Comments 32
Вопрос: Вы не могли бы выложить код вашего решенния?
Комментарий: Усреднение 26 fine-tuned VGG16 с аугментацией, где подвыборки выделялись по водителям => 0.19 Public Leaderboard, 0.22 Private LeaderBoard
Это соревнование очень интересное в том смысле, что влоб cross validation не работает. Но при желании можно найти подход. Мне оно тоже очень понравилось, хотя я изрядно оверфитил и меня в результате кинуло на 56 мест.
Комментарий: Усреднение 26 fine-tuned VGG16 с аугментацией, где подвыборки выделялись по водителям => 0.19 Public Leaderboard, 0.22 Private LeaderBoard
Это соревнование очень интересное в том смысле, что влоб cross validation не работает. Но при желании можно найти подход. Мне оно тоже очень понравилось, хотя я изрядно оверфитил и меня в результате кинуло на 56 мест.
Решение собиралось из кучи отдельных кусков, всего порядка 25 проектов сейчас лежит. При этом часть на питоне в убунте писались, всякие обработчики базы в винде на шарпе, там же с лицами и их выделением кусок. Мне, честно говоря лень это всё собирать в единый код, нужно 2-3 дня потратить чтобы всё проверить и запустить:)
Если какие-то отдельные куски нужны, могу выложить. Но ничего нового и особенного нет.
Нас чуть-чуть вперёд кинуло, позиций на 10 после private. Я думаю тут ещё не последнюю роль сыграло, что мы сами ручками разметили 1.5 тысячи и прежде чем отсылать проверяли по ним, стабильно ли решение. Точность эти 1.5к не показывали, но понятно было стало ли лучше решение или нет.
Если какие-то отдельные куски нужны, могу выложить. Но ничего нового и особенного нет.
Нас чуть-чуть вперёд кинуло, позиций на 10 после private. Я думаю тут ещё не последнюю роль сыграло, что мы сами ручками разметили 1.5 тысячи и прежде чем отсылать проверяли по ним, стабильно ли решение. Точность эти 1.5к не показывали, но понятно было стало ли лучше решение или нет.
Мне вполне хватит куска про python с убунтой с кратким описанием того, что данный файл/функция делает.
Вы похоже масштаба проблемы не понимаете;)
https://yadi.sk/d/DQY8g0Dptzqke — вот все питоновские исходники.
Подписывать что какая функция делает и структурировать это всё я не буду — это и есть два дня работы;)
pycaffe — питоновские слои для загрузки данных каффе.
*.ipynb — проекты для обучения и тестирования
pascal_multilabel_with_datalayer — используемые описания сетей
https://yadi.sk/d/DQY8g0Dptzqke — вот все питоновские исходники.
Подписывать что какая функция делает и структурировать это всё я не буду — это и есть два дня работы;)
pycaffe — питоновские слои для загрузки данных каффе.
*.ipynb — проекты для обучения и тестирования
pascal_multilabel_with_datalayer — используемые описания сетей
Сталкивался с похожей в какой-то мере проблемой, когда реализовывал одну статью с конференции. У авторов все было идеально. У меня на валидации было % 99 accuracy. Когда дело дошло до реальных фотографий начался лютый треш. Это немного расстраивает. Я не очень понимаю как в таких случаях добиваться по-настоящему рабочего состояния. ;(
Методично, плавно вылавливая каждую ошибку и делая для неё затычку. Где программно, где новым алгоритмом, где дообучая, где постулируя административно.К сожалению это единственный путь.
Если честно, то 80% статей — дикий шлак. Результаты нельзя ни повторить, ни довести. Либо получаются куда слабее и проще. Я даже как-то на Хабре писал пример одной такой попытки. А вообще у меня таких примеров относящихся к работе с десятки есть. Даже если выложен код — он часто на примерах авторов даёт другой результат.
Если честно, то 80% статей — дикий шлак. Результаты нельзя ни повторить, ни довести. Либо получаются куда слабее и проще. Я даже как-то на Хабре писал пример одной такой попытки. А вообще у меня таких примеров относящихся к работе с десятки есть. Даже если выложен код — он часто на примерах авторов даёт другой результат.
А вот ещё такой вопрос: «Сколько времени на итерацию при тренировке различных сетей уходит на GTX 1080 с caffe?»
Интересует порядок величины, чтобы я знал, пора ли мне апгрейд делать.
Интересует порядок величины, чтобы я знал, пора ли мне апгрейд делать.
