Comments 354
AND `hash`='".$_COOKIE['auth']
sql injection
"AND `user_agent`='".$_SERVER['HTTP_USER_AGENT']."' ".
sql injection
Хотя это конечно очень не очевидно для стороннего человека, что такое вообще есть. Не зная исходников :)
На самом деле, сильно код не поменяется. Ну будет mysql_real_escape_string($_SERVER['HTTP_USER_AGENT']). Читать сложнее, пример же больше как учебный писался. Но в целом да, лучше сделать так. Согласен абсолютно здесь.
Примерно знать про security through obscurity, не слышать про kali, но при этом писать обучающую статью "Надежная авторизация". Вы серьезно?
А вообще, для начала можно было открыть код любого нормального фреймворка и посмотреть, как реализована авторизация в нем.
Наверное вы читали подобное предупреждение:
«Не забудьте добавить валидацию и проверки на ошибки в реальном приложении.»
или
«Безопасность отдаётся на личное изучение читателя»
или
«Конечно, Вам придётся писать тесты»
Этим и отличается хороший учебный материал от плохого.
А я всегда выполняю проверки на ошибки. То, что тут их не оказалось — это не система. А разовый недосмотр :)
Про безопасность — тоже очень мудро, пока сам шишек не набьёшь, не поймёшь, что нужно проверять, когда и зачем. Тоже кстати был опыт, на своих ошибках учился.
Насчёт тестов — пока как-то судьба миловала. Видимо, проекты не столь большие и сложные, обхожусь без них. Но иногда приходится прибегать к ухищрениям и разбивать алгоритм на составные этапы, тестируя каждый из них в отдельности, и лишь потом переходя к следующему, иначе просто велик риск получить полностью нерабочий код, отчаяться и опустить руки.
PDO всё же удобнее: легко менять драйвер без внесения изменений в код.А зачем Вам вообще менять драйвер? Обычно БД выбирается один раз при старте проекта, и больше не меняется уже. Если вы, допустим, фрилансер — то и вовсе наверное одну и ту же предпочтёте использовать, ибо так проще. Соответственно, и драйвер будет один и тот же. Разве может быть драйвер быстрее и надёжнее нативного?
Обычно БД выбирается один раз при старте проекта, и больше не меняется уже.
Обычно это работает если СУБД выбирается из принципа упрощения разработки, чтобы не морочиться с хранением и получением структурированных и не очень данных по принципу "без СУБД надо будет много кода писать, а эту СУБД я лучшего всего знаю". Если же СУБД выбирается по требованиям к проекту типа "обеспечить максимальную скорость записи с синхронной репликацией в дата-центры по всей Земле с соблюдением транзакционной целостности на любой момент времени", то проект может переезжать по нескольку раз с одной СУБД на другую в зависимости от того, какая здесь и сейчас показывает лучшие результаты (недавно показательный перевод поста про переезд Uber на MySQL был).
При одном условии это делается без особых проблем — код работы с базой максимально переносим, переезд не будет сравним по трудозатратам с написанием с нуля, а то и больше.
ORM нужны больше для отделения данных от storage layer, то есть мы оперируем не запросами к базе, а объектами, а те сами себя получают и сохраняют (через ещё одну прослойку), если я правильно понимаю. Но это больше делается ради привычности кода (для тех, кто любит ООП) и ради общей красоты.
А переезд из-за того, что возможностей движка мало… Я не знаю. Наверное, должен быть реально гигантский проект, чтобы упереться в потолок того же MySQL. Плюс есть MariaDB, которая несколько производительнее, но работает с тем же API абсолютно. И потом, многое можно решить, взяв более мощное железо, либо докупив серверов. Это может оказаться сильно выгоднее, чем переписывать код.
И вообще, прелесть ORM я понимаю, прелесть PDO — вообще нет.
И что, переписывать весь код?
Таки да! Создать отдельную ветку и переписывать все вызовы к базе. Не весь проект конечно с нуля переписать, но процентов 30-40. Либо создать родительский абстрактный класс или интерфеййс, от него отнаследоваться, и старую реализацию оставить параллельно с новой. Вот поэтому и не надо такие переезды делать, себе дороже :)
И я бы не сказал, что PDO сильно медленнее нативного.
Ну чуть-чуть всё же медленнее должен быть. Он ведь обращается к базе не напрямую, а через ещё один драйвер по сути.
И правда смотрится изящно. Плюсанул бы вам, жаль не могу :)
в целом рановато вам еще рассуждать о безопасности, на данный момент статья — набор вредных советов из 1999 года.
Наконец, я рассуждал про безопасность на уровне браузера. Не все браузеры дают менять юзер-агент, а те, что дают — там надо ещё найти, где это делается. Всё же такой код безопаснее стандартного варианта. Не забывайте, что взломщик не знает исходников.
Идентификация — представление пользователя, "я — такой-то" (юзернейм в форме логина)
Аутентификация — доказательство личности идентифицированного пользователя, "и вот секрет, который знаю только я" (пароль в форме логина)
Авторизация — проверка прав пользователя на осуществление конкретного действия, "мы верим, что вы "юзернейм", но вы не имеет права на действия, которое пытаетесь совершить" (бан по юзернейму или невозможность редактировать комментарии никем кроме автора и админов)
Это если "на пальцах".
Спасибо, но это уж очень дотошно… Зачем разбивать действие по заполнению простой формы из двух полей на два разных понятия? Насчёт авторизации — я прекрасно знаком и с этим значением термина, да. Проверка прав доступа, уровни, привилегии) Но это из другой области совсем.
Смотрите, форму, куда вы вбиваете пароль — в веб всё время называют формой авторизации. Никто не называет её "формой аутентификации", я по крайней мере такого не слышал.
1. Идентификация вас по имени пользователя, которое вы ввели в поле «логин»
2. Аутентификация — проверка, правильный ли пароль был введен в поле «пароль»
3. Авторизация — предоставление доступа в соответствии с вашими правами.
Все логично, так как с точки зрения пользователя он в итоге авторизуется на сервисе для доступа к своим ресурсам. Не писать же теперь «форма идентификации, аутентификации и авторизации», ведь аутентификация и идентификация это в данном случае просто компоненты необходимые для авторизации.
Давайте на хабре будем использовать термины правильно.
1. Многие сидят за NAT.
2. Некоторые провайдеры используют короткие сессии, выделяя каждый раз новый IP клиенту.
3. У клиента может быть несколько провайдеров с балансировкой траффика.
Насчёт пункта 3 — не встречал, и даже не очень знаю, как такое реализовать, а 1 и 2 сплошь и рядом, да.
Но надо всё-таки понимать, что я не уникальность клиента по IP определяю. ВК ведь тоже IP берёт в расчёт, и при заходе откуда-нибудь из-за границы просит подтвердить номер телефона (раньше просил капчу ввести). Только вчера на эту особенность наткнулся при смене хостинга на заграничный, токен перестал работать, пришлось проходить валидацию.
Насчёт пункта 3 — не встречал, и даже не очень знаю, как такое реализоватьметодов — десятки. Обобщенно — load balancing.
Да и даже проще: какой-нибудь человек со смартфоном, гуляющей по квартире — может легко метаться между домашней wifi сетью через наземного провайдера и интернетом опсоса — как минимум метания между двумя разными адресами.
mysql_query — вы серьёзно? Почитайте на досуге.Суть-то вообще не в этом. А как сделать авторизацию, работающую по лучшим принципам, так сказать. С ведением логов заходов, возможностью «прибивать» сессии на разных устройствах, и прочее.
А что с mysql_query не так? Стандартная функция для запроса к mysql, вроде как.
mysql_query очень не так, хотя бы потому что Warning This extension was deprecated in PHP 5.5.0, and it was removed in PHP 7.0.0. Instead, the MySQLi or PDO_MySQL extension should be used.
Так а в чём огурцы-то? Вот вы говорите, в таком-то фреймворке/CMS реализовано лучше. Так расскажите, в каком, и чем именно лучше, давайте обсудим. Надо позицию ведь хоть немного аргументировать.
И я не очень уверен, что все минусующие самостоятельно за вечер написали бы более грамотную реализацию (не глядя в сторонний код).
Все. На этом уже надо ставить точку.
Кстати половина минусующих может быть вообще не программисты, а специалисты по безопасности, которые не пишут код -)
А в чём дыры-то? Отсутствие вызова mysql_real_escape_string в паре мест (учитывая, что это просто не пришло в голову, о другом были мысли при разработке)? Ну это уже слишком толсто, ребят. Не про это ведь текст. Или вообще никто не читает, а только комменты почитать заходят?
Потому что огурцы вредны. А данный код, если без инъекций — вроде как не особо… Хотя может, я ещё чего-то не учитываю)
А так — да, первое — инъекции, второе — привязка к ip
В итоге шикарная яичница, только яйца просрочены и масло прогорклое…
Хотя про огурцы я конечно погорячился, они стоят на втором месте после воды по причине смертности… ведь все умершие хоть раз но ели огурцы…
А с привязкой что плохого? Она с одной стороны позволяет сработать как некоторый триггер ("айпи поменялся — значит, что-то изменилось, повод перепройти авторизацию/аутентификацию"). Но при этом это не принуждает вручную заполнять заново форму.
Вы никогда не замечали, что если взять телефон с открытым в браузере вк, выйти из дома, отключившись от вайфай, пройтись по улице, а потом обновить страницу — то у вас будет 1-2 редиректа с передачей в GET-параметре какого-то хэш-кода? И не говорите после этого, что там нет привязки по IP. Ещё как есть :)
\PDO, то к вашему коду на порядок меньше придирались.Я почитал специально про PDO. Про синтаксис со знаками вопроса, как в JDBC на Java (в Android и Spring, к примеру). Знакомо. Но как по мне, удобства это не прибавляет.
Пишут, что там автоматически производится экранирование, и таким образом защита от инъекций идёт из коробки… Согласен, так проще, чем каждый раз вручную. Зато вручную контроля больше. Можно более жёсткие преобразования делать над входными данными, чем просто экранирование.
Нет, никто не мешает совместить это с PDO, но производительность чуть просядет, если преобразование делать дважды для каждого аргумента.
Ну и на самом деле, меня просто так учили. В хорошем учебнике от Bhv-Петербург по PHP5, который ещё 2005 года издания, вроде (я его читал в 2006-2007) использовалось только mysql расширение. И оно мне очень нравится своей простотой и интуитивностью, чего уж там.
К слову, я долго гуглил, и не нашёл серьёзных "дыр" в нём, разве что менее богатый функционал и отсутствие новых функций вроде поддержки транзакций. Но там для начала движок СУБД должен поддерживать транзакции (не любой поддерживает!), а если он их поддерживает — можно их и через mysql_query точно так же инициировать, выполнять какие-то запросы, и завершать.
Также есть такой момент, что mysqli умеет работать с хранимыми процедурами. В принципе, я понимаю, что имеется в виду — чтобы сразу иметь возможность получать результат в переменную. Но мне на практике хватало создать хранимую процедуру через phpMyAdmin, вызвать её в нужных местах в самих SQL-запросах, и получить уже готовый результат. То есть это тоже как бы не то, без чего нельзя жить :)
Спасибо, интересный сайт. Но там опять про 7.1, прямо начиная с главной :) Нет у вас каких-нибудь Best Practices под PHP 5.3-5.4?
Но всё равно почитаю. Интересно же, что рекомендуют в качестве советов и правил хорошего стиля.
Не люблю, когда меня к чему-то принуждает разработчик платформы. И только. Так ничего против семёрки не имею.
Это знаете, как с NetBeans. Вот стоит у меня версия 6.8, всем она нравится… Но нет под неё расширений. Ни для CodeIgniter (вообще), ни под новый клиент SVN (а старый не поддерживается серверами, небезопасным считается). И приходится либо ставить что-то новее, либо без поддержки SVN сидеть. А казалось бы, что стоило авторам разрешить установку новой версии модуля (всё равно API небось не поменялся существенно) на старую версию IDE.
У меня стоит TortoiseSVN, к счастью, версия 1.7 на моей ОС поддерживается ещё. Но хочется-то сразу из IDE чтобы было)) К хорошему быстро привыкаешь. Хотя конечно это всё ерунда, можно без проблем работать и в 7.х, или какие уже там, может и восьмые.
Просто меня в момент выхода 7.0 добили две вещи: огромное количество варнингов к моему Java коду, которые я понятия не имел, как исправить, чтобы их стало хотя бы на треть меньше, и то, что они полностью убили встроенный Javadoc. Все имена переменных в выпадающих элементах справки поменялись на i1, i2, i3… Помучился неделю и снёс. Возможно, к версии так 7.4 это и исправили. Но вообще-то такое сразу в идеале должно работать. Не RC ведь ставил, релиз нормальный.
Ну когда их было в прошлой версии 0, а стало over 80 штук (на файл, где около 1500 строк кода) — это не нормально… И я честно пытался рефакторить код. Избавился от силы штук от 4-5.
Тем более, это не варнинг в стиле "всё плохо, красная иконка", это предупреждения о нарушении некоего стайлгайда в области композиции классов. И они там были буквально на каждый чих.
Код не был кстати настолько ужасен, это была курсовая. Будь там всё плохо — мне бы препод раньше вставил за это :)
Насчёт движков — InnoDB поддерживает, MyISAM, вроде как, нет (раньше точно не умел).
все минусующие самостоятельно за вечер написали бы более грамотную реализацию
Штука в том, что писать собственный механизм авторизации "за один вечер" в принципе не стоит. Гораздо правильнее использовать проверенные решения (например, входящие в состав используемого фреймворка) и не писать велосипеды.
И я не очень уверен, что все минусующие самостоятельно за вечер написали бы более грамотную реализацию (не глядя в сторонний код).
Я бы не написал. Но я бы и не взялся. Зачем, если уже есть работающие готовые решения?
Есть ощущение что статья опоздала лет на 10. MySQL PDO уже давно пора освоить. Я это к тому что mysql_result() в php7 работать не будет.
Есть ещё правда mysqli, но лично мне с этим интерфейсом менее удобно работать. Хотя говорят, он лучше. Возможно, дело привычки просто.
Я до сих пор на всех серверах благополучно 5.3 использую.Сегодня можно благополучно пользоваться бричками, как транспортом, но почему-то людям больше нравятся автомобили.
Спасибо, обязательно почитаю. Люблю статьи в таком формате.
Насчёт бенчмарков — вы уверены, что эти цифры получены не только за счёт оптимизаций в ООП и скалярного тайпхинтинга? Просто не очень верится, что всё остальное можно было ускорить, а не сделать медленнее, тем более, что внутренней кодировкой вроде как стал двухбайтовый юникод (а раньше однобайтовая была). Хотя возможно, это ещё с версии 5.6, я не помню, увы...
И была даже статья на Хабре про то, что "PHP6 не будет", там писали, что у авторов возникли огромные проблемы со скоростью при попытке перевести все строковые функции на работу с двухбайтовой кодировкой. В итоге оставили всё как есть, а чуть оптимизированную версию выпустили как 5.5.
Тайпхинтинг, ИМХО, должен ускорять процесс. Потому что он позволяет заранее рассчитать необходимые объёмы памяти под данные, и избавиться от кучи динамических проверок (которые неизбежны, когда переменная часто меняет тип). Опять же, где-то читал в авторитетном источнике, что это даёт большой прирост в скорости :)
tl;dr:
Today, the use of scalar and strict types in PHP7 does not enhance performance.
Because scalar type hints guarantee that a passed argument will be of a certain type within a function body (at least initially), this could be used in the Zend Engine for optimisations. For example, if a function takes two float-hinted arguments and does arithmetic with them, there is no need for the arithmetic operators to check the types of their operands.
In previous version of php there was no way to know what kind of parameter could be passed to a function, which makes really hard to have JIT compilation approach to achieve superior performance, like facebook's HHVM do.
@ircmaxell in his blog mentions the possibility of bringing all this to the next level with native compilation, which would be even better than JIT.
Последний абзац особенно здесь интересен. Если сделать компиляцию в нативный код (в strict mode-то кто мешает, хотя бы на уровне отдельных функций), то будет очень быстро. То есть как раз речь о том, чтобы скомпилировать один раз, и использовать постоянно.
Как минимум со времён 5.3 оптимизировали работу с массивами, если не трогать ООП.
В итоге оставили всё как есть, а чуть оптимизированную версию выпустили как 5.5.
В этом отношении и в 7 оставили всё как есть и пока планов по изменению не будет.
