Comments 159
Разработка новой версии языка определенно не идет за закрытыми дверями…
Так в чем вопрос, надо просто открыть двери
1 Множественное наследование.
2 virtual static function
P.S. Я лично против множественного наследования в том виде, как это сделано в C++. Если делать что-то подобное, то лучше реализовать систему mixin'ов.
Как же не существует, если мы ее обсуждаем?
И не вижу причин, по которым невозможно, это реализовать в C#. (это конечно не значит, что таких причин не существует)
Слово «виртуальная» означает, что:
— функция может быть переопределена в производных классах.
— конкретная реализация функции определяется в момент исполнения программы в зависимости от объекта, у которого она вызывается.
Вы можете наследовать статические классы и вызывать в них функции базовых классов — никто этого не запрещает. Вы можете сокрыть функцию с той же сигнатурой. Но вы не можете сделать статическую функцию виртуальной, потому что нет объекта, который бы отвечал за выбор конкретной реализации функции.
Наверное, как объектно-ориентированных языках, класс, это тоже такой объект.
типа
abstract class Animal{
abstract virtual static string GetDescription();
}
class Dog{
static string GetDescription()
{
return "собака";
}
}
var animalClasses = new []{Dog, Cat, Squirell};
Animal CreateByDescription(string description)
{
return animalClasses
.Where(x => x.GetDescription() == descriuption)
.First()
.CreateNewInstance();
}Речь идет об изменении языка => можно ввести такое
Для этого вам придется не только язык поменять, но и солидный кусок CLR.
Не факт. Можно какой-нибудь трюк типа автобоксинга сделать. При приведении к типу MetaClass генерировать какой-нибудь класс с членами статическими методами.
… которые хранить где?
Не знаю. Может быть в сборке с классом. Тогда, наверное, надо его генерить по атрибуту а не при приведении. Вы лучше меня знаете дотнет, придумайте сами :)
Я просто не могу придумать никакого сценария, при котором я обращаюсь именно к статическому методу в терминах CLR (т.е. <typename>.<method>) и при этом у меня работает subclass polymorphism.
Есть дженерики, конечно, но там на момент развертывания известен точный тип.
SuperType.classType t = SubType.class;
t.StaticVirtualMethod();Мне такая идея тоже не нравится — но это не значит что она нереализуема.
AnimalFactory[] factories = new[]{ new CatFactory(), new DogFactory(), new SquirellFactory(), };
Animal CreateByDescription(string description)
{
return factories
.Where(x => x.Description == description)
.First()
.Create();
}
Как бонус мы получаем состояние, (почти) не используя статических полей. Также возможность иметь несколько настраиваемых фабрик и передавать их параметром. И отдельную фабрику для тестов.
Ну оно больше и не выглядит как статический метода, а выглядит как инстанс. Я об этом и говорю.
Тот код который вы привели можно спокойно реализовать при помощи рефлексии, то бишь атрибутов, и не нужно всякого там статического полиморфизма...
interface IDeserealizable
{
static IDeserealizable deserialize(IDeserializer deserializer)
}
А ещё:
— указание нескольких интерфейсов в качестве типа поля
— реализация интерфейсов через расширение
Собственно, это фичи Objective-C.
В случае с C# — не знаю, никогда не пытался :) Но сама затея в C# на данный момент выглядит безнадёжной по той причине, что для статических методов почти нет фич, где бы их можно было использовать.
Для статической функции объект совсем не обязателен, вполне хватит и самого класса.
Похоже, что действительно возникло недопонимание в определении, что такое virtual static, даю пример
class A
{
public virtual static string info() {return «a»;}
}
class A2:A
{
public virtual static string info() {return «a2»;}
}
Вне зависимости от того, что именно вы хотите сделать — это можно сделать через сокрытие (new на функции)
class A {
public static string info() {return "a";}
}
class A2:A {
public new static string info() {return "a2";}
}
С точки зрения языка, виртуальная статическая функция — бессмысленна, виртуальные методы нужны для маршрутизации с вызовом типа, который на самом деле лежит под базовым типом/интерфесом.
При вызове статической функции — тип строго определен, маршрутизация типов не нужна.
Тогда естественно виртуальность статик функции теряет смысл.
Так что появилось еще одно пожелание:
Возможность вызова статик функции через экземпляра класса.
Сейчас модификатор static — принадлежность функции типу целиком, а не экземпляру.
Она не должна знать ничего о «нестатических» полях/методах/св-вах.
class A {
public static string info() {return «a»;}
}
A a = new A();
string s = a.info(); < — тут баг
Идея выглядит разумной. Но при этом не рассматривается вопрос вызова статической функции не по объекту, а по типу (generic).