ResNet-101 с батчем в 11-12 картинок где-то чуть меньше секунды на прогон сети. Но все изображения в оперативку перед стартом грузил. Сколько времени чистая тренировка, сколько передача данных — не знаю.
VGG-16 и 19 подольше, там батч плохо помню, где-то в районе 30. Думаю секунды по 2 на шаг.
За ночь где-то 40к итераций по ResNet-101 у меня пролетало.Я периодически даже делал чтобы несколько независимых тренировок проходило. Сетей обученных более чем на 30к итераций мы вроде в итоговый ответ не включали.
VGG-16 и 19 подольше, там батч плохо помню, где-то в районе 30. Думаю секунды по 2 на шаг.
За ночь где-то 40к итераций по ResNet-101 у меня пролетало.Я периодически даже делал чтобы несколько независимых тренировок проходило. Сетей обученных более чем на 30к итераций мы вроде в итоговый ответ не включали.
А я что-то собиралась-собирался поучавствовать в этом конкурсе, да так и забыл про него(
И вдруг мы поняли, что SegNet имеет закрытую не OpenSource лицензию.
Хм, а чего там такого инновационного? Энкодер + Декодер? Можно было тогда попробовать FCN тренировать, с ним вроде бы нет проблем в плане лицензии.
Ну. Когда времени немного — страшно пробовать что-то новое настроить. На то чтобы SegNet запустить и протестировать у нас в своё время дня два ушло. Так что решили обойтись без этого подхода. Так да, я встречал похожие, но не видел никакого сравнения по качеству/точности/количеству примеров для тренировки.
Сейчас на kaggle лидируют либо сверточные сети (для изображений), либо xgb (для всего остального). Другие алгоритмы, похоже, за последние 3 года канули в Лету.
Я с kaggle достаточно плохо знаком в этом плане. Даже про xgboost лишь краем уха слышал. А задач на рекуррентные сети там не бывает?
Бывают, но редко:
https://www.kaggle.com/c/grasp-and-lift-eeg-detection
https://www.kaggle.com/c/how-much-did-it-rain-ii
И это очень печально.
https://www.kaggle.com/c/grasp-and-lift-eeg-detection
https://www.kaggle.com/c/how-much-did-it-rain-ii
И это очень печально.
Огромное спасибо за рассказ, особенно за разбор других опубликованных решений! Больше нейросетей!
Точность можно повысить сильно, обработав сначало автомобиль, белая заниженная приора, тонированные фонари или тонер по кругу, громкость выхлопа итд
Автору респект за интересный пост!
Интересно, а как вы отнесетесь к идее того, чтобы использовать нейронную сеть для извлечения фич, а не как классификатор.
Я имею ввиду следующие, делаем на нейронной сети классификатор, берем выход препоследнего слоя и работаем с ним как с обычными фичами. Здесь уже появляется большое поля для манерва, можно использовать другие методы, например, SVM.
Что думаете?
Интересно, а как вы отнесетесь к идее того, чтобы использовать нейронную сеть для извлечения фич, а не как классификатор.
Я имею ввиду следующие, делаем на нейронной сети классификатор, берем выход препоследнего слоя и работаем с ним как с обычными фичами. Здесь уже появляется большое поля для манерва, можно использовать другие методы, например, SVM.
Что думаете?
Я имею ввиду следующие, делаем на нейронной сети классификатор, берем выход препоследнего слоя и работаем с ним как с обычными фичами. Здесь уже появляется большое поля для манерва, можно использовать другие методы, например, SVM.
Что думаете?
Ну сетки примерно это и делают: сначала сверточные слои отрабатывают для feature extraction и генерируют на выходе набор карт, поверх которых уже запускается классификатор, реализованный в виде либо полносвязнных слоев, либо в виде GAP, ну а SVM — это частный случай полносвязных нейронных сетей, разве что тренируется немного по другому.
Это вы про что-то типа автокодировщика говорите.
Спасибо! Очень интересный, цельный и законченный пост со справделивыми выводами. И поздравляю с хорошим результатом!
На тренировочной и тестовой выборках у вас получались схожие результаты, когда уже оказались в первой сотне? Касательно слова «оверфит» в названии статьи и склеивания полукартинок… В этом плане синтетически увеличить тренировочный набор — очень интересная идея. Можно понять, есть ли склонность алгоритма к оверфиту. И если всё хорошо, то дообучить. Интересно было бы посмотреть, что даст склеивание четвертинок и далее
Вот тут наша динамика и по Public и по Private
В целом оно идентично идёт и в первой сотне и выше.