А вообще проект на Symfony 1 с минимальными правками самого фреймворка на 7.0 стал показывать процентов на 30 меньшее время генерации ответа по сложным запросам и процентов на 70 меньшее потребление памяти по сравнению с 5.3.
Так вы не сравнивайте Symfony (один из самых тяжёлых фреймворков) с легковесными проектами, где PHP только выборку из БД делает да результаты в виде JSON возвращает (ну максимум — какой-то HTML генерирует для выдачи в браузер). Там не так всё медленно, чтобы видеть прирост, мне кажется. Про массивы выше уже мне написали — но это только на очень большом числе итераций можно заметить, на малых объёмах сильно роли не сыграет.
На самом деле, на очень маленьких проектах, и если хостинг не очень слабый, разницы можно не ощутить. У меня была даже совсем странная история, когда на простом веб-приложении (в рамках одного веб-хостинга с возможностью переключать версии) 5.3 работал быстрее чем 5.4, а 5.2 ещё быстрее, чем 5.3. И в целом, это может даже быть объяснимо: меньше функций, меньше синтаксических возможностей — меньше потребление RAM, где-то быстрее интерпретация. Хотя может, я и не прав. Трудно сказать.
Между 5.4 и 5.6 я тоже разницу ощущаю с трудом (хотя 5.6 вроде как побыстрее, но может, это эффект плацебо в действии такой).
Я до сих пор на всех серверах благополучно 5.3 использую.
Вы это серьёзно? Статья по безопасности с целевой версией языка, поддержка которой полностью, включая закрытие уязвимостей, прекращена 2,5 года назад? Даже для 5.6 активная поддержка прекращена уже, только уязвимости будут закрывать ещё какое-то время.
Конечно, серьёзно. Статья не по безопасности вообще, а с идеей, как немного улучшить стандартную базовую авторизацию, которую предлагают в простых учебниках начинающим.
Какая разница, какая версия? Если использовать общий и простой стиль написания кода, то код одинаково будет работать на любой версии (и везде без ошибок и предупреждений). Ну кроме расширения mysql, тут да, проблема.
А что такое composer и зачем он вообще?)
Это не поделки, а вполне реально работающие проекты, между прочим. Этот модуль довольно простой, но даже в нём была применена пара оригинальных фишек (пароль в открытом виде не хранится нигде, файл security инклюдится во все разделы как второй механизм проверки в придачу к обычной проверке $_SESSION['user_id']). У меня есть разработки существенно сложнее, естественно. Просто решил поделиться вот этой, подумал, кому-то будет интересно… Может, я ошибся, и это тривиально для всех.
готовые, безопасные приемы
В чём они безопаснее? Использование готового — обычно отупляет и отучает думать и писать код самостоятельно. А то да, встречал уже одного товарища, который библиотеку для авторизации на гитхабе нагуглил, вместо того, чтобы написать самому за пару часов.
и не пробовать «новые» аспекты
Не, попробовать-то можно, ради интереса. Только не надо всех обращать в свою религию, и убеждать, что эти аспекты жизненно важны и необходимы)
Извините, почему же? А импорт пакетов в Java в начале файла класса — не тупость? А объявление неймспейса в C++? Не будьте так категоричны. Это всего одна строка, а файлов, куда надо её добавить (и больше не убирать) — штук 5-6. Прямо так сложно, Боже мой.
Абсолютно ничем.
Если вы про многократный инклюд одного и того же — require_once() есть на этот случай. Ну и при грамотной архитектуре все инклюды идут в главном модуле, а не где попадя.
Абсолютно ничем.
То есть тот малозначительный факт, что одно выполняет код, а другое — нет, вас не смущает?
Иногда такое выполнение бывает очень удобно. Смотрите это как на вызов внешней процедуры с глобальными параметрами.
Вот нужно мне кусок шаблона вставить (календарь вывести или виджет какой-то). Что проще всего для этого использовать? Конечно, require или include. И уже там писать макароны, а не засорять основной файл-"каркас".
Иногда такое выполнение бывает очень удобно.
Никто и не спорит с тем, что удобно. Спорят с тем, что include и import — разные вещи.
Смотрите это как на вызов внешней процедуры с глобальными параметрами.
Ну то есть как на абсолютное зло?
Вот нужно мне кусок шаблона вставить (календарь вывести или виджет какой-то). Что проще всего для этого использовать? Конечно, require или include.
Проще — возможно (вам). Правильнее? Далеко не факт, я всегда предпочту явный вызов кода.
Собственно, с этого же все и начиналось — правильно ли подключать проверку безопасности через include. Нет, неправильно — потому что можно забыть сделать include и кусок останется незащищенным. Правильно ли подключать через import и вызов кода? Да тоже не очень, потому что можно забыть вызов.
Правильно взять фреймворк, который позволяет подключать промежуточные обработчики на каждый вызов безотносительно того, что там написано в файле, и включить механизмы безопасности в него.
При грамотной архитектуре (да и вообще в любом проекте в 2017ом году) инклуд только один на весь проект — require '... autoload.php'; — остальное декларативные методы ссылок на нужные вендорные (и не только) либы.
Автозагрузку функций пока ещё не сделали.
И что? Вы документацию композера пропустили, где для этого есть специально прописанная секция files? ;)
Прошу заметить, что в проекте как был, так и остаётся один единственный require. Моих слов это не отменяет.
Я где-то в документации читал, что использование автозагрузки через регистрацию функции-автозагрузчика может давать сильные тормоза по сравнению с её неиспользованием. Вы не могли бы прокомментировать как-то этот момент?
И потом, вы сейчас говорите про проект, написанный в объектном стиле. Если это не так, зачем нам autoload?
Просто я бы не согласился, что проект, не использующий ООП — сразу с порога проект с плохой архитектурой. Смотря как сделано...
Вы не могли бы прокомментировать как-то этот момент?
Нет, десятитысячные доли секунд на виртуалках за 100 рублей\мес меня мало волнуют =)
И потом, вы сейчас говорите про проект, написанный в объектном стиле. Если это не так, зачем нам autoload?
А зачем писать как-то иначе и жрать кактусы? Есть инструмент — используйте, если инструмент не достаточно удобен, значит он не для этого.
Просто я бы не согласился, что проект, не использующий ООП — сразу с порога проект с плохой архитектурой. Смотря как сделано...
Я бы посмотрел на проекты с более чем 20ю метрами исходного кода в процедурном стиле, а ещё такой грамотный по архитектуре… Примеров не найдёте? Ну таких, чтобы сразу в помойку не выкидывать, а чуть-чуть повосхищаться дерзостью автора.
ООП, хоть и критикуемый, но по праву заслужил свои позиции. Действительно крупные проекты, ну или чуть круче лендингов при других подходах слабореализуемы.
Почему кактусы? Для меня, например, объектный стиль менее удобен. Существенно причём.
А не подскажете, где такие дешёвые виртуалки? Я вроде искал варианты, и везде намного дороже всё...
Действительно крупные проекты, ну или чуть круче лендингов при других подходах слабореализуемы.
Ну 20 метров — это очень много. Таких у меня, я думаю, нет. Но и круче лендингов я делал много разных вещей, и процедурный стиль там более чем уместен. Более того, если оформить всё чуть опрятнее и задействовать разделение на файлы и шаблонизацию более активно, то и в команде над таким кодом работать совсем не так болезненно будет, как вы думаете.
Пока их совсем мало — довольно удобно.
Я понимаю, что выглядит обычно хуже (хотя бы потому, что глобальная область видимости — это фу), но зато сразу снимается ответственность за написание красивой архитектуры (которая автоматом появляется, когда создаёшь модель классов).
Объектный код — к нему ведь при оценке другие программисты придираются не меньше, даже больше часто :)
Примерно представляю, про что речь...) Но index.php с кучей роутов — это тоже та ещё жесть.
Я раньше делал архитектуру двух типов, на самом деле (оба страшно выглядели, но оно более-менее работало). Первый вариант — это куча макарон (шаблон и пара блоков с бизнес-логикой в одном файле) на каждую крупную страницу системы (например, кабинет администратора, чтобы уровень детализации был понятен). При этом данные при загрузке получаются синхронно, чтобы юзер не ждал, параллельно реализуются точки отдачи данных в JSON в виде отдельных файлов — для AJAX.
Второй подход — как первый, но в этом случае синхронно ничего не загружается, чтобы избежать макарон, всё загружается только через JSON из JavaScript. Выглядит красивее, по ощущениям от использования приложения — похуже.
В последнем проекте применил вообще немного сумбурный и слегка нелогичный метод с помещением скриптов выборки данных в отдельные файлы. При этом эти файлы используются и при получении данных аяксом, и через инклюды (в файлах есть ветвления). Формат отдачи и сам набор данных, например, все ли строки отдавать или с фильтрацией — определяется через переменную, то есть перед инклюдом, грубо говоря, ставятся некоторые флаги прямо в $_GET массив. Звучит не очень, но это позволило вынести кучу кода из основного файла, и слегка уменьшить число файлов-обработчиков (не в два раза, но всё-таки).
А импорт пакетов в Java в начале файла класса — не тупость? А объявление неймспейса в C++?
Там такую необходимость даже специально проигнорировать не получится — компилятор/линковщик напомнит.
А то да, встречал уже одного товарища, который библиотеку для авторизации на гитхабе нагуглил, вместо того, чтобы написать самому за пару часов
Ну, вот вы написали, а толку? Дыра на дыре сидит и дырой погоняет. Причём вы ещё и принципиально отказываетесь понимать что вам говорят. Ваш товарищ поступил гораздо мудрее.
(это добрая шутка если что)
К чему в вашем предложении слово "современного"? Как будто понятие безопасности и устойчивости к разным угрозам зависит от времени.
Код посмотрю, спасибо. Пока из описания понял, что это некая надстройка над модулями Zend… В котором уже и так есть что-то для аутентификации.
Я не сам это придумал. Функция md5 используется, например, в CMS Joomla 1.5 для хранения хэшей паролей (собственно, сам формат хранения и идею делать равными по длине соль и хэш я взял оттуда в своё время). Более того, в другой CMS (не очень популярной, типа Street CMS) я видел ещё менее стойкое шифрование — там очень короткие на вид были строки.
Выдержка с php.com:
«Why are common hashing functions such as md5() and sha1() unsuitable for passwords?
Hashing algorithms such as MD5, SHA1 and SHA256 are designed to be very fast and efficient. With modern techniques and computer equipment, it has become trivial to „brute force“ the output of these algorithms, in order to determine the original input.
Because of how quickly a modern computer can „reverse“ these hashing algorithms, many security professionals strongly suggest against their use for password hashing.»
Я читал опять же статьи на эту тему, — какой нужен объём диска, сколько памяти, и сколько процессорного времени для подбора хэшей MD5. Выходило довольно много. Под 300-450 Gb радужных таблиц на диске (тогда как 500-гигабайтный USB жёсткий диск стоил довольно прилично, хоть и не заоблачно, и не каждый мог позволить его пустить на такое даже при большом желании), плюс существенное время, исчисляемое сутками. И то там рассматривалось вскрытие хэшей, полученных без соли, и вроде даже частично содержащих слова.
Так что мне кажется, авторы слегка перестраховываются (как и все специалисты по криптографии), играя на опережение, и предупреждая всех заранее, чтобы потом всех не застало врасплох.
<cap-mode>Ну, 450 Гб довольно мало.
За несколько тысяч рублей можно HDD на 2000 Гб купить.</cap-mode>
Ну, в 2009-ом это стоило несколько дороже (когда я ту статью смотрел). Хотя тоже было конечно же вполне реально :)
Но вот году ещё в 2008-ом в самом начале, когда родители этот Seagate покупали — там полутерабайтные внешние накопители стоили прилично. Тысяч 8-10 минимум.
То есть это надо было выкинуть 8-9к, чтобы с некоторой вероятностью что-то подобрать (а скорее, ничего не подобрать). Плюс скорость доступа у этих винтов была сильно не очень.
Да хорошая же система) Я между прочим частично читал её исходники. Красивый там код.
А аргументировать как-то это слабо? :)
Особенно учитывая, что там всё в лучших традициях ООП сделано.
там всё в лучших традициях ООП сделаноСмешно.
Я посмотрел код по первой ссылке (по первым двум, у вас там одинаковая вставилась). Лаконично, абстрактно, но не очень понятно, что же там на самом деле происходит. Это очень высокоуровневый код, он сильно на код Zend опирается. Вы и код Zend мне почитать предлагаете?)
Но БД существенно производительнее файловой системы (попробуйте запустить 2-3 скрипта на longpoll от одного юзера и попытаться в цикле подёргать сессию, будет не очень здорово). Насчёт инъекций — есть функции экранирования, есть PDO, как сказали выше, есть здравый смысл наконец. Не вижу никаких причин её не использовать. Более того, можно создать свой обработчик PHP сессий, который будет сохранять их в БД, а не в файлах, в языке предусмотрели даже такую возможность. Вот здесь об этом упоминается: http://www.php.su/articles/?cat=protocols&page=009
Вот мне правда интересно узнать, как реализовать безопасно, я же не троллинга ради спрашиваю.
Если в БД хранить можно — то из недостатков остаётся только низкий уровень абстракции и привязка к деталям реализации. Код можно сделать красивее и разнести его на несколько уровней абстракции, хотя его станет побольше. Но это к вопросу о красивой архитектуре, а не о безопасности :)
Нет, я имею в виду, что в текущем варианте не ок. Ну код там не красивый в самом скрипте аутентификации — это понятно, я как бы не старался его делать хорошим. А с остальным всё ведь хорошо?
Опять же, хочу напомнить, что общую идею хранения идентификационных данных в сессии придумал не я. Это в каждой первой статье делать предлагают. Да и в CMS по-моему так же сделано, например в той же Joomla, откуда я брал формат хранения паролей.
Вообще способов-то не так много: нам нужен клиентский контейнер, транспорт и серверный контейнер. Клиентский контейнер — очевидно, cookie (их проще всего выставить с сервера).
Транспорты рассматриваются по ссылке в статье, которую я приводил в комментарии выше. Обычно, опять же, используют cookies, поскольку они очень редко отключены у пользователей, и при этом не нужно городить параметров в адресной строке и виртуальных каталогов.
Остаётся серверный контейнер — по дефолту для сессий в PHP это файлы. Я, по сути, реализовал свой независимый контейнер хранения (можно считать это велосипедом, конечно), который работает совместно со стандартным, основан не на файлах а на MySQL, и хранит немного другие вещи.
При этом кука с хэшом ставится сервером при аутентификации (и шифруется им же), а затем передаётся клиентом с каждым запросом. И специальным модулем проверяется на корректность (как признак валидности клиента, она ведь получена из пароля). Вроде всё нормально сделано.
1. md5. даже не sha1. при том, что давным-давно практически во всех уголках инета рекомендуются спец.функции. Раньше был crypt, сейчас очень рекомендуется использовать password_*.
2. mysql. ну про это выше неоднократно написали.
3. sql-inj. тоже написали.
4. хранение пароля в сесии (не важно, php- или своей). Что-за бред? Почему в базе храним хешированный пароль, а в сесии нет? Храним хешированный с другой солью + подпись для проверки целостности данных. Эти 2 простых приема дадут больше пользы, чем весь код в посте.
5. Привязка к ip — это жесть. Вы часто приводите в пример vk, но я уверен, что там это реализовано иначе — проверям, сменилась-ли страна/регион/город с момента последнего обращения, а не смену ip. Не должна аутентификация быть привязана к чему-то, кроме самого пользователя.
6. Никогда(!) и никому(!) не говорите ничего про джумлу. Хуже кода, лично я, не видел ни разу.
И да, хотите сделать что-то правильно — хотя-бы(!) изучите то, что сделали и проверили в работе другие люди.
P.S.: отдельная жесть — php 5.3, svn. Тут даже не знаю что сказать…
Не знаю, UnitPay (платёжка, с которой мы год работали) только полгода как от md5 в пользу sha1 отказался. Там это используется для получения контрольной подписи. Принципиально есть какие-то аргументы, почему md5 не есть гуд? Ещё раз, я читал анализ, за вменяемые сроки там ничего не получить. А то, что получить — обычно это то, что УЖЕ когда-то было скомпрометировано, и теперь просто мы детектируем, что это тот самый хэш, или очень близкий. Тем более, не используя GPU, и на хэшах, где использовалась соль (любая).
Никто так и не объяснил, что не так с mysql. Один человек жаловался на особенность mysql_connect на Тостере, что функция не создаёт ему новое соединение, если не передан четвёртый параметр — но это называется "неумение читать документацию", библиотека тут ни при чём. То, что в неё давно не пилят какие-то новые фичи — не проблемы разработчика, коль скоро эти фичи ему не нужны.