Почему же?
Для A a; одинаково должно вызываться и
A.info();
и
a.info();
A a = new B();
A.info() — вызов статического метода класса A
a.info() — вполне может быть вызовом метода info класса B
В прочем я нашел способ решить эту проблему с помощью reflection, но решение мне не нравится.
Хочется возможностей самого языка, тем более, что новый синтаксис для этого не нужен.
А явных проблем, почему это нельзя сделать, лично я не вижу.
Будет два метода: статический, который можно вызвать по имени класса, и аналогичный ему виртуальный, который можно вызвать через экземпляр. Оверхед на передачу ненужного параметра this в любом случае ниже, чем затраты на рефлексию.
Возможность вызова статик функции через экземпляра класса.
Но зачем?
А так это дает более объектно ориентированный доступ к параметрам и функциям которые меняются при наследовании, но не нуждаются для расчетов в самом объекте.
Это хорошо проявляется в задачах типа фабрика объектов.
Как минимум, наличие возможности лучшее ее отсутствия.
Нет. Слишком много возможностей нарушает целостность.
А так это дает более объектно ориентированный доступ к параметрам и функциям которые меняются при наследовании, но не нуждаются для расчетов в самом объекте.
Если они не нуждаются для расчетов в объекте — это не функции этого объекта. И именно поэтому синтаксис объект.метод по отношению к ним будет вводить в заблуждение.
Я так понимаю вы поклонник асемблера и противник библиотек и объектного программирования?
> Если они не нуждаются для расчетов в объекте — это не функции этого объекта.
Конечно — это функция класса. Но для того, что бы она вызвалась у объекта именно того класса которым он является, ее нужно вызывать непосредственно у этого экземпляра класса. Пояснить примером?
Я так понимаю вы поклонник асемблера и противник библиотек и объектного программирования?
Нет, я поклонник консистентных систем и противник избыточности.
Но для того, что бы она вызвалась у объекта именно того класса которым он является, ее нужно вызывать непосредственно у этого экземпляра класса.
Нет такого "нужно". Если вам нужна функция класса, вам нужно вызывать ее на классе. Типичный пример такого (на псевдоязычке) выглядел бы так:
yourObject -> getType -> someMethod>yourObject -> getType -> someMethod
Именно! Но зачем «getType ->» если его нужно писать всегда? Можно и пропустить двузначностей это не принесет.
Тем более «нормального» getType к сожалению нет :( и вроде делать его не собираются.
Или вас возмущает, что вызов функций у объекта и через ссылку на объект идет через "."?
Тогда да, тогда я понимаю вашу принципиальность.
Но зачем «getType ->» если его нужно писать всегда?
Не всегда, а только тогда, когда обращение идет к методам класса, а не объекта. И именно за этим и нужно — чтобы четко видеть, к какому объекту мы обращаемся.
Можно и пропустить двузначностей это не принесет.
Да ну? yourObject -> Name — имя чего я сейчас получу? yourObject -> setMaxCount(15) — у чего ограничился пул?
Тем более «нормального» getType к сожалению нет
Так вот лучше сделать нормальный getType, который не нарушает парадигму, чем вводить неявный вызов статиков, который парадигму нарушает.
Что функция вернет то и будет. Я имел в виду неоднозначностей для компилятора.
>Так вот лучше сделать нормальный getType
Это бесспорно «нормальный getType» без рефлектинга по мне тоже куда важнее. Хотя и проблем вызовом статиков я не вижу.
Похоже я больше склонен к универсальности и общему синтаксису, а вы за строгость и явные разграничения.
вы за строгость и явные разграничения.
И это правильно. Чтобы стрелять в ноги, у нас уже есть C++, оставьте C# в покое.
:) Расскажите мистер паладин, чем именно ужасен вызов статика из объекта?
А самое забавное, что вызов статической функции НИКАК не может вызвать NullReferenceException.
>И вообще тогда какие отличия от экземплярных методов, кроме потери доступа к this в теле метода?
В том что их можно вызвать и без наличия экземпляра класса.
>> А самое забавное, что вызов статической функции НИКАК не может вызвать NullReferenceException.
Вы противоречите сами себе.
class A { public static virtual info() {...}; }
class B: A { public static override info() {...}; }
A a = null;
a.info(); // что произойдет по-вашему?
Если речь о том, чтобы сделать две одинаково работающих возможности вызова статик метода: A.info() и a.info(), то действительно работать будет. Только непонятно, зачем.
Но о виртуальных статических методах можно забыть из-за возможного null.
Конечно класса А.
