массив пар, с другой стороны — у факториала кэш специфичный, больше почти ни для кого не пригодный.
Дело в том, что 8! мы можем считать и как 7!*8 и как 9!/9, то есть нам надо ближайшее с любой стороны.
И добавление в кэш специфическое. Если в кэше есть 5! и 10! то между ними нет смысла добавлять элемент. 2-3 умножения-деления — это немного.
Может вы и memcpy на пяток модулей разобьете? А то в ней 286 строк. :-) Факториал с кэшем — это строк 60-70, не больше.
Кстати, попробуйте придумать unit-тесты для memcpy. Там тоже много разных красивых граничных случаев.
А это зависит исключительно от реализации модуля кеша и окружения, на котором он исполняется.
Все проще. Как только у функции появляется внутреннее состоянии, становится возможной и гонка при многонитевом исполнении и псевдогонка при однонитевом. С настоящей гонкой справится проще — ставим функцию в критсекцию и дальше гонка невозможна. А вот зависимость от предыдущего вызова так просто не устраняется.
Чтобы не спорить о том, стоит ли разбивать факториал на два (или четыре) модуля — можете подумать над тем же вопросом про memcpy. насколько массив нужных тестов будет зависеть от реализации? И что надо тестировать для приведенной выше версии в 286 строк.
И что надо тестировать для приведенной выше версии в 286 строк.И что нужно будет делать если версия на 286 строк вдруг превратится в версию на 3000 строк.
Хм… 286 строк?.. Глянул исходники — так это же по сути ассемблер! Да я вижу там некоторые красоты с/с++, но это всё-же ассемблер. А он, скотина, многострочный… Для языков высокого уровня и 30 строк на функцию имхо слишком много.
Что именно в нём тестировать я говорить не возьмусь — недостаточно знаю ассемблер, чтобы бегло прочитать и понять, а тратить много времени как-то не очень тянет...
Ну а в целом — тестировать надо исходя из степени приемлемости инструмента. Юнит-тестирование — для мелких блоков-функциональностей. В приведённом вами примере есть два блока-функциональности: вычисление факториала и кеш-машина. Неважно что обе функции в примере простые как полешки — это именно различные компоненты. Каждый из них можно тестировать своим юнит-тестом, но сопряжение этих элементов уже будет сложной функциональностью, которую надо гнать через интеграционное тестирование (даже если оно будет запущено силами юнит-тестирующих библиотек/фреймворков).
Глянул исходники — так это же по сути ассемблер!Это не «по сути», а полностью ассемблер. Расширение
.S (не путать с .s !) — это ассемблер с обработкой C препроцессором.Что именно в нём тестировать я говорить не возьмусь — недостаточно знаю ассемблер, чтобы бегло прочитать и понять, а тратить много времени как-то не очень тянет...«Краевые случаи», однако.
Современные CPU могут очень быстро копировать блоки в 16 или 32 байта, но хорошо бы, чтобы хотя бы один из них был ещё и выровнян на 16 и/или 32 байта, а «остатки» ведь тоже кто-то должен копировать? Отсюда — куча «краевых случаев»…
Неважно что обе функции в примере простые как полешки — это именно различные компоненты.Это только если вам не интересует скорость. Но если вас не интересует скорость — нафига вам там кеш?
Я сам, лично, имел опыт ускорения программ на порядок (то есть в 10-12 раз) избавляясь от таких вот «различных компонент», так что не надо говорить о том, что это «копейки».
Современные CPU могут очень быстро копировать блоки в 16 или 32 байта, но хорошо бы, чтобы хотя бы один из них был ещё и выровнян на 16 и/или 32 байта, а «остатки» ведь тоже кто-то должен копировать? Отсюда — куча «краевых случаев»…
Вот только современные процессоры (от Intel — так точно) уже не имеют падения производительности при работе с невыровненными данными. MOVUPS = MOVAPS в общем случае.
Можно пруф? Речь идет о скорости только процессора или и процессора и всей подсистемы памяти?
Речь идёт о latency: PDF
Видно, что у AMD задержка для выровненных данных (FA/M) меньше. А у Intel, начиная с Sandy Bridge, задержка выполнения — 1 такт что для (V)MOVUPS, что для (V)MOVAPS.
Ну и дополнительно: Link
On the Sandy Bridge, there is no performance penalty for reading or writing misaligned memory operands, except for the fact that it uses more cache banks so that the risk of cache conflicts is higher when the operand is misaligned. Store-to-load forwarding also works with misaligned operands in most cases.
Вот только современные процессоры (от Intel — так точно) уже не имеют падения производительности при работе с невыровненными данными.Вот только не надо рассказывать сказок, а? Кеши и шину данных никто не отменял.
MOVUPS = MOVAPS в общем случае.Не путайте разные вещи. Необходимость использования двух инструкций — да, осталось в прошлом. При работе с выровняными данными MOVUPS так же быстр нонче, как и MOVAPS. При работе с невыровненными… увы. Необходимость делать два цикла на шине вместо одного никакой «современный процессов» изжить не может.
При работе с невыровненными… увы. Необходимость делать два цикла на шине вместо одного никакой «современный процессов» изжить не может.
Вы давно читали мануалы по использованию векторнх инструкций? Давно использовали векторные инструкции на практике?
Во времена SSE-процессоров мне действительно при написании векторизованного кода для работы с изображениями приходилось писать код с оглядкой на медленный невыровненный доступ. С покупкой процессора от Intel с поддержкой AVX я заметил, что больше никакого прироста произодительности от использования выровненных данных нет.
Мне не важно, как Intel технически добилась этого, но то, что потери в скорости при работе с невыровненными данными больше нет, это факт, а не сказка.
У меня, кстати, есть опыт ускорения на 3 порядка и тоже за счет хитрого кэша и сортировки кэшей. И тоже — не делится на модули.
Задача была такая. Есть таблица, в ней строки и столбцы. Запоминаем для некоторых (маркированных строк) набор значений в столбцах. Потом берем иную таблицу, вообще говоря с другим (но пересекающимся набором) набором столбцов. И надо было отметить запомненные (маркированные строки). В худшем случае у нас даже первичный ключ менялся.
Редкая ситуация, когда я с вами согласен. :-)Мы немного о разном.
У меня, кстати, есть опыт ускорения на 3 порядка и тоже за счет хитрого кэша и сортировки кэшей.Я не про это говорю. Я не про кеширование.
В моём случае я просто обрабатывал поток команд x86 процессора, декодировал их и проверял некоторые свойства. И оригинальная программа — использовала много уровней по типу «неважно что обе функции в примере простые как полешки — это именно различные компоненты». Один модуль — выделял опкод, другой — разбирал операнды и т.д. и т.п. Всё было красиво обвешано тестами, вот только работало медленно.
Я переписал программу используя макросы,
inline-функций и автогенерённого кода так, чтобы компилятор мог выкинуть вычисление ненужных данных. Алгоритм при этом не изменился, но программа стала работать в 12 раз быстрее (прототип работал в 20 раз быстрее на GCC и Clang'е, но пришлось от него отказаться из-за ограничений MSVC, который, видя функция на 20000 строк «поднимал лапки кверху» и отказывался её оптимизировать).Специально работаю на старой технике, зато знаю, что если у меня оно ворочается, то у пользователей будет бегать.Не всегда хороший варинт: это обозначает, в частности, что вы не можете перенести работу со времени исполнения на время компиляции — а это часто даёт ощутимую прибавку к скорости…
Перенести работу на время компиляции могу. Хотя лучше наоборот — сделать компиляцию во время исполнения. Вообще, человек, привыкший к тому, что компиляция всего проекта идет порядка часа — может очень многое.
А час на проект последний раз было в 1993 году, на СУБД Libra… Тогда как раз компиляцией поисковых запросов в машинный код удалось достигнуть скорости полнотекстового поиска по базе в 2 раза меньше, чем скорость считывания файла базы с диска. И это на I386. Собственно компиляцию писал Антон…
А кто мешает тестировать inline-функции, генератор автогенеренного кода и так далее?Никто не мешает. Так и было сделано. Но, понимаете ли, когда вы тестируете функцию реализующую конечный автомат на полторы тысячи состояний, то любимые фанатами TDD трёхстрочники как-то «не срастаются». Подсистема тестирования получается достаточно сложная сама по себе и на классические юнит-тесты с мокапами всего, в чём больше 10 строк кода — нифига не похожая.
P.S. Понятно что, собственно, функцию реализующую вышеописанный автомат никто не тестировал: автомат-то был порождённый! Так что тестировались свойства самого автомата и программы, порождающей из него код (хотя она-то как раз достаточно простая).
Вдумчивое написание и ревью 2-3-10 разработчиками — для небольших компонент, где цена ошибки высока и производительность таки важна.
Если же вам нужно разработать систему на сто миллионов строк с максимальной производительностью… ну могу верёвку с мылом, разве что, подарить…
Ну а поскольку отлаживать то, что еле ворочается, неудобно, то волей-неволей узкие места ускоряешь.
Все-таки даже в большой системе на производительность серьезно влияет пара процентов кода.
Что именно в нём тестировать я говорить не возьмусь
Видите как тесты зависят не только от функциональности модуля, но и от его внутренних алгоритмов? Функцию, которой вы пользуетесь
В приведённом вами примере есть два блока-функциональности: вычисление факториала и кеш-машина.
Увы, факториал — это не синус. Для синуса вы были бы правы. Но 8! = 8*7! = 8*7*6! = 9!/9 = 10!/10/9. То есть кэш нам нужен особенный, выдающий ближайшее значение. И записывать в к кэш надо хитро, не все подряд, а так чтобы охватить диапазон. И само вычисление факториала хитрое — две ветки, от большего считать или от меньшего.
Так что на два модуля делить — неправильно. слишком уж межмодульных завязок много. Получается один сложный модуль.
Впрочем, достаточно примера с memcpy.
Функцию, которой вы пользуетесь ежедневно часто, вы не возьметесь тестировать, не зная внутренних алгоритмов.
Нет, я её не возьмусь тестировать, т.к. я ей не пользуюсь, не знаю её контракта и не могу его вычислить по её коду — слишком слабо знаком с языком, на котором она написана.
Вам не кажется, что это приговор всесильности TDD?
Думаю предыдущим комментарием я развеял ваши заблуждения на тему того, почему я функцию не могу протетстировать? Ну а по поводу этой фразы — я как раз таки не осилил переход на TDD, я не умею мыслить в нужной парадигме.
Так что на два модуля делить — неправильно. слишком уж межмодульных завязок много. Получается один сложный модуль.
Было бы желание. Вы просто не хотите придумать модульный вариант.
слишком слабо знаком с языком, на котором она написана.
Для сферического TDD в вакууме неважно, на каком языке функция написана. Важно — её API на том языке, с которого на вызывается. Так что достаточно знать С или С++ или ещё что, основанное на POSIX.
Вы просто не хотите придумать модульный вариант.
Придумать модульный вариант как раз легко. Модуль-хранилище, модуль извлечения ближайшего значения, модуль выборочного запоминания в кэше, модуль расчета факторала об большего, модуль расчета от меньшего, модуль-дирижер. Итого — 7 модулей. Бинго! :-)))
А вот вам советую попробовать придумать двухмодульный вариант, и написать межмодульное API. Тогда и поймете, что это мягко говоря неправильно.
Так что достаточно знать С или С++ или ещё что, основанное на POSIX.
О чём я и говорю — контракта я не знаю. А попытка вычислить по коду проваливается из-за недостаточного знания языка.
А вот вам советую попробовать придумать двухмодульный вариант, и написать межмодульное API. Тогда и поймете, что это мягко говоря неправильно.
А я где-то говорил, что должно получиться строго два модуля?
Таким образом, для сильно оптимизированных функций, основная идея TDD неверна. Мы не можем писать хорошие тесты до программирования. ибо на этом этапе не знаем, какие случаи будут выделены для оптимизации.
Что касается деления на модули, ну да, memcpy так и просится разделить её на полторы сотни модулей Примерно столько частных случаев и есть в приведенном коде. Вот только или бескомпромиссная оптимизация — или деление на модули. В том же факториале, выигрывая десяток тактов на умножении — нет смысла их терять на межмодульных связях.
Думаю, что на примере memcpy очевидно, что быдлокод — прост для изменения, а хорошо оптимизированный, вылизанный код — для изменения сложен.
Вот только контракт — недостаточен для написания исчерпывающих тестов.
Не надо выдавать общую проблему программирования за нормальное явление.
Таким образом, для сильно оптимизированных функций, основная идея TDD неверна.
Сильная оптимизация функций не должна ломать контракт. А TDD работает именно с контрактом.
Вот только или бескомпромиссная оптимизация — или деление на модули. В том же факториале, выигрывая десяток тактов на умножении — нет смысла их терять на межмодульных связях.
очень зависит от соотношения затрат на вычисления.
Думаю, что на примере memcpy очевидно, что быдлокод — прост для изменения, а хорошо оптимизированный, вылизанный код — для изменения сложен.
Вы уверены, что там быдлокод? Быдлокод и вусмерть оптимизированный — вещи разного порядка.
Иными словами — полнота тестирования по TDD в отдельных случаях — липовая. В данном случае TDD проверит меньше процента того, что нужно проверить.
Что касается быдлокода — гляньте в вики. Первая версия — быдлокодистая. но простая для понимания и модификации. Оптимизированная версия — уже не быдлокод, но понимается и модифицируется хуже. А «вусмерть оптимизированный» код вообще модифицируется с большим трудом. В отличие от быдлокода.
P.S. Если под быдлокодом вы понимаете что-то иное, то опишите, что именно.
Сильная оптимизация функций не должна ломать контракт.Я провильно понимаю, что TDD предлагается использовать там где некое априорное знание говорит нам о том, что фунция всегда будет соблюдать свой контракт?
А TDD работает именно с контрактом.Нет, она, как бы с кодом работает. А дальше — возникает дилемма: что и как тестировать-то? Два случайно выбранных варинта или десять? А может сто? А что ещё вы можете придумать не имея кода (а в TDD, как бы, тесты пишутся до кода, да).
Я уже рассказывал про обработку x86 кода. Так вот там, среди прочего, был ещё и конечный автомат, который выделял опкоды и другие части валидных инструкций. В нём было порядка трёх тысяч состояний. Для тестирования — была написана программа, которая просто загружала этот автомат и строила все последовательности байт, которые этот автомат, в приниципе, мог принять, выкидывала «неинтересные» различия (иначе последовательностей получалось уж слишком много: один mov с 64-битным числом даст вам квинтиллионы допустимых последовательностей), затем проверяла разными способами результат работы на этих последовательностях.
А куда вы тут свой любимый TDD прикрутите? Как тут осмысленный тест до написания кода написать?
TDD требует «нашинковать программу» в мелкую лапшу — такую мелкую, чтобы каждый кусочек не имел никакой сложной внутренней логики! Но, простите, далеко не всего программ имеет смысл так писать — да и не факт, что так вообще все задачи в принципе решить можно (хотя, пожалуй, можно — если скорость работы нас не волнует от слова «совсем»).
Я провильно понимаю, что TDD предлагается использовать там где некое априорное знание говорит нам о том, что фунция всегда будет соблюдать свой контракт?
Нет, тесты в TDD как раз проверяют, исполняет ли функция контракт.
Два случайно выбранных варинта или десять? А может сто?
Зависит от контракта. Из него выделяются области эквивалентности параметров и пишется столько тестов, сколько нужно для их перекрытия. Если в ходе имплементации контракта разработчику становится очевидным, что есть особые случаи типа арифметического переполнения, не предусмотренных контрактом, то пишется тест их выявляющий и добавляется код обхода. или контракт изменяется. Если разработчик не заметил, что в его реализации есть особые случаи, не предусмотренные контрактом, то рано или поздно приходит баг-репорт с таким случаем, пишется тест и обход случая. Ну или заявление "это не баг, это фича" :)
хотя, пожалуй, можно
Нельзя. TDD применим только к задачам, где есть чётко детерминированный результат заранее известный для тестируемого состояния системы. На моей практике в геймдеве и финансах TDD был не применим для моделирования процессов зависящих от ГСЧ и текущего времени. Можно тем или иным способом из тестируемого модуля вынести генерацию СЧ или получение времени в зависимость модуля и протестировать логику зависимости для конкретных значений, но полностью процесс — нет: на каком-то уровне приходилось хардкодить получение СЧ и времени и этот уровень (и вышележащие) тестированию уже не поддавался. И это только по тестированию контрактов, что в голову пришло.
Если упарываться, модуль с факториалом ещё определяет конкретные стратегии (sparse'вость кеша, политика его опустошения и тому подобное)
Вот-вот и я про это. Стратегии кэша определяет вовсе не модуль кэша, а модуль факториала. В итоге модульные тесты ни модуля факториала, ни модуля кэша не проверяют эффективность стратегии. Для её проверки — надо тестировать оба модуля сразу.
Можно наоборот, определять стратегию в модуле кэша, а ему давать каждый вычисленный результат. Тогда кэш очень много будет знать о факториале. Этот способ чуть проще, ибо для того, чтобы решить, запихивать ли в кэш 37! нам надо знать, есть ли там 36! или 38! Модуль кэша об этом знает, а модулю факториала — надо для этого давать лишние ручки.
В итоге, что так, что так — нехорошо. Лучше уж единый модуль.
Знание применённых методов оптимизации позволяет вам существенно сузить это пространство.
Конечно. Вот только это уже не TDD. потому что сначала — разработка методов оптимизации, а уж потом — написание тестов. Этот пример показывает, что TDD — не универсален. Он хорошо работает, если логика очевидна из ТЗ. А если есть куча оптимизаций, не прописанных в ТЗ, то TDD лажает.
А юнит-тесты и не должны проверять эффективность.
Если вы пурист, то можете при наличии любого библиотечного вызова считать, что у нас не unit-тест. Я предпочитаю обратный подход. Есть модуль — и есть то, что он использует (библиотека). И тест эффективности — это тест именно модуля.
В целом приложении неэффективность размазывается по модулям. Тестируя отдельную операцию, мы понимаем, правильный ли уровень оптимизации алгоритма выбран. Не надо ли переписать в 100 раз длиннее и в 10 раз быстрее. :-)
Но лучше — сразу писать корректноКонечно, лучше. А еще лучше — сразу писать программу, которую Google за миллиард купит.
Написать корректно — дорого, но реально.Я вот не знаю методов, которые позволили бы получить гарантию соответствия кода ТЗ, а также соответствия ТЗ тому, что в голове у заказчика (внутреннего или внешнего). Если у вас есть какая-то релевантная информация — поделитесь, я бы с радостью изучил подходы, дающие такие результаты.
Подход дорогой, но у нас было 2 часа на отладку в месяц.
Мой коллега — так просто пишет без ошибок. Зато медленно…
А учитывая отсутствие гарантии получается, что совет «пишите сразу корректный код» — это «за все хорошее и против всего плохого». Я бы и не против сразу все правильно написать, вот только риск ошибки у меня есть всегда. И поэтому чаще всего, то есть в случаях, если цена ошибки достаточно высока, придется как-то ошибку искать и исправлять.
Я бы и не против сразу все правильно написать,
А экономика? Можно писать со скоростью 5-10 строк в день и без ошибок, но эффективней — писать в 20 раз быстрее, но с отладкой.
И поэтому чаще всего, то есть в случаях, если цена ошибки достаточно высока, придется как-то ошибку искать и исправлять.
Вы о тестировании или о ситуации, когда ошибка как-то проявляется? Если проявляется — искать и исправлять. А тестировать драйвера тяжко, тут по-хорошему нужна виртуальная машина с имитатором той микросхемы, для которой пишется драйвер. Ну в общем проще сразу хорошо написать чем возиться.
вы втроем этот код не только вычитывали, но и писалиНет.
Вы о тестировании или о ситуации, когда ошибка как-то проявляется? Если проявляется — искать и исправлять. А тестировать драйвера тяжко, тут по-хорошему нужна виртуальная машина с имитатором той микросхемы, для которой пишется драйвер.Я говорю о тестировании. А если при вашем подходе регулярно встречается ситуация «бага была обнаружена конечным пользователем», то я бы не сказал, что вы «сразу пишете работающий код».
А насчет сложности тестирования драйверов — казалось бы, это бизнес-вопрос. Если потери от баги будут больше, чем затраты на тестирование, то тестирование у вас будет. Собственно именно это я и понимаю как «цена ошибки достаточно высока». Разумеется, пока пользователь готов мириться с ошибками, а тестирование стоит дорого, никто его не будет делать. Но только в этом случае.
А если при вашем подходе регулярно встречается ситуация «бага была обнаружена конечным пользователем
Это КАК, простите? И сразу в голове багрепорт:
Купив новую стиральную машину, я решил её проверить. Случайно у меня в кустах завалялся рояль десятиканальный осциллограф. Исследовав обмен с датчиком температуры, я выяснил, что он занимает 112 микросекунд вместо положенных по даташиту 98. Прошу немедленно исправить, а то мне стремно с этим багом стирать носки.
Пользователь для драйвера — это мы сами. Конечный пользователь получает устройство. И рапортовать об ошибке в драйверах — просто не может.
Если потери от баги будут больше, чем затраты на тестирование, то тестирование у вас будет
Не-а. Будет вычитка кода
Реальный пример. Комп MOXA IA3341-LX, ключ Guardant Code micro, linux 2.6.9. Незадолго до отправки заказчику обнаружили, что примерно через 3 часа обмен с ключом по USB прекращается и не восстанавливается вплоть до перезагрузки. Разработчики ключа чешут репу, разработчики компа — молчат как партизаны.
Для тестирования нужен минимум анализатор протокола USB со сроками поставки недели 3. Ну и согласие разработчиков ключа на реверс-инжениринг их протокола.
В итоге плюнули на тесты и я сел читать код USB-подсистемы linux. И за пару дней нашел подозрительный кусок. А в следующей версии — патч, который эту ошибку исправлял.
А теперь подумайте, сколько дней мы бы ждали логического анализатора USB и сколько дней бы занимались тестированием? :-)
Собственно именно это я и понимаю как «цена ошибки достаточно высока».
См. выше. Перезагрузка раз в 3 часа вместо пары раз в год была абсолютно неприемлема для заказчика. И баг был не наш. И все равно — обошлись без тестирования.
Я не против тестирования там, где затраты на него малы. Но там, где дешевле написать код заново, чем тестировать — там лучше вычитка кода вместо тестов.
Незадолго до отправки заказчику обнаружили
В процессе тестирования?
Ошибки у нас в коде — это понятно, ошибки в радиостанции — тоже не новость, а вот ошибки в ядре — мы совсем не ожидали.
А вы? Вы тестируете ядро операционной системы?
Это КАК, простите?А вот так:
Пользователь купил стиральную машину, нажимает на кнопку «постирать», а она пищит и ничего не делает. Он обращается в техподдержку, которая, убедившись в наличии проблемы, создает во внутренней системе багу на команду, которая делала кнопку «постирать». Там команда разбирается, выясняет, что это из-за того, что драйвер датчика температуры отвечает медленнее, чем нужно, и создает багу на вашу команду.
Не-а. Будет вычитка кодаСтоимость поиска баги довольно быстро растет при повышении требуемого уровня качества. В какой-то момент станет просто дешевле сделать небольшое тестирование, помимо вычитки. То же самое, кстати, верно и в случае, если используется только тестирование, если оно довольно дешевое — при повышении требуемого уровня качества оно быстро становится дороже и заменяется на комбинацию этих подходов.
Я не против тестирования там, где затраты на него малы. Но там, где дешевле написать код заново, чем тестировать — там лучше вычитка кода вместо тестов.Абсолютно согласен, вот мы и пришли к взаимопониманию.
Собственно, по изначальному сообщению
Но лучше — сразу писать корректно. А ошибки искать — вычиткой кода.Я сделал вывод, что вы знаете какой-то идеальный метод, позволяющий вам лично писать абсолютно безошибочный код, а ошибки других, по вашему мнению, всегда и везде лучше искать вычиткой кода. С этими утверждениями я и спорил.
Там команда разбирается, выясняет, что это из-за того, что драйвер датчика температуры отвечает медленнее, чем нужно, и создает багу на вашу команду.
А если на производстве не тот кварц поставили? А если процессор с другой тактовой? Ну в общем запас менее 10 раз по скорости работы датчиков — это профнепригодность прикладной команды. Скорее всего используют асинхронный датчик как синхронный и вообще таймаут не сделали.
Стоимость поиска баги довольно быстро растет при повышении требуемого уровня качества.
Неоднозначненько. Если вы про обнаружение, есть ли баг вообше — то согласен. А если известно, что ошибка есть (и стабильно проявляется) и вы про обнаружение неправильного кода в модуле, то как правило, есть брутто-методы, гарантирующие нахождение ошибочной строки за какой-то большой, но конечный срок.
Я сделал вывод, что вы знаете какой-то идеальный метод, позволяющий вам лично писать абсолютно безошибочный код,
Есть он. Просто не для всех годится. Ну вот есть у меня коллега, который пишет без ошибок. Разумеется, у него это получается медленно. Но в итоге — все равно быстрее, чем писать с ошибками, а потом править. Так что метод — поручить коллеге, дать ему всю информацию и вагон времени. :-))))
Но у коллеги так — каждый вызов функции проверяется по API. Даже то, что пишется по 5 раз за день — все равно каждый вызов пишется по документации. Ну в общем это человек, который в одиночку написал фоторадар.
Но мы его никому не отдадим. Такой монстр нам самим нужен. :-)
Если вы про обнаружение, есть ли баг вообше — то согласен. А если известно, что ошибка есть <...>, гарантирующие нахождение ошибочной строки за какой-то большой, но конечный срок.Да, я про обнаружение неизвестного бага. Если есть сценарий воспроизведения, все гораздо проще.
Ну вот есть у меня коллега, который пишет без ошибок.Извините, как-то не верится, что у него прямо никогда не бывает ошибок и в будущем никогда не будет, ибо я встречал немало людей, которые тоже очень внимательны и документацию все время смотрят, но ошибки у них всегда были. Может, у него еще какой-то секрет есть?
Может, у него еще какой-то секрет есть?
У одного коллеги был секрет — всё, что я стараюсь юнит-тестами отловить, он отлавливал просто запуском программы (иногда специально "взломанной" для получения нужного исходного состояния) и ручным вводом тех же параметров.
Да, я про обнаружение неизвестного бага.
Согласен. Тяжело искать черную кошку в черной комнате, особенно когда её нет. Если известно, что баг есть — все становится немного проще.
Может, у него еще какой-то секрет есть?
Синтетик он, чистый. То есть в чужом коде разобраться — это для него огромный труд. Проще свой собственный код написать.
Извините, как-то не верится, что у него прямо никогда не бывает ошибок и в будущем никогда не будет,
При недостатке времени — бывают. А достаток времени — это год какая-то функция не пишется, потому что непонятно, как хорошо обработать частный случай, который бывает в 0.01% ситуаций.
Но реально, код очень простой и надежный.
Если мы хотим найти побольше ошибок — эффективней обычно вычитка.
Если мы знаем, что в коде есть ошибка, и имеем информацию, как она проявляется — вычитка становится сильно эффективней тестов.
Другой момент, что вычитка автором — неэффективна совсем. Вычитывать должен другой программист.
Советую вам поспорить с любителями стат.анализа. В конце концов стат.анализ — это автоматизированная вычитка.
TDD (как и любое тестирование) — вообще не ищет ошибку. Оно лишь дает признаки, что ошибка есть. А сама ошибка в коде все равно находится вычиткой. Так что мала концентрация внимания или нет — но все равно все ошибки найдены вычиткой.
С концентрацией внимания в TDD все хуже, чем при вычитке. И дело не только в if (arr[3] == 'a') launch_missiles();, но больше в том, что тестирование — это вгляд на программу с другой стороны. Не со стороны синтеза, а со стороны анализа. Программеры — синтетики, а для написания хороших тестов надо быть аналитиком.
Статический анализ — это автоматизированная вычитка. И обладает всеми преимуществами и недостатками вычитки. В том числе и нахождением ошибочной строки кода, а не признаков ошибки. Мощная система типов — это полезно. Собственно за повышенную мощность типов (диапазонные типы, множества) мне и нравится Дельфи.
К сожалению, при вычитке, как при тестировании, автор кода работает плоха. Глаза замыливаются и автор читает то, что ему кажется, а не то, что написано в коде. Ровно так же при тестировании — тестирование автором не находит очень многих ошибок.
В целом — я вас прошу определить позицию в виде тезисов. Мой тезис простой: TDD часто используется как карго-культ, без понимания реальных ограничений.
Вычитка (слово понравилось, надо зафиксировать) и тесты ортогональны, тесты ловят проблемы, которые не замечаются человеком из-за специфики мышления (то же «замыливание» только первый эффект из многих) и проблемы соответствия внешней среды ожидаемому, а вычитка — что реализация в принципе делает то, что ожидает человек. Тесты без вычитки превращаются в формальность, не требующую работы кода за пределами тестов, а вычитка без тестов — в сферическую работу в вакууме. При хорошем качестве разработчиков (как Вы уверждаете про своих) глупых ошибок и мифов — очень мало, остаются ошибки и несоответствия внешней среды (тот пример с USB за 3 часа — очень показателен).
Основная беда TDD — тестирование по модели белого ящика. То есть при написании кода заведомо известны тесты ( что они проверяют, а что не проверяют). При классическом тестировании (черный или серый ящик) вообще не встает вопрос о том, что пишется раньше — тесты или код. Они пишутся независимо. И шансы, что и тестер и девелопер пропустят какой-то случай — равны произведению шансов на пропуск одним из них.
Если девелопер или тест забывают какую-то сложную ситуацию с шансом 10%, то шансы, что забудут оба — всего лишь 1%. Таким образом, отказ от TDD в пользу независимых тестов в 10 раз улучшает работу программы в сложных ситуациях.
Это только кратковременная задача для одноразовых тестов. Долговременная же задача — обеспечить условия для проверки по сути (вычитка, верификация).
В это может входить что угодно вплоть до проверки базовых свойств среды. У меня в одном проекте есть в тестах assert(sizeof(long)) == 8 — вот решили, что лучше завязаться и обложить проверками.
Но чаще ими покрываются крайние случаи.
Да, я видел и помню Ваши предыдущие реплики по поводу, например, невыгодности написания тестов авторами кода. У меня другая специфика, и >90% тестирования идёт таки авторами. Поэтому тут идеально общей позиции не будет.
> А в TDD проблема в решении обратной задачи — «доказать, что ошибок нет». И вот эта обратная задача — решается ещё хуже, чем прямая.
А её в принципе нельзя решать тестами. Для этого есть верификация. Тесты — средство обеспечения надёжности самой верификации.
TDD к этому ни при чём — это средство управления добавлением функциональности при разработке, а не обеспечения качества.
> Основная беда TDD — тестирование по модели белого ящика.
Не тестирование. А написание кода под тесты.
> Если девелопер или тест забывают какую-то сложную ситуацию с шансом 10%, то шансы, что забудут оба — всего лишь 1%. Таким образом, отказ от TDD в пользу независимых тестов в 10 раз улучшает работу программы в сложных ситуациях.
Это аргументы за независимое тестирование — они сильнее, чем просто против TDD.
У меня в одном проекте есть в тестах assert(sizeof(long)) == 8
Рекомендую использовать CCASSERT, то есть assert времени компиляции. И коли ваш проект кроссплатформенный, то делать это не в тестах, а в основном коде. Верещать о том, что компиляция идет не на ту платформу — надо при компиляции, а не при выполнении или тестировании.
Долговременная же задача — обеспечить условия для проверки по сути (вычитка, верификация).
Предпочитаю разделять задачи. Проверки во время выполнения — нужны для робастности. То есть отдельно — подсистема логгирования, отдельно — контроль инвариантов, отдельно — подсистемы перезапуска систем. И совсем отдельно — тесты. Цели у них разные.
Задача тестирования — найти ошибку. Задача проверок в рантайме — как можно раньше найти сбой инвариантов. Задача логгирования — зафиксировать все необычное (и часть обычного). Задача перезапуска — обеспечить работу приложения несмотря на ошибки в нем.
TDD к этому ни при чём — это средство управления добавлением функциональности при разработке, а не обеспечения качества.
Как средство разработки я его тоже иногда использую (и использовал задолго до того, как этот метод получил имя). Но… вы видели менеджера, который при TDD со «100% покрытием» будет тратить средства на полноценное тестирование? Вот и получается, что или тестировании или TDD.
А чем static_assert не угодил?
Его нет в Си.
Когда вы пишите библиотечные код, возможность его компиляции в Си является достоинством. А исходный assert прямо указывает на библиотечный код.
Чтоб два раз не вставать — в Си-style намного лучше с инкапсуляцией. Можно написать в заголовке struct internal_data; и пяток методов, в которые передается эта структура. Описание полей самой структуры и приватные процедуры будет только в.с/.cpp. А вот в С++ в заголовочном файле будут и приватные члены и приватные методы.
Ну и ещё один момент. Си намного проще запускается на голом железе. Обработчик прерываний на С++ написать можно, но это сложнее, чем на Си. Так что все, потенциально вызываемое из прерываний (а также асинхронных вызовов ОС и так далее) — сишное. Точнее — транслируемое и в Си и в С++.
Разумеется, если те же классы нужны по делу, то есть упрощают написание в 2-3 раза — надо их использовать. Как и все прочие фишки С++. но если получается 5% туда-сюда, то лучше на Си.
Если вы потом собираетесь это из других языков дёргать, то да, например.
Тогда жду ссылку на ОС, написанную на С++. Или делающую вызовы в стиле С++. В конечном итоге любой С++ный код дергается через Cишный вызов. Когда это только main — это не так страшно, можно переходниками. В windows GUI -уже неудобно, сишных вызовов многовато. Ну а когда их совсем много…
В любом случае, мне не нужно, чтобы библиотечный код компилировался в С.
А вам много чего не нужно. Обработчики прерываний писать не нужно, например. Работать на FreeRTOS не нужно. Упихиваться в 512К ПЗУ и 392 ОЗУ не нужно. А у нас обратная картина. Большинство возможностей С++ не нужно. Зато возможность компиляции на Си — очень полезна. Ну хотя бы потому, что есть шансы нарваться на машинку без С++.
Вы слышали что-нибудь про идиому pimpl?
Глянул. Сложный путь сделать то, что в Си делается просто. Хороший пример, как на пустом месте наворачиваются абстракции. Очень рекомендую почитать мнение моего бывшего коллеги про таких любителей ООП. Впрочем, рекомендую прочесть всю книжку — она реально полезная.
Какая библиотека нужна для вариадиков? Для лямбд? Для move semantics?
А вы слинкуйтесь без с++ библиотеки — и увидите. А самая гадость в том, что С++ библиотека вывод сообщений об ошибке делает через iostream, так что ещё и его за собой тащит.
Если вы потом собираетесь это из других языков дёргать, то да, например.
Я не понял этого логического перехода вот сейчас.
Печалька! Увы, пока ОС не написана на С++, С++ный код будет вызываться из Сишного. Говоря вашим языком «дергаться из других языков». В нашем случае — в нескольких десятках мест.
Это подавляющему большинству программистов не нужно, включая тех, кто (добровольно) пишет на С.
Вы предлагаете мне сменить работу? Ну так, если менять работу — то на delphi, oberon, modulu-2, kotlin, rust, а не на С++. Нам — нужно. На этом точка.
На плюсах я упихивался в attiny, кстати, в своё время. Ну, да, -fno-rtti -fno-exceptions, какой ужас.
АГА, АГА. Без iostream, без new, без pure virtual и так далее. Многое там остается от С++? Многие части С++ будут жить без new?
И вот тут и встает вопрос. Что удобнее для задачи — писать на С++, но помнить, что большую часть использовать нельзя или писать на практически полном Си? Если есть полиморфизм — может быть удобнее и на С++. Если его нету — удобнее полный Си.
С полутора макросами это всё вообще начинает выглядеть вполне красиво и пристойно
А если ещё написать свой препроцессор — так и вообще красота. :-)) Не пугайтесь, это сарказм был. я просто RATFOR вспомнил.
отбросим необходимость перекомпилировать клиентский код при изменении хедера.
А вы не отбрасывайте. А то получите необходимость поставлять все библиотеки в исходниках. Или перекомпилировать ядро при изменении любого драйвера.
А основной плюс — уменьшение размера заголовков. Некоторым намного удобнее, когда заголовочные файлы короткие.
Кому удобнее?
Программисту удобнее, когда весь внешний интерфейс модуля — это страничка. Особенно это если это linux oldscool, то есть работа в командной строки с редактором vi (а GUI нет, ибо частенько ходим через ssh).
Да, можно иметь отдельно настоящие хеадеры, а отдельно их урезанную часть без private и потрохов темплейтов. И менять оба варианта синхронно или генерить один по другому. Ну или вообще делать документацию на внутренние модули. Но это увеличивает трудоемкость и сроки.
Одно дело, если у нас сотня программистов и трудоемкость человеко-годы.
Тут параллельная документация может и ускорить проект. Другое дело, если у нас 1-3 программиста и меньше человеко-года на проект. Тут лучше иметь смодокументируемые читаемые хеадеры.
Зачем? У вас наружу интерфейсы торчат, и всё. Ну, если уж правильно инкапсуляцию делать.
Ну сделайте на своем собственном проекте по вычислению производной в compile time. :-) Если сделаете — покажите. :-) Код у вас весьма неплохой, кстати.
Эм, я сходу не припомню, где в «C++ библиотеке» вообще вывод сообщений об ошибке?
Ну почитайте про __cxa_pure_virtual и __cxa_guard_acquire. Это чисто С++ прибамбасы, на Си они не нужны. Вывод сообщения есть в __cxa_pure_virtual и __cxa_deleted_virtual. Это старый С++, а что уж там добавлено в новом — чет его знает.
Как-то странно делить задачи по критерию «есть полиморфизм — нет полиморфизма».
Вы так уверены что ООП — в любой бочке затычка? Ну значит вас не учили программировать в процедурном стиле, поэтому понять, что в одних задачах ООО дает выигрыш в производительности, а в других — проигрыш, вам трудно. Тогда просто поверьте, что это и вправду так.
Вариадики, лямбды, мувы и constexpr, которым нужна какая-то библиотека, ага.
Дались они вам! Не вы ли писали, что ни разу в жизни не использовали функции с переменным числом параметров? Правда потом выяснилось, что про printf забыли. Ну вот и у меня ни разу не было необходимости использовать вариардики.
Понимаете, С++ это язык, который плодит проблемы, а потом их мужественно затыкает. Зачем нужны move? Прежде всего для возврата объектов из функции через return. То есть вначале в С++ не запретили возврат объектов из функции. Ну мало ли, объект маленький, накладные расходы будут не так велики. А потом стали использовать это и для больших объектов. И тут жестко потребовался move. А если мы не передаем объекты через return — никакой move нам не нужен.
constexpr — ну может доделают когда-нибудь. Пока что inline работает предсказуемей.
Лямбды — пока в них нужды не было.
Зато есть куча других вещей, которых в C++ не хватает. Например finally, property, interafce, отображения hadrware exception в исключения и так далее. Вы ими никогда не пользовались, потому даже не буду пытаться объяснить, зачем они нужны. Но это не только синтаксический сахар, но и реально ускоряющие разработку некоторых программ вещи.
Или вы на проде файлики редактируете?
Что такое прод? Вот есть у меня 20 роутеров, кто из них прод, а кто нет? Воткнули USB-флэшку — это ещё прод или уже нет? Загрузили полный linux с флэшки — 'это ещё прод? Воткнули консоль в разъем — это ещё прод?
Фактически прод от «не прода» отличается тем, что технологический разъем можно не впаивать. Но обычно впаивается — он для диагностики полезен. А так — памяти на linux-машинках на компиляцию хватает, а если веши железоспецифичные, то цикл отладки на самой железке хватает. Ну а на x86-машинках вообще стоит полный дебиан (только что без GUI), там просто нету смысла buildroot ставить. Там где linux нету — там иначе.
Про остальное — потом отвечу
Это не старый С++, это вообще не часть стандарта С++, это деталь реализации.
Ну скажем так, это деталь реализации, обусловленная стандартом. Мы не можем выполнить чисто виртуальный метод, но что-то должны сделать. Разумнее всего — завершиться с выводом сообщения. Если бы стандарт требовал вызвать исключение — было бы проще. Впрочем, завершение по непойманному исключению — тоже требует вывода сообщения. Ну по стандарту, небось, можно и втихую завершиться, но разумнее — выдавать сообщения. Так что в каждом С++ рантайме какая-то выдача сообщений будет.
На всякий случай уточню: как-то странно делить задачи по критерию «есть полиморфизм — нет полиморфизма» в контексте спора C vs C++
Знаете, писать полиморфизм на Си — это ещё то извращение. Если уж полиморфизм есть, то С++ даст выигрыш во времени написания и отладки. А если полиморфизма нет — то Си может быть дешевле. Или как у нас — Си с элементами С++.
Можно, конечно, носиться туда-сюда с указателями, но вам теперь резко нужна куча, не самое быстрое выделение памяти и так далее.
Угу, возвращаются указатели (или ссылки), а не сами объекты. Выделение памяти — быстрое, за счет предварительно накачанных список. Мы этой техникой ещё 25 лет назад пользовались. В куче выделяются области памяти, кратные 16. Создаем массивы с указателями на области памяти. Один массив — на длину 16 байт, другой на 32, третий на 48… И на каждый массив — битовую шкалу, кто выделен, а кто нет. Получается очень быстрое выделение памяти, намного быстрее копирования объектов.
У меня есть свои претензии, но чем именно вас не устраивают чистые абстрактные классы в плюсах?
Множественным наследованием. Но вы правы, можно и так делать.
Вот это да, нету. Но это всё равно платформозависимо, как это может быть в рамках языка?
Здрасти, приехали. signal — плаитформеннонезависим, почему его отображение в исключения будет платформенно зависимо?
От платформенной информации нам нужна только запись в лог. А основное, что нужно — не зависит от платформы. Это деление на классы:
- Внешние действия, вроде SIGABRT и SIGINT
- Ошибки в коде, вроде SIGILL, SIGSEGV
- Что-то исправимое, вроде нехватки памяти (оно и так exception)l
А в итоге получаем, что при любом сбое программа сохраняет свои данные. Если вы так боитесь, что данные могут быть испорчены — то защитите их CRC и делайте две копии, переключаемые атомарно.
Реализовывал ещё будучи школьником в бородатом 2003-ем. Ну, да, из коробки нет, ужас.
Вы просто не понимаете, зачем они нужны. Вот есть у вас класс, в классе — поле. И при помощи пропертей, вы легко делаете обработчик на чтение или запись этого поля. При этом код, использующий ваш класс, вообще не меняется. Это одно из средств, позволяющих легко исправлять ошибки дизайна.
Ни разу ни один предикат не нужно было создать для std::find_if/all_of/partition/whatever?
Угу. Мы же пишем на Си с элементами С++. Так что STL не используется.
Зачем писать код, компилируемый только С++, если нам не нужны классы?
Потому что C++ — это не только классы.
С тем же успехом можно протестовать против перехода на C++11 и старше, по причине того, что хочется совместимости с C++03.
А вот в С++ в заголовочном файле будут и приватные члены и приватные методы.
Я не понимаю, почему для бибилиотеки нельзя сделать C-compatible заголовочный файл (т.е. extern C и #ifdef __cplusplus), а саму реализацию на C++?
Ну и закончу тем, что для компиляции C, C++03, C++11 и т.д. зачастую используется один и тот же компилятор с разными ключами. Но даже если компиляторы и разные, то линкер все равно один. Вы не получите преимущества от ограничения на использование только С.
Единственная причина, по которой сейчас стоит использовать именно C — отсутствие компилятора C++ под целевую архитектуру.
Потому что C++ — это не только классы.
А что в неё есть полезного для машинки с 64К ОЗУ? Ну или для довольно большой машинки с 512К ОЗУ?
Ну как пример — есть поточный ввод-вывод. Вот только размер библиотеки… Реальность такова, что даже обычный printf слишком велик. В итоге используется xprintf размером в 200 строк.
И так примерно со всеми возможностями С++. Или они не нужны в данной задаче или просто не лезут во все области применения.
С тем же успехом можно протестовать против перехода на C++11 и старше, по причине того, что хочется совместимости с C++03.
Единственная причина, по которой сейчас стоит использовать именно C — отсутствие компилятора C++ под целевую архитектуру.
Вы противоречите сами себе. Отсутствие компилятора С++11 под одну из возможных архитектур — достаточное основание.
Вы не получите преимущества от ограничения на использование только С.
Поржал. Для начала — попробуйте втиснуть ваше приложение ну скажем в 64К ПЗУ. А потом сами увидите, от чего стоит отказаться.
С++ очень полезен, когда в самой задаче есть полиморфизм. Но когда его нет, попытки искусственно приделать иерархию классов приводят к лишь увеличению кода.
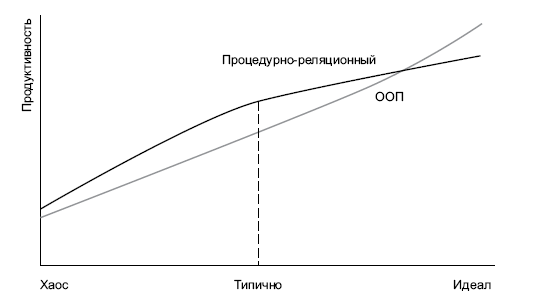
Вам я тоже очень рекомендую почитать про ООП у Сергея Тарасова. А ещё лучше — всю книгу целиком.
Мы не планируем отказаться от С++ в тех местах, где он нужен. Но где не нужен — лучше писать на Си.
А что в неё есть полезного для машинки с 64К ОЗУ? Ну или для довольно большой машинки с 512К ОЗУ?
Вспомните Borland Turbo C++, который под DOS.
Ну вот навскидку вещи, которые не увеличивают объём кода, но делают программирование более приятным:
- Вышеупомянутый static_assert.
- enum class, не засирающий глобальное пространство имён.
- Сами пространства имён.
- Шаблоны. Если их использовать аккуратно, могут оказаться вполне полезны, чтобы избежать дублирования исходного кода (но, понятное дело, не скомпилированного). Конечно, в С можно использовать макросы, но тестировать и отлаживать шаблонный код намного приятнее.
Вы противоречите сами себе. Отсутствие компилятора С++11 под одну из возможных архитектур — достаточное основание.
Да, основание, и я об этом написал. Но ограничивать себя в языке, если под все возможные архитектуры есть современный компилятор, плохо.
С++ очень полезен, когда в самой задаче есть полиморфизм. Но когда его нет, попытки искусственно приделать иерархию классов приводят к лишь увеличению кода.
Ещё раз: C++ — это не классы. Вы можете использовать возможности С++, которых нет в С, но не прибегать к использованию классов.
Если вы скомпилируете C-код C-компилятором и C++-компилятором, вы не увидите разницы. Так в чём проблема, кроме отсутствия C++ компилятора, отказывать себе в удовольствии?
Вспомните Borland Turbo C++, который под DOS.
Помню. 640К обычно не хватало, надо было UMB задействовать. Кстати, или Turbo C++ для Windows или Borland C++ под MS-DOS.
Так в чём проблема, кроме отсутствия C++ компилятора, отказывать себе в удовольствии?
А! Так вы программируете для удовольствия? Тогда есть много хороших вариантов. Oberon, например. Или Kotlin. Да и вместо собственной платы весом в 110 грамм можно использовать 10 килограммовый сервер на x86. И сразу рассчитывать на 16 гигов ОЗУ и 120гигов диска.
Мы как бы работаем, а не программируем для удовольствия.
Беда С++ — в жирных библиотеках. А если от них отказываться — преимущества не так велики.
Подумай о том, что самолет — намного быстрее автомобиля. Но многие ли ездят на работу на личном самолете? Ведь дело не в цене — сесна подешевле ягуара будет и сравнима с мерседесом.
Напишите для начала обработчик прерывания на С++. Или вместите С++ код в 64К ПЗУ.
Так что на С++ — только то, где у С++ есть преимущества. А где нету — лучше на Си. Обратите внимание, что почти все системные библиотеки написаны на Си.
Помню. 640К обычно не хватало, надо было UMB задействовать. Кстати, или Turbo C++ для Windows или Borland C++ под MS-DOS.
Turbo C++ 3.0 был под DOS.
Мы как бы работаем, а не программируем для удовольствия.