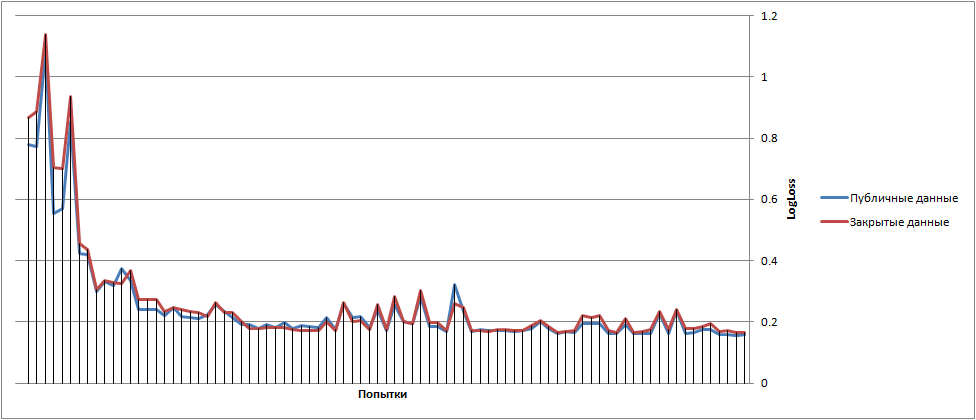{kind=link}
В целом оно идентично идёт и в первой сотне и выше.
А есть такой же график, но ещё с качеством по кросс-валидации на обучающей выборке? И как, кстати, делали кросс-валидацию?
Неа, нету.
Сначала пробовали выделить кусок из тренировочной выборки. Но она аццки коррелированна бы тогда была. Чтобы корректно её проверять нужно было несколько водителей целиком выкидывать, а это ухудшало точность. Поэтому для тестирования взяли 1.5к из тестовой выборки и разметили руками.
Но тут есть проблема. Руками разметить можно с меньшей точностью, чем результат обучения. Так что такая разметка особо для проверки и не годилась. Как только мы дошли до точностей 0.21 она любой смысл потеряла. Дальше тестировались только по тому что отправляли на Kaggle
Сначала пробовали выделить кусок из тренировочной выборки. Но она аццки коррелированна бы тогда была. Чтобы корректно её проверять нужно было несколько водителей целиком выкидывать, а это ухудшало точность. Поэтому для тестирования взяли 1.5к из тестовой выборки и разметили руками.
Но тут есть проблема. Руками разметить можно с меньшей точностью, чем результат обучения. Так что такая разметка особо для проверки и не годилась. Как только мы дошли до точностей 0.21 она любой смысл потеряла. Дальше тестировались только по тому что отправляли на Kaggle
Я примерно ожидал, что вы сделали кросс-валидацию «честную», т.е. с выкидыванием водителей, а не просто случайную. Не совсем понимаю, почему ты говоришь, что это ухудшало точность. Вроде в обучающей выборке было 27 водителей и можно было устроить например Leave One Driver Out кросс-валидацию :) В добавок, в статье ведь написано, что если обучить несколько моделей на разных подвыборках, а потом усреднить — качество может улучшиться.
А как тогда происходил подбор гиперпараметров? По размеченной вручную части тестовой выборки? Или только по Public LB? В данной задаче повезло, конечно, что вы не разошлись в результатах между Public и Private, но так опасно делать…
А как тогда происходил подбор гиперпараметров? По размеченной вручную части тестовой выборки? Или только по Public LB? В данной задаче повезло, конечно, что вы не разошлись в результатах между Public и Private, но так опасно делать…
1) Один водитель — нерепрезентативен. Нужно выкидывать сразу 5-10. Там есть старушка в обучающей выборке, которая в 30% не то делает. Обычно смотрит на пассажира.
2) Время обучения. У нас было всего 2.5 недели. Полноценную модельку обучить — ночь времени. Время бы увеличилось пропорционально числу фолдов.
3) «если обучить несколько моделей на разных подвыборках» мы ту же точность получили, склеив 3 сетки обученные с разными гиперпараметрами
4) Мы всё же по нашей выборе могли понять, выше у нас или ниже, чем 0.21. Плюс смотрели насколько результаты друг с другом скоррелированны получились. Пробовали стабилизировать различными сложениями результатов с максимальной корреляцией.
5) Подбор гиперпараметров это всё же подбор learnng rate, подбор точки остановки. Мы этими инструментами точность не настраивали. Мы старались получить точность добавлением dropout|приращений и прочей глобальной фигни, которая должна увеличивать вариативность выборки.
