Comments 23
Первый в силу того, что при ежесекундном добавлении записей, размер индекса будет равен количеству записей в самой базе.Странный аргумент. В MySQL у любого индекса размер в записях будет равен количеству записей в таблице (а не в базе, кстати) и независимо от интенсивности вставки.
Выполним запрос:План запроса смотрели?
SELECT * FROM CDR WHERE src=***** AND calldate>'2016-06-21' AND calldate<'2016-06-22';
/* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 00:09:36 */
Почти 10 минут ожидания.
Имхо, хватило бы индекса (src,calldate). Поля в индексе должны быть именно в таком порядке, чтобы диапазон по calldate работал.
у любого индекса размер в записях будет равен количеству записей в таблице
Некорректно выразился, имелось в виду количество ключей в индексе, по которым скуль отбирает диапазоны для сканирования.
План запроса смотрели?
Имхо, хватило бы индекса (src,calldate). Поля в индексе должны быть именно в таком порядке, чтобы диапазон по calldate работал.
Эти индексы работают только для точной выборки, при выборке по диапазону значений они будут проигнорированы. Из CDR в 90% случаев как раз выбирают по диапазону дат и исходящих номеров (групп пользователей) или номеров назначения. Стоит ли поддерживать составной индекс для незначительного ускорения 10% запросов, с учетом того что индекс по дате и так дает прирост производительности? Пробовал на этой базе делать составные индексы, на реальной нагрузке профит оказался меньше, чем казалось в теоретической части. В продакшене можно легко от составных индексов отказаться без существенной потери производительности. Зато время пересчета индексов будет меньше.
MySQL может использовать только один индекс за разВ сформулированном виде — это неверно.
Как минимум, см. http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
приходитНе игнориуются, если поля в индексе в правильном порядке для конкретного запроса.ься выбирать диапазоны, а в этом случае составные индексы игнорируются MySQL, т.е. происходит FullScan
http://dev.mysql.com/doc/refman/5.7/en/range-optimization.html
Как минимум, см. http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
Это я тоже читал. На практике, скуль ни разу не применил объединение индексов, предпочитая полное сканирование строк, даже если их было несколько миллионов.
Завтра постараюсь более подробно предоставить EXPLAIN запросов, которыми тестировал базу.
Не игнориуются, если поля в индексе в правильном порядке для конкретного запроса.
Утром повторю эксперимент с индексами на базе, выложу EXPLAIN.
Если окажется что был не прав, дополню статью составными индексами. Но статья родилась после нескольких дней изучения вопроса и практического применения.
Завтра постараюсь более подробно предоставить EXPLAIN запросов, которыми тестировал базу.И укажите, пожалуйста, кардинальность полей и диапазоны значений.
Это облегчит понимание причин неиспользования формально подходящих индексов.
Например, если залиты данные всего за трое суток, то при отборе данных за сутки от индекса, скорее всего, толку будет мало.
В базе 80 млн записей, диапазон — последние 4 года с одного из серверов (реальные данные).
Добавил индексы:
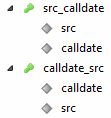
Запрос:

Ключ calldate,src отработал. НО:
6 секунд против 0,577 сек из статьи. Использование такого индекса пока под вопросом.
Добавил индексы:
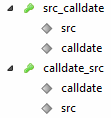
Запрос:

Ключ calldate,src отработал. НО:
SELECT * FROM CDR WHERE src=*****AND calldate>'2016-06-21' AND calldate<'2016-06-22';
/* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 6,068 sec. */
6 секунд против 0,577 сек из статьи. Использование такого индекса пока под вопросом.
Я, конечно, знал что в MySQL с оптимизацией запросов все плохо — но не настолько же!
Этот запрос должен хорошо ложиться на индекс (src, calldate). А вот индекс (calldate, src) особо помогать и не должен.
А вот индекс (calldate, src) особо помогать и не должен.Да, там по key_len видно, что использовано только первое поле из индекса.
И литерал во фрагменте src=***** должен быть того же типа, что само поле src, т.к. иногда MySQL ошибается с направлением неявного преобразования типов.
Ну я же ничего не придумал, сухая практика.
Иногда теория и практика вещи разные, увы.
Иногда теория и практика вещи разные, увы.
Вот кстати план запроса из статьи по индексу date:

Он быстрее отрабатывает из-за того что приходиться лопатить меньше ключей в индексе, и возвращает меньшее число строк для сканирования.
Возможно имеет смысл скомбинировать два варианта и сделать индекс date+src. Попробую, но индексация займет несколько часов.

Он быстрее отрабатывает из-за того что приходиться лопатить меньше ключей в индексе, и возвращает меньшее число строк для сканирования.
Возможно имеет смысл скомбинировать два варианта и сделать индекс date+src. Попробую, но индексация займет несколько часов.
Проиндексировалось.
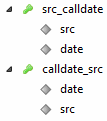
Но MySQL предпочел его не использовать:

Если форсировать использование индекса, то видим такую картину:

У меня большая часть запросов при написании статьи, составные индексы не использовала. Кроме того, диапазон для сканирования строк, которые получаются при составных ключах всегда больше, если брать именно CDR таблицы.
Индексы:

Такие дела.

Но MySQL предпочел его не использовать:

Если форсировать использование индекса, то видим такую картину:

У меня большая часть запросов при написании статьи, составные индексы не использовала. Кроме того, диапазон для сканирования строк, которые получаются при составных ключах всегда больше, если брать именно CDR таблицы.
Индексы:

Такие дела.
Что за мода давать картинки не по теме? Ну пишите вы про Астериск, так сделайте нормальную картинку. 3 минуты втыкал что к чему.
А зачем делать триггер? Если у вас уже есть поле, то просто можно сделать где надо
exten… => SET(CDR(date)=${STRFTIME(${EPOCH},,%d%m%Y)}))
exten… => SET(CDR(date)=${STRFTIME(${EPOCH},,%d%m%Y)}))
Мне кажется, если бы у вас calldate был в формате unixtime, работало бы шустро без дополнительного поля date.
Ещё вариант, вместо одного datetime сделать два поля: date и time.
если бы у вас calldate был в формате unixtime
Пробовал, разницы не заметил.
Ещё вариант, вместо одного datetime сделать два поля: date и time.
И еще объяснить астериску, что нужно поле разбивать. А если делать эти поля дополнительными, то смысла в них нет. Мало кто использует статистику по времени, чаще всего это дни. Если нужно временная выборка, можно использовать два поля calldate и date, выборка будет моментальная. Необходимость поля time — сомнительная.
Duration и billsec я бы не занулял. толку от знания про звонок, если по факту у него длительность 3 секунды до автоответчика на той стороне. или же наоборот, полтора часа разговора на нерабочие темы, например.
Sign up to leave a comment.
CDR. Сохранить и приумножить