С этим я согласился и исправил :)
С чего вы взяли что пароль(!) хранится в сессии? Такое ощущение, что вы вообще не читали статью, либо читали её через абзац. В сессии хранится хэш. Причём другой, не тот, что в БД. Как вы и предложили, ровно таак и работает это.
Частично согласен, что это может создавать неудобства, но это не доставляет сильных проблем обычному юзеру, поскольку автоматический перелогин происходит мгновенно. Да, это незачем, возможно, это глупость… Впрочем, не глупость. Это позволяет записывать в лог каждое изменение IP пользователя. Может я как администратор хочу знать, с каких провайдеров и как долго человек сидел на моём ресурсе? :)
- Вы зря настроены так против Joomla. Там прекрасный код в стиле ООП. И судя по тому, что я слышал о Wordpress (и частично видел сам) Joomla намного лучше. Это просто земля и небо. Да и API для расширений там очень и очень вменяемое. Смотрел видеоуроки даже по написание расширений под неё.
P. S. К SVN какие претензии? :)
Никто так и не объяснил, что не так с mysql
Если того, что уже практически не поддерживается, мало, то, навскидку, ничего не знает о транзакциях и подготовленных выражениях.
2. Ну как объяснить… Ок, давайте попробую так: пилите-пилите проект, разросся он до нескольких гигабайт и тут решили переехать на новую версию php (7-я реально сильно быстрее 5.х). И? Начинаются костыли и рвание волос в одном месте, т.к. использование различается кардинально. Поверьте, не на ровном месте это говорю — проходил на личном опыте, когда надо было обновить проект с историей более 10 лет. Это только одна из причин, их можно легко набрать пару десятков.
4. видимо не внимательно прочел, прошу прощения.
5. Эмм…
>Это позволяет записывать в лог каждое изменение IP пользователя.
Как это связано с аутентификацией? Логи — это совсем другое. Логируйте смену ip, в чем проблема-то? Но ip точно не должно быть частью авторизации/аутентификации.
6. Ммм… Давно не трогал, решил посмотреть — может что изменилось… Ан нет… god-объект Application, по всему коду синглтоны, за такое руки оторвал-бы, тут «на всякий случай»? И это я пару файлов наугад ткнул. По поводу вордпресса — я вроде не предлагал учится на его коде).
>К SVN какие претензии? :)
Их слишком много) От тормозной работы (т.к. только diff, а не полная копия), до stash и удобства разруливания конфликтов.
А насчет ссылки… Обсуждалось-же уже на хабре. Как говорится — «ложь и провокация»)))
А что касается скорости/юзабельности — лично я на свн уже ни ногой никогда. Использовал лет 5-7 (в основном из-за возможности lock/unlock + исторически).
>Вы просто не умеете его готовить.
Возможно, даже не спорю… Но отвечу в вашем стиле: «Не заманите вы меня на ваш хромой svn, не пытайтесь.»)
Если коммитишь в git, он делает непонятно что, в чём без чтения документации каждый раз не разобраться
Если коммитишь в гит — код именно коммитится. В локальную репу. И это огромный плюс. Позволяет разделять задачу на мелкие подзадачи и выполнять их отдельными коммитами, а в ветку пушится общий результат.
после чего надо выдавать ещё какие-то непонятные команды, чтобы код таки попал в сетевой репозиторий
Это git push не понятный?)) Ну оок…
При работе с проектом, где используется git, у меня очень много времени уходит на борьбу с ним.
Сорри, но в это я не верю. От слова совсем. Скажем так — если вы действительно используете гит, то либо юзаете 5-6 комманд (которые запоминаются через минуты 2-3), либо используете возможности ide/gui/etc. В любом случае, получается точно не сложнее чем с svn. А вот разруливать конфликты в гите значительно удобнее.
Например, на написание скриптов, которые делают с его помощью то, что с SVN делается одной командой.
А можно пример подобного? Мне реально интересно. Не смог вспомнить ни одного случая, когда svn был-бы проще и удобнее. Мне вот часто необходимо слить несколько коммитов в 1, объединить несколько веток в одну, поправить часть кода и запушить в новую ветку, не трогая мастер. Такое проще в svn сделать?
Я не троллю, мне реально интересно. Последний раз, когда трогал svn, последний был версии 1.5 или 1.6, уже точно и не помню. Тогда использование его было целой трагедией. Сейчас многое поменялось?
Как отключить локальную репу в git?
А как в svn сделать локальные репы?
Я пишу код и хочу, чтобы он, чёрт побери, попал в сетевую репу в нужную ветку.
Круто. git commit & git push. В чем проблема? А как сделать в svn, чтобы в сетевую репу не попали куча разных коммитов, а попал только один, финальный?
В SVN это делается одной командой.
Верно. Потому (только не злитесь) что svn ущербен. На большее, кроме как получить/отдать, он от рождения не способен. Да, в простых случаях этого хватает. Но не всем и не всегда.
Зачем сливать коммиты?
Чтобы в истории видеть 1 коммит = 1 задаче, но при этом в разработке дробить эту задачу на 100500 мелких и решать их отдельно разными коммитами.
Не пуше каком-то, я не понимаю что это такое и зачем это нужно.
Ну так вот она проблема, а не в гите ;). Ну серьезно.
Не вижу проблем в SVN при объединении веток или коммите в новую.
Я тоже в гите таких проблем не вижу. Но коммит, для меня, это локальное действие.
Я отправляю свой код в сетевой репозиторий, и это — коммит.
Да, в svn это «коммит», т.к., повторюсь, он ущербен от рождения. Как будет работать такой коммит в самолете, например? Мне вот необходимо разделение:
коммит — фиксирование изменений кода
пуш — обновление кода в ветке
И все сразу становится на свои места. А что такое коммит в svn? Только обновление кода. Теперь представим, что необходимо во время разработки переключаться между 3-мя ветками (пусть, для простоты понимания, мы работаем с микросервисами). Как в таком случае быть с svn? Удобно?)
Это вносит путаницу. И лично меня — бесит неимоверно.
Нет. Ни гит, ни svn путаницу не вносят — их вносите вы сами. Вас-же не бесит, что у велосипеда и мотоцикла по 2 колеса, но работают они иначе, да и пользуются ими совсем по разному? А чай вы из тарелки ложкой употребляете? Нет-же, верно? Так и тут — если нет желания, найдется 100500 причин (причем местами довольно смешных) чтобы только себя позлить.
Честно, как только svn научится работать с локальными изменениями, объединением/разделением коммитов (в том числе с возможностью удалить/отредактировать 3-й из 10-и коммит) — тогда я начну воспринимать эту детскую игрушку более-менее серьезно.
Но если вас устраивает svn — используйте. Повторюсь — на вкус и цвет… Мне вот hg совсем не подошел, а svn уже не достаточен — потому и git. Да, в гите тоже есть свои неудобства, свои кривоватости и прочее, но они как-то проще что-ли…
Зачем мне две команды на одно действие? Глупость какая-то.
Это разные действия).
Вы хотите спрятать подробности разработки от сообщества? Не понимаю, зачем это надо. Мне лично нечего скрывать в своём коде.
Прятать? Вы о чем? Я не хочу, чтобы недоделанная задача повлияла на пару десятков других разработчиков. В svn это сложно.
Причина в том, что мне не нужны эти операции по отдельности, потому я не понимаю, зачем их разделили.
А многим нужны именно по отдельности. И желание появилось не на ровном месте.
Приведите пример, зачем это может быть нужно.
Я уже приводил выше: решение одной большой задачи итерационно, разбивая ее на множество мелких.
Зачем работать с 3 ветками одновременно? Создайте свою и работайте в ней, потом затащите изменения из неё в другие. Создаёте проблемы на пустом месте.
Можно я не буду на это отвечать?)))
Я теперь не могу работать над своим кодом в сообществах, используя SVN, понимаете?
И это хорошо! Чем меньше плохого инструмента в обращении — тем лучше.
Мне вот не нравится drupal, но это не означает что он плохой, верно? Хотя нет — для меня он ужасен.
А для меня извращенцы — это пользователи git
На вкус и цвет… Если-бы svn был удобен — с него не убегали бы. А с него бегут. Не только в git, но и в hg и в bazaar. Бегут именно по причине того, что svn не дает работать.
Думаю, на этом и закончим. Мне уже понятно, что у вас чисто эмоциональная неприязнь инструмента.
Между прочим, Хромиум использовал именно SVN раньше, в 2013-ом по крайней мере точно, когда я впервые выкачивал их исходники. Ну и мы в вузе использовали SVN с первого курса. Поэтому да, возможно во мне говорит привычка. Но я всё-таки за централизованный подход. Любая децентрализованная система — это обычно хаос. В SVN один репозиторий и много рабочих копий у разработчиков. В Git у каждого разработчика по репозиторию. Что за бред вообще?) И как это синхронизировать, чтобы твой репозиторий был постоянно актуален. Жесть же. И логически (при конфликтах), и по ресурсам на синхронизацию.
И как это синхронизировать, чтобы твой репозиторий был постоянно актуален.
Приблизительно так же, как синхронизируются локальные рабочие копии с центральным репозиторием.
А зачем мне постоянно актуальный репозиторий, кстати?
И логически (при конфликтах),
Конфликты — они между ветками обычно, а не между репозиториями, так что здесь нет никаких дополнительных накладных расходов.
Чтобы в истории видеть 1 коммит = 1 задаче, но при этом в разработке дробить эту задачу на 100500 мелких и решать их отдельно разными коммитами.
Что за маниакальное желание делать коммит каждого мелкого изменения? Вам кнопочки Save мало? Я уже молчу про то, что многие IDE поддерживают Local History для отката изменений.
Если же изменений много, и это целая подзадача — наверное, логично сделать обычный сетевой коммит, как он делается в SVN.
Да, в svn это «коммит», т.к., повторюсь, он ущербен от рождения. Как будет работать такой коммит в самолете, например?
А зачем вам делать коммит в самолёте? Достаточно сохраниться, а закоммитить всегда можно при приземлении. Вы придумываете проблемы там, где их нет)
Что за маниакальное желание делать коммит каждого мелкого изменения?
А почему нет? Это бывает удобно.
А зачем вам делать коммит в самолёте?
Чтобы видеть историю работы.
Бывает, но не всем. Давайте тогда остановимся на том, что это личные пристрастия каждого. И не будем никого оскорблять)
Кроме того, есть и аналоги, позволяющие видеть историю изменений, но при этом не держать локально целый репозиторий (в любой системе контроля версий). Простейший — это "вшитые" в IDE модули локальной истории, но я верю, что есть варианты ещё мощнее (но не такие мощные и универсальные, как тот же Git). Просто мне это было не нужно, не изучал вопрос.
P. S. И правда может быть удобно откатить мелкий фрагмент изменений, но на то, чтобы во время написания кода думать о том, где провести границы между этими фрагментами — уходят мыслительные ресурсы и время. Тут спорно, будет ли выигрыш. Я бы не заморачивался :)
Бывает, но не всем. Давайте тогда остановимся на том, что это личные пристрастия каждого. И не будем никого оскорблять
Это говорит человек, написавший слово "маниакальное"?
Простейший — это "вшитые" в IDE модули локальной истории
Для меня не работает.
верю, что есть варианты ещё мощнее (но не такие мощные и универсальные, как тот же Git).
… но зачем, если просто есть DVCS, которая делает и это, и контроль версий для совместной разработки? Зачем использовать два инструмента, когда есть один, который прекрасно справляется с задачей?
И правда может быть удобно откатить мелкий фрагмент изменений, но на то, чтобы во время написания кода думать о том, где провести границы между этими фрагментами — уходят мыслительные ресурсы и время
У кого-то уходят, у кого-то — нет. Я задачу заранее разбиваю на кванты обычно, потому что иначе она может выглядеть неподъемной. Сделал квант — сделай коммит.
И это мы еще переключения не рассматриваем.
Что за маниакальное желание делать коммит каждого мелкого изменения?
Как минимум, это удобно для ревью. Ну и если используется что-то типа TDD, то даже это минимальное изменение не нарушает работу кода. Коммитить неработающий код — обычно зло. В процессе работы над новой фичей часто код становится неработающим, а потом становится работающим, пускай фича пока и н ереализована до конца. Имеет смысл фиксировать шаги когда код рабочий.
Итак, если при коммите возникла какая-то очередная непонятная ошибка
Например? Мне кажется — вы сейчас сильно лукавите. Если проблема в коммите — у вас проблема с настройками и/или правами. Если в пуше — значит у вас конфликт, который легко разруливается. А ваш «рецепт» похож на мазохизм, из серии «пусть мне будет плохо, но я так хочу»…
Вот svn в качестве молотка отвратителен — сбитый боек, треснутая ручка, не работает когда не подключен к интернету, не работает, когда нужен сразу нескольким трудягам — один ручку забрал, другой боек и ни у одного не получается забить гвоздь.
А когда им обоим говорят — вот, возьмите бесплатно каждый по новому молотку с удобной ручкой, говорят нет, у новых молотков ручка слишком удобная, не привычно, тяжело себе по пальцам ударить…
VCS не про сеть, это просто контроль версий. А версии бывают и локальные. Git разделяет собственно контроль версий и работу с удаленными репозиториями, ка частный её случай. Для git существование удаленного репозитория — малозначащий в процессе разработки нюанс. Для svn — основа процесса.
Git именно что позволяет разрабатывать не думая о существовании сетевых репозиториев пока не решишь залить код в сетевой репозиторий или получить обновления. SVN же принуждает работать с сетевым репозиторием, даже если вообще удаленный репозиторий не нужен, если ни с кем делиться не собираешься.
VCS нужна для обеспечения совместной работы
Вот, наверное, откуда ваше неприятие git и подобных систем. Вам она нужна только для обеспечения совместной работы, а я использую её для обеспечения работы вообще, о том, что она совместная — нюанс, о котором вспоминаю только когда нужно поделиться своими результатами или получить чужие. Но коммиты, создание веток, переключение между ними, слияние и т. п. — это не касается этого нюанса, это просто обычный процесс работы, независимо от того, совместная она или нет, создан сетевой репозиторий или нет. И бэкапами сложно заменить, с одной стороны, а с другой, можно представить локальную работу с гит как удобную систему работы с множеством бэкапов, просмотром диффов между ними, отслеживанием связей какой от какого "вырос", слиянием и т. т.п.
Мне нужны "костыли", чтобы этого не нужно было помнить, особенно когда в рамках одного проекта делаю несколько задач параллельно. Да даже при чисто линейной разработке (что большая редкость) последовательность коммитов в VCS куда удобнее, чем последовательность обычных бэкапов. "Вкалывают роботы — счастлив человек" ©
И так со всеми своими проектами помните последовательность? За все "около 18 лет"? А что делаете когда важна не временная последовательность, а логическая? Её тоже помните?
Зачем куда-то что выгружать? Всё дерево истории можно прямо из каталога проекта смотреть, хоть содержимое файлов в коммите, хоть различия содержимого в любых коммитах в любых ветках. Да, можно сделать что-то похоже на снэпшотах/бэкпах, сделать в проекте папочку backups, в ней с пяток минимум папочек типа "production", "redesign", "feature-1", "bugfix-2" и т. п., в них папочки на каждій значимій шаг с комментирующим названием типа "merge with feature-1", "redesign logo", "add mock for backend", "workaround" и т. п., копировать туда проект после каждого шага, сравнивать их между собой стандартным diff-ом, сливать как-то. Но в итоге получится папочка типа .git
Вот буквально вчерашний пример. Откопал сайт, к которому не прикасался год. Делал его я один, соответственно никакой удалённый репозиторий ради командной разработки не был нужен. Откопал, потому что заметил, что один пункт меню пропал (не слишком важный пункт, поэтому целый год никто ничего не замечал). Открываю nav.html — нету пункта. При этом я точно помню, что этот пункт раньше был. Соответственно, логично захотелось посмотреть, каким nav.html был раньше.
Что бы было, если бы были только бэкапы? Да ничего. Народ обычно удаляет старые версии бэкапов (особенно через целый год-то), вот и я бы тоже удалил всё старое и оставил бы только последний актуальный бэкап. Но предположим, все старые бэкапы есть — и как бы я в них искал, когда пропал пункт меню из nav.html? Сидеть распаковывать десятки-сотни архивов и смотреть содержимое nav.html в каждом? Данунафиг блин.