А если (B(null)).info(); то от B; Что вас смущает?
>Но о виртуальных статических методах можно забыть из-за возможного null.
Откуда null, в статик функции? Даже у виртуальной.
Здесь — ничего. А если так:
A a = new B();
a.info();
Должен вызваться метод A.info() или B.info()?
>> Откуда null, в статик функции? Даже у виртуальной.
А как CLR должен в рантайме определить, виртуальную статическую функцию какого класса вызывать? Видимо, по экземпляру класса. Если он null, все плохо. Если не по экземпляру, то как еще?
B.info() или есть сомнения?
>Если он null, все плохо
Все хорошо — тип объекта то есть. Вот по типу и вызовет.
Вот в этом и проблема. Типа объекта нет.
1. Во время компиляции конкретный тип объекта неизвестен.
2. Во время исполнения у вас, грубо говоря, в памяти 0 (т.е. null). Метаданные связываются с конкретным экземпляром класса, а не со ссылкой на него. Соответственно, по null ссылке вы никак не узнаете, на экземпляр какого типа она указывает.
Поэтому давайте решим так, если бы вы реализовывали вызовы виртуальных функций вы бы не смогли сделать вызов функций у null объектов.
Скорее всего у вас нет специфических знаний по вызовам виртуальных функций в рантайме.
Так просветите, интересно же.
Мне вот кажется, что это вы не знаете, как CLR хранит ссылки на объекты и сами объекты. Если бы со ссылкой связывалась информация о типе объекта, тогда да, проблем нет. Но информации о типе у ссылки нет.
О чем и речь. Мы получили экземплярный виртуальный метод. Зачем тогда делать статический метод виртуальным, чтобы он вел себя ровно так же, как экземплярный? Причем это полное нарушение концепции статических методов.
О каком единообразии может идти речь, когда это фундаментально разные вещи? Такое единообразие мозг сломает в момент. И еще раз, нельзя называть метод статическим, если он требует наличия созданного экземпляра класса для своего вызова.
Можно вести речь о том, чтобы заиметь в языке что-то вроде "класса как объекта", и писать, например:
class A { static virtual void foo() {...}}
class B : A { static override void foo() {...}}
Class<A> a = A;
a.foo(); // вызывает A.foo()
a = B;
a.foo(); // вызывает B.foo()
a = (new B())->class;
a.foo(); // вызывает B.foo()Но вызывать статику на экземплярах — увольте.
у них общий набор типовых характеристик например
static Name, Type, Width, Height, у каждого класса свои значения. И возможно они зависит от расчета в родителе.
Эти данные используются как без объектов, так и внутри объектов.
Как удобней писать? в месте каждого вызова A1.Width() или просто Width()?
И сколько будет ошибок при copy/paste.
А если бы у этих статик функций было наследование, то можно было бы общую часть их обработки вообще отдать родителю:
Например классу А реализовать функцию
static int Perimetr() {return (Width() + Height())*2;}
Которая нормально работала бы для все наследников.
у них общий набор типовых характеристик например
static Name, Type, Width, Height, у каждого класса свои значения. И возможно они зависит от расчета в родителе.
Почему бы не сделать какое-нибудь статическое свойство Meta, куда в статическом конструкторе положить экземпляр класса характеристик с нужными значениями, привязкой к базовым характеристикам и т.п.? Будет у вас A1.Meta.Width, например. Реализация чуть сложнее, но снаружи разницы особо нет. Можно добавить еще экземплярное свойство Meta, которое просто возвращает значение статического. Тогда и на экземплярах удобно будет звать статику.
Как удобней писать? в месте каждого вызова A1.Width() или просто Width()?
По мне, удобнее писать одни и те же вещи одинаково, и разные вещи по-разному. Именно поэтому для статики писать везде A1.Width лучше, чем где-то A1.Width, а где-то a.Width (который статический, но пишется почему-то как экземплярный).
class A
{
public static string inf;
}
class A2: A
{
}
A.inf = «a»;
A2.inf = «a2»;
после такого в A.inf будет «a2».
Или я не так понял идею?
Немного не так:
class A { public static string inf; }
class A2 : A { public static new string inf; }
A.inf = "a";
A2.inf = "a2";Хотя решение не очень красивое, конечно.
using System;
class Meta
{
string _meta;
public Meta(string meta)
{
_meta = meta;
}
public override string ToString()
{
return _meta;
}
}
class A
{
public static Meta meta;
}
class A1 : A
{
public static new Meta meta;
}
class A2 : A
{
public static new Meta meta;
}
public class Program
{
public static void Main()
{
A1.meta = new Meta("a1");
A2.meta = new Meta("a2");
Console.WriteLine(A.meta);
Console.WriteLine(A1.meta);
Console.WriteLine(A2.meta);
}
}Может, стоило бы вообще убрать такого рода информацию из статических полей и организовать доступ к ней как-то еще. Например, importantInfoProvider.Get().Width. А внутри по типу определять, что вернуть. Не думаю, что решение через статику — единственное или лучшее возможное.
interface IDerivedStatic
{
int Width();
int Height();
}
class A<T>
where T : struct, IDerivedStatic
{
static T data = new T();
public static int Width() => data.Width();
public static int Height() => data.Height();
public static int Perimetr() => Width() * Height();
}
class A1
: A<A1.Static>
{
public struct Static
: IDerivedStatic
{
public int Height() => A1.Height();
public int Width() => A1.Width();
}
static new int Width() => 12;
static new int Height() => 14;
}Использование struct заставляет JIT генерировать отдельный для каждого типа, а не вызывать интерфейс + нет оверхеда по памяти.
Делал замеры — всё инлайнится, производительность идентична прямому вызовы.
Если над идеей статических виртуальных функции хорошо подумать, то может, что-то годное и выйдет. Одной из возможных реализаций этого механизма была бы следующая: GetType() возвращает не Type, а унаследованный от Type объект, содержащий вызовы статических методов. А для упрощения синтаксиса можно добавить ключевое слово какое-нибудь (a.class — см.выше).
То есть
class A
{
static virtual void foo() { ... }
}разворачивается в
class A.Static: Type
{
virtual void foo() { A.foo(); } }
}
class A
{
static void foo() { ... }
A.Static GetType();
}И используется так, например:
void Generic<T>(T a) where T: A
{
a.GetType().foo();
}
void Generic<T>() where T: A
{
// typeof(T) возвращает объект T.Static, приведённый к A.Static
// это можно сделать точно так же, как реализован механизм new T()
typeof(T).foo();
}В таком виде я был бы даже не против увидеть это в языке.
Но чисто умозрительно, как бы выглядело все с моим подходом:
class A
{
public virtual static int Width() => 10;
public virtual static int Height() => 11;
public static int Square() => Width() * Height();
}
class A1: A
{
pubilc override static int Width() => 12;
pubilc override static int Height() => 14;
}
По моему проще.
И вызовы были единообразные
A1.Square();
и
A a1 = new A1();
a1.Square();
вообще красота (по мне) :)|
Практически же передача одного параметра (ещё и через регистр) — ничто по сравнению с виртуальным вызовом (переходом по адресу), а язык и CLR усложнит.
Что функция вернет то и будет. Я имел в виду неоднозначностей для компилятора.
Меня мало волнует компилятор, меня волнует, как я это читать буду. И вот мне это читать очень неудобно.
Это бесспорно «нормальный getType» без рефлектинга по мне тоже куда важнее.
Вообще-то GetType и сейчас не использует Reflection.
Реализация статических интерфейсов потребует довольно серьёзное изменение CLR, на что MS пойти не сможет точно.
Прямо сейчас этот функционал можно сэмулировать путём создания дженерик класса со статическим полем — делегатом на статический метод, который создаётся единожды через рефлексию в статическом конструкторе, что-то вроде:
struct Deserializer<T> where T: IDeserializable
{
public static readonly Func<T> deserialize(IDeserializer deserializer);
static Deserializer()
{
deserialize = что-то типа typeof(T).GetMethod("deserialize", BindingFlags.Static | BindingFlags.Public).CreateDelegate(typeof(Func<T>)) as Func<T>;
}
}и вызывать как
Deserializer<T>.Deserialize(...);Generic-типов и интерфейсов
Для полного счастья нужна возможность реализовывать интерфейс используя расширения и указывать несколько интерфейсов для поля (без указания класса).
И тогда статические методы становятся мощным инструментом для написания фабрик с простым синтаксисом из без магии рантайма внутри.
class function ObjectName(AObject: TObject): String; virtual
Нужны ли метаклассы????
метаданные объектов
TVirtClass = class of TBaseVirtClass.
В Delphi метакласс это ссылка на VMT и все виртуальные методы класса (не экземпляра класса) располагаются с отрицательным смещением
И все метаклассы наследуются от
TClass= class of TObject.
{ Virtual method table entries }
vmtSelfPtr = -76;
vmtIntfTable = -72;
vmtAutoTable = -68;
vmtInitTable = -64;
vmtTypeInfo = -60;
vmtFieldTable = -56;
vmtMethodTable = -52;
vmtDynamicTable = -48;
vmtClassName = -44;
vmtInstanceSize = -40;
vmtParent = -36;
vmtSafeCallException = -32 deprecated; // don't use these constants.
vmtAfterConstruction = -28 deprecated; // use VMTOFFSET in asm code instead
vmtBeforeDestruction = -24 deprecated;
vmtDispatch = -20 deprecated;
vmtDefaultHandler = -16 deprecated;
vmtNewInstance = -12 deprecated;
vmtFreeInstance = -8 deprecated;
vmtDestroy = -4 deprecated;
Например, есть дженерик класс, но оператор хочу определить только для конкретных типов.
Почему я в этом случае могу определить метод-расширение Add, не не могу — operator +? Почему нельзя сделать так, чтобы при ненайденном операторе + автоматически искался бы метод-расширение Add?
А вот generic constraint для числовых типов был бы очень кстати. Так можно было бы писать обобщенные арифметические функции без извращений типа
dynamic:public T Add<T>(T a, T b)
where T: numeric // например, так
{
return a + b;
}
Для этого нужен не T: numeric, а T: has (T + T). И в F#, кстати, такое есть.
T. Либо под капотом dynamic, хотя очень сомневаюсь.После работы с Typescript вообще начинает не хватать структурной типизации. Но сомневаюсь, что ее приделают в C# в каком-либо обозримом будущем.
Скорее всего, это вопрос затрат и удобочитаемости. Тем более, что это можно уже сделать с помощью интерфейсов.
И чем же a.Add(b.Multiply©) лучше a + b * c?
https://visualstudio.uservoice.com/forums/121579-visual-studio-ide/suggestions/17335231-extend-operator-overloading
Вообще дизайн стандартной библиотеки C# склоняется к методам и интерфейсам. Если хотите примеров того, насколько неудобочитаемым становится код при активном использовании (кастомных) операторов — вот, например, когда-то мы писали парсер на F#…
Ещё мне очень нехватает строковых Enum-ов. Простая вещь, а сделает код более красивым и удобным в написании.
Ещё мне очень нехватает строковых Enum-ов
А можно пример?
Вместо:
public static class StringEnum
{
public const string ValueA = «A»;
public const string ValueB = «B»;
}
public string Field {get; set;} = StringEnum.ValueA;
Сделать так:
public enum StringEnum
{
ValueA = «A»,
ValueB = «B»
};
public StringEnum Field {get; set;} = StringEnum.ValueA;
Преимущества:
— одинаковый подход к перечисляемым типам
— точно знаешь что присваивать в поле (т.к. в текущей реализации — это просто строка и можно присвоить что угодно, а в предлагаемой — только значения из списка)
Может быть вообще можно расширить до объектного enum-а (т.е. создавать перечисления любого типа) — не думаю что это будет часто-используемая фича, но вполне полезная.
В каких случаях второй пункт может быть использован? Почему нужно присваивать именно строку, а не значение enum, которое позже преобразуется в строку?
Преимущества:
— одинаковый подход к перечисляемым типам
— точно знаешь что присваивать в поле (т.к. в текущей реализации — это просто строка и можно присвоить что угодно, а в предлагаемой — только значения из списка)
А почему бы просто не пользоваться Енумом в том виде, который сейчас есть? Ну вот допустим
enum VehicleType {
Light,
Medium,
Heavy
}
class Vehicle {
private readonly VehicleType type;
public Vehicle (VehicleType type) {
this.type = type;
}
public string GetImageUrl () {
return "/images/" + type + ".png";
}
}
new Vehicle(VehicleType.Heavy).GetImageUrl(); // "/images/Heavy.png"
Меня больше огорчает, что енум не наследуется. Например у меня есть аддон, который расширяет оригинал и я хотел бы добавить типы:
enum ExtendedVehicleType : VehicleType {
Spg, Spatg
}
new Vehicle(VehicleType.Spg);
Приходится для такого делать костыль вместо енума, а это имеет ряд своих недостатков:
class VehicleType {
public static readonly Light = new VehicleType("Light");
public static readonly Medium = new VehicleType("Medium");
public static readonly Heavy = new VehicleType("Heavy");
// ..
}
Может есть какой-либо вменяемый способ это использовать в c#?
А почему бы просто не пользоваться Енумом в том виде, который сейчас есть?
Как бы сделать (де)сериализацию того, что нельзя выразить идентификатором C# (пробелы, пунктуация и прочее)? Конечно, сейчас можно навесить кучу аттрибутов под каждый используемый сериализатор, но это смотрится плохо.
Привычный — объявить enum в классе и рядом положить статический Dictionary<enum, string > с нужными строками(некрасиво)
Красивый — использовать атрибуты.
Другое дело, что
public static string GetDescription(this Enum value)
{
DescriptionAttribute[] descriptionAttributeArray = (DescriptionAttribute[]) value.GetType().GetField(value.ToString()).GetCustomAttributes(typeof (DescriptionAttribute), false);
...
работает медленно, и enum вида
private enum Verdict : byte {
[Description(" ")]
Space,
[Description(",")]
Comma
}
не всех стилистически радует.
Тогда да, перечислимые строки были бы решением, если просто строковые константы не устраивают.
enum MyStrings : string {
One = "One with whitespaces",
Two = "Two with whitespaces",
Three = "Three with whitespaces"
}
MyStrings enVal = MyStrings::One;
var json = JsonConverter.Serialize<string>(enVal);
В C# очень неудачная реализация async/await, идея хорошая но перемудрили конкретно. Поэтому в Main всё это не работает, хотя и должно по задумке. Весь интернет пестрит непонятками.
Что касается генерации кода это прекрасно, однако как я могу судить — снова перемудрили и теперь нужно будет при отладке большого проекта ещё и искать «кто же включает очередную функцию в этот класс». Самая верная реализация генерации это у Хаскеля.
А неудачной я считаю реализацию планировщика. Главная прелесть асинхронности — выполнение всех задач в одном потоке, что существенно снижает расходы на межпотоковую синхронизацию и переключение между ними.
Но в C# используется либо ThreadPool (по умолчанию), либо циклы сообщений WinForms/WPF. Всё это не даёт большого выигрыша в производительности от использования асинхронности, а при низкой гранулярности задач производительность ещё и падает.
Как итог — в своих проектах я использую собственный планировщик и собственные обёртки над сокетами. Заодно получаю полноценную кроссплатформенность — при запуске под Windows используется IOCP, под Linux — epoll.
Если вы напишете await asyncFunction() то не будет выделено нового потока, если внутри asyncFunction он нигде явно не выделяется
Это зависит от текущего SynchronizationContext. Обратите внимание, что по ссылке приведён конкретный пример работы асинхронных вызовов для Windows Forms.
Это зависит от текущего SynchronizationContext
Это зависит в первую очередь от того, что вернула asyncFunction, и если она вернула уже выполненный таск, то SynchronizationContext вообще не будет использован.
Следующий код будет выдавать разный результат в зависимости от контекста:
Console.WriteLine(Thread.CurrendThread.ManagedThreadId);
await Task.Yield();
Console.WriteLine(Thread.CurrendThread.ManagedThreadId);Если оформить его как асинхронную функцию и вызвать напрямую из Main (Task.Run.Wait()), то вывод на экран будет разный.
Замечание 1: ManagedThreadId разный для разных потоков.
Замечание 2: вместо Task.Yield может быть любая задача, не являющаяся автоматически завершённой.
Не совсем так. Task.Yield — это все-таки не задача, а требование уступить поток. Там отдельный Awaiter написан для него.
Если смотреть задачи — то они как раз работают довольно адекватно. При установленном контексте синхронизации метод в него возвращается. А без контекста синхронизации — метод продолжает исполняться в том же потоке, который задачу выполнил (исключение — если синхронное продолжение было явно запрещено в свойствах задачи).
Вот здесь можно посмотреть реализацию этого метода: если контекст задан, то вызывается функция помещения задачи в очередь из контекста (Post), а если контекта нет, то продолжение задачи планируется к выполнению в пуле потоков.
Аналогично можно посмотреть на Task.GetAwaiter, но там чёрт ногу сломит. В конечном итоге вызывается TaskContinuation.Run, который вызывает всё тот же Post или лезет в ThreadPool.
Для YieldAwaiter приведенное поведение — ожидаемое!
Что же до TaskAwaiter, то тут все тоже просто, если разобраться. Если не было захвачено ни контекста синхронизации, ни планировщика задач — то используется класс AwaitTaskContinuation. Этот класс по возможности вызывает продолжение синхронно.
Task.Run(async () =>
{
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
await Task.Delay(10);
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}).Wait();
Но это не беда. Простой планировщик решает эту проблему.
А как, по-вашему, этот код вообще может работать? После истечения 10ти миллисекунд выполнение обязано вернуться в пул потоков. Почему для вас так важно, чтобы это был тот же самый поток? Все потоки пула одинаковы.
Лучше посмотрите на вот этот код:
public static void Main()
{
A().Wait();
}
static async Task A() {
await B();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}
static async Task B() {
await C();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}
static async Task C() {
await Task.Yield();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}В данном случае, все три оператора Console.WriteLine выполнятся в одном и том же потоке, что показывает, что продолжения и правда вызываются синхронно.
В данном случае, все три оператора Console.WriteLine выполнятся в одном и том же потоке, что показывает, что продолжения и правда вызываются синхронно.
Ага, только у меня периодически получается так:
4
5
5
Почему для вас так важно, чтобы это был тот же самый поток?
Потому что я хочу, чтобы все задачи работали последовательно в одном потоке:
1. Нет затрат на синхронизацию между потоками — никаких блокировок и ожиданий, мьютексы и эвенты не нужны.
2. Нет затрат на переключение контекста между потоками в планировщике. Делегировать выполнение задачи в другой поток — это очень долго: за то время, пока поток-воркер проснётся, пока сообщит другому потоку о готовности результата, можно выполнить с сотню задач в основном потоке.
Когда я написал свой планировщик, пиковое количество выполняемых сетевых операций в секунду выросло больше, чем на порядок.
"периодически" — это как?
Запустил код на трех разных компьютерах. Каждый раз все три числа совпадали… Вы что-то делаете не так.
А код уже написан и оттестирован — тесты проходят, а в продакшене почему-то всё падает.
Если вы вызовете 3 раза подряд ThreadPool.QueueЧтоТоТам, то эти 3 задачи могут быть запущены как на одном потоке, так и на нескольких, никакой гарантии здесь нет.
Не надо объяснять мне что такое race condition, я это знаю.
В коде, который я привел, окончания всех трех задач всегда выполняются в одном и том же потоке. Если они оказались в разных потоках — вы что-то сделали не так.
В коде, который я привел, окончания всех трех задач всегда выполняются в одном и том же потоке
Если они всегда выполняются конкретно на вашем компьютере в одном и том же потоке, это ещё ничего не значит:
http://funkyimg.com/i/2kCET.png
Запустите 10, 20, 30 раз, попробуйте debug/release поменять, запускать без отладчика. Это именно race condition.
Что такое Utilities.Asynchronius? Если убрать этот using и все лишние референсы — ошибка останется?
Вот мой скриншот:
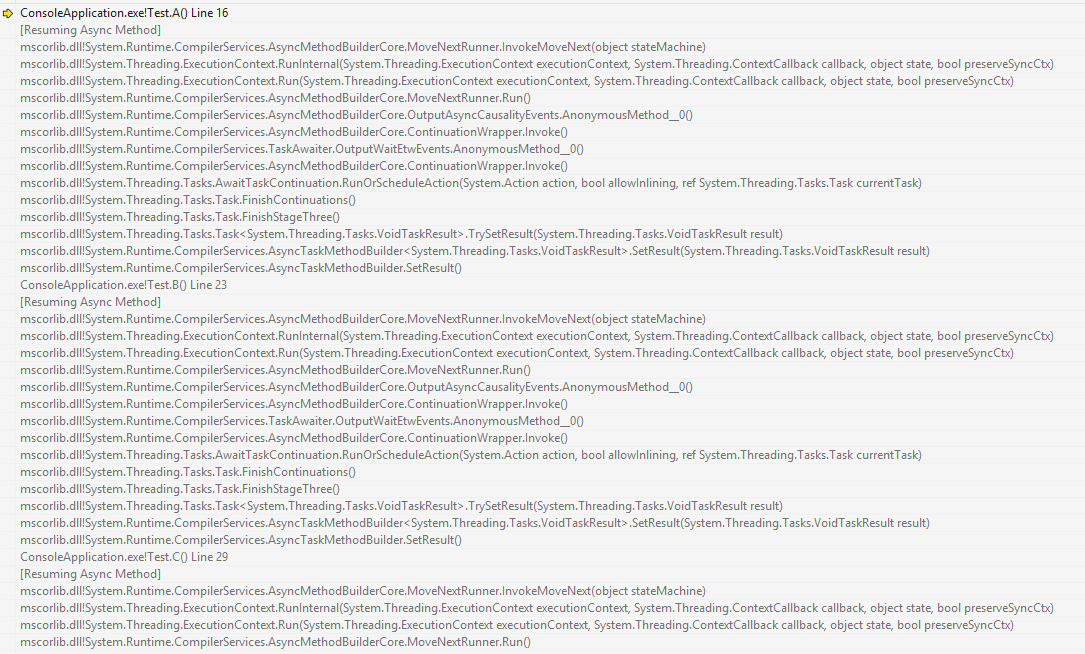
Отсюда прекрасно видно, что продолжения были вызваны синхронно. Если у вас меняется номер потока — значит, что-то мешает синхронному вызову. Какой-нибудь extension-метод, который перекрыл системный, или класс. Или просто установленный контекст синхронизации. Или хитрый аспект, который что-то нарушил.
Ну, или же просто какой-то необычный рантайм.
Выполнение программы детерминировано.
Объясните же, а?
http://funkyimg.com/i/2kCUY.png
Оно не должно попадать в планировщик.
PS не буду вам больше отвечать, потому что вы спорите для того чтобы спорить, а не чтобы разобраться в чем дело.
Скорее всего, причина в разных фреймворках, но зависеть от поведения в конкретном фреймворке, к тому же недокументированного, я считаю неправильным.
На самом деле, ответ значения не имеет. Для меня важно то, что в стандартном планировщике (не Forms/WPF) после любых IO операций, которые не могут быть завершены прямо сейчас, продолжение задачи осуществляется не в вызвавшем потоке, а когда таких задач несколько — в разных потоках.
Мои результаты:
Debugger: not attached .NET version: 4.0.30319.42000 Platform: 64 bit Same ThreadId: 98,94%
Получается, что в 1 случае из 100 программа ведёт себя не так, как должна себя вести. Это типичный пример неверного предположения о работе программы в многопоточной среде, которое может привести к очень неприятным и трудноуловимым ошибкам.
По-моему, вы только что продемонстрировали, что модель TPL в .net сделана удобно: для вашей конкретной задачи стандартный планировщик не подошел (это не значит, что он не подойдет другим, у меня он прекрасно работает) — и вы легко заменили его на свой.
Сейчас там же можно вызвать наследуемый PropertyChanged метод без дубликтов логики или применить логирование через action filter в крайнем случае dynamic proxy, благо для AOP в дотнете инструментария уже очень много.
С трудом вериться с учетом сопровождение этого кода, тестируемости, переносимость, использование АПИ привязанного к конкретному комплиятору, оно реально удобней — кроме что разве красивого и на первый взгял гибкого функционала.
А что не так с "конкретным компилятором" если сам компилятор — переносимый и открытый?
Ааа, вот же лютый костыль, почему бы не сделать множественное наследование.
>> Superseding members — замещение модификатора для того, чтобы дать больше возможностей инструментам генерации кода
опять же приведенный механизм использования нормально решается множественным наследованием
И вместо адекватных трейтов для того же INotifyPropertyChanged, будет просто костыль, который непонятно как работает, непонятно где цепляется, с кодом не содержащем подсветку синтаксиса, с неработающими фичами навигации в среде разработки, без работающего Intellisense. Без возможности покрытия тестами. Как говорится: «Счастливой отладки».
Вкупе с variadic templates и развитым выводом типов это дает возможность писать крайне гибкий код. И это уже есть в C++/CLI.
Вот только пользоваться этим в C++ зачастую неудобно. Расширения компилятора выглядят лучше.
Расширения компилятора выглядят лучше.
Очень спорно. Семантически это больше на миксины похоже, чем на шаблоны.
Так ведь это зависит от целей использования. Расширение компилятора позволяет сделать и миксин, и шаблон.
Расскажите, пожалуйста, чем же это удобнее пресловутых шаблонов?
Логика работы расширений описывается на том же самом языке, для которого эти расширения пишутся.
Шаблоны в c++ — это отдельный функциональный (!) язык (мета)программирования, при том что основной язык — императивный...
- В расширении можно произвольно управлять наличием и именами методов — в то же время шаблоны C++ ограничены заданным при их написании набором методов, а управлять их наличием нужно через местами контринтуитивный механизм SFINAE.
И да, описывать требования удобнее на декларативном языке, как это реализовано для дженериков в C#.
Шаблоны в c++ — это отдельный функциональный (!) язык (мета)программирования, при том что основной язык — императивный...
C++ мультипарадигменный, в том числе и функциональный.
В расширении можно произвольно управлять наличием и именами методов
А в чем отличие от шаблонов? Наличие методов определяется и без каких-то особых трюков с SFINAE. Причем, мне кажется, расширения компилятора здесь работают так же. А переименовывать вы можете так же свободно.
А также пустой nameof(), который возвращает имя текущего свойства/метода:
public string Property
{
get { return field; }
set
{
if (field == value) return;
field == value;
OnPropertyChanged(nameof());
}
}
А также пустой nameof(), который возвращает имя текущего свойства/метода:А это уже есть, но немного по-другому записывается:
void OnPropertyChanged([CallerMemberName] string propertyName = "") { .. }
...
public string Property1
{
set
{
OnPropertyChanged();
}
}
public string Property2
{
set
{
OnPropertyChanged();
}
}https://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.callermembernameattribute(v=vs.110).aspx
Возможные нововведения C#