А что, ситуация, когда работа приносит удовольствие, это плохо?
Беда С++ — в жирных библиотеках. А если от них отказываться — преимущества не так велики.
Я написал преимущества, которые использую лично я. Например, DLL для работы с изображениями, нужно сделать 32 варианта одной и той же функции для нескольких вариантов комбинации типов изображений и режима обработки. Функции низкоуровневые, жутко оптимизированные. Вариант на C++ использует классы-шаблоны, чтобы избежать дублирования кода, который неизбежно бы был на C.
Подумай о том, что самолет — намного быстрее автомобиля. Но многие ли ездят на работу на личном самолете? Ведь дело не в цене — сесна подешевле ягуара будет и сравнима с мерседесом.
Причём тут это?
Напишите для начала обработчик прерывания на С++. Или вместите С++ код в 64К ПЗУ.
Без проблем. Просто пишем на C++ в стиле С.
Обратите внимание, что почти все системные библиотеки написаны на Си.
А раньше на ассемблере писали, и что из этого?
Turbo C++ 3.0 был под DOS.Не совсем. Если память вас подводит, то можете скачать и убедиться:
TC.EXE, TCC.EXE, and TLINK.EXE are now hosted under DPMI. These filesМинимальный обьём памяти был 2MB, кажется. Что больше всего бесило — так это то, что эта сволочь хотела DPMI, но компилировать подобные программы (в отличие от Pascal'я) не умела.
support protected-mode compilation and replace the files of the same
name in Turbo C++ Second Edition. Turbo C++ Second Edition should
continue to be used in instances where real-mode compilation is desired.
С другой стороны если вас интересует DOS, а не конкретно «компилятор в кофеварке», то и сейчас можно скачать свежий GCC 7.1.1 и поиметь поддержку C++14 (и частичную поддержку C++17)…
Вариант на C++ использует классы-шаблоны, чтобы избежать дублирования кода, который неизбежно бы был на C.
Ну если дублирование бинарного кода не важно (а важно лишь дублирование исходного кода) — я бы тоже так сделал. Но это у вас такая особая задача, где С++ полезен. У нас задачи другие. И в большинстве случаев — преимуществ от С++ нет.
Просто пишем на C++ в стиле С
И чем это лучше Си??? Тем, что не скомпилится Си-компилятором? Или тем, что нужно помнить, какие части С++ нельзя использовать? А список огромный, вообще-то. С++ные библиотеки вывод об ошибках через iostream делают.
Мне жаль, что вы не поняли аналогию. Попробуйте перечитать и понять её.
Кстати, системные библиотеки до сих пор пишут на Си. И с сишным интерфейсом. И переходить на С++ массово не собираются. И только там, где С++ дает реальное преимущество — библиотеки пишут на С++.
Собственно с чего это С++ной библиотеке делать ввод-вывод через Сишные функции?
Программировал на плюсах для удовольствия под attiny, что я делаю не так?
Да не на настоящих плюсах, а на жутко обрезанной диалекте. Плюс ещё и со специальной библиотекой для С++ или кем-то написанными заглушками. Да, можно и так извратится. И, если, задача подходящая — может быть и удобней, чем на Си. А если в задаче ничего от С++ не надо — будет чистой воды изврат. Такой С++-------, который больше похож на Си, чем на С++.
я вас понимаю, когда знаешь всего несколько языков — хочется писать на том языке, к которому привык. а когда знаешь языков много — выбираешь язык под задачу. Ваше управление лазером я бы предпочел на форте писать.
Начнем с малого — printf использует malloc. Даже в NewLib. Можно использовать xprintf, но возможности там обрезанные. Iostream нету по той же причине.
Как понимаете, std::vector тоже не будет. Как и 99% процентов STL. Соответственно не будет большей части boost и всех остальных библиотек.
Теперь конструкторы. Создавать объект в куче уже не получится — только статика и стек. А в статике с конструктором не очень. То есть придется реальные параметры передавать не в конструкторе, а через метод init. В стеке тоже размещать большие объекты не хорошо. Есть изврат с Placement new, но это ещё то извращение.
Дальше — многопоточность. Она обычно есть, но совсем не та, что в С++11. Потом exception. Их тоже обычно нету.
Ну вот и получается у вас С--, а не С++. А вот обычный Си страдает намного меньше.
я вам секрет открою. На самом деле формально у нас тоже С++. только от С++ там комментарии через // и передача по ссылке. Ну капелька классов и темплейтов — там, где они полезны. Фактически это Си с некоторыми расширениями.
я понимаю, вам сложно выучить Си после С++. Это известная проблема — тому, кто сразу учил С++ выучить Си очень сложно. Ну и потом — чем меньше языков знаешь, тем лучше к ним относишься. Мне легче — я довольно много языков знаю, почему предпочитаю подбирать язык под задачу, а не держаться за выученный однажды язык.
в языке всё равно остаётся куча полезных и приятных плюшек.
В С++ два сорта плюшек: те, которых нет, и те, которые есть. Вначале апологеты С++ утверждают, что то, чего нет, им в принципе не нужно. А когда оно появляется в языке — начинают утверждать, что без этого не обойтись.
Тогда всё-таки попробуйте выучить адекватный современный С++,
Нету такого языка. Верблюд — это монстр, созданный комитетом. Есть довольно адекватный С++, созданный Страустрапом. Лет через 30, наверное, С++ дорастет до нового адекватного состояния. Появятся модули и многое другое, чего мне в С++ не хватает.
А пока — никакой адекватности нет. Некая пародия на PL/1. Как говорил мой учитель химии «Без порток, но в шляпе».
Но если не знать иных языков — то и нынешний С++ может показаться адекватным.
То у вас 64К ПЗУ, то большие объекты.
«Большие» в стеке — это от пары сотен байт. Кстати, стек в ОЗУ, а комбинации ОЗУ и ПЗУ бывают очень разные.
А что до задач — ну, опять же, задач, где нужен именно С, исчезающе мало.
А какой структурный ассемблер вы предлагает? GO? Увы, он пока работает не на всех платформах. Но это хорошая замена.
Кроме структурного ассемблера, нам нужен язык для написания прикладной части. И что не вводить два рантайма — есть смсыл использовать один язык. В итоге получается, что лучше всего Си.
какие основания у вас говорить, что вы подбираете язык под задачу, недостаточно экспериментальных точек, как по мне.
Ох уж эти С++ники. Сколько раз вы должны жениться, чтобы иметь основания говорить, что вы жену себе выбираете? Раз 20, небось? :-)
Язык таки эволюционирует, и это нормально.
Не совсем. Нормально — это чистые расширения. А у C++ ещё и семантика иногда меняется. Не читали, как мучались с компиляцией cfront современным компилятором?
Жениться можно и разок, но вот множество знакомых девушек желательно иметь мощностью больше единицы.
Ну давайте посчитаем… Много писал: АЛГАМС (диалект ALGOL-60), FORTRAN(IV и 66), ассемблер (PDP-11), Cи, С++, Pacsal, Delphi, FORTH, Focal, MGR (язык командных скриптов RSX-11). Просто писал: PL/1, BASIC, JAVASCRIPT, bash, свой собственный куцый язычок, Ladder, Functional, IL, ST, ассемблер Z-80, ассемблер IBM-360, SQL, PHP, 1С, CMD. ассемблер 8086. аассемблер Минск-22, Б3-34… Наверное забыл половину… Плюс ещё пара десятков языков, которые изучал for fun: СНОБОЛ, JAVA, APL, LISP, OCCAM…
Конечно в старости как-то не хватает времени для изучения новых языков. Но будет подходящая задач — изучу. Потому и присматриваюсь и к Rust и GO и к Kotlin…
У С++ есть своя ниша. Но за пределами этой ниши — С лучше. Точнее С с некоторыми расширениями C++. Просто язык не поворачивается называть это С++. Скорее уж С++-------.
Что из семантики существенно поменялось с тех пор?Откройте стандарт и почитайте. Приложение C. Там довольно много всего. В частности валидный printf:
printf ("argc is stored at address %"PRIdPTR" decimal.\n", &argc);
вдруг в С++11 стал невалидным, хотя был валидным в C++03. Но в основном это порождает ошибки компиляции, что не слишком страшно…
Первый стандарт С++ был выпущен в 1998 году.
Это первый стандарт ISO. Первый стандарт С++ «вообще» — это 1985 год. Стандарт 90ого года называется C++ V2.0 и использовался много кем.
Что из семантики существенно поменялось с тех пор?
Мелочи поменялись. Чтобы точно описать, нужно порыться в коде, но в общем там дело в разнице семантики имени массива. у вас есть
typedef double *d1 и typedef double d2[3]. Ну и ссылки на них. Ну и совместимость типов — разная в разных версиях.А pre-K&R-C-код сейчас успешно соберется всеми современными компиляторами?
Это что? Язык B? Или вы про
=+? K&R — 1978ого года. И более ранний код — найти сложно.Не, вы, конечно, можете назвать вашу область (ну, с 64К ПЗУ и вот этим всем) «всем остальным», а дополнение этого пространства — нишей C++, но это как-то не очень консистентно с обычными коннотациями.
А все просто. Если у вас задача легко ложиться на ООП, то есть вы видите классы и их наследование — пишите на С++. Если для применения наследования вам приходится натягивать сову на глобус, а код состоит из кучи солитонов — вам лучше Си.
Если у вас товары, продажи, сделки, то есть неопределенное число однотипных объектов — это С++ или другой ООП язык. А если вам нужно рассчитывать координаты спутников — ООП тут лишнее. И С++ тоже не в тему. Ибо удоражает проект.
Увы, слишком часто вижу, как мучаются программисты, пытаясь высосать иерархию объектов из пальца. И как хреново получается в итоге.
Вы не думали, почему в linux очень многие утилиты (и само ядро) написано на Си? Да вот потому, что на Си реально дешевле.
Стандарт 90ого года называется C++ V2.0 и использовался много кем.V2.0 — это, вообще-то, не версия стандарта, а версия cfront'а. Вы с тем же успехом можете взять промежуточные версии C, в которые постепенно добавлялись и изменялись разные фичи — и пытаться их использовать.
Увы, слишком часто вижу, как мучаются программисты, пытаясь высосать иерархию объектов из пальца. И как хреново получается в итоге.Ну так это от программиста зависит. Есть хорошее правило: не порождать иерархий обьектов пока у вас нет 2-3 разных рализаций, на которых вы сможете посмотреть — как эти абстракции будут работать.
Все эти вычисления времени копиляций, шаблоны и прочее — они реально облегчают жизнь. Но для этого нужно сначала сделать 2-3-5 версий без всех этих абстракций — а уже потом сделать рефакторинг соотвествующий.
Но если у вас ситуация «мне некогда точить топор, заказчик ждёт», то C++ вам не подходит, наверное.
Вы не думали, почему в linux очень многие утилиты (и само ядро) написано на Си?Потому что принцип «работает — не трогай» блюдётся строго. Подавляющее большинство утилит написано в стародавние времена, когда у C++ было много «детских болезней». В частности лозунгом C++ всегда было «не плати за то, что не используешь» — но, увы, в GCC с этим были сложности примерно до GCC 4.0-4.2. А это, как бы, 2005-2007й годы. С одной стороны — уже почти 10 лет прошло, с другой — все те утилиты, о которых вы так вздыхаете, с тех пор почти не менялись.
То, что меняется активно (скажем, собственно, компилятор C, линкер и прочее) — потихоньку переходит на C++.
Да вот потому, что на Си реально дешевле.Это уже довольно давно не так. До 2005-2007го — можно было получить выигрыш от некоторых фишек C++, но при этом — замедление и увеличение размера «на ровном месте» из-за проблем GCC. Сейчас — выбор для новых проектов, как бы, очевиден — но из этого вовсе не следует, что нужно всё бросать и переписывать работающий код только потому что появился более удобный язык.
V2.0 — это, вообще-то, не версия стандарта, а версия cfront'а.
Это версия (издание) книги "The C++ Programming Language", которая и была стандартом С++ до появления стандарта ISO.
Есть хорошее правило: не порождать иерархий обьектов пока у вас нет 2-3 разных рализаций
сначала сделать 2-3-5 версий без всех этих абстракций — а уже потом сделать рефакторинг соотвествующий.
Отлично! Мы начинаем сходится во мнениях. Аналогично пишет и Торвальдс:
inefficient abstracted programming models where two years down the road you notice that some abstraction wasn't very efficient, but now all your code depends on all the nice object models around it, and you cannot fix it without rewriting your app.То есть живем 5-10 лет на Си, а потом, если приперло, то переводим на С++. Ну это разумный путь, но с одной оговоркой.
Подавляющее большинство утилит написано в стародавние времена, когда у C++ было много «детских болезней».
Казалось бы, прошло много лет, абстракции понятны — почему бы из не переписать на С++? Вы правы, потому что незачем. Оно и так хорошо работает. И даже когда утилиты полностью переписывают — нужды в С++ нет.
сначала сделать 2-3-5 версий без всех этих абстракций — а уже потом сделать рефакторинг соотвествующий.
Чувствуете, что в итоге получается, что писать на С++ дольше? Потому что язык такой, что с первого раза сложно написать хорошо. А на Си — пишется сразу набело.
Это уже довольно давно не так. До 2005-2007го — можно было получить выигрыш от некоторых фишек C++, но при этом — замедление и увеличение размера «на ровном месте» из-за проблем GCC.
Да нет, до сих пор дороже. Я не про скорость выполнения и не про размер программы. Я про цену написания и отладки. Если мы берем дешевого юниора — то на С++ он будет отлаживаться намного дольше, чем на Си. И через пару лет случится затык в абстракциях и все придется переписывать. Если берем дорого сеньора — ну просто будем платить зарплату сеньора там, где на Си хватит зарплаты юниора.
Дело не в компиляторе, дело в размерах описания языка и сложности написания на нем.
Дело даже не в ООП. Вот в дельфи нет такой проблемы с неверно выбранными абстракциями. Могу объяснить почему:
- Все классы — наследники TObject, там, где в С++ придется передавать void *, передается TObject с динамическим определением типа. Стоит это дешево — у экземпляров классов без виртуальных методов тоже есть ссылка на VMT.
- Вместо указателей используются ссылки.
- Все экземпляры классов сидят в куче.
- Множественного наследования нет.
- Макропрограммирования нет.
- Есть указатели на метод конкретного экземпляра и их вызов
В итоге проблемы с неверной архитектурой оказываются лишь небольшим неудобством.
Сейчас — выбор для новых проектов, как бы, очевиден
И в большинстве случаев — это не С++. Дельфи, Си, Java, Rust, Кotlin, Go…
С++ — хороший выбор, если лично вы достигли стадии сеньора, а другие языки знаете плохо. Это выбор для вас, как для работника. А для работодателя — пока что Delphi и Си, как языки с меньшей стоимостью разработки.
И только при наличии специфики (linux, не только x86, довольно большой объем, задач хорошо ложиться на ООП, в компании есть хорошие С++ программисты) — С++ будет оптимальным выбором.
Какой магический язык. Большие программы, с разными уровнями абстракции и реализации, и сразу набело.
В С++ и количество уровней абстракции больше, и цена ошибки в абстракции выше. То есть там, где в С++ «без рефакторинга идти дальше не можем», в Си или дельфи будет «гм, неэффективно, процентов 10 на этом теряем».
А, как вы уже писали ранее, не большие программы? А тогда и в плюсах-то 2-3-5 версий совершенно не нужно.
Ваши коллеги почему-то утверждают, что нужно. Если хотите — спорьте с ними. На С++ всех тянет написать что-то такое глобальное, суперабстракцию типа собственного STL. А в итоге получается плохо.
Собственно и на С++ можно писать в стиле Си или дельфи. И будут такие же предсказуемые результаты. В этом смысле и мы на С++ пишем. Вот только стоит ли называть это С++? Это будет Си с отдельными фичами С++.
Или ему, как уже писалось рядом, можно просто предоставить такие абстракции, на которых трудно сделать ошибку.
Можно. Но в итоге товарищ будет писать не на С++, а на неком сильно урезанном диалекте. Фактически — на Си с расширениями.
А когда и зачем в С++ нужно передавать void*?
Когда ошиблись в иерархии классов, например. В Дельфи такие ошибки не являются фатальными и обходятся малой кровью.
А чем это хорошо?
О!!! А это запрещает передавать экземпляры в качестве результата функции. Вместо них передается ссылка на экземпляр. Так что нужда в move-семантике возникает крайне редко. И код в итоге более эффективен.
всё больше вещей можно сделать через темплейты или constexpr,
Темплейты — это тоже макропрограмирование. Тут у нас чуть термины разные, я к макропрограммиированию отношу все, что compile-time.
Жирные указатели-то небось?
Нет, не жирные, там 2 указателя (на экземпляр и на метод), то есть всего 8 байт для 32битной архитектуры. Безумно удобно, вместо наследования и виртуальных методов — просто привешиваем callback из экземпляра другого класса. Тоже сильно уменьшает цену ошибки в абстракциях.
И в чём разница в разных версиях?
Если очень надо — то найду. Просто лень тратить час времени, чтобы найти пример в исходниках.
Я аналогично ни разу не встречался с кодом, который мне действительно надо было собрать, и который был написан до ISO-стандартизации.
У меня вагон такого кода. Специфика предметной области. Довольно часто надо если не собрать, то хотя бы понять, что там делается и зачем.
Не могу сказать, что на С вышло бы дешевле или быстрее (что с точки зрения разработки, что с точки зрения выполнения).
У вас вышло одинаково. У вас, а не у среднего программера. А ваш уровень — очень серьезный, я же видел код.
Потому что Торвальдс ненавидит С++.
Почитал Торвальдса. С удивлением увидел, что у него те же аргументы против С++, что и у меня.
It's made more horrible by the fact that a lot of substandard rogrammers use it, to the point where it's much much easier to generate total and utter crap with it.Гм, ну вот ровно это я и втолковываю вам уже две недели.
inefficient abstracted programming models where two years down the road you notice that some abstraction wasn't very efficient, but now all your code depends on all the nice object models around it, and you cannot fix it without rewriting your app.И об этом я писал. Ну может не так четко, как Линус.
Ну приятно, когда умный человек поддерживает твою точку зрения. Собственно почти со всеми его тезисами я согласен. Ну кроме того, что я считаю, что есть ниша, где С++ лучше.
Да не на настоящих плюсах, а на жутко обрезанной диалекте.Нет никаких «настоящих» плюсов в природе, это вас кто-то жестого обманул. Процентов 90 современного C++ не генерирует никакого кода вообще (кроме того, что вы сами закажете). Какая-нибудь Boost::Hana ни байта не породит, кроме того, что вам нужно. Библиотека ввода-вывода — да, она тяжела. Но это одна старейших частей стандартной библиотеки и, в общем-то, на микроконтроллерах ей делать нечего.
Такой С++-------, который больше похож на Си, чем на С++.Вызов принят. Перепишите, пожалуйста, вот это пример (почти из тьюториала, я только переменную добавил, чтобы вообще хоть какой-то «выхлоп» был), на C:
// Most be in header
extern const int calculated_distance;
template <typename X, typename Y>
struct _point {
X x;
Y y;
};
template <typename X, typename Y>
constexpr _point<X, Y> point(X x, Y y) { return {x, y}; }
template <typename P1, typename P2>
constexpr auto distance(P1 p1, P2 p2) {
auto xs = p1.x - p2.x;
auto ys = p1.y - p2.y;
return sqrt(xs*xs + ys*ys);
}
// This goes into .cc
const int calculated_distance = distance(point(3_c, 5_c), point(7_c, 2_c));
Ждём версии на C! Только чур, чтобы она порождала не больше кода, чем версия на C++, которая порождает вот это:
.text
.file "integral2.cpp"
.type calculated_distance,@object # @calculated_distance
.section .rodata,"a",@progbits
.globl calculated_distance
.p2align 2
calculated_distance:
.long 5 # 0x5
.size calculated_distance, 4
.ident "Android clang version 5.0.300080 (based on LLVM 5.0.300080)"
.section ".note.GNU-stack","",@progbits
Ваше управление лазером я бы предпочел на форте писать.В килобайт флеша? Форт? Покажите, просто интересно.
На С++ можно писать компактно и понятно, но у khim это не вышло. И у многих — не выходит.
Нету идеального языка «вообще». Есть оптимальный язык для связки задача + программист. Для многих связок на С++ трудоемкость написания и отладки будет больше. Прежде всего потому. что любители С++ очень любят решить не только ту задачу, которую надо, но и десяток лишних задач.
Мог khim написать компактно? Да может и мог бы, если бы знал, что clang воспринимает sqrt как constexpr (а без этого у него бы не свернулось в константу, сколько темплейтов не наделай). Но предпочел писать код в силе «смотрите, сколько красивых штук я знаю».
Вот так и остальные любители С++ пишут многословный, плохо читаемый и плохо отлаживаемый код вместо простого и понятного.
На Си места для демонстрации собственной крутости мало. Так что код получается компактней, читаемей и проще.
Да, есть монстры, которые и на С++ пишут красиво и понятно. Ну скажем в исходники eigen можно заглянуть — там все по делу.
Ну в общем детям бензопилу лучше не давать. Особенно если им лобзика хватает. Лобзиком они за пару уроков справятся, а с бензопилой — выстрелят себе в ногу. Благо на С++ способов выстрелить себе в ногу более, чем хватает.
При всем при этом — да, есть задачи. которые намного проще решаются на С++. Видите в задаче иерархию классов? Нужен полиморфизм? Значит ООП и С++. Ничего такого нет — подумайте, надо ли давать детишкам играть с бензопилой.
Для многих связок на С трудоемкость написания и отладки будет больше. Прежде всего потому. что любители С очень любят void* и переполнение буфера.
Скорее, это связано с тем, что пользователи C просто не любят вводить новые абстракции, потому что это противоречит принципам компактного кода.
Для кода из комментария не указан важный момент: потеряна абстракция point. Оставим в стороне момент, что код довольно кривой (зачем-то разный тип у X и Y, зачем-то лишняя функция point вместо конструктора, почему-то distance принимает всё, что угодно, а не только point-ы), но без этой абстракции функция distance — это просто функция, принимающая какие-то 4 значения.
С моей точки зрения любители С++ очень любят вводить абстракции не по делу. Грубо говоря, они пишут одноразовую программу на 100 строк (сишных) так, как они бы писали многократно используемую часть к программе размером в миллион строк и тысячу использований.
Кстати, я не фанат Си. Дельфи и форт мне нравятся больше. Но для своей ниши. как структурный ассемблер, Си очень хорош.
С моей точки зрения любители С++ очень любят вводить абстракции не по делу.
Да нет, как раз по делу, просто язык очень многословный, из-за чего нагромождение абстракций занимает кучу времени и выглядит не очень презентабельно.
Ну значит не только мне опыт показывает, что все наоборот. Хотя — от программиста зависит.
Что касается по делу или нет, у меня простые критерии:
- Сокращение исходного кода (многократное использование)
- Сокращение времени модернизации (правим в одном месте, а не в 10)
Соответственно «не по делу» — это когда абстракции удлиняют код и используются однократно.
Для меня из того, что можно выделить какую-то абстракцию не вытекает, что её надо выделять.
- Для автора — это персонажи + мир + сюжет.
- Для наборщика — главы и абзацы.
- Для верстальщика — шрифты, формат страницы.
- Для брошюровщика — коленкор, клей, форзацы
- Для упаковщика — вес, размеры, количество в пачке
- Для продавца — цена и рубрика
Но если вы сделаете объект со всеми этими свойствами, то никогда не отладите программу. Особенно с использованием множественного наследования, ведь у нас есть не только книги, но и брошюры, газеты, дыроколы… И у многих из них есть общие черты, которые хочетяс убрать в базовые классы.
_point был бы по делу, если бы находился в .h (тогда его можно было бы использовать однократно) В .cpp — это одноразовая, то есть ненужная абстракция.
Ну учили их так — на маленьких примерах с абстракциями для большого проекта. Как учили — так и пишут.
Вон khim хотел показать отрабатывание темплейтов в copmpli-time, а сколько наворотил? И другие наворачивают, причем на пустом месте.
Но хорошо, что вы признаете, что pointы можно не писать. Это достижение по сравнению с основной массой С++ников.
Обычно на С++ пишут так: выделим все имеющиеся абстракции, запишем их в коде, а потом — пишем то, что нужно в задаче. Для большого кода такой подход оправдан, для маленького — нет.
На Си — обратный подход. Поймем, что нужно в задаче, потом выделим абстракции, делающие код компактней.
Зачем писать такие вещи на С, впрочем, не очень понятно
Причин две:
1) C работает везде. И на linux и в bare metal и в windows,
2) Раньше все знали фортран, сейчас все знают Си.
3) Многоязыковая стыковка — сложная штука. Если основной проект на Си или С++ логично писать одноразовый модуль на Си.
Речь идет о НИР, о том что нужно сделать модуль и посмотреть, как оно будет работать с реальными данными.
Вы троллите или патологически неспособны осознать само понятие, концепцию, так сказать, примера?
Вы не понимаете, что ли?! В примере наворотили и в реальном коде ровно так же наворачивают. Традиция такая в С++ — писать так, будто у нас миллион строк в проекте.
Беда не в переусложненном примере. Беда в том, что реальный код пишут ровно так же, как примеры. Потому что ничего, кроме переусложненных примеров никогда не видели.
Вот и решили, что хороший стиль — это писать сложно. А на самом деле, чем квалифицированней программист — тем проще читать его код.
Вы ж не пишете на плюсах,
Если 100 тысяч строк мало — то да, не писал. :-) Но мне кажется, что проекта такого размера — хватит. Это я сейчас пишу на сознательно урезанном диалекте и называю язык Си. А тогда был полный С++.
Откуда вы знаете, как на С++ пишут обычно?
Мне кажется, что анализа кода десятка программистов — достаточно для понимания.
Под «обычно — имеется ввиду программист с той зарплатой, которую мы можем предложить. То есть обычный рядовой junior или middle, Сеньоры пишут иначе, но это уже иные деньги.
То есть проблема в том, что за одну и ту же зарплату мы получаем лучший код на Си, чем на С++. И в меньшие сроки.
Ещё раз. Дело не в языке. Дело в связке язык + программист + задача. И вне этой связки бесполезно обсуждать недостатки языка. я вижу, что в eigen хороший код. Но нанять его авторов — слишком дорого.
Я бы сказал, сейчас нет универсального языка, который бы знали все.
Ну не все, но процентов 90 Си так или иначе изучали. как и JavaScript. Собственно и С++ массово преподается, но… выпускник института, знающий Си — может работать. А знающего С++ — ещё надо долго учить.
Если в проекте при этом действительно миллион строк, ну или хотя бы 10 тысяч, то это оправдано.
Для 10 тысяч — не оправданно. Особенно если 10 тысяч строк на С++ заменяются на 5 тысяч строк на Си.
запретить всякое взрывоопасное прям в вашем CI
Это любопытно. Можно ссылочку?
В С вам это будет сделать чуть сложнее.
В си такой потребности нету. Количество способов выстрелить себе в ногу меньше.
Более того, джунам на С++ вы можете навернуть всяких разных абстракций одним синиором
ВОТ! Начинаем сходится во мнениях.
Иными словами на С++ синьору надо влезать во все локальные задачи и продумывать за джуниоров абстракции. Потому что цена ошибки при выборе абстракций — очень высока.
А на Си цена этой ошибки ниже. То есть джуниоры пишут свой кусок самостоятельно. Заткнутся — можно будет отрефакторить. Не заткнутся — ну хрум-хрум-хрум, но задач решена и отлажена. да, на 15-20 процентов тормознее. Но эти проценты — не важны.
Уж не знаю, на каком языке их учили программировать, но на С++ вполне можно писать в стиле Си или в стиле delphi. Или даже в стиле basic. Просто это не совсем С++ будет. Скорее — совсем не С++.
Просто на C++ обычно пишут чуть более крупные системы, где приходится заранее ориентироваться на последующую расширяемость.
Вот об этом и речь. С++ — это язык написания крупных систем программерами уровня Страустрапа. А Си — язык для написания небольших утилит. Структурный ассемблер. Не читали кода от создателей Си? У них размер утилиты редко превышал тысячу строк.
У меня всё чётче складывается впечатление, что при виде слов про вариадики, констекспры, мувы и прочее вы зачем-то закрываете глаза.
Угу, угу. Типичный пейсатель на С++ старается включить в программу все самые новые фишки языка. Просто потому, что это «стильно, модно, молодёжно». Да и учили его так — впихивать все возможности языка в каждую программку. Я не спорю — все эти возможности можно использовать и по делу.
Не забывайте, что С++ получил популярность без всех этих новых возможностей. И популярности они ему не добавили.


У меня такое впечатление, что вы решили со всем миром спорить. Ну спорьте, только увольте меня от этого разговора.
Так вот, что делать в том случае, если вам таки надо написать просто немаленькую систему, которая в любом случае, дубово-хардкодно-будто-завтра-не-будет займёт 10-20-50 тысяч строк кода
К слову — ваши коллеги по С++ считают, что немаленькая — это от 250 KLoc.
А будет ровно то же, что и в остальных случаях — смотреть условия и считать экономику. Например, если там только Windows и не очень важна скорость выполнения — то Delphi. Да, будет процентов на 30 медленней. Зато и отладится быстро.
Если что-то сильно большое и не критичное к скорости — то скорее котлин (или java).
Ну и так далее, вариантов много.
А С++ — это если большое, скорость очень важна или надо, чтобы компилилось везде.
Но я не спорю, что хороших программистов на плюсах (уровня Страуструпа) мало.
Важнее, что они стоят дорого.
Если я пишу программу, чтобы познакомиться с новыми фишками в деле, то да, я буду пытаться их использовать. Это учебная программа.
Увы, типичный программист на С++ пишет так, как его учили. А учат — именно так, показывать все возможные фишки.
Как минимум, конкретно тут похожую позицию и другие люди разделяют, вроде бы.
Никогда с сектантами не общались? У них ровно такие же аргументы.
Не вижу ничего странного в том, что спелись 3 человека, считающих С++ вершиной языкописания.
Котлин я не тыкал, признаться, вне чтения статеек о нём. Но, по моему скромному мнению, современные плюсы сами по себе таки поприятнее современной джавы будут. Ну, лично для меня, по крайней мере.
Java/Kotlin/Scala лично для меня наиболее оправданы были бы в том случае, если бы нужно было взаимодействовать с кодом, написанным под JVM. И то, даже в этом случае вполне серьёзно стоило бы рассмотреть вариант FFI/JNI.
А вот это вы зря…
Один только мавен (ну или грейдл) делает java на порядки более вкусной экосистемой, чем c++.
А экосистема — часть языка (точнее часть группы языков, конечно, но и так сказать тоже можно).
Так же как и плюшки jvm с её менеджментом памяти и оптимизацией горячего кода.
Да и в целом…
выстрелить себе в ногу в java сложнее…
написать непонятно — в java сложнее…
многолословность в java уже необязательно (да здравствует ломбок!)...
В общем java сейчас можно действительно не любить только за две вещи:
- она немного менее универсальна (в системные языки не годится...)
- вкусовые пристрастия.
При этом плюсов-то у неё хватает.
Когда это действительно важно, пишется аллокатор с ареной. В подавляющем большинстве это не очень важно, ибо есть стек и move semantics.
Разницу между пишется и есть чувствуете? Есть надёжное, прокачанное в плане производительности решение.
Зачем, если можно собрать с -march=native, попрофилировать, дёрнуть Intel IPP/Intel MKL/интринсики руками и быть уверенным, что оно не сломается при апгрейде JVM или при изменении кода где-то рядом, потому что после инлайнинга размер функции превысил критический, и JIT теперь ведёт себя как-то по-другому?
А в jvm в большинстве случаев не приходится профилировать! Ну и тем, кому этого реально не хватает — могут уже сами профилировать и оптимизировать.
Непонятно — это как? :)
самое простое — почему-то не припоминаю в java undefined behavior, в отличие от плюсов...
А var там уже появился?
в 10ой версии обещают, но острой потребности в таком способе объявления переменной что-то не ощущаю…
Ну и ещё за отсутствие дженериков и всякого такого.
Вы уверены, что пользовались java версией старше 4ой? Дженерикам уже фиг знает сколько. Есть у них, правда, прокол — в рантайме не узнать на что за класс был целевым для дженерика. Но вроде хотели пофиксить. Чего ещё не хватает? Лямбды — есть, что-то вроде замыканий с ними добавили.
Ну а вообще да, я не спорю, что язык неплохой, экосистема и рантайм так вообще хорошие, но современные плюсы тоже достаточно хороши.
Таки изначально вы заявили:
Но, по моему скромному мнению, современные плюсы сами по себе таки поприятнее современной джавы будут. Ну, лично для меня, по крайней мере.
Java/Kotlin/Scala лично для меня наиболее оправданы были бы в том случае, если бы нужно было взаимодействовать с кодом, написанным под JVM. И то, даже в этом случае вполне серьёзно стоило бы рассмотреть вариант FFI/JNI.
А это уже, имхо, некорректно. Здесь больше вкусовые пристрастия и целевая "платформа" рулят.
PS не знаю как сейчас, но в 6ке JNI были ещё теми плясками с бубном...
Разницу между пишется и есть чувствуете?Конечно. В C++ — у вас есть выбор. В Java — его нет.
Есть надёжное, прокачанное в плане производительности решение.На большинстве устройств (а это, напомню, Android и iOS, а вовсе не Windows) — нету. Есть огрызок. И даже там, где оно есть — нужна куча «ручек», чтобы как-то где-то это чудо заставить работать.
А в jvm в большинстве случаев не приходится профилировать!А вот не надо рассказывать сказок, а? Профилировать нужно там, где векторизатор не сработал. В Java — он даже до уровня GCC не дотягивает, а с Intel'ом — его и сравнивать смешно. Причём в C++ вы можете быть уверены в том, что вы «напрофилировали», а в Java — выход новой версии JIT'а может всё как ускорить, так и замедлить, вы над этим не властны. Недаром всякие серьёзные пользователи зачастую с собой приносят JDK. Переносимость, ага.
PS не знаю как сейчас, но в 6ке JNI были ещё теми плясками с бубном...Во всех версиях Java это «пляски с бубном». Именно ради обеспечения того самого прокачанное в плане производительности решения. Которое призвано, вроде бы, решать проблемы, а на практике — превращается в смирительную рубашку.
Конечно. В C++ — у вас есть выбор. В Java — его нет.
Вы будете очень удивлены — но выбор в java у вас есть (только отказаться нельзя). Просто он не обязательный. Впрочем есть ещё одна разница — выбор у вас есть только для всего приложения целиком, а не для какой-то отдельной части.
На большинстве устройств (а это, напомню, Android и iOS, а вовсе не Windows) — нету. Есть огрызок. И даже там, где оно есть — нужна куча «ручек», чтобы как-то где-то это чудо заставить работать.
Простите, вы сейчас про что? Я наивно полагал что мы про java и jvm говорим… Покажите мне jvm на Android или iOS… Да и java я там что-то не очень вижу… есть только устаревшая реализация спек языка для Android с собственным sdk, не соответствующим стандартам языка (что намекает на то, что это и не java вовсе)
А вот не надо рассказывать сказок, а? Профилировать нужно там, где векторизатор не сработал. В Java — он даже до уровня GCC не дотягивает, а с Intel'ом — его и сравнивать смешно. Причём в C++ вы можете быть уверены в том, что вы «напрофилировали», а в Java — выход новой версии JIT'а может всё как ускорить, так и замедлить, вы над этим не властны. Недаром всякие серьёзные пользователи зачастую с собой приносят JDK. Переносимость, ага.
А вот вы сперва в тему поглубже погрузитесь, потом сами сказки выдумывать не будете. Ручные оптимизации и прочие радости прилетают ~0.05% пользователям jvm.
Ну и про способности оптимизаций JIT vs GCC/Intel вы просто замечательно-смешные вещи пишите. Вся фишка JIT как раз в том, что он строит динамическую модель исполнения. Он может целые блоки отбрасывать из основной цепочки для ускорения вызовов. Не подскажете, как с этим быть в статическом коде, генерируем gcc/Intel?
Во всех версиях Java это «пляски с бубном». Именно ради обеспечения того самого прокачанное в плане производительности решения. Которое призвано, вроде бы, решать проблемы, а на практике — превращается в смирительную рубашку.
хм? Вы определённо знакомы с платформой весьма поверхностно… И относитесь к ней как к недо-плагину к вашим любимым плюсам… но ведь в том и дело, что она абсолютно самостоятельная...
Просто остальные компилируемые императивные языки ещё хуже
А вы на чем из процедурных языков писали, кроме C++? Такое впечатление — что ни на чем.
Мне вы напоминаете мотогонщка, гонящего на старой яве-350 с форсажем, но без глушителя и не в шлеме. Да, при вашем умении ездить — вы на ней редко падаете. я вам пытаюсь объяснить, что у меня перевозки. Что лучше я найму обычных водителей на вольво, чем мотогонщиков. А вы мне про то, что только мотоцикл и только без шлема дает ощущение скорости.
А мне не нужна скорость. Мне надо быстро и надежно привезти груз. И при этом — нанять самых обычных дешевых водителей. А не гонщиков.
У С++ — два плюса. Во-первых он ходит очень много где. Во-вторых — у него уйма способов
С моей точки зрения второй плюс — это недостаток для работодателя, но достоинство для работника. Поскольку я сейчас ближе к работодателю, то лучше все, что угодно, но не breinfuck и не С++.
Обсуждение некоторых сферических типичных программистов на С++ в вакууме не очень конструктивно.
А это основное возражение. Самолет очень хорош, просто в городе неудобен. Мотоцикл считают небезопасным все, кроме мотогонщиков.
Нельзя рассматривать язык в отрыве от задачи и программистов, которые будут на нем писать.
И таки на каком языке это стоило бы реализовать соответствующий модуль, по-вашему?
Да вот на чем-то вроде хаскеля и стоит. Си у нас только из-за желания. чтобы компилировалось везде. Ну не фортране же писать! Хотя 30 лет назад — писали бы на фортране. Ровно по той же причине — он был везде.
«Немаленькая кодовая база на С++» и «немаленькая кодовая база для того, чтобы С++ был оправданным выбором» — разные вещи.
Мне сложно придумать пример, чтобы С++ давал сильный выигрыш в производительности написания и отладки кода. языков много и многие — лучше С++. Вот например, такой отзыв
Пока есть стойкое ощущение, что Rust заставляет писать так, как в принципе пишут хорошие поседевшие сишники, повидавшие всякого нехорошего.
Это вот именно то, чем дельфи лучше С++. Паскалеподобные языки сильно мешают стрелять себе в ногу. Если Rust ещё лучше — значит надо будет выучить.
То у вас перевозки, то у вас одноразовые мелкие проекты.
Это у человека просто прелестная демагогия:
— Дайте мне аргументы, что технологию А можно использовать для мелких проектов!
— Вот аргументы!
— Видите, сами утверждаете, что технология А подходит только для мелких проектов, а мне необходимо для крупных.
Есть довольно большая программа (не мерял, но полсотни тысяч строк точно). Для неё нужен модуль сравнения двух траекторий. Такая одноразовая задача для одного испытания.
И человек наворотил на плюсах 10 тысяч строк, где 2 тысячи по делу, а остальное — слой абстракций. Глючит по черному, то есть работает на избранных данных.
Основная претензия к товарищу — он почему-то решил, что абстракции важнее реального мира. Ну как пример, что сначала трактор стоит, а потом — едет. А попалась запись, которая сразу начинается с движения. ну так на испытаниях вышло. И не переделать её. А в абстракции — оно не лезет. Пришлось его абстракции ломать и через задний проход делать обработку.
Далее тому же товарищу поручили интегрирование измерений от БИНС. Ну понятно, он взял за основу свои же абстракции (это разумно). Но оказалось, что в новую задачу эти абстракции не лезут. Соответственно товарищ сделал новую версию, абстракций, несовместимую со старым прикладным кодом. Но тоже не фига не отладил. А когда понял, что нагородил абстракций столько, что и не отладит — предпочел уволиться.
А программисты на голову хуже — вполне себе пишут нормальный компактный код. И это чудо писало бы нормально, если бы его не приучили выделять слой абстракций в каждой бочке.
А вся работа — состоит из множества небольших, мало связанных между собой модулей и ядра.
И мне нужно, чтобы модули были сделаны и отлажены в заранее известный срок.
Мне кажется, что это у всех так. Да, есть сеньоры, которые ведут большие приложения. И есть рядовые программисты, которые делают модули небольшого размера и изолированной функциональности.
Так что модель перевозок — правильная. Только не регулярные маршруты, а развозка заказов из интернет -магазина. Каждая поездка — разовая и небольшая. А вместе — нужна предсказуемость.
Ещё раз (в шестой раз, что ли). я не говорю, что С++ плох. Я говорю, что связка С++ + задача + типичный (дешевый) программист не годится.
Ровно тоже самое говорят и многие другие в форме «у С++ высокая кривая обучения», у «С++ большой порог входа», на «С++ много способов выстрелить себе в ногу» и так далее…
Может, если бюджет неограничен, С++ и неплох. Но в нашей реальности — он сильно проигрывает.
Конечно, у нас не совсем чистый Си. Например передача по ссылке — это очень удобная штука. Как и комментарии через две косых. Или встроенный тип bool. Но то, на чем мы пишем, настолько непохоже на С++, что в общем-то это Си с элементами С++.
Основная претензия к товарищу — он почему-то решил, что абстракции важнее реального мира. Ну как пример, что сначала трактор стоит, а потом — едет. А попалась запись, которая сразу начинается с движения. ну так на испытаниях вышло. И не переделать её. А в абстракции — оно не лезет. Пришлось его абстракции ломать и через задний проход делать обработку.
Как же так получилось, что вы не контролировали этот процесс, ведь это было очень важно для вас? да еще и дали ему другую задачу. И он делал без обсуждения с вами, ведь вы заказчик?
А потом… Если падавана постоянно контролировать — ничего из него не вырастет. Да и не виноват он, что его так учили — писать сложно, со всеми фишками С++ по делу и не по делу.
Впрочем, когда я был юниором, то тоже был такой же.
Собственно посмотрите на khim и попытайтесь его переубдить. «молодежь нынче пошла испорченная, старших не слушают» (с) 2 тысячи лет до рождества христова.
Да и не виноват он, что его так учили — писать сложно, со всеми фишками С++ по делу и не по делу.
Его «учили», а вы сидели и смотрели :))
Собственно посмотрите на khim и попытайтесь его переубдить. «молодежь нынче пошла испорченная, старших не слушают» (с) 2 тысячи лет до рождества христова.
khim все правильно говорит. Он как раз за разумное использование «фишек» С++. Я с ним согласен. Да и не особо молодежь он, насколько я понял.
khim все правильно говорит.
Ну да, подросткам важнее слова, а взрослым дела. Мне все равно, что он говорит, но пишет он переусложнный дурной код, абсолютно непропорциональный поставленной им же самим задаче.
Например передача по ссылке — это очень удобная штука.В чём удобство, интересно? В коде Chrome'а она, скажем, запрещена.
Как и комментарии через две косых.Коментарии через две косых — это C99.
Или встроенный тип bool.Аналогично.
В коде Chrome'а она, скажем, запрещена.
По просто референсу запрещена, а по const разрешена. Логично, дабы не вводить в заблуждение вызывающего юзера.
Jef239 наверное имел в виду const &.
References .. have value syntax but pointer semantics. Ну и решили, что им важнее, чтобы любые выходные параметры можно было бы не указывать (а передавать NULL). Это такой сишный подход.А в подходе со стороны других языков нету pointer semantics, а есть передача параметров по значению (копированием), по значению-результату (копирование туда и обратно) и по ссылке.
А в итоге при использовании ссылки получается, что у меня одинаковое обращение к члену класса, к локальным и глобальным переменным и к параметру. Причем независимое от типа — простая переменная или структура. Поэтому структуры — лучше передавать через ссылку. Тогда нету проблем сделать параметр вместо глобальной переменной.
Ну
_Bool + stdbool — это не совсем bool. Натуральный капельку удобнее.— Есть ли крылья у слона
— Да они равны нулю
То есть трактор конечно вначале стоит. Но вреям стояния равно нулю, что товарищ и не учел.
То есть он развил абстракции в сторону — а какую бы ещё задачу мне решать на базе этих сорцов. А надо было — а с какими ещё данными может справиться мой код.
Но увы — его так в институте учили. И большинство книг по С++ именно так и учат. Если сильно надо — могу проанализировать с этой точки зрения пример от khim.
Разные типы для точек — он сделал. А вот про семантику — забыл. Никакого вменяемого перехода от геоцентрических координат к топоцентрическим не предусмотрено. Перехода между разными топоцентрическими — тоже.
То есть, если бы я усложненно писал такой пример — он был бы сильно проще, но с механизмом перевода систем координат. Ну и на 3D, а не на 2D.
Она и в случае Сей не сильно годится. Берите Go, например.
Сильно — не сильно, но годится. А Go надо вначале попробовать самому.
И в большинстве случаев и получается, что человек и дальше пишет с кучей наворотов на ровном месте, считая сие правильным и современным стилем.
А так — чистая сишеча (ага), C#, PHP, JS (о, ошибки детства), чутка питона,
Заметно. То есть из универсальных языков только С++ и С#. Ни delphi, ни java, ни PL/1, ни алгол-68, ни ада не не знаете. Ну абсолютно не мудрено, что С++ для вас венец творения.
но мне казалось, что мы обсуждаем профит от современных версий C++ по сравнению с тем, что было раньше.
Это называется соломенное чучело. я никогда не утверждал что новые версии С++ хуже старых. Так что не выдумывайте.
Сильный выигрыш по сравнению с чем?
С большей частью процедурных языков. С Си, с Дельфи и так далее
Я утверждал, что вы считаете, что новые фишки из С++ не нужны.
Лично мне в моей работе — не нужны. Вам — очевидно, что нужны. Более того, мне и большинство фишек старого С++ не нужны. Ну примерно как вам диграфы, триграфы и функции с переменным числом параметров.
А насчет выигрыша — ну покажите пример, напсанный на Си и на С++. И померьте выигрыш. Сколько там будет 10-15 процентов? И процентов 50 по сравнению с Delphi из-за слабой оптимизации в его компиляторе?
Сильный выигрыш для меня — это десятки и тысячи раз. Но он дается сменой алгоритма. А все эти ускорения на 5-10 процентов — не интересны.
Уже писал — задач или укладывается в возможности процессора или не укладывается. Даже если у нас GUI, то оператор не заметит изменения реакции со 100 на 125 мс. 200 мс от 100 мс — операторы отличают, проверенно. А 125 и 100 — для оператора одинаково.
Если вы укладываетесь в 100 мс отклика в GUI приложении, то дальше оптимизировать смысла нет. Все равно это для любого оператора будет «Мгновенно». Ну может кроме хардкорных геймеров, они, может быть и меньшие интервалы словят.
С другой стороны, время отладки у дельфи (и Си) сильно ниже. Стоимость разработки (ФОП) — ниже. Код среднего программера — проще, то есть читабельней.
А главный параметр, по которому идет выбор — это ФОП (фонд оплаты труда) при заданном уровне надежности.
У вас — другие задачи и совсем другой уровень оплаты. Думаю, что вы получаете 4-5 тысяч долларов в месяц, то есть ФОП 7-8 тысяч долларов в месяц.
Сумеете заменить собой 5-10 рядовых программистов? Если сумеете — вы (и С++) выгодны. Если нет — то у вас (и у С++) другая ниша.
Дешевых программистов, пишущих приемлемый код на С++ я не видел. На Си, Дельфи и так далее — их хватает.
Эти языки не настолько различаются концептуально, чтобы нельзя было обойтись чтением чужого кода,
Синтез и анализ — это очень разные процессы. Поэтому нужно именно писать.
У меня есть примеры, когда использование move semantics увеличивало производительность кода достаточно существенно.
И у меня есть. Причем 1993его года, когда вся эта семантика делалась руками. Да, при выдаче экземпляра класса в качестве результата функции — без неё не обойтись. Мораль тут простая — не надо выдавать экземпляр класса через return. Надо создавать экземпляр в куче и выдавать указатель на него. Если скорость new мала — он ускоряется для нужных размеров будет создания списков с уже выделенными областями.