Но зато у меня есть локальный репозиторий git! Простейший git log nav.html — и вот я уже вижу все изменения этого конкретного файла. Не прошло и минуты, а я уже нашёл коммит, в котором пункт меню пропал. 4 апреля 2016, описание «Rewrite nav.html». Всё стало ясно: отрефакторил файлик, а пункт меню просто забыл добавить и не заметил. В итоге я просто скопировал пункт меню из старого nav.html в новый, не пришлось писать ни строчки нового кода. git add nav.html && git commit -m 'Restored some nav items'
Пример примитивный, но ничего не мешает случиться чему-нибудь аналогичному на более глобальных изменениях, вроде выпиливания большой фичи, которую внезапно понадобится вернуть. Бэкапы — не замена контролю версий, контроль версий — не замена бэкапам. Если вы способны помнить всё, что делали во всех своих проектах, к которых не прикасались годами — поздравляю, у вас на удивление хорошая память, такая очень мало у кого есть :) А я помнить не только не могу, но и не хочу: зачем, если помнить за меня может обладающий бесперебойной памятью git, причём не требуя удалённого репозитория?) А крутить в голове я лучше буду те проекты, которыми занимаюсь в настоящий момент, а вышеупомянутый сайт к ним не относится.
С VCS надо куда-то выгружать данные
О чём тут речь? В моём случае кроме git add и git commit я ничего не делал, а просмотреть всё могу как простым git log, так и каким-нибудь графическим gitk
Что ж, поздравляю, вы уникальный :) Мне (и, думаю, многим другим) в первую очередь нужны и важны именно логи.
Перед крупными изменениями я бэкаплюсь, а мелкие восстановить — дело пары минут.
Даже спустя год? И храните все столь старые бэкапы? Вы всё ещё уникальный, можете гордиться этим))
Ну кстати, если графику в бэкапы не включать — смысл их удалять вообще? Код весит не так много, и отлично сжимается зипом :)
Я регулярно создаю бэкапы перед крупными изменениями, а старые никогда не удаляю. Пример: был сайт, который я делал и поддерживал примерно год. За это время накопилось 40 бэкапов клиентской части и 32 бэкапа админки. Плюс следующие два года я поступал немного по-извращенски, внося вручную изменения в самые последние 1-2 архива во время важных security-фиксов и исправлений крупных багов.
Проект довольно крупный. При этом мне ни разу даже в голову не пришло удалить какие-то старые архивы. Так что я с коллегой солидарен, пока код знаешь хорошо, и есть бэкапы (в идеале ещё и с краткими чейнджлогами) — VСS вообще не особо нужна.
Если пользовать VCS, бэкапы вообще не особо нужны. ;)
Хранение и просмотр изменений — непосредственная задача VCS. Пытаться адаптировать под это бэкапы — костыль и жевание кактуса. Делать по новому бэкапу с чейнджлогом на каждое мелкое изменение — какая-то глупость, а для VCS (кроме SVN, я так понимаю, лол) совершенно нормальная и очень полезная практика. И для VCS никакой графики выпиливать не надо.)
примерно год. За это время накопилось 40 бэкапов
В то время как сделать 40 коммитов к гите дело нескольких дней — история получается в разы подробнее, а откатывать отдельные изменения в случае чего (да, их иногда приходится откатывать) гораздо проще.
пока код знаешь хорошо
Вы тоже из тех, кто способен помнить старые крупные проекты годами? Ох, вас уже целых двое.
последовательные бэкэпы с ченжлогами и есть примитивная VCS по сути :)
Если проект командный и у меня вдруг нет интернетов, я буду спокойно сидеть и кодить, а потом, когда сеть появится — залью всё одним коммитом. Никто от этого не пострадает, в комментарии к коммиту я просто напишу чуть больше.
То есть идея про атомарные изменения вам чужда?
Когда не подключен к интернету — зачем тебе VCS? Сидишь, кодишь локально,
Чтобы внести одно сложное изменение, потом начать вносить следующее, имея легкий откат обратно. Я за собой заметил, что я иногда делаю локальные репозитории даже на присланных партнерами сэмплах, чтобы легко отличать мои изменения от их кода.
Я просто не редактирую напрямую чужой код. Мне присылают архив, я распаковываю его, но не удаляю. Таким образом у меня всегда есть копия оригинального кода.
… а потом надо найти, какие изменения вы сделали, чтобы заработало.
Откаты же мне практически никогда не требуются, потому что я заранее знаю, что и как хочу написать.
Да вы гений. Или просто у вас очень простая система.
Но опять же — архивы, бэкапы. Мне норм.
Вам "норм", а кто-то не любит использовать костыли там, где за них уже написано решение.
Нет никаких проблем с настройками и правами. Просто почему-то рушатся локальные данные.
Вас не смущает, что у других подобных проблем не возникает?))))))))
С чего вы взяли проблемы с памятью? Зачем мне запоминать в какой последовательности я что делал 10 лет назад?
Напрасно вы считаете это троллингом.
Нет, не напрасно. Иначе просто объяснить подобное нельзя)
оказывается, у большинства разработчиков проблемы с памятью
о_О серьезно? Т.е. вы без проблем можете помнить все изменения в коде, например, размером 200мб? Вот 2 проекта, над которыми работаю параллельно в последнее время:


Никогда не поверю, что кто-то может помнить такой объем. Отсюда вывод — вы троль.
Как средство командной работы же он менее удобен, чем SVN, как раз из-за своей хвалёной децентрализации.
Лол… Именно локальное хранилище дает большие плюсы. Я вот часто делаю различные эксперименты с помощью гита и виртуалки и мне не приходится заливать ненужный код в общий репозиторий.
Там по ссылке вам правильно сказали — вы просто не смогли осилить. И поэтому решили всех троллить, в надежде найти поддержку. Но ее не будет, потому как svn реально говно, по сравнению с git/hg.
У вас просто реально очень крупные проекты, в этом случае, конечно, весь код помнить не реально. Но я всё равно не верю, что вы там правите ВСЁ.
Обычно разработчик в большом проекте берёт себе одну задачу. Как правило — небольшую, особенно если он не тимлид (но тимлид хотя бы сам не пишет особо код, так что тут тоже проще). А так разбиваются на команды, и над одним модулем работают человека 2-4. Вот честно скажите, вам при работе над модулем надо помнить ВЕСЬ код проекта? Правда?
Интеграция модуля в систему — это да, но API обычно чётко определены, и меняются редко. Да и API обычно делают с ядром, а не со всем на свете.
Ну тут конечно VCS незаменима. Я про индивидуальную разработку говорил
А начался вообще этот тред со спора, нужен ли локальный репозиторий.
Моя позиция была в том, что если не делать коммиты очень мелкими (2-3 строчки кода, не являющиеся цельным изменением) — то такой коммит не нужен. А если строчек много, и есть одно или более значимых функциональных изменений — то можно в ряде случаев и в сетевой репозиторий коммит залить. Тут уже как разработчики договорятся/как в компании принято.
Но я всё равно не верю, что вы там правите ВСЁ.
Очень зря. По первому проекту примерно 30 коммитов в сутки на команду (от меня лично — 3-4). Думаю это видно на скрине ;) И да, затрагивается абсолютно весь код, какой-то чаще, какой-то реже.
Вот честно скажите, вам при работе над модулем надо помнить ВЕСЬ код проекта? Правда?
Скажите честно — вы хоть раз работали в команде на 10-20 человек над большим проектом? Просто судя по заданному вопросу — нет. Тогда мне сложно будет вам объяснить, что как-раз НЕ НАДО помнить весь код (и особенно последние изменения) — их можно посмотреть в гите.
но API обычно чётко определены, и меняются редко.
Realy?)))) Я даже не знаю что сказать, если честно. Посмотрите на 2-й скрин, в котором код поменьше. За последние 5-6 месяцев в этом проекте переписано процентов 80 кода. Как думаете — апи остался без изменений?))))
Позволяет разделять задачу на мелкие подзадачи и выполнять их отдельными коммитами
А почему нельзя каждую подзадачу коммитить в ветку непосредственно? Не вижу в этом большой проблемы. И имхо, во многих крупных проектах делают именно так. Глянуть хотя бы репозиторий хромиума или SKIA какой-нибудь. Там довольно небольшие коммиты и мелкие изменения.
А почему нельзя каждую подзадачу коммитить в ветку непосредственно?
Вы, наверное, имели в виду "в ветку удаленного репозитория". Так вот, потому, что код на этом этапе может быть еще не полностью готов — и, например, не проходить весь набор тестов.
Я вот, скажем, регулярно первым коммитом пишу тест (особенно если это баг). Если это попадет в общий репозиторий с CI, там начнут валиться билды.
Окей, с тестом — согласен, логичный сценарий.
В общем же случае — я бы просто не коммитил до тех пор, пока код не станет готов, и все тесты не будут им пройдены.
Так вот, потому, что код на этом этапе может быть еще не полностью готов — и, например, не проходить весь набор тестов.
Но если задача столь сложна, что за вечер или два её не решить — да, Вы правы, Git будет удобнее.
Хотя наверное можно извратиться и коммитить такие куски, чтобы тесты не падали. Но это потребует изрядной смекалки и лишних сил. Этот ресурс можно на другое пустить :)
В общем же случае — я бы просто не коммитил до тех пор, пока код не станет готов, и все тесты не будут им пройдены.
… и все это время вам нельзя отрываться от задачи. Это, конечно, круто, но не всегда достижимо.
Но если задача столь сложна, что за вечер или два её не решить — да, Вы правы, Git будет удобнее.
У меня есть задачи, которые "решаются" неделями. И за это время я их на сервер пушу только из-за паранойи "а вдруг диск накроется" — и при этом я имею иногда почасовую историю того, что и зачем я делал, с соответствующими записями в blame/annotate.
В смысле, что у Вас куча задач параллельно, или так много кода требуется? В этом случае m0Ray предлагал создать отдельную ветку под свою задачу в общем репозитории. Не знаю, насколько это уместно, но вариант рабочий.
А почему нельзя каждую подзадачу коммитить в ветку непосредственно?
На это есть огромная куча причин. Основная — в истории желательно видеть кто и что сделал В ПРЕДЕЛАХ конкретной задачи. Если над задачей работает несколько человек — это вообще критично становится. Если один — желательно видеть, какой коммит за какую часть задачи отвечает (хотя-бы для ревью, но это так-же важно для тестов и выкладки).
Что значит "только diff"? Объясните поподробнее. И как бы это, объём данных, которые приходится выкачивать при клонировании Git репозитория, сильно удручает. Для больших проектов это целые десятки гигабайт.
Пост от 2013-го года
Это называется "слышал звон, да не знает, где он". Видно, что вы вообще не разбираетесь в сути вопроса.
По пунктам:
Первого марта 2005 года было продемонстрировано первое использование указанной уязвимости на практике. Группа исследователей представила два сертификата X.509 с разными наборами ключей, но с идентичными контрольными суммами. В том же году Властимил Клима опубликовал алгоритм, позволяющий обнаруживать коллизии на обычном ноутбуке за несколько часов. В 2006 он пошел дальше. Восемнадцатого марта 2006 года исследователь обнародовал алгоритм, находящий коллизии за одну минуту!
Найти коллизию для некоторых двух хэшей — не то же самое, что взломать конкретный хэш (найти некие исходные данные, которые вернут ту же контрольную сумму). Это сильно разные задачи, и вероятность успеха сильно разная.
Большая работа была также проделана и для ускорения взлома хешей. В 2007 году Кевин Бриз представил программу, использующую Sony PlayStation3 для взлома MD5. Он сумел добиться очень неплохих результатов: 1,4 миллиарда MD5-хешей генерировались всего лишь за одну секунду!
Давайте посчитаем: за месяц с такой скоростью можно получить примерно 3628800 миллиардов хэшей. Посмотрим, как это соотносится с длиной хэша (128 бит). Math.log2(3628800000000000) = 51.688413968703216. Это даже не квадратный корень от общего числа комбинаций. Но даже если бы это был корень, чтобы подобрать все хэши, понадобилось бы примерно… 302400000000000 лет. Лет, Карл!
Мы используем вышеприведенный способ для взлома одного определенного хеша, сгенерированного при помощи алгоритма MD5. Максимальная длина возможного пароля составляет семь символов. Через какое-то время пароль будет найден (qwerty). Теперь давай попробуем взломать еще один хеш, но с немного другими условиями. Пусть наш хеш имеет вид d11fd4559815b2c3de1b685bb78a6283, а пароль включает в себя буквы, цифры, знак подчеркивания и имеет суффикс «_admin». В данном случае мы можем использовать перебор пароля по маске, чтобы упростить программе задачу
Теперь давай попробуем взломать сразу несколько паролей одновременно. Предположим, что к нам в руки попала база данных хешей паролей. При этом известно, что каждый пароль оканчивается символами c00l
В реальной жизни, если пароль не имеет вид "111111", задачу упростить таким образом не получится. Последний пример (с одинаковыми постфиксами на всю пользовательскую базу) — вообще сферический идиотизм в вакууме, в жизни такого не бывает.
Видно, что вы вообще не разбираетесь в сути вопроса.
Оохх… Ну ок, пусть будет «не разбираюсь»)). Мне реально не хочется с вами на эту тему общаться.
Также важно помнить, что стойкость хэш-суммы имеет значение лишь в случае, когда база утекла с сервера. Если база утечёт — скорее всего, админ об этом узнает. В этом случае ответственный админ сразу же сбросит пароли всем пользователям. Если сайт совсем не содержит критических данных (небольшой блог или форум) — то и вовсе можно сделать рассылку и предоставить пользователям решить самостоятельно, хотят они обновить свой пароль или нет. Тут мне могут возразить, что такая утечка ставит под удар доступ юзера ко ввсем ресурсам, где есть такой же пароль. Но пароли всё равно меняют раз в 1-2 года самое крайнее, а как правило намного чаще.
Я к тому, что даже 2-3 месяца в запасе — уже немалый срок. Те же цифры, что я посчитал, хоть они и взяты не на текущий год, а на тот год, про который писалось в статье — они настолько астрономические, что, кхм, вряд ли что-то существенно поменялось.
Предлагаю в общем всем желающим провести простой эксперимент. Берёте пароль длиной 7-8 символов, сгенерированный случайно, объединяете с 32-символьной солью (тоже псевдослучайной), получаете MD5 хэш. Скачиваете соответствующий софт и пробуете взломать. И потом увидим, сколько времени для этого понадобится, и выйдет ли оно вообще.
Я даже хэшей могу накидать для такого теста.
Если база утечёт — скорее всего, админ об этом узнает.
Не узнает.
В этом случае ответственный админ сразу же сбросит пароли всем пользователям.
Если в здравом уме — нет.
Но пароли всё равно меняют раз в 1-2 года самое крайнее, а как правило намного чаще.
99% нет.
Те же цифры, что я посчитал, хоть они и взяты не на текущий год, а на тот год, про который писалось в статье — они настолько астрономические, что, кхм, вряд ли что-то существенно поменялось.
1. В посте говорилось про взлом/исследование на ноуте/PS3/видюхе.
2. Берете кластер в амазон/google и все меняется настолько существенно, что…
Берёте пароль длиной 7-8 символов, сгенерированный случайно
А пароли пользователи выбирают такие-же? По вашему, радужные таблицы не нужны в реальности?)))
Вы бы хоть основы поизучали… Меня обвинили в том, что я в этом не разбираюсь, при этом пишите такие глупости, которые я лично проходил на своем опыте… Не позорились-бы…
Не согласен почти ни с одним пунктом)
Не узнает.
Может узнать. Например, хостер доведёт до сведения, или взломщик по глупости оставит следы своего присутствия. В крупных проектах, например, есть специальные люди, которые мониторят логи. В них что-то может остаться.
99% нет.
Может Вы и правы. Но это зря) Лучше менять раз в полгода хотя бы, особенно в критичных местах.
В посте говорилось про взлом/исследование на ноуте/PS3/видюхе.
Насколько я знаю, видюха даёт выигрыш всего на 2-3 порядка. Это не так много.
Берете кластер в амазон/google и все меняется настолько существенно, что…
Да ладно) И насколько? И сколько это будет стоить?
Если в здравом уме — нет.
А вот этого я совсем не понял… Объясните, пожалуйста, почему. Если главная цель — защитить пользователей, логично сбросить пароли, разве нет? Иначе есть риск взлома аккаунтов.
А пароли пользователи выбирают такие-же?
