Comments 45
В чём смысл писать
itertools.chain(*[l1, l2]) вместо itertools.chain(l1, l2)?Да, так выглядит более логично и понятно, исправил на Ваш вариант.
PS: оба вариант дают корректный ответ.
PS: оба вариант дают корректный ответ.
В первоначальном варианте вы делаете две лишних операции, сначала создаёте список, а потом распаковываете его. Поэтому предложеный вариант является ещё и более рациональным вариантом.
А вот если бы у вас был список списков, скажем, нам нужно развернуть матрицу в список, тогда рационально будет использовать `itertools.chain.from_iterable`:
А вот если бы у вас был список списков, скажем, нам нужно развернуть матрицу в список, тогда рационально будет использовать `itertools.chain.from_iterable`:
matrix = [[1, 2, 3, 4], [6, 7, 8], [10, 11, 12]]
list(itertools.chain.from_iterable(matrix))
# [1, 2, 3, 4, 6, 7, 8, 10, 11, 12]
Можете добавить кстати пример с `itertools.chain.from_iterable` в 7.1.2, он намного быстрее чем генератор списков.
В пункт 5.2:
# dict_a = dict(x: x**2 for x in list_a) # invalid
dict_a = dict((x, x ** 2) for x in list_a) # valid
В пункт 9.2:
transposed = list(map(list, zip(*matrix)))
В пункт 7.3:
Преимущество от комбинирования генераторов на примере сложной функции f(x) = u(v(x))
Преимущество от комбинирования генераторов на примере сложной функции f(x) = u(v(x))
list_c = [t + t ** 2 for t in (x ** 3 + x ** 4 for x in range(-2, 4))]
Задача выбора только рабочих дней:
days = [d + 1 for d in range(31) if d % 7 < 5]
Ух ты! Шикарно, добавил в решение под спойлером.
А разве каждый первый день месяца начинается с понедельника? :-)
Ну, и на самом деле, не все так просто. В России есть много нерабочих дней, которые не попадают на выходные. И наоборот, несколько рабочих переносятся на выходные.
Поэтому такая наивная реализация подойдет не всем.
По поводу похожести list comprehension и SELECT в SQL:
В январе на Python Meetup был доклад про PythonQL — язык запросов к самым разным БД, которые позволяют писать в Python-коде конструкции, похожие одновременно и на list comprehension и на SQL.
Вот пример из их слайдов:
[ select (d.model, d.make, reviews)
for d in dealer_db, p in product_db
let p_make = try p.man[‘company’] except p.man
where d.model = p.model and d.make = p.make
let reviews = [ select r for r in p.reviews where r.stars == 5 ]
where len(reviews) > 1 ]
В январе на Python Meetup был доклад про PythonQL — язык запросов к самым разным БД, которые позволяют писать в Python-коде конструкции, похожие одновременно и на list comprehension и на SQL.
Вот пример из их слайдов:
[ select (d.model, d.make, reviews)
for d in dealer_db, p in product_db
let p_make = try p.man[‘company’] except p.man
where d.model = p.model and d.make = p.make
let reviews = [ select r for r in p.reviews where r.stars == 5 ]
where len(reviews) > 1 ]
Ни один рассказ про range() в Python 2.x не должен умалчивать о том, что range(очень_большое_число) валится по памяти, потому при code review всегда надо либо заменять на xrange(), либо очень внимательно следить за тем, чтобы не влепить туда большое число. Выглядит примерно так:
>>> range(100000000000000)
python(5218,0x7fff797dc000) malloc: *** mach_vm_map(size=800000000000000) failed (error code=3)
*** error: can't allocate region
*** set a breakpoint in malloc_error_break to debug
Traceback (most recent call last):
File "", line 1, in MemoryError
То, что в Python 2.x range() создает структуру целиком, а не работает как генератор, об этом в статье сказано.
Соответственно, какого другого поведения тут тогда можно ожидать? Разве генератор списка (list comprehension) в данных условиях поведет себя иначе при проблеме с нехваткой памяти для загрузки создаваемой структуры целиком?
Соответственно, какого другого поведения тут тогда можно ожидать? Разве генератор списка (list comprehension) в данных условиях поведет себя иначе при проблеме с нехваткой памяти для загрузки создаваемой структуры целиком?