Есть примеры, когда перенос вычислений в компил-тайм (какой-нибудь несчастный недоORM, например, надо бы обновить код и переписать на constexpr if, кстати) обеспечивал соответствующий выигрыш в рантайм-производительности.
Соответствующий — это сколько? 10-20 процентов? У меня есть пример, когда динамическая компиляция бинарного кода под конкретный поисковый запрос в СУБД давала выигрыш от 20 до 100 раз.
Кроме того, ускорение времени разработки означает, что я могу потратить больше времени на профилирование и выяснение, что на самом деле тормозит и где на самом деле можно поменять хоть низкоуровневые детали реализации, хоть алгоритм.
Согласен на 100%. Вот только это у вас на С++ — ускорение. А у среднего юниора или мидла — торможение, за счет увеличения времени отладки.
Беда не в языке, беда в связке язык + програмvист. С++ обычно провоцирует overenginering, тогда как другие языки приучают писать просто. Ну хотя бы потому, что на них нужно сильно извращаться, чтобы написать сложно.
Если это консьюмерское приложение, то имеет смысл. Например, оно будет жрать на одну пятую меньше процессора, а значит и батареи. Или, если параллельно будут работать другие приложения (а они будут работать), оно будет уже заметно отзывчивее.
Ну давайте посчитаем. Время работы приложения — 20 минут в сутки. Пользователь нажимает кнопку часто, ну скажем раз в 5 секунд. Итого время загрузки процессора — 24 секунды. 20% от этого — 4.8 секунды загрузки процессора. Батарея малощная, дает 2 часа загрузки проца, то есть 7200 секунд. Итого ваш выигрыш — менее 0.1% емкости батареи. Чистый перфекционизм.
С отзывчивостью то же самое, 80 мс от 100 мс отличимо только для хардкордных геймеров.
Сходу нагугленные вещи вроде таких говорят, что зарплаты примерно одинаковые.
Вы не то смотрите, поищите разницу во времени обучения. Общеизвестный факт, что кривая обучения С++ круче. Сеньор действительно будет стоит примерно одинаково на любом языке. Вопрос не в этом, а в производительности юниоров и мидлов.
Вызов принят. Перепишите, пожалуйста, вот это пример (почти из тьюториала, я только переменную добавил, чтобы вообще хоть какой-то «выхлоп» был), на C:
Спойлеры не осилили? Никак, да? У вас типичный С++ многословно. коряво и не по делу.
extern double sqrt (double __x);
#define sqr(x) ((x)*(x))
#define distance(x1,y1,x2,y2) (sqrt(sqr((x2)-(x1))+sqr((y2)-(y1))))
int calculated_distance(void) {return distance(3,5,7,2);};
.text
.def @feat.00;
.scl 3;
.type 0;
.endef
.globl @feat.00
@feat.00 = 1
.def _calculated_distance;
.scl 2;
.type 32;
.endef
.globl _calculated_distance
.p2align 4, 0x90
_calculated_distance: # @calculated_distance
# BB#0: # %entry
movl $5, %eax
retl
В килобайт флеша? Форт? Покажите, просто интересно.
Игра "Ну погоди"

А вот и данные процессора КБ1013ВК1-2 — 1827 байт ПЗУ, 32.5 байт ОЗу

В обоих случаях (С и С++) какая-то ерунда получается. Компилятор просто вычисляет значение на этапе компиляции и подставляет его вместо реального вызова функции. Давайте уж нормальный вариант.
Вариант с макросами же плох тем, что с ними плохо работает IDE, и может сгенериться избыточный код, например, двойное вычисление x в sqr, если аргументы макроса distance не будут являться переменными.
Двойного вычисления не будет из-за оптимизации подвыражений. А без оптимизации оба примера будут далеко не так коротки.
Пример как раз хорошо показывает, что там, где на Си пишут просто, на С++ начинают выпендриваться и писать сложно.
#include <math.h>
extern const int calculated_distance;
inline double sqr(double x) {return x*x;}
inline double distance(double x1,double y1,double x2,double y2) {return sqrt(sqr(x2-x1)+sqr(y2-y1));}
const int calculated_distance = distance(3,5,7,2);
.text
.def @feat.00;
.scl 3;
.type 0;
.endef
.globl @feat.00
@feat.00 = 1
.section .rdata,"dr"
.globl "?calculated_distance@@3HB" # @"\01?calculated_distance@@3HB"
.p2align 2
"?calculated_distance@@3HB":
.long 5 # 0x5
Вот только настоящие с++ники так не пишут. Как это — 5 строчек, когда можно и 20 и 25 и 30? Как это обойтись без темплейтов? Как это — не всадить в кд все новомодные навороты? Ну вы поняли, что сарказм.
Честно говоря, я удивлен, что khim обошелся без лямбд. Явно с лямбдами — было бы ещё круче.
А Си — это не соревнование в крутизне. это просто рабочий код. Им не похвалишься. но он пашет.
А без оптимизации оба примера будут далеко не так коротки.Давайте проверим, а?
$ ./clang++ -S -std=c++14 -O0 integral2.cpp -o-
.text
.file "integral2.cpp"
.type __hana_tmp_113,@object # @__hana_tmp_113
.data
.globl __hana_tmp_113
__hana_tmp_113:
.zero 1
.size __hana_tmp_113, 1
.type calculated_distance,@object # @calculated_distance
.section .rodata,"a",@progbits
.globl calculated_distance
.p2align 2
calculated_distance:
.long 5 # 0x5
.size calculated_distance, 4
.ident "Android clang version 5.0.300080 (based on LLVM 5.0.300080)"
.section ".note.GNU-stack","",@progbits
$ ./clang++ -S -std=c++14 -O0 integral2.cpp -o-
.text
.file "integral3.cpp"
.section .rodata.cst8,"aM",@progbits,8
.p2align 3
.LCPI0_0:
.quad 4613937818241073152 # double 3
.LCPI0_1:
.quad 4617315517961601024 # double 5
.LCPI0_2:
.quad 4619567317775286272 # double 7
.LCPI0_3:
.quad 4611686018427387904 # double 2
.section .text.startup,"ax",@progbits
.p2align 4, 0x90
.type __cxx_global_var_init,@function
__cxx_global_var_init: # @__cxx_global_var_init
.cfi_startproc
# BB#0:
pushq %rbp
.Lcfi0:
.cfi_def_cfa_offset 16
.Lcfi1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
.Lcfi2:
.cfi_def_cfa_register %rbp
movsd .LCPI0_0(%rip), %xmm0 # xmm0 = mem[0],zero
movsd .LCPI0_1(%rip), %xmm1 # xmm1 = mem[0],zero
movsd .LCPI0_2(%rip), %xmm2 # xmm2 = mem[0],zero
movsd .LCPI0_3(%rip), %xmm3 # xmm3 = mem[0],zero
callq _Z8distancedddd
cvttsd2si %xmm0, %eax
movl %eax, calculated_distance
popq %rbp
retq
.Lfunc_end0:
.size __cxx_global_var_init, .Lfunc_end0-__cxx_global_var_init
.cfi_endproc
.section .text._Z8distancedddd,"axG",@progbits,_Z8distancedddd,comdat
.weak _Z8distancedddd
.p2align 4, 0x90
.type _Z8distancedddd,@function
_Z8distancedddd: # @_Z8distancedddd
.cfi_startproc
# BB#0:
pushq %rbp
.Lcfi3:
.cfi_def_cfa_offset 16
.Lcfi4:
.cfi_offset %rbp, -16
movq %rsp, %rbp
.Lcfi5:
.cfi_def_cfa_register %rbp
subq $48, %rsp
movsd %xmm0, -8(%rbp)
movsd %xmm1, -16(%rbp)
movsd %xmm2, -24(%rbp)
movsd %xmm3, -32(%rbp)
movsd -24(%rbp), %xmm0 # xmm0 = mem[0],zero
subsd -8(%rbp), %xmm0
callq _Z3sqrd
movsd -32(%rbp), %xmm1 # xmm1 = mem[0],zero
subsd -16(%rbp), %xmm1
movsd %xmm0, -40(%rbp) # 8-byte Spill
movaps %xmm1, %xmm0
callq _Z3sqrd
movsd -40(%rbp), %xmm1 # 8-byte Reload
# xmm1 = mem[0],zero
addsd %xmm0, %xmm1
movaps %xmm1, %xmm0
callq sqrt
addq $48, %rsp
popq %rbp
retq
.Lfunc_end1:
.size _Z8distancedddd, .Lfunc_end1-_Z8distancedddd
.cfi_endproc
.section .text._Z3sqrd,"axG",@progbits,_Z3sqrd,comdat
.weak _Z3sqrd
.p2align 4, 0x90
.type _Z3sqrd,@function
_Z3sqrd: # @_Z3sqrd
.cfi_startproc
# BB#0:
pushq %rbp
.Lcfi6:
.cfi_def_cfa_offset 16
.Lcfi7:
.cfi_offset %rbp, -16
movq %rsp, %rbp
.Lcfi8:
.cfi_def_cfa_register %rbp
movsd %xmm0, -8(%rbp)
movsd -8(%rbp), %xmm0 # xmm0 = mem[0],zero
mulsd -8(%rbp), %xmm0
popq %rbp
retq
.Lfunc_end2:
.size _Z3sqrd, .Lfunc_end2-_Z3sqrd
.cfi_endproc
.section .text.startup,"ax",@progbits
.p2align 4, 0x90
.type _GLOBAL__sub_I_integral3.cpp,@function
_GLOBAL__sub_I_integral3.cpp: # @_GLOBAL__sub_I_integral3.cpp
.cfi_startproc
# BB#0:
pushq %rbp
.Lcfi9:
.cfi_def_cfa_offset 16
.Lcfi10:
.cfi_offset %rbp, -16
movq %rsp, %rbp
.Lcfi11:
.cfi_def_cfa_register %rbp
callq __cxx_global_var_init
popq %rbp
retq
.Lfunc_end3:
.size _GLOBAL__sub_I_integral3.cpp, .Lfunc_end3-_GLOBAL__sub_I_integral3.cpp
.cfi_endproc
.type calculated_distance,@object # @calculated_distance
.bss
.globl calculated_distance
.p2align 2
calculated_distance:
.long 0 # 0x0
.size calculated_distance, 4
.section .init_array,"aw",@init_array
.p2align 3
.quad _GLOBAL__sub_I_integral3.cpp
.ident "Android clang version 5.0.300080 (based on LLVM 5.0.300080)"
.section ".note.GNU-stack","",@progbitsДа, ключевой момент, что clang сворачивает sqrt. А делает он это из-за особенностей стандартов Си/C++.Нет. Он это делает потому что может. И потому что иначе у людей — фанатов C код распухает.
А Си — это не соревнование в крутизне. это просто рабочий код. Им не похвалишься. но он пашет.До тех пор пока кто-нибудь две строчки не поправит и код «вдруг» вместо вычисленной во время компиляции не начнёт содержать два килобайта плавучки отрабатывающей в рантайме.
Хорошо хоть constexpr при -O0 нормально раскрывается в код.
До тех пор пока кто-нибудь две строчки не поправит
Ну в вашем коде достаточно подправить один байт (заменить xs на ys) как долгие мучение при отладке вам обеспечены. Так что вам ещё и покрытие тестами надо обеспечить.
Забавно, что специально предназначенный для таких вещей constexpr вам просто в голову не пришел. Видимо потому, что было бы как в Си, просто constexpr (или inine) вместо #define.
Увы, С++ники предпочитают писать максимально сложно, даже когда в языке специально добавлена возможность, позволяющая писать просто.
Хорошо хоть constexpr при -O0 нормально раскрывается в код.Не раскрывается.
Забавно, что специально предназначенный для таких вещей constexpr вам просто в голову не пришел.Как я уже сказал — я просто взял первый попавшийся пример. Давать версию, которая «работает» во время компиляции с типами, а не с числами, не захотел — но, возможно, напрасно.
template <typename X, typename Y>
struct _point {
X x;
Y y;
}
Вот зачем тут два разных типа? x — в милях, а y в километрах? а где проверка на существование приведения? А результат у нас в чем? В футах???
template <typename P1, typename P2>
constexpr auto distance(P1 p1, P2 p2) {
auto xs = p1.x - p2.x;
auto ys = p1.y - p2.y;
return sqrt(xs*xs + ys*ys);
}
Ну и зачем тут два разных типа? Имеет ввиду, что одна точка в геоцентрической системе, а другая в топоцентрической? Или одна в WGS84, а вторая в ПЗ-90?
Увы, так всегда у любителей С++. Ну хорошо, почти всегда, за исклюением отдельных монстров.
Вот за это С++ и не люблю. На Си — вы написали бы нормально. На С++ — что выросло, то выросло.
Вот зачем тут два разных типа?Когда вы пишите функцию для метапрограммирования вы всегда должны закладываться на то, что данные могут быть в типе. То есть X у вас может быть «длина 3», а Y — соотвественно «длина 4». Переменная при этом может быть пустой и её компилятор «изведёт».
Вот за это С++ и не люблю.Ну да — на C++ люди, обычно, пишут так, как пишут на C++, а не на Haskell'е — удивительно, правда?
На Си — вы написали бы нормально.То есть с вычслениями в рантайме, которые могли бы быть «свёрнуты» так и тогда, когда компилятор этого захочет.
На С++ — что выросло, то выросло.Не совсем так: на C++ можно вырастить то, что вам нужно. Говорить о том, что вам не нужно лодка, потому что вы живёте в пустыне — глупо: в программировании никогда нельзя сказать однозначно. Сегодня — вы в пустыне, а завтра — роза ветров изменилась…
Когда вы пишите функцию для метапрограммирования вы всегда должны закладываться на то, что данные могут быть в типе. То есть X у вас может быть «длина 3», а Y — соотвественно «длина 4». Переменная при этом может быть пустой и её компилятор «изведёт».
Как раз ради этого и придумали constexpr, чтобы избавиться от подобного метапрограммирования. В противном случае теряется преимущество статической типизации.
Я разумным виду следующий вариант на C++:
#include <math.h>
template <class TCoordinate>
struct Point
{
TCoordinate x, y;
constexpr inline Point(TCoordinate x, TCoordinate y)
: x(x), y(y) {}
constexpr inline auto DistanceTo(const Point<TCoordinate> &other)
{
auto v1 = x - other.x;
auto v2 = y - other.y;
return sqrt(v1 * v1 + v2 * v2);
}
};
int main()
{
constexpr auto v = Point(2, 3).DistanceTo({ 1, 5 });
}
Зачем тут inline?
Согласен: constexpr functions and constexpr constructors are implicitly inline.
Ну и DistanceTo в таком виде лично мне не очень нравится ввиду очевидной асимметрии.
Мне показалось, что это будет лучше, чем
Point<int>.distance({2, 3}, {1, 5});потому что здесь придётся явно указывать тип.
Можно, конечно, объявить функцию distance вне класса — тоже вариант.
test10.cpp:22:24: error: cannot refer to class template 'Point' without a template argument list constexpr auto v = Point(2, 3).DistanceTo({ 1, 5 });Как говорил Торвальдс —
infinite amounts of pain when they don't workНо даже, если исправим ошибку, все равно получим
test10.cpp:16:16: note: non-constexpr function 'sqrt' cannot be used in a constant expression return sqrt(v1 * v1 + v2 * v2); И пока где-нибудь в С++35 не будет сказано, что все стандартные процедуры надо трактовать как constexpr — так оно и будет. А вариант на Си — работает. причем независимо от компилятора.
P.S. Проверял на clang 3.8.
test10.cpp:16:16: note: non-constexpr function 'sqrt' cannot be used in a constant expression return sqrt(v1 * v1 + v2 * v2);? constexpr тоже «не для того сделан»?Вам не кажется симптоматичным, что и DistortNeo и khim ошиблись?
Вывод-то простой — если хорошие программисты ошибаются на какой-то конструкции, значит лучше эту конструкцию вообще не использовать без нужды.
inline не гарантирован, но зато работает предсказуемо. constexpr — приводит к ошибкам даже у хороших программистов. И пока в нем не разрешат стандартные процедуры — лучше его не использовать без особой нужды.
Ну так что и что там с test10.cpp:16:16: note: non-constexpr function 'sqrt' cannot be used in a constant expression return sqrt(v1 * v1 + v2 * v2);?А это у вас нужно спросить — это вы написали, не кто-то другой.Вам не кажется симптоматичным, что и DistortNeo и khim ошиблись?Нет, мне кажется симтоматичным что вы взяли работающий, но иллюстративый пример (где, разумеется,
const легко меняется на constexpr — как уже говорилось константные целые числа дают гарантии и без явного написания constexpr), после чего «выкинули из купели ребёнка» и с увлечением начали исследовать оставшуюся в купели воду.Это много говорит о вас, и совсем немного — о C++.
Как, собственно, говорилось изначально — это пример из тьюториола и в нём, разумеется, ошибок нет, всё копилируется и работает — можете сами убедиться.
А то, что вы сразу начали его обсуждать исключительно с позиций исключительно своей предметной области — тоже говорит о вам много и мало о С++.
Так что в сухом остатке остаётся разве что ваше нежелание читать что написано собеседником, что и делает дальнейшее обсуждение бессмысленным.
А это у вас нужно спросить — это вы написали, не кто-то другой.
Увы, DistortNeo не мой фейк (да и вообще не фейк). И это его пример.
где, разумеется, const легко меняется на constexpr
Ну так потрудитесь заменить в своем примере const на constyexpr и убедиться, что ничего кроме
test1.cpp:21:15: error: constexpr variable 'calculated_distance' must be initialized by a constant expression constexpr int calculated_distance = distance(point(3, 5), point(7, 2));
вы там не получите. Ну как минимум при -std=C++14 и обычном clang 3.8, который ставится из репозитария. Чем срамиться — затратьте минуту времени на компиляцию.А если вы рассчитываете на что более новое, чем С++14 — то к чему это в разговоре про то, что С+14 уже есть везде и все его фишки стоит использовать?
это пример из тьюториола и в нём, разумеется, ошибок нет, всё копилируется и работает — можете сами убедиться.
Конечно! Ибо в тьюториале есть… свой constexpr sqrt
template <typename T, typename = std::enable_if_t<!hana::Constant<T>::value>>
constexpr T sqrt(T x) {
T inf = 0, sup = (x == 1 ? 1 : x/2);
while (!((sup - inf) <= 1 || ((sup*sup <= x) && ((sup+1)*(sup+1) > x)))) {
T mid = (inf + sup) / 2;
bool take_inf = mid*mid > x ? 1 : 0;
inf = take_inf ? inf : mid;
sup = take_inf ? mid : sup;
}
return sup*sup <= x ? sup : inf;
}
Это много говорит о вас, и совсем немного — о C++.
Да нет, это как раз о С++. На Си или дельфи ни вы, ни @DistorNeo не сделали бы таких ошибок. А на С++ — да, очень легко спутать, что дает язык, что библиотека, что — компилятор. И на пустом месте — сесть в лужу.
Речь-то именно об этом, о том, что два опытных сеньора сели в лужу, не проверив свои примеры перед публикацией.
И это не сеньоры плохи, это язык чрезмерно сложен. Для команды сеньоров — терпимо. Для бригады сеньор + мидлы и юниоры — на Си производительность больше.
P.S. Компилятор в руки и убеждайтесь, что вы не правы, несмотря на ваш огромный опыт. :-)
Ну так потрудитесь заменить в своем примереВот прямо даже так? Вы таки написалиconstнаconstyexprи убедиться, что ничего кромеtest1.cpp:21:15: error: constexpr variable 'calculated_distance' must be initialized by a constant expression constexpr int calculated_distance = distance(point(3, 5), point(7, 2));
distance(point(3_c, 5_c), point(7_c, 2_c));, как в моём примере, а компилятор, сволочь такая, взял и заменил 3_c на 3? Плохой у вас компилятор, негодный, что я ещё могу сказать.Чем срамиться — затратьте минуту времени на компиляцию.Вы это глядя в зеркало, я надеюсь, пишите? Потому как я-то свой пример проверил, перед тем как писать. И с
const и с constexpr. Да, забыл написать изначально constexpr, каюсь. Вернее — давно покаялся, только вы на разьяснение внимания не обратили и продолжаете воевать с изобретёнными вами призраками… Уже изобретаете уже десятый, наверное, способ мой пример исковеркать так, чтобы он работать перестал.Конечно! Ибо в тьюториале есть… свой constexpr sqrtТам много чего еще есть. В частности там
using namespace hana::literals; есть — как у вас константные целые без этого вообще работают, ума не приложу. Вернее знаю как — никак.А на С++ — да, очень легко спутать, что дает язык, что библиотека, что — компилятор. И на пустом месте — сесть в лужу.То что вы это сумели сделать уже раз 10, наверное, не обозначает, что это — единственный возможный вариант использования. Я вас уверяю: подход «а что это тут за пуковки, которые программу понимать мешают, дай-ка я их удалю — за ненадобностью» могут к слезам на любом языке привести.
Речь-то именно об этом, о том, что два опытных сеньора сели в лужу, не проверив свои примеры перед публикацией.А каком втором сеньоре вы говорите? И о каком примере? Тут вроде больше людей, чем двое отметились, кроме вас. Я-то свой пример проверил. И он работал — до того, как вы его начали уродовать и свои измышления пристраивать.
Для бригады сеньор + мидлы и юниоры — на Си производительность больше.От сеньоров зависит. Конечно если у вас и сеньоры C++ не знаю — беда будет, но тут, как бы, С++ ничем из общего ряда не выбивается. Кто-то в команде должен таки знать язык, на котором всё пишется. Если вы не знаете C++, но знаете Delphi — то у вас на Delphi будет быстрее, в моём случае — наоборот.
P.S. Компилятор в руки и убеждайтесь, что вы не правы, несмотря на ваш огромный опыт. :-)Да легко. Но только после того, как вы мне покажите компилятор, где на строку с
distance(point(3_c, 5_c), point(7_c, 2_c)); будет выдано сообщение об ошибке оных _c не вклющее и обьясняение — как вы этого добилиcь. Все известные мне компиляторы уж по всякому в сообщении об ошибке пишут строку, в которой ошибка, а не отсебятину всякую.Там много чего еще есть. В частности там using namespace hana::literals; есть — как у вас константные целые без этого вообще работают, ума не приложу. Вернее знаю как — никак.
Скажите, а это моя ошибка, что своем примере вы пропустили
#include, constexpr sqrt и using namespace? Это я вас заставил привести неработающий код? Или это С++ такой язык, что сделать ошибку на нем слишком просто?
Да, с
_с не компилится никак. Но я не воюю с типографскими опечатками. Мало ли что там вылезло при переносе из rich text в plain. Это не повод для придирок. А вот забытые строки — это уже не опечатка, а ваша ошибка. Которую я вас сильно прошу исправить и привести пример, компилируемый на Clang 3.8 или более ранних.Потому как я-то свой пример проверил, перед тем как писать.
Именно что как-то. На официально не выпущенном компиляторе (clang 5.0) до вставки в пост, а при вставке — удаляли лишнее и напортачили. Проверьте уж нормально, то, что было приведено в вашем посте. И нормальным официальным компилятором. И убедитесь, что оно не компилится. А после этого — приведите уж нормальный компилируемый код. Руку на отсечение пока не дам, но на 90% уверен, что без
constexpr sqrt не получится присвоить constexpr переменной.А каком втором сеньоре вы говорите? И о каком примере?
Ссылочку на пример от DistortNeo открыть религия не позволяет? А откомпилировать и убедиться, что он тоже налажал?
Конечно если у вас и сеньоры C++ не знаю — беда будет, но тут, как бы, С++ ничем из общего ряда не выбивается.
Ну то есть ни вы ни DistortNeo в сеньоры не годитесь. Ибо налажали на простых примерах. И как будете реагировать? Признаете себя мидлом или все-таки согласитесь, что С++ излишне сложен и налажать на нем пара пустяков?
А мы просто не называем язык, на котором пишем, С++. Это Си с отдельными элементами С++. Зато — 6 операционок, 6 компиляторов, 3 архитектуры процессора — и везде компилится без особых проблем. У нас опыт в том, чтобы писать совместимо. И не лажать по пустякам.
Если вы не знаете C++, но знаете Delphi — то у вас на Delphi будет быстрее, в моём случае — наоборот.
Вот только в вашем случае речь пойдет о зарплате в 5-10 тысяч долларов в месяц. А хороший сеньор на Си или Дельфи стоит намного меньше. И не факт, что вы дадите отлаженный код быстрее чем программист на дельфи. А уж тем более — 5-10 сеньоров.
Дело-то прежде всего в экономике, а не в самом С++. Да, есть области, где С++ экономически выгоден. Но они не так велики.
Я-то свой пример проверил. И он работал — до того, как вы его начали уродовать и свои измышления пристраивать.
Значит проверьте ещё раз и убедитесь, что вы его исковеркали при вставке в пост.
Ну а что касается новых фишек: обычно известно, каким множеством компиляторов код будет компилироваться. В вашем случае это 6 компиляторов, в моём — один-два. В вашем случае это мелкие проекты, где можно обойтись С с элементами С++, причём набор элементов ограничен компиляторами под конкретные платформы. В моём — сложные проекты, где каждая новая фича упрощает написание кода и снижает вероятность ошибки.
P.S. А я на сеньора C++ я и не претендую. Ну нет у нас сеньоров, есть только инженеры и программисты.
Если вдруг нужно будет компилить clang вместо gcc/intel — придётся вставить костыль или отказаться от constexpr sqrt.
Гм, у вас в коде нету собственного constexpr sqrt. И тем не менее, на gcc — v действительно constexpr. Не понимаю, каким же образом gcc обходит запрет на вызов не constexpr функций? Если поясните (хотя бы в личку) буду благодарен.
Ну показали вы, что мой код не компилируется clang, что дальше?
Да просто С++ такой язык, что даже очень опытные программисты не могут сходу написать пример на стандартном С++. У вас — какая-то фишка за рамками С++ 14, khim пропустил кучу инклудов…
Собственно из-за сложности С++ стоимость разработки на нём и получается больше, чем на Си.
Ну а что касается новых фишек: обычно известно, каким множеством компиляторов код будет компилироваться
У нас — неизвестно. То есть даже gcc может и не быть. Зато Си — легко проходит через любой компилятор.
В моём — сложные проекты, где каждая новая фича упрощает написание кода и снижает вероятность ошибки.
Не согласен, что вероятность ошибки снижается. Судя по приведенному тут коду — ошибки есть даже в маленьких примерах.
Но самое — растет стоимость. То есть для С++ нужны программисты с намного 5-10 раз большей зарплатой. А соответствующего (в 5-10 раз) ускорения написания кода он не дает.
Собственно этот тезис я и отстаиваю.
Другой момент, если размер проекта и так требует высокооплачиваемых программистов. Тогда вполне возможно получить выгоду от С++.
Тем не менее пример linux показывает, что можно писать большие проекты и на Си. Или как мы — на Си с безопасными фишками из С++.
Да просто С++ такой язык, что даже очень опытные программисты не могут сходу написать пример на стандартном С++. У вас — какая-то фишка за рамками С++ 14, khim пропустил кучу инклудовВообще — вы первый человек, который считает, что иллюстрационные примеры — должны быть всегда и исключительно полной программой. Хорошо хоть Makefile.am и configure.ac прилагать не требуете…
Зато Си — легко проходит через любой компилятор.Я бы сказал, что оно легко входит в любой компилятор — а вот уж что оттуда выходит… это другой вопрос.
Судя по приведенному тут коду — ошибки есть даже в маленьких примерах.По приведённым примерам мало о чём можно судить, уж извините. Задача большинства конструкций C++ — сделать так, чтобы ошибка была обнаружена во врема компиляции и не дожила до стадии запуска программы (не говоря уже о её развёрывании и прочем).
Так как чем позднее ошибка обнаружена — тем дороже её исправлять. Ни одной ошибки не стадии компиляции мы тут не видели, так что и обсуждать нечего.
Тем не менее пример linux показывает, что можно писать большие проекты и на Си.А пример Multics показывает, что и на PL/1 можно — но вот стоит ли?
Вообще — вы первый человек, который считает, что иллюстрационные примеры — должны быть всегда и исключительно полной программой.
Примеры должны не только компилиться, но и работать. Неработающих красивых примеров я вам на любом языке пачку напишу.
Ни одной ошибки не стадии компиляции мы тут не видели, так что и обсуждать нечего.
Ну со стадией исполнения в вашем примере — совсем плохо. «Ух ты, как оно считается в compile-time» — это для студентиков. А реально, какие преимущества от того, что вы написали 20 строк на С++ вместо 4х на Си? Оптимизация и в #define и в inline работает прилично. Зачем вам темплейты и куча кода?
iВам очень не повезло — я как раз работаю с подобным кодом. Основная ошибка, в которую можно вляпаться — это вычисление расстояний между точками с разными системами координат. Земля, к сожалению, круглая, поэтому топоцентрические системы координат (ENU, то есть восток-север-вверх) отличаются направлением осей даже на расстоянии 100 метров.
Так вот, вполне разумно в типе точки упрятать знание о её системе координат. И или не давать вычислять расстояние, когда точки из разных систем координат или автоматически преобразовывать.
Так что увы. Ваш код лучше #define или inline лишь синтаксическими красотами. Зато — хуже читается и более многословный. То есть в лучшем дял вас случае — баш на баш.
Что касается вычислений в compile-time… ну я могу представить себе школьника, который записывает исходные данные прямо в код. Но в реальной программе — данные будут в файле или в конфигурации. То есть сие преимущество — не нужно для этой задачи.
Так что увы, доказать превосходство современного С++ у вас не получилось.
Собственно вопрос на засыпку — чем ваш код лучше простого inline? От чего он страхует?
Я бы сказал, что оно легко входит в любой компилятор — а вот уж что оттуда выходит… это другой вопрос.
Достаточно немного понимать процесс компиляции, чтобы Си давал абсолютно предсказуемый код. С С++ это несколько сложнее.
А пример Multics показывает, что и на PL/1 можно — но вот стоит ли?
PL/1 — это такой FORTRAN++, он был удобен при наличии большого числа программистов на фортране. Судя по тому, что multics при небольшом на современный взгляд объеме обладала возможностями, которых нет в современном linux — язык был выбран вполне разумно.
Скажите, а это моя ошибка, что своем примере вы пропустилиНет, ваша ошибка в том, что вы, увидев чего-то, чего вы не понимаете сразу решили, что я «облажался» (ну эта — «настоящие» программисты, они ж идиоты по определению и ничего писать не могут без IDE) и вместо конструктивной дискуссии занялись обсиранием. Если вы бы спросили про инклуды и константные числа две недели назад — я бы объяснил откуда что берётся, но вам же этого не нужно было, ведь так?#include,constexpr sqrtиusing namespace?
Да, с _с не компилится никак. Но я не воюю с типографскими опечатками. Мало ли что там вылезло при переносе из rich text в plain.Ну да, мы ж самые умные. А я ведь старался, подсказки давал.
Которую я вас сильно прошу исправить и привести пример, компилируемый на Clang 3.8 или более ранних.Ну если вам так сильно хочется увидеть килотонны бойлерплейта, то, вот, пожалуйста Не забудьте, что там кнопочка download есть — чтобы в будущем не пенять на то, что откуда-то rich text выскчил и всю малину вам испортил.
На официально не выпущенном компиляторе (clang 5.0)Может он официально ещё и не вышал, но одна официально уже вышедшая операционка собрана именно им — и мне было лень искать что-то ещё.
Руку на отсечение пока не дам, но на 90% уверен, что безНе получится. И не должно было получиться. Как я написал с самого начала — я взял кусок примера — а так как разconstexpr sqrtне получится присвоитьconstexprпеременной.
constexpr sqrt был. Это таки не баг, а фича.Ссылочку на пример от DistortNeo открыть религия не позволяет?Позволяет — но я не телепат угадывать кого ещё вы имели в виду.
А откомпилировать и убедиться, что он тоже налажал?Открыл, проверил. Всё работает.
Ну то есть ни вы ни @DistortNeo в сеньоры не годитесь. Ибо налажали на простых примерах. И как будете реагировать?Обьяснять работодателям, что людей, которые ведут риторику по принципу Все пидорасы, а я — д’Артаньян на работу лучше не брать. Оба примера — работают (хотя второй — только с GCC… мой немного сложнее, но зато пресловутый «C++35» не нужен и потому работает и с clang'ом и с GCC).
Признаете себя мидлом или все-таки согласитесь, что С++ излишне сложен и налажать на нем пара пустяков?Ну это у вас надо спросить — потому как только вы тут налажали (причём многими разными способами) с C++. Ваш вариант с C, надо сказать, меня удивил — не знал, что clang может вычислять корни во время компиляции… но, как уже было сказано — речь-то не о корне, а о гарантированных вычислениях во время компиляции. С++ их даёт, С — нет. Проверять ассемблерный вывод всё время — как-то в XXI веке странно.
Значит проверьте ещё раз и убедитесь, что вы его исковеркали при вставке в пост.Вы уж извините, но я его специально скопировал из поста в pastebin, чтобы не было разночтений. Ничего там не исковеркано и Хабр показывает то, что было задумано, уж извините.
Опыт показывает — что весьма-весьма большой. А для Си — хватает намного меньшего уровня и зарплаты. И вот эта разница в зарплатах в 5-10 раз не оправдывается уменьшением времени написания и отладки на С++.
Поэтому во многих случаях — Си экономически выгодней, чем С++.
Не важно, кто лично ошибся. Важно, что ошиблись сеньоры и в коде копеечной длины. А на си — иногда и 500 строк кода сразу начинают работать.
Вообще-то мы обсуждаем, какой уровень компетентности и зарплат должен быть у программиста, чтобы писать примеры в 20 строчек на С++ безошибочно.То, что вы лично на это не способны — не говорит о требуемом опыте. Наш опыт показывает, что хорошие студенты на это вполне способны и для этого не требуется 30 лет опыта работы с C++.
Опыт показывает — что весьма-весьма большой.
Не важно, кто лично ошибся.Ну Ok.
Важно, что ошиблись сеньоры и в коде копеечной длины.Понятно. Принцип Все пидорасы, а я — д’Артаньян — абсолютно незыблем, потому когда вдруг оказывается, что единственный невменяемый сеньор тут — это вы, то резко становится полезно забыть о том кто лично ошибся.
А для Си — хватает намного меньшего уровня и зарплаты. И вот эта разница в зарплатах в 5-10 раз не оправдывается уменьшением времени написания и отладки на С++.Ну если единственное преимущество Си — это пониженная зарплата, то с точки зрения соискателя лучше C++ — и просто не стоит идти на работу туда, где используется Си, разве нет?
То, что вы лично на это не способны — не говорит о требуемом опыте
Вы где-то нашли ошибки в моем коде? :-) А может не стоит переворачивать с ног на голову? Как и ваши студентики, я не считаю себя непогрешимым гуру, поэтому любые примеры проверяю до отправки.
Другой момент, что на всех остальных языках ошибки компиляции идут только от опечаток при вводе. Как у меня, так и у юниоров. И только на С++ мы видим ошибки у сеньоров, связанные с незнанием языка.
Задача-то у вас была — продемонстрировать достоинства С++14. DistortNeo написал на диалекте, не поддерживаемом clang. Возможно это и С++17 — не разбирался. А вы просто выкинули ребенка вместе с водой.
Принцип Все пидорасы, а я — д’Артаньян — абсолютно незыблем,
Поскольку я вам в отцы гожусь, то не советую вам пользоваться этим принципом. Напоретесь рано или поздно.
Ну если единственное преимущество Си — это пониженная зарплата, то с точки зрения соискателя лучше C++ — и просто не стоит идти на работу туда, где используется Си, разве нет?
А выбор у юниора куцый:
- сидеть дома и кропать игрушки на С++
- писать на Си или очень урезанном С++
- писать на полном современном С++ и удивляться очередному увольнению за срыв сроков
Ну не нужен никому писатель на полном современном С++ без опыта создания больших систем. Ну вот, например идея от 0xd34df00d об ограничения для юниоров. Насколько такие ограничения дадут развиваться?
Пока что я вижу, что юниоры идут по третьему пути. Ну почти как вы написали — «вы все старперы, я один знаю С++, я вам покажу». Ну и показывается полный срыв сроков. То есть код красивы, запутанный, современный, но глючащий на каждом шагу.
Что творят выпускники курсов переподготовки при центрах занятости — подумать страшно.
А когда я начинал работать — 70-80% программистов имели совсем иное образование. Иногда даже не инженерное. И ничего. 2-3 месяца на изучение языка, хорошее знание прикладной области — и их программы работали.
Ну как пример. Программа прочностных расчетов зданий «Ладога» использовалась для расчета в сотне институтов по всему СССР. Тысячи рассчитанные по ней зданий до сих пор стоят. Размер — порядка 50 тысяч строк. В авторском коллективе — ни одного человека с программистским образованием. Язык — FORTRAN-66.
А вот теперь подумайте, что было бы, если бы её писали на современном С++ такой командой? Сколько бы в ней было ошибок? Сколько зданий бы упало? А вот на Си такая система пишется не хуже, чем на фортране. Собственно даже лучше.
Главная беда С++ — даже не сложность. А желание программистов воткнуть эту сложность не по делу.
P.S. Строго формально — у нас тоже С++. Но поскольку мы слабо используем С++ные фишки, то лучше считать это расширенным Си.
Когда вы пишите функцию для метапрограммирования вы всегда должны закладываться на то, что данные могут быть в типе.
А если ещё один шажок сделать? Какие данные удобно хранить в типе? Да прежде всего данные о системе координат! То есть о начале системы координат, ориентации осей и единицах измерения. А у вас — ни два, ни полтора.
Если уж используете разные типы — используйте перекрываемые операции для приведения к единой системе координат. Или — используйте единый тип, ибо только для единого типа мы можем быть уверены, что система координат общая.
То есть это обычная для С++ников история, когда думают о совершенстве кода и забыли о прикладной области. Пар в свисток уходит.
На Си — чуть проще, там не надо тратить время на красоты С++, поэтому можно сразу думать о прикладной задаче.
Ну да — на C++ люди, обычно, пишут так, как пишут на C++, а не на Haskell'е — удивительно, правда?
Нет, не удивительно. С++ хорош там, где действительно нужны эти красоты. А там, где нужен рабочий код — лучше Си. Как там у Торвальдса:
limiting your project to C means that people
don't screw that up, and also means that you get a lot of programmers that do actually understand low-level issues and don't screw things up with any idiotic "object model" crap.То есть с вычислениями в рантайме, которые могли бы быть «свёрнуты» так и тогда, когда компилятор этого захочет.
#include <math.h>
extern const int calculated_distance;
template <typename X, typename Y>
struct _point {
X x;
Y y;
};
template <typename X, typename Y>
constexpr _point<X, Y> point(X x, Y y) { return {x, y}; }
template <typename P1, typename P2>
constexpr auto distance(P1 p1, P2 p2) {
auto xs = p1.x — p2.x;
auto ys = p1.y — p2.y;
return sqrt(xs*xs + ys*ys);
}
// This goes into .cc
const int calculated_distance = distance(point(3, 5), point(7, 2));
.text
.file «test1.cpp»
.section .text.startup,«ax»,@progbits
.align 16, 0x90
.type __cxx_global_var_init,@function
__cxx_global_var_init: # @__cxx_global_var_init
.cfi_startproc
# BB#0:
pushl %ebp
.Ltmp0:
.cfi_def_cfa_offset 8
.Ltmp1:
.cfi_offset %ebp, -8
movl %esp, %ebp
.Ltmp2:
.cfi_def_cfa_register %ebp
pushl %esi
subl $68, %esp
.Ltmp3:
.cfi_offset %esi, -12
leal -16(%ebp), %eax
movl $3, %ecx
movl $5, %edx
movl %eax, (%esp)
movl $3, 4(%esp)
movl $5, 8(%esp)
movl %edx, -36(%ebp) # 4-byte Spill
movl %ecx, -40(%ebp) # 4-byte Spill
calll _Z5pointIiiE6_pointIT_T0_ES1_S2_
subl $4, %esp
leal -24(%ebp), %eax
movl $7, %ecx
movl $2, %edx
movl %eax, (%esp)
movl $7, 4(%esp)
movl $2, 8(%esp)
movl %edx, -44(%ebp) # 4-byte Spill
movl %ecx, -48(%ebp) # 4-byte Spill
calll _Z5pointIiiE6_pointIT_T0_ES1_S2_
subl $4, %esp
movl -16(%ebp), %eax
movl -12(%ebp), %ecx
movl -24(%ebp), %edx
movl -20(%ebp), %esi
movl %eax, (%esp)
movl %ecx, 4(%esp)
movl %edx, 8(%esp)
movl %esi, 12(%esp)
calll _Z8distanceI6_pointIiiES1_EDaT_T0_
fstpl -32(%ebp)
movsd -32(%ebp), %xmm0 # xmm0 = mem[0],zero
cvttsd2si %xmm0, %eax
movl %eax, calculated_distance
addl $68, %esp
popl %esi
popl %ebp
retl
.Lfunc_end0:
.size __cxx_global_var_init, .Lfunc_end0-__cxx_global_var_init
.cfi_endproc
.section .text._Z8distanceI6_pointIiiES1_EDaT_T0_,«axG»,@progbits,_Z8distanceI6_pointIiiES1_EDaT_T0_,comdat
.weak _Z8distanceI6_pointIiiES1_EDaT_T0_
.align 16, 0x90
.type _Z8distanceI6_pointIiiES1_EDaT_T0_,@function
_Z8distanceI6_pointIiiES1_EDaT_T0_: # @_Z8distanceI6_pointIiiES1_EDaT_T0_
# BB#0:
pushl %ebp
movl %esp, %ebp
pushl %esi
subl $52, %esp
movl 20(%ebp), %eax
movl 16(%ebp), %ecx
movl 12(%ebp), %edx
movl 8(%ebp), %esi
movl %esi, -16(%ebp)
movl %edx, -12(%ebp)
movl %ecx, -24(%ebp)
movl %eax, -20(%ebp)
movl -16(%ebp), %eax
movl -24(%ebp), %ecx
subl %ecx, %eax
movl %eax, -28(%ebp)
movl -12(%ebp), %eax
movl -20(%ebp), %ecx
subl %ecx, %eax
movl %eax, -32(%ebp)
movl -28(%ebp), %ecx
imull %ecx, %ecx
imull %eax, %eax
addl %eax, %ecx
cvtsi2sdl %ecx, %xmm0
movl %esp, %eax
movsd %xmm0, (%eax)
calll sqrt
fstl -40(%ebp)
movsd -40(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd %xmm0, -48(%ebp) # 8-byte Spill
addl $52, %esp
popl %esi
popl %ebp
retl
.Lfunc_end1:
.size _Z8distanceI6_pointIiiES1_EDaT_T0_, .Lfunc_end1-_Z8distanceI6_pointIiiES1_EDaT_T0_
.section .text._Z5pointIiiE6_pointIT_T0_ES1_S2_,«axG»,@progbits,_Z5pointIiiE6_pointIT_T0_ES1_S2_,comdat
.weak _Z5pointIiiE6_pointIT_T0_ES1_S2_
.align 16, 0x90
.type _Z5pointIiiE6_pointIT_T0_ES1_S2_,@function
_Z5pointIiiE6_pointIT_T0_ES1_S2_: # @_Z5pointIiiE6_pointIT_T0_ES1_S2_
# BB#0:
pushl %ebp
movl %esp, %ebp
pushl %esi
subl $8, %esp
movl 8(%ebp), %eax
movl %eax, %ecx
movl 16(%ebp), %edx
movl 12(%ebp), %esi
movl %esi, -8(%ebp)
movl %edx, -12(%ebp)
movl -8(%ebp), %edx
movl %edx, (%eax)
movl -12(%ebp), %edx
movl %edx, 4(%eax)
movl %ecx, %eax
addl $8, %esp
popl %esi
popl %ebp
retl $4
.Lfunc_end2:
.size _Z5pointIiiE6_pointIT_T0_ES1_S2_, .Lfunc_end2-_Z5pointIiiE6_pointIT_T0_ES1_S2_
.section .text.startup,«ax»,@progbits
.align 16, 0x90
.type _GLOBAL__sub_I_test1.cpp,@function
_GLOBAL__sub_I_test1.cpp: # @_GLOBAL__sub_I_test1.cpp
.cfi_startproc
# BB#0:
pushl %ebp
.Ltmp4:
.cfi_def_cfa_offset 8
.Ltmp5:
.cfi_offset %ebp, -8
movl %esp, %ebp
.Ltmp6:
.cfi_def_cfa_register %ebp
subl $8, %esp
calll __cxx_global_var_init
addl $8, %esp
popl %ebp
retl
.Lfunc_end3:
.size _GLOBAL__sub_I_test1.cpp, .Lfunc_end3-_GLOBAL__sub_I_test1.cpp
.cfi_endproc
.type calculated_distance,@object # @calculated_distance
.bss
.globl calculated_distance
.align 4
calculated_distance:
.long 0 # 0x0
.size calculated_distance, 4
.section .init_array,«aw»,@init_array
.align 4
.long _GLOBAL__sub_I_test1.cpp
.ident «clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)»
.section ".note.GNU-stack","",@progbits
Или вы закладываетесь на поведение используемой вами версии компилятора? Ну да, на clang 4.0 — не так. А на 3.8 — так.
Не, если вы программист на «Android clang version 5.0» — то вопросов нет. А если на С++ — рассчитывайте сразу на все компиляторы.
Не совсем так: на C++ можно вырастить то, что вам нужно.
Можно. Но слишком часто — что выросло, то выросло, как у вас в примере.
Си в этом плане намного более предсказуем. По крайне мере пока речь не идет о программистах с зарплатой 5-10 тысяч долларов в месяц и выше. Вот на этом уровне — и С++ становится предсказуемым.
Вернемся к нашим баранам. Как я уже писал, разработка С++ — обычно дороже разработки на Си. То есть требуемый ФОП программистов С++ не оправдывается сокращением сроков. См. выше слова Торвальдса.
Написать темплейт так, чтобы его можно было параметризовать только либо декартовыми координатами
Нет. Написать темплейт так, чтобы он параметризовался положением начало координат и направлениями осей (система только декартова). При этом чтобы расстояние между точками в разной системе или считалось корректно или выдавало сообщение об ошибке (что вроде «нет метода приведения»). Желательно, чтобы начало координат и направления осей не занимали место в типе, а количество написанных руками операций приведения было порядка О(N-1).
Ну а если это сложно — то distance должно работать лишь с объектами одного типа.
Смогите уже, пожалуйста, написать constexpr int вместо const int в объявлении переменной.
Молодой человек, ну так вперед, напишите. Только не «на салфетке», а так, чтобы оно компилилось и работало.
Что касается меня, то я тупой, и сразу проверил, что constexpr приводит лишь к
test1.cpp:21:15: error: constexpr variable 'calculated_distance' must be initialized by a constant expression constexpr int calculated_distance = distance(point(3, 5), point(7, 2))
// Most be in header
#include <math.h>
extern const int calculated_distance;
template <typename X, typename Y>
struct _point {
X x;
Y y;
};
template <typename X, typename Y>
constexpr _point<X, Y> point(X x, Y y) { return {x, y}; }
template <typename P1, typename P2>
constexpr auto distance(P1 p1, P2 p2) {
auto xs = p1.x - p2.x;
auto ys = p1.y - p2.y;
return sqrt(xs*xs + ys*ys);
}
// This goes into .cc
constexpr int calculated_distance = distance(point(3, 5), point(7, 2));Так что выводы простые — даже любители С++ вроде вас по настоящему его не знают и садятся в лужу регулярно. Вот потому более простой язык — ускоряет написание и отладку кода.
Во-первых, не следует множить сущее без необходимости. Я понимаю, что С++ на этапе компиляции просто выбросит всё неиспользуемое, но усложнение кода ни к чему хорошему не приведёт.
Во-вторых, даже в этом случае у вас, скорее всего, координаты будут иметь одинаковый тип. В подавляющем большинстве случаев это будет int, float или double.
Ну и в-третьих, расстояние — это свойство векторного поля, а не точки, поэтому код в этом случае должен выглядеть как:
EuclideanField.Distance(p1, p2);
ManhattanField.Distance(p1, p2);и т.д.
Долгие — потому что качество
Впрочем, хорошие программеры на С++ — редкость. И стоят совсем иных денег.
Вариантов отладки, по большому счету, всего три:
- Пакетная. Запускаем с разными входными данными, выводим результаты и гадаем, а где же у нас баг притаился.