Вообще-то да. Это в любой инструкции для чайников указано, вы чего. Да и по своим знакомым я знаю, какие пароли ставят на критичные сервисы, например, на админки своих собственных проектов.
Вы бы хоть основы поизучали…
Да я же не против совсем. Просто тут очень агрессивно все нападают, вместо того, чтобы просто указывать на оплошности. После такого и желание изучать что-то у многих пропадает… :)
Например, хостер доведёт до сведения
Да ёлки-палки… Забудьте о «хостере». Во-первых, они точно не узнают, что вашу базу слили. Во-вторых, они не сообщат об этом, потому как это не их дело.
Не так давно был пост про yahoo. Взломали в 2013-м, узнали в 2016-м… Крупная компания. И где админы, которые легко узнают? Где спец.люди по логам? Где «хостер»?)))
В крупных проектах, например, есть специальные люди, которые мониторят логи
Серьезно? Можете дать примеры таких проектов? Вот честно — ни разу даже не встречал упоминание подобного, хотя вроде знаю разработчиков/админов/владельцев некоторых крупных проектов.
Лучше менять раз в полгода хотя бы, особенно в критичных местах.
Хм… Я вроде не говорил это давать возможность/заставлять менять пароли пользователями — плохо. Я сказал, что админ не будет менять. Об этом ниже.
А вот этого я совсем не понял… Объясните, пожалуйста, почему. Если главная цель — защитить пользователей, логично сбросить пароли, разве нет? Иначе есть риск взлома аккаунтов.
Потому, что это точно не задача админа. Даже больше — админ не имеет права вносить правки ни в код, ни в базу. При любом раскладе. За подобное увольняют без вопросов, не зависимо от причин.
Насколько я знаю, видюха даёт выигрыш всего на 2-3 порядка. Это не так много.
Хм… Давайте подумаем… 2-3 порядка от 2млрд — это 0,2-2трлн хешей в секунду. До сих пор считаете что это «не так много»?
Да ладно) И насколько? И сколько это будет стоить?
А какая разница?))) Вот 2 сценария:
1. Необходимо поломать наибольшее количество аккаунтов пользователей google/yahoo/yandex. Скорее всего (пруфов нет), у 1% пользователей будет 1 пароль на акк и на платные сервисы различных систем. Предположим, есть 1млрд аккаунтов, значит 1% даст 10млн потенциальных жертв (не говоря о побочных «плюсах» в виде переписок, например). Так-же предположим, что пароли у этих «жертв» не сложные (иначе они не попадают под первое условие — 1 пароль на разные аккаунты). Кластер обеспечит несколько триллионов хешей в секунду, что составляет n * 86400 * 31 трл хешей в мес (довольно большая цифра, согласитесь). Имеет смысл потратить на это пару-тройку тысяч долларов? Имеет. Даже не пытайтесь спорить)
2. То-же самое, но на коммерческой основе, когда предоставляем услуги по взлому тем, кому дорого/лень организовывать платформу. Тут намного выгоднее. платим пару-тройку тысяч долларов, но берем по 1$ за каждый аккаунт (а их, как посчитали выше, с десяток миллионов).
Все еще думаете, что это очень дорого?)))
Вообще-то да. Это в любой инструкции для чайников указано, вы чего. Да и по своим знакомым я знаю, какие пароли ставят на критичные сервисы, например, на админки своих собственных проектов.
Да вы шутите))) Топ-10 паролей базы yahoo:
123456
password
welcome
ninja
abc123
123456789
12345678
sunshine
princess
qwerty
Пруф.
Топ-25 паролей взломанных сервисов в 2016-м году:
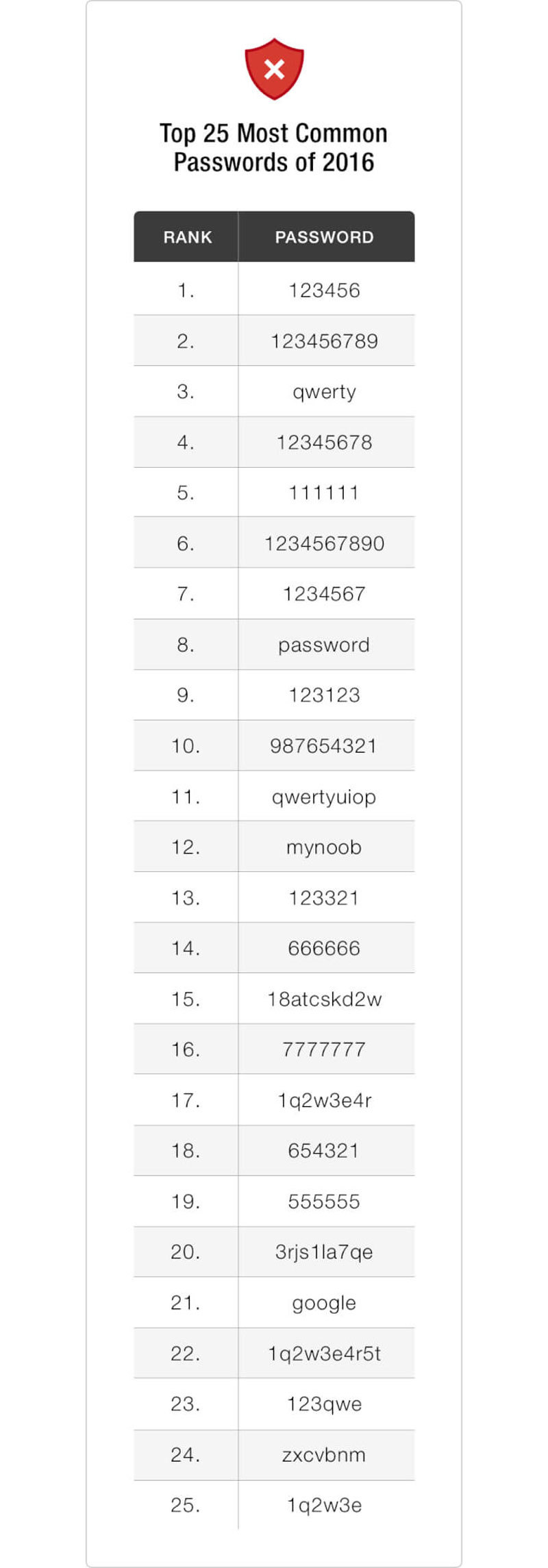
Продолжать или сами погуглите?)
Просто тут очень агрессивно все нападают, вместо того, чтобы просто указывать на оплошности.
Так вы слушайте, а не пытайтесь приводить в ответ очевидные глупости ;)
И где админы, которые легко узнают? Где спец.люди по логам? Где «хостер»?)))
У Yahoo нет хостеров, они сами себе хостер, ну либо Амазон какой-нибудь используют. Но их взламывать гораздо перспективнее с точки зрения возможных "дивидендов", вот и желающих много. Логично, что кому-то удалось. А админы могли и просто замолчать факт утечки (а узнали, скорее всего, слишком поздно). Либо взломщик был настолько гениален, что вообще не оставил никаких следов, но я в это слабо верю. Хоть какие-то запросы он ведь делал. Просто логи видимо лень читать админам...
Серьезно? Можете дать примеры таких проектов?
Примеры, увы, не дам. Но как минимум на Хабре (или другом ресурсе) была статья, где в комментах человек писал, зачем это нужно. Там даже выражение устойчивое есть в админской среде — "курить логи". Если админы этого не делают — они или хреновые админы, или перегружены, и им не хватает сотрудников.
Для этого целые средства обработки логов создают для UNIX систем, между прочим. С выгребанием, разбивкой и обработкой в реальном времени. И мониторится абсолютно всё: обращения к серверам баз данных, обращения к фронтенду, обращения админов к админке… И одна из целей такой обработки — потенциально снизить объём для чтения админом, выкинув явный мусор.
Даже больше — админ не имеет права вносить правки ни в код, ни в базу. При любом раскладе.
Да ладно, "здрасте приехали". А кто блокирует доступ, например, к почтовому ящику, когда система обнаруживает, что ящик взломан, и пароль скомпрометирован (взять к примеру мейл.ру или всем известный вк)? Автоматика, скажете вы. Но ведь эту автоматику писали программисты. С согласия руководства проекта :)
А если автоматики по каким-то причинам нет, или она своевременно не сработала, но точно известно, что аккаунт взломан — это кто же запретит компании заблочить аккаунт пользователя? Вы серьёзно? Понятно, что это действие, возможно, не в полномочиях простого админа. Хотя, если фирмочка маленькая, и админу явно разрешили такие действия прямым текстом — то может даже, это как раз его задача.
А админы могли и просто замолчать факт утечки (а узнали, скорее всего, слишком поздно). Либо взломщик был настолько гениален, что вообще не оставил никаких следов, но я в это слабо верю. Хоть какие-то запросы он ведь делал. Просто логи видимо лень читать админам...
Но как минимум на Хабре (или другом ресурсе) была статья, где в комментах человек писал, зачем это нужно. Там даже выражение устойчивое есть в админской среде — «курить логи». Если админы этого не делают — они или хреновые админы, или перегружены, и им не хватает сотрудников.
Как Вы выше сказали? «Слышал звон, да не знает где он»?)))
Для этого целые средства обработки логов создают для UNIX систем, между прочим. С выгребанием, разбивкой и обработкой в реальном времени. И мониторится абсолютно всё: обращения к серверам баз данных, обращения к фронтенду, обращения админов к админке…
Да ладно? Серьезно? «А мужики-то не знают»))). Ну реально, для чего вы говорите примитивные вещи? Вы хотя-бы представляете объем логов более-менее среднего проекта?
И одна из целей такой обработки — потенциально снизить объём для чтения админом, выкинув явный мусор.
Нет.
А кто блокирует доступ, например, к почтовому ящику, когда система обнаруживает, что ящик взломан, и пароль скомпрометирован (взять к примеру мейл.ру или всем известный вк)? Автоматика, скажете вы. Но ведь эту автоматику писали программисты. С согласия руководства проекта :)
Вы вроде про админов начинали отвечать, а пришли к программерам и руководству)))) Что-то тут не так с логикой ответа))
А если автоматики по каким-то причинам нет, или она своевременно не сработала, но точно известно, что аккаунт взломан — это кто же запретит компании заблочить аккаунт пользователя?
Никто. Просто потом уволят и все… Есть правила. Вы хоть основы работы команд изучите, прежде чем подобное заявлять…
Хотя, если фирмочка маленькая, и админу явно разрешили такие действия прямым текстом
То в этой «фирмочке» огромные проблемы. Вас совсем не смущает тот факт, что вместе с блокировкой какого-то аккаунта могут выполняться дополнительные действия (логирование, запрет доступа в другие подсистемы, отправка информации о блокировке менеджерам/программистам, остановка отправки смс/email уведомлений, etc)?! И тут приходит админ и шлёт нафиг всю логику, т.к. ему захотелось кого-то в базе забанить)))) Лол.
Когда речь идёт о числах с 18-25 нулями, то разница на 2-3 порядка — это и правда немного. Простая логика же. Да, всё ещё считаю.
Да ёлки-палки… Когда у вас число с 1-2 нулями — 2-3 порядка действительно не много, а когда с 18-25 — 2-3 порядка == огромное количество. Представьте, вы работали за компом с 1Ггц проца и вам дали с 0,1-1Тгц. Что скажете? «Да ладно, почти нет разницы»?)))))))))))))
Таких людей тоже стоит учитывать :)
Исключения есть всегда, но они, обычно, подтверждают правила ;)
Вплоть до 20-40 процентов, как подсказывает логика :)
Ну тогда такие пользователи как вы вообще не интересны взломщикам. Что вы есть, что вас нет — не принципиально)
Вы слишком упрощаете.
Серьезно?))))
Тут нужен или очень богатый покупатель, или очень много покупателей. Дай бог вы продадите 5-10 процентов.
Никому подобного не говорите))))
Я уже молчу о том, что если спалиться на таком, можно и перед законом ответить — не все рискнут взяться за это дело.
Чего?! В каком законодательстве запрещен подбор хешей?! Я что-то пропустил?! Ну хватит нести бред-то!
Тут надо иметь пару-тройку тысяч долларов, которые не жалко на такое пустить, и уметь организовать такой кластер.
Перечитайте мои предыдущие комменты. Пара-тройка тысяч — копейки, если необходимо взломать несколько миллионов аккаунтов ;) Это примерно зар.плата 1 (ОДНОГО) программиста ;)
Ну и самое главное — надо перед этим получить утекшую базу данных :)
Это уже из другой оперы. Мы-же говорили про md5 и пр. ;)
Кстати, я вообще не очень хорошо представляю, как можно слить базу в системе, которая достаточно надёжна защищена.
Вариантов море. От кривого сервисного софта до sql-inj.
Можно слить её шеллом, даже не зная структуры — это, кажется, логично. Но в нормально защищённую систему нельзя залить шелл.
Чего?! Это шутка? Шелл юзают для получения доступа к системе, для повышения привелегий и еще много для чего, но точно не для того, чтобы слить базу))). А залить шелл можно очень часто. Есть загрузка аватарок/изображений — есть потенциальная дыра. Используются get-параметры — есть потенциальная дыра. И т.д.
Феерический идиотизм. Ибо подобрать такое даже проще, чем дату рождения. Для подбора такого пароля даже не нужно лично знать пользователя, чтобы взломать его аккаунт. :)
Так я вам про это выше и говорил — большинство пользователей поступают именно так. Причин для этого нет (адекватных), но большинство людей очень далеки от ИБ.
Но это почему-то никому не мешает их читать, даже в крупных проектах))
> Как Вы выше сказали? «Слышал звон, да не знает где он»?)))
Я в любом случае не скажу вам, в какой компании тот человек работал, но что такое было на одном из форумов, и я это читал — это факт.
> Никто. Просто потом уволят и все… Есть правила.
Слушайте, ну не надо нести откровенный бред. Кто кого уволит? Это нормальная практика. Если компания решила, что она блокирует аккаунты с подозрительной активностью, и очевидно, что такая активность была, но автоматический алгоритм «заглючил» и не сработал — конечно же, блокировку произведут вручную. Это может спасти от спам-рассылок или чего похуже — того, что может сделать взломщик, если аккаунт не заблочить и оставить как есть.
> И тут приходит админ и шлёт нафиг всю логику, т.к. ему захотелось кого-то в базе забанить)))) Лол.
Лолшто?)) Где я говорил «потому что админу захотелось»?.. Я сказал — если объективно есть необходимость в блокироввке, но автоматический алерт не сработал, и блокировка не произошла.
> Да ёлки-палки… Когда у вас число с 1-2 нулями — 2-3 порядка действительно не много, а когда с 18-25 — 2-3 порядка == огромное количество. Представьте, вы работали за компом с 1Ггц проца и вам дали с 0,1-1Тгц. Что скажете? «Да ладно, почти нет разницы»?)))))))))))))
Вы не с той стороны заходите. В плане относительного прироста — 2-3 порядка это всегда много. Но когда у нас число с 25-26 нулями, и мы говорим о том, что теперь у нас в месяц перебирается не 1000, а, например, 100 000 паролей (цифры взяты от балды) — это туфта.
> Ну тогда такие пользователи как вы вообще не интересны взломщикам. Что вы есть, что вас нет — не принципиально)
Пфф, вы серьёзно? После утверждений о том, что 2-3 нуля — это очень много на таких числах, вы говорите, что 20-30 процентов от общей массы пользователей, которые пользуются нормальными надёжными паролями — это «что есть, что нет — не принципиально»?.. Что?)
> Чего?! В каком законодательстве запрещен подбор хешей?! Я что-то пропустил?! Ну хватит нести бред-то!
Подбор хэшей — не запрещён. А вот покупка и продажа украденных баз (заведомо зная, что это украденные базы) — тут уже другая история. Мне очень интересно, как вы будете перед ребятами из отдела «К» оправдываться, если вас, не дай бог, на таком поймают :)
> От кривого сервисного софта
Отсутствие такого софта — ответственность хостера (ну или сисадмина, если у вас выделенный сервер). Не разработчика.
> до sql-inj
А вот здесь уже надо внимательно и аккуратно писать код. Это именно к разработчику, да =)
> Есть загрузка аватарок/изображений — есть потенциальная дыра
Лишь потенциальная. Можно ли через эту дыру залить код и исполнить его? Большой вопрос.
> Используются get-параметры — есть потенциальная дыра.
Согласен, но с эксплуатацией такой дыры ещё несколько сложнее, мне кажется. Если просто напихать PHP-код в какие-то параметры — скорее всего, ничего не получится. Надо его сохранить и запустить, либо хотя бы сохранить, если мы знаем, что он запустится без нашего участия. Пока мне в голову приходит только вариант «что-то инклюдится, и мы туда пишем данные, пришедшие с клиента», либо «в коде есть eval, и он берёт что-то из базы данных/из файла на сервере, куда до этого писали данные, пришедшие от клиента». Оба этих варианта — такой лютый трэш, что я просто уверен на все сто, что никто так не делает.
> но точно не для того, чтобы слить базу)
Можно ведь и для этого использовать :)
>Так я вам про это выше и говорил — большинство пользователей поступают именно так
Ну мы-то с вами как грамотные пользователи (я даже не говорю «как разработчики», это не важно в данном контексте) так не поступаем? :)
Но это почему-то никому не мешает их читать, даже в крупных проектах))
давайте еще раз спрошу — назовите компании, в которых есть люди отвечающие за логи ;)
но что такое было на одном из форумов, и я это читал — это факт.
ага, знакомо… «где-то слышал, что знакомый знакомого имеет знакомого, который знаком со знакомом того-самого!»…
Слушайте, ну не надо нести откровенный бред. Кто кого уволит?
Ооок… У нас уволят. На всех работах где я работал — уволят без вопросов. Не имеет права админ вмешиваться в работу системы.
Если компания решила, что она блокирует аккаунты с подозрительной активностью, и очевидно, что такая активность была, но автоматический алгоритм «заглючил» и не сработал — конечно же, блокировку произведут вручную.
Верно. Но НЕ админ, а люди, отвечающие за это.
Я сказал — если объективно есть необходимость в блокироввке, но автоматический алерт не сработал, и блокировка не произошла.
Ага. Увольнение)
После утверждений о том, что 2-3 нуля — это очень много на таких числах, вы говорите, что 20-30 процентов от общей массы пользователей, которые пользуются нормальными надёжными паролями — это «что есть, что нет — не принципиально»?..
Именно. Почитайте о популярном нынче вирусе — скорость распостранения очень важна, пользователи под защитой не важны, т.к. ориентир на пользователей без обновлений. И подумайте после этого))))
А вот покупка и продажа украденных баз (заведомо зная, что это украденные базы) — тут уже другая история.
Так вы не юлите ;). Мы говорили как-раз про подбор md5, а не про взломы/кражи ;)
Оба этих варианта — такой лютый трэш, что я просто уверен на все сто, что никто так не делает.
Мдя… Вы хоть погуглите что-ли, раз вообще в теме не разбираетесь))) Есть куча готового софта, который ищет (И НАХОДИТ) подобные дыры. А дыры сложнее — да, разрабатываются и эксплуатируются ручками…
Я же говорил про человека, который всё это знает, понимает последствия, и которому не могут запретить это сделать (либо он этот шаг согласовали получил разрешение).
Выше вы говорили про рядового админа ;)
У меня было несколько проектов, где я был и единственным разработчиком, и админом (но не владельцем). После согласования с владельцем (а иногда и уведомления в одностороннем порядке) я делал такие вещи, и ещё ни разу на меня не наезжали за излишнюю инициативу.
Хаааа… Ключевые слова этого предложения: «де я был и единственным разработчиком, и админом» и «После согласования с владельцем (а иногда и уведомления в одностороннем порядке) я делал».
Выше речь шла про любую нормальную компанию. Возьмем даже мелкую — 5-6 разработчиков, 1-2 админа.
Именно. Почитайте о популярном нынче вирусе — скорость распостранения очень важна, пользователи под защитой не важны, т.к. ориентир на пользователей без обновлений. И подумайте после этого))))
При чём тут это? Кстати, никто из моих друзей этот вирус не подхватил (может, везение). А в крупных компаниях вообще обновления накатываются через групповые политики принудительно. То есть вы утверждаете, что пользователей без обновлений в этом случае было сильно больше половины? Ну и ок. В любом случае, грамотные пользователи оказались защищены. А неграмотные — сами виноваты.
Есть куча готового софта, который ищет (И НАХОДИТ) подобные дыры.
Подобные — это какие? Вы сами-то верите, что именно описанные мной сценарии хоть где-то применяются (в любой CMS, даже самой древней и дырявой)?
Выше речь шла про любую нормальную компанию. Возьмем даже мелкую — 5-6 разработчиков, 1-2 админа.
Ну ОК, тогда по согласованию. Но мне почему-то кажется, что в такой компании (особенно если там всего 7 человек) админам это даже пропишут официально одним из пунктом их обязанностей. Потому что безопасность пользователей крайне важна, это же репутационные риски.
Выше вы говорили про рядового админа ;)
У рядового это вполне может быть одним из пунктов в обязанностях, особенно если он в отделе безопасности трудится ;)
давайте еще раз спрошу — назовите компании, в которых есть люди отвечающие за логи ;)
makeasite.ru/how-to-check-server-logs.html
Полагаю, любой более-менее крупный интернет-портал. Я уже не говорю про большие highload проекты типа вк или твиттера.
При чём тут это?
Почитайте переписку ранее — вспомните ;). Мы разговаривали о том, что защищенные аккаунты не интересны и упор всегда делается на НЕ защищенные, в том числе с простыми паролями ;)
То есть вы утверждаете, что пользователей без обновлений в этом случае было сильно больше половины?
В случае с вирусами (ваннакрай и петя) — это 100% ;).
Подобные — это какие?
Отсутствие фильтрации/валидации get/post/cookie параметров и их использование для взлома систем.
Вы сами-то верите, что именно описанные мной сценарии хоть где-то применяются (в любой CMS, даже самой древней и дырявой)?
Не только верю, знаю на 100% ;) Надеюсь, гуглить умеете сами.
Но мне почему-то кажется, что в такой компании (особенно если там всего 7 человек) админам это даже пропишут официально одним из пунктом их обязанностей.
Нет конечно. Скорее наоборот)
Потому что безопасность пользователей крайне важна, это же репутационные риски.
Для этого есть CTO/PM. Без них, подобные решения, никто не будет принимать.
У рядового это вполне может быть одним из пунктов в обязанностях
Не может. Только если в шарашкиной конторе «Рога и копыта» ;)
Полагаю, любой более-менее крупный интернет-портал. Я уже не говорю про большие highload проекты типа вк или твиттера.
Так где ссылка на такие компании?)) По вашей ссылке не нашел подобного) Еще раз — нет такой должности «читать логи» )). Это работа CTO/TL/разработчиков… Никто и никогда не нанимает отдельных людей для наблюдения за логами))))
Ну хоть-бы немного задумался…
Для этого есть CTO/PM. Без них, подобные решения, никто не будет принимать.
Может и так, вам виднее.
Никто и никогда не нанимает отдельных людей для наблюдения за логами
Всё-таки я считаю, что этим занимаются люди из отдела безопасности. Читал примеры таких случаев, не на пустом месте говорю.
По вашей ссылке не нашел подобного
Зато там сказано, для чего бывает нужно хотя бы время от времени изучать логи. Мало вам — вот держите ещё. Можете сразу в конец статьи прокрутить :)
xakep.ru/2014/05/25/is-incedent-research
Это работа CTO/TL/разработчиков
Что такое TL? Нагуглить не смог…
Нет конечно. Скорее наоборот)
И почему же наоборот?)
Не только верю, знаю на 100% ;) Надеюсь, гуглить умеете сами.
Немного лень гуглить такую глупость. Если уверены, что такое есть — ткните, пожалуйста, носом. Категорически не верю в такое. Ибо даже я бы такое не наваял (а у меня уровень куда ниже, чем у разработчиков популярных CMS).
Всё-таки я считаю, что этим занимаются люди из отдела безопасности.
Люди из ОБ занимаются, та-да-м, безопасностью, а не чтением логов). Да, конечно, анализ логов — часть работы, но только автоматический, а не ручной просмотр ;)
Читал примеры таких случаев, не на пустом месте говорю.
Ну дайте хоть чуток подобного почитать, а?))
Что такое TL? Нагуглить не смог…
Team Leader.
И почему же наоборот?)
А я выше раз 5 уже написал про это ;). Не имеет права ни один админ лезть в приложение/данные. Это не его область работы.
Немного лень гуглить такую глупость.
Т.е. писать глупости вам не лень, а гуглить секьюр-листы лень?))) Ну давайте посмотрим:
>что-то инклюдится, и мы туда пишем данные, пришедшие с клиента
Очень напоминает любую базу данных, не?)
>в коде есть eval, и он берёт что-то из базы данных/из файла на сервере, куда до этого писали данные, пришедшие от клиента
Шаблонизация?)))
Зато там сказано, для чего бывает нужно хотя бы время от времени изучать логи.
А я где-то говорил, что не надо изучать логи?!)))))) Я утверждал, что в компаниях НЕТ СПЕЦИАЛЬНЫХ людей, работа которых состоит в изучении логов.
Мало вам — вот держите ещё.
А давайте вы лучше дадите ссылки, в которых рассказано кто и для чего держит отделы чтения логов ;). Пока ваши ссылки напоминают детский лепет, если честно.
Честно говоря — я не понимаю, что вы пытаетесь доказать. Вы утверждали, что подобрать md5 не реально — это было опровергнуто выше. Утверждали, что в крупных компаниях есть отделы чтения логов — не привели ни одного названия/ссылки. Доказываете, что админы могут изменять данные по своему хотению — это показывает, что вы не работали в более-менее средней компании, не говоря о крупных.
Ну хотите и дальше пребывать мире с розовыми слонами — ок, это ваш выбор. Просто не пишите глупости ;)
назовите компании, в которых есть люди отвечающие за логи
Подозреваю, что SRE в Google вполне попадают под это описание.
Вас совсем не смущает тот факт, что вместе с блокировкой какого-то аккаунта могут выполняться дополнительные действия (логирование, запрет доступа в другие подсистемы, отправка информации о блокировке менеджерам/программистам, остановка отправки смс/email уведомлений, etc)
Не только могут, но и должны выполняться =)
Если человек на такой низкой должности, что всего этого не знает, и у него нет чётких инструкций сверху — он не имеет права делать никакую блокировку. Я же говорил про человека, который всё это знает, понимает последствия, и которому не могут запретить это сделать (либо он этот шаг согласовали получил разрешение).
У меня было несколько проектов, где я был и единственным разработчиком, и админом (но не владельцем). После согласования с владельцем (а иногда и уведомления в одностороннем порядке) я делал такие вещи, и ещё ни разу на меня не наезжали за излишнюю инициативу.
Понятное дело, что чем крупнее компания — тем больше инстанций и больше возни. Но там и автоматические алгоритмы есть для совершения таких блокировок (чего нет у меня).
Хм… Давайте подумаем… 2-3 порядка от 2млрд — это 0,2-2трлн хешей в секунду. До сих пор считаете что это «не так много»?
Когда речь идёт о числах с 18-25 нулями, то разница на 2-3 порядка — это и правда немного. Простая логика же. Да, всё ещё считаю.
Так-же предположим, что пароли у этих «жертв» не сложные (иначе они не попадают под первое условие — 1 пароль на разные аккаунты).
Вот это, имхо, зря. У меня сравнительно сложные (рандомные) пароли. Но при этом их не так много, в пределах 3-4 штук. И поэтому они много где повторяются. Таких людей тоже стоит учитывать :)
А вы написали, что раз везде одинаковый пароль, то он непременно простой. Это не так. Другое же дело, что там далеко не 1% наберётся, а сильно больше. Вплоть до 20-40 процентов, как подсказывает логика :)
Тут намного выгоднее. платим пару-тройку тысяч долларов, но берем по 1$ за каждый аккаунт (а их, как посчитали выше, с десяток миллионов).
Вы слишком упрощаете.
а) Не все взломанные аккаунты выкупят (если исходить из того, что вы сразу сделаете полный перебор и не будете регулировать скорость подбора в процессе исходя из спроса). Тут нужен или очень богатый покупатель, или очень много покупателей. Дай бог вы продадите 5-10 процентов. Я уже молчу о том, что если спалиться на таком, можно и перед законом ответить — не все рискнут взяться за это дело.
б) Тут надо иметь пару-тройку тысяч долларов, которые не жалко на такое пустить, и уметь организовать такой кластер. Очень многие не подходят ни по первому, ни по второму пункту. Ну и самое главное — надо перед этим получить утекшую базу данных :)
Кстати, я вообще не очень хорошо представляю, как можно слить базу в системе, которая достаточно надёжна защищена. Можно слить её шеллом, даже не зная структуры — это, кажется, логично. Но в нормально защищённую систему нельзя залить шелл. Или я что-то упускаю ввиду отсутствия знаний по этому предмету?
Да вы шутите))) Топ-10 паролей базы yahoo:
Ну так эти люди — ССЗБ, знаете такое выражение? Раз они для важных, критичных систем вроде главного почтового ящика (или даже больше того, компании вроде гугла и yahoo предоставляют множество сервисов под единым паролем) используют qwerty и 123123. Феерический идиотизм. Ибо подобрать такое даже проще, чем дату рождения. Для подбора такого пароля даже не нужно лично знать пользователя, чтобы взломать его аккаунт. :)
Вообще-то да. Это в любой инструкции для чайников указано, вы чего. Да и по своим знакомым я знаю, какие пароли ставят на критичные сервисы, например, на админки своих собственных проектов.
Ну вот и пример использования «стойкого пароля» для админа, использования подбора пароля по хешу через радужные таблицы и примерное время взлома (явно не годами измеряется) ;)
https://youtu.be/_i1d9M40-qc?t=20m48s
Вот здесь кстати докладчик высказывает ту же мысль, что при утечке базы лучше всего сбросить доступ для всех юзеров.
На самом деле, она довольно полезна для тех, кто не тупо копипастит решения, а вдумчиво читает комментарии.
Потому как именно в них рассмотрены разнообразные ошибки, которые теоретический читатель сможет избежать.
Уж простите, но у меня подгорает стул от того, что разработчики, с не первым годом опыта, до сих пор смешивают понятия авторизации и аутентификации.
Потому что то, что грамотно считается авторизацией, по факту мало где нужно — только в CMS и на всяких форумах. А вообще чаще авторизацией называют логин. Не надо занудствовать)
Потому что то, что грамотно считается авторизацией, по факту мало где нужно — только в CMS и на всяких форумах.
Ну то есть вы все бизнес-системы так вот взяли и выкинули? Всю почту? Все социальные сети?
Социальные сети и бизнес-системы — это очень круто, не мой масштаб точно. Но это да, конечно)
Почта — а зачем там авторизация-то? Там обычно один пользователь. Мы же про персональные ящики?
А, логично. Я когда делал мессенджер проверял всё это ровно так же, что мы пишем именно от себя, и в ту комнату, куда имеем доступ.
Просто там зависит от реализации. Если бы у нас была не огромная почтовая система, а мини веб-почта, то возможно, эта авторизация бы просто испарилась, уйдя целиком в условие выборки по базе данных (вида "SELECT * FROM messages WHERE to_uid=$user_id"). Это не так красиво выглядит, но в очень простом проекте воспринимается даже проще и органичнее, чем целый класс по проверке прав доступа, с объектами-контенейрами этих прав, и прочими радостями.
Хотя при получении одного конкретного сообщения… Да, думаю, придётся ещё раз проверить, что оно именно наше.
Проблема решений "авторизация бы просто испарилась, уйдя целиком в условие выборки" в том, что при усложнении проекта очень легко можно забыть что это не просто фильтр выборки, но и проверка авторизации. Или наоборот, забыть, что это не просто проверка на наличие прав, но и условие выборки. Лучше уж по умолчанию считать, что авторизации просто нет, чем надеяться на "невидимую".
Такие решения нарушают принцип единственной ответственности и потом сильно усложняют разработку, если закопаны где-то глубоко, либо приводят к дырам типа "Хотя при получении одного конкретного сообщения…"
Пожалуй вы правы. Хотя, таким образом можно добиться оптимизации, получив всё в один запрос. Скорость тоже важна.
Это ведь только одно из условий. Их в запросе несколько. Можно написать перед выборкой развёрнутый комментарий. Или сделать понятную документацию к проекту, где будет описано, какая выборка за то отвечает, и наоборот, где у нас авторизация закопана. Ну и плюс тесты, чтобы ни один глюк не просочился… :)
С точки зрения кода отдельно проверка ACL — это лучше. Но боюсь, по производительности это будет не очень айс. Разве что, если у нас запрос всего на один элемент — там скорее всего не так важно, один запрос или два.
Социальные сети и бизнес-системы — это очень круто, не мой масштаб точно
Есть разница между "не мой масштаб" и "по факту мало где нужно".
Почта — а зачем там авторизация-то? Там обычно один пользователь.
Затем, что там больше одного ящика обычно, и у каждого пользователя доступ к своему ящику. И это не считая администраторов.
"В мелких проектах мало где нужно", так лучше?) Почта — уже не мелкий проект.
Насчёт ящиков — да, не подумал. Мне почему-то казалось, что вы хотите сделать проверки прав доступа к отдельным письмам в пределах аккаунта.
Ну там опять же это просто логичнее всего сделать дописав ещё один LEFT JOIN к запросу, либо поставив условие на столбец ("WHERE folder_id=1 AND user_id=976"). То есть даже при выборке единичного элемента, если условие на автора не будет соблюдено — вернётся пустое множество строк.
В качестве одного из индексов, кстати, можно сделать составной индекс (user_id, folder_id), при этом глобально в системе id папок могут быть не уникальны, это может быть удобно (например, "Входящие" у всех будут с folder_id=1).
Дело в том, что этот метод предполагает хранение авторизации в сессиях. Это статья не относится к конкретному языку, и справедлива для любой платформы, но я буду иллюстрировать всё на примере PHP.
… а в asp.net в сессии авторизацию не хранили никогда. И аутентификацию — тоже.
Просто сохраняют в собственной куке айди пользователя. Но поскольку просто айди хранить как-то уж слишком стрёмно (любой может поставить любое число и получить доступ к произвольному аккаунту), то часто вместе с айди за компанию сохраняют и пароль. В открытом виде.
То есть та идея, что в куку надо шифровать на сервере — она слишком сложная и продвинутая? Да, в этом случае остаются атаки через session hijacking, но от них защищаются (дополнительными) одноразовыми токенами (и очень короткой сессией вообще).
Впрочем, я вообще хочу заметить, что сессии и аутентификация — это немножко разные задачи, и не надо их смешивать в одну кучу.
Вот про одноразовые токены и про перехват сессий я бы с удовольствием почитал… Я так понимаю, там сервер вместе с каждым запросом выдаёт клиенту новый токен, так? Что будет, если этот токен будет перехвачен вместе с сессией? Злоумышленник делает запрос, потом клиент делает запрос, сервер видит, что такой токен уже был, и закрывает соединение?
Что будет, если этот токен будет перехвачен вместе с сессией?
… им можно будет воспользоваться ровно один раз, после чего он перестанет быть валиден.
И может так оказаться, что им воспользуется перехвативший, а клиент получит отлуп. Не очень здорово как-то же?
… зато в симметричном случае отлуп получит перехвативший, и мы не получим, например, лишнюю транзакцию с карты. Пусть даже в одном случае из двух — все равно неплохо.
Вообще, (почти) любая защита ведет к понижению комфорта пользователя, это нормально. Неприятно, но неизбежно.
Пока не думал. Я так понимаю, схема такая: клиент генерирует свой закрытый ключ, сообщает серверу открытый к нему, и сервер использует его для расшифровки трафика от клиента? Вообще вариант. Не подскажете, какими штатными средствами такое реализуется? Это будет тот же самый SSL по сути, только с клиентским сертификатом?
Вот ты тоже про аутентификацию в таком ключе напиши. Тоже будет о чем поговорить :)
О май гад. Мне кажется, или в 1998-ом всё было сильно проще (даже при том, что не было даже пятёрки ещё)?
Имхо, надо соразмерять задачу и используемые средства, и не стрелять из пушек по воробьям.
Сейчас играют в программирование :)
Я не о том. Я про то, что на старте (хотя сам кодинг что на PHP, что на JS был несколько сложнее из-за отсутствия удобных фич и глюков браузеров, если говорить о клиентском коде) не было всей этой мути. И жить было сильно проще. Ведь как посмотришь псевдо-коды, который используются во всех этих шаблонизаторах и хитрые закрученные схемы взаимодействия этого всего — волосы дыбом встают. Намного ведь лучше писать простой и приятный код, который легко читать и отлаживать, и который предсказуем. Над которым не надо ломать мозг. Так зачем это всё? :)
Я когда-то думал, что jQuery местами слишком упрощает жизнь программисту; потом я думал, что она добавляет сложности, поскольку кроме чистого JS надо помнить её методы, особенности их работы, какой и когда лучше использовать. Теперь, глядя на этот трэш, я понимаю, что jQuery-то просто сама няшность по сравнению со всем остальным.
Да, есть жуткие проекты типа WordPress, в которых чёрт ногу сломит.
Добавлю, что зачастую жуть таких проектов обусловлена именно отсутствием в то время инструментов подобных современным и желанием/необходимостью тянуть и сейчас лямку обратной совместимости с принятыми тогда "лучшими" решениями. Может код того же WordPress несовместим сейчас даже с 5.3, но архитектура его хорошо если по лучшим практикам 4.0 построена.
Не вижу, чем первый вариант хуже. Работает к тому же чуть быстрее. Дольше печатать — ну так Ctrl+C/Ctrl+V никто не отменял :)
От библиотек, облегчающих работу с DOM/XML/изображениями/чем угодно на сервере я нос не ворочу. Вовсе нет. Я про тот код, что по ссылке, которую brevis скинул выше. Вот это у меня язык не повернётся назвать читаемым :) jQuery я наоборот похвалил в комментарии выше за чрезвычайную человекопонятность.
И всё равно получалось дыряво, и ночами сидел, искал глюки, отлаживал
Это PHP был так плох? У меня нет сильных глюков, и всё не так дыряво (в основном), при этом я пишу едва ли не в стиле PHP4, ну разве что всякие суперглобальные масссивы и глобальные переменные (когда $_GET и $_POST автоматом в переменные разворачиваются) не использую. И я бы не сказал, что очень тяжело, и много отладки. Бывают глупые синтаксические ошибки, но в новой версии ISP Manager есть подсветка синтаксиса и синтаксический анализатор кода на JS. Там все ошибки подчёркиваются мгновенно, так что ошибиться стало просто негде. Ну и плюс внимательность.
Более того, если писать код в ООП стиле, шансов накосячить ещё меньше.
Со мной такое редко, поверьте) Числовые значения я привожу к int, а строковых у меня мало, когда они и встречаются — сначала делаю проверку на формат, прежде чем что-то в базу писать.
Насчёт ламповости — ну я это время как-то не застал, мне в 98 ещё 6 лет всего было :)
Взял фреймворк, усвоил философию и стиль кода — и поехал вперёд, не отвлекаясь на мелочи.
Так в том-то и дело, что писать свой фреймворк, постоянно его развивая — это не мелочи. И это очень интересно. Кстати, именно так вырос первый Symfony, по словам авторов книги (самих разработчиков).
Чтобы сделать Ctrl+V, надо сначала найти кусок, где надо сделать Ctrl+C. А когда код вот из-за таких десятиэтажных конструкций раздут, будете очень долго искать.
Да, бывает тяжко. Но обычно мотать не очень далеко, у меня таких конструкций повсюду тонны.
Он хуже как по читаемости, так и по переносимости
Читаемость — таки во многом вопрос привычки (да и кто вам мешает сделать короткий шорткат, как сделал разработчики вк, ge('id')?
А с переносимостью ровно наоборот. Ваш вариант требует тащить за собой jQuery (хоть она в минифицированном виде и не так много весит). Плюс новые версии jQuery имеют свойство не работать в очень старых браузерах. Мой же код не будет требовать сторонних библиотек и будет работать почти везде. Почти — потому что со старыми IE всё сложно, к сожалению. Но даже там код на чистом JS исполнится хоть как-то с гораздо большей вероятностью, если совсем повезёт — то вообще без ошибок).
Но зачем Вам нужен IE5? (jQuery 1.12: "Internet Explorer 6-8, Opera 12.1x or Safari 5.1+").
Ваш код полностью потонет в костылях.
То-то я смотрю у меня 70-80 процентов сайтов, сделанных на фреймворках, не работает в Opera 11 и даже 12 (про IE 8 я вообще молчу). Не, я верю, что виноват не фреймворк, а плагины к нему (которые не настолько кроссбраузерны). Но когда используешь фреймворк, обвешать проект плагинами — уже очень велик соблазн. Потому что если всё пишешь сам — зачем фреймворк тогда :)
То-то я смотрю у меня 70-80 процентов сайтов, сделанных на фреймворках, не работает в Opera 11 и даже 12
Попробуйте открыть из MS DOS. Я думаю это решит вашу проблему. Если не получится — можно попробовать со спектрума...
К чему этот троллинг? Я ответил на конкретную цитату. Со слов разработчиков, поддержка jQuery "Internet Explorer 6-8, Opera 12.1x or Safari 5.1+".
Так вот, по факту в IE8 не работает уже даже и 10 процентов сайтов корректно. А Opera 11, хотя технически гораздо совершеннее, отсутствует в этом списке даже официально. При чём тут "Спектрумы", если речь про браузер 2012-ого года релиза?.. 5 лет не прошло ещё даже.
Это просто ответ и вам и автору коммента выше. Наверное надо было его тоже упомянуть. Сабж ( m0Ray ) не знает о транспайлерах под JS, а вы ведётесь и предлагаете проверять в том, что никто не использует указанные 5 лет (если не больше).
Примерно как с вашим кодом из начала двухтысячных =) Сами себе буратино, что ещё можно сказать.
Я напишу код без всяких фреймворков и библиотек, который не будет работать в старых Операх и ИЕ, не поддерживающих хотя бы на 90% ES2015. Простейший код типа const str = 'test'; alert(str); Так что фреймворки тут не причём, это обычно сознательное решение разработчика отказаться от совместимости со старьём. Под фреймворки, библиотеки и плагины ограничивают совместимость только "снизу", а разработчик ограничивает её "сверху".
Не очень вас понял, что значит "снизу"? Фреймворки же не ограничивают никого в использовании новых функций. Про ES2015 я вообще очень недавно узнал, кстати. Да, такой код работать не будет, если его специально не сконвертировать каким-то образом в пригодный.
И имхо это не очень хорошо. У людей могут быть причины использовать старый браузер, а у них ломается две трети интернета :)
jQuery, например, поддерживает IE6-8 — если в проекте используется jQuery, то на IE5.5 он вряд ли запустится. Это ограничение снизу. Но если в коде проекта есть const, то работать не будет и в IE10, только в IE11 — это ограничение сверху. Правильней будет, конечно, поднятие ограничения снизу разработчиком по сравнению с фреймворком.
Не очень понял это утверждение. Оба ограничения — снизу (браузер не старше чем версия N). Просто установлены они разными субъектами: в первом случае "платформой", т.е. фреймворком, а во-втором — разработчиком приложения. Ограничений сверху я практически не встречал ещё (что работает только на браузерах не новее чем версия N) — спасибо обратной совместимости, с которой у разработчиков браузеров всё прекрасно.
Правильней будет, конечно, поднятие ограничения снизу разработчиком по сравнению с фреймворком.
А вообще есть и нормальные ограничения сверху, например использование каких-то фич реализованными по драфту w3c или whatwg, который потом изменился. И надо либо браузер замораживать, либо фронт переписывать, либо код бэкенда менять иногда.
В 1998-м ещё даже четверки не было (как сейчас помню — какого-то нового Президента РФ вроде выбрали, а я выход PHP 4.0 RC ждал), то есть никакого ООП вообще, и, тем более, инструментов, сравнимых хоть как-то с Symfony, Doctrine, React и т. п., позволяющих почти сразу переходить к бизнес-логике, а не заниматься инфраструктурніми задачами, переходящими из проекта в проект.
Имхо, можно основные задачи решить единожды и дальше таскать тупо из проекта в проект. Ну или накодить заново, если не лень. Та же паджинация, например, в простейшем случае пишется минут за 15-20.
Ну так юмор ситуации в том, что многие не используют ни React, ни Symfony, ни даже ООП. А просто пишут код, который работает.
На самом деле, часто даже функции бывают лишними: если кода очень мало, можно часть вынести во внешние файлы и подключить в шаблон (в этих файлах можно создать одну или несколько функций как раз), ещё часть файлов будет служить точками получения данных из базы (в JSON или HTML, либо комбинированный вариант в зависимости от параметров), а всё остальное — это просто шаблоны, то есть HTML с вкраплениями PHP, и JS даже бывает удобно размещать прямо там же, когда его не очень много.
То есть нет даже такой задачи, ради которой требовалось бы писать много чистого кода, бизнес-логики в вакууме — в отрыве от HTML, баз данных, переменных HTTP-запроса и прочего.
То есть нет даже такой задачи, ради которой требовалось бы писать много чистого кода, бизнес-логики в вакууме — в отрыве от HTML, баз данных, переменных HTTP-запроса и прочего.
Вы забыли важную оговорку: у вас нет "такой задачи, ради которой..."
Это сначала кажется, что так проще, потом же, в процессе разработки, всё это превращается в ужасный кусок кашеподобного кода. Его очень сложно поддерживать, отлаживать, изменять.
На каком-то этапе так, к сожалению, бывает. Но не всегда. И обычно на этот момент все фичи уже написаны и новые не добавляются. Только исправляются ошибки.
Вы что, пишете только мелкие, одноразовые задачки? Ваши проекты не растут, не развиваются, не живут долго?
Вообще, видимо так, вы правы. Ну как недолго — год-два максимум. И да, задачки не настолько крупные :)
Почему в пещере? Автор, с вашего позволения, с 2007 года пишет на PHP проекты разной сложности. Примерно с 2012-ого года более-менее серьёзные. И про ООП знает, и даже читал про позднее статическое связывание (правда не очень понял). И про трейты в курсе. И cURL, GDlib, DomParser и ещё пару расширений юзал. И даже по Symfony 3 немного читал учебник. Зря вы на автора гоните :)
даже читал про позднее статическое связывание (правда не очень понял)
Ну, хоть честно.
Мне тогда показалось, что даже в Java это всё как-то попроще устроено. Плюс в самом же мануале и в чейнджлогах есть оговорки, что поведение PHP от версии 5.2 к версии 5.4 весьма сильно менялось в этих моментах… Вплоть до того, что при доступе к элементам через определённый синтаксис можно было получить один элемент, либо другой элемент, либо ошибку. Вроде касалось это как раз статических методов и наследования.
Данный код можно, наверное, сделать ещё лучше и надёжнее.…
А вы можете коротко и непротиворечиво сформулировать эту "идею"?
Для «хардкорности» можно юзер агент и другие данные в куках каким то образом шифровать, что бы взломщику было не понятно как подобрать хак.
я так понял идею автора.
В целом идея автора — создать свой механизм "запомнить меня в этом браузере" и реализовать привязку к IP/UA/другой "секретной" технической информации.
Давайте разобьем на две части.
Использовать для валидации сессии не только идентификатор сессии, но и другие данные. Идея не новая (та же привязка к IP регулярно встречается). Тут вопрос в том, какие именно данные использовать — потому что, как мы понимаем, если я смог перехватить куку, то что мне мешает заодно и юзер-агент перехватить? А привязываться к IP нельзя по уже описанным причинам.
- Где хранить "другие данные" — в куке или где-то на сервере. Это просто компромис между "что нагружать" — клиент и канал или сервер. Ну и да, данные, хранящиеся на сервере, немного сложнее подменять/анализировать.
"По моей оценке" это старая идея, имеющая много недостатков. Лучше брать готовые реализации.
Собственно, вот тут все уже написано, раздел "Binding the Session ID to Other User Properties":
With the goal of detecting (and, in some scenarios, protecting against) user misbehaviors and session hijacking, it is highly recommended to bind the session ID to other user or client properties, such as the client IP address, User-Agent, or client-based digital certificate. If the web application detects any change or anomaly between these different properties in the middle of an established session, this is a very good indicator of session manipulation and hijacking attempts, and this simple fact can be used to alert and/or terminate the suspicious session.
Although these properties cannot be used by web applications to trustingly defend against session attacks, they significantly increase the web application detection (and protection) capabilities. However, a skilled attacker can bypass these controls by reusing the same IP address assigned to the victim user by sharing the same network (very common in NAT environments, like Wi-Fi hotspots) or by using the same outbound web proxy (very common in corporate environments), or by manually modifying his User-Agent to look exactly as the victim users does.
Ну вот про это была и вся моя статья, по сути. И там кстати было сказано, что это не панацея. Что и подтверждает второй абзац Вашего текста :)
… а если это не панацея, и при этом HTTPS от всей этой белиберды защищает, то зачем возиться?