М… Возможно, у меня замылился взгляд, но после двух дополнительных прочтений статьи не нашёл в хоть сколь явном виде информации о том, что Python 2.x range() создаёт структуру целиком.
https://habrahabr.ru/post/320288/#8
В Python 2 были 2 функции:
range(...) которая аналогична выражению list(range(...)) в Python 3 — то есть она выдавала не итератор, а сразу готовый список;
Вот потому я и написал «в хоть сколь явно виде». :)
Моя критика этого пункта основана на разборе кода на собеседованиях и кода junior'ов. Так вот, пусть в множестве статей и описывается опасность range(), крайне редко читающий осознаёт, чем это оборачивается на практике. Когда начинаешь спрашивать, мол, товарищ, а что же такое «сразу готовый список», чем это плохо, как выглядит это «плохо», начинаются проблемы.
Потому в педагогических целях (вы ведь новичкам помогаете) мне видится гораздо более конструктивным явная и ясная демонстрация, а не информация глубиной в n уровней: [готовый список] —> [выделение памяти, о чём начинающие питонисты не думают никогда] —> [памяти может не хватить] —> [в продакшене MemoryError].
У вас хорошая статья, но ведь её можно и улучшить.
Моя критика этого пункта основана на разборе кода на собеседованиях и кода junior'ов. Так вот, пусть в множестве статей и описывается опасность range(), крайне редко читающий осознаёт, чем это оборачивается на практике. Когда начинаешь спрашивать, мол, товарищ, а что же такое «сразу готовый список», чем это плохо, как выглядит это «плохо», начинаются проблемы.
Потому в педагогических целях (вы ведь новичкам помогаете) мне видится гораздо более конструктивным явная и ясная демонстрация, а не информация глубиной в n уровней: [готовый список] —> [выделение памяти, о чём начинающие питонисты не думают никогда] —> [памяти может не хватить] —> [в продакшене MemoryError].
У вас хорошая статья, но ведь её можно и улучшить.
Еще в itertools есть много полезных комбинаторных функций.
Например, itertools.permutations для генерации перестановок и itertools.product для создания декартовых произведений. Последнюю удобно использовать для генерации тестовых наборов данных.
Спасибо! Замечательная статья!
В пункте 9.2 в общем виде range(4) можно заменить на len(matrix):
В пункте 9.2 в общем виде range(4) можно заменить на len(matrix):
transposed = [[row[i] for row in matrix] for i in range(len(matrix))]
for i in range(len(matrix)):
Это было бы справедливо, если бы матрица была квадратной, а в примере матрица специально выбрана не квадратной, а прямоугольной, чтобы показать этот нюанс:
Заменил исходный пример на более наглядный:
matrix = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]
print(len(matrix)) # 3 - количество элементов первого уровня (строк)
print(len(matrix[0])) # 4 - количество элементов второго уровня (столбцов)
Заменил исходный пример на более наглядный:
for i in range(len(matrix[0])):
Не хочу вас расстраивать, но:
a = [[0, 1, 2, 3],[10, 11, 12, 13],[20, 21, 22, 23]]
sum(a, [])
a = [[0, 1, 2, 3],[10, 11, 12, 13],[20, 21, 22, 23]]
sum(a, [])
Никаких расстройств, наоборот очень интересное решение, спасибо!
Добавил в статью с указанием авторства (под спойлером).
Собственно, задачей статьи было показать принципы применения выражений-генераторов на простых и понятных примерах. Естественно, данные задачи можно было решить и другими, зачастую более оптимальными способами.
Добавил в статью с указанием авторства (под спойлером).
Собственно, задачей статьи было показать принципы применения выражений-генераторов на простых и понятных примерах. Естественно, данные задачи можно было решить и другими, зачастую более оптимальными способами.
Не хочу вас расстраивать, но sum(a, []) имеет квадратическую сложность(O(n^2)) и потому совсем не рекомендуется к использованию для таких целей.
Как автор уже сказал статья про «принципы применения выражений-генераторов», я свой пример попросил добавить так как он самый эффективный, и было бы полезно его упомянуть.
P.S. DaneSoul, этот пример лучше убрать из статьи.
Как автор уже сказал статья про «принципы применения выражений-генераторов», я свой пример попросил добавить так как он самый эффективный, и было бы полезно его упомянуть.
P.S. DaneSoul, этот пример лучше убрать из статьи.
Спасибо за дополнение!