- Как только стала дешевой вставка оператора пришла технология отладки путем вставки перфокарт с отладочной печатью. На перфолентах оператор тяжело вставляется — надо её разрезать и сделать две вклейки. А вот с перфокартами все проще.
- Ну и с появлением терминалов и отладчиков расцвела отладка интерактивная. Поставили точку останова и смотрим, а что же у нас в переменных.
Каждый шаг на этом пути ускорял скорость отладки примерно на порядок. Так что возврат к пакетной отладке — это очень плохо. Пакетные методы — пригодны для тестирования (особенно регрессионного), а не для отладки.
Надеюсь, что вы не путаете два этих понятия.
sin вместо cos — и это скомпилируется. Более того — запустится. Только результаты будут неверными.Да, на простых алгоритмах вы по результатам теста вполне можете понять, что у вас неверно. А в сложных — нужна вычитка, вычитка, вычитка и проход по шагам. Да, можно заменить проход по шагам на включение отладочной печати. Обычно используются оба решения — и отладочная печать и проход по шагам.
Критерии отличия сложных алгоритмов от простых — элементарные.
1) Если вы знаете (можете за минуту предсказать), как изменится результат при любой опечатке (ну скажем от замены плюса на минус) — у вас, возможно, простой алгоритм.
2) Если вы до окончания отладки понимаете, какой код будет наилучшим — у вас, возможно, простой алгоритм.
Сложные алгоритмы часто отличаются тем, что оптимальный код получается лишь в процессе отладки. Ну как пример — есть зашумленные данные, часть из них недостоверна. Какой алгоритм будет оптимален? С какими параметрами настройки?
Ещё пример — передача данных через сбойный канал. Какой алгоритм будет лучше на конкретном канале? С какими параметрами настройки?
Подумайте о том, когда был придуман TCP/IP. И до сих пор идет его отладка в части увеличения пропускной способности. Последние предложения от гугла были совсем недавно.
А то, что вы описываете — это очень простые алгоритмы. Вы ещё до написания знаете, как они должны работать оптимально.
Что касается проверки инвариантов — ну когда можно придумать инвариант, его нужно придумать и вставить в программу. Вот с этим я согласен.
А на шаблонах сложные алгоритмы обычно не пишут.
Пишут-пишут. В eigen загляните.
Вывод-то простой. Можно отладить все, что угодно. Но трудоемкость интерактивной отладки меньше.
Или написать на этот инвариант тесты, чтобы во время выполнения не тратить время.
Ну это примерно как убрать тормоза после обучения вождению. Процентов 5 скорости стоит заплатить, чтобы при реальной работе не выдать лажу.
Это от возраста зависит. Молодежь думает, что может отладить так, что ошибок не останется, а старики уже знают, что это невозможно. Рано или поздно — но, что-нибудь вылезет. И лучше, чтобы это было обнаружено… ну скажем на этапе расчета прочности заводского цеха. А не тогда, когда этот цех уже рухнул и госкомиссия проверяет все расчеты.
Так что пусть чуть тормозит, но себя проверяет.
Какие алгоритмы там на шаблонах?
Да все, вообще-то. В код посмотрите… Там всюду примерно так
template<typename Derived>
template<typename Func>
internal::traits<Derived>::Scalar Eigen::DenseBase< Derived >::
redux(const Func & func)const
Другое дело, что они не умничают, а пишут понятно.
в некоторых задачах жертвовать 5-10-15-50% производительности ради того, чтобы снизить вероятность ошибки, условно, с 1e-4 до 1e-5, не имеет особого смысла,
В некоторых да. Но… в realtime вы или влезаете в производительность процессора или не влезаете. И если вы влезли, то не важно, у вас запас в 10 раз или в 2 раза. Вопрос только в энергопотреблении. То есть если у вас беспилотник — то излишне батарейку загружать не стоит. Но и цена ошибки — высока. А если у вас трактор на дизеле, то лишние милливаты считать не стоит. Зато и цена ошибки поменьше.
Так что, если оптимизация ускоряет на проценты, а не в разы — лучше её в realtime не делать. А вот надежность обычно лишней не бывает.
Case 1. Если ваш сервис кому-то нужен, он должен работать 365*24. В противном случае не так важно, тормозит он или нет.
Для работы 365*24 в случае «одного» сервера нужно иметь второй сервер в резерве. То есть резерв у нас получается 100%. А если у вас распределено на 100 простых машинок, то можно даже без резерва. Отказ одной машинки даст лишь 1% увеличения времени обработки, что несущественно. Кроме того, 100 маломощных серверов можно запустить в очень щадящем режиме — безвентиляторном, с пониженными тактовыми частотами. С точки зрения надежности — такой вариант намного лучше.
Case 2. Ваш месячный ФОП (фонд оплаты труда) — это примерно десяток серверов. Так что 18 серверов вместо 20 выгоднее лишь тогда, когда вы тратите на оптимизацию 3-4 рабочих дня. Уж не говорю о том, что сервера дешевеют, а зарплаты программистов растут.
Case 3. Расход ОЗУ практически не оптимизируется компилятором. И тут не важно, С++, Си или Delphi. Все равно оптимизация тут алгоритмическая, за счет усилий программиста.
Case 4. Или у вас «с запасом», то есть вы укладываетесь в 4-5 мс среднего времени и 10 мс на выбросах или никакого запаса нет и среднее время у вас 9.5 мс (а пиковое 20-30 мс).
Резюме. Ускорение в 10 раз и более — всегда полезно. Обычно полезно ускорение от 1.5 раз. А вот ускорение на 3-5% — обычно не оправдывается экономически. Это чистой воды перфекционизм.
Разумеется, есть узенький класс задач, где каждый процент важен. Если ваш расчет идет 10 лет, то 3% от него — это 3.5 месяца. Можно потратить месяц, но посчитать быстрее.
Но в большинстве задач — лучше (экономический выгодней) иметь простой, понятный, легко модифицируемый и легко отлаживаемый код. И не гнаться за оптимизациями, меньшими 50%.
Хотя… перфекционизм — это как та жаба, он сильно душит. И меня тоже.
Компилятор просто вычисляет значение на этапе компиляции и подставляет его вместо реального вызова функции. Давайте уж нормальный вариант.А чем этот ненормален? Собственно вычисления во время компиляции — это то, чего, в общем-то, и хотелось. Вот только в версии с
constexpr все вычисления гарантированно производятся во время компиляции. Вариант на C — оставляет это на усмотрение компилятора. Компиляция без оптимизации породит вызов sqrt и cvttsd2si. Что, возможо, вас может и устроить — в зависимости от поставленных перед вами задач.Не удивлюсь что именно из-за подобного у меня
swapoff отраьатывает на 8 секунд, а 8 часов… ну подумаешь — где-то какие-то высчисления «не там вычислились»… Делов-то…Вот только в версии с constexpr все вычисления гарантированно производятся во время компиляции.
Чё, серьёзно? А
extern "C" constexpr double sqrt (double __x);
extern const int calculated_distance;
constexpr double sqr(double x) {return x*x;}
constexpr double distance(double x1,double y1,double x2,double y2) {return sqrt(sqr(x2-x1)+sqr(y2-y1));}
const int calculated_distance = distance(3,5,7,2);
.text
.def @feat.00;
.scl 3;
.type 0;
.endef
.globl @feat.00
@feat.00 = 1
.def "??__Ecalculated_distance@@YAXXZ";
.scl 3;
.type 32;
.endef
.globl __real@4008000000000000
.section .rdata,"dr",discard,__real@4008000000000000
.p2align 3
__real@4008000000000000:
.quad 4613937818241073152 # double 3
.globl __real@4014000000000000
.section .rdata,"dr",discard,__real@4014000000000000
.p2align 3
__real@4014000000000000:
.quad 4617315517961601024 # double 5
.globl __real@401c000000000000
.section .rdata,"dr",discard,__real@401c000000000000
.p2align 3
__real@401c000000000000:
.quad 4619567317775286272 # double 7
.globl __real@4000000000000000
.section .rdata,"dr",discard,__real@4000000000000000
.p2align 3
__real@4000000000000000:
.quad 4611686018427387904 # double 2
.text
.p2align 4, 0x90
"??__Ecalculated_distance@@YAXXZ": # @"\01??__Ecalculated_distance@@YAXXZ"
# BB#0: # %entry
pushl %ebp
movl %esp, %ebp
andl $-8, %esp
subl $40, %esp
movsd __real@4008000000000000, %xmm0 # xmm0 = mem[0],zero
movsd __real@4014000000000000, %xmm1 # xmm1 = mem[0],zero
movsd __real@401c000000000000, %xmm2 # xmm2 = mem[0],zero
movsd __real@4000000000000000, %xmm3 # xmm3 = mem[0],zero
movsd %xmm0, (%esp)
movsd %xmm1, 8(%esp)
movsd %xmm2, 16(%esp)
movsd %xmm3, 24(%esp)
calll "?distance@@YANNNNN@Z"
fstpl 32(%esp)
movsd 32(%esp), %xmm0 # xmm0 = mem[0],zero
cvttsd2si %xmm0, %eax
movl %eax, "?calculated_distance@@3HB"
movl %ebp, %esp
popl %ebp
retl
.def "?distance@@YANNNNN@Z";
.scl 2;
.type 32;
.endef
.section .text,"xr",discard,"?distance@@YANNNNN@Z"
.globl "?distance@@YANNNNN@Z"
.p2align 4, 0x90
"?distance@@YANNNNN@Z": # @"\01?distance@@YANNNNN@Z"
# BB#0: # %entry
pushl %ebp
movl %esp, %ebp
andl $-8, %esp
subl $80, %esp
movsd 32(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd 24(%ebp), %xmm1 # xmm1 = mem[0],zero
movsd 16(%ebp), %xmm2 # xmm2 = mem[0],zero
movsd 8(%ebp), %xmm3 # xmm3 = mem[0],zero
movsd %xmm0, 72(%esp)
movsd %xmm1, 64(%esp)
movsd %xmm2, 56(%esp)
movsd %xmm3, 48(%esp)
movsd 64(%esp), %xmm0 # xmm0 = mem[0],zero
movsd 48(%esp), %xmm1 # xmm1 = mem[0],zero
subsd %xmm1, %xmm0
movl %esp, %eax
movsd %xmm0, (%eax)
calll "?sqr@@YANN@Z"
fstpl 40(%esp)
movsd 40(%esp), %xmm0 # xmm0 = mem[0],zero
movsd 72(%esp), %xmm1 # xmm1 = mem[0],zero
movsd 56(%esp), %xmm2 # xmm2 = mem[0],zero
subsd %xmm2, %xmm1
movl %esp, %eax
movsd %xmm1, (%eax)
movsd %xmm0, 16(%esp) # 8-byte Spill
calll "?sqr@@YANN@Z"
fstpl 32(%esp)
movsd 32(%esp), %xmm0 # xmm0 = mem[0],zero
movsd 16(%esp), %xmm1 # 8-byte Reload
# xmm1 = mem[0],zero
addsd %xmm0, %xmm1
movl %esp, %eax
movsd %xmm1, (%eax)
calll _sqrt
fstl 24(%esp)
movsd 24(%esp), %xmm0 # xmm0 = mem[0],zero
movsd %xmm0, 8(%esp) # 8-byte Spill
movl %ebp, %esp
popl %ebp
retl
.def "?sqr@@YANN@Z";
.scl 2;
.type 32;
.endef
.section .text,"xr",discard,"?sqr@@YANN@Z"
.globl "?sqr@@YANN@Z"
.p2align 4, 0x90
"?sqr@@YANN@Z": # @"\01?sqr@@YANN@Z"
# BB#0: # %entry
pushl %ebp
movl %esp, %ebp
andl $-8, %esp
subl $16, %esp
movsd 8(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd %xmm0, 8(%esp)
movsd 8(%esp), %xmm0 # xmm0 = mem[0],zero
mulsd %xmm0, %xmm0
movsd %xmm0, (%esp)
fldl (%esp)
movl %ebp, %esp
popl %ebp
retl
.def __GLOBAL__sub_I_test3.cpp;
.scl 3;
.type 32;
.endef
.text
.p2align 4, 0x90
__GLOBAL__sub_I_test3.cpp: # @_GLOBAL__sub_I_test3.cpp
# BB#0: # %entry
pushl %ebp
movl %esp, %ebp
calll "??__Ecalculated_distance@@YAXXZ"
popl %ebp
retl
.bss
.globl "?calculated_distance@@3HB" # @"\01?calculated_distance@@3HB"
.p2align 2
"?calculated_distance@@3HB":
.long 0 # 0x0
.section .CRT$XCU,"dr"
.p2align 2
.long __GLOBAL__sub_I_test3.cpp
p.s.зато можно отладчиком по шагам пройтись. или из отладчика вызвать функцию с иными параметрами.
А всё дело в том, что компиляторы воспринимают constexpr через одно место. Здесь должна быть ошибка компиляции, потому что использование одновременно extern и constexpr недопустимо. Не знаю как сейчас, но раньше компилятор, когда видел, что функция не может быть constexpr, просто игнорировал эту директиву.
Не знаю как сейчас, но раньше компилятор, когда видел, что функция не может быть constexpr, просто игнорировал эту директиву.Это, несомненно, ошибка, но главная проблема — не в компиляторе, а в «мужиках», которые «не знают».
Указание constexpr для функции само по себе ничего не гарантирует — это просто пометка, которая указывает, что данную функцию можно использовать для вычислений во время компиляции.
А вот уже указание constexpr для переменной — оно гарантирует что вычислений в рантайме не будет (но ошибка компиляции, разумеется, возможна).
Ну или подождите С++35 — там все нормально будет,
У inline таких ограничений нет.И никаких гарантий — тоже нет. Фактически единственное, что
inline гарантирует — это внутреннее связывание. Больше — ничего.constexpr выражений, так что всё гарантируется, но сама переменная описана как const int, а не constexpr int.Если то же самое изобразить не на константных числах, а на обычных — то гарантии пропадут.
constexpr у функции — это такая пометка компилятору, что если функция вызывается в соответствующем контексте, внутрь хотя бы имеет смысл смотреть. Вы, конечно, можете написать
constexpr int foo() { throw "omfg C++ sucks for real, C rulezzzz"; }
но вы её не сможете вызвать в соответствующем требующем constexpr контексте.
Интересно, что есть идиоты, которые плюсуют очевидную бредятину. :-(
constexpr int sqr(int x) {return x*x;};
extern int x1[sqr(5)];
int x1[sqr(5)];
Ну численные значения enumов ещё. Вроде всё, больше популярных контекстов нет?
Тем более что время инициализации переменных — это копейки по сравнению с временем работы программы. То есть для перфекционизма — constexpr сильно полезен. А для реальной работы — только для хитрых структур. Но в хитрой структуре делаем так:
#define sqr(x) ((x)*(x))
extern int x1[sqr(5)];
int x1[sqr(5)];
Так что ничего революционного нет. И не будет, пока в constexpr нельзя будет использовать стандартные функции.
С другой стороны, назовите платформу, где у всех компиляторов нету управления include? То есть платформу, на которой нет gcc, но есть С++.
Много таких знаете? И что там с с++11? А с С++14?
Я вот одну такую платформу знаю. Вот SDK, можете сами проверить
Copyright (c) 2002-2007 Interstron, Ltd.
-inline : Enable inline substitution
-Tc : compile as C source code
-Tc99 : compile as C99 source code
-Tp : compile as C++ source code
-Tp98 : compile as C++ source code (1998-2003 standard mode)
То есть управление инлайнами есть, а С+11 уже не очень.
Если интересно — вот немного об этом компиляторе. А вот повесть о том, как его писали.
Да, теоретически компилятор с С++11 и без управления инлайнами может сущестовать. Совсем гипотетически можно представить, что это будет единственный компилятор на платформе.
А практически — не найдете. Без полного С++11 — запросто, сколько угодно. А без управления инлайнами — только самоделки на x86, где и так хватает нормальных компиляторов.
А пример — реальный, нам на 1879ХБ1Я запуститься скоро надо будет. И перенос части работы на DSP-ядро — вполне возможен.
Беда в том, что пригодных для наших задач процессоров с 5ой приемкой — раз два и обчелся.
А из того, на что портировали, самое старое — это МСВС 3.0 с ядром 2.4 gcc 2.95.4.Это все прелести технологии двойного назначения.
Кстати, самый смак NetoMatrix — это 32битные байты. То есть sizеof(char) == sizeof(float). Ваши алгоритмы на темплейтах такое выдержат?
Что значит «без управления инлайнами»?
Гарантия мне нужна лишь, когда я через sqrt и sin задаю размер массива. Но С++ пока этого не может. То есть в 99% случаев, выражение, использующее лишь операции и стандартные функции — не может быть
constexpr. 1% — это стандартные функции, реализованные через tmeplate, вроде std::max.А гарантия того, что inline будет управляться ключами компилятора — намного больше того, что компилятор будет реализовывать полный C++14. И даже больше, чем для С++11.
Ровно это мне и нужно — возможность при отладке пройтись по коду, сгенерированному так, как написано. И иметь быстрый код после завершения отладки.
И не важно, считается ли код целиком в compile-time. Наносекунды на старте экономить нет смысла. Есть смысл, если уж что-то задается константой — то задавать одной константой, а не десятком зависимых друг от друга констант.
Но пока sqrt, sin, cos не constexpr — такие вещи лучше делать через inline. А когда они станут constexpr — то надо будет подождать 20 лет, чтобы на всех потенциально возможных платформах обновились компиляторы.
Наша специфика — мы не знаем, на каком железе будет очередной проект. Но мы пишем так, чтобы работать на любой железке. Для нас железка без С++ вообще — ну неприятно, но не фатально. А вот если бы мы использовали все фичи С++14…
P.S. У NeoMatrix есть одно следствие 32битных байтов: sizeof(float)==1. Так что подсчет числа битов, как 8*sizeof — не работает. Если у вас есть битовые операции — скорее всего работать перестанет.
Это не поблажка и не ограничение, это достаточно разумное требование для того, чтобы функция была и compile-time, и runtime-вычислима.
Мы с вами это уже обсуждали, но раньше вы держались противоположной позиции. Почитайте в стандарте раздел «17.6.4.3 Reserved names».
If a program declares or defines a name in a context where it is reserved, other than as explicitly allowed by this Clause, its behavior is undefined.То есть несмотря на то, что sin или fabs не constexpr, компилятор вполне может её вычислить в compile-time. Но… для этого пришлось бы обязать компиляторы помнить все процедуры из стандартной библиотеки. Потому и сделали поблажку.
Про то, почему inline тут вообще ни при чём, я уже написал рядом.
А
constexpr functions and constexpr constructors are implicitly inline Это из «7.1.5 The constexpr specifier».Надеюсь, к моменту этого комментария тот вы ещё просто не прочитали.
И до сих пор не прочел. Ибо работы много. Дойдут руки — прочту.
Аналогично, компилятор может заложить, что sin считает именно sin, и ровно так, как описано в стандарте. И вычислить синус в compile-time, опираясь на свою собственну., слинкованную с компилятором библиотеку. А не на ту. что будет в runtime.
И какую поблажку вы имели в виду в исходном случае?
Поблажка в том, что компилятор не обязан вычислять sin в constexpr. В стандарте можно было написать, что все стандартные функции — это constexpr, несмотря на то что они extern. Но пока — так не написали. Хотя дело именно к этому и идет.
#include <cmath>
constexpr double sqrt2 = sqrt(2);
constexpr double sin45 = sin(M_PI/4);
Но, пока стандарт не доделан и это не работает. Зато работает так
#include <math.h>
extern const double sqrt2, sin45;
const double sqrt2 = sqrt(2.);
const double sin45 = sin(M_PI/4.);
.text
.file "test6.cpp"
.type sqrt2,@object # @sqrt2
.section .rodata,"a",@progbits
.globl sqrt2
.align 8
sqrt2:
.quad 4609047870845172685 # double 1.4142135623730951
.size sqrt2, 8
.type sin45,@object # @sin45
.globl sin45
.align 8
sin45:
.quad 4604544271217802188 # double 0.70710678118654746
.size sin45, 8
.ident "clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)"
.section ".note.GNU-stack","",@progbits
Нынешнее состояние — это поблажка для разработчиков компиляторов от разработчиков стандарта Лет через 10-15 исправится. Или разрешат extern constexpr для стандартных фнукций или стандартные функции все перепишут в .h, или просто потребуют, чтобы компилятор считал все стандартные функции constexpr.
Но в нынешнем виде мне constexpr не нужен.
Поэтому компилятор имеет право такие функции имеет инлайнить и constexprить. То, что этого ещё нет в стандарте — это следствие разработки комитетом. Ну как обычно, одни ратовали за то, чтобы не обязывать компилятор помнить алгоритмы всех функций, другие — что надо точно описать, что компилятор делает, без всяких «имеет право»…
Ну и получили, что sqrt инлайнится при inline и не инлайнится при constexpr, если не применить финт ушами (extern «C» constexpr)
Мораль простая — хочешь, чтобы вычислялось при компиляции в большем числе случаев — забудь про constexpr.
Работает оно. Чуть ругается на финт, но при -O3 инлайнится в константу.
По стандарту С++ стандартные функции обязаны делать то, что описано в стандарте.Серьёзно? Ну ок.
Ну и получили, что sqrt инлайнится при inline и не инлайнится при constexpr, если не применить финт ушами (extern «C» constexpr)Так они должны делать то, что написано в стандарте или нет?
Работает оно. Чуть ругается на финт, но при -O3 инлайнится в константу.Вот только никакого отношения это всё к
constexpr не имеет. constexpr, как и положено, не компилируется — хоть ты -O100 задавай.Мораль простая — хочешь, чтобы вычислялось при компиляции в большем числе случаев — забудь про constexpr.Нет — мораль другая: хочешь применять инструмент — изволь узнать как он работает. А не сетуй на то, что коммитет там чего-то недодумал и пытаясь использовать воображаемый C++35 в компиляторе, который никакого отношения к C++35 не имеет.
Стандарт достаточно хорошо описывает что и когда можно использовать во время компиляции.
::sqrt из math.h в этот список не входит.Нет — мораль другая: хочешь применять инструмент — изволь узнать как он работает.
Стандарт достаточно хорошо описывает что и когда можно использовать во время компиляции. ::sqrt из math.h в этот список не входит.
Угу, угу. А теперь объясните, почему в вашем примере sqrt в constexpr-функции, если оно «в этот список не входит»?
Не потому ли, что вашей квалификации не хватает для написания на полном С++? А те, у кого квалификации хватает — стоят несколько иных денег. И эта их огромная зарплата — обычно не оправдывается сокращением времени на написание и отладку кода.
Ну кроме специфических областей, где в любом случае нужны программеры высочайшей квалификации. Ну скажем код размеров больше сотни человеко-лет.
Чё, серьёзно? АПервая версия была правильной. Тот факт, что вы не знаете C++ и потому воюете с ним, не меняет сути.мужикикомпилятор-то не в курсе
…Ой. const… а где же expr? Ах, ну да — мы же на глобус сову натягиваем, зачем нам стандартам следовать?
const int calculated_distance = distance(3,5,7,2);
А если добавить expr — то gcc всё свернёт (что неправильно), а clang — выдаст ошибку (что более правильно). Никакога кода в рантейме не будет.
Тот факт, что вы не знаете C++ и потому воюете с ним, не меняет сути.
Ну-ну… Ох уж эта
Давайте для начала что-то простенькое, ну скажем MSDN
Функция constexpr относится к тем функциям, возвращаемое значение которых может быть вычислено во время компиляции, когда оно требуется коду-потребителю.
Ну а теперь заглянем в стандарт, точнее в бесплатный драфт. Раздел 7.1.5 The constexpr specifier, пункт 2.
constexpr functions and constexpr constructors are implicitly inline (7.1.2).
Ой. const… а где же expr?
А что у вас, что у меня идет
extern const int calculated_distance;
extern "C" constexpr double sqrt (double __x);
//extern const int calculated_distance;
constexpr double sqr(double x) {return x*x;}
constexpr double distance(double x1,double y1,double x2,double y2) {return sqrt(sqr(x2-x1)+sqr(y2-y1));}
const int calculated_distance = distance(3,5,7,2);
.text
.file "test3.cpp"
.ident "clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)"
.section ".note.GNU-stack","",@progbits
В отличие от вас, я не меняю условия задачи на ходу.
Ах, ну да — мы же на глобус сову натягиваем, зачем нам стандартам следовать?
Не нервничайте так, не корову проигрываете. Все по стандарту. Просто вы почему-то путаете constexpr функции с constexpr переменными.
extern "C" constexpr double sqrt (double __x);
extern const int calculated_distance;
constexpr double sqr(double x) {return x*x;}
constexpr double distance(double x1,double y1,double x2,double y2) {return sqrt(sqr(x2-x1)+sqr(y2-y1));}
const int calculated_distance = distance(3,5,7,2);
.text
.file "test3.cpp"
.type calculated_distance,@object # @calculated_distance
.section .rodata,"a",@progbits
.globl calculated_distance
.align 4
calculated_distance:
.long 5 # 0x5
.size calculated_distance, 4
.ident "clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)"
.section ".note.GNU-stack","",@progbits
.text
.file "test3.cpp"
.section .rodata.cst8,"aM",@progbits,8
.align 8
.LCPI0_0:
.quad 4613937818241073152 # double 3
.LCPI0_1:
.quad 4617315517961601024 # double 5
.LCPI0_2:
.quad 4619567317775286272 # double 7
.LCPI0_3:
.quad 4611686018427387904 # double 2
.section .text.startup,"ax",@progbits
.align 16, 0x90
.type __cxx_global_var_init,@function
__cxx_global_var_init: # @__cxx_global_var_init
.cfi_startproc
# BB#0:
pushl %ebp
.Ltmp0:
.cfi_def_cfa_offset 8
.Ltmp1:
.cfi_offset %ebp, -8
movl %esp, %ebp
.Ltmp2:
.cfi_def_cfa_register %ebp
subl $40, %esp
movsd .LCPI0_0, %xmm0 # xmm0 = mem[0],zero
movsd .LCPI0_1, %xmm1 # xmm1 = mem[0],zero
movsd .LCPI0_2, %xmm2 # xmm2 = mem[0],zero
movsd .LCPI0_3, %xmm3 # xmm3 = mem[0],zero
movsd %xmm0, (%esp)
movsd %xmm1, 8(%esp)
movsd %xmm2, 16(%esp)
movsd %xmm3, 24(%esp)
calll _Z8distancedddd
fstpl -8(%ebp)
movsd -8(%ebp), %xmm0 # xmm0 = mem[0],zero
cvttsd2si %xmm0, %eax
movl %eax, calculated_distance
addl $40, %esp
popl %ebp
retl
.Lfunc_end0:
.size __cxx_global_var_init, .Lfunc_end0-__cxx_global_var_init
.cfi_endproc
.section .text._Z8distancedddd,"axG",@progbits,_Z8distancedddd,comdat
.weak _Z8distancedddd
.align 16, 0x90
.type _Z8distancedddd,@function
_Z8distancedddd: # @_Z8distancedddd
.cfi_startproc
# BB#0:
pushl %ebp
.Ltmp3:
.cfi_def_cfa_offset 8
.Ltmp4:
.cfi_offset %ebp, -8
movl %esp, %ebp
.Ltmp5:
.cfi_def_cfa_register %ebp
subl $88, %esp
movsd 32(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd 24(%ebp), %xmm1 # xmm1 = mem[0],zero
movsd 16(%ebp), %xmm2 # xmm2 = mem[0],zero
movsd 8(%ebp), %xmm3 # xmm3 = mem[0],zero
movsd %xmm3, -8(%ebp)
movsd %xmm2, -16(%ebp)
movsd %xmm1, -24(%ebp)
movsd %xmm0, -32(%ebp)
movsd -24(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd -8(%ebp), %xmm1 # xmm1 = mem[0],zero
subsd %xmm1, %xmm0
movl %esp, %eax
movsd %xmm0, (%eax)
calll _Z3sqrd
fstpl -40(%ebp)
movsd -40(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd -32(%ebp), %xmm1 # xmm1 = mem[0],zero
movsd -16(%ebp), %xmm2 # xmm2 = mem[0],zero
subsd %xmm2, %xmm1
movl %esp, %eax
movsd %xmm1, (%eax)
movsd %xmm0, -64(%ebp) # 8-byte Spill
calll _Z3sqrd
fstpl -48(%ebp)
movsd -48(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd -64(%ebp), %xmm1 # 8-byte Reload
# xmm1 = mem[0],zero
addsd %xmm0, %xmm1
movl %esp, %eax
movsd %xmm1, (%eax)
calll sqrt
fstl -56(%ebp)
movsd -56(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd %xmm0, -72(%ebp) # 8-byte Spill
addl $88, %esp
popl %ebp
retl
.Lfunc_end1:
.size _Z8distancedddd, .Lfunc_end1-_Z8distancedddd
.cfi_endproc
.section .text._Z3sqrd,"axG",@progbits,_Z3sqrd,comdat
.weak _Z3sqrd
.align 16, 0x90
.type _Z3sqrd,@function
_Z3sqrd: # @_Z3sqrd
# BB#0:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movsd 8(%ebp), %xmm0 # xmm0 = mem[0],zero
movsd %xmm0, -8(%ebp)
mulsd %xmm0, %xmm0
movsd %xmm0, -16(%ebp)
fldl -16(%ebp)
addl $16, %esp
popl %ebp
retl
.Lfunc_end2:
.size _Z3sqrd, .Lfunc_end2-_Z3sqrd
.section .text.startup,"ax",@progbits
.align 16, 0x90
.type _GLOBAL__sub_I_test3.cpp,@function
_GLOBAL__sub_I_test3.cpp: # @_GLOBAL__sub_I_test3.cpp
.cfi_startproc
# BB#0:
pushl %ebp
.Ltmp6:
.cfi_def_cfa_offset 8
.Ltmp7:
.cfi_offset %ebp, -8
movl %esp, %ebp
.Ltmp8:
.cfi_def_cfa_register %ebp
subl $8, %esp
calll __cxx_global_var_init
addl $8, %esp
popl %ebp
retl
.Lfunc_end3:
.size _GLOBAL__sub_I_test3.cpp, .Lfunc_end3-_GLOBAL__sub_I_test3.cpp
.cfi_endproc
.type calculated_distance,@object # @calculated_distance
.bss
.globl calculated_distance
.align 4
calculated_distance:
.long 0 # 0x0
.size calculated_distance, 4
.section .init_array,"aw",@init_array
.align 4
.long _GLOBAL__sub_I_test3.cpp
.ident "clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)"
.section ".note.GNU-stack","",@progbits
Как видите — работает так, как я описал. При -O0 — инициализация в рантайме, при -O1 — в compile time. Намного удобнее для поиска ошибок, чем ваш вариант.
Если будете возражать — так потрудитесь привести цитаты из стандарта.
P.S. Открою секрет — чукча не писатель, чукча читатель. Главное амплуа — сопровождающий програмист. Тот, кто из чужого дерьма конфетку делает, изничтожая баги. Потому и внимание именно к этой стороне кода.
Насажать багов — это любой С++ник горазд. Обратный процесс, увы, тяжелее.
Так что гарантий, что компилятор писали не совсем идиоты, вам никто не даст. С другой стороны — кто будет пользоваться компилятором, написанным идиотами? Поэтому inline работает нормально во всех компиляторах.
А вот constexpr… В IAR он есть? В Keil? В LCC? а если есть — то какой? Из С++11 или C++14? Или что-то среднее? Не, пока у вас только gcc и clang — можно помнить, какая версия что умеет. А если компиляторов много?
#include <array> inline int foo(int val) { return val; } int main() { std::array<int, foo(5)> arr; }
Не понимаю, в чему вас проблемы? Си это уже лет 40 может.
#define sqr(x) ((x)*(x))
extern int x1[sqr(5)];
int x1[sqr(5)];
.text
.file "test8.c"
.type x1,@object # @x1
.comm x1,100,4
.ident "clang version 3.8.1-12~bpo8+1 (tags/RELEASE_381/final)"
.section ".note.GNU-stack","",@progbits
Это что-то из вечных развлечений С++ников — создавать себе проблемы, потом их героически преодолевать. Да, каждый раз синтаксического сахара больше, не спорю. Но ничего нового — не появляется.
Я начинаю понимать, откуда у вас такой cognitive bias.
ну да, надо 5 раз повторить, что плох не язык, а связка «язык+программист+задача», чтобы вы это поняли. Людей, нормально пишущих на Си — много. а люди, нормально пишущие на С++ — это «уже совсем другие деньги», как говорят в Одессе.
Мне нравится, как вы подряд доказываете два противоположных тезиса. Снимаю шляпу перед вашим двоемыслием.
Слишком сложная логика? Ну давайте, разжую.
Нестандартный компилятор — вещь обычная. У того же gcc были версии с неполной поддержкой С++11/C++14. Ну вот вам состояние на начало 2016 года. Более того, вполне представляю себе версию компилятора, делающую какую-то вещь поперек стандарта. Ну как пример — реализация по раннему драфту. Если постараться — можно найти примеры.
А вот компилятор, не умеющий управлять inline, никто не будет использовать. Да, вполне возможен самописный компилятор, вообще не умеющий инлайнить или инлайнящий всегда. Но кто заставит его использовать? Кстати, в примере по ссылке темплейтов нет вообще.
Ну не может быть такого, чтобы компилятор без управления инлайнами был единственным компилятором на платформе.
Собственно с темплейтами — та же история. Компилятор может их не оптимизировать и раскручивать в очень сложный код. Просто массовые компиляторы ведут себя иначе и никто не заставляет вас пользоваться компилятором, плохо работающим с темплейтами.
Мне кажется, что логика тут очевидна, странно что вы её не понимаете.
Я в одном из проектов брал хеш от __FILE__, чтобы более-менее гарантировать уникальность типа. Напишите мне это на дефайнах, очень прошу!
Да я уже показывал этот код. Ничего там сложного нет. Лучше объясните, зачем вам хэш и «более-менее», если использование __FILE__ и __LINE__ без хэша гарантируют вам уникальность типа без всякого «более-менее».
Не сильно больше, чем на плюсах.
При зарплате в 1.1-2 раза больше средней по региону — сильно больше. Это вообще-то эквивалент общеизвестного факта — у С++ круче кривая обучения. Ну а если денег у вас немеряннно и вы готовы платить в 20 раз больше средней зарплаты — то, да, тогда уже язык не важен.
Опыт показываете, что всякие решения, работающие в 99.9 случаев — это плохие решения. В самый нужный момент приходит пушной звере и выстреливает тот самый 0.1%. Как в известном примере про вероятность встретить 100 мужчин подряд и полк солдат.
Так что лучше
Обратите внимание, что почти все системные библиотеки написаны на Си.На «умерших» платформах — да. На Windows, MacOS/iOS, Android и прочих — уже либо переписаны на C++, либо в процессе.
P.S. Будете удивлены, но андроид — надстройка над linux.
Мне кажется вы рано празднуете смерть linux, FreeBSD и так далее…Ну зачем же смерть… Переход в статус «живое ископаемое». Так-то и AmigaOS ещё поддерживается (пару лет назад вышло обновление firmware, позволяющее использовать USB клавиатуры и мыши, к примеру), но вряд ли кто будет судить о состоянии дел в разработке ОС исходя из того, что там в AmigaOS 3.9, пусть и со всеми обновлениями, сотворили.
P.S. Будете удивлены, но андроид — надстройка над linux.Не буду удивлён, многие Linux'оиды так считают. Хотя на самом деле Linux там — временная заглушка до тех пор, пока нормальное ядро не готово. Оно, кстати, тоже на C++. Хотя, конечно, как и с любыми проектами глобального переписывания всего с нуля успех не гарантирован и мы, я думаю, с Linux'ом ещё поживём…
Оно, кстати, тоже на C++.
Ох уж эти сказки, ох уж эти сказочники… На Си оно, можете сами убедиться. Пара частей на С++ есть, но это периферийные части (VM, PCI-express...), причем те, где нужен полиморфизм. Ядро и без них жить может.
Похоже, что в отличие от вас, авторы этого ядра хорошо подумали, что лучше писать на Си, а что на С++.
Наверное, вас удивит, но гугл считает основным языком для Андроид -Java.Java в той же степени «основной язык Android» в какой Visual Basic — основной язык Windows XP. Ну да, не все могут «осилить» C++ — тут уж ничего не поделать.
На Си оно, можете сами убедиться.В указанной вами директории и поддиректориях 10 файлов на C и 14 — на C++. Натягивание совы на глобус продолжается.
но это периферийные части (VM, PCI-express...)Серьёзно? А ничего, что VM — это управление процессами? Без которого ядро вообще никому и ни для чего не нужно?
Похоже, что в отличие от вас, авторы этого ядра хорошо подумали, что лучше писать на Си, а что на С++.Ага-ага-ага. И именно поэтому старые части ядра (Copyright © 2008-2015 Travis Geiselbrecht) — в основном на C, в то время как новые (Copyright 2016 The Fuchsia Authors) — на C++.
То, что разработчики не стали изобретать велосипед совсем с нуля и не стали весь работающий код переписывать на C++ просто потому что им делать больше нечего плохо о них не говорит IMO. А вот попытка обьяснить что нечто, в чём C++ больше, чем C — это программа на C… ну тут читетель сам может додумать…
Есть у меня набор серверов, двухголовых ксеонов с 384 гигами оперативки, где считается много всякой разной ерунды. Вы мне туда предлагаете ставить Windows, iOS или таки Android?Всему своё время. Производители «больших» UNIX'ов в 90е тоже любили PC'шников подобными вопросами подкалывать.
Только нишу ОС для больших машин занял таки Linux, и таковая ниша была в известном смысле чуть более свободна, чем сейчас.Linux оказался просто дешевле. Android стоит столько же, так что посмотрим чем кончится
А вот Фуксия… Это попытка урезать возможности, предоставленные конкретным программам с целью сделать возможным работу этих программ совместно на разных устройствах.
Добавлять фишки всегда проще, чем обрезать. Так что в Фуксию я, что говорится, «поверю, когда увижу». Может быть она вытеснит и Android и GNU/Linux. А может из этого вообще ничего путного не выйдет… Посмотрим.
Вот именно. А должно быть static_assert(sizeof(long) == 8).
Подумайте о том, что самолет — намного круче автомобиля. Но на работу большинство ездит на машине. Причем даже те, у кого лицензия пилота есть.
Более того, велосипед в мегаполисе ездит быстрее общественного транспорта. Особенно на короткие расстояния.
Да, почти любую задачу можно решить на С++. Ну так на ассемблере — вообще любую. И что дальше? Дело не в том, можно ли решить. А в том, что эффективнее. Эффективнее прежде всего с точки зрения времени написания и отладки. Для конкретной задачи.
И вот тут я вижу много примеров, как любители С++ садятся в лужу. Начинается конструирование швейцарского ножа, то есть универсального кода, который заодно решает и нужную задачу. В итоге все сроки провалены. а код как глючил. так и дальше глючит. Хотя если бы человек не увлекался возможностями С++, то доделал бы свой код в срок.
Опыт показывает, что, начиная с некоторого (весьма небольшого, причём) объема это таки становится нужно.
Вот-вот. И я об этом. Накрутили то, се, пятое, десятое. Все универсально, современно, круто, модно. но… не работает. Заказанная функциональность не пашет. Зато — пашет много чего ненужного. И размер кода — раза в 3 больше, чем на Си.
Собственно это общеизвестный факт, погуглите насчет порога входа для С++. Причем «вход» заканчивается не на изучении языка, а на стадии когда человек начинает писать простой и понятный код.
Есть задачи, которые действительно стоит решать на С++. Точно так же, как в Нью-Йорк есть смысл летать самолетом. Но в нашей области С++ — не лучший выбор. я бы предпочел дельфи (там мало способов выстрелить себе в ногу), но он не подерживается нигде, кроме Window, linux и Android. Аналогично — Rust и все прочие попытки написать «хороший С++». А по уровню поддержки — лучше всего Си.
Если вам так нравится — пишите все на С++. А мне приятнее подбирать язык плод задачу.
Да, язык сложный, с этим трудно поспорить, кривая обучения покруче и подлиннее, чем у С, но это странный аргумент против языка вообще.
Увы, это главный аргумент — экономика. Сколько денег нужно заплатить за отлаженную программу? В какие сроки она будет сделана и отлажена? И выясняется, что для многих программ на Си и затраты и сроки меньше.
Тезис-то скорее в том, что случаев, в которых C подходит лучше других языков, исчезающе мало — отсутствие компилятора плюсов под целевую платформу, скажем.
Тезис в том, что людей, способных написать и отладить на С++ за те же деньги и те же сроки, что и на Си — исчезающе мало.Есть всего несколько исключений — ну скажем есть готовый фреймворк, делающий 99% работы и при этом предназначенный только для С++. Ну или хобби-проект, не подразумевающий оплату. Или заказчику вообще плевать на стоимость и сроки, например, когда программируют рабы или заключенные.
А самый важный плюс Си — он компилится везде и всегда. Код, написанный 30 лет назад на Си — это вполне живой код. А вот С++… Не видели С++ 90ого года? И нет никаких шансов, что С++ и дальше не будет мутировать.
А если у вас только windows или только linux — есть много иных вариантов. Они могут быть и лучше Си. Например дельфи (object pascal) почти не оставляет шансов выстрелить себе в ногу. Для многих вещей хорошая Java. Сейчас пошла мода писать на javascript… Если хочется «как С++, но лучше» — есть Go, Rust и так далее…
Так что не фантазируйте, Си не самый лучший язык. Такого тезиса я не выдвигал, вы его сами выдумали. Просто для многих задач он экономически выгодней С++.
Но! Если задача такова, что с ООП её писать явно проще — тогда С++ будет лучше Си. Просто очень много задач, где ООП скорее вредно, чем полезно.
На С++ можно писать компактно и понятно, но у khim это не вышло. Мы с вами сумеем написать этот же пример через constexpr (или inline) компактно и понятно, но большинство любителей С++ напишет как khim.
Если ещё проще — для верификации (как и для вычитки) используется исходный текстовый код. А для тестирования — нужен исполняемый бинарный код. Посему верификациия и вычитка — вещи близкие.
С моей точки зрения будущее за разделением обязанностей.
Есть программист, который пишет код.
Есть разработчик тестов, который пишет юнит-тесты.
Сначала разрабатывается интерфейс, где принимают участие оба разработчика и бизнес-аналитик (если необходимо).
Далее независимо пишется код и тесты. Т.к. для обоих разработчиков чужая работа является чёрным ящиком, то результат работы будут более объективными. Результаты сливаются в билде и далее идёт верификация упавших тестов с выъяснением причин и исправлением либо кода, либо тестов.
Такой подход может быть крайне полезным для критически важных частей системы. Другое дело, что это дорого и не всякий заказчик готов платить за это.
Так что прежде всего — независимое комплексное тестирование. А уж для уменьшения его стоимости (и повышения эффективности) — unit-тесты и TDD. Вот интересная статья про устройство тестирования в большом проекте.
И unit-тесты и TDD полезны лишь вспомогательные инструменты, уменьшающие стоимость итогового тестирования.
Но… в критически важных системах цена, которую менеджмент готов платить за вовремя найденный баг, возрастает в десятки и сотни раз. Так что там можно и TDD и юнит-тесты и итоговые и все в полном объеме без экономии средств.
Во-вторых, если о _формальной_ корректности — то вычитка и верификация как раз дают её, и остаётся вопрос в качестве самой формальности. В ней могут лежать (и очень часто лежат) неверные представления о среде исполнения. Тесты приближают _фактическую_ корректность, а не формальную.
При редком стечении обстоятельств при заполненном кэше у одной из пар заменяется значение х!, но не заменяется значение х. Получаем ((6,6!), (8, 7!), (9, 9!).
А это не настоящая гонка. А просто гонкоподобный сбой в кэше. Возникает лишь после редкой последовательности вставок в кэш. Посему — легче выявляется вычиткой кода, чем тестированием. Ну или (если повезет) статанализом, как автоматизированной вычиткой.
- В конец
- Вставкой
- Заменой меньшего элемента
- Заменой большего элемента
При замене меньшего элемента меняем ключ, не меняя значение. Было (7, 7!) должно было стать (8, 8!), а стало (7, 8!).
Такой баг легче берется вычиткой, чем TDD.
С другой стороны можно иметь отдельный метод проверки консистентности кэша, который запускать в конце работы. Но… комаров не бьют из пушки…
Получается, что у вас методика отладки будет диктовать архитектуру. То есть вам придется сделать функцию, умеющую работать без кэша и в качестве обертки прилепить к ней кэш. А логика вычисления функции бывает такой, что кэши лучше использовать изнутри функции. То есть иметь ключом не аргумент, а некое промежуточное значение.
Ещё раз повторю — комаров не бьют из пушки. Вычисткой такой баг ловится на ура.
Считать баги на тысячу строк — ну совсем никак? я думал, что это очевидно,
Как маргинальный пример — хорошо. Но в реальности значительно чаще будут люди, у которых другие ошибки, и они их способны осознавать, и видеть, когда чем-то ткнуло.
А что важно тут — это то, что, пока автор находится в контексте, ему осознать, что именно надо включать в тест и почему, легче, чем любому постороннему.
И Ваше правило
> Никогда не тестировать свой собственный код.
для большинства случаев методологически является абсолютно некорректным. Правильный вариант был бы — никогда не полагаться на результаты тестирования собственного кода. Потому что Ваш вариант даёт возможность делать тупейшие ошибки и возлагать на тестеров проблему их поиска, а исправленный — снижает суммарные затраты — некоторое увеличение времени работы автора на представленные им тесты окупается уменьшением времени работы тестеров и ревьюеров на переосознание не только задачи, но и того, где могут быть проблемы.
Исключение — когда такого сокращения затрат времени нет — это когда необходимость совместного понимания кода настолько высока, что ближайшие коллеги, ответственные за подсистему, обязаны весь код понимать в мельчайших деталях, как будто сами его написали. Но тогда тестеры уже не занимаются этим кодом, а смотрят только на «чёрный ящик» отдельных подсистем.
> Тесты (что железа, что софта) бывают двух видов. Одни — чтобы доказать, что ошибок нет. Другие — чтобы найти ошибки. TDD дает лишь тесты первого рода.
Полностью согласен, но я бы переформулировал. Слово «доказать» некорректно — разве что «подтвердить», «подкрепить уверенность». Доказательство возникает только в результате верификации, пусть и ручной (глазной? не знаю, как лучше сказать), тесты же обеспечивают выполнение условий этой верификации (рядом уже писал то же более сжатой формулировкой).
> оценка работы программеров — по тому, чтобы багов было меньше и самой малой значимости.
И они в этих условиях сами себя не тестируют? Что-то я сильно сомневаюсь. Может, тестируют, но подпольно? :)
> Но массовое использование TDD, где надо и где не надо — это карго-культ.
+100.
Но в реальности значительно чаще будут люди, у которых другие ошибки, и они их способны осознавать, и видеть, когда чем-то ткнуло.
В реальности работы тестером — у каждого программера был свой, типичный для него тип ошибок. С делением примерно 50 на 50 — 50% типичных, 50% случайных. Точнее уже не скажу — 20 лет назад было.
Правильный вариант был бы — никогда не полагаться на результаты тестирования собственного кода.
Согласен.
Потому что Ваш вариант даёт возможность делать тупейшие ошибки и возлагать на тестеров проблему их поиска, а исправленный — снижает суммарные затраты
А теперь учтите, что зарплата тестеров — в 5 раз ниже зарплаты сеньора. И что сеньор — не делает глупых ошибок, видимых на поверхностных тестах. И что сеньор — синтетик, а тестер — аналитик, то есть один любит писать код, а второй — искать в нем ошибки.
Ну и получается, что нам выгодно сложить с сеньора все обязанности по тестированию, документированию и так далее.
Более того, такой способ позволяет нам растить из подаванов новых сеньоров. Это как раз они из самых лучших способов наращивания профессионального мастерства — работа в паре с гуру.
Все это описано у Брукса как «Бригада главного хирурга». А вот о том же самом — лекция Терехова. А вот ода выделенному тестировщику у Алексея Бабия. Почитайте, там очень похоже на то, что я пишу.