6) А чем подборка гиперпараметров по 3-4 водителям будет лучше, чем подборка по LB? По мне точность одинаковы должна быть.
2) Время обучения. У нас было всего 2.5 недели. Полноценную модельку обучить — ночь времени. Время бы увеличилось пропорционально числу фолдов.
3) «если обучить несколько моделей на разных подвыборках» мы ту же точность получили, склеив 3 сетки обученные с разными гиперпараметрами
4) Мы всё же по нашей выборе могли понять, выше у нас или ниже, чем 0.21. Плюс смотрели насколько результаты друг с другом скоррелированны получились. Пробовали стабилизировать различными сложениями результатов с максимальной корреляцией.
5) Подбор гиперпараметров это всё же подбор learnng rate, подбор точки остановки. Мы этими инструментами точность не настраивали. Мы старались получить точность добавлением dropout|приращений и прочей глобальной фигни, которая должна увеличивать вариативность выборки.
6) А чем подборка гиперпараметров по 3-4 водителям будет лучше, чем подборка по LB? По мне точность одинаковы должна быть.
Понял, времени на подсчёт 27 фолдов просто не было. Но если бы было возможно — то тогда возможно схема с Leave One driver Out (27 фолдов обучить на 26 водителях и тестировать на 1 «выкинутом» водителе) могла дать довольно хорошую почти несмещённую оценку того, как ваш алгоритм ведёт себя на ранее не виданных водителях. Вероятно такая оценка может быть точнее, чем вручную размеченная часть тестовой выборки, и чем Public LB.
Во всяком случае, мне было бы страшно настраиваться на Public LB из-за переобучения. Но, похоже, в данном случае, этого не произошло, поэтому можно считать ваш метод подходящим.
Во всяком случае, мне было бы страшно настраиваться на Public LB из-за переобучения. Но, похоже, в данном случае, этого не произошло, поэтому можно считать ваш метод подходящим.
Спасибо за статью, прочитал с огромным удовольствием.
Был ещё один серый механизм, который мы всё же не решили использовать, но долго думал. Хотя от администрации не было явного на него запрета. Механизм: найти на тестовой выборке фотографии которые соответствуют разным машинам, построить их модель и вычесть из фотографий фон. Работы тут где-то на 2-3 дня. Но не хотелось: не верили ни в то, что выведет в десятку, ни в то, что идею не запретят.
Почему?
Причины описанные в разделе «От игрушек к делу» (потому что странно? не спортивно?) мне кажутся для данного случая неподходящими. Для реализации в модуле, который будет снимать это вариант идеальный — можно при установке модуля сделать калибровку, снять изображение салона без водителя
Причины по которым мы не использовали на конкурсе:
1) Времени было мало
2) Не было явного разрешения от админов на манипуляцию с тестовой выборкой.
В полноценной реализации да, возможно и получиться использовать. Но нужно сперва смотреть ряд факторов:
1) это одиночные кадры или видеопоток? Механизмы будут разными. Для одиночных кадров вычитание куда менее эффективно. Машина которая проехала по тоннелю и которая выехала на солнышко — плохо вычитается. Другие яркости другие градиенты.
2) За рулём всегда один водитель или разные?
Снять изображение салон без водителя — малорабочий вариант. Это неудобный кейс для массового пользователя. Мне кажется что когда есть конечная постановка задачи — набор алгоритмов нужно выбирать исходя из неё. В такой набор мог бы попасть алгоритм который вычитает фон, а мог бы и не попасть.
1) Времени было мало
2) Не было явного разрешения от админов на манипуляцию с тестовой выборкой.
В полноценной реализации да, возможно и получиться использовать. Но нужно сперва смотреть ряд факторов:
1) это одиночные кадры или видеопоток? Механизмы будут разными. Для одиночных кадров вычитание куда менее эффективно. Машина которая проехала по тоннелю и которая выехала на солнышко — плохо вычитается. Другие яркости другие градиенты.
2) За рулём всегда один водитель или разные?
Снять изображение салон без водителя — малорабочий вариант. Это неудобный кейс для массового пользователя. Мне кажется что когда есть конечная постановка задачи — набор алгоритмов нужно выбирать исходя из неё. В такой набор мог бы попасть алгоритм который вычитает фон, а мог бы и не попасть.
Sign up to leave a comment.
Kaggle – наша экскурсия в царство оверфита