Например потому, что есть куча горе-стартапов (либо личных бложиков), у которых даже нет денег на сертификат. Ну или жаба душит)
После 12 апреля 2016 года отсутствие денег не является оправданием отсутствия HTTPS.
(да и до того были варианты вполне себе)
Привязываться к IP можно, реальное использование этого кода доказало, что неудобств это не вызывает (напротив, позволяет как side-эффект фиксировать каждую смену IP-адреса).
Ну и главный плюс этой схемы, о котором все комментирующие забыли — возможность сделать инвалидацию (принудительное закрытие) любой сессии. Что при коде вида
if (!isset($_SESSION['user_id'])) {
/* redirect to auth.php */
}сделать нормально практически невозможно. Пjтому что простым образом сбросить можно только свою сессию, но не чужую :)
Привязываться к IP можно, реальное использование этого кода доказало, что неудобств это не вызывает
У кого не вызывает? У человека, который с планшетиком переходит от вайфая к вайфаю?
Ну и главный плюс этой схемы, о котором все комментирующие забыли — возможность сделать инвалидацию (принудительное закрытие) любой сессии.
Это плюс не вашей схемы, это плюс привязки сессий к пользователю. Которую привязку можно делать на сервере прямо в хранилище сессий.
У кого не вызывает? У человека, который с планшетиком переходит от вайфая к вайфаю?
Да, или от вайфая к безвайфайной зоне. И не обязательно с планшетиком. Смартфон не сильно хуже работает :)
Которую привязку можно делать на сервере прямо в хранилище сессий.
Извините, не очень понял Вашу мысль. То есть без подобной программной надстройки реально сделать это средствами голого PHP? Я про инвалидацию всех сессий данного пользователя. Нельзя находясь в одной сессии инвалидировать другие, насколько я знаю. Ну только если через прямой доступ к файловой системе, но тогда всё равно придётся где-то имена файлов с сессиями для каждого юзера хранить. Не сильно это красивее…
Сессии необязательно хранятся в файловой системе, могут, например, в базе данных и подобных хранилищах. А там поиск идентификатора текущей сессии по имени юзера обычно "из коробки". Высокоуровневая абстракция сессий типа имплементации SessionHandlerInterface может это делать "под капотом".
Да, или от вайфая к безвайфайной зоне. И не обязательно с планшетиком. Смартфон не сильно хуже работает
И вы мне хотите сказать, что IP при этом не меняется?
То есть без подобной программной надстройки реально сделать это средствами голого PHP?
Я не очень знаю, что такое "средства голого PHP", но если иметь нормальное серверное хранилище сессий, то можно сделать. Речь же идет про "клиент vs сервер", а не про "программировать vs не программировать".
И вы мне хотите сказать, что IP при этом не меняется?
Меняется. Только что в этом плохого? Пара редиректов — и всё продолжает работать как раньше. Причём пользователь может этого даже не увидеть, если смена IP произойдёт во время, например, poll-инга сообщений какого-нибудь чата по таймеру из JavaScript.
но если иметь нормальное серверное хранилище сессий
Что в вашем понимании есть нормальное хранилище сессий? В PHP сессии хранятся в виде файлов, и для каждой копии Apache (каждого сайта на хостинге) складываются все вперемешку в один каталог. PHP не даёт прав на удаление произвольной сессии (и правильно делает). Можно удалить нужный файл сессии, выставив ему перед этим права доступа, если нужно, но для этого как-то нужно вести реестр этих файлов сессий — например, в виде таблицы в БД. Получается двухкомпонентное хранилище такое.
Я сделал то же самое по сути, только вообще с минимальной привязкой к реальным PHP сессиям: у меня БД — ключевой компонент, все данные открытой сессии хранятся там. Можете считать, что я сам написал простенькое хранилище.
Понятно, что это всё равно велосипед, и есть готовые реализации того же самого, но ведь это работает.
Меняется. Только что в этом плохого? Пара редиректов — и всё продолжает работать как раньше
Для этого надо, чтобы там, куда вы редиректитесь, IP не учитывался. И в чем пойнт тогда?
Что в вашем понимании есть нормальное хранилище сессий?
БД, индексированная по идентификатору сессии и идентификатору пользователя.
Для этого надо, чтобы там, куда вы редиректитесь, IP не учитывался. И в чем пойнт тогда?
Ну выходит, что ни в чём, да… То есть он учитывается «здесь», но не учитывается «там». А чтобы «здесь» снова всё стало ок, нужен редирект. Однако же стандартные сессии PHP вроде привязываются к IP. Я ведь прав? Почему вас не смущает это, а то, что я сделал точно так же как у них — смущает…
БД, индексированная по идентификатору сессии и идентификатору пользователя.
В моей реализации можно без проблем сделать эти индексы :)
У нас просто пользователей так мало, что и без индексов всё быстро работало…
Однако же стандартные сессии PHP вроде привязываются к IP. Я ведь прав?
Понятия не имею, что там в "стандартных сессиях PHP".
В моей реализации можно без проблем сделать эти индексы
Не в индексах дело, а в том, что если у вас есть серверное хранилище данных о сессии, то в куке достаточно держать идентификатор, а все остальное не нужно. Что, как бы, сводит всю идею выше на нет.
Прошу автора написать статью с учетом правок и новых идей, в идеале, на php 7.1.
Может кто подскажет, как правильно организовать следующее:
- есть сайт, условно site.com
- есть форма входа/регистрации, возможно, с капчей
- зарегистрированный пользователь получает своё 'поле деятельности', например, индивидуальную схему в базе данных postgresql
- для пользователей (как разовых, так и зарегистрированных) заложена система
push_уведомлений (подписка),…, чат ...
1. Сайт предоставляет функционал как для зарегистрированных пользователей, так
и для разовых (точнее, разовый == не зарегистрированный).
2. Пользователь, имеющий регистрацию, может зайти на сайт, но не пройти авторизацию,
и действовать по правилам разового.
Возможно, есть ещё вариации, или моменты на которые нужно обратить внимание.
Как разграничить задачи сессий и аутентификации и правильно организовать функционал такого сайта?
Чтобы был учет всех посетителей, их статусов, ip, действий… попыток взлома…
Подскажите, пожалуйста, лучшие практики.
Открывать сессию при заходе на сайт, сохранять всё что нужно/можно, при успешной аутентификации сохранять в сессии id пользователя, при доступе к общей функциональности писать логи доступа с данными сессии, анализировать на подозрительную активность и т. п., если что блокировать по сессии (записать в сессию признак блокировки), при доступе к закрытой функциональности блокировать не только сессию, но и учетку пользователя.
Насчёт хранилища сессий — PHP хранит их в виде файлов. Мне выше уже писали в комментариях насчёт «нормального хранилища сессий», но не очень раскрыли мысль. Смотрите, в чём идея. Стандартная сессия PHP жёстко привязана к браузеру и IP. Допустим, вы хотите дать возможность пользователю завершить все свои открытые сессии. Как вы это реализуете?
Ну и по теме…
Забыли про XSS, CSRF, данный код от них ну никак не защищает/предохраняет/перекрывает/прекрывает и т д.
mysql_real_escape_string не панацея, а использование данной функции для фильтрации входящих целых чисел вообще добавляет уязвимость, в особенности если память не изменяет, то в кодировках SHIFT_JIS, BIG5, GB2312, EUC-JP, EUC-KR (мультибайтовых, utf8 не подвержен вроде как, хотя видел случаи с ним). Так же не стоит забывать, что функция mysql_real_escape_string не учитывает кодировку соединения(насколько помню на момент 2006 года), потому надо не забыть проставить mysql_set_charset()… Именно эта функция пакета mysql должна использоваться должна использоваться для выставления клиентской кодировки вместо запроса SET NAMES.
md5 давно уже не рекомендуется к использованию, если память не изменяет, то автоматизировали поиск коллизий по алгоритму md5 еще в 2006 году. Не зря от него отказались git в пользу sha1, так же sha1 широко используется не только в контроле версий но и в системах подписи… Да куда уж тут ходить, sha1 находится в основе SHACAL, что так же добавляет к нему доверие… За исключением гугла, они в него верить перестали :D
Насчет передачи айди. Все известные системы wp, bitrix, dle используют аналогичный подход(единственное он более совершенен в плане хранения) и где автор видел подход функции «запомнить» с передачей в куку только айди пользователя — не могу понять, вроде такая проблема была в php nuke, но уже столько воды утекло, что даже и представить не могу кто его еще использует О_о…
Так же во многих комментариях проскальзывало про mysql_* функции… С 2006 года весь пакет mysql находился в состоянии discouraged, потому что небыло человека который бы им занимался, а сообщество уже активно рекомендовало использовать mysqli расширение. Само расширение mysql вылетело в статус deprecated только с ветки php 5.5… Собственно не удивительно, ведь текущая разработка интерпретатора ведет и к постепенному выпиливанию mysqli расширения в пользу PDO.
P.S. Тем кто не верит в CSRF, она реальна и в последние годы набирает обороты в использовании. Не зря во всех популярных фреймворках идут встроенные методы защиты для передаваемых форм.
Спасибо за развёрнутый комментарий.
Забыли про XSS, CSRF, данный код от них ну никак не защищает/предохраняет/перекрывает/прекрывает и т д.
Это тема отдельной статьи. Тем более, согласитесь, CSRF актуален далеко не только на этапе авторизации :)
md5 давно уже не рекомендуется к использованию
Но всё ещё много где используется, хотя возможно, это не есть хорошо. В целом я не настаиваю на использовании именно md5, можно заменить на любую другую хэш-функцию.
С 2006 года весь пакет mysql находился в состоянии discouraged, потому что небыло человека который бы им занимался, а сообщество уже активно рекомендовало использовать mysqli расширение
Знаю об этом. Но всё же это не делает его использование катастрофой, я полагаю.
а использование данной функции для фильтрации входящих целых чисел вообще добавляет уязвимость, в особенности если память не изменяет, то в кодировках SHIFT_JIS, BIG5, GB2312, EUC-JP, EUC-KR
Целые числа я ей не фильтрую, к счастью.
Так же не стоит забывать, что функция mysql_real_escape_string не учитывает кодировку соединения(насколько помню на момент 2006 года), потому надо не забыть проставить mysql_set_charset()… Именно эта функция пакета mysql должна использоваться должна использоваться для выставления клиентской кодировки вместо запроса SET NAMES.
Расскажите, пожалуйста, подробней, почему так. Я использую именно SET NAMES в силу простоты этой команды. Если это опасный подход — хотелось бы понять причину.
Насчет передачи айди. Все известные системы wp, bitrix, dle используют аналогичный подход(единственное он более совершенен в плане хранения) и где автор видел подход функции «запомнить» с передачей в куку только айди пользователя — не могу понять
Ну видите, уже поэтому этот подход нельзя назвать "вредным советом". Насчёт "только айди" — это было скорее в плане шутки. Ну знаете, человек, который пишет первый в жизни Hello World, может не знать, что айди в куке — это никакая не защита. Не тот ресурс я выбрал для такого капитанства, согласен. Хотя… вдруг кто-то в поиске нагуглит :)
Но всё ещё много где используется, хотя возможно, это не есть хорошо. В целом я не настаиваю на использовании именно md5, можно заменить на любую другую хэш-функцию.
А может лучше воcпользоваться встроенными в php? Почитать manual по php, где чёрным по белому написано, что md5 использовать нельзя. А потом открыть ещё одну страничку, где есть встроенная в язык функция для хеширования паролей? Думаю всё же не глупые люди всё это писали =)
Ну раз авторы языка рекомендуют, я спорить с ними не буду =)
Однако хочу заметить, что данная функция появилась лишь в версии 5.5, то есть относительно недавно. А раньше юзали md5 ещё как — очень многие CMS тому пример. Хотя, конечно, были и альтернативы: Blowfish, SHA1.
Мне впрочем раньше казалось, что Blowfish — алгоритм симметричного шифрования, а не хэширующий. Надо будет погуглить ещё раз.
Хотя, если совсем честно — я бы поставил эксперимент. Поскольку я не имею знаний в области криптографии, а также практического опыта по взламыванию чего-либо, трудно просто так взять и поверить на слово, что алгоритм уязвим. У меня конечно далеко не самое мощное железо, но я бы мог выделить часть ресурсов на своём домашнем сервере на 2-3 месяца с той целью, чтобы попытаться вскрыть хотя бы один MD5 хэш. Если за это время ничего не выйдет — надо полагать, использование алгоритма не так опасно, или я ошибаюсь?
Такие вещи делают не на «домашнем сервере», а в каких-нибудь амазоновских облаках за небольшую (вроде) плату. А там это займёт всего 2-3 недели)
Фрагмент из доклада про безопасность веб-приложений https://youtu.be/_i1d9M40-qc?t=1030. Там, в числе прочего, про то, почему для паролей MD5 использовать опасно.
Я не очень понял со скоростью. То есть понял, но там приводилась скорость перебора хэшей на алгоритме bcrypt. Хотелось бы узнать скорость перебора MD5 хэшей для сравнения.
Я просто года три назад разрабатывал свой несложный алгоритм шифрования. В своих расчётах я даже не учитывал время на генерацию MD5 сумм (которых на каждый вариант нужно создать две штуки). Не знаю, верно ли так делать, но я взял некий абстрактный одноядерный процессор (считайте, ядро), взял количество тактов в секунду, поделил на три (в процессе одной проверки нужно сделать три операции XOR, не знаю, может это как-то всё параллелится, но мы же одноядерный случай рассматриваем). И посчитал. Кстати, такты на сравнение полученных строк и конкатенацию я тоже не учитывал никак.
По моим расчётам вышло, что 2^64 комбинаций — уже такое множество, для полного перебора значений перебора которой несколько миллиардов лет потребуется.
Скажите — я неправильно считал, или в чём проблема? Ведь алгоритм подсчёта MD5 намного более комплексный (и содержит больше итераций), поэтому и тактов больше требует примерно на два порядка. Само использование видеокарты примерно на порядок даёт выигрыш (ну может на два, не в курсе), плюс можно сделать кластер из 2-4 видеокарт, но это даже не на порядок даёт ускорение, а соответственно в N раз.
В общем, хочется какую-то ссылку на конкретные скорости подбора и расчёт, либо на математическое обоснование. Я вот например не знаю, надо ли при подсчёте половинить значение (типа, что с вероятностью 50 процентов искомый хэш попадёт в первый промежуток, поэтому в среднем нахождение займёт 0.5 от полного перебора).
В смысле?)
Вы упорно считаете, что взлом идет на современном телефоне, хотя еще 10 лет назад для этого применялись куда более совершенные (в it-плане) методы и инструменты.
А где я писал про телефон? Я писал про мощный компьютер — возможно, с использованием GPU. Вы чуть исказили мои слова, но мысль вашу я понял.
Кстати — не все алгоритмы хорошо распараллеливаются. Я читал, например, бенчмарки разных приложений на процессорах с разным количеством ядер. Так вот, выигрыш сильно зависел как и от алгоритма, так и от используемого приложения (например, в случае тех же архиваторов).
Насчёт паролей в Windows — я немного читал про их протоколы шифрования и аутентификации (PAP, MS-CHAP, MS-CHAPv2). Они сами по себе полны концептуальных дыр, и дело тут вовсе не в брутфорсе и недостаточной длине ключей.
https://vk.com/popov654?w=wall1845668_3885
Вот те подсчёты. Под "64-битным ключом в котором использован только латинский алфавит, цифры и спецсимволы" имелся в виду на самом деле 6-символьный пароль. Что конечно не одно немного неграмотно сформулировано, но суть ясна, я думаю :)
Так же если обратится к самой документации mysql, а именно к C API методу mysql_real_escape_string. Так же существуют предупреждения насчет SET NAMES — https://dev.mysql.com/doc/refman/5.5/en/mysql-real-escape-string.html
Вроде ничего не упустил.
Большое спасибо, понятно.
А такой момент интересует — если я всё же сделал неправильно в существующем уже коде, и использовал SET NAMES, при этом кодировка сервера utf8, и кодировка хранения даннных в базе такая же, а кодировка соединения — cp1251, есть ли при этом проблемы безопасности? Например, возможность обойти экранирование?
То есть, если я правильно понял, экранирование будет работать так, как будто у нас UTF-8. В нижнем диапазоне там полностью совпадает всё? Одиночная кавычка, несколько я знаю, входит в ASCII набор, значит, по логике, должна иметь одинаковый код...
Надёжная авторизация для веб-сервиса за один вечер