Во-первых, тестировщик лучше всех знает текущее состояние системы. В этом плане он хорошо дополняет хирурга: тестировщик знает систему «снаружи», а хирург — «изнутри». С вопросами о том, насколько отлажен модуль, обращались обычно к тестировщику, а не к автору модуля.
Во-вторых, тестировщик оказался полезным на стадии проектирования. Тесты начали готовиться ещё до кодирования, как только были готовы внешние спецификации, поэтому некоторые ляпы успели ликвидировать до того, как они воплотились в текст программы. Тестировщик — это, фактически, первый пользователь системы, единственный человек в коллективе, чья работа заключается не в создании, а в использовании. Бывает так, что система не имеет ошибок, соответствует проектной документации, но в работе неудобна, нетехнологична; обычно это обнаруживается после сдачи, тестировщик же обнаруживает эти неудобства и погрешности значительно раньше, и исправить их можно «по-семейному», среди своих.
В третьих, централизация тестирования повышает его качество. Есть известный психологический феномен: то, что человек сам создал, он с трудом разрушает, поэтому тестирующий собственные модули невольно выбирает «щадящие» тесты. Тестировщик же действует намного жёстче и объективнее. Вообще, у нас тестировщику с самого начала было предъявлено два условия: 1. Что он лично отвечает за каждую ошибку, найденную заказчиком, но не найденную им. 2. Что качество его работы будет оцениваться по количеству непрошедших тестов.
Что касается первого условия: действительно, заказчик, интенсивно используя систему, не нашёл в ней новых для нас ошибок — все они были обнаружены тестировщиком, но не все удалось вовремя исправить. Второе условие тоже существенно: на первых порах тестировщик огорчался, когда очередной тест не проходил (по своим старым программистким привычкам), и стоило больших трудов его убедить её что на самом деле это хорошо, что это показывает её хорошую работу.
В-четвёртых, централизация тестирования убрала рутину с программистов и исключила дублирования усилий. Тесты теперь хранятся в одном месте, один и тот же тест с различными вариациями может использоваться для различных случаев, а главное, работа с тестами ведётся специалистом именно в области тестирования.
Наш опыт показывает, что независимо от того, используется или нет «хирургическая бригада», выделение отдельного тестировщика очень полезно, а в условиях промышленного производства программ и необходимо, в сущности, это ОТК и даже нечто большее.
Полностью согласен, но я бы переформулировал. Слово «доказать» некорректно — разве что «подтвердить», «подкрепить уверенность».
Соглашусь.
И они в этих условиях сами себя не тестируют? Что-то я сильно сомневаюсь. Может, тестируют, но подпольно? :)
Есть такие люди, которые пишут медленно, но безошибочно. Как правило, они мигрируют в те области, где тесты писать нереально. Например в написание драйверов. Тестировать-то можно — осциллографом, логическим анализатором, а вот юнит-тестами — никак. :-)
Позавчерашний диалог:
— Проблемы с записью ключей в одноразовую память.
— Может я потестирую?
— А ты понимаешь, что каждый непрошедший тест — это испорченный процессор?
— Мда… Ну тогда давайте вычиткой кода…
Если вы меняете архитектуру ради TDD, то вы проигрываете в другом. Как минимум приходится выбирать кристалл с большей памятью данных и кода.
Я бы это описал так: использование TDD заставляет программиста писать код, соответствующий принципам SOLID. А уже следование SOLID даёт оверхед по памяти и процу за счёт использования абстракций.
- Результаты теста нужно куда-то выводить — значит нужен дополнительный канал вывода.
- Тест должен моделировать входные значения — значит их нельзя читать прямо с аппаратуры, а нужен промежуточный слой.
- Выходные значения нельзя выдавать прямо на железо. Одни выдали — таки, так вторая ступень запустилась прямо над первой, в итоге — трупы.
В итоге программка в 30 строк разбухает до тысячи или вообще пишется виртуальный контроллера размеров 10 тысяч строк. И в дополнительном коде — тоже бывают ошибки. Хотя лучшее тестирование для программ такого размера — это просто чтение кода парой специалистов, не участвовавших в написании.
Мы пошли последним путем — в программе в 300 строк за 15 лет эксплуатации не было найдено ни одной ошибки. А если бы использовали TDD — пришлось бы устранять ошибки во время эксплуатации.
Дело в том, что если программер не догадывается, что какая-то сиутация особая — он не догадывается об этом ни в тесте, ни в коде. Забыл, что делить на ноль нельзя — значит не будет этой проверки ни в тесте, ни в коде.
В итоге TDD — это больше имитация проверки системы, чем реальная проверка.
Что касается SOLID — рекомендую попробовать писать по принципам SOLID на языке Ladder. Да и вообще, на любом языке из IEC 61131-3, то есть на языках, предназначенных для высоконадежного промышленного программирования. Будете сильно удивлены. :-)
Дело в том, что если программер не догадывается, что какая-то сиутация особая — он не догадывается об этом ни в тесте, ни в коде. Забыл, что делить на ноль нельзя — значит не будет этой проверки ни в тесте, ни в коде.
Тесты, кроме своей основной функции (детектирование нарушения ожидаемого поведения), реализуют и функцию документирования, показывая ревьюверу какие особые случаи программер обрабатывает.
В целом ЭП — это такая методика написания быдлокода, точнее удержания быдлокода в рамках приемлемого качества. Вполне себе подходящая методика для части проектов.
А нынешнее применении TDD где надо и где не надо — это карго-культ, то есть религия.
Не бывает технологий без отрицательных черт. Не бывает технологий, применимы везде. Попробуйте сами назвать отрицательные черты TDD и где эта технология не применима. Если не получится — значит для вас это религия, а не осознанный выбор.
Я не везде использую тесты вообще и TDD в частности. В основном только на бизнес-логику.
Как минимум, когда облегчение дальнейшей разработки и поддержки важнее оптимизации по потребляемым ресурсам.
Хм… а отменный холивар поднялся от моего единственного… в общем-то обычного комментария...
@Jef239 Вам везёт работать на малых строгих объёмах кода… Если кода становится много (+ он многомодульный), или он становится слабо-связным нестрогим — у нас получается сразу уйма радости если тестов нет… рефакторишь простейший метод, допускаешь глупую ошибку и не можешь её увидеть… т.к. даже тестовый фреймворк не впилен в проект! А цена ошибки долетевшей до QA выше цены ошибки, вылеченой после простейшего теста (а он бы показал бесконечный цикл!)
А при правильной организации тестирования тестер — член бригады
А у вас — сотни миллионов строк?Именно. Понятно, что речь не идёт об одном модуле на сто миллионов строк, но, в частности, проблемы с тем, что один бинарник в Linux не может быть размером более 2 гигабайт у нас были.
А что вас удивляет? Windows XP — это 45 миллионов строк кода, Android — вплотную к 100 миллионам подбирается…
Просто не надо использовать TDD как карго-культ, у этой технологии есть свои сферы применимости.
А для компилятора собственного языка я использовал TDD больше 25 лет назад и при этом не чувствовал себя первопроходцем. Ещё тогда это была общеизвестная старая методика, просто никто не удосужился дать ей звучное имя.
Нет, я отношусь к другой ветви — труднотестируемого кода: слабо-связным нестрогим.
Слой DB — Oracle,
Слой бекэнда — java + spring + jsp
Слой фронтенда — html, css, js, angular
Отсюда вырастают проблемы:
- тестируемости (функционал размазан по всем слоям)
- идентичности (я пока не встречал способа формализовать единство даже FE + BE хотя бы в части структур данных и их валидации)
Ну и в целом состояния тестов в проекте удручающее — в частности тестирования FE кода просто нет. От слова совсем. Я вот локально прикрутил тестовый фреймворк, в следующем спринте буду коммитить, а пока у нас никаких гарантий поведения FE кода. А рефакторить — приходится.
Не согласен. Ну разве что вы себе и рюкзаки сами шьете, и дом строите и обувь тачаете…
Код быстрее пишут синтетики, а находят ошибки — аналитики.
Мой сотрудник будет три дня ковыряться с ошибкой, которую я найду за 15 минут. Зато он может делать то, что не могу я.
Если мой коммит, в котором была банальная опечатка долетел до QA — мы потеряли минимум день в плане сроков вывода задачи в релиз. Если я увидел сам на упавших тестах — 15 минут, есть разница?
Если у вас такой длинный канал до QA — ну или примите оргмеры для уменьшения длины канала или используйте коллегу в качестве QA (это называется парное программирование). Взамен вы потом проверите его кусок.
ОргМеры — это не то, что возможно в нашем проекте. Если QA находятся в паре тыс. км и, соответственно в другой тайм-зоне (+2 часа), если оно разлапистое-многочисленное, но обслуживает несколько проектов… В общем уменьшение канала — малореалистично.
Парное программирование сложноосуществимо по похожей причине — программисты в 3-х локациях (по 2-3 человека в каждой), в пределах одной локации — занимаются разными кусками проекта. В целом — даже код-ревью до сих пор не удалось в проект протащить (вот вам и орг-меры!)...
В общем — у каждого проекта своя боль. Я знаю как должно быть в идеале, но в текущем проекте — даже пол пути не преодолено… и жизненный цикл разработки данного проекта приближается к концу (планируется ~ летом вывод его на поддержку силами другой команды… впрочем это планировалось ещё прошлой весной сделать… впрочем гос-заказ он такой… в этом году прошли гос-закупку, в следующем — не удастся и амба...)
А цена ошибки долетевшей до QA выше цены ошибки, вылеченой после простейшего теста (а он бы показал бесконечный цикл!)
Не согласны?
Код быстрее пишут синтетики, а находят ошибки — аналитики.
Мой сотрудник будет три дня ковыряться с ошибкой, которую я найду за 15 минут. Зато он может делать то, что не могу я.
О, аналитики-то тут причём? В моей вселенной аналитики формулируют требования к системе, функциональные и нефункциональные. Потом тестировщики готовят функциональные, нагрузочные и подобные тест-кейсы для проверки выполнения системой требований (или даже тест-кейсы аналитики предоставляют), пишут код, автоматизирующий тесты по возможности, а параллельно разработчики реализуют эти требования,, решая без привлечения аналитиков и тестировщиков использовать юнит-тесты или нет, если использовать то создавая их до кода или после, думая неделями до первой строчки кода или "… и в продакшен". Использование методик типа TDD — решение, касающееся сугубо разработчиков и менеджеров.
Аналитик — это в данном случае не должность, а «Человек, умеющий хорошо анализировать, склонный к аналитическому мышлению»." (словарь Ожегова)
Ну в общем это чисто психологические термины. Пока вы не руководите людьми — вам не обязательно в них разбираться. Начнете руководить — сами увидите, кто быстрее пишет код с нуля, а кому лучше удается нахождение ошибок в чужом коде.
P.S. Про должности — вы правы. Но я не о них писал.
Какая-то аналогия левая. Это ведь просто разные жанры или стили. При чем тут быдлотехнологии?
Ну тогда опишите, что такое по вашему быдлокод.
Для меня это код без строгой структуры. Если в ООП мы выделяет структуру иерархией классов (и дорого платим за ошибку в организации иерархии), то в быдлокоде структура размазана по коду и изменяется проще.
Эй, не забывайте — мы каждые три недели отдаем серию пользователю, тысячи машинок вручную не вырежешь.
5-10 минут на вырезание, то есть 6-12 в час, 48-96 за смену.10-20 таджиков — вот вам и тысяча в сутки. Далее масштабирование за счет китайцев. Меньше 100 тысяч — нет смысла заморачиваться с литьем.
Реально, наше оборудование позволяет выпуск до тысячи плат в месяц, реальный выпуск — до 50.
И плевать, что у меня 10 лет опыта в индустрии.
Да какая разница, какой опыт? Не опыт определяет должность.
Просто на уровне тимлида — видны дальние перспективы, на уровне юниора — можно думать, что их нет.
У вас сейчас стадия «боюсь, ограничить изменения, а вдруг понадобиться». ну и у меня она 15-20 лет назад была. С тех пор стал глубже изучать предметную область, потому и не боюсь.
может, вы просто не знаете, как написать хороший код, чтобы он при этом легко поддерживался и изменялся
Или — красивый код или легкость поддержки и изменений, то есть быдлокод. Вместе — не получится.
Легко из красивого кода сделать уродливый, не спорю. А вот на то, чтобы код оставался красивым — потребуется куча усилий, включая рефакторинг при сильных изменениях.
Впрочем, дайте своё определение быдлокода. Для меня, например — экстремальное программирование — это хорошая методика написания именно быдлокода. Быстро пишется, быстро меняется и никакого вылизывания.
Запускать технический долг выгодно только в одном случае — вы закончите продукт как его видите и никогда не будете поддерживать
Такое впечатление, что вы берете кредит лишь тогда, когда можно его не отдавать. На самом деле это вопрос о цене кредита, а в качестве инфляции выступает тот факт, что первый снимает с рынка сливки, а те, кто пришел после китайцев, получает лишь убытки. Собственно вот вам ещё одна статья о преимуществах технического долга.
Технический долг не мешает развивать системы десятилетиями. Думаете в linux или FreeBSD нету технического долга? Его там порядочно. Мы ушли с FreeBSD, обнаружив, что драйвер ком-порта для нужной нам SoC просто не работает на высоких скоростях (выше 19200 бод). А в тексте драйвера нашелся комментарий «я знаю, это будет сбоить на высоких скоростях, если кому нужно — исправьте сами».
Ещё смешнее технический долг в процессорах. Самая смешная история — 1986ого года. Иногда программа вылетает по нереализованной операции. Разбираемся, выясняется что при старте делится мусор на мусор. Смотрю в микрокод процессора и вижу, что нормализация операндов перед делением не сделана, а если операнд не нормализован — дается прерывание по нереализованной операции. Меняем микрокод процессора с 14ой версии на 18ую — и все работает. Кстати, меняли перетыканием платы с микрокодом. Он хоть и микро, но занимал отдельную плату в корзине процессора.
Правильно я понимаю, что вы работали лишь в системе бардак? И что вы никогда не понимали планов на ближайшие 3-5 лет? Обратите внимание, что бардак — это не базар. Что во многих открытых проектах есть roadmap на годы вперед.
И разработка игр не всегда ведется вашим любимым методом тыка. Mortal Kombat, как вы можете прочесть, создавался с пониманием результата. И почти по водопадной модели. И вообще, метод разработки (водопад, скрам, канбан) перпендикулярен тому, понимаем мы результат или нет. Канбан придумывался для сборки машин, то есть ситуации, когда конечный результат полностью определен.
Ну и о быдлокоде.
Во-первых, быдлокод, как правило, это медленный код. Нивелируется это тем, что машина разработчика должна быть медленней машин пользователей.Тогда то, что шевелится у разработчика — будет летать у пользователей. С другой стороны, чем более вылизан код, тем он специализированнее и труднее модифицируется.
Во-вторых, быдлокод — это некрасивый, невылизанный код. Опять-таки, вылизывание специализирует код и ухудшает его модификацию.
В-третьих, быдлокод — это простой код. Кстати, чем больше программист зарабатывает — тем проще он пишет.
Теперь о сложности модификации. По моему опыту хуже всего модифицируется качественный ООП-код. Не во всех случаях, но как раз в ситуации «летающего ледокола». Продумана иерархия классов, разработаны контракты и тут появляется нечто странное, что ломает всю иерархию.
Или, как в нашей ситуации, не странное, а просто разработчик рассчитывал на сферическую лошадь в вакууме. И при столкновении с реальными данными все абстракции улетели в мусорную корзину. А вот быдлокод от этого более-менее застрахован.
Если нужен пример, то представьте в WoW этот самый летающий ледокол. Корневая иерархия — плавающие, едущие, летающие… Потом иерархии второго уровня. Ну и что вы сделаете с летающим ледоколом? Новый тип «плавающие-летающие»? Или множественное наследование?
Более-менее тут помогают интерфейсы, наподобие тех, что в JAVA.
Ну и последнее — это усталость кода. Вот она прежде всего зависит от того, что удалось предусмотреть при выборе архитектуры. Не предусмотрели — получите усталость или рефакторинг. Предусмотрели — все норм.
Наоборот, вылизывание обобщает и понижает зависимости, повышая стойкость к изменениям.
Расширение области применимости — это не вылизывание. Это чуть иной процесс. Скорее всего мы спорим о терминах.
Ну вот вам две версии memcpy — какая легче модифицируется? А вот и реально вылизанная версия memcpy, размером в 286 строк. Сумеете в ней разобраться? А найти причину, почему в ней машина вылетает?
Видите, насколько быдло-версия из 5 строк проще вылизанной версии из 286 строк?
Значит, плохо продумали. Некачественный код, значит.
Скорее уж слишком качественный.
Ну что ж, приведете пример, как вылизывание упрощает код? :-) Или согласитесь, что код все-таки усложняется.
Да не важно чья ошибка, нельзя, по-моему, считать ошибкой внезапные идеи законодателя, которые ни один эксперт предметной области предсказать не мог. Не было на рынке ни одного решения с такой функциональностью, не было просьб от заказчиков её предусмотреть, не назвали они её в ходе опросов "а что может понадобиться в будущем ещё?". Максимум говорили, что вероятно власть усилит регулирование отрасли, но в чём оно будет выражаться были совсем другие идеи, которые и предусматривали в архитектуре.
Это очень редкий подход, по-моему, в области обычного софта (мой опыт работы со встраиваемым софтом весьма ограничен) выдавать изменения ТЗ типа "заменить то-то на то-то" за дополнения типа "добавляем одно, не вызываем другое". Вернее на практике он встречается, но именно как признак кривой архитектуры, не позволяющей безболезненно удалять вроде бы больше неиспользуемые участки кода.
Вернее на практике он встречается, но именно как признак кривой архитектуры, не позволяющей безболезненно удалять вроде бы больше неиспользуемые участки кода.
ОГО! Удалять — это как??? Неиспользуемые — это как????
У вас 350 моделей стиральных машин. Вы собрались на них иметь 350 комплектов исходников? И каждый баг ядра править в 350 местах?
Делается один комплект исходников. И 350 файлов конфигурации к нему. Или путем задания дефайнов или путем присваивания указателям на процедуры (а что не вызывается — линкер выкинет).
Замена датчика — только в новых машинах. Новый режим стирки — только в новых машинах, Изменение параметров режима стирки — тоже только в новых.
А вот правка ошибок — касается всех машин. И старых и новых. Потому что вылезет баг на машине, снятой с производства — значит туда перезальют новую прошивку в сервисцентре.
У вас что, единый софт для всех банков и всех стран? И никаких правок для отдельных банков? ну так вам везет, не надо с зоопарком версий мучаться.
У нас тоже не 350 вариантов, но пара десятков наберется. 6 операционок, 6 компиляторов, 3 архитектуры процессора… Так что прежде чем выкидывать — надо понимать, точно ли ни одно из живых устройств никогда не потребует выкидываемого кода…
Да и вообще, выкидывание кода — дело линкера. Он это сделает лучше.
Проблема наша общая, но ошибкой её никто не считает в принципе. Тем более, что архитектура системы была заложена в 2011-м году.
У нас значительно меньше "моделей стиральных машин", ядро вынесено в отдельный репозиторий, а для "моделей" форки от него.
Удалять просто: в ТЗ одной из "моделей" изменяется, например, алгоритм расчёта пени. Процентов так 90% строк кода стратегии начисления, если сравнивать. Если одновременно по двум считать не надо, то удаляем старую, добавляем новую. Если надо — то пишем алгоритм выбора, добавляем новую. Старую удаляем когда надобность в ней полностью исчезает. В "прошивке" каждой из "моделей" только актуальный для неё код.
Вы живёте в мире c/c++. В других языках линкера может и не быть, да и сама линковка, нередко, динамическая. Есть средства, которые пытаются просчитать, есть ли использования того или иного класса/метода/функции, но они именно вспомогательный инструмент, т.к. не всегда способны отследить реальное использование.
Удаление мы производим не с целью уменьшить объём результирующего билда, а с целью уменьшить объём исходного кода для облегчения поддержки.
По сравнению с поддержкой одного устройства/бизнеса — любые движения по поддержке второго являются увеличением затрат на поддержку. Думаю, каждый из трёх основных вариантов (общая кодовая база, выделенное общее ядро и отдельные надстройки над ним, плюс просто несвязанные кодовые базы) имеет право на жизнь и универсального варианта нет.
МДА. Ну или у вас аналитики действуют методом тыка, или вы путаете изменения ТЗ с дополнениями, из у вас какое-то "настоящее" программирование типа поддержи сайта.
"У нас" было "совершенно настоящее" программирование, например, биллинговой системы плюс софтсвича, или системы мониторинга реального времени с субсекундными реакциями.
Да, значительная часть хотелок превращалась в дополнения, но были и такие, которые требовали рефакторинга с самого нижнего слоя.
Наши проекты всегда связаны с реальным миром. Мы знаем, что атомный ледокол не полетит над Москвой (даже низенько-низенько), что газонокосилка не будет печь блины, а стан для оцинковки стали не станет вязать веники.
"У нас" точно так же стойка наблюдаемых железяк не начинала улетать в космос, и даже переместиться в соседний ряд не могла. И печь блины не начинала. Но когда оказывалось, что сокращение предельного времени реакции на событие X означало, что вся старая логика детекта этого события на основании характерных свойств последовательности значений датчиков не работает, и надо менять алгоритм детекта или вводить новые датчики — в некоторых местах уровень проблем от изменения был более чем заметным.
Никакая "реальность" задачи, в Ваших терминах, не защитит от таких проблем.
Точно так же я понимаю, что на компе может не быть часов, а в байте неожиданно может оказать 32 бита,
У нас без часов там не бывало, и 32 бита на системе наблюдения — тоже, хотя для этого не нужно гоняться за изделиями загадочной российской военщины — простой Cray тоже отлично подойдёт на это. Некоторым приближением к таким диверсиям были вычислительные модули на Cell.
Так что если я решил, что какого-то изменения не будет, а оно произошло — это моя ошибка.
Вот тут принципиально расходимся. Не ошибка. Ошибка — это когда на такое изменение не успеешь отреагировать. А когда оно просто непредсказуемо, но ты сохраняешь способность реагировать на новости — это как раз нормальное рабочее состояние.
В качестве мини-примера: одно из таких направлений, очень перспективное, сорвалось из-за того, что генподрядчик попал под санкции. (Это было ещё в 11-м году, так что с нынешней политикой прямо не связано.) В результате были запущены другие направления развития. Несмотря на материальность сферы, предсказать такое невозможно. Можно только быть готовым держать систему наготове к движению в любую разумную сторону.
И да, мы могли предсказать, что направление A потребует такого-то изменения, B — другого. Но пока нет никаких достоверных данных о движении в эту сторону — браться менять смысла нет. А изменения между собой слабо совместимы, скорее конфликтуют. Так зачем спешить вводить одно, даже если видишь, куда и как оно могло бы двинуться? Чем проще и прямее реализация на каждом этапе под его требования и под гарантированную (а не предполагаемую) перспективу, тем лучше.
Чтобы было понятней — вспомните дискуссию про goto сороколетней давности. Код с goto -очень гибкий. Но и некрасивый.
Я скорее отношусь к тем, кто "GOTO considered harmful" considered harmful. Потому что и return из середины, и break/continue это смягчённое goto, и автогенерация кода может их рожать пачками, и в машинном коде оно, а не if/while, и ваще. Сам иногда применяю в типичных шаблонах (например, на голом C — объединить код cleanup-веток некоторой функции). У меня критерий к нему — чтобы код был понятен тем, кто не заражён религиозной неприязнью.
И вот это
Код с goto -очень гибкий. Но и некрасивый.
неадекватно потому, что важно не то, что "некрасивый", а потому, что бесконтрольное использование GOTO приобрело ужасающие формы совершенно без причины, и никак не на пользу производительности или другим объективным показателям.
Делая код эффективным — мы теряем в его универсальности. Делая код красивым — опять теряем в универсальности.
Второе совсем сомнительно. Первое, как правило, верно (оптимизация под конкретные частные случаи применения, если не вообще под компилятор и рантайм), но при этом ничто не мешает вернуться к универсальной версии, когда потребуется.
В моей юности процедуры на 5 страниц считались отличным (и понятным кодом). Именно в этом стиле и писали в журналах и книгах по программированию. Ну и блок глобальных данных — был вообще единственным способом эффективной связи по данным.
Не знаю, как это соотносится с моей юностью, но начинал я на Fortran. Common-блоки использовались скорее для удобства не-передачи контекста каждый раз и для замены не существовавших тогда структур, чем для собственно эффективности.
Процедуры на 5 страниц и более там и сейчас норма (на днях копался в BLAS), но в специфическом контексте, где это почти не мешает. В системном программировании такие или там, где ну очень тяжело разрезать иначе (как tcp_input() в классическом BSD), или в очень специфическом стиле (sendmail).
А что было неэффективным в случае иной связи? Слишком много возни с указателями?
Да, значительная часть хотелок превращалась в дополнения, но были и такие, которые требовали рефакторинга с самого нижнего слоя.
Давайте не путать изменения ТЗ с дополнениями, которые потребовали рефакторинг из-за непродуманности структуры.
Но когда оказывалось, что сокращение предельного времени реакции на событие X означало, что вся старая логика детекта этого события на основании характерных свойств последовательности значений датчиков не работает,
Ну вот примерно ради такого мы и отлаживали СУБД на миллион записей в секунду при том, что реально у нас всего 10 тысяч в пике (и до 200 без пика).
Никакая «реальность» задачи, в Ваших терминах, не защитит от таких проблем.
Да, тут только опыт. Помните у Туполева "сломается здесь"? 100% не предусмотришь, но 95% — вполне.
Вот тут принципиально расходимся. Не ошибка.
Уточню. Моя ошибка как аналитика предметной области. Ну или ошибка того аналитика, кто подписался, что уж такого — точно не будет.
Можно только быть готовым держать систему наготове к движению в любую разумную сторону.
И я об этом же. Если система к движению в какую-то сторону не готова — это ошибка аналитика. Или команда программистов вообще не видит дальше спринта (а надо смотреть на 5-10 лет вперед).
Второе совсем сомнительно
Красота — это ещё и выкидывание лишнего. Разных зацепок, закомментированного кода «на будущее», полировка разных мест, по которым видна история кода… В итоге красивый код модифируется хуже.
Красиво:
printf("V=%.1f\n",GetV());
Некрасиво:
double V = GetV());
printf("V=%.1f\n",V);
Но второй вариант проще и в отладке и в модификации.
А что было неэффективным в случае иной связи?
Обращение к переменным объемлющей процедуры. Алгол-60 это позволял. Указателей в алголе-60 и фортране-IV вроде не было (или не было в тех реализациях, с которыми я работал). В алголе-60 можно было немного оперировать с метками, но это указатели на код, а не на данные.
Давайте не путать изменения ТЗ с дополнениями, которые потребовали рефакторинг из-за непродуманности структуры.
Почему не путать? Как раз я не вижу причины вводить тут вообще какую-то принципиальную разницу. Формально дополнение очень часто вызывает необходимость перестройки, а изменение столь же часто вызывает всего лишь поверхностную переделку отдельных компонентов. В любом случае это изменение ТЗ, а какое оно даст эффекты — непредсказуемо. Иллюстрация в тему.
100% не предусмотришь, но 95% — вполне.
В 95% мы вполне вкладывались. Оставшихся 5% хватало, чтобы последствия обсуждать ещё много лет. :) И Туполеву наверняка не ставили задачи в виде "самолёт должен летать год без посадки".
И я об этом же. Если система к движению в какую-то сторону не готова — это ошибка аналитика. Или команда программистов вообще не видит дальше спринта (а надо смотреть на 5-10 лет вперед).
Реально получалось видеть с достаточным качеством на год, в общих чертах — на три.
double V = GetV());
printf("V=%.1f\n",V);
Но второй вариант проще и в отладке и в модификации.
Ну, опустим, что они неравнозначны (вот в варианте
printf("V=%.1f\n", (double) GetV()) есть действительно полное соответствие). Если отладка это распечатать V и/или не спутать пошаговый проход GetV() с printf() — да, согласен.Но с модификацией связи не вижу. Наоборот, первый кажется проще для модификации — за счёт отсутствия лишних сущностей. Ту же переменную V надо проследить, чтобы её значение нигде дальше не использовалось. Вот если бы был оператор типа unvar (del в Python), чтобы поставить после printf и после этого чтобы V была неизвестна — тогда не надо было бы смотреть вниз.
Указателей в алголе-60 и фортране-IV вроде не было (или не было в тех реализациях, с которыми я работал).
В Фортране IV всё передавалось по указателю. Передача по значению появилась позже. От этого возникал ряд неприятных эффектов. Но я понял идею этого пункта, спасибо.
С тем, что для пользователя мало понятно, какие изменения и дополнения ТЗ сделать легко, а какие нет — согласен. Архитектору ПО, как правило, это понятно.
И Туполеву наверняка не ставили задачи в виде «самолёт должен летать год без посадки»
Не только ставили, но и решили. Летчики в свинцовой кабине, в салоне — атомный реактор с выбросом в атмосферу. Более того, оно летало. По устной информации из музея ИАЭ имени Курчатова, на случай атомной войны планировалась автономность до года — то есть использование как оружия возмездия.

В 95% мы вполне вкладывались. Оставшихся 5% хватало, чтобы последствия обсуждать ещё много лет. :)
Соглашусь, где-то так и получается. 3-5% того, что не лезет в структуру. От них или отказываться или менять структуру или писать заплаты…
Реально получалось видеть с достаточным качеством на год, в общих чертах — на три.
Ну тоже примерно так. Ну может 5-7, а не 3, но примерно так…
Но с модификацией связи не вижу. Наоборот, первый кажется проще для модификации — за счёт отсутствия лишних сущностей
Во втором варианте проще вставить дополнительные операции между вызовом процедуры и использованием её результата. Например — искажение при нарушении защиты. Что касается unvar — в Си для ограничения области действия используются фигурные скобки, я решил не загромождать пример ими.
В Фортране IV всё передавалось по указателю. Передача по значению появилась позже.
По ссылке все-таки, не по указателю. Указателей на данные там вообще не было.
Видимо, тут таки конфликты в понимании слова «ошибка». Слишком уж оно эмоциональное. Но, даже если его применять, то в разработке на заказ такие «ошибки» будут даже не неустранимой составляющей работы, а просто константой обстановки (отсюда и все веяния в сторону agile). Если заказчик — внутренний, влиять обычно легче, но полного избавления от таких ошибок я не предполагаю.
> на случай атомной войны планировалась автономность до года
Р-радикально. :) Впрочем, тогда и не такие взлёты мысли были. И устройство было упрощено до предела. Не думаю, что кто-то из современных конструкторов сейчас возьмётся повторять этот подвиг в варианте с хоть каким-то расчётом на более современные средства, а не уровня древней Спарты.
> Ну тоже примерно так. Ну может 5-7, а не 3, но примерно так…
Ook.
> Во втором варианте проще вставить дополнительные операции между вызовом процедуры и использованием её результата.
Да. Но это сейчас такая вещь, которую всякие IDE должны вообще на автомате делать по указанию программиста о выделении куска выражения (и многие и делают), как и обратно. Строить на этом теорию, мне кажется, уже давно не имеет смысла.
> По ссылке все-таки, не по указателю. Указателей на данные там вообще не было.
Это я переупростил для ясности. С точки зрения C++-like терминологии это таки ссылка, даже если внутри чистейший указатель.
Но, даже если его применять, то в разработке на заказ такие «ошибки» будут даже не неустранимой составляющей работы, а просто константой обстановки (отсюда и все веяния в сторону agile).
И все равно, ошибка анализа предметной области остается ошибкой. Да, не вашей, а аналитиков заказчика.
Просто то, что не ошибка, а реальное изменение условий у заказчика — выливается в дополнение, а не в изменение. Ну например. Торговал заказчик носками, потом стал торговать гольфами. Вместо изменения слов «носки» на «гольфы» вы делаете дополнение в конфигурацию. Ибо никто не гарантирует, что через год заказчик не вернется к носкам.
Не думаю, что кто-то из современных конструкторов сейчас возьмётся повторять этот подвиг
Там летчики за день получали облучение по годовому лимиту для работников радиостанций. :-) Да и падение атомолета в жилом районе представляете?
С точки зрения C++-like терминологии это таки ссылка, даже если внутри чистейший указатель.
Если C++ like, то стандарт фортрана допускал реализацию с копированием по значению-результату. То есть одно копирование — на входе в функцию. И, если надо — второе, на выходе. Сделано это было, чтобы держать параметр в регистре и не беспокоиться о том, что он синхронно не обновляется в памяти.
Как уже сказал, считаю это только вопросом терминологии. Хотите называть это ошибкой — не возражаю.
> то стандарт фортрана допускал реализацию с копированием по значению-результату. То есть одно копирование — на входе в функцию. И, если надо — второе, на выходе.
Хм, интересно, такого не видел. Но вот требование копирования обратно тут 1) не соответствует более новым традициям, 2) и непонятно, как называть — «по ссылке» уже не совсем корректно. В любом случае, я рад, что в новых языках этого нет, а где есть — есть и тенденция явно обозначать такое (var в Pascal, но ещё лучше ref и out в C#, где надо его указывать и в списке вызова).
Копирование по значению-результату называется inout и вполне используется в языках типа IDL. Вот вам цитата из MIDL:
The [in] and [out] attributes are known as directional parameter attributes because they specify the direction in which parameters are passed. A parameter can be defined as [in], [out], or [in, out].
А вот и про in out в языке Ада.
Inout эффективней ссылки тем, что не подразумевает алиасов. Соответственно нет всех проблем, связанных с алисасингом (это когда в качестве разных параметров одной процедуры мы имеем одну и ту же ссылку).
return только частный не самый интересный для обсуждения случай. Интереснее с break. До сих пор масса языков позволяет им выйти только с самого нижнего уровня. Пример Java, где можно даже выйти из тела именованного if, до сих пор остаётся приятным исключением.
> Поэтому, например, писать руками код с goto в 2017 году на каких-нибудь даже плюсах я особых причин не вижу.
На плюсах — тот же выход из множества вложенных циклов (когда неудобно порождать отдельную функцию; хотя с появлением лямбд стало значительно проще делать их эффективно). На C — объединение веток очистки за собой является стандартнейшим и полезнейшим приёмом (альтернатива чудовищно хрупка).
Мда… Что это за анализ предметной области, если код нужно править в ближайшие полгода?
Как минимум, бизнес развивается, государство ограничители придумывает, а у пользователей появляются новые хотелки.
Но вообще внутренний софт редко пишется нормально…
Правка — довольно частое явление, причём очень значительная, в корне меняющая модель, а то и архитектуру. Из личного опыта, например, предоставление новых услуг, в том числе анонимно (много лет была одна единственная по предъявлению паспорта и заведения клиента в базе) или требование государства обеспечивать фискальную регистрацию, да ещё в режиме онлайн, когда архитектура вообще интеграции с периферией не предусматривала и понятий типа "закрытие кассы", "Z-отчёт" и т. п. не было.
Подумайте о том, почему в 1С-предприятии при тех же изменениях в законах не пришлось ничего переписывать.Потому же, почему при изменениях в ТЗ не нужно переписывать код компилятора С или интерпретатора BASIC?
Вынуждан признать — с 1С я сам лично не общался. Но на болезненный процесс переписывания модулей при выходе новых законов моя сестра, бухгалтер, жалуется регулярно…
Уверяю вас, при изменениях в законах в системах, созданных на базе 1С приходится переписывать массу всего. А интерпретатор — он интерпретатор и есть, чего с него взять-то?
А «много переписывать» — это такая мантра, при помощи которой программисты на 1С набивают цену. Потому что можно ничего не переписывать, а сделать новый документ с новой функциональностью.
А дописывать — намного проще, чем переписывать. Так вот, структура 1С позволяет в большинстве случаев просто дописать новые документы (модули).
А я сочувствую тем программистам, которые вместе разработки кода бизнес-логики занимаются рисованием бизнес-процессов в конструкторе, а потом объясняют клиентам "ну вы же понимаете, что бизнес-процесс сложная штука, его надо загрузить из базы данных, распарсить, интерпретировать и т. д., поэтому он не может работать быстро".
Я тоже не переписываю PHP при изменениях в законах. Вот надо интеграцию с ККМ делать теперь бизнесу — пишу PHP-код технической интеграции и делаю изменения в код бизнес-процессов.
Лично мы словили кучу кайфа, когда сделали конструктор и смогли привлечь к написанию системы (АСУТП) не программирующих технологов. Для связи модулей между собой у нас использовался калькулятор с тернарной операций. Правда потом тернарной операции стало не хватать и в калькултяор пришлось добавить условные операторы и циклы. Технологи догадывались, что это уже программирование, но было поздно.
Что касается эффективности — то у нас один и тот же технологический код отлаживался на персоналке, а выполнялся под DOS на 80188 с 40 МГц.

Заказчики очень удивлялись, что мы делаем серьезную автоматизацию производства на таких вот крохах.
Так что не преувеличивайте потери скорости — они не больше 5%. Зато у такой системы два важных плюса:
- Отладка на конструкторе в десятки раз быстрее, чем на контроллере.
- Процесс описания ТЗ сливался с процессом конструирования. То есть ТЗ было проще описать прямо на конструкторе, лишь отдельные места описав словами.
Похоже вам просто нравится разрабатывать инструменты для программистов, пускай они ещё не догадываются, что они уже программируют :) Или может ваша бизнес-модель не оставляет вам другого выхода.
В целом такой путь раз в несколько раз дешевле для написания серии систем, чем писать с нуля каждую систему. А при модификации — встают лишь технологические проблемы.
Ну я же говорю бизнес-модель :) Вы и Сименс разрабатываете серии систем. Если бы перед нами стояла задача разрабатывать серию систем с возможностью адаптации под множества вариаций схожих глобально бизнес-процессов, то вариант создания конфигурируемой администраторами со стороны бизнеса мы бы, как минимум, рассмотрели. Но если вариаций одна-две, изменениях в процессах не настолько часты, то проще реализовывать бизнес-процессы в коде.
Быдлокод не позволяет быстро определить место(а), где нужно сделать изменения для фикса ошибки и(или) реализации нового/уточненного требования, и не позволяет сделать эти изменения с уверенностью, что реализации остальных требований не сломались. Быдлокод не позволяет масштабировать разработку горизонтально.
Изменений у нас немного именно в потоке исполнения рабочих процессов, в общих стратегиях, но часто меняются спецификации, точки входа, интерфейсы, добавляются интеграции с внешними системами и т. п.
И не путайте дописывание с переписыванием. Дописывание намного меньше вызывает усталость кода.
Ну если if ( *(byte *)0x449 == 0x13) для вас хороший код — то вы на 100% правы. Потому что до такого мы даже в прототипах не скатываемся.А в чём проблема с данным кодом? Два хорошо известных (в те годы) числа сравниваются друг с другом — в чём проблема? 0x449 — это текущий видеорежим, 0x13 — это VGA-графика (которую, соответственно, нужно отключить).
Эти числа в годы написания DOOM'а чуть ли не на столбах клеились! Уж во всяких книжках по программированию они были точно и, зачастую, в книжках, прилагаемых к компьютеру, они тоже существовали.
А влияние добавления сотни строк к коду на скорость компиляции в те годы оказазывало заметное влияние…
А элементарно задефайнить константы слабо? Ну скажем на случай смены видеорежима?Вы притворяетесь или издеваетесь? После VGA — уже ничего никогда не было. Вообще. Никогда. SuperVGA — уже не было стандартом и, соответственно, простой заменой чисел не обойтись. Нужно будет добавить таблицы известных видеоадаптеров (да-да, это DOS, детка), код для их распознавания и прочее.
А оно точно надо во внутренней утилите конвертации файлов? Может лучше просто решить что вот конкретно она — будет работать только в VGA и всё?
Что касается технической оправданности — вполне можно было подумать о порте под аркадный автомат с конкретным видоадаптером. Или о будущем порте под iPhone.
В любом случае, если бы я писал такой код, то он минимум был бы под #ifdef PC_VGA. Потому что #ifndef __NeXT__ это мягко говоря неправильно. Ну неверно же считать, что всё, что не NeXT — это именно IBM_PC и VGA!
вполне можно было подумать о порте под аркадный автомат с конкретным видоадаптеромЭто вы утилиту конвертации файлов под аркадный автомат портировать собрались? Нафига она там?
Ну неверно же считать, что всё, что не NeXT — это именно IBM_PC и VGA!Внутри студии id Software во времена создания Doom'а? Почти наверняка.
Ещё раз: вы смотрите на код вспомогательной утилиты, которая никогда не поставлялась вместе с Doom'ом.
Сам Doom был портирован… куда он только не был портирован! Разве что на калькуляторах его нет (хотя нет — есть). А утилита конвертации… изначально она только под NeXT затачивалась, а потом её ещё и на PC с горем пополам запустили.
Уже велась разработка Quake, уже было понятно, что этой утилите долго не жить — и вы хотите, чтобы её затачивали под аркадные автоматы???
В любом случае, быдлокод — есть быдлокод.
А что касается технических преимуществ быдлокода — то согласен с вами, они есть.
bool isTextVideoMode()
Тогда оптимизатор мог и не заинлайнить подобную функцию, а вызов функции мог оказаться слишком дорогим. Вот макрос с параметрами был бы нормальным решением.
Учитывая, где эта функция вызывалась, она точно не могла быть узким местом.
А использование макросов стоит избегать настолько, насколько это возможно.
Не стоит оценивать качество тогдашнего кода с позиций сегодняшнего дня. Чушь получается. Даже если сегодня пишется код под DOS (а он пишется, не сомневайтесь — вот прямо тут и пишется), но даже при этом они на этой крохе свои проекты не компилируют! А тогда… Вы думаете все эти NOKANJI и NOSERVICE от хорошей жизни появились?
Но верно и то, что линейка Win95 загнулась, потому что просто не смогла развиваться.
Связано ли это с качеством её кода? Или всё-таки с тем, что принципиально беззащитный дизайн перестал котироваться, а компы дотянули до мощности, когда NT-based решения перестали быть аццким тормозом?
Насколько я в курсе, там существенные затраты шли таки на проблемы совместимости с DOS. Избавление от неё сначала при переходе на Win2000, а затем (в Vista) при устранении DOS mode и 16-битки — были громкими праздниками.
Вы таки удивитесь, но таки Win2000 из линейки nt. И оно изначально было самостоятельной операционкой, а не надстройкой над DOS. Равно как и её продолжатель XP.
Линейка 9х кончилась в виде:
95 (+апгрейды), 98 (+апгейды), миллениум.
Другое дело — старт Windows 3.1 как приложения MS-DOS и использование досовых драйверов. Вот тут и были основные проблемы. Они решаемые, Win95 уже обычно использовала 32битные собственные драйвера для диска дисплея, звуковой карты и так далее… Но сказалась усталость кода…
Вы путаете разные вещи.
Нет, не путаю. Я явно указал, что тут два разных этапа избавления от этого наследия.
Одно дело — подсистема WoW
Про WoW я ничего не говорил. Говорил про то, что в линии NT называется NTVDM, а в 9x как-то иначе. Сейчас уточнил — да, оно в 32-битных версиях вроде бы есть и сейчас.
Но сказалась усталость кода…
Или скорее то, что альтернативный перспективный код был давно стабилизирован и готов к использованию.
NTVDM (NT Virtual DOS Machine — «виртуальная машина DOS для системы NT») — компонент, входящий в состав 32-разрядных редакций операционных систем семейства Windows NT, позволяющий запускать 16-разрядные приложения Windows и 16/32-разрядные приложения DOS
Для справки. Windows NT вышла в июле 1993 года, OS/2 Warp на той же кодовой базе в октябре 1994ого.
А линейка Win 3.1 загнулась после крайне неудачной WinMe:
Windows Me сильно критиковалась пользователями из-за её нестабильности и ненадёжности, частых зависаний и аварийных завершений работы. В одной из статей в журнале PC World аббревиатуру МЕ расшифровали как «Mistake Edition» (ошибочное издание) и поместили на 4-е место в списке «Худших продуктов всех времён».
Почитайте "Inside Windows 95" или Unofficail windows 95 — поймете, что только титаническим трудом они смогли заставить Win95 работать настолько стабильно. То есть падать раз в несколько часов, а не раз в 5 секунд. Но к WinMe даже возможностей микрософт для поддержания гавнокода не хватило.
Но к WinMe даже возможностей микрософт для поддержания гавнокода не хватило.Не совсем так. Windows 98SE — последняя запланированная версия Windows 9X — была весьма стабильной. А Windows ME пришлось срочно выпускать, чтобы «закрыть дыру», когда-то с Windows Neptune вышел облом-с.
Разумеется изделие сделанное далеко не лучшими программистами, знавшими к тому же, что они делают продукт «на выброс» оказалось не самым лучшим…
RTFM, NTVDM — это основной компонент подсистемы WoW16:
Это никак не следует ни из процитированного Вами текста, ни из просто определения win-on-win. Скорее надо говорить, что NTVDM — нижележащее средство для WoW16.
Почитайте "Inside Windows 95" или Unofficail windows 95 — поймете, что только титаническим трудом они смогли заставить Win95 работать настолько стабильно.
Читал, и именно об этом и говорю. И там как раз написано, почему так — не потому, что просто вдруг оказался там кривой код (с их ресурсами они всё это исправили бы), а потому, что само построение ОС не давало шансов сделать беспроблемное устройство.
А линейка Win 3.1 загнулась после крайне неудачной WinMe:
Которую мало кто ставил.
Из этого следует интересный технический вывод — в консольной DOS-программе под Windows NT можно использовать то, что было в WIn16, но отсутствовало в DOS. Например — обращаться к сетевым файлам.
само построение ОС не давало шансов сделать беспроблемное устройство.
Это и называется «усталость кода». А кривизна там возникала из-за необходимости сделать совместимость с софтом, накопленным за 20 лет.
А отдельной подсистемы DOS — нету, она считается «Win16 console».
Ну, стандартные источники таки разделяют их, но не буду тут спорить только из-за терминологии.
в консольной DOS-программе под Windows NT можно использовать то, что было в WIn16, но отсутствовало в DOS. Например — обращаться к сетевым файлам.
Ну там очень много чего можно было использовать через спец. интерфейсы. Например, то, что запускалось через DOS4G[W] и тому подобные экстендеры, под Win95 запускалось нативно (а даже если программа просила экстендер, тот просто "встраивал" свои действия в Windows). Для сети Win95 эмулировала SMB интерфейсы стиля Lantastic и аналогов. Но если это не выглядело Win бинарником, а был просто досовским .exe — то прямой путь к Windows-интерфейсам был недоступен (можно было требовать её dllʼки, но там требовалась особая осторожность).
Вообще, этот слой там чуть ли не высшее произведение инженерной осторожности за всю историю осестроения — заслуживает отдельного рассказа (увы, я знаю оттуда дай бог чтобы 2%, и не возьмусь).
В таком случае, почему вы позволяете этому происходить, если деструктивная природа действий вам очевидна? Если работник, преследуя личные интересы, вредит производственному процессу и лично вашей работе — чем это отличается от воровства, например? Если вас реально волнует результат работы, почему вы позволяете кому-то обесценивать ваш труд и вредительствовать? Хата с краю?
Повторюсь, в конце концов, если невозможно исправить ситуацию — из неё всегда можно выйти. Было бы желание реально что-то делать, а не уныло констатировать факты.
Так что какие бы красивые схемы в учебниках не предлагали на тему реализации изменений — в реальной жизни они очень редко применимы.
Скорее, хочешь поменять — пробуй разные подходы, делай выводы, пока не получится или не придёт понимание причин невозможности перемен. Надоест тратить силы впустую — уходи, ищи своё.
Стиль управления и мотивы решений можно научиться оперативно распознавать. Это приходит с опытом, если целенаправленно стараться этот опыт получить. Более того, многие детали о стиле руководства, отношении к сотрудникам, условиях и процессах в компании можно узнать ещё на этапе интервью, просто задав нужные вопросы. Собеседование это двусторонний процесс, а не кастинг, вы точно так же присматриваетесь, подходит ли компания вам, кап и предсиавители компании — подходите ли вы им.
Что касается схем в учебниках — признаться, тут я некомпетентнн, ибо ни единого на эту тему не прочёл, так что судить, работают ли какие-то методики, не могу. Однако, предполагаю, что истина где-то посередине — работают, в общих чертах. Ожидать, что кто-то выдаст вам универсальные, всегда работающие решения там, где замешана человеческая психология, по меньшей мере, наивно.