Убирать не стоит, если способ есть — его все равно найдут, лучше явно его показать и сразу упомянуть о недостатках. Добавил там под спойлером комментарии об эффективности для обеих способов.
Убирать не стоит, если способ есть — его все равно найдут, лучше явно его показать и сразу упомянуть о недостатках. Добавил там под спойлером комментарии об эффективности для обеих способов.
Вообще-то всё вышеперечисленное тоже не рекомендуется для таких целей.
Numpy.array.flatten() в несколько раз быстрее будет.
Numpy.array.flatten() в несколько раз быстрее будет.
Numpy — это отдельная библиотека, которая еще должна быть установлена в системе.
Так что я бы все-таки не стал приводить пример с Numpy как стандартное решение.
Так что я бы все-таки не стал приводить пример с Numpy как стандартное решение.
Вообще-то всё вышеперечисленное тоже не рекомендуется для таких целей.Это где такие рекомендации?
`itertools.chain.from_iterable` все же отличное решение для такой задачи, при условии что у нас список с глубиною = 2.
Numpy обычно не на каждом проекте есть, и устанавливать её только ради этой задачи не всегда целесообразно.
Numpy.array.flatten() в несколько раз быстрее будет.Это правда только если у нас уже есть `Numpy.array`, а вот если у нас изначально обычный python список, то сначала нужно будет создать из него `Numpy.array` и только потом применить метод .flatten(), что в итоге будет в 10 раз медленнее чем при помощи itertools.
Скриншот измерений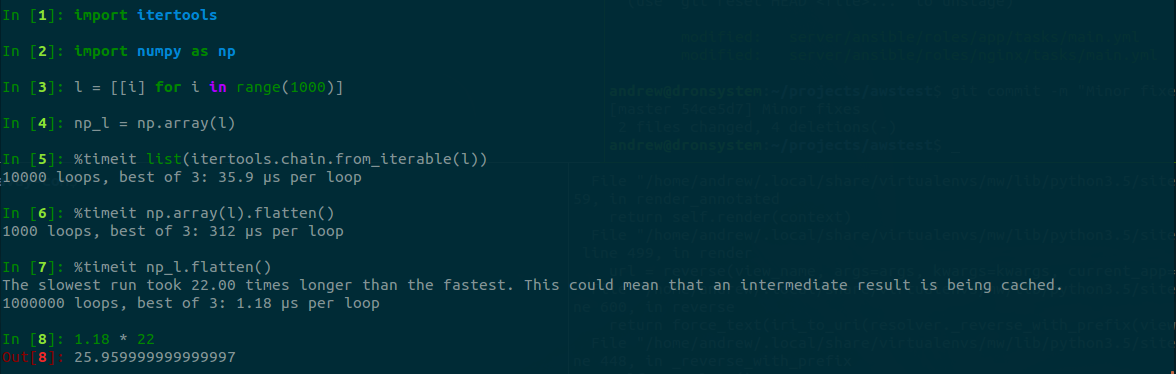

Скриншот измерений на большом списке
Тут уже хорошо видно выигрыш от использования Numpy, но опять же, только если мы будем использовать ещё какие-то другие возможности данной библиотеки.

Тут уже хорошо видно выигрыш от использования Numpy, но опять же, только если мы будем использовать ещё какие-то другие возможности данной библиотеки.
великолепная статья!!! да что там, весь цикл очень хорош.
А от решения выше:
кто может рассказать об этом подробнее, почему так работает и что происходит на самом деле?
А от решения выше:
sum(a, [])
кто может рассказать об этом подробнее, почему так работает и что происходит на самом деле?
Да, я тоже не знал о такой возможности, в Python много подобных ньюансов, которые при первом взгляде кажутся магией. На StackOverflow на этот вопрос отвечали.
Там объясняется, что в функции sum(iterable[, start]) второй аргумент не обязан быть цифровым.
Задав его как [ ], дальнейшее применение операции сложения (что делает наша функция) к нему будет аналогично операции сложения для списков, которая, как известно, ведет к добавлению элемента в список.
Там объясняется, что в функции sum(iterable[, start]) второй аргумент не обязан быть цифровым.
Задав его как [ ], дальнейшее применение операции сложения (что делает наша функция) к нему будет аналогично операции сложения для списков, которая, как известно, ведет к добавлению элемента в список.
Sign up to leave a comment.
Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей