Comments 159
Также я бы рекомендовал ( а может и посоветуют мне? =) ) отказаться от хранения рабочих файлов и конфигов внутри докер контейнеров и мапить их с самого сервера. Почему:
1. Чтобы изменить файл, нужно зайти сначала на сервер, потом сделать docker exec, изменить файл, выйти и закоммитить контейнер. А если у нас какой-нибудь легкий alpine образ, а не FROM: ubuntu:16.04, то это становится огромной проблемой.
2. При обновлении контейнера не нужно думать, что что-то в процессе обновления пойдет не так. Мы просто обновляем докер образ, убиваем контейнер, создаем заново из композа и вуаля, новый обновленный контейнер без лишних хлопот.
volumes:
- .:/opt/project
- .docker/app/parameters.yml:/opt/project/app/config/parameters.yml
Обычно вопрос конфигурации решают через environment variables, особенно это актуально в облачных деплойментах, где смонтировать файл в контейнер может быть большой проблемой
А история изменений хранится (как в системах версий)?
Здесь логичнее хранить Dockerfile в какой-то системе контроля версий.
Из него всегда можно сделать образ. И тут история изменний будет прозрачна.
Я тоже пока не эксперт, но стараюсь локальную разработку переводить на докер, есть и кое-что в продакшене.
Рекомендую сразу использовать docker-compose — отличная вещь!
некий аналог git
Это и есть docker registry. Я писал о ней в статье.
Но историю изменений там не увидишь. Можно просто хранить несколько версий одного образа, назначая версию вручную, при помощи тэга.
Кстати, я вот когда заходил на сайты с архивами LaTex, R, Ada, Sage и что то не заметил использования предлагаемых пользователям контейнеров докера — только обычные образы нашел и виртуальные машины — нет ли тут скрытых камней, на которые можно напороться, из за которых образы-контейнеры докера не используются?
Вот по слову Ada, например.
Хотя, думаю, эти образы сделаны энтузиастами и непонятно, как хорошо они работают.
Отлично справляются с проблемами тиражируемости серверов
В этом смысле, они подвержены тем же проблемам. Хотя, конечно, они лучше справляются с задачей, чем самописные shell скрипты.
Мне кажется вы несколько путаете их цели. Докер для виртуализации конкретных приложений, Ansible — для первичной установки и настройки того, что должно быть вне контейнеров.
Мне не нравится только использование ansible, puppet и т п в качестве единсвенного средства deployment-a.
Поэтому, в теории, любой сломанный пользовательский сервер на котором что-то случилось, puppet/chef приведет в эталонное рабочее состояние (обычное использование — синхронизация раз в час и принудительный возврат всех измененных параметров в эталонные значения).
В этом смысле использование Configuration management более «дуракоупорное», чем docker — он сам себя чинит.
Неспроста огромное количество программного обеспечения распространяется через chef-solo (дистрибутив и настройщик в одном флаконе)
Эта задача заведомо более сложная, чем то, что делает докер — тупо запускает заранее подготовленные процессы — никакой кастомной логики во время установки не выполняется.
Другими словами, в случае с паппетом есть чему ломаться во время установки на продакшен.
В случае с докером поломки будут не во время установки, а во время сборки образа. То есть для их устранения не нало иметь доступ на production server.
2) Здесь все сложнее. По умолчанию докер создает виртуальную сеть для каждого контейнера. Если использовать docker compose, то его умолчание — виртуальная сеть, в которой каждый контейнер будет хостом. Можно управлять виртуальными сетями гибко. А можно и вовсе их отключить и заставить все контейнеры напрямую использовать сеть хоста.
В последнем случае порты окажутся в общем адресном пространстве. Но так тоже делают, когда очен важен performance. Виртуальная сеть докера может добавить задержку до 70мс.
На самом деле умолчания у докера и docker-compose одинаковы: виртуальная сеть, в которой каждый контейнер будет хостом
Docker также это и реально крутой способ развертывания development окружения для разработчика
Да. И даже более того.
Некоторые считают, что сам deployment вообще исчезнет, как отдельный процесс.
Dockerfile будет создаваться в процессе разработки.
Образы будут сразу тестироваться а потом, как есть отправляться в production.
Звучит интересно.
— разных паролях и хостах с БД
— разных требованиях к памяти и CPU affinity (например, на dev'е nginx работает в минимальной конфигурации на 2-х ядрах, а в проде ему надо выдать кучу памяти и 16 ядер)
— запрете разработчикам подключаться к прод-серверам (т.е. другие имена/пароли/ключи локальных пользователей системы)
разных паролях и хостах с БД
Здесь проще всего задать пароль, имя пользователя, хост и имя базы данных переменными окружения, передаваемыми самому контейнеру с СУБД. Так, чтобы они совпали с вашими.
разных требованиях к памяти и CPU affinity
Здесь обычно создаётся volume с конфигурацией, этот volume мэпится на директорию хост системы и там конфигурация правится руками. Некоторые параметры тоже можно передавать переменными окружения. Другой вариант — отнаследовать production image от development image и поменять там конфигурацию, просто перекрыв её новой при помощи директивы COPY.
запрете разработчикам подключаться к прод-серверам
Тут даже не скажу. Я написал «некоторые считают, что deployment исчезнет», но это не значит, что он уже исчез конкретно у нас.
Думаю, можно поступить также, как с конфигурацией, вынесенной на отдельный volume. Или опять отнаследовать образ.
Но сам я такого не делал.
До применения докера мы тратили массу времени на интеграцию этого компонента.
То авторы добавили новую зависимость, которой у нас нет и которая конфликтует с чем-то еще на нашем сервере.
То их бинарник просто почему-то не запускается, а при попытке сборки из сорцов вылетает ошибка компиляции.
Теперь они предоставляяют этот компонент, как докер image. Проблем больше нет. Вообще.
Можно, конечно, было передавать все архивом и раскладывать файлы по местам, а старые удалять. Но это — неустойчиво к человеческим ошибкам.
Сразу вопрос — у нас большая часть приложений на стеке Microsoft. Умеет ли с ним работать docker?
Надо понимать важный момент. В основе докера изначально лежит технология LXC, что подразумевает необходимость линукса и, соответственно, для разных ОС будут и разные, несовместимые образы. В основе докера для винды лежит технология hyper-v и некоторое кол-во костылей для получений специфичных особенностей ядра линукса.
Только, оно пока выглядит недоделанным. Но раз МС взялась, возможно сделают.
Поясняю — по статье выходит, что данная система по принципу построения мало отличается от принципа построения ОС от Майкрософт, т.е. у них — один программный код работает с раздельными данными и сбой в работе кода ведет к сбою работы со всеми данными. И в самом плачевном случае — сбою всей системы. Поэтому при установке ПО ОС надо перезагружать. Поэтому и вечные проблемы с надежностью работы.
В *nix-ах каждый код работает со своими данными — что и дает надежность.
То, что описано в статье, на мой взгляд — попытка привнести неудачный подход в надежности работы системы.
Ниже уже утверждается — да — надо перезагружаться при обновлениях, да — влияет на работоспособность всех зависимых контейнеров.
Мое мнение — этот инструмент больше подходит для тестировщиков (где надо промоделировать схожие ситуации в работе ПО и/или собрать статистику), чем для внедрения в реальные системы.
да — надо перезагружаться при обновлениях
А если вы обновили скажем tomcat, postgre или ваш собственный код БЕЗ докера, то перегружаться не надо?
Host систему никто не перегружает. А перезапуск контейнера делается очень быстро. Контейнеры вообще быстры и легковесны. По сравнению с native процессами penalty составляет 1-2%
да — влияет на работоспособность всех зависимых контейнеров
Напрямую не влияет. Они изолированы. Влияет в то же степени, в которой остановка сервера управления базой данных повлияет на приложение, которое его использует.
А если вы обновили скажем tomcat, postgre или ваш собственный код БЕЗ докера, то перегружаться не надо?
нет — не надо — во всяком случае пока этот код работает с этими данными — код будет работать, а вот при следующем вызове запустится уже обновленный новый экземпляр кода. И да — в системе могут работать сразу два кода. Даже ядро так работает. И да — даже при обновлении ядра не надо перезагружать всю систему (ну уж если не совсем все поменяли).
Это все уже давно-давно есть в *nix-ах.
Влияет в то же степени, в которой остановка сервера управления базой данных повлияет на приложение, которое его использует.
Ну и чем это не подход от МС — сбой в работе с данными приводит к сбою приложения (и соответственно с другими данными)?
Так что нового и удобного дает докер для «нетестировщиков»?
И да — в системе могут работать сразу два кода
Как вы себе представляете работу сразу двух application серверов в одной системе? Как они порты поделят, например? А если они еще и данные кэшируют? А если новая версия приложения вносит изменения в схему базы данных?
сбой в работе с данными приводит к сбою приложения
Давайте уточним терминологию. Что вы называете «данными»? Неужели docker image? Или что?
На всякий случай: для хранения persistent данных в докере используются volumes. Данные хранятся отдельно от контейнеров и сохраняются при рестарте или обновлении. Docker image — это не данные. Это, если хотите — параметризованный код.
а вот при следующем вызове запустится уже обновленный новый экземпляр кода. И да — в системе могут работать сразу два кода. Даже ядро так работает. И да — даже при обновлении ядра не надо перезагружать всю систему (ну уж если не совсем все поменяли).
Вы про hot-reload что ли?
данные — то, над чем оперирует код (информация)
холодная перезагрузка — перезагрузка системы при помощи аппаратного механизма (железо)
горячая перезагрузка (hot-reload) — перезагрузка системы при помощи команды (кода) процессору
то о чем я писал — обновление и запуск ядра системы «не лету» — без перезагрузок вообще.
Насколько я понимаю — докер хранит и использует разность кода от базового образа как свои данные, которые передает на исполнение. Фактически контейнер это разностная копия данных. Так?
Также получается, что сбой в организации хранения и вызова данных для исполнения контейнера (докера) может привести к сбою работы других контейнеров — это как раз пример
Влияет в то же степени, в которой остановка сервера управления базой данных повлияет на приложение, которое его использует.
То есть при «падении» докера — «упадут» и все контейнеры — со всеми своими пользовательскими приложениями и данными? И времени до «падения» будет ровно столько, пока к докеру не обратится.
От чего зависит в итоге конечный пользователь:
Зависимость от хост-системы,
зависимость от докера,
зависимость от изначального образа для контейнера
зависимость от настройки контейнера,
зависимость настройки конечного ПО в контейнере
Сравните с работой при использовании гипервизора (который намного легче и проще хост-системы — а значит и надежнее)
В итоге:
Это более надежная система? Нет. Удобная по быстроте разворачивания? Да.
Т.е. область применения — девелоперы и тестировщики.
Фактически контейнер это разностная копия данных. Так?
Нет. Union FS работает не так.
То есть при «падении» докера — «упадут» и все контейнеры — со всеми своими пользовательскими приложениями и данными?
Тоже нет. Процессы продолжат работать даже если упадет docker daemon.
Зависимость от хост-системы
Минимальна. В идеале её нет вовсе.
зависимость от докера
Да. Докер контейнеры зависят от докера. Если бы докер был ненадежным или некачественным продуктом, это было бы важным аргументом против.
зависимость от настройки контейнера
Как эта зависимость влияет на надежность? Настройка конейнера не может «упасть» и потянуть за собой какие-то проблемы. Настройка контейнера — это конфигурация.
зависимость настройки конечного ПО в контейнере
То есть ваше ПО зависит от его настройки. Неудивительно.
При этом докер как раз сильно снижает количество проблем такого рода, позволяя проверить ваш контейнер заранее точно в таком же окружении, в котором ему предстоит работать.
Нет. Union FS работает не так.
По приведенной ссылке — именно так — с построением древовидной структуры и приоритетом доступа.
Тоже нет. Процессы продолжат работать даже если упадет docker daemon.пока не надо будет к нему обратится, а обратится надо будет — если вдруг перезапуск системы или сверка с изначальным образом, или чтение конфигурации…
Зависимость от хост-системы
Минимальна. В идеале её нет вовсе.
не надо лукавить — докер — одино из приложений в хост-системе — со всеми вытекающими
Если бы докер был ненадежным или некачественным продуктом, это было бы важным аргументом против.Сбои происходят с любым ПО — насколько часто — это зависит от многих факторов. Я указал что это еще один уровень в возможном сбое. То же относится и настройке конечного ПО — это уровень возможного отказа (сбоя).
позволяя проверить ваш контейнер заранее точно в таком же окружении
В итоге мы пришли к мнению о применении у тестировщиках и девелоперах. Пользователям незачем проверять работу приложения — пользователям надо чтобы оно уже работало.
Только в этом плане гипервизор — предмет для точно такой же критики.
Любое добавление сложности добавляет и хрупкость.
Вопрос всегда в том ради чего идти на такое усложнение и насколько качественна добавляющая сложность вещь.
В итоге мы пришли к мнению о применении у тестировщиках и девелоперах. Пользователям незачем проверять работу приложения — пользователям надо чтобы оно уже работало.
Мало смысла использовать докер для тестировщиков, если потом не запускать тот же самый образ в production. Получится тестировали одно, а работает другое.
сразу надо с ОС поставлять — но так же не делаю — верно?
По сути, докер так и делает :)
А вообще ситуации бывают разные. Я начал статью с типовых ситуаций, где докер применять есть смысл.
Совершенно очевидно, что в массе других ситуаций докер не нужен, а нужно как раз «отдельное ПО».
Докер же как мне представляется, делает с точностью до наоборот — все сводится к полной централизации. Т.е.придется прилагать усилия для обеспечения его надежной работы, а также используемых линий связи — в сложных и распределенных системах.
Так можно упрекнуть в полной централизации и операционную систему.
Как Вы этого добились? Я по-прежнему вижу такое поведение в последней на текущий момент версии 1.12.1:
[root@home ~]# docker run -d alpine sleep 100500 5875809562f9be61f52de3d863a26d2aa45b9446e7b8a4683c1083727ea1d705 [root@home ~]# docker run -d alpine sleep 100500 4d60cf6ca2a64f711b93c1b67f1b6605d93ac4501782a6325a46d7fa94818626 [root@home ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4d60cf6ca2a6 alpine "sleep 100500" 4 seconds ago Up 3 seconds agitated_agnesi 5875809562f9 alpine "sleep 100500" 7 seconds ago Up 5 seconds serene_meitner [root@home ~]# systemctl restart docker [root@home ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES [root@home ~]#
В докере процессы порождаются не системой инициализации, а самим докер-демоном. Умирает демон — умирают его дети.
Rkt и systemd-nspawn запускают контейнеры правильно. Docker, увы, по-прежнему нет.
Но попробуйте убить его процесс через
kill -9
Дети останутся. Так же они останутся, если докер демон закрэшится из-за внутренней ошибки. Именно об этом шла речь.
Вдобавок, проблема не в том, что докер может упасть. Мне ещё не встречались падения его на ровном месте, поэтому в этом плане можно считать его достаточно надёжным. Проблема в обновлениях самого докера, к примеру, из системных пакетов, при котором происходит стандартный рестарт. С убийством детей.
Докер берёт на себя роль супервизора процессов. Апофеоз такого подхода — RancherOS, где systemd заменен на докер. Я бы не рискнул использовать это в продакшене. Просто потому, что при всём уважении к труду авторов докера, он не может сравниться с инструментом, который специально создан для управления всеми системными процессами.
Сравните с работой при использовании гипервизора (который намного легче и проще хост-системы — а значит и надежнее)
Работая на более низком уровне гипервизор НАМНОГО сложнее чем докер. И требования к надежности гипервизова намного выше. Так как при ошибке в докере упадет конкретный контейнер (наверно, я не знаю, кто знает — поправьте), а при ошибке в гипервизоре у вас упадет все, что выше него: хост-система(ы), докер и все остальное.
Докер, к слову, работает за счет механизмов ОС, поэтмоу его надежность упрощенно можно приравнять надежности самой ОС.
Работая на более низком уровне гипервизор НАМНОГО сложнее чем докер
Ничего удивительного — гипервизор реально управляет системой (ее основными функциями), а докер — всего лишь приложение и много чего передает для отработки хост-системе и работает в принципе из-под нее (с меньшим приоритетом)
И поэтому его надежность выносится отдельно от надежности хост-системы. Упрощенно.
холодная перезагрузка — перезагрузка системы при помощи аппаратного механизма (железо)
горячая перезагрузка (hot-reload) — перезагрузка системы при помощи команды (кода) процессору
Холодная перезагрузка и горячая отличаются тем, что при «горячей» не производится проверка памяти, так как она была проверена при холодной, за счет чего ПК загружается быстрее. В большинстве случаев, простая перезагрузка ПК будет как раз-таки горячей. Полное выключение и последующий запуск — тоже, в каком-то смысле холодная перезагрузка. Reload и Restart, это, кстати, разные вещи.
код — то, что передается на исполнение (команда процессору)
данные — то, над чем оперирует код (информация)
Ок, теперь объясните:
1. что такое «свои» данные и чем они отличаются от «не своих»
2. Что означает ваша фраза:
в системе могут работать сразу два кода.
докер хранит и использует разность кода от базового образа как свои данные, которые передает на исполнение.
Ну… очень корявая формулировка, но направление мысли примерно правильное. Docker image хранит слои файловой системы с нужным конкретному процессу набором файлов. В таком же смысле можно сказать что любая ОС «хранит и использует разность кода от базового образа (свежеустановленного) как свои данные, которые передает на исполнение».
Фактически контейнер это разностная копия данных. Так?
Нет, контейнер — это процесс(ы) запущенный в и изолированном окружении, которое предоставляет image.
Также получается, что сбой в организации хранения и вызова данных для исполнения контейнера (докера) может привести к сбою работы других контейнеров
Какого рода «сбой»? Что такое «организация хранения и вызова данных»? Если вы о файловой системе контейнера, то нет, проблемы одного контейнера никак не повлияют на остальные.
То есть при «падении» докера — «упадут» и все контейнеры — со всеми своими пользовательскими приложениями и данными?
Вроде бы с версии 1.12.0 контейнеры должны спокойно относиться к рестартам docker демона, в любом случае, хороший контейнер должен быть stateless и ему должно быть наплевать на то перезагружают его или нет. Пользовательские данные хранить в контейнере не нужно.
И времени до «падения» будет ровно столько, пока к докеру не обратится.
Эту фразу я вообще не понял
гипервизора (который намного легче и проще хост-системы — а значит и надежнее)
В каком смысле он легче и проще? Вы теплое с мягким сравниваете, гипервизора работает поверх хост системы. В этом смысле докер легче и проще, тк по сути предоставляет средства изоляции на уровне ядра ОС хост системы. Как раз гипервизор менее надежен, тк его падение гарантированно уюивает все виртуальные машины.
Это более надежная система? Нет. Удобная по быстроте разворачивания? Да.
Более надежная и удобная по быстроте чем что?
Т.е. область применения — девелоперы и тестировщики.
Неверно
1. что такое «свои» данные и чем они отличаются от «не своих»
Извините, но тут уж должен направить на изучение работы процессора в защищенном режиме (хотя бы в общих чертах)
2. Что означает ваша фраза:
в системе могут работать сразу два кода.
А здесь к общим понятием запуска и работы процессов (кода) в *nix системах.
гипервизора работает поверх хост системы.
Извините — но это Вы путаете понятие гипервизора и систему виртуализации.
Чтобы попроще — гипервизор устанавливается на железо, система виртуализации — на хост-систему. И тут гипервизор более надежен — т.к. у него меньше код, а значит и меньше верятность сбоя.Также гипервизор не работает с пользовательским ПО — он работает с системным ПО — его надежность намного выше, чем хост-системы.
Более надежная и удобная по быстроте чем что?Чем стандартно установленная ОС.
Извините, но тут уж должен направить на изучение работы процессора в защищенном режиме (хотя бы в общих чертах)
Извините, но ответ не принимается, к контексту нашей беседы защищенный режим никакого отношения не имеет. Вы противопоставляли операционки МС и *nix, по-вашему что, в винде процессы в реальном режиме работают?
А здесь к общим понятием запуска и работы процессов (кода) в *nix системах.
Тут видимо отсылка к многозадачности, ну так я вас удивлю, в винде тоже реализованна такая абстракция как процесс и есть в наличии средства управления процессами и многозадачность.
Извините — но это Вы путаете понятие гипервизора и систему виртуализации.
Это одно и то же, гипервизоры бывают как реализованные поверх железа так и поверх ОСи, но эта деталь никак не влияет на тот факт, что падение гипервизора приведет к падению всех гостевых операционок.
Ну и по поводу «направления на изучение», вы несете бред и демонстрируете полное непонимание темы, лучше бы уж помолчали, чем направлять меня куда-то, потому что выглядит это глупо и смешно :)
Насчет ОС от МС — по умолчанию (для оптимизации использования памяти) ОС делает интересные «финты» с кодом и данными — и надо использовать доп системные утилиты и настройки чтобы использовать возможность действительно независимого использования кода и данных.
ну так я вас удивлю, в винде тоже реализованна такая абстракция как процесс
Да не надо меня удивлять — просто внимательно прочитайте свои же слова.
И про гипервизоры — ну хоть википедию почитайте внимательнее что-ли.
ОФФ И кстати — переход на личности, и личные характеристики говорит о невозможности аргументировать свою точку зрения и отсутствию самой возможности конструктивного решения нашего спора. Не любите критику — лучше молчите.
В статье и комментариях утверждается обратное.
Где именно в статье утверждется обратное?
f0rk
докер легче и проще, тк по сути предоставляет средства изоляции на уровне ядра ОС хост системы.
«Уровень ядра» — это прямое обращение к аппаратуре — т.к. у ядра ОС наивысший приоритет обычно.
Далее — что произойдет если докер упадет?
Из обсуждений ниже и этой фразы выходит что, докер посредством cgroups запускает на исполнение образ системы с изменениями взятыми из конфига для контейнера?
Этот код независим уже или все-таки управляется докером?
Как это работает с распределенной сложной системой? Типа удаленной загрузки?
Из конфига для контейнера берутся переменные окружения и некоторые параметры определяющие, как именно стартовать контейнер.
Код независим. Но процесс является child-ом от докеровского демона.
Докер может этот процесс остановить (послав ему SIGTERM, а если не реагирует то просто убить)
Если докеровский демон умрёт, контейнеры станут сиротами (orphan) со всеми вытекающими.
Как это работает с распределенной сложной системой? Типа удаленной загрузки?
А вот это поясните, пожалуйста. На первый взгляд кажется, что это вообще не относится к делу.
существует ли у докера возможность работать с несколькими физическими серверами
Существует. Но это — самостоятельный продукт. Docker swarm
Обычный докер работает в рамках одного физического сервера.
Далее — что произойдет если докер упадет?
Насчет падения не уверен, на моей практике он ни разу не падал, но скорее всего если его получится сразу рестартануть, ничего плохого не случится, хотя могут быть и траблы с доступом к контейнерам по сети. Если контейнеры запущены с --net=host и работают с сетевыми интерфейсами хоста, то вероятность проблем меньше. Но это мои предположения, их нужно проверять. Просто рестарт демона контейнеры переживают без проблем, по сути, контейнеризованные процессы — такие же полноценные процесы в рамках ОС, просто разбитые по namespace.
докер посредством cgroups запускает на исполнение образ системы
Не совсем понятно, что вы имеете в виду под «образом системы». Докер запускает процесс в хост системе, этот процесс использует ядро хост системы для системных вызовов, по сути разница с обычным процессом в том, что он не видит файловую систему хоста и не видит остальные процессы запущенные вне его контейнера.
с изменениями взятыми из конфига для контейнера
Эту часть не понял, что вы подразумеваете под «конфигом для контейнера»?
Этот код независим уже или все-таки управляется докером?
Процесс в контейнере независим настолько, насколько независим любой дочерний процесс.
Как это работает с распределенной сложной системой?
На каждом хосте должен быть свой демон, контейнеры могут общаться через overlay network, можете тут почитать
И про гипервизоры — ну хоть википедию почитайте внимательнее что-ли
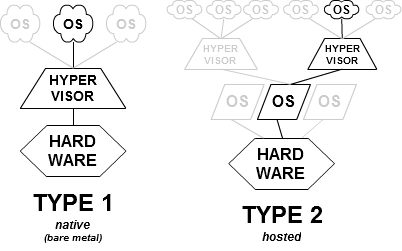
Вот картинка из Википедии:
невозможности аргументировать свою точку зренияТо что вы абсолютно не разбираетесь в теме настолько очевидно, что у меня нет никакой необходимости что либо аргументировать, я кстати могу нести полнейшую чушь и все равно будет смешно :)
я кстати могу нести полнейшую чушь и все равно будет смешно :)я рад что Вы весело провели время
В таком же смысле можно сказать что любая ОС «хранит и использует разность кода от базового образа (свежеустановленного) как свои данные, которые передает на исполнение».
Ваше утверждение не верно.
Образ системы — это сохраненная копия кода и (возможно) данных на определенный момент времени. Как правило для его создания используются сторонние инструменты, т.к. обычно ОС имеет наивысший приоритет выполнения и не дает доступа к критическому коду.
Даже в обычном ПК (с х86 архитектурой) код ОС не изменяется произвольно. Я уж не говорю о других системах (ну навскидку были процессоры PowerMac или реализации суперЭВМ, встроенные системы) — для изменения кода требовался особый алгоритм и средства.
К тому что Вы описали больше подходят системы с произвольно изменяемой архитектурой к созданию которых только подошли, и в какой-то мере нейросистемы.
были процессоры PowerMac
А можно подробнее про них? Я о таких к своему стыду не слышал.
В данном контексте упомянул, т.к. в них аппаратно была разделена память программ (для кода) и память данных. (надо заметить что зависали они тоже довольно часто, но все же меньше чем с х86 архитектурой). В принципе подобных подход в архитектуре наблюдаем в микроконтроллерах.
надо заметить что зависали они тоже довольно часто, но все же меньше чем с х86 архитектурой
Чтож от них отказались, раз они так хороши?
Насколько я помню, кэш L1 в x86 тоже разделяет код и данные.
Насколько я помню, кэш L1 в x86 тоже разделяет код и данные.Не совсем так. Он хранит их отдельно — соответственно к частоте обращений. Ну и при многоядерности и/или эмуляции многоядерности — это дает неплохой прирост производительности.
Даже в обычном ПК (с х86 архитектурой) код ОС не изменяется произвольно.Когда-то давно (я еще зеленым школьником был) у меня было хобби компилять ядро для слаки, так вот, что-то не припомню, чтоб мой пень (с х86 архитектурой) как-то противился таким экспериментам.
Может я тут плохо понял
Я думаю, что предположение из первого коммента в ветке верное.
Поясняю — по статье выходит, что данная система по принципу построения мало отличается от принципа построения ОС от Майкрософт, т.е. у них — один программный код работает с раздельными данными и сбой в работе кода ведет к сбою работы со всеми данными. И в самом плачевном случае — сбою всей системы. Поэтому при установке ПО ОС надо перезагружать. Поэтому и вечные проблемы с надежностью работы.
В *nix-ах каждый код работает со своими данными — что и дает надежность.
Что понимается под кодом, работающим с «раздельными» данными, и что понимается под «своими» данными. И что понимается под кодом в данном случае. И как сбой в работе «кода» приводит к «сбою работы со всеми данными».
у них — один программный код работает с раздельными данными и сбой в работе кода ведет к сбою работы со всеми данными
Что под этим понимается? Какой код, с какими данными? Что понимается под «раздельными» данными? Процессы изолированы друг от друга, в общем случае они друг на друга не влияют, поэтому падение одного никак не трогает другие. Синий экран — ошибка в ядре (или в драйвере, так как они работают в одном АП с ядром).
В *nix-ах каждый код работает со своими данными — что и дает надежность.
Что понимается под «своими» данными?
В докере идея в том, что каждый процесс считает, что он единственный запущен, хотя на самом деле их может быть много, точно также, как ОС в виртуальный машине считает, что она работает на голом железе и больше никто на этом железе не работает. Отличие в том, что докер «недо-виртуализует» окружение, все процессы работают на физическом процессоре и напрямую читают/пишут в физическую память, не обращаясь сначала к виртуальной машине. С точки зрения хостовой ОС — это просто процессы, которыми она управляет, как ей привычно.
т.е. есть у тебя ~100 контейнеров унаследованных от образа, к примеру Ubuntu LInux 16.04.
Тут появляется 0-day уязвимость, надо обновить образ операционной системы.
Правильно ли я понимаю что тогда будет нужно пересобрать все контейнеры Docker и перезапустить их все с пересобранного образа?
В случае уязвимости — просто пересобрать образ (он при этом обновится), перезалить его в регистри и, да, перезапустить все контейнеры.
Для этого, кстати, иногда настраивают крон, который периодически проверяет наличие новых версий образа в регистри и, если находит, то делает обновление самостоятельно. Так удобно делать, если серверов много.
Что не рекомендуется авторами докера: https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices/#/apt-get
Авторы докера еще не рекомендуют запускать в контейнере более одного процесса.
А вот эти авторы очень популярного base image другого мнения.
У любого решения есть плюсы и минусы. Взвешивать их и принимать решения только тому, кто несёт ответствнность за результат.
Докер — это отличная возможность переложить проблемы поддержания актуальных версий системных библиотек (того же самого libssl) с поставщиков ОС и сисадминов на никого
Разве это не организационный вопрос? Пусть тот же сисадмин следит за актуальностью образов.
Итого мы приходим что все таки нам нужен админ который теперь вместо того чтоб разбираться с правилами сборки пакетов под используемый дистрибутив и построения единообразной системы, будет заниматься изучением чьих то контейнеров.
Кроме того, если практически во всех дистрибутивах есть средства для мониторинга устаревшего/уязвимого ПО, как это делать в случае повсеместного использования контейнеров — не понятно, опять же доставлять нужное ПО в контейнеры? Или пересобирать все образы самому? Тогда в чем профит?
Кроме того, если практически во всех дистрибутивах есть средства для мониторинга устаревшего/уязвимого ПО, как это делать в случае повсеместного использования контейнеров — не понятно, опять же доставлять нужное ПО в контейнеры? Или пересобирать все образы самому?
Пересобирать самому. Это не сложнее чем просто поставить новый пакет на машине. В принципе можно использовать те же средства для автоматического мониторинга и внутри контейнера, но хз… я бы не хотел чтоб у меня на live машине что-то само переустанавливалось.
А админ нужен, да, куда без него…
Процесс докера работает а host-системе и взаимодействует с ядром host-системы.
Проблемой может быть только такая уязвимость, благодаря которой уязвимым станет сам бинарник процесса еще на этапе сборки.
Кто-нибудь смог TensorFlow запустить под докером? Хоть убейте не пойму как это работает, и главное — почему оно должно работать!
https://www.tensorflow.org/versions/r0.10/get_started/os_setup.html#docker-installation
Контейнер успешно скачивается и деплоится, сервер блокнота доступен на нужном порту.
Вопрос:
На шаге https://www.tensorflow.org/versions/r0.10/get_started/os_setup.html#test-the-tensorflow-installation
Open a terminal and type the following
Я терминал должен где открыть? На машине на своей? С какой стати у меня питон должен знать, что такое tensorflow, tf же контейнирезован?!?!?!
Поймите, простите за оффтоп, помогите.
Спасибо.
Хотя лично мне докер очень нравится.
но вот этот самый vendor-lock-in…
Их проблема в исполнении кастомного кода во время установки.
Это — бОльшая хрупкость, по сравнению с докером у которого кастомный установочный код выполняется во время сборки образа.
В первом случае для устранения сбоев при установке нужен доступ на production.
Во втором сбои устраняются заранее во время сборки образа.
Другими словами, первая группа инструментов отправляет в продакшен код, который должен там исполниться в незнакомой среде хост системы.
Докер отправляет в продакшен заранее собранный процесс и требуемые ему данные. Здесь нет стадии исполнения кода во время установки. А нет исполнения — нет ошибок.
Нужен ли будет более мощный сервер, или можно будет по-прежнему на крохотных vps-ках держать какие-то сервисы?
(У некоторых проектов, к примеру у sentry, рекомендуемый способ установки теперь уже через docker, а классический уже как бы почти deprecated)
Вот тут, например, обсуждают мажину с 12гб памяти 12 свопа, где запущено 183 контейнера и там докер съел 5гб виртуальной памяти.
Вообще, процесс докера работает через cgroups и использует системные вызовы ядра хост системы. Он не тащит с собой дополнительный линукс в свою память.
Такое ощущение, что со stateless-сервисами (типа веб-серверов) сравнительно легко что с docker, что без docker. А вот что делать со stateful?
Насколько я понял, концепт упирается на т.н. микросервисы: не нужно упаковывать всю систему в один контейнер (иначе разница с полноценной виртуальной машиной невелика), а запускать интеграцию, например, из трех контейнеров: веб-сервер+приложение, сервер приложений и СУБД.
В статьях увлекательно пишут, о том, что если это работало на машине разработчика, то без изменений будет крутиться в эксплуатации.
Первый вопрос, параметры системы (речь о системе уровня небольшой ERP) у разработчика, у испытателей и в эксплуатации у клиентов принципиально разные, поскольку разные цели. Как это совместить?
Второй вопрос, какой смысл упаковывать в контейнер терабайтную… ладно, даже 50 Гб базу данных?
Третий вопрос, с какого масштаба системы докер становится бесполезен и использование полноценной виртуальной среды (а то и физической) становится выгоднее (могу ошибаться, но у меня есть подозрения на уровень LAMP-приложения до 100К строк кода и 100 таблиц в БД)?
Спасибо за пояснения на реальных примерах.
Да, тут немного лукавят. Обычно через переменные окружения передаются такие параметры. Например, количество памяти, которое может использовать сервис в проде и в тестовой среде обычно отличаются. Однако, отличия почти всегда сводятся к ограничениям ресурсов, налагаемых на проект в тестовом окружении. Что позволяет делать вывод: работает в тестовом окружении, значит заработает и в проде с очень высокой вероятностью
Второй вопрос:
Ответ — никакого. Так никто и не делает. Данные вообще не пакуют в контейнеры, так как они не должны уничтожаться при уничтожении контейнеров. Для данных есть volumes.
Третий вопрос:
Вот тут habrahabr.ru/post/247969 описывали довольно масштабное использование докера. Я с таким сам не сталкивался.
Но вот по сравнению с виртуальной машиной, контейнеризация докера скорее выигрывает в performance. В докере все процессы на самом деле работают в host системе, используя механизм cgroups. Накладных расходов там меньше, чем в виртуалках.
Если данные живут отдельно от контейнеров, можно ли вообще говорить об идентичности окружения? Разница уровня одной строки в таблице параметров может полностью менять поведение системы.
Если докер работает в виртуальной среде, как он может быть быстрее непосредственной работы приложения в этой среде? Каждый уровень виртуализации, пусть даже тонкий, только снижает производительность.
Docker. Зачем и как