словоблудием я мог бы заниматься, но во-первых, читать многабукав никто не будет, во-вторых, «спасибо за мнение, но мы всё равно будем делать как нам хочется, а не как по уму надо». то есть, всё решает политика. и бабло. по уму ведь делать — дольше и дороже.
Конечно же, эта пламенная речь должна сопровождаться хотя бы парой слайдов
Не перебор ли для предупреждения попыток руководства наступить на грабли? Пара "продающих" слайдов — это день работы минимум.
Это только в первый раз, и то только при неоптимальном подходе. Я б даже сказал — неправильном. Любой доклад надо выносить, в один присест мало кто способен сделать.
Основная часть вообще времени не занимает — проблемы находятся сами в рабочее время, возможные решения, равно как и повествовательная часть, формируются в уме фоновым процессом в любое время вообще, эксперименты, тесты, прототипы — зависит от желания: в личное (ну не прикручивать же очередной сторадж к реакту), в рабочее попутное или специально выделенное. Всё зависит от вовлечённости и желания реально достичь результата.
А слайды — скорее выжимка тезисов, изредка графики или скриншоты. Это несложно. Это же презентация технаря, а не маркетологов, тут смысл важен.
За 15+ лет сформировалось по этому поводу не сколько утверждений, вот пара из них:
— больше чем указывающего на недостатки (даже с приведенными решениями) люди ненавидят того, кто оказывается в этих случаях прав.
— осуществлять критику и предлагать решения имеет смысл только в том случае, если изменения осуществимы.
Это называется "подтверждаю"? Вы понимаете, что вы только что намекнули человеку что все его предложения могли быть неосуществимы? :)
и только наличие определённого опыта позволяет определять такие задачи заранее и поднимать панику, пока оно ещё не пошло в работу.
Указывать недостатки надо уметь. Можно ныть и поносить всё и вся, безрезультатно. А можно предлагать возможные решения и обсуждать их, совместно доводя до идеала. Важность социальных навыков программистами бывает сильно недооценена.
Хорошо думать надо о критикал пасе, о фаллбэках и о риск митигейшен. А как конкретно какой код писать — да в целом срать, код дело такое, сегодня написал, завтра переписал, послезавтра вообще выкинул. Учитывая то, что любой софт в принципе гавно и всегда не работает, думать надо о том, как с этим жить, а не как этого избежать.
Либо бизнес устраивает состояние продукта, и тогда всё хорошо, либо не устраивает, но не потому, что там «копипаст и нет юнит-тестов» (отсутствие копипасты и наличие юнит-тестов — это вообще не цель, это средство достижения других целей), а потому, что расходы на продукт высоковаты, а скорость внесения изменений низковата, и через это прибыль мала плюс идёт потеря рынка.
И вот только тогда, когда доказано, что дело в копипасте и юнит-тестах — вот тогда надо за них бороться.
Ну и конечно вы вольны работать там, где вам хочется работать, просто в любой успешной конторе экстремизма довольно мало, и отношение ко всем вот таким вот штукам практичное и, даже можно так сказать — циничное. О чём нам и рассказывают в интервью.
Отдельно отмечу, что не понимаю, почему девелоперы не любят раскапывать баги, это же интересно.
Кому интересно, кому нет. Да и баг багу рознь, начиная с баг-репорта: "у меня система не работает" против "если я использую вот такое сочетание полей A и B в форме документа от юзера в группе "менеджеры", то документ идёт по маршруту 1, а согласно п. 7.3.4 описания системы должен идти по маршруту 3."
Поэтому возникает грусть и некий налёт скуки.
Т.е. первый комментатор прав:
«прогрессирующее занудство, исчезающая самоирония и старческая слезливость»
И ещё раздражение со стороны менеджмента, он же приносит "новую прорывную идею, изобретённую долгими вечерами" а вы ему сообщает что это уже было и кончилось "ни чем"
(извините за повтор — мне 52 и я кодирую)
40-летние программисты, как мне кажется, никуда не деваются, они просто растворяются в толпе прибывающей бешеными темпами молодёжи
Да я и 25-30 летних динозавров уже успел повидать: что изучили в 20 лет, тем дальше и пользуются без расширения кругозора.
если кодер проникся предметной областью — у него шикарные шансы стать успешным в ней
(мне не повезло — я любил сам кодинг слишком сильно… и стал сисадмином )))
О Яндекс! Грааль мечты! Только у тебя люди не просто перекладывают данные, а делают с ними что-то осмысленное.
Это настолько высокопарно, что начинает выглядывать сарказм. Хотя вы его умело скрываете.
Если все же сарказма не было, имейте в виду, некоторые там тоже перекладывают данные.
И некоторые программисты уходят оттуда именно по этой причине.
Этот персонаж (Andrey Lyashenko) в Яндексе местный мем. Распространяться не буду, но его словам о Яндексе я бы доверять не стал.
А не иду туда, потому что могут опять отреджектить, и это будет обидно. Последний раз там был году в 2007-м — отреджектили. И не уверен, что сейчас пройду. И если еще раз отреджектят — то уже не сбудется мечта детства :) Шутка. Когда Яндекс сделали, мне уже был под тридцатник.
Да и чтобы идти туда, надо целый отпуск двухнедельный брать: на подготовку и на собесы.
Да нет, не надо. Я не брал двухнедельный отпуск для этого, например. Собеседования чаще в один день. Подготовиться можно, что-то почитав(для освежения) и покодив те же пару недель после работы.
что-то почитав(для освежения)
Как можно соваться всего лишь «что-то почитав» к цвету софтверной индустрии? Надо уж прилично выглядеть — например, выучить наизусть алгоритмы на графах (у меня сейчас идет чтение Скиены, Algorithms Design Manual), проштудировать Кнута, хотя бы 1-3 тома. Университетский курс повторить надобно, интегральчики освежить. Задачки на сообразительность порешать. Я не перенесу второго фейла. Лучше уж никуда не ходить, чем не быть уверенным в успехе и пойти.
Не очень понятно, троллите вы или нет. Дело ваше, а задачки на сообразительность нынче не в моде.
Не рассматривать собеседование как экзамен прежде всего. Не считать, что у известной фирмы требования жёстче чем у "ноунейм", если тексты вакансий в части требований совпадают — по факту всё равно будет субъективная оценка. Практика показывает, что достаточно примерно 50% из списка "требуется" и 30% из списка "будет плюсом", если пригласили на техническое собесодование, чтобы попасть на следующий круг, где работодатель уже не отсеивает неподходящих, а выбирает из подходящих.
Вот нашел не далее как вчера замечательную вакансию.
$8000-$8250. Москва. C++ Chief Software Architect. Некая фирма Crossover. С вызывающим текстом.
Are you one of top Software Architects in the world? Do enjoy solving incredibly complex problems that no one else has been able to complete? Are you 10x more productive than the typical developer? и т.д. и т.п.… There will be a series of interviews and online skills examinations. We realize these are challenging and can require a decent amount of time — so we thank you in advance for your efforts.
От это суперинтервью будет! Как из сериала «Apprentice»! Народ ломится, видимо, табунами, на такую з-п. Так просто не отделаешься 30% из списка «будет плюсом». Кто-нибудь собирается туда?
Может приведёте пруфы тогда? Я вот вижу, что компания движется, растёт и развивается. Где-то бывают отдельные косяки управления, наверное, но это неизбежно, потому что люди совершают ошибки.
(если честно, я тоже не знаю ответа на этот вопрос, и хотел быть его найти.)
Но проблема есть — потолок в профессии, кажется, достигнут, вот я и думаю, это тупик или нет и что делать дальше.
Меняйте профессию. Кроме программизма, в мире есть ещё много интересных инженерных дисциплин. :)
Или, как вариант, откройте стартап. Скучать не придётся. :)
С одной стороны сам видел, как провожали на пенсию одного из разработчиков (65 лет). Т.е. писать программы можно и в этом возрасте.
С другой стороны по себе замечаю, что в свои 30 я уже не так эффективен, каким был в 25. Т.е. с точки зрения производительности я пока ещё дам фору 25и-летним, а вот с обучением всё уже намного хуже. Например я уже не готов жертвовать сном, чтобы написать какой-то тестовый проект и попробовать новую технологию; семья и дом отнимают бОльшую часть времени вне работы; технологии развиваются очень быстро и даже с моими попытками не отстать, всё равно отстаю. Вон уже Angular2 вышел, а я с Angular 1 ещё дальше простых примеров не продвинулся.
И если в 30 лет всё можно списать на проскатинацию (и начать бороться с ней — притом довольно эффективно), то страшно подумать что будет в 45-50.
Также правда была сказана про «стеклянный потолок». Компаниям не нужны программисты с 15-20 годами опыта, им достаточно 3-5 лет. Т.е. у разработчика с 3-5 годами опыта есть достаточно знаний (притом актуальных), умеренные апетиты в зарплате и лёгкая обучаемость по причине молодости), а то что вы писали 10 лет назад на VB6 или Delphi уже никого не интересует.
Куда же деются 40-летние программисты: мне кажется есть несколько вариантов:
— расти и учиться постоянно и со всё большим усердием, и быть умеренным в зарплате (и оставаться обычным разработчиком)
— уйти в менеджеры или техлиды (но это путь не для всех)
— развивать экспертизу и стремиться и стать уникальным специалистом (но есть шанс, что экспертиза или технология устареет морально)
— учить архитектуру и идти в направлении системного архитектора (их требуется очень мало + обычно растят внутри компании).
Так что разработчики — это как спорт или балет, пока молодой всё красиво и есть шанс заработать, но с возрастом — либо тренером, либо спиться :(
ЗЫ: На самом деле не всё так грустно. Спрос на разработчиков пока ещё огромный, а квалифицированных людей всегда нехватает. Если ваш уровень хотя бы чуть выше среднего, то без работы вы не останетесь…
Спрос на разработчиков пока ещё огромный, а квалифицированных людей всегда нехватает. Если ваш уровень хотя бы чуть выше среднего, то без работы вы не останетесь…
Спрос не превышает предложения и вполне можно остаться без работы с любым уровнем.
Вообще работать 20 лет программистом это скорее исключение из правил, многим уже через 5-10 лет становится понятно, что надо уходить во что-то другое.
Не хватает тех, кто способен думать головой, исследовать, брать ответственность, принимать решения, развиваться и тащить банду обормотов, что бы они не отстрелили себе все подряд :) И биологический возраст тут не важен.
А это скорее не из-за возраста, а из-за опыта. Мой личный опыт показывает, что многие «новейшие» технологии на самом деле сырые и полные костылей и часто находятся на уровне proof-of-concept. Короче смысл перебирать все что модно-молодежно прямо сейчас как-то теряется, потому как время убивает, а серебряной пулей в итоге не становится. Начинаешь понимать медленный энтерпрайз с выверенным стеком устаревших технологий, но работающий. В одной из контор где я работал до сих пор используют программы на фортране, написанные в 90х, а может и раньше.
Иметь представление о новых технологиях нужно. Просто потому, что в один прекрасный день они могут стать мейнстримом, и нужно быть готовым их использовать.
Серьезно, некоторые технологии пока я хотел изучить, но не было времени, успели стать немодными и чуть ли не deprecated. Why bother then?
А раз уж топик про старость, тут тоже есть подвох. С годами мозг всё меньше и меньше формирует новых нейронных связей, всё больше следует ранее проторенным дорожкам. И так как признать свою неполноценность человек неспособен, мозг начинает вырабатывать подобные реакции на абсолютно несознательном уровне, типа «как я раньше делал — единственный правильный путь, все остальные просто глупые и этого не понимают». Если пообщаться со стариками (60-80 лет), слышишь это постоянно, тут и там.
Поэтому критично постоянно изучать что-то новое, развиваться. Даже если это новое кажется не нужно и глупо. Даже если это приходится делать вместо сна и семьи (ну, баланс надо искать). Это единственное что спасает мозг от старения.
Т.е. хвататься за каждый «о, чуваки новую крутую штуку придумали, версия аж 0.2.137, надо срочно пробовать» не стоит, только распыляешь свое время.
То есть изучать все подряд что появляется действительно не очень разумно, но хотя бы знать что это — стоит.
Я это не просто так говорю, мне уже довелось попрыгать по граблям «новейших» технологий прямо в продакшене. Так что теперь я стараюсь выбирать только устоявшиеся решения с какой-никакой базой.
А если оно и в самом деле глупо, и без него производственная задача решается быстрее? И не надо никому сказок при этом рассаказывать, что ты сейчас-вот-вот освоишь и разберешься с очередной херью Jscript-овой вместо того чтобы взять и сделать проект.
А ещё иногда бывает открыл новость о чём-то "новом", и в голове всплывает — "я же это уже видел n лет назад" :)
И не иногда, а очень часто. И чем больше опыта, тем чаще. :(
Вот, скажем, до меня только недавно дошло, что Модная Технология MapReduce, с которой так носятся возбуждённые пионеры, это тупо вариации на тему grep/map блоков, которыми я пользовался в перле в конце 90-х. И которые изобрели ещё чёрти когда вообще, задолго до того, как я до них добрался.
Хы-хы, сказали суровые сибирские мужики и пошли пить пиво.
Маркетинг-с!
Вот, скажем, до меня только недавно дошло, что Модная Технология MapReduce, с которой так носятся возбуждённые пионеры, это тупо вариации на тему grep/map блоков, которыми я пользовался в перле в конце 90-х.Дык. Решаемые задачи похожи, похожи и решения.
MapReduce — это такой способ разбить задачу на три части: две (Map и Reduce) — известные «бизнес-аналитикам» и не требующие от них умения программировать кластеры и связывающая их распределённая сотировка, над которой «ломают голову лучшие умы» — но которая вообще никак не зависит от того, какая задача решается.
grep/map блок — это в точности то же самое, только сортировка там выделена отдельно, не чтобы использовать 100'000 компьютеров в кластере, а мощь языка C, который гораздо быстрее perl'а.
Дык. Решаемые задачи похожи, похожи и решения.
Всё уже украдено до нас. Иногда от этого даже грустно становится. :(
grep/map блок — это в точности то же самое, только сортировка там выделена отдельно, не чтобы использовать 100'000 компьютеров в кластере, а мощь языка C, который гораздо быстрее perl'а.
<зануда="вкл">
В блоке grep { ... } map { ... } сортировка не выделена отдельно, её там вообще нет. Потому что для этого добавляется блок sort { ... }. :) А всё вместе называется Schwartzian transform.
Что касается мощи языка C, который гораздо быстрее Perl, то это тоже не на 100% верно. Во многих задачах перловый код существенно быстрее чисто сишного.
</зануда>
:)
Примеры перолового кода, который быстрее сишного?
Например парсинг текста с помощью регулярных выражений. Перловый regex движок чертовски быстр и чем сложнее выражение, тем заметнее преимущество.
Сравнения можете сами погуглить, если интересно. Во времена оно была популярная тема вполне.
В перле регулярные выражения встроены в синтаксис языка, это не отдельная библиотека, как в PHP или Java. Движок regex написан на C, с блекджеком и макросами. Я конкретно в ту часть не смотрел, но судя по другим кускам кода, без бутылки там не разберёшься и с бодуна такое не напишешь.
Зато перловая программа для поиска шаблонов в тексте скорее всего будет работать быстрее вашей самопальной на C, и чем больше текст и сложнее выражения, тем больше будет разница.
C вообще не лучший выбор для работы со строками, а тем более с большими объёмами строк. Никаких чудес, просто malloc/free, обнуления, копирования, защита от переполнений и ручная работа с UTF-8 будет стоить вам циклов CPU и седых волос задолго до того, как вы вообще доберётесь до регулярных выражений.
А perl для этих задач оптимизировали два десятка лет, пусть даже ценой читабельности кода. Смотреть в него не обязательно, можно просто пользоваться.
C вообще не лучший выбор для работы со строками, а тем более с большими объёмами строкВы, случаем, не из параллельной вселенной, где движки Google и Yandex на Perl'е написаны, нет?
Можно спорить по поводу удобства работы на строками на C (хотя чего там спорить — неудобно), но по-поводу скорости… Вы на цифры-то смотрели? Ну так взгляните: RE2 быстрее perl'а обычно, C'шный grep быстрее на порядок (хотя это и достигнуто за счёт использования более ограниченных регулярных выражений).
Зато перловая программа для поиска шаблонов в тексте скорее всего будет работать быстрее вашей самопальной на C, и чем больше текст и сложнее выражения, тем больше будет разница.Ни разу не очевидно — см. egrep, опять-таки.
Никаких чудес, просто malloc/free, обнуления, копирования, защита от переполнений и ручная работа с UTF-8 будет стоить вам циклов CPU и седых волос задолго до того, как вы вообще доберётесь до регулярных выражений.Опять-таки — это вопросы удобства, а не скорости. Ну так с дуру можно и х@й сломать. А вы, как бы, обещали большую скорость. Ну и где она? Примеры можно, а не абстрактные «махания руками»?
Можно спорить по поводу удобства работы на строками на C (хотя чего там спорить — неудобно), но по-поводу скорости… Вы на цифры-то смотрели? Ну так взгляните: RE2 быстрее perl'а обычно, C'шный grep быстрее на порядок (хотя это и достигнуто за счёт использования более ограниченных регулярных выражений).
Вообще давно уже не смотрел ни на какие сравнения, тем более такие смехотворно притянутые за уши. Ну правда, мизерный набор данных, простейшие шаблоны поиска и сравнение свежих на тот момент библиотек с древним Perl 5.8 разлива 2002 года?
Но вот вы меня заинтриговали. Давайте попробуем. Текстовых файлов, достаточно больших, чтобы дать какую-то заметную разницу на современном железе, у меня не нашлось. Погуглил "sample csv data 2 gb", первая ссылка на эту страницу: https://sdm.lbl.gov/fastbit/data/samples.html (Sample Datasets from STAR Experiment). Я не в курсе, что это за эксперимент, но файл с данными http://sdm.lbl.gov/fastbit/data/star2002-full.csv.gz это текст и 2 GB вполне есть:
~/Downloads/foo$ file star2002-full.csv
star2002-full.csv: ASCII text
~/Downloads/foo$ ls -lh star2002-full.csv
-rw-r--r--@ 1 nohuhu staff 2.0G Mar 29 12:51 star2002-full.csvДавайте сперва попробуем найти много-много строк. Чтобы файловое I/O нам не мешало, мы это на шелл повесим и будем просто читать из stdin и писать в stdout:
~/Downloads/foo$ time egrep ',\s?\-[0-9]+[^.]' < star2002-full.csv > subset1.csv
real 1m19.848s
user 1m16.655s
sys 0m3.134s
~/Downloads/foo$ time perl -n -e '/,\s?\-[0-9]+[^.]/ && print' < star2002-full.csv > subset2.csv
real 0m50.479s
user 0m47.595s
sys 0m2.852sУпс, perl как-то быстрее на 30 секунд, на погрешность не спишешь. Может, мы не то нашли? Да нет, результаты одинакового размера и совпадают:
~/Downloads/foo$ ls -l subset{1,2}.csv
-rw-r--r-- 1 nohuhu staff 1174943004 Mar 29 15:38 subset1.csv
-rw-r--r-- 1 nohuhu staff 1174943004 Mar 29 15:39 subset2.csv
~/Downloads/foo$ diff subset1.csv subset2.csv
~/Downloads/foo$ Но этот эксперимент не совсем про скорость regex движка — совпадений много, писать в stdout тоже пришлось целый гигабайт. Давайте попробуем поискать строку, которой в файле нет; заодно и шаблон поиска чуть усложним (но только чуть, POSIX regex убогий):
~/Downloads/foo$ time egrep '^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$' < star2002-full.csv > subset3.csv
real 1m10.132s
user 1m9.276s
sys 0m0.847s
~/Downloads/foo$ time perl -n -e '/^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$/ && print' < star2002-full.csv > subset4.csv
real 0m6.745s
user 0m6.104s
sys 0m0.638sОй-вей, разница в 10 раз это совсем упс. А точно ничего не нашли? Точно:
~/Downloads/foo$ ls -l subset{3,4}.csv
-rw-r--r-- 1 nohuhu staff 0 Mar 29 15:39 subset3.csv
-rw-r--r-- 1 nohuhu staff 0 Mar 29 15:41 subset4.csvА, да, чуть не забыл. Perl тоже не шибко свежий, системного разлива:
~/Downloads/foo$ perl -v
This is perl 5, version 18, subversion 2 (v5.18.2) built for darwin-thread-multi-2level
(with 2 registered patches, see perl -V for more detail)В общем, вы это… Не трогайте меня за perl, не надо. Знаем, Любим, Ценим. :)
Опять-таки — это вопросы удобства, а не скорости. Ну так с дуру можно и х@й сломать.
Вы сами-то давно работали с Unicode в C? Нудно это и больно. Синьёру не завидно свой сломать, не то, что юниору.
Упс, perl как-то быстрее на 30 секунд, на погрешность не спишешь.Зато можно списать на неумение пользоваться инструментами. Только люди твёрдо уверенные что «grep — это фигня и ничего кроме perl'а в природе нет» не знают, что grep — «сливает» (причём чудовищно «сливает») в UTF-8 режиме. Ничего хорошего в этом нет, но если вы хотите им пользоваться — знать про это необходимо. Ибо если UTF-8 не использовать, то он, как и было написано, зачастую быстрее perl'а.
$ export LC_ALL=C
$ time egrep ',\s?\-[0-9]+[^.]' < star2002-full.csv > subset1.csv
real 0m11.069s
user 0m8.827s
sys 0m1.855s
$ time perl -n -e '/,\s?\-[0-9]+[^.]/ && print' < star2002-full.csv > subset2.csv
real 0m28.601s
user 0m27.093s
sys 0m1.504s
Давайте попробуем поискать строку, которой в файле нет; заодно и шаблон поиска чуть усложним
$ time egrep '^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$' < star2002-full.csv > subset3.csv
real 0m5.380s
user 0m5.046s
sys 0m0.332s
$ time perl -n -e '/^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$/ && print' < star2002-full.csv > subset4.csv
real 0m4.690s
user 0m4.263s
sys 0m0.428s
Но давайте на RE2 посмотрим, что ли?
$ time re2g '^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$' ~/star2002-full.csv > ~/subset1
real 0m4.959s
user 0m4.281s
sys 0m0.677s
$ time re2g '^(?:3|5),.*?,\s+0,\s0+,(?:\s+0,\s+0)?.*\-9{4}$' ~/star2002-full.csv > ~/subset3
real 0m4.676s
user 0m4.178s
sys 0m0.496s
В общем, вы это… Не трогайте меня за perl, не надо. Знаем, Любим, Ценим. :)Знайте, любите и цените — дело ваше. Только если вы умеете пользоваться только perl'ом — то не стоит это выдавать за достоинство.
Вы сами-то давно работали с Unicode в C? Нудно это и больно. Синьёру не завидно свой сломать, не то, что юниору.А с этим, как бы, никто и не спорит. Если бы C/C++ был не только быстрее, но ещё и более удобен, чем всякие Perl'ы и Python'ы — кто бы ими пользовался? Вы же обещали совсем другое:
Во многих задачах перловый код существенно быстрее чисто сишного.Пока что… пшик.
Ибо если UTF-8 не использовать, то он, как и было написано, зачастую быстрее perl'а.
Оба-це-на! Как бы на дворе 2017 год, UTF-8 был изобретён аж 25 лет назад и уже почти 10 лет как перехватил лидерство у однобайтных кодировок в интернетах.
И вот прямо сейчас, на минуточку, мне тут поют песни о том, что семибитный ASCII это, типа, фича? Которой, оказывается, надо уметь пользоваться?
Товарищ, у вас вещества просроченные. Уж 21-й век в разгаре, срочно меняйте дилера!
Нельзя сказать что RE2 выиграла во втором случае, но и проигрыша «выликому, могучему и совершенно непобедимому» perl'у нет, извините.
Про "великий, могучий и совершенно непобедимый" это вы откуда взяли? Не надо мне свои эротические фантазии приписывать.
RE2 как инструмент мне совершенно не интересен. Судя по описанию, это узко заточенный под нужды гугля движок, который не поддерживает большинства возможностей перловых регексов. Ну, скажем, рекурсию я вряд ли когда использую, и даже отсутствие backreferences могу простить. Но без поддержки look(around) это что за движок и чем он лучше тупенького egrep?
В стандартную поставку макоси и CentOS оно не входит; стало быть, в скриптах использовать смысла нет. Так что с чем мы сравниваем сейчас?
А-а-а, нет, мы же не сравниваем, мы за уши притягиваем.
Только если вы умеете пользоваться только perl'ом — то не стоит это выдавать за достоинство.
О, как я люблю этот блистательный дивизион Диванных Военов Интернэта. Кто-то упомянул Ненавистный Проклятый Перл, да ещё и осмелился сделать это в позитивном свете! И, (gasp), даже цифрами подтвердил, негодяй!
Острый Батхёрт, все в Отаку!!11
Для справки: я умею пользоваться разными инструментами и не стесняюсь выбирать их под конкретные задачи и конкретные системы, а что и как вы там себе делаете, мне глубоко фиолетово.
Во многих задачах перловый код существенно быстрее чисто сишного.
Пока что… пшик.
Вы как чукча-читатель уже состоялись в жизни, или ещё в процессе? Прочитайте внимательно мою фразу, которую только что сами же процитировали. Ещё раз прочитайте, подумайте.
Вы просили подтверждений, я привёл два вполне реалистичных примера. Больше не будет, ибо времени жалко. Если результаты нечаянно разбили вашу хрустальную мечту, то это ваши проблемы.
И вот прямо сейчас, на минуточку, мне тут поют песни о том, что семибитный ASCII это, типа, фича?Нет. Фича — это тот факт, что ваш конкретный regexp не требует всех наворотов Юникода и будет корректно обработан в локали C даже притом, что в данных будет Юникод.
Про «великий, могучий и совершенно непобедимый» это вы откуда взяли? Не надо мне свои эротические фантазии приписывать.Вот это вот чьи фантазии:
Перловый regex движок чертовски быстр и чем сложнее выражение, тем заметнее преимущество.
Далее.
RE2 как инструмент мне совершенно не интересен.Очередной «перенос ворот»?
В стандартную поставку макоси и CentOS оно не входит; стало быть, в скриптах использовать смысла нет. Так что с чем мы сравниваем сейчас?С вашими обещаниями, однако:
Во многих задачах перловый код существенно быстрее чисто сишного.
Пока мы видим усиленное махание руками и полнейшую неспособность предоставить работающий пример.
Вы просили подтверждений, я привёл два вполне реалистичных примера.Вы привели два примера в обоих из которых вы неправильно использовали инструменты. Какое это имеет отношение к «во многих задачах перловый код существенно быстрее чисто сишного»? Очевидно что сравнивать имеет смысл только хорошо сделанные вещи! Ибо тот факт что любую программу на любом языке можно замедлить в любое количество раз — сомнений не вызывает.
Да, если вы не умеете пользоваться C и умеете пользоваться perl'ом — так и будет. Ну так это от вас зависит, а не от языка!
P.S. Я отнюдь не утверждаю, что нужно обрабатывать тексты на C — во многих случаях это сложнее и дольше пишется. Но вот чтобы «перловый код был быстрее чисто сишного» — это нужно очень специфический сишный код и очень специфический perl'овый код выбирать…
В перле регулярные выражения встроены в синтаксис языка, это не отдельная библиотека, как в PHP или Java
Да, я знаю. Тот же движок, на самом деле, используется и в php и, вроде, в JS. И его в Си можно использовать, наверное. Просто я не совсем понял, как можно сравнивать движок написаный на Си и просто Си и при чем тут Перл? Ну да, в перле клевый движок используется, но он ведь на Си написан, как этот движок может свидетельствовать о скорости Перла?
Тот же движок, на самом деле, используется и в php и, вроде, в JSВы, наверное, про PCRE? Ну так он только в PHP и используется, у Perl'а и JS — свои движки.
— учить pet-проекты генерировать доход.
— работать удаленно. В интернете никто не знает что ты
— отправить работать жену.
Т.е. с точки зрения производительности я пока ещё дам фору 25и-летним, а вот с обучением всё уже намного хуже. Например я уже не готов жертвовать сном, чтобы написать какой-то тестовый проект и попробовать новую технологию; семья и дом отнимают бОльшую часть времени вне работы; технологии развиваются очень быстро и даже с моими попытками не отстать, всё равно отстаю.
Я случайно для себя нашёл ответ на этот вопрос :) Когда внезапно стал тимлидом. И в должности тимлида стал доступен лайфхак — даёшь задание молодым: «вот тебе мануал по продукту/технологии/протоколу, разберись и через недельну доложи коротенько, стоит с этим возиться или нет». Как минимум — уменьшает время на перебор разных продуктов (подойдёт или не подойдёт, т. к. чтобы это понять — надо посидеть и поразбираться. И когда «не подойдёт», то жалко потраченного времени).
А так все в профите — молодёжь прокачивается, тимлид не тратит своё драгоценное время на фильтрацию технологий, и может сразу начинать разбираться с тем, что реально будет использоваться. Причём не с нуля — молодой-то уже ознакомился с продуктом, и обладает информацией о плюсах и минусах, где брать толковые методички, примеры использования показать и т. п.
Цена ошибки может быть слишком высокой: молодежь при оценке технологии/библиотеки/софта может не учесть важных факторов, не протестировать ее как следует или ошибиться при их оценке. А ваш софт уже будет написан и ответственность ляжет на вас.
А во-вторых — да, указанный вами риск есть. Но от ошибок не застрахован никто, даже ракеты вон падают из-за программерских ошибок.
Тут вступает в дело уже вопрос управления рисками. Если цена ошибки велика — стоит дать задачу на изучение одной и той же технологии двум или более людям независимо, и затем сверить их показания.
А куда, в какую область помимо программирования, еще можно податься, не представляю. Вообще нет идей.
Как-то друг дал девайс чинить. Знаете такие девайсы Lacie (мини-комп с RAID-массивом). Так вот, друг поставил в устаревший Lacie диски больше 3Гб и девайс не забутился, потому что boot был старый и не поддерживал большие диски. Я нашел апдейт и перепрошил, но речь не об этом. Я посмотрел исходники этого boot image, чтобы проверить патч, который эту проблему лечит. Весь имадж 256 кбайт. Но mama mia. Это ассемблер для ARM-процессора Motorola 68000. Что-то мне подсказывает, что я этим не хотел бы заниматься. Там страшный код. Если не сказать большего. Как туда после С++ перейти? Немыслимо.
68000 не является ARM-процессором. И это не какое-то сакральное знание, а здравый смысл в нашей индустрии, сродни «свиньи не летают» (потому что 68000 был в свое время очень популярным процессором, а ARM — современная лидирующая архитектура, неплохо бы специалисту IT отличать одно от другого). Так что «жизнь после C++» есть, да и под 40 может захотеться таки меть более-менее полное представление о своей области, а не так, сумбурно-урывочное.
А если беспокоит проблема стеклянного потолка — так вариантов много. Вот к теме про процессоры — ну забабахайте стартап по производству «мини-компов с RAID-массивом» на RISC-V. Ну разве плохо? Вы когда-нибудь поднимали новую архитектуру? Да, вы прогорите в конце-концов, ну так мы все умрем. Но стеклянный? Потолок?
А насчет этих девайсов я думаю, что это просто выкачка денег из юзеров: за стоимость Lacie, скажем, можно купить куда более мощную старую тачку, чем этот Lacie и в 5 раз более объемные диски. Так что какой там стартап? По обману юзеров? :)
Я понимаю, понимаю, что юзера сами линукса не настроят. Но все же могут привлечь специалиста, не правда ли?
А насчет этих девайсов я думаю, что это просто выкачка денег из юзеров: за стоимость Lacie, скажем, можно купить куда более мощную старую тачку, чем этот Lacie и в 5 раз более объемные диски.Вот только более объёмные диски могут быть не нужны, а разницу между стоимостью Lacie и «куда более мощной старой тачкой» покроют счета за электричество. Если вы живёте в Калифорнии. 18 центов за киловатт-час — это средняя цена, в отдельных местах может быть дороже и заметно дороже.
Я понимаю, понимаю, что юзера сами линукса не настроят. Но все же могут привлечь специалиста, не правда ли?Могут — но это его ещё найти надо. И неизвестно, сколько он за услуги запросит.
> Так что какой там стартап? По обману юзеров? :)
Ну, так вообще грустно жить, ибо любой бизнес можно классифицировать как обман. Вот и сделайте стартап, который будет производить девайс, за цену которого можно купить диски объемнее только в 3 раза. Налицо движение в сторону торжества справедливости, и с ласями всякими можно конкурировать (ну и себя не обидеть).
Наверно, здесь нет универсального решения, но существуют какие-то достаточно очевидные пути, из которых выбираем:
— Работать там, где не уволят (крупная компания, государство и т.п.) Предвижу ухмылки, но тут всё зависит от конкретных мест и обстоятельств, всё может оказаться не так плохо.
— Переходить в тимлиды/мендежеры и проч. Тут штука в том, что на эту должность сложно попасть не пройдя какой-то другой карьерный этап (того же программиста), поэтому среди молодых ребят конкурентов не будет.
— Всё-таки заняться узкой специализацией. Ну право слово, не угонишься за модой. Получали в юности удовольствие от Delphi, ну а почему бы и нет? На наш век Delphi-проектов хватит, даже на Коболе до сих пор программисты требуются. Понятно, что вакансий мало, но нельзя иметь всё и сразу.
Самому мне кажется, что проблема несколько преувеличена. Если совсем упрощать, то опыт конвертируется в более быстрое и качественное решение задач. Да, может, вы не владеете всеми новомодными технологиями, но в итоге ваши решения гибче и содержат меньше багов изначально, что в долгосрочной перспективе важнее.
Если работодатель этого не понимает, ну и к чёрту его. Мой опыт общения с разными людьми за последние годы не слишком позитивен. Желающих работать много, но средний уровень невысок. Если большего и не требуется, тогда да, проблема, но стоит чуть-чуть повысить планку, и уже очень немногие сумеют её взять.
Уверен был, что это будет связано с компьютерами, а чем конкретно – понятия не имел. Даже не был уверен, кем стану: программистом или сисадмином.
Мне 37 и я всё ещё не программист. Да, я кое-как пишу программы, но всё ещё не зарабатываю этим себе на жизнь. Чёрт, я даже не знаю, смогу ли вообще. Что, если нет? Кто сказал, что я доживу хотя бы до 60?
Не об этом я думал, когда в юности гадал, что со мной будет в будущем. А ведь это единственная сфера (как я считал ранее), в которой я могу спокойно ошибаться, а потом исправлять свои ошибки, и ничего плохого из-за моих ошибок не случится. Оказалось, многие мыслят быстрее, безошибочнее, чем я, мгновенно дают ответы, над которыми мне нужно думать неделями. В школе, среди будущих трактористов, я считал себя программистом, а вот уже в институте, среди программистов, я понял, что я тракторист.
Если вы сами не деградируете во всех смыслах к этому возрасту, то я думаю в любом случае это будет лучше, даже учитывая предвзятое отношение работодателей к тем, кому «за».
Не могли бы вы поискать ссылку на эту историю?
И вот тогда, в свои 38 я понял, что и 80 не предел. Дотянуть бы, а там разберемся!
Александр, 42 года
Но есть и такие которые дальше усердно работают на компании либо сами на себя.
Сначала стек. В процессе работы элементы перекладываются в очередь.
https://ru.wikipedia.org/wiki/LIFO
Абстрактный механизм LIFO, применяемый в вычислениях, реализуется в реальных структурах данных в виде стека, название которого совершенно очевидно имеет отношение к «пачке бумаги», «стопке тарелок» и т. п. (англ. stack переводится как «штабель, кипа, стопка»).
А потом… потом я думаю посвящу себя квиркам браузеров. Хорошенько в них закопаюсь… Ох какие квирки, прям жду не дождусь
Даже не был уверен, кем стану: программистом или сисадмином.
И стали программистом. А меня интересует вопрос: «Куда деваются сисадмины после 40?»
— Но молодые специалисты это тоже знают. Почему мы должны платить вам на 15% больше?
— Но у меня семья, дети, ипотека…
Никогда не понимал подобных "причин" для обоснования повышенной по сравнению с другими зарплатой. Правда, обычно, такое характерно как раз для "молодых специалистов": "Я женился и хочу ипотеку — повысьте зарплату". Думал, к 40 годам ко всем приходит понимание, что твои проблемы никого не волнуют, ни за "выслугу лет", ни за "жену и детей" платить никто не будет, если это не явно заявленная политика фирмы. В основном платят за то, что ты можешь делать. Если к 40 годам не можешь сформулировать почему тебе надо хотя бы на 15% больше чем "студенту" платить, то, скорее всего, и не за что.
</zanuda mode off>
Никогда не понимал подобных «причин» для обоснования повышенной по сравнению с другими зарплатой
Никогда не понимал причин, почему надо объяснять свою зарплату относительно других. «Я хочу» — это уже сама по себе достаточная причина хотеть такую зарплату. А платить или нет — это решать работодателю.
понимание, что твои проблемы никого не волнуют
а так же понимание, что и тебя проблемы компании не волнуют. Не хотят платить, сколько ты хочешь? Найдутся те, кто заплатит. Если, конечно, дела обстоят не так, что
платить, то, скорее всего, и не за что
Хотеть можно сколько угодно. Но если приходишь с предложением поднять тебе зарплату до твоих хотелок, особенно если не с нуля (устройство на новое место), а с какого-то уровня, то неплохо бы иметь какое-то обоснование, чтобы разговор получился конструктивным. Заявления типа "хочу миллион долларов в месяц" на плюс-минус обычную вакансию в лучшем случае как шутка воспримутся.
Обоснование может быть только рыночным. Мне сейчас платят X, я сижу на булках ровно и чувствую себя хорошо. Если я вам нужен, давайте X + 15%. Не даёте? Будьте здоровы, не чихайте.
Конечно же, для этого нужно, чтобы компания хотела вашу голову поймать, а не наоборот. Поэтому умение аккуратно обозначить себя как потенциальную добычу для корпоративных браконьеров я считаю одним из наиважнейших soft skills специалиста в любой ценной области.
А если X и есть твоя реальная рыночная цена? Менять работу с рисками разного рода "не сложилось" из-за шанса, что получится развести текущее руководство на +15%? По-моему, за применение очень похожих скиллов есть уголовная ответственность.
Полностью согласен, особенно с пунктом 2, о котором многие вообще не думают почему-то.
Больше одного раза такое не прокатит, ибо после первого руководство будет готово к подобному повороту.Прокатывает и 3 и 5 и 10 раз. Только с одним отличием: нужно не пугать тем, что вы уйдёте, а сходить на пару собеседований и вернуться с реальным предложением от команды куда вы, в принципе, были бы готовы реально уйти.
С некоторой вероятностью вам скажут «скатертью дорога» — и вы, со спокойной душой, уйдёте. Ну и отлично, задача решена.
А если такой компании всё никак не находится — то значит вы и стоите столько стоите, сколько вам платят — и нефиг кого-то шантажировать и расстраивать.
Ну на самом деле «гоните бабло или я ухожу» это проиграшная стратегия.
Это не стратегия, это тактика. Работает она тогда, когда стратегическая ситуация позволяет сделать выигрышный ход.
По поводу пунктов: у вас такой опыт есть или вы теоретически рассуждаете? У меня есть, и он работает. Но только в том случае, если реально готов уйти в другое место и на руках предложение оттуда с конкретными цифрами.
Вы посмотрите на это со стороны вашего начальника: он, может, и не против поднять вам зарплату, но ему ведь тоже какое-то обоснование нужно. Наличие предложения от другой конторы на X + Y% это железобетонный повод пойти к своему начальству и сказать: вот, смотри какой ценный кадр. Даже уходить не хочет, просто денег хочет. Давай удержим.
Я в такой ситуации был с обеих сторон и никаких проблем в этом не вижу. Главное, поменьше эмоций, только бизнес.
Когда я готов уйти, я ухожу. Не вижу смысла требовать больше денег, если уже решил уйти.
Случаи разные бывают. Обычно когда решаешь уйти с работы, то для этого есть определённые причины: платят мало, не устраивает то и сё. А теперь представьте, что начальство предлагает и деньги поднять, и устранить то и сё. Будете срываться нипочему, или подумаете?
У меня были и такие ситуации, и не такие. Всё относительно.
Так как я не практикую подход «башляйте или свалю», то в таких ситуациях я не бывал.
Я не думаю, что кто-либо может практиковать такой подход сколько-нибудь долго. Речь идёт не о том, чтобы выкручивать руки работодателю на ровном месте, а о возможности поднять себе цену путём поисков другой работы. Совершенно разные вещи на мой взгляд.
Во-первых, раз в полгода походить по собеседованиям всегда полезно для понимания трендов на рынке и того, где у вас пробелы в знаниях, а также чтобы не терять навык прохождения собеседований, так что у вас всегда есть (или вот-вот будут) на руках активные предложения.
Дальше, получив предложение, приходим к руководителю и говорим:
Сейчас я получаю X рублей, но мне дали оффер на 30% больше. Это меня расстраивает, я чувствую себя недооцененным в нашей компании, так что, если есть возможность, я бы хотел получить повышение зп, или бонус, или акции, или что угодно еще. Это не шантаж, если ответ будет «нет», я не уйду и приложу все усилия к тому, чтобы и дальше работать продуктивно, но, сам понимаешь, это все будет меня демотивировать.На моей практике никто ни разу не отказал и потом никаких козней не строил.
Разумеется, это текст для случая, если уходить не хочешь. Если хочешь уходить — стоит сразу об этом сказать, но дать возможность обсудить варианты твоего удержания, просто из лояльности и уважения к текущему работодателю.
Мы с вами о разных рынках разговариваем? Рыночная цена === сколько платят или сколько готовы платить в другом месте. Если платят X, а хочется Y, то поди найди, где будут платить Y. Если найдётся и контракт на подписи, значит рыночная цена — Y. А если нет, то X. Чудес не бывает.
А вот что делать, когда контракт уже на подписи — бежать или пытаться добиться повышения на текущем месте, это уже вопрос растяжимый.
По-моему, за применение очень похожих скиллов есть уголовная ответственность.
Ага, ещё есть томные грёзы работодателей добавить в УК статью за попытку уйти с текущего места. Даёшь крепостное право обратно в массы! Это для их же пользы!
Я не про ситуацию, когда есть на руках конкретное предложение, а когда приходишь и говоришь "мне предложили +100%, давайте столько же или я уйду", прекрасно понимая что на рынке вряд ли получишь хотя бы +10%.
Я таким манером никогда не блефую, потому что риск велик и надо быть готовым к тому, что тебе откажут. А если откажут и останешься, то всем станет понятно, что это был блеф, и в следующий раз можно вопрос даже не задавать.
Переговоры надо вести с сильной позиции, когда готов и уйти на повышение, и остаться на повышение. Искусство стратега не в том, чтобы найти путь к победе, а в том, чтобы все пути так или иначе вели к победе. :)
Поэтому умение аккуратно обозначить себя как потенциальную добычу для корпоративных браконьеров я считаю одним из наиважнейших soft skills специалиста в любой ценной области.
Да на любом конкурентном рынке умение продать важнее всего остального. Пусть даже продать себя потенциальным работодателям. Сегодня этот скилл действительно должен быть основным, если хочется карьеру программиста, конкуренция огромная. Как бонус, это избавит и от пузырьковых сортировок, ну и сама тема пиара и маркетинга должна быть интересна программистам.
А вот по поводу рыночного обоснования, если это не аутстаф и аутсорс, то компаниям все-таки выгодно удерживать работников как можно дольше. И они вполне могут платить гораздо выше рыночных денег тем, кто будет за это бороться. Опять же, все в руках работника, soft skills и все остальное.
И они вполне могут платить гораздо выше рыночных денег тем, кто будет за это бороться.
Никто никогда не будет платить выше рынка, в том-то и фикус. Рынок это конкурентная среда, баланс спроса и предложения. У меня есть предложение, у работодателей есть спрос.
Если я приду к начальству и скажу: хочу +10% к зарплате, это не даст результата. Если я приду и скажу: у меня на руках job offer от другой конторы, они дают мне +15%, это даст результат. Потому что конкуренция за ресурс (мою голову). И результатом этой конкуренции является рыночная цена в +15%.
Т.е. это не другая компания хочет платить выше рынка, это текущая платит ниже рынка. Почему так, это уже другой вопрос: могли недоплачивать изначально, или просто рынок вырос, а зарплата нет.
Многие люди сидят годами на одном месте и с одной зарплатой, в лучшем случае индексированной. Это нормально. Другие люди пытаются найти свою цену на рынке и меняют работодателей, как перчатки. Это тоже нормально.
Никто никогда не будет платить выше рынка, в том-то и фикусЧеткого рынка не существует в принципе, вот в чем фокус.
Кого-то контора наняла когда ей остро нужен был сотрудник и переплатила 20%, теперь фиг понизишь. Кого-то контора наняла когда ему остро нужна была работа и недоплачивает 20% и будет недоплачивать, т.к. уйдет этот — придет другой, вакансия не критична. Кто-то согласился на 20% зарплату ниже потому что компания ближе к дому на 2 часа. Кому-то заплатили на 20% выше потому что мало кандидатур согласных ездить 2 часа к ним в офис в е-ня.
Рынок — миф. Для средней квалификации разброс в 30% в зарплате норма. Чем выше квалификация — тем меньше вакансий и специалистов — тем больше разброс.
Это и есть рынок, просто в нём не 2 измерения как в упрощённой модели а гораздо больше.
Рынок — миф. Для средней квалификации разброс в 30% в зарплате норма. Чем выше квалификация — тем меньше вакансий и специалистов — тем больше разброс.
Это и есть рынок, я Вам как обладатель учёной степени Магистра по Экономике, говорю. Просто в данном случае он не насыщен, и потому Вы наблюдаете такую картину. Насыщенный — это то когда очень много работодателей и очень много работников, как например, в случае каких-нибудь продавцов шаурмы, в этом случае зарплаты примерно уравниваются.
Никогда не понимал подобных «причин» для обоснования повышенной по сравнению с другими зарплатой.. Думал, к 40 годам ко всем приходит понимание, что твои проблемы никого не волнуют, ни за «выслугу лет», ни за «жену и детей» платить никто не будет, если это не явно заявленная политика фирмы. В основном платят за то, что ты можешь делать.Это потому что Вы со стороны руководителя на это не смотрели. Платят еще и за надежность.
-хочу на 15% больше.
-почему?
-я не сменю работу, доведу проект до конца, буду стабилен
-с чего бы?
-у меня дети, ипотека, куда я денусь — надо пахать.
В упомянутом Вами сценарии 3 и 4 фраза пропущены как самоочевидные обоим сторонам. Обременения и платежи подразумевают что человек не забьет на все и не слиняет за лишней пару рублей или обещания карьеры.
Мы как-то фрилансера нанимали молодого, через месяц после работы над проектом пропал, появился через месяц с шикарной отмазой (цитируем по памяти) «ну лето, пиво, расслабился, решил отдохнуть, живу у мамы, кормит сестра, чего мне у тебя на проекте ж-пу рвать, другой найду»©
Как по мне, то требование повысить зарплату на 15% из-за "-у меня дети, ипотека, куда я денусь" — первый звоночек что не откажется от ещё +15% в другом месте. Собственно сам такой по большому счёту. Когда один, то размер зарплаты после какого-то уровня — дело десятое. Когда семья, у которой, как правило есть неудовлетворенные материальные потребности из-за ограниченного бюджета, да ещё под гнетом платежей типа ипотечных, то несколько по другому смотришь даже на +5%. Грубо, если я получаю N на текущем месте и знаю, что N мне заплатят "где угодно", то предложение N+5% буду рассматривать серьезно, в случае наличия долгосрочных обязательств.
первый звоночек что не откажется от ещё +15% в другом месте.Может да, может нет. Но если ипотечника будет удерживать необходимость стабильности, то не ипотечника она удерживать не будет.
Когда семья, у которой, как правило есть неудовлетворенные материальные потребности из-за ограниченного бюджета, да ещё под гнетом платежей типа ипотечных, то несколько по другому смотришь даже на +5%.И по другому смотришь на вероятность потерять 100% на неизвестный срок.
У Вас ипотека-то есть?:) Можно ужать расходы на еду, на транспорт, даже на пиво в конце концов. Но ипотечный платеж — это то что надо выкладывать каждый месяц и риск потери этой возможности — не стоит ни 5%, ни 15%, ни даже 30% прибавки.
Но ипотечник гораздо больше заинтересован в увеличении дохода, чем неипотечник.
Вероятность потерять 100% на заметный срок для нормального специалиста практически равна вероятности погибнуть или получить серьёзную инвалидность. Уже нет, в том числе благодаря условным "+15% на старом месте и +15% на новом".
Но ипотечник гораздо больше заинтересован в увеличении дохода, чем неипотечник.У ипотечника приоритеты «стабильность — доход», у неипотечника «доход- что-то еще, что-то еще — стабильность». В этом суть.
Но даже если принять Вашу точку зрения, то получится то же самое в результате. Если ипотечник больше заинтересован в увеличении дохода, значит если ему не повысить доход, то есть риск его ухода, а значит для сохранения кадра доход придется повысить. Поэтому и аргументируют ипотекой. Мы с этим не согласны, но логически это верно.
Как вы например относитесь к аргументации — предлагают +25%, так как зарплаты на рынке выросли, а отказываться не хочется, так как ипотека? :)
Моя точка зрения: ипотека, жена и дети не должны влиять на принятие решения о приёме на работу и(или) повышении зарплаты. Второй вариант — должны влиять отрицательно, если кандидат/сотрудник об этом сообщает как о причине почему его нужно брать или повышать ему зарплату. Исключение разве что готовность ему платить выше рынка, чтобы он понимал, что большей зарплаты он нигде не получит.
Ипотека, это такой же признак как женат не женат, негр или латинос, знает урду или нет. Да, не зная подоплеки нельзя сказать, почему человеку с взявшему черную ручку, а не синюю дали зарплату на 5% выше, при той же видимой пользе для компании.
Но факт есть факт, человек с ипотекой более стабилен, а бОльшая стабильность работника это тоже актив за который можно заплатить.
Это ваше мнение. У нас в компании в общем случае ипотека является минусом, поскольку, как показывает практика, человек с ипотекой более чувствителен к предложениям с зарплатой выше текущей, а платить выше рынка мы не готовы.
Во многих странах за попытку выяснить на собеседовании, есть ли у меня жена, дети, негр ли я с марса или мусульманин с ипотекой, я смогу засудить компанию к чёртовой матери. На кучу денег. Потому что дискриминация нелегальна.
Похоже, в России есть ещё над чем работать законодателям.
А в России некоторым работодателям для этого даже не нужно ничего спрашивать — сами найдут всю информацию.
Вот я и говорю: есть ещё над чем поработать депутатам госдумы, чтобы искоренить этот произвол.
Тут ведь неважно, спрашивают, находят или сам расскажешь. Учитывать эту информацию нельзя по-любому.
Тут ведь неважно, спрашивают, находят или сам расскажешь. Учитывать эту информацию нельзя по-любому.Напротив, ее необходимо учитывать.
Сначала компания собирает коллектив из несовместимых людей (потому что нельзя спрашивать об индивидуальных особенностях), а потом они выбрасываются из окон (не выдержав напряжения).
Гениально, блин.
Напротив, ее необходимо учитывать.
Каким образом? Кто-то дал лично вам особое разрешение на то, чтобы судить людей по их обстоятельствам?
Сначала компания собирает коллектив из несовместимых людей (потому что нельзя спрашивать об индивидуальных особенностях), а потом они выбрасываются из окон (не выдержав напряжения).
У вас на производстве много было таких несчастных случаев? У меня не было ни разу. Конфликты были, несовместимости были, приходилось увольнять людей или самому увольняться. Это рынок, он так работает. В чём проблема?
Мы же не о женитьбе тут разговариваем, а о производственных отношениях. Не надо драматизировать.
Каким образом?Про Big Data слышали?
В америке есть анекдот.
Человек идет по улице и падает в открытый люк, потом в другой, потом в третий. Кто он? Борец за права дорожных люков. Ему нельзя дискриминировать дорожные люки по признаку их открытия.
Кто-то дал лично вам особое разрешение на то, чтобы судить людей по их обстоятельствам?Наука. Эволюция. Опыт.
Нам правда не хочется на полном серьезе обсуждать обиженного 300 фунтового 70 летнего деда выигравшего суд против стрип-клуба barely legal teens, когда ему отказали узнав о весе и возрасте и поле. Это настолько махровая фигня, что мы уже давно на это не ведемся, так что не прокатит — идите на фиг:)
Это рынок, он так работает. В чём проблема?Проблема в том, что Вы на рынке пытаетесь ставить во главу угла «как бы кого не обидеть», а не «как бы сделать бизнес успешным».
Эдак завтра Вы запретите спрашивать информацию об образовании и опыте и знаниях, т.к. «а кто сказал что человек без всего этого будет хуже работать»? А вдруг будет? Случаи-то бывали, когда человек с улицы работал лучше чем образованный профи с опытом. Так что теперь — и это запретить спрашивать? В маразм не впадайте.
Про Big Data слышали?
Слышал много шума из ничего. Каким образом это относится к обсуждаемой теме дискриминации при приёме на работу?
В америке есть анекдот.
Сколько лет здесь живу, анекдота не слышал. Это очередное из разряда "мы тут придумали, чтобы поржать с поцонами?"
Наука. Эволюция. Опыт.
Правая рука ещё не дёргается в попытках изобразить зиг хайль?
Проблема в том, что Вы на рынке пытаетесь ставить во главу угла «как бы кого не обидеть», а не «как бы сделать бизнес успешным».
Я не вижу, каким образом запрет дискриминации помешал бы делать бизнес успешным, а вот наборот — легко. Подумайте, поймёте.
Эдак завтра Вы запретите спрашивать информацию об образовании и опыте и знаниях,
У вас юношеский максимализм ещё не отбулькал, или просто врождённая страсть всё доводить до абсурда? Именно об этом речь и шла: когда вам нужно делать работу, то вас должна интересовать способность человека выполнить эту работу: квалификация, опыт, и т.д. А возраст, наличие семьи и финансовые обстоятельства к работе отношения не имеют.
В маразм не впадайте.
То-то я смотрю, экономика впавших в маразм стран растёт хорошими темпами, спрос на специалистов тоже. И зарплаты подтягиваются. И никакой дискриминации, потому что законы такие, а за несоблюдение законов могут засудить нафиг. И оштрафуют ещё потом, чтобы неповадно было.
А у вас как? Маразма не подвезли ещё? Ну, вы держитесь там. Добра и всего хорошего.
Если живёте здесь, то поймёте, что это at-will employment в абсолюте без соответствующего билля о правах.
Я не знаю, где именно вы имеете в виду под словом "здесь". Я в Калифорнии живу, и работаю на калифорнийскую же компанию. Для меня at-will employment означает, что я могу уйти в любой момент, или меня могут уволить в любой момент без объяснения причин. Чем это отличается от ситуации в России? Я там давно не работаю, за изменениями в ТК не слежу.
Лично я предпочитаю называть это методом доказательства от противного.
Доказательство "от противного" возможно, если есть чётко определённая противоположность. В математике это бывает, в жизни не всегда.
В России вас уйти при отсутствии вашего на то желания не могут.
Прогулы, пьянство и прочее служебное несоответствие уже отменили? Чудны дела творятся.
Мне вот интересно, как люди вообще живут, не применяя формальный метод к жизни?
Очень неплохо, спасибо. Пожаловаться особо не на что.
работника, хорошо исполняющего свои рабочие обязанности, а не прогуливающего и пьющего
Что хоть и затруднит его обвинение, но все же до конца не помешает. Я не готов говорить о странах кроме России, но с учетом того что люди везде более-менее одинаковые и способны найти дырку в любой системе, то если работника очень захотят уволить, то скорее всего возможность найдется. От страны зависит только количество необходимых для этого усилий и, следовательно, сила желания уволить.
— Чем это отличается от ситуации в России?
— Я там давно не работаю, за изменениями в ТК не слежу. В России вас уйти при отсутствии вашего на то желания не могут. Хотя я тоже уже пару лет не слежу.
Это что, размышления евреев, неспешно пьющих немецкое пиво на отдыхе в Гоа и постоянно проживающих в Англии о судьбе рынка труда в России?
Вместо ответа по сути сообщения весь Ваш пост — переходы на личности.
Потрясающая иллюстрация Вашего лицемерия, после Ваших лозунгов «личность человека не важна, важны результаты его деятельности».
Дело не в том, что мне не нравится. Дело в том, что такие вопросы задавать запрещено законом там, где я живу и работаю. И вне зависимости от того, нравятся ли эти законы моему работодателю, он их соблюдает. Потому что если не будет, то это очень-очень чревато. Нет, не уголовной отвественностью, а просто кучу денег будет стоить.
Лично мне такие законы нравятся, потому как защищают мои права от ущемления работодателем. И ещё многие законы нравятся, и другие штуки, поэтому я здесь и живу. Законы и другие штуки в России мне не нравились, поэтому я там больше не живу.
А вы живите там, где вам нравится. На то он и свободный рынок, правда?
Вы, конечно, молодец, но возьмут средний ответ по вашему возрасту-полу.
Гадать на кофейной гуще законом не запрещено, да и незачем. Речь ведь не о том, чтобы нельзя было оценивать потенциальных кандидатов, а о том, чтобы нельзя было оценивать их на основании конфиденциальной информации, которая не имеет отношения к рабочему процессу.
Кстати, а как вы угадаете мой возраст по телефонному интервью? У вас модуль телепатии так тонко настроен? Круто, завидую.
Моё мнение — чем раньше мы с работодателем поймём, подходим ли мы друг другу или нет, тем лучше для всех.
Вы жениться собираетесь или делать работу за деньги? Зачем так драматизировать? Не подойдёте, уволитесь и уйдёте в другое место.
Did you just assume my country?
Читайте внимательнее написанное, не гадайте между строк. Речь шла о дискриминации при приёме на работу, которая по эту сторону лужи запрещена законом, а по ту… честно, не знаю. Мне здесь больше нравится, а где нравится вам — это исключительно ваше дело.
Можно спорить до посинения… но это не так.
Обожаю категоричные утверждения без малейшего намёка на обоснование. Моментально повышает статус собеседника, он ведь без сомнений точно знает, о чём говорит.
Потому что если я сижу допоздна на работу
Если вы сидите на работе допоздна, это говорит о вашем неумении сделать свою работу в отведённое для неё время. Более ни о чём.
потому, что у меня спиногрызы и ипотека
а) Ипотека это норма, а не исключение, перестаньте уже к ней цепляться. Я свою первую квартиру покупал в 2003, к тому моменту ипотечные кредиты уже давно перестали быть новостью.
б) Судя по использованию слова "спиногрызы", детей у вас либо нет, либо они для вас обуза. Не надо судить людей по себе. Да и вообще судить людей это плохая идея.
У меня трое, и я с гораздо большим удовольствием проведу время с ними и женой, вместо того, чтобы пялиться в говнокод с утра до вечера.
Ну, у вас в резюме же есть прошлые места работ?
А вы чем-то таким особо специальны, чтобы иметь доступ к моему резюме на этапе телефонного интервью? За последние 6 лет я проходил несколько собеседований, и везде резюме просили уже на последнем этапе, "ну так, надо глянуть".
На текущем месте работы даже интервью толком не было. Просто посмотрели на мой код на гитхабе и предложили две позиции на выбор.
Если у меня семья и ипотека, то в гробу я видал всех этих задротов
Судя по всему, у вас нет ни того, ни другого. О чём мы разговариваем?
то чувак, которому за что не плочено, то не интересно, и который в столовке обсуждает свой быт и выходные с семьёй, а не прочитанные книги, тоже не располагает меня к себе.
Посмотрите в зеркало, пристально. Различаете на лбу третий глаз и огненную надпись "я велик и интересен любому чуваку"? Нет? Какая жалость.
Давайте сначала действительно разберёмся с дискриминацией людей без высшего образования
С такой дискриминацией я лично сталкивался только на собеседовании в Yahoo!, куда меня знакомый тащил за руку. У меня нет высшего образования и я этого не скрываю, но вопрос об этом был почему-то задан на самом последнем этапе, уже перед выставлением job offer. Услышав честный ответ, Yahoo! скисло и мне стало понятно, что работать там не стоит при любом раскладе.
А кроме говноконтор типа Yahoo! и Google, где ценится бумажка, есть ещё много других компаний. Страна большая, работы хватит.
а потом продолжим эту тему, как смотрите?
Можно и не продолжать, мне с вами скучно.
Если вы сидите на работе допоздна, это говорит о вашем неумении сделать свою работу в отведённое для неё время. Более ни о чём.
Бывает, что человеку тупо нечем заняться в свободное время. Видел трёх особ женского пола, которые зависали на работе до поздней ночи, а затем в выходные приходили поработать, просто тупо потому что дома их никто не ждёт.
А бывает, что у человека какие-то другие проблемы. Видел мужика, у которого какие-то не лады в семье, и потому он до поздней ночи торчит на работе. Ещё один рассказывал, что он будучи джуниором… жил на работе круглосуточно, чтобы сэкономить на оплате арендного жилья.
Всё бывает, я сам когда-то жил на рабочем месте пару недель, потому что негде было.
Но мы же о работе говорим, которую люди делают за деньги? Если человек сидит на рабочем месте в рабочее время, это ещё не означает, что он работает. Если человек сидит на рабочем месте в нерабочее время и работает, это означает, что человек не умеет планировать свою работу и скорее всего отдыхать тоже не умеет.
Отдыхать и отключаться от работы необходимо всем, выгорание это реальная и большая проблема в любом возрасте, просто выражается по-разному. Когда молод, считаешь себя суперменом и работаешь сутками напролёт. Мой личный рекорд — 70 часов на ногах, потом не помню.
Результаты, правда, одинаково плохие в любом возрасте и переделывать приходится в любом случае. Поэтому людей, сидящих на работе по вечерам и выходным, я восприму скорее негативно, как не умеющих организовать свою работу и досуг. Исключения бывают, конечно, но правилом становиться не должны.
Один коллега по бывшему цеху любил фразу: Plan your work. Work your plan. В ней есть сермяжная мудрость.
А как надо уметь отдыхать-то? Что после работы правильно делать?
Моя практика показывает, что лучше всего заниматься чем-нибудь, отвлечённым от компьютеров вообще. Я вот на днях фрезер прикупил, в выходные возьму старшего сына в охапку и пойдём в какаш(*) ящички для верстака строгать. А до этого кофемашину починял, забавная штука оказалась. Унутре у неё неонка и булькатель.
Если я прихожу домой, часик туплю, а потом сажусь за хобби-проект, или за книги, или что-то такое, это норм или не норм и я скоро выгорю и умру?
Не умрёте, не надейтесь. :) Книги хорошо, кино хорошо, музыка, что угодно, кроме компьютеров, планшетов и прочей электронной папоры. Интернет это зло, особливо в нерабочее время.
(*) "Какаш" это в переводе со слов среднего, "гараж". Но там обычно как раз какаш, сколько ни прибирайся. :(
так зачем оставлять эту ремарку?
Не глумленья ради, но сарказма для. Вы делаете спорное утверждение по вопросу, на который вообще нет верных ответов, совершенно безапелляционным тоном. И рассчитываете при этом, что вам за это ничего не прилетит в ответ? Не-не, на такое я пойтить никак не могу.
Или я сделал свою работу и занимаюсь теперь своей инициативой, чтобы через пару недель показать начальству прототип ИИ на хаскеле, который нас всех зохавает.
А вот с такими штуками рекомендую быть очень осторожным, особенно если вы работаете в каком-либо из соединённых штатов. Даже таком продвинутом в плане ТК, как Калифорния.
Вы в курсе, что код, написанный на рабочем лаптопе, или даже просто находясь в офисе в нерабочее время, принадлежит компании? И распоряжаться этим кодом может только компания?
Т.е. даже если вы слабали мелкую утилитку и без спроса выложили её на гитхаб под GPL лицензией, это уже может считаться причинением ущерба интересам компании. Тому есть судебные прецеденты.
И от чистого сердца колдую: вам очень-очень не хочется узнать, что такое судебный иск на миллион долларов в ваше честное, открытое физическое лицо.
Или ныкаюсь от жены и детей.
Или ныкаюсь от гнетущей пустоты холостяцкого дома.
Да мало ли.
Если бы я был вашим начальником, то мне было бы совершенно всё равно, от кого вы ныкаетесь, это ваши половые сложности. Зато мне был бы совершенно не пофигу сам факт вашего нахождения на рабочем месте в неположенное время. Потому что если, скажем, вы налабали свой прототип ИИ и он таки всех зохавал, то прилетит за это нарушение ТК мне. Или вы потребуете чего-нибудь за свой прототип, чтобы он не зохавал, тоже разбираться мне. Или даже просто премии попросите за переработку, оно мне надо?
Не говоря уже о потенциальных нарушениях режима доступа к информации, буде таковой наличествует. И о многих ещё других штуках, о которых вы, как простой наёмный инженегр, понятия не имеете и не думаете. В мелких говностартапах всем пофигу, потому что до проверки DOL они как правило не доживают. В более крупных компаниях вам таких вольностей не увидеть.
Но речь-то, обратите внимание, не о вас, а о конфликте интересов, непонимании поколений и всяком таком.
Нет никакого конфликта интересов и быть не может. Вы почему-то исходите из неверной посылки, что ваш внутренний мир кому-то интересен и до вас кому-то есть дело.
Вы работу делаете? Деньги за неё получаете? Далее свободны.
А как вы туда попадаете? Одним гитхабом, что ли?
Да фих его знает, "шамо приполжло". Сколько ни отбивайся, всё равно стучатся постоянно. Иногда даже дельно.
В моём гитхабе коммиты примерно с 2007-го. Можно предположить, что мне не меньше 25, а скорее — лет 30 (на самом деле таки 25).
А на моём гитхабе коммиты с 2011, потому что до этого я пользовался локальными Subversion, а ещё раньше локальными CVS. А в программерском резюме опыт трудоустройства начинается с 2012, потому что до этого я занимался совершенно другими штуками.
Давайте, вычисляйте мой возраст.
О том, что вы меня не поймёте, а я — вас.
В свои 25 я тоже так думал. Знаете, почему люди старше вас обычно с вами не спорят? Потому что скучно и времени жалко. Плавали, знаем. Были точно такими же балбесами и думали точно такие же мысли. Со временем они надоедают.
Но только, если не секрет, вы в какой области работаете?
Жабаскрипт лабаю, будь он неладен. В печёнках уже сидит, но кормят хорошо, поэтому каторгу приходится терпеть.
Однако, опыт показывает, что наличие образования таки немножечко расширяет перспективы как само по себе (если не заборостроительный кончать, конечно), так и за счёт формальных критериев, как бы это ни было печально.
Образование !== диплому, а перспективы вполне расширяет умение решать задачи, которые никто больше не может решить, в сроки, которые никто больше не может обеспечить.
Последняя попытка зохавать мою голову в Москве исходила от маленькой международной компании с миллиардной капитализацией, и предлагали они, по странному совпадению, тоже 100к. Только не рублей в месяц, а долларов в год. Я отказался, потому что виза уже была в кармане и одна нога на тёмной стороне.
Вы в курсе, что код, написанный на рабочем лаптопе, или даже просто находясь в офисе в нерабочее время, принадлежит компании? И распоряжаться этим кодом может только компания?
Вы в курсе, что в РФ всем на это положить? Доказательства возьмите у Сысоева.
Вы в курсе, что в РФ всем на это положить? Доказательства возьмите у Сысоева.
Я отлично в курсе, что в РФ многим положить на многое, а некоторым вообще на всё. Это одна из причин, почему я там не живу.
Какого Сысоева вы имеете в виду, я не в курсе. Фамилия распространённая, сам знаю нескольких Сысоевых.
А вышенаписанный абзац относился в основном не к РФ, цитирую:
особенно если вы работаете в каком-либо из соединённых штатов.
И да, я рад, что вам занятно меня читать. Развлекаться, так вместе. :)
А вы точно со мной спорите?
Я с вами даже не спорю, в данном случае просто советую. Опять же исходя из личного опыта.
А то я ведь сказал, что показать начальству. Не гитхабу, не всему миру, не инвесторам на питче под маркетинг лин стартап смузи, а начальству. Чтобы потом это использовать в работе, очевидно.
Если ваше начальство это директор конторы и он(а) хороший человек, то вполне прокатит. А бывают и другие случаи: когда начальник-то может и хороший парень, но есть ещё CEO, инвесторы и другие заинтересованные лица. И можно оказаться крайним, даже если ничего такого вроде не делал.
У адвокатов логика очень особенная, инженерам её понять очень трудно. Просто я на это уже напарывался, а вы ещё нет. Хорошо, если и не придётся.
За какое такое нарушение ТК в США?
В США есть National Labor Code, и у штатов может быть свой локальный. В Калифорнии весьма продвинутый по сравнению, скажем, с Техасом. Всех подробностей я не знаю, т.к. labor law в мои интересы до сих пор входил только очень умеренно.
Я не знаю про Калифорнию конкретно, но вроде как в остальных штатах закон не запрещает вам хоть круглые сутки на работе сидеть.
Кроме прямых запретов, бывают другие соображения. Пример: вы сидите на рабочем месте поздно ночью, лабаете свой ИИ. У вас начинает болеть спина из-за неудобного стула. День болит, месяц болит, вы идёте к врачу. Врач вам говорит: поздравляю, у вас искривление позвоночника, нужна операция стоимостью $чуть-более-чем-дохрена. Вы идёте в суд и подаёте иск на компанию, требуя компенсации прямого ущерба в виде стоимости операции + моральный ущерб + всё, что придумает ваш адвокат.
Установить, заболела ли у вас спина в результате нарушения правил OSHA или это с работой не связано, кто должен оплачивать операцию и прочие обстоятельства сможет только суд. Чтобы дойти до суда, понадобится в лучшем случае пара лет + Очень Дохрена Денег на адвокатов. Или можно просто выплатить вам компенсацию в $сколько-нибудь, чтобы покрыть операцию и на пиво с чипсами осталось, попутно подписав бумаги о том, что вы больше претензий не имеете.
В любом случае компания в проигрыше. А как можно этого избежать? Проще всего — выгнать вас нафиг с рабочего места после окончания смены.
Потому что если у вас спина разболелась дома, это уже ваши проблемы.
Потребую — откажете — я сделаю выводы, вы сделаете выводы, в чём проблема?
См. выше. Судебные иски это очень дорого и больно.
И который возможен только в нерабочее время?
Если вы нарушаете режим доступа к информации в рабочее время, виноваты вы. Если это случается в нерабочее время, то виноваты вы за нарушение + ваш начальник, который допустил возможность нарушения режима.
Я исхожу из того, что, к сожалению, я человек, а не машина, и работаю с людьми, а не машинами, и эмоциональное состояние влияет на отношения с окружающими, удовольствие от работы, производительность и вот это всё.
Совершенно необязательно поддерживать запанибратские отношения с коллегами. Быть вежливым и хорошо выполнять свою работу обычно бывает достаточно. Вы попробуйте, у вас получится.
Окей, конкретно с вами будет сложнее. Но в среднем такой метод вполне прокатывает.
Это у вас профессиональная деформация такая, всех усреднять? :)
Это объясняет, спасибо.
А я пишу околоматанный код на плюсах и на хаскеле. Такие дела.
Очень рад, что моё признание в интимной близости с JavaScript позволило вам слегка самоутвердиться и почувствовать себя чуточку круче меня. Мне это ничего не стоило, а вам приятно. :)
Приведёте, любопытства ради, пару примеров таковых задач из вашей практики?
Пару не приведу, долго писать. Вот один:
Конец 2005 года, небольшой московский провайдер домашнего интернета недавно куплен амбициозными инвесторами и имеет наполеоновские планы по зохаванию рынка в Москве. Им нужен колл-центр для поддержки абонентов. В тендере участвуют зубры рынка и мы — тоже свежесозданный интегратор-стартап с инженерным подразделением из одного меня.
Тендер проходит в конце сентября, колл-центр должен заработать 1 января. Конец года, оборудование ползёт через таможню долго, никто не хочет гарантировать сроки. Кроме нас, рисковых парней и девчонок с хорошими связями в дистрибьюторах.
CTO провайдера, один из первых CCIE в России, звонит мне и честно говорит: ваше решение на базе вендора A мне совершенно не нравится, но Cisco утверждает, что в сроки уложиться вообще нереально. Я, говорит, пообещал владельцам, что 1 января колл-центр будет работать. Если ты мне дашь своё личное слово, что он заработает, то мы выберем вас. Я говорю: 100% функциональности не обещаю, но звонки пойдут и операторы смогут работать, это гарантия.
Мы каким-то чудом выигрываем тендер, размещаем заказ. Я уже говорил, что это была чуточку лотерея? Ну, мы победители по жизни, и минимально нужная часть оборудования прошла таможню и была доставлена на объект вечером 26 декабря. Первая очередь внедрения была рассчитана на 100 операторских мест, обычно это две недели работы. Я вышел из их помещения в 4:30 утра 30-го декабря, когда мы прогнали тестовые звонки и убедились, что всё работает.
Я отлично помню дату и время, потому что когда вышел на улицу, обнаружил, что кто-то заблокировал мою машину между сугробом и немаленьким мусорным контейнером. Видимо, в спешке я как-то неудачно припарковался и занял чьё-то место, на что мне любезно указали перед уходом на новогодние каникулы. 30-е декабря, 4:30 утра, промзона на юге Москвы… А мне домой в Королёв… Машину я всё-таки вытащил из сугроба враскачку, 4x4 и хорошая резина творят чудеса. Особенно когда больше суток на ногах и все чувства обострены лёгким ночным морозцем. :)
1-го января мне позвонил CTO провайдера и сказал, что он лично проверил переключение на новое оборудование, всё прошло штатно и новый колл-центр уже принимает звонки. Клиенты довольны, владельцы провайдера тоже, всем спасибо.
Эти ребята несколько лет оставались нашими клиентами, мы с ними весьма интересные проекты делали. Колл-центр за это время вырос до 1100 или 1200 мест (точно не помню), а потом этого провайдера купил большой пчелиный опсос и нас оттуда выдавили, потому что политика.
С релокейшном или прям в Москве столько платить готовы были?
В Москве конечно, 100к зарплата + соцпакет + всякие плюшки типа корпоративной машины и проч. Плюс, тут надо специфику рынка понимать — позицию мне предлагали очень вкусную, в плане перспектив всяких разных, в т.ч. финансовых. Даже оставаясь в рамках закона можно было иметь очень некислую прибавку к пенсии, а уж если плюнуть и как все...
Но всё это в Москве, а я уже был одной ногой "там". Если б речь шла о потенциальном переезде куда-нибудь, я б ещё три раза подумал, перед тем как отказаться. Да если честно, и так думал целую неделю. И отказался.
На презентации оракла было неплохо показано как не только возраст выяснять, но и то что на днях богатый дядя умер и вы вероятный наследник, и да примеры из США, такие запреты в законах просто увеличивают занятость в т.ч. в it.
А так, чем лучше вы знаете человека тем больше у вас шансов интегрировать его в команду.
Кстати, а как вы угадаете мой возраст по телефонному интервью? У вас модуль телепатии так тонко настроен? Круто, завидую.
Если бы вы разбирались в людях так же хорошо, как в своей предметной области, то знали бы, что (даже не вербально) профайлить человека посредством «вопрос-ответ» достаточно просто. Если профайлер имеет достаточный опыт, разумеется. Социальную инженерию никто не отменял.
Лично мне такие законы нравятся, потому как защищают мои права от ущемления работодателем.Эти законы ущемляют Ваши права, но Вы этого не понимаете, потому что это пока Вас не коснулось.
Слышали это известное
Когда они пришли за коммунистами, я молчал — я не был коммунистом.
Когда они пришли за социал-демократами, я молчал — я не был социал-демократом.
Когда они пришли за профсоюзными активистами, я молчал — я не был членом профсоюза.
Когда они пришли за мной — уже некому было заступиться за меня.
Сейчас Вы радуетесь что Вас не спрашивают о том, что Вы хотели бы скрыть.
Это ровно до того момента, пока то что скрывают другие не ударит Вас по голове.
Кроме того, Вы явно троллите. Мы не верим в том, что Вы неспособны понять разницу между «запрещено задавать вопросы о расе» и «запрещено отказывать в работе на основании расы». А Ваша агитка в пользу первого свидетельствует о том, что Вы пытаетесь подменить второе в пользу первого.
Мы не верим в том, что Вы неспособны понять разницу между «запрещено задавать вопросы о расе» и «запрещено отказывать в работе на основании расы».Законом запрещено последнее.
А Ваша агитка в пользу первого свидетельствует о том, что Вы пытаетесь подменить второе в пользу первого.Это не агитка. Это то, что вдалбливается всем интервьюерам (мне, в том числе) каждый год. Под роспись. Потому что если где-то в суде, не дай бог, как-то всплывёт письмо в котором будет сказано «что-то староват кандидат — ну его нафиг», то фирма налетит на очень хорошие бабки.
Есть юристы, которые на этом специализируются просто. Это неплохой бизнес.
Законом запрещено последнее.Вы абсолютно правы, мы именно об этом.
Несомненно отказывать из-за расы самой по себе — нельзя, так же как из-за возраста или пола или еще чего-то.
Но в ряде случаев этот фактор может играть роль, так например, нельзя нанимать для обыска женщин в аэропорту мужчин, даже если они «считают себя женщинами», поэтому вопрос о поле тут закономерен, а отказ с полом будет не связан.
потому что если где-то в суде, не дай бог, как-то всплывёт письмо в котором будет сказано «что-то староват кандидат — ну его нафиг», то фирма налетит на очень хорошие бабки.А вот это подмена лечения болезни (дискриминация по возрасту) лечением симптомов (а давайте запретим спрашивать возраст). И это печальнее всего.
Но в ряде случаев этот фактор может играть роль, так например, нельзя нанимать для обыска женщин в аэропорту мужчин, даже если они «считают себя женщинами», поэтому вопрос о поле тут закономеренИ даже в этом случае — вы будете регулярно «налетать на бабки» и отстаивать своё право не брать на работу мужчин. Вот тут есть хороший пример — про то, чего стоит известной сети ресторанов не брать на работу официантками мужчин.
поэтому вопрос о поле тут закономерен, а отказ с полом будет не связан.Ага. Конечно. Нет, вы конечно можете попробовать, но на последнем тренинге нам настоятельно не рекомедовалось использовать слова «he» и «she» при описании отзыва.
А вот это подмена лечения болезни (дискриминация по возрасту) лечением симптомов (а давайте запретим спрашивать возраст). И это печальнее всего.И чего ж тут такого печального, интересно? Это — работает. Не идеально — но работает.
И даже в этом случае — вы будете регулярно «налетать на бабки» и отстаивать своё право не брать на работу мужчин.Так мы не отрицаем что будем, мы говорим о том, что это неправильно.
И чего ж тут такого печального, интересно? Это — работает. Не идеально — но работает.Оно работает в плане избавления от штрафов, лечит симптомы. А проблему — усугубляет.
«не думай о красной обезьяне»© — это не тот метод.
«не думай о красной обезьяне»© — это не тот метод.Если человеку не давать возможность обсуждать «юнцов» или «стариков», то «думать о красной обезьяне» — становится гораздо сложнее.
Оно работает в плане избавления от штрафов, лечит симптомы. А проблему — усугубляет.Ну если для вас проблема — это какие-то глубоко внутренние философские переживания, то да, может быть. Если для вас проблема — устроиться на работу (вот как тут, например), то нет — лечится именно проблема. Женщин и пожилых разработчиках я в США видел гораздо больше, чем в России.
Если человеку не давать возможность обсуждать «юнцов» или «стариков», то «думать о красной обезьяне» — становится гораздо сложнее.Напротив. В этом и смысл красной обезьяны. Это из ходжи насреддина, читаните.
Ну если для вас проблема — это какие-то глубоко внутренние философские переживания, то да, может быть. Если для вас проблема — устроиться на работу (вот как тут, например), то нет — лечится именно проблемаЭ, вообще мы не о себе говорили, а о тех у кого с этим проблема.
Но еще раз — лечение симптомов, а не болезни, откладывает и усугубляет проблему.
Утрированный пример. Допустим у человека паталогическая фобия красного цвет, но о ней нельзя спрашивать. И его нанимают в коллектив где все фанаты red socks, о чем их тоже нельзя было спрашивать. Человек нанят — симптомов нет. Но как насколько эффективно сможет работать, как будет психологически травмирован, насколько здоровая атмосфера будет в коллективе, чем это закончится? Поэтому лечение симптомов (не спрашивать) приводит к усугублению проблемы (неэффективности).
Напротив. В этом и смысл красной обезьяны. Это из ходжи насреддина, читаните.Я знаю эту притчу. Но она — как и все причти, утрирована. Запретить о чём-либо думать мы не можем. А вот говорить — можем.
На практике человеку, как существу социальному, тяжело долго думать о чём-то, о чём нельзя говорить. Какое-то время — да. Запретный плод сладок и всё такое. Но со временем — находятся другие интересы. И потому запреты на рекламу курения и запреты на обсуждение пола и возраста — таки действуют.
Поэтому лечение симптомов (не спрашивать) приводит к усугублению проблемы (неэффективности).Только в том случае если речь идёт у найме людяй с геронтофобией. Однако статистика показывает, что таких — в общем и целом — не так много.
Утрированный пример. Допустим у человека паталогическая фобия красного цвет, но о ней нельзя спрашивать.Вот только не надо доводить до абсурда, а? Человек, который патологически боится женщин — таки болен. И если ему некомфортно работать в коллективе, где есть представительницы прекрасного пола — то лучше бы ему пройти курс реабилитации, а не требовать, чтобы его фобии «уважали».
На практике человеку, как существу социальному, тяжело долго думать о чём-то, о чём нельзя говорить. Какое-то время — да.Вы не запретили ему об этом говорить, Вы запретили ему об этом говорить во время интервью на работе. Дав тем самым повод говорить еще больше во всех остальных местах.
Вот только не надо доводить до абсурда, а?Это не абсурд, это вполне реальный сценарий. Одно дело коллектив сформированный по общим взглядам и интересам, другое дело коллектив в который набрали кого попало.
Человек, который патологически боится женщин — таки болен. лучше бы ему пройти курс реабилитацииВау. А куда делась толерантность? И право на боязнь женщин и проявление себя таким образом? Право идентифицировать себя с группой людей боящихся женщин? А то что гомосексуализм болезнью до сих пор многие врачи даже в сша называют, а в некоторых странах он болезнь официально? Не должны ли люди боящиеся женщин сейчас подать на Вас в суд и устроить демонстрацию с призывом растреллять Вас за нетерпимость?
Вы вообще понимаете, что Вы только что сказали? Похоже нет.
Вы не запретили ему об этом говорить.Об этом именно что запрещено говорить. Вообще. В принципе. Где-бы-то-ни-было.
Вы запретили ему об этом говорить во время интервью на работе.Просто во время интервью проще нарваться на судебный иск, только и всего. Тренинг, объясняющий почему не нужно определённые вещи делать — касается как служебной переписки так и разговоров в курилке.
Дав тем самым повод говорить еще больше во всех остальных местах.Если вы будете об этом «говорить еще больше во всех остальных местах» то вас сначала вызовет ваш менеджер, а потом — могу и уволить, извините.
У себя дома, там где работодатель не может узнать — говорите, но только не в присутствии коллег с работы.
Вы вообще понимаете, что Вы только что сказали? Похоже нет.Я-то прекрасно понимаю. Но, как известно свобода вашего кулака кончается там, где начинается нос вашего соседа! И вопрос «а кто решает по каким параметрам можно дискриминировать, а по каким нельзя» — решается примерно на этом уровне.
И право на боязнь женщин и проявление себя таким образом?В данном случае вы предлагает в угоду одному человеку дискриминировать сотни и тысячи. Разумеется выбор делается в пользу них, а не в пользу одного гинофоба.
В данном случае вы предлагает в угоду одному человеку дискриминировать сотни и тысячи. Разумеется выбор делается в пользу них, а не в пользу одного гинофоба.Мы фигеем с Вашей логики.
Т.е. человеку боящемуся женщин Вы отказываете в правах, потому что он ОДИН. Вот реально, один такой на планете?
А то что из-за одного гея дискриминируют кучу гетеросексуалов, это типа норма?
Опять же — махровые двойные стандарты. Одно отклонение Вам нравится, другое нет — вот и весь Ваш критерий. Хотя объективно и то и другое одно и то же.
как известно свобода вашего кулака кончается там, где начинается нос вашего соседа!При условии что он свой нос не сует куда не надо.
А если чуть серьёзнее, где проходит граница между болезнью и оправданным дискомфортом, и кто её там проводит?
Насколько я понимаю граница находится там, где ее в данный момент устанавливает общество. Разные общества, естественно могут устанавливать в разных местах. А проводит эту границу государство устанавливая законы. На основании своего понимания общественных настроений, как на обсуждаемую тему, так и на смежные, вроде толерантности и на основании своей выгоды.
Это если строго. Я не говорю что это все правильно, просто пытаюсь сформулировать.
На мой взгляд правильнее было бы делать это с учетом особенностей человеческого мышления в первую очередь, но современные государства слишком подверженны влиянию популизма, к сожалению.
P.S. Вся эта тирада не означает что я согласен с вашим оппонентом.
А если чуть серьёзнее, где проходит граница между болезнью и оправданным дискомфортом, и кто её там проводит?Закон и суд. Я уже приводил ссылку на историю с Hooters, вот более поздний иск.
Задача всех этих тренингов — не сделать вас «белым и пушистым интервьюером», а тупо — минимизировать риски работодателя…
Похоже, в России есть ещё над чем работать законодателям.Не россии, а многим странам.
-Знаешь как называется научный подход к различиям между людьми?
-Расизм.
Любопытства ради, вы готовы отказаться от информации о том, что происходит в компании (от методов стимуляции сотрудников до атмосферы)? Ну от всяких glassdoor и прочее.
А я ей и не пользуюсь, ибо ценности у подобной информации нет никакой. Я был и подчинённым, и начальником, работал на многих проектах и видел кучу разных ситуаций. Всё относительно, и обиды тоже.
Потому что непонятно, почему подобная защита информации должна работать только в одну сторону.
Например потому, что у работодателя гораздо больше возможностей ущемить права работника, нежели наборот. И чем крупнее работодатель, тем больше этих возможностей.
А раз это фактор, то узнать его о работнике важно, вот и всё.
У ипотечника и человека с семьёй немного больше требований к рабочему месту(если мы не рассматриваем ситуацию когда семье на базовые запросы не хватает), это и стабильность и режим работы и расстояние до дома и есть ещё один фактор, повышение ему дохода в будущем (индексация на инфляцию к примеру) даст больший эффект чем одинокому работнику. Так что не так всё однозначно на мой взгляд :)
Я как-то неправильно рассуждаю?
PS: у самого дети и ипотека, не надо писать «вырастешь — поймешь».
и вдруг бац — совок скончался. и никто не гарантирует тебе стабильную среду, надобность в твоем опыте, вообще надобность в тебе. никто устраивать твою жизнь, в том числе трудовую уже не собирается. А сам этого не умеешь, никто не учил этому…
гражданских институтов, которые обеспечили бы какой-то комфортный уровень жизни нет, ты предоставлен сам себе — хочешь живи, если есть остаток сил и здоровья — бодайся за место под солнцем, а нет — сдохни, всем пофигу.
К сожалению, наша система подготовки программистов — очень слабая, сотрудников приходится обучать на работе.
А что, возможны какие-то другие варианты?
Подтверждаю про оба города :)
Все, что должен знать программист, чтобы его после 40 лет не выбросили на Помойку,
Целая статья на основе чьих-то личных интерпретаций.
Приведенный список это бред. Смысл IT — в тысячах специализаций. Нужно двигаться в одном направлении, тем более после 30 лет выбрать наконец свою область и двигаться в ней в ногу со временем, а не хапать всё подрят и в результате быть никем во всех областях.
Но надо сказать, что «под руководством молодняка» я не работал. Не иду работать в фирмы, где руководство вызывает у меня малейшие сомнения в своей адекватности. Думаю, что дело не в возрасте начальства, а в адекватности.
Я немного устал от веба, самое динамичное направление вроде как. Реально хоть каждый день какую нибудь новую штуку можно учить. Я пошел в «железные» программисты ) чистый С, электроника, verilog, ассемблер наконец ) Интересно, не скучно ) смешно смотреть на достаточно замшелые принципы С, после новомодного веба.
До 80-ти ещё тридцать лет. Полагаю, что 30-ти лет хватит, чтобы написать то, на что в молодсти не хватило времени.
Что значит "пора"? Далеко не все хотят своё дело в принципе, а некоторые переросли этап "сам себе начальник" и только если работы совсем не будет начнут думать в эту сторону.
С работодателем обычно сотрудничают, заключают с ним договор как равноправные сторона, которая берёт на себя обязательства и получает за это вознаграждение. Можно даже взять обязательство покрасить волосы в радикально черный цвет, если будет соответствующее вознаграждение. Лично я бы на это согласился тысячи за три долларов в месяц дополнительно к обычным условиям.
А по личному опыту "своего дела" на себя "горбатиться" приходиться гораздо больше, причём без всяких гарантий того, что получишь хотя бы свою рыночную стоимость как специалиста. Как по мне, то следует разделять роли специалиста и бизнесмена. Если уж решил их совместить, то начинать надо с заключения (хотя бы мысленного) трудового договора самого с собой :) Чтобы четко видеть что ты получил за обычную 40-часовую неделю программиста, а что как бизнесмен, а то легко не заметить на фоне формально увеличившихся доходов, что как специалист ты стал получать раза в полтора меньше в час, просто работать стал по 80 часов в неделю, а как бизнесмен, тратя часов по 20 в неделю вообще выходишь в минус, даже не смотря на то, что нашел лоха, который по 80 часов горбатится на тебя, получая в 1,5 раза меньше своей нормальной ставки.
Я как раз такой. Для меня очень важно чтобы меня похвалили. Даже деньги особо не важны. Например, я делаю все задачи очень быстро и качественно, за последние полгода никто не нашёл в моих пуллреквестах ни единой бани, решения задач очень полные и качественные, внимательно продуманные. Делаю в 2-3 раза больше чем молодёжь и в 4 раза более качественно. И требую всего ничего — чтобы меня похвалили. И получаю от этого моральное удовлетворение.
Моя мечта не такая. Одно место или тридцать поменяю за оставшиеся лет 30 мне без разницы, хотя тридцать даже лучше. Работаю не от забора до обеда. А вот гарантированный доход, в размере достаточном чтобы не думать о бытовых проблемах, законно решаемых за деньги — важно. Риски неполучения доходов за продукт, в разработке которого я участвую в роли ведущего разработчика или руководителя разработки, без гарантированного приличного дохода, я отдаю работодателю. Если риски не реализуются, то он получит значительную часть доходов, а если реализуются, то заплатит мне из своего кармана.
Если когда-нибудь государство или кто-то другой обеспечит мне гарантированный доход порядка 300 000 рублей в текущих ценах, то я буду разрабатывать проекты чисто по техническому интересу без всякой оглядки на коммерческие перспективы. А сейчас большинство проектов имеют и финансовый интерес в виде получения пускай и небольшого (относительно потенциальных доходов от проекта), но гарантированного заработка.
Да, относительно молодой и расходы просто огромны: семья, ипотека, дети...
Если для траты денег нужно привлекать фантазию, то в общем случае это вряд ли окажется эффективной тратой.
У меня вот стандартный ответ есть для тех, кому «некуда деньги тратить» — создайте грант на исследования в области медицины, например, в геронтологии.
По-вашему, неэффективная трата? А ведь замечательно подойдет для сумм до миллионов долларов в год включительно.
А каковы гарантии, что деньги не окажутся выкинутыми на ветер?
Даже если 99%, что результат будет нулевой, неужели оставшийся 1% вероятности лично продлить жизнь представителей человечества (и свою в первую очередь) того не стоит?
Но это вариант в первую очередь для больших сумм (а, скорее всего, если они у вас есть — то и навыки управления людьми уже есть, что резко повышает шансы на успех). А в пределах $1mln любую сумму можно эффективно потратить на благо семьи. Грубо говоря, высшее образование пяти детям оплатить.
По-моему, очевидно, что за избыточную квалификацию никто платить не будет. А для большинства современной разработки, действительно не нужно какой-то особой квалификации.
Недавно для клиента смотрели модуль для бронирования гостиницы, конечно, код мы не видели, но по сути, там работа для много джунов, и над ними можно было поставить одного синьора, как надсмотрщика, чтобы код оставался читаем.
Вот работа бизнес-аналитиков была проделана огромная, но на уровне исполнения, там нужно много несложного кода.
Так зачем платить больше?
И проблема программистов, которые очень много времени в профессии не в том, что технологии постоянно меняются, а в том, что они, в большинстве своем "клепают формочки" и в принципе, нет разницы, человек это делает один год или десять лет. И давайте будем честными, реально не большой процент постоянно растет и развиваются, послушайте хотя бы уровень вопросов на конференциях (кстати, от людей, которые все-таки ходят на конференции, а что говорить про остальных...).
Вывод один, получая свои годы стажа, задумайтесь, а что Вы получаете кроме формально стажа?
Проблема в том, что окружающая действительность на 1/6 части суши не требует компетентности. Ты можешь быть талантливым программистом, но будешь загнивать под руководством молодого управленца, который руководит проектом, а поскольку он давно в школе учил бейсик, он прекрасно знает, как надо строить архитектуру приложения, и что «вот эту функцию» ну точно можно реализовать к понедельнику, потому что в понедельник презентация, и надо показать продукт жизнедеятельности.
Смена места работы проблемы не решает, потому что, во-первых, у тебя действительно семья и ты не можешь всё бросить и уехать в поисках лучшей жизни куда-либо, а во-вторых, на потенциально новом месте на тебя будут смотреть как на лузера. Потому что в 40 лет, по мнению кадровичек, человек не может менять работу только потому, что предыдущая ему надоела, а его компетентность однозначно подвергается сомнению. Поэтому работать он должен практически бесплатно, тем более, он же не знает сотен этих современных штучек, технологий, модных тенденций и т.д. (о которых никто и не вспомнит через год-другой).
Не требуется удовлетворенность результатами. Бывает даже, что важен процесс, а не результат — под процесс (ну скажем, разработки мощной информационной системы) выделяются деньги, большие деньги, которые необходимо освоить, делается нечто, которое потом благополучно «забывается». В таких условиях сгниёт любой специалист. Но кто-то находит в этом выход: можно умело дожить до пенсии, получать отличную зарплату, не сделать ничего полезного, и совершенно не напрягаться по этому поводу. Главное — свято верить, что «наше дело правое».
Лекарство «чтобы не зачерстветь»:
- определиться с языком, и чем раньше, тем лучше;
- изучать его;
- научиться обходиться без библиотек — это и чистота кода, и переосмысление, и опыт, и всё вместе.
Добра.
определиться с языком, и чем раньше, тем лучше;
изучать его;
научиться обходиться без библиотек — это и чистота кода, и переосмысление, и опыт, и всё вместе.
Определились, изучили от корки до корки, читаем по нему самый «свежак», последние стандарты, можем обойтись совсем-совсем без библиотек, даже без stl родимого, написав его с нуля (а зачем писать? можно закопипастить, он же неплох, как грится писали люди with decades of experience, а лучше вряд ли получится :), и что дальше? И дальше что?
Менять профессию, равно как и изучать все «новомодное» вне имеющегося профиля он не хочет, и прямо сказал — когда я перестану справляться или стану мешать, то просто увольте. Что касается зарплаты, то получает он на 15-20% больше, чем 22-х летние работники при соизмеримом объеме работы.
у нас молодой коллектив
типичный пример снобизма начинающего и дерзкого стартапа, наспех и на коленке сляпанного на (всегда) заёмных, но (иногда) больших средствах.
Лучшее противоядие на такой обертон на собеседовании\при получении оффера — это вопрос-полушутка из старого программистского анекдота о степени альфосамцовости участников данного «каллэктива» с уточнением о количестве багов и вылетов этих самых альф в их типичной рабочей среде.
Адекватный эйчар всегда оценит юмор бывалого, а неадекват высадится и собес закроется, экономя ваше время, нервы и деньги.
ПС: всё написанное выше взято из личного опыта и публикуется строго на правах «имхо».
Разве понятие стартапа не исключает заемные средства в принципе? Мне всегда казалось, что стартап это всегда собственные средства, с постепенным размыванием долей первоначальных учредителей в пользу венчурных, а далее и обычных инвесторов.
Кризис среднего возраста, скука, казалось, что выгорание, смены мест работ, метания в разные хобби. Сейчас работаю по-прежнему программистом в компании, непосредственно с программированием не связанной, но на нём все построено. Слегка совладелец, кодю на работе, кодю дома как хобби. Танчики :) велосипед, фотография.
Жека, 52 года
PS. Офигеть! Уже 52 года!
да, мне уже не интересны эти новомодные 100500 фреймворков, все эти окошки, менюшки, интерфейсы.
интересны сложные алгоритмы, сложные структуры данных, оптимизация. стало неожиданно приятно сисадминить, настраивать чтонибудь, разбираться.
изза этого я не интересен современному работодателю, где надо демонстрировать умение пользоваться чужими ошибками, когда мне милее создавать свои )
Проектов больше нет, потому что гладиолус. Хотя до 2014 были проекты с компаниями национального масштаба, в том числе и в ближнем зарубежье.
Переквалифицируюсь в программисты, прошел bootcamp, писали на си, с++, java, сейчас пишу на python, впереди еще sql, mvc и небольшой pet-проект и поиск работы.
Короче, жизнь повернулась так, что приходится не думать, о том что же я буду делать после 40. Пришлось принять тот факт, что карьера завернутая на внутренний рынок пошла по п***де, хотя сулила профиты гораздо большие, чем у моих друзей девов (в планах было выйти на уровень партнера).
Так вот, сейчас я думаю, что зря я не начал карьеру программиста эдак 10-15 лет назад, хотя были предпосылки и возможности. А автору рекомендую задуматься, что бы он делал после 40, если бы он не были программистом. Имхо, в других профессиях все обстоит не лучше, а скорее гораздо хуже (и в плане денег и в плане предвзятом отношении) и молодых специалистов не меньше.
А Вы слишком на многих языках пишете для начала. И на С, и на Java, и на python. Вот вы знаете/используете декораторы и метаклассы в python? Или там не знаю продвинутые фичи в С++? Уж не знаю какой пример привести. Variadic templates и perfect forwarding? Уж лучше освоить что-то одно, но очень глубоко.
Вообще говоря, каждый уважающий себя программист должен знать (хорошо знать) какой-нибудь язык низкого уровня (например, С), среднего уровня (например, C#, Java) и скриптовый язык (например, Python, Perl).
язык низкого уровня (например, С):facepalm:
asm, не?
Обратите внимание на слово "например".
Даже в виде «примера».
Есть. В моей вселенной (обработка изображений) C и C++ — языки низкого уровня. Причина проста: использование интринсиков полностью заменяет ассемблер и даже превосходит его. Код на ассмеблере требует на порядок больше затрат на написание и поддержку, а выхлоп получается нулевой — код может получиться даже медленнее плюсового за счёт оптимизаций компилятора.
C#/Java — языки высокого уровня для написания интерфейса для C++ кода.
Python/Matlab — языки скриптового уровня для быстрого прототипирования и исследований
Во всех остальных вселенных язык нижнего уровня это язык непосредственно машинных кодов и ни С ни С++ к ним никоим образом не относятся.
asm стопудово да, smali с небольшой натяжкой.
Во всех остальных вселенных язык нижнего уровня это язык непосредственно машинных кодов и ни С ни С++ к ним никоим образом не относятся.
Всё относительно. Относительно Java C является языком низкого уровня, а относительно ассемблера — высокого. Сложность систем возрастает, и если в 80-е язык С был языком высокого уровня, то сейчас у меня не поворачивается язык назвать его высокоуровневым.
Моё утверждение относилось к тому, что полезно знать языки с разными уровнями абстракций, чтобы не писать пару дней на С++ то, что на питоне делается за час, и не писать на питоне то, что будет работать на порядки медленнее, чем на C++.
Потому что у Вас все перевернуто с ног на голову, ассемблер у Вас видите ли не низкоуровневый
Где я это утверждаю?
О_о?! WTF?!
Современные процессоры настолько сложны, что ручная оптимизация зачастую хуже, чем оптимизации компилятора. Я просто не вижу смысла в современном мире использовать ассемблер как язык разработки, за исключением ассемблерных вставок.
Всё относительно.Нет.
Есть четкое определение языков нижнего уровня.
Ни С ни С++ к ним не относятся, по определению.
И никакие Ваши рассуждизмы о том, что си Вам кажется слишком низким, а ассемблер слишком медленным этого не изменят. 2*2=4, вне зависимости от того кажется Вам 4 слишком маленьким числом или нет.
Рекомендуем Вам ознакомиться с базовыми общепринятыми определениями уровней языков, а не изобретать свой велосипед.
Вы принципиально не хотите улавливать суть и зачем-то цепляетесь к словам. Не надо так.
Да, по классификации по учебнику единственный язык низкого уровня — это семейство ассемблеров, а всё остальное — языки высокого уровня. В 60-е годы, когда было введено определение языков низкого и высокого уровней, оно было актуально.
Сейчас же определение в таком виде не имеет никакого смысла и нуждается в доработке, потому что оно делит языки на чёрное и белое — ассемблер (доля — 2% во версии TIOBE) и все остальные. Причём все остальные — вне зависимости от уровня абстракций. Вы же правда не ставите в один ряд С и Python?
Рекомендуем Вам ознакомиться с базовыми общепринятыми определениями уровней языков, а не изобретать свой велосипед.
Отсутствие подобных академических знаний (да, я не знал, что С — язык высокого, а не низкого уровня) мне почему-то совершенно не мешает программировать. Я знаю, что существуют работотадели, которых интересуют не умение программировать, а правильные ответы на вопросы (включая определение языка низкого уровня), но меня это не беспокоит — к таким я бы точно не пошёл работать.
Господа, не надо флеймить и засорять ветку. Все все прекрасно знают — что такое С, что такое asm, а флеймят.
Вы принципиально не хотите улавливать суть и зачем-то цепляетесь к словам. Не надо так.Это не цепляние к словам, это попытка донести до Вас тот простой факт, что если Вы говорите на выдуманном Вами языке, то Вас не будут понимать.
Отсутствие подобных академических знаний (да, я не знал, что С — язык высокого, а не низкого уровня) мне почему-то совершенно не мешает программировать.Как минимум мешает адекватно дискутировать — говорите одно, подразумеваете другое.
С другой стороны, возможно и программировать тоже.
Понимаете, если Вы говорите «язык низкого уровня» подразумевая «С», то что нам, например, думать когда Вы скажете «ООП» или «инкапсуляция» или «наследование»? Может у Вас и на эти случаи свои определения?
И что хуже всего — когда Вам указали на Вашу ошибку, Вы вместо того что бы проверить факт и сказать спасибо — начали многословно нападать и защищаться.
Так что определения — они не универсальны, и надо бы уточнять каким именно вы пользуетесь, раз уж хотите к ним апеллировать.
</zanuda mode off>
Современные процессоры настолько сложны, что ручная оптимизация зачастую хуже, чем оптимизации компилятора.Ни разу такого не видел.
А зато видел другое: выходила новая версия процессора — и старый код, скомпилированный с новыми инструкциями работал быстрее, чем старый код, написанный на ассемблере.
Написать код на ассемдлере — это полдела, это ещё можно себе представить. Но переписывать его каждые год-два — это уже перебор.
Ни разу такого не видел.
Я такое увидел, когда решил попробовать Intel Compiler
До этого же пытался писать узкие места на ассемблере
Я такое увидел, когда решил попробовать Intel CompilerЕсли только вы не попали на известный разработчикам ICC peephole (который суть руками же написанный код), то этого обычно не происходит.
Да, там есть разные чудеса (типа сгенерированных полным перебором кратчайших способов умножить на константу) — ну так и вы, разрабатывая программу на ассемблере, можете сделать так же.
Во всех остальных вселенных
Меньше LSD, товарищи!!! Переходите на зелёный чай :)
Агентство поставило нам около двадцати человек с солидным опытом, а собственными силами найдены разработчики 25-30 лет.
Общее впечатление от первой группы полностью перекликается с данным постом. Депрессивное, гнетущее, склонное к конкуренции мировосприятие. Запросы около 200 тысяч, знание актуальных технологий на уровне «да ладно, завтра выучу». Технически собеседовать часто было невозможно — сплошная апелляция к опыту, уважению и т.д. Приходилось прерывать собеседование и спрашивать, действительно человек хочет на эту позицию? Не будет ли ему скучно? Хоть кто-то сказал бы свое «нет». Напротив, человек упорно рассказывает о былых годах, о своих проектах, пытаясь на всякий случай победить в собеседовании. Игра с ненулевой суммой, главное отличие от нового поколения с win-win «старичков». Идеальное собеседование для такого кандидата было бы, если я погуглил факты из его резюме и просто восхищался, не в коем случае не оскорбляя вопросами, сказал бы «да», даже если это было бы собеседование на должность джуниора, которая ему не нужна.
В общем решать психологические проблемы взрослого человека совершенно не хотелось, составить хоть какое-то впечатление не удавалось, мало того, было очень странно, когда человек прожив больше меня лет на 10-15 лет мог сформулировать, что ему не нравится лучше, чем то, что ему хочется.
Зато были единицы адекватных, по-настоящему взрослых профессионалов, которые не стеснялись быстро ответить на простые вопросы и перейти к сложным.
Что касается второй группы, там причиной отказа часто была недостаточная мотивация, но в основном никто не стеснялся признаться в отсутствии знаний или интереса прямо во время собеседования. Те, кто продолжал, давали честные ответы. Опять же, тот самый win-win о котором я говорил выше, многие сразу предупреждают о своих слабых и сильных сторонах, думая о будущей комфортной в коллективе.
Так вот, какой смысл нанимать 40+ разработчика, работающего по Negative Driven Development за 200К или середнячка, знающего свое место за 100-150К? Опыт, мотивация пары не сломавшихся сеньеров вполне покрывает потребности группы разработки.
Что бы не растворится к сорока, разумным кажется вкладываться в сеансы психоаналитика, путешествия, спорт и хобби, что бы не угаснуть так рано. В крайнем случае перейти на антидепрессанты, если не повезет с гормональным фоном.
На самом деле хотелки такие высокие из-за:
- Чрезмерно высокой квалификации, которая не нужна работодателю.
- Высокой зарплаты на предыдущем месте работы.
- Желания побороть отсутствия интереса к работе денежной мотивацией.
Наверное, стоит просто сменить область и стать снова junior?
Забыли:
пункт 4. наличие семьи с подросшими детьми, которым не только одним пелёнки требуются.
пункт 5. родители на пенсии.
PS Даже, просто наличие девушки/подруги/жены/нужное_вписать заметно повышает хотелки по зарплате в сравнении с её отсутствием.
Высокие расходы не являются оправданием высоких запросов.
Пункт 4 компенсируется отсутствием расходов на жильё. Если в 25-35 лет львиная доля расходов — это съём или ипотека, то к 40 годам хорошо уже иметь собственное жильё, тогда освободившиеся деньги можно тратить на детей.
Пункт 5 актуален и для 25-30-летних.
Размер хотелки может и просто зависеть от реальной рыночной стоимости специалиста. Если человек может продать свой труд за N денег, то логично, что на собеседовании он будет отталкиваться от этой суммы. И жена, дети, ипотека тут непричем.
Очевидно с т.з. работника. Неочевидно с т.з. работодателя, который вечно уповает на какую-то там адекватность, какой-то там компромисс.
С точки зрения работодателя неочевидно, почему он должен платить работнику больше, если у того жена, дети и ипотека, если он может платить одинокому тому, кто об этом ничего не говорит, на 50% меньше. А вот очень многим работникам это очевидно — у семейного расходов больше,
Так ведь, речь шла о том, что DistortNeo удивлялся и недоумевал "почему семейные не хотят получать как джуниоры, а имеют наглости сметь просить больше?".
Не делает. У семейного планы могут быть содержать семью на прожиточный минимум с учетом зарплаты жены, материнского капитала и бесплатной помощи бабушек-дедушек, а у одинокого на выходные по миру кататься на личной яхте или виноградники в Тоскане разводить :) Работодателя это всё не касается.
Наверное, стоит просто сменить область и стать снова junior?
Порадуйте Вашу жену известием, что Вы теперь будете получать зарплату junior'а, и расскажите об её реакции.
Дауншифтинг — это нормально. Да и не думаю я, что человек с опытом и хоть немного работающими мозгами долго продержится джуниором.
Нормально, когда Вы только вдвоём и нет расходов на содержание детей, тогда возможно и бросив всё отправиться вдвоём в кругосветку автостопом.
А наличие детей, всё таки налагает определённые материально-финансовые обязанности.
Хорошая практика в таком случае — иметь запас денег на случай продолжительного отсутствия высокооплачиваемой работы.
Одна из важнейших при этом — создание подушки безопасности, позволяющей заметное время обеспечивать детей всем необходимым при уменьшении или полной потере дохода, будь-то добровольный "дауншифтинг", или обстоятельства непреодолимой силы.
Любящая жена ответит: "не переживай о деньгах — прорвёмся, лишь бы ты на работу не ходил как на каторгу, пускай даже не срываяь на нас".
А вам не кажется, что делать резкие телодвижения со своей карьерой, чреватые значительным ухудшением материального положения для вас и жены, попросту нечестно по отношению к жене? И что такие вещи требуют как минимум согласия обеих сторон?
Или жена, которая не согласна просто взять и поставить ваше самодурство (мне скучно! хочу в пампасы!) выше своих интересов, по определению считается не любящей?
В какой-то мере требуется, да. Как минимум есть риски, что на развод подаст из-за ухудшения материального положения. Но можно ли тогда говорить о любви? А если вдруг потеря трудоспособности или, скажем, запрет суда занимать определенные должности и вытекающая необходимость идти на неквалифицированную работу, то тоже развод?
И речь не о "мне скучно", а о "каторга, а не работа, пускай и кормят хорошо".
Это, конечно о ситуации когда нет брачного договора, обязывающего обеспечивать какой-то доход.
В какой-то мере требуется, да. Как минимум есть риски, что на развод подаст из-за ухудшения материального положения. Но можно ли тогда говорить о любви?
А давайте развернём ситуацию в другую сторону. Скажем, ваша жена всю жизнь мечтала выиграть парусную регату, да вот всё никак. Годы идут, здоровье не улучшается, другого шанса не будет. Сейчас или никогда.
Вы готовы больше работать, меньше кушать и взять на себя детей, чтобы поддержать жену и дать ей возможность осуществить мечту жизни? Безоговорочное "да"? Поздравляю, вы — любящий муж.
А если вдруг потеря трудоспособности
На этот предмет существуют страховки, на которые разумный человек может подписаться.
или, скажем, запрет суда занимать определенные должности и вытекающая необходимость идти на неквалифицированную работу
Несколько надуманный пример, нет? Потеря трудоспособности может произойти в результате несчастного случая, но совершение незаконных действий никак нельзя назвать несчастным случаем. Действуйте в рамках закона и думайте, перед тем как что-то делать. Семья это не только фан и развлекуха, но и изрядная доля ответственности.
то тоже развод?
Вы всегда ставите вопрос ребром, похоже. Чёрное-белое, всё или ничего. Либо жена на всё согласная, либо не любит и развод. А как насчёт дикого стресса и седых волос, причинённых вашими метаниями в поисках работы своей мечты? Вы считаете себя вправе подвергнуть близкого человека таким испытаниям просто потому, что вас не устраивает текущая работа?
А если ещё и взять в расчёт возможный провал? Ну, не сможете вы найти работу по новой профессии. Или карьера не сложится. Или на полдороги поймёте, что это тоже "не то". Жена ведь любящая, пусть всё терпит?
И речь не о "мне скучно", а о "каторга, а не работа, пускай и кормят хорошо".
Вы там на галерах кайлом машете по 18 часов в сутки, не иначе? Если кормят хорошо, то работа каторгой быть не может. Может быть недовольство текущей ситуацией и желание её изменить.
А желание всё бросить и поменять без учёта интересов своей же семьи и есть самодурство в чистом виде.
Тоже из личного опыта говорю. В какой-то момент надоело плевать сверху в стеклянный потолок, и я решил бросить успешную карьеру, открыть стартап и "валить". Путь оказался трудным и каменистым, будущее туманным, перспективы неопределёнными. Жена осталась любящей и верной, за что я её нереально уважаю.
Сейчас-то уже можно сказать, что кривая вывезла и всё хорошо. Но того стресса, через который мне и жене пришлось пройти поначалу, я себе никогда не прощу.
Если кормят хорошо, но вы всю свою рабочую жизнь проводите за разгребанием говнокода, в результате самореализация и вот это всё — по нулям, то это как-то ну очень сильно печально.
Печальна такая ситуация только тому, кто не был в худшей. И самореализация совершенно не идентична работе, до этого тоже доходишь не сразу.
Only football gives us thrills, rock'n'roll just pays the bills. ©
В худшей — это в какой?
Например, когда только переехал в другую страну, а все твои расчёты оказались неверны, партнёры оказались ненадёжны, перспективы совершенно туманны, а что делать — непонятно. Твой продукт, с таким трудом разработанный за год и в спешке доведённый до беты под сезон и обещание тестовой площадки оказался "не приоритетом", площадки нет, клиентов нет, ничего нет. Планета Железяка.
От денежной подушки осталось N, которых хватит месяца на три, а может и меньше, т.к. стоимость переезда и жизни ты недооценил кардинально, а доходов нет и когда будут, неизвестно. Жена работать не может, всё на тебе. По новой специальности резюме пустое, а по старой работать нельзя, т.к. виза. Ищи работу, корми семью.
Плохой период был, до сих пор вспоминать не хочу.
Самореализация не идентична работе, конечно, но куда лучше и эффективнее 8 часов самореализовываться на работе, а потом 8 часов самореализовываться дома, чем только 8 часов дома.
Золотые слова. Жаль, после работы сил не остаётся на самореализацию. Если, конечно, работать, а не на хабре тупить.
существуют страховки, на которые разумный человек может подписаться.
Вы явно живёте не в России. Здесь подавляющее большинство если и страхует что-либо, то себя как правило в последнюю очередь, как правило
Даже в США большая часть населения до Obama-care сидела без нормальной страховки.
Когда я жил в России, у меня была страховка от потери трудоспособности. Это было дорого, но я считал, что оправданно. Сейчас я живу в Калифорнии, страховка от потери трудоспособности у меня есть и здесь. И это тоже дорого, хотя часть оплачивает работодатель и это как бы "дешевле". В конце концов это всё равно деньги из моего кармана, так или иначе.
Кому как, а мне спокойствие дороже денег.
2. Я во время собеседований просто прошу оценить свой уровень и задаю пару контрольных вопросов необходимой сложности. Если ответы не устраивают, то уже копаю дальше. Смысл задавать человеку с большим опытом простые вопросы? Ну и я всегда гуглю все по резюме, смотрю социалки, аккаунты на GitHub и StackOverflow. В основном пытаюсь понять как он думает и принимает решения. Больше интересуюсь личными качествами, чем конкретными мелочами.
3. Пессимисты то же нужны в команде :)
4. А вот фраза «знающего своё место» это уже перегиб.
Пессимисты то же нужны в команде :)
Вроде на баше было что-то вроде "Эстимэйты пессимистов на практике самые точные" :)
Это потому, что как правило, пессимист — это хорошо побитый жизнью информированный оптимист.
В бытностью мою юниором, один из коллег сказал мне: nohuhu, молод ты и глуп, и не видал больших за$уп.
Ну вот, уже не молод. Видал уж много разных, пардон за мой французский. Отсюда и склонность не верить в чудеса и "да мы щас всё по-быстрому".
Кстати, с этим же связан и популярный миф о том, что "молодые умнее, всё схватывают на лету". Мозгов-то им обычно как раз и не хватает, как и опыта. Палец покажи, они заржут и побегут лабать галопом, потому что круто-круто же!
А стреляный воробей смотрит на эти штуки в древнерусской тоске, потому что уже там был и сям был, синяков наставил и шишек набил, по голове говно текло, да за шиворот не попало. Браться за эту фигню бессмысленно, оно сперва не взлетит, а потом тебя же, многогрешного, и накроет обломками. И "каркать" смысла тоже нет, никто пессимистов не любит и за предсказанье-всё-пропало премию не выпишет.
Вот и спускают молча на тормозах, или ещё хуже, идут работать в Ацкый Кровавый Ынтырпрайз, Где Всё Говном Мамонта Поросло.
Тупыыыые. :)
Это потому, что как правило, пессимист — это хорошо побитый жизнью информированный оптимист.
Почему пессимисты всегда заблуждаются в том, что их пессимизм — это реализм? Обычно пессимисты — всегда пессимисты.
Не всегда. Сам я себя считаю реалистом, а вот остальные члены команды — пессимистом. :)
По-моему, со стороны пессимистов это лицемерие)
Идеальное собеседование для такого кандидата было бы, если я погуглил факты из его резюме и просто восхищался, не в коем случае не оскорбляя вопросами, сказал бы «да»
Вы будете смеяться, но именно такое «собеседование» я прошел по телефону в известной компании на букву «M» (нет, не той, что делает операционки). Позвонили, уточнили, что это на самом деле я, поинтересовались, смогу ли посещать различные мероприятия, уточнили, что устраивает предложенная оплата. И все — вы приняты. Правда, работа там оказалась весьма скучной и через год пришлось уволиться.
Полет нормальный, вижу что дальше лучше.
Главное — ваше желание и возможность потратить время на старте.
Могу по 10-12 часов в день изучать новую интересную технологию, потому что интересно, вот почему я в этой профессии.
и ждет подачек от алгоритма пенсофонда
Можно, всё можно. И создать полный продукт, и продать, и поддерживать, и ещё много чего можно. В одно рыло, да.
Времени только много уходит и сил, зато скучать некогда.
Я не просто так говорю, а из собственного опыта. Когда прижмёт, и сайтики на WordPress научишься лабать, и картиночки в Photoshop рисовать, хотя всегда считал, что не можешь, никогда не делал и таланта нет.
Главное, это научиться правильно загнать себя в угол. Мотивация — великая сила.
Всяко лучше пойти в конторку софт пописать, чем рисковать своим стартапом. Вдруг он не взлетит, а ты израсходуешь время и усилия? А так хоть 100 тыс, но свои! За 100-то всяко возьмут!
Да просто заниматься стартапом часов по 20 в неделю, продолжая работать обычно и отказываясь от привычного отдыха — нормально. Но потом приходит понимание, что 20 часов мало, что чтобы через год позволить себе уйти с работы надо сейчас работать по стартапу 40 часов, и их уже вытягиваешь из сна, из семьи, да и работы, но и этого оказывается мало через несколько месяцев, нужно или вкладывать деньги, которые зарабатываешь, чтобы кого-то нанять, или увольняться и работать над стартапом по 80 часов (уже с опасениями что через несколько месяцев окажется, что надо работать будет и 120 часов в неделю, а то и 200). Это уже далеко не "Вдруг он не взлетит, а ты израсходуешь время и усилия?" — это уже "Вдруг он не взлетит, а ты потеряешь почти всё, что имел, да ещё и должен останешься"
чтобы 1 полушарием писать продукты а 2 полушарием продавать
суровое испытанеи для психики
умным людям тяжко заводить коллектив и друзей
возможно одиночество дает шанс плыть в лодке 1
Прекрасно работает, продуктивность высокая, задачи в срок, жизнерадостный, бывший военный летчик, медработники на него чуть ли не молятся.
Рядом мед. эксперты, тоже 40-50 лет срединй возраст — у них полное взаимопоинмание.
Начальство тоже довольно, отчеты есть, новый фунцкионал разрабатывается, человек серьезный, опытный.
Сделали для него рабочую неделю 3 дня на базе + 2 дома + выходные, так он за 2 дня дома делает больше чем за 3 на базе, потому что не дергают, не отвлекают и не мешают.
Задач не боится, способен к самоорганизации, в общем его возраст — только плюс.
1. учиться и пытаться устроится на работу, тут вопрос кому я нужен такой с таким багажом знаний и возрастом.
2. учиться и не париться требованиями работодателя а работать на себя, а именно разработка собственных торговых роботов, (опыт ручной успешной торговли есть).
И там и там перспективы неизвестны, получится ли. Ребят, у кого какие мысли на этот счет, подскажите.
Выберите один технологический стэк (желательно по требованиям к интересным вам вакансиям) и развивайте только его, чтобы получить первую работу в ИТ. Как вариант, на фрилансе — там возраст практически ничего не значит.
Пытаться создать бизнес на базе софта собственной разработки без реального опыта промышленной разработки — очень рискованно, по-моему.
Пытаться создать бизнес на базе софта собственной разработки без реального опыта промышленной разработки — очень рискованно, по-моему.Да вообще создавать бизнес на основе софта это не здраво.
Это попытка совместить в себе и бизнесмена и разработчика, не надо так. Умеешь разрабатывать — разрабатывай для бизнеса и получай за это деньги. Умеешь делать бизнес — делай бизнес и нанимай разработчиков.
Иначе получается и не бизнесмен и не разработчик и ни рыба и ни мясо.
Иначе получается и не бизнесмен и не разработчик и ни рыба и ни мясо.
Ну почему же, вот например бизнесмен-разработчик
Мы говорим о том, что выбрав одну стезю они были бы успешнее.
Вы не написали в чем суть примера, но если суть в торговом роботе, то удачно его продав можно наварить куда больше, чем торгуя им на свои. А это по сути и есть переход к программисту от бизнесмена-разработчика.
И там и там перспективы неизвестны, получится ли. Ребят, у кого какие мысли на этот счет, подскажите.
По первому пункту. Если зарплатные ожидания большие, то маловероятно.
По второму. Торговля на форексе это замаскированное казино, об этом уже была подробная статья на хабре. То есть согласно теории вероятности, если долго играть в игру с нулевой суммой и фиксированным капиталом, то когда нибудь потеряешь деньги. Если же игра с отрицательной суммой, то потеряешь деньги быстрее. Если же сумма положительная (растущий тренд на акции), то 50 на 50, в зависимости от Ваших способностей.
По первому пункту. Если зарплатные ожидания большие, то маловероятно.— очень даже небольшие, для начала нужна не столько зарплата (хотя она не помешает), сколько возможность набраться опыта, поработать в реальном проекте, т.е. если бы взяли джуном я был бы вполне доволен :)
По второму. Торговля на форексе это замаскированное казино...— не, я имел ввиду фондовый рынок.
Вот, тоже некоторое время назад стал прикидывать для себя дальнейшие перспективы на рынке труда в IT и затраты, которые потребуются, чтобы удержаться на позициях или продвинуться повыше. Ситуевина напомнила мне эпизод бега с Черной Королевой из "Алисы в Зазеркалье". И, признаться, идея бежать изо всех сил до гробовой доски мне как-то не понравилась. Правда, я для себя нашел непопулярное решение — ушел из программистов (правда, иногда до сих пор что-то для кого-то делаю "по старой памяти") а потом и из IT вообще… Но у меня давнишнее хобби, которое я развернул в профессию. Графика, полиграфия и фотостаж более 30 лет — было что развернуть.
Вероятно, этот путь подходит не каждому.
Вполне возможно, кому-то лучше сделать свою "конюшню", в которой будут работать те самые молодые под мудрым присмотром. А кому-то, и впрямь, лучше в менеджеры податься. Ну и я вполне допускаю варианты, в которых люди находят свою нишу "маленькую, но фейербаховскую", и в которых десятилетиями "сидят на теме". Каждому свое. Главное, чтобы оно было именно "свое".
Уверен, чтобы никуда не деться после сорока, надо разумно сочетать в себе два фактора: достаточный, без гипертрофии, интерес к новому и спокойное (надо — значит, надо) отношение к рутине. Эти два фактора можно слить в одно понятие, которым не блещет молодёжь, а именно — надёжность. Причём надо быть в первую очередь — надёжным, и лишь во вторую — динамичным. "Папа может в си" при всей своей гротескности мне импонирует больше того, кто "Я знаю c, c#, java, angular, react, php, oop и много других умных слов". Потому, что один "может", а другой всего лишь "знает"...
Что хочу сказать сверстникам (не конкретно автору этого поста, но всем создателям развернувшейся, в последнее время, серии) — ваш возраст для вас — благо. Оправдывались бы так в 20 — послали бы. А тут уважение к старшим срабатывает, плюс неизвестность, пугающая некоторых из последователей, слушают.
Дорогая молодежь — будете перекладывать ответственность наружу — появится соблазн включиться в марафон постов с подобными заголовками. Но, уверен, по всем рыночным законам — к тому времени такой товар сильно обесценится в связи с простотой вхождения и перепроизводством.
Дорогие «старики». Не знаю как вам, а мне, в конце 80-х, очень не хватало адекватных взрослых коллег. Давайте не допускать повторения трагедии, не нужно самоустраняться.
В целом настрой положительный, «динозавры» оседают в крупных компаниях.
Но вот проблема одна не раскрыта.
1) Вы покупаете футболку в магазине. Вам пытаются продать товар с наворотами, но зачем спрашиваете вы, мне ведь просто на 1 сезон, обычную, не нужна мне защита от влаги и солнца.
С работой тоже самое, вы говорите работодателю что ему нужно, и обижаетесь когда ваши взгляды на жизнь не совпадают. Если компании «А» не нужны супер профи, заказчик не будет платить больше просто за то что продукт будет хорошего качество, нужно ведь быстро и дешево. Это нужно не только заказчику, но и вам, в магазине. Вы обижаетесь на свои же взгляды на жизнь. И это не значит что продукт не выполняет своих функций, он их выполняет, но хуже чем товар более дорогой категории. Не всем нужен люкс.
Что бы сделать сайт блог не нужен профи, это не ракеты запускать и медицинское оборудование проектировать.
2) Истории из собеседований.
Иногда истории похожи на бред, но.
— Если HR менеджер задает технические вопросы это значит что он экономит время технических специалистов, которые устали выслушивать всех подряд. Это просто фильтр, который защищает рабочую силу от напрасной траты времени. Не надо обижаться, вопросы либо простые, на которые можно дать однозначный ответ и HR специалист сможет их проверить, либо они составлены не правильно. Но и это не ваша проблема, к вам на кухню никто не заходит что бы сказать как там все плохо, но когда туда не пускают вас, это огорчает.
HR специалист не обязан знать все и про всех, это невозможно, найм может вестись сразу по многим направлениям.
Не чините чужие «фильтры», ищете тот что пропустит вас.
3) — Но молодые специалисты это тоже знают. Почему мы должны платить вам на 15% больше?
— Но у меня семья, дети, ипотека… Да я и английский знаю.
Это что за ответ такой? Естественно вам откажут.
Вы заявляетесь к работодателю и говорите, дай мне больше денег, у меня проблемы, мне ведь нужнее чем другим.
И в тоже самое время люди пишут что «видят» на 20 шагов дальше чем их младшие коллеги, так вот об это и надо говорить на интервью, а не о своих проблемах.
Поставьте себя на место работодателя, это ведь тоже человек, какую команды вы хотели бы собрать, а хватит ли у вас средств и заказов что бы все это работало не в убыток.
Вопрос скорее о качестве и цене, а не возрасте и частных случаев прохождения интервью.
2) hr без знаний в предметной области — это вам не бомбила без шашечек. вы видимо считаете, что, в отличие от специалиста, кандидату не должно быть жаль своего личного времени на «интервью» c hr? ибо «работать в нашей фирме — такая честь...»
3) у меня уровень жизни такой, к которому привык я и мои близкие и, если это не дауншифт, он должен оставаться таким и впредь. т. е. качество моей жизни должно быть заложено в стоимость вашего продукта, а не наоборот. потому что, я работаю, чтобы жить, а не живу, как часто внушают молодым, чтобы работать.
3) Всё это работодателю в общем случае не интересно. Ему интересно какие преимущества его продукт получит, если заложить в его стоимость вашу (желаемую) зарплату. В общем и в целом, приводя какие-то "левые" по отношению к своей ценности для продукта аргументы, вы, как минимум, теряете позицию полноправного партнера по переговорам, становитесь просящей стороной, которая ничего особо ценного предложить не может. Говорить о своих расходах допустимо, по-моему, если работодатель, услышав желаемую зарплату задаёт вопросы типа: "Да куда тебе столько денег?!", но лучше при таких вопросах держаться от такого работодателя подальше.
Ну а то, что совок не умер и на периферии предлагают поработать на совесть за идею и интерес, при такой постановке вопроса как «интересно какие преимущества мой продукт получит» просто умиляют.
В противном случае непонятно, почему работодателю-капиталисту неинтересно сколько стоит на рынке трудовой ресурс.
С другой стороны вы часто видите в магазине, чтобы на продукте писали обоснование его цены? Т.е. мы «делаем офигительный хлеб и он стоит столько-то, потому что...» Да никогда. Все просто: купи и ощути разницу, или не ощути. Почему в этом смысле соискатель должен объясняться с работодателем?
А я думал, что предмет дискуссии в том, что допустимо ли в переговорах о сумме компенсации субъективно вербально обосновывать её своими финансовыми потребностями, или допустимы только ссылки на объективные товарно-денежные отношения на рынке труда в индустрии пускай и с субъективной оценкой своего места на нём.
Моя точка зрения в том, что обоснование в виде ссылок на имеющуюся или планируемую финансовую нагрузку недопустим. С обеих сторон, кстати.
Моя точка зрения в том, что обоснование в виде ссылок на имеющуюся или планируемую финансовую нагрузку недопустим. С обеих сторон, кстати.Допустимо ли требовать декретный отпуск по уходу за детьми? В конечном итоге эта причина сводится к финансовой.
Декретный отпуск — объективный фактор трудовых отношений, закрепленный действующим законодательством.
Очень велика. Законодатель не является непосредственной стороной объективных товарно-денежных отношений на рынке труда. К нему обращаются, когда рыночными методами свои интересы отстоять не получается в надежде (в теории), что он найдёт твои интересы совпадающими с долгосрочными интересами государства, например демографическими или инвестиционной привлекательности.
В противном случае непонятно, почему работодателю-капиталисту неинтересно сколько стоит на рынке трудовой ресурс.Ему именно что интересно сколько стоит трудовой ресурс! Но определяется это соотношением зарплат и умений. А ваша ипотека — его не волнует.
Хотя есть один ньюанс: работодатель может выступить гарантом и уменьшить вам процент на ипотеку — и тем самым обеспечить вам тот же уровень жизни, что и в других компаниях при меньших затратах на рекламу.
поскольку оплата моего труда целиком и полностью зависит от рынкаИменно так. На рынке есть работодатели и разработчики. Кто-то ничего не умеет, но готов работать за «похлёбку риса», кто-то — в одиночку может создать операционку за полгода, но и просит как целая команда разработчиков… а вот куда эти деньги он собирается пустить — работодателя не волнует в принципе. Его какое дело?
от того каким количеством материальных благ я смогу компенсировать потраченное на работу над продуктом времяСколько вы там получите материальных благ — работодателя не волнует и не должно волновать. Его волнует соотношение затрат на вас и получаемого от вас результата, не более того.
Чтобы быть успешным, нужно не столько образование и опыт, сколько энергия. В таких случаях я всегда говорю: «Одержимость важнее образования!». Это в плане достижения материальных благ и широкой известности. Пример, Крис Касперски (который недавно вроде как случайно(?) погиб) Но если целью является серьезный результат, то только тогда на первом месте будет качественное образование и только на втором одержимость. Однако в любом случае без одержимости делов не будет. Даёшь адекватную одержимость – вот главный лозунг.
Тем, у кого мало собственной энергии, можно дать совет. Энергию порождает Намерение и Воля. Ни то, ни другое энергии не требуют. Однако выбирать нужно ту деятельность, уже сам процесс от которой вызывает удовлетворение. Тогда можно рассчитывать на Результат.
Попутно замечу, что Желание Энергию не порождает, но Желание может служить основой Намерения, что немаловажно. Собственной Энергией обладает Страсть, хотя страсть может быть не только положительной, но отрицательной. Некоторые отрицательные эмоции тоже могут порождать Энергию. Такие как Месть, Зависть, Ненависть, Жадность и т.п. Но это уже скорее разрушительная энергия, чем созидательная, которая часто служит основой для Хищного Творчества или Творчества Хищников.
Что по сути статьи, но проблем будет меньше, если программировать ради удовольствия, а не за деньги, тем более которые не особо стремятся платить чуть ли не всем «кому за 30». Есть места, где хороших специалистов мало, например, у нас здесь в ЛНР / ДНР. Все одержимые уехали в Россию, профессиональной конкуренции практически нет, если не брать крупные фирмы в Донецке и Луганске (да и там вакансии имеются). Платят, правда, немного, зато есть свободное время, которое можно тратить на самообразование и программирование ради удовольствия. А стремиться надо к Интернет бизнесу, благо технические возможности для этого сейчас имеются. Единственное ограничение неразвитая межбанковская связь. Но этот вопрос, думаю, решится в ближайшие годы. А пока ничто не мешает самосовершенствоваться :).
вроде как случайно(?) погиб
не хочется «прикручивать политоту», как выразились на ксакепе, но слишком уж явным выглядит лаг между сливом ВикиЛикса и этим событием.
А на ВикиЛикс есть сливы по случаю подобных смертей хакеров?
Некоторые случаи уж очень подозрительны и описаны полицией как "застрелился".
По моему скромному разумению, в первую голову должен цениться опыт решения конкретных задач, а не ковыряние инструментом X во фреймворке Y
Если что, меня так научили в ВШ, если сейчас в ВШ учат как-то по-другому, извините.
Из основных ошибок при «лимоне» — не поели перед спортзалом, не попили в спортзале, не поели после спортзала.
Гуглить проблему самому — тут проблема в том, что для правильной постановки вопроса надо знать 90% ответа. Вы просто не знаете что гуглить.
После пары занятий с ней я неделю работал из дома, потому что ходить мог только через боль на одной ноге держась за стену. Так что тренер тренеру волк… А все было из побуждений составить программу и делать все правильно.
А вы обговаривали ваш уровень и ваши цели? Просто судя по тому, что вы говорите у вам составили программу на несколько более высокий уровень физ подготовки и с целью значимого увеличения показателей этой самой подготовки… Т.е. вам дали интенсивную программу и ваше состояние по её результатам — вполне корректное (нужно было ещё питание сбалансировать и держать планку и через месяц-другой вы бы этот уровень нагрузки не замечали).
Я это все к тому, что все тренеры одинаково полезны и можно нарваться и на такую (была представлена как мастер спорта где-то там в чем-то там, сейчас не припомню даже).
И вы ещё удивляетесь результату?
- она МС (ей сложно рассчитывать на обывателя, она привыкла к спортсменам)
- был офигенный перерыв (который вы сами задолбаетесь учитывать… я бы при таком перерыве все результаты кроме остаточной мышечной памяти свёл в ноль… которая даст бонус только в скорости освоения, но не в объёме нагрузки)
PS и да — магний надо пить! Магний!.. ну и ещё можно белков-кальция и прочих необходимых микроэлементов...
Был перерыв, да. Поэтому вводные данные для нее были такие: начать абсолютно с нуля.
Я просто рассказал про прошлый опыт встречи с «первоклассным тренером», дабы показать что можно нарваться и на такие чудесные последствия от общения с не очень компетентными в своей области людьми.
Ни в прошлые, ни в последующие разы (от этого случая) не было такой проблемы.
Да, мышцы болели, да от этого никуда, но так чтобы до туалета 10 минут брести… никогда.
После пары занятий с ней я неделю работал из дома, потому что ходить мог только через боль на одной ноге держась за стену
Ага, я тоже когда второй раз начинал имел тот же опыт.
В первый день качали ноги — мышца так задубела, что уже даже не болела, просто невозможно было согнуть ногу.
Потом спину, бицепс — не мог за ухом почесать.
На каждую часть тела 2-3 таких тренировки и пройдет. Можно BCAA попить паралельно, чтобы мышцы быстрее восстановились
Вот именно: тренер нужен, чтобы просто грамотно научиться делать упражнения и составить индивидуальный план. Но в сложных случаях тренер, скорее всего, помочь не сможет из-за недостаточной квалификации.
Чаще всего тренер в клубе — это бывший мастер спорта (в лучшем случае) или просто человек с хорошими физическими задатками, который добился значительных результатов и теперь решил, что может и других людей сделать такими же. Но при этом этот человек не имеет медицинского образования, без которого не сможет помочь человеку, если проблема лежит, например, в области эндокринологии.
Также стоит отметить, что тренировка спортсменов и тренировка обычных людей — это совершенно разные вещи, потому что обычных людей в профессиональном спорте нет. Профессиональный спорт ставит задачу отобрать лучших и выжать из них максимум. Поэтому тренер — мастер спорта оказывается просто неспособен разобраться с проблемами обычного человека, потому что в спорте таких людей просто отсеивали как неспособных.
Ну и просто психология — проецирование собственного опыта тренера на других: "я смог, и ты сможешь", что неверно.
Вот и остаётся единственный вариант штудировать литературу и гуглить.
Одно дело когда кмс по поверлифтингу.
Другое дело когда это тренер с 15 летним стажем закончивший лесгафта.
Отзывы опять же.
Никтож не говорит что надо идти к «какому-то тренеру», право выбора и анализа к кому идти — на фига дадено?
Конечно, не все молодые и зелёные коллективы готовы взять к себе программиста старше себя, тем более «тётеньку» в моём случае. Особенно тяжко было, когда сменила специализацию и хотела пойти на позицию джуниора — поучиться в бою, так сказать. 100% отказов получила. И что? Ушла во фриланс, набралась опыта, обзавелась хорошим портфолио. Когда решила вернуться на постоянку, ещё и выбирала из нескольких офферов.
А когда я стану старая, осяду на каком-нибудь Апворке и перееду в тропический климат. :)
В сорок лет жизнь только начинается (с) одно очень известное кино.
Линн, 41 год.
Я вам сейчас страшную вещь скажу: нет никакого тоннеля, есть только эффект туннельного зрения.
Учите английский, участвуйте в open source проектах. Создайте парочку своих на Github. Лучше всего по теме, в которой глубоко понимаете. Когда работали юристом, были у вас какие-нибудь пожелания на тему: а вот если бы была такая программа, или можно было бы сделать вот так и так, было бы очень круто? Вот вам и тема.
Ваш опыт в юриспруденции бесценен, потому что очень мало кто из инженеров вообще способен мыслить юридическими понятиями. И бывает, очень больно на этом обжигаются.
А карьеру поменять никогда не поздно. Я это делал в 25, в 28, в 33 (с горкой); скоро 40 и крепнет ощущение, что опять надо что-то делать.
Причем ведь не говорят, почему именно не берут, и в этом самое неприятное. Под пытками не выдадут. Обычно просто тупо погружаются в вечное молчание. Редко-редко пришлют отказ на е-майл.
Желаю вам проявить бешеное упорство. Посетить ВСЕ фирмы, которые существуют в вашем регионе. Откликнуться на ВСЕ вакансии, которые могут подойти. Посетить ВСЕ собеседования, на которые вас пригласят. Прорешать ВСЕ тестовые задания, которые вам дадут. Добиться от ВСЕХ, почему вам отказывают. Удачи!
Тут многие пишут, что один из вариантов развития карьеры — это уход в свой стартап, и дело тут не только в выходе из отношений «работодатель- сотрудник». Если я верю, что могу создать приличный продукт, зачем мне тратить время на попытку вписать себя в шаблон (изучив новомодный фреймворк или вспомнив университетский курс алгоритмов?) Но и без стартапа это можно, хоть и сложно: надо искать место, где ваша уникальная комбинация навыков выстрелит. Ничего ведь не проходит задаром: для кого-то окажется очень важным именно сочетание ваших навыков программирования и юриспруденции. Может, вы ещё что-нибудь умеете, например, вязать свитерочки, а у кого-то фирма по производству программируемых вязальных машин, и даже если программист вы средненький, эффект от сочетания окажется важнее любого конкретного провала.
Это сложный путь, но в вашем случае, я бы сказал, потенциально самый выигрышный, потому что в крысиной гонке вам не победить.
а продажники больше треплобезумцы :))
и выталкать продукт 1 крайне сложно
Мне же, чтобы дорасти до минимального «проходного» уровня Яндекса (я трезво оцениваю свои знания) необходимо 2-3 года интенсивной подготовки.
Мне кажется, что у автора серьезные проблемы с самооценкой. К сожалению, универсального рецепта нет. Кому-то нужно просто начать ходить по собеседованиям, чтобы убедиться своей ошибочной оценке, а кому-то идти в команду с более опытными коллегами, чтобы учиться у них. В любом случае, когда жизнь тебе бросает вызов, всегда есть два пути. И лёгкий путь не всегда правильный.
Роман, 38 лет
Из вашего прошлого ответа могу сделать вывод, что офферов было два-три, как минимум. Для этого нужно было пройти не менее 40 собеседований.
Удивился и ужаснулся.
Про этот печальный опыт я писал ранее на Хабре: https://habrahabr.ru/post/285600/
Не считаю себя совсем уж никудышным специалистом, но наверно, работодатели иногда читают у меня в глазах полное равнодушие и скуку и не делают офер. Возможно, я просто не умею себя подать и продать. А возможно, по формальным критериям где-то не прохожу.
Те же, кто делают офер, потом не хотят со мной расставаться.
читают у меня в глазах полное равнодушие и скуку и не делают оферНо зачем ходить на собеседование, если скука и полное равнодушие?
Но тем не менее я прочитал вашу статью от 2013 года. Вопрос — вы определились-то со специализацией? или до сих пор не знаете, что вам интересно?
В среднем — это больше, чем по одному собеседованию в месяц в течение четырёх лет)) Похоже, что вы любите ходить по собеседованиям))
В период поиска работы я очень интенсивно ходил по собеседованиям, естественно. Не раз в месяц, а несколько раз в неделю. А когда работа уже есть и она меня устраивает, в принципе — зачем мне ходить куда-то?
Но зачем ходить на собеседование, если скука и полное равнодушие?
Я не знаю заранее, что будет в компании, куда я приду и кого я там встречу. Иногда это разочаровывает, но не ходить я не мог — нельзя упускать ни единого шанса.
Но тем не менее я прочитал вашу статью от 2013 года. Вопрос — вы определились-то со специализацией? или до сих пор не знаете, что вам интересно?
Я по факту определился со специализацией, точнее, за меня ее определили — я программист С++ с 2000 года. Нравится ли мне это или нет? Ну это не противно по крайней мере. И иногда даже доставляет удовольствие. Могло быть и хуже :) По сути до сих пор не знаю, что могло бы быть интереснее программирования на С++.
Затем, например, что надо как КВС — постоянно мониторить окружающее пространство и постоянно отслеживать потенциальные аэродромы для внештатной посадки.
Если вы ответили «да», срочно телеграфируйте адрес и быстро, решительно отсыпьте — я немедля вылетаю первым рейсом и скуплю оптом всё, что у вас там есть\осталось.
то после 40 будете работать на себя, а не на «дядю».
Работать на себя — это не столько программировать, сколько заниматься бизнесом, даже если речь о простом фрилансе. Не, ну есть вариант типа основать фирму, нанять генерального директора и остальных, а самому в эту фирму программистом устроиться. Но херня получается — пробовал, даже если только генеральный знает, что один из программистов учредитель фирмы.
Программирование может быть как денежный вклад в банк
Вкладами занимаются инвесторы, бизнесмены, а не работники. И слово "пенсия" тут не уместно.
Но все же на пенсии я хотел бы заняться своим проектом наконец, на который сейчас не хватает времени. Пусть он будет не так успешен, как проект, над которым я сейчас работаю. :)
Если лично вам нравится жить в каком-нибудь месте без инфраструктуры, то учитывайте, что не все такие.
Так говорите, что хотите бросить работу программистом и основать какой-то бизнес, может даже с программированием не связанный вообще.
— Вам уже 45? Но у нас коллектив очень молодой. Вы уверены, что хотели бы у нас работать?
Из свежего опыта прохождения собеседований в 42: из примерно 15 собеседований за последний месяц только один раз был подобный вопрос и то в смысле будет ли мне комфортно работать в команде, где большинство, включая непосредственное руководство, лет на 15 моложе. Ответ вроде "мне важны компетенции, а не возраст" вполне работодателя удовлетворил.
Куда деваются программисты после 40